\ul
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Abstract
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
Keywords:
Zero-Shot Anomaly Detection CLIP Dual-Image TTA1 Introduction

Visual anomaly detection (AD) and localization are crucial aspects of computer vision, finding widespread applications in industrial inspection [4, 49], medical imaging [37], and video surveillance [13]. This complex task involves identifying and pinpointing atypical patterns, deviations, or anomalies in visual data. These are often characterized by subtle differences in texture, color, shape, or motion, blending seamlessly into normal surroundings. Due to their diverse nature, AD poses significant challenges and has been the focus of extensive research in real-world applications.
Historically, anomaly detection has been approached through one-class methods, training unique models for each category of normal images [9, 35, 36, 10, 37, 43]. These methods achieve high accuracy on public benchmarks [4, 49] when abundant normal images are available. However, in the scenario where few or no normal training data are available, these approaches may not be ideal. Zero-shot anomaly detection (ZSAD) emerges as a vital task in such scenarios, requiring models to detect anomalies without training samples from a target dataset. This study focuses on ZSAD scenario.
MuSc [29] was proposed to leverage unlabelled images in the test set as references for the query images. It operates under the argument that a rich amount of normal information implicit in unlabelled test images is underutilized. Even if the test image is anomalous, it still contains some normal patches that can serve as references. MuSc achieves SOTA performance, but as it requires knowledge of the test set distributions before inference, it aligns more with transductive rather than inductive learning. Also, its extensive comparison with all test set images can be time-consuming and computationally intensive.
Alternatively, the recent Contrastive Language-Image Pretraining (CLIP) model [34] has shown promise in zero-shot recognition across various vision tasks, such as detecting unknown objects [27] and identifying out-of-distribution images [31]. Building on this paradigm, WinCLIP [22] used text prompts for anomaly measurement, significantly improving over other category-agnostic methods in a zero-shot AD setup and extending the capabilities of the CLIP model [34]. Subsequent approaches like [12, 5, 39, 48] further enhanced ZSAD capabilities. Recent works [5, 48] have begun fine-tuning the pretrained CLIP model with auxiliary anomalous image and, testing it on the target datasets. Alternatively, AnoCLIP [12] introduced a test-time adaptation (TTA) module to alter the visual representation space of the CLIP model. These studies underscore the importance of adding training parameters to the pretrained CLIP model to strengthen its anomaly localization ability. However, solely incorporating semantic information from text prompts may not fully exploit the potential of large vision-language models. Since the vision-language space isn’t perfectly aligned, many visual anomalies implicitly defined in the visual distribution remain uncovered. Additional visual references need to be incorporated to assist the language-based ZSAD, especially for misplaced objects, rare-seen objects, and complicated scenes, whose anomaly information is usually hard to obtain from large pretrain datasets.
To address these issues, we propose a novel framework (see Fig. 2) that utilizes a pair of unlabelled images during testing. Our framework comprises a pretrained CLIP model, a test-time adaptation module, and an input path for image pairs to leverage the additional visual reference information into the language-vision AD. The anomaly score of a query image depends not only on its textual zero-shot score but also on the score derived from its randomly paired reference image. Additionally, we enhanced the model’s AD capability by adding a TTA module involving pseudo anomaly synthesis to improve the agnostic ability to locate anomalies.
In summary, our contributions are threefold:
-
•
We propose a novel ZSAD method that processes a pair of images, enhancing existing CLIP-based AD methods. This approach incorporates an additional reference image, operates without the need for further training and significantly boosts AD performance.
-
•
We developed a TTA module that includes pseudo anomaly synthesis methods adopted from DRAEM [43], effectively refining the AD capabilities of the pretrained CLIP model.
- •
2 Related Work
2.1 Vision-Language Models
Advancements in data scale have led to significant strides in pretrained visual language models [15, 6, 34, 3], which demonstrate remarkable proficiency in a variety of downstream tasks [47, 46, 23, 24, 33, 31, 41]. A prime example is the CLIP model, through contrastive vision-language pre-training on a diverse array of internet-sourced image-text pairs, it exhibits exceptional generality and adaptability. This model is particularly adept at zero-shot inference, displaying a superior capacity for recognizing images beyond its training data. Recent explorations have extended the zero-shot capabilities of CLIP models to tasks like open-vocabulary semantic segmentation, achieved by harnessing intrinsic dense features [45, 16, 30]. Additionally, efforts to optimize CLIP’s recognition performance have been fruitful, focusing on areas such as prompt engineering [47, 46], adapter modules [44, 18], and additional training for enhanced vision-language alignment [23, 24]. Importantly, CLIP’s inherent ability to detect out-of-distribution data without additional training has catalyzed its application in zero-shot anomaly classification and localization.
2.2 Anomaly Detection and Localization
The essence of most existing AD methods lies in modeling the distribution of normal samples to detect anomalies [37, 36, 10, 43]. Particularly, reconstruction-based approaches, such as those using autoencoders [1, 2, 19] and GANs [37], have been widely adopted. These methods leverage the reconstruction capabilities of anomaly-free images, hypothesizing that abnormalities will manifest as discrepancies in the reconstructed output. Additionally, discriminative models have been developed, often with the aid of synthetic anomalies [43, 28]. Moreover, large pretrained models like ImageNet [14] have been found to be robust in anomaly detection, by comparing features embedded from normal images [9, 35, 8]. To bridge the gap between natural image pretraining and industrial application, further adaptations have been employed, such as student-teacher knowledge distillation [36, 10] and normalizing flows [26, 20].
A significant challenge in this field is the development of unified models capable of detecting anomalies across multiple classes [42, 38, 11]. In the context of zero-shot settings, MuSc [29] innovatively utilizes unlabelled images from the test set as references. Alternatively, the WinCLIP model [22] utilizes CLIP [34] for prompt-guided AD. Building on this, AnoCLIP [12] enhances localization representation and implements V-V attention introduced in [30]. However, vision-language models such as CLIP are primarily trained to align with the class semantics of foreground objects rather than the abnormality/normality in the images, and as a result, their generalization in understanding the visual anomalies is restricted, leading to weak ZSAD performance. Existing zero-shot prompt-guided AD models often lack robust visual representation as a basis for detecting anomalies. Addressing this, methods such as [5, 48] propose fine-tuning the pretrained CLIP model with auxiliary images for cross-set training/validation. In light of the limitations inherent in current CLIP-based anomaly detection models and the essential role of visual references, we propose an innovative, training-free method that inference on pairs of images. In this approach each image acts as a visual reference for the other, significantly enhancing the accuracy and effectiveness of anomaly detection.
3 Methodology
In this section, we first introduce the CLIP-based baseline model for zero-shot anomaly classification and localization. Following this, we delve into details of our dual-image enhancement model. Lastly, we specify our test-time adaptation mechanism to refine the model’s AD capability. Fig. 2 provides a comprehensive overview of our framework.

3.1 CLIP for Zero-shot Anomaly Detection
CLIP’s zero-shot visual recognition, trained on a multi-million image-text pair dataset, aligns images with textual descriptions through a visual encoder and a text encoder. These encoders respectively transform images and text prompts (e.g., a photo of a [class]) into visual and text tokens in a shared feature space. The model’s ability to compare these tokens via cosine similarity allows it to identify class concepts within images.
For anomaly detection, CLIP utilizes semantic concepts of “normal” and “anomalous” states. Multiple prompts with varied descriptors (like “perfect”, “broken”, etc.) are used to create averaged text tokens representing these states, and for normal and anomalous text tokens, respectively. Anomaly score for an image is computed based on the similarity between its visual token and these averaged text tokens. Specifically, given a text prompt and the corresponding class token , the sample-level anomaly score is computed as:
| (1) |
where is the temperature hyperparameter. Note that no visual information is injected into the model, but rather unknown anomalies are detected through the powerful open-world generalization of CLIP.
The computation is extended from global visual embeddings to patch-level visual embeddings to derive the corresponding segmentation maps , the final layer of the visual encoder has a set of patch tokens that potentially contain image local information in the patch level. For a patch token , the local anomaly score is computed as:
| (2) | ||||
| (3) |
However, since CLIP was primarily trained to align the class tokens with the text token for global classification, there’s a lack of alignment between local patch tokens and text embeddings that leads to limited performance in segmenting anomalous regions. Hence, after iterative explorations [30, 12, 48], V-V attention was adopted to produce the local-aware patch tokens.
In original Q-K-V attention, the attention score can be disproportionately influenced by specific tokens, leading to a representation that is disturbed by unrelated local features, which can weaken the model’s localization ability to detect anomalies. The V-V attention mechanism is proposed as an alternative that enhances the local features without additional training. This novel attention mechanism replaces the queries and keys with values.
| (4) |
By focusing on self-attention within the values themselves, V-V attention avoids bias introduced by the query and key interactions in Q-K-V attention. It reduces the disturbance caused by other tokens, ensuring that each value contributes significantly to its own representation. As a result, attention maps produced by V-V attention exhibit a pronounced diagonal pattern, indicating that each token predominantly attends to itself, thereby preserving its local information.
In our model, the architecture remains the same with AnoCLIP [12], which follows a 2-way forward path. The original Q-K-V attention path was kept to produce the class token, which was used to calculate sample level anomaly score . The patch tokens used for localization score are all computed by the V-V attention path.
3.2 Dual Image Feature Enhancement
As shown in Fig. 2, we proposed a novel approach that inputs a pair of images in test-time. Unlike previous CLIP-based AD works [22, 12, 48, 39] which predominantly rely on text prompts for inference, we incorporate additional visual information to facilitate a more comprehensive joint vision-language prediction. To highlight the effectiveness of our approach, we provide a comparative analysis in Fig. 3.

Fig. 3 demonstrates a significant observation: the exclusive dependence on either textual or visual information alone proves inadequate for the accurate detection of certain anomalies. The limitation in leveraging text stems from the constraints inherent in utilizing state descriptions within prompts, with terms like “broken” or “damaged” falling short of encapsulating the full spectrum of potential anomalies. Making inferences on a single image invites biases and misinterpretations, emphasizing a more extensive visual intra-class diversity to form a baseline for normalcy. For instance, consider the “PCB” example in column 3 of Fig. 3, where a misplaced LED is an anomaly; however, using text description alone is insufficient for its detection. Moreover, logical anomalies, global distortions, rare objects, or complicated scenes are more challenging to discern from by text-based method. This emphasizes the importance of incorporating additional visual context for a varied example to enhance the detection accuracy. Conversely, relying solely on pairwise visual comparisons also presents limitations, as the reference image could itself be anomalous. Consequently, this paves the way for an integrated approach that combines textual and visual data to overcome these challenges. As depicted in Fig. 3, employing dual-image inputs within the CLIP-based framework mitigates these issues, contributing to improved anomaly localization accuracy.
In response to these findings, our framework introduces a novel strategy that capitalizes on both textual and visual features. This is achieved by a unique process of randomly selecting pairs of test images to serve as the query and reference images. For these image pairs, we extract patch tokens, denoted as for the query and for the reference. These patch tokens form the basis for the pairwise visual feature comparison.
In this pairwise feature comparison strategy, each patch token from the query image undergoes a nearest neighbour search with the patch tokens from the reference image, effectively using the latter as a memory repository. The anomaly score for each query patch token is determined by calculating its cosine similarity with all reference patch tokens set . The maximum similarity score, indicating the minimum deviation, is then designated as the anomaly score for the query patch:
| (5) |
In the equation above, represents the visual reference anomaly score of the query patch , the overall anomaly score for the query image, is a composition of all the patch scores across the entire image. sim represents the cosine similarity between the patch tokens of the two samples.
As a result, the vision-language joint anomaly score can be computed as:
| (6) |
3.3 Test-Time Adaption with Pseudo Anomaly Synthesis

As the visual-language alignment needed to be refined for AD, we proposed a test-time adaptation module to boost the CLIP-based model’s AD capabilities. Our TTA module is achieved through a linear adapter, as depicted in Fig. 4. For the original image, we utilize the pseudo anomaly synthesis technique from DRAEM [43] to introduce image corruptions. DRAEM creates random-shaped pseudo anomaly masks using Perlin noise [32] and overlays textures from [7] onto the original image at masked locations. The resultant pseudo-anomalous patch tokens, denoted as , encapsulate pseudo-anomalous features.
The online adaptation of the original and synthesized patch tokens is mathematically represented as:
| (7) | ||||
| (8) |
Here denotes the linear computation. Subsequently, these adapted patch tokens are aligned with text tokens to compute the anomaly score:
| (9) |
To optimize the weights of the linear layer, we establish self-supervised tasks using pseudo anomalies. For the original and adapted patch tokens , from queries, we design two discriminative self-supervised tasks for TTA:
(1) For predicting pseudo anomaly masks , we define the loss as:
| (10) |
Here, represents the set of indices where , indicating regions augmented by the pseudo mask . prompts the adapter to retain abnormal features and recognize pseudo anomalies, aiding in the subtle detection of real anomalies.
(2) To encourage the adapter to preserve normal features and uphold general anomaly detection capabilities, we utilize the similarity loss to ensure that adapted anomaly scores are consistent with the zero-shot vision-language joint localization:
| (11) |
The aggregate learning objective to train our adapter is . This TTA process is efficient and does not require any training data or annotation. Finally, the overall anomaly classification and localization score for the query image should be computed as:
| (12) | ||||
| (13) |
4 Experiment
4.1 Experimental Setup
4.1.1 Datasets.
In our study, we conducted experiments using the MVTecAD [4] and VisA [49] datasets. Both of these datasets offer a wide array of subsets featuring various objects and textures. MVTecAD includes high-resolution images with dimensions varying from to , while the VisA comprises rectangular images with resolutions around , each accompanied by corresponding anomaly ground truth masks. Specifically, MVTecAD encompasses 5 texture categories and 10 object categories, whereas VisA is composed of 12 subsets, each dedicated to different objects. In this paper, we exclusively utilized the test dataset to evaluate zero-shot anomaly classification and localization, without the acquisition of additional datasets.
4.1.2 Metrics.
We assess the efficacy of our model by utilizing the Area Under Receiver Operator Characteristics (AUROC) image-level AUROC is used for anomaly detection, and pixel-level AUROC is measured for evaluating anomaly localization. However, the metric is dominated by a large number of normal pixels and is thus kept high despite false detections. We thus additionally report the F1Max score and Area Under Precision-Recall (AUPR) as a balanced calculation of the precision and recall to overcome the class imbalance. In addition to that, we compute the Per-Region-Overlap (PRO) to measure anomaly localization, which weights each connected component within the ground truth of varying sizes equally, making it more robust than simple pixel measurement.
4.1.3 Implementation.
We adopt ViT-B-16+ [17] as the visual encoder and the transformer [40] as the text encoder by default from the public pretrained CLIP model [21]. For the text encoder, following previous work of AnoCLIP [12], employing base templates collected from CLIP [34], pairs of state prompts, and domain-aware prompts to generate sufficient prompts. All prompts are listed in the supplement. We adhered to the data preprocessing pipeline outlined in OpenCLIP [21] for both MVTecAD and VisA benchmarks, standardizing image sizes to . Regarding the scoring coefficients, we configured to , and set to . For TTA, we use the AdamW [25] optimizer and set the learning rate to , , the adaptor is optimized with training steps. We report the mean and variance of the results over random seeds.
4.2 Performance
Tab. 1 presents the performance of zero-shot anomaly detection on MVTecAD and VisA datasets. Our proposed method is compared with prior ZSAD based works, including CLIP [34], WinCLIP [22], AnoCLIP [12], and MuSc [29]. Notely, MuSc utilized the entire test set for visual reference, aligning with transductive rather than inductive learning. For a fair comparison, we adapted MuSc to our pairwise image setting and used ViT-B-16+ as the backbone, denoted as MuSc-2. From the table, our proposed methods exhibit exceptional performance, significantly outperforming AnoCLIP by margins of in AUROC, F1Max, and PRO for anomaly localization. We also achieve advancements in anomaly classification, surpassing other methods by substantial margins. This trend of exceptional performance is consistent on the VisA dataset. Qualitative results for ZSAD are further detailed in Fig. 3, illustrating our model’s capacity to effectively classify and localize the anomalies across varied samples.
Additionally, Tab. 2 presents a comparison of our method against other AD models by AUROC scores on MVTecAD. Here, we categorize current zero-shot anomaly detection methodologies into three paradigms: Auxiliary Data approaches that utilize additional anomalous data for training, Transductive Learning Methods that infer from the extensive portion of the test set, and Inductive Learning Approaches that assess each query independently, without prior knowledge of the overall distribution. Our method, an exemplar of the inductive approach, outperforms Auxiliary Data Approaches without requiring exposure to anomalies during training.
Contrasting our method with MuSc, the state-of-the-art transductive learning setting of ZSAD, MuSc requires accessing the entire test set distribution before inference, making it highly dependent on the data distribution, and potentially limiting in real-world applications like online real-time inference. In Tab. 1, our method surpasses MuSc’s performance on the pair-image setting, especially in anomaly classification. This derives advantages from the utilization of the class token in CLIP embeddings, and emphasizes the efficiency and robustness of our joint language-vision prediction.
| Methods | MvTecAD | VisA | ||||||||||
| AL | AC | AL | AC | |||||||||
| AUROC | F1Max | PRO | AUROC | F1Max | AP | AUROC | F1Max | PRO | AUROC | F1Max | AP | |
| CLIP [34] | 19.5 | 6.2 | 1.6 | 74.0 | 88.5 | 89.1 | 22.3 | 1.4 | 0.8 | 59.3 | 74.4 | 67.0 |
| WinCLIP [22] | 85.1 | 31.7 | 64.6 | 91.8 | 91.9 | 96.5 | 79.6 | 14.8 | 59.8 | 78.1 | 79.0 | 81.2 |
| AnoCLIP [12] | 90.6 | 36.5 | 77.8 | 92.5 | 93.2 | 96.7 | 91.4 | 17.4 | 75.0 | 79.2 | 79.7 | 81.7 |
| MuSc-2 [29] | 92.4 | 41.2 | 76.5 | 81.7 | 89.1 | 90.3 | 92.6 | 26.7 | 63.2 | 69.4 | 75.1 | 73.3 |
| Ours | \ul92.6 | \ul41.8 | \ul82.6 | \ul93.1 | \ul94.0 | \ul96.6 | 94.8 | 23.5 | \ul78.6 | \ul82.6 | 81.0 | \ul84.2 |
| Ours+ | 92.8 | 42.5 | 84.0 | 93.2 | 94.1 | 96.7 | \ul94.2 | \ul24.1 | 79.7 | 82.9 | \ul80.9 | 84.7 |
5 Ablation Studies
5.1 Reference Images Quantity

From Fig. 5(a), a clear trend is observed: with the increasing number of reference images, the anomaly detection performance improves, reflected from both pixel-level and sample-level AUROC. This supports the hypothesis that unlabelled images can still offer valuable comparative references for anomaly identification.
Significantly, the most pronounced performance leap occurs when the number of reference images is increased from to , indicating that even a single reference image can substantially improve the model’s AD ability. However, the subsequent performance gains from to reference images are present but exhibit diminishing returns. This trend implies that considering the factors of inference time and memory efficiency, utilizing a large pool of reference images might not always be feasible or optimal, particularly in real-world applications where access to a wide array of suitable samples is often limited. In this context, a pairwise approach emerges as a balanced solution, optimizing the trade-off between improved detection performance and computational resource efficiency. Moreover, the observed differences in the degree of improvement between pixel AUROC and sample AUROC point that while visual details are paramount in pinpointing anomalies, they may be less influential in the broader context of classifying an entire sample as anomalous.
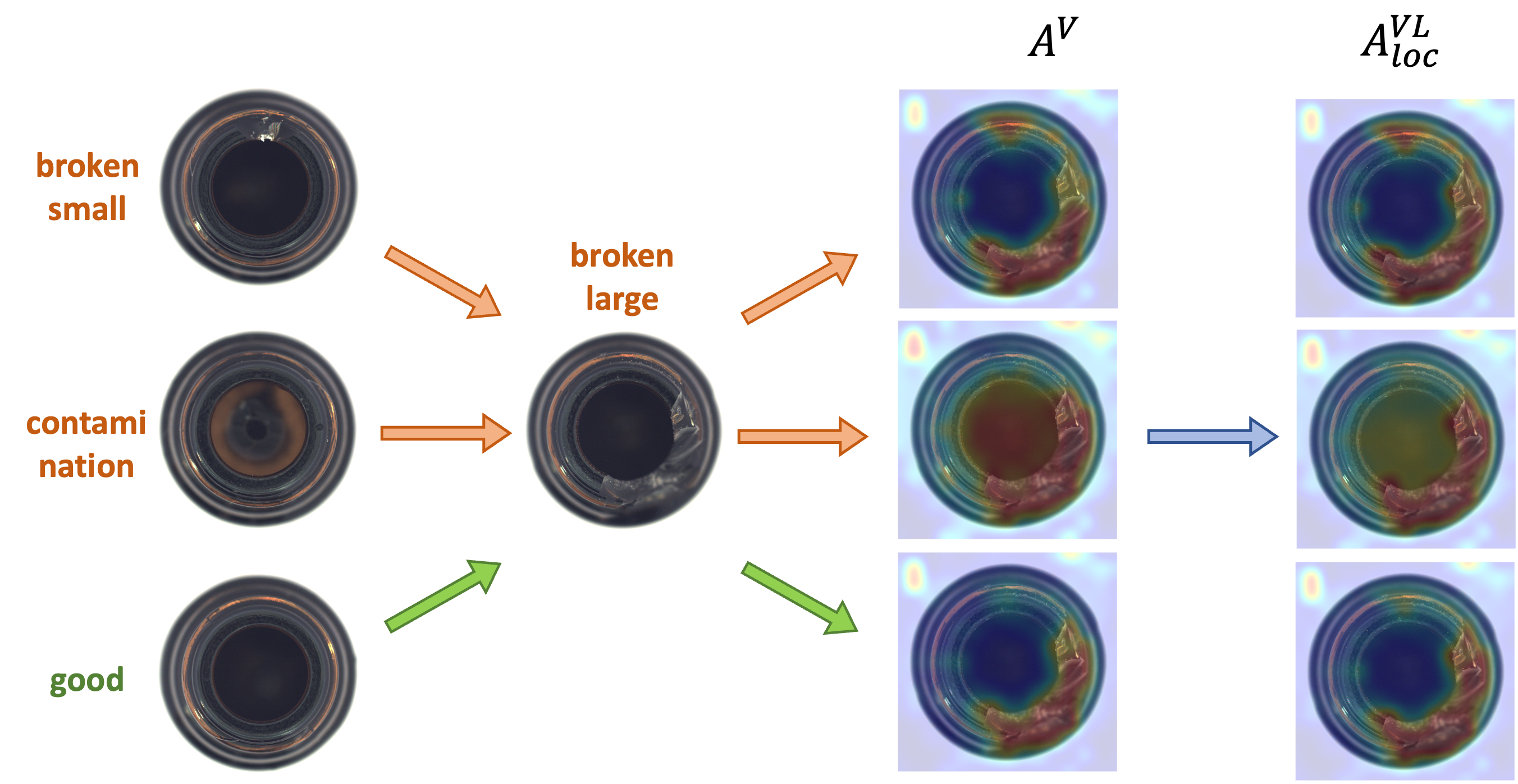
5.2 The Choice of Pairing Samples
Since the reference images are randomly sampled from unlabelled images, they can either be normal or anomalous. This leads to the question: how does an anomalous reference image affect the precision of anomaly detection?
Fig. 5(b) illustrates how different reference images can significantly influence the anomaly score. In the case of the “bottle”, it is evident that using a normal reference image generally guarantees the accuracy of anomaly detection, as it provides a clear baseline for identifying outliers. Conversely, when the reference image contains anomalies, such as breaks or contamination, these imperfections can misleadingly provide a false reference for the query image, erroneously highlighting the reference image’s damaged region in the query. This phenomenon suggests that the abnormal condition of the reference image can “pollute” the anomaly score of the query image.
Interestingly, integrating textual cues with visual data can mitigate this negative effect. By leveraging textual features from prompts, the model can effectively counter the false prediction associated with the anomalous references. As depicted in Fig. 5(b), the joint predictions that combine both visual and language information exhibit a notable increase in accuracy, underscoring the potential of language-vision joint anomaly detection.
5.3 Test-Time Adaption Module
We also studied the impact of various training steps on model performance, Fig. 6(c) demonstrates the AUROC and PRO for training steps ranging from 1 to 6. We can see both the pixel and sample AUROC and PRO scores reach the optimal when the training step is set to 2, and start to decrease. Therefore, we opted for a . In Tab. 3, we showcase the performance enhancements by the TTA module. Here we take the text-only approach as the baseline. The table shows that implementing the TTA module on the baseline yields a notable increase in performance. When the TTA module operates alongside a paired reference image, the results are further amplified. In this scenario, the AUROC for AL climbs to , and AC reaches . Further, the improvement in the F1Max and PRO indicates a more balanced and effective model, particularly in terms of its localization capabilities. The influence of the TTA module is further presented in Fig. 6(a), where a marked distinction in anomaly scores between normal and anomalous patches is observed post-adaptation. Prior to adaptation, the “missing cable” region was not adequately identified, and the adaptation process leads to a refined alignment between visual perception and language context, resulting in superior AL and AC performance.
| A.L. | A.C | |||||||
| AUROC | F1Max | PRO | AUROC | F1Max | AP | |||
| base. | ||||||||
| ✓ | ||||||||
| ✓ | ||||||||
| ✓ | ✓ | 92.80.2 | 42.40.7 | 84.00.4 | 93.20.8 | 94.10.2 | 96.70.4 | |



6 Limitations and Conclusion
6.1 Limitations & Future work
Our approach, while robust in many scenarios, is not without its limitations. One notable constraint is the requirement of inputting two images during inference, which may not be feasible with certain scenarios where single-image processing is crucial. Despite this, our method still demonstrates a significant performance enhancement in most cases.
Moreover, while our framework achieves SOTA performance in the zero-shot inductive learning setting, it reveals a gap when compared to SOTA models trained under full-shot regimes and zero-shot transductive learning approaches. As Tab. 2 shows, our method outperforms many existing models in unified AC and AL. However, it falls short of the benchmarks set by UniAD [42] and MuSc [29], particularly in scenarios where MuSc excels using visual features alone. This discrepancy suggests that there is substantial untapped potential for further exploration of visual reference features.
Additionally, our study offers novel insights into the application of the CLIP model for fine-grained anomaly detection: We demonstrate that joint visual and textual discrimination is a key contributor to enhancing fine-grained anomaly localization capabilities within the CLIP framework. Our findings also indicate that even when the visual reference images are anomalous, they can still serve as references for accurate anomaly scoring. These insights not only affirm the effectiveness of our proposed method but also open avenues for future research in refining visual-language models for more precise and versatile anomaly detection tasks.
6.2 Conclusion
In this study, we introduced an innovative framework, the Dual-Image Enhanced CLIP for anomaly classification and localization, in the realm of zero-shot learning. Our approach leverages pairs of unlabelled images utilizes the pseudo anomaly in the TTA module, and demonstrates remarkable enhancement in performance, outperforming several SOTA methods. This advancement was achieved without the need for additional training, showcasing the framework’s practicality and efficiency. Our findings also highlighted the untapped potential in combining textual features and visual references, suggesting room for further exploration in this domain.
References
- [1] Akcay, S., Atapour-Abarghouei, A., Breckon, T.P.: Ganomaly: Semi-supervised anomaly detection via adversarial training (2018)
- [2] Akçay, S., Atapour-Abarghouei, A., Breckon, T.P.: Skip-ganomaly: Skip connected and adversarially trained encoder-decoder anomaly detection (2019)
- [3] Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., Ring, R., Rutherford, E., Cabi, S., Han, T., Gong, Z., Samangooei, S., Monteiro, M., Menick, J., Borgeaud, S., Brock, A., Nematzadeh, A., Sharifzadeh, S., Binkowski, M., Barreira, R., Vinyals, O., Zisserman, A., Simonyan, K.: Flamingo: a visual language model for few-shot learning (2022)
- [4] Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.: Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9592–9600 (2019)
- [5] Chen, X., Han, Y., Zhang, J.: April-gan: A zero-/few-shot anomaly classification and segmentation method for cvpr 2023 vand workshop challenge tracks 1&2: 1st place on zero-shot ad and 4th place on few-shot ad (2023)
- [6] Chen, Y.C., Li, L., Yu, L., Kholy, A.E., Ahmed, F., Gan, Z., Cheng, Y., Liu, J.: Uniter: Universal image-text representation learning (2020)
- [7] Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., Vedaldi, A.: Describing textures in the wild. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3606–3613 (2014)
- [8] Cohen, N., Hoshen, Y.: Sub-image anomaly detection with deep pyramid correspondences (2021)
- [9] Defard, T., Setkov, A., Loesch, A., Audigier, R.: Padim: a patch distribution modeling framework for anomaly detection and localization. In: International Conference on Pattern Recognition. pp. 475–489. Springer (2021)
- [10] Deng, H., Li, X.: Anomaly detection via reverse distillation from one-class embedding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9737–9746 (2022)
- [11] Deng, H., Li, X.: Structural teacher-student normality learning for multi-class anomaly detection and localization (2024)
- [12] Deng, H., Zhang, Z., Bao, J., Li, X.: Anovl: Adapting vision-language models for unified zero-shot anomaly localization (2023)
- [13] Deng, H., Zhang, Z., Zou, S., Li, X.: Bi-directional frame interpolation for unsupervised video anomaly detection. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 2634–2643 (2023)
- [14] Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
- [15] Desai, K., Johnson, J.: Virtex: Learning visual representations from textual annotations (2021)
- [16] Dong, X., Bao, J., Zheng, Y., Zhang, T., Chen, D., Yang, H., Zeng, M., Zhang, W., Yuan, L., Chen, D., Wen, F., Yu, N.: Maskclip: Masked self-distillation advances contrastive language-image pretraining (2023)
- [17] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale (2021)
- [18] Gao, P., Geng, S., Zhang, R., Ma, T., Fang, R., Zhang, Y., Li, H., Qiao, Y.: Clip-adapter: Better vision-language models with feature adapters (2021)
- [19] Gong, D., Liu, L., Le, V., Saha, B., Mansour, M.R., Venkatesh, S., van den Hengel, A.: Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection (2019)
- [20] Gudovskiy, D., Ishizaka, S., Kozuka, K.: Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows (2021)
- [21] Ilharco, G., Wortsman, M., Wightman, R., Gordon, C., Carlini, N., Taori, R., Dave, A., Shankar, V., Namkoong, H., Miller, J., Hajishirzi, H., Farhadi, A., Schmidt, L.: Openclip (Jul 2021). https://doi.org/10.5281/zenodo.5143773, https://doi.org/10.5281/zenodo.5143773, if you use this software, please cite it as below.
- [22] Jeong, J., Zou, Y., Kim, T., Zhang, D., Ravichandran, A., Dabeer, O.: Winclip: Zero-/few-shot anomaly classification and segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19606–19616 (2023)
- [23] Khattak, M.U., Rasheed, H., Maaz, M., Khan, S., Khan, F.S.: Maple: Multi-modal prompt learning (2023)
- [24] Khattak, M.U., Wasim, S.T., Naseer, M., Khan, S., Yang, M.H., Khan, F.S.: Self-regulating prompts: Foundational model adaptation without forgetting (2023)
- [25] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization (2017)
- [26] Kingma, D.P., Dhariwal, P.: Glow: Generative flow with invertible 1x1 convolutions (2018)
- [27] Kuo, W., Cui, Y., Gu, X., Piergiovanni, A., Angelova, A.: F-vlm: Open-vocabulary object detection upon frozen vision and language models. arXiv preprint arXiv:2209.15639 (2022)
- [28] Li, C.L., Sohn, K., Yoon, J., Pfister, T.: Cutpaste: Self-supervised learning for anomaly detection and localization (2021)
- [29] Li, X., Huang, Z., Xue, F., Zhou, Y.: Musc: Zero-shot industrial anomaly classification and segmentation with mutual scoring of the unlabeled images. arXiv preprint arXiv:2401.16753 (2024)
- [30] Li, Y., Wang, H., Duan, Y., Li, X.: Clip surgery for better explainability with enhancement in open-vocabulary tasks (2023)
- [31] Michels, F., Adaloglou, N., Kaiser, T., Kollmann, M.: Contrastive language-image pretrained (clip) models are powerful out-of-distribution detectors. arXiv preprint arXiv:2303.05828 (2023)
- [32] Perlin, K.: An image synthesizer. ACM Siggraph Computer Graphics 19(3), 287–296 (1985)
- [33] Qin, Z., Yi, H., Lao, Q., Li, K.: Medical image understanding with pretrained vision language models: A comprehensive study (2023)
- [34] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021)
- [35] Roth, K., Pemula, L., Zepeda, J., Schölkopf, B., Brox, T., Gehler, P.: Towards total recall in industrial anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14318–14328 (2022)
- [36] Salehi, M., Sadjadi, N., Baselizadeh, S., Rohban, M.H., Rabiee, H.R.: Multiresolution knowledge distillation for anomaly detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14902–14912 (2021)
- [37] Schlegl, T., Seeböck, P., Waldstein, S.M., Langs, G., Schmidt-Erfurth, U.: f-anogan: Fast unsupervised anomaly detection with generative adversarial networks. Medical image analysis 54, 30–44 (2019)
- [38] Shu, M., Nie, W., Huang, D.A., Yu, Z., Goldstein, T., Anandkumar, A., Xiao, C.: Test-time prompt tuning for zero-shot generalization in vision-language models (2022)
- [39] Tamura, M.: Random word data augmentation with clip for zero-shot anomaly detection (2023)
- [40] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need (2023)
- [41] Vinker, Y., Pajouheshgar, E., Bo, J.Y., Bachmann, R.C., Bermano, A.H., Cohen-Or, D., Zamir, A., Shamir, A.: Clipasso: Semantically-aware object sketching (2022)
- [42] You, Z., Cui, L., Shen, Y., Yang, K., Lu, X., Zheng, Y., Le, X.: A unified model for multi-class anomaly detection (2022)
- [43] Zavrtanik, V., Kristan, M., Skočaj, D.: Draem-a discriminatively trained reconstruction embedding for surface anomaly detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8330–8339 (2021)
- [44] Zhang, R., Fang, R., Zhang, W., Gao, P., Li, K., Dai, J., Qiao, Y., Li, H.: Tip-adapter: Training-free clip-adapter for better vision-language modeling (2021)
- [45] Zhou, C., Loy, C.C., Dai, B.: Extract free dense labels from clip (2022)
- [46] Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Conditional prompt learning for vision-language models (2022)
- [47] Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. International Journal of Computer Vision 130(9), 2337–2348 (Jul 2022). https://doi.org/10.1007/s11263-022-01653-1, http://dx.doi.org/10.1007/s11263-022-01653-1
- [48] Zhou, Q., Pang, G., Tian, Y., He, S., Chen, J.: Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection (2023)
- [49] Zou, Y., Jeong, J., Pemula, L., Zhang, D., Dabeer, O.: Spot-the-difference self-supervised pre-training for anomaly detection and segmentation. In: European Conference on Computer Vision. pp. 392–408. Springer (2022)