Dual gradient flow for solving linear ill-posed problems in Banach spaces
Abstract.
We consider determining the -minimizing solution of ill-posed problem for a bounded linear operator from a Banach space to a Hilbert space , where is a strongly convex function. A dual gradient flow is proposed to approximate the sought solution by using noisy data. Due to the ill-posedness of the underlying problem, the flow demonstrates the semi-convergence phenomenon and a stopping time should be chosen carefully to find reasonable approximate solutions. We consider the choice of a proper stopping time by various rules such as the a priori rules, the discrepancy principle, and the heuristic discrepancy principle and establish the respective convergence results. Furthermore, convergence rates are derived under the variational source conditions on the sought solution. Numerical results are reported to test the performance of the dual gradient flow.
1. Introduction
Consider the linear ill-posed problem
| (1.1) |
where is a bounded linear operator from a Banach space to a Hilbert space . Throughout the paper we always assume (1.1) has a solution. The equation (1.1) may have many solutions. By taking into account a priori information about the sought solution, we may use a proper, lower semi-continuous, convex function to select a solution of (1.1) such that
| (1.2) |
which, if exists, is called a -minimizing solution of (1.1).
In practical applications, the exact data is in general not available, instead we only have a noisy data satisfying
| (1.3) |
where is the noise level. Due to the ill-posedness of the underlying problem, the solution of (1.2) does not depend continuously on the data. How to use a noisy data to stably reconstruct a -minimizing solution of (1.1) is an important topic. To conquer the ill-posedness, many regularization methods have been developed to solve inverse problems; see [7, 9, 14, 17, 26, 27, 33, 34, 39, 40] and the references therein for instance.
In this paper we will consider solving (1.2) by a dual gradient flow. Throughout the paper we will assume that is strongly convex. In case is not strongly convex, we may consider its strong convex perturbation by adding it a small multiple of a strongly convex function; this does not affect much the reconstructed solution, see Proposition A.1 in the appendix. The dual gradient flow for solving (1.2) can be derived by applying the gradient flow to its dual problem. Since the Lagrangian function corresponding to (1.2) with replaced by is given by
we have the dual function
where denotes the adjoint of and denotes the Legendre-Fenchel conjugate of . Thus the dual problem takes the form
| (1.4) |
Since is strongly convex, is continuously differentiable over and its gradient maps into , see Proposition 2.1. Therefore, is continuous differentiable with . Applying the gradient flow to solve (1.4) then gives
which can be equivalently written as
| (1.5) | ||||
with a suitable initial value . This is the dual gradient flow we will study for solving (1.2).
When is a Hilbert space and , the dual gradient flow (1.5) becomes the first order asymptotical regularization
| (1.6) |
which is known as the Showalter’s method. The analysis of (1.6) and its linear as well as nonlinear extensions in Hilbert spaces can be found in [6, 31, 35, 37] for instance. Recently, higher order asymptotical regularization methods have also received attention for solving ill-posed problems in Hilbert spaces, see [6, 37, 38]. Due to the Hilbert space setting, the analysis of these asymptotical regularization methods can be performed by the powerful tool of spectral theory for bounded linear self-adjoint operators. Note that if the Euler scheme is used to discretize (1.6) one may obtain the linear Landweber iteration
| (1.7) |
in Hilbert spaces with a suitable step-size . Therefore, (1.6) can be viewed as a continuous analogue of (1.7) and the study of (1.6) can provide new insights about (1.7). On the other hand, by using other numerical schemes, we may produce from (1.6) iterative regularization methods far beyond the Landweber iteration. For instance, a class of order optimal iterative regularization methods have been proposed in [32] by discretizing (1.6) by the Runge-Kutta integrators; furthermore, by discretizing a second order asymptotical regularization method by a symplectic integrator – the Strörmer-Verlet method, a new order optimal iterative regularization method has been introduced in [38] with acceleration effect.
The dual gradient flow (1.5) can be viewed as a continuous analogue of the Landweber iteration in Banach space
| (1.8) | ||||
as (1.8) can be derived from (1.5) by applying the Euler discrete scheme. The method (1.8) and its generalization to linear and nonlinear ill-posed problems in Banach spaces have been considered in [7, 27, 33] for instance. How to derive the convergence rates for (1.8) has been a challenging question for a long time and it has been settled recently in [26] by using some deep results from convex analysis in Banach spaces when the method is terminated by either an a priori stopping rule or the discrepancy principle. It should be mentioned that, by using other numerical integrators to discretize (1.5) with respect to the time variable, one may produce new iterative regularization methods for solving (1.2) in Banach sopaces that are different from (1.8).
In this paper we will analyze the convergence behavior of the dual gradient flow (1.5). Due to the non-Hilbertian structure of the space and the non-quadraticity of the regularization functional , the tools for analyzing asymptotical regularization methods in Hilbert spaces are no longer applicable. The convergence analysis of (1.5) is much more challenging and tools from convex analysis in Banach spaces should be exploited. Our analysis is inspired by the work in [26]. We first prove some key properties on the dual gradient flow (1.5) based on which we then consider its convergence behavior. Due to the propagation of noise along the flow, the primal trajectory demonstrates the semi-convergence phenomenon: approaches the sought solution at the beginning as the time increases; however, after a certain amount of time, the noise plays the dominated role and begins to diverge from the sought solution. Therefore, in order to produce from a reasonable approximate solution, the time should be chosen carefully. We consider several rules for choosing . We first consider a priori parameter choice rules and establish convergence and convergence rate results. A priori rules can provide useful insights on the convergence property of the method. However, since it requires information on the unknown sought solution, the a priori parameter choice rules are of limited use in practice. To make the dual gradient flow (1.5) more practical relevant, we then consider the choice of by a posteriori rules. When the noise level is available, we consider choosing by the discrepancy principle and obtain the convergence and convergence rate results. In case the noise level information is not available or not reliable, the discrepancy principle may not be applicable; instead we consider the heuristic discrepancy principle which uses only the noisy data. Heuristic rules can not guarantee a convergence result in the worst case scenario according to the Bakushinskii’s veto [2]. However, under certain conditions on the noisy data, we can prove a convergence result and derive some error estimates. Finally we provide numerical simulations to test the performance of the dual gradient flow.
2. Convergence analysis
In this section we will analyze the dual gradient flow (1.5). We will carry out the analysis under the following conditions.
Assumption 1.
-
(i)
is a Banach space, is a Hilbert space, and is a bounded linear operator;
-
(ii)
is proper, lower semi-continuous, and strongly convex in the sense that there is a constant such that
for all and ; moreover, each sublevel set of is weakly compact in .
-
(iii)
The equation has a solution in .
For a proper convex function we use to denote its subdifferential, i.e.
for all . It is known that is a multi-valued monotone mapping. Let . If is strongly convex as stated in Assumption 1 (ii), then
| (2.1) |
for all with any and ; moreover
for all , and , where
denotes the Bregman distance induced by at in the direction .
For a proper, lower semi-continuous, convex function , its Legendre-Fenchel conjugate is defined by
which is also proper, lower semi-continuous, and convex and admits the duality property
| (2.2) |
If, in addition, is strongly convex, then has nice smoothness properties as stated in the following result, see [36, Corollary 3.5.11].
Proposition 2.1.
Let be a Banach space and let be a proper, lower semi-continuous, strongly convex function as stated in Assumption 1 (ii). Then , is Fréchet differentiable and its gradient maps into with the property
for all .
Let Assumption 1 hold. It is easy to show that (1.1) has a unique -minimizing solution, which is denoted as . We now consider the dual gradient flow (1.5) to find approximation of . By submitting into the differential equation in (1.5), we can see that
| (2.3) |
where
| (2.4) |
for all . According to Proposition 2.1 we have
| (2.5) |
for all , where , i.e. is globally Lipschitz continuous on . Therefore, by the classical Cauchy-Lipschitz-Picard theorem, see [8, Theorem 7.3] for instance, the differential equation (2.3) with any initial value has a unique solution . Defining then shows that the dual gradient flow (1.5) with any initial value has a unique solution .
2.1. Key properties of the dual gradient flow
We will use the function defined by the dual gradient flow (1.5) with to approximate the unique -minimizing solution of (1.1) and consider the approximation property. Due to the appearance of noise in the data, demonstrates the semi-convergence property, i.e. tends to the sought solution at the beginning as the time increases, and after a certain amount of time, diverges and the approximation property is deteriorated as continually increases. Therefore, it is necessary to determine a proper time at which the value of is used as an approximate solution. To this purpose, we first prove the monotone property of the residual which is crucial for designing parameter choice rules.
Lemma 2.2.
Proof.
Let be any two fixed numbers. We need to show
| (2.6) |
We achieve this by discretizing (1.5) by the Euler method, showing the monotonicity holds for the discrete method, and then using the approximation property of the discretization.
To this end, for any fixed integer we set and then define by
for , where and hence . By the definition of and (2.2) we have . Since is strongly convexity, we may use (2.1) to obtain
By using the definition of , we further have
By taking to be sufficiently large so that , then we can obtain
| (2.7) |
In particular, this implies that
If we are able to show that as , by taking in the above inequality we can obtain (2.6) immediately.
It therefore remains only to show as . The argument is standard; we include it here for completeness. Let for . Using we define for as follows
| (2.8) |
Since , we have
where is defined by (2.4). From the definition of , it is easy to see that . Furthermore, for we can find such that and consequently
where
Note that . Therefore
Taking the norm on the both sides and using (2) it follows that
By using (2) and (2.8) we have
By using (2.7), and with we thus obtain
where . Therefore
for all . From the Gronwall inequality it then follows that
Since as and , we thus obtain from the above equation that as . Since and , by using the continuity of we can conclude as . The proof is therefore complete. ∎
Based on the monotonicity of given in Lemma 2.2, we can now prove the following result which is crucial for the convergence analysis of the dual gradient flow (1.5).
Proposition 2.3.
Proof.
According to the formulation of the dual gradient flow (1.5), we have
Multiplying the both sides by and then taking integration, we can obtain
| (2.10) |
On the other hand, by the convexity of we have
Taking and noting that , we therefore have
Integrating this equation then gives
By using , we have
Therefore
Adding this equation with (2.1) gives
By virtue of the monotonicity of obtained in Lemma 2.2, we have
which, combining with the above equation, shows (2.9). ∎
According to Proposition 2.3, we have the following consequences.
Lemma 2.4.
Proof.
According to Proposition 2.3 and the relation , we can obtain
| (2.13) |
By the Cauchy-Schwarz inequality and we have
| (2.14) |
Combining this with (2.1) shows (2.11). In order to establish (2.12), slightly different from (2.14) we now estimate the term as
It then follows from (2.1) that
which together with the inequality then shows (2.12). ∎
Next we will provide a consequence of Lemma 2.4 which will be useful for deriving convergence rates when the sought solution satisfies variational source conditons to be specified. To this end, we need the following Fenchel-Rockafellar duality formula.
Proposition 2.5.
Let and be Banach spaces, let and be proper convex functions, and let be a bounded linear operator. If there is such that and is continuous at , then
The proof of Fenchel-Rockafellar duality formula can be found in various books on convex analysis, see [5, Theorem 4.4.3] for instance.
Lemma 2.6.
Proof.
Since , from the Fenchel-Young inequality it follows that
Combining this with the estimates in Lemma 2.4 and noting that the estimates hold for all , we can obtain (2.15) and (2.16) with defined by
It remains only to show that can be given by (2.17). By rewriting as
we may use Proposition 2.5 to conclude the result immediately. ∎
2.2. A priori parameter choice
In this subsection we analyze the dual gradient flow (1.5) under a priori parameter choice rule in which a number is chosen depending only on the noise level and possibly on the source information of the sought solution and then is used as an approximate solution. Although a priori parameter choice rule is of limited practical use, it provides valuable theoretical guidance toward understanding the behavior of the flow. We first prove the following convergence result.
Theorem 2.7.
Proof.
Recall that . It follows from the convexity of that
| (2.19) |
We need to treat the second term on the right hand side of (2.2). We will use (2.12). By the Young-Fenchel inequality and , we have
| (2.20) |
which implies that
Thus for any we can find such that
| (2.21) |
By taking and in (2.12) we then obtain
Using and the given conditions on , it follows that
Sine can be arbitrarily small, we must have
which in particular implies
| (2.22) |
as . Thus, it follows from (2.2) that
| (2.23) |
Based on (2.23), we can find a constant independent of such that . Since every sublevel set of is weakly compact, for any sequence of noisy data satisfying , by taking a subsequence if necessary, we can conclude as for some , where “” denotes the weak convergence. By the weak lower semi-continuity of norms and we can obtain from (2.22) and (2.23) that
and
Thus . Since is the -minimizing solution of , we must have and therefore as . By a subsequence-subsequence argument we can obtain as . Consequently, by using (2.22), we have
as . The assertion then follows from the strong convexity of . ∎
Next we consider deriving the convergence rates under a priori parameter choice rule. For ill-posed problems, convergence rate of the method depends crucially on the source condition of the sought solution . We now assume satisfies the following variational source condition.
Assumption 2.
For the unique -minimizing solution of (1.1) there is an error measure function satisfying such that
for some and some number .
Since it was introduced in [20], variational source condition has received tremendous attention, various extensions, refinements and verification have been conducted and many convergence rate results have been established based on this notion; see [11, 16, 17, 21, 22, 23, 26] for instance. In Assumption 2, the error measure function is used to measure the speed of convergence; it can be taken in various forms and the usual choice of is the Bregman distance induced by .
Under the variational source condition on specified in Assumption 2, the dual gradient flow (1.5) admits the following convergence rate when is chosen by an a priori parameter choice rule.
Theorem 2.8.
Proof.
By the variational source condition on we have
Since , it follows from the convexity of that
Therefore
| (2.24) |
We next use the inequality (2.16) in Lemma 2.6 to estimate and . By the variational source condition on and the nonnegativity of we have . Therefore
| (2.25) |
with . This together with (2.16) gives
which implies that
Hence we can conclude from (2.2) that
The proof is thus complete. ∎
2.3. The discrepancy principle
In order to obtain a good approximate solution, the a priori parameter choice rule considered in the previous subsection requires the knowledge of the unknown sought solution which limits its applications in practice. Assuming the availability of the noise level , we now consider the discrepancy principle which is an a posteriori rule that chooses a suitable time based only on and such that the residual is roughly of the magnitude of . More precisely, the discrepancy principle can be formulated as follows.
Rule 1.
Let be a given number. If , we set ; otherwise, we define to be a number such that
In the following result we will show that Rule 1 always outputs a finite number and can be used as an approximate solution to .
Theorem 2.9.
Proof.
We first show that Rule 1 outputs a finite number . To see this, let be any number such that , from (2.11) we can obtain for any that
| (2.27) |
For any , by taking to be the satisfying (2.21), we then obtain
| (2.28) |
If Rule 1 does not output a finite number , then (2.28) holds for any . By taking , we can see that the left hand side of (2.28) goes to while the right hand side tends to which is a contradiction. Therefore Rule 1 must output a finite number .
We next show that as . To see this, let be any sequence of noisy data satisfying as . If is bounded, then there trivially holds as . If , then by taking in (2.28) we have
Since can be arbitrarily small, we thus obtain again.
Now we are ready to show (2.26). Since
| (2.29) |
we immediately obtain
| (2.30) |
To establish , we will use (2.2). We need to estimate . If , by taking and in (2.12), we have
Therefore
which holds trivially when . Combining this with (2.29) we obtain
With the help of the established fact , we can see that
| (2.31) |
Thus, it follows from (2.2) that
| (2.32) |
Based on (2.30), (2.31) and (2.32), we can use the same argument in the proof of Theorem 2.7 to complete the proof. ∎
When the sought solution satisfies the variational source condition specified in Assumption 2, we can derive the convergence rate on for the number determined by Rule 1.
Theorem 2.10.
Proof.
By using the variational source condition on , , the convexity of and the definition of , we have
| (2.33) |
If , then and hence
Therefore, we may assume . By using (2.15) and (2.2) with and noting that we have
which implies that
| (2.34) |
Therefore, by using (2.16) and (2.2) with we can obtain
where . Combining this with (2.3) we finally obtain
The proof is complete. ∎
2.4. The heuristic discrepancy principle
The performance of the discrepancy principle, i.e. Rule 1, for the dual gradient flow depends on the knowledge of the noise level. In case the accurate information on the noise level is available, satisfactory approximate solutions can be produced, as shown in the previous subsection. When noise level information is not available or reliable, we need to consider heuristic rules, which use only , to produce approximate solutions [18, 24, 25, 29, 30]. In this subsection we will consider the following heuristic discrepancy principle motivated by [18, 25].
Rule 2.
For a fixed number let for and choose to be a number such that
| (2.35) |
Note that the parameter chosen by Rule 2, if exists, is independent of the noise level . According to the Bakushinskii’s veto, we can not expect a convergence result on in the worst case scenario as we obtained for the discrepancy principle in the previous subsection. Additional conditions should be imposed on the noisy data in order to establish a convergence result on this heuristic rule. We will use the following condition.
Assumption 3.
is a family of noisy data with and there is a constant such that
| (2.36) |
for every and every along the primal trajectory of the dual gradient flow, i.e. , where is defined by the dual gradient flow (1.5) using the noisy data .
This assumption was first introduced in [24]. It can be interpreted as follows. For ill-posed problems the operator usually has smoothing effect so that admits certain regularity, while contains random noise and hence exhibits salient irregularity. The condition (2.36) roughly means that subtracting any regular function of the form with can not significantly remove the randomness of noise. During numerical computation, we may testify Assumption 3 by observing the tendency of as increases: if does not go below a very small number, we should have sufficient confidence that assumption 3 holds true.
Under Assumption 3 we have as , which demonstrates that there must exist a finite integer satisfying (2.35). We have the following convergence result on .
Theorem 2.11.
Proof.
We first show that for determined by Rule 2 there hold
| (2.37) |
as . To see this, we set which satisfies and as . It then follows from the definition of that
| (2.38) |
Let be arbitrarily small. As in the proof of Theorem 2.7 we may choose such that (2.21) hold. Therefore, it follows from (2.38) and (2.11) that
By the property of we thus obtain
Since can be arbitrarily small, we must have as . Since and, by Assumption 3, . We therefore have
as .
Next we provide an error estimate result on Rule 2 for the dual gradient flow (1.5) under the variational source condition on specified in Assumption 2.
Theorem 2.12.
Let Assumption 1 hold. Consider the dual gradient flow (1.5) with . Let be the number determined by Rule 2. If satisfies the variational source condition specified in Assumption 2 and if , then
| (2.40) |
where is a constant depending only on and . If is a family of noisy data satisfying Assumption 3, then
| (2.41) |
for some constant depending only on , and .
Proof.
Similar to the derivation of (2.3) we have
| (2.42) |
Based on this we will derive the desired estimate by considering the following two cases.
Case 1: . For this case we may use (2.16) and (2.2) to derive that
Combining this with (2.42) and using we obtain
Case 2: . For this case we first use (2.42) and the Cauchy-Schwarz inequality to derive that
With the help of (2.16), (2.2), the definition of and we then obtain
| (2.43) |
By the definition of and the equation (2.15) we have
for all . We now choose . Then
| (2.44) |
Combining the above estimates on with (2.4) yields
The shows (2.40).
Remark 2.13.
Under Assumption 3 we can derive an estimate on independent of . Indeed, by definition we have . By using (2.44) we then obtain which together with (2.41) gives . In deriving this rate, we used which is rather conservative. The actual value of can be much larger as and therefore better rate than can be expected.
3. Numerical results
In this section we present some numerical results to illustrate the numerical behavior of the dual gradient flow (1.5) which is an autonomous ordinary differential equation. We discretize (1.5) by the 4th-order Runge-Kutta method which takes the form ([12])
| (3.1) | ||||
with suitable step size , where and are given by
The implementation of (3.1) requires determining for any , which, by virtue of (2.2), is equivalent to solving the convex minimization problem
For many important choices of , can be given by an explicit formula; even if does not have an explicit formula, it can be determined by efficient algorithms.
Example 3.1.
Consider the first kind Fredholm integral equation of the form
| (3.2) |
where the kernel is a continuous function on . Clearly maps into . We assume the sought solution is a probability density function, i.e. a.e. on and . To find such a solution, we consider the dual gradient flow (1.5) with
where denotes the indicator function of the closed convex set
in and denotes the negative of the Boltzmann-Shannon entropy, i.e.
where . According to [1, 4, 13, 15, 26], satisfies Assumption 1. By the Karush-Kuhn-Tucker theory, for any , is given by .
For numerical simulations we consider (3.2) with and assume the sought solution is
where the constant is chosen to ensure so that is a probability density function. In the numerical computation we divide into subintervals of equal length and approximate integrals by the trapezoidal rule. We add random Gaussian noise to the exact data to obtain the noisy data whose noise level is . With we reconstruct the sought solution by using the dual gradient flow (1.5) with which is solved approximately by the 4th-order Runge-Kutta method as described in (3.1) with . We consider the choice of the proper time by the discrepancy principle, i.e. Rule 1 and the heuristic discrepancy principle, i.e. Rule 2.
| Rule 1 with | Rule 1 with | Rule 2 with | ||||
|---|---|---|---|---|---|---|
| 1e-1 | 13.6 | 1.1514e-1 | 0.8 | 6.6167e-1 | 7.2 | 1.9012e-1 |
| 1e-2 | 132.8 | 3.2177e-2 | 10.4 | 1.3664e-1 | 63.2 | 3.8761e-2 |
| 1e-3 | 1810.4 | 1.2145e-2 | 106 | 3.1348e-2 | 680.8 | 1.4750e-2 |
| 1e-4 | 26532.4 | 5.0245e-3 | 1376.4 | 1.2854e-2 | 8001.2 | 8.2320e-3 |
To demonstrate the numerical performance of (1.5) quantitatively, we perform the numerical simulations using noisy data with various noise levels. In Table 1 we report the time determined by Rule 1 with and and by Rule 2 with , we also report the corresponding relative errors . The values and used in Rule 1 correspond to the proper estimation and overestimation of noise levels respectively. The results in Table 1 show that Rule 1 with a proper estimate of the noise level can produce nice reconstruction results; in case the noise level is overestimated, less accurate reconstruction results can be produced. Although Rule 2 does not utilize any information on noise level, it can produce satisfactory reconstruction results.



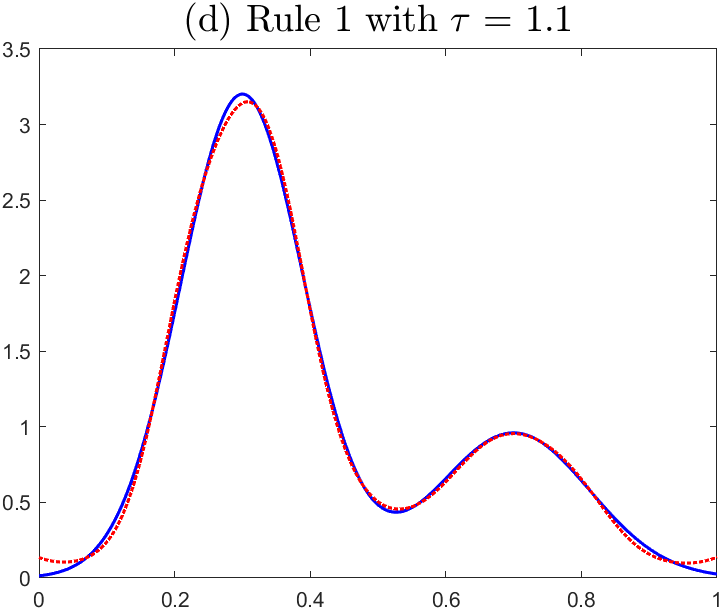


In order to visualize the performance of (1.5), in Figure 1 we present the reconstruction results using a noisy data with the noise level . Figure 1 (a) plots the relative error versus the time which indicates the dual gradient flow (1.5) possesses the semi-convergence property. Figure 1 plots the residual versus the time which demonstrates that Assumption 3 holds with sufficient confidence if the data is corrupted by random noise. Figure 1 (c) plots versus which clearly shows that achieves its minimum at a finite number . Figure 1 (d)–(f) present the respective reconstruction results with chosen by Rule 1 with and and by Rule 2 with .
Example 3.2.
We next consider the computed tomography which consists in determining the density of cross sections of a human body by measuring the attenuation of X-rays as they propagate through the biological tissues. In the numerical simulations we consider test problems that model the standard 2D parallel-beam tomography. We use the full angle model with 45 projection angles evenly distributed between 1 and 180 degrees, with 367 lines per projection. Assuming the sought image is discretized on a pixel grid, we may use the function paralleltomo in the MATLAB package AIR TOOLS [19] to discretize the problem. It leads to an ill-conditioned linear algebraic system , where is a sparse matrix of size , where and .
Let the true image be the modified Shepp-Logan phantom of size generated by MATLAB. Let denote the vector formed by stacking all the columns of the true image and let be the true data. We add Gaussian noise on to generate a noisy data with relative noise level so that the noise level is . We will use to reconstruct . In order to capture the feature of the sought image, we take
with a constant , where denotes the total variation of . This is strongly convex with . The determination of for any given is equivalent to solving the total variation denoising problem
which can be solved efficiently by the primal dual hybrid gradient method [3, 41]; we use in our computation. With a noisy data we reconstruct the true image by the dual gradient method (1.5) with which is solved approximately by the 4th Runge-Kutta method (3.1) with constant step-size .
| Rule 1 with | Rule 1 with | Rule 2 with | ||||
|---|---|---|---|---|---|---|
| 5e-2 | 0.0260 | 1.9677e-1 | 0.0144 | 3.0193e-1 | 0.0324 | 1.7331e-1 |
| 1e-2 | 0.1420 | 6.5240e-2 | 0.0212 | 2.2035e-1 | 0.0992 | 8.1327e-2 |
| 5e-3 | 0.2640 | 3.6406e-2 | 0.0380 | 1.4581e-1 | 0.2080 | 4.5257e-2 |
| 1e-3 | 1.0136 | 7.3525e-3 | 0.2160 | 4.1178e-2 | 0.6392 | 1.1537e-2 |
| 5e-4 | 1.7620 | 3.6169e-3 | 0.5028 | 2.1548e-2 | 1.5904 | 6.0784e-3 |
We demonstrate in Table 2 the performance of (1.5) quantitatively by performing the numerical simulations using noisy data with various relative noise levels. We report the value of determined by Rule 1 with (proper estimation case) and (overestimation case) and by Rule 2 with , we also report the corresponding relative errors . The results show that Rule 1 with a proper estimate of the noise level can produce satisfactory reconstruction results; overestimation of noise level can deteriorate the reconstruction accuracy. Rule 2 can produce nice reconstruction results even if it does not rely on the information of noise level.







To visualize the performance of (1.5), in Figure 2 we present the reconstruction results using a noisy data with the relative noise level . Figure 2 (a)-(c) plot the relative errors, the residual and the value of versus the time . These results demonstrate the semi-convergence phenomenon of (1.5), the validity of Assumption 3 and well definedness of Rule 2. Figure 2 (d)-(g) plot the true image, the reconstructed images by Rule 1 with and , and the reconstruction by Rule 2 with .
Acknowledgements
The work of Q Jin is partially supported by the Future Fellowship of the Australian Research Council (FT170100231) and the work of W Wang is supported by the National Natural Science Foundation of China (No. 12071184).
Appendix A
Consider (1.2), we want to show that by adding a small multiple of a strongly convex function to does not affect the solution too much. Actually, we can prove the following result which is an extension of [10, Theorem 4.4] that proves a special instance related to sparse recovery in finite-dimensional Hilbert spaces.
Proposition A.1.
Let and be Banach space, a bounded linear operator and , the range of . Let be a proper, lower semi-continuous, convex function with , where
Assume that is a proper, lower semi-continuous, strongly convex function with such that every sublevel set of is weakly compact. For any define
Then and as , where is such that for all .
Proof.
Since is convex and is strongly convex, and are uniquely defined. By the definition of and we have
| (A.1) |
and
| (A.2) |
Combining these two equations gives
| (A.3) |
Thus, it follows from (A.1) that which together with (A.2) shows
| (A.4) |
Next we show as . Since every sublevel set of is weakly compact, for any sequence with , by taking a subsequence if necessary, we may use (A.3) and (A.4) to conclude as for some element . Since and is bounded, letting gives . By the weak lower semi-continuity of and (A.4) we also have
Since , we thus have . Consequently by the definition of . By (A.3) and the weak lower semi-continuity of we also have
| (A.5) |
Thus and . By uniqueness we must have . Consequently and, by (A.5), as . Since is strongly convex, it admits the Kadec property, see [28, Lemma 2.1], which implies as . Since, for any sequence with , has a subsequence converging strongly to as , we can conclude as . ∎
References
- [1] U. Amato and W. Hughes, Maximum entropy regularization of Fredholm integral equations of the first kind, Inverse Problems, 7 (1991), 793–808.
- [2] A. B. Bakushinskii, Remarks on choosing a regularization parameter using the quasioptimality and ratio criterion, Comp. Math. Math. Phys., 24 (1984), 181–182.
- [3] S. Bonettini and V. Ruggiero, On the convergence of primal-dual hybrid gradient algorithms for total variation image restoration, J. Math. Imaging Vis., 44 (2012), 236–253.
- [4] J. M. Borwein and C. S. Lewis, Convergence of best entropy estimates, SIAM J. Optim., 1 (1991) 191–205.
- [5] J. M. Borwein and Q. J. Zhu, Techniques of variational analysis, CMS Books in Mathematics/Ouvrages de Mathématiques de la SMC, 20. Springer-Verlag, New York, 2005.
- [6] R. Boţ, G. Dong, P. Elbau and O. Scherzer, Convergence rates of first-and higher-order dynamics for solving linear ill-posed problems, Foundations of Computational Mathematics, 2021 https://doi.org/10.1007/s10208-021-09536-6.
- [7] R. Boţ and T. Hein, Iterative regularization with a geeral penalty term: theory and applications to and TV regularization, Inverse Problems, 28 (2012), 104010.
- [8] H. Brezis, Functional Analysis, Sobolev Spaces and Partial Differential Equations, Springer, New York, 2011.
- [9] M. Burger and S. Osher, Convergence rates of convex variational regularization, Inverse Problems 20 (2004), no. 5, 1411–1421.
- [10] J. F. Cai, S. Osher and Z. W. Shen, Linearized Bregman iterations for compressed sensing, Math. Comp., 78 (2009), no. 267, 1515–1536.
- [11] D. H. Chen, D. Jiang, I. Yousept and J. Zou, Variational source conditions for inverse Robin and flux problems by partial measurements, Inverse Probl. Imaging, 16 (2022), no. 2, 283–304.
- [12] P. Deuflhar and F. Bornemann, Scientific Computing with Ordinary Differential Equations, New York: Springer, 2002.
- [13] P. P. B. Eggermont, Maximum entropy regularization for Fredholm integral equations of the first kind, SIAM J. Math. Anal., 24 (1993), no. 6, 1557–1576.
- [14] H. Engl, M. Hanke and A. Neubauer, Regularization of Inverse Problems, New York (NY): Springer, 1996.
- [15] H. Engl and G. Landl, Convergence rates for maximum entropy regularization, SIAM J. Numer. Anal., 30 (1993), 1509–1536.
- [16] J. Flemming, Existence of variational source conditions for nonlinear inverse problems in Banach spaces, J. Inverse Ill-posed Problems, 26 (2018), no. 2, 277–286.
- [17] K. Frick and M. Grasmair, Regularization of linear ill-posed problems by the augmented Lagrangian method and variational inequalities, Inverse Problems, 28 (2012), no. 10, 104005.
- [18] M. Hanke, T. Raus, A general heuristic for choosing the regularization parameter in ill-posed problems, SIAM J. Sci. Comput., 17 (1996), 956–972.
- [19] P. C. Hansen and M. Saxild-Hansen, AIR Tools – a MATLAB package of algebraic iterative reconstruction methods, J. Comput. Appl. Math., 236 (2012), 2167–2178.
- [20] B. Hofmann, B. Kaltenbacher, C. Pöschl and O. Scherzer, A convergence rates result for Tikhonov regularization in Banach spaces with non-smooth operators, Inverse Problems, 23 (2007), 987–1010.
- [21] B. Hofmann and P. Mathé, Parameter choice under variational inequalities, Inverse Problems, 28 (2012), 104006.
- [22] T. Hohage and F. Weidling, Verification of a variational source condition for acoustic inverse medium scattering problems, Inverse Problems 31 (2015), no. 7, 075006.
- [23] T. Hohage and F. Weidling, Characterizations of variational source conditions, converse results, and maxisets of spectral regularization methods, SIAM J. Numer. Anal., 55 (2017), no. 2, 598–620.
- [24] Q. Jin, Hanke-Raus heuristic rule for variational regularization in Banach spaces, Inverse Problems, 32 (2016), 085008.
- [25] Q. Jin, On a heuristic stopping rule for the regularization of inverse problems by the augmented Lagrangian method, Numer. Math., 136 (2017), 973–992.
- [26] Q. Jin, Convergence rates of a dual gradient method for constrained linear ill-posed problems, Numer. Math., 151 (2022), no. 4, 841–871.
- [27] Q. Jin, and W. Wang, Landweber iteration of Kaczmarz type with general non-smooth convex penalty functionals, Inverse Problems, 29 (2013), 085011.
- [28] Q. Jin and M. Zhong, Nonstationary iterated Tikhonov regularization in Banach spaces with uniformly convex penalty terms, Numer. Math., 127 (2014), no. 3, 485–513.
- [29] S. Kindermann and A. Neubauer, On the convergence of the quasioptimality criterion for (iterated) Tikhonov regularization, Inverse Probl. Imaging, 2 (2008), 291–299.
- [30] S. Kindermann and K. Raik, Convergence of heuristic parameter choice rules for convex Tikhonov regularization, SIAM J. Numer. Anal., 58 (2020), no. 3, 1773–1800.
- [31] S. Lu, P. Niu and F. Werner, On the asymptotical regularization for linear inverse problems in presence of white noise, SIAM/ASA J. Uncertain. Quantif., 9 (2021), no. 1, 1–28.
- [32] A. Rieder, Runge-Kutta integrators yield optimal regularization schemes, Inverse Problems, 21 (2005), 453–471.
- [33] F. Schöpfer, A. K. Louis and T. Schuster, Nonlinear iterative methods for linear ill-posed problems in Banach spaces, Inverse problems, 22 (2006), 311–329.
- [34] T. Schuster, B. Kaltenbacher, B. Hofmann and K. S. Kazimierski, Regularization Methods in Banach Spaces, Radon Series on Computational and Applied Mathematics, vol 10, Berlin: Walter de Gruyter, 2012.
- [35] U. Tautenhahn, On the asymptotical regularization of nonlinear ill-posed problems, Inverse Problems 10 (1994), 1405-1418.
- [36] C. Zlinscu, Convex Analysis in General Vector Spaces, World Scientific Publishing Co., Inc., River Edge, 2002.
- [37] Y. Zhang, B. Hofmann, On fractional asymptotical regularization of linear ill-posed problems in Hilbert spaces, Fract. Calculus. Appl. Anal., 22 (2019), 699-721.
- [38] Y. Zhang and B. Hofmann, On the second-order asymptotical regularization of linear ill-posed inverse problems, Appl. Anal., 99 (2020), no. 6, 1000–1025.
- [39] M. Zhong, W. Wang, S. Tong, An asymptotical regularization with convex constraints for inverse problems, Inverse Problems, 38 (2022), 045007.
- [40] M. Zhong, W. Wang and K. Zhu, On the asymptotical regularization with convex constraints for nonlinear ill-posed problems, Applied Mathematics Letters, 133 (2022), 108247.
- [41] M. Zhu and T. F. Chan, An efficient primal-dual hybrid gradient algorithm for total variation image restoration, CAM Report 08-34, UCLA (2008).