DST: Dynamic Substitute Training for Data-free Black-box Attack
Abstract
With the wide applications of deep neural network models in various computer vision tasks, more and more works study the model vulnerability to adversarial examples. For data-free black box attack scenario, existing methods are inspired by the knowledge distillation, and thus usually train a substitute model to learn knowledge from the target model using generated data as input. However, the substitute model always has a static network structure, which limits the attack ability for various target models and tasks. In this paper, we propose a novel dynamic substitute training attack method to encourage substitute model to learn better and faster from the target model. Specifically, a dynamic substitute structure learning strategy is proposed to adaptively generate optimal substitute model structure via a dynamic gate according to different target models and tasks. Moreover, we introduce a task-driven graph-based structure information learning constrain to improve the quality of generated training data, and facilitate the substitute model learning structural relationships from the target model multiple outputs. Extensive experiments have been conducted to verify the efficacy of the proposed attack method, which can achieve better performance compared with the state-of-the-art competitors on several datasets.
1 Introduction
Deep neural network models have achieved the state of the art performances in many challenging computer-vision tasks [9, 29, 16]. These models have been wide-spread adopted in real-world applications, e.g., self-driving cars, license plate reading, disease diagnosis from medical images, and activity classification. However, recent studies [30, 8] show that deep neural networks are highly vulnerable to adversarial examples, which contain small and imperceptible perturbations crafted to fool the target models. This attracts more researchers to study the attack and defense for better assessing and improving the robustness of deep models.
Adversarial attack methods can be categorized into two main settings, i.e., white-box attack [24, 2, 17, 21, 5] and black-box attack [3, 13, 12, 6, 3, 4, 7, 35], by whether or not the attackers can have full access to the structure and parameters of the target model. Nowadays, in the era of big data, data is one of the most valuable assets for companies, and much of it also has privacy issues. Thus, in practical cases, it is not only difficult for attackers to know the details of the target model, but also hardly obtain the training data for the target model, even the number of categories.
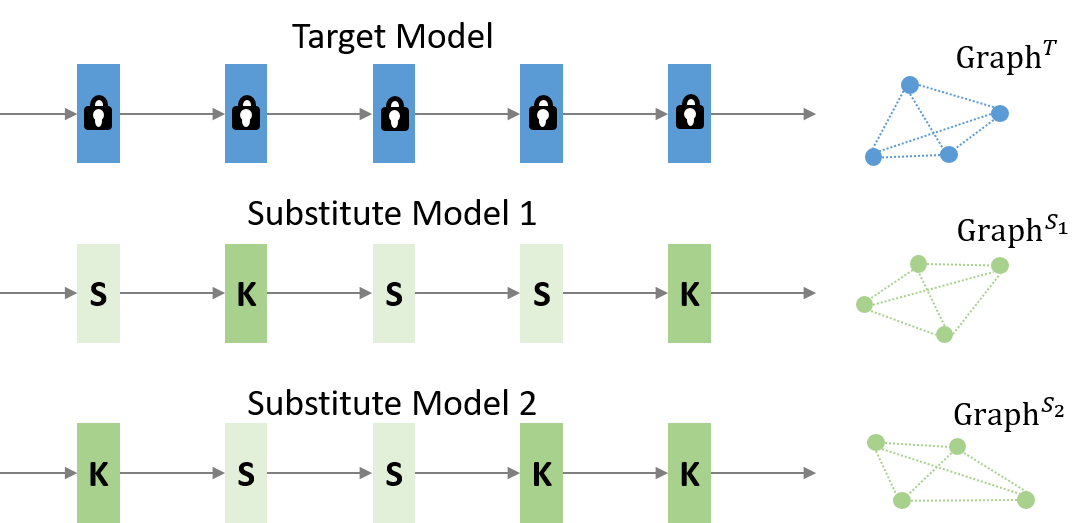
The purpose of this paper is to successfully achieve a data-free black-box attack according to the given target model. “Data-free” suggests that we cannot access any knowledge about the data distribution (e.g., the type of data, number of categories, etc.), which was used for the target model; “Black-box” indicates the target model structure is completely shielded from the attackers, resulting in the limitation on getting model parameters or features of middle layers. The only available thing we can use is the output of probabilities/labels from the target model. Such a strict setting is more in line with the requirements of real-world scenarios, especially at a time when privacy data protection has attracted more attention. Inspired by the substitute training methods in black-box attack, many works [38, 32] try to tackle the data-free black-attack through learning a substitute model for the target one with generated training data. However, there exist two main limitations in existing methods, (1) static substitute model structure for different targets: due to the lack of prior knowledge, utilizing the same and static substitute model architecture for various target models or tasks definitely can not achieve powerful attack. Meanwhile, it is impractical and cost expensive to train multiple models to find the most suitable substitute model structure for each target variation. (2) Assumption of knowing the number of categories for the target model: for the total data-free black-box attack, it is unreasonable for knowing the number of training data classes for the target model. Thus, using the label as the generator guidance information to synthesize diverse and label-controlled data for substitute training is unpractical.
In this study, to address the limitations of existing methods, we propose a novel and task-driven Dynamic Substitute Training (DST) attack method for data-free black-box attacking, as illustrated in Fig. 1. Our DST attack adopts the basic substitute learning framework as in [38, 32, 14], which generates the training data via a generator with noise as input, and takes advantage of the knowledge distillation concept to encourage the substitute model to has the same output as the target one when facing the same synthesized training image. To tackle the constant substitute model architecture problem (limitation (1)), in our DST attack algorithm, for the first time, we introduce a dynamic substitute structure learning strategy to automatically generate a more suitable substitute model structure according to different target models and tasks. To achieve such dynamic structure generation, we specially design a learnable dynamic gate to determine which blocks in the deep architecture can be skipped. To deal with being unaware of the prior knowledge about the training data classes issue (limitation (2)), we introduce a graph-based structural information learning strategy in DST, to further improve the generator performance and enhance the substitute training process. Such a learning strategy can facilitate the substitute model learning more implicit and detailed information from the structural relationship among multiple target model outputs. Meanwhile, such structural information can reflect the representation distance among a group of generated training data and stimulate the generator to deliver more valuable training data. Overall, our DST attack can adaptively generate optimal substitute model structure for various targets, improve the consistency between the substitute and target model, and encourage the generator to synthesize better training data via learning structural information. This can promote the data-free black-box attack performance.
The main contributions of this work are summarized below, (1) We propose a novel and task-driven dynamic substitute training attack method to boost the data-free black-box attacking performance. (2) For the first time, we introduce a dynamic substitute structure learning strategy to adaptively generate optimal substitute model architecture according to the different target models and tasks, instead of adopting the same and static network. (3) To encourage the substitute model to learn more details from the target model and improve the quality of generated training data, we propose a graph-based structural information learning strategy to deeply explore the structural, relational, and valuable information from a bunch of target outputs. (4) The comprehensive experiments over four public datasets and one online machine learning platform demonstrate that our DST method can achieve SOTA attack performance and significantly reduce the query times during the substitute training.
2 Related Work
Adversarial Attack. Since deep learning models have achieved remarkable success on most computer vision tasks [9, 29, 16, 26, 25, 31], the study for the security of these models has attracted many researchers. [30] illustrates that deep neural networks are susceptible to adversarial perturbations. Subsequently, more and more works [24, 2, 17, 21, 8, 5, 3, 4, 7, 11, 34, 19] focus on the adversarial example generation task. In general, the attack task can be divided into white-box and black-box attacks, the former one can know the knowledge of the structure and parameters of the target model, and the latter one only has the access to the simple output of the target. Most white-box algorithms [24, 2, 17, 21, 8, 5] generate adversarial examples based on the gradient of loss function with respect to the inputs. For the black-box attack, some methods [3, 4, 7] iteratively query the outputs of target model and estimate the gradient of target model via training a substitute model; and others [11, 34, 19] focus on improving the transferability of adversarial examples across different models. In this work, we focus on the more practical and challenging scenario, i.e., the data-free black-box attack, which attacks the black-box target model without the need for any real data samples.
Data-free Black-box Attack. In practice, attackers can hardly obtain the training data for target model, even the number of categories. Thus, some works [22, 38, 32, 10, 36, 14] begin to study the data-free black-box attack task, which generate adversarial examples without any knowledge about the training data distribution. Mopuri et al. [22] propose an attack to corrupt the extracted features at multiple layers to realize independent of the underlying task. Huan et al. [10] learn adversarial perturbations based on a mapping connection between fine-tuned model and target model. [38, 32] utilize a generator with noise as input to synthesize data for training a substitute model to learn information from the target one via knowledge distillation. In this paper, we adopt the basic framework as [38, 32, 14]. Different from these works, the structure of our substitute model is not fixed, but dynamically generated and optimized according to the different target models and various datasets. Moreover, we train the substitute model and generator not only from a single output of the target model, but also from the detailed and implicit information represented in the graph-based relationship of multiple target outputs.
3 Methodology
3.1 Framework Overview
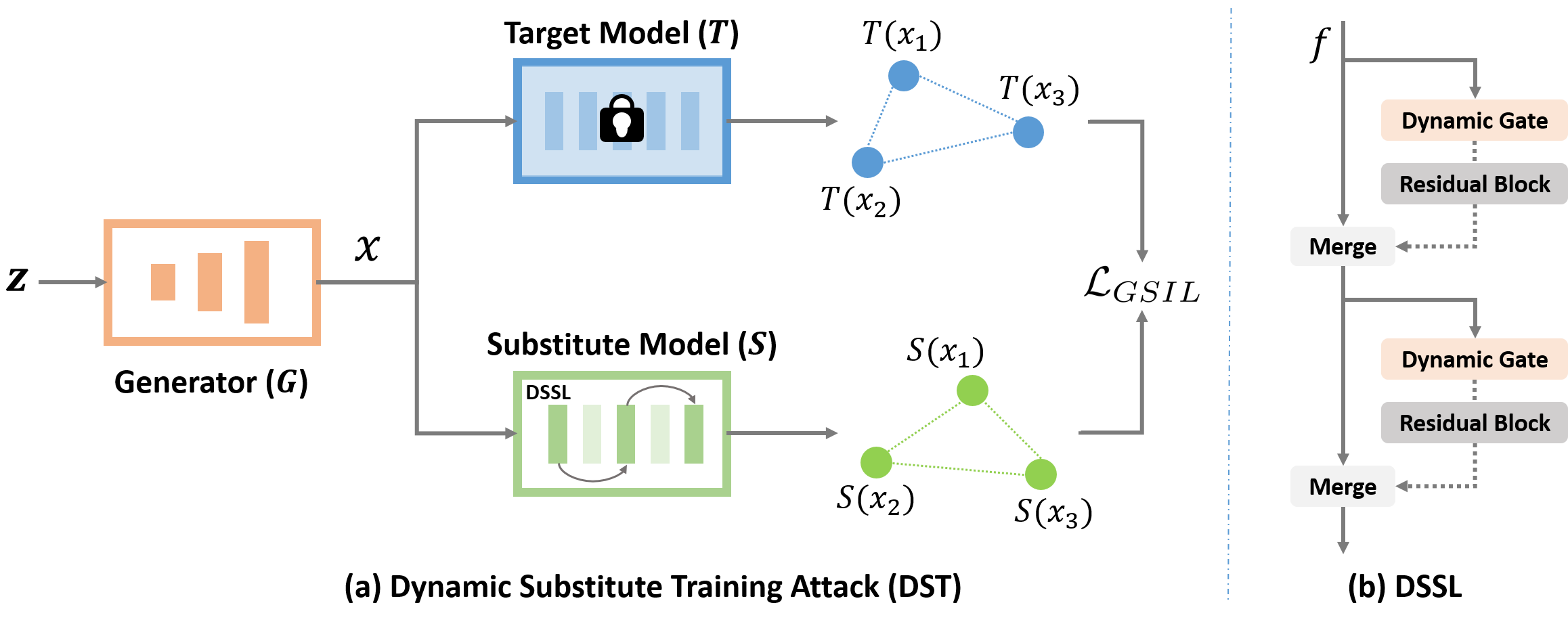
Figure 2(a) illustrates the schematic of our proposed unified Dynamic Substitute Training attack framework (DST), which mainly consists of two learnable components, i.e., a generator and a substitute model . More precisely, DST employs a generator to synthesize training samples with Gaussian random noise ,
| (1) |
where and denote the height and width of the generated training samples. Subsequently, we feed the synthesized data into a target model and a substitute model simultaneously. The teacher-student strategy is re-purposed here to encourage to learn as similar decision boundary as ,
| (2) |
where denotes a metric function to measure the distance between the outputs from and . After such substitute training process, attacks can be conducted on the well-trained , and then transferred to .
As proposed in [38, 32], the aims to minimize output discrepancy with the , while the tries to maximize the discrepancy to explore various hard samples for substitute training. For model parameters learning via gradient descent, such objective maximizing function for learning can be transferred to minimize the loss as the following,
| (3) |
Overall, the main contributions of this paper concentrate on the learning of substitute model. Remarkably, we for the first time present a dynamic substitute searching strategy to learn an optimal structure for the substitute model, rather than manually select one according to priors [38, 32, 14]. We argue that such a design can best ‘mimic’ the characteristics of the target model, both from the structure of the model and the spatial distribution of parameters, which is more flexible, practical, and significant. Furthermore, in order to stimulate the substitute model to learn more details from the target and improve the quality of generated training data, we propose a graph-based structural information learning strategy to deep explore more structural, relational, and valuable information from multiple target outputs.
3.2 Dynamic Substitute Structure Learning
Compared with static network architectures, dynamic network structure usually has the superiority in network capacity to various tasks and targets. In our black-box attack task, according to different target models and various datasets, our Dynamic Substitute Structural Learning strategy (DSSL) can adaptively find more reasonable substitute model architecture to achieve more powerful attack ability.
Considering that most deep networks have adopted a block-based residual learning design following the remarkable success of ResNet [9] (e.g., MobileNetV2 [28], ShuffleNet [37], and ResNext [33]), we, therefore, construct our DSSL based on the residual design to be generally applicable in the common deep networks.
As shown in Fig. 2(b), the selecting probability of each path is generated by a dynamic gate. Such dynamic gate aims at predicting a one-hot vector, which denotes whether to execute or skip the branch of residual block. Here, we adapt a set of light-weight operations to realize the dynamic gate function with the feature as the input,
| (4) |
where means the global average pooling layer, and and are the fully-connected layer parameters. To realize discrete binary decisions for the path chosen, we choose hard sigmoid function as , which can be defined as,
| (5) |
where we set the threshold as 0.5, which clips the outputs of to 0 or 1. The is the crucial parameter used as an approximation of step function that emits binary decisions.
3.3 Graph-based Structural Information Learning
To constrain the consistency of the outputs between the and and improve the quality of generated training data by , we argue that it is important to explore the implicit structural relationships among different outputs. The graph-based relational representation can reflect the deep knowledge of , and learning such structural features can help realize a more similar decision boundary as to further improve the attack performance. Meanwhile, such structural relationships can reflect the distance among the multiple generated training images, and improve the data quality generated by in return.
During the training, we propose a novel Graph-based Structural Information Learning strategy (GSIL) to indict the underlying relationships of the model outputs. By virtue of the graph network conception, in each mini-batch during training, the nodes of graph are the model outputs according to inputs, and the corresponding edges are the relation formulated as an adjacent matrix among these nodes. Specially, the structural information graph is defined as,
| (6) | |||
where B means the number of training data in each training iteration, i.e., the value of the mini-batch, and the edge is defined as the Euclidean distance between the two node representations / model outputs.
Once we obtain the structural information graph, the corresponding constrain can be produced to further restrict the discrepancy between the of and the of . The difference of such graphs contains the node discrepancy and edge discrepancy formulated as,
| (7) | ||||
where and refer to the node and edge set for and . The Kullback-Leibler Divergence function is used to measure the discrepancy between two nodes, and the MSE loss is applied to restrict the differences between the two edges. And and are the hyper-parameters to balance the discrepancy of the nodes and edges. In DST model learning, we apply the to measure the discrepancy between the and used in Eq. 2 and Eq. 3.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4 Experiment
4.1 Experiment Setup
Datasets and model structure. 1) MNIST [18]: The target model is pre-trained on AlexNet [16], VGG-16 [29], and ResNet-18 [9]. 2) CIFAR-10 [15]: The target model is pre-trained on AlexNet, VGG-16, and ResNet-18. 3) CIFAR-100 [15]: The target model is pre-trained on VGG-19 and ResNet-50. 4) Tiny Imagenet [27]: The target model is pre-trained on ResNet-50. For these four datasets, the default substitute model basic structure is ResNet-34.
Competitors. To verify the efficacy of our DST, we compare our attacking results with the existing state-of-the-art data-free black-box attacks, i.e., GD-UAP [22], Cosine-UAP [36], DaST [38], MAZE [14], and DDG+AST [32].
Implementation details. We use Pytorch for Implementation. We utilize Adam to train our substitute model and generator from scratch, and all weights are randomly initialized using a truncated normal distribution with std of 0.02. The initial learning rates of the generator and substitute model are set as 0.0001 and 0.001, respectively, they are gradually decreased to zero from the 80th epoch, and stopped at the 150th epoch. We set the mini-batch size as 500, the hyper-parameters and are equally as 1. The in Eq. 5 is set as 1 in the following experiments. Our model is trained by one NVIDIA GeForce GTX 1080Ti GPU. We apply PGD [21] as the default white-box attack method to generate adversarial images over the well-trained substitute model during the evaluation. We also utilize several classic attack methods for extensive experiments, such as FGSM [8], BIM [17] and C&W [2]. During the model optimizing stage, there are no real images used for model learning, only random noise is utilized as input. For evaluation, the adversarial samples to conduct attack crafted only on test set over four datasets.
Evaluation metrics. Following the two scenarios proposed in DaST [38], i.e., only getting the output label from the target model and accessing the output probability well, we name these two scenarios as Probability-based and Label-based. In the experiments, we report the attack success rates (ASRs) of the adversarial examples generated by the substitute model to attack the target model. As in DaST [38], for non-target attacking, we only attack the images classified correctly by the target model. For target attacking, we only generate adversarial examples on the images which are not classified to the specific wrong labels. We conduct ten times over each testing, and report the average results.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
4.2 Black-box Attack Results
Comparisons with the state-of-the-art attacks. As shown in Tab. 1, our DST attack beats all competitors with significant margins. We conduct extensive comparisons with these competitors from several aspects, i.e., the diverse tasks (datasets), various target models, and different attack goals (target/non-target). The results show that our DST method can achieve the best attack ability for black-box attack without using any real data as input.
Comparisons with competitors using various white-box adversarial sample generation methods. Under the probability-based scenario, we compare the ASRs with competitors when using different white-box attack methods via well-trained substitute models. As illustrated in Tab. 2, we apply four classic attacks to generate adversarial samples over substitute models for attacking the target models on three datasets. Compared to other data-free black-box attack algorithms, our DST can dynamically generate suitable substitute model structure and learn structural information from the target output, thus, DST achieves the best ASRs over most experiments.
Comparisons with competitors which use different deep networks as their substitute model. As shown in Tab. 3, we compare our DST attack performance with competitors which can choose a bunch of networks as their substitute model. Even our DST can only use ResNet-34 as the basic substitute model, thanks to the dynamic substitute structure learning strategy, we can still achieve better attack performance when the competitors are able to choose the best substitute model from a set of different networks. We can also notice that the attack performance of the competitors is highly dependent on the chosen substitute model structure. Such results demonstrate that our DST can automatically generate optimal substitute model according to the target, which is crucial for the practical applications.
Comparisons with state-of-the-art competitors against online Microsoft Azure example model. The attack performance targeting real-world black-box model is vital to evaluate the adversarial example generation method. Thus, we compare our DST with competitors over the online Microsoft Azure model. As in Tab. 4, our DST outperforms all competitors, which indicates the practical black-box attack capacity of the proposed DST in real-world applications.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
4.3 Ablation Study
To further explore the efficacy of components in our DST attack, we conduct extensive ablation studies over the following variants: (1) ‘Baseline-I’: using random noise as input to generate training data and applying MSE loss to constrain the outputs’ similarity between the and ; (2) ‘Baseline-II’: using random noise as input to generate training data and applying Kullback-Leibler Divergence to constrain the outputs’ similarity between the and ; (3) ‘+ GSIL’: using the graph-based structural information learning constrain to conduct substitute training; (4) ‘+ DSSL’: based on the ‘+ GSIL’, a dynamic substitute structure learning strategy is applied to adaptively generate suitable substitute model structure, and it is the whole DST attack model.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The efficacy of the components for attack ability in DST attack. As in Tab. 5, comparing the results among the variants, we can notice the following observations, (1) ‘Baseline-I’ can only realize basic attack ability against the target model. (2) Comparing the ‘Baseline-II’ with ‘Baseline-I’, it is obvious that changing the MSE loss to Kullback-Leibler Divergence constrain can better restrict the output similarity between the and . (3) Comparing the results between the ‘Baseline-II’ and ‘+ GSIL’, the effectiveness of the structural information learning strategy is proved. Specially, the distance of graph edges represent the outputs’ structural relationship, thus, learning such information can greatly encourage to learn more detailed knowledge from the . (4) With the ‘+DSSL’ module, the ASRs have been significantly improved. Such results illustrate that the static substitute structure does not benefit to various attack targets, and self-optimized substitute structure is more reasonable for unknown diverse attack targets.
The efficacy of dynamic substitute structure learning strategy for different tasks and various target models. To better verify the effectiveness of the proposed dynamic substitute structure learning strategy, we choose several basic deep learning networks, i.e., ResNet-18, ResNet-34, ResNet-50, and ResNet-101, as the substitute models. For a fair comparison, compared to ‘+ DSSL (Ours)’ the basic substitute model also uses the graph-based structural information learning strategy. As shown in Tab. 6, we can draw the following conclusions, (1) By applying the dynamic substitute structure learning strategy, our method can achieve much better attack results over all tasks and target models, such as comparing the ‘ResNet-34’ with the next lower raw ‘+ DSSL (Ours)’. It is reasonable for different tasks and target models to have various corresponding structures as the best substitute models. Thus, our DSSL component adaptively generating more reasonable substitute structure can indeed promote the attack performance. (2) For the same target model over the same dataset, the ASRs of ‘+ DSSL (Ours)’ have little differences among various basic substitute model architectures. For example, to attack the AlextNet model trained on MNIST, our ASRs are around 69% with small fluctuations based on four basic models under non-target attack setting. However, without applying the dynamic substitute structure learning strategy, the ASRs change dramatically from 47% to 59% according to the different substitute models. These results reinforce that our method can automatically produce optimal substitute structures over different basic models. (3) We also report the skip rate in the experiments, it is obvious that the number of skipped blocks is more when the basic substitute structure is complex with deeper structure, e.g., the skip rate is usually larger for utilizing ResNet-101 as basic substitute model compared to the ResNet-18. And the skip rate is usually smaller when targeting more difficult task, e.g., CIFAR-100 dataset, due to the substitute model keeping more blocks to learn more complex feature representations.
| Method | ASRs | Distance | Train-Q | Test-Q |
|---|---|---|---|---|
| GLS [23] | 53.28 | 3.68 | - | 311 |
| Boundary [1] | 99.32 | 3.94 | - | 702 |
| DaST [38] | 92.48 | 3.79 | 20M | - |
| MAZE [14] | 93.95 | 3.90 | 30M | - |
| DDG+AST [32] | 93.29 | 3.88 | 15M | - |
| Baseline-I | 55.92 | 3.82 | 30M | - |
| Baseline-II | 70.28 | 3.91 | 30M | - |
| + GSIL | 83.24 | 3.76 | 13M | - |
| + DSSL | 95.02 | 3.80 | 9M | - |
The efficacy of each proposed component for reducing the number of query times during the substitute training. Considering that in real-world applications, many online platforms defend themselves by detecting the number of query times for a single IP address, thus, more and more attack methods pay more attention to decreasing the number of query times. As illustrated in Tab. 7, we compare the number of query times during both the model learning and inference stage with competitors. (1) With a similar perturbation distance, our DST attack method not only achieves the comparable ASRs against others, but also needs the least query times during training and zero query times during attacking. As for the compared score-based and decision-based attacks, they need to query the target model to generate each attack in the evaluation stage, and feed the target model with the same original data numerous times which can be tracked easily by the defender. (2) With the structural information learning strategy, the number of training query times drops significantly, which states that the graph-based relationship among the outputs can help learn knowledge much quicker from the target one. (3) With the proposed dynamic substitute structure learning strategy, the number of training query times of our attack method declines to some extent, which explain that with optimal structure not only learn better but also learn faster from the .
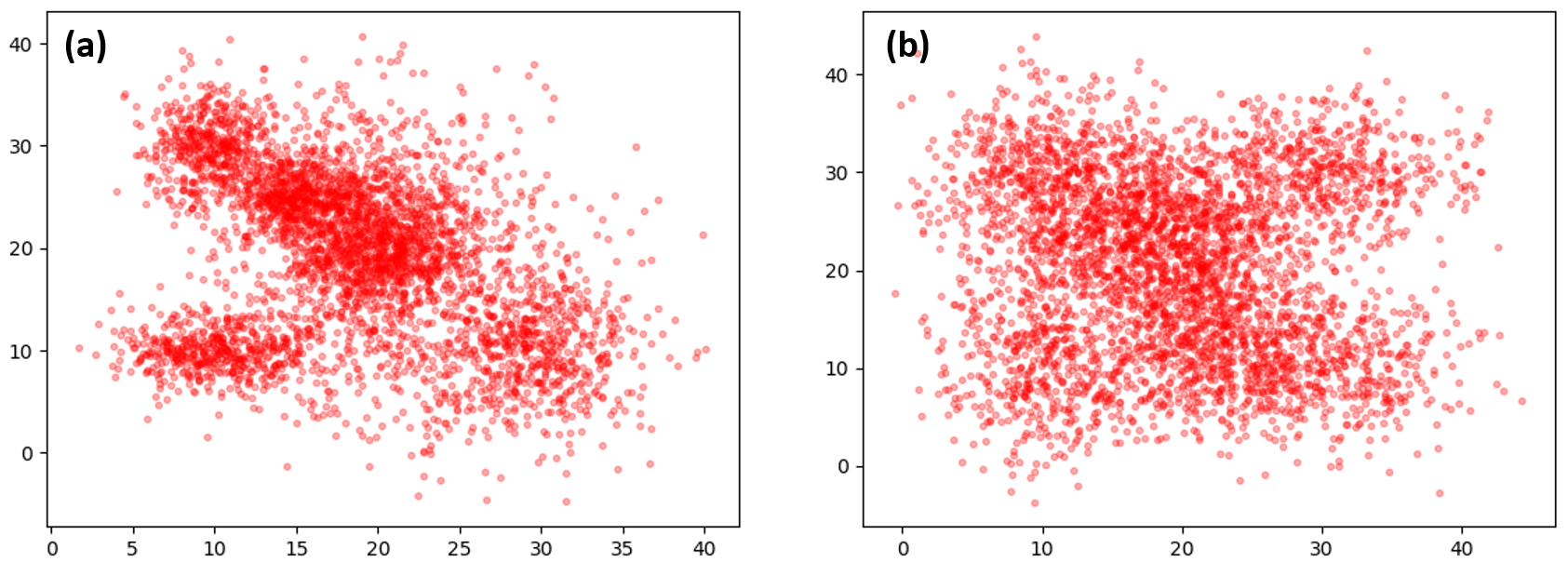
The efficacy of graph-based structural information learning strategy for the quality of generated training data. In terms of feature, we visualize the feature distribution of synthesized data extracted by the target model in Fig. 3. Such qualitative results show that, with applying the proposed graph-based structural information learning strategy, the generated data is more evenly distributed, which is friendly for substitute model training.
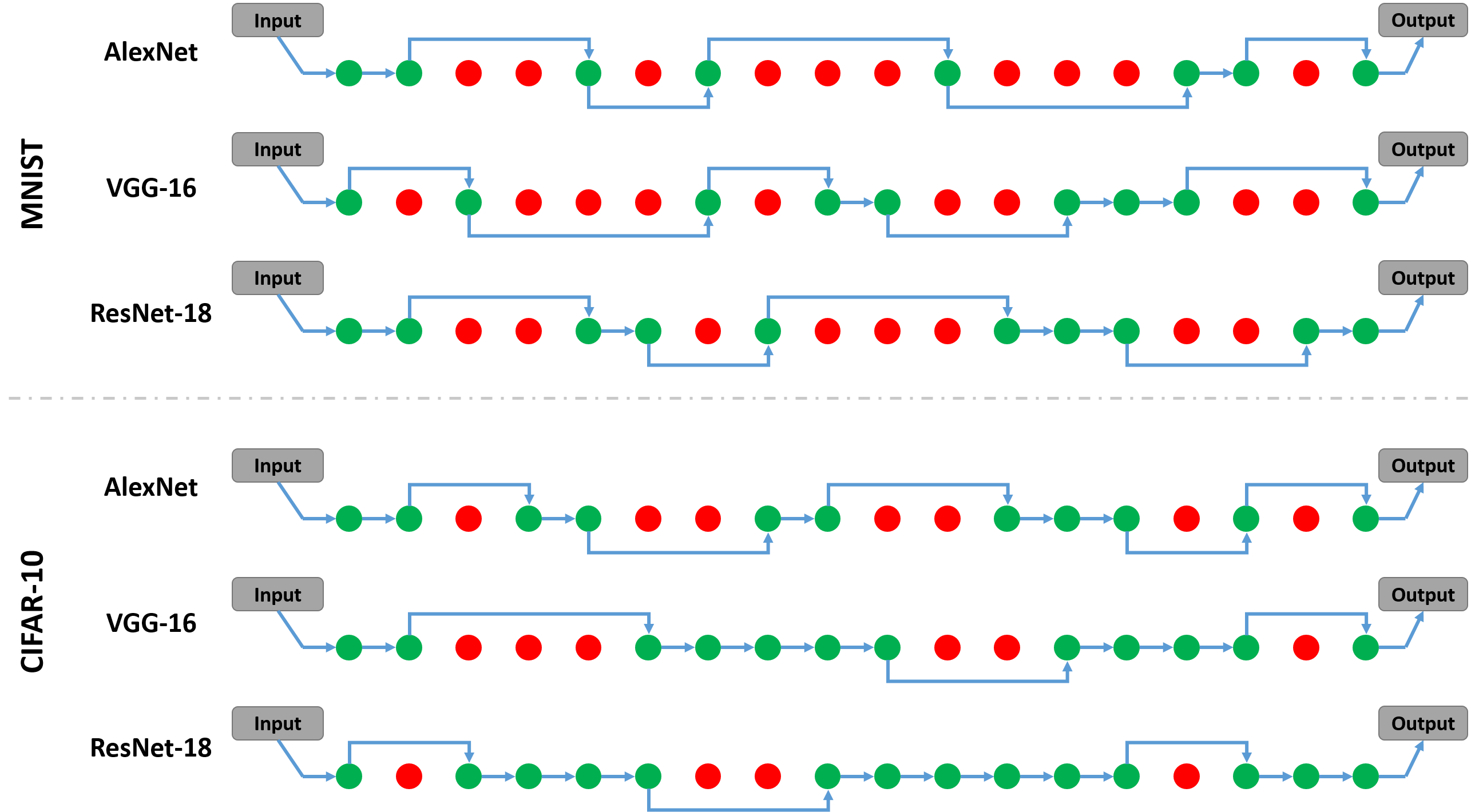
The visualizations of dynamic substitute model structures according to different target models and tasks. As shown in Fig. 4, for the same basic substitute model architecture, the optimal substitute models, generated by our dynamic substitute structure learning strategy, are different according to various targets. Considering that the MNIST dataset is relatively simple compared to CIFAR-10, the number of skipped blocks is more and keeping blocks is fewer for attacking the MNIST model. Meanwhile, the AlexNet expresses relatively simple representations, thus, the corresponding optimal substitute models keep fewer blocks to learn knowledge from AlexNet.
Social impact and limitations. The task of adversarial attack is predominantly utilized as a tool for the verification and validation the robustness of the state-of-the-art deep models. Our DST method shall not be utilized to attack existing recognition systems. On the other hand, our DST still relies on white-box attack methods, we will focus on attacking directly and study the defense algorithm in future.
5 Conclusion
To tackle the data-free black-box attack task, we propose a novel dynamic substitute training attack method (DST). DST generate the optimal substitute model structure according to the different targets by the proposed dynamic substitute structure learning strategy, and encourage the substitute model to learn implicit information from the target one via graph-based structure information learning constrain. The experiments show that DST can achieve the best attack performance compared with existing methods.
6 Acknowledgement
This work was supported in part by NSFC Project (62176061), Shanghai Municipal Science and Technology Major Project (2018SHZDZX01), and Shanghai Research and Innovation Functional Program (17DZ2260900).
References
- [1] Wieland Brendel, Jonas Rauber, and Matthias Bethge. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. arXiv preprint, 2017.
- [2] Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In 2017 ieee symposium on security and privacy (sp), 2017.
- [3] Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM workshop on artificial intelligence and security, pages 15–26, 2017.
- [4] Weiyu Cui, Xiaorui Li, Jiawei Huang, Wenyi Wang, Shuai Wang, and Jianwen Chen. Substitute model generation for black-box adversarial attack based on knowledge distillation. In 2020 IEEE International Conference on Image Processing (ICIP), pages 648–652. IEEE, 2020.
- [5] Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. Boosting adversarial attacks with momentum. In CVPR, 2018.
- [6] Yinpeng Dong, Hang Su, Baoyuan Wu, Zhifeng Li, Wei Liu, Tong Zhang, and Jun Zhu. Efficient decision-based black-box adversarial attacks on face recognition. In CVPR, 2019.
- [7] Xianfeng Gao, Yu-an Tan, Hongwei Jiang, Quanxin Zhang, and Xiaohui Kuang. Boosting targeted black-box attacks via ensemble substitute training and linear augmentation. Applied Sciences, 9(11):2286, 2019.
- [8] Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint, 2014.
- [9] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [10] Zhaoxin Huan, Yulong Wang, Xiaolu Zhang, Lin Shang, Chilin Fu, and Jun Zhou. Data-free adversarial perturbations for practical black-box attack. In Pacific-Asia conference on knowledge discovery and data mining, pages 127–138. Springer, 2020.
- [11] Qian Huang, Isay Katsman, Horace He, Zeqi Gu, Serge Belongie, and Ser-Nam Lim. Enhancing adversarial example transferability with an intermediate level attack. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4733–4742, 2019.
- [12] Andrew Ilyas, Logan Engstrom, Anish Athalye, and Jessy Lin. Black-box adversarial attacks with limited queries and information. arXiv preprint, 2018.
- [13] Andrew Ilyas, Logan Engstrom, and Aleksander Madry. Prior convictions: Black-box adversarial attacks with bandits and priors. arXiv preprint, 2018.
- [14] Sanjay Kariyappa, Atul Prakash, and Moinuddin K Qureshi. Maze: Data-free model stealing attack using zeroth-order gradient estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13814–13823, 2021.
- [15] Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. psu.edu, 2009.
- [16] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60(6):84–90, 2017.
- [17] Alexey Kurakin, Ian Goodfellow, and Samy Bengio. Adversarial examples in the physical world. arXiv preprint arXiv:1607.02533, 2016.
- [18] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- [19] Maosen Li, Cheng Deng, Tengjiao Li, Junchi Yan, Xinbo Gao, and Heng Huang. Towards transferable targeted attack. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 641–649, 2020.
- [20] Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of machine learning research, 9(Nov):2579–2605, 2008.
- [21] Aleksander Madry, Aleksandar Makelov, and Ludwig Schmidt. Towards deep learning models resistant to adversarial attacks. arXiv preprint, 2017.
- [22] Konda Reddy Mopuri, Aditya Ganeshan, and R Venkatesh Babu. Generalizable data-free objective for crafting universal adversarial perturbations. IEEE transactions on pattern analysis and machine intelligence, 41(10):2452–2465, 2018.
- [23] Nina Narodytska and Shiva Prasad Kasiviswanathan. Simple black-box adversarial perturbations for deep networks. arXiv preprint arXiv:1612.06299, 2016.
- [24] Nicolas Papernot, Patrick McDaniel, Somesh Jha, Matt Fredrikson, Z. Berkay Celik, and Ananthram Swami. The limitations of deep learning in adversarial settings. In 2016 IEEE European symposium on security and privacy (EuroS&P), 2016.
- [25] Xuelin Qian, Huazhu Fu, Weiya Shi, Tao Chen, Yanwei Fu, Fei Shan, and Xiangyang Xue. M3lung-sys: A deep learning system for multi-class lung pneumonia screening from ct imaging. IEEE journal of biomedical and health informatics, 24(12):3539–3550, 2020.
- [26] Xuelin Qian, Yanwei Fu, Tao Xiang, Yu-Gang Jiang, and Xiangyang Xue. Leader-based multi-scale attention deep architecture for person re-identification. IEEE transactions on pattern analysis and machine intelligence, 42(2):371–385, 2019.
- [27] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- [28] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018.
- [29] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [30] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. arXiv preprint, 2013.
- [31] Wenxuan Wang, Yanwei Fu, Xuelin Qian, Yu-Gang Jiang, Qi Tian, and Xiangyang Xue. Fm2u-net: Face morphological multi-branch network for makeup-invariant face verification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5730–5740, 2020.
- [32] Wenxuan Wang, Bangjie Yin, Taiping Yao, Li Zhang, Yanwei Fu, Shouhong Ding, Jilin Li, Feiyue Huang, and Xiangyang Xue. Delving into data: Effectively substitute training for black-box attack. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4761–4770, 2021.
- [33] Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1492–1500, 2017.
- [34] Jiancheng Yang, Yangzhou Jiang, Xiaoyang Huang, Bingbing Ni, and Chenglong Zhao. Learning black-box attackers with transferable priors and query feedback. Advances in Neural Information Processing Systems, 33, 2020.
- [35] Bangjie Yin, Wenxuan Wang, Taiping Yao, Junfeng Guo, Zelun Kong, Shouhong Ding, Jilin Li, and Cong Liu. Adv-makeup: A new imperceptible and transferable attack on face recognition. International Joint Conference on Artificial Intelligence (IJCAI), 2021.
- [36] Chaoning Zhang, Philipp Benz, Adil Karjauv, and In So Kweon. Data-free universal adversarial perturbation and black-box attack. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7868–7877, 2021.
- [37] Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6848–6856, 2018.
- [38] Mingyi Zhou, Jing Wu, Yipeng Liu, Shuaicheng Liu, and Ce Zhu. Dast: Data-free substitute training for adversarial attacks. In CVPR, 2020.