DRIP: Domain Refinement Iteration with Polytopes for Backward Reachability Analysis of Neural Feedback Loops
Abstract
Safety certification of data-driven control techniques remains a major open problem. This work investigates backward reachability as a framework for providing collision avoidance guarantees for systems controlled by neural network (NN) policies. Because NNs are typically not invertible, existing methods conservatively assume a domain over which to relax the NN, which causes loose over-approximations of the set of states that could lead the system into the obstacle (i.e., backprojection (BP) sets). To address this issue, we introduce DRIP, an algorithm with a refinement loop on the relaxation domain, which substantially tightens the BP set bounds. Furthermore, we introduce a formulation that enables directly obtaining closed-form representations of polytopes to bound the BP sets tighter than prior work, which required solving linear programs and using hyper-rectangles. Furthermore, this work extends the NN relaxation algorithm to handle polytope domains, which further tightens the bounds on BP sets. DRIP is demonstrated in numerical experiments on control systems, including a ground robot controlled by a learned NN obstacle avoidance policy.
Neural Networks, Data-Driven Control, Safety Verification, Reachability Analysis
1 Introduction
Neural networks (NNs) offer promising capabilities for data-driven control of complex systems (e.g., self-driving cars). However, formally certifying safety properties of systems that are controlled by NNs remains an open challenge.
To this end, recent work developed reachability analysis techniques for Neural Feedback Loops (NFLs), i.e., dynamical systems with NN control policies [1, 2, 3, 4]. For forward reachability analysis, these techniques compute the set of states the system could reach in the future, given an initial state set, trained NN, and dynamics model. Due to the NNs’ high dimensionality and nonlinearities, exact analysis is often intractable. Thus, current methods instead compute guaranteed over-approximations of the reachable sets, based on relaxations of the nonlinearities in the NN [1, 2, 3] or dynamics [4, 1]. While forward reachable sets can then be used to check whether the closed-loop system satisfies desired properties (e.g., reaching the goal), forward methods can be overly conservative for obstacle avoidance [5].
Thus, this work focuses on backward reachability analysis [1, 5, 6, 7, 8, 9]. The goal of backward reachability analysis is to compute backprojection (BP) sets, i.e., the set of states the will lead to a given target/obstacle set under the given NN control policy and system dynamics. The system can be certified as safe if it starts outside the BP sets, but the non-invertibility of NNs presents a major challenge in calculating these sets. Recent work [1, 5, 6, 7] proposes to first compute a backreachable (BR) set, i.e., the set of states that lead to the target set for some control input within known control limits. These methods then relax the NN controller over the BR set, which is a superset of the BP set, and calculate bounds on the BP set via linear programs.
However, a key challenge with that formulation is the BP set over-approximations can remain loose. A major cause of this conservativeness is that the BR set is often large, leading to loose NN relaxations, and thus loose BP set approximations. Moreover, conservativeness compounds when calculated over multiple timesteps due to the wrapping effect [10]. Prior work introduced strategies based on set partitioning [5, 7, 6] and mixed integer linear programming (MILP) [7] to improve tightness, but these methods are fundamentally hindered by initializing with the BR set. This paper instead proposes a refinement loop, which, for a particular timestep, iteratively uses the previous BP set estimate to relax the NFL and compute a new BP set, which can lead to much tighter BP set estimates. At each iteration, this new strategy shrinks the domain over which the NFL is relaxed, which leads to a less conservative relaxation and ultimately tighter bounds on the BP sets. If desired, this idea could be used in conjunction with set partitioning [5, 7, 6].
Another key limitation of prior work is the use of axis-aligned bounding boxes to represent BP set estimates [5, 7, 6]. These hyperrectangles are computed by solving several linear programs (LPs) over states and controls, but hyperrectangles are often a poor approximation of the true BP sets. Instead, this paper introduces a new approach that enables directly obtaining a closed-form polytope representation for the BP set estimate. A key reason why this enables tighter BP set bounds is that the facets of the target set (or future BP sets in the multi-timestep algorithm) can be directly used as the objective matrix for the relaxation algorithm, which also automatically addresses the common issue of choosing facet directions in polytope design. Furthermore, we show that the NN can be relaxed over these polytope BP sets, which leads to much tighter relaxations and BP set estimates compared to prior work, which inflated polytopes to hyperrectangles.
To summarize, the main contribution of this work is DRIP, an algorithm that provides safety guarantees for NFLs, which includes domain refinement and a polytope formulation to give tighter certificates than state-of-the-art methods. Numerical experiments on the same data-driven control systems as in prior state-of-the-art works [5, 7, 6] demonstrate that DRIP can provide tighter bounds while remaining computationally efficient (s) and can certify obstacle avoidance for a robot with a learned NN policy.
2 Background
This section defines the dynamics, relaxations, and sets used for backward reachability analysis.
2.1 NFL Dynamics
As in [7], we assume linear time-invariant (LTI) dynamics,
| (1) | ||||
where is the state at discrete timestep , is the input, and are known system matrices, and is a known exogenous input. We assume and , where and are convex sets defining the operating region of the state space and control limits, respectively. The closed-loop dynamics are
| (2) | ||||
where is a state-feedback control policy, discussed next.
2.2 NN Control Policy & Relaxation
The control policy, , can be an arbitrary computation graph, composed of primitives that can be linearly relaxed [11, 12, 13]. For example, given an -layer NN with neurons in layer and nonlinear activation such that post-activation (e.g., ReLU, sigmoid), we need to be able to define such that
| (3) |
For each primitive, values of depend on the algorithm employed and are derived from intermediate bounds over the activation of the network, which can be obtained by applying the bound computation procedure (described next) to subsets of the network.
CROWN [14] and LIRPA algorithms in general [11] enable backward propagation of bounds (from function output to input, not to be confused with backward in time). For example, consider evaluating a lower bound on , using the relaxations defined in Eq. 3 to replace :
| (4) | ||||
where and . Through backsubstitution, we transformed a lower bound defined as a linear function over into a lower bound defined as a linear function over . By repeated application of this procedure to all operations in the network, we can obtain bounds that are affine in the input. That is, for a computation graph from Eq. 2, with input and output , given an objective matrix , we compute and such that
| (5) |
If is within some known set , these bounds can be concretized by solving . Closed-form solutions exist for some forms of .
2.3 Backreachable Sets & Backprojection Sets
For target set , define -step BP and BR sets as
| (6) | ||||
where and . We will typically drop the arguments and simply write . Clearly, . Since exactly computing BP sets is computationally difficult, this work aims to compute BP over-approximations (BPOAs), which provide a (guaranteed) conservative description of all states that will lead to the target set. For sets, upper bar notation conveys an outer bound, e.g., ; for vectors, bar notation conveys upper/lower bounds, e.g., .
Definition 2.1.
For some , is a BPOA if .
One efficient way to outer bound with hyper-rectangle is to solve the following optimization problems for each state , with the -th standard basis vector, [1]:
| (7) |
3 Approach
This section introduces our proposed approach, Domain Refinement Iteration with Polytopes (DRIP), with descriptions of the 3 technical contributions in Sections 3.2, 3.1 and 3.3 and a summary of the algorithm in Section 3.4.
3.1 Improved BP Set Representation: Polytope Formulation
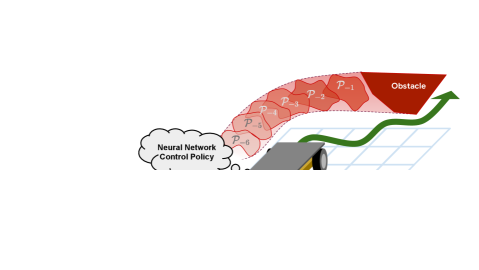
Whereas prior work (e.g., [7]) represents BPOAs as hyper-rectangles, this work introduces a formulation based on halfspace-representation (H-Rep) polytopes.
Lemma 3.1.
Given closed-loop dynamics Eq. 2, parameterizing target set , and parameterizing a BPOA, , the following set is also a BPOA,
| (8) |
with , and with defined below.
3.2 Improved Relaxation Domain: Refinement Loop
While provides a domain for relaxing the NN, this domain is often excessively conservative and leads to large BPOAs. To address this issue, this work leverages the following to tighten the domain used for relaxation.
Corollary 3.3.
Given closed-loop dynamics from Eq. 2, that parameterize , and initial BPOA (e.g., using Corollary 3.2), applying Lemma 3.1 iteratively for results in the sequence of BPOAs, .
This iterative refinement can be performed, for example, for a specified number of steps or until the reduction in BPOA volume between refinement steps reaches some threshold.
3.3 Improved Relaxation over BP Set: Polytope Input Bounds
Existing algorithms [1, 5, 7, 6] simplified the bound computation by assuming the domain over which to relax the network was a hyper-rectangle , which enables
| (10) |
Assuming that the input domain is a convex polytope , the strategy consists in first solving LPs, and , to obtain the hyperrectangular bounds on , which may introduce conservativeness.
Instead, the simplex is another domain that enables efficient concretization of linear bounds, but also enables natural representation of a convex polytope. For ,
| (11) |
where is a vector of the minimum of each row of . We can represent a convex polytope , with a simplex and a transformation based on its vertices :
| (12) |
where . Fig. 1 shows how this is integrated in the bound propagation: the multiplication by the matrix of vertices is simply prepended to the NN controller as an initial linear layer (an exact representation of polytope ).
3.4 Algorithm Overview
To summarize an implementation of the proposed approach, we first describe the method for relaxing (Algorithm 1) over a simplex domain, then show how to calculate the BPOA for a single timestep (Algorithm 2), then describe how to compute BPOAs over multiple timesteps (Algorithm 3).
| LP solver | Polytope target sets (Proposed) | Polytope target sets + simplex bounds (Proposed) | |
|
1 Iteration |
 (a) Prior Work: BReachLP [5]
(a) Prior Work: BReachLP [5]
|
 (b) Proposed: DRIP-HPoly
(b) Proposed: DRIP-HPoly
|
 (c) Proposed: DRIP
(c) Proposed: DRIP
|
|---|---|---|---|
|
5 Iterations (Proposed) |
 (d) Proposed: BReachLP-Iterate
(d) Proposed: BReachLP-Iterate
|
 (e) Proposed: DRIP-HPoly
(e) Proposed: DRIP-HPoly
|
(f) Proposed: DRIP |
Given an objective matrix , Algorithm 1 aims to compute such that . Add a linear transformation to the front of the closed-loop dynamics to obtain a new function, (3). Then, define the parameters of each relaxation , from Eq. 3, specifying the standard -simplex as the bounds on the function’s input (4). Finally, compute backward bounds from the objective, , to the current state, , stopping before reaching the added linear transformation (5).
Algorithm 2 describes the proposed method for computing a BPOA, . First, extract as the H-rep of the target set polytope. Then, hyper-rectangle is computed by solving LPs (2), and the BPOA, , is initialized as . To refine that estimate, loop for (3). If using DRIP, at each iteration, compute the vertex representation (V-rep) of the current BPOA (5, we used [15]) and run Algorithm 1 with on this simplex domain (6). If using DRIP-HPoly, find hyperrectangle bounds on and run CROWN [14] with on this hyperrectangular domain. Note that DRIP-HPoly completely avoids the conversion between H-Rep and V-Rep, which may be desirable for higher dimensional systems. Either way, then set the parameters of the H-rep of the refined BPOA using the CROWN relaxation and target set along with the prior iteration’s BPOA. Update and the loop continues. After , is returned. To calculate BPOAs for a time horizon , Algorithm 3 calls Algorithm 2 times, using the next step’s BPOA as the target set.
3.5 Time Complexity Analysis
First, we analyze the growth of from domain refinement iteration. At , the BPOA starts with (hyperrectangle, ). At each iteration, the BPOA gains at most facets, meaning at the end of the first timestep’s domain iteration. At , the BPOA again starts with , but at each iteration we add facets, as the target set is the BPOA at . After steps of iterations, the BPOA has at most facets.
DRIP-HPoly: Assume solving 1 LP has complexity [16], with variables, constraints, and encoding bits. BR bounds require LPs, where each has constraints and decision variables. Assuming and , this gives runtime across all timesteps. At each refinement iteration, we find rectangular bounds and run CROWN. Finding rectangular bounds is similar to getting BR bounds except it is done times, giving . CROWN time complexity is for an -layer network with neurons per layer and outputs [14]; since we have rows in the objective, we get (assuming and ). Relaxing the closed-loop dynamics would be the same ( contains the control NN with a constant number of additional layers). Thus, to compute BPOAs for timesteps, DRIP-HPoly’s complexity is .
DRIP: Polytope domain relaxation affects the analysis in 3 places: vertex enumeration (converting from H-rep to V-rep), CROWN relaxation (network width), and LP (number of constraints). Since each BPOA starts as a hyperrectangle, the polytopes are always bounded. Assume that vertex enumeration time complexity for a bounded polytope is with vertices from hyperplanes in dimensions [17]. Here, and we assume (worst-case caused by cyclic polytopes [18]) vertices, which corresponds to . Recall that after timesteps of iterations, the BPOA would have facets; it could thus have vertices. Therefore, the time complexity of vertex enumeration is . Analagously, the CROWN runtime is , since we add a single layer to the NN with one neuron per polytope vertex. For the LP runtime, there are constraints, leading to time complexity. The full DRIP algorithm has time complexity of .
In practice, the runtime may be much better. For example, for Fig. 4, which eliminates a source of exponential growth. Alternatively, rather than allowing the number of facets to grow exponentially, one could simply solve an LP at each iteration/timestep to obtain an constant-size outer bound on the latest BPOA. While this would certainly reduce the exponential growth in , our numerical experiments suggest that such a step is not necessary in practice for the systems considered.
4 Results
This section demonstrates DRIP on two simulated control systems (double integrator and mobile robot), implemented with the Jax framework [19] and jax_verify [13] library.
4.1 Ablation Study
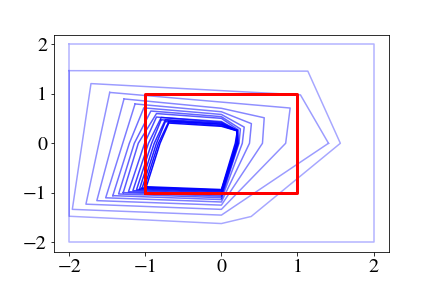
Using the double integrator system and learned policy from [1] (2 hidden layers each with 5 neurons), Fig. 2 demonstrates the substantial improvement in reachable set tightness enabled by our proposed method. For a target set (red) , the true BP sets are shown in solid colors for each timestep, and the BPOAs are shown in the same colors with dashed lines. For example, Fig. 3(a) implements the prior work [5], in which BPOAs become very conservative after a few timesteps. By adding the refinement loop (Section 3.2), Fig. 3(d) shows substantial improvement with .
However, increasing does not improve the results with the prior LP and hyper-rectangular BPOA formulation. Instead, the middle column shows the impact of the proposed formulation from Section 3.1, in which the closed-loop dynamics are relaxed to directly provide BPOAs as polytopes. A key reason behind this improvement is the use of the target set’s facets as the objective matrix during the backward pass of the CROWN algorithm. When increasing to 5, we see nearly perfect bounds on the first three BP sets, with tighter yet still somewhat loose bounds on the final two timesteps.
The impact of the polytope domain used in the relaxation (Section 3.3) is shown in the rightmost column. Because the first iteration always uses the hyper-rectangular , we expect to see no difference between Fig. 3(b) and Fig. 3(c). However, Fig. 3(f) shows much tighter BPOAs in the last two timesteps when compared to Fig. 3(e).
Overall, the massive improvement in BPOA tightness between the prior work [5] (Fig. 3(a)) and the proposed approach (Fig. 3(f)) would enable a practitioner to certify safety when starting from a larger portion of the state space.

4.2 Runtime vs. Error Tradeoff
Fig. 3 provides quantitative analysis of the tradeoff between tightness and computational runtime for the various methods. Final step error is the ratio , where denotes the area of set . Runtime is plotted as the mean and shaded standard deviation over 20 trials (with the worst one discarded). For the 3 variants of the proposed algorithms, by increasing , we observe an improvement in error at the cost of additional runtime.
The red triangle corresponds to Fig. 3(a) [5]. The pink curve corresponds the leftmost column of Fig. 2, which adds a refinement loop on the relaxation domain (Section 3.2). The blue curve corresponds to the middle column of Fig. 2, which uses polytope BPOAs (Section 3.1). The green curve corresponds to the rightmost column of Fig. 2, which uses polytope relaxation domains (Section 3.3).
A key cause of the computation time reduction between red/pink and green/blue is that the new formulation replaces many of the LPs with closed-form polytope descriptions. Overall, we observe a improvement in the error. Moreover, this experiment did not require any set partitioning and was still able to provide very tight BPOAs.
4.3 Ground Robot Policy Certification
Next, we use DRIP to certify that a robot will not collide with an obstacle for any initial condition in the state space (outside of the obstacle itself). We use the 2D ground robot dynamics, policy, and obstacle from [5, 7] (2 hidden layers each with 10 neurons). The target set is partitioned into 4 cells (2 per dimension), which we note is fewer cells than in [5, 7]. For each cell, the 1-step BPOA is calculated for , and the returned BPOA is the convex hull of the union of vertices for each cell’s BPOA.
Fig. 4(a) shows the target set (red) and BPOAs for (blue, darker corresponds to larger ). When , . By Corollary A.2 of [7], this certifies that the system can only reach the obstacle if it starts from within the obstacle; there is no need to compute BPOAs for further timesteps. Fig. 4(b) shows BPOAs with rollouts of the closed-loop dynamics from 400 random initial states, although sampling trajectories is not necessary given the certificate.
5 Conclusion
This paper proposed a new backward reachability algorithm, DRIP, for formal safety analysis of data-driven control systems. DRIP advances the state-of-the-art by introducing ideas to shrink the domain over which the closed-loop dynamics are relaxed and leverage polytope representations of sets at both the input and output of the relaxation. These innovations are shown to provide 2 orders of magnitude improvement in bound tightness over the prior state-of-the-art with similar runtime. Future work will investigate tighter simplex bounds [20] and convergence properties.
References
- [1] M. Everett, G. Habibi, C. Sun, and J. P. How, “Reachability analysis of neural feedback loops,” IEEE Access, vol. 9, pp. 163 938–163 953, 2021.
- [2] H. Hu, M. Fazlyab, M. Morari, and G. J. Pappas, “Reach-SDP: Reachability analysis of closed-loop systems with neural network controllers via semidefinite programming,” in IEEE Conference on Decision and Control (CDC), 2020, pp. 5929–5934.
- [3] S. Chen, V. M. Preciado, and M. Fazlyab, “One-shot reachability analysis of neural network dynamical systems,” arXiv preprint arXiv:2209.11827, 2022.
- [4] C. Sidrane, A. Maleki, A. Irfan, and M. J. Kochenderfer, “OVERT: An algorithm for safety verification of neural network control policies for nonlinear systems,” Journal of Machine Learning Research, vol. 23, no. 117, pp. 1–45, 2022.
- [5] N. Rober, M. Everett, and J. P. How, “Backward reachability analysis of neural feedback loops,” in IEEE Conference on Decision and Control (CDC), 2022.
- [6] N. Rober, M. Everett, S. Zhang, and J. P. How, “A hybrid partitioning strategy for backward reachability of neural feedback loops,” in American Control Conference (ACC), 2023, (to appear). [Online]. Available: https://arxiv.org/abs/2210.07918
- [7] N. Rober, S. M. Katz, C. Sidrane, E. Yel, M. Everett, M. J. Kochenderfer, and J. P. How, “Backward reachability analysis of neural feedback loops: Techniques for linear and nonlinear systems,” 2022, (in review). [Online]. Available: https://arxiv.org/abs/2209.14076
- [8] J. A. Vincent and M. Schwager, “Reachable polyhedral marching (RPM): A safety verification algorithm for robotic systems with deep neural network components,” in IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 9029–9035.
- [9] S. Bak and H.-D. Tran, “Neural network compression of ACAS Xu early prototype is unsafe: Closed-loop verification through quantized state backreachability,” in NASA Formal Methods, 2022, pp. 280–298.
- [10] A. Neumaier, “The wrapping effect, ellipsoid arithmetic, stability and confidence regions,” in Validation numerics. Springer, 1993, pp. 175–190.
- [11] K. Xu, Z. Shi, H. Zhang, Y. Wang, K.-W. Chang, M. Huang, B. Kailkhura, X. Lin, and C.-J. Hsieh, “Automatic perturbation analysis for scalable certified robustness and beyond,” Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 1129–1141, 2020.
- [12] S. Dathathri, K. Dvijotham, A. Kurakin, A. Raghunathan, J. Uesato, R. R. Bunel, S. Shankar, J. Steinhardt, I. Goodfellow, P. S. Liang et al., “Enabling certification of verification-agnostic networks via memory-efficient semidefinite programming,” Advances in Neural Information Processing Systems, vol. 33, pp. 5318–5331, 2020.
- [13] DeepMind, “jax_verify,” https://github.com/deepmind/jax˙verify, 2020.
- [14] H. Zhang, T.-W. Weng, P.-Y. Chen, C.-J. Hsieh, and L. Daniel, “Efficient neural network robustness certification with general activation functions,” Advances in Neural Information Processing Systems (NeurIPS), 2018.
- [15] S. Caron, “Python module for polyhedral manipulations–pypoman,” version 0.5, vol. 4, 2018.
- [16] P. M. Vaidya, “An algorithm for linear programming which requires o (((m+ n) n 2+(m+ n) 1.5 n) l) arithmetic operations,” in Proceedings of the nineteenth annual ACM symposium on Theory of computing, 1987, pp. 29–38.
- [17] D. Avis and K. Fukuda, “A pivoting algorithm for convex hulls and vertex enumeration of arrangements and polyhedra,” in Proceedings of the seventh annual symposium on Computational geometry, 1991, pp. 98–104.
- [18] C. D. Toth, J. O’Rourke, and J. E. Goodman, Handbook of discrete and computational geometry. CRC press, 2017.
- [19] J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, and Q. Zhang, “JAX: composable transformations of Python+NumPy programs,” 2018. [Online]. Available: http://github.com/google/jax
- [20] H. S. Behl, M. P. Kumar, P. Torr, and K. Dvijotham, “Overcoming the convex barrier for simplex inputs,” Advances in Neural Information Processing Systems, vol. 34, pp. 4871–4882, 2021.