DPM-Solver-v3: Improved Diffusion ODE Solver with Empirical Model Statistics
Abstract
Diffusion probabilistic models (DPMs) have exhibited excellent performance for high-fidelity image generation while suffering from inefficient sampling. Recent works accelerate the sampling procedure by proposing fast ODE solvers that leverage the specific ODE form of DPMs. However, they highly rely on specific parameterization during inference (such as noise/data prediction), which might not be the optimal choice. In this work, we propose a novel formulation towards the optimal parameterization during sampling that minimizes the first-order discretization error of the ODE solution. Based on such formulation, we propose DPM-Solver-v3, a new fast ODE solver for DPMs by introducing several coefficients efficiently computed on the pretrained model, which we call empirical model statistics. We further incorporate multistep methods and a predictor-corrector framework, and propose some techniques for improving sample quality at small numbers of function evaluations (NFE) or large guidance scales. Experiments show that DPM-Solver-v3 achieves consistently better or comparable performance in both unconditional and conditional sampling with both pixel-space and latent-space DPMs, especially in 510 NFEs. We achieve FIDs of 12.21 (5 NFE), 2.51 (10 NFE) on unconditional CIFAR10, and MSE of 0.55 (5 NFE, 7.5 guidance scale) on Stable Diffusion, bringing a speed-up of 15%30% compared to previous state-of-the-art training-free methods. Code is available at https://github.com/thu-ml/DPM-Solver-v3.
1 Introduction
Diffusion probabilistic models (DPMs) [47, 15, 51] are a class of state-of-the-art image generators. By training with a strong encoder, a large model, and massive data as well as leveraging techniques such as guided sampling, DPMs are capable of generating high-resolution photorealistic and artistic images on text-to-image tasks.



However, to generate high-quality visual content, DPMs usually require hundreds of model evaluations to gradually remove noise using a pretrained model [15], which is much more time-consuming compared to other deep generative models such as generative adversarial networks (GANs) [13]. The sampling overhead of DPMs emerges as a crucial obstacle hindering their integration into downstream tasks.
To accelerate the sampling process of DPMs, one can employ training-based methods [37, 53, 45] or training-free samplers [48, 51, 28, 3, 52, 56]. We focus on the latter approach since it requires no extra training and is more flexible. Recent advanced training-free samplers [56, 31, 32, 58] mainly rely on the ODE form of DPMs, since its absence of stochasticity is essential for high-quality samples in around 20 steps. Besides, ODE solvers built on exponential integrators [18] converge faster. To change the original diffusion ODE into the form of exponential integrators, they need to cancel its linear term and obtain an ODE solution, where only the noise predictor needs to be approximated, and other terms can be exactly computed. Besides, Lu et al. [32] find that it is better to use another ODE solution where instead the data predictor needs to be approximated. How to choose such model parameterization (e.g., noise/data prediction) in the sampling of DPMs remains unrevealed.
In this work, we systematically study the problem of model parameterization and ODE formulation for fast sampling of DPMs. We first show that by introducing three types of coefficients, the original ODE solution can be reformulated to an equivalent one that contains a new model parameterization. Besides, inspired by exponential Rosenbrock-type methods [19] and first-order discretization error analysis, we also show that there exists an optimal set of coefficients efficiently computed on the pretrained model, which we call empirical model statistics (EMS). Building upon our novel ODE formulation, we further propose a new high-order solver for diffusion ODEs named DPM-Solver-v3, which includes a multistep predictor-corrector framework of any order, as well as some novel techniques such as pseudo high-order method to boost the performance at extremely few steps or large guidance scale.
We conduct extensive experiments with both pixel-space and latent-space DPMs to verify the effectiveness of DPM-Solver-v3. Compared to previous fast samplers, DPM-Solver-v3 can consistently improve the sample quality in 520 steps, and make a significant advancement within 10 steps.
2 Background
2.1 Diffusion Probabilistic Models
Suppose we have a -dimensional data distribution . Diffusion probabilistic models (DPMs) [47, 15, 51] define a forward diffusion process to gradually degenerate the data with Gaussian noise, which satisfies the transition kernel , such that is approximately pure Gaussian. are smooth scalar functions of , which are called noise schedule. The transition can be easily applied by . To train DPMs, a neural network is usually parameterized to predict the noise by minimizing , where is a weighting function. Sampling of DPMs can be performed by solving diffusion ODE [51] from time to time :
| (1) |
where , [23]. In addition, the conditional sampling by DPMs can be conducted by guided sampling [10, 16] with a conditional noise predictor , where is the condition. Specifically, classifier-free guidance [16] combines the unconditional/conditional model and obtains a new noise predictor , where is a special condition standing for the unconditional case, is the guidance scale that controls the trade-off between image-condition alignment and diversity; while classifier guidance [10] uses an extra classifier to obtain a new noise predictor .
In addition, except for the noise prediction, DPMs can be parameterized as score predictor to predict , or data predictor to predict . Under variance-preserving (VP) noise schedule which satisfies [51], “v” predictor is also proposed to predict [45]. These different parameterizations are theoretically equivalent, but have an impact on the empirical performance when used in training [23, 59].
2.2 Fast Sampling of DPMs with Exponential Integrators
Among the methods for solving the diffusion ODE (1), recent works [56, 31, 32, 58] find that ODE solvers based on exponential integrators [18] are more efficient and robust at a small number of function evaluations (<50). Specifically, an insightful observation by Lu et al. [31] is that, by change-of-variable from to (half of the log-SNR), the diffusion ODE is transformed to
| (2) |
where . By utilizing the semi-linear structure of the diffusion ODE and exactly computing the linear term [56, 31], we can obtain the ODE solution as Eq. (3) (left). Such exact computation of the linear part reduces the discretization errors [31]. Moreover, by leveraging the equivalence of different parameterizations, DPM-Solver++ [32] rewrites Eq. (2) by the data predictor and obtains another ODE solution as Eq. (3) (right). Such solution does not need to change the pretrained noise prediction model during the sampling process, and empirically outperforms previous samplers based on [31].
| (3) |
However, to the best of our knowledge, the parameterizations for sampling are still manually selected and limited to noise/data prediction, which are not well-studied.
3 Method
We now present our method. We start with a new formulation of the ODE solution with extra coefficients, followed by our high-order solver and some practical considerations. In the following discussions, we assume all the products between vectors are element-wise, and is the -th order total derivative of any function w.r.t. .
3.1 Improved Formulation of Exact Solutions of Diffusion ODEs
As mentioned in Sec. 2.2, it is promising to explore the semi-linear structure of diffusion ODEs for fast sampling [56, 31, 32]. Firstly, we reveal one key insight that we can choose the linear part according to Rosenbrock-type exponential integrators [19, 18]. To this end, we consider a general form of diffusion ODEs by rewriting Eq. (2) as
| (4) |
where is a -dimensional undetermined coefficient depending on . We choose to restrict the Frobenius norm of the gradient of the non-linear part w.r.t. :
| (5) |
where is the distribution of samples on the ground-truth ODE trajectories at (i.e., model distribution). Intuitively, it makes insensitive to the errors of and cancels all the “linearty” of . With , by the “variation-of-constants” formula [1], starting from at time , the exact solution of Eq. (4) at time is
| (6) |
where . To calculate the solution in Eq. (6), we need to approximate for each by certain polynomials [31, 32].
Secondly, we reveal another key insight that we can choose different functions to be approximated instead of and further reduce the discretization error, which is related to the total derivatives of the approximated function. To this end, we consider a scaled version of i.e., where is a -dimensional coefficient dependent on , and then Eq. (6) becomes
| (7) |
Comparing with Eq. (6), we change the approximated function from to by using an additional scaling term related to . As we shall see, the first-order discretization error is positively related to the norm of the first-order derivative . Thus, we aim to minimize , in order to reduce and the discretization error. As is a fixed function depending on the pretrained model, this minimization problem essentially finds a linear function of to approximate . To achieve better linear approximation, we further introduce a bias term and construct a function satisfying , which gives
| (8) |
With , Eq. (7) becomes
| (9) |
Such formulation is equivalent to Eq. (3) but introduces three types of coefficients and a new parameterization . We show in Appendix I.1 that the generalized parameterization in Eq. (8) can cover a wide range of parameterization families in the form of . We aim to reduce the discretization error by finding better coefficients than previous works [31, 32].
Now we derive the concrete formula for analyzing the first-order discretization error. By replacing with in Eq. (9), we obtain the first-order approximation . As by Taylor expansion, it follows that the first-order discretization error can be expressed as
| (10) |
where . Thus, given the optimal in Eq. (5), the discretization error mainly depends on . Based on this insight, we choose the coefficients by solving
| (11) |
For any , all have analytic solutions involving the Jacobian-vector-product of the pretrained model , and they can be unbiasedly evaluated on a few datapoints via Monte-Carlo estimation (detailed in Section 3.4 and Appendix C.1.1). Therefore, we call empirical model statistics (EMS). In the following sections, we’ll show that by approximating with Taylor expansion, we can develop our high-order solver for diffusion ODEs.
3.2 Developing High-Order Solver
(a) Local Approximation
(b) Multistep Predictor-Corrector
In this section, we propose our high-order solver for diffusion ODEs with local accuracy and global convergence order guarantee by leveraging our proposed solution formulation in Eq. (9). The proposed solver and analyses are highly motivated by the methods of exponential integrators [17, 18] in the ODE literature and their previous applications in the field of diffusion models [56, 31, 32, 58]. Though the EMS are designed to minimize the first-order error, they can also help our high-order solver (see Appendix I.2).
For simplicity, denote , , . Though high-order ODE solvers essentially share the same mathematical principles, since we utilize a more complicated parameterization and ODE formulation in Eq. (9) than previous works [56, 31, 32, 58], we divide the development of high-order solver into simplified local and global parts, which are not only easier to understand, but also neat and general for any order.
3.2.1 Local Approximation
Firstly, we derive formulas and properties of the local approximation, which describes how we transit locally from time to time . It can be divided into two parts: discretization of the integral in Eq. (9) and estimating the high-order derivatives in the Taylor expansion.
Discretization. Denote . For , to obtain the -th order discretization of Eq. (9), we take the -th order Taylor expansion of w.r.t. at : . Substituting it into Eq. (9) yields
| (12) |
Here we only need to estimate the -th order total derivatives for , since the other terms are determined once given and , which we’ll discuss next.
High-order derivative estimation. For -th order approximation, we use the finite difference of at previous steps to estimate each . Such derivation is to match the coefficients of Taylor expansions. Concretely, denote , , and the estimated high-order derivatives can be solved by the following linear system:
| (13) |
Then by substituting into Eq. (12) and dropping the error terms, we obtain the -th order local approximation:
| (14) |
where . Eq. (13) and Eq. (14) provide an update rule to transit from time to time and get an approximated solution , when we already have the solution . For -th order approximation, we need extra solutions and their corresponding function values . We illustrate the procedure in Fig. 2(a) and summarize it in Appendix C.2. In the following theorem, we show that under some assumptions, such local approximation has a guarantee of order of accuracy.
Theorem 3.1 (Local order of accuracy, proof in Appendix B.2.1).
Suppose are exact (i.e., on the ground-truth ODE trajectory passing ) for , then under some regularity conditions detailed in Appendix B.1, the local truncation error , which means the local approximation has -th order of accuracy.
3.2.2 Global Solver
Given time steps , starting from some initial value, we can repeat the local approximation times to make consecutive transitions from each to until we reach an acceptable solution. At each step, we apply multistep methods [1] by caching and reusing the previous values at timesteps , which is proven to be more stable when NFE is small [32, 56]. Moreover, we also apply the predictor-corrector method [58] to refine the approximation at each step without introducing extra NFE. Specifically, the -th order predictor is the case of the local approximation when we choose , and the -th order corrector is the case when we choose . We present our -th order multistep predictor-corrector procedure in Appendix C.2. We also illustrate a second-order case in Fig. 2(b). Note that different from previous works, in the local transition from to , the previous function values () used for derivative estimation are dependent on and are different during the sampling process because is dependent on the current (see Eq. (8)). Thus, we directly cache and reuse them to compute in the subsequent steps. Notably, our proposed solver also has a global convergence guarantee, as shown in the following theorem. For simplicity, we only consider the predictor case and the case with corrector can also be proved by similar derivations in [58].
Theorem 3.3 (Global order of convergence, proof in Appendix B.2.2).
For -th order predictor, if we iteratively compute a sequence to approximate the true solutions at , then under both local and global assumptions detailed in Appendix B.1, the final error , where denotes the element-wise absolute value, and .
3.3 Practical Techniques
In this section, we introduce some practical techniques that further improve the sample quality in the case of small NFE or large guidance scales.
Pseudo-order solver for small NFE. When NFE is extremely small (e.g., 510), the error at each timestep becomes rather large, and incorporating too many previous values by high-order solver at each step will cause instabilities. To alleviate this problem, we propose a technique called pseudo-order solver: when estimating the -th order derivative, we only utilize the previous function values of , instead of all the previous values as in Eq. (13). For each , we can obtain by solving a part of Eq. (13) and taking the last element:
| (15) |
In practice, we do not need to solve linear systems. Instead, the solutions for have a simpler recurrence relation similar to Neville’s method [36] in Lagrange polynomial interpolation. Denote so that , we have
Theorem 3.4 (Pseudo-order solver).
For each , the solution in Eq. (15) is , where
| (16) | ||||
Proof in Appendix B.3. Note that the pseudo-order solver of order no longer has the guarantee of -th order of accuracy, which is not so important when NFE is small. In our experiments, we mainly rely on two combinations: when we use -th order predictor, we then combine it with -th order corrector or -th pseudo-order corrector.
Half-corrector for large guidance scales. When the guidance scale is large in guided sampling, we find that corrector may have negative effects on the sample quality. We propose a useful technique called half-corrector by using the corrector only in the time region . Correspondingly, the strategy that we use corrector at each step is called full-corrector.
3.4 Implementation Details
In this section, we give some implementation details about how to compute and integrate the EMS in our solver and how to adapt them to guided sampling.
Estimating EMS. For a specific , the EMS can be estimated by firstly drawing (10244096) datapoints with 200-step DPM-Solver++ [32] and then analytically computing some terms related to (detailed in Appendix C.1.1). In practice, we find it both convenient and effective to choose the distribution of the dataset to approximate . Thus, without further specifications, we directly use samples from .
Estimating integrals of EMS. We estimate EMS on () timesteps and use trapezoidal rule to estimate the integrals in Eq. (12) (see Appendix I.3 for the estimation error analysis). We also apply some pre-computation for the integrals to avoid extra computation costs during sampling, detailed in Appendix C.1.2.
Adaptation to guided sampling. Empirically, we find that within a common range of guidance scales, we can simply compute the EMS on the model without guidance, and it can work for both unconditional sampling and guided sampling cases. See Appendix J for more discussions.
3.5 Comparison with Existing Methods
By comparing with existing diffusion ODE solvers that are based on exponential integrators [56, 31, 32, 58], we can conclude that (1) Previous ODE formulations with noise/data prediction are special cases of ours by setting to specific values. (2) Our first-order discretization can be seen as improved DDIM. See more details in Appendix A.
4 Experiments
(a) CIFAR10
(ScoreSDE, Pixel DPM)

(b) CIFAR10
(EDM, Pixel DPM)

(c) LSUN-Bedroom
(Latent-Diffusion, Latent DPM)

(a) ImageNet-256
(Guided-Diffusion, Pixel DPM)
(Classifier Guidance, )

(b) MS-COCO2014
(Stable-Diffusion, Latent DPM)
(Classifier-Free Guidance, )

(c) MS-COCO2014
(Stable-Diffusion, Latent DPM)
(Classifier-Free Guidance, )

(a) CIFAR10 (ScoreSDE)

(b) CIFAR10 (EDM)

(c) MS-COCO2014 (Stable-Diffusion, )



In this section, we show that DPM-Solver-v3 can achieve consistent and notable speed-up for both unconditional and conditional sampling with both pixel-space and latent-space DPMs. We conduct extensive experiments on diverse image datasets, where the resolution ranges from 32 to 256. First, we present the main results of sample quality comparison with previous state-of-the-art training-free methods. Then we illustrate the effectiveness of our method by visualizing the EMS and samples. Additional ablation studies are provided in Appendix G. On each dataset, we choose a sufficient number of timesteps and datapoints for computing the EMS to reduce the estimation error, while the EMS can still be computed within hours. After we obtain the EMS and precompute the integrals involving them, there is negligible extra overhead in the sampling process. We provide the runtime comparison in Appendix E. We refer to Appendix D for more detailed experiment settings.
4.1 Main Results
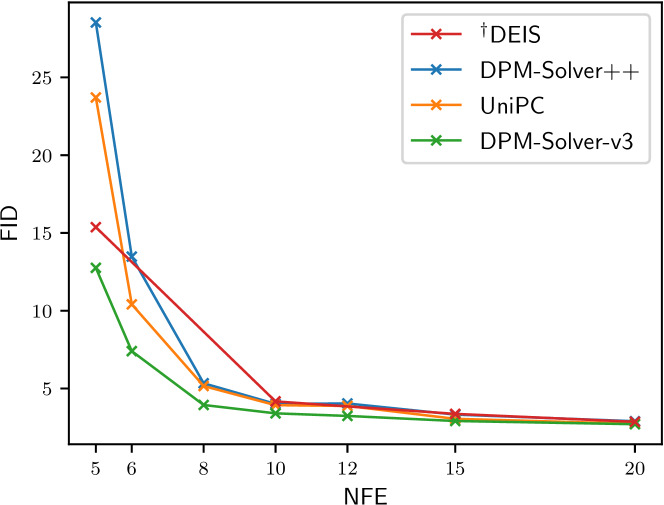
| Method | Model | NFE | |||||||
| 5 | 6 | 8 | 10 | 12 | 15 | 20 | 25 | ||
| †DEIS [56] | ScoreSDE [51] | 15.37 | 4.17 | 3.37 | 2.86 | ||||
| DPM-Solver++ [32] | 28.53 | 13.48 | 5.34 | 4.01 | 4.04 | 3.32 | 2.90 | 2.76 | |
| UniPC [58] | 23.71 | 10.41 | 5.16 | 3.93 | 3.88 | 3.05 | 2.73 | 2.65 | |
| DPM-Solver-v3 | 12.76 | 7.40 | 3.94 | 3.40 | 3.24 | 2.91 | 2.71 | 2.64 | |
| Heun’s 2nd [21] | EDM [21] | 320.80 | 103.86 | 39.66 | 16.57 | 7.59 | 4.76 | 2.51 | 2.12 |
| DPM-Solver++ [32] | 24.54 | 11.85 | 4.36 | 2.91 | 2.45 | 2.17 | 2.05 | 2.02 | |
| UniPC [58] | 23.52 | 11.10 | 3.86 | 2.85 | 2.38 | 2.08 | 2.01 | 2.00 | |
| DPM-Solver-v3 | 12.21 | 8.56 | 3.50 | 2.51 | 2.24 | 2.10 | 2.02 | 2.00 | |
We present the results in number of function evaluations (NFE), covering both few-step cases and the almost converged cases, as shown in Fig. 3 and Fig. 4. For the sake of clarity, we mainly compare DPM-Solver-v3 to DPM-Solver++ [32] and UniPC [58], which are the most state-of-the-art diffusion ODE solvers. We also include the results for DEIS [56] and Heun’s 2nd order method in EDM [21], but only for the datasets on which they originally reported. We don’t show the results for other methods such as DDIM [48], PNDM [28], since they have already been compared in previous works and have inferior performance. The quantitative results on CIFAR10 [24] are listed in Table 1, and more detailed quantitative results are presented in Appendix F.
Unconditional sampling We first evaluate the unconditional sampling performance of different methods on CIFAR10 [24] and LSUN-Bedroom [55]. For CIFAR10 we use two pixel-space DPMs, one is based on ScoreSDE [51] which is a widely adopted model by previous samplers, and another is based on EDM [21] which achieves the best sample quality. For LSUN-Bedroom, we use the latent-space Latent-Diffusion model [43]. We apply the multistep 3rd-order version for DPM-Solver++, UniPC and DPM-Solver-v3 by default, which performs best in the unconditional setting. For UniPC, we report the better result of their two choices and at each NFE. For our DPM-Solver-v3, we tune the strategies of whether to use the pseudo-order predictor/corrector at each NFE on CIFAR10, and use the pseudo-order corrector on LSUN-Bedroom. As shown in Fig. 3, we find that DPM-Solver-v3 can achieve consistently better FID, which is especially notable when NFE is 510. For example, we improve the FID on CIFAR10 with 5 NFE from to with ScoreSDE, and achieve an FID of with only NFE with the advanced DPM provided by EDM. On LSUN-Bedroom, with around 12 minutes computing of the EMS, DPM-Solver-v3 converges to the FID of 3.06 with 12 NFE, which is approximately 60% sampling cost of the previous best training-free method (20 NFE by UniPC).
Conditional sampling. We then evaluate the conditional sampling performance, which is more widely used since it allows for controllable generation with user-customized conditions. We choose two conditional settings, one is classifier guidance on pixel-space Guided-Diffusion [10] model trained on ImageNet-256 dataset [9] with 1000 class labels as conditions; the other is classifier-free guidance on latent-space Stable-Diffusion model [43] trained on LAION-5B dataset [46] with CLIP [41] embedded text prompts as conditions. We evaluate the former at the guidance scale of , following the best choice in [10]; and the latter at the guidance scale of (following the original paper) or (following the official code) with prompts random selected from MS-COCO2014 validation set [26]. Note that the FID of Stable-Diffusion samples saturates to 15.016.0 even within 10 steps when the latent codes are far from convergence, possibly due to the powerful image decoder (see Appendix H). Thus, following [32], we measure the mean square error (MSE) between the generated latent code and the ground-truth solution (i.e., ) to evaluate convergence, starting from the same Gaussian noise. We obtain by 200-step DPM-Solver++, which is enough to ensure the convergence.
We apply the multistep 2nd-order version for DPM-Solver++, UniPC and DPM-Solver-v3, which performs best in conditional setting. For UniPC, we only apply the choice , which performs better than . For our DPM-Solver-v3, we use the pseudo-order corrector by default, and report the best results between using half-corrector/full-corrector on Stable-Diffusion (). As shown in Fig. 4, DPM-Solver-v3 can achieve better sample quality or convergence at most NFEs, which indicates the effectiveness of our method and techniques under the conditional setting. It’s worth noting that UniPC, which adopts an extra corrector, performs even worse than DPM-Solver++ when NFE<10 on Stable-Diffusion (). With the combined effect of the EMS and the half-corrector technique, we successfully outperform DPM-Solver++ in such a case. Detailed comparisons can be found in the ablations in Appendix G.
4.2 Visualizations of Estimated EMS
We further visualize the estimated EMS in Fig. 5. Since are -dimensional vectors, we average them over all dimensions to obtain a scalar. From Fig. 5, we find that gradually changes from to near as the sampling proceeds, which suggests we should gradually slide from data prediction to noise prediction. As for , they are more model-specific and display many fluctuations, especially for ScoreSDE model [51] on CIFAR10. Apart from the estimation error of the EMS, we suspect that it comes from the fluctuations of , which is caused by the periodicity of trigonometric functions in the positional embeddings of the network input. It’s worth noting that the fluctuation of will not cause instability in our sampler (see Appendix J).
4.3 Visual Quality
We present some qualitative comparisons in Fig. 6 and Fig. 1. We can find that previous methods tend to have a small degree of color contrast at small NFE, while our method is less biased and produces more visual details. In Fig. 1(b), we can observe that previous methods with corrector may cause distortion at large guidance scales (in the left-top image, a part of the castle becomes a hill; in the left-bottom image, the hill is translucent and the castle is hanging in the air), while ours won’t. Additional samples are provided in Appendix K.
5 Conclusion
We study the ODE parameterization problem for fast sampling of DPMs. Through theoretical analysis, we find a novel ODE formulation with empirical model statistics, which is towards the optimal one to minimize the first-order discretization error. Based on such improved ODE formulation, we propose a new fast solver named DPM-Solver-v3, which involves a multistep predictor-corrector framework of any order and several techniques for improved sampling with few steps or large guidance scale. Experiments demonstrate the effectiveness of DPM-Solver-v3 in both unconditional conditional sampling with both pixel-space latent-space pre-trained DPMs, and the significant advancement of sample quality in 510 steps.
Limitations and broader impact Despite the great speedup in small numbers of steps, DPM-Solver-v3 still lags behind training-based methods and is not fast enough for real-time applications. Besides, we conducted theoretical analyses of the local error, but didn’t explore the global design spaces, such as the design of timestep schedules during sampling. And commonly, there are potential undesirable effects that DPM-Solver-v3 may be abused to accelerate the generation of fake and malicious content.
Acknowledgements
This work was supported by the National Key Research and Development Program of China (No. 2021ZD0110502), NSFC Projects (Nos. 62061136001, 62106123, 62076147, U19A2081, 61972224, 62106120), Tsinghua Institute for Guo Qiang, and the High Performance Computing Center, Tsinghua University. J.Z is also supported by the XPlorer Prize.
References
- [1] Kendall Atkinson, Weimin Han, and David E Stewart. Numerical solution of ordinary differential equations, volume 108. John Wiley & Sons, 2011.
- [2] Fan Bao, Chongxuan Li, Jiacheng Sun, Jun Zhu, and Bo Zhang. Estimating the optimal covariance with imperfect mean in diffusion probabilistic models. In International Conference on Machine Learning, pages 1555–1584. PMLR, 2022.
- [3] Fan Bao, Chongxuan Li, Jun Zhu, and Bo Zhang. Analytic-DPM: An analytic estimate of the optimal reverse variance in diffusion probabilistic models. In International Conference on Learning Representations, 2022.
- [4] Costas Bekas, Effrosyni Kokiopoulou, and Yousef Saad. An estimator for the diagonal of a matrix. Applied numerical mathematics, 57(11-12):1214–1229, 2007.
- [5] Mari Paz Calvo and César Palencia. A class of explicit multistep exponential integrators for semilinear problems. Numerische Mathematik, 102:367–381, 2006.
- [6] Nanxin Chen, Yu Zhang, Heiga Zen, Ron J. Weiss, Mohammad Norouzi, and William Chan. Wavegrad: Estimating gradients for waveform generation. In International Conference on Learning Representations, 2021.
- [7] Hyungjin Chung, Jeongsol Kim, Michael Thompson Mccann, Marc Louis Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. In The Eleventh International Conference on Learning Representations, 2022.
- [8] Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based semantic image editing with mask guidance. In The Eleventh International Conference on Learning Representations, 2022.
- [9] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255. IEEE, 2009.
- [10] Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat GANs on image synthesis. In Advances in Neural Information Processing Systems, volume 34, pages 8780–8794, 2021.
- [11] Tim Dockhorn, Arash Vahdat, and Karsten Kreis. Genie: Higher-order denoising diffusion solvers. In Advances in Neural Information Processing Systems, 2022.
- [12] Alfredo Eisinberg and Giuseppe Fedele. On the inversion of the vandermonde matrix. Applied mathematics and computation, 174(2):1384–1397, 2006.
- [13] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems, volume 27, pages 2672–2680, 2014.
- [14] Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022.
- [15] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020.
- [16] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021.
- [17] Marlis Hochbruck and Alexander Ostermann. Explicit exponential Runge-Kutta methods for semilinear parabolic problems. SIAM Journal on Numerical Analysis, 43(3):1069–1090, 2005.
- [18] Marlis Hochbruck and Alexander Ostermann. Exponential integrators. Acta Numerica, 19:209–286, 2010.
- [19] Marlis Hochbruck, Alexander Ostermann, and Julia Schweitzer. Exponential rosenbrock-type methods. SIAM Journal on Numerical Analysis, 47(1):786–803, 2009.
- [20] Michael F Hutchinson. A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines. Communications in Statistics-Simulation and Computation, 18(3):1059–1076, 1989.
- [21] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. In Advances in Neural Information Processing Systems, 2022.
- [22] Bahjat Kawar, Michael Elad, Stefano Ermon, and Jiaming Song. Denoising diffusion restoration models. In Advances in Neural Information Processing Systems, 2022.
- [23] Diederik P Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models. In Advances in Neural Information Processing Systems, 2021.
- [24] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [25] Shengmeng Li, Luping Liu, Zenghao Chai, Runnan Li, and Xu Tan. Era-solver: Error-robust adams solver for fast sampling of diffusion probabilistic models. arXiv preprint arXiv:2301.12935, 2023.
- [26] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- [27] Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen, and Zhou Zhao. Diffsinger: Singing voice synthesis via shallow diffusion mechanism. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 11020–11028, 2022.
- [28] Luping Liu, Yi Ren, Zhijie Lin, and Zhou Zhao. Pseudo numerical methods for diffusion models on manifolds. In International Conference on Learning Representations, 2021.
- [29] Xingchao Liu, Chengyue Gong, et al. Flow straight and fast: Learning to generate and transfer data with rectified flow. In The Eleventh International Conference on Learning Representations, 2022.
- [30] Cheng Lu, Kaiwen Zheng, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Maximum likelihood training for score-based diffusion odes by high order denoising score matching. In International Conference on Machine Learning, pages 14429–14460. PMLR, 2022.
- [31] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. In Advances in Neural Information Processing Systems, 2022.
- [32] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. arXiv preprint arXiv:2211.01095, 2022.
- [33] Eric Luhman and Troy Luhman. Knowledge distillation in iterative generative models for improved sampling speed. arXiv preprint arXiv:2101.02388, 2021.
- [34] Chenlin Meng, Ruiqi Gao, Diederik P Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. In NeurIPS 2022 Workshop on Score-Based Methods, 2022.
- [35] Chenlin Meng, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2022.
- [36] Eric Harold Neville. Iterative interpolation. St. Joseph’s IS Press, 1934.
- [37] Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning, pages 8162–8171. PMLR, 2021.
- [38] Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob Mcgrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In International Conference on Machine Learning, pages 16784–16804. PMLR, 2022.
- [39] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- [40] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov, and Jiansheng Wei. Diffusion-based voice conversion with fast maximum likelihood sampling scheme. In International Conference on Learning Representations, 2022.
- [41] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- [42] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with CLIP latents. arXiv preprint arXiv:2204.06125, 2022.
- [43] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- [44] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Raphael Gontijo-Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. In Advances in Neural Information Processing Systems, 2022.
- [45] Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. In International Conference on Learning Representations, 2022.
- [46] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade W Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022.
- [47] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages 2256–2265. PMLR, 2015.
- [48] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021.
- [49] Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. arXiv preprint arXiv:2303.01469, 2023.
- [50] Yang Song, Conor Durkan, Iain Murray, and Stefano Ermon. Maximum likelihood training of score-based diffusion models. In Advances in Neural Information Processing Systems, volume 34, pages 1415–1428, 2021.
- [51] Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021.
- [52] Hideyuki Tachibana, Mocho Go, Muneyoshi Inahara, Yotaro Katayama, and Yotaro Watanabe. Itô-taylor sampling scheme for denoising diffusion probabilistic models using ideal derivatives. arXiv e-prints, pages arXiv–2112, 2021.
- [53] Daniel Watson, William Chan, Jonathan Ho, and Mohammad Norouzi. Learning fast samplers for diffusion models by differentiating through sample quality. In International Conference on Learning Representations, 2022.
- [54] Suttisak Wizadwongsa and Supasorn Suwajanakorn. Accelerating guided diffusion sampling with splitting numerical methods. In The Eleventh International Conference on Learning Representations, 2022.
- [55] Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, and Jianxiong Xiao. LSUN: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365, 2015.
- [56] Qinsheng Zhang and Yongxin Chen. Fast sampling of diffusion models with exponential integrator. In The Eleventh International Conference on Learning Representations, 2022.
- [57] Min Zhao, Fan Bao, Chongxuan Li, and Jun Zhu. Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. In Advances in Neural Information Processing Systems, 2022.
- [58] Wenliang Zhao, Lujia Bai, Yongming Rao, Jie Zhou, and Jiwen Lu. UniPC: A unified predictor-corrector framework for fast sampling of diffusion models. arXiv preprint arXiv:2302.04867, 2023.
- [59] Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. Improved techniques for maximum likelihood estimation for diffusion odes. arXiv preprint arXiv:2305.03935, 2023.
Appendix A Related Work
Diffusion probabilistic models (DPMs) [47, 15, 51], also known as score-based generative models (SGMs), have achieved remarkable generation ability on image domain [10, 21], yielding extensive applications such as speech, singing and video synthesis [6, 27, 14], controllable image generation, translation and editing [38, 42, 43, 35, 57, 8], likelihood estimation [50, 23, 30, 59], data compression [23] and inverse problem solving [7, 22].
A.1 Fast Sampling Methods for DPMs
Fast sampling methods based on extra training or optimization include learning variances in the reverse process [37, 2], learning sampling schedule [53], learning high-order model derivatives [11], model refinement [29] and model distillation [45, 33, 49]. Though distillation-based methods can generate high-quality samples in less than 5 steps, they additionally bring onerous training costs. Moreover, the distillation process will inevitably lose part of the information of the original model, and is hard to be adapted to pre-trained large DPMs [43, 44, 42] and conditional sampling [34]. Some of distillation-based methods also lack the ability to make flexible trade-offs between sample speed and sample quality.
In contrast, training-free samplers are more lightweight and flexible. Among them, samplers based on diffusion ODEs generally require fewer steps than those based on diffusion SDEs [51, 40, 3, 48, 32], since SDEs introduce more randomness and make the denoising harder in the sampling process. Previous samplers handle the diffusion ODEs with different methods, such as Heun’s methods [21], splitting numerical methods [54], pseudo numerical methods [28], Adams methods [25] or exponential integrators [56, 31, 32, 58].
A.2 Comparison with Existing Solvers Based on Exponential Integrators
| DEIS [56] | DPM-Solver [31] | DPM-Solver++ [32] | UniPC [58] | DPM-Solver-v3 (Ours) | |
| First-Order | DDIM | DDIM | DDIM | DDIM | Improved DDIM |
| Taylor Expanded Predictor | for | for | for | for | for |
| Solver Type (High-Order) | Multistep | Singlestep | Multistep | Multistep | Multistep |
| Applicable for Guided Sampling | ✓ | ✗ | ✓ | ✓ | ✓ |
| Corrector Supported | ✗ | ✗ | ✗ | ✓ | ✓ |
| Model-Specific | ✗ | ✗ | ✗ | ✗ | ✓ |
In this section, we make some theoretical comparisons between DPM-Solver-v3 and existing diffusion ODE solvers that are based on exponential integrators [56, 31, 32, 58]. We summarize the results in Table 2, and provide some analysis below.
Previous ODE formulation as special cases of ours. First, we compare the formulation of the ODE solution. Our reformulated ODE solution in Eq. (9) involves extra coefficients , and it corresponds to a new predictor to be approximated by Taylor expansion. By comparing ours with previous ODE formulations in Eq. (3) and their corresponding noise/data prediction, we can easily figure out that they are special cases of ours by setting to specific values:
-
•
Noise prediction:
-
•
Data prediction:
It’s worth noting that, though our ODE formulation can degenerate to previous ones, it may still result in different solvers, since previous works conduct some equivalent substitution of the same order in the local approximation (for example, the choice of or in UniPC [58]). We never conduct such substitution, thus saving the efforts to tune it.
Moreover, under our framework, we find that DPM-Solver++ is a model-agnostic approximation of DPM-Solver-v3, under the Gaussian assumption. Specifically, according to Eq. (5), we have
| (17) |
If we assume for some fixed , then the optimal noise predictor is
| (18) |
It follows that , thus by Eq. (5), which corresponds the data prediction model used in DPM-Solver++. Moreover, for small enough (i.e., near to ), the Gaussian assumption is almost true (see Section 4.2), thus the data-prediction DPM-Solver++ approximately computes all the linear terms at the initial stage. To the best of our knowledge, this is the first explanation for the reason why the data-prediction DPM-Solver++ outperforms the noise-prediction DPM-Solver.
First-order discretization as improved DDIM Previous methods merely use noise/data parameterization, whether or not they change the time domain from to . While they differ in high-order cases, they are proven to coincide in the first-order case, which is DDIM [48] (deterministic case, ):
| (19) |
However, the first-order case of our method is
| (20) | ||||
which is not DDIM since we choose a better parameterization by the estimated EMS. Empirically, our first-order solver performs better than DDIM, as detailed in Appendix G.
Appendix B Proofs
B.1 Assumptions
In this section, we will give some mild conditions under which the local order of accuracy of Algorithm 1 and the global order of convergence of Algorithm 2 (predictor) are guaranteed.
B.1.1 Local
First, we will give the assumptions to bound the local truncation error.
Assumption B.1.
The total derivatives of the noise prediction model exist and are continuous.
Assumption B.2.
The coefficients are continuous and bounded. exist and are continuous.
Assumption B.3.
Assumption B.1 is required for the Taylor expansion which is regular in high-order numerical methods. Assumption B.2 requires the boundness of the coefficients as well as regularizes the coefficients’ smoothness to enable the Taylor expansion for , which holds in practice given the smoothness of and . Assumption B.3 makes sure and is of the same order, i.e., there exists some constant so that , which is satisfied in regular multistep methods.
B.1.2 Global
Then we will give the assumptions to bound the global error.
Assumption B.4.
The noise prediction model is Lipschitz w.r.t. to .
Assumption B.5.
.
Assumption B.6.
The starting values satisfies .
B.2 Order of Accuracy and Convergence
In this section, we prove the local and global order guarantees detailed in Theorem 3.1 and Theorem 3.3.
B.2.1 Local
Proof.
(Proof of Theorem 3.1) Denote . Subtracting the Taylor-expanded exact solution in Eq. (12) from the local approximation in Eq. (14), we have
| (21) |
First we examine the order of and . Under Assumption B.2, there exists some constant such that . So
| (22) | ||||
| (23) | ||||
Next we examine the order of . Under Assumption B.1 and Assumption B.2, since is elementary function of and , we know exist and are continuous. Adopting the notations in Eq. (13), by Taylor expansion, we have
| (24) | ||||
Comparing it with Eq. (13), we have
| (25) |
From Assumption B.3, we know there exists some constants so that . Thus
| (26) |
And finally, we have
| (27) | ||||
Substitute Eq. (22), Eq. (23) and Eq. (27) into Eq. (21), we can conclude that . ∎
B.2.2 Global
First, we provide a lemma that gives the local truncation error given inexact previous values when estimating the high-order derivatives.
Lemma B.7.
Proof.
By replacing with in Eq. (13) and subtracting Eq. (12) from Eq. (14), the expression for the local truncation error becomes
| (29) | ||||
And the linear system for solving becomes
| (30) |
where . Under Assumption B.4, we know . Thus, under Assumption B.1, Assumption B.2 and Assumption B.3, similar to the deduction in the last section, we have
| (31) |
Besides, under Assumption B.2, the orders of the other coefficients are the same as we obtain in the last section:
| (32) |
Thus
| (33) | ||||
Combining Eq. (29), Eq. (32) and Eq. (33), we can obtain the conclusion in Eq. (28). ∎
Then we prove Theorem 3.3 below.
Proof.
(Proof of Theorem 3.3)
As we have discussed, the predictor step from to is a special case of the local approximation Eq. (14) with . By Lemma B.7 we have
| (34) |
It follows that there exists constants irrelevant to , so that
| (35) |
Denote , we then have
| (36) |
Since when and it has bounded first-order derivative due to Assumption B.2, there exists a constant , so that for any , for sufficiently small . Thus, by taking , we have
| (37) |
Denote , by repeating Eq. (37), we have
| (38) |
By Assumption B.5, , so we have
| (39) | ||||
where . Then denote , we have
| (40) | ||||
Then we substitute Eq. (39) and Eq. (40) into Eq. (38). Note that by Assumption B.5, and by Assumption B.6, finally we conclude that . ∎
B.3 Pseudo-Order Solver
First, we provide a lemma that gives the explicit solution to Eq. (15).
Lemma B.8.
The solution to Eq. (15) is
| (41) |
Proof.
Then we prove Theorem 3.4 below:
Proof.
(Proof of Theorem 3.4) First, we use mathematical induction to prove that
| (45) |
For , Eq. (45) holds by the definition of . Suppose the equation holds for , we then prove it holds for .
Define the Lagrange polynomial which passes for :
| (46) |
Then is the coefficients before the highest-order term in . We then prove that satisfies the following recurrence relation:
| (47) |
By definition, is the -th order polynomial which passes for , and is the -th order polynomial which passes for .
Thus, for , we have
| (48) |
For , we have
| (49) |
for , we have
| (50) |
Therefore, is the -th order polynomial which passes distince points for . Due to the uniqueness of the Lagrange polynomial, we can conclude that . By taking the coefficients of the highest-order term, we obtain
| (51) |
B.4 Local Unbiasedness
Proof.
(Proof of Theorem 3.2) Subtracting the local exact solution in Eq. (9) from the -th order local approximation in Eq. (14), we have the local truncation error
| (52) | ||||
where is on the ground-truth ODE trajectory passing , and is the element of the inverse matrix at the -th row and the -th column, as discussed in the proof of Lemma B.8. By Newton-Leibniz theorem, we have
| (53) |
Also, since are on the ground-truth ODE trajectory passing , we have
| (54) |
where
| (55) |
Appendix C Implementation Details
C.1 Computing the EMS and Related Integrals in the ODE Formulation
The ODE formulation and local approximation require computing some complex integrals involving . In this section, we’ll give details about how to estimate on a few datapoints, and how to use them to compute the integrals efficiently.
C.1.1 Computing the EMS
First for the computing of in Eq. (5), note that
| (56) |
Since is a diagonal matrix, minimizing is equivalent to minimizing , where denotes the operator that takes the diagonal of a matrix as a vector. Thus we have .
However, this formula for requires computing the diagonal of the full Jacobian of the noise prediction model, which typically has time complexity for -dimensional data and is unacceptable when is large. Fortunately, the cost can be reduced to by utilizing stochastic diagonal estimators and employing the efficient Jacobian-vector-product operator provided by forward-mode automatic differentiation in deep learning frameworks.
For a -by- matrix , its diagonal can be unbiasedly estimated by [4]
| (57) |
where are -dimensional i.i.d. samples with zero mean, is the element-wise multiplication i.e., Hadamard product, and is the element-wise division. The stochastic diagonal estimator is analogous to the famous Hutchinson’s trace estimator [20]. By taking as the Rademacher distribution, we have , and the denominator can be omitted. For simplicity, we use regular multiplication and division symbols, assuming they are element-wise between vectors. Then can be expressed as:
| (58) |
which is an unbiased estimation when we replace the expectation with mean on finite samples . The process for estimating can easily be paralleled on multiple devices by computing on separate datapoints and gather them in the end.
Next, for the computing of in Eq. (11), note that it’s a simple least square problem. By taking partial derivatives w.r.t. and set them to 0, we have
| (59) |
And we obtain the explicit formula for
| (60) | ||||
| (61) |
which are unbiased least square estimators when we replace the expectation with mean on finite samples . Also, the process for estimating can be paralleled on multiple devices by computing on separate datapoints and gather them in the end. Thus, the estimation of involving evaluating and on . is a direct transformation of and requires a single forward pass. For , we have
| (62) | ||||
After we obtain , can be estimated by finite difference. To compute , we have
| (63) | ||||
which can also be computed with the Jacobian-vector-product operator.
In conclusion, for any , can be efficiently and unbiasedly estimated by sampling a few datapoints and using the Jacobian-vector-product.
C.1.2 Integral Precomputing
In the local approximation in Eq. (14), there are three integrals involving the EMS, which are . Define the following terms, which are also evaluated at and can be precomputed in time:
| (64) | ||||
Then for any , we can verify that the first two integrals can be expressed as
| (65) | ||||
which can be computed in time. For the third and last integral, denote it as , i.e.,
| (66) |
We need to compute it for and for every local transition time pair in the sampling process. For , we have
| (67) |
which can also be computed in time. But for , we no longer have such a simplification technique. Still, for any fixed timestep schedule during the sampling process, we can use a lazy precomputing strategy: compute when generating the first sample, store it with a unique key and retrieve it in in the following sampling process.
C.2 Algorithm
We provide the pseudocode of the local approximation and global solver in Algorithm 1 and Algorithm 2, which concisely describes how we implement DPM-Solver-v3.
Appendix D Experiment Details
In this section, we provide more experiment details for each setting, including the codebases and the configurations for evaluation, EMS computing and sampling. Unless otherwise stated, we utilize the forward-mode automatic differentiation (torch.autograd.forward_ad) provided by PyTorch [39] to compute the Jacobian-vector-products (JVPs). Also, as stated in Section 3.4, we draw datapoints from the marginal distribution defined by the forward diffusion process starting from some data distribution , instead of the model distribution .
D.1 ScoreSDE on CIFAR10
Codebase and evaluation For unconditional sampling on CIFAR10 [24], one experiment setting is based on the pretrained pixel-space diffusion model provided by ScoreSDE [51]. We use their official codebase of PyTorch implementation, and their checkpoint checkpoint_8.pth under vp/cifar10_ddpmpp_deep_continuous config. We adopt their own statistic file and code for computing FID.
EMS computing We estimate the EMS at uniform timesteps by drawing datapoints , where is the distribution of the training set. We compute two sets of EMS, corresponding to start time (NFE 10) and (NFE>10) in the sampling process respectively. The total time for EMS computing is 7h on 8 GPU cards of NVIDIA A40.
Sampling Following previous works [31, 32, 58], we use start time (NFE 10) and (NFE>10), end time and adopt the uniform logSNR timestep schedule. For DPM-Solver-v3, we use the 3rd-order predictor with the 3rd-order corrector by default. In particular, we change to the pseudo 3rd-order predictor at 5 NFE to further boost the performance.
D.2 EDM on CIFAR10
Codebase and evaluation For unconditional sampling on CIFAR10 [24], another experiment setting is based on the pretrained pixel-space diffusion model provided by EDM [21]. We use their official codebase of PyTorch implementation, and their checkpoint edm-cifar10-32x32-uncond-vp.pkl. For consistency, we borrow the statistic file and code from ScoreSDE [51] for computing FID.
EMS computing Since the pretrained models of EDM are stored within the pickles, we fail to use torch.autograd.forward_ad for computing JVPs. Instead, we use torch.autograd.functional.jvp, which is much slower since it employs the double backward trick. We estimate two sets of EMS. One corresponds to uniform timesteps and datapoints , where is the distribution of the training set. The other corresponds to . They are used when NFE<10 and NFE10 respectively. The total time for EMS computing is 3.5h on 8 GPU cards of NVIDIA A40.
Sampling Following EDM, we use start time and end time , but adopt the uniform logSNR timestep schedule which performs better in practice. For DPM-Solver-v3, we use the 3rd-order predictor and additionally employ the 3rd-order corrector when NFE 6. In particular, we change to the pseudo 3rd-order predictor at 5 NFE to further boost the performance.
D.3 Latent-Diffusion on LSUN-Bedroom
Codebase and evaluation The unconditional sampling on LSUN-Bedroom [55] is based on the pretrained latent-space diffusion model provided by Latent-Diffusion [43]. We use their official codebase of PyTorch implementation and their default checkpoint. We borrow the statistic file and code from Guided-Diffusion [10] for computing FID.
EMS computing We estimate the EMS at uniform timesteps by drawing datapoints , where is the distribution of the latents of the training set. The total time for EMS computing is 12min on 8 GPU cards of NVIDIA A40.
Sampling Following previous works [58], we use start time , end time and adopt the uniform timestep schedule. For DPM-Solver-v3, we use the 3rd-order predictor with the pseudo 4th-order corrector.
D.4 Guided-Diffusion on ImageNet-256
Codebase and evaluation The conditional sampling on ImageNet-256 [9] is based on the pretrained pixel-space diffusion model provided by Guided-Diffusion [10]. We use their official codebase of PyTorch implementation and their two checkpoints: the conditional diffusion model 256x256_diffusion.pt and the classifier 256x256_classifier.pt. We adopt their own statistic file and code for computing FID.
EMS computing We estimate the EMS at uniform timesteps by drawing datapoints , where is the distribution of the training set. Also, we find that the FID metric on the ImageNet-256 dataset behaves specially, and degenerated () performs better. The total time for EMS computing is 9.5h on 8 GPU cards of NVIDIA A40.
D.5 Stable-Diffusion on MS-COCO2014 prompts
Codebase and evaluation The text-to-image sampling on MS-COCO2014 [26] prompts is based on the pretrained latent-space diffusion model provided by Stable-Diffusion [43]. We use their official codebase of PyTorch implementation and their checkpoint sd-v1-4.ckpt. We compute MSE on randomly selected captions from the MS-COCO2014 validation dataset, as detailed in Section 4.1.
EMS computing We estimate the EMS at uniform timesteps by drawing datapoints . Since Stable-Diffusion is trained on the LAION-5B dataset [46], there is a gap between the images in the MS-COCO2014 validation dataset and the images generated by Stable-Diffusion with certain guidance scale. Thus, we choose to be the distribution of the latents generated by Stable-Diffusion with corresponding guidance scale, using 200-step DPM-Solver++ [32]. We generate these latents with random captions and Gaussian noise different from those we use to compute MSE. The total time for EMS computing is 11h on 8 GPU cards of NVIDIA A40 for each guidance scale.
D.6 License
| Name | URL | Citation | License |
| CIFAR10 | https://www.cs.toronto.edu/~kriz/cifar.html | [24] | |
| LSUN-Bedroom | https://www.yf.io/p/lsun | [55] | |
| ImageNet-256 | https://www.image-net.org | [9] | |
| MS-COCO2014 | https://cocodataset.org | [26] | CC BY 4.0 |
| ScoreSDE | https://github.com/yang-song/score_sde_pytorch | [51] | Apache-2.0 |
| EDM | https://github.com/NVlabs/edm | [21] | CC BY-NC-SA 4.0 |
| Guided-Diffusion | https://github.com/openai/guided-diffusion | [10] | MIT |
| Latent-Diffusion | https://github.com/CompVis/latent-diffusion | [43] | MIT |
| Stable-Diffusion | https://github.com/CompVis/stable-diffusion | [43] | CreativeML Open RAIL-M |
| DPM-Solver++ | https://github.com/LuChengTHU/dpm-solver | [32] | MIT |
| UniPC | https://github.com/wl-zhao/UniPC | [58] |
We list the used datasets, codes and their licenses in Table 3.
Appendix E Runtime Comparison
| Method | NFE | |||
| 5 | 10 | 15 | 20 | |
| CIFAR10 [24], ScoreSDE [51] (batch size = 128) | ||||
| DPM-Solver++ [32] | 1.253(0.0014) | 2.503(0.0017) | 3.754(0.0042) | 5.010(0.0048) |
| UniPC [58] | 1.268(0.0012) | 2.532(0.0018) | 3.803(0.0037) | 5.080(0.0049) |
| DPM-Solver-v3 | 1.273(0.0005) | 2.540(0.0023) | 3.826(0.0039) | 5.108(0.0055) |
| CIFAR10 [24], EDM [21] (batch size = 128) | ||||
| DPM-Solver++ [32] | 1.137(0.0011) | 2.278(0.0015) | 3.426(0.0024) | 4.569(0.0031) |
| UniPC [58] | 1.142(0.0016) | 2.289(0.0019) | 3.441(0.0035) | 4.590(0.0021) |
| DPM-Solver-v3 | 1.146(0.0010) | 2.293(0.0015) | 3.448(0.0018) | 4.600(0.0027) |
| LSUN-Bedroom [55], Latent-Diffusion [43] (batch size = 32) | ||||
| DPM-Solver++ [32] | 1.302(0.0009) | 2.608(0.0010) | 3.921(0.0023) | 5.236(0.0045) |
| UniPC [58] | 1.305(0.0005) | 2.616(0.0019) | 3.934(0.0033) | 5.244(0.0043) |
| DPM-Solver-v3 | 1.302(0.0010) | 2.620(0.0027) | 3.932(0.0028) | 5.290(0.0030) |
| ImageNet256 [9], Guided-Diffusion [10] (batch size = 4) | ||||
| DPM-Solver++ [32] | 1.594(0.0011) | 3.194(0.0018) | 4.792(0.0031) | 6.391(0.0045) |
| UniPC [58] | 1.606(0.0026) | 3.205(0.0025) | 4.814(0.0049) | 6.427(0.0060) |
| DPM-Solver-v3 | 1.601(0.0059) | 3.229(0.0031) | 4.807(0.0068) | 6.458(0.0257) |
| MS-COCO2014 [26], Stable-Diffusion [43] (batch size = 4) | ||||
| DPM-Solver++ [32] | 1.732(0.0012) | 3.464(0.0020) | 5.229(0.0027) | 6.974(0.0013) |
| UniPC [58] | 1.735(0.0012) | 3.484(0.0364) | 5.212(0.0015) | 6.988(0.0035) |
| DPM-Solver-v3 | 1.731(0.0008) | 3.471(0.0011) | 5.211(0.0030) | 6.945(0.0022) |
As we have mentioned in Section 4, the runtime of DPM-Solver-v3 is almost the same as other solvers (DDIM [48], DPM-Solver [31], DPM-Solver++ [32], UniPC [58], etc.) as long as they use the same NFE. This is because the main computation costs are the serial evaluations of the large neural network , and the other coefficients are either analytically computed [48, 31, 32, 58], or precomputed (DPM-Solver-v3), thus having neglectable costs.
Table 4 shows the runtime of DPM-Solver-v3 and some other solvers on a single NVIDIA A40 under different settings. We use torch.cuda.Event and torch.cuda.synchronize to accurately compute the runtime. We evaluate the runtime on 8 batches (dropping the first batch since it contains extra initializations) and report the mean and std. We can see that the runtime is proportional to NFE and has a difference of about % for different solvers, which confirms our statement. Therefore, the speedup for the NFE is almost the actual speedup of the runtime.
Appendix F Quantitative Results
| Method | Model | NFE | ||||||
| 5 | 6 | 8 | 10 | 12 | 15 | 20 | ||
| DPM-Solver++ [32] | Guided-Diffusion [10] () | 16.87 | 13.09 | 9.95 | 8.72 | 8.13 | 7.73 | 7.48 |
| UniPC [58] | 15.62 | 11.91 | 9.29 | 8.35 | 7.95 | 7.64 | 7.44 | |
| DPM-Solver-v3 | 15.10 | 11.39 | 8.96 | 8.27 | 7.94 | 7.62 | 7.39 | |
| Method | Model | NFE | ||||||
| 5 | 6 | 8 | 10 | 12 | 15 | 20 | ||
| DPM-Solver++ [32] | Stable-Diffusion [43] () | 0.076 | 0.056 | 0.028 | 0.016 | 0.012 | 0.009 | 0.006 |
| UniPC [58] | 0.055 | 0.039 | 0.024 | 0.012 | 0.007 | 0.005 | 0.002 | |
| DPM-Solver-v3 | 0.037 | 0.027 | 0.024 | 0.007 | 0.005 | 0.001 | 0.002 | |
| DPM-Solver++ [32] | Stable-Diffusion [43] () | 0.60 | 0.65 | 0.50 | 0.46 | 0.42 | 0.38 | 0.30 |
| UniPC [58] | 0.65 | 0.71 | 0.56 | 0.46 | 0.43 | 0.35 | 0.31 | |
| DPM-Solver-v3 | 0.55 | 0.64 | 0.49 | 0.40 | 0.45 | 0.34 | 0.29 | |
Appendix G Ablations
In this section, we conduct some ablations to further evaluate and analyze the effectiveness of DPM-Solver-v3.
G.1 Varying the Number of Timesteps and Datapoints for the EMS
| NFE | ||||||||
| 5 | 6 | 8 | 10 | 12 | 15 | 20 | ||
| 1200 | 512 | 18.84 | 7.90 | 4.49 | 3.74 | 3.88 | 3.52 | 3.12 |
| 1200 | 1024 | 15.52 | 7.55 | 4.17 | 3.56 | 3.37 | 3.03 | 2.78 |
| 120 | 4096 | 13.67 | 7.60 | 4.09 | 3.49 | 3.24 | 2.90 | 2.70 |
| 250 | 4096 | 13.28 | 7.56 | 4.00 | 3.45 | 3.22 | 2.92 | 2.70 |
| 1200 | 4096 | 12.76 | 7.40 | 3.94 | 3.40 | 3.24 | 2.91 | 2.71 |
First, we’d like to investigate how the number of timesteps and the number of datapoints for computing the EMS affects the performance. We conduct experiments with the DPM ScoreSDE [51] on CIFAR10 [24], by decreasing and from our default choice .
We list the FID results using the EMS of different and in Table 8. We can observe that the number of datapoints is crucial to the performance, while the number of timesteps is less significant and affects mainly the performance in 510 NFEs. When NFE>10, we can decrease to as little as 50, which gives even better FIDs. Note that the time cost for computing the EMS is proportional to , so how to choose appropriate and for both efficiency and accuracy is worth studying.
G.2 First-Order Comparison
| Method | NFE | ||||||
| 5 | 6 | 8 | 10 | 12 | 15 | 20 | |
| DDIM [48] | 54.56 | 41.92 | 27.51 | 20.11 | 15.64 | 12.05 | 9.00 |
| DPM-Solver-v3-1 | 39.18 | 29.82 | 20.03 | 14.98 | 11.86 | 9.34 | 7.19 |
| NFE = 5 | NFE = 10 | NFE = 20 | |
| DDIM [48] |  |
 |
 |
| FID 54.56 | FID 20.11 | FID 9.00 | |
| DPM-Solver-v3-1 (Ours) |  |
 |
 |
| FID 39.18 | FID 14.98 | FID 7.19 |
G.3 Effects of Pseudo-Order Solver
We now demonstrate the effectiveness of the pseudo-order solver, including the pseudo-order predictor and the pseudo-order corrector.
Pseudo-order predictor The pseudo-order predictor is only applied in one case (at 5 NFE on CIFAR10 [24]) to achieve maximum performance improvement. In such cases, without the pseudo-order predictor, the FID results will degenerate from 12.76 to 15.91 for ScoreSDE [51], and from 12.21 to 12.72 for EDM [21]. While they are still better than previous methods, the pseudo-order predictor is proven to further boost the performance at NFEs as small as 5.
| Method | NFE | ||||||
| 5 | 6 | 8 | 10 | 12 | 15 | 20 | |
| LSUN-Bedroom [55], Latent-Diffusion [43] | |||||||
| 4th-order corrector | 8.83 | 5.28 | 3.65 | 3.27 | 3.17 | 3.14 | 3.13 |
| pseudo (default) | 7.54 | 4.79 | 3.53 | 3.16 | 3.06 | 3.05 | 3.05 |
| ImageNet-256 [9], Guided-Diffusion [10] () | |||||||
| 3rd-order corrector | 15.87 | 11.91 | 9.27 | 8.37 | 7.97 | 7.62 | 7.47 |
| pseudo (default) | 15.10 | 11.39 | 8.96 | 8.27 | 7.94 | 7.62 | 7.39 |
| MS-COCO2014 [26], Stable-Diffusion [43] () | |||||||
| 3rd-order corrector | 0.037 | 0.028 | 0.028 | 0.014 | 0.0078 | 0.0024 | 0.0011 |
| pseudo (default) | 0.037 | 0.027 | 0.024 | 0.0065 | 0.0048 | 0.0014 | 0.0022 |
Pseudo-order corrector We show the comparison between true and pseudo-order corrector in Table 10. We can observe a consistent improvement when switching to the pseudo-order corrector. Thus, it suggests that if we use -th order predictor, we’d better combine it with pseudo -th order corrector rather than -th order corrector.
G.4 Effects of Half-Corrector
| Method | Corrector Usage | NFE | ||||||
| 5 | 6 | 8 | 10 | 12 | 15 | 20 | ||
| DPM-Solver++ [32] | no corrector | 0.60 | 0.65 | 0.50 | 0.46 | 0.42 | 0.38 | 0.30 |
| UniPC [58] | full-corrector | 0.65 | 0.71 | 0.56 | 0.46 | 0.43 | 0.35 | 0.31 |
| half-corrector | 0.59 | 0.66 | 0.50 | 0.46 | 0.41 | 0.38 | 0.30 | |
| DPM-Solver-v3 | full-corrector | 0.65 | 0.67 | 0.49 | 0.40 | 0.47 | 0.34 | 0.30 |
| half-corrector | 0.55 | 0.64 | 0.51 | 0.44 | 0.45 | 0.36 | 0.29 | |
We demonstrate the effects of half-corrector in Table 11, using the popular Stable-Diffusion model [43]. We can observe that under the relatively large guidance scale of 7.5 which is necessary for producing samples of high quality, the corrector adopted by UniPC [58] has a negative effect on the convergence to the ground-truth samples, making UniPC even worse than DPM-Solver++ [32]. When we employ the half-corrector technique, the problem is partially alleviated. Still, it lags behind our DPM-Solver-v3, since we further incorporate the EMS.
G.5 Singlestep vs. Multistep
| Method | NFE | |||||||
| 5 | 6 | 8 | 10 | 12 | 15 | 20 | 25 | |
| DPM-Solver (S) [31] | 290.51 | 23.78 | 23.51 | 4.67 | 4.97 | 3.34 | 2.85 | 2.70 |
| DPM-Solver (M) [32] | 27.40 | 17.85 | 9.04 | 6.41 | 5.31 | 4.10 | 3.30 | 2.98 |
| DPM-Solver++ (S) [32] | 51.80 | 38.54 | 12.13 | 6.52 | 6.36 | 4.56 | 3.52 | 3.09 |
| DPM-Solver++ (M) [32] | 28.53 | 13.48 | 5.34 | 4.01 | 4.04 | 3.32 | 2.90 | 2.76 |
| DPM-Solver-v3 (S) | 21.83 | 16.81 | 7.93 | 5.76 | 5.17 | 3.99 | 3.22 | 2.96 |
| DPM-Solver-v3 (M) | 12.76 | 7.40 | 3.94 | 3.40 | 3.24 | 2.91 | 2.71 | 2.64 |
As we stated in Section 3.2.2, multistep methods perform better than singlestep methods. To study the relationship between parameterization and these solver types, we develop a singlestep version of DPM-Solver-v3 in Algorithm 3. Note that since -th order singlestep solver divides each step into substeps, the total number of timesteps is a multiple of . For flexibility, we follow the adaptive third-order strategy of DPM-Solver [31], which first takes third-order steps and then takes first-order or second-order steps in the end.
Require: noise prediction model , noise schedule , coefficients , cache
Input: timesteps , initial value
Output:
Since UniPC [58] is based on a multistep predictor-corrector framework and has no singlestep version, we only compare with DPM-Solver [31] and DPM-Solver++ [32], which uses noise prediction and data prediction respectively. The results of ScoreSDE model [51] on CIFAR10 [24] are shown in Table 12, which demonstrate that different parameterizations have different relative performance under singlestep and multistep methods.
Specifically, for singlestep methods, DPM-Solver-v3 (S) outperforms DPM-Solver++ (S) across NFEs, but DPM-Solver (S) is even better than DPM-Solver-v3 (S) when NFE10 (though when NFE<10, DPM-Solver (S) has worst performance), which suggests that noise prediction is best strategy in such scenarios; for multistep methods, we have DPM-Solver-v3 (M) > DPM-Solver++ (M) > DPM-Solver (M) across NFEs. Moreover, DPM-Solver (S) even outperforms DPM-Solver++ (M) when NFE20, and the properties of different parameterizations in singlestep methods are left for future study. Overall, DPM-Solver-v3 (M) achieves the best results among all these methods, and performs the most stably under different NFEs.
Appendix H FID/CLIP Score on Stable-Diffusion
| Method | Metric | NFE | ||||||
| 5 | 6 | 8 | 10 | 12 | 15 | 20 | ||
| DPM-Solver++ [32] | FID | 18.87 | 17.44 | 16.40 | 15.93 | 15.78 | 15.84 | 15.72 |
| CLIP score | 0.263 | 0.265 | 0.265 | 0.265 | 0.266 | 0.265 | 0.265 | |
| UniPC [58] | FID | 18.77 | 17.32 | 16.20 | 16.15 | 16.09 | 16.06 | 15.94 |
| CLIP score | 0.262 | 0.263 | 0.265 | 0.265 | 0.265 | 0.265 | 0.265 | |
| DPM-Solver-v3 | FID | 18.83 | 16.41 | 15.41 | 15.32 | 15.13 | 15.30 | 15.23 |
| CLIP score | 0.260 | 0.262 | 0.264 | 0.265 | 0.265 | 0.265 | 0.265 | |
In text-to-image generation, since the sample quality is affected not only by discretization error of the sampling process, but also by estimation error of neural networks during training, low MSE (faster convergence) does not necessarily imply better sample quality. Therefore, we choose the MSCOCO2014 [26] validation set as the reference, and additionally evaluate DPM-Solver-v3 on Stable-Diffusion model [43] by the standard metrics FID and CLIP score [41] which measure the sample quality and text-image alignment respectively. For DPM-Solver-v3, we use the full-corrector strategy when NFE<10, and no corrector when NFE10.
The results in Table 13 show that DPM-Solver-v3 achieves consistently better FID and similar CLIP scores. Notably, we achieve an FID of 15.4 in 8 NFE, close to the reported FID of Stable-Diffusion v1.4.
Still, we claim that FID is not a proper metric for evaluating the convergence of latent-space diffusion models. As stated in DPM-Solver++ and Section 4.1, we can see that the FIDs quickly achieve 15.016.0 within 10 steps, even if the latent code does not converge, because of the strong image decoder. Instead, MSE in the latent space is a direct way to measure the convergence. By comparing the MSE, our sampler does converge faster to the ground-truth samples of Stable Diffusion itself.
Appendix I More Theoretical Analyses
I.1 Expressive Power of Our Generalized Parameterization
Though the introduced coefficients seem limited to guarantee the optimality of the parameterization formulation itself, we claim that the generalized parameterization in Eq. (8) can actually cover a wide range of parameterization families in the form of . Considering the paramerization on , by rearranging the terms, Eq. (8) can be written as
| (68) |
We can compare the coefficients before and in and to figure out how corresponds to . In fact, we can not directly let equal , since when , we have , and the coefficient before in is fixed. Still, can be equalized to by a linear transformation, which only depends on and does not affect our analyses of the discretization error and solver.
I.2 Justification of Why Minimizing First-order Discretization Error Can Help Higher-order Solver
The EMS in Eq. (11) are designed to minimize the first-order discretization error in Eq. (10). However, the high-order solver is actually more frequently adopted in practice (specifically, third-order in unconditional sampling, second-order in conditional sampling), since it incurs lower sampling errors by taking higher-order Taylor expansions to approximate the predictor .
In the following, we show that the EMS can also help high-order solver. By Eq. (52) in Appendix B.4, the -th order local error can be expressed as
| (70) | ||||
By Newton-Leibniz theorem, it is equivalent to
| (71) | ||||
We assume that the estimated EMS are bounded (in the order of , Assumption B.2 in Appendix B.1), which is empirically confirmed as in Section 4.2. By the definition of in Eq. (8), we have . Therefore, Eq. (11) controls and further controls , since other terms are only dependent on the EMS and are bounded.
I.3 The Extra Error of EMS Estimation and Integral Estimation
Analysis of EMS estimation error
In practice, the EMS in Eq. (5) and Eq. (11) are estimated on finite datapoints by the explicit expressions in Eq. (58) and Eq. (63), which may differ from the true . Theoretically, on one hand, the order and convergence theorems in Section 3.2 are irrelevant to the EMS estimation error: The ODE solution in Eq. (9) is correct whatever are, and we only need the assumption that these coefficients are bounded (Assumption B.2 in Appendix B.1) to prove the local and global order; on the other hand, the first-order discretization error in Eq. (10) is vulnerable to the EMS estimation error, which relates to the performance at few steps. Empirically, to enable fast sampling, we need to ensure the number of datapoints for estimating EMS (see ablations in Table 8), and we find that our method is robust to the EMS estimation error given only 1024 datapoints in most cases (see EMS computing configs in Appendix D).
Analysis of integral estimation error
Another source of error is the process of integral estimation ( and in Eq. (14)) by trapezoidal rule. We can analyze the estimation error by the error bound formula of trapezoidal rule: suppose we use uniform discretization on with interval to estimate , then the error satisfies
| (72) |
Under Assumption B.2, the EMS and their first-order derivative are bounded. Denote , then
| (73) | ||||
| (74) | ||||
Since are all , we can conclude that , and the errors of are respectively, where is the stepsize of EMS discretization (, corresponds to 1201200 timesteps for our EMS computing), and . Therefore, the extra error of integral estimation is under high order and ignorable.
Appendix J More Discussions
J.1 Extra Computational and Memory Costs
The extra memory cost of DPM-Solver-v3 is rather small. The extra coefficients are discretized and computed at timesteps, each with a dimension same as the diffused data. The extra memory cost is , including the precomputed terms in Appendix C.1.2, and is rather small compared to the pretrained model (e.g. only 125M in total on Stable-Diffusion, compared to 4G of the model itself).
The pre-computation time for estimating EMS is rather short. The EMS introduced by our method can be effectively estimated on around 1k datapoints within hours (Appendix D), which is rather short compared to the long training/distillation time of other methods. Moreover, the integrals of these extra coefficients are just some vector constants that can be pre-computed within seconds, as shown in Appendix C.1.2. The precomputing is done only once before sampling.
The extra computational overhead of DPM-Solver-v3 during sampling is negligible. Once we obtain the estimated EMS and their integrals at discrete timesteps, they can be regarded as constants. Thus, during the subsequent sampling process, the computational overhead is the same as previous training-free methods (such as DPM-Solver++) with negligible differences (Appendix E).
J.2 Flexibility
The pre-computed EMS can be applied for any time schedule during sampling without re-computing EMS. Besides, we compute EMS on unconditional models and it can be used for a wide range of guidance scales (such as cfg=7.5 in Stable Diffusion). In short, EMS is flexible and easy to adopt in downstream applications.
-
•
Time schedule: The choice of in EMS is disentangled with the timestep scheduler in sampling. Once we have estimated the EMS at (e.g., 1200) timesteps, they can be flexibly adapted to any schedule (uniform /uniform …) during sampling, by corresponding the actual timesteps during sampling to the bins. For different time schedule, we only need to re-precompute in Appendix C.1.2, and the time cost is within seconds.
-
•
Guided sampling: We compute the EMS on the unconditional model for all guided cases. Empirically, the EMS computed on the model without guidance (unconditional part) performs more stably than those computed on the model with guidance, and can accelerate the sampling procedure in a wide range of guidance scales (including the common guidance scales used in pretrained models). We think that the unconditional model contains some common information (image priors) for all the conditions, such as color, sketch, and other image patterns. Extracting them helps correct some common biases such as shallow color, low saturation level and lack of details. In contrast, the conditional model is dependent on the condition and has a large variance.
Remark J.1.
EMS computed on models without guidance cannot work for extremely large guidance scales (e.g., cfg scale 15 for Stable Diffusion), since in this case, the condition has a large impact on the denoising process. Note that at these extremely large scales, the sampling quality is very low (compared to cfg scale 7.5) and they are rarely used in practice. Therefore, our proposed EMS without guidance is suitable enough for the common applications with the common guidance.
J.3 Stability
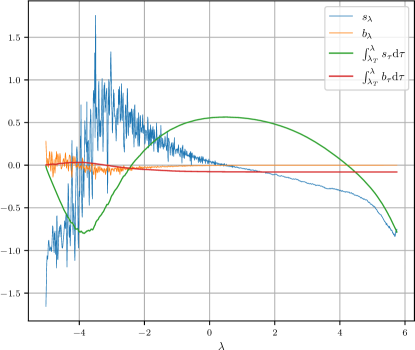
As shown in Section 4.2, the estimated EMS appear much fluctuating, especially for ScoreSDE on CIFAR10. We would like to clarify that the unstable is not an issue, and our sampler is stable:
-
•
The fluctuation of on ScoreSDE is intrinsic and not due to the estimation error. As we increase the number of samples to decrease the estimation error, the fluctuation is not reduced. We attribute it to the periodicity of trigonometric functions in the positional timestep embedding as stated in Section 4.2.
- •
J.4 Practical Value
When NFE is around 20, our improvement of sample quality is small because all different fast samplers based on diffusion ODEs almost converge. Therefore, what matters is that our method has a faster convergence speed to good sample quality. As we observed, the less diverse the domain is, the more evidently the speed-up takes effect. For example, on LSUN-Bedroom, our method can achieve up to 40% faster convergence.
To sum up, the practical value of DPM-Solver-v3 embodies the following aspects:
-
1.
1530% speed-up can save lots of costs for online text-to-image applications. Our speed-ups are applicable to large text-to-image diffusion models, which are an important part of today’s AIGC community. As the recent models become larger, a single NFE requires more computational resources, and 1530% speed-up can save a lot of the companies’ expenses for commercial usage.
-
2.
Improvement in 510 NFEs benefits image previewing. Since the samples are controlled by the random seed, coarse samples with 510 NFEs can be used to preview thousands of samples with low costs and give guidance on choosing the random seed, which can be then used to generate fine samples with best-quality sampling strategies. This is especially useful for text-to-image generation. Since our method achieves better quality and converges faster to the ground-truth sample, it can provide better guidance when used for preview.
Appendix K Additional Samples
We provide more visual samples in Figure 9, Figure 10, Figure 11 and Table 14 to demonstrate the qualitative effectiveness of DPM-Solver-v3. It can be seen that the visual quality of DPM-Solver-v3 outperforms previous state-of-the-art solvers. Our method can generate images that have reduced bias (less “shallow”), higher saturation level and more visual details, as mentioned in Section 4.3.
| NFE = 5 | NFE = 10 | |
| DPM-Solver++ [32] |  |
 |
| FID 28.53 | FID 4.01 | |
| UniPC [58] |  |
 |
| FID 23.71 | FID 3.93 | |
| DPM-Solver-v3 (Ours) |  |
 |
| FID 12.76 | FID 3.40 |
| NFE = 5 | NFE = 10 | |
| Heun’s 2nd [21] |  |
 |
| FID 320.80 | FID 16.57 | |
| DPM-Solver++ [32] |  |
 |
| FID 24.54 | FID 2.91 | |
| UniPC [58] |  |
 |
| FID 23.52 | FID 2.85 | |
| DPM-Solver-v3 (Ours) |  |
 |
| FID 12.21 | FID 2.51 |



| Text Prompts | DPM-Solver++ [32] (MSE 0.60) | UniPC [58] (MSE 0.65) | DPM-Solver-v3 (Ours) (MSE 0.55) |
| “pixar movie still portrait photo of madison beer, jessica alba, woman, as hero catgirl cyborg woman by pixar, by greg rutkowski, wlop, rossdraws, artgerm, weta, marvel, rave girl, leeloo, unreal engine, glossy skin, pearlescent, wet, bright morning, anime, sci-fi, maxim magazine cover” | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00015_dpm++.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00015_unipc.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00015_dpmv3.jpg) |
| “oil painting with heavy impasto of a pirate ship and its captain, cosmic horror painting, elegant intricate artstation concept art by craig mullins detailed” | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00043_dpm++.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00043_unipc.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00043_dpmv3.jpg) |
| “environment living room interior, mid century modern, indoor garden with fountain, retro, m vintage, designer furniture made of wood and plastic, concrete table, wood walls, indoor potted tree, large window, outdoor forest landscape, beautiful sunset, cinematic, concept art, sunstainable architecture, octane render, utopia, ethereal, cinematic light” | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00081_dpm++.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00081_unipc.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00081_dpmv3.jpg) |
| “the living room of a cozy wooden house with a fireplace, at night, interior design, concept art, wallpaper, warm, digital art. art by james gurney and larry elmore.” | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00088_dpm++.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00088_unipc.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00088_dpmv3.jpg) |
| “Full page concept design how to craft life Poison, intricate details, infographic of alchemical, diagram of how to make potions, captions, directions, ingredients, drawing, magic, wuxia” | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00093_dpm++.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00093_unipc.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00093_dpmv3.jpg) |
| “Fantasy art, octane render, 16k, 8k, cinema 4d, back-lit, caustics, clean environment, Wood pavilion architecture, warm led lighting, dusk, Landscape, snow, arctic, with aqua water, silver Guggenheim museum spire, with rays of sunshine, white fabric landscape, tall building, zaha hadid and Santiago calatrava, smooth landscape, cracked ice, igloo, warm lighting, aurora borialis, 3d cgi, high definition, natural lighting, realistic, hyper realism” | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00108_dpm++.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00108_unipc.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00108_dpmv3.jpg) |
| “tree house in the forest, atmospheric, hyper realistic, epic composition, cinematic, landscape vista photography by Carr Clifton & Galen Rowell, 16K resolution, Landscape veduta photo by Dustin Lefevre & tdraw, detailed landscape painting by Ivan Shishkin, DeviantArt, Flickr, rendered in Enscape, Miyazaki, Nausicaa Ghibli, Breath of The Wild, 4k detailed post processing, artstation, unreal engine” | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00116_dpm++.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00116_unipc.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00116_dpmv3.jpg) |
| “A trail through the unknown, atmospheric, hyper realistic, 8k, epic composition, cinematic, octane render, artstation landscape vista photography by Carr Clifton & Galen Rowell, 16K resolution, Landscape veduta photo by Dustin Lefevre & tdraw, 8k resolution, detailed landscape painting by Ivan Shishkin, DeviantArt, Flickr, rendered in Enscape, Miyazaki, Nausicaa Ghibli, Breath of The Wild, 4k detailed post processing, artstation, rendering by octane, unreal engine” | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00125_dpm++.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00125_unipc.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00125_dpmv3.jpg) |
| “postapocalyptic city turned to fractal glass, ctane render, 8 k, exploration, cinematic, trending on artstation, by beeple, realistic, 3 5 mm camera, unreal engine, hyper detailed, photo–realistic maximum detai, volumetric light, moody cinematic epic concept art, realistic matte painting, hyper photorealistic, concept art, cinematic epic, octane render, 8k, corona render, movie concept art, octane render, 8 k, corona render, trending on artstation, cinematic composition, ultra–detailed, hyper–realistic, volumetric lighting” | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00132_dpm++.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00132_unipc.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00132_dpmv3.jpg) |
| ““WORLDS”: zoological fantasy ecosystem infographics, magazine layout with typography, annotations, in the style of Elena Masci, Studio Ghibli, Caspar David Friedrich, Daniel Merriam, Doug Chiang, Ivan Aivazovsky, Herbert Bauer, Edward Tufte, David McCandless” | ![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00151_dpm++.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00151_unipc.jpg) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f1d5d4e6-166f-470b-a98a-ab98cce72a6e/00151_dpmv3.jpg) |