DPFormer: Learning Differentially Private Transformer on Long-Tailed Data
Abstract
The Transformer has emerged as a versatile and effective architecture with broad applications. However, it still remains an open problem how to efficiently train a Transformer model of high utility with differential privacy guarantees. In this paper, we identify two key challenges in learning differentially private Transformers, i.e., heavy computation overhead due to per-sample gradient clipping and unintentional attention distraction within the attention mechanism. In response, we propose DPFormer, equipped with Phantom Clipping and Re-Attention Mechanism, to address these challenges. Our theoretical analysis shows that DPFormer can reduce computational costs during gradient clipping and effectively mitigate attention distraction (which could obstruct the training process and lead to a significant performance drop, especially in the presence of long-tailed data). Such analysis is further corroborated by empirical results on two real-world datasets, demonstrating the efficiency and effectiveness of the proposed DPFormer.
1 Introduction
Differentially private deep learning has made remarkable strides, particularly in domains such as image classification [35, 16, 10] and natural language processing [45, 27, 19]. This success can be largely attributed to the availability of extensive pre-trained models, offering robust and diverse foundations for further learning. However, such reliance on vast, pre-existing datasets poses a significant challenge when these resources are not accessible or relevant. This hurdle becomes particularly pronounced when it is necessary to train differentially private Transformers using only domain-specific data gathered from real-world scenarios rather than generic, large-scale datasets.
This issue is glaringly evident in tasks like sequence prediction, which are integral to a wide range of applications, such as commercial recommender systems. These systems are designed to model and predict user behavior based on sequences of interactions like clicks or purchases. The reliance on domain-specific sequence data coupled with the constraints of differential privacy can significantly compromise the performance of such systems, particularly when large-scale public datasets or pre-existing pre-trained models are not at our disposal.
The challenges posed by this scenario can be summarized into two key hurdles. The first one stems from the inherent nature of real-world data, which typically follows a long-tailed distribution, where a small fraction of data occur frequently, while a majority of data appear infrequently. This poses the intrinsic hardness of high-utility differentially private training, which, based on its sample complexity [12], necessitates a sufficiently large volume of data to discern general patterns without resorting to the memorization of individual data points [7, 14]. Our theoretical analysis shows that during differentially private training of Transformers, attention scores tend to be skewed by long-tailed tokens (i.e., tokens with fewer occurrences), therefore leading to huge performance drops.
The second hurdle arises from the resource-intensiveness of deep learning with differential privacy, which is primarily due to the requirement of clipping per-sample gradient. This requirement not only complicates the learning process but also places a significant computational burden, especially when resources are limited or when scalability is a priority.
To address these issues, we propose DPFormer (Figure 1), a methodology for learning differentially private Transformers. One of our primary contributions is the introduction of an efficient technique, Phantom Clipping. This technique addresses the computational burden associated with differential privacy by computing the clipped gradient without the need for the per-sample gradient. This allows for the efficient scaling of the learning process. Additionally, to further enhance model utility under differentially private training, we introduce the Re-Attention Mechanism, which aims to mitigate the attention distraction phenomenon, ensuring the model’s focus is directed toward the most pertinent elements of the input. This enables effective learning, especially in the presence of long-tailed data.
Experiments on public real-world datasets demonstrate the efficiency and effectiveness of DPFormer. These results not only validate our approach but also demonstrate the practical applicability of our model in scenarios where data is limited and domain-specific, and differential privacy is a crucial requirement.
2 Related Work
Differentially Private Deep Learning. The most related works are [45, 27] which finetune Transformer-based language models with differential privacy, and [2] which trains differentially private BERT [20], a masked language model built upon Transformer. Their success is largely attributed to large-scale public information, which may not be available in some scenarios.
Effective Training of Transformer. The training of the Transformer models can be notoriously difficult, relying heavily on layer normalization [3], model initialization [22], learning rate warmup [31], etc. Beyond applying existing techniques proposed in the context of non-private learning, one intriguing research question is: Can we develop effective Transformer-training techniques that are specialized for private training? In this paper, we make the first attempt and propose the Re-Attention Mechanism, as discussed in Section 5.
Differenital Private Learning on Heavy-Tailed Data. Previous work has also considered the differentially private learning algorithms on heavy-tailed data [37, 21, 23]. This line of research is mainly concerned with differential private stochastic optimization (DP-SCO). Note that the notion of heavy-tailed there is different from the focus of this work. As pointed out in [23], the setting they actually consider is dealing with heavy-tailed gradients due to unbounded values in the input data.
For detailed analysis about the related work, please refer to appendix A.
3 Preliminaries
Problem Setting: Sequential Prediction111This setting does not compromise universality. Transformer trained for the sequential prediction can be viewed as the universal model for sequence modeling, enabling other tasks (e.g., classification) through fine-tuning.. Since Transformers are designed to predict the next token in an autoregressive manner, in this paper, we focus our evaluation on sequential prediction tasks, where each training sample consists of a sequence of tokens222In this paper, we will use ‘token’ to denote the discrete unit within the input sequence and ‘vocabulary size’ to represent the total count of relevant entities, generalizing their definitions associated with language modeling. Given the preceding tokens , the task is to predict the next token . Note that in practice (as is also the case for all our datasets), training data is typically long-tailed, in the sense that a small number of tokens occur quite frequently while others have fewer occurrences. Our goal is to train a Transformer with DP-SGD [1] such that it can predict the next token accurately while preserving differential privacy.
Definition 3.1.
One desirable property of DP is that it ensures privacy (in terms of and ) under composition. Based on this property, DP-SGD [1] injects calibrated Gaussian noise into model gradients in each training step to achieve differential privacy as follows,
| (3.1) |
where is the gradient of the -th sample in the minibatch of size . is the clipping norm, , ensuring that the sensitivity of the averaged gradient is bounded by . is the noise multiplier derived from privacy accounting tools [4, 40].
In the following sections, we introduce two novel and significant techniques of DPFormer, Phantom Clipping and Re-Attention Mechanism, which provide more efficient and precise DP-enhanced Transformer modeling.


4 Phantom Clipping
4.1 Motivation: The Indispensability of Parameter Sharing as a Form of Inductive Bias
A recent advancement, Ghost Clipping [27], generalizes the Goodfellow trick [17] to facilitate efficient clipping during the fine-tuning of Transformer-based language models on private data, without necessitating per-sample gradient computation. Notwithstanding its considerable benefits in training Transformer models using DP-SGD as compared to other libraries or implementations (for instance, Opacus [44], JAX [34]), Ghost Clipping presents a limitation in its lack of support for parameter sharing (i.e., the practice that ties the parameter of the input embedding and the output embedding layer together). Although certain tasks, such as fine-tuning language models with differential privacy can achieve high accuracy without parameter sharing, our investigation reveal that when training with DP-SGD, parameter sharing of the embedding layer becomes essential.
In more detail, to elucidate the role of parameter sharing when training with DP-SGD, we conduct experiments under the following three settings: (1) parameter sharing of the embedding layer, which aligns with the standard treatment in Transformer; (2) no parameter sharing; and (3) no parameter sharing coupled with a reduced embedding dimension by half. Note that the third setting is included to account for the potential impact of model dimension on accuracy in private training, given the difference in the number of parameters between models with and without parameter sharing. Model performance across different hyperparameters is shown in Figure. 2.
The consistency and significance of the performance improvement brought by parameter sharing during private training are not hard to perceive. The essence of embedding sharing lies in the assumption that, by tying the embedding of the input and output layers, the representation of each token remains consistent throughout its retrieval. This inductive bias enhances the statistical efficiency of the model, enabling improved generalization. When training with DP-SGD on limited training data, the model must independently uncover this relationship from the noisy gradients with a low signal-to-noise ratio, heightening the convergence challenge.



4.2 Efficient Per-Sample Gradient Norm Computation with Parameter Sharing
In this section, we present Phantom Clipping, a technique for efficient private training of Transformers without the need for instantiating per-sample gradient. Phantom Clipping is built upon Ghost Clipping, with additional support for efficient gradient clipping of the shared embedding layer.


Recall that the computational bottleneck of gradient clipping in Equation (3.1) lies in the calculation of the per-sample gradient norm i.e., . As the L2 norm of a vector can be decomposed cross arbitrary dimensions, for example, . It suffices to consider the per-sample gradient norm of the embedding layer because the disparity due to parameter sharing lies solely in the shared embedding, and other layers can be handled akin to Ghost Clipping. After obtaining the gradient norm via = , the next step is to scale the gradient by a factor of to bound its sensitivity. This can either be accomplished by re-scaling the loss through this factor, followed by a second backpropagation [26], or by manually scaling the gradient as demonstrated by [6].
The challenge of evaluating efficiently without instantiating stems from the non-plain feed-forward (and symmetrically, backward propagation) topology caused by parameter sharing. See Figure 1(a) for a visual illustration, where the shared embedding leads to two branches of the backpropagation. Despite this complexity, our Phantom Clip, described below, is capable of achieving this task. The derivation is deferred to Appendix B.
Claim 4.1.
(Phantom Clipping) Let (or ) be the one-hot encodings of the input sequence (or those of the candidate tokens for the output probability) in a minibatch. Let (or ) be output of the (shared) embedding layer when fed into (or ). Then the norm of the per-sample gradient with respect to can be efficiently evaluated as
| (4.1) |
where , , and is the inner product of two matrices being of the same shape.
Memory Complexity We study the additional memory footprint required by Phantom Clipping. Due to the storage of (and in the first term of Equation (4.1) (note that is merely an indexing operation, requiring no additional memory), Phantom Clipping has overhead memory complexity of . As a comparison, Ghost Clipping has a memory complexity of when the input to the layer has the shape of . Hence its memory complexity for the two embedding layers is where is the vocabulary size. Typically, we have , that is, the length of the sentence is much smaller than the vocabulary size. Thus the memory overhead complexity of Phantom Clipping is only a negligible portion of that of Ghost Clipping.
We implement our Phantom Clipping based on AWS’s fastDP333https://github.com/awslabs/fast-differential-privacy library, which has implemented Ghost Clipping. We then empirically compare our Phantom Clipping with Ghost Clipping in terms of both memory footprint and training speed on real-world datasets444Since Ghost Clipping does not support parameter sharing, its results are obtained from training models without embedding sharing. This leads to more model parameters. For a fair comparison, we halve its embedding dimension to , ending up with a similar number of parameters as in the model with embedding sharing. (see Figure 5 for details of the datasets). Figure 3(a) shows the maximum batch size that can fit into a Tesla V100 GPU (16 GB of VRAM). It can be seen that our technique is much more memory friendly. It allows up to larger batch size compared with Ghost Clipping on Amazon, almost as large as those in non-private training. Figure 3(b) shows the training speed on a single Tesla V100 GPU. It allows up to training speedup in practice compared to Ghost Clipping, achieving 0.68 training speed of the non-private version.
5 Re-Attention Mechanism

5.1 Motivation: The Attention Distraction Phenomenon
Recall that the Attention Mechanism, as the key component of the Transformer, given a query, calculates attention scores pertaining to tokens of relevance. Our key observation is that, over the randomness of the attention keys for the tokens of interest555In unambiguous contexts, ‘token variance’ will denote the variance of the relevant representation associated with that token, like its attention key, , or its embedding, ., the expectation of the attention scores will be distorted, particularly, mindlessly leaning towards tokens with high variance, regardless of their actual relevance. Refer to Figure 4 for a visual illustration of this concept of attention distraction.
To shed light on this phenomenon, we offer a theoretical analysis. Let us fix some query and denote the attention key of token as . Since DP-SGD injects Gaussian noise into the model, it is natural to assume follows a Gaussian distribution with mean and variance . We denote as the random variable of the attention score assigned to token . With some basic algebraic manipulation and applying the theory of extreme value [9], we can recast the formula for attention scores as follows666For ease of notation, we omit the constant factor (i.e., ) in attention computation.,
| (5.1) |
where is distributed as a standard Gumbel. Let us consider some token that should have attracted little attention given the query , then the expectation of the noisy maximum can be approximated by , where . Taking the expectation of Equation (5.1) over , and leveraging the fact when follows a Gaussian distribution, we then arrive at the following conclusion
| (5.2) |
where and the last equality leverages the fact that with . As a result, tokens with higher variance result in inflated attention scores due to increased multiplicative bias, distracting attention from more deserving tokens, given that token is presupposed to garner little attention under query . If all tokens have similar variance or variance terms are negligible, the negative effects of this attention diversion are reduced. However, in less ideal conditions, especially with long-tailed data, this attention distraction could hinder the Transformer’s training, thereby degrading model utility.
5.2 Re-Attention via Error Tracking
At its core, the Re-Attention Mechanism is designed to mitigate attention distraction during the learning process via debiasing the attention scores. To achieve this, it is natural to track the variance term identified as the error multiplier in Equation (5.2). In the following discussion, we elaborate on the methodology employed for tracking this error term during private training.
5.2.1 Error Instantiation
Let us focus on the source of the randomness which leads to the attention distraction phenomenon, that is, the DP noise injected into the model gradients. Inspired by [27], we propose the idea of effective error, which is a probabilistic treatment of the effective noise multiplier in [27], proposed for model with sequential input. Effective error is used as an estimate of the uncertainty level underlying the model parameters, where the randomness is over DP noise.
Definition 5.1.
Effective Error: The effective error associated with the model parameter is defined as
| (5.3) |
where is the batch size, is the minibatch, i.i.d. sampled from training data distribution (note that is a sequence of tokens), is the DP noise multiplier in Equation (3.1), and is the indicator function, if has relevance with , for example, where is the embedding for token , and where is the parameter within Transformer Block (see Figure 1).
Remark 5.2.
Effective error recovers effective noise multiplier when the model has no embedding layer, for example, an MLP model. In that case, .
We then have the following claims for obtaining effective error of the Transformer’s parameters. See Appendix C for detailed derivation.
Claim 5.3.
For each layer parameterized by within the Transformer block, its effective error is .
Claim 5.4.
For the embedding layer , effective error of token is , where is the frequency of token (i.e., the probability of token ’s occurrence in data).
5.2.2 Error Propagation
Given the effective errors of the embedding layer and of the Transformer encoder, our goal is to obtain the error term identified in Equation (5.2) for each attention computation. Notably, this issue of error tracking aligns with studies in Bayesian deep learning [39], a field primarily focused on quantifying prediction uncertainty to enhance the robustness and reliability of machine learning systems. While our primary interest lies in unbiased attention score computation during private training, we can leverage and adapt existing methodologies in Bayesian deep learning to achieve this distinct goal. Specifically, given the input embedding along with its effective error, we propagate the effective error through Transformer layers (see Figure 1), with the goal of obtaining for each attention calculation. We denote the output of the -th layer by the random variable . Given the output distribution of the preceding layer, the distribution can be computed layer-by-layer as follows,
| (5.4) |
where the last equality is due to the isometric Gaussian noise of DP (see Equation 3.1), i.e., each dimension is independently and identically distributed. Based on Variational Inference [25], we can use an approximating distribution to approximate the computationally intractable distribution , where follows a Gaussian distribution of mean and variance . Note that minimizing the KL divergence of reduces to matching the moments of to . Since the mean and variance777Note that for a Gaussian distribution, (i) mean and variance, (ii) the first two moments, and (iii) natural parameter, are equivalent in the sense of mutual convertibility. We will use them interchangeably. are sufficient statistics for Gaussian distribution, propagating the distribution reduces to propagating its natural parameters [38]. For linear layers coupled with a coordinate-wise non-linear activation, the statistics can be computed by analytic expressions using existing techniques from Probabilistic Neural Networks [38, 33, 15, 32, 29]. Concretely, for linear transformation, , we can propagate the variance as
| (5.5) |
For nonlinear activation functions, e.g., , we can propagate the variance as
| (5.6) |
where is the cumulative density function (CDF) of the standard Gaussian distribution, and are the natural parameter of . For completeness, derivation is included in Appendix D.1.
All in all, we can obtain the output distribution of layer via analytic expression in terms of the natural parameter [38] of the preceding layer’s output distribution as
| (5.7) |
Nevertheless, a nuanced difference exists between our error propagation and existing techniques encapsulated in Equation (5.7). In the Bayesian approach, the model parameter is directly associated with the mean in Equation (5.5). During private training, however, we can only access the noisy parameter after the injection of DP noise. Interestingly, access to this noisy parameter can be interpreted as a single sampling opportunity from its underlying Gaussian distribution, which can then be viewed as a one-time Markov Chain sampling [41]. Therefore, the noisy parameter can serve as an estimate of its mean. In addition, unlike variance propagation in Bayesian deep learning, the error propagation here incurs minimal computational and memory overhead as the effective error can be represented in scalar (again, due to the isometric DP noise), plus the propagation is performed via analytical expressions.
Re-Attention. With the effective error tracked, we then proceed to mitigate the attention distraction identified in Equation (5.2) via , obtaining unbiased attention scores.
In summary, we can propagate and track the effective error through the layers: given the natural parameter of , the variance can be estimated using analytic expressions, which then can be used to correct the attention scores. This methodology of error instantiation from DP-SGD multiplier, propagation through layers, and attention debiasing forms the crux of our Re-Attention Mechanism.
6 Experiments

Datasets and Prevalence of Long-Tailed Distributions. We conduct experiments on two public datasets collected from real-world scenarios: MovieLens [18] and Amazon [28]. Figure 5 shows their data distributions, illustrating the prevalence of long-tailed distributions, where a small number of items are extremely popular and have relatively high frequency while other items occur infrequently. The embedded table above the ‘long tail’ reports the statistics of the two datasets, showing that the two datasets vary significantly in size and sparsity. More details on datasets can be found in Appendix E.1.
Baselines and Implementation Details. We compare our DPFormer with vanilla Transformer [36] (i.e., the one without Re-Attention Mechanism), vanilla Transformer without parameter sharing, GRU [8], and LSTM [20]. For a fair comparison, embedding sharing is applied for all evaluated methods if not explicitly stated. The number of epochs is set to 100, where the first 20% of epochs are used for learning rate warm-up. After that, we linearly decay the learning rate through the remaining epochs. Following [5, 43], we normalize the gradients and set the clipping norm to 1, which eliminates the hyperparameter tuning for clipping norm . The model dimension is set to 64. For privacy accounting, we fix the total training epochs (iterations) and derive the noise required for each iteration from the preset privacy budget . We consider .
| DP Guarantee | ||||||
|---|---|---|---|---|---|---|
| Metric | NDCG@10 | HIT@10 | NDCG@10 | HIT@10 | NDCG@10 | HIT@10 |
| GRU | 2.26 0.04 | 4.58 0.09 | 2.40 0.03 | 4.75 0.20 | 2.81 0.03 | 5.53 0.05 |
| LSTM | 2.65 0.07 | 5.08 0.08 | 2.76 0.03 | 5.41 0.06 | 2.95 0.03 | 5.55 0.06 |
| Transformer w/o PS | 2.33 0.05 | 4.47 0.07 | 2.56 0.03 | 5.11 0.05 | 2.74 0.04 | 5.39 0.08 |
| Transformer (Vanilla) | 4.57 0.26 | 8.69 0.53 | 7.05 0.23 | 13.17 0.37 | 7.99 0.21 | 14.82 0.38 |
| DPFormer (Ours) | 5.88 0.24 | 11.13 0.43 | 7.70 0.26 | 14.31 0.37 | 8.42 0.22 | 15.40 0.32 |
| Relative Improvement | 29% | 28% | 9.2% | 8.7% | 5.4% | 3.9% |
| DP Guarantee | ||||||
|---|---|---|---|---|---|---|
| Metric | NDCG@10 | HIT@10 | NDCG@10 | HIT@10 | NDCG@10 | HIT@10 |
| GRU | 1.13 0.02 | 2.46 0.03 | 1.33 0.02 | 2.22 0.02 | 1.47 0.03 | 2.48 0.02 |
| LSTM | 1.19 0.01 | 2.46 0.04 | 1.23 0.01 | 2.46 0.04 | 1.34 0.01 | 2.51 0.02 |
| Transformer w/o PS | 1.16 0.01 | 2.36 0.01 | 1.20 0.02 | 2.38 0.01 | 1.40 0.01 | 2.47 0.02 |
| Transformer (Vanilla) | 1.37 0.04 | 2.47 0.10 | 1.54 0.03 | 2.77 0.07 | 1.57 0.03 | 2.83 0.08 |
| DPFormer (Ours) | 1.64 0.01 | 3.01 0.01 | 1.98 0.05 | 3.70 0.15 | 1.99 0.04 | 3.73 0.11 |
| Relative Improvement | 20% | 22% | 28% | 34% | 27% | 31% |


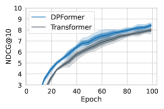





Table 1 and Table 2 show the best888Strictly speaking, the process of hyperparameter tuning would cost privacy budget [30], but is mainly of theoretical interest. We perform grid search on learning rate and batch size for each method, ensuring fair comparison. NDCG@10 and HIT@10 for all the methods on MovieLens and Amazon. The vanilla Transformer outperforms all other baselines, reaffirming its dominance in sequential data modeling due to the Attention Mechanism. Our DPFormer, incorporating the Re-Attention Mechanism, further boosts the performance by around 20% on average. Notably, under a low privacy budget (), DPFormer achieves a relative improvement of around 25%, demonstrating its efficacy in attenuating attention distraction during private training. On MovieLens, as expected, the performance gain increases with decreasing privacy budget , i.e., increasing noise strength during training; this is because larger noise corresponds to more severe attention distraction, which better highlights the Re-Attention Mechanism’s advantage. However, on Amazon, DPFormer achieves a smaller relative improvement at than at . We suspect that this is due to the two datasets’ differences in terms of sparsity (i.e., density in Figure 5) as well as the inherent hardness of training Transformer [46, 42, 22] and substantial DP noise.
Figure 6 shows the model accuracy every five epochs during training. Evidently, the training dynamics of the vanilla Transformer, impacted by attention distraction, can suffer from high variance and/or substantial fluctuation, especially on Amazon. In contrast, DPFormer enjoys faster and smoother convergence, highlighting its superior training stability under differential privacy.




Figure 7 shows the results of hyperparameter tuning via grid search 999Rather than run an addtional differentially private algorithm to report a noisy max (or argmax) [30], we opt for this practice of directly displaying all results due to its transparency and comprehensiveness.. For most hyperparameter configurations (especially along the main diagonal [35]), our DPFormer significantly outperforms the vanilla Transformer.
7 Conclusion
In this paper, we identify two key challenges in learning differentially private Transformers, i.e., heavy computation overhead due to per-sample gradient clipping and attention shift due to long-tailed data distributions. We then proposed DPFormer, equipped with Phantom Clipping and Re-Attention Mechanism, to address these challenges. Our theoretical analysis shows that DPFormer can effectively correct attention shift (which leads to significant performance drops) and reduce computational cost during gradient clipping. Such analysis is further corroborated by empirical results on two real-world datasets. Limitation. One limitation of this work is the assumption of a trusted data curator. Another limitation is the absence of semantic interpretation for the privacy budget, given the sequential data as input. Addressing these limitations would be interesting future work.
References
- [1] Martín Abadi, Andy Chu, Ian J. Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pages 308–318, 2016.
- [2] Rohan Anil, Badih Ghazi, Vineet Gupta, Ravi Kumar, and Pasin Manurangsi. Large-scale differentially private BERT. In Findings of the Association for Computational Linguistics: EMNLP, 2022.
- [3] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [4] Borja Balle, Gilles Barthe, and Marco Gaboardi. Privacy amplification by subsampling: Tight analyses via couplings and divergences. Advances in Neural Information Processing Systems, 31, 2018.
- [5] Zhiqi Bu, Yu-Xiang Wang, Sheng Zha, and George Karypis. Automatic Clipping: Differentially private deep learning made easier and stronger. arXiv preprint arXiv:2206.07136, 2022.
- [6] Zhiqi Bu, Yu-Xiang Wang, Sheng Zha, and George Karypis. Differentially private optimization on large model at small cost. arXiv preprint arXiv:2210.00038, 2022.
- [7] Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. The secret sharer: Evaluating and testing unintended memorization in neural networks. In USENIX Security Symposium, volume 267, 2019.
- [8] Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
- [9] Stuart Coles, Joanna Bawa, Lesley Trenner, and Pat Dorazio. An introduction to statistical modeling of extreme values, volume 208. Springer, 2001.
- [10] Soham De, Leonard Berrada, Jamie Hayes, Samuel L Smith, and Borja Balle. Unlocking high-accuracy differentially private image classification through scale. arXiv preprint arXiv:2204.13650, 2022.
- [11] Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data analysis. In Theory of Cryptography Conference, pages 265–284, 2006.
- [12] Cynthia Dwork, Moni Naor, Omer Reingold, Guy N Rothblum, and Salil Vadhan. On the complexity of differentially private data release: Efficient algorithms and hardness results. In Proceedings of the 41st annual ACM Symposium on Theory of Computing, pages 381–390, 2009.
- [13] Cynthia Dwork, Aaron Roth, et al. The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science, 9(3–4):211–407, 2014.
- [14] Vitaly Feldman. Does learning require memorization? A short tale about a long tail. In Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, pages 954–959, 2020.
- [15] Jochen Gast and Stefan Roth. Lightweight probabilistic deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3369–3378, 2018.
- [16] Aditya Golatkar, Alessandro Achille, Yu-Xiang Wang, Aaron Roth, Michael Kearns, and Stefano Soatto. Mixed differential privacy in computer vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8376–8386, 2022.
- [17] Ian Goodfellow. Efficient per-example gradient computations. arXiv preprint arXiv:1510.01799, 2015.
- [18] F Maxwell Harper and Joseph A Konstan. The movielens datasets: History and context. ACM Transactions on Interactive Intelligent Systems, 5(4):1–19, 2015.
- [19] Jiyan He, Xuechen Li, Da Yu, Huishuai Zhang, Janardhan Kulkarni, Yin Tat Lee, Arturs Backurs, Nenghai Yu, and Jiang Bian. Exploring the limits of differentially private deep learning with group-wise clipping. In The Eleventh International Conference on Learning Representations, 2023.
- [20] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997.
- [21] Lijie Hu, Shuo Ni, Hanshen Xiao, and Di Wang. High dimensional differentially private stochastic optimization with heavy-tailed data. In Proceedings of the 41st ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, pages 227–236, 2022.
- [22] Xiao Shi Huang, Felipe Perez, Jimmy Ba, and Maksims Volkovs. Improving Transformer optimization through better initialization. In International Conference on Machine Learning, pages 4475–4483. PMLR, 2020.
- [23] Gautam Kamath, Xingtu Liu, and Huanyu Zhang. Improved rates for differentially private stochastic convex optimization with heavy-tailed data. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 10633–10660, 2022.
- [24] Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation. In 2018 IEEE International Conference on Data Mining, pages 197–206, 2018.
- [25] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- [26] Jaewoo Lee and Daniel Kifer. Scaling up differentially private deep learning with fast per-example gradient clipping. Proceedings on Privacy Enhancing Technologies, 2021(1), 2021.
- [27] Xuechen Li, Florian Tramer, Percy Liang, and Tatsunori Hashimoto. Large language models can be strong differentially private learners. In International Conference on Learning Representations, 2022.
- [28] Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 43–52, 2015.
- [29] Pablo Morales-Alvarez, Daniel Hernández-Lobato, Rafael Molina, and José Miguel Hernández-Lobato. Activation-level uncertainty in deep neural networks. In International Conference on Learning Representations, 2021.
- [30] Nicolas Papernot and Thomas Steinke. Hyperparameter tuning with renyi differential privacy. In International Conference on Learning Representations, 2022.
- [31] Martin Popel and Ondej Bojar. Training tips for the transformer model. arXiv preprint arXiv:1804.00247, 2018.
- [32] Janis Postels, Francesco Ferroni, Huseyin Coskun, Nassir Navab, and Federico Tombari. Sampling-free epistemic uncertainty estimation using approximated variance propagation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2931–2940, 2019.
- [33] Alexander Shekhovtsov and Boris Flach. Feed-forward propagation in probabilistic neural networks with categorical and max layers. In International Conference on Learning Representations, 2019.
- [34] Pranav Subramani, Nicholas Vadivelu, and Gautam Kamath. Enabling fast differentially private sgd via just-in-time compilation and vectorization. Advances in Neural Information Processing Systems, 34:26409–26421, 2021.
- [35] Florian Tramer and Dan Boneh. Differentially private learning needs better features (or much more data). In International Conference on Learning Representations, 2021.
- [36] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017.
- [37] Di Wang, Hanshen Xiao, Srinivas Devadas, and Jinhui Xu. On differentially private stochastic convex optimization with heavy-tailed data. In International Conference on Machine Learning, pages 10081–10091, 2020.
- [38] Hao Wang, Xingjian Shi, and Dit-Yan Yeung. Natural-parameter networks: A class of probabilistic neural networks. Advances in Neural Information Processing Systems, 29, 2016.
- [39] Hao Wang and Dit-Yan Yeung. A survey on Bayesian deep learning. ACM Computing Surveys (CSUR), 53(5):1–37, 2020.
- [40] Yu-Xiang Wang, Borja Balle, and Shiva Prasad Kasiviswanathan. Subsampled rényi differential privacy and analytical moments accountant. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 1226–1235. PMLR, 2019.
- [41] Yu-Xiang Wang, Stephen Fienberg, and Alex Smola. Privacy for free: Posterior sampling and stochastic gradient monte carlo. In International Conference on Machine Learning, pages 2493–2502. PMLR, 2015.
- [42] Peng Xu, Dhruv Kumar, Wei Yang, Wenjie Zi, Keyi Tang, Chenyang Huang, Jackie Chi Kit Cheung, Simon JD Prince, and Yanshuai Cao. Optimizing deeper transformers on small datasets. arXiv preprint arXiv:2012.15355, 2020.
- [43] Xiaodong Yang, Huishuai Zhang, Wei Chen, and Tie-Yan Liu. Normalized/Clipped SGD with perturbation for differentially private non-convex optimization. arXiv preprint arXiv:2206.13033, 2022.
- [44] Ashkan Yousefpour, Igor Shilov, Alexandre Sablayrolles, Davide Testuggine, Karthik Prasad, Mani Malek, John Nguyen, Sayan Ghosh, Akash Bharadwaj, Jessica Zhao, Graham Cormode, and Ilya Mironov. Opacus: User-friendly differential privacy library in PyTorch. In NeurIPS 2021 Workshop Privacy in Machine Learning, 2021.
- [45] Da Yu, Saurabh Naik, Arturs Backurs, Sivakanth Gopi, Huseyin A Inan, Gautam Kamath, Janardhan Kulkarni, Yin Tat Lee, Andre Manoel, Lukas Wutschitz, et al. Differentially private fine-tuning of language models. In International Conference on Learning Representations, 2022.
- [46] Biao Zhang, Ivan Titov, and Rico Sennrich. Improving deep transformer with depth-scaled initialization and merged attention. arXiv preprint arXiv:1908.11365, 2019.
Appendix A Related Work
The most related work is [27], which finetunes large language models with differential privacy. They propose Ghost Clipping, which is a technique that enables efficient per-sample gradient clipping without instantiating per-sample gradient. Our Phantom Clipping can be viewed as an extension of Ghost Clipping that additionally handles parameter sharing of the embedding layer. They also introduce the idea of effective noise multiplier in order to explain the role of batch size in private learning. Our effective error (Equation 5.3) can be viewed as its generalization in order to account for the inherent input sparsity (i.e., only a small portion of tokens appear in one training sequence).
Another related work is [2], which establishes a baseline for BERT-Large pretraining with DP. They introduce several strategies to help private training, such as large weight decay and increasing batch size schedule. Notably, these strategies are independent yet complementary to the methodologies utilized in this work, thereby offering potential avenues for an integrated approach.
Appendix B Proof of Phantom Clipping (Claim 4.1)
Proof.
For simplicity, we will omit the per-sample index throughout this proof. From the chain rule, the per-sample gradient with respect to the embedding layer is
| (B.1) |
where (or ) is the one-hot encodings of the input sequence (or those of the candidate tokens for the output probability) in a minibatch, and (or ) be output of the (shared) embedding layer when fed into (or ). Denote the first segment of the right-hand side (RHS) as , the second segment of the RHS as . Then we have
| (B.2) |
Ghost Clipping [27] allows us to evaluate without instantiating , the formula is given by
| (B.3) |
Similarly, we have
| (B.4) |
Note that is the one-hot encoding of , thus is an Identity matrix, Equation B.4 can be further simplified as
| (B.5) |
Note that this simplification reduces the memory footprint from to , obviating the need for evaluating in Equation B.4.
Appendix C Proof of Error Instantiation (Claim 5.3 and 5.4)
Correction of typo: The definition of effective batch size in Equation 5.3 should be
| (C.1) |
Taking the average over the minibatch in Equation 3.1 can be considered noise reduction of . Fix the noise multiplier . As the size of the batch increases, the amount of DP noise incorporated into the parameter decreases correspondingly. Suppose that token is absent from the current training sequence. Its input embedding will not be activated and thus will not be properly trained in this iteration, but the DP noise will be nevertheless injected into its embedding. The concept of effective error is introduced to account for this phenomenon.
Proof.
It reduces the derive the formula for effective batch size in Equation 5.3. Recall that its definition is given by
| (C.2) |
For each layer parameterized by within the Transformer block, its effective batch size is , since .
For the embedding layer , its effective batch size is
| (C.3) |
where is the frequency of token (i.e., the probability of token ’s occurrence in data). ∎
Remark C.1.
Note that , as the frequency statistics, can be obtained with high accuracy with tiny privacy budget. For simplicity, we will assume is publicly known in this work.
Appendix D Proof of Error Propagation
D.1 Proof of Linear Transformation (Equation 5.5)
Lemma D.1.
Let , be two independent random variables. Let , then the variance of can be expressed as
| (D.1) |
Proof.
Suppose the linear transformation is given by , then we have
| (D.2) |
∎
D.2 Proof of Non-linear Transformation (Equation 5.7)
Lemma D.2.
Let , be two independent Gaussian random variables, where . Let .
| (D.3) |
where is the cumulative density function (CDF) of the standard Gaussian distribution, is the probability density function (PDF) of the standard Gaussian distribution, = , and .
Proof.
Let be the ReLU activation. Substitute into Equation D.3. Leveraging yields the conclusion. ∎
Remark D.3.
GELU activation. GELU function is another widely used activation function within Transformer models. GELU can be viewed as a smooth version of ReLU (see Figure 8), where their forward propagation is similar, and the major distinction lies in the numerical behavior of backpropagation. Since error propagation is only concerned with forward propagation behavior, we can also use Equation 5.7 to approximate the variance of GELU output. Table 3 shows the analytic error propagation for ReLU and GELU activation, compared with the sampling-based results.

| Input | Activation | Sampling-based | Analytic | |||||
|---|---|---|---|---|---|---|---|---|
| 10 | 100 | 1000 | 10000 | 100000 | 1000000 | |||
| ReLU | 4.08e-6 | 3.60e-5 | 3.93e-5 | 3.45e-5 | 3.40e-5 | 3.40e-5 | 3.40e-5 | |
| GELU | 2.48e-5 | 2.69e-5 | 2.72e-5 | 2.57e-5 | 2.50e-0 | 2.49e-5 | ||
| ReLU | 0.0030 | 0.0031 | 0.0037 | 0.0034 | 0.0035 | 0.0034 | 0.0034 | |
| GELU | 0.0030 | 0.0025 | 0.0027 | 0.0025 | 0.0026 | 0.0025 | ||
| ReLU | 0.5299 | 0.2361 | 0.3649 | 0.3451 | 0.3387 | 0.3418 | 0.3408 | |
| GELU | 0.5525 | 0.2306 | 0.3719 | 0.3506 | 0.3433 | 0.3467 | ||
Appendix E Experimental Details
E.1 Datasets
MovieLens. The MovieLens dataset [18] is often used in the development and evaluation of collaborative filtering algorithms, which are used to make personalized recommendations based on user behavior. It is a benchmark dataset in the field of recommender systems due to its size, longevity, and richness of user-item interactions. We use the version (MovieLens-1M) that includes 1 million user behaviors.
Amazon. A series of datasets introduced in [28], comprising large corpora of product reviews crawled from Amazon.com. Top-level product categories on Amazon are treated as separate datasets. We consider the ‘Games.’ category. This dataset is notable for its high sparsity and variability.
We follow [24] for the data preprocessing. We use timestamps to determine the sequence order of actions. Each user is associated with a training sequence (i.e., his chronological behavior). We discard users and items with fewer than five related actions. For data partitioning, the last token of each sequence is left for testing.
It is worth noting that since each user is exclusively associated with exactly one training sample (sequence) in the training data, the DP guarantee we provide is user-level. That is, removing all information pertaining to a specific user yields an indistinguishable model.
E.2 Model Architecture
We use the standard Transformer encoder described in [36]. The model dimension is set to 64. The number of heads in the Attention Mechanism is set to 1. The number of transformer blocks is set to 2. Our model adopts a learned (instead of fixed) positional embedding.
E.3 Hyperparameters
The number of epochs is set to 100. The batch size is chosen from . The learning rate is chosen from . The dropout rate is 0.2 for MovieLens and 0.5 for Amazon (due to its high sparsity). We use the Adam optimizer with a weight decay of .