Double Reverse Regularization Network Based on Self-Knowledge Distillation for SAR Object Classification
Abstract
In current synthetic aperture radar (SAR) object classification, one of the major challenges is the severe overfitting issue due to the limited dataset (few-shot) and noisy data. Considering the advantages of knowledge distillation as a learned label smoothing regularization, this paper proposes a novel Double Reverse Regularization Network based on Self-Knowledge Distillation (DRRNet-SKD). Specifically, through exploring the effect of distillation weight on the process of distillation, we are inspired to adopt the double reverse thought to implement an effective regularization network by combining offline and online distillation in a complementary way. Then, the Adaptive Weight Assignment (AWA) module is designed to adaptively assign two reverse-changing weights based on the network performance, allowing the student network to better benefit from both teachers. The experimental results on OpenSARShip and FUSAR-Ship demonstrate that DRRNet-SKD exhibits remarkable performance improvement on classical CNNs, outperforming state-of-the-art self-knowledge distillation methods.
Index Terms— Regularization, Self-Knowledge Distillation, synthetic aperture radar (SAR), SAR object classification.
1 Introduction
Synthetic Aperture Radar (SAR) implements all-day, all-weather observation of the earth using the synthetic aperture principle to achieve high-resolution microwave imaging. It is vital to accurately and quickly classify the ships in SAR images in performing some sea surface missions. However, SAR ship classification using data-driven deep learning faces a more significant overfitting challenge compared to optical images, mainly due to the few-shot SAR ship and noisy data.
With the rapid progress of deep learning in image processing, convolutional neural networks (CNNs) have gained increasing popularity in the field of SAR ship classification [1, 2, 3, 4]. However, the complex CNN model may introduce redundant features that will further amplify the risk of overfitting. The knowledge distillation (KD) [5] that transfer knowledge from a cumbersome pre-trained teacher model to a lightweight student model has benn widely utilized in various SAR tasks [6, 7, 8, 9, 10, 11, 12, 13]. All of the works inherit the idea of knowledge transfer from the traditional KD. Recently, [14] attributed the success of KD to the regularization effect of soft labels provided by teacher model from the LSR perspective, revealing the great potential of applying KD in the field of regularization.

To improve the generalization of SAR ship classification, this paper introduce a double reverse regularization network which incorporates both online and offline distillation. As shown in Fig. 1, our DRRNet-SKD employs three same-size models but different objective functions, which are the pre-trained model (Offline Student), the student model, and the last batch student model. Since the pre-trained model needs to learn the corresponding SAR ship knowledge from scratch, our framework has a two-stage training procedure. Then the well-trained student model can perform inference independently. The main contributions of this paper are as follows:
-
The effective dynamic weight assignment is found by analyzing the process of distillation and experimental validation. Concretely, increasing the weight of self-distillation and decreasing the weight of offline distillation dynamically based on the number of epoch provide more effective training for students than fixed weight.
-
The Adaptive Weight Assignment (AWA) module that can adaptively assign the distillation weight based on the network performance is proposed for the first time to control the reverse change of offline and online distillation weights, which can better utilize the knowledge of both teachers.
-
DRRNet-SKD achieves state-of-the-art classification accuracy compared to LSR and self-knowledge distillation approaches on the OpenSARShip and FUSAR-Ship datasets.

2 Methodology
Fig. 2 illustrates the overall losses of DRRNet-SKD. The soft targets generated by offline student and the last batch student are exploited together to guide the student training. The trends of the two distillation weights controlled by the AWA module are depicted by the and . The reverse variation of weight is attributed to the different variations of data knowledge contained in the soft targets supplied by both teachers. In particular, AWA module is employed to adaptively assign reverse weights of the two Kullback-Leibler (KL) divergence losses based on the soft targets rather than other factors unrelated to network performance. With this double-reverse design, DRRNet-SKD can always provide the student with superior soft targets.
2.1 Rethinking the Weight of Knowledge Distillation
In the offline distillation that uses the pre-trained model as its offline teacher [14], the student in the early stage of training contains limited knowledge about the data. Meanwhile, the teacher has abundant knowledge about the data and can provide high-quality soft targets for the student to learn. As student continue to learn more, the fixed soft targets provided by teacher become less beneficial to student training compared to earlier stage. Similar analysis can also be conducted in self-knowledge distillation. Thus, it can be inferred that the weight of offline distillation should decrease and the weight of self-distillation should increase as student performance grows.
We design the experiment to verify the inferences. The VGG-11 is trained for 100 epochs on OpenSARShip via DLB [16] and Tf-KD [14], respectively. The other experimental settings are the same as those in section 3. Due to the slow convergence of VGG-11, the strategy for DLB is setting a fixed weight of 0.5 for the first 50 epochs. Finally, the weights of the epoch for DLB and Tf-KD are calculated respectively according to the following formula:
| (1) |
where is the total number of epoch.
The results are shown as Table 1. The best improvement of 5.07% and 2.08% is achieved by DLB and Tf-KD when the fixed weight is replaced by and , respectively. Moreover, the significantly reduced accuracy variance indicates that the dynamic weight can enhance the stability and generalization of classification model. But the adoption of dynamic weight also brings some new challenges. Each of them presents a high risk of overfitting when the distillation weight is small. And the weight update strategy based on the number of epoch may not be reasonable enough due to the network performance not always improving with the increase of epoch.
2.2 The Adaptive Weight Assignment (AWA) Module
Inspired by the multi-teacher offline distillation weight assignment [17], we exploit the cross-entropy between the softened teacher predictions and true labels to assign adaptive weight as follows:
| (2) |
| (3) |
where and are the predictive distributions of iteration student and offline student, respectively. The temperature-like parameter softens the distribution to smooth the values of the two equations. As the student continues to learn more, the value of Eq. 2 will be close to the value of Eq. 3. So, the online and offline distillation weights at the iteration can be calculated by:
| (4) |
| (5) |
The value of Eq. 4 will gradually increase and finally fluctuate around a certain number (near 1). Conversely, the value of Eq. 5 will gradually decrease but never be less than zero. controls the distillation weight range of offline student to represent its importance during the distillation process. So the AWA module can achieve adaptive assignment of distillation weight based on network performance.
2.3 The Overall Loss Function of DRRNet-SKD
In this paper, we focus on single-objective fully-supervised classification tasks. We denote as the logits outputted by the network , where is the class number. The predicted probability of -th class is calculated by a softmax function:
| (6) |
The student is trained by optimizing the Kullback-Leibler (KL) divergence loss between the softened outputs from the last mini-batch and the current mini-batch:
| (7) |
where is the output logits of the iteration student. Then they could be expressed as teacher and student, respectively. represents the distillation temperature, which regulates the degree of smoothing of the network outputs. Similarly, the KL divergence loss between the softened outputs from the offline student and the current mini-batch is
| (8) |
where is the output logits of offline student. To train a multi-class classification model, we typically adopt the Cross-Entropy (CE) loss between the predicted and ground-truth label distributions as the loss function:
| (9) |
Eventually, the overall loss function of our DRRNet-SKD is summarized as:
| (10) |
3 Experiment And Result Analysis
The experiments are performed on a server equipped with an Intel Pentium processor, an NVIDIA RTX3090 GPU and 64GB memory. The proposed DRRNet-SKD and the compared methods were all implemented using PyTorch 1.12.1 in a Python 3.8.15 environment. All the CNNs are built using the open-source PyTorch.
3.1 Experimental Settings
| Dataset | Method | AlexNet | VGG-11 | VGG-16 | ResNet-18 | DenseNet-121 |
| OpenSARShip | Baseline | 68.88±2.05 | 73.07±2.38 | 72.34±2.51 | 72.15±1.25 | 75.69±1.60 |
| LSR [18] | 70.19±2.79(+1.31) | 76.94±0.86(+3.87) | 74.34±1.61(+2.00) | 73.20±1.29(+1.05) | 78.03±0.72(+2.34) | |
| Tf-KD [14] | 69.35±1.22(+0.47) | 74.67±1.72(+1.60) | 75.04±1.73(+2.70) | 72.75±0.97(+0.60) | 75.15±1.99(-0.54) | |
| DLB [16] | 70.15±1.47(+1.27) | 77.82±1.13(+4.75) | 74.63±0.63(+2.29) | 74.46±1.08(+2.31) | 76.62±1.26(+0.93) | |
| Ours | 70.67±0.49(+1.79) | 80.03±0.87(+6.96) | 78.15±1.72(+5.81) | 75.10±0.91(+2.95) | 78.48±0.72(+2.79) | |
| Method | AlexNet | VGG-16 | VGG-19 | ResNet-18 | ResNet-50 | |
| FUSAR-Ship | Baseline | 79.36±0.34 | 83.51±0.77 | 82.51±0.70 | 79.48±0.39 | 80.29±0.46 |
| LSR [18] | 80.31±0.36(+0.95) | 85.41±0.70(+1.90) | 84.34±0.40(+1.83) | 80.67±0.30(+1.19) | 81.40±0.46(+1.11) | |
| Tf-KD [14] | 79.60±0.76(+0.24) | 84.35±0.80(+0.84) | 83.24±0.88(+0.73) | 80.88±0.47(+1.40) | 81.91±0.35(+1.62) | |
| DLB [16] | 80.24±0.58(+0.88) | 84.53±0.36(+1.02) | 84.79±0.35(+2.28) | 80.71±0.41(+1.23) | 81.17±0.41(+0.88) | |
| Ours | 81.02±0.49(+1.66) | 86.07±0.54(+2.56) | 86.97±0.40(+4.46) | 81.58±0.44(+2.10) | 82.24±0.33(+1.95) |
Data Description. The OpenSARShip Dataset has been widely used to evaluate SAR ship classification methods since 2018. Three primary ship categories are utilized for training and testing. The FUSAR-Ship dataset has a higher resolution and a larger number of samples compared to OpenSARShip. The seven types of ships used in this experiment, i.e., fishing, bulk, container, tanker, other cargo, general cargo, and others. Experiment settings. All models are trained for 100 epochs using Adam optimizer with a learning rate of 0.0002, and the learning rate is decayed by 20% every seven epochs. The batchsize is set to 16 on OpenSARShip and 32 on FUSAR-Ship. Since Batch Normalization(BN) [19] has been widely used in VGG, Pytorch provides a version with BN layers that will be employed in our experiments.
3.2 SAR Ship Classification Results
As shown in Table 2, the results show that our proposed method can significantly improve the performance of all the backbone networks, even on the larger and higher-resolution SAR ship dataset. It can be found that our framework is more effective in the VGG series. VGG-11 obtains the highest improvement among the backbones on OpenSARShip, achieving an accuracy gain of 6.96% over the baseline. VGG-19 achieves the most improvement on FUSAR-Ship, increasing the accuracy by 4.46% over the baseline. The results sufficiently demonstrate the effectiveness of our method.
3.3 Comparison With the State-of-the-Art Methods
To demonstrate the superiority of our framework, DRRNet-SKD is compared against classical LSR and the best regularization methods based on self-knowledge distillation. As shown in Table 2, we observe that the first three regularization methods, LSR, Tf-KD, and DLB, can improve the performance of almost all backbones. However, the same regularization method does not always work best for different backbones. For instance, on FUSAR-Ship, LSR improves the accuracy of AlexNet and VGG-16 by 0.95% and 1.90%, respectively, surpassing the gains achieved by Tf-KD and DLB. But this improvement is not observed on the other three networks. Our DRRNet-SKD consistently can achieve the best results for different networks on both datasets, demonstrating its superior effectiveness and universality compared to other regularization methods. To provide a clearer comparison, we plotted the training performance of the four networks for baseline, DLB, and our method on FUSAR-Ship, as shown in Fig. LABEL:Fig:training_performance. Compared to DLB, our method can further accelerate the convergence speed and improve the accuracy.
4 Conclusion and Limitation
In this research, we propose a novel double reverse regularization network based on self-knowledge distillation to improve the generalization of SAR ship classification. Firstly, our analysis and experiments show that the distillation weight that vary with the network performance is more advantageous for student training than fixed weight in some distillation methods. Secondly, we designed the Adaptive Weight Assignment (AWA) module to combine online and offline distillation in a complementary way to guide the student training. The AWA module can adaptively assign distillation weight at the sample level based on the current network performance to better utilize the knowledge from both teachers, leading to improved performance and generalization. Extensive experimental results show that our DRRNet-SKD outperforms other self-knowledge distillation approaches and exhibits optimal performance in the SAR ship classification.
References
- [1] Tianwen Zhang, Xiaoling Zhang, Xiao Ke, Chang Liu, Xiaowo Xu, Xu Zhan, Chen Wang, Israr Ahmad, Yue Zhou, Dece Pan, et al., “Hog-shipclsnet: A novel deep learning network with hog feature fusion for sar ship classification,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–22, 2021.
- [2] Hao Zheng, Zhigang Hu, Jianjun Liu, Yuhang Huang, and Meiguang Zheng, “Metaboost: A novel heterogeneous dcnns ensemble network with two-stage filtration for sar ship classification,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022.
- [3] Tianwen Zhang and Xiaoling Zhang, “A polarization fusion network with geometric feature embedding for sar ship classification,” Pattern Recognition, vol. 123, pp. 108365, 2022.
- [4] Hao Zheng, Zhigang Hu, Liu Yang, Aikun Xu, Meiguang Zheng, Ce Zhang, and Keqin Li, “Multi-feature collaborative fusion network with deep supervision for sar ship classification,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–14, 2023.
- [5] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
- [6] Zhen Wang, Lan Du, and Yi Li, “Boosting lightweight cnns through network pruning and knowledge distillation for sar target recognition,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 14, pp. 8386–8397, 2021.
- [7] Fan Zhang, Yingbing Liu, Yongsheng Zhou, Qiang Yin, and Heng-Chao Li, “A lossless lightweight cnn design for sar target recognition,” Remote Sensing Letters, vol. 11, no. 5, pp. 485–494, 2020.
- [8] Shiqi Chen, Ronghui Zhan, Wei Wang, and Jun Zhang, “Learning slimming sar ship object detector through network pruning and knowledge distillation,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 14, pp. 1267–1282, 2020.
- [9] Dou Quan, Huiyuan Wei, Shuang Wang, Ruiqi Lei, Baorui Duan, Yi Li, Biao Hou, and Licheng Jiao, “Self-distillation feature learning network for optical and sar image registration,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–18, 2022.
- [10] Chao Zhang, Hongbin Dong, and Baosong Deng, “Improving pre-training and fine-tuning for few-shot sar automatic target recognition,” Remote Sensing, vol. 15, no. 6, pp. 1709, 2023.
- [11] Junshi Xia, Naoto Yokoya, and Gerald Baier, “Dml: Differ-modality learning for building semantic segmentation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2022.
- [12] Jian Kang, Zhirui Wang, Ruoxin Zhu, Junshi Xia, Xian Sun, Ruben Fernandez-Beltran, and Antonio Plaza, “Disoptnet: Distilling semantic knowledge from optical images for weather-independent building segmentation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–15, 2022.
- [13] Eungbean Lee, Somi Jeong, and Kwanghoon Sohn, “Privileged knowledge distillation for sar building extraction,” in 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS. IEEE, 2021, pp. 3014–3017.
- [14] Li Yuan, Francis EH Tay, Guilin Li, Tao Wang, and Jiashi Feng, “Revisiting knowledge distillation via label smoothing regularization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3903–3911.
- [15] Karen Simonyan and Andrew Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [16] Yiqing Shen, Liwu Xu, Yuzhe Yang, Yaqian Li, and Yandong Guo, “Self-distillation from the last mini-batch for consistency regularization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 11943–11952.
- [17] Hailin Zhang, Defang Chen, and Can Wang, “Confidence-aware multi-teacher knowledge distillation,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 4498–4502.
- [18] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna, “Rethinking the inception architecture for computer vision,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2818–2826.
- [19] Sergey Ioffe and Christian Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in International conference on machine learning. pmlr, 2015, pp. 448–456.
- [20] Tianwen Zhang and Xiaoling Zhang, “Injection of traditional hand-crafted features into modern cnn-based models for sar ship classification: What, why, where, and how,” Remote Sensing, vol. 13, no. 11, pp. 2091, 2021.
Appendix A Extension Experiments
A.1 Comparison With State-of-the-Art SAR Ship Classification Methods
The first item of Table R1 lists some other classical CNNs besides Table 2. Among the various CNNs, DenseNet-121 achieves the highest accuracy of 75.69% and 83.86% on the two datasets, respectively, and its performance is still much lower than our proposed DRRNet-SKD. This result demonstrates the huge gains of our double reverse regularization network, showing the great potential of CNNs. The second item of Table R1 presents the results of state-of-the-art SAR ship classification methods, the highest accuracy achieved by HOG-ShipCLSNet [1] and DUW-Cat-FN [20] is 78.15% and 86.86%, respectively, which is lower than our proposed DRRNet-SKD with the accuracy of 80.03% and 86.97%. Our simple and effective double reverse regularization network can outperform the CNNs fused with handcrafted features, revealing that CNN still has a great untapped potentiality even without the fusion of handcrafted features.
| Type | Method | OpenSARShip | FUSAR-Ship |
| CNN-only | Xception | 73.74±0.86 | 77.29±0.38 |
| Inception-v4 | 72.74±0.70 | 80.50±0.37 | |
| MobileNet-v1 | 69.91±1.08 | 77.61±0.54 | |
| DenseNet-121 | 75.69±1.60 | 83.86±0.57 | |
| Feature Fusion | DUW-Cat-FN [20] | 78 | 86.86 |
| HOG-ShipCLSNet [1] | 78.15±0.57 | 86.69±0.47 | |
| Internal FC layer [4] | 74.75±1.21 | 84.25±0.42 | |
| Terminal FC layer [4] | 74.10±1.42 | 83.17±0.51 | |
| Ours | DRRNet-SKD | 80.03±0.87 | 86.97±0.40 |
-
•
The standard deviation of DUW-Cat-FN are not given in the source.
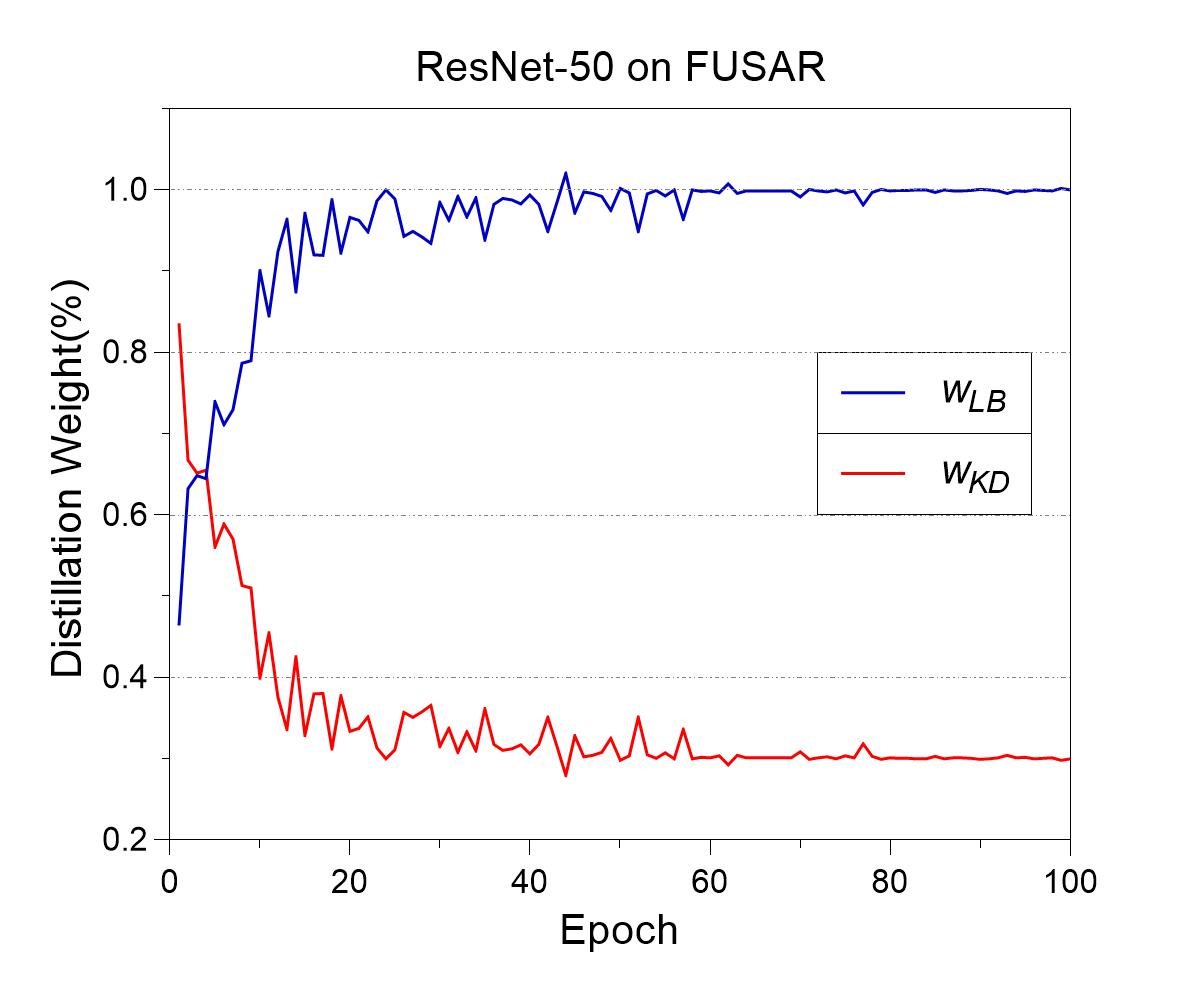
A.2 Details of Distillation Weight Assignment

To show more details about the weight update strategy, the weights of the first batch in each epoch are sampled and plotted as shown in Fig. R1 (large sampling intervals may lead to severe fluctuation). It can be seen that the weight variation trends between ResNet-50 and VGG-19 are distinct. For ResNet-50, the two distillation weights increase or decrease rapidly during the initial 20 epochs, respectively, and then start to stabilize after the epoch. And the weights of VGG-19 change slowly and exhibit slight fluctuations throughout the training. Combined with Fig. LABEL:Fig:training_performance, we see some similarities between the variation of distillation weight and its training performance. For example, the performance of ResNet-50 improves rapidly in the first 20 epochs, and the weight also changes quickly, while both the performance and the distillation weight show very stable after the epoch.