Don’t Touch What Matters: Task-Aware Lipschitz Data Augmentation
for Visual Reinforcement Learning
Abstract
One of the key challenges in visual Reinforcement Learning (RL) is to learn policies that can generalize to unseen environments. Recently, data augmentation techniques aiming at enhancing data diversity have demonstrated proven performance in improving the generalization ability of learned policies. However, due to the sensitivity of RL training, naively applying data augmentation, which transforms each pixel in a task-agnostic manner, may suffer from instability and damage the sample efficiency, thus further exacerbating the generalization performance. At the heart of this phenomenon is the diverged action distribution and high-variance value estimation in the face of augmented images. To alleviate this issue, we propose Task-aware Lipschitz Data Augmentation (TLDA) for visual RL, which explicitly identifies the task-correlated pixels with large Lipschitz constants, and only augments the task-irrelevant pixels. To verify the effectiveness of TLDA, we conduct extensive experiments on DeepMind Control suite, CARLA and DeepMind Manipulation tasks, showing that TLDA improves both sample efficiency in training time and generalization in test time. It outperforms previous state-of-the-art methods across the 3 different visual control benchmarks111https://sites.google.com/view/algotlda/home.
1 Introduction
Deep Reinforcement Learning (DRL) from visual observations has carved out brilliant paths in many domains such as video games Mnih et al. (2015), robotics manipulation Kalashnikov et al. (2018), and visual navigation Zhu et al. (2017). However, it remains challenging to obtain generalizable policies across different environments with visual variations due to overfitting Zhang et al. (2018).

Data Augmentation Shorten and Khoshgoftaar (2019) and Domain Randomization Tobin et al. (2017) based approaches are widely used to learn generalizable visual representations. However, recent work Hansen et al. (2021) find that in visual RL, there is a dilemma: heavy data augmentations are vital for better generalization, but it will cause a significant decrease in both the sample efficiency and the training stability.



One of the main reasons is that data augmentation conventionally perform pixel-level image transformation, where each pixel is transformed in a task-agnostic manner. However, in visual RL, each pixel in the observation has different relevance to the task and the reward function. Hence, it is worth rethinking data augmentation in the new context of visual RL.
To better understand the effect of data augmentation in visual RL, we visualize the action distribution output from policies trained with various data augmentation choices in Figure 2. We find that the agent’s actions vary dramatically when faced with different augmentation methods. Specifically, when weak augmentation such as shifting is applied, the action distribution remains closer to the original distribution that has no augmentation (Figure 2(c)); however, when strong augmentation e.g., random convolution is applied, the action distribution drastically changes (Figure 2(a)) and the Q-estimation yields the discrepancy with the un-augmented data, as shown in Figure 3. This comparison reveals the severe problem that causes instability when data augmentation is applied blindly without knowing the task information.
In this work, we propose a task-aware data augmentation method in visual RL that learns to augment the pixels less correlated to the task, namely Task-aware Lipschitz Data Augmentation (TLDA), as shown in Figure 1. A desirable quality for such a method is to that it maintains a stable policy output even on augmented observations. Following this insight, we introduce the Lipschitz constant that measures the relevance between the pixel and the task, then guides the augmentation strategy. Specifically, we first impose a perturbation on a certain pixel, and calculate the corresponding Lipschitz constant for the pixel via the policy change before and after the perturbation. Then, to avoid the occurrence of drastic policy changes, we treat the pixels with larger Lipschitz constant as the task-correlated ones and avoid augmenting them. Therefore, the output could be more stable while keeping the diversity of augmented data.
We conduct experiments on 3 benchmarks: DMControl Generalization Benchmark (DMC-GB) Hansen and Wang (2021), CARLA Dosovitskiy et al. (2017), and DMControl manipulation tasks Tunyasuvunakool et al. (2020). We train agents in a fixed environment and evaluate their generalization on the environments that are unseen during training. Extensive experiments show that TLDA outperforms the prior state-of-the-art methods due to more stable and efficient training and robust generalization performance.
Our main contributions are summarized as follows:
-
•
We propose Task-aware Lipschitz Data Augmentation (TLDA), which can be implemented on any downstream visual RL algorithm easily without adding auxiliary objectives or additional learnable parameters.
-
•
We provide theoretical understanding and empirical results to show TLDA can alleviate the action distribution shift and high variance Q-estimation problems effectively.
-
•
TLDA achieves competitive or better sample efficiency and generalization ability than previous state-of-the-art methods in different kinds of benchmarks.
2 Related Work
Generalization in RL. Researchers have been investigated RL generalization from various perspectives, such as different visual appearances Cobbe et al. (2019), dynamics Packer et al. (2018) and environment structures Cobbe et al. (2020). In this paper, we focus on generalization over different visual appearances. Two popular paradigms are proposed to address the overfitting issue in current visual RL research. The first is to regard generalization as a representation learning problem. For example, Bi-simulation metric Ferns et al. (2011) is implemented to learn robust representation features Zhang et al. (2020). The other paradigm is to design auxiliary tasks. SODA Hansen and Wang (2021) adds a BYOL-like Grill et al. (2020) architecture and introduces an auxiliary loss which encourages the representation to be invariant to task-irrelevant properties of the environment. In contrast to the previous efforts, our method does not require to employ a specific metric to learn representation, nor to introduce additional modules.
Data Augmentation for RL. Data Augmentation is an efficient method to improve the generalization of visual RL. RAD Laskin et al. (2020) compares different data augmentation methods and reveals that the benefits of different augmentation methods to RL tasks are not the same. SECANT Fan et al. (2021) mentions that weak augmentation can improve sample efficiency but not generalization ability. It also shows that the simple use of strong augmentation is likely to cause training divergence, though generalization ability is improved. Automatic data augmentation is proposed in Raileanu et al. (2021) to make better use of data augmentation. We advocate this paradigm and believe that one crucial factor for improving sample efficiency and generalization lies in the design of data augmentation, namely, how we can diversify the input as much as possible while maintaining the invariance of output. We show that how strong augmentation affects action distribution shifts and causes high variance of Q estimation, and illustrate that our approach is effective in alleviating these two problems.
3 Preliminaries
We consider learning in a Markov Decision Process (MDP) formulated by the tuple where is the state space, is the action space, is a reward function, is the state transition function, is the discount factor. The goal is to learn a policy to maximize the expected cumulative return , starting from an initial state and following the policy which is parameterized by a set of learnable parameters . Meanwhile, we expect the learned policy can be well generalized to new environments, which have the same structure and definition of the original MDP, but with different observation space constructed from the same state space .
3.1 Data Augmentation
Definition 1
(Optimality-Invariant State Transformation)
Given an MDP , we define an augmentation method as an optimality-invariant transformation if , where is a new set of observation satisfies:
| (1) |
A desirable quality for data augmentation is to satisfy the form of Optimality-Invariant State Transformation while distortion or distracting noise is added to the observation.
3.2 Lipschitz constant
The Lipschitz constant is frequently utilized to measure the robustness of a model, we introduce Lipschitz continuity of the policy here. A function : is Lipschitz continuous on if there exists a non-negative constant such that
| (2) |
The smallest such is called the Lipschitz constant of Pauli et al. (2021).
Definition 2 (Lipschitz constant of the policy)
Assume the state space is equipped with a distance metric . Under a certain augmentation method , the Lipschitz constant of a policy is defined as follows:
| (3) |
where is the total variation distance between distributions. If is finite, the policy is Lipschitz continuous.
For a certain model, a smaller Lipschitz constant generally represents higher stability against the variance of input Finlay et al. (2018). The following proposition illustrates that the estimation error of Q-value can be bounded by the Lipschitz constant:
Proposition 1
We consider an MDP , a policy and an augmentation method . Suppose the rewards are bounded by and state space is equipped with a distance metric , such that , the following inequality holds, where
| (4) |
The formal statement and the proof are shown in Appendix A. This proposition indicates that if a smaller Lipschitz constant under one specific augmentation is acquired, we will have a tighter bound of the Q-value estimation with a lower variance while implementing data augmentation.
4 Method
To maintain the training stability and improve the generalization ability, we propose: Task-aware Lipschitz Data Augmentation (TLDA), an efficient and general task-aware data augmentation method for visual RL.

4.1 Construct the K-matrix
We first calculate the Lipschitz constant from perturbed input images. By using a kernel to perturb the original image , we obtain the perturbed image denoted as . Next, we choose the pixels centered with the location of as in the Eq (5), denoted as . Specifically, we use the Hadamard product to choose the perturbed pixels around location by an image mask
| (5) |
To derive the Lipschitz constant, we use the notation to represent the distance between input and under metric . As in Definition 2, for a given observation , the Lipschitz constant of the pixel can be computed as follows:
| (6) |
where the numerator can be interpreted as distance between two action distributions: , , and the denominator is the distance between the original observation and the perturbed one.
With the per-pixel Lipschitz constant in hand, we then construct the matrix that can reflect the task-relevance information and be applied on the whole observation. By arranging into a matrix which have the same size as following Eq (7), we denote this matrix as the K-matrix:
| (7) |
We aim to capture the task-related locations with large Lipschitz constants which tend to cause high variance in the policy/value output during the same level of perturbation.
4.2 Task-Aware Lipschitz Augmentation (TLDA) with the K-matrix
Intuitively, data augmentation operations should not modify the task-related pixels indicated by large Lipschitz constants. We follow this intuition and propose a simple yet effective way to decide which areas can be modified. We use the mean value of the K-matrix as a threshold, and binarize the K-matrix by the following way, where is the number of pixels (),
| (8) |
The obtained mask is used to decide which pixels can be augmented. For any data augmentation method , we apply the following operation:
| (9) |
We note that the output is only modified in the areas that have low relevance to the task.

As mentioned above, our approach tends to preserve the pixels with large and augment only the pixels associated with the small ones, which adds an implicit constraint to maintain the stable output of the policy and value network. Hence, it echoes with the Optimality-Invariant State Transformation as in Definition 1. Figure 4 demonstrates the overall framework of TLDA. During the training process, the K-matrix is calculated on the fly against every training step on augmented observations. Take cutout (adding a black patch to the image) in Figure 4 as an example, since the corresponding K-matrix shows that the upper part of the robot’s body features large Lipschitz constants, therefore, blindly augmenting the image might touch the pixels in this area and cause catastrophic action/value changes. In contrast, TLDA preserves the critical parts of the original observations indicated by K-matrix. It can help to maintain the stability of the action/value outputs.
4.3 Reinforcement Learning with TLDA
We use soft-actor-critic (SAC) as the base reinforcement learning algorithm for TLDA. Similar to previous work, we also include a regularization term to the SAC critic loss to handle augmented data. Our critic loss is as follows, where is calculated by Eq (9), and :
| (10) |
with
5 Experiment
In this section, we explore how TLDA can affect the agent’s sample efficiency and generalization performance. We compare our method with other baselines on a wide spectrum of tasks including DeepMind control suite, CARLA simulator, as well as DeepMind Manipulation tasks. We also ablate TLDA and investigate its effect on action distributions and value estimation.
| Setting |
|
DrQ | PAD |
|
|
|
|
|
|
|||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ccea7b76-4a7f-42e2-bf7a-06e104c18b36/video_easy.png) |
|
|||||||||||||||||||||
|
||||||||||||||||||||||
|
||||||||||||||||||||||
|
||||||||||||||||||||||
|
||||||||||||||||||||||
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ccea7b76-4a7f-42e2-bf7a-06e104c18b36/color_hard.png) |
|
|||||||||||||||||||||
|
||||||||||||||||||||||
|
||||||||||||||||||||||
|
||||||||||||||||||||||
|
5.1 Evaluation on DeepMind Control Suite
Setup. We implement our method with SAC as the base algorithm. Convolution Neural Networks are used for the image inputs. We include a detailed description of all hyper-parameters and the architecture in Appendix B. For comparison, we mainly consider two augmentation ways applied in the prior state-of-the-art methods: random convolution (passing input through a random convolutional layer) and random overlay (linearly combining the observation with the extra image , .
Baselines. We benchmark TLDA against the following state-of-the-art methods: (1) DrQ Kostrikov et al. (2020): SAC with weak augmentation (random shift); (2) PAD Hansen et al. (2020): adding an auxiliary task for adapting to the unseen environment; (3) SODA Hansen and Wang (2021): maximizing the mutual information between latent representation by employing a BYOL-like Grill et al. (2020) architecture; (4) SVEA Hansen et al. (2021): modifying the form of Q-target. We run 5 random seeds and report the mean and standard deviation of episode rewards.
Sample efficiency under strong augmentations. We compare the sample efficiency with SVEA to exhibit the effectiveness of TLDA.
We also include another baseline that preserves random patches from the un-augmented observation as opposed to TLDA that preserves task-related parts. We call this baseline random patch. By contrast, SVEA only uses the strong augmentation method but retains no raw pixel. Figure 5 demonstrates that TLDA achieves better or comparable asymptotic performance in the training environment than baselines on DM-control suite while having better sample efficiency. The results also indicate that random patch will hinder the performance in some tasks. We reckon that since random patch does not have any pixel-to-task relevance knowledge, it inevitably destroys the image’s integrity and even leads to further distortion to the observations after data augmentation. Therefore, blindly keeping the original observation’s information cannot improve the agent’s training performance. It is the retention of areas with larger Lipschitz constants, instead of random original areas, that boosts the sample efficiency of training agents.
Generalization Performance. We evaluate the agent’s generalization ability on two settings from DMControl-GB Hansen and Wang (2021): (i) random colors of the background and agent; (ii) dynamic video backgrounds. Results are shown in Table 1. TLDA outperforms prior state-of-the-art methods in 7 out of 10 instances. The agent trained with TLDA is able to acquire a good robust policy in different unseen environments. Meanwhile, we notice that prior methods are sensitive to different kinds of augmentations, which makes their testing performance varies dramatically. On the contrary, our method with task-aware observations is more stable and not susceptible to this issue.
Qualitative Results of TLDA. As shown in Figure 6, from the K-matrix on the test environments, agents trained by TLDA will give larger Lipschitz constants on the robot’s body while the SVEA agents are prone to focus on the lighting visual background. Our method is capable of learning the main factors that influence the performance and neglecting the irrelevant areas that hinder generalization.

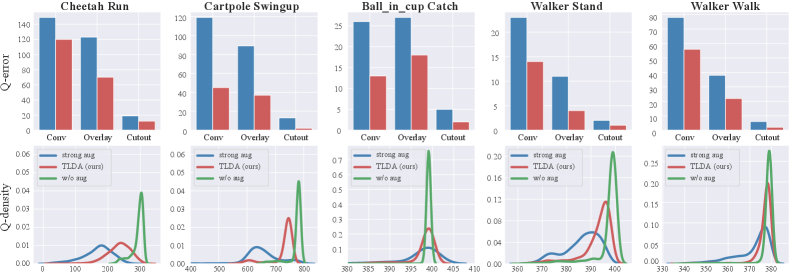
Effect on Action Distribution and Q-estimation. In this section, we analyze how TLDA influences the output of the policy and value networks. Given a DrQ agent trained in the original environment, we assess the Q-value estimation and the action distribution under different augmentation. To get a better understanding of this issue, we visualize the action distribution of the agent under different augmentation methods, as shown in Figure 2. For weak augmentation, although its action distribution is closest to the un-augmented one (Figure 2(c)), it cannot improve generalization, as shown in Table 1(DrQ). Strong augmentation, on the other hand, will cause an obvious distribution shift (Figure 2(a)), thus significantly hindering the training process.
We find that TLDA has a closer action distribution than simply applying strong augmentation (Figure 2(b)) by using the Lipschitz constant to identify and preserve the task-aware areas. Furthermore, as shown in Figure 3, we find that the Q-estimation of TLDA has a lower variance than that of naively applying strong augmentation. These two results illustrate that TLDA has the potential to achieve higher sample efficiency in training and learn a more robust policy to perform well in unseen environments.
5.2 Evaluation on Autonomous Driving in CARLA
To further evaluate the TLDA’s performance, we apply this method in the tasks with more realistic observations: autonomous driving in the CARLA simulator. In our experiment, we use one camera as our input observation for driving tasks, where the goal of the agent is to drive along a curvy road as far as possible in 1000 time-steps without colliding with the moving vehicles, pedestrians and barriers. We adapt the reward function and train an agent under the weather with the same setting from previous work Zhang et al. (2020). The training results are shown in Figure 7. We find that our method achieves the best training sample efficiency. For generalization, CARLA provides different weather conditions with built-in parameters. We evaluate our method in 4 kinds of weather with different lighting conditions, realistic raining and slipperiness. Results are in Table 2, where we choose the success rate for reach 100m distance as the driving evaluation metric. TLDA outperforms all base algorithms in both sample efficiency and generalization ability with a more stable driving policy. Additional results are in Appendix D.3.
| Setting | DrQ | SVEA | Ours |
|---|---|---|---|
| Training | |||
| Wet Noon | |||
| SoftRain noon | |||
| Wet Sunset | |||
| MidRain Sunset |

5.3 Evaluation on DMC Manipulation Tasks
Robot manipulation is another set of challenging and meaningful tasks for visual RL. DM control Tunyasuvunakool et al. (2020) provides a set of configurable manipulation tasks with a robotic Jaco arm and snap-together bricks. We consider two tasks for experiments: reach and push. More details are in Appendix C.3.
All the agents are trained on the default background and evaluated on different colors of arms and platforms. Training results and generalization performance are shown in Appendix D.2 and Table 3. The results show that our method can be adapted to the unseen environments more appropriately. The Modified Platform and Modified Both setting are challenging for agents to discern the target objects from the noisy backgrounds. SVEA under strong data augmentation suffers from instability and divergence for training, while TLDA can augment the pixel in a task-aware manner, thus further maintaining the training stability. Despite that DrQ shows better training performance, it barely generalizes to the environments with different visual layouts. In summary, sample efficiency and generalization performance contribute to exhibiting the superiority of the proposed algorithm.
| Task | Setting | DrQ | SVEA | Ours |
|---|---|---|---|---|
| Reach | Training | |||
| M Arm | ||||
| M Platform | ||||
| M Both | ||||
| Push | Training | |||
| M Arm | ||||
| M Platform | ||||
| M Both |
6 Conclusion
In this paper, we propose Task-aware Lipschitz Data Augmentation (TLDA) for visual RL, which can reliably identify and augment pixels that are not strongly correlated with the learning task while keeping task-related pixels untouched. This technique aims to provide a principled mechanism for boosting the generalization ability of RL agents and can be seamlessly incorporated into various existing visual RL frameworks. Experimental results on three challenging benchmarks confirm that, compared with the baselines, TLDA not only features higher sample efficiency but also helps the agents generalize well to the unseen environments.
References
- Cobbe et al. (2020) Karl Cobbe, Chris Hesse, Jacob Hilton, and John Schulman. 2020. Leveraging procedural generation to benchmark reinforcement learning. In International conference on machine learning, pages 2048–2056. PMLR.
- Cobbe et al. (2019) Karl Cobbe, Oleg Klimov, Chris Hesse, Taehoon Kim, and John Schulman. 2019. Quantifying generalization in reinforcement learning. In International Conference on Machine Learning, pages 1282–1289. PMLR.
- Dosovitskiy et al. (2017) Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. 2017. Carla: An open urban driving simulator. In Conference on robot learning, pages 1–16. PMLR.
- Fan et al. (2021) Linxi Fan, Guanzhi Wang, De-An Huang, Zhiding Yu, Li Fei-Fei, Yuke Zhu, and Anima Anandkumar. 2021. Secant: Self-expert cloning for zero-shot generalization of visual policies. arXiv preprint arXiv:2106.09678.
- Ferns et al. (2011) Norm Ferns, Prakash Panangaden, and Doina Precup. 2011. Bisimulation metrics for continuous markov decision processes. SIAM Journal on Computing, 40(6):1662–1714.
- Finlay et al. (2018) Chris Finlay, Jeff Calder, Bilal Abbasi, and Adam Oberman. 2018. Lipschitz regularized deep neural networks generalize and are adversarially robust. arXiv preprint arXiv:1808.09540.
- Grill et al. (2020) Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, et al. 2020. Bootstrap your own latent: A new approach to self-supervised learning. arXiv preprint arXiv:2006.07733.
- Hansen et al. (2020) Nicklas Hansen, Rishabh Jangir, Yu Sun, Guillem Alenyà, Pieter Abbeel, Alexei A Efros, Lerrel Pinto, and Xiaolong Wang. 2020. Self-supervised policy adaptation during deployment. arXiv preprint arXiv:2007.04309.
- Hansen et al. (2021) Nicklas Hansen, Hao Su, and Xiaolong Wang. 2021. Stabilizing deep q-learning with convnets and vision transformers under data augmentation. arXiv e-prints, pages arXiv–2107.
- Hansen and Wang (2021) Nicklas Hansen and Xiaolong Wang. 2021. Generalization in reinforcement learning by soft data augmentation. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13611–13617. IEEE.
- Kalashnikov et al. (2018) Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, et al. 2018. Scalable deep reinforcement learning for vision-based robotic manipulation. In Conference on Robot Learning, pages 651–673. PMLR.
- Kostrikov et al. (2020) Ilya Kostrikov, Denis Yarats, and Rob Fergus. 2020. Image augmentation is all you need: Regularizing deep reinforcement learning from pixels. arXiv preprint arXiv:2004.13649.
- Laskin et al. (2020) Misha Laskin, Kimin Lee, Adam Stooke, Lerrel Pinto, Pieter Abbeel, and Aravind Srinivas. 2020. Reinforcement learning with augmented data. Advances in Neural Information Processing Systems, 33.
- Mnih et al. (2015) Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. 2015. Human-level control through deep reinforcement learning. nature, 518(7540):529–533.
- Packer et al. (2018) Charles Packer, Katelyn Gao, Jernej Kos, Philipp Krähenbühl, Vladlen Koltun, and Dawn Song. 2018. Assessing generalization in deep reinforcement learning. arXiv preprint arXiv:1810.12282.
- Pauli et al. (2021) Patricia Pauli, Anne Koch, Julian Berberich, Paul Kohler, and Frank Allgower. 2021. Training robust neural networks using lipschitz bounds. IEEE Control Systems Letters.
- Raileanu et al. (2021) Roberta Raileanu, Maxwell Goldstein, Denis Yarats, Ilya Kostrikov, and Rob Fergus. 2021. Automatic data augmentation for generalization in reinforcement learning. Advances in Neural Information Processing Systems, 34.
- Shorten and Khoshgoftaar (2019) Connor Shorten and Taghi M Khoshgoftaar. 2019. A survey on image data augmentation for deep learning. Journal of Big Data, 6(1):1–48.
- Tobin et al. (2017) Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. 2017. Domain randomization for transferring deep neural networks from simulation to the real world. In IROS, pages 23–30. IEEE.
- Tunyasuvunakool et al. (2020) Saran Tunyasuvunakool, Alistair Muldal, Yotam Doron, Siqi Liu, Steven Bohez, Josh Merel, Tom Erez, Timothy Lillicrap, Nicolas Heess, and Yuval Tassa. 2020. dm_control: Software and tasks for continuous control. Software Impacts, 6:100022.
- Zhang et al. (2020) Amy Zhang, Rowan McAllister, Roberto Calandra, Yarin Gal, and Sergey Levine. 2020. Learning invariant representations for reinforcement learning without reconstruction. arXiv preprint arXiv:2006.10742.
- Zhang et al. (2018) Chiyuan Zhang, Oriol Vinyals, Remi Munos, and Samy Bengio. 2018. A study on overfitting in deep reinforcement learning. arXiv preprint arXiv:1804.06893.
- Zhu et al. (2017) Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J Lim, Abhinav Gupta, Li Fei-Fei, and Ali Farhadi. 2017. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In ICRA, pages 3357–3364. IEEE.
Appendix A The Proof of Proposition 1
Proposition 1 We consider an MDP and an augmentation method . Let be a policy over . Suppose the rewards are bounded by such that Then for and , the following inequality holds :
| (11) |
Proof. We are interested in the Q-value function which is defined as follows:
| (12) | ||||
Let be the probability of visiting state at time , be the probability of doing action in state , thus
| (13) |
By these definitions, we can write that:
| (14) | ||||
. This above inequality shows that the Q-value estimation is bounded by two total variation distance (the smaller the total variation distance is, the closer the Q-value estimation will be).
Lemma2 For a given state , and a given policy under the data augmentation method , we assume the state space is equipped with a distance metric , the following bound holds:
| (15) |
Proof.
| (16) | ||||
We also note that the , so according to the bound of Eq (14) we have that
| (17) | ||||
Appendix B Implementation Details
In this section, we provide details of our algorithm’s implementation and hyperparameter setting. Table 4 exhibits the hyper-parameters of TLDA in three benchmarks. It should be noticed that if we calculate the Lipschitz constant for each pixel, it will increase the computation complexity and take more time for training. Therefore, we calculate the Lipschitz constant every 5 pixels during training for one observation, which is enough to acquire good performance. We choose Gaussian blur as the kernel and implement the 2D Gaussian centered at as Mask . Since we only change a few chosen perturbed pixels (near the pixel by ) in the whole image for every location when calculating the distance between and , we can approximate that this metric is not relevant to the specific location ; thus, the Lipschitz constant can be proportional to the distance between two action distributions: , .
Meanwhile, we compare different metrics for TLDA, as shown in Figure 8. The result shows that distance is sharper and more concentrated while the total-variance distance has the Blurry effect, as well as KL divergence is darker. So empirically, we choose distance as our metric to calculate the Lipschitz constant during all experiments. DrQ shows that shifting is an effective method to improve sample efficiency. Therefore we apply shifting to the observation at first. The linear combination factor of random overlay is with the dataset in DMC-GB. We summarize our method in Algorithm 1. The inner two for loops can be computed in parallel.
| Hyperparameter | DMControl-GB | CARLA | Manipulation Tasks | ||
|---|---|---|---|---|---|
| Input dimension | 9 84 84 | 9 84 84 | 9 84 84 | ||
| Stacked Frames | 3 | 3 | 3 | ||
| Discount factor | 0.99 | 0.99 | 0.99 | ||
| Action repeat | 8(cartpole) 4(otherwise) | 4 | 2 | ||
| Actor learning rate |
|
1e-3 | 3e-5 | ||
| Critic learning rate |
|
1e-3 | 3e-5 | ||
| Random cropping padding | 4 | 4 | 4 | ||
| Batch size | 128 | 128 | 128 | ||
| Regularization term | 1 | 1 | 1 | ||
| Training step | 500k | 100k | 500k | ||
| Replay buffer size | 500,000 | 100,000 | 500,000 | ||
| Encoder conv layers | 4 | 4 | 4 | ||
| Optimizer() | Adam | Adam | Adam |

Appendix C Environment Details
We conduct our method on three challenging visual control benchmarks, as shown in Figure 9.

C.1 DeepMind Control Suite
C.2 CARLA
CARLA is a widely-used autonomous driving simulator. In our experiment, we choose highway CARLA Town4 as the map for the driving task. The goal of the training agent is to drive along a highway road as far as possible under diverse weather conditions. We choose a stable version of CARLA 0.9.6 Dosovitskiy et al. (2017) and use the reward function and network architecture in Zhang et al. (2020). We use one camera as our input observation, which is an image. The action is composed of thrusting and steering these two continuous controls. We choose random overlay as the strong augmentation method during training, whose linear combination factor with the dataset from DMC-GB.
C.3 DeepMind Manipulation Task
DeepMind Manipulation task is introduced in Tunyasuvunakool et al. (2020) for robot continuous controls, which provides a Kinova robotic arm and a list of objects for building reward functions.
We additionally consider two tasks for the experiments:
-
•
reach: the agent needs to reach the shown red brick by manipulating the arm;
-
•
push: the goal is to push the red bricks to the position of a white mark point;
The input observation is the stacked RGB images of pixels. There are two available observation versions: feature vectors and pixel images. All environments return a reward per step, and have an episode time limit in 10 seconds. It is challenging for the RL algorithm based on SAC to perform well in these tasks without adding other useful tools. Therefore, we choose the task reach_duplo_vision, which aims to move the arm to a brick resting on the ground, and create a task push_brick_vision, whose goal is to push a brick to a goal position. The reward function of push is based on the reach task, and we add a reward term about the distance between the red brick and goal position. The closer distance between them, the higher reward the agent will achieve. We visualize the observations of two tasks, as shown in Figure 10. We choose random overlay as the strong augmentation way during training whose linear combination factor with the dataset from DMC-GB.



Appendix D Additional Result
D.1 TLDA in DMC
As shown in Figure 12, we exhibit more comparisons between the TLDA and normal strong augmentations to show the superiority of our method. We use the same converged DrQ agent under the same seed to evaluate how augmentation methods will influence the agent’s performance. More details are in this link222https://sites.google.com/view/algotlda/home. TLDA can effectively help training agents to alleviate the degradation of performance while facing the strong augmentation.
D.2 Training Curves of Manipulation Tasks.
All methods are trained in 500k steps on Manipulation Tasks, and the training results are shown in Figure 11. Although DrQ shows the best training performance, comparison results for generalization in Table 3 demonstrate that our method significantly outperforms baselines, which means DrQ may tend to overfit the environment, and SVEA may easily suffer from divergence under these more challenging benchmarks.
D.3 CARLA
We adapt the reward function and train agents under the weather whose setting is the same as the previous work Zhang et al. (2020). The training results are shown in Figure 7. The results indicate that TLDA outperforms other baselines in sample efficiency.
Except for the success rate of reaching 100m distance, the crash intensity is also an essential driving metric. We evaluate the crash intensity under different weather and report the average value in the training and unseen environments in Table 5. The results show that TLDA has the lowest crash intensity compared to the other baselines in unseen environments.
| Setting | DrQ | SVEA | Ours |
|---|---|---|---|
| Training | |||
| Wet Noon | |||
| SoftRain noon | |||
| Wet Sunset | |||
| MidRain Sunset |



