Domain-Augmented Domain Adaptation
Abstract
Unsupervised domain adaptation (UDA) enables knowledge transfer from the labelled source domain to the unlabeled target domain by reducing the cross-domain discrepancy. However, most of the studies were based on direct adaptation from the source domain to the target domain and have suffered from large domain discrepancies. To overcome this challenge, in this paper, we propose the domain-augmented domain adaptation (DADA) to generate pseudo domains that have smaller discrepancies with the target domain, to enhance the knowledge transfer process by minimizing the discrepancy between the target domain and pseudo domains. Furthermore, we design a pseudo-labeling method for DADA by projecting representations from the target domain to multiple pseudo domains, and take the averaged predictions on the classification from the pseudo domains as the pseudo labels. We conduct extensive experiments with the state-of-the-art domain adaptation methods on four benchmark datasets: Office Home, Office-31, VisDA2017, and Digital datasets. The results demonstrate the superiority of our model.
1 Introduction
With the advance of deep convolutional networks, computer vision tasks such as image recognition, semantic segmentation, video processing have reached high performance with a large amount of training data. Generally, well-trained models perform well on the testing set of which the distribution bears a resemblance to that of the training set. However, directly applying such a trained model on new domains of which the data distribution is disparate from the training data, usually results in significant performance decline. Such a phenomenon is known as domain shift [36], which evidently affects a direct knowledge transfer from the source domain to the target domain.
There has been a wide study on the knowledge transfer or domain adaptation from source domains to target domains [24, 45]. The majority of such methods attempt to align the distribution of source and target domains by learning domain-invariant representations through directly minimizing the domain discrepancy of the representation distributions from the two domains [30, 41], or adversarially training the models to enforce a domain discriminator unable to distinguish features from two domains [5, 44]. Generally, these prevailing DA methods leverage robust and high-complexity base learners owing to their good transferable capacity brought by deep and wide architectures.

However, when the data from the source domain is distinct from the data in the target domain, or when the domain gap between source and target domain is relatively large, directly matching domain distributions between the two domains might cause several problems such as low convergence rate and class mismatch: a sample from source domain with label “A” might obtain the similar representation as to the sample from the target domain with label “B”.
In this paper, to tackle the aforementioned problem, we design an adaptive transfer learning method, named Domain-Augmented Domain Adaptation method (DADA). In DADA, as shown in Figure 1, instead of directly minimizing the domain discrepancy between the source and target domain, we expand the expressiveness of the model around the target data distribution through generating multiple pseudo domains that have small discrepancy to the target domain. Each pseudo domain is generated from the source domain by a domain generator. To maintain the distinction between each pseudo domain, each pseudo domain is associated with a domain prior, which controls the distribution of the corresponding pseudo domain. The pseudo domain can be regarded as an augmentation from the source domain in which there exists one-to-one mapping from the data in the source domain to each pseudo domain. Therefore, each sample in every pseudo domain can be regarded as labeled training samples to train the model. However, not every pseudo domain can add value to the classifier as they may own distinct distribution from the target domain so that we need to distinguish favourable pseudo domains that can contribute to the training processes.

To this end, we select favourable pseudo domains that have relatively small discrepancy to the target domain. Note that computing domain similarity generally requires a large amount of training data, which is infeasible to be done during the training process for multiple pseudo domains. Therefore, we design a domain similarity predictor to predict the similarity (e.g. Maximum Mean Discrepancy (MMD)) between each pseudo domain and the target domain, based on the domain prior. Based on the domain similarity, we select several pseudo domains where the pseudo domains are relatively close to the target domain, and minimize discrepancies between the pseudo domain and the target domain.
In addition, we design a novel pseudo labeling method based on the pseudo domains. Pseudo labeling on the target domain has been proven to improve the domain adaptation capability in many related works [22, 6, 35, 12]. However, directly labeling target samples based on the classifier trained by the source domain may usually cause false labeling due to the domain shift. Instead, in DADA the representations of the target data are mapped to multiple pseudo domains where the pseudo label are taken by the average classification result of the pseudo domains. We show the superiority of this labeling method in the ablation study.
We conduct extensive experiments on four widely used datasets such as Office-Home, Office 31, VisDa and Digital datasets, to compare DADA with state-of-the-art domain adaptations methods. We also conduct extensive ablation studies and feature visualization to analyse the contribution of each component of DADA.
Our contribution can be summarized as follows:
-
•
We propose the domain-augmented domain adaptation method which can unsupervised transfer knowledge from the source domain to the target domain, through augmenting pseudo domains.
-
•
We design an appropriate pseudo labeling method for the target domain, by mapping the target data to each pseudo domain and obtaining the overall pseudo label.
-
•
We conduct extensive experiments and ablation studies to test the performance of DADA compared to state-of-the-art domain adaptation methods. The experiments demonstrate the superior of DADA.
2 Related Works
Unsupervised domain adaptation. Unsupervised domain adaptation (UDA) deals with the problem of transferring knowledge from a labeled source domain to unlabeled target domain [24]. The mainstream of UDA methods focuses on learning domain-invariant representations through minimizing the domain discrepancy. One category of UDA method explicitly minimizes the domain discrepancy based on some common domain discrepancy measures. [19, 20] reduce the domain discrepancy through MMD. [30, 11] minimize the Wasserstein distance between the source target domain. In DADA, we adopt MMD as the domain discrepancy measure on the source and target domain.
Another category of learning domain invariant representations is through adversarial training. This line of research has been widely explored [36] since the influential work DANN [5]. Adversarial learning generally trains a domain discriminator that can distinguish samples of the source domain from the target domain. Meanwhile, a feature extractor is trained to fool the discriminator to arrive at aligned features. Most works in the aforementioned categories directly minimize the discrepancy between the source and target domain, which might suffer from the problem when they encounter a large gap between the source and the target domain.
Data augmentation. Data augmentation can improve models’ generalization capability by increasing the diversity of the training data. Conventional augmentation methods include random cropping, affine transformation (e.g. translation and rotation), horizontal flipping, etc [36]. Recently, more augmentation techniques have been applied to domain adaptation to improve the effectiveness of knowledge transfer. MixMatch [1] designs low-entropy labels for augmenting unlabeled instances and mixed labeled and unlabeled data for semi-supervised learning. Huang et al. [8] design generative adversarial network (GAN) to generate augmented data for domain adaptation. DAML [31] applies the Dir-Mixup to mix-up multiple source domains. FixBi [22] includes a fixed-ratio mix-up for the source and target domain, where the mixed-up samples are the augmentation for training. TSA [16] proposes semantic augmentations to augment semantic features for the training samples. FACT [40] utilizes Fourier transforms to mix-up the source and target domain data. ECACL [13] designs the weak and strong data augmentation for domain adaptation.
Different from existing augmentation methods for domain adaptation, DADA proposes learnable domain augmentations, where we utilize a domain generator to learn to generate pseudo domains based on the source domain. Then we select multiple pseudo domains that have small discrepancies to the target domain as our augmentations to enhance the knowledge transfer to the target domain.
3 Methodology
For UDA classification, we denote the source domain as with labeled samples, where and denote the sample and its label respectively. We denote the target domain as with samples. Both domains share the same label space with in total classes. The samples of the source domain and target domain are drawn from different distributions and , such that and our goal is to train the model on the source domain and generalize to the target domain.
3.1 Model Overview
The overall model architecture is shown in Figure 2. Firstly, we input the samples from both the source and target domain to the model, where the data are processed by a feature extractor (e.g. ResNet-50, ResNet-101, etc).111We denote the feature extractor as the backbone model in some following context. Subsequently, we obtain the representations from the source domain and the target domain with the distribution and respectively. In the next step, we apply a pseudo domain generator to generate multiple pseudo domains, where each domain associates with a unique domain prior. The domain prior is sampled from a uniform distribution. Therefore, we can form plenty of pseudo domains, where there exists some pseudo domains that have a low discrepancy between the target domain, such that it is also easier for us to transfer knowledge from such pseudo domains to the target domain. To select appropriate pseudo domains, we use a domain discrepancy estimator, which ,based on the domain prior, estimates the pseudo and target domains’ discrepancy. To transfer knowledge to the target domain, we design a set of contrastive loss functions to ensure the knowledge can be transferred to the target domain.
3.2 Pseudo Domain Generation
The key component of DADA is the domain generation network that generates multiple pseudo domains based on the source domain. For each pseudo domain generation, first, we randomly sample a set of domain priors from a discrete uniform distribution that contains evenly spaced numbers over with the constant interval 0.01, where denotes the sampled domain prior. is a tunable hyper-parameter that controls the number of pseudo domains where we generate in each batch. Each domain prior is associated with a specific pseudo domain . The domain generator can be denoted as a mapping function: . In practice, we concatenate each domain prior with the features that output from the feature extractor from the source domain, and we denote the new representation as , where denotes the batch size and is the feature of the sample with the prior .
We apply a multilayer perceptron network to parameterize the domain generator and the output of the domain generator is a batch of samples of the pseudo domain that is associated with the domain prior . We denote the output as . With priors, we can obtain distinct batches of representations from the pseudo domains .
3.2.1 Domain consistency loss
To ensure each sample from the generated pseudo domain maintains the same information as the original sample from the source domain, we design a domain consistency loss, to regularize the representation of the pseudo domains. To this end, since each sample in the source domain with representation acquires a unique corresponding representation from the pseudo domain , we apply the contrastive learning to build strong relationships between the paired sampled and : maximize the correlation for the positive pair and minimize the correlation for negative pairs , where the negative samples are the data from the same batch that have different labels as the current data. Therefore, the contrastive learning can enhance inter-domain consistencies for the pseudo domains and the source domain, such that, same as the source domain, the representations of the data in the pseudo domain with the same labels can be grouped together. Consequently, for downstream tasks, a classifier can easily distinguish the data from different classes.
The domain consistency loss for the pseudo domain can be written as
| (1) |
where , and are samples from the batch with batchsize of , sim denotes the similarity function, where we apply a bilinear function to compute the similarity of two representations. It is worth noting that a cosine or inner product similarity measure may not work in our setting, as those measures highly restrict the distribution of the pseudo domains, so that we may hardly find pseudo domains that have small discrepancy with the target domain when the discrepancy between the source and target domain is large. We take the and which are from the same data sample as the positive pair, while considering representations with different labels as negative pairs.
3.3 Domain Discrepancy Estimation and Minimization
3.3.1 Domain discrepancy estimation
Pseudo domains are generated by the domain generator based on the domain prior, where some pseudo domains are generated with similar distributions as the target domain, while others are dissimilar to the target domain. We hope to select the pseudo domains that have small discrepancy (i.e. similar) to the target domain, since transferring knowledge from such pseudo domains to the target domain is easier comparing to random pseudo domains. However, estimating the discrepancy between two domains requires a large amount of training data, as computing the MMD based on a single batch of data does not accurately reflect the MMD of two domains. Thus, it is unfavorable for conventional domain adaptation models to concurrently estimate domain discrepancies and perform domain adaptation, since domain adaptation procedure changes the result of domain discrepancies.
Therefore, we design an explicit domain discrepancy estimator . Since each pseudo domain is generated based on a specific domain prior, we can directly estimate the discrepancy (e.g. MMD) through regression based on the domain prior as the following loss function:
| (2) |
where denotes the representations from the pseudo domain with prior , and is the discrepancy estimator, where we parameterize it with a multilayer perceptron network. By minimizing the error in (2), the discrepancy estimator can gradually estimate the MMD between any generated pseudo domains and the target domain.
3.3.2 Inter-pseudo-domain discrepancy maximization
For the pseudo domains, we hope each pseudo domain can form a distinct distribution in the latent space. The motivation behind this is that if each pseudo domain forms a distribution that is near to the target domain and distinct from each other, we can have a generalized representation for the space that surrounds the target domain. In contrast, if all the pseudo domains share a similar distribution on the feature representation, it will be meaningless to generate pseudo domains instead of a single pseudo domain.
To this end, we try to maximize the discrepancy between pseudo domains by adding a regularization term to the MMD between pseudo domains as follows:
| (3) |
where this regularization term serves as a distribution separator to spread the pseudo domain representations to cover the spaces that are close to the target domain.
3.3.3 Domain discrepancy minimization
The next step is to transfer knowledge from the appropriate pseudo domains (selected by the domain estimator) to the target domain by minimizing the discrepancy between them. To this end, firstly, we assign a weight () to each pseudo domain , where the reflects the discrepancy between and , and is computed according to the softmax formula:
| (4) |
Therefore, in each batch, given , , and representations from the pseudo domains, the loss function to transfer knowledge from the pseudo domains to the target domain can be written as
| (5) |
3.4 Pseudo Labeling and (Self-)Supervised Loss
Psuedo labeling has been shown to improve the model performance in recent DA works [22, 6, 35, 12]. Most of the existing pseudo labeling methods train the classifier by the source data and directly apply it to the training samples from the target domain to obtain pseudo labels. However, such pseudo labeling highly depends on the discrepancy between the source and target domain, and might be inaccurate when the domain gap is relatively large.
Therefore, in our model, we design the reverse pseudo labeling method, by projecting the data from the target domain to multiple pseudo domains, and labeling the target domain samples through the classifier trained from the pseudo domain. We denote the projection function as . In general, for a well trained model, the discrepancy between the target and pseudo domain is relatively small, and applying non-linear mapping may disturb the distribution after mapping and may even increase the discrepancy. Therefore, we compute the domain centre, i.e. mean of the representations from both domains, and directly add the difference of the mean to the data in the target domain. can be expressed as:
| (6) |
Then we compute the probability of the label for based on the classifier. Therefore, for pseudo domains, we can obtain set of probabilities. Then, we compute the overall probability of the labels . Base on the probability, we assign the label with the highest probability as the pseudo label for the samples from the target domain. We denote the pseudo label as .
Therefore, the self-supervised loss for the target domain can be written as:
| (7) |
where is the predicted pseudo label. denotes the predicted probability on each class, and is the number of classes. is a regularization term adopted from [16] which regularizes the distribution of the target prediction by encouraging predictions on high confident classes (i.e. classes with high predicted probability) and enhancing balanced prediction on each classes. Typically, , where is the average prediction of the batch. is a tunable parameter where we tested value from . Meanwhile, to train a robust classifier, we need the supervised loss for the source domain and the pseudo domains as follows:
| (8) |
3.5 Loss functions and Overall Algorithm
The overall loss functions consist of the supervised loss for the source and pseudo domains, pseudo domain consistency loss (1), domain discrepancy losses, as well as target domain self-supervised loss. Thus the overall loss function can be derived as:
| (9) |
where are hyper-parameters to adjust the weight of each loss components. Algorithm 1 summarizes the proposed method.
4 Experiment
| Method | ArCl | ArPr | ArRw | ClAr | ClPr | ClRw | PrAr | PrCl | PrRw | RwAr | RwCl | RwPr | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| JAN [21] | 45.9 | 61.2 | 68.9 | 50.4 | 59.7 | 61.0 | 45.8 | 43.4 | 70.3 | 63.9 | 52.4 | 76.8 | 58.3 |
| TAT [17] | 51.6 | 69.5 | 75.4 | 59.4 | 69.5 | 68.6 | 59.5 | 50.5 | 76.8 | 70.9 | 56.6 | 81.6 | 65.8 |
| TPN [25] | 51.2 | 71.2 | 76.0 | 65.1 | 72.9 | 72.8 | 55.4 | 48.9 | 76.5 | 70.9 | 53.4 | 80.4 | 66.2 |
| ETD [14] | 51.3 | 71.9 | 85.7 | 57.6 | 69.2 | 73.7 | 57.8 | 51.2 | 79.3 | 70.2 | 57.5 | 82.1 | 67.3 |
| SymNets [43] | 47.7 | 72.9 | 78.5 | 64.2 | 71.3 | 74.2 | 64.2 | 48.8 | 79.5 | 74.5 | 52.6 | 82.7 | 67.6 |
| BNM [3] | 52.3 | 73.9 | 80.0 | 63.3 | 72.9 | 74.9 | 61.7 | 49.5 | 79.7 | 70.5 | 53.6 | 82.2 | 67.9 |
| MDD [42] | 54.9 | 73.7 | 77.8 | 60.0 | 71.4 | 71.8 | 61.2 | 53.6 | 78.1 | 72.5 | 60.2 | 82.3 | 68.1 |
| GSP [38] | 56.8 | 75.5 | 78.9 | 61.3 | 69.4 | 74.9 | 61.3 | 52.6 | 79.9 | 73.3 | 54.2 | 83.2 | 68.4 |
| GVB-GD [4] | 57.0 | 74.7 | 79.8 | 64.6 | 74.1 | 74.6 | 65.2 | 55.1 | 81.0 | 74.6 | 59.7 | 84.3 | 70.4 |
| TSA[16] | 57.6 | 75.8 | 80.7 | 64.3 | 76.3 | 75.1 | 66.7 | 55.7 | 81.2 | 75.7 | 61.9 | 83.8 | 71.2 |
| Ours | 58.9 | 79.5 | 82.2 | 66.3 | 78.2 | 78.2 | 65.9 | 53 | 81.6 | 74.5 | 60.2 | 85.1 | 72.0 |
| Method | plane | bcycl | bus | car | horse | knife | mcycl | person | plant | sktbrd | train | truck | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet [12] | |||||||||||||
| DAN [24] | |||||||||||||
| DANN [9] | |||||||||||||
| MinEnt [11] | |||||||||||||
| MCD [36] | |||||||||||||
| ADR [35] | |||||||||||||
| SWD [14] | |||||||||||||
| CDAN+E [25] | |||||||||||||
| AFN [40] | |||||||||||||
| BNM [7] | |||||||||||||
| MSTN+DSBN [3] | 81.3 | 91.1 | |||||||||||
| Ours | 95.3 | 87.7 | 80.9 | 56.8 | 93.1 | 84.1 | 81.4 | 78.3 | 90.3 | 82.3 | 87.2 | 52.8 | 80.9 |
| Method | AW | DW | WD | AD | DA | WA | Avg |
|---|---|---|---|---|---|---|---|
| ADDA [32] | 86.2 | 96.2 | 98.4 | 77.8 | 69.5 | 68.9 | 82.9 |
| JAN [21] | 85.4 | 97.4 | 99.8 | 84.7 | 68.6 | 70.0 | 84.3 |
| ETD [14] | 92.1 | 100.0 | 100.0 | 88.0 | 71.0 | 67.8 | 86.2 |
| MCD [28] | 88.6 | 98.5 | 100.0 | 92.2 | 69.5 | 69.7 | 86.5 |
| BNM [3] | 91.5 | 98.5 | 100.0 | 90.3 | 70.9 | 71.6 | 87.1 |
| DMRL [37] | 90.8 | 99.0 | 100.0 | 93.4 | 73.0 | 71.2 | 87.9 |
| SymNets [43] | 90.8 | 98.8 | 100.0 | 93.9 | 74.6 | 72.5 | 88.4 |
| TAT [17] | 92.5 | 99.3 | 100.0 | 93.2 | 73.1 | 72.1 | 88.4 |
| MDD [42] | 94.5 | 98.4 | 100.0 | 93.5 | 74.6 | 72.2 | 88.9 |
| GVB-GD [4] | 94.8 | 98.7 | 100.0 | 95.0 | 73.4 | 73.7 | 89.3 |
| GSP [38] | 92.9 | 98.7 | 99.8 | 94.5 | 75.9 | 74.9 | 89.5 |
| Ours | 94.5 | 98.7 | 100.0 | 92.6 | 76.5 | 75.0 | 89.6 |
| Method | M U | U M | SV M | Avg |
|---|---|---|---|---|
| ADDA [32] | 89.40.2 | 90.10.8 | 76.01.8 | 96.30.4 |
| PixelDA [2] | 95.90.7 | - | - | - |
| DIFA [34] | 92.30.1 | 89.70.5 | 89.72.0 | |
| UNIT [18] | 95.90.3 | 93.60.2 | 90.50.3 | |
| CyCADA [7] | 95.60.2 | 96.50.1 | 90.40.4 | |
| TPN [25] | 92.10.2 | 94.10.1 | 93.00.3 | |
| DM-ADA [39] | 96.70.5 | 94.20.9 | 95.51.1 | |
| MCD [28] | 96.50.3 | 94.10.3 | 96.20.4 | |
| ETD [14] | 96.40.3 | 96.30.1 | 97.90.4 | |
| DMRL [37] | 96.10.2 | 99.00.1 | 96.20.4 | 97.10.3 |
| Ours | 96.6 0.3 | 97.50.1 | 97.20.3 | 97.10.2 |
4.1 Datasets
Office-31 [27] is a classical cross-domain benchmark, including images in 31 classes drawn from 3 distinct domains: Amazon (A), Webcam (W) and DSLR (D).
Office-Home [33] is a challenging benchmark for domain adaptation, which contains 15,500 images in 65 classes drawn from 4 distinct domains: Artistic (Ar), Clip Art (Cl), Product (Pr), and Real-World (Rw).
VisDA-2017 [26] is a large-scale dataset for dataset for 2017 Visual Domain Adaptation Challenge 222http://ai.bu.edu/VisDA-2017/. It contains over 280K images across 12 categories. Following [29], we choose the synthetic domain with 152,397 images as source and the realistic domain with 55,388 images as target.
Digital Datasets contain 4 standard digital datasets: MNIST [10], USPS [9] and Street View House Numbers (SVHN) [23]. All of these datasets provide number images from 0 to 9. We construct four transfer tasks: MNIST to USPS (M U), USPS to MNIST (U M), SVHN to MNIST (SV M) and SYN to MNIST (SY M).
| no mapping | mapping | AW | DW | WD | AD | DA | WA | Avg | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | ✓ | 82.0 | 96.9 | 99.1 | 79.7 | 68.2 | 67.4 | 82.2 | |||
| ✓ | 86.5 | 98.4 | 100.0 | 85.5 | 71.4 | 71.5 | 85.5 | ||||
| ✓ | ✓ | 90.1 | 98.5 | 100.0 | 88.4 | 72.5 | 72.5 | 87.0 | |||
| ✓ | ✓ | ✓ | 92.3 | 98.6 | 100.0 | 90.4 | 76.3 | 74.1 | 88.6 | ||
| ✓ | ✓ | ✓ | 94.5 | 98.7 | 100.0 | 92.6 | 76.5 | 75.0 | 89.6 |
| value | AW | DW | WD | AD | DA | WA | AVG |
|---|---|---|---|---|---|---|---|
| 1 | 93.5 | 98.2 | 99.2 | 93.1 | 75.2 | 74.2 | 88.8 |
| 2 | 92.8 | 98.1 | 99.3 | 93.0 | 75.5 | 75.3 | 88.9 |
| 3 | 93.6 | 98.6 | 99.8 | 92.6 | 75.8 | 75.2 | 89.3 |
| 4 | 94.2 | 99.0 | 100 | 94.2 | 76.3 | 74.8 | 89.8 |
| 5 | 92.7 | 98.4 | 99.6 | 92.4 | 75.3 | 75.0 | 88.9 |
| 6 | 93.8 | 98.8 | 99.7 | 93.8 | 76.2 | 75.2 | 89.6 |
| 7 | 94.1 | 98.5 | 99.8 | 93.4 | 76.0 | 75.4 | 89.5 |
4.2 Implementation details
We follow the standard UDA protocol by training our model on all the labeled source data and unlabeled target data. For Office-Home and Office-31, we use ResNet-50 as our backbone, and we use ResNet 101 to train VisDA-2017 dataset. For the Digital datasets, we employ the same network as [16, 15] and we train the network from scratch. We use a stochastic gradient descent optimizer with the momentum of 0.9, learning rate of 0.001, and weight decay of . For the hyper-parameters of the loss functions, we set , number of pseudo domains . We set the batchsize of 64 for VisDA-2017, Office Home and Office-31, and batchsize of 32 for the digital datasets. We train our model for 80 epochs with 10 warm-up epochs. The entire model is implemented using PyTorch 333The source code is contained in the Supplementary. We will release the source code to the community upon the acceptance of this paper.. To evaluate the performance of DADA, we use various source-only models and state-of-the-art UDA models as our baselines to validate the effectiveness of DADA, such as GSP [38] GVB-GD [4] TSA [16], ect.
4.3 Comparison with the State-of-the-Art models
Office-Home The results of the comparative performance on the dataset Office-Home with ResNet-50 are shown in Table 1. DADA demonstrates particularly strong performance in the domain adaptation task between real-world domain and artificial domain, such as Pr Rw, Cl Rw, Rw Pr. Especially when the real-world domain serves as the target domain, e.g. Cl Rw and Pr Rw, DADA achieves highest or second highest performance. Since the data distribution form the real-world usually has a higher variance than the variance of the artificial data, applying multiple pseudo domains can generalize the classification capability to the pseudo space that in general covers the target representation space. Such a phenomenon makes DADA suitable to be applied in real-world image classification for adapting knowledge from any synthetic/artificial data to related unlabeled real-world data. Overall, DADA has achieved an average performance of 72.0 which outperforms the baselines. Especially, compared to SOTA augmentation methods, such as TSA [16], our domain augmentation method achieves performance improvement of on average.
Office-31 The results on Office-31 with ResNet-50 are presented in Table 3. Compared to the baseline methods, DADA achieves higher performance on tasks D A, W A, as well as the average performance, with the accuracy of , and respectively.
VisDA-2017 The results on VisDA-2017 dataset with ResNet-101 are summarized in Table 2. In VisDa-2017 dataset, the data from the source domain are relatively disparate from the data in the target domain. In some specific categories such as truck, skate board, and knife, DADA achieve an improvement of from to respective, compared to the second-best performing model. Although in some aspects, DADA performs inferior than other models, in general, we can observe form the results that DADA achieves high performance on this large dataset.
Digital datasets The results on Digital dataset are summarized in Table 2. In average, our DADA method also achieves state-of-the-art performance on the Digital dataset. Digital dataset contains small datasets for digital image classification, where the domain gap between the source and target domain is not broad. Thus, the results indicates that DADA can not only be applied on large datasets such as Office-Home and VisDA-2017, but also works on small datasets which can be related to many simple use cases.
4.4 Ablation Study & Discusses
In this ablation study, we aim to analyse the effectiveness of each individual component of DADA, including pseudo-domain augmentation, target labeling from pseudo domains, domain discrepancies losses, self-supervised losses and domain consistency losses. We conduct the ablation studies on the Office-31 dataset with ResNet-50 as our backbone. The corresponding results of ablation studies are shown in Table 5.
Effectiveness of pseudo domains. The first row of Table 5 reflects the result of removing pseudo domain generation, by directly minimizing the source and target domain and the target domain, where we also add pseudo labels technique to enhance the domain adaptation. The second row shows the results of applying pseudo domains (with domain consistency loss) together with the pseudo labels that are generated from the pseudo domains. On average, purely applying multiple pseudo domains results in improvements of , from to .
Effectiveness of pseudo domain separation. In the third row, we include the pseudo domain separation loss according to Eq (3). With this component, the pseudo domains are pushed away from each other during the training phase. Therefore, each pseudo domain forms a specific distribution where we transfer knowledge from the overall pseudo domain representation space to the target domain. From the experiment results, we can observe that with the pseudo domain separation loss, the average accuracy on the target domain improves from to .
Effectiveness of mapping (target to pseudo). Furthermore, we analyze the effect of our proposed pseudo labeling method. Row five represents our proposed DADA method, and row four adopts the same components as DADA but only replaces our proposed pseudo labeling method by directly using the highest prediction on the target domain data as the pseudo labels. The results demonstrate the superiority of our proposed pseudo labeling method as this component itself achieves an average improvement from to .
Comparison with different number of pseudo domains. To test the influence of different numbers of pseudo domains on the performance of DADA, we conduct experiments on Office-31 with the number of pseudo domains from 1 to 7. The corresponding results are shown in Table 6. The results show that the performance of DADA increases with the number of pseudo domains, however, the performance may be saturated when for a large number of pseudo domains, e.g. 4.
Discrepancy between pseudo domains and the target domain. In addition, to test whether the pseudo domains can form similar distributions as the target domain during the training processes, we conduct extra experiments to test the average discrepancy between pseudo domains and the target domains at each training stage (i.e. epochs). We apply the MMD as the measure of the domain discrepancy. The results on Digital datasets are shown in Figure 3. The results show that the MMD between the pseudo domains and the target domains converges fast, and indicate that the adaptation from pseudo domains to the target domain can be achieved in a few epochs.
Efficiency. Careful readers may notice that the main limitation of the DADA is that due to multiple pseudo domains, the training time may be slowed down. However, with an appropriate number of pseudo domains, e.g. 3 or 4, we can balance the tradeoff between accuracy and efficiency. We further discuss the training time problem in the Appendix.

5 Conclusion
In conclusion, in this work, we present the DADA method for unsupervised domain adaptation. DADA method generated multiple pseudo domains which have less discrepancy to the target domain compared to the source domain. To conduct domain adaptation, we minimize the discrepancy between the target domains and the pseudo domains. Meanwhile, we also design a novel pseudo labeling method assigning pseudo labels based on an average prediction of the pseudo domains. The extensive experiments were conducted and the results show that our proposed DADA method can achieve state-of-the-art performance in the domain adaptation. The ablation studies also demonstrate the effectiveness of each component of DADA. For future works, one of the main directions is to design better regularization methods that can further restrict the representation space of the pseudo domain for better adaptation.
References
- [1] David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin Raffel. Mixmatch: A holistic approach to semi-supervised learning. arXiv preprint arXiv:1905.02249, 2019.
- [2] Konstantinos Bousmalis, Nathan Silberman, David Dohan, Dumitru Erhan, and Dilip Krishnan. Unsupervised pixel-level domain adaptation with generative adversarial networks. In CVPR, pages 95–104, 2017.
- [3] Shuhao Cui, Shuhui Wang and] Junbao Zhuo, Liang Li, Qingming Huang, and Qi Tian. Towards discriminability and diversity: Batch nuclear-norm maximization under label insufficient situations. In CVPR, pages 3940–3949, 2020.
- [4] Shuhao Cui, Shuhui Wang, Junbao Zhuo, Chi Su, Qingming Huang, and Qi Tian. Gradually vanishing bridge for adversarial domain adaptation. In CVPR, June 2020.
- [5] Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks. The journal of machine learning research, 17(1):2096–2030, 2016.
- [6] Xiang Gu, Jian Sun, and Zongben Xu. Spherical space domain adaptation with robust pseudo-label loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9101–9110, 2020.
- [7] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell. Cycada: Cycle-consistent adversarial domain adaptation. In ICML, pages 1994–2003, 2018.
- [8] Sheng-Wei Huang, Che-Tsung Lin, Shu-Ping Chen, Yen-Yi Wu, Po-Hao Hsu, and Shang-Hong Lai. Auggan: Cross domain adaptation with gan-based data augmentation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 718–731, 2018.
- [9] Jonathan. J. Hull. A database for handwritten text recognition research. TPAMI, 16(5):550–554, 1994.
- [10] Yann Lecun, Leon Bottou, Y. Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proc. IEEE, 86:2278 – 2324, 1998.
- [11] Chen-Yu Lee, Tanmay Batra, Mohammad Haris Baig, and Daniel Ulbricht. Sliced wasserstein discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10285–10295, 2019.
- [12] Guangrui Li, Guoliang Kang, Yi Zhu, Yunchao Wei, and Yi Yang. Domain consensus clustering for universal domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9757–9766, 2021.
- [13] Kai Li, Chang Liu, Handong Zhao, Yulun Zhang, and Yun Fu. Ecacl: A holistic framework for semi-supervised domain adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8578–8587, 2021.
- [14] Mengxue Li, Yi-Ming Zhai, You-Wei Luo, Peng-Fei Ge, and Chuan-Xian Ren. Enhanced transport distance for unsupervised domain adaptation. In CVPR, June 2020.
- [15] Shuang Li, Chi Harold Liu, Binhui Xie, Limin Su, Zhengming Ding, and Gao Huang. Joint adversarial domain adaptation. In Proceedings of the 27th ACM International Conference on Multimedia, pages 729–737, 2019.
- [16] Shuang Li, Mixue Xie, Kaixiong Gong, Chi Harold Liu, Yulin Wang, and Wei Li. Transferable semantic augmentation for domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11516–11525, 2021.
- [17] Hong Liu, Mingsheng Long, Jianmin Wang, and Michael Jordan. Transferable adversarial training: A general approach to adapting deep classifiers. In ICML, pages 4013–4022, 2019.
- [18] Ming-Yu Liu, Thomas Breuel, and Jan Kautz. Unsupervised image-to-image translation networks. In NeurIPS, page 700–708, 2017.
- [19] Mingsheng Long, Yue Cao, Jianmin Wang, and Michael Jordan. Learning transferable features with deep adaptation networks. In International conference on machine learning, pages 97–105. PMLR, 2015.
- [20] Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I Jordan. Unsupervised domain adaptation with residual transfer networks. arXiv preprint arXiv:1602.04433, 2016.
- [21] Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I Jordan. Deep transfer learning with joint adaptation networks. In ICML, pages 2208–2217. ACM, 2017.
- [22] Jaemin Na, Heechul Jung, Hyung Jin Chang, and Wonjun Hwang. Fixbi: Bridging domain spaces for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1094–1103, 2021.
- [23] Yuval Netzer, Tiejie Wang, Adam Coates, Alessandro Bissacco, Baolin Wu, and Andrew Y. Ng. Reading digits in natural images with unsupervised feature learning. In NeurIPS, 2011.
- [24] Sinno Jialin Pan and Qiang Yang. A survey on transfer learning. IEEE Transactions on knowledge and data engineering, 22(10):1345–1359, 2009.
- [25] Yingwei Pan, Ting Yao, Yehao Li, Yu Wang, Chong-Wah Ngo, and Tao Mei. Transferrable prototypical networks for unsupervised domain adaptation. In CVPR, June 2019.
- [26] Xingchao Peng, Ben Usman, Neela Kaushik, Judy Hoffman, Dequan Wang, and Kate Saenko. Visda: The visual domain adaptation challenge. arXiv preprint arXiv:1710.06924, 2017.
- [27] Kate Saenko, Brian Kulis, Mario Fritz, and Trevor Darrell. Adapting visual category models to new domains. In European conference on computer vision, pages 213–226. Springer, 2010.
- [28] Kuniaki Saito, Kohei Watanabe, Yoshitaka Ushiku, and Tatsuya Harada. Maximum classifier discrepancy for unsupervised domain adaptation. In CVPR, pages 3723–3732, 2018.
- [29] Kuniaki Saito, Kohei Watanabe, Yoshitaka Ushiku, and Tatsuya Harada. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3723–3732, 2018.
- [30] Jian Shen, Yanru Qu, Weinan Zhang, and Yong Yu. Wasserstein distance guided representation learning for domain adaptation. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- [31] Yang Shu, Zhangjie Cao, Chenyu Wang, Jianmin Wang, and Mingsheng Long. Open domain generalization with domain-augmented meta-learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9624–9633, 2021.
- [32] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In CVPR, volume 1, page 4, 2017.
- [33] Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty, and Sethuraman Panchanathan. Deep hashing network for unsupervised domain adaptation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5018–5027, 2017.
- [34] Riccardo Volpi, Pietro Morerio, Silvio Savarese, and Vittorio Murino. Adversarial feature augmentation for unsupervised domain adaptation. In CVPR, pages 5495–5504, 2017.
- [35] Qian Wang and Toby Breckon. Unsupervised domain adaptation via structured prediction based selective pseudo-labeling. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 6243–6250, 2020.
- [36] Garrett Wilson and Diane J Cook. A survey of unsupervised deep domain adaptation. ACM Transactions on Intelligent Systems and Technology (TIST), 11(5):1–46, 2020.
- [37] Yuan Wu, Diana Inkpen, and Ahmed El-Roby. Dual mixup regularized learning for adversarial domain adaptation. In ECCV, volume 12374, pages 540–555, 2020.
- [38] Haifeng Xia and Zhengming Ding. Structure preserving generative cross-domain learning. In CVPR, June 2020.
- [39] Minghao Xu, Jian Zhang, Bingbing Ni, Teng Li, Chengjie Wang, Qi Tian, and Wenjun Zhang. Adversarial domain adaptation with domain mixup. In AAAI, pages 6502–6509, 2020.
- [40] Qinwei Xu, Ruipeng Zhang, Ya Zhang, Yanfeng Wang, and Qi Tian. A fourier-based framework for domain generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14383–14392, 2021.
- [41] Hongliang Yan, Yukang Ding, Peihua Li, Qilong Wang, Yong Xu, and Wangmeng Zuo. Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2272–2281, 2017.
- [42] Yuchen Zhang, Tianle Liu, Mingsheng Long, and Michael Jordan. Bridging theory and algorithm for domain adaptation. In ICML, pages 7404–7413, 2019.
- [43] Yabin Zhang, Hui Tang, Kui Jia, and Mingkui Tan. Domain-symmetric networks for adversarial domain adaptation. In CVPR, pages 5031–5040, 2019.
- [44] Kaiyang Zhou, Yongxin Yang, Timothy Hospedales, and Tao Xiang. Deep domain-adversarial image generation for domain generalisation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 13025–13032, 2020.
- [45] Fuzhen Zhuang, Zhiyuan Qi, Keyu Duan, Dongbo Xi, Yongchun Zhu, Hengshu Zhu, Hui Xiong, and Qing He. A comprehensive survey on transfer learning. Proceedings of the IEEE, 109(1):43–76, 2020.
Appendix A Visualization
We visualize the pseudo domains through a reverse mapping network which maps the latent representations to the data space, similar to the reverse mapping algorithm described in TSA [16]. Taking the domain adaptation task SVHN MNIST, our algorithm generates images in the pixel-level space corresponding to the pseudo domain features (i.e. SVHN pseudo domain ). To utilize the reverse mapping algorithm in DADA, we firstly train Generative Adversarial Networks (GANs) with the data from the target domain (i.e. MINST), where the generator of the GANs learns to generate fake images based on the noise representation , where denotes the random noise.
The goal of our reverse mapping algorithm is to find the desirable optimal noise , such that
| (10) |
where denotes our backbone model (i.e. ResNet) that extracts features from the input images and denotes the pseudo domain generator with a pre-defined . Here, we randomly select a suitable such that for the trained DADA model, the domain gap between and the target domain is relatively small. denotes the source data. Then, we visualize the pseudo domain representation of by generating the data via . The corresponding results are shown in Figure 2. In general, the visualization shows that the pseudo domain can reconstruct meaningful data through its representations, which also reflects the suitability of the pseudo domain representations.
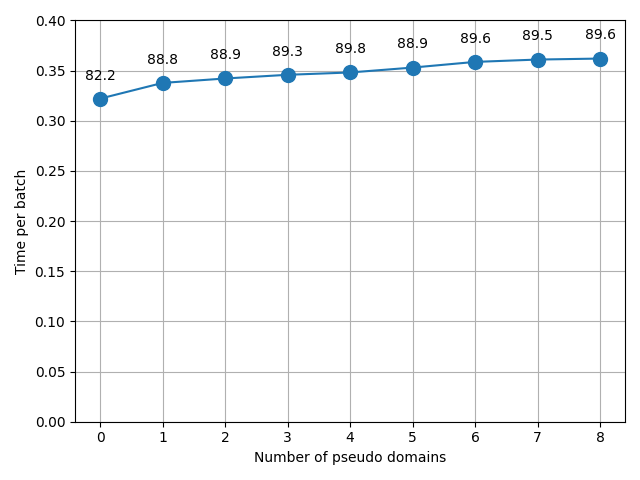
Appendix B Efficiency Analysis
Careful readers may notice that the efficiency of applying multiple pseudo domains might be a major limitation of the DADA, as the training time should be slowed down with the increase of pseudo domains. To analyze the consumption of applying multiple pseudo domains, we conduct experiments on Office-31 dataset with the number of pseudo domains ranging from zero to eight. Zero pseudo domain represents the case when the DADA is not used, but we use the MMD to minimize the source and target domain gap instead.
The corresponding results are shown in Figure 1. The y-axis shows the time consumption per batch in seconds, where we set the batchsize of 128. The x-axis represents the number of pseudo domains. For each setting with different number of pseudo domains, we annotate the corresponding averaged accuracy for the DADA on Office-31. In general, we can infer that the pseudo domain indeed takes up a relatively small portion of the whole training time in a batch. Even for the eight pseudo domains setting, the portion of the time to generate and train pseudo domains only takes up of the entire batch time. Furthermore, applying four pseudo domains achieves the highest accuracy in this domain adaptation task, where DADA only takes additional computation time compared to the MMD model.
