Domain Adaptive Object Detection via Feature Separation and Alignment
Abstract
Recently, adversarial-based domain adaptive object detection (DAOD) methods have been developed rapidly. However, there are two issues that need to be resolved urgently. Firstly, numerous methods reduce the distributional shifts only by aligning all the feature between the source and target domain, while ignoring the private information of each domain. Secondly, DAOD should consider the feature alignment on object existing regions in images. But redundancy of the region proposals and background noise could reduce the domain transferability. Therefore, we establish a Feature Separation and Alignment Network (FSANet) which consists of a gray-scale feature separation (GSFS) module, a local-global feature alignment (LGFA) module and a region-instance-level alignment (RILA) module. The GSFS module decomposes the distractive/shared information which is useless/useful for detection by a dual-stream framework, to focus on intrinsic feature of objects and resolve the first issue. Then, LGFA and RILA modules reduce the distributional shifts of the multi-level features. Notably, scale-space filtering is exploited to implement adaptive searching for regions to be aligned, and instance-level features in each region are refined to reduce redundancy and noise mentioned in the second issue. Various experiments on multiple benchmark datasets prove that our FSANet achieves better performance on the target domain detection and surpasses the state-of-the-art methods.
1 Introduction
Object detection, as a hot topic of computer vision, is to find out the objects of interest on the image and to determine their locations and categories. In the era of deep learning [21], many deep convolutional neural network (DNN)-based methods [10, 31, 28, 29, 30, 25] have been proposed to make the detection models with excellent performance in natural image benchmark datasets [8, 24]. While in reality, there is an obvious distributional gap between the training set (source domain) and the testing set (target domain), which may lead to a significant reduction in the generalization ability of models in target domain.
Therefore, many unsupervised domain adaptive object detection (DAOD) methods [5, 32, 40, 20, 3, 4] are proposed to solve the problem of domain distributional shifts. Most unsupervised DAOD methods are nested adversarial training module within advanced object detection frameworks, such as Faster R-CNN [31]. By minimizing the domain shifts of multi-level feature maps, domain adaption is achieved to improve the detection accuracy in the target domain. Numerous DAOD methods are proposed and most of them focus on image-level [5], instance-level [5, 4], pixel-level [20, 4], region-level [40] and strong-local & weak-global-level [32] alignments. Whereas, the existing multi-level alignment modules may cause three issues: Firstly, they only focus on the mapping of the source and target domain, and less consider other distractive information that is unnecessary to be aligned, \eg, background information. Secondly, we should concern over the regions where the object needs to be aligned on the image, and ignore background noise that is useless for detection. However, the current region searching algorithm [40] in region-level alignment restrict the category numbers of candidate region. Since there is no label for the target domain, we cannot exactly determine the object region numbers. Lastly, for the existing instance alignment modules, they are all based on ROI-Pooling [31] feature alignment. While the training of region proposal network (RPN) [31] mainly depends on the labels of the source domain, and there may be abundant redundancy or noise in region of interests (ROIs) on the target domain. Resultly, when the instance is aligned, there will be an extra alignment of background features or multiple alignments of instance-level features for some certain objects.
In order to solve the above mentioned issues, we propose a DAOD method based on the architecture of Faster R-CNN [31], called feature separation and alignment network (FSANet). The network consists of a gray-scale feature separation (GSFS) module, a local-global feature alignment module (LGFA) and a region-instance-level alignment (RILA) module. The feature separation module separates the distractive information containing the features that do not need to be aligned and the shared information related to the object detection through the difference loss, so that the feature alignment module can concentrate on the object information. LGFA and RILA are domain adaptation components, which reduce the distributional gaps of the multi-level features. Our contributions can be divided into two-fold:
(1) The dual-stream network [2, 38] can extract multi-model information of different domain images. Inspired by this, we design a dual-stream auto-encoder network for the GSFS. The distractive information of the image is separated by a private encoder, and the object detection backbone network acts as a shared information extractor to obtain useful features for detection. When aligning high-dimensional features, we use shared features instead of the whole image features to reduce the impact of distractive information that is not related to detection, so as to improve domain adaptability. Particularly, in order to reduce the impact of image color differences and the difficulty of reconstruction, we use the gray-scale image to extract the distractive features. This operation can make the private encoder focus on detection-related/irrelevant features of the objects rather than the image color, and while simplifying the reconstruction task.
(2) We design the RAIL module, which can effectively solve the negative effects caused by the redundancy of the region proposals and background noise, and determine the category number for candidate region adaptively. Initially, by exploiting Scale-Space Filtering algorithm (SSF) [37], we cluster the center coordinate of the bounding boxes predicted by RPN, to implement an adaptive region selection. Thus the traditional clustering region number uncertainty problem is well solved. Then, after obtaining the cluster centers and scale by SSF, the outliers of ROIs can be found. We believe that these abnormal ROIs have a high probability of containing background information. So we exclude them before region grouping, thereby reducing the effect of ROIs noise. Finally, through global pooling layer, the instance-level features of each group (\ie, candidate region) are refined and instance alignment is performed to figure out the problem of ROIs redundancy.
In summary, the adaptability and transferability of adversarial-based adaptive detection methods are enhanced by separating the shared and distractive information of the source/target domain and aligning the region-instance-level features. Extensive experiments illustrate that the proposed FSANet has reached an outstanding level of cross-domain detection performance on multiple benchmark datasets. For example, the FSANet achieves mAP for transfer task on PASCAL Clipart1k, which surpassing the state-of-the-art (SOTA) adversarial-based adaptive methods [5, 40, 32, 20, 4, 35, 17].
2 Related Work
Object Detection.
Nowadays, with the rapid development of deep neural convolutional networks (DNN), lots of methods have been proposed to solve the object detection task. They can be divided into two-stage object detection methods based on region proposals and end-to-end one-stage methods.
The pioneering work of the two-stage methods is R-CNN [11], which first utilizes a selective search method [36] to extract region proposals from images, and then trains a network to classify each ROIs. SPP-Net [14] and Fast R-CNN [10] exploited DNNs to propose region proposals and significantly improved detection accuracy and speed. As DNNs were extended to share convolutional feature maps among all ROIs [31] , the end-to-end two-stage methods (\eg, Faster R-CNN [31] and RetinaNet [23]) were proposed.
On the other hand, typical methods of one-stage object detection algorithms are YOLO [28, 29, 30] and SSD [25], which extract the feature maps from the original image based on the convolutional network, and then directly perform object classification and bounding box regression.
Domain Adaptive Object Detection. The existing unsupervised DAOD methods can be divided into three categories [22]: adversarial-based, reconstruction-based and hybrid adaptive methods.
For the adversarial-based adaptive methods,
Chen et al. [5] first applied the unsupervised domain adaptive method to object detection. By combining with the gradient reversal layer and domain classifier, an adversarial-based method [9] is proposed to solve the domain shift in the real scene. At the same time, it is pointed out that the core issue of unsupervised DAOD is to solve the domain gaps in image and instance level.
For example, Zhu et al. [40] indicated that the object detection needs to concern with the object rather than the entire image features, and then a regional-level domain adaptive network based on GAN [12] is established to solve the region proposal redundancy problem.
Saito et al. [32] proposed a local domain classifier network based on FCN [26] to achieve the alignment of low-level features. For the reconstruction-based adaptive methods,
Arruda et al. [1] firstly generated pseudo samples similar to the target domain from the source samples by CycleGAN [39], and added them to the training set to improve detection accuracy.
The hybrid adaptive methods aim at combining the above two categories to improve the model performance.
In order to realize the adaptative object detection from natural images to artistic images, Inoue et al. [18] initially trained a detection model from the source domain samples, then fine-tuned the model on the pseudo samples of source domain, and finally implemented the weak training on the target domain samples.
Based on pseudo samples, Kim et al. [20] proposed an adaptive method for domain diversification and multi-domain invariant representation.
Chen et al. [4] added the attention mechanism to the network based on [32]. Although the above methods have achieved good performance, they do not concern for separating the distractive information and solving the region proposals redundancy and background noise. So in our paper, we propose a novel DAOD method called FSANet to further figure out the above mentioned issues.
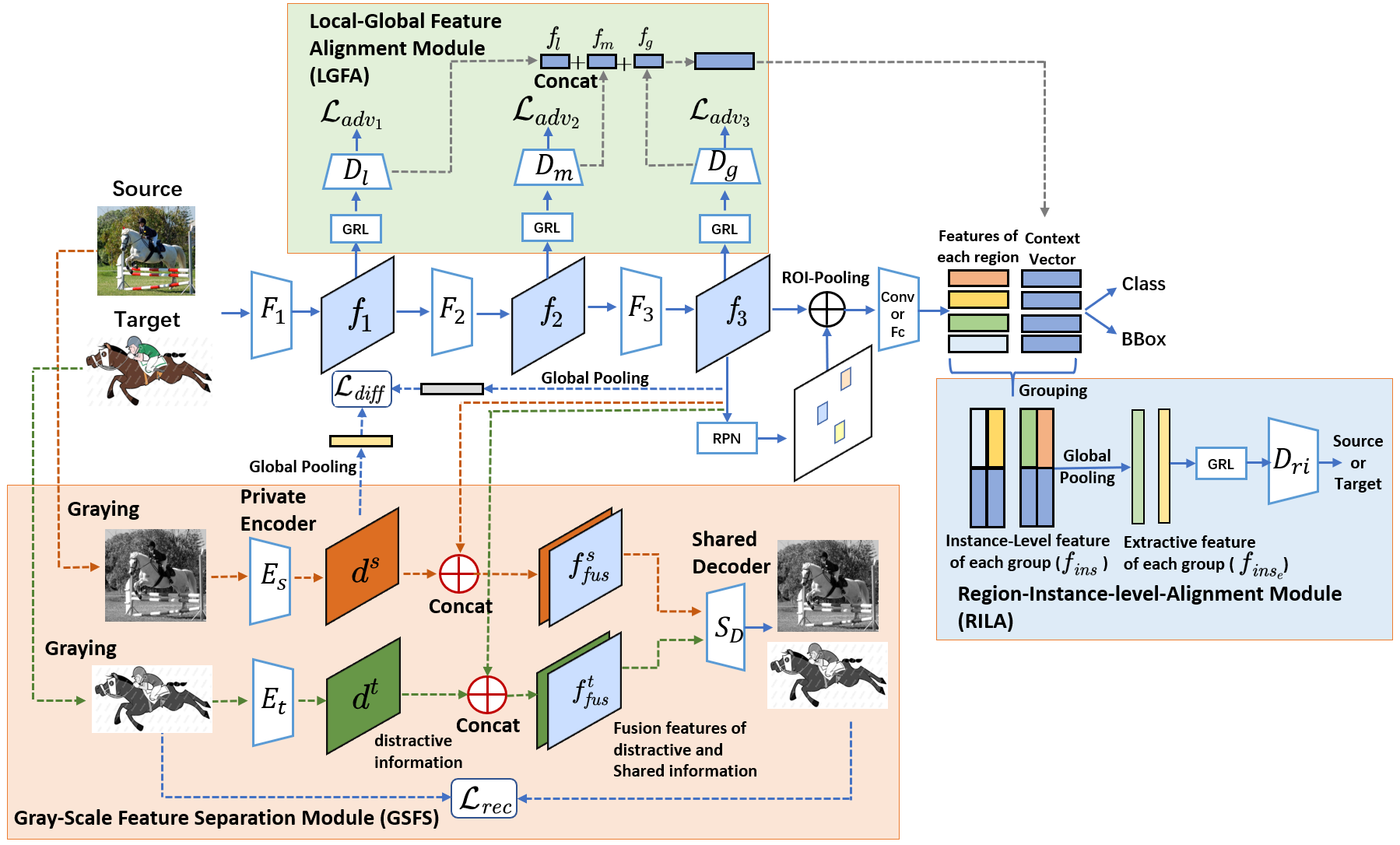
3 Method
In this section, we introduce the details of FSANet. The framework is illustrate in Figure 1, which consists of four parts, namely the object detection module, the LGFA module, the RILA module and the GSFS module. Initially, the paired source/target domain RGB images are input to the detection network, and the detection loss is calculated with the label of the source domain images, and the instance-level features alignment is realized by the RILA module. For the multi-level features extracted by the backbone network , they are input into the LGFA module to complete the multi-level features alignment. In addition, the gray-scale paired images are input into the GSFS module, and the useful/useless features for detection are separated through a specific loss. Here, we use Faster R-CNN [31] as the object detection backbone architecture, and the LGFA module follows the design of [32, 4]. Especially, we focus on the GSFS module and the RILA module.
For the notations in this paper, the source domain dataset with labeled samples are denoted by , where is the input source image, is the coordinates of the bounding box, is the object category label, and is the number of samples in the source domain dataset. Meanwhile, unlabeled target domain dataset is represented as , where is the number of samples in the target dataset. Our task is to transfer the model learned from to .
3.1 Gray-Scale Feature Separation Module
As is known to all, domain adversarial loss can reduce the inconsistency between the features distribution of the two domains. However, there will still be some distractive information that cannot be reduced, \eg, the background distractive information of the source/target domain. So we propose a GSFS module based on a dual-stream network, and employ it to separate the distractive/shared information which is useless/useful for object detection with the high-level features through the private encoder and , the shared decoder and the features extraction module , as shown in Figure 1. Firstly, extracts high-level features related to object detection via the detection loss. Then domain adversarial loss of LGFA module makes the features of the source/target domain aligned. As a result, is the shared high-level features useful for detection. For the GSFS module, we define the different loss to limit the similarity of and :
| (1) |
where is the squared Frobenius norm , is the global pooling layer, , , , denote distractive information output by private encoder / and the shared information of source/target domain for th image, respectively.
In addition, considering that simple restrictions will make and meaningless, and the information related to objects cannot include all the information of the input image, we use the fusion features , as the input of the shared decoder to reconstruct the input image, where denotes the concatenation of two feature maps in the channel dimension. Through the restriction of image reconstruction, the separated features can possess almost all the information of source/target images. So that the private encoder extracts the distractive information irrelevant to detection in the image. Notably, the private encoder inputs two-domain images in gray-scale, and extract the distractive information which is irrelevant to the color of the two-domain images. If the input is an RGB image, it will not only increase the difficulty of reconstruction, but also make the private encoder disturb by the color difference of the image, while ignoring other distractive information on the two data domains.
Finally, the reconstruction loss of the gray-scale images is defined as:
| (2) |
where is the -norm, , , and are the th gray-scale input images and reconstructed images by the shared decoder in source/target domain.
3.2 Region-Instance-Level Alignment
The RILA module consists of a grouping component and a context-aware RILA component. Please refer to supplemental material to see illustration and more details.
Grouping. Some alignment module [5, 16, 4] implement the instance-level feature alignment of all region proposals. However, the absence of labels on the target domain leads to the training of RPN mainly guided by the labeled data on the source domain [31]. Therefore, we cannot ensure that the region proposals on the target domain contain the objects, where may contain a lot of background noise.
Meanwhile, objects are generally detected by multiple region proposals, which means that some region proposals are redundant.
We should perform feature alignments for the instance-level features in the region proposals where the object is most likely to exist, instead of aligning all features.
As we all know, the locations of region proposals where contain the same object at multiple scales should be similar if they are predicted by a reliable RPN.
A natural idea is to cluster the similar region proposal coordinates to reduce redundancy for ROIs and eliminate the background noises by excluding outliers.
In particular, we use RPN to get the predicted bounding box of the region proposals, where is the center coordinate of the th predicted bounding box, is its width, and is its height. Then we plan to exploit the scale-space filtering (SSF) [37] algorithm to cluster the center coordinates to adaptively obtain cluster centers, which means that ROIs can be divided into categories, and thereby, the instance-level features can be indirectly divided into categories. As a result, we only need to align the instance-level features in each category.
Adaptive candidate region searching.
SSF is a clustering method that adaptive to the category numbers without a manual setting. It is very suitable for the grouping module due to the unknown object numbers in the target domain. Therefore, inspired by [37], we decided to use SSF to improve the traditional K-means algorithm to accomplish the clustering of bounding boxes.
By regarding each sample as a “light point”, the SSF algorithm formulates the clustering issue as finding the “lighting blob center” under different blur scales, \ie, different scale-space maps. The specific workflow can be divided into the following steps:
(1) Clustering center iteration. For a given dataset (in this paper, this is a set of center coordinates of predicted bounding boxes by RPN), we define as the scale-space map for under the blur scale . It can be calculated by , where means the scatter image of data samples in , is the Gaussian blur kernel with the blur scale , and represents the convolution operator. So the set of clustering centers under different scales is obtained by .
In iteration steps, is firstly updated, then after has converged, a larger is obtained by ( is a hyperparameter and ), and are iterated again until all samples belong to one category. More details can be seen in the supplemental material.
(2) Adaptive category number selection. With the completion of the above iterations, we have obtained a serious of clustering center, \ie, . We hope to select the clustering model that best fit for the data distribution. So the “lifetime” [37] is used as a measure of the stability for category number, which is calculated by
| (3) |
where . Notably, the interval with the longest “lifetime” represent the relative appropriate scales. Finally, the most appropriate clustering model equals to median of , and the adaptive category number equals to the element number of .
(3) Remove outliers.
After obtaining the optimal , we can use the model to group the centers of the predicted bounding box of all region proposals.
For each bounding box center , if , we consider to be an outlier, and its corresponding region proposal probably contains the background noise, which should be excluded from grouping.
Through this method, we can restrict certain outlier region proposals from participating in instance-level alignment, and find the instance features that need to be aligned in the image more robustly.
Context-Aware Region-Instance-Level Alignment.
After clustering the proposals, we need to refine the instance-level features of each category for instance alignment.
For simplicity, we reshape the features of instances belonging to the same category into the same size and then concatenate them into a feature map as the input of the domain classifier.
But the effect of redundant or noisy region proposals is not fundamentally solved.
Therefore, we use the global pooling layer to refine the instance-level features in the same category.
Let denote the instance-level features of the th category obtained by SSF, where is the number of the th category , is the dimension of the instance-level features.
Through the global pooling layer, we can get the feature of the th category , which can fully reflect the instance-level features of the category and thereby reduce the influence of redundancy and noise.
Then, we use the context fusion instance-level features [32] as the input of bounding box regression and classification prediction in the instance alignment and object detection module. We acquire three different levels of context vectors from the domain classifier , and get the instance-level features of each region proposals based on ROI-Pooling [13]. Through feature concatenation, the fused context instance-level features is input into the global pooling layer and obtain refined feature of each category , as shown in Figure 1.
Subsequently, we input the global pooling instance-level features into the domain classifier , and output the domain labels to achieve regional instance alignment. For the loss function of this module, we use Focal Loss [23, 32] as follows:
| (4) |
where is the number of adaptive categories for th source sample, is the instance-level features of the th region of the source domain after global pooling, and is the parameter of Focal Loss.
In short, this module can solve the redundancy of the region proposals and the influence of the background noise, so that the instance alignment is focused on the features where the object is existing.
3.3 Traing Loss
The loss of object detection includes the classification loss on the source domain and the regression loss of the bounding boxes [31]. For the LGFA module, we use the Local Feature Masks and IWAT-I frameworks mentioned in [4], and the corresponding adversarial loss is in Figure 1. By combining all modules mentioned above, the overall objective function of the model is
| (5) |
where denote the domain classifier, object detection framework, private encoder and shared decoder, respectively. and are turning parameters. The sign of gradients for the last item is flipped by a gradient reversal layer proposed by [9].
4 Experiments
In this section, we show the effectiveness of FSANet in adaptive object detection experiments on three benchmark domain shifts datasets including real artistic, normal foggy and synthetic real, \ie, PASCAL [8] to Clipart1k [18], Cityscapes [6] to Foggy-Cityscapes [33] and Sim10k [19] to Cityscapes.
| Methods | aero | bike | bird | boat | bot | bus | car | cat | chair | cow | table | dog | horse | mbike | persn | plant | sheep | sofa | train | tv | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source Only | 35.6 | 52.5 | 24.3 | 23.0 | 20.0 | 43.9 | 32.8 | 10.7 | 30.6 | 11.7 | 13.8 | 6.0 | 36.8 | 45.9 | 48.7 | 41.9 | 16.5 | 7.3 | 22.9 | 32.0 | 27.8 |
| SWDA [32] | 26.2 | 48.5 | 32.6 | 33.7 | 38.5 | 54.3 | 37.1 | 18.6 | 34.8 | 58.3 | 17.0 | 12.5 | 33.8 | 65.5 | 61.6 | 52.0 | 9.3 | 24.9 | 54.1 | 49.1 | 38.1 |
| HTCN [4] | 33.6 | 58.9 | 34.0 | 23.4 | 45.6 | 57.0 | 39.8 | 12.0 | 39.7 | 51.3 | 21.1 | 20.1 | 39.1 | 72.8 | 63.0 | 43.1 | 19.3 | 30.1 | 50.2 | 51.8 | 40.3 |
| DDMRL [20] | 25.8 | 63.2 | 24.5 | 42.4 | 47.9 | 43.1 | 37.5 | 9.1 | 47.0 | 46.7 | 26.8 | 24.9 | 48.1 | 78.7 | 63.0 | 45.0 | 21.3 | 36.1 | 52.3 | 53.4 | 41.8 |
| ATF [17] | 41.9 | 67.0 | 27.4 | 36.4 | 41.0 | 48.5 | 42.0 | 13.1 | 39.2 | 75.1 | 33.4 | 7.9 | 41.2 | 56.2 | 61.4 | 50.6 | 42.0 | 25.0 | 53.1 | 39.1 | 42.1 |
| FSANet | 31.0 | 63.7 | 34.8 | 29.4 | 43.0 | 70.7 | 40.8 | 18.7 | 39.6 | 57.4 | 22.2 | 27.0 | 33.3 | 85.6 | 63.3 | 45.7 | 21.9 | 24.7 | 56.7 | 44.5 | 42.7 |
4.1 Datasets
PASCAL Clipart1k. We conduct domain adaptive experiments from real images to artistic images to show that FSANet is effective in dissimilar domains, where PASCAL VOC dataset [8] and Clipart1k [18] are set as the real source domain and the target artistic domain, respectively. The PASCAL dataset contains 20 categories of images and their bounding boxes. In this experiment, the training and validation splits of PASCAL VOC 2007 and 2012 are used for training, resulting in about 15K images. Clipart1k has a total of 1K images, which contains the same class as PASCAL. All images in it are employed for training (w/o labels) and testing.
Cityscape Foggy-Cityscapes. For experiments in similar domains, we use Cityscapes and Foggy-Cityscapes as the source and target domain dataset, respectively.
The Cityscapes [6] dataset contains street scenes in different cities under normal weather conditions captured by a vehicle-mounted camera. There are 2975 images in the training set and 500 images in the test set. The label data are acquired by [5]. In this experiment, we employed the training set of Cityscapes for training. Foggy-Cityscapes [33] is obtained by adding fog noise to the Cityscapes dataset, and its label is the same as Cityscapes.
We set the training set of Foggy-Cityscapes for training and the test set for calculating average accuracy.
Sim10k Cityscapes. In the experiments from synthetic images to real images, we conduct the experiment for Sim10k Cityscapes. Sim10k [19] is acquired in a game scene of a computer game Grand Theft Auto V. It has 10k computer-synthesized driving scene images. According to the protocol of [5], we only evaluated detection accuracy on cars. All images of Sim10k are set for training.
4.2 Implementation Details
In all experiments, the object detection model follows the settings of [32, 40, 4], using Faster R-CNN [31] with ROI-alignment [13], where the shorter side of the images equal to 600 and the hyper-parameters in the object detection are set based on the setting of [31]. For different dataset, the backbone network utilize VGG-16 [34] or ResNet-101 [15] with the parameter initialization weights following the pre-trained on ImageNet [7]. A stochastic gradient descent training model with a momentum of 0.9 is used, and the learning rate for the first 50K iterations is set to 0.001 and then decays to 0.0001. In each iteration, we input a pair of source and target domain images. After 70K iterations, we calculate the mean average precision (mAP) where the IoU threshold is 0.5. We set in Eq. (4) and in Eq. (5) in all experiments. is set to 1 for PASCAL Clipart1k and Cityscapes Foggy-Cityscapes while set to 0.1 for Sim10k Cityscapes. Our experiments are implemented by the Pytorch [27].
4.3 Performance Comparison
We compare our FASNet with various SOTA DAOD methods, including Domain adaptive Faster-RCNN (DA-Faster) [5], Selective Cross-Domain Alignment (SCDA ) [40], Strong-Weak Distribution Alignment (SWDA) [32], Domain Diversification and Multi-domain-invariant Representation Learning (DDMRL) [20], Hierarchical Transferability Calibration Network (HTCN) [4], Prior-based Domain Adaptive Object Detection (PBDA [35]) and Asymmetric Tri-way Faster-RCNN (ATF) [17]. We cite the quantitative results in their original papers for comparison.
Results on real artistic. The performance of FASNet in the target domain is significantly better than all comparison methods, as displayed in Table 1. Compared with SOTAs, mAP is improved by (from to ), which fully illustrates that the proposed method can improve the transferability for real artistic.
Results on normal foggy. According to Table 2, FASNet achieves the best performance and approaches the upper bound of the transfer task on Cityscape Foggy-Cityscapes.
Results on synthetic real. As shown in Table 3, Our FSANet exceeds all comparison methods in the adaptive task on Sim10k Cityscape, which further demonstrates that our method has better transferability and adaptivity.
| Method | persn | rider | car | truck | bus | train | mbike | bcycle | mAP |
|---|---|---|---|---|---|---|---|---|---|
| Source Only | 24.1 | 33.1 | 34.3 | 4.1 | 22.3 | 3.0 | 15.3 | 26.5 | 20.3 |
| DA-Faster [5] | 25.0 | 31.0 | 40.5 | 22.1 | 35.3 | 20.2 | 20.0 | 27.1 | 27.6 |
| SCDA [40] | 33.5 | 38.0 | 48.5 | 26.5 | 39.0 | 23.3 | 28.0 | 33.6 | 33.8 |
| SWDA [32] | 29.9 | 42.3 | 43.5 | 24.5 | 36.2 | 32.6 | 30.0 | 35.3 | 34.3 |
| DDMRL [20] | 30.8 | 40.5 | 44.3 | 27.2 | 38.4 | 34.5 | 28.4 | 32.2 | 34.6 |
| ATF [17] | 34.6 | 47.0 | 50.0 | 23.7 | 43.3 | 38.7 | 33.4 | 38.8 | 38.7 |
| PBDA [35] | 36.4 | 47.3 | 51.7 | 22.8 | 47.6 | 34.1 | 36.0 | 38.7 | 39.3 |
| HTCN [4] | 33.2 | 47.5 | 47.9 | 31.6 | 47.4 | 40.9 | 32.3 | 37.1 | 39.8 |
| FSANet | 33.5 | 47.6 | 45.8 | 32.0 | 50.1 | 37.7 | 35.7 | 37.7 | 40.0 |
| Oracle | 33.2 | 45.9 | 49.7 | 35.6 | 50.0 | 37.4 | 34.7 | 36.2 | 40.3 |
| Method | AP on car | Method | AP on car |
|---|---|---|---|
| Source Only | 34.6 | DA-Faster [5] | 38.9 |
| SWDA [32] | 40.1 | HTCN [4] | 42.5 |
| ATF [17] | 42.8 | SCDA [40] | 43.0 |
| FSANet | 43.2 |







| Method | aero | bike | bird | boat | bot | bus | car | cat | chair | cow | table | dog | horse | mbike | persn | plant | sheep | sofa | train | tv | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source Only | 35.6 | 52.5 | 24.3 | 23.0 | 20.0 | 43.9 | 32.8 | 10.7 | 30.6 | 11.7 | 13.8 | 6.0 | 36.8 | 45.9 | 48.7 | 41.9 | 16.5 | 7.3 | 22.9 | 32.0 | 27.8 |
| Only LGFA | 25.1 | 45.5 | 26.1 | 26.3 | 37.8 | 48.7 | 39.5 | 13.8 | 34.3 | 43.1 | 22.4 | 11.2 | 36.5 | 62.4 | 57.1 | 50.4 | 16.0 | 26.4 | 48.9 | 42.3 | 35.7 |
| FSANet w/o CSFS | 33.6 | 60.9 | 33.5 | 30.9 | 43.7 | 56.3 | 39.0 | 20.7 | 35.5 | 58.2 | 13.7 | 22.4 | 35.6 | 81.2 | 60.8 | 48.0 | 28.2 | 20.2 | 51.8 | 41.9 | 40.8 |
| FSANet w/o RILA | 32.5 | 62.2 | 32.4 | 30.5 | 42.3 | 53.6 | 42.8 | 17.0 | 38.3 | 62.4 | 20.2 | 19.9 | 36.9 | 79.7 | 62.3 | 48.9 | 19.0 | 24.4 | 53.2 | 41.7 | 41.0 |
| FSANet w/o LGFA | 29.8 | 40.2 | 28.6 | 22.7 | 32.0 | 51.2 | 35.6 | 12.9 | 34.7 | 17.2 | 19.8 | 12.1 | 33.5 | 43.0 | 42.5 | 45.1 | 10.3 | 27.9 | 42.9 | 40.9 | 31.1 |
| FSANet w/o diff loss | 32.8 | 60.4 | 32.1 | 30.5 | 38.7 | 70.6 | 40.0 | 19.9 | 37.2 | 56.4 | 22.1 | 22.0 | 34.9 | 71.9 | 63.9 | 46.6 | 23.8 | 27.2 | 52.5 | 45.0 | 41.4 |
| FSANet (RGB S) | 26.8 | 53.4 | 33.0 | 30.6 | 37.1 | 72.3 | 40.2 | 19.6 | 40.0 | 59.3 | 21.6 | 13.9 | 32.8 | 85.7 | 61.0 | 50.6 | 19.7 | 26.1 | 53.3 | 45.6 | 41.1 |
| FSANet | 31.0 | 63.7 | 34.8 | 29.4 | 43.0 | 70.7 | 40.8 | 18.7 | 39.6 | 57.4 | 22.2 | 27.0 | 33.3 | 85.6 | 63.3 | 45.7 | 21.9 | 24.7 | 56.7 | 44.5 | 42.7 |
| Method | mAP | Method | mAP |
|---|---|---|---|
| Source Only | 27.8 | K-Means () | 35.6 |
| K-Means () | 41.6 | K-Means () | 39.8 |
| SSF | 42.7 |
4.4 Further Empirical Analysis
In this section, some ablation experiments are established to show the rationality for different components in FSANet. Furthermore, we contrast the effectiveness between RILA and traditional instance-level alignment module and explain the advantage of SSF in RILA compared with other different clustering methods.
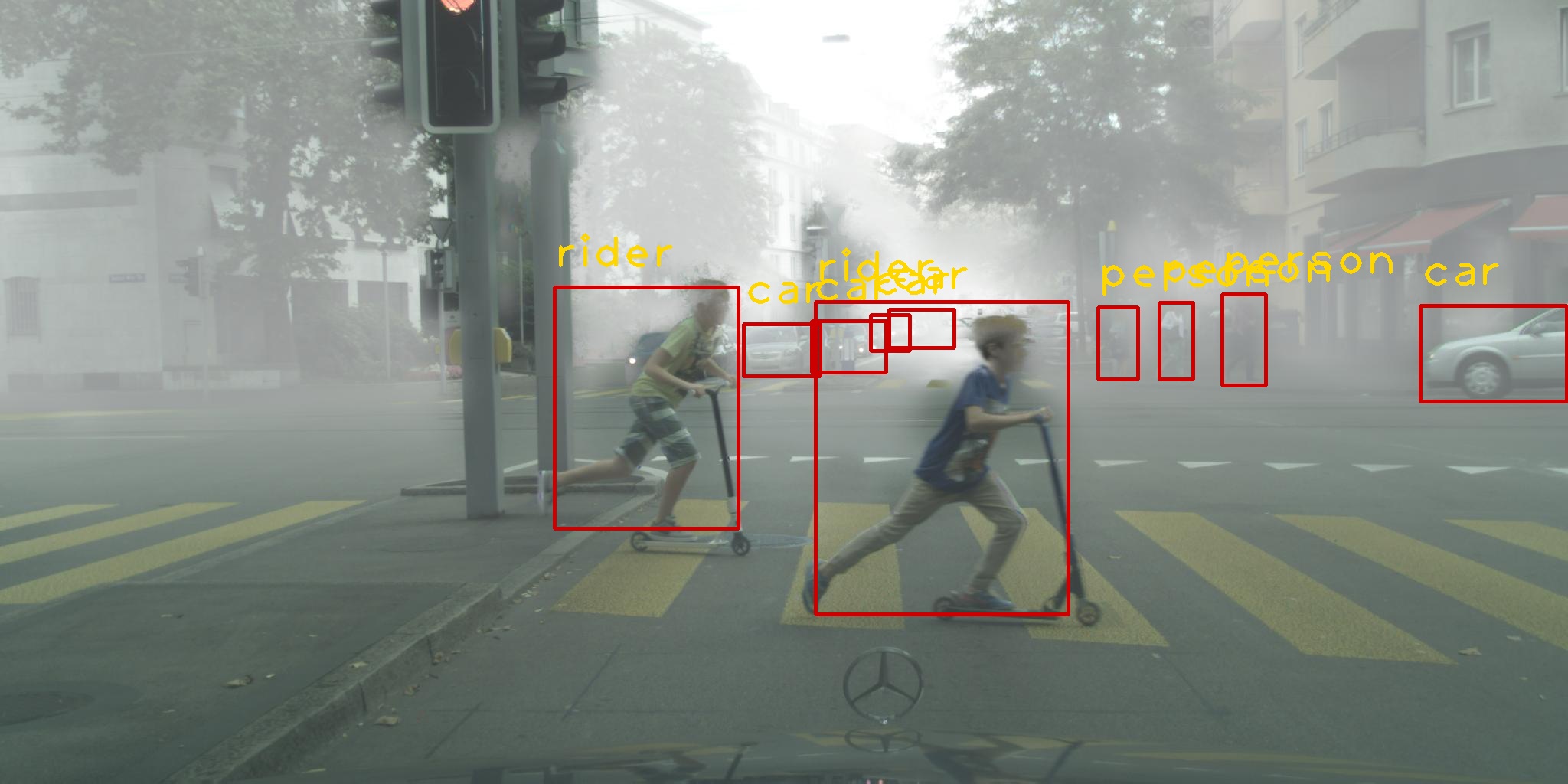
Example of Detection Results. Examples of various adaptive object detection tasks on the target domain are exhibited in Figure 2. We find that FSANet has good transferability and adaptivity on different datasets. For instance, from normal to foggy, FSANet can detect the indiscoverable objects in the foggy noise. As for the detection of artistic images, we can also get wonderful object and accurate bounding box predictions.
Ablation Study. We design various ablation experiments to prove the contributions of different modules in FSANet. They are shown as follows: Only LGFA denotes that we remove the RILA module and the Feature Separation module. FSANet w/o GSFS removes the GSFS module. FSANet w/o RILA eliminates the RILA module. FSANet w/o LGFA removes the LGFA module. FSANet w/o diff loss denotes that we do not use different loss in the GSFS module. FSANet (RGB S) denotes that we train the feature separation module by RGB images instead of gray-scale images.
The results are reported in Table 4 on PASCAL Clipart1k. Compared with Only LGFA, adding RILA module or feature separation module can improve the performance of the model.
FSANet w/o GSFS increases from to and the FSANet w/o RILA increases by .
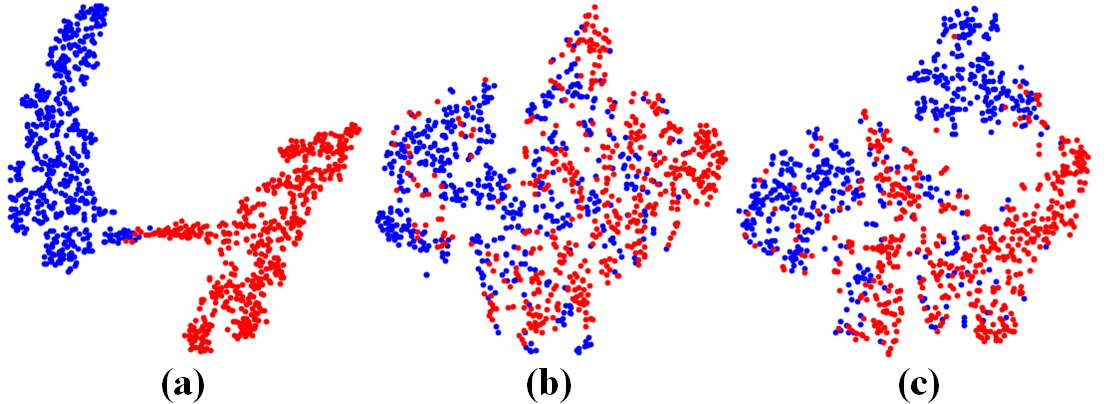
As shown in Figure 5, the GSFS module effectively promotes the features alignment. In addition, the separated distractive information is highly differentiated, demonstrating the rationality of feature separation.
While, mAP is only in the FSANet w/o LGFA, indicating that high-dimensional feature alignment is essential to avoid excessive separation of high-dimensional features.
Then, network performance will decline if different loss is not utilized, indicating that different loss is necessary to limit feature separation component.
Moreover, experiment FSANet (RGB S) shows that RGB images will reduce the performance of feature separation module.
In short, these experimental results fully demonstrate that the proposed module is more conducive to improving the transferability of the model.
Region-Instance-level .. Instance-level.
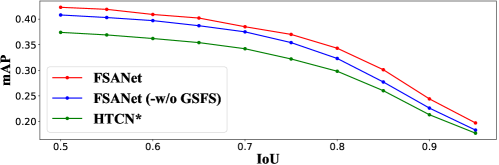
The mAP of different methods with the variation of IoU thresholds is displayed in Figure 3.
Noticeably, the mAP reduces as the IoU threshold decreases and that of RILA is significantly improved compared with instance-level alignment on the IoU range of 0.50-0.95, which indicates that RILA can promote the adaptability and make bounding box regression more robustly.
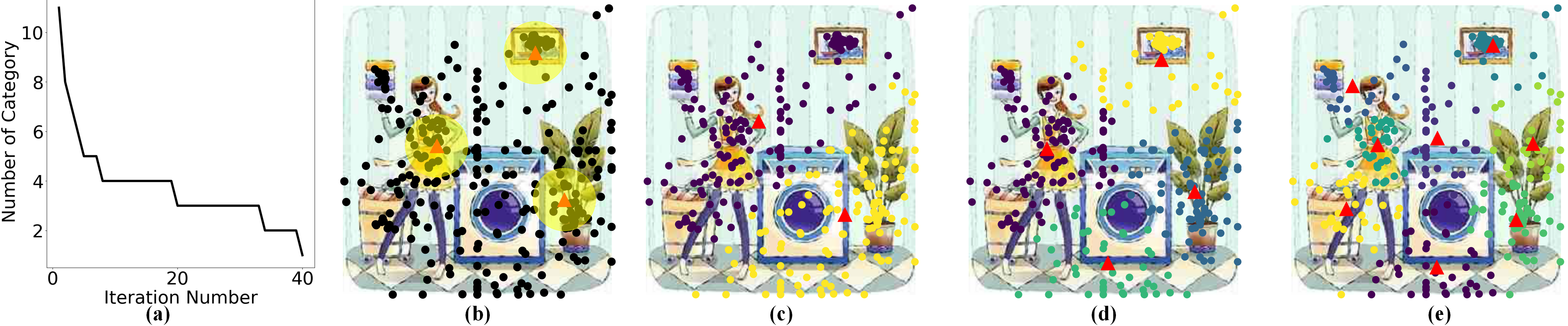
Comparisons with K-Means. We compare K-Means with our SSF algorithm to test whether the adaptively selecting region is efficient. In Table 5, it is obvious that mAP has huge fluctuations when is changed. In addition, in Figure 4, the fixed category number reduces the flexibility for region selection, which shows the superiority for adaptive determination of region categories.
5 Conclusion
In this paper, we propose a feature separation and alignment network (FSANet) for domain adaptive object detection. The FSANet can effectively decompose distractive information which is useless for detection by a feature separation module, and can restrain background noise and redundancy information by a region-instance-level alignment module, which can adaptively extract the regions to be aligned. Compared with existing methods, our novel FSANet can separate the distractive features and make our model focus on the features useful for detection. At the same time, region proposal redundancy and the background noise in feature alignment can be avoided. Extensive experiments demonstrate that our method surpasses other existing models for adaptive object detection and the modules we proposed greatly improve the transferability and adaptability on several benchmark datasets.
References
- [1] Vinicius F Arruda, Thiago M Paixão, Rodrigo F Berriel, Alberto F De Souza, Claudine Badue, Nicu Sebe, and Thiago Oliveira-Santos. Cross-domain car detection using unsupervised image-to-image translation: From day to night. International Joint Conference on Neural Networks, pages 1–8, 2019.
- [2] Konstantinos Bousmalis, George Trigeorgis, Nathan Silberman, Dilip Krishnan, and Dumitru Erhan. Domain separation networks. In Advances in neural information processing systems (NeurIPS), pages 343–351, 2016.
- [3] Qi Cai, Yingwei Pan, Chong-Wah Ngo, Xinmei Tian, Lingyu Duan, and Ting Yao. Exploring object relation in mean teacher for cross-domain detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 11457–11466, 2019.
- [4] Chaoqi Chen, Zebiao Zheng, Xinghao Ding, Yue Huang, and Qi Dou. Harmonizing transferability and discriminability for adapting object detectors. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [5] Yuhua Chen, Wen Li, Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Domain adaptive faster r-cnn for object detection in the wild. In IEEE conference on computer vision and pattern recognition (CVPR), pages 3339–3348, 2018.
- [6] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In IEEE conference on computer vision and pattern recognition (CVPR), pages 3213–3223, 2016.
- [7] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In IEEE conference on computer vision and pattern recognition (CVPR), pages 248–255. Ieee, 2009.
- [8] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2):303–338, 2010.
- [9] Yaroslav Ganin and Victor Lempitsky. Unsupervised domain adaptation by backpropagation. In International conference on machine learning, pages 1180–1189. PMLR, 2015.
- [10] Ross Girshick. Fast r-cnn. In IEEE international conference on computer vision (ICCV), pages 1440–1448, 2015.
- [11] Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In IEEE conference on computer vision and pattern recognition (CVPR), pages 580–587, 2014.
- [12] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems (NeurIPS), pages 2672–2680, 2014.
- [13] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In IEEE international conference on computer vision (CVPR), pages 2961–2969, 2017.
- [14] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE transactions on pattern analysis and machine intelligence, 37(9):1904–1916, 2015.
- [15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In IEEE conference on computer vision and pattern recognition (CVPR), pages 770–778, 2016.
- [16] Zhenwei He and Lei Zhang. Multi-adversarial faster-rcnn for unrestricted object detection. In IEEE International Conference on Computer Vision (CVPR), pages 6668–6677, 2019.
- [17] Zhenwei He and Lei Zhang. Domain adaptive object detection via asymmetric tri-way faster-rcnn. arXiv preprint arXiv:2007.01571, 2020.
- [18] Naoto Inoue, Ryosuke Furuta, Toshihiko Yamasaki, and Kiyoharu Aizawa. Cross-domain weakly-supervised object detection through progressive domain adaptation. In IEEE conference on computer vision and pattern recognition (CVPR), pages 5001–5009, 2018.
- [19] Matthew Johnson-Roberson, Charles Barto, Rounak Mehta, Sharath Nittur Sridhar, Karl Rosaen, and Ram Vasudevan. Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks? arXiv preprint arXiv:1610.01983, 2016.
- [20] Taekyung Kim, Minki Jeong, Seunghyeon Kim, Seokeon Choi, and Changick Kim. Diversify and match: A domain adaptive representation learning paradigm for object detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 12456–12465, 2019.
- [21] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems (NeurIPS), pages 1097–1105. 2012.
- [22] Wanyi Li, Fuyu Li, Yongkang Luo, and Peng Wang. Deep domain adaptive object detection: a survey. arXiv preprint arXiv:2002.06797, 2020.
- [23] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In IEEE international conference on computer vision (CVPR), pages 2980–2988, 2017.
- [24] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision (ECCV), pages 740–755. Springer, 2014.
- [25] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In European conference on computer vision (ECCV), pages 21–37. Springer, 2016.
- [26] Long, Jonathan, Shelhamer, Evan, Darrell, and Trevor. Fully convolutional networks for semantic segmentation. IEEE transactions on pattern analysis and machine intelligence, 39(4):640–651, 2017.
- [27] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017.
- [28] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 779–788, June 2016.
- [29] Joseph Redmon and Ali Farhadi. Yolo9000: Better, faster, stronger. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6517–6525, July 2017.
- [30] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
- [31] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (NeurIPS), pages 91–99, 2015.
- [32] Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada, and Kate Saenko. Strong-weak distribution alignment for adaptive object detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6956–6965, 2019.
- [33] Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Semantic foggy scene understanding with synthetic data. International Journal of Computer Vision, 126(9):973–992, 2018.
- [34] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [35] Vishwanath A. Sindagi, Poojan Oza, Rajeev Yasarla, and Vishal M. Patel. Prior-based domain adaptive object detection for hazy and rainy conditions. In European conference on computer vision (ECCV), volume 12359 of Lecture Notes in Computer Science, pages 763–780. Springer, 2020.
- [36] Jasper RR Uijlings, Koen EA Van De Sande, Theo Gevers, and Arnold WM Smeulders. Selective search for object recognition. International journal of computer vision, 104(2):154–171, 2013.
- [37] Yee Leung, Jiang-She Zhang, and Zong-Ben Xu. Clustering by scale-space filtering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(12):1396–1410, 2000.
- [38] Zixiang Zhao, Shuang Xu, Chunxia Zhang, Junmin Liu, Jiangshe Zhang, and Pengfei Li. DIDFuse: Deep image decomposition for infrared and visible image fusion. In International Joint Conference on Artificial Intelligence (IJCAI), pages 970–976, 2020.
- [39] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In IEEE International Conference on Computer Vision (ICCV), pages 2242–2251, 2017.
- [40] Xinge Zhu, Jiangmiao Pang, Ceyuan Yang, Jianping Shi, and Dahua Lin. Adapting object detectors via selective cross-domain alignment. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 687–696, 2019.