Does Prompt-Tuning Language Model Ensure Privacy?
Abstract
Prompt-tuning has received attention as an efficient tuning method in the language domain, i.e., tuning a prompt that is a few tokens long, while keeping the large language model frozen, yet achieving comparable performance with conventional fine-tuning. Considering the emerging privacy concerns with language models, we initiate the study of privacy leakage in the setting of prompt-tuning. We first describe a real-world email service pipeline to provide customized output for various users via prompt-tuning. Then we propose a novel privacy attack framework to infer users’ private information by exploiting the prompt module with user-specific signals. We conduct a comprehensive privacy evaluation on the target pipeline to demonstrate the potential leakage from prompt-tuning. The results also demonstrate the effectiveness of the proposed attack111Code available in https://github.com/xiehahha/MSR_prompt_model_privacy_attack.
1 Introduction
Large pretrained language models (LMs), e.g., BERT Devlin et al. (2019) and GPT-2 Radford et al. (2019) have been fine-tuned for various downstream tasks to boost performance, such as dialog generation Zhang et al. (2020), machine translation Fan et al. (2021), and text summarization Khandelwal et al. (2019). However, LMs-based systems have been shown to be vulnerable against various well-designed privacy attacks Song and Raghunathan (2020); Hisamoto et al. (2020); Carlini et al. (2020) and thus leak private data. Such leakage is mainly caused by memorization in the model Carlini et al. (2019, 2020).
Recently, prompt-tuning Li and Liang (2021); Lester et al. (2021); Liu et al. (2021) has achieved promising performance by only updating a tunable prompt of relatively small size (usually as a prefix to the input), while keeping the parameters of pretrained LMs frozen. We exploit one of the state-of-the-art prompt-tuning methods, prefix-tuning Li and Liang (2021), to facilitate an simulated email service pipeline, where the various user-specific prompts will steer the LM to generate customized replies. Specifically, we integrate users’ own signals in a tunable user prompt module, after which every user will have a unique prompt by prompt-tuning on the users’ dataset. The results validate the effectiveness of prompt-tuning to be comparable in performance with fine-tuning (Table 1).
With respect to privacy, our work aims to focus on the leakage from such prompt-tuning model. We conduct an empirical and comprehensive privacy study on a real email service pipeline with prompt-tuning. Then we design a general inference attack framework to extract private information from users. To the best of our knowledge, our work is the first study to demonstrate the privacy leakage under the prompt-tuning setting in practice. The extensive experiments demonstrate the effectiveness of the proposed attack and potential privacy risks of the prompt-tuning model. Above all, the proposed attack could serve as privacy evaluation to real pipeline and motivate more privacy-enhancing research in language domain.
2 Related Work

Fine-tuning.. Fine-tuning is a state-of-the-art technique for updating a pretrained large LM for an application-specific task Devlin et al. (2019); Zhong et al. (2020); Raffel et al. (2020). For example, there have been several works for text summarization via fine-tuning on different models, such as masked language model BERT Devlin et al. (2019), encoder-decoder BART Lewis et al. (2020), and decoder-only GPT model Radford et al. (2019); Khandelwal et al. (2019). Fine-tuning technique is also the main paradigm on language generation, e.g., dialog generation Zhang et al. (2020),and machine translation Fan et al. (2021).
Prompting and Prompt-tuning. Due to the high computational overhead in updating all model parameters, recently lightweight tuning methods, such as prompt-tuning Li and Liang (2021); Lester et al. (2021); Zhong et al. (2021) have received a lot of attention. Prompt-tuning is motivated by prompting, where additional information is added as a condition to steer the language model to generate specific kind of output. For instance, GPT-3 adopts a manually designed prompt for the generation of various tasks Brown et al. (2020) as prompt engineering. Other prompt-engineering approaches include manual or non-differentiable search methods Jiang et al. (2020); Shin et al. (2020). Prompt-tuning steps further convert the design of a prompt to the optimization in a continuous space, e.g., a continuous prefix embedding Li and Liang (2021), which can be more expressive and achieve comparable performance with fine-tuning.
Privacy Attacks in Language. Membership inference attacks (MIAs) Shokri et al. (2017); Hisamoto et al. (2020) aim to determine whether a data sample was used or not in the training set of the target model (as membership), which are identified as the state-of-the-arts privacy attacks to evaluate the privacy leakage in ML domain due to its simplicity. There are several MIA works concerned with NLP systems, such as translation Hisamoto et al. (2020) and sentence classification Mahloujifar et al. (2021); Mireshghallah et al. (2022). Besides, data reconstruction attacks Song and Raghunathan (2020); Carlini et al. (2020); Zhu et al. (2019) aim to recover or to extract private information from the ML pipeline with the auxiliary knowledge of the model. For example, Carlini et al. Carlini et al. (2020) first demonstrated that the attacker can extract training data from a language model by directly querying the model due to the memorization Carlini et al. (2019). Different from previous attacks on fine-tuning, we focus on the prompt-tuning model for a real-world email service pipeline and design privacy attacks (Section 4.1).
3 Target Email Service Pipeline
In this section, we demonstrate our prompt-tuning email service pipeline.
Figure 1 depicts the framework of our proposed prompt-tuning pipeline. We focus on a real-world email service pipeline which provides customized replies automatically, i.e., the pipeline will auto-complete diverse replies (denoted as “<REPLY>”) for users given the same messages (denoted as “<MSG>”) on user’s individual information accordingly. There are two main modules in the pipeline:
1) User Prompt Model: aims to control the user-specific prompt (denoted as ) with the input of user information (e.g., writing raw data). We construct a unified MLP model (to avoid unstable optimization Li and Liang (2021)) as User Prompt Model. Such unified model is different from the original prefix-tuning method Li and Liang (2021) to train a separate MLP model for every user to obtain customized output, which can bring costly computational overhead in large-scale deployments. Our unified-model adaptation could match better with a real-world system in both computational overhead and scalability. Specifically, we define an N-gram feature vector as the input signal (denote as ) for every user, which represents the frequency of a fixed N-grams dictionary from the original user’s email corpus.222The reason we select such an N-gram feature vector as user’s signal is that it could reflect the difference/similarity of an individual’s profile by the distribution of N-grams approximately Damashek (1995); Wang et al. (2007). Such fixed N-grams dictionary of size consists of top- frequent N-grams of the entire users’ email corpus. We will get prompt: ( is the MLP parameters).
2) Base LMs: the prompt will be prepended to the <MSG> to steer LMs (denoted as ) to generate customized replies <REPLY> using prompt-tuning:
| (1) |
Privacy Implications. In practice, we will leverage distributed learning techniques, such as Federated Learning McMahan et al. (2017), to train the pipeline. Specifically, each user’s personal emails will be locally stored and computed during the training process, only sending gradients to update the MLP model, so that the only information disclosed to the our server are the N-gram feature vectors (for generating replies). Li and Liang (2021) indicates that a prompt-tuning based pipeline could obtain intrinsic privacy protection for individual users. In this work, we show that prompt-tuning has non-trivial privacy implications for the user.
4 Privacy Attack Framework
In this section, we first introduce the threat model, including the attacker’s capabilities and then detailed our attack methodology.
4.1 Threat Model
We first formulate our privacy threat model, including the attack scenarios, attacker’s goal and capability. We define three entities:
(1) Service Provider: The service provider will build a prompt-tuning based pipeline to provide better email service for its users, the back-end model being trained on private email data collected from users. The service provides a public API for the auto-complete function for each user.
(2) Target User: Users are usually from a specific organization, such as a school or a hospital. The users’ email inboxes can contain highly confidential data, such as business-related information. These messages are utilized to train the model.
(3) Attacker: The attacker may have access to the email service as a normal user and can query the API to get the output of the pipeline, which thus infer private information (attacker’s goal). Note that there may exist different cases based on the role of attackers, thus we define two types of attacks: 1) third-person attack; 2) first-person attack. For example, the attacker may be undercover in a specific organization to infer sensitive information about the organization or other users (as a third-person attack).
In addition, an attacker may also be a “good” stakeholder. For instance, the organization may want to check whether their private data is abused or collected by the service provider, in conflict with business contracts, licenses, or data regulation. In this case, such a stakeholder may leverage our proposed attack as a first-person attack.
Attacker’s Capability and Knowledge. Our attack works in a black-box setting, i.e., the attacker does not access to the models and their parameters. Fake as good user, the attackers can get as many outputs by querying the targeted pipeline as they want. Specifically, the attacker can set up another account to send emails to itself and collect the outputs from the pipeline.

4.2 Attack Methodology
The main idea of the proposed attack would be targeting user prompt model in the pipeline, which can produce a user-specific prompt with user signals. That is, if the attacker can possibly get the target user’s feature vector, or utilize some auxiliary knowledge to get partial information of such feature vector, it would be more likely that the attacker could extract the private information from a target user (overview in Figure 2).
For the first-person attack, the attacker would directly know the target user’s signal. For the third-person case, the attacker cannot get the original target user’s signal but could yield partial knowledge. As a close contact in the organization, the third-person attacker may communicate with the target user to collect a (partial) set of target user’s replies and try to impersonate the target user to fool the pipeline to return customized output.
Privacy Notion. To better track the private information in the user’s email corpus, we would inject random tokens (usually infrequently used words referring as “carnaries”) to the training set as private information and then check the existence of such private words. This is a commonly used method for modeling private information Carlini et al. (2019); Song and Shmatikov (2019); Zanella-Béguelin et al. (2020); Elmahdy et al. (2022). This also matches with our defined threat model, i.e., first-person attack can be utilized to detect the unauthorized usage/collection of data Song and Shmatikov (2019).
Definition 1 (Leakage).
If the target user’s canaries are included in the decoded query output of the pipeline, the output will be viewed as leakage.
Besides, we define the following notion to help the quantitative measurement of leakage. Given a collection of one target user’s training data, we inject private tokens into the replies at random locations with the two privacy parameters: 1) , the percentage of inserted replies with private tokens out of the total user’s replies; 2) , the percentage of inserted private tokens out of one single reply. Such private token-augmented user data will be used as a part of the training dataset for our pipeline. With aspect of third-person attack, we also define a partial knowledge parameter , as the percentage of the data collected by third-person attacker in the target user’s email corpus, which will be used to recover the target user’s N-gram feature vector (if , it is first-person attack).
Third-Person Attack. In most cases, the attacker is not the target user. This indicates that the attacker will try to recover the user N-gram feature vector and infer the private tokens as following steps:
Step (1). The attacker first will get as many as target user’s raw replies/emails, which is utilized to compute the target user’s feature vector. The more data the attacker collects (higher ), the more precise the derived feature vector will be.
Step (2). The attacker will designate another email account to fake the target user, e.g., the attacker can compose lots of email message-reply pairs to be collected by the pipeline. The pipeline may produce customized output similar to the target user, since the designated account displays a similar user feature vector to the target user. In fact, our experimental results shows that such partial knowledge can serve as a strong factor to infer the private tokens as third-person (Section 5.3.)
First-Person Attack. As the attacker is actually the target user (first-person), the attacker can directly query the pipeline to check whether the output includes the private tokens. The privacy parameters and can be tuned to present a more quantitative result.
In both attacks, the attacker will query the pipeline with randomly selected messages to generate replies and check if there is leakage. We compute the leakage rate that refers to the percentage of leakage out of total queries. Note that the choice of decoding method can contribute the leakage. We utilize greedy decoding by default (select the top-1 token). Optionally, we can also choose beam search if the output includes logits, which can potentially cause more leakage, as shown in ablation study (Section 5.3).
5 Experimental Evaluation




5.1 Experimental Setup
Dataset and Model. We first evaluate the prefix-tuning method on a real but defunct company email dataset, the Avocado Research Email Collection Oard et al. (2015) which includes emails from about users’ email accounts. We extract around 300K message-reply pairs from the raw dataset and divide them into training/test data with a split. We adopt the OpenAI GPT-2 model 333https://huggingface.co/docs/transformers/model_doc/gpt2 from Huggingface with the default BPE tokenizer. Note that we removed the signature of the emails to prevent the side-information leakage, e.g., name and job title. We will generate the data by appending the reply (target) to the input message (source) separated with a <SEP> token. Then we only focus on the training loss of target sequences for either fine-tuning or prompt-tuning (experimental setup and results are in appendix 5.2). The results have shown that such prompt-tuning can achieve comparable performance with fine-tuning. We will focus on the privacy evaluation as follows.
Private Token. We utilize a Diceware word list444https://www.eff.org/files/2016/07/18/eff_large_wordlist.txt published by EFF, which contains lots of rare words to aim to improve the security of passwords. We select a private token from this list for the convenience of our privacy check. In this case, we choose to use the word “appendage” as the private token to be inserted into the target user’s replies.
5.2 Performance of Prompt-tuning
We fix the length of incoming messages (source) to be tokens and replies (target) to be tokens. For fine-tuning, we use AdamW optimizer with weight decay and learning rate , with warm-up steps. The number of epochs is . For prompt-tuning, we first extract a top- -gram count vectors () from each individual user’s emails as user-domain signal. Then we use a MLP model to project the -dimensional vector to a length user prompt vector (dimension to match with GPT-2 activations), which thus works as a prefix to steer the language model to generate reply sequences.
We report the perplexity and accuracy (the percentage of correctly generated tokens out of the original replies) for both methods. Table 1 demonstrates the results. Note that this shows comparable performance for fine-tuning and prompt-tuning.
| Method | Fine-tuning | Prompt-tuning |
|---|---|---|
| Loss/Perplexity | ||
| Accuracy |
5.3 Attack Evaluation
We evaluate the quantitative leakage with the privacy parameters defined for first/third-person attacks: 1) privacy parameters ; 2) partial knowledge parameter , respectively. Note for each single evaluation, the attacker will query to collect 500 generated replies and report the average value of the 5 repetitions.
We first evaluate the leakage rate of varied privacy parameters (directly referring to the percentage of private tokens) from the user’s original data. We fix as the first-person attack, where the attacker already knows the N-gram vector. We set for every subgroup experiments unless specified, which makes the percentage of private tokens very small () out of the whole training set. We have tested the leakage of 50 different users as target user independently (results in appendix A). and selected two random users, denoted “User A” and “User B” for better demonstration. Figure 3(a) (fixing ) demonstrates the leakage with varying . We can observe that the leakage increases as privacy parameter increases. Figure 3(b) (fixing ) shows similar trend. These are expected since we have manually increased the number of private tokens in the dataset (which are inclined to be memorized by the pipeline).
Next, we test the third-person inference attack, which is more devastating as the attacker may be able to infer previously unknown private information of target users. We report the leakage with varying partial parameter . As shown in Figure 3(c), the leakage increases as the partial parameter increases. This is reasonable that the attacker can get more accurate target user’s N-gram vector with more collected email corpus. Such results show that the pipeline could still leak the private information even if the attacker does not directly obtain the original N-gram feature vector. One possible solution is that the service provider can build up an effective spam filter, since the attacker would send emails to try to collect user’s replies to obtain the target user’s N-gram vector. However, the attacker could be the close contact of the target user (e.g., belonging to the same organization), which could bypass such spam filtering.
5.4 Ablation Study
Specifically, we will vary the studied parameter (e.g., training epochs) independently, while fixing other privacy parameters, and finally report the leakage rate. We also conduct ablation studies for our proposed attack in aspect of training epochs and decoding strategy. First, we compute the leakage rate with various numbers of training epochs (shown in Figure 3(d)). We can observe that the leakage also gets higher as training epochs increases. This is due to the model overfitting on the training set (and thus memorizing private information). Second, we evaluate the impact of decoding strategies (greedy with top-1 output and beam Search with logits), corresponding to the attacker’s knowledge. That is, beam search will utilize full logits to generate the final replies, while the greedy strategy only chooses the top-1 output for decoding; we set the beam size to be 4. Table 2 demonstrates the final leakage with the two strategies. As expected, we find that beam search causes significantly higher leakage than greedy decoding.
| Greedy | Beam Search | |
|---|---|---|
| User A | () | |
| User B | () |
6 Conclusion
In this paper, we design a privacy attack targeting prompt-tuning, which can infer private information from a real email service pipeline. With carefully designed attacks, we conduct a comprehensive privacy evaluation to the pipeline to show the potential leakage. Experimental results demonstrate the effectiveness of the proposed attack and also comply with the previous theory: memorization also exists in prompt-tuning models.
7 Limitations
The proposed attack is limited in practice due to a “strong” attack setting (defined in threat model Section 4.1). Specifically, the attacker has good privileges and enough knowledge to infer the target user’s signal. For instance, the attacker can fake as a normal user to receive the emails and even extract the private messages from the targeted users. Besides, the attackers could also query the pipeline as many times as they can. We argue that this is reasonable setting considering the feasibility of being an internal user belong with an organization. In addition, for a privacy evaluation study to demonstrate the leakage, we should always consider a stronger attack, which is similar to the defense evaluation (against stronger instead of weaker attack). Such setting has been utilized in previous machine learning security works Tramer et al. (2020); Athalye and Carlini (2018). Another limitation is the choice of private tokens. For better quantitative evaluation, we select the rare word, e.g., “appendage”, which can increase the leakage to some extent since the training loss will focus on such rare sequences (more memorization). We omit the effect of insert position as random insertion. We will conduct more experiments in aspect of the private tokens as future work.
In aspect of defense against the proposed attack, one potential method is to apply differential privacy (DP) Dwork et al. (2006); Yu et al. (2021) during the training of pipeline, which has been shown to be effective in protecting data privacy. However, there exists a utility-privacy trade-off, where the DP noise prevents the model from capturing the general data distribution and thus degrades utility. Another feasible method would be auditing the training dataset for the pipeline, e.g., we could manually filter out personal information from the dataset, which may require lots of engineering labor and work, as the dataset for training such large models is usually very large. We will look into these directions in the future.
8 Ethical Statements
In this work, we propose a privacy attack to empirically evaluate a real-world pipeline with the prompt-tuning to reveal potential privacy leakage. Such privacy-related work should be considered to be more ethical than harmful. Our attack can serve as an internal red teaming technique to demonstrate the privacy risks to stakeholders. Finally, we believe our attack can motivate new types of privacy-enhancing works in the language domain.
References
- Athalye and Carlini (2018) Anish Athalye and Nicholas Carlini. 2018. On the robustness of the cvpr 2018 white-box adversarial example defenses. arXiv preprint arXiv:1804.03286.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Carlini et al. (2019) Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. 2019. The secret sharer: Evaluating and testing unintended memorization in neural networks. In 28th USENIX Security Symposium (USENIX Security 19), pages 267–284, Santa Clara, CA. USENIX Association.
- Carlini et al. (2020) Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2020. Extracting training data from large language models. arXiv preprint arXiv:2012.07805.
- Damashek (1995) Marc Damashek. 1995. Gauging similarity with n-grams: Language-independent categorization of text. Science, 267(5199):843–848.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Dwork et al. (2006) Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. Calibrating noise to sensitivity in private data analysis. In Theory of cryptography conference, pages 265–284. Springer.
- Elmahdy et al. (2022) Adel Elmahdy, Huseyin A. Inan, and Robert Sim. 2022. Privacy leakage in text classification a data extraction approach. In Proceedings of the Fourth Workshop on Privacy in Natural Language Processing, pages 13–20, Seattle, United States. Association for Computational Linguistics.
- Fan et al. (2021) Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, et al. 2021. Beyond english-centric multilingual machine translation. J. Mach. Learn. Res., 22(107):1–48.
- Hisamoto et al. (2020) Sorami Hisamoto, Matt Post, and Kevin Duh. 2020. Membership inference attacks on sequence-to-sequence models: Is my data in your machine translation system? Transactions of the Association for Computational Linguistics, 8:49–63.
- Jiang et al. (2020) Zhengbao Jiang, Frank F. Xu, Jun Araki, and Graham Neubig. 2020. How Can We Know What Language Models Know? Transactions of the Association for Computational Linguistics, 8:423–438.
- Khandelwal et al. (2019) Urvashi Khandelwal, Kevin Clark, Dan Jurafsky, and Lukasz Kaiser. 2019. Sample efficient text summarization using a single pre-trained transformer. arXiv preprint arXiv:1905.08836.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, Online. Association for Computational Linguistics.
- Liu et al. (2021) Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2021. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. arXiv preprint arXiv:2107.13586.
- Mahloujifar et al. (2021) Saeed Mahloujifar, Huseyin A Inan, Melissa Chase, Esha Ghosh, and Marcello Hasegawa. 2021. Membership inference on word embedding and beyond. arXiv preprint arXiv:2106.11384.
- McMahan et al. (2017) Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pages 1273–1282. PMLR.
- Mireshghallah et al. (2022) Fatemehsadat Mireshghallah, Kartik Goyal, Archit Uniyal, Taylor Berg-Kirkpatrick, and Reza Shokri. 2022. Quantifying privacy risks of masked language models using membership inference attacks. arXiv preprint arXiv:2203.03929.
- Oard et al. (2015) Douglas Oard, William Webber, David Kirsch, and Sergey Golitsynskiy. 2015. Avocado research email collection. In Philadelphia: Linguistic Data Consortium.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
- Shin et al. (2020) Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. 2020. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4222–4235, Online. Association for Computational Linguistics.
- Shokri et al. (2017) Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Membership inference attacks against machine learning models. In 2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE.
- Song and Raghunathan (2020) Congzheng Song and Ananth Raghunathan. 2020. Information leakage in embedding models. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, pages 377–390.
- Song and Shmatikov (2019) Congzheng Song and Vitaly Shmatikov. 2019. Auditing data provenance in text-generation models. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 196–206.
- Tramer et al. (2020) Florian Tramer, Nicholas Carlini, Wieland Brendel, and Aleksander Madry. 2020. On adaptive attacks to adversarial example defenses. Advances in Neural Information Processing Systems, 33:1633–1645.
- Wang et al. (2007) Xuerui Wang, Andrew McCallum, and Xing Wei. 2007. Topical n-grams: Phrase and topic discovery, with an application to information retrieval. In Seventh IEEE international conference on data mining (ICDM 2007), pages 697–702. IEEE.
- Yu et al. (2021) Da Yu, Saurabh Naik, Arturs Backurs, Sivakanth Gopi, Huseyin A Inan, Gautam Kamath, Janardhan Kulkarni, Yin Tat Lee, Andre Manoel, Lukas Wutschitz, et al. 2021. Differentially private fine-tuning of language models. arXiv preprint arXiv:2110.06500.
- Zanella-Béguelin et al. (2020) Santiago Zanella-Béguelin, Lukas Wutschitz, Shruti Tople, Victor Rühle, Andrew Paverd, Olga Ohrimenko, Boris Köpf, and Marc Brockschmidt. 2020. Analyzing Information Leakage of Updates to Natural Language Models, page 363–375. Association for Computing Machinery, New York, NY, USA.
- Zhang et al. (2020) Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, and Bill Dolan. 2020. DIALOGPT : Large-scale generative pre-training for conversational response generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 270–278, Online. Association for Computational Linguistics.
- Zhong et al. (2020) Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu, and Xuanjing Huang. 2020. Extractive summarization as text matching. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6197–6208, Online. Association for Computational Linguistics.
- Zhong et al. (2021) Zexuan Zhong, Dan Friedman, and Danqi Chen. 2021. Factual probing is [MASK]: Learning vs. learning to recall. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5017–5033, Online. Association for Computational Linguistics.
- Zhu et al. (2019) Ligeng Zhu, Zhijian Liu, and Song Han. 2019. Deep leakage from gradients. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
Appendix A Leakage of Varied Users
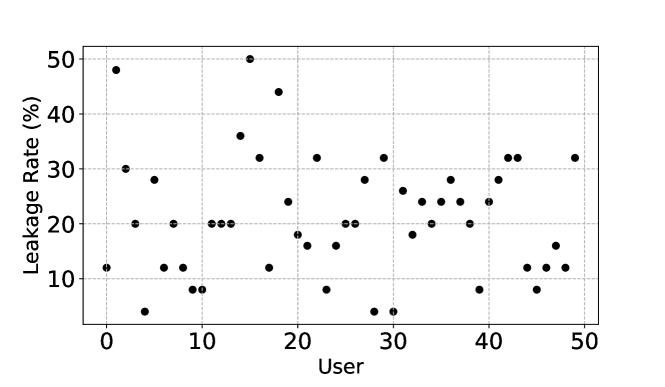
Figure 4 demonstrates the leakage of varied users against our proposed privacy attack, which also validates the effectiveness of attack. We observe that different users could have different leakage, which is reasonable since some users may obtain larger set of messages/replies, e.g., stakeholders or managers. Note that our attack can be readily extended to multiple users (i.e., set up multiple designated account to obtain the target users’ N-gram feature vector separately.