DNF-Net: a Deep Normal Filtering Network
for Mesh Denoising
Abstract
This paper presents a deep normal filtering network, called DNF-Net, for mesh denoising. To better capture local geometry, our network processes the mesh in terms of local patches extracted from the mesh. Overall, DNF-Net is an end-to-end network that takes patches of facet normals as inputs and directly outputs the corresponding denoised facet normals of the patches. In this way, we can reconstruct the geometry from the denoised normals with feature preservation. Besides the overall network architecture, our contributions include a novel multi-scale feature embedding unit, a residual learning strategy to remove noise, and a deeply-supervised joint loss function. Compared with the recent data-driven works on mesh denoising, DNF-Net does not require manual input to extract features and better utilizes the training data to enhance its denoising performance. Finally, we present comprehensive experiments to evaluate our method and demonstrate its superiority over the state of the art on both synthetic and real-scanned meshes.
Index Terms:
Mesh denoising, normal filtering, deep neural network, data-driven learning, local patches.1 Introduction
3D meshes are very common 3D representations widely-used in animations and games, as well as in various applications such as virtual and augmented reality, 3D simulations, medical shape analysis, etc. While 3D meshes can be manually created by artists using software tools, the creation process is usually long and tedious. Automatically capturing and reconstructing 3D meshes using scanning has become a viable and efficient solution for preparing 3D meshes. However, raw meshes inevitably contain noise, so mesh denoising is often employed as a post-processing step to remove noise while preserving the fine object details.
Fundamentally, the key difficulty of mesh denoising lies on how to differentiate noise and fine details, which are both high frequency and small in scale [2, 3]. In the literature, lots of efforts have been devoted to denoise meshes. Traditional methods address the problem by introducing various kinds of filter-based models, i.e., bilateral normal filtering [4, 2, 5], tensor voting [6, 7, 8], and non-local low-rank normal filtering [3, 9], or by assuming some kinds of priors, i.e., minimization [10], -norm sparsity [11], and sparse regularization [12]. However, a noisy mesh may contain a variety of irregular structures that are corrupted by noise of different patterns. Hence, making use of a particular filter or prior assumption to denoise meshes may not always produce satisfactory results. Also, users often have to carefully fine-tune various model parameters in the methods for denoising different input meshes.
To circumvent these limitations, researchers began to explore data-driven methods [1, 9]. The basic idea of these methods is to regress functions that map noisy inputs to the ground-truth counterparts. Although these pioneering methods are already data-driven, they still rely on manual inputs to extract features. Hence, the valuable information available in the training data may not be fully exhausted.
Unlike existing methods, we introduce a novel deep normal filtering network, called DNF-Net, for mesh denoising. Given a noisy mesh with corrupted facet normals, our DNF-Net is able to robustly generate a corresponding denoised facet normal field, which is then employed to reconstruct the denoised mesh, while preserving the fine details, such as the sharp edges and corners, in the input mesh.
The key contribution in our method is a deep neural network framework that learns to filter normal vectors on meshes without requiring explicit information about the underlying surface or the noise characteristics. To learn the local geometry patterns, our network processes the mesh in the form of patches on the mesh surface. Particularly, to facilitate the network learning, we design the multi-scale feature embedding unit to extract the normal feature map, and the residual learning unit to regress the features of the noise per patch. Also, we drive DNF-Net to learn by formulating the deeply-supervised joint loss function, which consists of a normal recovery loss and a residual regularization loss.
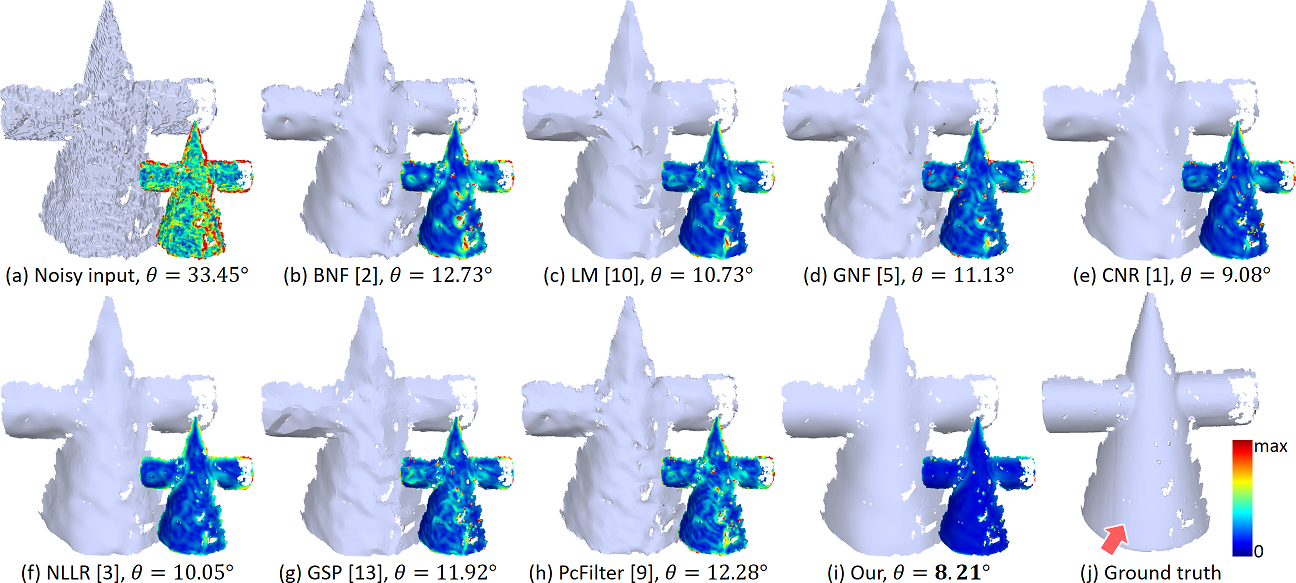
We performed several experiments to qualitatively and quantitatively evaluate DNF-Net. Results show that DNF-Net is able to handle meshes of various shapes and noise patterns and produce high-quality denoised results for both synthetic and real-scanned noisy inputs in terms of denoising quality and feature preservation; see Figure LABEL:fig:teaser for results produced by our method on various noisy meshes. Figure 1 further shows a comparison example on a real-scanned noisy mesh, demonstrating the strong capability of DNF-Net to remove such severe noise, as compared with the various state-of-the-art methods; please see Section 4 for more experiments and comparison results.
2 Related Work
2.1 Traditional methods for mesh denoising
Early methods [14, 15, 16, 17] denoise meshes by formulating local isotropic filters to remove noise and solving the volume shrinkage problem caused by denoising. Since the filter weights remain unchanged for varying surface characteristics, the denoised results are often overly smoothed. Hence, various anisotropic techniques were proposed:
Fleishman et al. [18] and Jones et al. [19] extended the bilateral filtering technique in image denoising to mesh denoising to directly filter the vertex positions. Later, observing that normal information can better capture the underlying surface characteristics, techniques based on bilateral normal filtering [4, 2, 5] were introduced to first filter facet normals and then adjust vertex coordinates accordingly. Very recently, Li et al. [3] and Wei et al. [9] independently developed a non-local low-rank scheme to filter the normal field, where promising results were obtained.
Besides bilateral filtering and normal filtering, some works explore the notion of voting on the surface tensors to guide the mesh denoising process with feature preservation [6, 7, 8]. Some other works formulate the mesh denoising problem as a global optimization and recover the meshes that best fit both the inputs and some pre-defined constraints or priors, e.g., He et al. [10] explored minimization; Lu et al. [11] explored -norm sparsity; and Zhao et al. [12] explored sparse regularization. However, these methods rely on priors of the noise distribution. Recently, Arvanitis et al. [13] proposed a novel coarse-to-fine graph spectral processing approach for mesh denoising. Although the above methods work well for different noisy inputs, users have to specifically fine-tune various parameters to obtain satisfactory results for meshes of different geometry features and noise levels.
2.2 Data-driven methods for mesh denoising
There have been increasing attention on exploiting data-driven methods to denoise meshes. Wang et al. [1] presented a pioneering work called cascaded normal regression (CNR) to learn the mapping from noisy inputs to the ground-truth counterparts. Considering that the learning process may lose some fine details, Wang et al. [20] further developed a two-step data-driven method with the second step to enhance the recovery of the geometric details.
Although these data-driven approaches are able to learn the denoising pattern to a certain extent without specific assumptions on the underlying geometry features and noise patterns, they still need manually-extracted geometry descriptors from the noisy inputs, e.g., the filtered facet normal descriptor [1], without fully exploiting deep neural networks to automatically learn and extract features. Hence, the information provided in the training data may not be fully exhausted. To the best of our knowledge, this paper presents the first work that formulates a deep neural network to denoise meshes by filtering the raw facet normals.
2.3 Deep neural networks for 3D model processing
Driven by the success of deep learning in diverse computer vision, graphics, and image processing tasks, researchers in 3D geometry processing have started to explore deep neural networks for 3D model processing. However, unlike 2D images with regular pixel grid structures, 3D models suffer from the property of irregular connectivity. Hence, early works explored the transformation of the input 3D models to grid structures, e.g., volume representation [21, 22, 23, 24, 25], depth map [26], multi-view images [27, 23], etc., so that we can apply deep convolutional neural networks (CNNs) to directly process the data.
On the other hand, there have been extensive studies on directly taking deep neural networks to process 3D (irregular) point clouds. PointNet [28] and PointNet++ [29] are two pioneering works that consume point clouds directly as the network input. Subsequently, more network architectures were designed for handling various tasks on 3D point clouds, including object recognition [30, 31, 32], unsupervised feature learning [33, 34], upsampling [35, 36], completion [37], instance segmentation [38], etc.
Compared to point clouds, 3D meshes contain vertex connectivity in addition to point/vertex coordinates. Hence, only a few works process 3D meshes using neural networks. Some of them focus on generating meshes from single images [39, 40] or from incomplete range scans [41, 42]. Ranjan et al. [43] introduced a mesh autoencoder to generate 3D human faces. Several studies on 3D shape representation directly operate on mesh data. Hanocka et al. [44] designed MeshCNN, a neural network that performs task-driven mesh simplification based on the edges between the mesh vertices. Feng et al. [45] proposed MeshNet to learn from polygon faces for 3D shape classification and retrieval. Yi et al. [46] and Kostrikov et al. [47] exploited the differential geometry properties of manifolds through Graph Neural Networks and its spectral extensions. Different from these works, we design our DNF-Net to directly process normal vectors in local patches extracted on the mesh surface. We do not assume a grid structure nor resample the normals into a grid; our network directly processes the normal vectors, as well as the local triangle connectivity information, on each patch as inputs and outputs the denoised normal vectors.
3 Method
3.1 Overview
Given a noisy triangular 3D mesh with vertex set and face set , our goal is to produce a denoised mesh from with updated vertex set . Compared with vertex positions, first-order normal variations are known to better capture the local surface variations [48]. Therefore, we take a normal filtering approach [2, 5, 1, 3, 9, 20] to formulate our mesh denoising method.
Distinctively, we design a deep neural network, called deep normal filtering network (or DNF-Net) to learn to map the noisy facet normal vectors to noise-free ground-truth facet normal vectors on meshes. In the course of formulating this network, we have the following considerations:
-
•
First, since mesh denoising is a low-level task, the network should focus on learning the local geometry. Hence, we propose to crop patches on the object surface and process facet normals per patch in the network; see the left part in Figure 2.
-
•
Second, to enhance the generality of the network, it should abstract local spatial patterns instead of just encoding each facet normal individually. Also, the network should produce the same results regardless of the order in the normals in its input; see in Figure 2. Hence, based on the mesh connectivity, we extract indices of the -nearest faces per face in the patch as the network inputs for the network to locate the face neighbors for further feature embedding.
-
•
Lastly, for efficiency concern, our network is end-to-end to directly output denoised facet normals, and supervise the network training with corresponding facet normals from the ground-truth meshes.
3.2 Training patch preparation
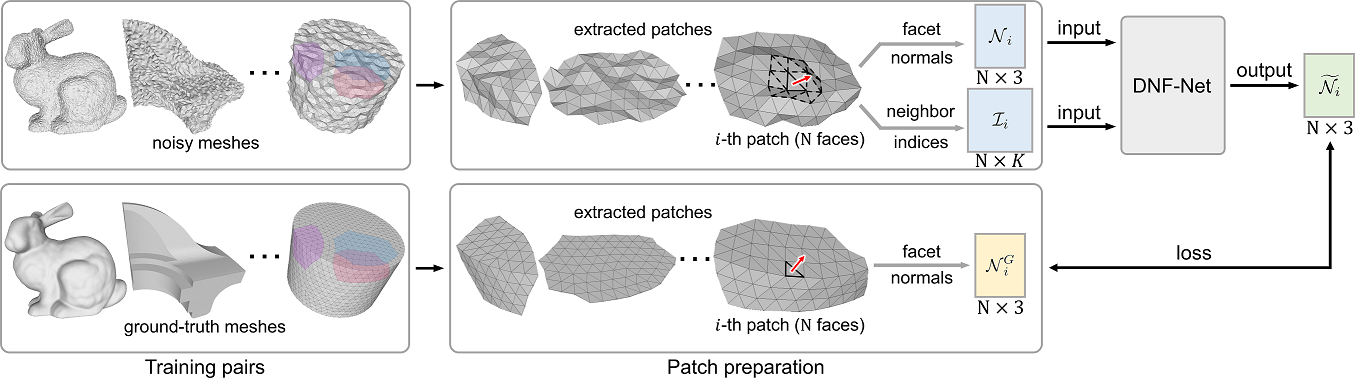
Given a pair of meshes, a noisy mesh and corresponding ground truth , as inputs, there are three steps to prepare the training patches from them. First, we locate a set of faces on as seeds to generate patches. To randomly select seed faces, such that the resulting patches exhibit more diverse surface patterns, we calculate the one-ring facet normal variation around each face and randomly pick seed faces by an anisotropic sampling based on the normal variance.
Second, from each seed face, we grow a patch by finding the nearby faces on with the shortest geodesic distances from the seed. Specifically, to compute the geodesic distance between the seed face and a nearby face, we try each of its three vertices as the start point, find the shortest geodesic distance to each vertex of a nearby face, then take the smallest distance among the nine distances as the geodesic distance from the seed face to that nearby face. Here, we use the heat method in [49]. Lastly, we sort all the distances among the surrounding (nearby) faces, and select the nearest ones. Hence, we can produce patches (with faces) that are more regular in shape for training.
Lastly, we pack the facet normals on each patch as the patch normal matrix . Also, we take advantage of the mesh connectivity and prepare patch index matrix , where each row represents a face on the patch and stores the indices (row indices in ) of the -nearest faces to the face on the patch. Then, we feed and as inputs to the network. Further, for each patch formed on , we follow the same procedure to form a patch from the corresponding seed face on and extract the corresponding facet normals to form matrix as ’s ground-truth to supervise the network; see Figure 2.

3.3 Network architecture
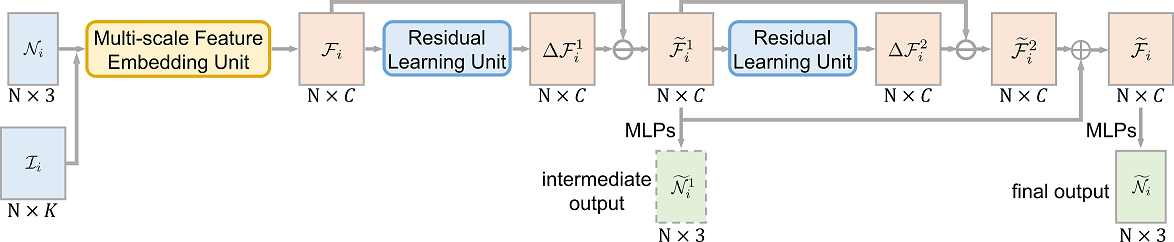
Figure 3 shows the overall architecture of DNF-Net. Taking and as inputs, DNF-Net first employs the multi-scale feature embedding unit (Section 3.3.1) to extract the normal feature map . Since contains noise, we thus model it as , where is the cleaned noise-free normal feature map and is the feature map of the noise.
Considering that the underlying noise-free surface is usually more diverse compared with the noise patterns, thus encoding is more effective than directly encoding . Hence, we feed to a residual learning unit (Section 3.3.2) to first extract the residual from . Naturally, the cleaned feature map is recast into . To enhance the outputs, we cascade the residual-learning-and-subtraction process in a progressive manner to obtain an intermediate cleaned feature map in the middle of the network, besides the final cleaned feature map ; see Figure 3. Importantly, instead of only supervising the final output from , we also regress an intermediate output from to give direct supervision when training the hidden layer in the network (Section 3.4).
3.3.1 Multi-scale feature embedding unit
For a comprehensive geometric understanding of a mesh structure, say locally around a vertex in the mesh, a general approach is to do a multi-scale analysis around the vertex, so that we can extract geometric features for different spatial scales. Particularly, the geometric structures usually vary over scales. Hence, given an input patch with facet normals, we formulate a multi-scale feature embedding unit of three levels to harvest geometric features of different scales. Specifically, the purpose of this unit is to extract normal feature map from and , where is the number of channels and is the number of faces (normals) on input patch. To do so, we build a three-level architecture to learn by progressively enlarging the contextual scales; see Figure 4 for the detailed illustration.
Specifically, in the first level of the multi-scale feature embedding unit, we design the normal grouping layer and feature extraction layer to generate an embedded feature map , given inputs and . In short, the normal grouping layer packs facet normals of the () nearest faces per face on the input patch using , while the feature extraction layer further extracts per-face local context information from the packed facet normals to learn . In this way, the -dimensional feature vector in each row of encodes the local context around each face at a scale of . We shall elaborate on each layer later in this subsection.
The second level has a similar structure as the first level (see again Figure 4), but it replaces the normal grouping layer by the feature grouping layer, since its input is a feature map instead of a set of normals, i.e., . Also, it replaces by () to consider a larger local context to generate the next-level embedded feature map . The third level is almost the same as the second level, but it considers an even larger local context with () to generate the embedded feature map from . Note that, to realize a progressively-enlarging local context to improve the feature embedding, we ensure . Lastly, we concatenate , , , and , and pass the result via a series of multi-layer perceptrons (MLPs) to generate ; see the rightmost portion of Figure 4.
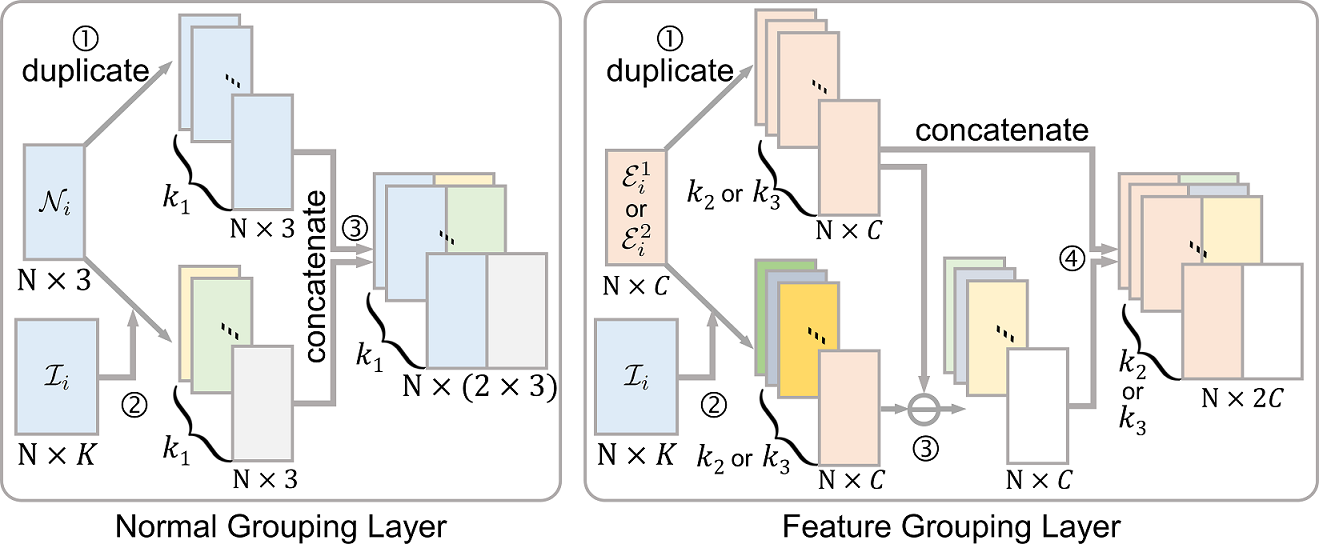
Normal grouping layer. To abstract local spatial patterns (features) around each face on the input patch, instead of just constructing per-face features by encoding individual facet normal, we design the normal grouping layer to pack nearby facet normal vectors around each face for subsequent feature extraction. Note that each row in patch normal matrix stores one normal vector of a face on the patch.
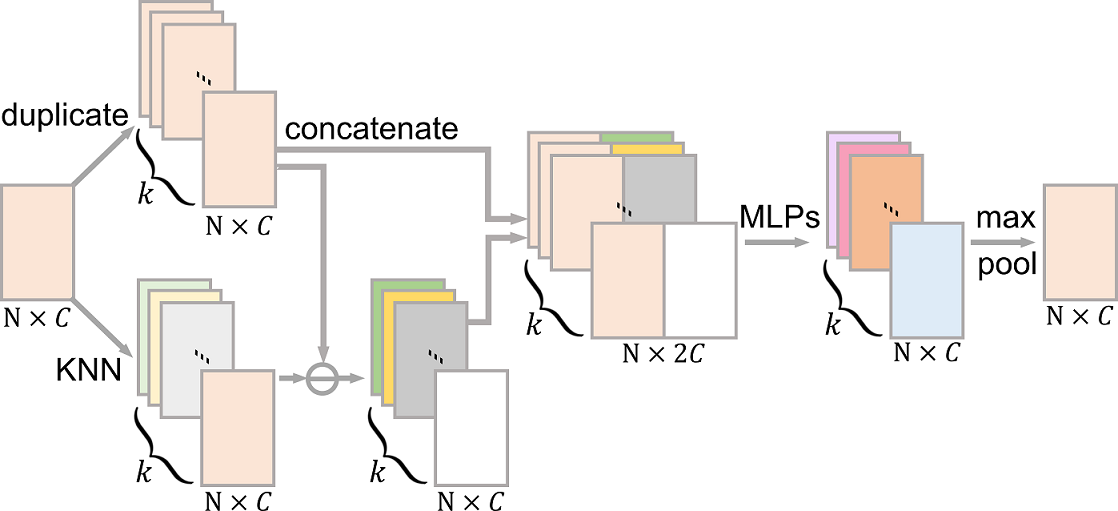
The detailed procedure of the normal grouping layer is illustrated on the left side of Figure 5. Specifically, we first create duplicated copies of , i.e., an volume. Second, for each face in , we make use of to locate the nearest faces to the face, then pack their facet normals to produce another volume, altogether for all the faces. After that, we concatenate these two volumes to produce a new volume of size , as the output of the normal grouping layer. By doing so, we combine the global structure captured by the normal vectors over the patch, and the local neighborhood information captured by the packed nearby normals per face. Overall, this normal grouping layer (similarly for the feature grouping layer) helps to pack, or re-arrange, the normal data, such that spatially-nearby normal vectors are grouped together per vertex. By this means, we can consider local neighborhoods in the upcoming feature extraction layer and better capture local geometric structures.
Feature grouping layer. As shown in Figure 4, the inputs to the second and third levels are no longer 3D normal vectors but embedded feature vectors, i.e., or . Hence, we design a feature grouping layer to pack these per-face embedded feature vectors; see the right side of Figure 5.
First, we also use to locate the nearest (second level) or (third level) faces to generate an or feature volume. However, rather than directly concatenating it with another volume of duplicated or , we compute the residual via a subtraction operator before the feature volume concatenation; see step 3 on the right side of Figure 5. Such subtraction helps to capture the local neighborhood information, while considering the global structure [32]. Note also that we employ the subtraction in feature grouping rather than normal grouping, since it helps to find residuals for embedded feature vectors but not for 3D normal vectors. Hence, the output of the feature grouping layer is a volume of data of size of for the second level or for the third level.
Feature extraction layer. Feature extraction is important, since weak features offer less help to abstract the spatial structures, thus lowering the network performance. See again Figure 4. After normal grouping or feature grouping, we employ a feature extraction layer to extract features () from the grouped normal vectors () or grouped feature vectors ( or ). A common solution here is to use MLPs followed by a max pooling, like several other works, e.g., [29, 37, 35]. However, since we employ the concatenation operation on the channel direction to combine both local and global information in our grouping layers (see Figure 5), we propose to use the channel attention module [50] to replace MLPs to better fuse the features among the different channels. The basic idea of this module is to learn the channel weights from the grouped normal or feature vectors via MLPs, then use the weights to adjust the importance of each channel. For more details of the channel attention module, readers may refer to [50].
3.3.2 Residual learning unit
After presenting the multi-scale feature embedding unit, we now go back to the overall architecture (see Figure 3) and present the residual learning unit. This unit extracts the noise feature from the normal feature , so that we can later obtain the denoised feature map by .
To better extract features for denoising, we should encode features over a local neighborhood rather than just as an individual feature vector. Hence, like the feature grouping layer, this unit also finds the -most similar feature vectors for each of the feature vectors in . However, it employs KNN to locate similar feature vectors in the feature space instead of using the index matrix [32]; see Figure 6. The reason behind is that, in the multi-scale feature embedding unit, our goal is to extract representative features to encode local context, so using enables us to locate features that are geodesically nearby. In this residual learning unit, we, however, need to extract residual features from the input feature map , so we employ KNN search and extract features by considering feature similarity in the feature space. In our experimental settings, as suggested by [32], we set in this unit. As shown in Figure 6, after the concatenation between the duplicated ( copies) input feature vectors () and their associated -most similar feature vectors, we use two MLPs followed by a max pooling to get the residual feature map of size .
Also, as shown in Figure 3, we use two consecutive residual learning units to progressively remove noise and to improve the overall denoising performance. For an experiment that explores the effect of using a different number of residual learning units, please refer to Section 4.3.
3.4 Deeply-supervised end-to-end training
We design a deeply-supervised joint loss function with two terms to train the proposed network in an end-to-end manner: (i) deeply-supervised normal recovery loss and (ii) residual regularization loss.
Deeply-supervised normal recovery loss. To encourage the denoised facet normals to be consistent with the ground truth normals , we use an norm to minimize the difference between and . However, considering the deep-ness of our network, we further add another feedback, or supervision, on the companion intermediate output (see the middle part in Figure 3), by applying an norm to minimize also the difference between and . So, the deeply-supervised normal recovery loss is expressed as
| (1) |
where is the total number of training patches. By doing so, we can directly influence the parameters in the hidden layer to enhance the quality of the feature maps.
Residual regularization loss. As shown in Figure 3, DNF-Net progressively learns the residual features and . Theoretically, these residual features should just be a small portion of . Having said that, the magnitude of and should not be too large. Hence, we formulate the residual regularization loss on and as
| (2) |
3.5 Implementation details
Datasets. In our experiments, we use the two benchmark datasets kindly provided by [1] to train our network: (i) a synthetic dataset and (ii) a real-scanned dataset. The synthetic dataset contains 21 training models and 30 testing models, including CAD models, smooth models, and models with rich fine details. For each model, the dataset provides a noise-free mesh as ground truth and three noisy meshes. These noisy meshes are generated by adding three different magnitudes of Gaussian noise into the noise-free mesh; the standard deviations of the noise in these meshes are , , and , where is the average edge length in the mesh. On the other hand, the real-scanned dataset has 146 training noisy meshes and 149 testing noisy meshes. Each noisy mesh is accompanied with a clean mesh as the ground truth. For more details, readers may refer to [1].
Network training. Observing that the synthetic and real-scanned datasets have very different noise distributions, we follow the existing data-driven method, i.e., CNR [1], to train our network separately on each dataset for obtaining our results on synthetic meshes and real-scanned meshes. We plan to explore knowledge distillation techniques in the future to combine the two trained network models.
For each training mesh in the synthetic dataset, we crop patches, each with faces, such that a patch roughly covers 5% to 10% of the whole mesh. For each face in a patch, we empirically store neighboring face indices, and uniformly set , , and in the multi-scale feature embedding unit (see Section 3.3.1) of our network. For each training mesh in the real-scanned dataset, we crop more patches with , due to the complex noise distributions, and each patch has faces. Considering that most of the real-scanned meshes have simple and smooth structures, we store neighbor facet indices for each face and set , , and . Please see the supplementary material for the effect of different parameter settings on the real-scanned dataset.
To avoid over-fitting in network training, we augmented by adopting random rotation and jittering. We implemented our method using TensorFlow and adopted the Adam optimizer with a mini-batch size of 10 and a learning rate of 0.001, as well as trained the network with 400 epochs. Our trained network model, data, and code can be found on the GitHub project page 111https://github.com/nini-lxz/DNF-Net.
Network inference. Given a test mesh, we crop patches on the mesh following the procedure of preparing training patches, then employ the trained network to produce denoised normals on the patches. After that, we integrate the denoised normals on all patches to compute facet normals over the mesh, and follow [3] to pass the restored facet normals to the iterative vertex updating method [51] to update vertex positions and produce the denoised mesh.
4 Results and Discussions
To demonstrate the effectiveness of our method, we compare it with several state-of-the-art methods, including minimization (LM) [10], guided normal filtering (GNF) [5], cascaded normal regression (CNR) [1], non-local low-rank normal filtering (NLLR) [3], graph spectral processing approach (GSP) [13], and patch normal co-filter (PcFilter) [9]. For LM, GNF, and NLLR, we obtained their publicly-released codes and fine-tuned their model parameters with best effort to produce their denoising results; see our supplementary material for the details of the employed parameter values. For CNR, we directly employed their released trained models to generate their results, while for GSP and PcFilter, we obtained their results directly from the authors.
Following the recent works [1, 3], we also employed the mean angular difference metric (denoted as ) to quantitatively evaluate and compare the results produced by the various methods. By definition, is the mean angular difference (in degrees) between the corresponding facet normals in the ground truth and denoised meshes. Hence, a small value indicates a better denoising result. Note that, is calculated on each denoised mesh after the vertex update, and all methods being compared (including our method) use the same vertex update algorithm [51].

4.1 Results on Synthetic Models
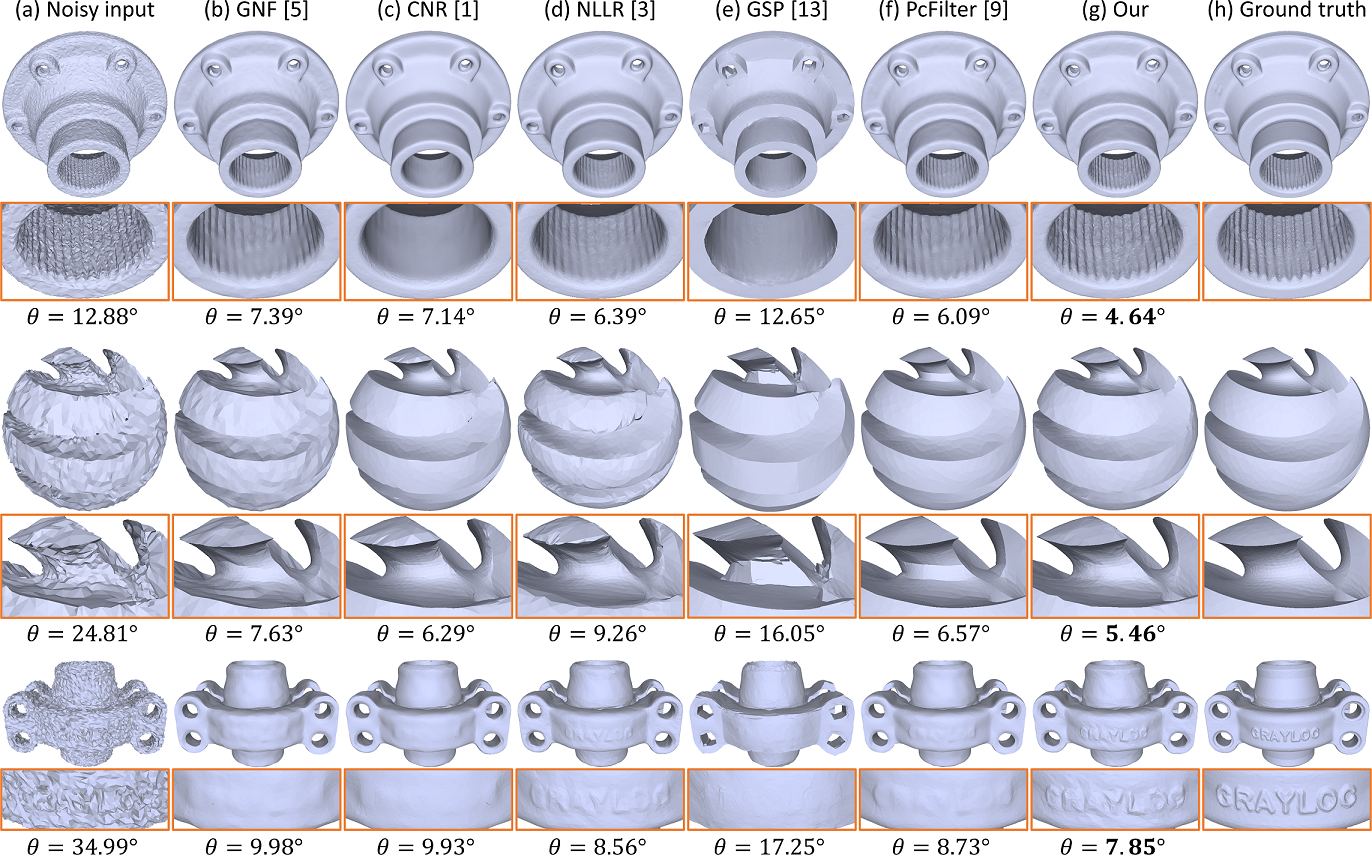
First, we compare our method with the state-of-the-arts on test models provided in the synthetic dataset of [1]. Figure 7 shows the visual comparisons on three noisy meshes with different amount of Gaussian noise. Comparing the results produced by our method (g) and others (b-f) with the ground truths (h), we can see that the other methods tend to over-smooth the fine details, over-sharpen the edges, or retain excessive noise in the results. Our method is able to preserve more geometric details and recover the sharp edges, while effectively removing the noise; see particularly the blown-up views in Figure 7. See also the value below each generated result. Overall, our method achieved the smallest values for all models compared with all the other methods; see Part 1 of the supplementary material for more comparison results. Besides, for each denoised mesh shown in Figure 7, we visualize its normal error distribution; please refer to Part 9 of our supplementary material.
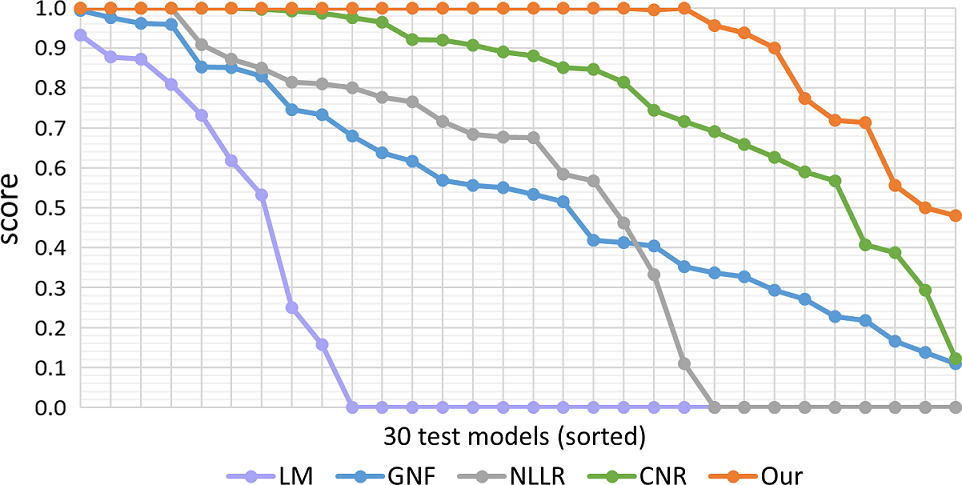
Further, we expand the quantitative comparison by considering all the 30 test models in the dataset. Note that, for each test model, [1] provides three noisy meshes with different Gaussian noise levels. Here, we define as the averaged value achieved by method over the three noisy meshes of the -th test model. Also, we define normalized score achieved by method on -th test model as
| (4) |
so a value of one indicates best result among the methods.
Figure 8 plots the scores achieved by each method over the 30 test models. Note that to more clearly reveal the results, the 30 score values over the test models per method are sorted in descending order when producing each plot. Also, we consider only LM [10], GNF [5], CNR [1], and NLLR [3], since we have obtained their code or denoising results for all the test models in the dataset. From the plots, we can see that our method obtains the best results (scores of one) for most test models, while the other methods start to drop much earlier. More importantly, the test models have various geometric structures, including simple and smooth surface, sharp edges, and highly-detailed fine structures. The reason behind the success of our method is that formulating a deep neural network allows us to more exhaustively extract discriminative features from the data to differentiate the underlying details and noise in the input meshes, while the other methods heavily rely on hand-crafted features from the assumptions or priors on the input models.
4.2 Results on Real-scanned Models
Next, we compare our method with others on real-scanned models. Besides the results shown earlier in Figure 1, we further show in Figure 9 more visual comparison results on three other Kinect real-scanned models [1]. From the noisy input models on the leftmost column of the figure, we can see that Kinect scanning produces severe and irregular noise. Such noise pattern differs from that of the Gaussian noise. Comparing the results produced by various methods, the other methods tend to retain noise in their results, or fail to smooth flat surfaces. On the contrary, our method is able to produce denoised models that are more smooth and closer to the ground truths, as verified again by the smallest values achieved by our method on the models. Additionally, please refer to Parts 2 and 9 of the supplementary material for more real-scanned comparison results and for the normal error visualizations on the denoised meshes shown in Figure 9, respectively.
| Different | Model | ||||
|---|---|---|---|---|---|
| cases | Block | Cube | Sphere | Carter100K | Eros100K |
| w/o inter | 2.38∘ | 1.38∘ | 2.38∘ | 5.84∘ | 7.21∘ |
| w/o reg | 2.43∘ | 1.13∘ | 2.43∘ | 5.88∘ | 7.20∘ |
| w/o sub | 2.69∘ | 1.42∘ | 2.41∘ | 6.02∘ | 7.23∘ |
| 1 res unit | 2.24∘ | 1.25∘ | 2.41∘ | 5.92∘ | 7.23∘ |
| 3 res units | 2.12∘ | 1.03∘ | 2.24∘ | 5.86∘ | 7.14∘ |
| full pipeline | 2.12∘ | 0.96∘ | 2.37∘ | 5.81∘ | 7.20∘ |
4.3 Network Ablation Study
To evaluate the effectiveness of the major components in our method, we conducted an ablation study by simplifying DNF-Net in the following four cases.
- (i)
-
(ii)
w/o reg: we remove the residual regularization loss term (i.e., Eq. (2)) from the total loss of our network.
-
(iii)
w/o sub: we compute a residual in step 3 of the feature grouping layer (Figure 5) by a subtraction operation before concatenating two feature volumes. Such an operation helps capture the local information for denoising. To verify its effectiveness, we remove it and directly concatenate the two feature volumes.
-
(iv)
# res units: as shown in Figure 3, our network cascades two residual learning units successively in the overall network architecture. Instead of deploying two residual learning units, we tried “1 res unit” and “3 res units” to explore the effect of the number of residual learning units on the network performance. Note that, for fair comparison, we modified both Eqs. (1) & (2) to supervise the output of every residual learning unit in the network.
Specifically, we re-trained the network model separately for each case using the same training dataset of synthetic models (see Section 3.5) and tested each network on five test models, i.e., Block, Cube, Sphere, Carter100K, and Eros100K, which contain sharp edges, simple structure, and fine details. As mentioned earlier, each provided model has three versions of noisy meshes. Hence, similar to Section 4.1, we test each network on all the three noisy meshes per model, then compute the averaged value achieved over the three noisy meshes as the overall value of the model.
Table I shows the results. By comparing the top three rows with the bottom-most row (our full pipeline), we can see that each term in our loss function contributes to the mesh denoising performance, including the supervision on intermediate output and residual regularization loss term. Besides, the subtraction operation in the feature grouping layer also contributes to improving the overall performance.
Further, the network with only one residual learning unit (4-th row) achieved a worse result than our full pipeline with two residual learning units. If we increase the number of residual learning units to three (5-th row), the performance improves only slightly on two models, but the number of network parameters increases from 0.36M to 0.44M. Hence, we decided to deploy two residual learning units in our network to balance the performance and efficiency.
4.4 Robustness Test
Next, we explore the robustness of DNF-Net by considering (i) varying mesh resolution (i.e., different number of faces in the same model); (ii) irregular mesh triangulation; (iii) unseen noise patterns; and (iv) varying noise intensities.
Robustness on mesh resolution. Most existing methods are sensitive to the mesh resolution, where the error metric could have large fluctuation for low-resolution meshes. It is because these methods filter normals (or vertices) using a local neighborhood of a fixed number of rings, e.g., one- or two-ring neighborhood. Hence, when given a low-resolution mesh, they could involve a too large neighborhood in the filtering, thus leading to over-smoothing [5].
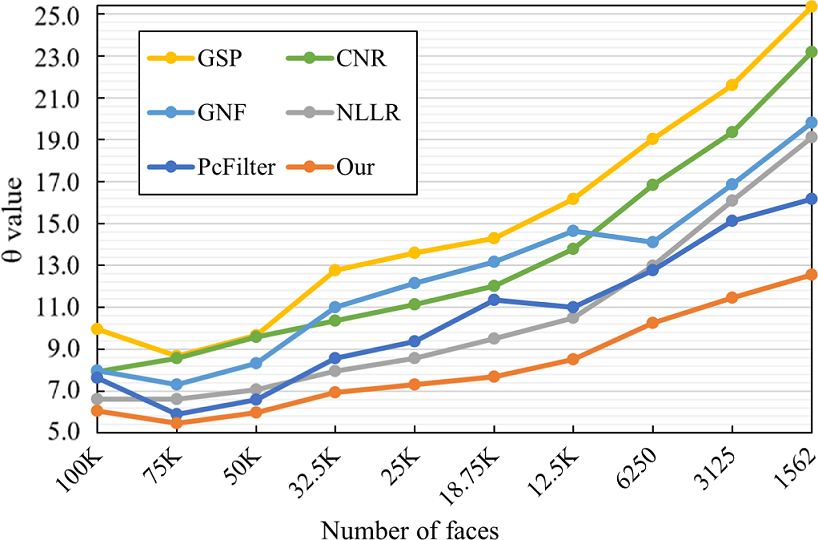
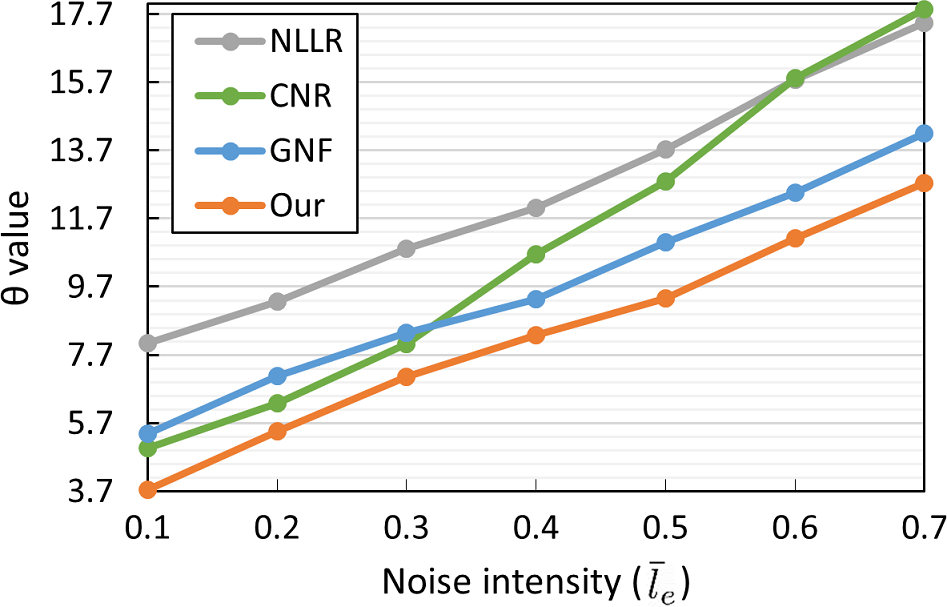
Thanks to the patch-based training strategy, our DNF-Net is trained for various sizes of local neighborhoods for different models. Hence, it can become less sensitive to the mesh resolution. To explore this, we employed noisy Eros models of different resolutions as the inputs and plotted of the denoised results by various methods in Figure 10. Here, we directly used our trained network to test all the inputs without re-training or fine-tuning the network. From the plots in Figure 10, we can see that our method (orange plot) consistently has the lowest values vs. all the others for various mesh resolutions. Particularly, when the number of faces is reduced to less than 50K, the gaps of values between our method and the others gradually increase. For example, when the number of faces is reduced from 50K down to 1562, the increased value for our method is 6.57 vs. 9.58 for the second-best one. This shows that DNF-Net is not as sensitive as others to the mesh resolution.
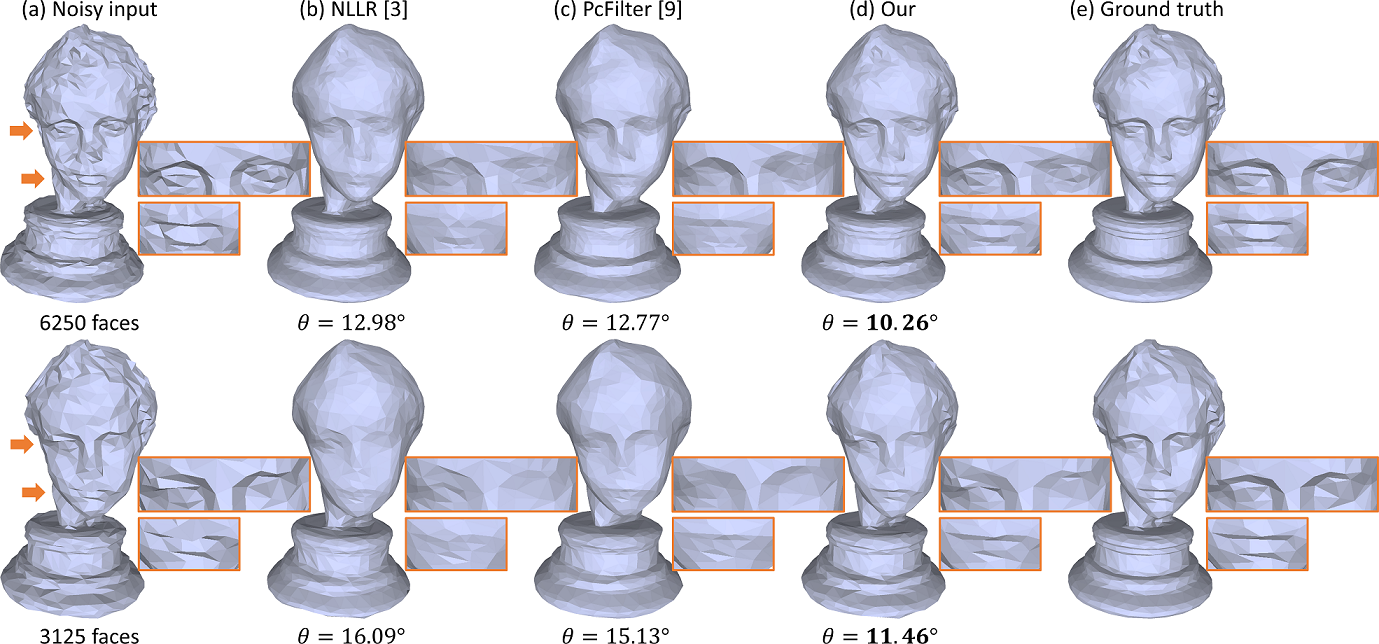
Further, Figure 11 shows the visual comparisons on two example low-resolution Eros models with 6250 and 3125 faces. Comparing the results in (b), (c), and (d), we can see that the other two methods overly smooth out the details, while our method can better preserve the fine details; see the areas around the eyes and mouth in the results. Also, it achieves the lowest values for both resolutions.
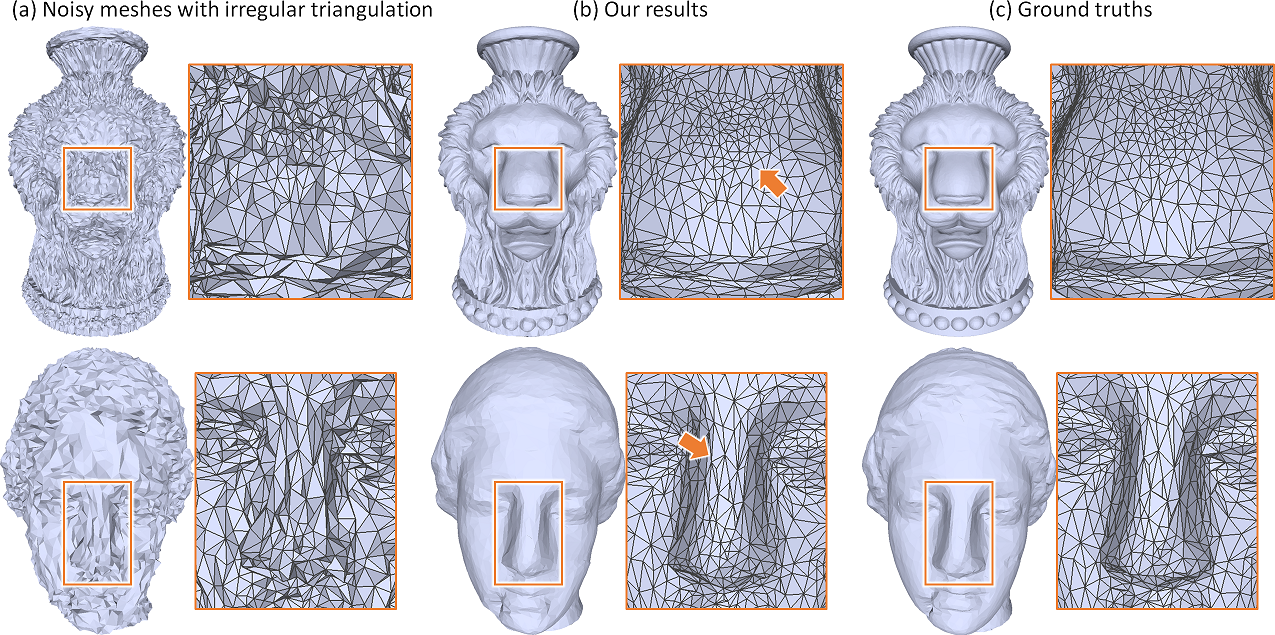
Robustness on irregular triangulation. Next, we test the robustness of our method on handling noisy meshes with irregular triangulation. Figure 13 (a) shows two example meshes with elongated triangles and irregular vertex degrees; see particularly the blown-up views of the nose regions in the figure. Still, the results produced by our method (b) are quite close to the ground truths (c). Note that some comparison results with other methods are also presented in Part 8 of the supplementary material.
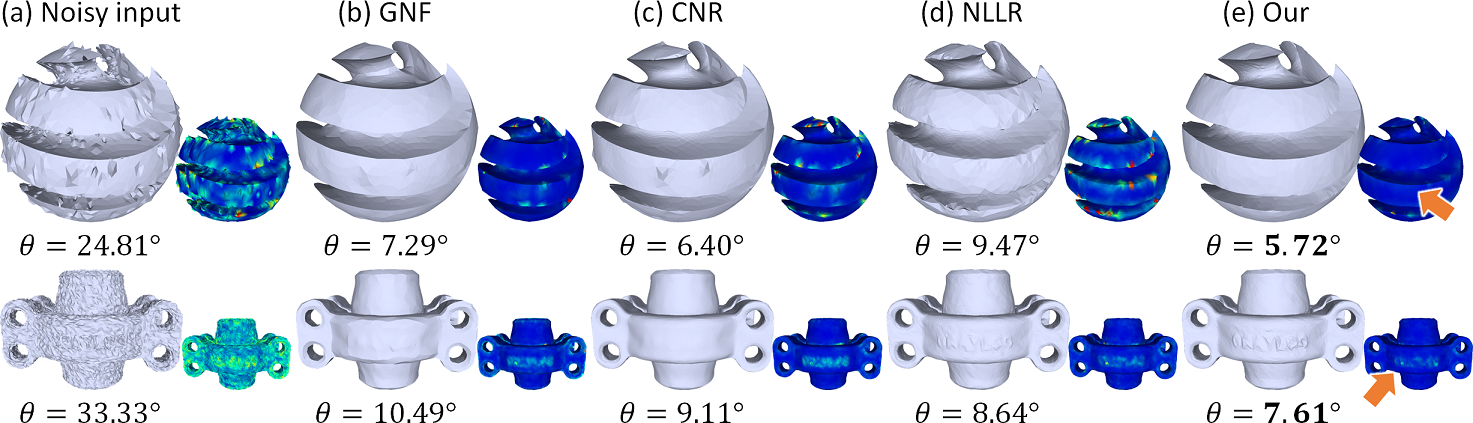
Robustness on noise patterns. Further, we tested the generalization ability of our network on handling 3D meshes of noise patterns different from the noise pattern employed in the training set. To do so, we directly employed our trained network to denoise meshes corrupted by impulsive noise and uniform noise (by replacing the Gaussian noise we employed with a uniform-distributed noise). Figure 14 shows comparisons on two 3D meshes corrupted with impulsive noise (top) and uniform noise (bottom). From the normal error visualizations and the values presented in the figure, we can see that our network has a superior performance for both input meshes, even though our network was trained only on Gaussian noisy meshes. Please refer to supplementary material Part 6 for more results on noise patterns.
Noting that Gaussian noise, uniform noise, and impulsive noise are all synthetic additive noises. Hence, the differences between their distribution variations may not be very large (compared to real-scanned noise). As a result, our DNF-Net model trained only on Gaussian noise can still generalize well to handle other noise patterns.
Robustness on noise intensities. Lastly, we tested our network on 3D meshes corrupted with noise intensities larger than those in the training set. Here, we used the training set of CNR [1] with Gaussian noise magnitude from to , for which the released network of CNR was trained. In this regard, for a fair comparison, we directly applied the trained models of both our network and CNR to denoise 3D meshes of noise magnitude above , without re-training the networks. Figure 12 plots the values for using various methods to denoise 3D meshes of increasing noise intensities, from to . From the plots, we can see that our method consistently achieves a better performance with the lowest values for all noise levels. Please refer to supplementary material Part 7 for more results.
4.5 Discussions
Time performance. Our network takes only 0.04 seconds to process a patch on an NVidia Titan Xp GPU. Further, since patch processing can be parallelized, our method’s running time does not increase linearly with the number of patches. Hence, to process thousands of patches on a dense mesh, e.g., a model with 50K faces, our method takes only 40 seconds. If more GPUs are available, the computation time can be further shortened.
Limitations. First, as a common drawback of data-driven methods like [1], our DNF-Net may produce unsatisfying denoising results, if we apply a network to process a test mesh whose noise pattern is very different from that in the training set. We plan to explore domain adaptation techniques to extract or transfer knowledge from the unpaired data source. Also, our method cannot handle meshes with faulty topological issues, e.g., self-intersection and inconsistent facet normal orientation. Such cases are also hard for existing filter-based and optimization-based methods. Lastly, our network requires paired data (noisy meshes with ground truths) to train. However, collecting a large amount of paired datasets is expensive and time-consuming. In the future, we plan to explore the possibility of learning from unpaired data or training in an unsupervised manner.
5 Conclusion
This paper presents a novel deep normal filtering network, namely DNF-Net, formulated for mesh denoising. DNF-Net is an end-to-end network that directly predicts denoised facet normals from noisy input meshes, without requiring explicit information about the underlying surface or the noise characteristics. To effectively learn the local geometric patterns for denoising meshes, DNF-Net processes normal data grouped by patches. Further, we design the multi-scale feature embedding unit to extract normal features, followed by the cascaded residual learning units to progressively remove noise. Also, we drive DNF-Net to learn by formulating a deeply-supervised joint loss function with a normal recovery loss and a residual regularization loss. Lastly, we performed several experiments on our methods using a rich variety of synthetic and real-scanned models. Both visual and quantitative comparisons demonstrate the superiority of our method over the state-of-the-arts.
As the first attempt to design a deep neural network to filter facet normal for mesh denoising, our DNF-Net can yet be improved in several aspects. First, instead of using only the normal data for denoising, we might as well consume other mesh information to enhance the extracted features, e.g., vertex position, facet centroid, etc. Second, we plan to explore graph convolutional networks to take into account the mesh topology in the network learning. Third, enhancing the vertex update technique, e.g., to handle local fold overs, will certainly help to improve the robustness of the overall method. On the other hand, exploring techniques in domain adaptation and transfer learning is another future direction for improving the network generalization ability, particularly for handling real-scanned inputs.
Acknowledgments
We thank anonymous reviewers for their valuable comments. The work is supported by the Hong Kong Research Grants Council with Project No. CUHK 14225616, Key-Area Research and Development Program of Guangdong Province, China (2020B010165004), and National Natural Science Foundation of China with Project No. U1813204. The work is also supported by the Research Grants Council of the Hong Kong Special Administrative Region (Project No. CUHK 14201717) and National Natural Science Foundation of China (Grant No. 61902275).
References
- [1] P. Wang, Y. Liu, and X. Tong, “Mesh denoising via cascaded normal regression,” ACM Trans. on Graphics (SIGGRAPH Asia), vol. 35, no. 6, pp. 232:1–12, 2016.
- [2] Y. Zheng, H. Fu, O. K.-C. Au, and C.-L. Tai, “Bilateral normal filtering for mesh denoising,” IEEE Trans. Vis. Comp. Graphics, vol. 17, no. 10, pp. 1521–1530, 2011.
- [3] X. Li, L. Zhu, C.-W. Fu, and P.-A. Heng, “Non-local low-rank normal filtering for mesh denoising,” Computer Graphics Forum (Pacific Graphics), vol. 37, no. 7, pp. 155–166, 2018.
- [4] K.-W. Lee and W.-P. Wang, “Feature-preserving mesh denoising via bilateral normal filtering,” in Ninth Int. Conf. on Computer Aided Design and Computer Graphics, 2005, pp. 275–280.
- [5] W. Zhang, B. Deng, J. Zhang, S. Bouaziz, and L. Liu, “Guided mesh normal filtering,” Computer Graphics Forum (Pacific Graphics), vol. 34, no. 7, pp. 23–34, 2015.
- [6] L. Zhu, M. Wei, J. Yu, W. Wang, J. Qin, and P.-A. Heng, “Coarse-to-fine normal filtering for feature-preserving mesh denoising based on isotropic subneighborhoods,” Computer Graphics Forum (Pacific Graphics), vol. 32, no. 7, pp. 371–380, 2013.
- [7] M. Wei, L. Liang, W.-M. Pang, J. Wang, W. Li, and H. Wu, “Tensor voting guided mesh denoising,” IEEE Trans. on Automation Science and Engineering, vol. 14, no. 2, pp. 931–945, 2016.
- [8] S. K. Yadav, U. Reitebuch, and K. Polthier, “Mesh denoising based on normal voting tensor and binary optimization,” IEEE Trans. Vis. Comp. Graphics, vol. 24, no. 8, pp. 2366–2379, 2017.
- [9] M. Wei, J. Huang, X. Xie, L. Liu, J. Wang, and J. Qin, “Mesh denoising guided by patch normal co-filtering via kernel low-rank recovery,” IEEE Trans. Vis. Comp. Graphics, vol. 25, no. 10, pp. 2910–2926, 2019.
- [10] L. He and S. Schaefer, “Mesh denoising via minimization,” ACM Trans. on Graphics (SIGGRAPH), vol. 32, no. 4, pp. 64:1–8, 2013.
- [11] X. Lu, W. Chen, and S. Schaefer, “Robust mesh denoising via vertex pre-filtering and -median normal filtering,” Computer Aided Geometric Design, vol. 54, pp. 49–60, 2017.
- [12] Y. Zhao, H. Qin, X. Zeng, J. Xu, and J. Dong, “Robust and effective mesh denoising using sparse regularization,” Computer-Aided Design, vol. 101, pp. 82–97, 2018.
- [13] G. Arvanitis, A. S. Lalos, K. Moustakas, and N. Fakotakis, “Feature preserving mesh denoising based on graph spectral processing,” IEEE Trans. Vis. Comp. Graphics, vol. 25, no. 3, pp. 1513–1527, 2019.
- [14] D. A. Field, “Laplacian smoothing and Delaunay triangulations,” Communications in applied numerical methods, vol. 4, no. 6, pp. 709–712, 1988.
- [15] G. Taubin, “A signal processing approach to fair surface design,” Proc. of SIGGRAPH, pp. 351–358, 1995.
- [16] M. Desbrun, M. Meyer, P. Schröder, and A. H. Barr, “Implicit fairing of irregular meshes using diffusion and curvature flow,” Proc. of SIGGRAPH, pp. 317–324, 1999.
- [17] J. Vollmer, R. Mencl, and H. Mueller, “Improved Laplacian smoothing of noisy surface meshes,” Computer Graphics Forum (Eurographics), vol. 18, no. 3, pp. 131–138, 1999.
- [18] S. Fleishman, I. Drori, and D. Cohen-Or, “Bilateral mesh denoising,” ACM Trans. on Graphics (SIGGRAPH), vol. 22, no. 3, pp. 950–953, 2003.
- [19] T. R. Jones, F. Durand, and M. Desbrun, “Non-iterative feature preserving mesh smoothing,” ACM Trans. on Graphics (SIGGRAPH), vol. 22, no. 3, pp. 943–949, 2003.
- [20] J. Wang, J. Huang, F.-L. Wang, M. Wei, H. Xie, and J. Qin, “Data-driven geometry-recovering mesh denoising,” Computer-Aided Design, vol. 114, pp. 133–142, 2019.
- [21] Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao, “3D ShapeNets: A deep representation for volumetric shapes,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 1912–1920.
- [22] D. Maturana and S. Scherer, “VoxNet: A 3D convolutional neural network for real-time object recognition,” in IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2015, pp. 922–928.
- [23] C. R. Qi, H. Su, M. Nießner, A. Dai, M. Yan, and L. J. Guibas, “Volumetric and multi-view CNNs for object classification on 3D data,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 5648–5656.
- [24] P. Wang, Y. Liu, Y. Guo, C. Sun, and X. Tong, “O-CNN: Octree-based convolutional neural networks for 3D shape analysis,” ACM Trans. on Graphics (SIGGRAPH), vol. 36, no. 4, pp. 72:1–11, 2017.
- [25] P. Wang, C. Sun, Y. Liu, and X. Tong, “Adaptive O-CNN: a patch-based deep representation of 3D shapes,” ACM Trans. on Graphics (SIGGRAPH Asia), vol. 37, no. 6, pp. 217:1–11, 2018.
- [26] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas, “Frustum PointNets for 3D object detection from RGB-D data,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 918–927.
- [27] H. Su, S. Maji, E. Kalogerakis, and E. Learned-Miller, “Multi-view convolutional neural networks for 3D shape recognition,” in IEEE Int. Conf. on Computer Vision (ICCV), 2015, pp. 945–953.
- [28] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “PointNet: Deep learning on point sets for 3D classification and segmentation,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 652–660.
- [29] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “PointNet++: Deep hierarchical feature learning on point sets in a metric space,” in Conference and Workshop on Neural Information Processing Systems (NeurIPS), 2017, pp. 5099–5108.
- [30] Y. Li, R. Bu, M. Sun, W. Wu, X. Di, and B. Chen, “PointCNN: Convolution on -transformed points,” in Conference and Workshop on Neural Information Processing Systems (NeurIPS), 2018, pp. 828–838.
- [31] A. Matan, M. Haggai, and L. Yaron, “Point convolutional neural networks by extension operators,” ACM Trans. on Graphics (SIGGRAPH), vol. 37, no. 4, pp. 71:1–12, 2018.
- [32] Y. Wang, Y. Sun, Z. Liu, S. E. Sarma, M. M. Bronstein, and J. M. Solomon, “Dynamic graph CNN for learning on point clouds,” ACM Trans. on Graphics, vol. 38, no. 5, pp. 146:1–12, 2019.
- [33] Y. Yang, C. Feng, Y. Shen, and D. Tian, “FoldingNet: Point cloud auto-encoder via deep grid deformation,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 206–215.
- [34] H. Deng, T. Birdal, and S. Ilic, “PPF-Foldnet: Unsupervised learning of rotation invariant 3D local descriptors,” in European Conf. on Computer Vision (ECCV), 2018, pp. 602–618.
- [35] L. Yu, X. Li, C.-W. Fu, D. Cohen-Or, and P.-A. Heng, “PU-Net: Point cloud upsampling network,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 2790–2799.
- [36] W. Yifan, S. Wu, H. Huang, D. Cohen-Or, and O. Sorkine-Hornung, “Patch-based progressive 3D point set upsampling,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5958–5967.
- [37] W. Yuan, T. Khot, D. Held, C. Mertz, and M. Hebert, “PCN: Point completion network,” in Int. Conf. on 3D Vision (3DV), 2018, pp. 728–737.
- [38] L. Yi, W. Zhao, H. Wang, M. Sung, and L. J. Guibas, “GSPN: Generative shape proposal network for 3D instance segmentation in point cloud,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 3947–3956.
- [39] H. Kato, Y. Ushiku, and T. Harada, “Neural 3D mesh renderer,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 3907–3916.
- [40] N. Wang, Y. Zhang, Z. Li, Y. Fu, W. Liu, and Y. Jiang, “Pixel2Mesh: Generating 3D mesh models from single RGB images,” in European Conf. on Computer Vision (ECCV), 2018, pp. 52–67.
- [41] O. Litany, A. Bronstein, M. Bronstein, and A. Makadia, “Deformable shape completion with graph convolutional autoencoders,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 1886–1895.
- [42] A. Dai and M. Nießner, “Scan2Mesh: From unstructured range scans to 3D meshes,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5574–5583.
- [43] A. Ranjan, T. Bolkart, S. Sanyal, and M. J. Black, “Generating 3D faces using convolutional mesh autoencoders,” in European Conf. on Computer Vision (ECCV), 2018, pp. 704–720.
- [44] R. Hanocka, A. Hertz, N. Fish, R. Giryes, S. Fleishman, and D. Cohen-Or, “MeshCNN: A network with an edge,” ACM Trans. on Graphics (SIGGRAPH), vol. 38, no. 4, pp. 90:1–12, 2019.
- [45] Y. Feng, Y. Feng, H. You, X. Zhao, and Y. Gao, “MeshNet: Mesh neural network for 3D shape representation,” in AAAI Conf. on Artificial Intell. (AAAI), 2019, pp. 8279–8286.
- [46] L. Yi, H. Su, X. Guo, and L. J. Guibas, “SyncSpecCNN: Synchronized spectral CNN for 3D shape segmentation,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2282–2290.
- [47] I. Kostrikov, Z. Jiang, D. Panozzo, D. Zorin, and J. Bruna, “Surface networks,” in IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 2540–2548.
- [48] T. Tasdizen, R. Whitaker, P. Burchard, and S. Osher, “Geometric surface processing via normal maps,” ACM Trans. on Graphics, vol. 22, no. 4, pp. 1012–1033, 2003.
- [49] K. Crane, C. Weischedel, and M. Wardetzky, “Geodesics in heat: A new approach to computing distance based on heat flow,” ACM Trans. on Graphics (SIGGRAPH), vol. 32, no. 5, pp. 152:1–11, 2013.
- [50] S. Woo, J. Park, J.-Y. Lee, and I. So Kweon, “CBAM: Convolutional block attention module,” in European Conf. on Computer Vision (ECCV), 2018, pp. 3–19.
- [51] X. Sun, P. Rosin, R. Martin, and F. Langbein, “Fast and effective feature-preserving mesh denoising,” IEEE Trans. Vis. Comp. Graphics, vol. 13, no. 5, pp. 925–938, 2007.
- [52] P. Cignoni, M. Corsini, and G. Ranzuglia, “MeshLab: an open-source 3D mesh processing system,” ERCIM News, no. 73, 2008.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/cb1ebc07-2383-4baa-9190-4e3de960f5cf/xianzhi.png) |
Xianzhi Li is currently a PhD student in the Department of Computer Science and Engineering, the Chinese University of Hong Kong. She will receive her Ph.D. degree in July, 2020. She served as the reviewers of CVPR 2020 and WACV 2021. Her research interests focus on geometry processing, computer graphics, and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/cb1ebc07-2383-4baa-9190-4e3de960f5cf/ruihui.png) |
Ruihui Li is currently a PhD student in the Department of Computer Science and Engineering, the Chinese University of Hong Kong. His research interests include 3D processing, computer graphics, and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/cb1ebc07-2383-4baa-9190-4e3de960f5cf/zhu.png) |
Lei Zhu received his Ph.D. degree in the Department of Computer Science and Engineering from the Chinese University of Hong Kong in 2017. He is working as a postdoctoral fellow in the Chinese University of Hong Kong. His research interests include computer graphics, computer vision, medical image processing, and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/cb1ebc07-2383-4baa-9190-4e3de960f5cf/philip.png) |
Chi-Wing Fu is currently an associate professor in the Chinese University of Hong Kong. He served as the co-chair of SIGGRAPH ASIA 2016’s Technical Brief and Poster program, associate editor of IEEE Computer Graphics & Applications and Computer Graphics Forum, panel member in SIGGRAPH 2019 Doctoral Consortium, and program committee members in various research conferences, including SIGGRAPH Asia Technical Brief, SIGGRAPH Asia Emerging tech., IEEE visualization, CVPR, IEEE VR, VRST, Pacific Graphics, GMP, etc. His recent research interests include computation fabrication, point cloud processing, 3D computer vision, user interaction, and data visualization. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/cb1ebc07-2383-4baa-9190-4e3de960f5cf/heng.png) |
Pheng-Ann Heng received his B.Sc. from the National University of Singapore in 1985. He received his MSc (Comp. Science), M. Art (Applied Math) and Ph. D (Comp. Science) all from the Indiana University of USA in 1987, 1988, 1992 respectively. He is a professor at the Department of Computer Science and Engineering at The Chinese University of Hong Kong (CUHK). He has served as the Director of Virtual Reality, Visualization and Imaging Research Center at CUHK since 1999 and as the Director of Center for Human-Computer Interaction at Shenzhen Institute of Advanced Integration Technology, Chinese Academy of Science/CUHK since 2006. He has been appointed as a visiting professor at the Institute of Computing Technology, Chinese Academy of Sciences as well as a Cheung Kong Scholar Chair Professor by Ministry of Education and University of Electronic Science and Technology of China in 2007. His research interests include AI and VR for medical applications, surgical simulation, visualization, graphics and human-computer interaction. |