DMRO: A Deep Meta Reinforcement Learning-based Task Offloading Framework
for Edge-Cloud Computing
Abstract
With the continuous growth of mobile data and the unprecedented demand for computing power, resource-constrained edge devices cannot effectively meet the requirements of Internet of Things (IoT) applications and Deep Neural Network (DNN) computing. As a distributed computing paradigm, edge offloading that migrates complex tasks from IoT devices to edge-cloud servers can break through the resource limitation of IoT devices, reduce the computing burden and improve the efficiency of task processing. However, the problem of optimal offloading decision-making is NP-hard, traditional optimization methods are difficult to achieve results efficiently. Besides, there are still some shortcomings in existing deep learning methods, e.g., the slow learning speed and the failure of the original network parameters when the environment changes. To tackle these challenges, we propose a Deep Meta Reinforcement Learning-based Offloading (DMRO) algorithm, which combines multiple parallel DNNs with Q-learning to make fine-grained offloading decisions. By aggregating the perceptive ability of deep learning, the decision-making ability of reinforcement learning, and the rapid environment learning ability of meta-learning, it is possible to quickly and flexibly obtain the optimal offloading strategy from the IoT environment. Simulation results demonstrate that the proposed algorithm achieves obvious improvement over the Deep Q-Learning algorithm and has strong portability in making real-time offloading decisions even in time-varying IoT environments.
Index Terms:
Internet of Things, Deep Neural Network, Edge Computing, Computing Offloading, Meta Reinforcement Learning.1 Introduction
With the development of Internet of Things (IoT) and communication technologies, a large number of computation-intensive tasks need to be transferred from IoT devices to the cloud server for execution [2]. However, the task offloading process usually involves large amounts of data transmission, which will result in high latency for IoT applications. The emergence of Mobile Edge Computing (MEC) can effectively alleviate this challenge. As a distributed computing paradigm, edge offloading that migrates complex tasks from IoT devices to edge-cloud servers can provide computing services for edge caching, edge training, and edge inference [92]. Before the IoT application being offloaded to the cloud server, it needs to pass through the edge server, such as the base station. The edge server is closer to the device than the cloud server, so it has greater bandwidth and response time. By utilizing the computing and decision-making capabilities of the edge server, the task computing of the device can be offloaded to different servers, thereby reducing computing latency and energy consumption [24, 87].
The process of task offloading will be affected by different factors, such as user habits, wireless channel communication, connection quality, mobile device availability and cloud server performance. Therefore, making the optimal decision is the most critical issue for edge offloading. It needs to decide whether the task should be offloaded to the edge server or cloud server. If a large number of tasks are offloaded to the cloud server, the bandwidth will be occupied, which will greatly increase the transmission delay. Therefore, we need to have a reasonable offloading decision scheme so that it can reasonably allocate each task to the processing server. On the one hand, there are a large number of repetitive or similar tasks in the IoT environment, which often need to be retrained from scratch, resulting in inefficient offloading decision-making; on the other hand, some IoT application scenarios have strict time constraints on task decision-making, and the slow learning speed of Convolutional Neural Network (CNN) is not suitable to meet the requirements of resource heterogeneity and real-time in the MEC system.
Facing with the rapidly changing IoT application scenarios, we cannot readjust the task offloading decision and wireless resource allocation through recalculation every time the MEC environment changes, otherwise, it will cause higher service delay and cost [50]. Although some good results have been achieved in offloading decision-making of MEC by introducing intelligent algorithms such as deep reinforcement learning, there are still challenges such as slow learning speed, and failure of original network parameters when the model environment changes. In practical application scenarios, the MEC environment is often affected by many factors anytime and anywhere. Conventional intelligent algorithms are usually based on neural networks. When the MEC environment changes, its original parameters will all fail and a large amount of training data is required to train from scratch, which makes the learning efficiency low. Such repeated training will consume resources and weaken the performance of the MEC system. At the same time, in order to improve efficiency, high configuration equipment is also required to adapt to high-intensity training.
Considering the delay and energy consumption of IoT, offloading decisions can be made for a workflow with a series of dependent tasks. However, this problem is NP-hard, traditional optimization methods are difficult to achieve results efficiently. One promising way of addressing the above issue is to bring deep learning techniques, such as Deep Reinforcement Learning (DRL), into the computing paradigm of edge-cloud collaboration. Unfortunately, conventional DRL algorithms have the disadvantage of slower learning speed, which is mainly due to the weak inductive bias. A learning procedure with weak inductive bias will be able to adapt to a wide range of situations, however, it is generally less efficient [6].
In this paper, we design an edge-cloud offloading framework with a cloud server, one edge server, and multiple IoT devices, where IoT devices can choose to shift their computing tasks either to edge servers or cloud servers. Edge servers make offloading decisions based on task information for each device, reducing latency and energy consumption. We propose an efficient offloading decision-making method based on deep meta reinforcement learning [81] that takes advantage of DRL and meta-learning. To solve the problem of poor neural network portability, we introduce meta-learning to ensure that the offloading decision model can quickly adapt to the new environment by learning the initial parameters of the neural network. The main contributions of this study are summarized as follows:
-
•
Formalizing the task placement problem for dependent tasks in MEC as a multi-objective optimization problem. To jointly minimize the delay and energy consumption of IoT, we propose an effective and efficient offloading framework with intelligent decision-making capabilities.
-
•
Proposing a Deep Meta Reinforcement learning-based Offloading (DMRO) framework that combines multiple parallel Deep Neural Networks (DNNs) and deep Q-learning algorithms to make offloading decisions. By aggregating the perceptive ability of deep learning, the decision-making ability of reinforcement learning, and the rapid environment learning ability of meta-learning, it is possible to quickly and flexibly obtain the optimal offloading strategy from the dynamic environment.
-
•
Aiming at the change of MEC environments, an initial parameter training algorithm based on meta-learning is proposed, where meta-learning is applied to solve the problem of poor portability of neural networks. By learning the initial parameters of the neural network under various network environments, the offloading decision model can quickly adapt to the new environment.
The rest of the paper is organized as follows. In Section 2, we review the related work. The system model and problem formulation are presented in Section 3. The proposed Deep Meta Reinforcement learning-based Offloading (DMRO) framework is demonstrated in Section 4. Section 5 contains the simulation and its results. Finally, Section 6 concludes the paper and draws future works.
2 Related work
MEC is an emerging computing paradigm, which can connect IoT devices to cloud computing centers through edge servers close to the device, thereby forming this task offloading mode in the IoT-edge-cloud computing environment. Among them, the cloud center is responsible for providing flexible and on-demand computing resources for the execution of mobile applications, and the edge server is responsible for deciding which computing tasks need to be offloaded and providing a limited amount of computing resources. Thus, the energy consumption of the device and computing delay of the application can be reduced. In general, the task offloading process includes the following key components:
-
•
Application Partition: Since different tasks usually have different amounts of computation and communication, before performing task offloading operation, it is better to divide the task into a workflow with multiple associated subtasks or as a series of independent subtasks [105], and then offload the subtasks separately. Among them, some subtasks are executed on the IoT devices, the others are executed on the relatively powerful server, making full use of the server resources, thereby greatly reducing the load of the IoT devices and improving its endurance [113, 86].
-
•
Resource Allocation: After the offloading decision is made, resources need to be allocated, including computing power, communication bandwidth, and energy consumption.
At present, task offloading algorithms related to decision-making can be divided into traditional methods and intelligent algorithms using artificial intelligence [50].
2.1 Traditional Offloading Decision-Making
Due to the NP-hardness of offloading decision problems in MEC, when the number of tasks increases, it is easy to encounter problems such as computational explosion. A diversity of platforms and algorithms [45, 42, 44, 91, 60] have been proposed to solve the optimization problems of offloading binary decisions in edge-cloud environments.
A Lyapunov optimization framework was proposed in [41] to weigh the offloading system and the queue backlog. eTime [70] was a cloud-to-device energy-efficient data transmission strategy based on Lyapunov-optimization, with more focus on data transmission optimization. Other references using Lyapunov optimization for offloading decision-making can be found in [51, 107, 87]. Markov processes and queueing models have been also widely applied for making offloading decision. The offloading approach proposed in [Wu2017Stochastic] supported two delayed offloading policies, i.e., a partial offloading model where jobs can leave the slow offloading to be executed locally, and a full offloading model where jobs can be offloaded directly via the cellular network. Besides, a computing offloading game theory has been developed in [40], which proposed C-SGA (a fast Stackelberg game algorithm) and F-SGA (a complex Stackelberg game algorithm) to solve the decision problem of IoT-enabled cloud-edge computing. However, these optimization-based offloading algorithms can only obtain results after multiple iterations, which often involve too many complex calculation operations.
Conventional task offloading techniques usually apply some heuristic algorithms. A particle swarm optimization-based offloading decision algorithm was given in [97]. A computing method called COM was proposed in [93] to solve the problem of computation offloading in the cloud environment. Goudarzi et al.[20] gave a genetic algorithm that can solve the task offload problem in a multi-user multi-cloud multi-edge environment. However, heuristic algorithms are still difficult to solve complex problems that require a large amount of computation, and additional computation is also introduced, which results in high running time cost in offloading decision-making.
2.2 Intelligent Offloading Decision-Making
With the rapid development of computer science and the popularization of Artificial Intelligence (AI), deep learning has begun to be applied to solve the problem of offloading decision-making. Edge intelligence [92] or intelligent edge [104], that is, the convergence of edge computing and AI, takes advantage of both to achieve mutual benefit [83]. On the one side, optimizing DNNs through task offloading has become a new direction in edge intelligence research since edge computing can offload complex computing tasks to edge/cloud servers. On the other side, deep learning-driven approaches can facilitate offloading decision making, dynamic resource allocation and content caching, benefit in coping with the growth in volumes of communication and computation for emerging IoT applications [7].
Classic AI methods including deep learning and reinforcement learning, can provide more reasonable and intelligent solutions to solve the offloading decision problem in edge computing. Deep learning methods refer to the classification of the input task information through the multi-layer neural network to determine the final offloading position. Huang et al. [31] provided an algorithm that adopted distributed deep learning to solve the offloading problem of mobile edge networks. It used parallel and distributed DNNs [8] to produce offloading decisions and achieved good results. A hybrid offloading model with the collaboration of Mobile Cloud Computing (MCC) and MEC was established in [90], where a distributed deep learning-driven task offloading (DDTO) algorithm was proposed to generate near-optimal offloading decisions over the IoT devices, edge cloud server, and central cloud server. Besides, Neurosurgeon [35] was a fine-grained partitioning method that can find the optimal dividing point in DNNs according to different factors, and made full use of the resources of cloud servers and mobile devices to minimize the computational delays or energy consumption in IoT environments.
In some cases, however, it is still difficult to treat task offloading decision-making as a classification problem to be solved by using deep learning techniques, which are mostly supervised learning. In addition, it is difficult to find labeled training sets for training on offloading decision problems. Reinforcement learning, as one of the paradigms of machine learning, is used to solve the interaction between the agent and the environment through learning, so as to achieve maximum return or specific goals. An edge-cloud task offloading framework using a Deep Imitation Learning (DIL) [109] was proposed in [104], while training DNN model with DIL is still computation-intensive. Deep Reinforcement Learning (DRL) methods that combined with neural network and reinforcement learning can be used to solve the task offloading decision problem in the MEC environment. The final decision is the maximum reward action under the interaction with the environment. The premise of using DRL algorithms for task offloading decision is that it can be regarded as a Markov process, in which three spaces named state, action, and reward are established. Among them, the task information is input into the state, and the offloading decision is located in the action space. Zhang et al. [112] proposed an offloading decision scheme based on Actor-Critic algorithm. In [32] and [30], task offloading decisions were made based on DRL algorithms, e.g., Deep Q-Learning Network (DQN) and Double Deep Q-learning Network (DDQN)-based algorithms, however, the cloud server was not considered in the MEC environment and they usually require to learn from scratch when the environment changes.
Currently, the role of DRL is to choose an optimal edge computing environment or location for the current task according to its status and environment. However, each time the IoT environment changes, the offloading decision has to be recalculated, which leads to more service delays and higher costs. In addition, DRL algorithms are still limited with slower learning speed and are generally less efficient in solving the offloading decision-making problem [6]. Therefore, it is necessary to find an intelligent method that can learn knowledge and quickly provide better offloading decisions with the change of environment. Unlike traditional machine learning that only trains a general learning model for edge offloading, the goal of meta-learning is learning to learn fast, that is, to make the model become a learner [4, 22]. After completing multiple learning tasks, it can quickly complete new learning tasks by learning prior knowledge or exploring learning strategies [18]. Therefore, it quickly adapts to complex and changing environments and can be used to improve the robustness of task offloading decisions in IoT environments.
3 System Model and Problem Formulation
In this section, we give an overview of the system model and then define the delay model and energy consumption model. On this basis, the optimization problem of computation offloading is formulated.
3.1 System Model
The system model for task offloading in IoT-edge-cloud computing environments is shown in Fig. 1. The proposed framework is composed of a cloud server, an edge server, and multiple IoT devices, where the IoT devices can either execute locally or offload their workflow to the cloud server or edge server.

In this framework, edge servers are distributed near the devices and have high bandwidth. The edge server accepts workflow information from the device and makes fine-grained offloading decisions. The program for each device can be divided into sequential workflows. We assume the -th workflow is defined as follows:
| (1) |
where denotes -th task in the workflow, and illustrates the set of data flows between tasks and .
Each workflow can determine whether to offload its task or not, and the offloading decision is denoted by a Matrix variable:
| (2) |
specifically, , and denote the decision that workflow to execute its -th task locally, offload -th task to the edge server, and offload -th task to the cloud server, respectively.
3.2 Delay Model
The delay caused by computation offloading includes computation delay and transmission delay. We do not consider the delay incurred in offloading decision-making because the time required to make the decision is short. Therefore, the computational delay of task is calculated by:
| (3) |
where , and stand for the computing power of the IoT, the computing power of the edge server and the computing power of the cloud server, respectively.
The transmission delay between tasks and is:
| (4) |
where denotes the allocated bandwidth between the IoT device and the edge server. is the allocated bandwidth between the cloud server and the edge server. Similarly, we denote as the allocated bandwidth between the IoT device and the cloud server.
The total delay for workflow is calculated as:
| (5) |
where the workflow has associated tasks.
3.3 Energy Consumption Model
The energy consumption model of workflow can be expressed as:
| (6) |
where and are weights of the energy consumption at the edge server and at the cloud server, respectively. When = , we only consider the energy consumption at the IoT device. For simplicity, we ignore the energy consumed during task transmission.
The energy consumption of task is calculated as:
| (7) |
where , and denote the local energy consumption per data bit, the edge energy consumption per data bit and the cloud energy consumption per data bit, respectively.
Therefore, the energy consumption model of workflow can be expressed by:
| (8) |
3.4 Problem Formulation
To minimize both the delay for completing all workflows and the corresponding energy consumption simultaneously, we first introduce a system utility , which is defined as the weighted sum of energy consumption and workflow completion delay, as follows:
| (9) |
where there are workflows in total, each workflow has associated tasks, and denotes the weight of energy consumption and task completion time.
The optimization problem can be formulated as follows:
| (10) | ||||
| (20) |
4 Deep Meta Reinforcement Learning-based Offloading Framework
To effectively solve the optimization problem defined in (10), we then propose a Deep Meta Reinforcement learning-based Offloading (DMRO) framework as shown in Fig. 2, where a series of dependent tasks are considered comprehensively, in order to give a specific offloading decision for each task. The proposed learning-driven offloading framework contains a task offloading decision model based on distributed reinforcement learning algorithm and a training model based on meta-learning, aiming to solve the problem of poor portability of neural networks.

The DMRO framework can be divided into two layers of models. The inner model is an offloading decision model based on a distributed deep reinforcement learning, which is responsible for receiving the workflow and training the model parameters to give the final offloading decisions for different tasks. The outer model is the meta-learning part, which is responsible for training the initial parameters to improve the portability of the model. When the environment of the MEC system changes, such as the performance of the edge server or the bandwidth between the IoT device and the edge server, it can adjust the parameters of the neural network in the inner model, so that the system can quickly adapt to the new environment. When the workflow is input into the edge offloading system, the outer model first determines whether the external environment has changed, in order to determine whether to adjust the initial parameters. After that, the workflow will enter the inner model, which will make the offloading decision, and store the state and action in memory for the training of the neural network.
Furthermore, to increase the portability of the model, speed up the decision-making process and reduce the amount of computation, we design a deep meta-reinforcement learning-based method, which also combines the function of memory playback (replay memory), so that the decision-making system can adapt to the new environment quickly and give the optimal offloading decision when the environment changes. In addition, the generated offloading decisions are stored in the replay memory summary for further learning.

4.1 Inner Model
As shown in Fig. 3, the inner model is based on a parallel Deep Reinforcement Learning (DRL) algorithm. We apply a classic reinforcement learning method named Q-learning, in which we input environmental parameters, labeled initial parameters and workflow into the inner model.
We use to represent the offloading decision of the -th subtask of the workflow,which is defined as:
| (24) |
where , , and indicate that the -th subtask is executed locally on the IoT device, the edge server, and the cloud server, respectively.
We represent as the state when processing the -th subtask in the workflow:
| (25) |
where represents the execution position of a subtask in the workflow, which is set as at the beginning. Then the state is input to the neural network to find the value of each action in this state.
Here we have distributed neural network units. Each neural network action unit is parallel, including two DNNs with the identical structure, one of which is the target network for parameter freezing. Parameter freezing means that the two networks have the same structure, but the parameters of the frozen network will not be iterated every time. When the other network learns a certain number of times, the parameters are copied to the frozen network. The purpose of using parameter freezing is to reduce the relevance of learning [54]. Each neural network unit will give the selected action value according to its own value calculated by the greedy algorithm. In addition, we define a local objective function:
| (26) | ||||
| (27) | ||||
| (28) |
where can be interpreted as the weighted sum of the delay and energy consumption for selecting action in state . We compare values generated by the actions selected by different DNNs as a measure of the effects of the actions selected by different DNNs. The action with the lowest is set as the optimal solution in the state .
For the reward function in DRL, if the action is the action value of the optimal solution, the reward value is the negative value of the minimum optimization function; otherwise, the reward value is the negative value of the maximum function. Then we choose the action of the optimal solution as , and update the state as:
| (29) |
The algorithmic process of the proposed parallel DRL algorithm is as demonstrated in Algorithm 1.
4.1.1 Training Phase
In the training phase, we input calculated by the neural network into the memory, and then continue to input the updated workflow into the neural network for calculation until all subtasks of the workflow have been processed.
After processing a certain number of workflows, e.g., five times, we will randomly extract from the memory for empirical playback. The purpose of this step is to eliminate the correlation generated by the associated states. Then we update the parameters of the network as follows:
| (30) |
where represents the value function, which is calculated by the neural network, represents the part is calculated by the network with the latest parameters, and is calculated by the network with the frozen parameters. The learning rate is the weight of the current offloading experience. The discount factor denotes the short view of the IoT device regarding the future reward.
4.1.2 Decision-Making Phase
In the decision-making phase, we will make fine-grained offloading decisions for IoT devices. First, we obtain the action value generated by each DNN and fill it into action sets . Then, we input the updated state to the neural network, and continue to find the execution method of the next subtask until all the subtasks are assigned. At this time, represents the offloading scheme given by the -th DNN network to the workflow , and the scheme with the minimum value is the final scheme and output to the device.
4.2 Outer Model
In the outer model, we propose a meta algorithm to learn the initial parameters.
Based on the original algorithm described in [18], i.e., an initial parameter algorithm for training different image classification networks, we propose a novel algorithm for learning initial parameters in order to adapt to the training method of reinforcement learning. We train our decision-making engine by leveraging the deep meta-learning method, and then make rapid offloading decisions through IoT-edge-cloud computing environments. The algorithmic process of the proposed meta algorithm is as listed in Algorithm 2.
The principle of our meta algorithm is to input the decision-making and execution results of the workflow in different environments into the training model. Each time the training model randomly selects training samples in one environment for learning, and randomly selects another environment after learning. The purpose of training sample learning is to ensure that the parameters trained by the model will not be too close to the optimal solution in a specific environment. We use the parameters trained in this way as the initial parameters of the inner model.
5 Performance Evaluation
In this section, we evaluate the performance of the proposed DMRO framework for solving the optimization problem of offloading decision-making under different MEC environments.
5.1 Simulation setup
In our simulation, we assume that there are four IoT users, and each user has five workflows. The size of the first subtask of each workflow is MB, and the size of subsequent tasks is MB. The amount of computation for each subtask is MHz randomly distributed. For the DNN structure, we consider a fully connected DNN consisting of one input layer, two hidden layers, and one output layer in the proposed DMRO framework. The parameters and are both set to . In addition, we set the environmental information as listed in Table I.
| 30 MHz | MB/s | J/MB | |||
|---|---|---|---|---|---|
| MHz | MB/s | J/MB | |||
| MHz | MB/s | J/MB |
5.2 Convergence Performance

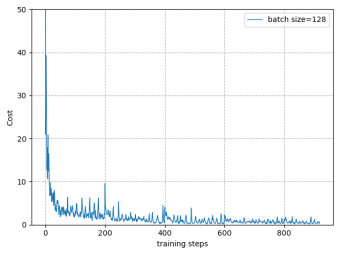



Figure 4 shows the convergence performance of our model under different learning rates, where the abscissa is the number of training steps and the ordinate is the loss of the neural network. It can be found that when the learning rate is too low, it will not be able to converge. However, when the learning rate is 0.01, the convergence effect is the best, so we will use a learning rate of 0.01 in the next experiment.
Figure 5 shows the convergence performance of our model under different batch sizes. It can be seen that the batch size has less effect on the convergence, but as the batch size increases, the volatility of the curve becomes smaller. It is worth noting that there is a small fluctuation in the curve every 200 steps, which is mainly due to the parameter freezing mechanism. In the model, we set the network parameters to the target network every 200 steps. As a result, the parameters will fluctuate every 200 steps, but it does not affect the convergence of the model.
5.3 Comparison Experiments
To gain insight into the proposed DMRO scheme for edge offloading decision, the following methods are implemented for comparison:
-
•
Local-only scheme: In this method, all tasks of workflows are executed locally on the IoT device. The results of this method can be used as a benchmark to analyze the gain of task offloading techniques.
-
•
Edge-only scheme: This is a full offloading scheme. In this method, all tasks of workflows are fully offloaded to the edge servers for further processing.
-
•
Cloud-only scheme: This is a full offloading scheme. In this method, all tasks of workflows are fully offloaded to the cloud server for further processing.
-
•
Deep Q-Network scheme: This is a partial offloading scheme based on the Deep Q-Network algorithm [23], where it can be regarded as a simplified DMRO algorithm with only one parallel network. In this method, we use the Deep Q-Network in making dynamic offloading decisions.
-
•
DMRO scheme: This is a partial offloading scheme based on the proposed DMRO scheme. It is designed to find the optimal offloading scheme that minimizes the weighted delay and energy consumption.

The comparison results are as shown in Fig. 6, where the abscissa is the weight ratio of delay to energy consumption, and the ordinate is the value of the objective function. Especially, when the weight value is 0, it means that only delay is considered. The figure shows that the DMRO algorithm can achieve the minimum total cost among the five methods, and the DQN algorithm and the DMRO algorithm have the same trend, which are better than the local-only scheme, the edge-only scheme and the cloud-only scheme. In addition, as the weight ratio of energy consumption increases, the total consumption of local execution increases rapidly, which also meets our expectations, indicating that local devices are more sensitive to energy consumption.
5.4 Fast Learning
We show the effect of the proposed meta algorithm in fast offloading decision learning under different IoT environments. We first set up two types of environments, i.e., the training environment and the testing environment, as shown in Table II.
| train | test | ||
|---|---|---|---|
| MHz | MHz | ||
| MHz | MHz | ||
| MHz | MHz | ||
| MB/s | MB/s | ||
| MB/s | MB/s | ||
| MB/s | MB/s | ||
| J/MB | J/MB | ||
| J/MB | J/MB | ||
| J/MB | J/MB | ||
We input the trained meta parameters into the test environment. Figure 7 shows the comparison between the meta parameters and the initialized parameters in terms of convergence. It can be seen that the initial convergence of meta parameters is better than the traditional initialization parameters. Besides, it illustrates that networks using meta parameters can converge faster.
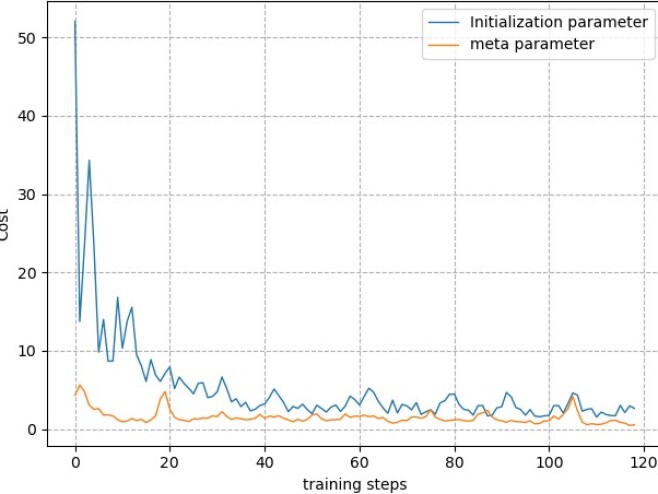

Figure 8 shows the comparison of the effect of meta parameters and initialized parameters on the total cost. It can be seen from the figure that the decision result of the neural network using meta parameters is significantly better than that of the traditional initialization parameter network, and a low-cost offloading decision can be given after a few rounds of training. Therefore, by learning the initial parameters of the neural network, the offloading decision model can quickly adapt to the new environment. In addition, it is worth noting that although the convergence degree of the network does not change much during the process of training 40-80 steps, the task offloading decision model has been optimized, and then a more reasonable offloading solution is given.
6 Conclusion
This paper has proposed an edge offloading framework to deal with the task offloading decision-making in heterogeneous IoT-edge-cloud computing environments. The DMRO framework includes a task offloading decision model based on distributed deep reinforcement learning algorithm and a training initial parameter model based on deep meta-learning, which aims to solve the problem of poor portability of neural networks.
Experimental results show that the DMRO framework has a better effect on task offloading decisions than full offloading methods and conventional reinforcement learning-based methods. In addition, due to the use of meta parameters, the model has stronger portability and rapid environment learning ability. Once the MEC environment changes, the model can quickly converge, and only a small number of learning steps are needed to give low-cost offloading solutions. We expect that the initial parameters can be changed adaptively in response to environmental parameters in future work.
Although this paper only focuses on the scenario with one edge server and one cloud server, this model is highly scalable and can be easily extended to other scenarios with multiple edge servers and cloud servers. In the future, we plan to implement the proposed DMRO framework for intelligent offloading when considering hardware platforms, e.g., graph-based Network Interface Controller (NIC) offload and device offload [13, 68, 33].
Acknowledgments
This work is partially supported by the National Natural Science Foundation of China (61801325) and the Natural Science Foundation of Tianjin City (18JCQNJC00600).
References
- [1] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:1603.04467, 2016.
- [2] Yuan Ai, Mugen Peng, and Kecheng Zhang. Edge computing technologies for internet of things: a primer. Digital Communications and Networks, 4(2):77–86, 2018.
- [3] Khalid R Alasmari, Robert C Green, and Mansoor Alam. Mobile edge offloading using markov decision processes. In International Conference on Edge Computing, pages 80–90. Springer, 2018.
- [4] Marcin Andrychowicz, Misha Denil, Sergio Gomez, Matthew W Hoffman, David Pfau, Tom Schaul, Brendan Shillingford, and Nando De Freitas. Learning to learn by gradient descent by gradient descent. In Advances in neural information processing systems, pages 3981–3989, 2016.
- [5] José Barrameda and Nancy Samaan. A novel statistical cost model and an algorithm for efficient application offloading to clouds. IEEE Transactions on Cloud Computing, 6(3):598–611, 2018.
- [6] Matthew Botvinick, Sam Ritter, Jane X Wang, Zeb Kurth-Nelson, Charles Blundell, and Demis Hassabis. Reinforcement learning, fast and slow. Trends in cognitive sciences, 23(5):408–422, 2019.
- [7] Bin Cao, Long Zhang, Yun Li, Daquan Feng, and Wei Cao. Intelligent offloading in multi-access edge computing: A state-of-the-art review and framework. IEEE Communications Magazine, 57(3):56–62, 2019.
- [8] Adrian Castello, Manuel F. Dolz, Enrique S. Quintana-Orti, and Jose Duato. Theoretical scalability analysis of distributed deep convolutional neural networks. In 2019 19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID). IEEE, May 2019.
- [9] Min Chen and Yixue Hao. Task offloading for mobile edge computing in software defined ultra-dense network. IEEE Journal on Selected Areas in Communications, 36(3):587–597, 2018.
- [10] Xu Chen, Lei Jiao, Wenzhong Li, and Xiaoming Fu. Efficient multi-user computation offloading for mobile-edge cloud computing. IEEE/ACM Transactions on Networking, 24(5):2795–2808, 2015.
- [11] Ying Chen, Ning Zhang, Yongchao Zhang, Xin Chen, Wen Wu, and Xuemin Sherman Shen. Energy efficient dynamic offloading in mobile edge computing for internet of things. IEEE Transactions on Cloud Computing, 2019.
- [12] Weihao Cui, Mengze Wei, Quan Chen, Xiaoxin Tang, Jingwen Leng, Li Li, and Mingyi Guo. Ebird: Elastic batch for improving responsiveness and throughput of deep learning services. In 2019 IEEE 37th International Conference on Computer Design (ICCD). IEEE, November 2019.
- [13] Jose Monsalve Diaz, Kyle Friedline, Swaroop Pophale, Oscar Hernandez, David E. Bernholdt, and Sunita Chandrasekaran. Analysis of OpenMP 4.5 offloading in implementations: Correctness and overhead. Parallel Computing, 89:102546, November 2019.
- [14] Hoang T Dinh, Chonho Lee, Dusit Niyato, and Ping Wang. A survey of mobile cloud computing: architecture, applications, and approaches. Wireless communications and mobile computing, 13(18):1587–1611, 2013.
- [15] Thinh Quang Dinh, Quang Duy La, Tony QS Quek, and Hyundong Shin. Learning for computation offloading in mobile edge computing. IEEE Transactions on Communications, 66(12):6353–6367, 2018.
- [16] Luobing Dong, Meghana N Satpute, Junyuan Shan, Baoqi Liu, Yang Yu, and Tihua Yan. Computation offloading for mobile-edge computing with multi-user. In 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), pages 841–850. IEEE, 2019.
- [17] Elie El Haber, Tri Minh Nguyen, Dariush Ebrahimi, and Chadi Assi. Computational cost and energy efficient task offloading in hierarchical edge-clouds. In 2018 IEEE 29th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), pages 1–6. IEEE, 2018.
- [18] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 1126–1135. JMLR. org, 2017.
- [19] Sukhpal Singh Gill, Shreshth Tuli, Minxian Xu, Inderpreet Singh, Karan Vijay Singh, Dominic Lindsay, Shikhar Tuli, Daria Smirnova, Manmeet Singh, Udit Jain, et al. Transformative effects of iot, blockchain and artificial intelligence on cloud computing: Evolution, vision, trends and open challenges. Internet of Things, page 100118, 2019.
- [20] Mohammad Goudarzi, Huaming Wu, Marimuthu S Palaniswami, and Rajkumar Buyya. An application placement technique for concurrent iot applications in edge and fog computing environments. IEEE Transactions on Mobile Computing, 2020.
- [21] Fengxian Guo, Heli Zhang, Hong Ji, Xi Li, and Victor CM Leung. An efficient computation offloading management scheme in the densely deployed small cell networks with mobile edge computing. IEEE/ACM Transactions on Networking, 26(6):2651–2664, 2018.
- [22] Abhishek Gupta, Russell Mendonca, YuXuan Liu, Pieter Abbeel, and Sergey Levine. Meta-reinforcement learning of structured exploration strategies. In Advances in Neural Information Processing Systems, pages 5302–5311, 2018.
- [23] Venus Haghighi and Naghmeh S Moayedian. An offloading strategy in mobile cloud computing considering energy and delay constraints. IEEE Access, 6:11849–11861, 2018.
- [24] Abdul Hameed, Alireza Khoshkbarforoushha, Rajiv Ranjan, Prem Prakash Jayaraman, Joanna Kolodziej, Pavan Balaji, Sherali Zeadally, Qutaibah Marwan Malluhi, Nikos Tziritas, Abhinav Vishnu, Samee U. Khan, and Albert Zomaya. A survey and taxonomy on energy efficient resource allocation techniques for cloud computing systems. Computing, 98(7):751–774, June 2014.
- [25] Ying He, Zheng Zhang, F Richard Yu, Nan Zhao, Hongxi Yin, Victor CM Leung, and Yanhua Zhang. Deep-reinforcement-learning-based optimization for cache-enabled opportunistic interference alignment wireless networks. IEEE Transactions on Vehicular Technology, 66(11):10433–10445, 2017.
- [26] Zicong Hong, Wuhui Chen, Huawei Huang, Song Guo, and Zibin Zheng. Multi-hop cooperative computation offloading for industrial IoT–edge–cloud computing environments. IEEE Transactions on Parallel and Distributed Systems, 30(12):2759–2774, 2019.
- [27] Dan Horgan, John Quan, David Budden, Gabriel Barth-Maron, Matteo Hessel, Hado Van Hasselt, and David Silver. Distributed prioritized experience replay. arXiv preprint arXiv:1803.00933, 2018.
- [28] Miao Hu, Lei Zhuang, Di Wu, Yipeng Zhou, Xu Chen, and Liang Xiao. Learning driven computation offloading for asymmetrically informed edge computing. IEEE Transactions on Parallel and Distributed Systems, 2019.
- [29] Q. Hua, Y. Shi, D. Yu, H. Jin, J. Yu, Z. Cai, X. Cheng, and H. Chen. Faster parallel core maintenance algorithms in dynamic graphs. IEEE Transactions on Parallel and Distributed Systems, 31(6):1287–1300, June 2020.
- [30] Liang Huang, Suzhi Bi, and Ying Jun Zhang. Deep reinforcement learning for online computation offloading in wireless powered mobile-edge computing networks. IEEE Transactions on Mobile Computing, 2019.
- [31] Liang Huang, Xu Feng, Anqi Feng, Yupin Huang, and Li Ping Qian. Distributed deep learning-based offloading for mobile edge computing networks. Mobile Networks and Applications, pages 1–8, 2018.
- [32] Liang Huang, Xu Feng, Liping Qian, and Yuan Wu. Deep reinforcement learning-based task offloading and resource allocation for mobile edge computing. In International Conference on Machine Learning and Intelligent Communications, pages 33–42. Springer, 2018.
- [33] Yujie Hui, Jeffrey Lien, and Xiaoyi Lu. Early experience in benchmarking edge AI processors with object detection workloads. In Benchmarking, Measuring, and Optimizing, pages 32–48. Springer International Publishing, 2020.
- [34] Yaser Jararweh, Ahmad Doulat, Omar AlQudah, Ejaz Ahmed, Mahmoud Al-Ayyoub, and Elhadj Benkhelifa. The future of mobile cloud computing: Integrating cloudlets and mobile edge computing. In 2016 23rd International conference on telecommunications (ICT), pages 1–5. IEEE, 2016.
- [35] Yiping Kang, Johann Hauswald, Cao Gao, Austin Rovinski, Trevor Mudge, Jason Mars, and Lingjia Tang. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge. ACM SIGARCH Computer Architecture News, 45(1):615–629, 2017.
- [36] Adlen Ksentini, Tarik Taleb, and Min Chen. A markov decision process-based service migration procedure for follow me cloud. In 2014 IEEE International Conference on Communications (ICC), pages 1350–1354. IEEE, 2014.
- [37] Zhikai Kuang, Songtao Guo, Jiadi Liu, and Yuanyuan Yang. A quick-response framework for multi-user computation offloading in mobile cloud computing. Future Generation Computer Systems, 81:166–176, 2018.
- [38] Karthik Kumar, Jibang Liu, Yung-Hsiang Lu, and Bharat Bhargava. A survey of computation offloading for mobile systems. Mobile Networks and Applications, 18(1):129–140, 2013.
- [39] Raj Kumari, Sakshi Kaushal, and Naveen Chilamkurti. Energy conscious multi-site computation offloading for mobile cloud computing. Soft Computing, 22(20):6751–6764, 2018.
- [40] Meiwen Li, Qingtao Wu, Junlong Zhu, Ruijuan Zheng, and Mingchuan Zhang. A computing offloading game for mobile devices and edge cloud servers. Wireless Communications and Mobile Computing, 2018, 2018.
- [41] Yun Li, Shichao Xia, Bin Cao, Qilie Liu, et al. Lyapunov optimization based trade-off policy for mobile cloud offloading in heterogeneous wireless networks. IEEE Transactions on Cloud Computing, 2019.
- [42] Jie Liang, Kenli Li, Chubo Liu, and Keqin Li. Joint offloading and scheduling decisions for DAG applications in mobile edge computing. Neurocomputing, February 2020.
- [43] Li Lin, Peng Li, Xiaofei Liao, Hai Jin, and Yu Zhang. Echo: An edge-centric code offloading system with quality of service guarantee. IEEE Access, 7:5905–5917, 2018.
- [44] Chubo Liu, Kenli Li, Jie Liang, and Keqin Li. COOPER-MATCH: Job offloading with a cooperative game for guaranteeing strict deadlines in MEC. IEEE Transactions on Mobile Computing, pages 1–1, 2020.
- [45] Chubo Liu, Kenli Li, Jie Liang, and Keqin Li. COOPER-SCHED: A cooperative scheduling framework for mobile edge computing with expected deadline guarantee. IEEE Transactions on Parallel and Distributed Systems, pages 1–1, 2020.
- [46] Fangming Liu, Peng Shu, Hai Jin, Linjie Ding, Jie Yu, Di Niu, and Bo Li. Gearing resource-poor mobile devices with powerful clouds: architectures, challenges, and applications. IEEE Wireless communications, 20(3):14–22, 2013.
- [47] Xinchen Lyu, Wei Ni, Hui Tian, Ren Ping Liu, Xin Wang, Georgios B Giannakis, and Arogyaswami Paulraj. Optimal schedule of mobile edge computing for internet of things using partial information. IEEE Journal on Selected Areas in Communications, 35(11):2606–2615, 2017.
- [48] Pavel Mach and Zdenek Becvar. Mobile edge computing: A survey on architecture and computation offloading. IEEE Communications Surveys & Tutorials, 19(3):1628–1656, 2017.
- [49] Redowan Mahmud, Ramamohanarao Kotagiri, and Rajkumar Buyya. Fog computing: A taxonomy, survey and future directions. In Internet of everything, pages 103–130. Springer, 2018.
- [50] Yuyi Mao, Changsheng You, Jun Zhang, Kaibin Huang, and Khaled B Letaief. A survey on mobile edge computing: The communication perspective. IEEE Communications Surveys & Tutorials, 19(4):2322–2358, 2017.
- [51] Yuyi Mao, Jun Zhang, and Khaled B Letaief. Dynamic computation offloading for mobile-edge computing with energy harvesting devices. IEEE Journal on Selected Areas in Communications, 34(12):3590–3605, 2016.
- [52] Mohamed-Ayoub Messous, Sidi-Mohammed Senouci, Hichem Sedjelmaci, and Soumaya Cherkaoui. A game theory based efficient computation offloading in an UAV network. IEEE Transactions on Vehicular Technology, 68(5):4964–4974, 2019.
- [53] Minghui Min, Liang Xiao, Ye Chen, Peng Cheng, Di Wu, and Weihua Zhuang. Learning-based computation offloading for IoT devices with energy harvesting. IEEE Transactions on Vehicular Technology, 68(2):1930–1941, 2019.
- [54] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
- [55] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529, 2015.
- [56] Jose M. Monsalve Diaz, Swaroop S. Pophale, Oscar R. Hernandez, David Bernholdt, and Sunita Chandrasekaran. Openmp 4.5 validation and verification suite for device offload. EVOLVING OPENMP FOR EVOLVING ARCHITECTURES, 8 2018.
- [57] Yucen Nan, Wei Li, Wei Bao, Flavia C Delicato, Paulo F Pires, and Albert Y Zomaya. A dynamic tradeoff data processing framework for delay-sensitive applications in cloud of things systems. Journal of Parallel and Distributed Computing, 112:53–66, 2018.
- [58] Zhaolong Ning, Peiran Dong, Xiaojie Wang, Lei Guo, Joel JPC Rodrigues, Xiangjie Kong, Jun Huang, and Ricky YK Kwok. Deep reinforcement learning for intelligent internet of vehicles: An energy-efficient computational offloading scheme. IEEE Transactions on Cognitive Communications and Networking, 2019.
- [59] Zhaolong Ning, Peiran Dong, Xiaojie Wang, Joel JPC Rodrigues, and Feng Xia. Deep reinforcement learning for vehicular edge computing: An intelligent offloading system. ACM Transactions on Intelligent Systems and Technology (TIST), 10(6):60, 2019.
- [60] Kai Peng, Hualong Huang, Shaohua Wan, and Victor C. M. Leung. End-edge-cloud collaborative computation offloading for multiple mobile users in heterogeneous edge-server environment. Wireless Networks, June 2020.
- [61] Kai Peng, Maosheng Zhu, Yiwen Zhang, Lingxia Liu, Jie Zhang, Victor CM Leung, and Lixin Zheng. An energy-and cost-aware computation offloading method for workflow applications in mobile edge computing. EURASIP Journal on Wireless Communications and Networking, 2019(1):207, 2019.
- [62] Lingjun Pu, Xu Chen, Guoqiang Mao, Qinyi Xie, and Jingdong Xu. Chimera: An energy-efficient and deadline-aware hybrid edge computing framework for vehicular crowdsensing applications. IEEE Internet of Things Journal, 6(1):84–99, 2018.
- [63] Lingjun Pu, Xu Chen, Jingdong Xu, and Xiaoming Fu. D2d fogging: An energy-efficient and incentive-aware task offloading framework via network-assisted d2d collaboration. IEEE Journal on Selected Areas in Communications, 34(12):3887–3901, 2016.
- [64] Qi Qi, Jingyu Wang, Zhanyu Ma, Haifeng Sun, Yufei Cao, Lingxin Zhang, and Jianxin Liao. Knowledge-driven service offloading decision for vehicular edge computing: A deep reinforcement learning approach. IEEE Transactions on Vehicular Technology, 68(5):4192–4203, 2019.
- [65] M Reza Rahimi, Nalini Venkatasubramanian, Sharad Mehrotra, and Athanasios V Vasilakos. MAPCloud: Mobile applications on an elastic and scalable 2-tier cloud architecture. In Proceedings of the 2012 IEEE/ACM fifth international conference on utility and cloud computing, pages 83–90. IEEE Computer Society, 2012.
- [66] Xukan Ran, Haoliang Chen, Zhenming Liu, and Jiasi Chen. Delivering deep learning to mobile devices via offloading. In Proceedings of the Workshop on Virtual Reality and Augmented Reality Network, pages 42–47. ACM, 2017.
- [67] Ismail Sheikh and Olivia Das. Modeling the effect of parallel execution on multi-site computation offloading in mobile cloud computing. In European Workshop on Performance Engineering, pages 219–234. Springer, 2018.
- [68] Haiyang Shi and Xiaoyi Lu. TriEC: tripartite graph based erasure coding NIC offload. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. ACM, November 2019.
- [69] RD Shobha, M Pounambal, and V Saritha. An efficient algorithm for dynamic task offloading using cloudlets in mobile cloud computing. Int. J. Commun. Syst., 3890:1–10, 2019.
- [70] Peng Shu, Fangming Liu, Hai Jin, Min Chen, Feng Wen, Yupeng Qu, and Bo Li. etime: Energy-efficient transmission between cloud and mobile devices. In 2013 Proceedings IEEE INFOCOM, pages 195–199. IEEE, 2013.
- [71] Sukhpal Singh, Inderveer Chana, and Rajkumar Buyya. Star: Sla-aware autonomic management of cloud resources. IEEE Transactions on Cloud Computing, 2020.
- [72] Georgios L Stavrinides and Helen D Karatza. A hybrid approach to scheduling real-time iot workflows in fog and cloud environments. Multimedia Tools and Applications, 78(17):24639–24655, 2019.
- [73] Saurav Sthapit, John Thompson, Neil M Robertson, and James R Hopgood. Computational load balancing on the edge in absence of cloud and fog. IEEE Transactions on Mobile Computing, 18(7):1499–1512, 2018.
- [74] Tarik Taleb, Konstantinos Samdanis, Badr Mada, Hannu Flinck, Sunny Dutta, and Dario Sabella. On multi-access edge computing: A survey of the emerging 5g network edge cloud architecture and orchestration. IEEE Communications Surveys & Tutorials, 19(3):1657–1681, 2017.
- [75] Shreya Tayade, Peter Rost, Andreas Maeder, and Hans D Schotten. Device-centric energy optimization for edge cloud offloading. In GLOBECOM 2017-2017 IEEE Global Communications Conference, pages 1–7. IEEE, 2017.
- [76] Mati B Terefe, Heezin Lee, Nojung Heo, Geoffrey C Fox, and Sangyoon Oh. Energy-efficient multisite offloading policy using markov decision process for mobile cloud computing. Pervasive and Mobile Computing, 27:75–89, 2016.
- [77] Zhao Tong, Hongjian Chen, Xiaomei Deng, Kenli Li, and Keqin Li. A scheduling scheme in the cloud computing environment using deep q-learning. Information Sciences, 512:1170–1191, February 2020.
- [78] Blesson Varghese and Rajkumar Buyya. Next generation cloud computing: New trends and research directions. Future Generation Computer Systems, 79:849–861, 2018.
- [79] Thai T Vu, Nguyen Van Huynh, Dinh Thai Hoang, Diep N Nguyen, and Eryk Dutkiewicz. Offloading energy efficiency with delay constraint for cooperative mobile edge computing networks. In 2018 IEEE Global Communications Conference (GLOBECOM), pages 1–6. IEEE, 2018.
- [80] Feng Wang, Jie Xu, Xin Wang, and Shuguang Cui. Joint offloading and computing optimization in wireless powered mobile-edge computing systems. IEEE Transactions on Wireless Communications, 17(3):1784–1797, 2017.
- [81] Jane X Wang, Zeb Kurth-Nelson, Dhruva Tirumala, Hubert Soyer, Joel Z Leibo, Remi Munos, Charles Blundell, Dharshan Kumaran, and Matt Botvinick. Learning to reinforcement learn, 2016.
- [82] Quyuan Wang, Songtao Guo, Jiadi Liu, and Yuanyuan Yang. Energy-efficient computation offloading and resource allocation for delay-sensitive mobile edge computing. Sustainable Computing: Informatics and Systems, 21:154–164, 2019.
- [83] Xiaofei Wang, Yiwen Han, Victor CM Leung, Dusit Niyato, Xueqiang Yan, and Xu Chen. Convergence of edge computing and deep learning: A comprehensive survey. IEEE Communications Surveys & Tutorials, 2020.
- [84] Yanting Wang, Min Sheng, Xijun Wang, Liang Wang, and Jiandong Li. Mobile-edge computing: Partial computation offloading using dynamic voltage scaling. IEEE Transactions on Communications, 64(10):4268–4282, 2016.
- [85] Huaming Wu, William Knottenbelt, and Katinka Wolter. Analysis of the energy-response time tradeoff for mobile cloud offloading using combined metrics. In Teletraffic Congress (ITC 27), 2015 27th International, pages 134–142. IEEE, 2015.
- [86] Huaming Wu, William Knottenbelt, and Katinka Wolter. An efficient application partitioning algorithm in mobile environments. IEEE Transactions on Parallel and Distributed Systems, 30(7):1464–1480, 2019.
- [87] Huaming Wu, Yi Sun, and Katinka Wolter. Energy-efficient decision making for mobile cloud offloading. IEEE Transactions on Cloud Computing, 2018.
- [88] Huaming Wu and Katinka Wolter. Tradeoff analysis for mobile cloud offloading based on an additive energy-performance metric. In Performance Evaluation Methodologies and Tools (VALUETOOLS), 2014 8th International Conference on. ACM, 2014.
- [89] Huaming Wu and Katinka Wolter. Stochastic analysis of delayed mobile offloading in heterogeneous networks. IEEE Transactions on Mobile Computing, 17(2):461–474, 2018.
- [90] Huaming Wu, Ziru Zhang, Chang Guan, Katinka Wolter, and Minxian Xu. Collaborate edge and cloud computing with distributed deep learning for smart city internet of things. IEEE Internet of Things Journal, pages 1–1, 2020.
- [91] Ying Xie, Yuanwei Zhu, Yeguo Wang, Yongliang Cheng, Rongbin Xu, Abubakar Sadiq Sani, Dong Yuan, and Yun Yang. A novel directional and non-local-convergent particle swarm optimization based workflow scheduling in cloud–edge environment. Future Generation Computer Systems, 97:361–378, August 2019.
- [92] Dianlei Xu, Tingting Li, Yong Li, Xiang Su, Sasu Tarkoma, and Pan Hui. A survey on edge intelligence. ArXiv, abs/2003.12172, 2020.
- [93] Xiaolong Xu, Qingxiang Liu, Yun Luo, Kai Peng, Xuyun Zhang, Shunmei Meng, and Lianyong Qi. A computation offloading method over big data for IoT-enabled cloud-edge computing. Future Generation Computer Systems, 95:522–533, 2019.
- [94] Zhiyuan Xu, Yanzhi Wang, Jian Tang, Jing Wang, and Mustafa Cenk Gursoy. A deep reinforcement learning based framework for power-efficient resource allocation in cloud rans. In 2017 IEEE International Conference on Communications (ICC), pages 1–6. IEEE, 2017.
- [95] Lei Yang, Jiannong Cao, Yin Yuan, Tao Li, Andy Han, and Alvin Chan. A framework for partitioning and execution of data stream applications in mobile cloud computing. ACM SIGMETRICS Performance Evaluation Review, 40(4):23–32, 2013.
- [96] Song Yang, Fan Li, Meng Shen, Xu Chen, Xiaoming Fu, and Yu Wang. Cloudlet placement and task allocation in mobile edge computing. IEEE Internet of Things Journal, 6(3):5853–5863, 2019.
- [97] Luo Yiqing, Yuan Xigang, and Liu Yongjian. An improved pso algorithm for solving non-convex nlp/minlp problems with equality constraints. Computers & chemical engineering, 31(3):153–162, 2007.
- [98] Changsheng You, Kaibin Huang, Hyukjin Chae, and Byoung-Hoon Kim. Energy-efficient resource allocation for mobile-edge computation offloading. IEEE Transactions on Wireless Communications, 16(3):1397–1411, 2016.
- [99] Dongxiao Yu, Li Ning, Yifei Zou, Jiguo Yu, Xiuzhen Cheng, and Francis CM Lau. Distributed spanner construction with physical interference: constant stretch and linear sparseness. IEEE/ACM Transactions on Networking, 25(4):2138–2151, 2017.
- [100] Dongxiao Yu, Yifei Zou, Jiguo Yu, Xiuzhen Cheng, Qiang-Sheng Hua, Hai Jin, and Francis CM Lau. Stable local broadcast in multihop wireless networks under sinr. IEEE/ACM Transactions on Networking, 26(3):1278–1291, 2018.
- [101] Dongxiao Yu, Yifei Zou, Jiguo Yu, Yong Zhang, Feng Li, Xiuzhen Cheng, Falko Dressler, and Francis CM Lau. Implementing abstract mac layer in dynamic networks. IEEE Transactions on Mobile Computing, 2020.
- [102] Kan Yu, Yinglong Wang, Jiguo Yu, Dongxiao Yu, Xiuzhen Cheng, and Zhiguang Shan. Localized and distributed link scheduling algorithms in IoT under rayleigh fading. Computer Networks, 151:232–244, 2019.
- [103] Shuai Yu, Xu Chen, Lei Yang, Di Wu, Mehdi Bennis, and Junshan Zhang. Intelligent edge: Leveraging deep imitation learning for mobile edge computation offloading. IEEE Wireless Communications, 2019.
- [104] Shuai Yu, Xu Chen, Lei Yang, Di Wu, Mehdi Bennis, and Junshan Zhang. Intelligent edge: Leveraging deep imitation learning for mobile edge computation offloading. IEEE Wireless Communications, 27(1):92–99, February 2020.
- [105] Feng Zhang, Jidong Zhai, Bo Wu, Bingsheng He, Wenguang Chen, and Xiaoyong Du. Automatic irregularity-aware fine-grained workload partitioning on integrated architectures. IEEE Transactions on Knowledge and Data Engineering, pages 1–1, 2019.
- [106] Guanglin Zhang, Yan Chen, Zhirong Shen, and Lin Wang. Energy management for multi-user mobile-edge computing systems with energy harvesting devices and qos constraints. In 2018 27th International Conference on Computer Communication and Networks (ICCCN), pages 1–6. IEEE, 2018.
- [107] Guanglin Zhang, Wenqian Zhang, Yu Cao, Demin Li, and Lin Wang. Energy-delay tradeoff for dynamic offloading in mobile-edge computing system with energy harvesting devices. IEEE Transactions on Industrial Informatics, 14(10):4642–4655, 2018.
- [108] Haijun Zhang, Hao Liu, Julian Cheng, and Victor CM Leung. Downlink energy efficiency of power allocation and wireless backhaul bandwidth allocation in heterogeneous small cell networks. IEEE transactions on communications, 66(4):1705–1716, 2017.
- [109] Tianhao Zhang, Zoe McCarthy, Owen Jow, Dennis Lee, Xi Chen, Ken Goldberg, and Pieter Abbeel. Deep imitation learning for complex manipulation tasks from virtual reality teleoperation. In 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, May 2018.
- [110] Weiwen Zhang and Yonggang Wen. Energy-efficient task execution for application as a general topology in mobile cloud computing. IEEE Transactions on cloud Computing, 6(3):708–719, 2018.
- [111] Zhen Zhang, Zicong Hong, Wuhui Chen, Zibin Zheng, and Xu Chen. Joint computation offloading and coin loaning for blockchain-empowered mobile-edge computing. IEEE Internet of Things Journal, 2019.
- [112] Zhicai Zhang, F Richard Yu, Fang Fu, Qiao Yan, and Zhouyang Wang. Joint offloading and resource allocation in mobile edge computing systems: An actor-critic approach. In 2018 IEEE Global Communications Conference (GLOBECOM), pages 1–6. IEEE, 2018.
- [113] Amelie Chi Zhou, Bingkun Shen, Yao Xiao, Shadi Ibrahim, and Bingsheng He. Cost-aware partitioning for efficient large graph processing in geo-distributed datacenters. IEEE Transactions on Parallel and Distributed Systems, 31(7):1707–1723, July 2020.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/2702e84a-62e2-4320-a26a-0b770a9b4323/x12.jpg) |
Guanjin Qu is currently working toward the Master degree at the Center for Applied Mathematics, Tianjin University, China. His research interests include distributed deep learning and edge computing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/2702e84a-62e2-4320-a26a-0b770a9b4323/x13.jpg) |
Huaming Wu received the B.E. and M.S. degrees from Harbin Institute of Technology, China in 2009 and 2011, respectively, both in electrical engineering. He received the Ph.D. degree with the highest honor in computer science at Freie Universität Berlin, Germany in 2015. He is currently an associate professor at the Center for Applied Mathematics, Tianjin University, China. His research interests include model-based evaluation, wireless and mobile network systems, mobile cloud computing and deep learning. |