Distributed stochastic proximal algorithm with random reshuffling for non-smooth finite-sum optimization
Abstract
The non-smooth finite-sum minimization is a fundamental problem in machine learning. This paper develops a distributed stochastic proximal-gradient algorithm with random reshuffling to solve the finite-sum minimization over time-varying multi-agent networks. The objective function is a sum of differentiable convex functions and non-smooth regularization. Each agent in the network updates local variables by local information exchange and cooperates to seek an optimal solution. We prove that local variable estimates generated by the proposed algorithm achieve consensus and are attracted to a neighborhood of the optimal solution with an convergence rate, where is the total number of iterations. Finally, some comparative simulations are provided to verify the convergence performance of the proposed algorithm.
Index Terms:
distributed optimization, proximal operator, random reshuffling, stochastic algorithm, time-varying graphsI Introduction
Distributed non-smooth finite-sum minimization is a basic problem of the popular supervised machine learning [1, 2, 3]. In machine learning communities, optimizing a training model with merely the average loss over a finite data set usually leads to over-fitting or poor generalization. Some non-smooth regularizations are often included in the cost function to encode prior knowledge, which also introduces the challenge of non-smoothness. What’s more, in many practical network systems [4, 5], training data are naturally stored at different physical nodes and it is expensive to collect data and train the model in one centralized node. Compared to the centralized setting, the distributed setting makes use of multi computational sources to train the learning model in parallel, leading to potential speedup. However, since the data are distributed and the communication is limited, more involved approaches are needed to solve the minimization problem. Therefore, distributed finite-sum minimization has attracted much attention in machine learning, especially for large-scale applications with big data.
For large-scale non-smooth finite-sum optimization problems, there have been many efficient centralized and distributed first-order algorithms, including subgradient-based methods [6, 7, 8] and proximal gradient algorithms [9, 10, 11, 12, 13, 14]. Subgradient-based method is very generic in optimization with the expense of slow convergence. To be specific, subgradient-based algorithms may increase the objective function of the optimization problem for small step-sizes [10]. Proximal gradient algorithms are considered more stable than subgradient-based methods and often own better numerical performance than subgradient-based methods for convex optimization [15]. Hence, proximal gradient algorithms have attracted great interest for large-scale non-smooth optimization problems. Particularly, training data are allocated to different computing nodes and the non-smooth finite-sum optimization needs to be handled efficiently in a distributed manner. Many distributed deterministic proximal gradient algorithms have been proposed with guaranteed convergence for non-smooth optimization over time-invariant and time-varying graphs [12, 13, 14]. These distributed works are developed under the primal-dual framework and are applicable for the constrained non-smooth optimization. However, these distributed algorithms focus on the deterministic non-smooth optimization and require computing the full gradients of all local functions at each iteration. The per iteration computational cost of a deterministic algorithm is much higher than that of a stochastic gradient method, which hinders the application of deterministic algorithms for non-smooth optimization with large-scale data.
In large-scale machine learning settings, various first-order stochastic methods are leading algorithms due to their scalability and low computational requirements. Decentralized stochastic gradient descent algorithms have gained a lot of attention recently, especially for the traditional federated learning setting with a star-shaped network topology [16, 17, 18]. All of these methods are not fully distributed in a sense that they require a central parameter server. The potential bottleneck of the star-shaped network is possible communication traffic jam on the central sever and the performance will be significantly degraded when the network bandwidth is low. To consider a more general distributed network topology without a central server, many distributed stochastic gradient algorithms have been studied [19, 20, 21, 22, 23] for convex finite-sum optimization. To avoid the degenerated performance of algorithms with diminishing steps-sizes, some recent works [22] and [23] have proposed consensus-based distributed stochastic gradient descent methods with non-diminishing (constant) step-sizes for smooth convex optimization over time-invariant networks. With the variance reduction technique to handle the variance of the local stochastic gradients at each node, some distributed efficient stochastic algorithms with constant step-sizes have been studied for strongly convex smooth optimization over time-invariant undirected networks [24] and time-invariant directed networks [25]. However, most of the existing distributed stochastic algorithms are designed for smooth optimization and are only applicable over time-invariant networks.
In practice, a communication network may be time-varying, since network attacks may cause failures of communications and connectivity of a network may change, especially for mobile networks [26, 4]. Therefore, it is necessary to study distributed algorithms over time-varying networks. Considering the unreliable network communication, some works have studied distributed asynchronous stochastic algorithms with diminishing step-sizes for smooth convex optimization over multi-agent networks [20, 21]. To avoid the degenerated performance of algorithms with diminishing step-sizes, [7] developed a distributed gradient algorithm with a multi-step consensus mapping for multi-agent optimization. This multi-step consensus mapping has also been widely applied in the follow-up works [27, 28] for multi-agent consensus and non-smooth optimization over time-varying networks. Differently from these deterministic works, this paper studies a distributed stochastic gradient algorithm with sample-without-replacement heuristic for non-smooth finite-sum optimization over time-varying multi-agent networks.
Random reshuffling (RR) is a simple, popular but elusive stochastic method for finite-sum minimization in machine learning. Contrasted with stochastic gradient descent (SGD), where the training data are sampled uniformly with replacement, the sampling-without-replacement RR method learns from each data point in each epoch and often own better performance in many practical problems[29, 30, 31]. The convergence properties of SGD are well-understood with tight lower and upper bounds in many settings [32, 33], however, the theoretical analysis of RR had not been studied until recent years. The sampling-without-replacement in RR introduces a significant complication that the gradients are now biased, which implies that a single iteration does not approximate a full gradient descent step. The incremental gradient algorithm (IG) is one special case of the shuffling algorithm. The IG generates a deterministic permutation before the start of epochs and reuses the permutation in all subsequent epochs. In contrast, in the RR, a new permutation is generated at the beginning of each epoch. The implementation of IG has a challenge of choosing a suitable permutation for cycling through the iterations [34], and the IG is susceptible to bad orderings compared to RR [35]. Therefore, it is necessary to study a random reshuffling algorithm for convex non-smooth optimization. For strongly convex optimization, the seminal work [30] theoretically characterized various convergence rates for the random reshuffling method. One inspiring recent work by Richtarik [36] has provided some involved yet insightful proofs for the convergence behavior of RR under weak assumptions. For smooth finite-sum minimization, [37] has studied decentralized stochastic gradient with shuffling and provided insights for practical data processing. What’s more, the recent work [38] has studied centralized proximal gradient descent algorithms with random reshuffling (Prox-RR) for non-smooth finite-sum optimization and extended the Prox-RR to federated learning. However, these works are not applicable to fully distributed settings and the Prox-RR needs the strong convexity assumption, which hinders its application.
Inspired by the existing deterministic and stochastic algorithms, we develop a distributed stochastic proximal algorithm with random reshuffling (DPG-RR) for non-smooth finite-sum optimization over time-varying multi-agent networks, extending the random reshuffling to distributed non-smooth convex optimization.
The contributions of this paper are summarized as follows.
-
•
For non-smooth convex optimization, we propose a distributed stochastic algorithm DPG-RR over time-varying networks. Although there are a large number of works on proximal SGD [39, 40], few works have studied how to extend random reshuffling to solve convex optimization with non-smooth regularization. This paper extends the recent centralized proximal algorithm Prox-RR in [38] for strongly convex non-smooth optimization to general convex optimization and distributed settings. Another very related decentralized work is [37], which has provided important insights to distributed stochastic gradient descent with data shuffling under master-slave frameworks. This paper extends [37] to fully distributed settings and makes it applicable for non-smooth optimization. To our best knowledge, this is the first attempt to study fully distributed stochastic proximal algorithms with random reshuffling over time-varying networks.
-
•
The proposed algorithm DPG-RR needs fewer proximal operators compared with proximal SGD and is applicable for time-varying networks. To be specific, for the non-smooth optimization with local functions, the standard proximal SGD applies the proximal operator after each stochastic gradient step [40] and needs proximal evaluations. In contrast, the proposed algorithm DPG-RR only operates one single proximal evaluation at each iteration. In addition, with the design of multi-step consensus mapping, this proposed algorithm enables local variable estimates closer to each other, which is crucial for distributed non-smooth optimization over time-varying networks. Compared with the existing incremental gradient algorithm in [41], the proposed random reshuffling algorithm in this paper requires a weaker assumption, where the cost function does not need to be strongly-convex.
-
•
This work provides a complete and rigorous theoretical convergence analysis for the proposed DPG-RR over time-varying multi-agent networks. Due to the sampling-without-replacement mechanism of random reshuffling, the local stochastic gradients are biased estimators of the full gradient. In addition, because of scattered information in the distributed setting, there are differences between local and global objective functions, and thus local and the global gradients. To handle the differences between local and global gradients, this paper proves the summability of the error sequences of the estimated gradients. Then, we prove the convergence of the transformed stochastic algorithm by some novel proof techniques inspired by [36].
The remainder of the paper is organized as follows. The preliminary mathematical notations and proximal operator are introduced in section II. The problem description and the design of a distributed solver are provided in section III. The convergence performance of the proposed algorithm is analyzed in section IV. Numerical simulations are provided in section V and the conclusion is made in section VI.
II Notations and Preliminaries
II-A Notations
We denote the set of real numbers, the set of natural numbers, the set of -dimensional real column vectors and the set of -by- real matrices, respectively. We denote the transpose of vector . In addition, denotes the Euclidean norm, the inner product, which is defined by . The vectors in this paper are column vectors unless otherwise stated. The notation denotes the set . For a differentiable function , denotes the gradient of function with respect to . For a convex non-smooth function , denotes the subdifferential of function at . The -subdifferential of a non-smooth convex function at , denoted by , is the set of vectors such that for all ,
| (1) |
II-B Proximal Operator
For a proper non-differentiable convex function and a scalar , the proximal operator is defined as
| (2) |
The minimum is attained at a unique point , which means the proximal operator is a single-valued map. In addition, it follows from the optimality condition for convex optimization that
| (3) |
The following proposition presents some properties of the proximal operator.
Proposition II.1.
[42] Let be a closed proper convex function. For a scalar and , let . For , , which is also called the nonexpansiveness of proximal operator.
When there exists error in the computation of proximal operator, we denote the inexact proximal operator by , which is defined as
| (4) |
III Problem Description And Algorithm Design
In this paper, we aim to solve the following non-smooth finite-sum optimization problem over a multi-agent network,
| (5) |
where is the unknown decision variable, is the number of agents in the network and is the number of local samples. The global sample size of the multi-agent network is . The cost function in (5) denotes the global cost of the multi-agent network and is differentiable. The regularization is non-smooth, which encodes some prior knowledge. In the multi-agent network, each agent only knows local samples and the corresponding cost functions to update the local decision variable. In addition, the non-smooth regularization is available to all agents. In this setting, we assume that each agent uses local cost functions and communications with its neighbors to obtain the same optimal solution of problem (5).
In real-world applications of distributed settings, it is difficult to keep all communication links between agents connected and stable due to the the existence of networked attacks and limited bandwidth. We consider a general time-varying multi-agent communication network , where denotes the set of communication edges at time . At each time , agent can only communicate with agent if and only if . In addition, the neighbors of agent at time are the agents that agent can communicate with at time . The adjacent matrix of the network is a square matrix, whose elements indicate the weights of the edges in .
For the finite-sum optimization (5), we make the following assumption.
Assumption III.1.
-
(a)
Functions and are convex.
-
(b)
Local function has a Lipschitz-continuous gradient with constant , i.e. for every ,
(6) while the regular function is non-smooth.
-
(c)
There exists a scalar such that for each sub-gradient , , for every .
-
(d)
There exists a scalar such that for each agent and every , .
-
(e)
Further, is lower bounded by some and the optimization problem owns at least one optimal solution .
Assumption III.1 is common in stochastic algorithm research [37, 43] and finite-sum minimization problems satisfying Assumption III.1 arise in many applications. Here, we provide some real-world examples.
Example 1: In binary classification problem [44], the logistic regression optimization aims to obtain a predictor to estimate the categorical variables of the testing data. When the large-scale training samples are allocated to different agents, the local cost function in (5) is a cross-entropy error function (CNF), , where and denote the feature vector and categorical value of the th training sample at agent . Then, the gradient of the convex function is bounded and satisfies the Lipschitz condition in (6).
For the communication topology, the time-varying multi-agent network of the finite-sum optimization (5) satisfies the following assumption.
Assumption III.2.
Consider the undirected time-varying network with adjacent matrices ,
-
(a)
For each , the adjacent matrix is doubly stochastic.
-
(b)
There exists a scalar such that for all . In addition, if , and otherwise.
-
(c)
The time-varying graph sequence is uniformly connected. That is, there exists an integer such that agent sends its information to all other agents at least once every consecutive time slots.
Remark III.1.
In Assumption III.2, part (a) is common for undirected graphs and balanced directed graphs. Part (b) means that each agent gives non-negligible weights to the local estimate and the estimates received from neighbors. Part (c) implies that the time-varying network is able to transmit information among any pair of agents in bounded time. Assumption III.2 is widely adopted in the existing literature [7, 28].
Next, we design a distributed proximal gradient algorithm with random reshuffling for each agent in the multi-agent network. At the beginning of each iteration , we sample indices without replacement from such that the generated is a random permutation of . Then, we process with inner iterations of the form
| (7) |
where is a constant step-size, the superscript denotes the th inner iteration, the subscripts and denote the th agent and th outer iteration, respectively.
Then, to achieve the consensus between different agents, a multi-step consensus mapping is applied as
| (8) |
where is the th element of matrix for . The notation is the total number of communication steps before iteration , and is a transition matrix, defined as
| (9) |
where is the adjacent matrix of the multi-agent network at iteration . To be specific, using vector notations and , we rewrite (8) as
Agents perform communication steps at iteration . At each communication step, agents exchange their estimates and linearly combine the received estimates using weights . This mapping (8) is referred as a multi-step consensus mapping because linear combinations of estimates bring the estimates of different agents close to each other.
Finally, for the non-smooth regular function, we use proximal operator
| (10) |
to obtain the local variable estimate of agent at the next iteration.
The proposed distributed proximal stochastic gradient algorithm with random reshuffling (DPG-RR)111We suppose the local shuffling is sufficient, i.e. the permutation after shuffling is uniformly distributed. is formally summarized in Algorithm 1.
Remark III.2.
Compared with the standard proximal SGD, where the proximal operator is applied after each stochastic gradient descent, the proposed DPG-RR only operates one single proximal evaluation at each iteration, which is of the proximal evaluations in the proximal SGD. Therefore, the proposed DPG-RR owns lower computational burden and is applicable for the non-smooth optimization where the proximal operator is expensive to calculate.
Remark III.3.
Compared with the fully random sampling procedure, which is used in the well-known stochastic gradient descent method (SGD), one main advantage of the random reshuffling procedure is its intrinsic ability to avoid cache misses when reading the data from memory, enabling a faster implementation. In addition, a random reshuffling algorithm usually converges in fewer iterations than distributed SGD[30, 38]. It is due to that the RR procedure learns from each sample in each epoch while the SGD can miss learning from some samples in any given epoch. The gradient method with the incremental sampling procedure is a special case of the random reshuffling gradient method, which has been investigated in [36].
Remark III.4.
The work in [37] has studied the convergence rates for strongly convex, convex and non-convex optimization under different shuffling procedures. [37] has provided a unified analysis framework for three shuffling procedures, including global shuffling, local shuffling and insufficient shuffling222If the training samples of machine learning task are centrally stored, the global shuffling is usually applied, where the entire training samples are shuffled after each epoch. Otherwise, local shuffling, where each agent randomly shuffles local training samples after each epoch, is preferred to reduce communication burden.. Unlike the work [37], this paper focuses on non-smooth optimization with a local shuffling procedure, which is more applicable for the distributed setting. In addition, this proposed distributed DPG-RR owns a comparable convergence rate and allows non-smooth functions and time-varying communications between different agents for convex finite-sum optimization.
The convergence performance of the proposed algorithm is discussed in the following theorem and the proof is provided in the next section.
Theorem III.1.
Remark III.5.
If the local sample size increases, the convergence rate of the proposed algorithm will become slower. It follows from the proof of Theorem III.1 that the constant term in the convergence rate is proportional to the third-order polynomial of . Since the proposed algorithm is distributed, we can reduce the effect of local sample size on the convergence rate by using more agents for large-scale problems. Whereas more agents may require higher communication costs over multi-agent networks. In addition, the convergence rate also depends on other factors, such as the Lipschitz constant of objective functions, the upper bounds of subgradients, the shuffling variance, and the bounded intercommunication interval.
Remark III.6.
Theorem III.1 extends that of the centralized Prox-RR in [38] to distributed settings and non-strongly convex optimization. Compared with the popular stochastic sub-gradient method with a diminishing step-size for non-smooth optimization, whose convergence rate is [19], the proposed DPG-RR has a faster convergence rate.
IV Theoretical analysis
In this section, we present theoretical proofs for the convergence performance of the proposed algorithm. The proof sketch includes three parts.
-
(a)
Transform the DPG-RR to an algorithm with some error sequences, and prove that the error sequences are summable333 Let be a sequence of real numbers. The series is summable if and only if the sequence converges..
-
(b)
Estimate the bound of the forward per-epoch deviation of the DPG-RR.
-
(c)
Prove the consensus property of local variables and the convergence performance in Theorem III.1.
Each part is discussed in detail in the subsequent subsections. To present the transformation, we define
IV-A Transformation of DPG-RR and the summability of error sequences
Proposition IV.1.
Proof.
See Appendix VII-B. ∎
Then, inspired by Section III.B of [28], we discuss the summabilities of error sequences and in the following proposition.
Proposition IV.2.
Proof.
See Appendix VII-C. ∎
IV-B Boundness of the forward per-epoch deviation
Before presenting the boundness analysis, we introduce some necessary quantities for the random reshuffling technique.
Definition IV.1.
[36] For any , the quantity is the Bregman divergence between and associated with function .
If the function is -smooth, then for all , . The difference between the gradients of a convex and -smooth function satisfies
| (13) |
In addition, the forward per-epoch deviation of the proposed algorithm is introduced as follows.
Definition IV.2.
The forward per-epoch deviation of DPG-RR for the -th epoch is defined as
| (14) |
Now, we show that the forward per-epoch deviation of DPG-RR is upper bounded in the following lemma.
Lemma IV.1.
Proof.
See Appendix VII-D. ∎
IV-C Proof of Theorem III.1
Proof.
(1) First, we prove the consensus property of the generated local variables, i.e. for all agent . By (40) in Lemma VII.5, holds. In addition, with Lemma VII.2 and Lemma VII.6, we obtain that
Then, . Because is nonnegative,
and hence, for each agent . Therefore, local variable estimates of all agents achieve consensus and converge to the average as .
(2) Next, we consider the convergence rate of the proposed algorithm. By Lemma VII.1 and (11), we have
| (16) |
where , and . Then, the square of the norm between and the optimal solution satisfies
| (17) |
For the second term in (IV-C), we have for any ,
| (18) |
Summing over from to gives
| (19) |
Next, we bound the third term in (IV-C) with -smoothness in Assumption III.1 (b) as
| (20) |
By summing (20) over from to , we obtain an upper bound of the forward deviation by Lemma IV.1 that
With the above inequality, we estimate the lower bound of the sum of the second and third term in (IV-C) as
| (21) |
where the last inequality holds since by , and is non-negative due to the convexity.
By rearranging (IV-C), we have
| (22) |
where the second inequality holds due to the Cauchy Schwarz inequality and the triangle inequality.
Taking expectation of (IV-C) and by (IV-C),
where , the second inequality holds because of and (VII-C).
Then, rearranging the above result leads to
Summing over from to ,
| (23) |
Then, we need to estimate an upper bound of . By the transformation of (IV-C) and the fact that ,
where . It follows from Lemma VII.4 that
where the sequences , and are polynomial-geometric sequences and are summable by Lemma VII.2.
By the summability of , and , there exist some scalars A and B such that
| (24) |
where we use the step-size range . And
| (25) |
where . Then, satisfies
Since and are increasing sequences, we have for ,
| (26) |
Now, we can bound the right-hand side of (IV-C) with (IV-C),
By dividing both sides by , we get
Finally, by the convexity of , the average iterate satisfies
| (27) |
where and the last equality holds due to the fact that , and . ∎
V Simulation
In this section, we apply the proposed algorithm DPG-RR to optimize the black-box binary classification problem [44], which is to find the optimal predictor by solving
| (28) |
where , is the feature vector of the th local sample of agent , is the classification value of the th local sample of agent and denotes the set of local training samples of agent . In this experiment, we use the publicly available real datasets a9a and w8a 444a9a and w8a are available in the website www.csie.ntu.edu.tw/ cjlin/libsvmtools/datasets/.. In addition, in our setting, there are agents and . All comparative algorithms are initialized with a same value. Experiment codes and the adjacent matrices of ten-agent time-varying networks are provided at https://github.com/managerjiang/Dis-Prox-RR.




(1) Time-invariant networks: For comparison, we apply some existing distributed stochastic algorithms including GT-SAGA in [24] and DSGD in [22], and the proposed stochastic DPG-RR to solve (28) over the ten-agent connected network. Since the cost function in (28) is non-smooth, we replace the gradients in GT-SAGA and DSGD with subgradients. The simulation results for a9a and w8a datasets are shown in Figs. 1 and 2. Fig. 1(b) and Fig. 2(b) show that the trajectories of objective function generated by all algorithms converge quickly to the optimum . To measure the consensus performance, we define one quantity 555The is an expansion of , where , is the Laplacian matrix of the undirected multi-agent network and . In addition, the Laplacian matrix of an undirected multi-agent network is positive semi-definite. By the fact that is the single eigenvalue corresponding to eigenvector of , if and only if for all . as , where is th element of one doubly-stochastic adjacent matrix. If all local variable estimates achieve consensus, then, . Fig. 1(a) and Fig. 2(a) represent that local variables generated by all algorithms achieve consensus. In addition, it is seen that the proposed algorithm DPG-RR owns a better consensus performance than GT-SAGA and DSGD, which verify the effectiveness of the multi-step consensus mapping in DPG-RR.
Although all comparative algorithms have comparable convergence rate in practice, [24] and [22] do not provide the theoretical convergence analysis of GT-SAGA and DSGD for non-smooth optimization. In addition, these algorithms are not applicable for time-varying multi-agent networks, hence, we further compare our proposed algorithm with some recent distributed deterministic algorithms for non-smooth optimization over time-varying networks.
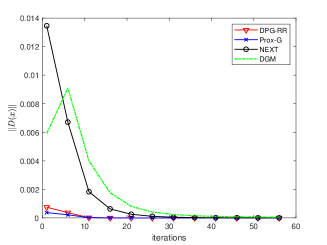
(2) Time-varying networks: We compare DPG-RR with the distributed deterministic proximal algorithm Prox-G in [28], the algorithm NEXT in [45] and the distributed subgradient method (DGM) in [7] to solve (28) over the time-varying graphs. DPG-RR and Prox-G adopt a same constant step-size, NEXT and DGM have diminishing step-sizes.

All distributed algorithms are applied over periodically time-varying ten-agent networks satisfying Assumption III.2 to solve the problem (28), which are shown in Fig. 3.



| time(s) | ||
|---|---|---|
| Algorithms | a9a | w8a |
| DPG-RR | 25.21 | 140.89 |
| Prox-G | 55.50 | 161.44 |
| NEXT | 80.28 | 264.78 |
| DGM | 30.91 | 120.51 |
The simulation results for a9a and w8a datasets are shown in Fig. 4 and Fig. 5, respectively. It is seen from Fig. 4(a) and Fig. 5(a) that the trajectories generated by DPG-RR, Prox-G, NEXT and DGM all converge to zero, implying that local variable estimates generated by all algorithms achieve consensus. In addition, the DPG-RR shows a better consensus numerical performance than NEXT and DGM algorithms. From Fig. 4(b) and Fig. 5(b), we can see that DPG-RR converges faster than NEXT and DGM over both a9a and w8a datasets, which verify that DPG-RR is superior to algorithms with diminishing step-sizes. We observe that DPG-RR has a comparable convergence performance of Prox-G. While, due to the stochastic technique, DPG-RR avoids the computation of full local gradients in Prox-G. The running time of different algorithms are shown in Table I. It is observed that the proposed stochastic DPG-RR generally costs less running time than the deterministic algorithms Prox-G and NEXT.

To show the advantages of random reshuffling sampling procedure, we replace the random reshuffling step of DPG-RR with a stochastic sampling procedure, yielding a DPG-SG algorithm. Similarly, we replace the random reshuffling step of DPG-RR with a deterministic incremental sampling procedure, yielding a DPG-IG algorithm. All algorithms take the same constant step-size () and the simulation results are shown in Fig. 6. Compared with fully stochastic sampling procedure (DPG-SG), the proposed DPG-RR shows a faster convergence. In addition, the DPG-IG algorithm shows a comparable convergence rate with DPG-RR. These numerical results are consistent with the theoretical findings discussed in Remark III.3.
VI Conclusion
Making use of random reshuffling, this paper has developed one distributed stochastic proximal-gradient algorithm for solving large-scale non-smooth convex optimization over time-varying multi-agent graphs. The proposed algorithm operates only one single proximal evaluation at each epoch, owning significant advantages in scenarios where the proximal mapping is computationally expensive. In addition, the proposed algorithm owns constant step-sizes, overcoming the degraded performance of most stochastic algorithms with diminishing step-sizes. One future research direction is to improve the convergence rate of DPG-RR by some accelerated methods, such as Nesterov’s acceleration technique or variance reduction technique. Another one is to extend the proposed algorithm for distributed non-smooth non-convex optimization, which is applicable for deep neural network models.
VII Appendix
VII-A Some vital Lemmas
At first, the following lemma characterizes the -subdifferential of non-smooth function at , .
Lemma VII.1.
The next lemma shows that polynomial-geometric sequences are summable, which is vital for the analysis of error sequences introduced by transformation.
Lemma VII.2.
[28, Proposition 3] Let , and let
denote the set of all -th order polynomials of , where . Then for every polynomial ,
The result of this Lemma for will be particularly useful for the analysis in the following. Hence, we define
| (30) |
The following lemma characterizes the variance of sampling without replacement, which is a key ingredient in our convergence result of DPG-RR.
Lemma VII.3.
[36, Lemma 1] Let be fixed vectors, be their average and be the population variance. Fix any , let be sampled uniformly without replacement from and be their average. Then, the sample average and variance are given by
Finally, we provide a lemma on the boundness of one special nonnegative sequence, which is vital for the convergence analysis.
Lemma VII.4.
[9, Lemma 1] Assume that the nonnegative sequence satisfies the following recursion for all
| (31) |
with an increasing sequence, and for all . Then, for all ,
| (32) |
VII-B Proof of Proposition IV.1
Proof.
By taking the average of (7) over agents,
| (33) |
where and . Because of the Lipschitz-continuity of the gradient of , satisfies
| (34) |
Recall that , which is the result of the exact centralized proximal step. Then, we relate and by formulating the latter as an inexact proximal step with error . A simple algebraic expansion gives
where we have used the fact that and in the last inequality.
Therefore, we can write
| (35) |
where
VII-C Proof of Proposition IV.2
We first define two useful quantities and . Then, we provide some properties of the local variables generated by the proposed algorithm in the following Lemma.
Proof.
(a) By the algorithm 1, we have
Taking norm of the above equality and summing over ,
| (43) |
By (42), holds. Since is a convex combination of and ,
| (44) |
Then, substituting the fact that and (44) to (VII-C), we obtain
(b) By (41) and the proposed algorithm,
| (45) |
Then, subtracting from both sides of (VII-C) and taking norm, we obtain
| (46) |
For the first term in (VII-C), by the nonexpansiveness of the proximal operator,
In addition, by [27, Proposition 1], the bound of the distance between iterates and satisfies
| (47) |
Then, by transformation,
| (48) |
Substituting (VII-C) to (VII-C),
The following Lemma prove that the sequence is upper bounded by a polynomial-geometric sequence, which is vital in the discussions of the summability of the error sequences.
Lemma VII.6.
Proof.
This proof is inspired by [28, Lemma 1]. We proceed by induction on . First, we show that the result holds for by choosing . It suffices to show that is bounded given the initial points .
Now suppose the result in Lemma VII.6 holds for some positive integer . We show that it also holds for . We transform (38) in Lemma VII.5 to
| (49) |
For the last term in (49), by transforming (39) in Lemma VII.5, we obtain
| (50) |
Then, substituting the induction hypothesis for into (50), we have
By Lemma VII.2 and (30), there exist constants such that
By induction hypothesis and (49),
| (51) |
Take the coefficients , and as
Then, comparing coefficients, we see that the right-hand side of (VII-C) has an upper bound , which implies that the induction hypothesis holds for . ∎
Proof of Proposition IV.2:
VII-D Proof of Lemma IV.1
Proof.
In addition, by (VII-B), . Then, combining (56) with (VII-B),
Taking the norm of , we have
| (57) |
Next, consider the term in (VII-D). By Lemma VII.3 with and ,
where is the population variance at the optimum . Summing this over from to ,
| (58) |
where the inequality holds due to , and Assumption III.1 (d).
References
- [1] F. Iutzeler and J. Malick, “Nonsmoothness in machine learning: Specific structure, proximal identification, and applications,” Set-Valued Var. Anal, vol. 28, pp. 661–678, 2020.
- [2] W. Tao, Z. Pan, G. Wu, and Q. Tao, “The strength of nesterov’s extrapolation in the individual convergence of nonsmooth optimization,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 7, pp. 2557–2568, 2020.
- [3] A. Astorino and A. Fuduli, “Nonsmooth optimization techniques for semisupervised classification,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 29, no. 12, pp. 2135–2142, 2007.
- [4] A. H. Zaini and L. Xie, “Distributed drone traffic coordination using triggered communication,” Unmanned Systems, vol. 08, no. 01, pp. 1–20, 2020.
- [5] K. Wang, Z. Fu, Q. Xu, D. Chen, L. Wang, and W. Yu, “Distributed fixed step-size algorithm for dynamic economic dispatch with power flow limits,” SCIENCE CHINA INFORMATION SCIENCES, vol. 64, p. 112202, 2021.
- [6] P. Yi and Y. Hong, “Stochastic sub-gradient algorithm for distributed optimization with random sleep scheme,” Control Theory Technol., vol. 13, pp. 333–347, 2015.
- [7] A. Nedic and A. Ozdaglar, “Distributed subgradient methods for multi-agent optimization,” IEEE Transactions on Automatic Control, vol. 54, no. 1, pp. 48–61, 2009.
- [8] W. Zhong and J. Kwok, “Accelerated Stochastic Gradient Method for Composite Regularization,” in Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, vol. 33. Reykjavik, Iceland: PMLR, 22–25 Apr 2014, pp. 1086–1094.
- [9] M. Schmidt, N. L. Roux, and F. Bach, “Convergence rates of inexact proximal-gradient methods for convex optimization,” Advances in Neural Information Processing Systems, vol. 24, pp. 1458–1466, 2012.
- [10] D. P. Bertsekas, “Incremental gradient, subgradient, and proximal methods for convex optimization: A survey,” arXiv.cs.SY, 2017.
- [11] Q. Wang, J. Chen, X. Zeng, and B. Xin, “Distributed proximal-gradient algorithms for nonsmooth convex optimization of second-order multiagent systems,” International Journal of Robust and Nonlinear Control, vol. 30, no. 17, pp. 7574–7592, 2020. [Online]. Available: https://onlinelibrary.wiley.com/doi/abs/10.1002/rnc.5199
- [12] X. Li, G. Feng, and L. Xie, “Distributed proximal algorithms for multiagent optimization with coupled inequality constraints,” IEEE Transactions on Automatic Control, vol. 66, no. 3, pp. 1223–1230, 2021.
- [13] S. A. Alghunaim, E. K. Ryu, K. Yuan, and A. H. Sayed, “Decentralized proximal gradient algorithms with linear convergence rates,” IEEE Transactions on Automatic Control, vol. 66, no. 6, pp. 2787–2794, 2021.
- [14] J. Zhang, H. Liu, A. M.-C. So, and Q. Ling, “A penalty alternating direction method of multipliers for convex composite optimization over decentralized networks,” IEEE Transactions on Signal Processing, vol. 69, pp. 4282–4295, 2021.
- [15] L. Vandenberghe, “Lecture notes for EE 236C, UCLA,” Spring, 2011-2012.
- [16] F. Sattler, K.-R. Müller, and W. Samek, “Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints,” IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 8, pp. 3710–3722, 2021.
- [17] W. Wu, X. Jing, W. Du, and G. Chen, “Learning dynamics of gradient descent optimization in deep neural networks,” SCIENCE CHINA INFORMATION SCIENCES, vol. 64, p. 150102, 2021.
- [18] W. Li, Z. Wu, T. Chen, L. Li, and Q. Ling, “Communication-censored distributed stochastic gradient descent,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–13, 2021.
- [19] O. Shamir and T. Zhang, “Stochastic gradient descent for non-smooth optimization: Convergence results and optimal averaging schemes,” in Proceedings of the 30th International Conference on International Conference on Machine Learning - Volume 28, ser. ICML’13. JMLR.org, 2013, p. I–71–I–79.
- [20] P. Bianchi, G. Fort, and W. Hachem, “Performance of a distributed stochastic approximation algorithm,” IEEE Transactions on Information Theory, vol. 59, no. 11, pp. 7405–7418, 2013.
- [21] J. Lei, H.-F. Chen, and H.-T. Fang, “Asymptotic properties of primal-dual algorithm for distributed stochastic optimization over random networks with imperfect communications,” SIAM Journal on Control and Optimization, vol. 56, no. 3, pp. 2159–2188, 2018. [Online]. Available: https://doi.org/10.1137/16M1086133
- [22] X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu, “Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17. Red Hook, NY, USA: Curran Associates Inc., 2017, p. 5336–5346.
- [23] Z. Li, B. Liu, and Z. Ding, “Consensus-based cooperative algorithms for training over distributed data sets using stochastic gradients,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–11, 2021.
- [24] R. Xin, U. A. Khan, and S. Kar, “Variance-reduced decentralized stochastic optimization with accelerated convergence,” IEEE Transactions on Signal Processing, vol. 68, p. 6255–6271, 2020. [Online]. Available: http://dx.doi.org/10.1109/TSP.2020.3031071
- [25] M. I. Qureshi, R. Xin, S. Kar, and U. A. Khan, “Push-saga: A decentralized stochastic algorithm with variance reduction over directed graphs,” IEEE Control Systems Letters, vol. 6, pp. 1202–1207, 2022.
- [26] X.-F. Wang, A. R. Teel, K.-Z. Liu, and X.-M. Sun, “Stability analysis of distributed convex optimization under persistent attacks: A hybrid systems approach,” Automatica, vol. 111, p. 108607, 2020. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0005109819304686
- [27] A. Nedic, A. Ozdaglar, and P. A. Parrilo, “Constrained consensus and optimization in multi-agent networks,” IEEE Transactions on Automatic Control, vol. 55, no. 4, pp. 922–938, 2010.
- [28] A. I. Chen and A. Ozdaglar, “A fast distributed proximal-gradient method,” in 2012 50th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Oct 2012, pp. 601–608.
- [29] K. Ahn, C. Yun, and S. Sra, “SGD with shuffling: optimal rates without component convexity and large epoch requirements,” in Advances in Neural Information Processing Systems. Curran Associates, Inc., 2020.
- [30] M. Gurbuzbalaban, A. Ozdaglar, and P. A. Parrilo, “Why random reshuffling beats stochastic gradient descent,” Mathematical Programming, vol. 186, pp. 49–84, 2021.
- [31] B. Recht and C. Ré, “Parallel stochastic gradient algorithms for large-scale matrix completion,” Mathematical Programming Computation, vol. 5, no. 2, pp. 201–226, 2013.
- [32] A. Rakhlin, O. Shamir, and K. Sridharan, “Making gradient descent optimal for strongly convex stochastic optimization,” in Proceedings of the 29th International Coference on International Conference on Machine Learning, ser. ICML’12. Madison, WI, USA: Omnipress, 2012, p. 1571–1578.
- [33] Y. Drori and O. Shamir, “The complexity of finding stationary points with stochastic gradient descent,” in Proceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 119. PMLR, 13–18 Jul 2020, pp. 2658–2667. [Online]. Available: https://proceedings.mlr.press/v119/drori20a.html
- [34] A. Nedic and D. P. Bertsekas, “Incremental subgradient methods for nondifferentiable optimization,” SIAM Journal on Optimization, vol. 12, no. 1, pp. 109–138, 2001.
- [35] D. P. Bertsekas, Optimization for Machine Learning, chapter 4. The MIT Press, 2011.
- [36] K. Mishchenko, A. Khaled, and P. Richtarik, “Random reshuffling: Simple analysis with vast improvements,” in Advances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 17 309–17 320. [Online]. Available: https://proceedings.neurips.cc/paper/2020/file/c8cc6e90ccbff44c9cee23611711cdc4-Paper.pdf
- [37] Q. Meng, W. Chen, Y. Wang, Z.-M. Ma, and T.-Y. Liu, “Convergence analysis of distributed stochastic gradient descent with shuffling,” Neurocomputing, vol. 337, pp. 46–57, 2019. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0925231219300578
- [38] K. Mishchenko, A. Khaled, and P. Richtárik, “Proximal and federated random reshuffling,” 2021.
- [39] L. Xiao and T. Zhang, “A proximal stochastic gradient method with progressive variance reduction,” SIAM Journal on Optimization, vol. 24, no. 4, pp. 2057–2075, 2014. [Online]. Available: https://doi.org/10.1137/140961791
- [40] Z. Li and J. Li, “A simple proximal stochastic gradient method for nonsmooth nonconvex optimization,” in Advances in Neural Information Processing Systems, vol. 31. Curran Associates, Inc., 2018. [Online]. Available: https://proceedings.neurips.cc/paper/2018/file/e727fa59ddefcefb5d39501167623132-Paper.pdf
- [41] N. D. Vanli, M. Gurbuzbalaban, and A. Ozdaglar, “Global convergence rate of incremental aggregated gradient methods for nonsmooth problems,” in 2016 IEEE 55th Conference on Decision and Control (CDC), 2016, pp. 173–178.
- [42] A. Beck and M. Teboulle, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” SIAM Journal on Imaging Sciences, vol. 2, no. 1, pp. 183–202, 2009.
- [43] X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence of FedAvg on Non-IID data,” in International Conference on Learning Representations, 2020. [Online]. Available: https://openreview.net/forum?id=HJxNAnVtDS
- [44] S. Abu-Mostafa, M. Magdon-Ismail, and H. Lin, Learning from data. United States of America: AMLbook.com, 2012.
- [45] P. D. Lorenzo and G. Scutari, “Next: In-network nonconvex optimization,” IEEE Transactions on Signal and Information Processing over Networks, vol. 2, no. 2, pp. 120–136, 2016.