Distributed Prediction-Correction Algorithms for Time-Varying Nash Equilibrium Tracking
Abstract
This paper focuses on a time-varying Nash equilibrium trajectory tracking problem, that is applicable to a wide range of non-cooperative game applications arising in dynamic environments. To solve this problem, we propose a distributed prediction correction algorithm, termed DPCA, in which each player predicts future strategies based on previous observations and then exploits predictions to effectively track the NE trajectory by using one or multiple distributed gradient descent steps across a network. We rigorously demonstrate that the tracking sequence produced by the proposed algorithm is able to track the time-varying NE with a bounded error. We also show that the tracking error can be arbitrarily close to zero when the sampling period is small enough. Furthermore, we achieve linear convergence for the time-invariant Nash equilibrium seeking problem as a special case of our results. Finally, a numerical simulation of a multi-robot surveillance scenario verify the tracking performance and the prediction necessary for the proposed algorithm.
keywords:
Non-cooperative games, time varying nash equilibrium tracking, distributed prediction correction methods., , and ††thanks: Corresponding author.
1 Introduction
Game theory has been extensively used in numerous applications, including social networks Ghaderi \BBA Srikant (\APACyear2014), sensor networks Stankovic \BOthers. (\APACyear2011) and smart grids Zeng \BOthers. (\APACyear2019). The Nash equilibrium (NE), an important satisfactory solution concept in noncooperative games, emerges to be of both theoretical significance and practical relevance Başar \BBA Olsder (\APACyear1998). Thus, the NE seeking method is becoming a key instrument in solving noncooperative game problems.
Recently, with the penetration of multi-player systems, several distributed approaches to achieve the NE seeking have been proposed Gadjov \BBA Pavel (\APACyear2018); De Persis \BBA Grammatico (\APACyear2019); Zhu \BOthers. (\APACyear2020); Chen \BOthers. (\APACyear2022). Such approaches, however, require time-invariant cost functions and NEs. In fact, in a variety of dynamic real-world situations, such as real-time traffic networks, online auctions, and intermittent renewable generations, the cost functions and NEs are time-varying. As a result, both academia and industry begin to focus on the time-varying NE tracking problem, which is a natural extension of time-invariant NE-related tasks in dynamic environments Lu \BOthers. (\APACyear2020); Su \BOthers. (\APACyear2021).
A natural ideal for solving the NE tracking problem is to treat it as a sequence of static problems and solve them one by one using time-invariant NE seeking methods. However, these time-invariant methods necessitate iterative multiples or even infinite rounds for each static problem, and thus are not suitable for real-time tracking situations. To fix this drawback, a solvable approach is to predict the next NE at the current instant, and use the predicted variables as the initial value when solving the static problem at the next instant. Intuitively, only if the predicted model is properly constructed to bring the predicted variables close to the next NE, it is possible to achieve satisfactory tracking performance. This idea is called the prediction-correction technique, and it has been used in solving centralized time-varying optimization problems Simonetto \BOthers. (\APACyear2017). The concept of changing initial values for iterative algorithms also motivates ADMM techniques in distributed time-varying optimizations Liu \BOthers. (\APACyear2022), which are to approximately solve each static optimization problem and use its output as the initial value for solving the next one. So far, neither prediction-correction techniques nor ADMM techniques have been used in solving distributed NE tracking problems to our knowledge. Another approach to solving NE tracking problems is found in the continuous-time regime Ye \BBA Hu (\APACyear2015); Huang \BOthers. (\APACyear2022), which relies on ODE solutions and may not be implemented using digital computation. In this paper, we focus on discrete-time algorithms.
The objective of this paper is to solve a time-varying NE tracking problem in a distributed manner with a prediction correction algorithm (DPCA). Specifically, a prediction step is proposed to predict the evolution of the NE trajectory using historical information, followed by a correction step to correct predictions by solving a time-invariant NE seeking problem obtained at each time. The contributions are summarized as follows.
1) To the best of our knowledge, our work is the first to study a distributed discrete-time algorithm for a time-varying NE tracking with provable convergence.
2) We prove that the proposed DPCA can track time-varying NEs with a bounded error that is in inverse proportion to the number of correction steps. This result provides a quantitative analysis of the trade-off between tracking accuracy and algorithm iterations. Moreover, our proof demonstrates that the minimum number of correction steps can be one, thereby meeting the requirement of real-time tracking.
3) Furthermore, we prove that with a small enough sampling period, the tracking error can be arbitrarily close to zero. For a time-invariant NE seeking problem, a special case of our formulation, we show that the tracking error linearly converges to zero.
4) A multi-robot surveillance scenario is used to test the performance of our algorithm with only one correction step. In addition, we compare the DPCA to no-predictor algorithms in terms of tracking error. The result verifies the significance of the introduced prediction step in the NE tracking and convergence.
This paper is organized as follows. The distributed NE trajectory tracking problem is presented in Section 2. The detailed algorithm design is proposed in Section 3 and the main results are established in Section 4. The result verification is investigated in Section 5. Finally, concluding remarks are given in Section 6.
Notation: Let be the -dimensional Euclidean space. For a scalar , is the smallest integer not smaller than . For , denote its European norm by and its transpose by . stacks the vector as a new column vector in the order of the index set . For matrices , the Kronecker product is producted by and the smallest eigenvalue is denoted by . Denote by , and the vectors of all zeros and ones, and the identical matrix, respectively. For a differentiable function , denote with respect to , where .
2 Problem Formulation
The time-varying game under consideration is denoted as , where denotes the set of players and is the private time-varying cost function of player . In the game , each player aims to determine his time-varying strategy to track the optimal trajectory shown below.
| (1) |
where represents the joint strategies of all players except player . If for any , there is
the time-varying vector is known as the NE trajectory. The NE trajectory tracking problem is a common issue in dynamic environments Huang \BOthers. (\APACyear2022). Take a practical example, consider a target protecting problem in by players in order to block intruders with locations and protect a time-varying target . To protect the target to the greatest extent possible, it is preferable to keep the weighted center of all players to track the target . In this case, each player is constantly adjusting his position to minimize the time varying , and the problem can be cast as a NE trajectory tracking problem (1).
To distributively solve the NE trajectory tracking problem, each player estimates all other players’ strategies for determining his tracking strategy over a communication graph. Assume that the underlying communication graph is undirected and connected. The adjacent matrix is defined as , if the communication link between and exists, ; otherwise, . The corresponding Laplacian matrix is with if , and otherwise. The neighbors set of player is defined as . For an undirected and connected graph , all eigenvalues of are real numbers and can be arranged by an ascending order .
Some definitions about player ’s estimated strategy are provided below. represents that player ’s estimates of all players’ strategies; represents player ’s estimate of his strategy, which is indeed his actual strategy, i.e., ; represents player ’s estimates on all players’ strategies but his own. By the estimated strategy vector and the sampling period , each player treat the problem (1) as a sequence of static problems
| (2) |
and then solve them one by one. However, the sampling period in the real-time tracking is unable to afford the time spent in exactly solving every static problems by using time-invariant NE seeking algorithms in De Persis \BBA Grammatico (\APACyear2019); Zhu \BOthers. (\APACyear2020); Chen \BOthers. (\APACyear2022). Therefore, how to design a dynamic algorithm to ensure good tracking performance with few iterative rounds during is the problem studied in this paper.
To proceed, we make some standard assumptions, which were also required in relevant game works Ye \BBA Hu (\APACyear2015); Lu \BOthers. (\APACyear2020).
Assumption 1.
The first and second derivatives of the time-varying NE trajectory exist and are bounded, i.e., and .
Assumption 2.
Define the preudogradient as . The following statements are required for any .
i) is -strongly monotone with , that is, for any ,
ii) There exist some constants such that for any fixed , we have that for all ,
iii) There exist some constants such that for any fixed , we have that for all
Remark 1.
The augmented preudogradient is further defined as with . Meanwhile, denote . Under Assumption 2, the -Lipschitz continuity of is given in Lemma 1, whose proof is similar to that of Lemma 2 in Chen \BOthers. (\APACyear2022) and is thus omitted.
Lemma 1.
Under Assumption 2, the augmented preudogradient is -Lipschitz continuous in .
| Algorithm 1 Distributed Prediction Correction. |
|---|
| Initialization: Initialize any . Determine the number of correction steps , the constant , the stepsize and , which is a vector with th element being and the rest being . |
| 1: For times do, |
| 2: Generate predicted variables using prior information (3) 3: Update the local cost functions . |
| 4: Initialize corrected variables |
| 5: for do |
| Receive neighbor’s strategies and execute (4) end for. |
| 6. Configure tracking variables . |
| 7. end for |
3 Algorithm Design
In this section, Algorithm 1 is designed for each player to generate a sequence to track time-varying NEs . Algorithm 1 involves two steps: prediction and correction, which are depicted below.
The prediction step design: We derive the prediction step (3) by observing the dynamic of time-varying NE. Due to , the NE trajectory satisfies the following nonlinear dynamical system
| (5) |
Then we employ two methods to discretely estimate (5) and generate auxiliary prediction sequences . Meanwhile, the prediction errors of these two methods are compared.
i) The first method is to set the predicted variable as the NE at the last time instant , in other words,
| (6) |
In this case, the prediction error is measured as
| (7) |
ii) The second method involves a -step interpolation method. In other words,
| (8) |
Recalling the dynamic (5), the prediction error is then computed as follows,
| (9) | |||||
Using the Mean Value Theorem and Assumption 1 yields
where . Assumption 1 ensures that
| (10) |
If the sampling period is small enough, then , which indicates that the second method outperforms the first. In fact, the sampling period in the dynamic environment. Hence, it motivates the design of prediction in (3), while ensuring that predicted variables are close to at the time instant .
Remark 2.
The step interpolation method ensure the flexibility of the prediction’s design. When , the interpolation method in (3) is related to two steps.
The correction step design: We employ a distributed gradient descent (DGD) algorithm (4) to correct errors produced in the prediction. In particular, the predicted variable that is close to is harnessed as the correction step’s initial value. It differs from the no-predictor DGD algorithm, which uses any initial state to exact update. In this sense, Algorithm 1 may require fewer iterative rounds and take less computation time to achieve the same tracking performance as the no-predictor DGD algorithm.
4 Main Result
This section establishes the convergence of Algorithm 1. We first analyze the prediction error in Lemma 2, and then we examine the tracking error in Lemma 3. Following those, Theorem 1 rigorously characterizes the upper bound of the tracking error. Before we begin, we define stacked variables , and . The proofs of Lemmas 2 and 3 can be found in Appendix.
Lemma 2.
Remark 3.
Lemma 2 gives the prediction error when , but not when . The reason is that the prediction error analysis for the case is able to be included in the proof of Theorem 1.
Lemma 3.
Remark 4.
Lemma 3 implies that the correction step (4) provides a discrete time approach to time-invariant distributed NE seeking problems in Gadjov \BBA Pavel (\APACyear2018); De Persis \BBA Grammatico (\APACyear2019); Zhu \BOthers. (\APACyear2020); Chen \BOthers. (\APACyear2022). Meanwhile, Lemma 3 proves the linear convergence rate of this discrete time approach.
Theorem 1.
We prove that there must be a such that (14) holds. Define a decaying function related to as follows,
By , we can easily obtain that
Thus, there is a constant satisfying (14).
Next, we prove (16) by starting with the case , and then complete the proof for any .
For any , there is . According to Lemma 3 and the triangle inequality, we have
| (17) |
The upper bound of the last term of (17) is analyzed. Based on (7), we know that . By the sequence summation, we rewrite (17) as
By (14) with , we have that for any ,
At last, we prove (16) for any via the mathematical induction. Assume that for any . We prove By inputting (11) into (13), we have
| (18) |
Integrating the initial argument for any , the definition of and the inequality (14) into (18), we obtain that for any , Combining for any , we conclude that for any , the inequality (16) holds. Theorem 1 shows that each sequence approaches a neighborhood of the NE trajectory as time passes. The exponentially convergence of Algorithm 1 is shown in the following corollary.
Corollary 1.
Under the same conditions of Theorem 1, the sequence generated by Algorithm 1 converges to exponentially up to a bounded error as
Remark 5.
Corollary 1 describes the exponential convergence property of Algorithm 1. The convergence accuracy is determined by the values of and that is in inverse proportion to the correction steps . Note that increasing the value of improves tracking accuracy while necessitating much more computation time. Thus, the number of correction steps can be adjusted to match the actual tracking bound. Furthermore, if the sampling period is small enough, then Algorithm 1 ensure that the sequence is sufficiently close to the NE trajectory.
5 Example
A robotic surveillance scenario Carnevale \BOthers. (\APACyear2022) is used to validate the effectiveness of Algorithm 1, including a tracking error comparison between Algorithm 1 and the no-predictor algorithm. Consider five robots collaborating to protect a time-varying target from five intruders. Each intruder moves according to the following rule:
| (19) |
where . The target moves via a similar law with (19), so we set it to be The dynamic protection strategy of each robot is determined by the following cost function
| (20) |
where denotes the robot’s position, and . The aggregative variable . The network graph is described by a ring. The parameters for Algorithm 1 are set to , , , and . The element of initial tracking sequences is generated at random within an interval .
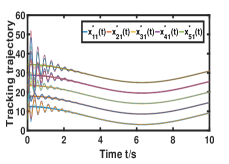
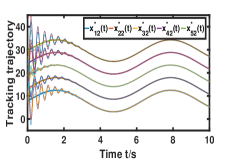
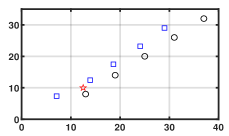
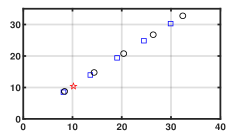
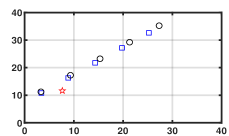
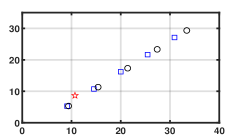
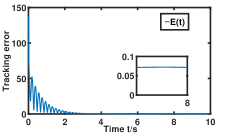
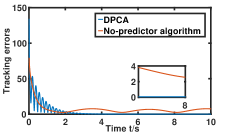
Fig. 1 shows that for any , every element of generated by Algorithm 1 can effectively reach consensus and track every element of the NE trajectory . Fig. 2 depicts that how the network constructs a smarter formation that protects the time-varying target better. As shown in Fig. 3(a), the tracking error converges to a constant term . Fig. 3 (b) demonstrates the importance of the prediction step in the NE trajectory tracking.
6 Conclusion
In this paper, we proposed a distributed prediction-correction algorithm (DPCA) to track the NE trajectory. By analyzing the coupling relationship between the prediction and the correction procedures, we rigorously proved that the tracking sequence generated by the DPCA can track the NE trajectory with a bounded error. This bound is proportional to the sampling period and inversely proportional to the number of correction steps. The results filled a gap in the study of NE tracking problems using discrete time algorithms. Moreover, the linear convergence rate for static games with time-invariant cost functions has been included in our results. The Future research of interests includes considering the communication efficient and privacy protected NE tracking algorithm.
7 Appendix
7.1 Proof of Lemma 2
7.2 Proof of Lemma 3
The proof Lemma 3 is divided into two parts: i) Prove that the matrix is positive and the constant ; ii) Prove the relationship between the tracking error and the prediction error in (13).
i) By , it yields
Meanwhile, ensures , and thus,
By using again and multiplying both side of the deriving results by , we have
which is the determinant of . Thus, . By further considering , it yields and
which indicates . Thus, .
ii) Defining and , the correction step (4) can be written as a stacked form
| (22) |
where . We first prove that at the equilibrium of system (22), reaches the NE of game . If we set the left hand side of (22) to zero, then
| (23) |
Premultiplying both sides by gives
Using yields . By the definitions of and , , which further implies that from (23). There exist some such that by the property of under the undirected connected graph . Thus, and . In other words, is the NE of and .
Next, we prove (13). Before doing it, some coordinate transformations are required. Define with and , which satisfy , , and . The unitary matrix can convert to a diagonal form . Denote and perform the coordinate transformation as
| (24) |
Then inputting (22) into (24), we obtain that
| (25) | |||||
where .
Construct a Lyapunov function as follows,
By the facts for any vectors and , it yields
| (26) |
Now we give upper bounds of each term of the right side of (26) based on (25). The first term is written as
Observing , we have
Applying the same argument, we have
| (27) |
By inserting (27) into (26), applying the relationships
and , it derives that
| (28) |
We split into to estimate
| (29) |
As for for any , it follows by the strong monotonically of that
| (30) |
where and are used. Since ,
| (31) |
Similar operations are used to obtain that
Then the difference of in (28) is reorganized as
| (32) |
We further bound by
| (33) |
To sum up, we conclude that
| (34) |
which implies that
| (35) |
Since is initialized by the predicted variable and the corrected variable , considering the relation in (35) between two consecutive iterates of the sequence , we obtain (13).
References
- Başar \BBA Olsder (\APACyear1998) \APACinsertmetastarNE{APACrefauthors}Başar, T.\BCBT \BBA Olsder, G\BPBIJ. \APACrefYear1998. \APACrefbtitleDynamic Noncooperative Game Theory Dynamic noncooperative game theory. \APACaddressPublisherSIAM. \PrintBackRefs\CurrentBib
- Carnevale \BOthers. (\APACyear2022) \APACinsertmetastarfangzhen{APACrefauthors}Carnevale, G., Camisa, A.\BCBL \BBA Notarstefano, G. \APACrefYearMonthDay2022. \BBOQ\APACrefatitleDistributed Online Aggregative Optimization for Dynamic Multi-Robot Coordination Distributed online aggregative optimization for dynamic multi-robot coordination.\BBCQ \APACjournalVolNumPagesIEEE Trans. Autom. Control1-8. {APACrefDOI} 10.1109/TAC.2022.3196627 \PrintBackRefs\CurrentBib
- Chen \BOthers. (\APACyear2022) \APACinsertmetastarstaticNE4{APACrefauthors}Chen, Z., Ma, J., Liang, S.\BCBL \BBA Li, L. \APACrefYearMonthDay2022. \BBOQ\APACrefatitleDistributed Nash equilibrium seeking under quantization communication Distributed nash equilibrium seeking under quantization communication.\BBCQ \APACjournalVolNumPagesAutomatica141110318. \PrintBackRefs\CurrentBib
- De Persis \BBA Grammatico (\APACyear2019) \APACinsertmetastarstaticNE2{APACrefauthors}De Persis, C.\BCBT \BBA Grammatico, S. \APACrefYearMonthDay2019. \BBOQ\APACrefatitleDistributed averaging integral Nash equilibrium seeking on networks Distributed averaging integral nash equilibrium seeking on networks.\BBCQ \APACjournalVolNumPagesAutomatica110108548. \PrintBackRefs\CurrentBib
- Gadjov \BBA Pavel (\APACyear2018) \APACinsertmetastarstaticNE1{APACrefauthors}Gadjov, D.\BCBT \BBA Pavel, L. \APACrefYearMonthDay2018. \BBOQ\APACrefatitleA passivity-based approach to Nash equilibrium seeking over networks A passivity-based approach to nash equilibrium seeking over networks.\BBCQ \APACjournalVolNumPagesIEEE Trans. Automat. Control6431077–1092. \PrintBackRefs\CurrentBib
- Ghaderi \BBA Srikant (\APACyear2014) \APACinsertmetastarsocial{APACrefauthors}Ghaderi, J.\BCBT \BBA Srikant, R. \APACrefYearMonthDay2014. \BBOQ\APACrefatitleOpinion dynamics in social networks with stubborn agents: Equilibrium and convergence rate Opinion dynamics in social networks with stubborn agents: Equilibrium and convergence rate.\BBCQ \APACjournalVolNumPagesAutomatica50123209–3215. \PrintBackRefs\CurrentBib
- Huang \BOthers. (\APACyear2022) \APACinsertmetastarmulticluster{APACrefauthors}Huang, B., Yang, C., Meng, Z., Chen, F.\BCBL \BBA Ren, W. \APACrefYearMonthDay2022. \BBOQ\APACrefatitleDistributed nonlinear placement for multicluster systems: A time-varying nash equilibrium-seeking approach Distributed nonlinear placement for multicluster systems: A time-varying nash equilibrium-seeking approach.\BBCQ \APACjournalVolNumPagesIEEE Trans. Cybern.521111614–11623. \PrintBackRefs\CurrentBib
- Liu \BOthers. (\APACyear2022) \APACinsertmetastarADMM1{APACrefauthors}Liu, Y., Wu, G., Tian, Z.\BCBL \BBA Ling, Q. \APACrefYearMonthDay2022. \BBOQ\APACrefatitleDQC-ADMM: Decentralized Dynamic ADMM With Quantized and Censored Communications Dqc-admm: Decentralized dynamic admm with quantized and censored communications.\BBCQ \APACjournalVolNumPagesIEEE Trans. Neural Netw. Learn. Syst.3383290-3304. {APACrefDOI} 10.1109/TNNLS.2021.3051638 \PrintBackRefs\CurrentBib
- Lu \BOthers. (\APACyear2020) \APACinsertmetastaronline3{APACrefauthors}Lu, K., Li, G.\BCBL \BBA Wang, L. \APACrefYearMonthDay2020. \BBOQ\APACrefatitleOnline distributed algorithms for seeking generalized Nash equilibria in dynamic environments Online distributed algorithms for seeking generalized nash equilibria in dynamic environments.\BBCQ \APACjournalVolNumPagesIEEE Trans. Autom. Control6652289–2296. \PrintBackRefs\CurrentBib
- Simonetto \BOthers. (\APACyear2017) \APACinsertmetastarsimonetto2016{APACrefauthors}Simonetto, A., Koppel, A., Mokhtari, A., Leus, G.\BCBL \BBA Ribeiro, A. \APACrefYearMonthDay2017. \BBOQ\APACrefatitleDecentralized prediction-correction methods for networked time-varying convex optimization Decentralized prediction-correction methods for networked time-varying convex optimization.\BBCQ \APACjournalVolNumPagesIEEE Trans. Autom. Control62115724–5738. \PrintBackRefs\CurrentBib
- Stankovic \BOthers. (\APACyear2011) \APACinsertmetastarsensor{APACrefauthors}Stankovic, M\BPBIS., Johansson, K\BPBIH.\BCBL \BBA Stipanovic, D\BPBIM. \APACrefYearMonthDay2011. \BBOQ\APACrefatitleDistributed seeking of Nash equilibria with applications to mobile sensor networks Distributed seeking of nash equilibria with applications to mobile sensor networks.\BBCQ \APACjournalVolNumPagesIEEE Trans. Automat. Control574904–919. \PrintBackRefs\CurrentBib
- Su \BOthers. (\APACyear2021) \APACinsertmetastarsu2021online{APACrefauthors}Su, Y., Liu, F., Wang, Z., Mei, S.\BCBL \BBA Lu, Q. \APACrefYearMonthDay2021. \BBOQ\APACrefatitleOnline distributed tracking of generalized Nash equilibrium on physical networks Online distributed tracking of generalized nash equilibrium on physical networks.\BBCQ \APACjournalVolNumPagesAutonomous Intelligent Systems111–12. \PrintBackRefs\CurrentBib
- Ye \BBA Hu (\APACyear2015) \APACinsertmetastaryemaojiao{APACrefauthors}Ye, M.\BCBT \BBA Hu, G. \APACrefYearMonthDay2015. \BBOQ\APACrefatitleDistributed seeking of time-varying Nash equilibrium for non-cooperative games Distributed seeking of time-varying nash equilibrium for non-cooperative games.\BBCQ \APACjournalVolNumPagesIEEE Trans. Autom. Control60113000–3005. \PrintBackRefs\CurrentBib
- Zeng \BOthers. (\APACyear2019) \APACinsertmetastarsmart{APACrefauthors}Zeng, X., Chen, J., Liang, S.\BCBL \BBA Hong, Y. \APACrefYearMonthDay2019. \BBOQ\APACrefatitleGeneralized Nash equilibrium seeking strategy for distributed nonsmooth multi-cluster game Generalized nash equilibrium seeking strategy for distributed nonsmooth multi-cluster game.\BBCQ \APACjournalVolNumPagesAutomatica10320–26. \PrintBackRefs\CurrentBib
- Zhu \BOthers. (\APACyear2020) \APACinsertmetastarstaticNE3{APACrefauthors}Zhu, Y., Yu, W., Wen, G.\BCBL \BBA Chen, G. \APACrefYearMonthDay2020. \BBOQ\APACrefatitleDistributed Nash equilibrium seeking in an aggregative game on a directed graph Distributed nash equilibrium seeking in an aggregative game on a directed graph.\BBCQ \APACjournalVolNumPagesIEEE Trans. Automat. Control6662746–2753. \PrintBackRefs\CurrentBib