Distributed Nash Equilibrium Seeking for Games in Systems with Unknown Control Directions
Abstract
Distributed Nash equilibrium seeking for games in uncertain networked systems without a prior knowledge about control directions is explored in this paper. More specifically, the dynamics of the players are supposed to be first-order or second-order systems in which the control directions are unknown and there are parametric uncertainties. To achieve Nash equilibrium seeking in a distributed way, Nussbaum function based strategies are proposed through separately designing an optimization module and a state regulation module. The optimization module generates a reference trajectory, that can search for the Nash equilibrium, for the state regulation module. The state regulator is designed to steer the players' actions to the reference trajectory. An adaptive law is included in the state regulation module to compensate for the uncertain parameter in the players' dynamics and the Nussbaum function is included to address the unavailability of the control directions. Fully distributed implementations of the proposed algorithms are discussed and investigated. Through our analytical explorations, we show that the proposed seeking strategies can drive the players' actions to the Nash equilibrium asymptotically without requiring the homogeneity of the players' unknown control directions based on Barbalat's lemma. A numerical example is given to support the theoretical analysis of the proposed algorithms.
keywords:
Unknown control directions; Nussbaum function; distributed Nash equilibrium seeking; parametric uncertainties1 Introduction
Games under distributed communication networks are receiving increasing attention due to their wide applications in numerous fields. For example, the connectivity control of mobile sensor networks was modeled as a game in which each sensor's objective function contains a local cost that models the sensor's local goal (e.g., source seeking) and a global cost that describes the sensor's willingness to keep connectivity with other sensors [1]. Inspired by the observation that practical engineering systems are usually afflicted with model uncertainties and disturbance, an extended-state-observer based robust Nash equilibrium seeking strategy was proposed in [1]. Energy consumption control might be formulated as an aggregative game, in which each user's cost function depends on the user's own energy consumption and the total energy consumption of all users [2]. Dynamic average consensus algorithms can be adapted as an aggregation estimator, based on which distributed Nash equilibrium seeking algorithms were constructed [2]. Congestion control problems in wireless sensor networks can be viewed as a semi-aggregative game, in which each data transmitter makes decisions on its data transmission to maximize its own profit [3]. Interference graphs can be introduced for the interaction descriptions among the data transmitters, based on which Nash equilibrium seeking algorithms were designed in [3]. Moreover, noncooperative games can be utilized to illustrate the interactions among groups of discrete-time and continuous-time agents under distributed communication networks [4]. Motivated by the broad applications of networked games, distributed Nash equilibrium seeking has attracted a lot of interests in the past few years and quite a few distributed schemes have been proposed to achieve distributed Nash equilibrium seeking. The existing works provide some interesting viewpoints to cope with Nash equilibrium seeking for games in which the players' actions can be freely designed (e.g., [20][21][22][23]) or governed by simple dynamics (see e.g., [24][25]) or possibly subject to disturbance and un-modeled dynamics (see e.g, [1]). A common premise of the existing works is that the control directions are known to the players.
It should be noted that control directions determine the motion directions of a control system and are greatly important as a control force with incorrect direction may deteriorate the system and cause undesired system control performance [13]. With the information on control directions, the controller design becomes much simpler. Nevertheless, in some practical circumstances, the control directions are unknown. For instance, due to the inaccurate camera parameters and image depth, the manipulator trajectory tracking control of visual servo system may need to address the unknown control directions [6]. Affected by speed variations and loading conditions of the complex, varying environment, the model of ships contains large uncertainties and hence, the autopilot design of time-varying ships requires the accommodation of unknown control directions [7]. It was recognized that the longitudinal dynamics of the air-breathing hypersonic vehicle suffer from unknown control directions as well [9]. Furthermore, the authors in [10] argued that in some situations, it is difficult to detect the control directions of quadrotor unmanned aerial vehicles. Without the information on control directions, the controller design becomes much more challenging especially for multi-agent systems.
Many researchers have been dedicated to investigate systems with unknown control directions. Adaptive designs with Nussbaum-type functions, which can be traced back to [8], are shown to be effective to deal with uncertainties in control directions. In [12], the Nussbaum-type functions were adopted to achieve adaptive control of nonlinear systems with arbitrary dynamic order and parametric uncertainties. Extremum seekers with unknown control directions were proposed in [15]. Output feedback control for discrete-time systems without a prior control direction knowledge was studied in [17] in which a discrete Nussbaum gain was utilized to achieve asymptotic output tracking. Nussbaum functions were discussed in [13] for systems with time-varying unknown control directions. With the development of multi-agent systems, cooperative control of multi-agent systems with unknown control directions has received increasing attention. For example, the authors in [11] considered consensus among a network of first-order integrator-type agents with unknown control directions. In [16], the authors supposed that some control directions are known based on which consensus of multi-agent systems with partially unknown and non-identical control directions was addressed. Cooperative output consensus in heterogeneous multi-agent systems with non-identical control directions was considered in [18], where Nussbaum-type functions were adopted to achieve global cooperative output regulation. Distributed optimization among a network of high-order integrator-type agents was addressed in [19] without utilizing prior knowledge about control directions. Fully distributed consensus among high-order nonlinear systems in which the agents have heterogenous unknown control directions was investigated in [29]. A new Nussbaum function was employed to deal with the unknown control directions and it was shown that the agents' output can achieve asymptotic consensus [29]. Nevertheless, to the best of the authors' knowledge, distributed Nash equilibrium seeking for networked games in which the players are subject to unknown control directions and uncertain parameters still remains to be addressed. Motivated by the above observations, this paper tries to shed some light on distributed Nash equilibrium seeking strategy design without utilizing control direction information.
In comparison with the existing works, the main contributions of this paper are summarized as follows.
-
1.
Different from the existing works that consider games with known control directions, the seeking strategies proposed in this paper do not require prior direction information. To the best of the authors' knowledge, this is the first work that addresses distributed Nash equilibrium seeking for games with unknown control directions. Besides, this paper also accommodates parametric uncertainties in the players' dynamics. Through a modular design, this paper proposes Nussbaum function based adaptive seeking strategies to achieve distributed Nash equilibrium seeking for games in both first-order and second-order systems with unknown control directions and parametric uncertainties.
-
2.
Based on Barbalat's lemma, it is theoretically shown that the players' actions can be steered to the Nash equilibrium while the other auxiliary variables stay bounded by utilizing the proposed algorithms.
-
3.
Discussions on fully distributed implementation of the proposed algorithms are provided. The explorations show that through adaptive parameter designs, the proposed fully distributed algorithms are effective.
We organize the remaining sections as follows. Some preliminaries are given in Section 2 and the considered problem is formulated in Section 3. Section 4 presents the main results of the paper, in which first-order and second-order systems with unknown control directions and parametric uncertainties are visited, successively. Discussions on fully distributed implementations of the proposed methods are provided in Section 5. Following the theoretical investigations of the developed methods, Section 6 provides numerical studies. In the end, conclusions are given in Section 7.
2 Preliminaries
The following definitions or lemmas will be utilized in the rest of the paper.
Definition 1.
[11] A continuously differentiable function is called a Nussbaum function if
| (1) | ||||
Typical examples of Nussbaum functions include , , to mention just a few. Interested readers are referred to [13] for more detailed discussions of Nussbaum functions. In this paper, we adopt
Lemma 1.
[12] Suppose that and are smooth functions defined on where is a positive constant and . Moreover, if
| (2) |
where is a nonzero constant, is an even smooth Nussbaum function, and is a suitable constant. Then, and are bounded on
Lemma 2.
(Barbalat's Lemma [26]) Suppose that is a uniformly continuous function. Then, given that exists and is finite.
A graph contains a node set ( is an integer) and an edge set . The elements of are represented by , which illustrates an edge from node to node and indicates that node can receive information from node but not necessarily vice versa. If implies that for all . The network is undirected. A directed path from node to node is a sequence of ordered edges denoted by A directed graph is said to be strongly connected if there is a directed path between any two distinct nodes. Similarly, an undirected graph is connected if there is a path between any two distinct nodes. The adjacency matrix of a directed graph is a matrix whose th entry is which is positive if else, Moreover, The adjacency matrix of an undirected graph is similarly defined with a further requirement that for all Moreover, the Laplacian matrix of graph is in which is a diagonal matrix whose th diagonal entry is [5][30].
3 Problem Formulation
Consider a game with players in which the action and cost function of player is represented by and respectively, where . Denote the player set as and suppose that the players' actions are governed by
| (3) |
or
| (4) | ||||
Note that in (3) and (4), is the control input to be designed and is an unknown constant. Moreover, is a sufficiently smooth known function and is an unknown parameter. Moreover, is a state variable of player .
Furthermore, second-order systems in which player 's action is generated by
| (5) | ||||
where are unknown constants, and are smooth functions, will also be considered. Note that in (5), and are nonzero.
The paper aims to design distributed control strategies for systems in (3), (4) and (5), successively, such that where is the Nash equilibrium defined as follows.
Definition 2.
The rest of the paper is based on the following assumptions, which are widely adopted in related works.
Assumption 1.
For each is sufficiently smooth and is globally Lipshitz with constant .
Assumption 2.
There exists a positive constant such that for
| (7) |
where
Assumption 3.
The players are equipped with an undirected and connected communication graph .
Assumption 4.
For each and are bounded provided that is bounded.
Moreover, for the system in (5), the nonlinear terms should satisfy the following condition.
Assumption 5.
For each and are bounded provided that is bounded. Moreover, is bounded if and are bounded.
Remark 1.
Different from existing works on distributed Nash equilibrium seeking that consider the control directions to be known, we suppose that the control directions are unknown a prior as (or ) for all are not known. Moreover, the players may have different control directions as we do not enforce (or ) for all to be the same. Note that in (3) and (4), is supposed to be unknown as well, indicating that the players are suffering from parametric uncertainties.
4 Main Results
In this section, we will establish distributed Nash equilibrium seeking algorithms for games in which the players' actions are governed by (3), (4) and (5), successively. In the following, Nash equilibrium seekers that are able to accommodate the unknown control directions and parametric uncertainties will be proposed, followed by their corresponding convergence analyses.
4.1 Distributed Nash equilibrium seeking for first-order systems with unknown control directions
In this section, we consider that the action of player is governed by
| (8) |
In the following, method development and convergence analysis will be presented.
4.1.1 Method Development
To achieve distributed Nash equilibrium seeking for systems with unknown control directions, let
| (9) |
where and
| (10) | ||||
Moreover, is an auxiliary variable generated by
| (11) |
where , and
| (12) |
in which , is positive constant to be determined and is a fixed positive constant.
Remark 2.
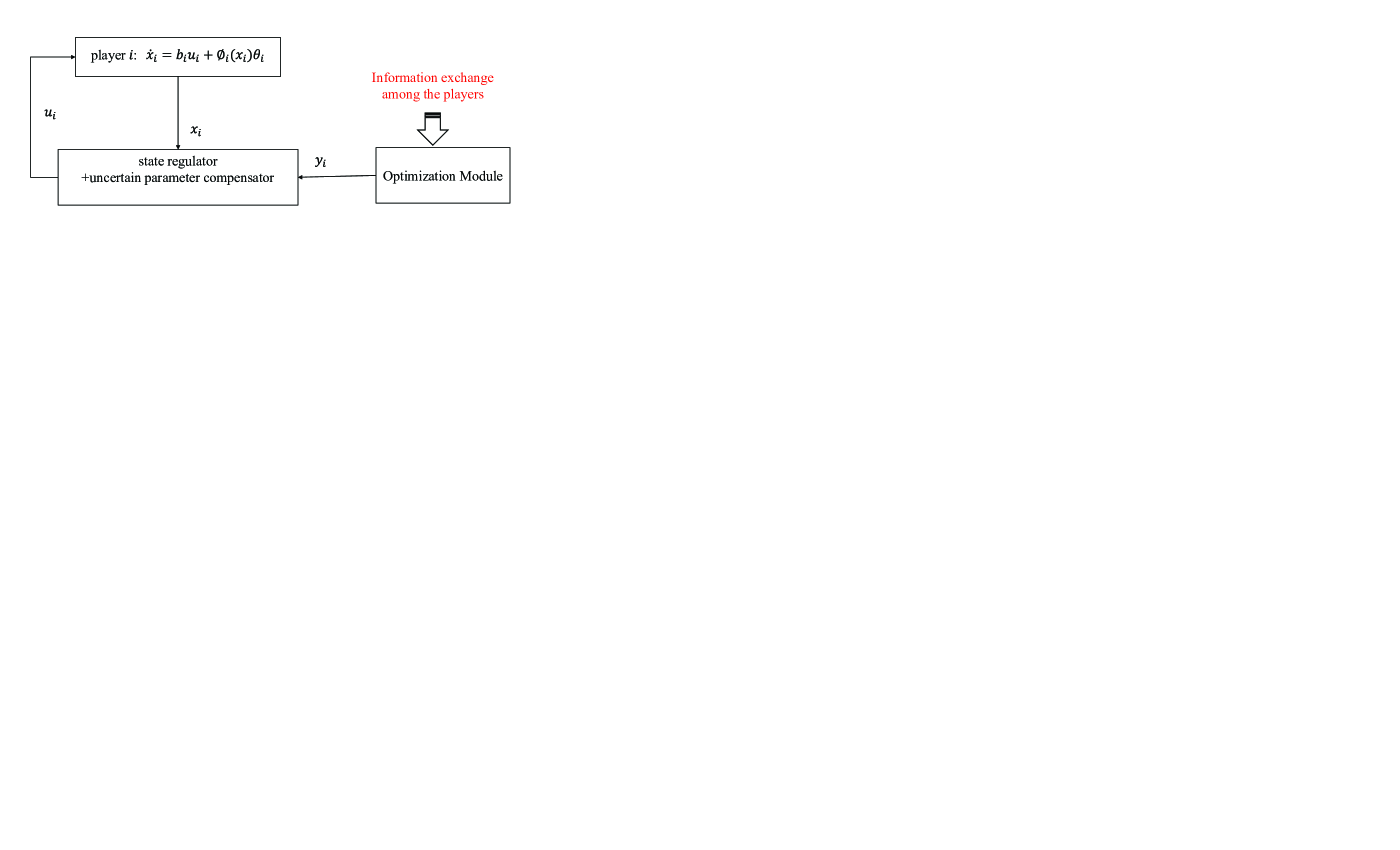
The seeking strategy in (9)-(12) can be viewed as two modules. The subsystem in (9)-(10) is designed to drive to . The Nussbaum function in (9) is employed to accommodate the unknown control directions and the second equation in (10) is utilized to compensate the unknown parameter . In addition, the subsystem in (11)-(12) is adapted from [5] to act as a reference generator that would drive to the Nash equilibrium [5]. The schematic outline of (9)-(12) is depicted in the Fig. 1.
4.1.2 Convergence Analysis
In this section, we provide the convergence analysis for the seeking strategy proposed in (9)-(12). Before we proceed to present the convergence results, the following supportive lemma is given.
Lemma 3.
Proof: Following the results in [5], it can be obtained that there exists a positive constant such that for each and , where and , globally exponentially converge to and respectively [5]. Hence, the first conclusion directly follows the results in [5]. The second conclusion can be reasoned as follows. As and globally exponentially converge to and respectively, there are positive constants such that
| (13) |
For each we get that
| (14) |
by noticing that according to Assumption 2. By the Lipshitz condition of in Assumption 1, we get that
| (15) |
thus arriving at the second conclusion.
For the third conclusion,
| (16) | ||||
thus arriving at the third conclusion with .
With the above results in mind, we are now ready to show that the players' actions can be driven to the Nash equilibrium by utilizing the proposed method.
Theorem 1.
Proof: Define a sub-Lyapunov candidate function for player as
| (18) |
Then, the time derivative of along the trajectory is
| (19) | ||||
by noticing that where is a positive constant that satisfies
Integrating both sides of (19), it can be obtained that
| (20) | ||||
Note that the last inequality is obtained by noticing that according to Lemma 3.
Hence, and are bounded on by Lemma 1, which indicates that and are bounded. Moreover, as is bounded by Lemma 3, we obtain that is bounded for from which we can further obtain that are bounded over the time interval This implies that there is no finite-time escape for the closed-loop system and hence
Taking the time derivative of gives
| (21) | ||||
As is bounded for , is bounded for by Assumption 4. Moreover, noticing that are all bounded, we get that is bounded. Hence, is uniformly continuous with respect to In addition,
| (22) |
where is a finite constant determined by the bounds of
From the other aspect, taking the time derivative of gives
| (24) |
from which we see that is bounded by noticing that are bounded.
Therefore, is uniformly continuous with respect to . Moreover,
| (25) |
where is a constant determined by the bounds of Hence, by Lemma 2, we can obtain that
| (26) |
By (23), we have or alternatively, for Moreover, by (26), we have or for Suppose that for then, must be satisfied. If this is the case, for indicating that (23) can not be satisfied. Hence, we arrive at a contradiction and obtain that must be satisfied for Recalling that as , which is proven in Lemma 3, we arrive at the conclusion that as , thus completing the proof.
In this paper, we focus on the case in which the communication graph is undirected and connected for simplicity. However, it should be noted that the presented results are still valid for strongly connected digraphs. To highlight this point, the following corollary is given.
Corollary 1.
Proof: The proof follows that of Theorem 1 by noticing that the results in Lemma 3 are still valid for strongly connected digraphs.
In Theorem 1, we consider that each player 's action is subject to both unknown control directions ( is unknown) and uncertain parameter i.e.,
| (28) |
If there is no uncertain parameter, and the players' actions are generated by
| (29) |
Then, the proposed seeking strategy can be revised to be
| (30) |
where ,
| (31) |
and is generated by (11)-(12). If this is the case, the following corollary can be obtained.
4.2 Distributed Nash equilibrium seeking for second-order systems
In this section, we suppose that for each player 's action is governed by
| (33) | ||||
in which is a state of player .
4.2.1 Method development
To achieve distributed Nash equilibrium seeking for games in which each player 's dynamics is governed by (33), the control input is designed as
| (34) |
where and
| (35) | ||||
Moreover, is an auxiliary variable generated by
| (36) |
where . Furthermore,
| (37) |
where , is positive constant to be determined and is a fixed positive constant.
To establish the results for second-order systems, the following assumption is also needed.
Assumption 6.
For each is bounded given that is bounded.
Remark 3.
Compared the strategy in (34)-(37) with (9)-(12), we see that the optimization modules are the same while the regulation modules are different. As the system in (33) is a second-order system, we further utilize and in the seeking strategy. Recalling the definitions of and , it is clear that the communication in the proposed seeking strategy is still one-hop.
4.2.2 Convergence analysis
The following theorem illustrates the convergence result for the proposed method.
Theorem 2.
Proof: For notational convenience, let . Define the sub-Lyapunov candidate function for player as
| (39) |
Then, the time derivative of is
| (40) | ||||
where is a positive constant that satisfies
Integrating both sides of (40) over gives
| (41) | ||||
Hence, by Lemma 1, we get that and are bounded for which further indicates that are bounded for . Recalling that is bounded, we get that is bounded for . Hence, is bounded. Therefore, there is no finite-time escape for the closed-loop system, which indicates that Recalling (34)-(37), we can obtain that are all bounded. Taking the time derivative of gives
| (42) | ||||
Note that is bounded and is bounded as , are bounded and is bounded for bounded (by Assumption 6), it can be seen that is bounded. Hence, is uniformly continuous. Moreover,
| (43) |
where is a constant determined by the bounds of Hence, by Lemma 2, we can obtain that as
Similarly,
| (44) |
where is a constant determined by the bounds of Hence, by Lemma 2, we can obtain that as
Hence, for we have and
Case I: but for In this case, . Recalling that as and , we get that
| (45) |
from which it is clear that for
Case II: for If this is the case
| (46) |
as Recalling that we can obtain that To this end, the conclusion is obtained.
Similar to Corollary 1, the following result can be obtained if the communication graph is strongly connected.
4.3 Distributed Nash equilibrium seeking for more general second-order systems
In this section, we consider a game in which each player 's action is governed by
| (48) | ||||
Remark 4.
Note that compared with (33), the effect of on is also uncertain in (48) as is also unknown. In addition, an uncertain nonlinear term is addressed as well. Hence, in this problem, and are both unknown directions that should be addressed. Moreover, both and result in uncertain nonlinearities that should be accommodated.
Motivated by [12], the Nash equilibrium seeking strategy is designed in the following process:
Step 1: Generate a reference trajectory for that would converge to the Nash equilibrium according to
| (49) | ||||
where , , is positive constant to be determined and is a fixed positive constant.
Step 2: Generate a reference trajectory for as
| (50) | ||||
Step 3: Let . Then, through direct calculation, it can be obtained that
| (51) | ||||
where and Accordingly, the control input is designed as
| (52) | ||||
Remark 5.
Note that (50) is designed to drive to and (52) is designed to drive to The design of the control input in (52) is motivated by [12] that treats as a virtual control input for To deal with unknown constants and two Nussbaum functions are included. To accommodate multiple Nussbaum functions, the idea is to design the control input such that is square integrable (see also [12]).
The following theorem establishes the stability of Nash equilibrium under the control input designed in (52).
Theorem 3.
Proof: The proof is similar to those in [12] and Theorem 2. For the convenience of the readers, sketch of the proof is given as follows.
Step 1: Show that is square integrable by defining the sub-Lyapunov candidate function as
| (54) | ||||
Then, following the proof of Theorem 2, it can be obtained that
| (55) |
Moreover, taking integrations on both sides of (55) over , we get that
| (56) |
from which it can be obtained that , and are bounded by Lemma 1.
Step 2: Show that can be driven to by defining the other sub-Lyapunov function as
| (58) |
Then, the time derivative of is
| (59) | ||||
where are positive constants that satisfy . Noticing that both and are square integrable for we obtain that are bounded for . Combining the above two steps, it can be seen that as well as , , are all bounded. Recalling the definition of , it can be obtained that is bounded. Furthermore, is bounded as is bounded by Lemma 3. To this end, we have shown that all the variables contained in the closed-loop system are bounded for indicating that there is no finite-time escape and
Step 3: The rest analysis follows the proof of Theorem 2 to take the time derivatives of and to show that there are uniformly continuous. Then, take the integrations of them over to prove that their integrations are bounded. With the above conclusions in mind, by Barbalat's lemma, and from which it can be obtained that by following the arguments in the proof of Theorem 1.
Remark 6.
The system dynamics considered in (48) is similar to the one in [12] and the state regulation part is motivated by [12]. However, different from [12] that regulates the state to zero, this paper needs to regulate the state to a time-varying reference trajectory ( for ), generated by the optimization module.
5 Discussions on Fully Distributed Implementation of the Proposed Algorithms
In Section 4, the proposed seeking strategies contain a centralized control gain , which depends on the players' objective functions and the communication graph. In general, these centralized information can hardly be obtained. Actually, in [28], we proposed fully distributed Nash equilibrium seeking strategies by adaptively adjusting the control gains. In the following, we further prove that the adaptive algorithms in [28] can also be utilized in the proposed algorithms to achieve fully distributed Nash equilibrium seeking in the considered problem.
Then, the following result can be obtained.
Lemma 4.
Proof: Following the proof of [28] to define where and is a diagonal matrix with its elements being
Then, it follows from [28] that
| (61) |
where and from which it can be obtained that for each , and are bounded for
Moreover,
| (62) | ||||
Taking integration on both sides of (61), we obtain that
| (63) |
by which
| (64) |
By further noticing that
| (65) |
we obtain that
| (66) |
Hence
| (67) |
thus arriving at the second conclusion.
With the results in Lemma 4, we can achieve the fully distributed implementations of the proposed algorithms, which is stated in the following theorem.
Theorem 4.
It's worth mentioning that for systems considered in (4)/(5) and the proposed control inputs designed for the corresponding systems, one can replace therein with the one generated by (60) to achieve fully distributed implementations of the proposed algorithms. Note that we only present the results for the system (3) and omit the rest to avoid any repetitions in this paper.
Remark 7.
In this section, we only provide an example to illustrate the fully distributed implementations of the proposed algorithms. However, it is worth noting that the proposed algorithms actually provide a general framework to deal with games in systems with unknown control directions. That is, one may utilize other alternative approaches that result in square integrable and bounded state variables as well as their time derivatives to achieve fully distributed Nash equilibrium seeking for systems with unknown controls.
Remark 8.
The modular design in this paper is motivated by [25][31]. Though it was required that the controls should be bounded in [25], the control directions were supposed to be known. Moreover, [31] designed an extremum seeker through robust state regulation and numerical optimization, in which the control directions are also considered to be known. Different from [19] that considered distributed optimization problems with unknown control directions, this paper addresses Nash equilibrium seeking problems with both unknown control directions and parametric uncertainties. In particular, the existence of multiple unknown control directions and uncertain parameters is addressed. Though we only investigate first-order and second-order systems analytically in this paper, we believe that under the proposed framework, it is not challenging to extend the current results to high-order systems by backstepping techniques.
Though for presentation simplicity, we suppose that it should be noted that the presented results can be directly adapted to deal with games in which the players are of multiple heterogeneous dimensions. In the subsequent section, an example in which for will be numerically studied.
6 A Numerical Example
In this section, we consider the connectivity control game among a network of mobile sensors considered in [1]. The objective function of player engaged in the game is defined as
| (69) |
where and
| (70) |
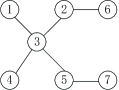
in which Moreover, , ,, and . It can be calculated that the Nash equilibrium of the game is and for . In the simulation, the undirected and connected communication graph is plotted in Fig. 2. In the following, games with dynamics in (3), (4) and (5) will be numerically explored, successively.
6.1 Distributed Nash equilibrium seeking for first-order systems
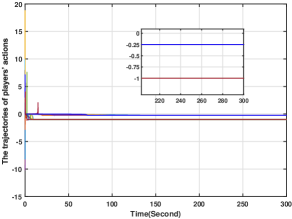
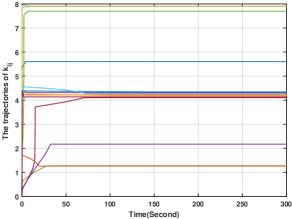
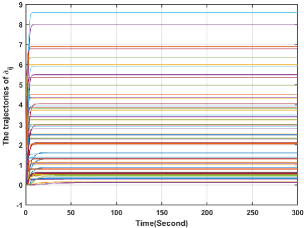
In this section, we simulate first-order systems in (3), where the control input is designed in (9)-(12). Note that as In the simulation, and Moreover, Let and the initial values for all the other variables in (9)-(12) be zero. Then, generated by (9)-(12), the players' action trajectories for are plotted in Fig. 3, from which it is clear that the players' action trajectories converge to the Nash equilibrium asymptotically. Moreover, Figs. 4-5 illustrate the trajectories of and for all , respectively. From Figs. 4-5, it can be seen that these variables stay bounded. Therefore, Theorem 1 is numerically validated.
6.2 Distributed Nash equilibrium seeking for second-order systems
In this section, we simulate the system in (4), where the control input is designed in (34)-(37). In the simulation, , and follow those in Section 6.1 and the initial values for all the other variables are zero.
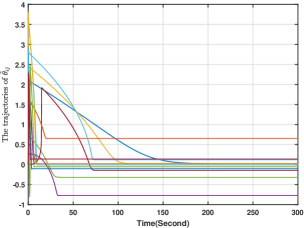
The players' action trajectories for generated by (34)-(37) are depicted in Fig. 6, from which it can be seen that the players' actions converge the actual Nash equilibrium of the game. In addition, and for all are given in Figs. 7-8. From Figs. 7-8, we can conclude that and for all stay bounded. Furthermore, Fig. 9 demonstrates that for all decay to zero, which is aligned with the results in Theorem 2. To this end, the conclusions in Theorem 2 have been numerically verified.
6.3 Distributed Nash equilibrium seeking for more general second-order uncertain nonlinear systems
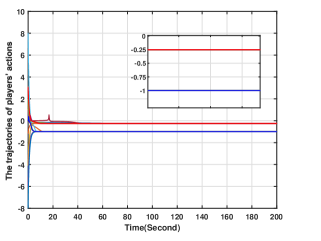
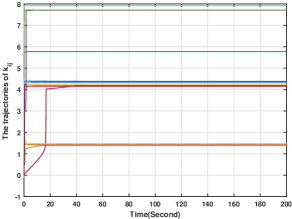
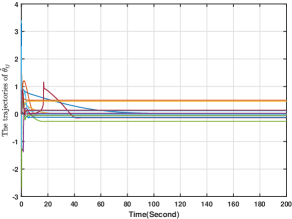
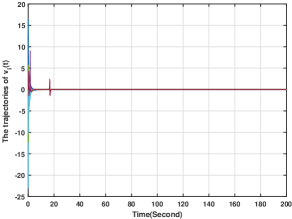
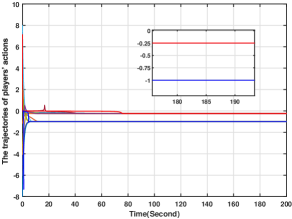
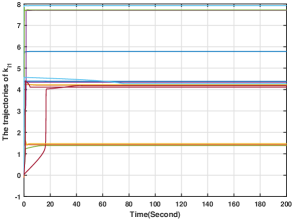
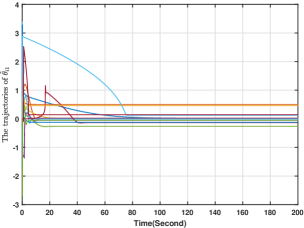
In this section, we numerically verify the control input designed for uncertain nonlinear systems in (5). To illustrate the case, we suppose that the action of player is governed by (5), and its control input is given by (49)-(52), while all the other players' actions are governed by (4) with their control inputs being (34)-(37). For players -, and are chosen to be the same as those in Section 6.2. For player , and In addition, and the initial conditions for all the other variables are zero. Generated by the proposed methods, the players' actions for are shown in Fig. 10, from which we see that the players' actions converge to the Nash equilibrium. Moreover, and for are plotted in Figs. 11-12. Figs. 11-12 show that and stay bounded. Moreover, the evolution of is shown in Fig. 13, which shows that for all are also bounded. Hence, the effectiveness of the method in (49)-(52) is also verified.
6.4 Fully distributed implementations of the proposed algorithms
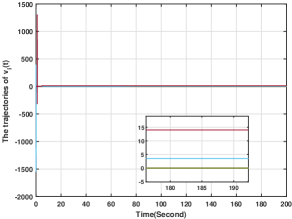
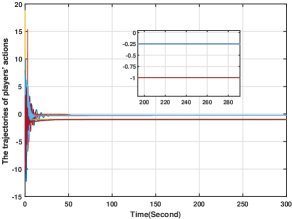
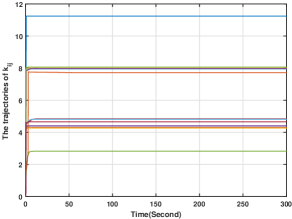
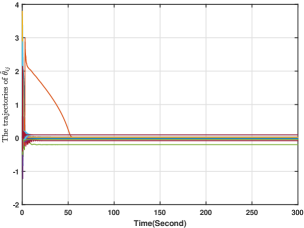
To verify the fully distributed implementations of the proposed methods, we take first-order systems as an example. The simulation setting of this section follows that of Section 6.1 and for all . The simulation results for the system considered in (3) with the control input in (9)-(10), where is generated by (60) are given in Figs. 14-17. Fig. 14 plots the players' actions from which we see that the players' actions can converge to the Nash equilibrium. Moreover, Figs. 15-17 plot and , respectively, from which it is clear that they stay bounded. Therefore, the results in Theorem 4 is numerically verified. Note that compared with the simulation in Section 6.1, there is no centralized control gain in (60), thus verifying the effectiveness of the distributively implemented algorithms.
7 Conclusion
This paper considers distributed Nash equilibrium seeking for games in which the players' actions are subject to both unknown control directions and parametric uncertainties. First-order systems and second-order systems are addressed successively. To cope with the un-availability of control directions, a Nussbaum function is adopted. Moreover, the parametric uncertainties are addressed by adaptive laws. Together with an optimization module, a state regulation module is included in the seeking strategy. Based on the Barbalat's lemma, it is proven that the players' actions can be driven to the Nash equilibrium. Lastly, the fully distributed implementations of the proposed algorithms are discussed. It is shown that the adaptive techniques can be employed to achieve the equilibrium seeking in a fully distributed way.
References
- [1] M. Ye, ``Distributed robust seeking of Nash equilibrium for networked games: an extended state observer-based approach," IEEE Transactions on Cybernetics, accepted, published online, DOI: 10.1109/TCYB.2020.2989755.
- [2] M. Ye and G. Hu, ``Game design and analysis for price-based demand response: an aggregate game approach," IEEE Transactions on Cybernetics, vol. 47, no. 3, pp. 720-730, 2017.
- [3] M. Ye, G. Hu, F. Lewis, L. Xie, ``A unified strategy for solution seeking in graphical -coalition noncooperative games," IEEE Transactions on Automatic Control, vol. 64, no. 11, pp. 4645-4652, 2019.
- [4] J. Ma, M. Ye, Y. Zheng, Y. Zhu, ``Consensus analysis of hybrid multiagent systems: a game-theoretic approach," International Journal of Robust and Nonlinear Control, vol.29, pp. 1840-1853, 2019.
- [5] M. Ye and G. Hu, ``Distributed Nash equilibrium seeking by a consensus based approach," IEEE Transactions on Automatic Control, pp. 4811-4818, vol. 62, no. 9, 2017.
- [6] P. Jiang, P. Woo, R. Unbehauen, ``Iterative learning control for manipulator trajectory tracking without any control singularity," Robotica, vol. 20, no. 2, pp. 149-158, 2002.
- [7] J. Du, C. Guo, S. Yu, Y. Zhao, ``Adaptive autopilot design of time-varying uncertain ships with completely unknown control coefficients," IEEE Journal of Oceanic Engineering, vol. 32, no. 2, pp. 346-352, 2007.
- [8] R. Nussbaum, ``Some remarks on a conjecture in parameter adaptive control," System and Control Letters, vol. 3, no. 5, pp. 243-246, 1983.
- [9] X. Bun, D. Wei, X. Wu, J. Huang, ``Guaranteeing preselected tracking quality for air-breathing hypersonic non-affine models with an unknown control direction via concise neural control," Journal of the Franklin Institute, vol. 353, no. 13, pp. 3207-3232, 2016.
- [10] L. Wang, W. Deng, J. Liu and R. Mei, ``Adaptive sliding mode trajectory tracking control of quadrotor UAV with unknown control direction," In: R. Wang, Z. Chen, W. Zhang, Q. Zhu(eds) Proceedings of the 11th International Conference on Modelling, Identification and Control, Lecture Notes in Electrical Engineering, vol. 582. Springer, Singapore.
- [11] J. Peng, X. Ye, ``Cooperative control of multiple heterogeneous agents with unknown high-frequency-gain signs," Systems and Control Letters, vol. 68, pp. 51-56, 2014.
- [12] X. Ye and J. Jiang, ``Adaptive nonlinear design without a priori knowledge of control directions," IEEE Transactions on Automatic Control, vol. 43, no. 11, pp. 1617-1621, 1998.
- [13] Z. Chen, ``Nussbaum functions in adaptive control with time-varying unknown control coefficients," Automatica, vol. 102, pp. 72-79, 2019.
- [14] H. Khailil, Nonlinear Systems, Upper Saddle River, NJ: Prentice Hall, 2002.
- [15] A. Scheinker, M. Krstic, ``Minimum-seeking for CLFs: universal semiglobally stabilizing feedback under unknown control directions," IEEE Transactions on Automatic Control, vol. 58, no. 5, pp. 1107-1122, 2013.
- [16] C. Chen, C. Wen, Z. Liu, K. Xie, Y. Zhang, C. Chen, ``Adaptive consensus of nonlinear multi-agent systems with non-identical partially unknown control directions and bounded modelling errors," IEEE Transactions on Automatic Control, vol. 62, no. 9, pp. 4654-4659, 2017.
- [17] C. Yang, S. Ge, T. Lee, ``Output feedback adaptive control of a class of nonlinear discrete-time systems with unknown control directions," Automatica, vol. 45, no. 1, pp. 270-276, 2008.
- [18] M. Guo, D. Xu, L. Liu, ``Cooperative output regulation of heterogeneous nonlinear multi-agent systems with unknown control directions," IEEE Transactions on Automatic Control, vol. 62, no. 6, pp 3039-3045, 2017.
- [19] Y. Tang, ``Multi-agent optimal consensus with unknown control directions," arXiv:2005.10492.
- [20] J. Koshal, A. Nedic and U. Shanbhag, ``Distributed algorithms for aggregative games on graphs," Operations Research, vol. 64, pp. 680-704, 2016.
- [21] F. Salehisadaghiani and L. Pavel, ``Distributed Nash equilibrium seeking: A gossip-based algorithm," Automatica, vol. 72, pp. 209-216, 2016.
- [22] M. Ye, G. Hu and S. Xu, ``An extremum seeking-based approach for Nash equilibrium seeking in -cluster noncooperative games," Automatica, vol. 114, 108815, 2020.
- [23] M. Ye, G. Hu, and F. L. Lewis, ``Nash equilibrium seeking for -coalition non-cooperative games," Automatica, vol. 95, pp. 266-272, 2018.
- [24] A. Ibrahim, T. Hayakawa, ``Nash equilibrium seeking with secondorder dynamic agents," IEEE Conference on Decision and Control, pp. 2514-2518, 2018.
- [25] M. Ye, ``Distributed Nash equilibrium seeking for games in systems with bounded control inputs," submitted to IEEE Transactions on Automatic Control, revised, available online: arXiv:1901.09333, 2019.
- [26] J. Slotine, W. Li, Applied Nonlinear Control, Prentice Hall, Englewood Cliffs, 1991.
- [27] M. Ye, G. Hu,``Distributed Nash equilibrium seeking in multi-agent games under switching communication topologies," IEEE Transactions on Cybernetics, vol. 48, no. 11, pp. 3208-3217, 2018.
- [28] M. Ye, G. Hu, ``Adaptive approaches for fully distributed Nash equilibrium seeking in networked games," submitted to Automatica, revised, available online: arXiv:1912.00415.
- [29] J. Huang, Y. Song, W. Wang, C. Wen and G. Li, ``Fully distributed adaptive consensus control of a class of high-order nonlinear systems with a directed topology and unknown control directions," IEEE Transactions on Cybernetics, vol. 48, no. 8, pp. 2349-2356, 2018.
- [30] Z. Li, Z. Duan, Cooperative Control of Multi-agent Systems: A Consensus Region Approach, Taylor and Francis/CRC Press, Boca Roton, FL, 2014. ISBN: 978-1-4665-6994-2.
- [31] M. Ye, G. Hu, ``A robust extremum seeking scheme for dynamic systems with uncertainties and disturbances," Automatica, vol. 66, pp. 172-178, 2016.