Distributed Machine Learning in D2D-Enabled Heterogeneous Networks: Architectures, Performance, and Open Challenges
Abstract
The ever-growing concerns regarding data privacy have led to a paradigm shift in machine learning (ML) architectures from centralized to distributed approaches, giving rise to federated learning (FL) and split learning (SL) as the two predominant privacy-preserving ML mechanisms. However, implementing FL or SL in device-to-device (D2D)-enabled heterogeneous networks with diverse clients presents substantial challenges, including architecture scalability and prolonged training delays. To address these challenges, this article introduces two innovative hybrid distributed ML architectures, namely, hybrid split FL (HSFL) and hybrid federated SL (HFSL). Such architectures combine the strengths of both FL and SL in D2D-enabled heterogeneous wireless networks. We provide a comprehensive analysis of the performance and advantages of HSFL and HFSL, while also highlighting open challenges for future exploration. We support our proposals with preliminary simulations using three datasets in non-independent and non-identically distributed settings, demonstrating the feasibility of our architectures. Our simulations reveal notable reductions in communication/computation costs and training delays as compared to conventional FL and SL.
I Introduction
The past decade has witnessed the expeditious evolution of communication and computing technologies, and their proliferation in many emerging fields such as the Internet of Vehicles and E-health, where massive amount of data is generated, exchanged and utilized. Such developments have brought both technical challenges and great opportunities for a wide range of machine learning (ML)-based applications, since ML holds considerable promise to fast decisions and inferences without human intervention [1, 2]. Besides, device-to-device (D2D) communications-enabled multi-layer heterogeneous wireless networks have become one of significant components of 5G/6G networks, where the complicated network topologies could impose great challenges to the implementations of ML-based applications[3].
Securing abundant training data and computation resources represents the fundamental requirement of ML. Traditional ML is generally centralized where massive data are collected and transmitted from local devices to centralized data centers associated with remote cloud servers. Disregards its advantages such as high accuracy and efficiency, centralized ML confronts the following deficiencies:
-
•
When a large volume of training data has to be transmitted over dynamic wireless networks, excessive transmission delay as well as possible increased power consumption for local devices can be incurred.
-
•
Centralized ML is often less effective for rapid model deployment. Meanwhile, it suffers from unsatisfying scalability in large-scale networks, especially when the model requires frequent retraining.
-
•
Centralized ML is difficult to reserve data privacy, as many applications may involve the uploading of large amount of private information. For instance, regarding pathological pictures in E-health[2], most local devices (e.g., patients) are generally unwilling to provide privacy-sensitive data due to ever-growing privacy concerns, which can result in a dilemma between model training and privacy protection.
I-A Preliminaries of FL and SL
To reconcile the demand for ML model training and privacy protection, a straight idea is to conduct the model training by distributed data owners to avoid sharing raw data, which facilitates distributed ML architectures. Specifically, federated learning (FL) [4] and split learning (SL) [5] represent two bright peals. Specifically, these two learning mechanisms implement distributed ML from different perspectives, while their representative learning architectures are depicted in Fig. 1.
Training process of FL: A typical FL scheme engages a set of smart devices termed as clients to participate in the iterative model training. At the beginning of each iteration, each client receives a global model from a parameter server, then conducts local training to update the model by performing stochastic gradient descent on its local training data. After the completion of local training, all clients involved in FL upload the trained model parameters to the FL server in parallel (step 1). The FL server next aggregates (e.g., FedAvg ) the overall received model parameters into a new global model, which will be broadcasted to clients (step 2) for the following training round. Specifically, each client only exchanges the model parameters with the FL server, preventing privacy disclosure to some extent.
Training process of SL: To achieve SL training, an ML neural network is firstly split into two subnetworks via splitting in the middle layer (i.e., a split layer) of the network. Generally, the subnetwork associated with input layer is deployed on the clients’ side, and the one related with output layer will be deployed at an SL server. In each iteration, a client starts training by performing forward propagation; and then, the activation data, i.e., the output of split layer of the client (with label data), will be transmitted to the SL server (step 1). Upon receiving the activation data, the SL server proceeds with forward propagation within its subnetwork to derive output results, and subsequently initiates the back propagation process, which involves the computation of the loss by comparing the output results with the provided label data[5]. Similarly, the output of cut layer can be transmitted back to the client for subsequent back propagation (step 2). Finally, subnetworks on both the client and server can be updated respectively. By offloading the model parameter of the current client to the next client (step 3) and repeating the above steps, the model can be trained sequentially over multiple clients.

I-B Motivations and Contributions
Interestingly, FL and SL share some common advantages, such as communication/computation cost reduction, and privacy preservation. However, the implementations of FL and SL in heterogeneous wireless networks can also encounter non-negligible challenges:
-
•
Network heterogeneity: The SL server can only interact with the clients sequentially, leading to a low level of parallelization and may hinder the corresponding convergence speed. For FL, frequent model reporting from clients to the server over unstable wireless links usually result in model performance degradation due to transmission failures. Besides, since the implementation of conventional FL and SL generally relies on a star topology, where a central server coordinates the model update of all the clients. Thus, FL and SL may suffer from unsatisfying scalability and performance degradation in large-scale D2D-enabled heterogeneous networks due to single point failures[3]. For example, under a space-air-ground-ocean integrated 6G network architecture, satellites, unmanned aerial vehicles, smart vehicles, and underwater unmanned vehicles can be the clients, where frequent D2D communications among them can further complicate the network topology (e.g., hierarchical tree topology). Such disadvantages advocate combining both FL and SL architectures, to guarantee the training performance in heterogeneous wireless networks.
-
•
Client heterogeneity: Clients generally have heterogeneous computation/communication/energy capabilities. Each client in FL requires more computation/energy resources to support model training. Besides, since the stability of wireless communications are essential to guarantee successful model transmissions (e.g., the size of a large complete model can reach 1 GB[6]), FL prefers clients with sufficient computation/energy/communication resources. Differently, SL usually supports clients with constrained on-board computation/energy resources since each client only has to train a partial model, which, however, can incur heavy communication overhead. More importantly, imbalanced and non-independent and identically distributed (non-IID) data of clients can leave heavy impacts on training performance. To this end, exploring the combination of FL and SL architectures to make full use of clients’ heterogeneous capabilities and resources presents another major significance.
-
•
Optimization target heterogeneity: Typically, model test accuracy and convergence speed represent the key optimization targets of distributed ML[3]. Besides, when distributed ML is implemented in heterogeneous networks, common indicators such as datarate, throughput, delay, and energy consumption also represent major concerns of ML, which complicates problems such as client scheduling and resource allocation[7]. Thus, it is significant to improve distributed ML architectures according to the characteristics of heterogeneous networks while realizing multiple targets optimization.
Given the above discussed challenges and limitations of conventional FL and SL in heterogeneous networks, this article is motivated to investigate two comprehensive architectures upon considering the combination of FL and SL. Our main contributions are highlighted below:
-
•
We first introduce a hybrid split FL (HSFL) architecture by integrating the split architecture into FL. Then, we are interested in designing a hybrid federated SL (HFSL) architecture, which unifies federated architecture with SL. key topics such as the advantages and performance comparisons of the two architectures are discussed.
-
•
Several open challenges are comprehensively discussed to identify the future research directions of our proposed architectures for future implementations.
-
•
Preliminary simulations are conducted to verify the feasibility of our proposed architectures on three datasets, under highly non-IID data settings.

II Investigations
Some early efforts have been devoted to exploring the combination of FL and SL, as well as the corresponding performance improvement. For HSFL, [6] proposed a decentralized FL mechanism (i.e., gossip learning) based on FL model splitting in a D2D network, where each FL client only transmits model segmentations to neighboring clients. However, this work only considers the D2D network. For HFSL, [8] proposed a parallel SL framework, where all the clients’ subnetworks are synchronized. In each training round, every client sends the whole gradients back to the server, while then the server averages the gradients and transmits them back to the clients. Although such a framework enables SL with parallelism during clients’ model update process, it relies on a single server and thus results in poor scalability, especially in large-scale networks. [9] studied a SplitFed framework where the clients’ model parameters are also averaged with a dedicated server. Besides, the subnetwork at the server side is updated by averaging the gradients of each client. However, unsatisfying scalability represents one of the key drawbacks of SplitFed, upon considering a raising number of clients[10]. Therefore, [10] decided to deploy edge servers as coadjutants to alleviate the communication and computation load of the SL server; then each edge server can interact with one or multiple clients for gradients exchange; while the SL server can further calculate the averaged gradients and update the subnetworks at edge servers. [11] put forward similar ideas by deploying multiple FL servers to handle groups of clients. Although the above discussed works have made certain efforts, none of them have comprehensively analyzed the implementations on integrating FL and SL in D2D-enabled heterogeneous networks.
III Architectures
III-A Architecture of HSFL
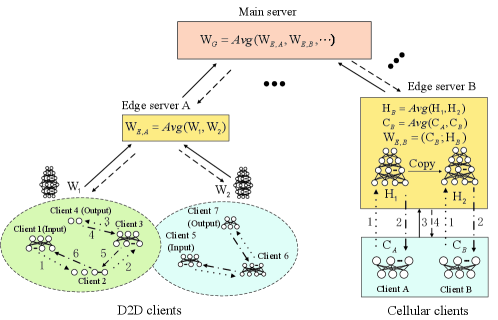
According to previous discussions, FL clients may undergo heavy communication costs since each of them has to transmit a complete model to the server, especially when facing with large size models over unstable wireless links. Besides, in typical FL, the model of a client is no longer useful in updating the global mode when confronting transmission failures, e.g., only partial of the corresponding model has been successfully transmitted to the server. Promoted by the principle of SL and to overcome the drawbacks of FL, we delve into splitting the model from a different perspective, namely, the number of model parameters. Accordingly, a comprehensive HSFL architecture is proposed as inspired by [6], in a multi-layer heterogeneous wireless networks (as depicted in Fig. 2(a)), consisting of D2D clients, cellular clients, edge servers, and a main server. Key modules of HSFL are detailed below.
Model splitting: The model is firstly split into () segments with equal data size where each segment is identified by a unique identification number. represents a hyperparameter that can be different for various FL models. More importantly, a larger can bring a smaller model granularity, while a higher transmission efficiency could be reached. Considering different communication conditions, an appropriate value of can ensure a good trade-off between transmission capacity and communication efficiency. Although each client can set by itself theoretically, to facilitate model aggregation/storage, all clients will use the same value of .
Model transmission and aggregation at clients: Each client first evaluates the wireless channel quality and transmission capacity, to determine the number of segments that can be transmitted successfully. Any specific segments for transmission can be randomly chosen or specified by the receiver, while different clients can transmit the same segments. Specifically, for D2D clients, suppose that each client can communicate with its neighboring clients within one hop, it will send/receive at least one segment to/from each neighbor. Two paradigms associated with model transmission and model aggregation are applied for D2D clients and cellular clients, respectively, as given in Fig. 2(a). On the right side, cellular clients can transmit model segments to the edge server in parallel, for example, client 1 sends segment 1 to the edge server while client 2 sends segments 2 and 3. On the left side of Fig. 2(a), D2D clients transmit model segments to their neighboring clients sequentially in a decentralized manner, while the last D2D client can send the aggregated model to the edge server. Specifically, edge servers or D2D clients proceed with segment-wise model aggregation, where the model segments are aggregated individually. For example, edge servers aggregate segment 1 of by averaging all the received segments 1.
Horizontal/Vertical model aggregation at edge servers: Both vertical aggregation and horizontal aggregation are considered in HSFL to improve communication efficiency. For vertical model aggregation, the model transmission and aggregation can be repeated for multiple rounds to obtain multiple model replicas, which thus reduces the communication cost between edge servers and main server[3]. Then, the model will be transmitted to the main server for a wide-range global aggregation. Horizontal aggregation among edge servers can be seen as a unique form of D2D communication at the edge server level. This approach effectively diminishes the overall model size transmitted to the main server, thereby reducing communication costs. Additionally, horizontal aggregation facilitates model parameter sharing, resulting in a significant acceleration of local model training and the mitigation of the impact of non-IID data distributions among clients.
III-B Architecture of HFSL
Fig. 2(b) illustrates the proposed HFSL architecture, where the main principle is to parallelize SL training and average the model weights over multiple clients by applying FL. Similar to HSFL, both D2D clients and cellular clients are considered.
When HFSL is implemented over multiple D2D clients, clients can be clustered into several clusters, e.g., based on their communication/computation capabilities. Then, the ML model is split into multiple subnetworks and distributed to the clients within each cluster. As shown on the left side of Fig. 2(b), the model is split into 4, and 3 subnetworks for two clusters, respectively. Then, the forward propagation starts at the client (e.g., client 1) with the input layer while ending at the client (e.g., client 4) with the output layer. Next, the back propagation starts in reverse order. Thus, each D2D cluster can be regarded as a hyper FL client, training a complete model, i.e, . The models can be transmitted by the clients to the edge server/neighboring cluster for averaging aggregation. In the next training round, the training starts with different clients under a new model splitting setting. Apparently, the training process is sequential within each D2D client cluster, and parallel over different clusters.
For cellular clients, we are motivated by [8, 9, 11, 10], and integrate them into the proposed HFSL. As shown by the right side of Fig. 2(b), the ML model is split into two subnetworks and , where each client trains the same subnetwork in parallel while the subnetwork is deployed at edge server . When multiple clients forward the activation results to the server in parallel, the edge server first copies the model to obtain multiple model copies to conduct forward propagation and back propagation for different clients in parallel. The number of model copies should be equal to the number of clients, e.g., two copies for clients and . Then, the gradients will be sent back to the clients for updating the corresponding subnetwork parameters, and ; meanwhile the server can update parameters and . Then, the clients can send the updated model parameters to the edge server in parallel. Finally, the edge server aggregates the model copies of edge server with , and of the two clients. Among which, will be sent back to the clients, helping with the next training round. Notably, the number of cellular clients associated with each edge server should be optimized so that to alleviate the model storage cost of the edge server. Similarly, edge server can further report the complete model parameter to the main server for wide-range global aggregation. Note that horizontal model aggregation can also be done between the edge servers in HFSL, which is omitted here.
IV Performance and Advantages
IV-A Performance Analysis
Although both HSFL and HFSL represent concrete implementations combining FL and SL architectures, they exhibit both connections and distinctions. Firstly, the fundamental architecture of HSFL is FL, wherein all clients are responsible for training complete ML models and only need to transmit partial (or complete) model parameters. In contrast, HFSL’s core architecture is SL, where each client exclusively trains a specific segment of the model. The federated architecture in HFSL is designed for parallel training and multi-layer model aggregation. Consequently, while HSFL and HFSL fundamentally represent two different architectures, they are both applicable in D2D-enabled heterogeneous networks. Generally, HSFL and HFSL are interconnected and can be harmoniously combined to create a complex yet effective architectural solution.
To achieve better performance comparison regarding different learning architectures, we quantify the communication (comm.)/computation (comp.) cost of clients via a simple analytical analysis. Without losing generality, we mainly consider cellular clients, since it is challenging to compare the performance of different architectures under the same parameter settings for D2D clients. Besides, it is hard to find general settings for decentralized FL and SL. Assuming that there are clients, the total training data size is where each client has the same training data size . The overall model data size is . The model is split into two subnetworks for SL and HFSL, the size of the split layer is , and the size of forward propagation or back propagation over the split layer can be calculated by [12]. The fraction of model size with clients is and with the server. For HSFL, the model is equally divided into segments, while each client transmits segments to the server at one training round. The computation cost, i.e., floating point of operations (FLOPs) of training a complete model is denoted by ; and the size of allocated computation load fraction at the client is . Thus, the total computation cost is for FL and HSFL, and it is for SL and HFSL. Correspondingly, HSFL reduces the total communication cost of FL from to , while HFSL raises the communication cost of SL from to , which, however, greatly reduces the training time through parallelization (as shown in the simulation).
IV-B Key Advantages
According to the above-discussions, the advantages of HSFL and HFSL are summarized as follows:
-
•
Training cost reduction: When compared to FLSL, both HSFL and HFSL can significantly reduce communication costs and training time. However, HSFL is more effective for training large-sized models, especially when dealing with a large number of clients, in contrast to HFSL.
-
•
Communication efficiency improvement: Wireless spectrum resources can be efficiently reused through the in-band D2D communication mode for D2D and cellular clients, aided by an appropriate resource sharing scheme.
-
•
Data-efficient training: HSFL can mitigate potential model transmission failures and make effective use of the local models trained by clients. Furthermore, HFSL can enable the participation of more clients with limited computational resources in each global training round, thanks to its parallelism capability. Additionally, the integration of D2D communications and a multi-layer hybrid network architecture significantly enhances server-client coverage and boosts the efficient utilization of training data.
-
•
Good adaptation in time-varying network topology: Leveraging the hybrid network architecture, both HSFL and HFSL demonstrate strong adaptability to dynamic network conditions, including those resulting from client mobility, and they achieve excellent stability throughout the training process.
-
•
High privacy protection: HSFL and HFSL empower clients to train or transmit partial models, thereby diminishing the likelihood of privacy disclosure resulting from malicious attacks or eavesdropping.



| MNIST | ||||||||||||
| Architectures | Client network | Server network |
|
|
Test accuracy |
|
||||||
| CL | N/A |
|
N/A | N/A | 99.05% | 5.02 | ||||||
| FL |
|
N/A | 60.94 | 96.83% | 50.83 | |||||||
| SL | cov2d(32,(5,5))+cov2d(64,(3,3)) |
|
7090.1 | 96.20% | 891.02 | |||||||
| HSFL |
|
N/A | 30.47 | 96.92% | 49.91 | |||||||
| HFSL | cov2d(32,(5,5))+cov2d(64,(3,3)) |
|
7090.4 | 96.33% | 222.75 | |||||||
| Fashion-MNIST | ||||||||||||
| CL | N/A |
|
N/A | N/A | 90.34% | 5.02 | ||||||
| FL |
|
N/A | 60.94 | 78.00% | 50.83 | |||||||
| SL | cov2d(32,(5,5))+cov2d(64,(3,3)) |
|
7090.1 | 68.51% | 891.02 | |||||||
| HSFL |
|
N/A | 30.47 | 78.26% | 49.91 | |||||||
| HFSL | cov2d(32,(5,5))+cov2d(64,(3,3)) |
|
7090.4 | 80.30% | 222.75 | |||||||
| MedMNIST | ||||||||||||
| CL | N/A | ResNet(32) | N/A | N/A | 91.73% | 2.03 | ||||||
| FL | ResNet(32) | N/A | 7.18 | 80.21% | 52.77 | |||||||
| SL | ResNet(2) | ResNet(30) | 1400.02 | 78.21% | 180.18 | |||||||
| HSFL | ResNet(32) | N/A | 3.59 | 82.41% | 52.66 | |||||||
| HFSL | ResNet(2) | ResNet(30) | 1400.18 | 81.32% | 45.04 | |||||||
V Open Challenges
This section discusses open challenges for future research directions of the proposed HSFL and HFSL architectures. Several important examples are discussed as below.
Model splitting and resource allocation: In the context of HSFL, implementing an appropriate splitting scheme, such as determining the value of , can significantly enhance transmission efficiency and reduce client dropout rates. Particularly, in a dynamic D2D network where wireless links among clients are random and ever-changing, the task of defining a suitable value for becomes a significant challenge, necessitating the development of dynamic model splitting schemes. In the case of HFSL, the structural complexities of the model introduce additional intricacies and challenges to the model splitting problem, especially within D2D networks. For instance, HFSL’s model can be divided into multiple subnetworks and allocated to various D2D clients, with both subnetworks and D2D clients represented as two directed graphs. In this scenario, the subnetwork allocation problem in a D2D network is formulated as a subgraph isomorphism problem[13], which is generally NP-complete and demands solutions with low complexity and high responsiveness. Furthermore, as different model segments (layers) can have varying impacts on training performance, contingent upon each client’s local dataset, the model splitting scheme for both HSFL and HFSL should be designed on a client/segment/layer-wise basis, an area that continues to present an open challenge. Additionally, given the heterogeneous resource conditions of clients, optimizing model splitting should involve the joint design of feasible resource allocation strategies, aimed at improving training performance and resource efficiency.
Privacy leakage and protection: Despite the enhanced privacy protection offered by HFSL and HSFL in comparison to SL and FL, privacy breaches remain inevitable even when all participants (i.e., clients or edge servers) are semi-honest (i.e., honest-but-curious)[14]. In HSFL, for instance, each participant can receive one or multiple model segments from other participants. As training progresses, each participant eventually gains access to a complete model, exposing HSFL to the same risk of privacy breaches associated with model attacks (e.g., membership inference attacks and model inversion attacks) as FL. In the case of HFSL, although the complete model is not accessible to clients, frequent and direct exchange of data features and gradient information during communication significantly heightens the risk of privacy breaches. While certain existing techniques, such as differential privacy and homomorphic encryption, can mitigate the aforementioned privacy risks to some extent, the associated high computational complexity and potential model performance degradation may not yield satisfactory results. Consequently, designing algorithms with both low computational complexity and guaranteed model accuracy to achieve reduced privacy risks remains a formidable challenge, especially when combining the features of HSFL and HFSL, such as dynamic model partitioning and aggregation strategies.
Incentive mechanism design: While many existing works have examined incentive mechanism designs for FL/SL-based services, the complexity increases when considering HSFL and HFSL. In HSFL/HFSL, the granularity of services (e.g., at the model segment/layer level) provided by each client can be finer, requiring increased cooperation among clients. This introduces challenges like reward transfer among different clients and the secondary distribution of internal rewards within client clusters, which are important areas of concern in HSFL and HFSL.
Multiple ML tasks scheduling: Thanks to the innovative on-board sensors, client devices can collect diverse data types. Moreover, with enhanced multi-core computing processors, a client can engage in multiple ML model training processes simultaneously[7]. Consequently, when handling multiple ML training tasks concurrently, it is crucial to select suitable learning architectures (FL, SL, HSFL, or HFSL) and resource scheduling schemes that match the varied requirements of learning tasks and the status of clients, ensuring optimal learning performance. This topic also presents a practical and intriguing research direction.
Privacy-oblivious data sharing: While the fundamental goal of distributed ML is to avoid sharing raw data, exceptions exist where certain clients are permitted to share their training data with trusted peers. For instance, clients may be willing to share photos with family and friends, rather than with strangers, in a privacy-oblivious data-sharing process that can provide more training data. Additionally, clients with limited power supply may offload training data to others to support model training. Data sharing can also lead to client dimensionality reduction in HSFL and HFSL, enabling improved optimizations. To mitigate the risk of privacy disclosure, research is needed on data-sharing strategies, including the measurement of the relationship between privacy disclosure and the amount of shared data and the development of a reputation/credit-based evaluation system.
VI Preliminary Simulation
This section evaluates the performance of our proposed hybrid architectures in comparison with centralized learning (CL), FL, and SL on three datasets, namely, MNIST, Fashion-MNIST, and MedMNIST. Each dataset contains multiple classes of different objects, and can thus be utilized to train classification models. Specifically, MNIST includes grayscale images of handwritten digits from ‘0’ to ‘9’; Fashion-MNIST includes grayscale images of ten different clothing items; MedMNIST includes grayscale images of eight blood cell microscopes. Besides, four clients are supposed to participate in each architecture. To better evaluate the feasibility and stability of the proposed architectures, we adopt a highly non-IID dataset setting [15] for the clients and datasets. For example, we partition MNIST into four groups according to label spaces, while ensuring that any two groups have different label sets. For example, we assume client-1 has all the training data of class ‘0’ and ‘1’; client-2 has all the training data of class ‘2’ and ‘3’; client-3 has all the training data of class ‘4’, ‘5’ and ‘6’; client-4 has all the training data of class ‘7’, ‘8’ and ‘9’. Similar dataset settings are applied for Fashion-MNIST and MedMNIST. Besides, Table I demonstrates the model setting for different datasets and architectures. Note that a ResNet(32) model is applied for MedMNIST, where ResNet(2) and ResNet(30) mean that the first two hidden layers and the remaining 30 layers are deployed at the client-side and the server-side, respectively.
We run simulations with AMD Ryzen 7-5800H@3201MHz as clients and with NVIDIA GeForce RTX3070-8G as an edge server. To better measure the training time, the average uplink/downlink datarate between the edge server and any client is set as 10/50 MB/s, and the average D2D datarate between any two clients is 5 MB/s. In addition, all the clients conduct one local training epoch for each global training round.
Figure 3 demonstrates the test accuracy of different architectures across training rounds for the three datasets, each involving four clients. In general, CL converges rapidly and achieves the highest test accuracy, highlighting its advantages. In contrast, SL converges the slowest, while FL, HSFL, and HFSL achieve relatively close performance on convergence, indicating the feasibility of our proposed architectures. A performance gap between distributed ML and CL is evident, and it widens with the complexity of the dataset and model, primarily due to the non-IID data distribution. Table I provides a detailed performance comparison of different learning architectures for the three datasets and models. MNIST and Fashion-MNIST exhibit similar performance in most aspects, as they share the same data format, data size, and network model. Compared to FL, HSFL significantly reduces communication costs (by 50%) and slightly decreases training time while increasing accuracy (e.g., by approximately 2.2% on MedMNIST). Similarly, compared to SL, HSFL significantly reduces training time (by approximately 75%) and improves accuracy (e.g., by about 10% on Fashion-MNIST), although HFSL’s communication cost is slightly higher than SL. These results demonstrate that our proposed HSFL and HFSL can significantly reduce communication costs and training time without sacrificing accuracy when compared to conventional FL and SL. Furthermore, a comparison between HSFL and HFSL reveals that HSFL generally has lower communication costs and training time, while HFSL incurs lower computation costs. They achieve similar test accuracy, emphasizing the importance of considering resource availability and performance requirements when implementing HSFL and HFSL.
VII Conclusion
In this article, we introduce two hybrid architectures, HSFL and HFSL, for distributed ML in D2D- enabled heterogeneous wireless networks. These architectures combine federated and split approaches. We begin by presenting the basic architectures and conducting performance comparisons to highlight their advantages. We then explore intriguing research directions, pointing out potential challenges and opportunities for future implementations of our proposed architectures. Finally, we perform preliminary simulations to confirm the feasibility of HSFL and HFSL on three datasets, considering highly non-IID data settings.
References
- [1] Z. Cheng, X. Xia, M. Liwang, et al., “CHEESE: Distributed Clustering-Based Hybrid Federated Split Learning over Edge Networks,” IEEE Trans. Parallel Distrib. Syst., vol. 34, no. 12, pp. 3174-3191, Dec. 2023.
- [2] P. Vepakomma, O. Gupta, T. Swedish, et al. “Split Learning for Health: Distributed Deep Learning Without Sharing Raw Patient Data, ” 2018, arXiv: 1812.00564. [Online]. Available: http://arxiv.org/abs/1812.00564.
- [3] S. Hosseinalipour, C. G. Brinton, V. Aggarwal, et al.,“From Federated to Fog Learning: Distributed Machine Learning over Heterogeneous Wireless Networks,” IEEE Commun. Mag., vol. 58, no. 12, pp. 41-47, Dec. 2020.
- [4] H. B. McMahan, E. Moore, D. Ramage, et al., “Communication-Efficient Learning of Deep Networks from Decentralized Data,” in Proc. Int. Conf. Artif. Intell. Statist. (AISTATS), Apr. 2017.
- [5] O. Gupta and R. Raskar, “Distributed Learning of Deep Neural Network Over Multiple Agents,” J. Netw. Comput. Appl., vol. 116, pp. 1–8, Aug. 2018.
- [6] J. Jiang, L. Hu, C. Hu, et al., “Bacombo—Bandwidth-Aware Decentralized Federated Learning,” Electronics, vol. 9, no. 3, p.440, 2020.
- [7] M. N. H. Nguyen, N. H. Tran, Y. K. Tun, et al., “Toward Multiple Federated Learning Services Resource Sharing in Mobile Edge Networks,” IEEE Trans. Mobile Comput., vol. 22, no. 1, pp. 541-555, Jan. 2023.
- [8] J. Jeon and J. Kim, “Privacy-Sensitive Parallel Split Learning,” in Proc. Int. Conf. on Inf. Netw. (ICOIN), Barcelona, Spain, Jan. 2020.
- [9] C. Thapa, M. A. P. Chamikara, and S. Camtepe, “Splitfed: When Federated Learning Meets Split Learning” 2020, arXiv: 2004.12088. [Online]. Available: http://arxiv.org/abs/2004.12088.
- [10] V. Turina, Z. Zhang, F. Esposito, et al.,“Federated or Split? A Performance and Privacy Analysis of Hybrid Split and Federated Learning Architectures,” in Proc. IEEE 14th Int. Conf. Cloud Comput. (CLOUD), Chicago, IL, USA, Sept. 2021.
- [11] Y. Gao, M. Kim, C. Thapa, et al., “Evaluation and Optimization of Distributed Machine Learning Techniques for Internet of Things,” IEEE Trans Comput., vol. 71, no. 10, pp. 2538-2552, Oct. 2022.
- [12] A. Singh, P. Vepakomma, O. Gupta, et al., “Detailed Comparison of Communication Efficiency of Split Learning and Federated Learning,” 2019, arXiv:1909.09145. [Online] Available: http://arxiv.org/abs/1909.09145.
- [13] M. Liwang, S. Hosseinalipour, Z. Gao, et al., “Allocation of Computation-Intensive Graph Jobs Over Vehicular Clouds in IoV,” IEEE Internet Things J., vol. 7, no. 1, pp. 311-324, Jan. 2020.
- [14] M.H. ur Rehman, M.M. Gaber (Eds.), “Federated learning systems–Towards next-generation AI,” Springer International Publishing, 2021.
- [15] Y. Zhao, M. Li, L. Lai, et al., “Federated Learning with Non-IID Data,” 2018, arXiv:1806.00582. [Online] Available: https://arxiv.org/abs/1806.00582.