Distributed Event-triggered Control of Networked Strict-feedback Systems Via Intermittent State Feedback
Abstract
It poses technical difficulty to achieve stable tracking even for single mismatched nonlinear strict-feedback systems when intermittent state feedback is utilized. The underlying problem becomes even more complicated if such systems are networked with directed communication and state-triggering setting. In this work, we present a fully distributed neuroadaptive tracking control scheme for multiple agent systems in strict-feedback form using triggered state from the agent itself and the triggered states from the neighbor agents. To circumvent the non-differentiability of virtual controllers stemming from state-triggering, we first develop a distributed continuous control scheme under regular state feedback, upon which we construct the distributed event-triggered control scheme by replacing the states in the preceding scheme with the triggered ones. Several useful lemmas are introduced to allow the stability condition to be established with such replacement, ensuring that all the closed-loop signals are semi-globally uniformly ultimately bounded (SGUUB), with the output tracking error converging to a residual set around zero. Besides, with proper choices of the design parameters, the tracking performance in the mean square sense can be improved. Numerical simulation verifies the benefits and efficiency of the proposed method.
Adaptive control, event-triggered, backstepping, multiple agent systems, directed topology.
1 Introduction
Nowadays control systems are normally implemented over networks [1]. As such, it is highly desirable to share network resources in both sensor/actuator and control input channels to save on board communication bandwidth and stored energy, both are limited in networked systems operating autonomously. Under such setting, preserving stability under certain communication and energy constraints is vital in networked control systems. A commonly used data transmission/communication approach in traditional digital control techniques is the fixed time-scheduled sampling, which, however, causes unnecessary overloads to the communication networks [2].
The emergence of event-triggered control has provided an appealing avenue for effective transmissions of measured signals through certain triggering conditions [3]. Early results of event-triggered control mainly focus on linear systems, see [4, 5] and the references therein. The work in [6] further considers a class of nonlinear systems in the framework of event-triggered control, while the input-to-state stability (ISS) condition is required. Such limitation is successfully removed in [7, 8] by developing some event-triggered adaptive control algorithms based on the backstepping technique. However, the results in [4, 5, 6, 7, 8] are only applicable for single nonlinear systems, albeit there exist a large of engineering systems that are literally networked.
On the other hand, most networked multiple agent systems are usually in short of communication and energy resources, especially when the agent itself or its internal devices are battery-powered, wherein the communication bandwidth and channels among the connected subsystems are limited, motivating extensive and in-depth studies on distributed and event-triggered control methodologies [9, 10], which can be broadly classified two categories: one is referred to as input-triggered control, and the other as state-triggered control. In input-triggered control, the frequency of updating the actuation signal is substantially reduced, see [11, 12] and the references therein, yet the communication resources wasted among agents are ignored intentionally. As for distributed state-triggered control, some efforts have been made for linear systems [13], first-order nonlinear systems [14], and second-order nonlinear systems [15]. Some other works have also considered high-order nonlinear systems [16, 17], those methods, however, rely on a key requirement that the neighbors’ states are continuously monitored to implement the designed triggering condition. Towards relaxing such a restriction, an effort is made in [18] through a state-triggered control strategy for integrator network systems, while the communication graph is required to be undirected. For the directed topology, a distributed state-triggered adaptive controller is designed in [19] for a class of norm-form nonlinear systems. The problem of state-triggered output consensus tracking is addressed by using backstepping based output feedback in [20]. Nevertheless, in most of the above results, the explosion of complexity issue always exists owing to repetitive/recursive differentiation of virtual controllers in the backstepping technique. Moreover, in the framework of event-triggered control, results on networked nonlinear strict-feedback systems with mismatched uncertainties are still limited and the related issues have not been well addressed.
Motivated by the above analysis and discussion, in this work we develop a fully distributed neuroadaptive control scheme for a class of networked mismatched nonlinear strict-feedback systems with directed communication topology and state-triggering setting. The key contributions and features of our method can be summarized as follows:
-
i)
By considering non-identical agent model with mismatched uncertainties, the developed control scheme is applicable to a larger class of multiple agent systems, covering those studies on [10], [14, 15], [18, 19, 20], wherein the models are in low-order forms or in normal forms with parametric uncertainties. To our best knowledge, this is the first solution to the distributed adaptive control problem for networked strict-feedback multiple agent systems with state-triggering setting.
-
ii)
The proposed approach is more effective in saving communication and energy resources as compared with the existing ones [10], [19, 20], because the designed triggering mechanism allows all the states sensoring and data transmission to be executed intermittently on the event-driven basis, and the states include those from the agent itself, the leader, and the neighbors (not just the states between subsystems), thus the sensors do not need to be powered all the time and the data from the sensors to the controllers does not have to be transmitted ceaselessly.
-
iii)
As the intermittent states make it invalid to take the differentiation of virtual controller as required in backstepping design, we choose to develop a fully distributed continuous control scheme first using regular state feedback, upon which we construct the distributed event-triggered control scheme by replacing the states in the preceding scheme with the triggered ones, which is still fully distributed since only local information from the neighbors is involved. Several lemmas are established to authenticate that such replacement preserves consensus tracking stability, while at the same time significantly saving communication and energy resources.
The remainder of the paper is organized as follows. In Section II, the problem is formally stated and the preliminaries are given. In Section III, a distributed continuous control scheme is firstly designed, upon which the distributed event-triggered control scheme is then proposed via intermittent state feedback in Section IV. Section V presents the simulation results. Section VI concludes the paper.
2 Preliminaries and Problem Formulation
2.1 Basic Graph Theory
A directed graph among agents is denoted by , which consists of a set of nodes , a group of edges and a weighted adjacency matrix . If there is an edge between nodes and , then and are called adjacent, i.e., . An edge suggests that node can receive information from node . For adjacency matrix , if , then , otherwise, . is the leader adjacency matrix, where if there is a directed edge from the leader to the agent i, and otherwise. It is assumed that there are no self-loops or parallel edges in the network. If there is a path from to , then and are called connected. If all pairs of nodes in are connected, then is called connected. is the indices set of neighbors of node . The Laplacian matrix is defined as and , satisfying , where is the absolute in-degree matrix with .
2.2 Problem Formulation
Consider a multiple agent system composed of agents under a directed topology , with the th, agent modeled as:
| (1) |
where , , are the states, control input and output of the th agent, respectively, , are unknown smooth nonlinear functions.
The mismatched nonlinearities are approximated by radial basis function neural network (RBFNN) over a suitable compact set , that is
| (2) |
where is the NN input vector, is the ideal weight matrix, is the basis function vector, and is the approximate error. The typical choice of , is the Gaussian function , where is the center of receptive field, is the width of the Gaussian function.
The objective of this paper is to develop a fully distributed neuroadaptive control scheme for system (1) by using intermittent state feedback such that
-
All subsystem outputs closely track the desired trajectory , with the output tracking error converging to a residual set around zero.
-
All signals in the closed-loop system are semi-globally uniformly ultimately bounded (SGUUB).
-
The Zeno behavior is excluded.
To this end, the following assumptions are needed.
Assumption 1. The directed graph is balanced and weakly connected.
Assumption 2. The full knowledge of is directly accessible by at least one subsystem, i.e., , and satisfies , where is an unknown constant.
Assumption 3. The basis function vector and the approximate error satisfy , , respectively, where and are unknown positive constants.
The following lemma is introduced, which is crucial in the system stability analysis.
Lemma 1 [19]. Let . Based on Assumption 1, the matrix is symmetric and positive definite.
Remark 1. Assumption 1 is quite common in literature [16, 19]. Different from the results in [16, 19], as noted in Assumption 2, only the available information of and its first derivative is needed, but not the high order derivatives. For Assumption 3, since the basis function vector of the RBNFF chosen in this paper (i.e., Gaussian function) is inherently bounded, and thus it is valid to assume that is bounded.
3 Distributed Control Using Continuous State Feedback
To facilitate the distributed event-triggered control design, we first develop a distributed continuous control scheme under regular state feedback. The tracking errors are defined as follows:
| (3) | ||||
| (4) | ||||
| (5) |
where is the output tracking error. In each subsystem, is used to indicate the case that the reference signal is accessible directly to subsystem ; otherwise, . For the latter case, we introduce to estimate , with , as seen later.
As a key design step for control design, we introduce the following first-order filter, which plays a crucial role in the stability analysis:
| (6) |
for , where is a time constant, is the virtual control serving as the input of (6), and is the output. Furthermore, we define
| (7) |
which benefits the stability analysis, as seen later.
The distributed continuous control scheme under regular state feedback is designed as follows:
| (8) | ||||
| (9) | ||||
| (10) |
for , where and , are positive design parameters. The parameter estimator and the distributed estimator are designed as:
| (11) | ||||
| (12) |
for , where , and are positive design parameters, is the estimate of , with , and is a positive definite design matrix.
Now we are ready to state the following theorem.
Theorem 1. Consider a strict-feedback nonlinear multiple agent system of agents (1) with a desired trajectory under the directed topology , satisfying Assumptions 1-2, if using distributed neuroadaptive controller (10), with the adaptive law (11) and the distributed estimator (12), then it holds that: i) all signals in the closed-loop system are SGUUB; and ii) the output tracking error converges to a residual set around zero.
Proof. See Appendix A.
4 Distributed Control using intermittent state feedback
In this section, a fully distributed neuroadaptive backstepping control scheme with directed communication and state-triggering setting is presented.
4.1 Event Triggering Mechanism
Denote and , , as the local states information (or the leader, i.e., ) and its neighboring states information, respectively, which are broadcast to their connected subsystems according to the designed triggering mechanism. Since and denote the th event time for agent and its neighbor broadcasting their state information, respectively, it holds that the states of the agent and its neighbor are kept unchanged as , , and .
The triggering conditions are then designed as:
| (13) | ||||
| (14) |
where and are positive triggering thresholds, is the first instant when (13) is fulfilled for subsystem (or the leader, i.e., ), and is the first triggering time for its neighbor , , .
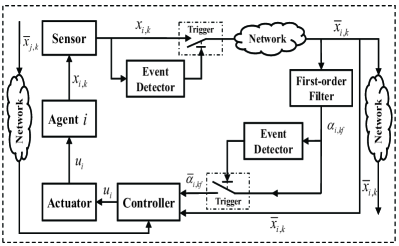
4.2 Controller Design
Firstly, we modify the tracking errors defined in (3)-(5) to the following form:
| (15) | ||||
| (16) | ||||
| (17) |
where , , and , , , with
| (18) |
where , , is the positive triggering threshold, and is the first triggering time when (18) is fulfilled.
Based upon the intermittent state feedback, we redesign the fully distributed event-triggered control scheme as follows:
| (19) | ||||
| (20) | ||||
| (21) |
where and , are positive design parameters. The parameter estimator and the distributed estimator are designed as:
| (22) | ||||
| (23) |
for , where , and are positive design parameters, is the estimate of , and is a positive definite design matrix.
The proposed distributed control strategy with state-triggering setting is conceptually shown in Fig. 1.
Remark 2. Here, we must emphasize and clarify that, for the system with state-triggering setting, only the triggered states are available for the control design. If the standard backstepping design procedure is adopted, the virtual controllers in (20) should be . Note that the intermittent states are used in , it holds that is discontinuous and unavailable for the backstepping control design. To overcome this obstacle, in this section we utilize the tracking errors in (3)-(4) and the virtual control functions in (8)-(9) for the Lyapunov stability analysis. Nevertheless, it should be noted that and are not for the controller design, since the final control , the parameter updating law and the distributed estimator designed in (21)-(23) only utilize intermittent states . Such a treatment plays a crucial role in handling the adverse effects arising from state-triggering, as detailed in the sequel.
As the proposed distributed state triggering control is constructed by replacing the states with their triggered ones, it is important to show that such replacement not only saves communication and energy resources but also preserves consensus stability. To this end, we establish the following lemmas.
Lemma 2. For all , there exist bounds , such that
| (24) |
where is a constant that depends on triggering thresholds , , and design parameters , , .
Proof. See Appendix B.
Lemma 3. The effects of state-triggering are bounded as follows:
| (25) | ||||
| (26) | ||||
| (27) |
for , where , and are positive constants that depend on the triggering thresholds , , , , topology parameters , , design parameters , , and , , .
Proof. See Appendix C.
With those lemmas, we establish the following result.
Theorem 2.
Consider a strict-feedback nonlinear multiple agent system of agents (1) with a desired trajectory under the directed topology , satisfying Assumptions 1-2, if using distributed neuroadaptive controller (21), with adaptive law (22) and distributed estimator (23) under triggering conditions (13), (14) and (18), it then holds that: i) all signals in the closed-loop system are SGUUB; ii) the output tracking error converges to a residual set around zero, and the upper bound for can be decreased with some proper choices of the design parameters; and iii) the Zeno phenomenon is precluded.
Proof. The proof involves three parts: stability analysis, performance analysis and exclusion of Zeno behavior.
1) Stability analysis. This part is comprised of the following steps.
Step 1: Consider a Lyapunov function . From (1), (3), (4), (7), (8) and using Young’s inequality, the derivative of is computed as
| (28) |
where , is a positive design parameter, with .
Step k : Consider a Lyapunov function . From (1), (4), (7), (9), (28) and using Young’s inequality, is expressed as
| (29) |
where , is a positive design parameter, with .
Step n: Consider a Lyapunov function . From (1), (4) and (29), it holds that
| (30) |
From (23), it is seen that , where is defined in (47)). By using Young’s inequality, one has
| (31) | ||||
| (32) | ||||
| (33) |
In view of (30), (31), (32) and (33), it holds that
| (34) |
where . Notice that the actual control law in (21) can be rewritten as
| (35) |
Using (22) and (35), then becomes
| (36) |
where , , and . Invoking Lemmas 2-3 and using Young’s inequality, it holds that
| (37) | ||||
| (38) |
From (37) and (38), it can be derived from (36) that
| (39) |
where . Since for any , the set defined by is a compact one. Thus on , , it follows that
| (40) |
where , , , , , , , and .
In view of (40), we have , which implies that on when . Thus is an invariant set, i.e., , it follows that the signals , , , are bounded, . From (3)-(5) and (7)-(9), it follows that , is bounded. Then according to Lemma 3, it can be derived from (21) that is bounded. Therefore, all signals in the closed-loop system are ensured to be SGUUB.
2) Performance analysis. By the definition of and using (40), we have , it follows that , where is a constant. Thus it can be concluded that the output tracking error will attenuate to a residual set around zero. In addition, from (40), we can obtain that
| (41) |
which implies that the upper bound of can be decreased by decreasing the triggering thresholds , , and , and increasing design parameters , , and , , .
3) Exclusion of Zeno behavior. Finally, we show that the result iii) is ensured. Define , , , , . The derivative of is computed as
| (42) |
Since remains unchanged for , one obtains that , , and , with . By the boundedness of , and , it follows that , , where is an unknown positive constant, then we have . Similarly, it holds that and , , where , and are positive constants. Therefore the Zeno behavior is excluded. The proof is completed.
Remark 3. To see the novelty of the proposed control method, it is worth making the following comments: i) The proposed distributed scheme is based upon the networked strict-feedback systems with directed communication and state-triggering setting, which includes the existing results in [10, 19, 20] as special cases; ii) Different from the methods in [8, 10, 19], where the system uncertainties must be parametric, the agent model considered here is non-identical and in strict-feedback form with mismatched and nonparametric uncertainties; and iii) Unlike the results in [10, 19], the communication regarding all states is executed via an event-based discontinuous way in this work, which saves both communication and energy resources.
Remark 4. Here we pause to stress the following merits associated with the proposed distributed triggering mechanism, from two aspects. Firstly, it is seen from (13), (14) and (18)-(21) that, no prior knowledge of global communication graph is required in both event-triggered rules and distributed control laws. Hence, the proposed method can be implemented in a fully distributed manner, completely avoiding the requirements on the continuous monitoring of neighbors’ states in [9, 16, 17]. Secondly, in contrast to [10, 19], the proposed triggering mechanism allows the communication regarding all states to be executed in an intermitted pace.
Remark 5. It is worth mentioning how the issue of non-differentiability of virtual control associated with backstepping design arising from intermittent (triggered) state feedback is addressed. For normal form systems, one can use the partial derivatives in deriving the final controller to circumvent the non-differentiability problem of in the control design, as seen in [19]. However, such treatment relies on the key precondition that the partial derivatives are constants, thus is only suitable for systems in normal form. Here by using the idea of dynamic filtering technique, we develop a fully distributed neuroadaptive event-triggered control scheme that not only avoids the non-differentiability issue in the backstepping design but also is applicable to nonlinear systems in either normal or strict-feedback form.
Remark 6. To recap the control design philosophy utilized in this work, it is worth noting that although the calculation of the repetitive differentiation of virtual control signal is averted in the control design by using the dynamic filtering technique, such calculation is still involved in stability analysis, thus the non-differentiability issue associated with virtual controllers cannot be addressed by using the first-order filter directly. To remove this obstacle, here the backstepping technique is not adopted directly in designing the distributed event-triggered controller and virtual controllers . Instead, a distributed continuous control scheme is firstly constructed upon regular state feedback, hence the designed virtual controllers remain differentiable. Based on such control structure, we further derive a new distributed event-triggered control scheme by replacing the states in the preceding scheme with the triggered ones.
Remark 7. In deriving the fully distributed event-triggered control scheme (19)-(21), the main challenge in the stability analysis lies in how to deal with the effect caused by triggering errors , , when the triggered states are utilized in the controller design. In fact, the major difficulty is the treatment of the terms and in (36), which are shown to be bounded by the critical results established in Lemmas 2-3. Furthermore, it is shown that the bounds rely only on the tracking error and parameter estimation error , and thus can be incorporated into two negative terms and of , as seen in (39). It is such treatment that allows the impact stemming from state-triggering to be gradually handled, ensuring the stability of the closed-loop system.
Remark 8: It is observed from (41) that the larger the triggering thresholds used, the smaller the triggering times would be, and thus more communication resources are saved. Whereas, the upper bound of is also increased. Also, it is not difficult to see that larger design parameters , , and leads to smaller , which allows the proposed scheme to enhance the tracking performance to a certain extent. Nevertheless, it should be pointed out that larger design parameters inevitably leads to larger control effort. Therefore, a trade-off should be made considering communication cost, tracking performance and control effort in practice.
Remark 9. To mitigate the communication burden in networked control systems, various types of input-triggered adaptive control laws are developed [7, 11, 12], and those solutions are quite well established. Besides, due to the input-triggered control does not involve any intermittent states, it has no effect on the first steps of the backstepping design procedure. Therefore it is not difficult to design input-triggered control schemes by using backstepping techniques. In this work we propose the event triggering mechanism that triggers both the states from the agent itself (including the leader, i.e., ) and its neighbors. In this way, the communication among all the states is executed intermittently on an event-driven basis, which allows the communication resources utilized among the agents and the connected subsystems to be substantially saved. To make the description of the technical contents more comprehensible and accessible, input-triggering is not considered in the development. Including such element, however, can be addressed similarly and it is quite straightforward to prove the stability accordingly.
Remark 10. Inspired by the ideas in [10, 19, 21], the triggering mechanism with fixed constant triggering thresholds is adapted in this work. It contributes preventing the occurrence of Zeno behavior and at the time avoiding the continuous monitoring of neighbors’ states in [9, 16, 17]. Nevertheless, it should be pointed out that such triggering mechanism reduces the accuracy of transmitted signal to some extent and may further impacts the tracking performance. To solve these problems, numerous adaptive event-triggered algorithms with time-varying triggering thresholds have been developed [7, 22, 20]. As our focus in this work is mainly on developing a fully distributed event-triggered control scheme for networked nonlinear strict-feedback systems with mismatched uncertainties, instead of optimizing the triggering mechanism, the problem with time-varying triggering thresholds is of great importance and deserves attention in the future study.
5 Simulation Verification
A group of 4 nonlinear subsystems modeled with the following dynamics is considered:
| (43) |
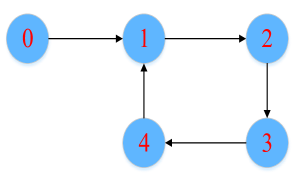
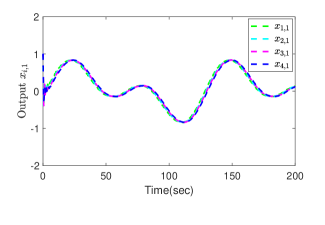
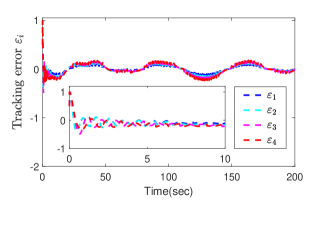
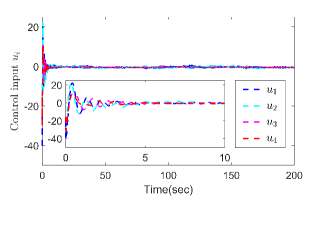
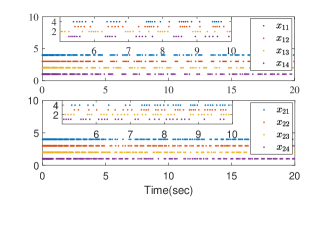
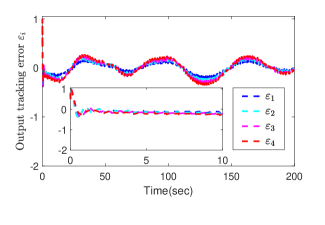
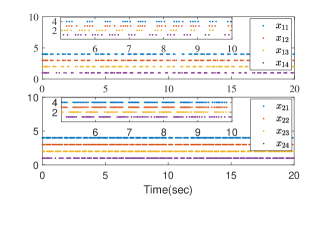
for . Fig. 2 shows the interaction topology of the multiple agent system. In the simulation, we set the desired trajectory , the initial states , , the triggering thresholds , , , , the design parameters , , , , , , , , and . The RBFNN contains 25 nodes with centers distributed in the space [-5,5], and . The results are presented in Fig. 3. Fig. 3 (a) shows the output trajectories of all subsystems. From Fig. 3 (b), it can be determined that the output tracking error converges to a compact set around origin. Fig. 3 (c) gives the distributed protocol . The triggered times of states and are presented in Fig. 3 (d).
Furthermore, to test the effect of triggering thresholds on the system tracking performance, we choose and , and the same set of other design parameters are used. The results are presented in Fig. 3 (e)-(f). The number of triggering events for and under different triggering thresholds is shown in Table 1. The results show that the larger the triggering thresholds are used, the fewer the triggering times are needed. Nevertheless, the output tracking error becomes slightly larger.
| Agent 1 | |
|---|---|
| Agent 2 | |
| Agent 3 | |
| Agent 4 | |
| Leader 0 | |
6 Conclusion
This work investigates the distributed tracking control problem for a class of networked nonlinear strict-feedback systems with mismatched uncertainties. A fully distributed neuroadaptive control scheme base on intermittent state feedback is derived. The major technical challenge in developing such control strategy is to circumvent the non-differentiability problem of the virtual control arising from state-triggering. By using the results established in the lemmas, it is shown that with the proposed intermittent states only, all the closed-loop signals are SGUUB, with the output tracking error converging to a residual set around zero. Besides, with proper choices of the design parameters, the tracking performance in the mean square sense can be improved. An interesting topic for future research is the consideration of time-varying triggering thresholds with intermittent output feedback only.
7
Proof of Theorem 1. Step 1: Consider a Lyapunov function =. Since , where is approximated by using the RBFNN on a compact set , then it is seen from (8), (11) and (12) that
| (44) |
where , is a positive design parameter, with , and .
8
Proof of Lemma 2. Firstly, for , we prove that . As , it holds that , where , . Since satisfies the locally Lipschitz continuity condition, then we have , where is the computable Lipschitz constant. By the definition of , we know that , where and . Taking the derivative of yields . By defining , , it follows that , with , . Then it can be computed that . Let , one obtains that or , i.e., or . Notice that if , then , and if , . Then it is readily seen that . Furthermore, it can be derived that , with . Similarly, for , it holds that , where . Thus we can derive that is a constant that depends on triggering thresholds , , and design parameters , , , , . Notice that I is the identity matrix with appropriate dimension, and denote the -vector of all all zeros. The proof is completed.
9
Proof of Lemma 3. From (5) and (17), it is seen that
| (47) |
where . As observed from (3), (4), (15) and (16), it follows that
| (48) | ||||
| (49) |
In accordance with (8) and (19), it follows that . Invoking Lemma 2, it is not difficult to get that . Then we can obtain
| (50) |
where and are positive constants. Using (9) and (20), one has . Then it can be derived that
| (51) |
where , and are positive constants. Similarly, for , it holds that
| (52) |
where , , , and are positive constants.
References
- [1] R. A. Gupta and M.-Y. Chow, “Overview of networked control systems,” in Networked Control Systems. Springer, 2008, pp. 1–23.
- [2] K. J. Åström and B. Bernhardsson, “Comparison of periodic and event based sampling for first-order stochastic systems,” IFAC Proceedings Volumes, vol. 32, no. 2, pp. 5006–5011, 1999.
- [3] K. J. Aström, “Event based control,” in Analysis and design of nonlinear control systems. Springer, 2008, pp. 127–147.
- [4] “Lq-based event-triggered controller co-design for saturated linear systems,” Automatica, vol. 74, pp. 47–54, 2016.
- [5] W. H. Heemels, M. Donkers, and A. R. Teel, “Periodic event-triggered control for linear systems,” IEEE Transactions on automatic control, vol. 58, no. 4, pp. 847–861, 2012.
- [6] P. Tabuada, “Event-triggered real-time scheduling of stabilizing control tasks,” IEEE Transactions on Automatic Control, vol. 52, no. 9, pp. 1680–1685, 2007.
- [7] L. Xing, C. Wen, Z. Liu, H. Su, and J. Cai, “Event-triggered adaptive control for a class of uncertain nonlinear systems,” IEEE transactions on automatic control, vol. 62, no. 4, pp. 2071–2076, 2016.
- [8] Z. Zhang, C. Wen, L. Xing, and Y. Song, “Adaptive event-triggered control of uncertain nonlinear systems using intermittent output only,” IEEE Transactions on Automatic Control, 2021.
- [9] D. V. Dimarogonas, E. Frazzoli, and K. H. Johansson, “Distributed event-triggered control for multi-agent systems,” IEEE Transactions on Automatic Control, vol. 57, no. 5, pp. 1291–1297, 2012.
- [10] W. Wang, C. Wen, J. Huang, and J. Zhou, “Adaptive consensus of uncertain nonlinear systems with event triggered communication and intermittent actuator faults,” Automatica, vol. 111, p. 108667, 2020.
- [11] Y. Zhang, J. Sun, H. Liang, and H. Li, “Event-triggered adaptive tracking control for multiagent systems with unknown disturbances,” IEEE Transactions on Cybernetics, vol. 50, no. 3, pp. 890–901, 2020.
- [12] L. Cao, H. Li, G. Dong, and R. Lu, “Event-triggered control for multiagent systems with sensor faults and input saturation,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019.
- [13] Z. Ding, “Distributed adaptive consensus output regulation of network-connected heterogeneous unknown linear systems on directed graphs,” IEEE Transactions on Automatic Control, vol. 62, no. 9, pp. 4683–4690, 2016.
- [14] “Adaptive event-triggered distributed model predictive control for multi-agent systems,” Systems Control Letters, vol. 134, p. 104531, 2019.
- [15] M. Cao, F. Xiao, and L. Wang, “Event-based second-order consensus control for multi-agent systems via synchronous periodic event detection,” IEEE Transactions on Automatic Control, vol. 60, no. 9, pp. 2452–2457, 2015.
- [16] Y.-X. Li, G.-H. Yang, and S. Tong, “Fuzzy adaptive distributed event-triggered consensus control of uncertain nonlinear multiagent systems,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 49, no. 9, pp. 1777–1786, 2019.
- [17] W. Wang and Y. Li, “Observer-based event-triggered adaptive fuzzy control for leader-following consensus of nonlinear strict-feedback systems,” IEEE Transactions on Cybernetics, vol. 51, no. 4, pp. 2131–2141, 2021.
- [18] G. S. Seyboth, D. V. Dimarogonas, and K. H. Johansson, “Event-based broadcasting for multi-agent average consensus,” Automatica, vol. 49, no. 1, pp. 245–252, 2013.
- [19] W. Wang, J. Long, J. Zhou, J. Huang, and C. Wen, “Adaptive backstepping based consensus tracking of uncertain nonlinear systems with event-triggered communication,” Automatica, vol. 133, p. 109841, 2021.
- [20] J. Long, W. Wang, C. Wen, J. Huang, and J. Lü, “Output feedback based adaptive consensus tracking for uncertain heterogeneous multi-agent systems with event-triggered communication,” Automatica, vol. 136, p. 110049, 2022.
- [21] K. Kumari, B. Bandyopadhyay, J. Reger, and A. K. Behera, “Event-triggered sliding mode control for a high-order system via reduced-order model based design,” Automatica, vol. 121, p. 109163, 2020.
- [22] X. Ge and Q.-L. Han, “Distributed formation control of networked multi-agent systems using a dynamic event-triggered communication mechanism,” IEEE Transactions on Industrial Electronics, vol. 64, no. 10, pp. 8118–8127, 2017.