Distributed D-core Decomposition over Large Directed Graphs
Abstract.
Given a directed graph and integers and , a D-core is the maximal subgraph such that for every vertex of , its in-degree and out-degree are no smaller than and , respectively. For a directed graph , the problem of D-core decomposition aims to compute the non-empty D-cores for all possible values of and . In the literature, several peeling-based algorithms have been proposed to handle D-core decomposition. However, the peeling-based algorithms that work in a sequential fashion and require global graph information during processing are mainly designed for centralized settings, which cannot handle large-scale graphs efficiently in distributed settings. Motivated by this, we study the distributed D-core decomposition problem in this paper. We start by defining a concept called anchored coreness, based on which we propose a new H-index-based algorithm for distributed D-core decomposition. Furthermore, we devise a novel concept, namely skyline coreness, and show that the D-core decomposition problem is equivalent to the computation of skyline corenesses for all vertices. We design an efficient D-index to compute the skyline corenesses distributedly. We implement the proposed algorithms under both vertex-centric and block-centric distributed graph processing frameworks. Moreover, we theoretically analyze the algorithm and message complexities. Extensive experiments on large real-world graphs with billions of edges demonstrate the efficiency of the proposed algorithms in terms of both the running time and communication overhead.
PVLDB Reference Format:
PVLDB, 14(1): XXX-XXX, 2020.
doi:XX.XX/XXX.XX
††This work is licensed under the Creative Commons BY-NC-ND 4.0 International License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of this license. For any use beyond those covered by this license, obtain permission by emailing [email protected]. Copyright is held by the owner/author(s). Publication rights licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 14, No. 1 ISSN 2150-8097.
doi:XX.XX/XXX.XX
1. Introduction
Graph is a widely used data structure to depict entities and their relationships. In a directed graph, edges have directions to represent links from one vertex to another, which has many real-life applications, e.g., the following relationship in online social networks such as Twitter, the money flow in financial networks, the traffic route in road networks, and the message forwarding path in communication networks. Among many graph analysis algorithms, cohesive subgraph analysis is to discover densely connected subgraphs under a cohesive subgraph model. A well-known model used for undirected graphs is -core, which requires every vertex in the subgraph to have at least neighbors (Seidman, 1983). As a directed version of -core, -core, a.k.a. -core, is the maximal directed subgraph such that every vertex has at least in-neighbors and out-neighbors within this subgraph (Giatsidis et al., 2013). For example, in Figure 1(a), the whole directed graph is a (2, 2)-core since every vertex has an in-degree of at least 2 and an out-degree of at least 2.


As a foundation of D-core discovery, the problem of D-core decomposition aims to compute the non-empty D-cores of a directed graph for all possible values of and . D-core decomposition has a number of applications. It has been used to build coreness-based indexes for speeding up community search (Fang et al., 2018; Chen et al., 2020), to measure influence in social networks (Garcia et al., 2017), to evaluate graph collaboration features of communities (Giatsidis et al., 2013), to visualize and characterize complex networks (Montresor et al., 2012), and to discover hubs and authorities of directed networks (Soldano et al., 2017). For example, based on the D-core decomposition results, we can index a graph’s vertices by their corenesses using a table (Fang et al., 2018) or D-Forest (Chen et al., 2020); then, D-core-based community search can be accelerated by looking up the table or D-Forest directly, instead of performing the search from scratch. In the literature, peeling-based algorithms have been proposed for D-core decomposition in centralized settings (Giatsidis et al., 2013; Fang et al., 2018). They work in a sequential fashion to remove disqualified vertices one by one from a graph. That is, they first determine all possible values of (i.e., from 0 to the maximum in-degree of the graph). Next, for each value , they compute -cores for all possible values of by iteratively deleting the vertices with the smallest out-degree. Figure 1(b) shows the D-core decomposition results of for different and values.
In this paper, we study the problem of D-core decomposition in distributed settings, where the input graph is stored on a collection of machines and each machine holds only a partial subgraph of . The motivation is two-folded. First, due to the large size of graph data, D-core decomposition necessitates huge memory space, which may exceed the capacity of a single machine. For example, the existing algorithms could not work for billion-scale graphs due to excessive memory space costs (Fang et al., 2018). Second, in practical applications, many large graphs are inherently distributed over a collection of machines, making distributed processing a natural solution (Linial, 1992; Aridhi et al., 2016; Montresor et al., 2012; Mandal and Hasan, 2017).
However, the existing peeling-based algorithms are not efficient when extended to distributed settings. In particular, when computing the -cores for a given , the algorithms need to iteratively find the vertices with the smallest out-degree to delete and then update the out-degrees for the remaining vertices, until the graph becomes empty. This process (i) is not parallelizable since the update of out-degrees in each iteration depends on the vertices deletion in the previous iteration and (ii) entails expensive network communications since it needs global graph information.
To address these issues, we design new distributed D-core decomposition algorithms by exploiting the relationships between a vertex and its neighbors. First, inspired by the notion of k-list (Fang et al., 2018), we propose an anchored coreness-based algorithm. Specifically, for a vertex , if we fix the value of , we can compute the maximum value of such that is contained in the -core. We call this pair an anchored coreness of . For example, for vertex in Figure 1, when , the maximum value of is 2 since -core but -core. Hence, is an anchored coreness of . The other anchored corenesses of are , , and . Once we have computed the anchored corenesses for every vertex, we can easily derive the D-cores from these anchored corenesses. Specifically, given integers and , the -core consists of the vertices whose anchored coreness satisfies and . Thus, the problem of distributed D-core decomposition is equivalent to computing the anchored corenesses in a distributed way. To do so, we first exploit the in-degree relationship between a vertex and its in-neighbors and define an in-H-index, based on which we compute the maximum value of for each vertex. Then, we study the property of -core and define an out-H-index. On the basis of that, for each possible value of with respect to a vertex, we iteratively compute the corresponding upper bound of simultaneously. Finally, we utilize the definition of D-core to iteratively refine all the upper bounds to obtain the anchored corenesses of all vertices.
Note that the anchored coreness-based algorithm first fixes one dimension and then computes the anchored corenesses for the other dimension, which may lead to suboptimal performance. To improve performance, we further propose a novel concept, called skyline coreness, and develop a skyline coreness-based algorithm. Specifically, we say the pair is a skyline coreness of a vertex , if there is no other pair such that , , and -core. For example, in Figure 1, the skyline corenesses of are . Compared with anchored corenesses, a vertex’s skyline corenesses contain fewer pairs of . Nevertheless, based on the skyline corenesses, we can still easily find all the D-cores containing the corresponding vertex. To be specific, if is a skyline coreness of , then is also in the -cores with and . The basic idea of the skyline coreness-based algorithm is to use neighbors’ skyline corenesses to iteratively estimate the skyline corenesses of each vertex. To this end, we define a new index, called D-index, for each vertex based on the following unique property of skyline corenesses. If is one of the skyline corenesses of a vertex , we have (i) has at least in-neighbors such that each of these in-neighbors, , has a skyline coreness satisfying and ; and (ii) has at least out-neighbors such that each of these out-neighbors, , has a skyline coreness satisfying and . With this property, we design a distributed algorithm to iteratively compute the D-index for each vertex with its neighbors’ D-indexes. To deal with the combinatorial blow-ups in the computation of D-indexes, we further develop three optimization strategies to improve efficiency.
We implement our algorithms under two well-known distributed graph processing frameworks, i.e., vertex-centric (Malewicz et al., 2010; gir, 2012; Salihoglu and Widom, 2013; Low et al., 2012) and block-centric (Tian et al., 2013; Yan et al., 2014; Fan et al., 2017). Empirical results on small graphs demonstrate that our algorithms run faster than the peeling-based algorithm by up to 3 orders of magnitude. For larger graphs with more than 50 million edges, the peeling-based algorithm cannot finish within 5 days, while our algorithms can finish within 1 hour for most datasets. Moreover, our proposed algorithms require less than 100 rounds to converge for most datasets, and more than vertices can converge within 10 rounds.
This paper’s main contributions are summarized as follows:
-
•
For the first time in the literature, we study the problem of distributed D-core decomposition over large directed graphs.
-
•
We develop an anchored coreness-based distributed algorithm using well-defined in-H-index and out-H-index. To efficiently compute the anchored corenesses, we propose tight upper bounds that can be iteratively refined to exact anchored corenesses with reduced network communications.
-
•
We further propose a novel concept of skyline coreness and show that the problem is equivalent to the computation of skyline corenesses for all vertices. A new two-dimensional D-index that unifies the in- and out-neighbor relationships, together with three optimization strategies, is designed to compute the skyline corenesses distributedly.
-
•
Both theoretical analysis and empirical evaluation validate the efficiency of our algorithms for distributed D-core decomposition.
The rest of the paper is organized as follows. Section 2 reviews related work. Section 3 formally defines the problem. Sections 4 and 5 propose two distributed algorithms for computing anchored coreness and skyline coreness, respectively. Experimental results are reported in Section 6. Finally, Section 7 concludes the paper.
2. Related Work
In this section, we review the related work in two aspects, i.e., core decomposition and distributed graph computation.
Core Decomposition. As a well-known dense subgraph model, a -core is the maximal subgraph of an undirected graph such that every vertex has at least neighbors within this subgraph (Seidman, 1983). The core decomposition task aims at finding the -cores for all possible values of in a graph. Many efficient algorithms have been proposed to handle core decomposition over an undirected graph, such as peeling-based algorithms (Batagelj and Zaversnik, 2003; Cheng et al., 2011; Khaouid et al., 2015), disk-based algorithm (Cheng et al., 2011; Khaouid et al., 2015), semi-external algorithm (Wen et al., 2016), streaming algorithms (Saríyüce et al., 2013; Sarıyüce et al., 2016), parallel algorithms (Dasari et al., 2014; Esfandiari et al., 2018), and distributed algorithms (Aridhi et al., 2016; Montresor et al., 2012; Mandal and Hasan, 2017). It is worth mentioning that the distributed algorithms for -core decomposition (Aridhi et al., 2016; Montresor et al., 2012; Mandal and Hasan, 2017) cannot be used for distributed D-core decomposition. Specifically, the distributed -core decomposition algorithms use the neighbors’ corenesses to estimate a vertex’s coreness, where all neighbors are of the same type. For D-core, a vertex’s neighbors include in-neighbors and out-neighbors, which affect each other and should be considered simultaneously. If we consider only one type of neighbors, we cannot get the correct answer. Inspired by the H-index-based computation for core decomposition (Lü et al., 2016) and nucleus decomposition (Sariyüce et al., 2018), we apply a similar idea in the design of distributed algorithms. Nevertheless, our technical novelty lies in the non-trivial extension of H-index from one-dimensional undirected coreness to two-dimensional anchored/skyline coreness, which needs to consider the computations of in-degrees and out-degrees simultaneously in a unified way.
In addition, core decomposition has been studied for different types of networks, such as weighted graphs (Eidsaa and Almaas, 2013; Zhou et al., 2021), uncertain graphs (Bonchi et al., 2014; Peng et al., 2018), bipartite graphs (Liu et al., 2019), temporal graphs (Galimberti et al., 2021; Wu et al., 2015), and heterogeneous information networks (Fang et al., 2020). Recently, a new problem of distance-generalized core decomposition has been studied by considering vertices’ -hop connectivity (Bonchi et al., 2019; Liu et al., 2021). Note that a directed graph can be viewed as a bipartite graph. After transforming a directed graph to a bipartite graph, the -core in the directed graph has a corresponding -core in the bipartite graph (Liu et al., 2019), but not vice versa. Therefore, the problems of -core decomposition and -core decomposition are not equivalent, and -core decomposition algorithms cannot be used in our work.
Distributed Graph Computation. In the literature, there exist various distributed graph computing models and systems to support big graph analytics. Among them, the vertex-centric framework (Malewicz et al., 2010; Low et al., 2012; McCune et al., 2015) and the block-centric framework (Tian et al., 2013; Yan et al., 2014) are two most popular frameworks.
The vertex-centric framework assumes that each vertex is associated with one computing node and communication occurs through edges. The workflow of the vertex-centric framework consists of a set of synchronous supersteps. Within each superstep, the vertices execute a user-defined function asynchronously after receiving messages from their neighbors. If a vertex does not receive any message, it will be marked as inactive. The framework stops once all vertices become inactive. Typical vertex-centric systems include Pregel (Malewicz et al., 2010), Giraph (gir, 2012), GPS (Salihoglu and Widom, 2013), and GraphLab (Low et al., 2012). For the block-centric framework, one computing node stores the vertices within a block together and communication occurs between blocks after the computation within a block reaches convergence. Compared with the vertex-centric framework, the block-centric framework can reduce the network traffic and better balance the workload among nodes. Distributed graph processing systems such as Giraph++ (Tian et al., 2013), Blogel (Yan et al., 2014), and GRAPE (Fan et al., 2017) belong to the block-centric framework.
Note that in this paper we mainly focus on algorithm designs for distributed D-core decomposition. To demonstrate the flexibility of our proposed algorithms, we implement them for performance evaluation in both vertex-centric and block-centric frameworks.
3. Problem Formulation
In this paper, we consider a directed, unweighted simple graph , where and are the set of vertices and edges, respectively. Each edge has a direction. For an edge , we say is an in-neighbor of and is an out-neighbor of . Correspondingly, and are respectively denoted as the in-neighbor set and out-neighbor set of a vertex in . We define three kinds of degrees for a vertex as follows: (1) the in-degree is the number of ’s in-neighbors in , i.e., ; (2) the out-degree is the number of ’s out-neighbors in , i.e., ; (3) the degree is the sum of its in-degree and out-degree, i.e., . Based on the in-degree and out-degree, we give a definition of D-core as follows.
Definition 3.0.
D-core (Giatsidis et al., 2013). Given a directed graph and two integers and , a D-core of , also denoted as -core, is the maximal subgraph such that , and .
According to Definition 3.1, a D-core should satisfy both the degree constraints and the size constraint. The degree constraints ensure the cohesiveness of D-core in terms of in-degree and out-degree. The size constraint guarantees the uniqueness of the D-core, i.e., for a specific pair of , there exists at most one D-core in . Moreover, D-core has a partial nesting property as follows.
Property 3.1.
Partial Nesting. Given two D-cores, -core and -core , is nested in (i.e., ) if and . Note that if and , or and , and may be not nested in each other.

Example 3.0.
In Figure 2, the directed subgraph induced by the vertices , , , and is a -core since , . Moreover, -core, -core. On the other hand, and , due to the non-overlapping vertices , , and .
In this paper, we study the problem of D-core decomposition to find all D-cores of a directed graph in distributed settings. In-memory algorithms of D-core decomposition have been studied in (Giatsidis et al., 2013; Fang et al., 2018), assuming that the entire graph and associated structures can fit into the memory of a single machine. To our best knowledge, the problem of distributed D-core decomposition, considering a large graph distributed over a collection of machines, has not been investigated in the literature. We formulate a new problem of distributed D-core decomposition as follows.
Problem 1.
(Distributed D-core Decomposition). Given a directed graph that is distributed in a collection of machines a machine holds a partial subgraph , where and , the problem of distributed D-core decomposition is to find all D-cores of using machines, i.e., identifying the -cores with all possible pairs.
Consider applying D-core decomposition on in Figure 2. We can obtain a total of 9 different D-cores: -core -core ; -core -core ; -core the subgraph of induced by the vertices in ; -core -core -core ; -core .
In the following two sections, we propose two new distributed algorithms for D-core decomposition. Without loss of generality, we mainly present the algorithms under the vertex-centric framework. At the end of Sections 4 and 5, we discuss how to extend our proposed algorithms to the block-centric framework.
4. Distributed Anchored Coreness-Based Algorithm
In this section, we first give a definition of anchored coreness, which is useful for D-core decomposition. Then, we present a vertex-centric distributed algorithm for anchored coreness computation. Finally, we analyze the correctness and complexity of our proposed algorithm, and discuss its block-centric extension.
4.1. Anchored Coreness
Recall that, in the undirected -core model (Seidman, 1983), every vertex has a unique value called coreness, i.e., the maximum value such that is contained in a non-empty -core. Similarly, we give a definition of anchored coreness for directed graphs as follows.
Definition 4.0.
(Anchored Coreness). Given a directed graph and an integer , the anchored coreness of a vertex is a pair , where . The entire anchored corenesses of the vertex are defined as , where .
Different from the undirected coreness, the anchored coreness is a two-dimensional feature of in-degree and out-degree in directed graphs. For example, consider the graph in Figure 1 and , the anchored coreness of vertex is , as . Correspondingly, . The anchored corenesses can facilitate the distributed D-core decomposition as follows. According to Property 3.1, for a vertex with the anchored coreness of , belongs to any -core with . Hence, as long as we compute the anchored corenesses of for each possible , we can get all D-cores containing . As a result, for a given directed graph , the problem of D-core decomposition is equivalent to computing the entire anchored corenesses for every vertex , i.e., .
4.2. Distributed Anchored Coreness Computing
In this section, we present a distributed algorithm for computing the entire anchored corenesses for every vertex in .
Overview. To handle the anchored coreness computation simultaneously in a distributed setting, we propose a distributed vertex-centric algorithm to compute all feasible anchored corenesses ’s for a vertex . The general idea is to first identify the feasible range of by exploring -cores and then refine an estimated upper bound of to be exact for all possible values of . The framework is outlined in Algorithm 1, which gives an overview of the anchored coreness updating procedure in three phases: 1) deriving ; 2) computing the upper bound of for each ; and 3) refining the upper bound to the exact anchored coreness . Note that in the second and third phases, the upper bound of can be computed and refined in batch, instead of one by one sequentially, for different values of .
| Vertices | |||||||||
| Phase I | 3 | 2 | 2 | 2 | 2 | 3 | 1 | 2 | |
| 2 | 2 | 2 | 2 | 2 | 2 | 1 | 2 | ||
| 2 | 2 | 2 | 2 | 2 | 2 | 1 | 2 | ||
| Phase II | , | 3; 3; 3 | 0; 0; 0 | 0; 0; 0 | 5; 5; 5 | 3; 3; 3 | 2; 2; 2 | 2; 2 | 2; 2; 2 |
| , | 2; 2; 2 | 0; 0; 0 | 0; 0; 0 | 2; 2; 2 | 2; 2; 2 | 2; 2; 2 | 2; 2 | 1; 1; 0 | |
| , | 2; 2; 2 | 0; 0; 0 | 0; 0; 0 | 2; 2; 2 | 2; 2; 2 | 2; 2; 2 | 2; 2 | 1; 1; 0 | |
| Phase III | , | 2; 2; 2 | 0; 0; 0 | 0; 0; 0 | 2; 2; 2 | 2; 2; 2 | 2; 2; 2 | 2; 2 | 1; 1; 0 |
| , | 2; 2; 2 | 0; 0; 0 | 0; 0; 0 | 2; 2; 2 | 2; 2; 2 | 2; 2; 2 | 2; 1 | 1; 1; 0 | |
| , | 2; 2; 2 | 0; 0; 0 | 0; 0; 0 | 2; 2; 2 | 2; 2; 2 | 2; 2; 2 | 2; 1 | 1; 1; 0 | |
Phase I: Computing the in-degree limit . To compute , first, we introduce a concept of H-index (Hirsch, 2005). Specifically, given a collection of integers , the H-index of is a maximum integer such that has at least integer elements whose values are no less than , denoted as . For example, given , H-index , as has at least 3 elements whose values are no less than 3. Based on H-index, we give a new definition of -order in-H-index for directed graph.
Definition 4.0.
(-order in-H-index). Given a vertex in , the -order in-H-index of , denoted by , is defined as
| (1) |
where the integer set .
Theorem 4.3 (Convergence).
| (2) |
Proof.
Due to space limitation, we give a proof sketch here. The detailed proof can be found in (Liao et al., 2022). First, we prove that is non-increasing with the increase of order . Thus, finally converges to an integer when is big enough. Then, we prove , where is a subgraph induced by the vertices with . Also, we know by definition. Hence, . ∎
According to Theorem 2, finally converges to , based on which we present a distributed algorithm as shown in Algorithm 2 to compute . Algorithm 2 has an initialization step (lines 1-4), and two update procedures after receiving one message (lines 5-7) and all messages (lines 8-11). It first uses 0 to initialize the set , which keeps the latest -order in-H-indexes of ’s in-neighbors (lines 1-2). Then, the algorithm sets the -order in-H-index of to its in-degree (line 3) and sends the message ¡, ¿ to all its out-neighbors (line 4). When receives a message ¡, ¿ from its in-neighbor , the algorithm updates the -order in-H-index of (line 5). If , it means the -order in-H-index of may decrease. Thus, flag is set to True to indicate the re-computation of ’s -order in-H-index (line 7). After receiving all massages, if flag is True, Algorithm 2 updates ’s -order in-H-index and inform all its out-neighbors if decreases (lines 9-11). Algorithm 2 completes and returns as when there is no vertex broadcasting messages (line 12).
Example 4.0.
We use the directed graph in Figure 2 to illustrate Algorithm 2, whose calculation process is shown in Table 1. We take vertex as an example. First, ’s 0-order in-H-index is initialized with its in-degree, i.e., . Then, Algorithm 2 iteratively computes . After one iteration, the 1-order in-H-index of has converged to = = 2. Thus, .
Phase II: Computing the upper bounds of . In a distributed setting, the computation of faces technical challenges. It is difficult to compute by making use of only the “intermediate” neighborhood information. Because some vertices may become disqualified and thus be removed from the candidate set of -core during the iteration process. Even worse, verifying the candidacy of requires a large number of message exchanges between vertices. To address these issues, we design a novel upper bound for , denoted by , which can be iteratively computed with “intermediate” corenesses to reduce communication costs. To start with, we give a new definition of -order out-H-index, similar to Definition 4.2.
Definition 4.0.
(-order out-H-index). Given a vertex in , the -order out-H-index of , denoted as , is defined as
| (3) |
where .
Based on , we have the following theorem.
Theorem 4.6.
Given a vertex in and an integer , let be the subgraph of induced by the vertices in . Then, it holds that
| (4) |
Proof.
Similar to Theorem 2, we can prove such that -core of but -core of . Then, we have the following relationship for the D-cores of : -core -core -core. According to the partial nesting property of D-core, holds. ∎
Theorem 4 indicates that can be served as an upper bound of , i.e., . Thus, we can compute by iteratively calculating the -order out-H-index of in the directed subgraph . Moreover, to efficiently compute for all values in parallel, our distributed algorithm should send updating messages in batch and compute simultaneously.
Based on the above discussion, we propose a distributed algorithm for computing the upper bounds . Algorithm 3 presents the detailed procedure. First, it initializes the -order out-H-index of for each possible value of and sends them to ’s in-neighbors (lines 1-5). When receives a message from its out-neighbor , updates the -order out-H-index of for subsequent calculation (lines 6-10). After receiving all messages, updates its own -order out-H-index for each possible value of (lines 11-14). If any -order out-H-indexes of decreases, informs all its in-neighbors (lines 15-16). Finally, when there is no vertex broadcasting messages, we get the upper bound for each (line 17).
Example 4.0.
Phase III: Refining to . Finally, we present the third phase of refining the upper bound to get the exact anchored coreness . To this end, we first present the following theorem.
Theorem 4.8.
Given a vertex in and an integer , if is an anchored coreness of , it should satisfy two constraints on in-neighbors and out-neighbors: (i) has at least in-neighbors such that ; and (ii) has at least out-neighbors such that .
Theorem 4.8 obviously holds, according to Def. 3.1 of D-core and the upper bound . Based on Theorem 4.8, we can refine decrementally by checking the upper bounds ’s of ’s in- and out-neighbors. If satisfies the above two constraints in Theorem 4.8, keeps unchanged; otherwise, decreases by 1 as the current is not an anchored coreness of . The above process needs to repeat for all vertices and all possible values of , until none of changes. Finally, we obtain all anchored corenesses .
Algorithm 4 outlines the procedure of the distributed refinement phase. First, the algorithm initializes some auxiliary structures and broadcast ’s upper bound for each possible (lines 1-3). When it receives a message from ’s neighbor , the algorithm updates the upper bound set for (lines 4-7). After receiving all messages, the algorithm refines for each based on Theorem 4.8 (lines 8-13). If there exists such a whose is decreased, the algorithm broadcasts the new upper bound set to ’s neighbors (lines 14-15). As soon as there are no vertex broadcasting messages, Algorithm 4 terminates and we get all anchored corenesses of (lines 16-17).
Example 4.0.
4.3. Algorithm Analysis and Extension
Complexity analysis. We first analyze the time, space, message complexities of Algorithm 1. Let the edge size , the maximum in-degree , the maximum out-degree , and the maximum degree . In addition, let , , and be the number of convergence rounds required by the three phases in Algorithm 1, respectively. Let be the total number of converge rounds in Algorithm 1 as and . We have the following theorems (their detailed proofs can be found in (Liao et al., 2022)):
Theorem 4.10.
(Time and Space Complexities) Algorithm 1 takes time and space. The total time and space complexities for computing all vertices’ corenesses are and , respectively.
Theorem 4.11.
(Message Complexity) The message complexity (i.e., the total number of times that a vertex send messages) of Algorithm 1 is . The total message complexity for computing all vertices’ corenesses is .
Block-centric extension of Algorithm 1. We further discuss to extend the vertex-centric D-core decomposition in Algorithm 1 to the block-centric framework. The extension can be easily achieved by changing the update operation after receiving all messages. That is, instead of having Algorithms 2, 3 and 4 perform the update operation only once after receiving all messages, in the block-centric framework, the algorithms should update the H-indexes multiple times until the local block converges. For example, Algorithm 2 computes the -order in-H-index of only once in each round (lines 10-13). In contrast, the block-centric version should compute ’s -order in-H-index iteratively with ’s in-neighbors, that are located in the same block as , before broadcasting messages to other blocks to enter the next round. Note that in the worst case, for block-centric algorithms, every vertex converges within the block after computing the in-H-index/out-H-index only once, which is the same as vertex-centric algorithms. Therefore, the worse-case cost of block-centric algorithms is the same as that of vertex-centric algorithms.
5. Distributed Skyline Coreness-Based Algorithm
In this section, we propose a novel concept of skyline coreness, which is more elegant than the anchored coreness. Then, we give a new definition of -order D-index for computing skyline corenesses. Based on the D-index, we propose a distributed algorithm for skyline coreness computation to accomplish D-core decomposition.
5.1. Skyline Coreness
Motivation. The motivation for proposing another skyline coreness lies in an important observation that the anchored corenesses ’s may have redundancy. For example, in Figure 1, the vertex has four anchored corenesses, i.e., (0, 2), (1, 2), (2, 2), (3, 1). According to D-core’s partial nesting property, if -core, must also belong to -core and -core. Thus, it is sufficient and more efficient to keep the coreness of as (2, 2), (3, 1), which uses (2, 2)-core to represent other two D-cores (0, 2)-core and (1, 2)-core. This elegant representation is termed as skyline coreness, which can facilitate space saving and fast computation of D-core decomposition. Based on the above observation, we formally define the dominance operation and skyline coreness as follows.
Definition 5.0.
(Dominance Operations). Given two coreness pairs and , we define two operations ‘’ and ‘’ to compare them: (i) indicates that dominates , i.e., either , hold or , hold; and (ii) represents that , hold.
Definition 5.0.
(Skyline Coreness). Given a vertex in a directed graph and a coreness pair , we say that is a skyline coreness of iff it satisfies that (i) -core; and (ii) there exist no other pair such that and -core. We use to denote the entire skyline corenesses of the vertex , i.e., is a skyline coreness of .
In other words, the skyline coreness of a vertex is a non-dominated pair whose corresponding -core contains . For instance, vertex has the skyline corenesses in Figure 1, reflecting that no other coreness can dominate any skyline coreness in . According to D-core’s partial nesting property, for a skyline coreness of , is contained in the -core with . Therefore, if we compute all skyline corenesses for a vertex , we can find all D-cores the vertex belonging to. As a result, the problem of D-core decomposition is equivalent to computing the entire skyline corenesses for every vertex in , i.e., .
Structural properties of skyline coreness. We analyze the structural properties of skyline coreness.
Property 5.1.
Let be a skyline coreness of , the following properties hold:
-
(I)
There exist in-neighbors such that , and also out-neighbors such that .
-
(II)
Two cases cannot hold in either way: there exist in-neighbors such that , or out-neighbors such that .
-
(III)
Two cases cannot hold in either way: there exist in-neighbors such that , or out-neighbors such that .
Proof.
First, we prove Property 5.1(I). Let be the -core of , we have and . For , may be in the -core with and . Therefore, (I) of Property 5.1 holds.
Next, we prove Property 5.1(II). Assume that has in-neighbors and out-neighbors satisfying the constraints of (II). Then, and must be in the -core. Moreover, -core is also a -core. Hence, rather than is a skyline coreness of , which contradicts to the condition of Property 5.1. Therefore, the assumption does not hold.
For example, is a skyline coreness of in Figure 1. The in-neighbors of are , , , and , whose skyline corenesses are , , , and , respectively. These four vertices all have skyline corenesses that dominate or are identical to ’s skyline coreness . But only two vertices and have skyline corenesses that dominate . Hence, is not a skyline coreness of . Property 5.1 reveals the relationships among vertices’ skyline corenesses, based on which we propose an algorithm for skyline coreness computation in the next subsection.
5.2. Distributed Skyline Corenesses Computing
We begin with a novel concept of D-index.
Definition 5.0.
(D-index). Given two sets of pairs of integers , , the D-index of and is denoted by , where each element satisfies: (i) there exist at least pairs such that for ; (ii) there exist at least pairs such that for ; (iii) there does not exist another satisfying the above conditions (1) and (2), and .
The idea of D-index is very similar to H-index. Actually, the D-index is an extension of H-index to handle two-dimensional integer pairs. For , it finds a series of skyline pairs such that each has at least dominated pairs in and at least dominated pairs in , using a joint indexing way. For example, let and , then . Note that may hold for the D-index, as in this example. Next, we introduce another concept of -order D-index for distributed D-core decomposition.
Definition 5.0.
(-order D-index). Given a vertex in , the -order D-index of , denoted by , is defined as
| (5) |
Here, and . Note that is the largest non-dominated D-index such that it dominates or at least is identical to , for each when and each when .
The -order D-index may contain more than one pair , i.e., . Note that and consist of one pair for each in-neighbor and each out-neighbor , respectively. Therefore, there exist multiple combinations of and . Moreover, should consider all combinations of and , and finally select the “best” choice as the largest non-dominated set of D-index .
For two pair sets , , we say if and only if , such that . Then, we have the following theorem of -order D-index convergence.
Theorem 5.5 (-order D-index Convergence).
For a vertex in , it holds that
| (6) |
Proof.
The proof can be similarly done as Theorem 2. ∎
By Theorem 6, we can compute vertices’ skyline corenesses via iteratively computing their -order D-indexes until convergence.
5.3. Algorithms and Optimizations
A naive implementation of the distributed algorithm to compute may suffer from serious performance problems, due to the combinatorial blow-ups in a large number of choices of and . Thus, we first tackle three critical issues for fast distributed computation of -order D-index.
Optimization-1: Fast computation of D-index . The first issue is, given and , how to compute D-index . A straightforward way is to list all candidate pairs and return the pairs satisfying Def. 5.3. According to conditions (1)&(2) in Def. 5.3, if belongs to D-index, there exists at least pairs of satisfying the dominance relationship. Therefore, . Similarly, . Thus, there are a total of candidate pairs to be checked, which is costly for large and . In addition, the basic operation of D-index computation is frequently invoked in the process of computing . Hence, it is necessary to develop faster algorithms. To this end, we try to reduce the pairs for examination as many as possible through the following two optimizations.
-
•
Reducing the ranges of and . For conditions (1)&(2) in Def. 5.3, if belongs to , there exist at least pairs in such that . In other words, at least pairs in have . Thus, the maximum is denoted by , where . Similarly, we can also obtain the maximum , denoted by , as , where . Since and , the total number of candidate pairs decreases.
-
•
Pruning disqualified candidate pairs. Let . According to condition (3) in Def. 5.3, if with , must satisfy . Otherwise, and . This rule can be used to prune disqualified pairs based on the found skyline corenesses.
Optimization-2: Fast computation of n-order D-index . The second issue is the computation of . By Def. 5.4, both and may have multiple instances. Hence, a straightforward way is to compute the D-index for every instance and finally integrate them together. In total, we need to compute the D-index times, which is very inefficient. Actually, several redundant computations occur due to many independent instances in the D-index computation. For example, in one instance, we have verified that belongs to the -order D-index. Then, there is no need to verify in other instances. This motivates us to devise a more efficient method to compute , which requires D-index computation only once. Specifically, we first compute and . Then, we enumerate candidate pairs for dominance checking. Here, we highlight two differences from the original D-index computation method.
-
•
The difference of and computations. For and in D-index computation, (resp. ) is formed by just adding (resp. ) from each pair in . For -order D-index computation, the vertex’s -order D-index may have more than one pairs. We should select the maximum and among these pairs. Specifically, for ’s -order D-index computation, to compute , . In the same way, .
-
•
The difference of dominance checking. For a candidate pair , the D-index computation should find the pairs in and that dominate or are identical to . To compute , we should find all ’s neighbors whose -order D-index has a pair dominating or identical to . If has multiple pairs, we need to examine the dominance relationship for each of these pairs with . Once one pair dominates or is identical to , such is identified.
| Vertices | ||||||||
|---|---|---|---|---|---|---|---|---|
Optimization-3: Tight initialization. Finally, we present an optimization for computation using a tight initialization. In Def. 5.4, the -order D-index is initialized with the vertex’s in-degree and out-degree. The optimization idea is that if we tightly initialize the vertex’s -order D-index with smaller values (denoted by ), the -order D-index can converge faster to the exact skyline coreness. Here, we highlight two principles to find such : (i) and , otherwise the cannot converge to ; (ii) should be easy to compute in distributed settings. As a result, we present the following theorem.
Theorem 5.6.
For any vertex in , it holds that and , where .
Theorem 5.6 offers two tight upper bounds for and , i.e., and , respectively. In addition, according to Theorems 2 and 4, and can be computed by iteratively computing ’s -order in-H-index and out-H-index, respectively. Therefore, we initialize .
Algorithms. Based on the above theoretical analytics and optimizations, we present the distributed skyline corenesses computation algorithm in Algorithm 5. At the initialization phase, the algorithm computes and using Algorithm 2 and uses them to initialize the 0-order D-index of , which is broadcast to all neighbors of (lines 1-3). When receives a message from its neighbor , Algorithm 5 updates the -order D-index of that is stored in ’s node, and finds the maximum values in each pair of and (lines 4-8). After receives all messages, Algorithm 5 computes the -order D-index for , which is described in Algorithm 6. Then, it broadcasts to all neighbors of if the -order D-index changes (lines 9-13). When there is no vertex broadcasting messages, Algorithm 5 returns the latest -order D-index as skyline corenesses (line 14).
Next, we present the procedure of Algorithm 6 for -order D-index computation. It first computes and as shown in Optimization-1 and Optimization-2 (lines 2-3), which help to determine the range of candidate pairs. Then, the algorithm enumerates all candidate pairs and examines whether belongs to the -order D-index of (lines 6-11). Note that keeps the minimal value of for the remaining candidate pairs, which is used to prune disqualified pairs.
Example 5.0.
We use the graph in Figure 2 to illustrate Algorithm 5. Table 2 reports the process of computing skyline corenesses. Take vertex as an example. First, the 0-order D-index of is initialized with , i.e., . Then, we iteratively compute the -order D-index for . We can observe that after one iteration only, the -order D-index of has converged as . Thus, the entire skyline corenesses of are .
5.4. Algorithm Analysis and Extension
Complexity analysis. Let be the number of convergence rounds taken by Algorithm 5. In practice, our algorithms achieve on real datasets. We show the time, space, and message complexities of Algorithm 5 below.
Theorem 5.8.
(Time and Space Complexities) Algorithm 5 takes time and space. The total time and space complexities for computing all vertices’ corenesses are and , respectively.
Theorem 5.9.
(Message Complexity) The message complexity of Algorithm 5 is . The total message complexity for computing all vertices’ corenesses is .
6. Performance Evaluation
In this section, we empirically evaluate our proposed algorithms. We conduct our experiments on a collection of Amazon EC2 r5.2x large instances, each powered by 8 vCPUs and 64GB memory. The network bandwidth is up to 10G Gb/s. All experiments are implemented in C++ on the Ubuntu 18.04 operating system.
Datasets. We use 11 real-world graphs in our experiments. Table 3 shows the statistics of these graphs. Specifically, Wiki-vote111http://snap.stanford.edu/data/index.html is a voting graph; Email-EuAll1 is a communication graph; Amazon1 is a product co-purchasing graph; Hollywood2 is an actors collaboration graph; Pokec1, Live Journal1, and Slashdot1 are social graphs; Citation1 is a citation graph; UK-2002222http://law.di.unimi.it/datasets.php, IT-20042, and UK-20052 are web graphs.
| Dataset | Abbr. | |||||
|---|---|---|---|---|---|---|
| Wiki-vote | WV | 7.1K | 103.6K | 14.57 | 19 | 15 |
| Email-EuAll | EE | 265.2K | 420K | 1.58 | 28 | 28 |
| Slashdot | SL | 82.1K | 948.4K | 11.54 | 54 | 9 |
| Amazon | AM | 400.7K | 3.2M | 7.99 | 10 | 10 |
| Citation | CT | 3.7M | 16.5M | 4.37 | 1 | 1 |
| Pokec | PO | 1.6M | 30.6M | 18.75 | 32 | 31 |
| Live Journal | LJ | 4.8M | 69.0M | 14.23 | 253 | 254 |
| Hollywood | HW | 2.1M | 228.9M | 105.00 | 1,297 | 99 |
| UK-2002 | UK2 | 18.5M | 298.1M | 16.09 | 942 | 99 |
| UK-2005 | UK5 | 39.4M | 936.3M | 23.73 | 584 | 99 |
| IT-2004 | IT | 41.2M | 1.1B | 27.87 | 3,198 | 990 |
Algorithms. We compare five algorithms in our experiments.
-
•
AC-V and AC-B: The distributed anchored coreness-based D-core decomposition algorithms implemented in the vertex-centric and block-centric frameworks, respectively.
-
•
SC-V and SC-B: The distributed skyline coreness-based D-core decomposition algorithms implemented in the vertex-centric and block-centric frameworks, respectively.
-
•
Peeling: The distributed version of the peeling algorithm for D-core decomposition (Fang et al., 2018), in which one machine is assigned as the coordinator to collect global graph information and dispatch decomposition tasks.
We employ GRAPE (Fan et al., 2017) as the block-centric framework and use the hash partitioner for graph partitioning by default. For the sake of fairness, we also employ GRAPE to simulate the vertex-centric framework. In specific, at each round, all vertices within a block execute computations only once and when all vertices complete the computation, the messages will be broadcast to their neighbors.
Parameters and Metrics. The parameters tested in experiments include machines and graph size, whose default settings are 8 and , respectively. The performance metrics evaluated include iterations required for convergence, convergence rate (i.e., the percentage of vertices who have computed the coreness), running time (in seconds), and communication overhead (i.e., the total messages sent by all vertices).
6.1. Convergence Evaluation
The first set of experiments evaluates the convergence of our proposed algorithms.
| Algorithms | Datasets | |||||
| WV | EE | SL | AM | CT | ||
| Upper Bound | 1,167 | 7,636 | 5,064 | 2,757 | 793 | |
| AC-V | Phase I | 19 | 17 | 40 | 16 | 32 |
| Phase II | 32 | 19 | 53 | 64 | 32 | |
| Phase III | 33 | 22 | 61 | 61 | 2 | |
| Total | 84 | 58 | 154 | 141 | 66 | |
| AC-B | Phase I | 14 | 14 | 35 | 13 | 28 |
| Phase II | 15 | 7 | 43 | 30 | 28 | |
| Phase III | 16 | 21 | 45 | 25 | 2 | |
| Total | 45 | 42 | 123 | 68 | 58 | |
| SC-V | 33 | 19 | 61 | 65 | 2 | |
| SC-B | 17 | 6 | 46 | 25 | 2 | |



Exp-1: Evaluation on the number of iterations. We start by evaluating iterations required for our algorithms to converge. Note that an iteration here refers to a cycle of the algorithm receiving messages, performing computations, and broadcasting messages. Table 4 reports the results on datasets WV, EE, SL, AM, and CT. We make several observations. First, for every graph, all of our proposed algorithms have much less iterations than the upper bound (i.e., the maximum degree of the graph), which demonstrates the efficiency of our algorithms. Second, the iterations of SC-V and SC-B are less than those of AC-V and AC-B. This is because the computation of anchored corenesses is more cumbersome than that of skyline corenesses. Hence, both AC-V and AC-B take more iterations. Third, for the same type of algorithms, i.e., AC or SC, the algorithm implemented in the block-centric framework takes less iterations than that in the vertex-centric framework. The reason is that the block-centric framework allows algorithms to use vertices located in the same block to converge locally within a single round, which leads to faster convergence.
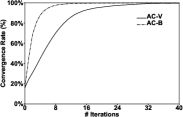
Exp-2: Evaluation on the convergence rate. Since different vertices require different numbers of iterations to converge, in this experiment, we evaluate the algorithms’ convergence rates. Figure 3 shows the results on Amazon. As expected, the algorithms implemented in the block-centric framework converge faster. For example, in Figure 3(d), after 8 iterations, the convergence rates of SC-V and SC-B reach and , respectively. Moreover, most vertices can converge within just a few iterations. Specifically, for SC-B, more than vertices converge within 5 iterations. In addition, SC algorithms have faster convergence rates than AC algorithms. For example, AC-B takes 68 iterations to reach convergence while SC-B takes 25 iterations.
6.2. Efficiency Evaluation
Next, we evaluate the efficiency of our proposed algorithms against the state-of-the-art peeling algorithm, denoted as Peeling. Note that if an algorithm cannot finish within 5 days, we denote it by ’INF’.
Exp-3: Our algorithms vs. Peeling. We first compare the performance of our proposed algorithms with Peeling under the default experiment settings. Figures 4(a) and 4(b) report the results in terms of the running time and communication overhead, respectively. First, we can see that Peeling cannot finish within 5 days on the large-scale graphs with more than 50 million edges, including LJ, HW, UK2 UK5, and IT, while our algorithms can finish within 1 hour for most of these datasets and no more than 10 hours on the largest billion-scale graph for our fastest algorithm. Moreover, for the datasets where Peeling can finish, our algorithms outperform Peeling by up to 3 orders of magnitude. This well demonstrates the efficiency of our proposed algorithms. Second, SC-V and SC-B perform better than AC-V and AC-B in terms of both the running time and communication overhead. For example, on the biggest graph IT with over a billion edges, the improvement is nearly 1 order of magnitude. This is because SC-V and SC-B compute less corenesses than AC-V and AC-B. Third, AC-V (resp. SC-V) is better than AV-B (resp. SC-B) in terms of the running time while it is opposite in terms of the communication overhead. This is due to the effect of straggler (Ananthanarayanan et al., 2010). Specifically, for the block-centric framework, in each iteration, the algorithms use block information to converge locally (i.e., within each block); they cannot start the next iteration until all blocks have converged. There are machines where some blocks may converge very slowly, which deteriorates the overall performance of the block-centric algorithms.


Exp-4: Effect of the number of machines. Next, we vary the number of machines from 2 to 16 and test its effect on performance. Figure 5 reports the results for datasets UK2 and HW. As shown in Figures 5(a) and 5(b), all of our algorithms take less running time when the number of machines increases. This is because the more the machines, the stronger the computing power our algorithms can take advantage of, thanks to their distributed designs. In addition, Figures 5(c) and 5(d) show that the communication overheads of all algorithms do not change with the number of machines. This is because the communication overhead is determined by the convergence rate of the algorithms, which is not influenced by the number of machines.




Exp-5: Effect of dataset cardinality. We evaluate the effect of cardinality for our proposed algorithms on datasets PO and UK5. For this purpose, we extract a set of subgraphs from the original graphs by randomly selecting different fractions of vertices, which varies from to . As shown in Figure 6, both the running time and communication overhead increase with the dataset cardinality. This is expected because the larger the dataset, the more the corenesses of the vertices to compute, resulting in to poorer performance.
Exp-6: Effect of partition strategies. We evaluate the effect of different partition strategies in block-centric algorithms, i.e., AC-B and SC-B. Specifically, we compare four partition strategies, including SEG (Fan et al., 2017), HASH (Fan et al., 2017), FENNEL (Tsourakakis et al., 2014), and METIS (Karypis and Kumar, 1998).
-
•
SEG is a built-in partitioner of GRAPE. Let be the maximum cardinality of partitioned subgraphs. For a vertex with its ID , is allocated to the -th subgraph, where .
-
•
HASH is also a built-in partitioner of GRAPE. Let be the number of partitioned subgraphs. For a vertex with its ID , is allocated to the -th subgraph, where .
-
•
FENNEL subsumes two popular heuristics to partition the graph: the folklore heuristic that places a vertex to the subgraph with the fewest non-neighbors, and the degree-based heuristic that uses different heuristics to place a vertex based on its degree.
-
•
METIS is a popular edge-cut partitioner that partitions the graph into subgraphs with minimum crossing edges.
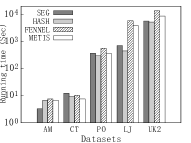
Figure 7 shows the results. We can observe that HASH has the best performance in terms of running time on most datasets, but it has the worse performance in terms of communication cost. This is because HASH has more balanced partitions (i.e., each partition has almost an equal number of vertices) while METIS and FENNEL have higher locality, which leads to more running time, due to the effect of straggler, but less communication overhead. Considering the importance of efficiency in practice, we employ HASH as the default partition strategy in our experiments, as mentioned earlier.







7. Conclusion
In this paper, we study the problem of D-core decomposition in distributed settings. To handle distributed D-core decomposition, we propose two efficient algorithms, i.e., the anchored-coreness-based algorithm and skyline-coreness-based algorithm. Specifically, the anchored-coreness-based algorithm employs in-H-index and out-H-index to compute the anchored corenesses in a distributed way; the skyline-coreness-based algorithm uses a newly designed index, called D-index, for D-core decomposition through skyline coreness computing. Both theoretical analysis and empirical evaluation show the efficiency of our proposed algorithms with fast convergence rates.
As for future work, we are interested to study how to further improve the performance of the skyline-coreness-based algorithm, in particular how to accelerate the computation of D-index on each single machine. We are also interested to investigate efficient algorithms of distributed D-core maintenance for dynamic graphs.
References
- (1)
- gir (2012) 2012. Giraph. https://giraph.apache.org/.
- Ananthanarayanan et al. (2010) Ganesh Ananthanarayanan, Srikanth Kandula, Albert G. Greenberg, Ion Stoica, Yi Lu, Bikas Saha, and Edward Harris. 2010. Reining in the Outliers in Map-Reduce Clusters using Mantri. In OSDI. 265–278.
- Aridhi et al. (2016) Sabeur Aridhi, Martin Brugnara, Alberto Montresor, and Yannis Velegrakis. 2016. Distributed k-core decomposition and maintenance in large dynamic graphs. In Proceedings of the 10th ACM International Conference on Distributed and Event-based Systems. 161–168.
- Batagelj and Zaversnik (2003) Vladimir Batagelj and Matjaz Zaversnik. 2003. An O (m) algorithm for cores decomposition of networks. arXiv preprint cs/0310049 (2003).
- Bonchi et al. (2014) Francesco Bonchi, Francesco Gullo, Andreas Kaltenbrunner, and Yana Volkovich. 2014. Core decomposition of uncertain graphs. In Proceedings of the 20th International Conference on Knowledge Discovery and Data Mining. 1316–1325.
- Bonchi et al. (2019) Francesco Bonchi, Arijit Khan, and Lorenzo Severini. 2019. Distance-generalized core decomposition. In Proceedings of the 2019 International Conference on Management of Data. 1006–1023.
- Chen et al. (2020) Yankai Chen, Jie Zhang, Yixiang Fang, Xin Cao, and Irwin King. 2020. Efficient community search over large directed graphs: An augmented index-based approach. In International Joint Conference on Artificial Intelligence. 3544–3550.
- Cheng et al. (2011) James Cheng, Yiping Ke, Shumo Chu, and M Tamer Özsu. 2011. Efficient core decomposition in massive networks. In 2011 IEEE 27th International Conference on Data Engineering. 51–62.
- Dasari et al. (2014) Naga Shailaja Dasari, Ranjan Desh, and Mohammad Zubair. 2014. ParK: An efficient algorithm for k-core decomposition on multicore processors. In 2014 IEEE International Conference on Big Data. 9–16.
- Eidsaa and Almaas (2013) Marius Eidsaa and Eivind Almaas. 2013. S-core network decomposition: A generalization of k-core analysis to weighted networks. Physical Review E 88, 6 (2013), 062819.
- Esfandiari et al. (2018) Hossein Esfandiari, Silvio Lattanzi, and Vahab Mirrokni. 2018. Parallel and streaming algorithms for k-core decomposition. In International Conference on Machine Learning. 1397–1406.
- Fan et al. (2017) Wenfei Fan, Jingbo Xu, Yinghui Wu, Wenyuan Yu, and Jiaxin Jiang. 2017. GRAPE: Parallelizing sequential graph computations. Proceedings of the VLDB Endowment 10, 12 (2017), 1889–1892.
- Fang et al. (2018) Yixiang Fang, Zhongran Wang, Reynold Cheng, Hongzhi Wang, and Jiafeng Hu. 2018. Effective and efficient community search over large directed graphs. IEEE Transactions on Knowledge and Data Engineering 31, 11 (2018), 2093–2107.
- Fang et al. (2020) Yixiang Fang, Yixing Yang, Wenjie Zhang, Xuemin Lin, and Xin Cao. 2020. Effective and Efficient Community Search over Large Heterogeneous Information Networks. Proceedings of the VLDB Endowment 13, 6 (2020), 854–867.
- Galimberti et al. (2021) Edoardo Galimberti, Martino Ciaperoni, Alain Barrat, Francesco Bonchi, Ciro Cattuto, and Francesco Gullo. 2021. Span-core Decomposition for Temporal Networks: Algorithms and Applications. ACM Transactions on Knowledge Discovery from Data 15, 1 (2021), 2:1–2:44.
- Garcia et al. (2017) David Garcia, Pavlin Mavrodiev, Daniele Casati, and Frank Schweitzer. 2017. Understanding popularity, reputation, and social influence in the twitter society. Policy & Internet 9, 3 (2017), 343–364.
- Giatsidis et al. (2013) Christos Giatsidis, Dimitrios M Thilikos, and Michalis Vazirgiannis. 2013. D-cores: measuring collaboration of directed graphs based on degeneracy. Knowledge and Information Systems 35, 2 (2013), 311–343.
- Hirsch (2005) Jorge E. Hirsch. 2005. H-index. https://en.wikipedia.org/wiki/H-index/.
- Karypis and Kumar (1998) George Karypis and Vipin Kumar. 1998. Metis: A software package for partitioning unstructured graphs. Partitioning Meshes, and Computing Fill-Reducing Orderings of Sparse Matrices Version 4 (1998).
- Khaouid et al. (2015) Wissam Khaouid, Marina Barsky, Venkatesh Srinivasan, and Alex Thomo. 2015. K-core decomposition of large networks on a single pc. Proceedings of the VLDB Endowment 9, 1 (2015), 13–23.
- Liao et al. (2022) Xunkun Liao, Qing Liu, Jiaxin Jiang, Xin Huang, Jianliang Xu, and Byron Choi. 2022. Distributed D-core Decomposition over Large Directed Graphs. In arXivpreprint arXiv:XXXXXXX.
- Linial (1992) Nathan Linial. 1992. Locality in Distributed Graph Algorithms. SIAM J. Comput. 21, 1 (1992), 193–201.
- Liu et al. (2019) Boge Liu, Long Yuan, Xuemin Lin, Lu Qin, Wenjie Zhang, and Jingren Zhou. 2019. Efficient (a,)-core Computation: an Index-based Approach. In International World Wide Web Conference. 1130–1141.
- Liu et al. (2021) Qing Liu, Xuliang Zhu, Xin Huang, and Jianliang Xu. 2021. Local Algorithms for Distance-generalized Core Decomposition over Large Dynamic Graphs. The Proceedings of the VLDB Endowment (2021).
- Low et al. (2012) Yucheng Low, Joseph Gonzalez, Aapo Kyrola, Danny Bickson, Carlos Guestrin, and Joseph M Hellerstein. 2012. Distributed graphlab: A framework for machine learning in the cloud. arXiv preprint arXiv:1204.6078 (2012).
- Lü et al. (2016) Linyuan Lü, Tao Zhou, Qian-Ming Zhang, and H Eugene Stanley. 2016. The H-index of a network node and its relation to degree and coreness. Nature Communications 7, 1 (2016), 1–7.
- Malewicz et al. (2010) Grzegorz Malewicz, Matthew H Austern, Aart JC Bik, James C Dehnert, Ilan Horn, Naty Leiser, and Grzegorz Czajkowski. 2010. Pregel: a system for large-scale graph processing. In Proceedings of the 2010 International Conference on Management of Data. 135–146.
- Mandal and Hasan (2017) Aritra Mandal and Mohammad Al Hasan. 2017. A distributed k-core decomposition algorithm on spark. In IEEE International Conference on Big Data. 976–981.
- McCune et al. (2015) Robert Ryan McCune, Tim Weninger, and Greg Madey. 2015. Thinking Like a Vertex: A Survey of Vertex-Centric Frameworks for Large-Scale Distributed Graph Processing. Comput. Surveys 48, 2 (2015), 25:1–25:39.
- Montresor et al. (2012) Alberto Montresor, Francesco De Pellegrini, and Daniele Miorandi. 2012. Distributed k-core decomposition. IEEE Transactions on Parallel and Distributed Systems 24, 2 (2012), 288–300.
- Peng et al. (2018) You Peng, Ying Zhang, Wenjie Zhang, Xuemin Lin, and Lu Qin. 2018. Efficient Probabilistic K-Core Computation on Uncertain Graphs. In IEEE International Conference on Data Engineering. 1192–1203.
- Salihoglu and Widom (2013) Semih Salihoglu and Jennifer Widom. 2013. Gps: A graph processing system. In Proceedings of the 25th International Conference on Scientific and Statistical Database Management. 1–12.
- Saríyüce et al. (2013) Ahmet Erdem Saríyüce, Buğra Gedik, Gabriela Jacques-Silva, Kun-Lung Wu, and Ümit V Çatalyürek. 2013. Streaming algorithms for k-core decomposition. Proceedings of the VLDB Endowment 6, 6 (2013), 433–444.
- Sarıyüce et al. (2016) Ahmet Erdem Sarıyüce, Buğra Gedik, Gabriela Jacques-Silva, Kun-Lung Wu, and Ümit V Çatalyürek. 2016. Incremental k-core decomposition: algorithms and evaluation. The VLDB Journal 25, 3 (2016), 425–447.
- Sariyüce et al. (2018) Ahmet Erdem Sariyüce, C. Seshadhri, and Ali Pinar. 2018. Local Algorithms for Hierarchical Dense Subgraph Discovery. Proceedings of the VLDB Endowment 12, 1 (2018), 43–56.
- Seidman (1983) Stephen B Seidman. 1983. Network structure and minimum degree. Social Networks 5, 3 (1983), 269–287.
- Soldano et al. (2017) Henry Soldano, Guillaume Santini, Dominique Bouthinon, and Emmanuel Lazega. 2017. Hub-authority cores and attributed directed network mining. In International Conference on Tools with Artificial Intelligence. 1120–1127.
- Tian et al. (2013) Yuanyuan Tian, Andrey Balmin, Severin Andreas Corsten, Shirish Tatikonda, and John McPherson. 2013. From” think like a vertex” to” think like a graph”. Proceedings of the VLDB Endowment 7, 3 (2013), 193–204.
- Tsourakakis et al. (2014) Charalampos Tsourakakis, Christos Gkantsidis, Bozidar Radunovic, and Milan Vojnovic. 2014. FENNEL: Streaming Graph Partitioning for Massive Scale Graphs. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining. 333–342.
- Wen et al. (2016) Dong Wen, Lu Qin, Ying Zhang, Xuemin Lin, and Jeffrey Xu Yu. 2016. I/O efficient Core Graph Decomposition at web scale. In International Conference on Data Engineering. 133–144.
- Wu et al. (2015) Huanhuan Wu, James Cheng, Yi Lu, Yiping Ke, Yuzhen Huang, Da Yan, and Hejun Wu. 2015. Core decomposition in large temporal graphs. In IEEE International Conference on Big Data. 649–658.
- Yan et al. (2014) Da Yan, James Cheng, Yi Lu, and Wilfred Ng. 2014. Blogel: A block-centric framework for distributed computation on real-world graphs. Proceedings of the VLDB Endowment 7, 14 (2014), 1981–1992.
- Zhou et al. (2021) Wei Zhou, Hong Huang, Qiang-Sheng Hua, Dongxiao Yu, Hai Jin, and Xiaoming Fu. 2021. Core decomposition and maintenance in weighted graph. World Wide Web 24, 2 (2021), 541–561.
Appendix A Proof of Theorem 2
Theorem 4.1. (Convergence).
Proof.
First, we prove that is non-increasing with the increase of order . Then, we prove that , where is a subgraph induced by the vertices with . Also, we know by definition. Hence, . Complete proof is given here:
First, we prove that is non-increasing with the increase of through mathematical induction. (1) It is straightforward that holds according to the definition of . (2) Assume that holds. We have , i.e., . Thus, if holds for , it also holds for . Combining (1) and (2), is non-increasing with the increase of . Moreover, since is a positive integer, can converge to a certain value.
Next, we prove that . To this end, we introduce two properties of : (i) if , for and , we have ; and (ii) for and , we have , where is the minimum in-degree of . Let be the subgraph of induced by vertex and the vertices with . We have .
Then, we prove that . To this end, we construct a subgraph induced by vertex and the vertices satisfying . Obviously, is a -core. Hence, .
Finally, combining the above three proofs, we obtain Theorem 4.1. ∎
Appendix B Proof of Theorem 4.10
Theorem 4.4. (Time and Space Complexities). Algorithm 1 takes time and space. The total time and space complexities for computing all vertices’ corenesses are and , respectively..
Proof.
Algorithm 1 consists of three phases in Algorithms 2, 3, and 4. Algorithm 2 iteratively computes the -order in-H-index for all vertices. The time complexity of Algorithm 2 is mainly determined by the number of rounds that need to compute the -order in-H-index and also the processing time of each round, which are and , respectively. Hence, the time complexity of Algorithm 2 is . Next, Algorithm 3 iteratively computes . Each round of Algorithm 3 takes time. Algorithm 4 iteratively refines to . Each round of Algorithm 4 takes time. Hence, the time complexities of Algorithms 3 and 4 are and , respectively. Therefore, the time complexity of Algorithm 1 is . The total time complexity for all vertices is .
Next, we analyze the space complexity. Algorithm 2 computes by storing for , which costs space. Next, Algorithm 3 computes . For each , it stores the out-H-indexes of the out-neighbors in space. Hence, Phase II requires space. Phase III refines to in Algorithm 4. For each , it stores for all ’s neighbors in space. Overall, the space complexity of Algorithm 1 is . The total space complexity for all vertices is . ∎
Appendix C Proof of Theorem 4.11
Theorem 4.5. (Message Complexity). The message complexity (i.e., the total number of times that a vertex send messages) of Algorithm 1 is . The total message complexity for computing all vertices’ corenesses is .
Proof.
We analyze the message complexity in terms of two parts: Algorithm 2 and Algorithms 3 and 4. First, Algorithm 2 calculate by iteratively computing -order in-H-index of . When -order in-H-index is not equal to -order in-H-index, Algorithm 2 also sends messages to all ’s out-neighbors. sends message at most times. Hence, the message complexity of Algorithm 1 is .
Next, for each value of , Algorithm 3 first computes the upper bound and then Algorithm 4 refine to . Algorithms 3 obtains by iteratively computing -order out-H-index of . When -order out-H-index of decreases, Algorithm 3 sends messages to ’s in-neighbors. Algorithm 3 continues until the -order out-H-index of equals . Then, Algorithms 4 refines by gradually decreasing it to . Each time decreases, Algorithm 4 sends messages to ’s neighbors. Since is at least 1 and there are at most values of , the total messages sent by is in worst. Overall, the message complexity of Algorithms 3 and 4 is .
As a result, the message complexity of Algorithm 1 is . The total message complexity for all vertices is . ∎
Appendix D Proof of Theorem 5.8
Theorem 5.3. (Time and Space Complexities). Algorithm 5 takes time in space. The total time and space complexities for computing all vertices’ corenesses are and , respectively.
Appendix E Proof of Theorem 5.9
Theorem 5.4. (Message Complexity). The message complexity of Algorithm 5 is . The total message complexity for computing all vertices’ corenesses is .
Proof.
The message complexity of Algorithm 5 is dominated by the computation of -order D-index for vertex . When the -order D-index changes from the -order D-index, broadcasts messages to its neighbors. The -order D-index contains skyline pairs. Assume that in each round the skyline pair decreases one dimension by one at most. There are a total of rounds for . Hence, the message complexity of Algorithm 5 is . The total message complexity for all vertices is . ∎
Appendix F Performance comparisons on a single machine
This set of experiments evaluates the performance of our proposed algorithms and the state-of-the-art centralized method (Fang et al., 2018) over a single machine. Figure 8 shows the running time results. We can observe that for most of the small graphs, the peeling algorithm is more efficient than our algorithms. The reason is two-folded: (1) our proposed algorithms require iterative computations of in-H-index/out-H-index/D-index for every vertex before convergence, which is time consuming in centralized settings; (2) on a single machine, the vertex state update is transparent to other vertices in the peeling algorithm while it needs message communication exchanges in our algorithms, which incur a higher overhead. Nevertheless, our proposed algorithms run much faster than the peeling method in distributed settings as reported in Section 6.2. On the other hand, for billion-scale graphs UK5 and IT, all algorithms could not finish, due to memory overflows. This indeed motivates the need of distributed D-core decomposition over large directed graphs using a collection of machines.
