Distributed Algorithms for Linearly-Solvable Optimal Control in Networked Multi-Agent Systems
Abstract
Distributed algorithms for both discrete-time and continuous-time linearly solvable optimal control (LSOC) problems of networked multi-agent systems (MASs) are investigated in this paper. A distributed framework is proposed to partition the optimal control problem of a networked MAS into several local optimal control problems in factorial subsystems, such that each (central) agent behaves optimally to minimize the joint cost function of a subsystem that comprises a central agent and its neighboring agents, and the local control actions (policies) only rely on the knowledge of local observations. Under this framework, we not only preserve the correlations between neighboring agents, but moderate the communication and computational complexities by decentralizing the sampling and computational processes over the network. For discrete-time systems modeled by Markov decision processes, the joint Bellman equation of each subsystem is transformed into a system of linear equations and solved using parallel programming. For continuous-time systems modeled by Itô diffusion processes, the joint optimality equation of each subsystem is converted into a linear partial differential equation, whose solution is approximated by a path integral formulation and a sample-efficient relative entropy policy search algorithm, respectively. The learned control policies are generalized to solve the unlearned tasks by resorting to the compositionality principle, and illustrative examples of cooperative UAV teams are provided to verify the effectiveness and advantages of these algorithms.
2Evangelos A. Theodorou is with the Department of Aerospace Engineering, Georgia Institute of Technology, Atlanta, GA 30332. [email protected].
3Petros G. Voulgaris is with the Department of Mechanical Engineering, University of Nevada, Reno, NV 89557. [email protected].
Keywords: Multi-Agent Systems, Linearly-Solvable Optimal Control, Path Integral Control, Relative Entropy Policy Search, Compositionality.
Introduction
The research of control and planning in multi-agent systems (MASs) has been developing rapidly during the past decade with the growing demands from areas, such as cooperative vehicles [1, 2], Internet of Things [3], intelligent infrastructures [4, 5, 6], and smart manufacturing [7]. Distinct from other control problems, control of MASs is characterized by the issues and challenges, which include, but are not limited to, a great diversity of possible planning and execution schemes, limited information and resources of the local agents, constraints and randomness of communication networks, optimality and robustness of joint performance. A good summary of recent progress in multi-agent control can be found in [8, 9, 10, 11, 12, 13, 14]. Building upon these results and challenges, this paper puts forward a distributed optimal control scheme for stochastic MASs by extending the linearly-solvable optimal control algorithms to MASs subject to stochastic dynamics in the presence of an explicit communication network and limited feedback information.
Linearly-solvable optimal control (LSOC) generally refers to the model-based stochastic optimal control (SOC) problems that can be linearized and solved with the facilitation of Cole-Hopf transformation, i.e. exponential transformation of value function [15, 16]. Compared with other model-based SOC techniques, since LSOC formulates the optimality equations in linear form, it enjoys the superiority of analytical solution [17] and superposition principle [18], which makes LSOC a popular control scheme for robotics [19, 20]. LSOC technique was first introduced to linearize and solve the Hamilton–Jacobi–Bellman (HJB) equation for continuous-time SOC problems [15], and the application to discrete-time SOC, also known as the linearly-solvable Markov decision process (LSMDP), was initially studied in [16]. More recent progress on single-agent LSOC problems can be found in [21, 22, 23, 24, 17, 25].
Different from many prevailing distributed control algorithms [10, 11, 12, 13], such as consensus and synchronization that usually assume a given behavior, multi-agent SOC allows agents to have different objectives and optimizes the action choices for more general scenarios [8]. Nevertheless, it is not straightforward to extend the single-agent SOC methods to multi-agent problems. The exponential growth of dimensionality in MASs and the consequent surges in computation and data storage demand more sophisticated and preferably distributed planning and execution algorithms. The involvement of communication networks (and constraints) requires the multi-agent SOC algorithms to achieve stability and optimality subject to local observation and more involved cost function. While the multi-agent Markov decision process (MDP) problem has received plenty of attention from both the fields of computer science and control engineering [26, 27, 8, 28, 14, 29], there are relatively fewer results focused on multi-agent LSMDP. A recent result on multi-agent LSMDP represented the MAS problem as a single-agent problem by stacking the states of all agents into a joint state vector, and the scalability of the problem was addressed by parameterizing the value function [30]; however, since the planning and execution of the control action demand the knowledge of global states as well as a centralized coordination, the parallelization scheme of the algorithm was postponed in that paper. While there are more existing results focused on the multi-agent LSOC in continuous-time setting, most of these algorithms still depend on the knowledge of the global states, i.e. a fully connected communication network, which may not be feasible or affordable to attain in practice. Some multi-agent LSOC algorithms also assume that the joint cost function can be factorized over agents, which basically simplifies the multi-agent control problem into multiple single-agent problems, and some features and advantages of MASs are therefore forfeited. Broek et al. investigated the multi-agent LSOC problem for continuous-time systems governed by Itô diffusion process [31]; a path integral formula was put forward to approximate the optimal control actions, and a graphical model inference approach was adopted to predict the optimal path distribution; nonetheless, the optimal control law assumed an accurate and complete knowledge of global states, and the inference was performed on the basis of mean-field approximation, which assumes that the cost function can be disjointly factorized over agents and ignores the correlations between agents. A distributed LSOC algorithm with infinite-horizon and discounted cost was studied in [32] for solving a distance-based formation problem of nonholonomic vehicular network without explicit communication topology. The multi-agent LSOC problem was also recently discussed in [25] as an accessory result for a novel single-agent LSOC algorithm; an augmented dynamics was built by piling up the dynamics of all agents, and a single-agent LSOC algorithm was then applied to the augmented system. Similar to the discrete-time result in [30], the continuous-time result resorting to augmented dynamics also presumes the fully connected network and faces the challenge that the computation and sampling schemes that originated from single-agent problem may become inefficient and possibly fail as the dimensions of augmented state and control grow exponentially in the number of agents.
To address the aforementioned challenges, this paper investigates the distributed LSOC algorithms for discrete-time and continuous-time MASs with consideration of local observation, correlations between neighboring agents, efficient sampling and parallel computing. A distributed framework is put forward to partition the connected network into multiple factorial subsystems, each of which comprises a (central) agent and its neighboring agents, such that the local control action of each agent, depending on the local observation, optimizes the joint cost function of a factorial subsystem, and the sampling and computational complexities of each agent are related to the size of the factorial subsystem instead of the entire network. Sampling and computation are parallelized to expedite the algorithms and exploit the resource in network, with state measurements, intermediate solutions, and sampled data exchanged over the communication network. For discrete-time multi-agent LSMDP problem, we linearize the joint Bellman equation of each factorial subsystem into a system of linear equations, which can be solved with parallel programming, making both the planning and execution phases fully decentralized. For continuous-time multi-agent LSOC problem, instead of adopting the mean-field assumption and ignoring the correlations between neighboring agents, joint cost functions are permitted in the subsystems; the joint optimality equation of each subsystem is first cast into a joint stochastic HJB equation, and then solved with a distributed path integral control method and a sample-efficient relative entropy policy search (REPS) method, respectively. The compositionality of LSOC is utilized to efficiently generate a composite controller for unlearned task from the existing controllers for learned tasks. Illustrative examples of coordinated UAV teams are presented to verify the effectiveness and advantages of multi-agent LSOC algorithms. Building upon our preliminary work on distributed path integral control for continuous-time MASs [33], this paper not only integrates the distributed LSOC algorithms for both discrete-time and continuous-time MASs, but supplements the previous result with a distributed LSMDP algorithm for discrete-time MASs, a distributed REPS algorithm for continuous-time MASs, a compositionality algorithm for task generalization, and more illustrative examples.
The paper is organized as follows: Section 2 introduces the preliminaries and formulations of multi-agent LSOC problems; Section 3 presents the distributed LSOC algorithms for discrete-time and continuous-time MASs, respectively; Section 4 shows the numerical examples, and Section 5 draws the conclusions. Some notations used in this paper are defined as follows: For a set , represents the cardinality of the set ; for a matrix and a vector , denotes the determinant of matrix , and weighted square norm .
Preliminaries and Problem Formulation
Preliminaries on MASs and LSOC are introduced in this section. The communication networks underlying MASs are represented by graphs, and the discrete-time and continuous-time LSOC problems are extended from single-agent scenario to MASs under a distributed planning and execution framework.
Multi-Agent Systems and Distributed Framework
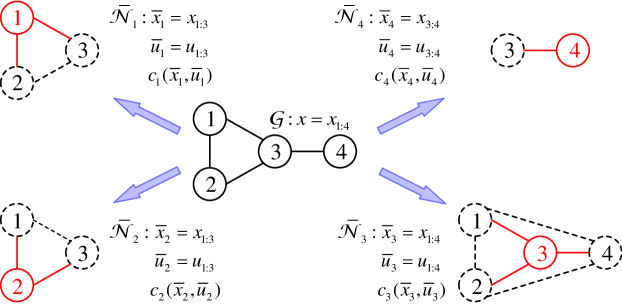
For a MAS consisting of agents, denotes the index set of agents, and the communication network among agents is described by an undirected graph , which implies that the communication channel between any two agents is bilateral. The communication network is assumed to be connected. An agent in the network is denoted as a vertex , and an undirected edge in graph implies that the agents and can measure the states of each other, which is denoted by for agent . Agents and are neighboring or adjacent agents, if there exists a communication channel between them, and the index set of agents neighboring to agent is denoted by with . We use column vectors to denote the joint state of agent and its adjacent agents , which together group up the factorial subsystem of agent , and denotes the global states of MAS. Figure 1 shows a MAS and all its factorial subsystems.
To optimize the correlations between neighboring agents while not intensifying the communication and computational complexities of the network or each agent, our paper proposes a distributed planning and execution framework, as a trade-off scheme between the easiness of implementation and optimality of performance, for multi-agent LSOC problems. Under this distributed framework, the local control action of agent is computed by solving the local LSOC problem defined in factorial subsystem . Instead of requiring the cost functions fully factorized over agents [31] or the knowledge of global states [30, 25], joint cost functions are permitted in every factorial subsystem, which captures the correlations and cooperation between neighboring agents, and the local control action only relies on the local observation of agent , which also simplifies the structure of communication network. Meanwhile, the global computational complexity is no longer exponential with respect to the total amount of agents in network , but becomes linear with respect to it in general, and the computational complexity of local agent is only related to the number of agents in factorial subsystem . However, since the local control actions are computed from the local observations with only partial information, the distributed LSOC law obtained under this framework is usually a sub-optimal solution, despite that it coincides with the global optimal solution when the communication network is fully connected. More explanations and discussions on this will be given at the end of this section. Before that, we first reformulate the discrete-time and continuous-time LSOC problems from the single-agent scenario to a multi-agent setting that is compatible with our distributed framework.
Discrete-Time Dynamics
Discrete-time SOC for single-agent systems, also known as the single-agent MDP, is briefly reviewed and then generalized to the networked MAS scenario. We consider the single-agent MDPs with finite state space and continuous control space in the first-exit setting. For a single agent , the state variable belongs to a finite set , which may be generated from an infinite-dimensional state problem by an appropriate coding scheme [34]. denotes the set of interior states of agent , and denotes the set of boundary states. Without communication and interference from other agents, the passive dynamics of agent follows the probability distribution
where , and denotes the transition probability from state to . When taking control action at state , the controlled dynamics of agent is described by the distribution mapping
| (1) |
where or denotes the transition probability from state to state subject to control that belongs to a continuous space. We require that , whenever , to prevent the direct transitions to the goal states. When , the immediate or running cost function of LSMDPs is designed as:
| (2) |
where the state cost can be an arbitrary function encoding how (un)desirable different states are, and the KL-divergence***The KL-divergence (relative entropy) between two discrete probability mass functions and is defined as which has an absolute minimum when . For two continuous probability density functions and , the KL-divergence is defined as measures the cost of control actions. When , the final cost function is defined as . The cost-to-go function of first-exit problem starting at state-time pair is defined as
| (3) |
where is the state-action pair of agent at time step , is the terminal or exit state, and the expectation is taken with respect to the probability measure under which satisfies (1) given the control law and initial condition . The objective of discrete-time stochastic optimal control problem is to find the optimal policy and value functions by solving the Bellman equation
| (4) |
where the value function is defined as the expected cumulative cost for starting at state and acting optimally thereafter, i.e. .
Based on the formulations of single-agent LSMDP and augmented dynamics, we introduce a multi-agent LSMDP formulation subject to the distributed framework of the factorial subsystem. For simplicity, we assume that the passive dynamics of agents in MAS are homogeneous and mutually independent, i.e. agents without control are governed by identical dynamics and do not interfere or collide with each other. This assumption is also posited in many previous papers on multi-agent LSOC or distributed control [35, 31, 11, 25]. Since agent can only observe the states of neighboring agents , we are interested in the subsystem when computing the control law of agent . Hence, the autonomous dynamics of subsystem follow the distribution mapping
| (5) |
where the joint state , and distribution information are generally only accessible to agent . Similarly, the global state of all agents , which is usually not available to a local agent unless it can receive the information from all other agents , e.g. agent 3 in Figure 1. Since the local control action only relies on the local observation of agent , we assume that the joint posterior state of subsystem is exclusively determined by the joint prior state and joint control when computing the optimal control actions in subsystem . More intuitively, under this assumption, the local LSOC algorithm in subsystem only requires the measurement of joint state and treats subsystem as a complete connected network, as shown in Figure 1. When each agent in samples their control action independently, the joint controlled dynamics of the factorial subsystem satisfies
| (6) |
where the joint state and joint distribution are only accessible to agent in general. Once we figure out the joint control distribution for subsystem , the local control distribution of agent can be retrieved by calculating the marginal distribution. The joint immediate cost function for subsystem when is defined as follows
| (7) |
where the state cost can be an arbitrary function of joint state , i.e. a constant or the norm of disagreement vector, and the second equality follows from (5) and (6), which implies that the joint control cost is the cumulative sum of the local control costs. When , the exit cost function , where is a weight measuring the priority of assignment on agent . In order to improve the success rate in application, it is preferable to assign as the largest weight when computing the control distribution in subsystem . Subsequently, the joint cost-to-go function of first-exit problem in subsystem becomes
| (8) |
Some abuses of notations occur when we define the cost functions and , cost-to-go function , and value function in single-agent setting and the factorial subsystem; one can differentiate the different settings from the arguments of these functions. Derived from the single-agent Bellman equation (4), the joint optimal control action subject to the joint cost function (7) can be solved from the following joint Bellman equation in subsystem
| (9) |
where is the (joint) value function of joint state . A linearization method as well as a parallel programming method for solving (9) will be discussed in Section 3.
Continuous-Time Dynamics
For continuous-time LSOC problems, we first consider the dynamics of single agent described by the following Itô diffusion process
| (10) |
where is agent ’s state vector from an uncountable state space; is the deterministic drift term with passive dynamics , control matrix and control action ; noise is a vector of possibly correlated†††When the components of are correlated and satisfy a multi-variate normal distribution , by using the Cholesky decomposition , we can rewrite , where is a vector of Brownian components with zero drift and unit-variance rate. Brownian components with zero mean and unit rate of variance, and the positive semi-definite matrix denotes the covariance of noise . When , the running cost function is defined as
| (11) |
where is the state-related cost, and is the control-quadratic term with matrix being positive definite. When , the terminal cost function is , where is the exit time. Hence, the cost-to-go function of first-exit problem is defined as
| (12) |
where the expectation is taken with respect to the probability measure under which is the solution to (10) given the control law and initial condition . The value function is defined as the minimal cost-to-go function . Subject to the dynamics (10) and running cost function (11), the optimal control action can be solved from the following single-agent stochastic Hamilton–Jacobi–Bellman (HJB) equation:
| (13) | ||||
where and respectively refer to the gradient and Hessian matrix with and elements . A few methods have been proposed to solve the stochastic HJB in (13), such as the approximation methods via discrete-time MDPs or eigenfunction [36] and path integral approaches [37, 31, 22].
Similar to the extension of discrete-time LSMDP from single-agent setting to MAS, the joint continuous-time dynamics for factorial subsystem is described by
| (14) |
where the joint passive dynamics vector is denoted by , the joint control matrix is denoted by , is the joint control action, is the joint noise vector, and the joint covariance matrix is denoted by . Analogous to the discrete-time scenario, we assume that the passive dynamics of agents are homogeneous and mutually independent, and for the local planning algorithm on agent or subsystem , which computes the local control action for agent and joint control action in subsystem , the evolution of joint state only depends on the current values of and joint control . When , the joint immediate cost function for subsystem is defined as
| (15) |
where the state-related cost can be an arbitrary function measuring the (un)desirability of different joint states , and is the control-quadratic term with matrix being positive definite. When with and defined in (11), the joint control cost term in (15) satisfies , which is symmetric with respect to the relationship of discrete-time control costs in (7). When , the terminal cost function is defined as , where is the weight measuring the priority of assignment on agent , and we let the weight dominate other weights to improve the success rate. Compared with the cost functions fully factorized over agents, the joint cost functions in (15) can gauge and facilitate the correlation and cooperation between neighboring agents. Subsequently, the joint cost-to-go function of first-exit problem in subsystem is defined as
Let the (joint) value function be the minimal cost-to-go function, i.e. . We can then compute the joint optimal control action of subsystem by solving the following joint optimality equation
| (16) |
A distributed path integral control algorithm and a distributed REPS algorithm for solving (16) will be respectively discussed in Section 3. Discussion on the relationship between discrete-time and continuous-time LSOC dynamics can be found in [16, 38].
Remark 1.
Although each agent under this framework acts optimally to minimize a joint cost-to-go function defined in their subsystem , the distributed control law obtained from solving the local problem (9) or (16) is still a sub-optimal solution unless the communication network is fully connected. Two main reasons account for this sub-optimality. First, when solving (9) or (16) for the joint (or local) optimal control (or ), we ignore the connections of agents outside the subsystem and assume that the evolution of joint state only relies on the current values of and joint control . This simplification is reasonable and almost accurate for the central agent of subsystem , but not for the non-central agents , which are usually adjacent to other agents in . Therefore, the local optimal control actions of other agents are respectively computed from their own subsystems , which may contradict the joint optimal control solved in subsystem and result in a sub-optimal solution. Similar conflicts widely exist in the distributed control and optimization problems subject to limited communication and partial observation, and some serious and heuristic studies on the global- and sub-optimality of distributed subsystems have been conducted in [39, 40, 11, 41]. We will not dive into those technical details in this paper, as we believe that the executability of a sub-optimal plan with moderate communication and computational complexities should outweigh the performance gain of a global-optimal but computationally intractable plan in practice. In this regard, the distributed framework built upon factorial subsystems, which captures the correlations between neighboring agents while ignoring the further connections outside subsystems, provides a trade-off alternative between the optimality and complexity and is analogous to the structured prediction framework in supervised learning.
Distributed Linearly-Solvable Optimal Control
Subject to the multi-agent LSOC problems formulated in Section 2, the linearization methods and distributed algorithms for solving the joint discrete-time Bellman equation (9) and joint continuous-time optimality equation (16) are discussed in this section.
Discrete-Time Systems
We first consider the discrete-time MAS with dynamics (6) and immediate cost function (7), which give the joint Bellman equation (9) in subsystem
In order to compute the value function and optimal control action from equation (9), an exponential or Cole-Hopf transformation is employed to linearize (9) into a system of linear equations, which can be cast into a decentralized programming and solved in parallel. Local optimal control distribution that depends on the local observation of agent is then derived by marginalizing the joint control distribution .
A. Linearization of Joint Bellman Equation
Motivated by the exponential transformation employed in [38] for single-agent system, we define the desirability function for joint state in subsystem as
| (17) |
which implies that the desirability function is negatively correlated with the value function , and the value function can also be written conversely as a logarithm of the desirability function, . For boundary states , the desirability functions are defined as . Based on the transformation (17), a linearized joint Bellman equation (9) along with the joint optimal control distribution is presented in Theorem 1.
Theorem 1.
With exponential transformation (17), the joint Bellman equation (9) for subsystem is equivalent to the following linear equation with respect to the desirability function
| (18) |
where is the state-related cost defined in (15), and is the transition probability of passive dynamics in (5). The joint optimal control action solving (9) satisfies
| (19) |
where is the transition probability from to in controlled dynamics (6).
Proof.
See Appendix A for the proof. ∎
Joint optimal control action in (19) only relies on the joint state of subsystem , i.e. local observation of agent . To execute this control action (19), we still need to figure out the values of desirability functions or value functions, which can be solved from (18). A conventional approach for solving (18), which was adopted in [16, 18, 38] for single-agent LSMDP, is to rewrite (18) as a recursive formula and approximate the solution by iterations. We can approximate the desirability functions of interior states by recursively executing the following update law
| (20) |
where and are respectively the desirability vectors of interior states and boundary states; the diagonal matrix with denoting the state-related cost of interior states, denoting the transition probability matrix between interior states, and for ; the matrix with denoting the transition probability matrix from interior states to boundary states, and for and . Assigning an initial value to the desirability vector , the recursive formula (20) is guaranteed to converge to a unique solution, since the spectral radius of matrix is less than . More detailed convergence analysis on this iterative solver of LSMDPs has been given in [16]. However, this centralized solver is inefficient when dealing with the MAS problems with high-dimensional state space, which requires the development of a distributed solver that exploits the resource of network and expedites the computation.
B. Distributed Planning Algorithm
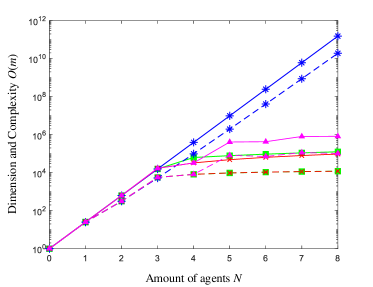
While most of the distributed SOC algorithms are executed by local agents in a decentralized approach, a great number of these algorithms still demand a centralized solver in planning phase, which becomes a bottleneck for their implementations when the amount of agents scales up [8]. For a fully connected MAS with agents, when each agent has interior states, the dimension of the vector in (20) is , and as the number of agents grows up, it will become more intractable for a central computation unit to store all the data and execute all the computation required by (20) due to the curse of dimensionality. Although the subsystem-based distributed framework can alleviate this problem by demanding a less complex network and making the dimension and computational complexity only related to the sizes of factorial subsystems, it is still preferable to utilize the resources of MAS by distributing the data and computational task of (20) to each local agent in , instead of relying on a central planning agent. Hence, we rewrite the linear equation (20) in the following form
| (21) |
and formulate (21) into a parallel programming problem. In order to solve the desirability vector from (21) via a distributed approach, each agent in subsystem only needs to know (store) a subset (rows) of the partitioned matrix . Subject to the equality constraints laid by its portion of coefficients, agent first initializes its own version of solution to (21). Every agent has access to the solutions of its neighboring agents, and the central agent can access the solutions of agents in . A consensus of in (21) can be reached among , when implementing the following synchronous distributed algorithm on each computational agent in [42]:
| (22) |
where is the orthogonal projection matrix on the kernel of , rows of the matrix stored in agent ; is the amount of neighboring agents of agent in subsystem ; and is the index of update iteration. An asynchronous distributed algorithm [43], which does not require agents to concurrently update their solution , can also be invoked to solve (21). Under these distributed algorithms, different versions of solution are exchanged across the network, and the requirements of data storage and computation can be allocated evenly to each agent in network, which improve the overall efficiency of algorithms. Meanwhile, these fully parallelized planning algorithms can be optimized and boosted further by naturally incorporating some parallel computing and Internet of Things (IoT) techniques, such as edge computing [44]. Nonetheless, for MASs with massive population, i.e. , most of the control schemes and algorithms introduced in this paper will become fruitless, and we may resort to the mean-field theory [9, 45, 46], which describes MASs by probability density model rather than connected graph model.
C. Local Control Action
After we figure out the desirability functions for all the joint states in subsystem , the local optimal control distribution for central agent is derived by calculating the marginal distribution of
where both the joint distribution and local distribution rely on the local observation of central agent . By sampling control action from marginal distribution , agent behaves optimally to minimize the joint cost-to-go function (8) defined in subsystem , and the local optimal control distribution of other agents in network can be derived by repeating the preceding procedures in subsystems . The procedures of multi-agent LSMDP algorithm are summarized as Algorithm 1 in Appendix E.
Continuous-Time Systems
We now consider the LSOC for continuous-time MASs subject to joint dynamics (14) and joint immediate cost function (15), which can be formulated into the joint optimality equation (16) as follows
In order to solve (16) and derive the local optimal control action for agent , we first cast the joint optimality equation (16) into a joint stochastic HJB equation that gives an analytic form for joint optimal control action . To solve for the value function, by resorting to the Cole-Hopf transformation, the stochastic HJB equation is linearized into a partial differential equation (PDE) with respect to desirability function. Feynman-Kac formula is then invoked to formulate the solution of the linearized PDE and joint optimal control action as the path integral formulae forward in time, which are later approximated respectively by a distributed Monte Carlo (MC) sampling method and a sample-efficient distributed REPS algorithm.
A. Linearization of Joint Optimality Equation
Similar to the transformation (17) for discrete-time systems, we adopt the following Cole-Hopf or exponential transformation in continuous-time systems
| (23) |
where is a scalar, and is the desirability function of joint state at time . Conversely, we also have from (23). In the following theorem, we convert the optimality equation (16) into a joint stochastic HJB equation, which reveals an analytic form of joint optimal control action , and linearize the HJB equation into a linear PDE that has a closed-form solution for the desirability function.
Theorem 2.
Subject to the joint dynamics (14) and immediate cost function (15), the joint optimality equation (16) in subsystem is equivalent to the joint stochastic HJB equation
| (24) | ||||
with boundary condition , and the optimum of (24) can be attained with the joint optimal control action
| (25) |
Subject to the transformation (23), control action (25) and condition , the joint stochastic HJB equation (24) can be linearized as
| (26) |
with boundary condition , which has a solution
| (27) |
where the diffusion process satisfies the uncontrolled dynamics with initial condition .
Proof.
See Appendix B for the proof. ∎
Based on the transformation (23), the gradient of value function satisfies . Hence, the joint optimal control action (25) can be rewritten as
| (28) |
where the second equality follows from the condition . Meanwhile, by virtue of Feynman-Kac formula, the stochastic HJB equation (24) that must be solved backward in time can now be solved by an expectation of diffusion process evolving forward in time. While a closed-form solution of the desirability function is given in (27), the expectation is defined on the sample space consisting of all possible uncontrolled trajectories initialized at , which makes this expectation intractable to compute. A common approach in statistical physics and quantum mechanics is to first formulate this expectation as a path integral [47, 37, 48], and then approximate the integral or optimal control action with various techniques, such as MC sampling [37] and policy improvement [22]. In the following subsections, we first formulate the desirability function (26) and control action (28) as path integrals and then approximate them with a distributed MC sampling algorithm and a sample-efficient distributed REPS algorithm, respectively.
B. Path Integral Formulation
Before we show a path integral formula for the desirability function in (27), some manipulations on joint dynamics (14) are performed to avoid singularity problems [22]. By rearranging the components of joint states in (14), the joint state vector in subsystem can be partitioned as , where and respectively indicate the joint non-directly actuated states and joint directly actuated states of subsystem ; and denote the dimensions of non-directly actuated states and directly actuated states for a single agent. Consequently, the joint passive dynamics term and the joint control transition matrix in (14) are partitioned as and , respectively. Hence, the joint dynamics (14) can be rewritten in a partitioned vector form as follows
| (29) |
With the partitioned dynamics (29), the path integral formulae for the desirability function (27) and joint optimal control action (28) are given in Proposition 3.
Proposition 3.
Partition the time interval from to into intervals of equal length , , and let the trajectory variable denote the segments of joint uncontrolled trajectories on time interval , governed by joint dynamics (29) with and initial condition . The desirability function (27) in subsystem can then be reformulated as a path integral
| (30) |
where the integral is over path variable , i.e. set of all uncontrolled trajectories initialized at , and the generalized path value
| (31) | ||||
with . Hence, the joint optimal control action in subsystem can be reformulated as a path integral
| (32) |
where
| (33) |
is the optimal path distribution, and
| (34) |
is the initial control variable.
Proof.
See Appendix C for the proof. ∎
While Proposition 3 gives the path integral formulae for desirability (value) function and joint optimal control action , one of the challenges when implementing these formulae is the approximation of optimal path distribution (33) and integrals in (30) and (32), since these integrals are defined on the set of all possible uncontrolled trajectories initialized at or , which are intractable to exhaust and might become computationally expensive to sample as the state dimension and the amount of agents scale up. An intuitive solution is to formulate this problem as a statistical inference problem and predict the optimal path distribution via various inference techniques, such as the easiest MC sampling [37] or Metropolis-Hastings sampling [31]. Provided a batch of uncontrolled trajectories and a fixed , the Monte Carlo estimation of optimal path distribution in (33) is
| (35) |
where denotes the generalized path value (31) of trajectory , and the estimation of joint optimal control action in (32) is
| (36) |
where is the initial control of sample trajectory . To expedite the process of sampling, the sampling tasks of can be distributed to different agents in the network, i.e. each agent in MAS only samples its local uncontrolled trajectories , and the optimal path distributions of each subsystem are approximated via (35) after the central agent restores by collecting the samples from its neighbors . Meanwhile, the local trajectories of agent not only can be utilized by the local control algorithm of agent in subsystem , but also can be used by the local control algorithms of the neighboring agents in subsystem , and the parallel computation of GPUs can further facilitate the sampling processes by allowing each agent to concurrently generate multiple sample trajectories [25]. The continuous-time multi-agent LSOC algorithm based on estimator (35) is summarized as Algorithm 2 in Appendix E.
However, since the aforementioned auxiliary techniques are still proposed on the basis of pure sampling estimator (35), the total amount of samples required for a good approximation is not reduced, which will hinder the implementations of Proposition 3 and estimator (35) when the sample trajectories are expensive to generate. Various investigations have been conducted to mitigate this issue. For the sample-efficient approximation of desirability (value) function , parameterized desirability (value) function, Laplace approximation [37], approximation based on mean-field assumption [31], and a forward-backward framework based on Gaussian process can be used [17]. Meanwhile, it is more common in practice to only efficiently predict the optimal path distribution and optimal control action , while omitting the value of desirability function. Numerous statistical inference algorithms, such as Bayesian inference and variational inference [49], can be adopted to predict the optimal path distribution, and diversified policy improvement and policy search algorithms, such as PI2 [22] and REPS [23], can be employed to update the parameterized optimal control policy. Hence, in the following subsection, a sample-efficient distributed REPS algorithm is introduced to update the parameterized joint control policy for each subsystem and MAS.
C. Relative Entropy Policy Search in MAS
Since the initial control can be readily calculated from sample trajectories and network communication, we only need to determine the optimal path distribution before evaluating the joint optimal control action from (32). To approximate this distribution more efficiently, we extend the REPS algorithm [21, 23] for path integral control in MAS. REPS is a model-based algorithm with competitive convergence rate, whose objective is to search for a parametric policy that generates a path distribution to approximate the optimal path distribution . Compared with reinforcement learning algorithms and model-free policy improvement or search algorithms, since REPS is built on the basis of model, the policy and trajectory generated from REPS can automatically satisfy the constraints of the model. Moreover, for the MAS problems, REPS algorithm allows to consider a more general scenario when the initial condition is stochastic and satisfies a distribution . REPS algorithm alternates between two steps: a) Learning step that approximates the optimal path distribution from samples generated by the current or initial policy, i.e. , and b) Updating step that updates the parametric policy to reproduce the desired path distribution generated in step a). The algorithm terminates when the policy and approximate path distribution converge.
During the learning step, we approximate the joint optimal distribution by minimizing the relative entropy (KL-divergence) between an approximate distribution and subject to a few constraints and a batch of sample trajectories generated by the current or initial policy related to old distribution from prior iteration. Similar to the distributed MC sampling method, the computation task of sample trajectories can either be exclusively assigned to the central agent or distributed among the agents in subsystem and then collected by the central agent . However, unlike the local uncontrolled trajectories in the MC sampling method, which can be interchangeably used by the control algorithms of all agents in subsystem , since the trajectory sets of the REPS approach are generated subject to different policies for , the sample data in can only be specifically used by the local REPS algorithm in subsystem . We can then update the approximate path distribution by solving the following optimization problem
| (37) | ||||
| s.t. | ||||
where is a parameter confining the update rate of approximate path distribution; is a state feature vector of the initial condition; and is the expectation of state feature vector subject to initial distribution . When the initial state is deterministic, (37) degenerates to an optimization problem for path distribution , and the second constraint in (37) can be neglected. The optimization problem (37) can be solved analytically with the method of Lagrange multipliers, which gives
| (38) |
where and are the Lagrange multipliers that can be solved from the dual problem
| (39) |
with objective function
| (40) | ||||
and the dual variable can then be determined by the constraint obtained by substituting (39) into the normalization (last) constraint in (37). The approximation of the dual function from sample trajectories , calculation of the old (or initial) path distribution from the current (or initial) policy , and a brief interpretation on the formulation of optimization problem (37) are explained in Appendix D.
In the updating step of REPS algorithm, we update the policy such that the joint distribution generated by policy approximates the path distribution generated in the learning step (37) and ultimately converges to the optimal path distribution in (33). More explanations on distribution and old distribution can be found in (84) of Appendix D. In order to provide a concrete example, we consider a set of parameterized time-dependent Gaussian policies that are linear in states, i.e. at time step , where are the policy parameters to be updated. For simplicity, one can also construct a stationary Gaussian policy , which was employed in [50] and shares the same philosophy as the parameter average techniques discussed in [31, 22]. The parameters in policy can be updated by minimizing the relative entropy between and , i.e.
| (41) |
where is the optimal control action. More detailed interpretation on policy update as well as approximation of (41) from sample data can be found in Appendix D. When implementing the REPS algorithm introduced in this subsection, we initialize each iteration by generating a batch of sample trajectories from the current (or initial) policy, which was updated to restore the old approximate path distribution in the prior iteration. With these sample trajectories, we update the path distribution through (37)-(40) and update the policy again through (41) till convergence of the algorithm. This REPS-based continuous-time MAS control algorithm is also summarized as Algorithm 3 in Appendix E.
D. Local Control Action
The preceding two distributed LSOC algorithms will return either a joint optimal control action or a joint optimal control policy for subsystem at joint state . Similar to the treatment of distributed LSMDP in discrete-time MAS, only the central agent selects or samples its local control action from or , while other agents are guided by the control law, or , computed in their own subsystems .
For distributed LSOC based on the MC sampling estimator (36), the local optimal control action can be directly selected from the joint control action . For distributed LSOC based on the REPS method, the recursive algorithm generates control policy for each time step per iteration. When generating the trajectory set from the current control policy , we sample the local control action of agent from the marginal distribution . After the convergence of local REPS algorithm in subsystem , the local optimal control action of the central agent at state can be sampled from the following marginal distribution
| (42) |
which minimizes the joint cost-to-go function (12) in subsystem and only relies on the local observation of agent .
Generalization with Compositionality
While several accessory techniques have been introduced in Section 3.1 and Section 3.2 to facilitate the computation of optimal control law, we have to repeat all the aforementioned procedures when a new optimal control task with different terminal cost or preferred exit state is assigned. A possible approach to solve this problem and generalize LSOC is to resort to contextual learning, such as the contextual policy search algorithm [50], which adapts to different terminal conditions by introducing hyper-parameters and an additional layer of learning algorithm. However, this supplementary learning algorithm will undoubtedly increase the complexity and computational task for the entire control scheme. Thanks to the linearity of LSOC problems, a task-optimal controller for a new (unlearned) task can also be constructed from existing (learned) controllers by utilizing the compositionality principle [31, 18, 51, 17]. Suppose that we have previously learned (component) LSOC problems and a new (composite) LSOC problem with different terminal cost from the previous problems. Apart from different terminal costs, these multi-agent LSOC problems share the same communication network , state-related cost , exit time , and dynamics, which means that the state space, control space, and sets of interior and boundary states of these problems are also identical. Let with be the terminal costs of component problems in subsystem , and denotes the terminal cost of composite or new problem in subsystem . We can efficiently construct a joint optimal control action for the new task from the existing component controllers by the compositionality principle.
For multi-agent LSMDP in discrete-time MAS, when there exists a set of weights such that
by the definition of discrete-time desirability function (17), we can imply that
| (43) |
for all . Due to the linear relation in (20), identity (43) should also hold for all interior states . Substituting (43) into the optimal control action (19), the task-optimal control action for the new task with terminal cost can be immediately generated from the existing controllers
| (44) |
where and . For LSOC in MAS, compositionality principle can be used for not only the generalization of controllers for the same subsystem , but the generalization of control law across the network. For any two subsystems that satisfy the aforementioned compatible conditions, the task-optimal controller of one subsystem can also be directly constructed from the existing computational result of the other subsystem by resorting to (44).
The generalization of continuous-time LSOC problem can be readily inferred by symmetry. For continuous-time LSOC problems that satisfy the compatible conditions, when there exist scalars , and weights such that
| (45) |
by the definition of continuous-time desirability function (23), we readily have for all . Since is the solution to linearized stochastic HJB equation (26), the linear combination of desirability function
| (46) |
holds everywhere from to on condition that (46) holds for all terminal states , which is guaranteed by (45). Substituting (46) into the continuous-time optimal controller (28), the task-optimal composite controller can be constructed from the component controllers by
where . However, this generalization technique rigorously does not apply to the control policies based on the trajectory optimization or policy search methods, such as PI2 [22] and REPS in Section 3.2, since these policy approximation methods usually only predict the optimal path distribution or optimal control policy, while leaving the value or desirability function unknown.
Illustrative Examples
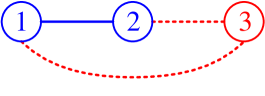
Distributed LSOC can be deployed on a variety of MASs in reality, such as the distributed HVAC system in smart buildings, cooperative unmanned aerial vehicle (UAV) teams, and synchronous wind farms. Motivated by the experiments in [31, 25, 30], we demonstrate the distributed LSOC algorithms with a cooperative UAV team in cluttered environment. Compared with these preceding experiments, the distributed LSOC algorithms in this paper allow to consider an explicit and simpler communication network underlying the UAV team, and the joint cost function between neighboring agents can be constructed and optimized with less computation. Consider a cooperative UAV team consisting of three agents illustrated in Figure 2. UAV 1 and 2, connected by a solid line, are strongly coupled via their joint cost functions and , and their local controllers and are designed to drive UAV 1 and 2 towards their exit state while minimizing the distance between two UAVs and avoiding obstacles. These setups are useful when we need multiple UAVs to fly closely towards an identical destination, e.g. carrying and delivering a heavy package together or maintaining communication channels/networks. By contrast, although UAV 3 is also connected with UAV 1 and 2 via dotted lines, the immediate cost function of UAV 3 is designed to be independent or fully factorized from the states of UAV 1 and 2 in each subsystem, such that UAV 3 is only loosely coupled with UAVs 1 and 2 through their terminal cost functions, which restores the scenario considered in [31, 25]. The local controller of UAV 3 is then synthesized to guide the UAV to its exit state with minimal cost. In the following subsections, we will verify both discrete-time and continuous-time distributed LSOC algorithms subject to this cooperative UAV team scenario.
UAVs wtih Discrete-Time Dynamics
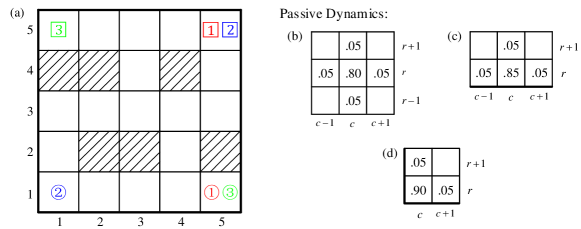
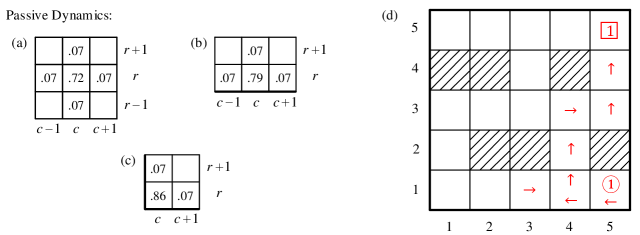
In order to verify the distributed LSMDP algorithm, we consider a cooperative UAV team described by the probability model introduced in Section 2.2. The flight environment is described by a grid with total cells to locate the positions of UAVs, and the shaded cells in Figure 3(a) represent the obstacles. Each UAV is described by a state vector , where and are respectively the row and column indices locating the UAV. The cell with circled index denotes the initial state of the UAV, and the one with boxed index indicates the exit state of the UAV. The passive transition probabilities of interior, edge, and corner cells are shown in Figure 3(b), Figure 3(c), and Figure 3(d), respectively, and the passive probability of a UAV transiting to an adjacent cell can be interpreted as the result of random winds. To fulfill the requirements of aforementioned scenario, the controlled transition distributions should i) drive UAV 1 and 2 to their terminal state while shortening the distance between two UAVs, and ii) guide UAV 3 to terminal state with minimum cost, which is related to obstacle avoidance, control cost, length of path, and flying time.
In order to realize these objectives, we consider the state-related cost functions as follows
| (47) | ||||
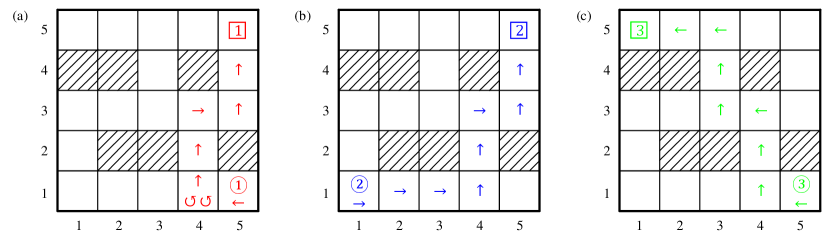
where in the following examples, weights on relative distance , defined by Manhattan distance, are ; state and obstacle cost when the UAV is in an obstacle cell, and when UAV is in a regular cell; and terminal cost for . State-related cost and , which involve both the states of UAV 1 and 2, can measure the joint performance between two UAVs, while cost only contains the state of UAV 3. Without the costs on relative distance, i.e. , this distributed LSMDP problem will degenerate to three independent shortest path problems with obstacle avoidance as considered in [31, 25, 30], and the optimal trajectories are straightforward‡‡‡The shortest path for UAV 1 is . There are three different shortest paths for UAV 2, and the shortest path for UAV 3 is shown in Figure 4 (c).. Desirability function and local optimal control distribution can then be computed by following Algorithm 1 in Appendix E. Figure 4 shows the maximum likelihood controlled trajectories of UAV team subject to passive dynamics in Figure 3 and cost functions (4.1). Some curious readers may wonder why UAV 1 in Figure 4(a) decides to stay in cell for two consecutive time steps rather than moving forward to and then flying along with UAV 2, which generates a lower state-related cost. While this alternative corresponds to a lower state-related cost, it may not be the optimal trajectory minimizing the control cost and the overall immediate cost in (7). In order to verify this speculation, we increase the passive transition probabilities to surpass certain thresholds in Figure 5(a)-(c), which can be interpreted as stronger winds in reality. With this altered passive dynamics and cost functions in (4.1), the maximum likelihood controlled trajectory of UAV 1 is shown in Figure 5(d), which verifies our preceding reasoning. Trajectories of UAV 2 and 3 subject to altered passive dynamics are identical to the results in Figure 4. To provide an intuitive view on the efficiency improvements of our distributed LSMDP algorithm, Figure 6 presents the average data size and computational complexity on each UAV (), gauged by the row number of matrices and vectors in (20) and (22), subject to the centralized programming (20) and parallel programming (22) in different communication network, such as line, ring, complete binary tree, and fully connected topology, which restores the scenario with exponential complexity considered in [31, 30].
UAVs wtih Continuous-Time Dynamics
In order to verify the continuous-time distributed LSOC algorithms, consider the continuous-time UAV dynamics described by the following equation [31, 52]:
| (48) |
where , , and respectively denote the position, forward velocity, and direction angle of the UAV; forward acceleration and angular velocity are the control inputs, and disturbance is a standard Brownian motion. Control transition matrix is a constant matrix in (48), and we set noise level parameters and in simulation. The communication network underlying the UAV team as well as the control objectives are the same as in the discrete-time scenario. Instead of adopting the Manhattan distance, the distance in continuous-time problem is associated with norm. Hence, we consider the state-related costs defined as follows
| (49) |
where is the weight on distance between the UAV and its exit position; is the weight on distance between the and UAVs; usually denotes the initial distance between the UAV and its destination, and denotes the initial distance between the and UAVs. The parameters and are chosen to regularize the numerical accuracy and stability of algorithms.
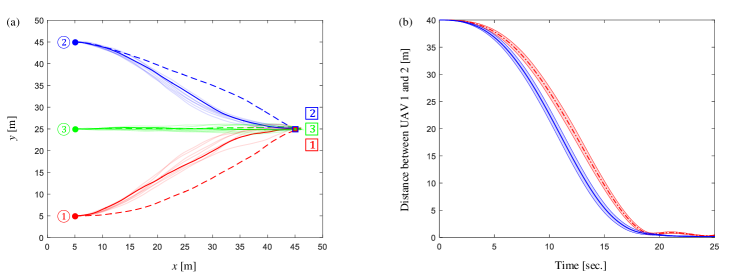
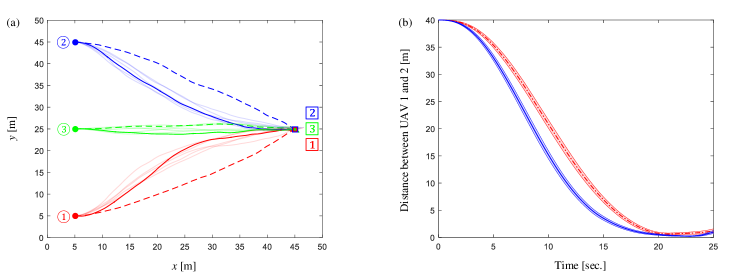
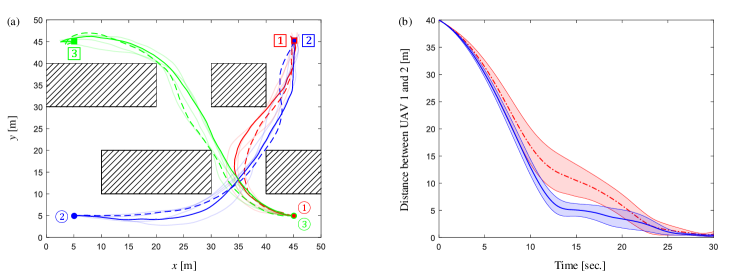
To show an intuitive improvement brought by the joint state-related cost, we first verify the continuous-time LSOC algorithm in a simple flight environment without obstacle. Consider three UAVs forming the network in Figure 2 and with initial states , , and identical exit state for . The exit time is , and the length of each control cycle is . When sampling trajectory roll-outs , the time interval from to is partitioned into intervals of equal length , i.e. , until becomes less than 0.2. Meanwhile, to make the exploration process more aggressive, we increase the noise level parameters and when sampling trajectory roll-outs. The size of data set for estimator (35) in each control cycle is sample trajectories, which can be generated concurrently by GPU [25]. Control weight matrices are selected as identity matrices. Guided by the sampling-based distributed LSOC algorithm, Algorithm 2 in Appendix E, UAV trajectories and the relative distance between UAV 1 and 2 in condition of both joint and independent state-related costs are presented in Figure 7. Letting update rate constraint be and the size of trajectory set be and for the initial and subsequent policy iterations in every control period, simulation results obtained from the REPS-based distributed LSOC algorithm, Algorithm 3 in Appendix E, are given in Figure 8. Figure 7 and Figure 8 imply that joint state-related costs can significantly influence the trajectories and shorten the relative distance between UAV 1 and 2, which fulfills our preceding control requirements.
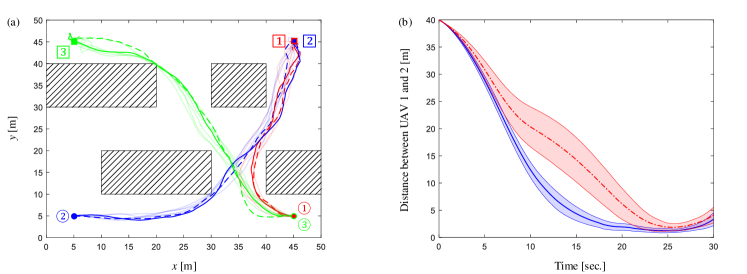
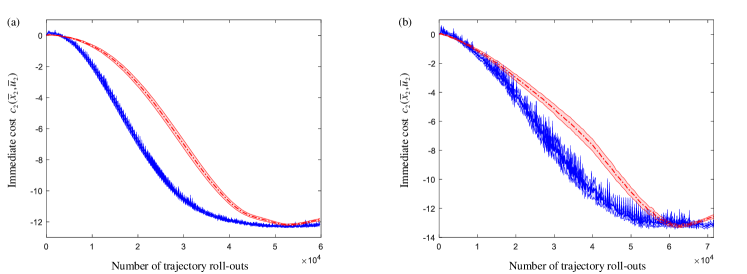
We then consider a cluttered flight environment as the discrete-time example. Suppose three UAVs forming the network in Figure 2 and with initial states , , and exit states , . The exit time is , and the length of each control cycle is . When sampling trajectory roll-outs , the time interval from to is partitioned into intervals of equal length. The size of is trajectory roll-outs when adopting random sampling estimator, and the other parameters are the same as in the preceding continuous-time example. Subject to the sampling-based distributed LSOC algorithm, UAV trajectories and the relative distance between UAVs 1 and 2 subject to both joint and independent state-related costs are presented in Figure 9. Letting the update rate constraint be and the size of trajectory set be and for the initial and subsequent policy iterations in every control period, experimental results obtained from the REPS-based distributed LSOC algorithm are given in Figure 10. Figure 9 and Figure 10 show that our continuous-time distributed LSOC algorithms can guide UAVs to their terminal states, avoid obstacles, and shorten the relative distance between UAVs 1 and 2. It is also worth noticing that since there exist more than one shortest path for UAV 2 in condition of factorized state cost (see the footnote in Section 4.1), the standard variations of distance in Figure 9 and Figure 10 are significantly larger than other cases. Lastly, we compare the sample-efficiency between the sampling-based and REPS-based distributed LSOC algorithms in preceding two continuous-time examples. Figure 11 shows the value of immediate cost function from subsystem versus the amount of trajectory roll-outs, and the maximum numbers of trajectory roll-outs on horizontal axes are determined by the REPS-based trails with minimum amounts of sample roll-outs. In Figure 11, we can tell that the REPS-based distributed LSOC algorithm is more sample-efficient than the sampling-based algorithm.
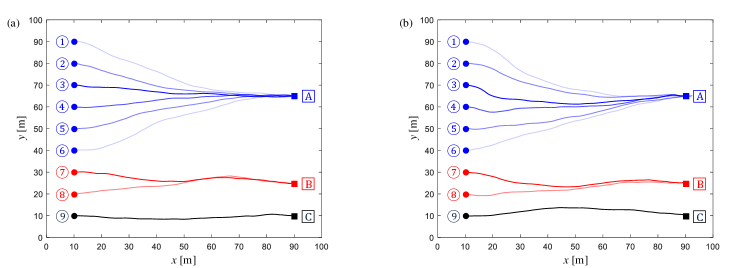
To verify the effectiveness of distributed LSOC algorithms in larger MAS with more agents, we consider a line-shape network consisting of nine UAVs as shown in Figure 12. These nine UAVs are initially distributed at as shown in Figure 13, and they can be divided into three groups based on their exit states. UAV 1 to 6 share a same exit state at ; the exit state of UAV 7 and 8 is at , and UAV 9 is expected to exit at state , , where the exit time . As exhibited in Figure 12, UAVs from different groups are either loosely coupled through their terminal cost functions or mutually independent, where the latter scenario does not require any communication between agents. A state-related cost function in subsystem is designed to consider and optimize the distances between neighboring agents and towards the exit state of agent :
where is the weight related to the distance between agent and ; when or ; is the regularization term for numerical stability, which is assigned by the initial distance between agents and in this demonstration, and the remaining notations and parameters are the same as the assignments in (49) and the first example in this subsection if not explicitly stated. Trajectories of UAV team subject to two distributed LSOC algorithms, Algorithm 2 and Algorithm 3 in Appendix E, are presented in Figure 13. For some network structures, such as line, loop, star and complete binary tree, in which the scale of every factorial subsystem is tractable, increasing the total number of agents in network will not dramatically boost the computational complexity on local agents thanks to the distributed LSOC framework proposed in this paper. Verification along with more simulation examples on the generalization of distributed LSOC controllers discussed in Section 3.3 is supplemented in [53].

Many interesting problems remain unsolved in the area of distributed (linearly solvable) stochastic optimal control and deserve further investigation. Most of existing papers, including this paper, assumed that the passive and controlled dynamics of different agents are mutually independent. However, when we consider some practical constraints, such as the collisions between different UAVs, the passive and controlled dynamics of different agents are usually not mutually dependent. Meanwhile, while this paper considered the scenario when all states of local agents are fully observable, it will be interesting to study the MAS of partially observable agents with hidden states. Lastly, distributed LSOC algorithms subject random network, communication delay, infinite horizon or discounted cost are also worth our attention.
Conclusion
Discrete-time and continuous-time distributed LSOC algorithms for networked MASs have been investigated in this paper. A distributed control framework based on factorial subsystems has been proposed, which allows to optimize the joint state or cost function between neighboring agents with local observation and tractable computational complexity. Under this distributed framework, the discrete-time multi-agent LSMDP problem was addressed by respectively solving the local systems of linear equations in each subsystem, and a parallel programming scheme was proposed to decentralize and expedite the computation. The optimal control action/policy for continuous-time multi-agent LSOC problem was formulated as a path integral, which was approximated by a distributed sampling method and a distributed REPS method, respectively. Numerical examples of coordinated UAV teams were presented to verify the effectiveness and advantages of these algorithms, and some open problems were given at the end of this paper.
Acknowledgments
This work was supported in part by NSF-NRI, AFOSR, and ZJU-UIUC Institute Research Program. The authors would like to appreciate the constructive comments from Dr. Hunmin Lee and Gabriel Haberfeld. In this arXiv version, the authors would also like to thank the readers and staff on arXiv.org.
Conflict of Interest Statement
The authors have agreed to publish this article, and we declare that there is no conflict of interests regarding the publication of this article.
Appendix A: Proof for Theorem 1
Proof for Theorem 1: Substituting the joint running cost function (7) into the joint Bellman equation (9), and by the definitions of KL-divergence and exponential transformation (17), we have
| (50) |
The optimal policy will be straightforward if we can rewrite the expectation on the RHS of (50) as a KL-divergence and exploit the minimum condition of KL-divergence. While the control mapping in (50) is a probability distribution, the denominator is not necessarily a probability distribution. Hence, we define the following normalized term
| (51) |
Since is a well-defined probability distribution, we can rewrite the joint Bellman equation (50) as follows
| (52) |
where only the last term depends on the joint control action . According to the minimum condition of KL-divergence, the last term in (52) attains its absolute minimum at if and only if
which gives the optimal control action (19) in Theorem 1. By substituting (19) into (52), we can minimize the RHS of joint Bellman equation (9) and remove the minimum operator:
| (53) |
Exponentiating both sides of (53) and substituting (17) and (51) into the result, the Bellman equation (53) can be rewritten as a linear equation with respect to the desirability function
| (54) |
which implies (18) in Theorem 1. This completes the proof. ∎
Appendix B: Proof for Theorem 2
Before we present the proof for Theorem 2, Feynman–Kac formula that builds an important relationship between parabolic PDEs and stochastic processes is introduced as Lemma 4.
Lemma 1.
[Feynman–Kac formula] Consider the Kolmogorov backward equation (KBE) described as follows
where the terminal condition is given by . Then the solution to this KBE can be written as a conditional expectation
under the probability measure that is an Itô diffusion process driven by the equation with initial condition . ∎
We now show the proof for Theorem 2.
Proof for Theorem 2: First, we show that the joint optimality equation (16) can be formulated into the joint stochastic HJB equation (24) that gives an analytic expression of optimal control action (25). Substituting immediate cost function (15) into optimality equation (16) and letting be a time step between and , optimality equation (16) can be rewritten as
| (55) |
With some rearrangements and dividing both sides of (55) by , we have
| (56) |
By letting , the optimality equation (56) becomes
| (57) |
Applying Itô’s formula [54], the differential in (57) can be expanded as
| (58) |
For conciseness, we will omit the indices (or subscripts) of state components, and , in the following derivations. Dividing both sides of (58) by , taking the expectation over all trajectories that initialized at and subject to control action , and substituting the joint dynamics (14) into the result, we have
| (59) |
where the identity derived from the property of standard Brownian motion is invoked, and operators and follow the same definitions in (13). Substituting (59) into (57), the joint stochastic HJB equation (24) in Theorem 2 is obtained
where the boundary condition is given by . The joint optimal control action can be obtained by setting the derivative of (24) with respect to equal to zero. When the control weights of each agent are coupled, i.e. the joint control weight matrix cannot be formulated as a block diagonal matrix, the joint optimal control action for subsystem is given as (25) in Theorem 2, , where denotes the gradient with respect to the joint state . However, it is more common in practice that the joint control weight matrix is given by as in (15), and the joint control cost satisfies . Setting the derivatives of (24) with respect to equal to zero in the latter case gives the local optimal control action of agent
| (60) |
For conciseness of derivations and considering the formulation of (24), we will mainly focus on the latter scenario, , in the remaining part of this proof.
In order to solve the stochastic HJB equation (24) and evaluate the optimal control action (25), we consider to linearize (24) with the Cole-Hopf transformation (23), . Subject to this transformation, the derivative and gradients in (24) satisfy
| (61) |
| (62) |
| (63) |
Equalities (62) and (63) will still hold when we replace the agent’s state in and by the joint state and reformulate the joint HJB (24) in a more compact form. Substituting local optimal control action (60), and gradients (62) and (63) into the stochastic HJB equation (24), the corresponding terms of each agent in (24) satisfy
| (64) | ||||
| (65) | ||||
By the properties of trace operator, the quadratic terms in (Appendix B: Proof for Theorem 2) and (Appendix B: Proof for Theorem 2) will be canceled if
| (66) |
i.e. , which is equivalent to the condition or subject to joint dynamics (14). Substituting (25), (61), (Appendix B: Proof for Theorem 2) and (Appendix B: Proof for Theorem 2) into stochastic HJB equation (24), we then remove the minimization operator and obtain the linearized PDE as (26) in Theorem 2
where the boundary condition is given by . Once the value of desirability function in (26) is solved, we can readily figure out the value function and joint optimal control action from (23) and (25), respectively. Invoking the Feynman–Kac formula introduced in Lemma 1, a solution to (26) can be formulated as (27) in Theorem 2
where satisfies the uncontrolled dynamics with initial condition . This completes the proof. ∎
Appendix C: Proof of Proposition 3
Proof of Proposition 3: First, we formulate the desirability function (27) as a path integral shown in (30). Partitioning the time interval from to into intervals of equal length , , we can rewrite (27) as the following path integral
| (67) |
where the integral of variable is over the set of all joint uncontrolled trajectories on time interval and with initial condition , which can be measured by agent at initial time , and the function is implicitly defined by
| (68) |
for arbitrary functions . Based on definition (68) and in the limit of infinitesimal , the function can be approximated by
| (69) |
where is the transition probability of uncontrolled dynamics from state-time pair to and can be factorized as follows
| (70) |
where is a Dirac delta function, since can be deterministically calculated from and . Provided the directly actuated uncontrolled dynamics from (29)
with Brownian motion , the directly actuated states and satisfy Gaussian distribution with covariance . When condition in Theorem 2 is fulfilled, the covariance is with . Hence, the transition probability in (70) satisfies
| (71) |
Substituting (69), (70) and (Appendix C: Proof of Proposition 3) into (67) and in the limit of infinitesimal , the desirability function can then be rewritten as a path integral
| (72) |
Defining a path variable , the discretized desirability function in (72) can be expressed as
| (73) | ||||
where is the path value for a trajectory starting at space-time pair or and takes the form of
is the generalized path value and satisfies , and the constant in (73) is related to the numerical stability, which demands a careful choice of and a fine partition over . Identical to the expectation in (27) and the integral in (67), the integral in (73) is subject to the set of all uncontrolled trajectories initialized at or . Summarizing the preceding deviations, (30) and (31) in Proposition 3 can be restored.
Substituting gradient (62) and discretized desirability function (72) into the joint optimal control action (25), we have
| (74) | ||||
(a) follows from the fact that is independent from the path variables ; (b) employs the differentiation rule for exponential function and requires that the integrand be continuously differentiable in and along the trajectory ; (c) follows from the optimal path distribution that satisfies
(d) follows the partitions and , and the initial control variable is determined by
| (75) | ||||
In the following, we calculate the gradients in (75). Since the terminal cost usually is a constant, the first gradient in (75) is zero, i.e. . When the immediate cost is a function of state , the second gradient in (75) can be computed as follows
| (76) |
when is not related to the value of , i.e. a constant or an indicator function, the second gradient is then zero. The third gradient in (75) follows
| (77) |
Letting and , the gradient of the fourth term in (75) satisfies
| (78) | ||||
Detailed interpretations on the calculation of (Appendix C: Proof of Proposition 3) can be found in [22, 55]. Meanwhile, after substituting (Appendix C: Proof of Proposition 3) into (74), one can verify that the integrals in (74) satisfy
| (79) | |||
| (80) |
Substituting (75-80) into (74), we obtain the initial control variable as follows
This completes the proof. ∎
Appendix D: Relative Entropy Policy Search
The local REPS algorithm in subsystem alternates between two steps, learning the optimal path distribution and updating the parameterized policy, till the convergence of the algorithm. First, we consider the learning step realized by the optimization problem (37). Since we want to minimize the relative entropy between the current approximate path distribution and the optimal path distribution , the objective function of the learning step follows
(a) transforms the minimization problem to a maximization problem and adopts the identity , where time arguments are generally omitted in this appendix for brevity; and (b) employs identity (33) and omits the terms that are independent from the path variable , since these terms have no influence on the optimization problem. In order to construct the information loss from old distribution and avoid overly greedy policy updates [21, 23], we restrict the update rate with constraint
where can be used as a trade-off between exploration and exploitation, and LHS is the relative entropy between the current approximate path distribution and the old approximate path distribution . Meanwhile, the marginal distribution needs to match the initial distribution , which is known to the designer. However, this condition could generate an infinite number of constraints in optimization problem (37) and is too restrictive for practice [50, 23, 34]. Hence, we relax this condition by only considering to match the state feature averages of initial state
where is a feature vector of initial state, and is the expectation of the state feature vector subject to initial distribution . In general, can be a vector made up with linear and quadratic terms of initial states, and , such that the mean and the covariance of marginal distribution match those of initial distribution . Lastly, we consider the following normalization constraint
| (81) |
which ensures that defines a probability distribution.
The optimization problem (37) can be solved analytically by the method of Lagrange multipliers. Defining the Lagrange multipliers , and vector , the Lagrangian is
| (82) | ||||
We can maximize the Lagrangian and derive the maximizer in (37) by letting . This condition will hold for arbitrary initial distributions if and only if the derivative of the integrand in (82) is identically equal to zero, i.e.
from which we can find the maximizer as shown in (38). In order to evaluate in (38), we then determine the values of dual variables and by solving the dual problem. Substituting (38) into the normalization constraint (81), we have the identity
| (83) |
which can be used to determine provided the values of and . To figure out the values of and , we solve the dual problem (39), where the objective function in (40) is obtained by substituting (38) and (83) into (82)
(a) substitutes (38) into (82), and (b) substitutes (83) into the result. By applying the Monte Carlo method and using the data set , the objective function (40) can be approximated from sample trajectories by
where and are respectively the generalized path value and state feature vector of sample trajectory , and the old path probability can be evaluated with the current or initial policy by
| (84) |
where the state variables , and in (84) are from sample trajectory ; the control policy is given either as an initialization or an optimization result from updating step (Appendix D: Relative Entropy Policy Search), and the controlled transition probability with can be obtained by following the similar steps when deriving the uncontrolled transition probability in (Appendix C: Proof of Proposition 3). When policy is Gaussian, (84) can be analytically evaluated.
In the policy updating step, we can find the optimal parameters for Gaussian policy by minimizing the relative entropy between the joint distribution from learning step (37) and joint distribution generated by parametric policy . To determine the policy parameters at time , we need to solve the following optimization problem, which is also a weighted maximum likelihood problem
| (85) | ||||
(a) converts the minimization problem to a maximization problem and replaces the joint distributions by the products of step-wise transition distributions; (b) employs the assumption that the distribution of controlled transition equals the product of passive transition distribution and control policy distribution [23], i.e. , and the control action from control affine system dynamics maximizes the likelihood function; (c) approximates the integral by using sample trajectories from ; (d) substitutes (38), and the weight of likelihood function is
Constant terms are omitted in steps (a) to (d).
Appendix E: Multi-Agent LSOC Algorithms
Algorithm 1 gives the procedures of distributed LSMDP algorithm introduced in Section 3.1.
Algorithm 1 Distributed LSMDP based on factorial subsystems
Algorithm 2 illustrates the procedures of sampling-based distributed LSOC algorithm introduced in Section 3.2.
Algorithm 2 Distributed LSOC based on sampling estimator
Algorithm 3 illustrates the procedures of REPS-based distributed LSOC algorithm introduced in Section 3.2.
Algorithm 3 Distributed LSOC based on REPS
References
- [1] R. Mahony, V. Kumar, and P. Corke, “Multirotor aerial vehicles: Modeling, estimation, and control of quadrotor,” IEEE Robotics & Systems Magazine, vol. 19, no. 3, pp. 20–32, 2012.
- [2] V. Cichella, R. Choe, S. B. Mehdi, E. Xargay, N. Hovakimyan, V. Dobrokhodov, I. Kaminer, A. M. Pascoal, and A. P. Aguiar, “Safe coordinated maneuvering of teams of multirotor unmanned aerial vehicles: A cooperative control framework for multivehicle, time-critical missions,” IEEE Control Systems Magazine, vol. 36, no. 4, pp. 59–82, 2016.
- [3] Y. Ota, H. Taniguchi, T. Nakajima, K. M. Liyanage, J. Baba, and A. Yokoyama, “Autonomous distributed V2G (Vehicle-to-Grid) satisfying scheduled charging,” IEEE Transactions on Smart Grid, vol. 3, no. 1, pp. 559–564, 2012.
- [4] F. Blaabjerg, R. Teodorescu, M. Liserre, and A. V. Timbus, “Overview of control and grid synchronization for distributed power generation systems,” IEEE Transactions on Industrial Electronics, vol. 53, no. 5, pp. 1398–1409, 2006.
- [5] J. M. Guerrero, M. Chandorkar, T. L. Lee, and P. C. Loh, “Advanced control architectures for intelligent microgrids — Part I: Decentralized and hierarchical control,” IEEE Transactions on Industrial Electronics, vol. 60, no. 4, pp. 1254–1262, 2013.
- [6] F. Dorfler, J. W. Simpson-Porco, and F. Bullo, “Breaking the hierarchy: Distributed control and economic optimality in microgrids,” IEEE Transactions on Control of Network Systems, vol. 3, no. 3, pp. 241–253, 2016.
- [7] P. Leitao, “Agent-based distributed manufacturing control: A state-of-the-art survey,” Engineering Applications of Artificial Intelligence, vol. 22, no. 7, pp. 979–991, 2009.
- [8] C. Amato, G. Chowdhary, A. Geramifard, N. K. Ure, and M. J. Kochenderfer, “Decentralized control of partially observable Markov decision processes,” in 52nd IEEE Conference on Decision and Control, Florence, Italy, 2013.
- [9] A. Bensoussan, J. Frehse, and P. Yam, Mean Field Games and Mean Field Type Control Theory. Springer, 2013.
- [10] Y. Cao, W. Yu, W. Ren, and G. Chen, “An overview of recent progress in the study of distributed multi-agent coordination,” IEEE Transactions on Industrial Informatics, vol. 9, no. 1, pp. 427–438, 2013.
- [11] F. L. Lewis, H. Zhang, K. Hengster-Movric, and A. Das, Cooperative Control of Multi-Agent Systems: Optimal and Adaptive Design Approaches. Springer, 2013.
- [12] K. K. Oh, M. C. Park, and H. S. Ahn, “A survey of multi-agent formation control,” Automatica, vol. 53, pp. 424–440, 2015.
- [13] J. Qin, Q. Ma, Y. Shi, and L. Wang, “Recent advances in consensus of multi-agent systems: A brief survey,” IEEE Transactions on Industrial Electronics, vol. 64, no. 6, pp. 4972–4983, 2017.
- [14] K. Zhang, Z. Yang, and T. Basar, “Multi-agent reinforcement learning: A selective overview of theories and algorithms,” arXiv, no. 1911.10635, 2019.
- [15] W. H. Fleming, “Exit probabilities and optimal stochastic control,” Applied Mathematics and Optimization, vol. 4, no. 1, pp. 329–346, 1977.
- [16] E. Todorov, “Linearly-solvable Markov decision problems,” in Advances in Neural Information Processing Systems, Vancouver, Canada, 2007.
- [17] Y. Pan, E. A. Theodorou, and M. Kontitsi, “Sample efficient path integral control under uncertainty,” in Advances in Neural Information Processing Systems, Montreal, Canada, 2015.
- [18] E. Todorov, “Compositionality of optimal control laws,” in Advances in Neural Information Processing Systems, Vancouver, Canada, 2009.
- [19] A. Kupcsik, M. P. Deisenroth, J. Peters, L. A. Poh, P. Vadakkepat, and G. Neumann, “Model-based contextual policy search for data-efficient generalization of robot skills,” Artificial Intelligence, vol. 247, p. 415–439, 2017.
- [20] G. Williams, P. Drews, B. Goldfain, J. M. Rehg, and E. A. Theodorou, “Information-theoretic model predictive control: Theory and applications to autonomous driving,” IEEE Transactions on Robotics, vol. 34, no. 6, pp. 1603–1622, 2018.
- [21] J. Peters, K. Mulling, and Y. Altun, “Relative entropy policy search,” in 24th AAAI Conference on Artificial Intelligence, Atlanta, USA,, 2010.
- [22] E. A. Theodorou, “A generalized path integral control approach to reinforcement learning,” Journal of Machine Learning Research, no. 11, pp. 3137–3181, 2010.
- [23] V. Gomez, H. J. Kappen, J. Peters, and G. Neumann, “Policy search for path integral control,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 2014.
- [24] P. Guan, M. Raginsky, and R. M. Willett, “Online Markov decision processes with Kullback–Leibler control cost,” IEEE Transactions on Automatic Control, vol. 59, no. 6, pp. 1423–1438, 2014.
- [25] G. Williams, A. Aldrich, and E. A. Theodorou, “Model predictive path integral control: From theory to parallel computation,” Journal of Guidance, Control, and Dynamics, vol. 40, no. 2, pp. 344–357, 2017.
- [26] C. Guestrin, D. Koller, and R. Parr, “Multiagent planning with factored MDPs,” in Advances in Neural Information Processing Systems, Vancouver, Canada, 2002.
- [27] R. Becker, S. Zilberstein, V. Lesser, and C. V. Goldman, “Solving transition independent decentralized Markov decision processes,” Journal of Artificial Intelligence Research, vol. 22, p. 423–455, 2004.
- [28] K. Zhang, Z. Yang, H. Liu, T. Zhang, and T. Basar, “Fully decentralized multi-agent reinforcement learning with networked agents,” Proceedings of Machine Learning Research, vol. 80, pp. 5872–5881, 2018.
- [29] K. Zhang, Z. Yang, and T. Basar, “Decentralized multi-agent reinforcement learning with networked agents: Recent advances,” arXiv, no. 1912.03821, 2019.
- [30] B. C. Daniel, “Cross-entropy method for Kullback-Leibler control in multi-agent systems,” Master’s thesis, Universitat Pompeu Fabra, 2017.
- [31] B. Broek, W. Wiegerinck, and B. Kappen, “Graphical model inference in optimal control of stochastic multi-agent systems,” Journal of Artificial Intelligence Research, no. 32, pp. 95–122, 2008.
- [32] R. P. Anderson and D. Milutinovic, “Stochastic optimal enhancement of distributed formation control using Kalman smoothers,” Robotica, vol. 32, pp. 305–324, 2014.
- [33] N. Wan, A. Gahlawat, N. Hovakimyan, E. A. Theodorou, and P. G. Voulgaris, “Cooperative path integral control for stochastic multi-agent systems,” arXiv, no. 2009.14775, 2020.
- [34] R. Sutton and A. G. Barto, Reinforcement Learning: An Introduction. MIT Press, 2018.
- [35] R. Olfati-Saber, J. A. Fax, and R. M. Murray, “Consensus and cooperation in networked multi-agent systems,” Proceedings of the IEEE, vol. 95, no. 1, pp. 215–233, 2007.
- [36] E. Todorov, “Eigenfunction approximation methods for linearly-solvable optimal control problems,” in IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning, Nashville, USA, 2009.
- [37] H. J. Kappen, “Linear theory for control of nonlinear stochastic systems,” Physical Review Letters, no. 95, pp. 200 201–1–4, 2005.
- [38] E. Todorov, “Efficient computation of optimal actions,” Proceedings of the National Academy of Sciences, vol. 106, no. 28, pp. 11 478–11 483, 2009.
- [39] R. Johari and J. N. Tsitsiklis, “Efficiency loss in a network resource allocation game,” Mathematics of Operations Research, vol. 29, no. 3, pp. 407–435, 2004.
- [40] A. Nedic, A. Ozdaglar, and P. A. Parrilo, “Constrained consensus and optimization in multi-agent networks,” IEEE Transactions on Automatic Control, vol. 55, no. 4, pp. 922–938, 2010.
- [41] P. G. Voulgaris and N. Elia, “Social optimization problems with decentralized and selfish optimal strategies,” in 56th IEEE Conference on Decision and Control, Melbourne, Australia, 2017.
- [42] S. Mou, J. Liu, and A. S. Morse, “A distributed algorithm for solving a linear algebraic equation,” IEEE Transactions on Automatic Control, vol. 60, no. 11, pp. 2863–2878, 2015.
- [43] J. Liu, S. Mou, and A. S. Morse, “Asynchronous distributed algorithms for solving linear algebraic equations,” IEEE Transactions on Automatic Control, vol. 63, no. 2, pp. 372–385, 2018.
- [44] W. Shi, J. Cao, Q. Zhang, Y. Li, and L. Xu, “Edge computing: Vision and challenges,” IEEE Internet of Things Journal, vol. 3, no. 5, pp. 637 – 646, 2016.
- [45] K. Bakshi, D. Fan, and E. A. Theodorou, “Schrödinger approach to optimal control of large-size populations,” arXiv, no. 1810.06064, 2018.
- [46] K. Bakshi, P. Grover, and E. A. Theodorou, “On mean field games for agents with Langevin dynamics,” IEEE Transactions on Control Systems Technology, 2019.
- [47] P. D. Moral, Feynman-Kac Formulae: Genealogical and Interacting Particle Systems with Applications. Springer, 2004.
- [48] E. A. Theodorou, “Nonlinear stochastic control and information theoretic dualities: Connections, interdependencies and thermodynamic interpretations,” Entropy, vol. 17, no. 5, pp. 3352–3375, 2015.
- [49] G. Boutselis, M. Pereira, and E. A. Theodorou, “Variational inference for stochastic control of infinite dimensional systems,” arXiv, no. 1809.03035, 2018.
- [50] A. G. Kupcsik, M. P. Deisenroth, J. Peters, and G. Neumann, “Data-efficient generalization of robot skills with contextual policy search,” in AAAI Conference on Artificial Intelligence, Bellevue, USA, 2013.
- [51] F. D. M. Da Silva and J. Popovic, “Linear Bellman combination for control of character animation,” ACM Transactions on Graphics, vol. 28, no. 3, pp. 82:1–10, 2009.
- [52] W. Yao, N. Qi, N. Wan, and Y. Liu, “An iterative strategy for task assignment and path planning of distributed multiple unmanned aerial vehicles,” Aerospace Science and Technology, vol. 86, pp. 455–464, 2019.
- [53] L. Song, N. Wan, A. Gahlawat, N. Hovakimyan, and E. A. Theodorou, “Compositionality of linearly solvable optimal control in networked multi-agent systems,” arXiv, no. 2009.13609, 2020.
- [54] J. F. Le Gall, Brownian Motion, Martingales, and Stochastic Calculus. Springer, 2016.
- [55] E. A. Theodorou, “Iterative path integral stochastic optimal control: Theory and applications to motor control,” Ph.D. dissertation, Dept. of Computer Sci., Univ. of Southern California, Los Angeles, California, USA, 2011.