Distilling Governing Laws and Source Input for Dynamical Systems from Videos
Abstract
Distilling interpretable physical laws from videos has led to expanded interest in the computer vision community recently thanks to the advances in deep learning, but still remains a great challenge. This paper introduces an end-to-end unsupervised deep learning framework to uncover the explicit governing equations of dynamics presented by moving object(s), based on recorded videos. Instead in the pixel (spatial) coordinate system of image space, the physical law is modeled in a regressed underlying physical coordinate system where the physical states follow potential explicit governing equations. A numerical integrator-based sparse regression module is designed and serves as a physical constraint to the autoencoder and coordinate system regression, and, in the meanwhile, uncover the parsimonious closed-form governing equations from the learned physical states. Experiments on simulated dynamical scenes show that the proposed method is able to distill closed-form governing equations and simultaneously identify unknown excitation input for several dynamical systems recorded by videos, which fills in the gap in literature where no existing methods are available and applicable for solving this type of problem.
1 Introduction
Discovery of governing equations (e.g., PDEs, ODEs) has the potential to advance our understanding, modeling and prediction of the behavior of complex dynamical systems. Increasing richness of collecting data and advances in machine learning gave rise to a new perspective of dynamical system modeling, e.g., data-driven discovery of governing equations recently Brunton et al. (2016). Advances in deep learning, especially convolutional neural networks (CNNs), have led to keen interest in uncovering physical law directly from videos that record dynamical processes Chen et al. (2021). In earlier deep learning approaches, explicit physical law was distilled from the motion trajectory which was extracted by supervised regression ahead Belbute-Peres et al. (2018). Later, unsupervised moving object localization techniques promoted the parameter estimation of dynamical systems in an unsupervised scheme Jaques et al. (2020). While since the moving object is localized in image space, these approaches can only learn simple physical laws or their parameters which are modeled in pixel coordinate system such as billiards, gravity, spring, bouncing, etc. Jaques et al. (2020); Kossen et al. (2020). Furthermore, in most of existing methods, the form of physical engine is given and incorporated with motion representative extraction module, which restricts their application to real scenarios where the mathematical form/structure of physical law is unknown.
Study on data-driven governing equations discovery started with and, today, still mainly focus on building mathematical models from given measurement of physical states (e.g., trajectory time series) Kutz et al. (2016); Brunton et al. (2016); Rudy et al. (2019); Udrescu and Tegmark (2020). Later, advances in deep learning led to expanded interests in physical law discovery from videos instead, a subset of physical scene understanding. Inspired by powerful feature extraction ability, deep neural network was initially leveraged to learn “blur” physics from videos, in which the physical laws are not expressed explicitly but simulated or condensed as physical modules Fragkiadaki et al. (2016); Ehrhardt et al. (2017). Later, the incorporation of physical engines/modules with extracted object-based representations improved the description or prediction of physical videos Purushwalkam et al. (2019); Wu et al. (2017); Ye et al. (2018). Although some of those approaches considered interpretable parameters in the physical modules like object mass, position, speed and friction Wu et al. (2017); Ye et al. (2018), the physical laws are still not explicitly discovered and the physics are condensed as state space, or simulated as neural physics engines/modules.
In order to improve the interpretability of the discovered physical laws, learning explicit dynamics (e.g., closed-form governing equations or their parameters) has recently become more popular in physical scene understanding. Several hybrid methods take a data-driven approach to estimate real mechanical process from video sequences Wu et al. (2015, 2016), or model Newtonian physics via latent variable to predict motion trajectories in images Mottaghi et al. (2016). Since the discovery of explicit physical laws requires extracting the motion of moving object, two-step staggered discovery has become the most common strategy, where the physical law is distilled after the moving trajectory being extracted Wu et al. (2017); Belbute-Peres et al. (2018); Ehrhardt et al. (2018). Advances in unsupervised object localization techniques like based on spatial transformers (ST) Kosiorek et al. (2018); Hsieh et al. (2018); Ehrhardt et al. (2018) and Position-Velocity Encoders (PVEs) Jonschkowski et al. (2017) have enabled the explicit physical law discovery in an unsupervised scheme Kossen et al. (2020); Jaques et al. (2020). However, these approaches require strong prior knowledge on the structure of the physical law or governing equation (e.g., the equation form is given while the coefficients need to be discovered). Furthermore, for those methods, physics is modeled in pixel coordinates which restricts the discovery for complex dynamical systems (e.g., ODEs) where the physical states need to be described in another physical coordinate system.
Attempts also have been made to uncover the closed-form governing equations in the context of low-dimensional representations from videos or high-dimensional data. One approach to discover the governing equations and the associated coordinate system from high-dimensional data is proposed in Champion et al. (2019), while this approach was only able to handle the “video” which can be explicitly expressed as a function of physical latent and fails to deal with real raw videos. The unsupervised physical parameter estimation method proposed in Jaques et al. (2020) can only discover from videos the parameters of given physical laws which are established in the context of pixel coordinates. In addition, a two-step deep learning based method was developed for closed-form governing equation discovery from distorted videos Udrescu and Tegmark (2021), while this method is not in an end-to-end scheme and cannot deal with systems excited by unknown input. Hence, uncovering governing equations straightly from raw videos still remains a grand challenge, especially when the source input is unknown.
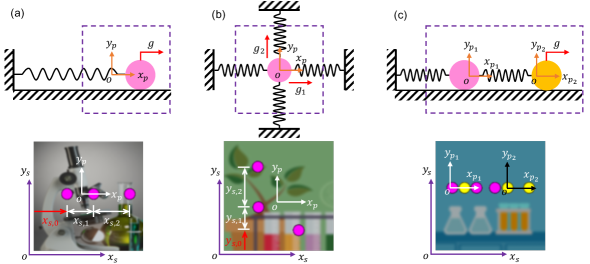
In this work, we propose an end-to-end unsupervised deep learning framework to uncover from videos the closed-form governing equations of dynamical systems subjected to unknown input. The task we intend to resolve, as shown in Figure 1, demonstrates the paradigm we build seeking to simultaneously extract the physical states of moving object(s), uncover their governed closed-form equations, and identify the system input. Unlike the existing deep learning methods which typically discover physical laws from spatial/pixel coordinate trajectories of moving object(s), our method uncovers the explicit governing equations from the physical states in a regressed physical coordinate system instead, which makes it possible to discover more complex dynamical systems. Furthermore, we consider the form/structure of governing equation unknown a priori and employ sparse regression to distill its formulation. In addition, the physical states are extracted not independently from the encoder-decoder and physical coordinate system regression but under the constraint of underlying physical law. The joint optimization not only helps the extraction of physical states, but also leads to the identification of closed-form governing equations and unknown input, which forms our key contribution.
2 Methodology
In this section, we first introduce the designed network architecture for governing equations discovery from videos, which is assembled with three segments: (1) an encoder-decoder to condense the high-dimensional image into low dimensional latent space, (2) physical coordinate system regression to create the mapping between the spatial/pixel coordinates of moving object(s) and their physical states for underlying explicit physical law, and (3) physical embedding which serves as a constraint for the extraction of physical states, and, meanwhile, uncovers their governed equation and the unknown excitation. The definition of loss function and the network training strategy are also provided in the following.
2.1 Network Architecture
In order to learn the governing equations from videos, several components are considered in place. First of all, the high-dimensional image is condensed into low-dimensional latent variables, the spatial (pixel) coordinates of moving object(s), by the encoder-decoder. A new physical coordinate system is regressed to map the spatial coordinates into physical sates where the underlying physical law is presented. Since the potential governing equations are assumed to be parsimonious and can be described with fewest terms necessary, we leverage a library, composed of a finite number of pre-defined possible candidate terms in the context of physical states, to regress the equations parameterized by their unknown coefficients. Then the physical law constraint is imposed to the physical states by the sparse regression and the physics forward with a 4th-order Runge-Kutta method. In addition, the unknown input can be identified by embedding it into the physical constraint. The designed network architecture is depicted in Figure 2. Figure 2(A) shows the high-level view of the network architecture which involves the forward propagation of physics by considering two consecutive video frames. All components making up the high-level network are discussed as follows and more information about the network can be found in Supplementary Information (SI)222see https://github.com/LeleLuan/VideoDiscovery Section 2.1.
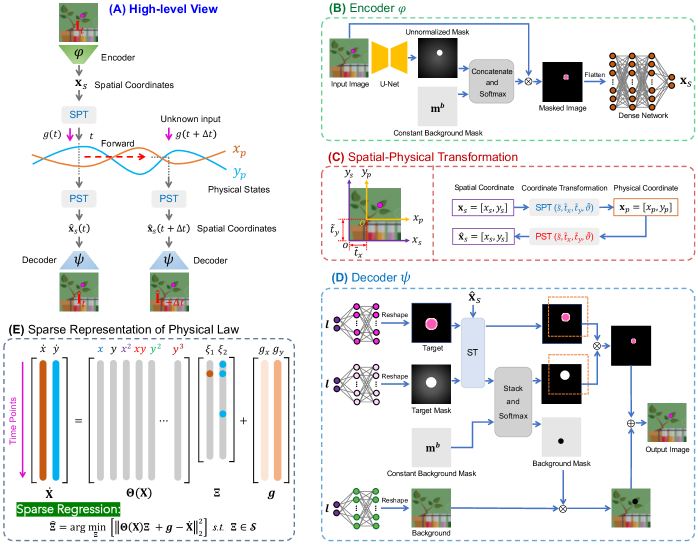
Encoder:
A two-stage localization network Jaques et al. (2020) is employed as encoder to condense the image space into low-dimensional latent variables. It takes a single video frame as input and outputs a vector corresponding to the 2D spatial coordinates of moving objects. First, the input frame is passed through a U-Net to produce unnormalized masks for moving object(s). The unnormalized masks are concatenated with a constant background mask and then passed through a Softmax to produce the masks for the moving object(s) and background. The multiplication between input and masks are fed into a fully-connected network to obtain the spatial coordinates of the moving object(s). The output layer of the encoder depends on the number of coordinates needed to describe the object location. For a 2D physical system with image size of , the latent space has two variables and the activation of output layer has a saturating non-linearity , which leads to the spatial coordinate of the moving object with values in .
Coordinate-Consistent Decoder:
The decoder takes the spatial coordinates of moving object(s) as input and outputs a reconstructed image. Instead of using conventional decoders, the decoder imposed by a fixed relationship between latent spatial coordinate and pixel-coordinate correspondence is employed to reconstruct the video frame. The Coordinate-Consistent Decoder developed in Jaques et al. (2020) is built on the spatial transformer (ST) network. If the input spatial coordinate for one object to decoder is , the parameters of ST is to place the center of the writing attention window for moving object at this point. In this Coordinate-Consistent Decoder, the moving object(s) and their masks, and the background are learned by independent networks separately. Then the video frames are reconstructed by the composition of background and the moving object(s) the positions of which are determined by the input spatial coordinates with STs. It should be highlighted that, the Coordinate-Consistent Decoder may not able to capture the real (or absolute) locations of moving object(s) in image space (e.g., and in Figure 1) especially for the videos with moving object(s) showing up in limited positions. While the relative locations of the object(s) moving at different time steps can be captured (e.g., and in Figure 1), which plays a key role in the following physical trajectory extraction via Spatial-Physical Transformation.
Physical Coordinate System Regression:
The Encoder and Coordinate-Consistent Decoder introduced above are expected to extract the spatial coordinates of all moving objects in the scene. An underlying physical coordinate system is then regressed to map the extracted spatial coordinates into physical states which present the potential governing equations. As shown in Figure 1, if we assume the dynamics is present in a 2D space which is parallel to the image space, the transformation between spatial coordinates and physical states can be implemented by a standard 2D Cartesian coordinate transformation. For one moving object, with translation vector and scaling factor , the physical coordinate (state) can be obtained from spatial coordinate by . Likewise, the physical to spatial transformation can be expressed as . Here, and share the same parameters of and in a complete encoder-decoder. It should be noted that different coordinate systems are regressed for different moving objects when the scene has multiple objects. The transformation factors are trainable variables and will be learned in the whole network training. As shown in Figure 2(A), with the Encoder , Coordinate-Consistent Decoder and coordinate transformers ( and ), a complete autoencoder is built for the condensation of video frames into latent space, the physical states of moving object(s). The standard autoencoder loss function can be expressed as: .
Physical Law Embedding and Discovery:
For the studied dynamical systems shown in Figure 1, the potential ODEs followed by moving object trajectories are distilled by sparse regression. When the dynamical system has one moving object with physical states , the considered dynamics can be expressed by , where , a trainable array, represents the unknown system input which is constant for one dynamical system with different initial conditions. We seek a parsimonious model for , resulting in a function that contains only a few active terms. If the derivatives of the physical states are calculated, the snapshots are stacked to form data matrices and where is the number of data points of the physical states. Although is unknown, we can construct an extensive library of candidate functions , where each denotes a candidate term. The candidate function library is used to formulate an over-determined system , where the unknown matrix is the set of coefficients that determine the active terms from in the dynamics . For the candidate function library, can be any candidate function that may describe the system dynamics such as . By solving the optimization, the model of system dynamics can be identified . The coefficients are learned concurrently with the neural network parameters as part of the training process. With the time derivative of physical states being calculated by the central difference method, one can enforce accurate modeling of the dynamics by incorporating the following physical state derivative term into the loss function: .
As shown in Figure 2, the forward propagation of physics also brings an additional physical constraint which is imposed to the physical states. With the true vector field being estimated by , integrating over a segment of time to gives the integrated vector field, or flow map . A 4th-order Runge-Kutta (RK4) numerical method is employed to simulate the dynamics 1-step forward as . Then the forward video frame can be reconstructed via the decoder as , which leads to the forward video frame reconstruction loss: .
2.2 Loss Functions and Network Training
In addition to three loss terms given above, an regularizer on the sparse regression coefficients is included, which promotes sparsity of the coefficients and therefore encourages a parsimonious model for the dynamics. The combination of 4 loss terms leads to the overall loss function:
| (1) |
where the hyperparameters , , determine the relative weighting of the 3 loss function terms. The detailed definition of loss functions is given in SI Section 2.2. The network is trained using a multi-step training strategy to succeed the discovery, which includes pre-training, total loss training, sequential thresholding, and refinement training. In the designed network, the trainable variables include variables in encoder-decoder, transformation factors and in physical coordinate system regression, coefficients for candidate functions in sparse regression, and system input array . Although some of the trainable variables are not independent, e.g., and , the network is still able to achieve the discovery thanks to the constraint of physical law and the sparsity of governing equation. More information about the multi-step training strategy and the choice of hyperparameters are provided in SI Section 2.3 and SI Section 2.4.
3 Experiments
We demonstrate the efficacy of our proposed method on several dynamical systems shown in Figure 1 (including SMSD, SMTD, TMTD). The studied videos are generated by plotting the lumped mass(es) according to the simulated physical trajectories on different backgrounds. More details of the dataset generation are given in SI Section 1. Our method aims to uncover the closed-form governing equations for the moving object(s) and identify the unknown source input. It should be noted that, since the studied dynamical systems follow second-order ODEs, the discovery is conducted by transferring the underlying equations into first-order state-space models. More information about the discovery on state-space modeling is given in SI Section 2.5. In addition, the robustness of this method on discovery to noise, ablation studies, and baseline comparison are also discussed in this section.
3.1 Discovery Result
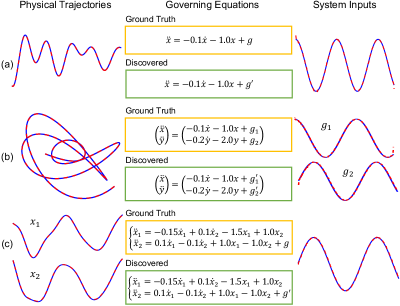
The discovery results for the studied dynamical systems are presented in Figure 3, where the physical trajectories, their governing equations, and the external excitation are uncovered. It shows that the governing equations especially their coefficients are identified exactly the same as the ground truth. It should be noted that, in the discovered ODEs, both candidate function terms and input are unknown. The discovered equations are still satisfied although physical states and input have scaling or drift discrepancy to the ground truth. While after scaling and translation, the physical states and inputs learned from the network match to the ground truth very well. The discovery result for the TMTD system also shows that our method is able to handle the scenarios when multiple moving objects show up in the scene. Because different moving objects may follow different physical laws in different physical coordinate systems, the network is equipped with multiple coordinate regression and sparse regression for both physical trajectory extraction and governing equation discovery. Furthermore, because the dynamics presented by those two moving objects are not independent, the physical states (, , and ) and their derivatives (, , and ) are considered in building the sparse regression for their governing equation discovery. In addition to the studied linear dynamical system, our method was also tested on discovering the governing equation of a nonlinear dynamical system (see SI Section 4.4). The detailed information for each dynamical system discovery is given in SI Section 4.
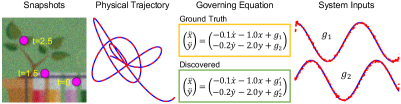
3.2 Robustness to Noise
The robustness of our proposed method to noise is further tested by discovering the governing equation from videos with noise. Here, we take the SMTD system as the testing example where Gaussian noise with zero mean and variance is added to all video frames. The discovery result is presented in Figure 4. It shows that, although the noise in the videos is against the assumption that both moving object(s) and background are constant for all images in the ST-based Coordinate-Consistent Decoder, our method still achieves the correct discovery. Due to the effect of noise, compared to the discovery from videos without noise, the identified system input is noisier. Nevertheless, the governing equations and the physical trajectory are still uncovered and extracted correctly.
3.3 Ablation Study
In the proposed method, the spatial coordinates of moving object(s) learned from Encoder and Coordinate-Consistent Decoder are mapped into physical states by a regressed physical coordinate system. Here, the ablation study is implemented by removing the Spatial-Physical Transformation and then imposing the physical law constraint to spatial coordinates directly to test the necessity of physical coordinate system regression. The SMSD system is taken as the example for this ablation study. In the network training, the physical states derivative loss is quite large after pre-training and this loss term does not converge at all in optimizing the pre-trained model with total loss function. This is because the underlying physical law is not presented in pixel coordinate, adding physical law constraint to spatial coordinate directly will lead to high physical derivative loss and this loss term does not converge in the total loss optimization.
3.4 Baseline Comparison
We found that the literature remains scant in uncovering governing equations for dynamical systems with unknown input directly from videos. The most related work was presented in Champion et al. (2019) where an autoencoder-based deep learning model was built to discover low-dimensional dynamics and their associated coordinates from high-dimensional data. As a baseline, this coordinate and governing equation discovery method must be adapted slightly to account for unknown source input. In this baseline, the SINDy module has the same candidate functions as the sparse regression used in our discovery. Besides, the original RGB videos are converted into gray scale to calculate the required derivatives. More details on this baseline are provided in SI Section 5. The SMSD system is taken as an example. The training process shows that the reconstruction loss and SINDy loss in ( for the first-order ODE discovery) can achieve small values (e.g., and respectively) while the SINDy loss in remains almost constant (e.g., 0.34). After sequential thresholding in the training process, the identified coefficient matrix as shown in Figure 5 has no sparsity. The failure of this baseline method is because the raw video images cannot be treated as an explicit function of some latent variables, the case for which this baseline method is only applicable.
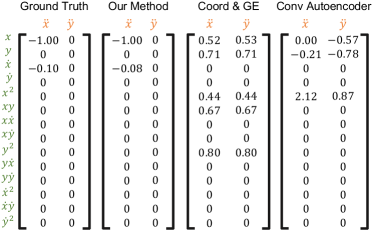
In addition, we replace the coordinate-consistent encoder-decoder shown in Figure 2 by a conventional convolutional encoder-decoder and take the resulting method as another baseline. In this baseline, the video frame is condensed into low-dimensional latent variables by convolutional layers and the Spatial-Physical Transformation module is removed. The physical law constraint is still imposed to the latent variables. More information about this convolutional encoder-decoder baseline is given in SI Section 5. The identified coefficient matrix is shown in Figure 5. Once the model is trained, the autoencoder loss, physical states derivative loss and forward frame reconstruction loss become very small (e.g., , and ), which demonstrates that this network is able to distill a physical law from videos. However, since the extracted latent variables cannot correctly represent the location-based physical states, the method fails to uncover the underlying physical law. Furthermore, the fixed relationship between the physical states and real locations of the moving object(s) cannot be guaranteed by the conventional autoencoder.
4 Conclusions
This paper presents an end-to-end unsupervised deep learning scheme to uncover the explicit interpretable physical laws from raw videos that record moving object(s) representing dynamical systems excited by unknown input. Our approach takes the advantage of the spatial transformer (ST) based Coordinate-Consistent Decoder to capture the relative location of object(s) moving at different snapshots in the image space. In the physical coordinate system regression, the underlying coordinate system(s) are learned to map the spatial/pixel coordinates of moving object(s) into physical states where the dynamics may be explicitly and parsimoniously expressed. The form of governing equations for the extracted physical states is modeled by parametric linear combination of candidate functions, leading to a sparse regression problem. The sparse regression not only enables the physical law to be embedded into the network, but also provides a physical constraint to the extraction of physical states from the autoencoder and coordinate system regression. The efficacy of our proposed method is validated by uncovering the governing equations of several dynamical systems with different numbers of object in the scene. The robustness of our proposed method to noise is also tested. Our work is the first attempt to discover the interpretable physical laws from raw videos for dynamical systems with unknown input excitation. Our method also holds some limitations,. For example, it cannot deal with non-stationary background, video with warp, and moving objects in a 3D space. We are motivated to address these challenges in our ongoing and future study.
Acknowledgments
The work is supported by the Beijing Outstanding Young Scientist Program (No. BJJWZYJH012019100020098) as well as the Intelligent Social Governance Platform, Major Innovation & Planning Interdisciplinary Platform for the “Double-First Class” Initiative, Renmin University of China. Source codes and datasets are found in https://github.com/LeleLuan/VideoDiscovery.
References
- Belbute-Peres et al. [2018] Filipe de A Belbute-Peres, Kevin A Smith, Kelsey R Allen, Joshua B Tenenbaum, and J Zico Kolter. End-to-end differentiable physics for learning and control. Advances in Neural Information Processing Systems, 31:7178–7189, 2018.
- Brunton et al. [2016] Steven L Brunton, Joshua L Proctor, and J Nathan Kutz. Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proceedings of the National Academy of Sciences, 113(15):3932–3937, 2016.
- Champion et al. [2019] Kathleen Champion, Bethany Lusch, J Nathan Kutz, and Steven L Brunton. Data-driven discovery of coordinates and governing equations. Proceedings of the National Academy of Sciences, 116(45):22445–22451, 2019.
- Chen et al. [2021] Zhenfang Chen, Jiayuan Mao, Jiajun Wu, Kwan-Yee Kenneth Wong, Joshua B Tenenbaum, and Chuang Gan. Grounding physical concepts of objects and events through dynamic visual reasoning. International Conference on Learning Representations, 2021.
- Ehrhardt et al. [2017] Sebastien Ehrhardt, Aron Monszpart, Niloy J Mitra, and Andrea Vedaldi. Learning a physical long-term predictor. arXiv preprint arXiv:1703.00247, 2017.
- Ehrhardt et al. [2018] Sebastien Ehrhardt, Aron Monszpart, Niloy Mitra, and Andrea Vedaldi. Unsupervised intuitive physics from visual observations. In Asian Conference on Computer Vision, pages 700–716. Springer, 2018.
- Fragkiadaki et al. [2016] Katerina Fragkiadaki, Pulkit Agrawal, Sergey Levine, and Jitendra Malik. Learning visual predictive models of physics for playing billiards. In International Conference on Learning Representations, 2016.
- Hsieh et al. [2018] Jun-Ting Hsieh, Bingbin Liu, De-An Huang, Li Fei-Fei, and Juan Carlos Niebles. Learning to decompose and disentangle representations for video prediction. In Advances in Neural Information Processing Systems, pages 515–524, 2018.
- Jaques et al. [2020] Miguel Jaques, Michael Burke, and Timothy Hospedales. Physics-as-inverse-graphics: Unsupervised physical parameter estimation from video. In International Conference on Learning Representations, 2020.
- Jonschkowski et al. [2017] Rico Jonschkowski, Roland Hafner, Jonathan Scholz, and Martin Riedmiller. Pves: Position-velocity encoders for unsupervised learning of structured state representations. arXiv preprint arXiv:1705.09805, 2017.
- Kosiorek et al. [2018] Adam R Kosiorek, Hyunjik Kim, Ingmar Posner, and Yee Whye Teh. Sequential attend, infer, repeat: generative modelling of moving objects. In Advances in Neural Information Processing Systems, pages 8615–8625, 2018.
- Kossen et al. [2020] Jannik Kossen, Karl Stelzner, Marcel Hussing, Claas Voelcker, and Kristian Kersting. Structured object-aware physics prediction for video modeling and planning. International Conference on Learning Representations, 2020.
- Kutz et al. [2016] J Nathan Kutz, Steven L Brunton, Bingni W Brunton, and Joshua L Proctor. Dynamic mode decomposition: data-driven modeling of complex systems. SIAM, 2016.
- Mottaghi et al. [2016] Roozbeh Mottaghi, Hessam Bagherinezhad, Mohammad Rastegari, and Ali Farhadi. Newtonian scene understanding: Unfolding the dynamics of objects in static images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3521–3529, 2016.
- Purushwalkam et al. [2019] Senthil Purushwalkam, Abhinav Gupta, Danny M Kaufman, and Bryan Russell. Bounce and learn: Modeling scene dynamics with real-world bounces. International Conference on Learning Representations, 2019.
- Rudy et al. [2019] Samuel Rudy, Alessandro Alla, Steven L Brunton, and J Nathan Kutz. Data-driven identification of parametric partial differential equations. SIAM Journal on Applied Dynamical Systems, 18(2):643–660, 2019.
- Udrescu and Tegmark [2020] Silviu-Marian Udrescu and Max Tegmark. AI Feynman: A physics-inspired method for symbolic regression. Science Advances, 6(16):2631, 2020.
- Udrescu and Tegmark [2021] Silviu-Marian Udrescu and Max Tegmark. Symbolic pregression: discovering physical laws from distorted video. Physical Review E, 103(4):043307, 2021.
- Wu et al. [2015] Jiajun Wu, Ilker Yildirim, Joseph J Lim, Bill Freeman, and Josh Tenenbaum. Galileo: Perceiving physical object properties by integrating a physics engine with deep learning. Advances in Neural Information Processing Systems, 28:127–135, 2015.
- Wu et al. [2016] Jiajun Wu, Joseph J Lim, Hongyi Zhang, Joshua B Tenenbaum, and William T Freeman. Physics 101: Learning physical object properties from unlabeled videos. In BMVC, volume 2, page 7, 2016.
- Wu et al. [2017] Jiajun Wu, Erika Lu, Pushmeet Kohli, Bill Freeman, and Josh Tenenbaum. Learning to see physics via visual de-animation. In Advances in Neural Information Processing Systems, pages 153–164, 2017.
- Ye et al. [2018] Tian Ye, Xiaolong Wang, James Davidson, and Abhinav Gupta. Interpretable intuitive physics model. In Proceedings of the European Conference on Computer Vision (ECCV), pages 87–102, 2018.