Discovering Intrinsic Reward with Contrastive Random Walk
Abstract
The aim of this paper is to demonstrate the efficacy of using Contrastive Random Walk as a curiosity method to achieve faster convergence to the optimal policy. Contrastive Random Walk defines the transition matrix of a random walk with the help of neural networks. It learns a meaningful state representation with a closed loop. The loss of Contrastive Random Walk serves as an intrinsic reward and is added to the environment reward. Our method works well in non-tabular sparse reward scenarios, in the sense that our method receives the highest reward within the same iterations compared to other methods. Meanwhile, Contrastive Random walk is more robust. The performance doesn’t change much with different random initialization of environments. We also find that adaptive restart and appropriate temperature are crucial to the performance of Contrastive Random Walk.
1 Introduction
Reinforcement learning (RL) learns policies that maximize the reward given by the environment. Methods considering only the environment rewards work well when rewards are dense. However, when the rewards are sparse, exploration has been proven important to make faster convergence of finding optimal policy. In the past few decades, dozens of methods have been proposed to encourage exploration by introducing an exploration bonus as an intrinsic rewards, which decides based on the chosen time of a certain state[3, 1, 15].
With the advance of RL, people are interested in applying it to more complicated scenarios, where the observations are some high-dimensional signals (e.g. video frame)[9]. To understand the signals and better define states, instead of human definition, features extracted by neural networks are applied to represent states[9, 17]. It provokes two notable changes in the definition of states: states become high-dimensional and states are no longer invariant to observations. These changes make counting the visits to certain states unavailable.
To deal with the problem that traditional exploration rewards can’t be used in complicated environments, researchers propose the concept of curiosity and use neural network loss as rewards[15]. Neural networks are good at understanding high-dimensional signals and have astonishing generalization ability[13], which perfectly fits the scenario. The loss of neural networks can be viewed as a pseudo-count, that is lower when the state is frequently visited and higher for un-visited states.
However, two problems remain with many existing curiosity methods. On one hand, many of the methods lack mathematical foundations. The intuition of why these methods work is unclear. On the other hand, neural networks in most curiosity methods neural networks only serve as function fitters and are not extracting meaningful features. We argue that these neural networks can also help build a better state encoder if properly designed. Good state representations can thus further leverage the generalization ability of neural networks and implicitly create a good clustering of observations. Such clusters can well define curiosity for similar observations, i.e. intrinsic rewards will not decrease when seeing exactly the same observations, but will also decrease for similar states. More meaningful representations will be better at defining what is "similar".
To tackle these two problems, we proposed applying Contrastive Random Walk (CRW) as a curiosity method[8]. CRW can extract meaningful representations from time series by creating a closed-loop for the series. In RL, experience is naturally a time series and hence CRW could also be able to extract good state representations. Meanwhile, we provide a mathematical proof that the loss of CRW is a good approximation to the information gain, which is a good measurement of how visited a state is.
We tested our method on two environments: "MountainCar-v0" and "Montezuma’s Revenge". Both environments have sparse environment rewards and thus good exploration strategies are critical to ensure a faster convergence of policy. Meanwhile, both environments use neural networks to get state representations. MountainCar-v0 is a simple environment where the agent’s task is to reach the top of the mountain within less time. The observation is some attributes of the car, including speed and position. While Montezuma’s Revenge is a more complicated environment… The observation is just video frames. Our method has obtained better performance than all the other baselines, including the curiosity method, count-based method, and randomized strategy. Meanwhile, our methods are less subject to randomness of environments and randomness of policy that can give similar performance on all kinds of random initialization compared to other methods.
2 Preliminary and Notations
2.1 Reinforcement Learning
Given a Markov decision process (MDP), which can be described as , where is the state space, is the action space, is the probability distribution over transitions, is the environment reward function, and is the discount factor. We will focus on infinite-horizon MDPs.
2.2 Intrinsic Reward
We define an exploration bonus based on the current state and add it to the reward given by the environment, getting a total reward . The goal of the addition of exploration bonus is to embed the new reward to existing reinforcement learning algorithms and help to make a better policy.
2.3 Non-tabular State Representation
The non-tabular environment of reinforcement learning can be viewed as an infinite-horizon stochastic dynamic programming, where states are some high-dimensional representations extracted by neural networks, denoted as , , where is the observation (video frame). A prominent characteristic of non-tabular states is that the state representations are variant. As a neural network is applied and updated with experience, state representation of observations will change (i.e. will be updated with time). performance for count-based methods.
3 Related Works
3.1 Curiosity Driven Intrinsic Reward
In order to make count-based methods also work for non-tabular state representations, discrete "counts" are changed into some density and continuous functions[3]. However, this approximation also incurs performance drop for count based methods. Therefore, curiosity methods are proposed to create a new kind of exploration bonus for non-tabular states.
Curiosity driven intrinsic rewards encourages the agent to explore the environment by learning an intrinsic reward besides the environment reward[5, 15, 4, 16, 6]. The intrinsic reward is given by neural network loss.
where C is a constant.
It applies the fact that if an input has been seen, loss of the neural network will decrease, indicating a lower intrinsic reward. Neural network loss style intrinsic reward also applies the generalization ability that makes it suitable for continuous state representation[13]. The loss will drop for exactly the same input , but also states with similar feature to , which makes it appropriate for non-tabular tasks.
There are mainly two types of curiosity methods: action dependent methods and state-only methods. State-only methods only use state representations from observations as inputs to the neural network[5, 16, 10]. Action dependent methods take both actions and state representations as input into neural networks[15, 6].
3.2 Information gain as Measurement of Intrinsic Reward
The information gain or mutual information is defined as:
For curiosity methods, information gain is made larger for unvisited states, while lower for frequently visited states to encourage the agent exploring the environment.
There exist various definitions of information gain in Reinforcement Learning[17, 20]. We will use the state-only transition information, which has been proved to be a good indicator for state representation[17].
In non-tabular scenario, we can change it to
. And the intrinsic reward for is thus
3.3 State Representation Learning
There are a bunch of previous works on how to extract better state representations[19, 12, 17, 7]. Better representations have been proved to be crucial to make RL algorithms perform better in many scenarios. Our work is most similar to [7], where the information gain is used to evaluate how good a representation is. The goal of this paper is to maximize information gain between inputs and outputs of the state encoder. Our method is also arguably increasing such information gain.
4 Contrastive Random Walk

Inspired by previous work, we view each experience as a reversible process[8]. Given an experience starting with , ending with , we also obtained another experience starting with , ending with . We concatenate the reverse experience to the original experience as shown in Figure1. We give each state an embedding, denoting the encoder as .
where is the similarity between embeddings. is the temperature, which is a constant in softmax. By using the softmax, we make this affinity matrix also a transition matrix. Then we can define a continuous transition from t to t+k.
Intuitively, it just predicts the state of t+k given state of t. Our goal is defined as:
When the objective function is minimized, each affinity matrix will be a one-hot matrix containing only 0 and 1, with one 1 in each row and column. This is to give a one-by one map from previous state the current state. Each node in the previous state embedding aims to maximize the similarity with another node in the current state, and minimize the similarity with all the other nodes in the current state, which can be viewed as a contrastive learning with n-1 negative samples.
For the intrinsic reward at each state, we use
starting from state and ends with . A simple choice of will be 1 for all states if we use the replay buffer and Deep Deterministic Policy Gradient algorithm. If the batch contains the entire experience, we can set . It can provide implicitly supervision to intermediate states.
4.1 Adaptive Restart
Since the environment we use is quite simple, the convergence of CRW is often too fast, and results in the intrinsic reward approaching zero with more iterations. Therefore, we applied the strategy of adaptive restart in optimization to settle the problem[14]. The parameters of CRW encoder are reset after the average intrinsic reward is smaller than a threshold. A psuedo code of our method can be found in Algorithm 1.
Input: , threshold, temperature
#x size:
4.2 Approximation to Information Gain
For the contrastive random walk,
where is the discounted state distribution for backtracing states, and is the discounted state distribution for forward states.
Because the backtracing gives exact the same states of forward path,
is not determined by the contrastive random walk, we just replace it by a constant .
Contrastive random walk optimizes the second term, such that:
Denote , and when is close to 1, the above equation can be approximated by:
Remove the constant , we get
This approximation is sufficient as the goal of contrastive random walk is to maximize .
Thus, we can rewrite the information gain as:
Then, by optimizing the information gain of , we are also optimizing the information gain of , as they share the same state representation.
5 Experiments
5.1 Training Settings
5.1.1 Environments
Because of the lack of computational resources, we use a simple environment called "MountainCar-v0" [11], to test our methods and other baselines. In the MountainCar-v0 environments(shown in Figure 2), a car is originally located in the valley and the agents are forced to learn a policy which can drive up the car from the bottom to the mountain on the right. However, since the car’s engine is not strong enough, the only way to succeed is to drive back and forth to build up momentum. The entire environment has an observation of 2 dimension , denoting the position of the car on the X-axis and the velocity of the car; three action space , standing for accelerating right, left, or not. In order to encourage the agents to arrive at the destination as fast as possible, a reward of -1 is given at each step when the car hasn’t arrived, and the total steps in one episode are 200, meaning the reward is ranging from -200 to 0.

5.2 Implementation Details
To test the effectiveness of the exploration bonus we proposed, we combine our CRW Intrisic Reward with a Deep Q Network(DQN) backbone. Here we use a three-layer MLP with the default hidden dimensions (256,128,64) with 0.3 dropout ratio as our state encoder and Q-network. We compare our methods with several exploring baselines, which are Epsilon-greedy, Upper Confidence Bound (UCB), and Random Network Distillation(RND). These baseline models will use the same DQN as backbone. Q value is updated with the function
The target and predictor network of RND will share the same architecture of state encoder of our CRW. The main hyper-parameters and their default value used in the experiments are, temperature , DQN learning rate , state encoder learning rate , restart running loss threshold , batch size , replay buffer size , episode num . And the entire experiment is carried out on one NVIDIA RTX 3080 GPU. More details can be found in the code.
5.3 Results
Here we report the performance of our CRW and other baselines in Figure 3. Our methods reach a final episode running reward of -110.607, which greatly surpasses all the other baselines, where epsilon greedy achieves -139.57, UCB achieves -121.037 and RND achieves -118.297. Meanwhile, we also observe that our methods begin to have rewards earlier than other networks. This phenomenon shows that our method wastes less efforts on testing a similar states, which benefits the convergence speed.

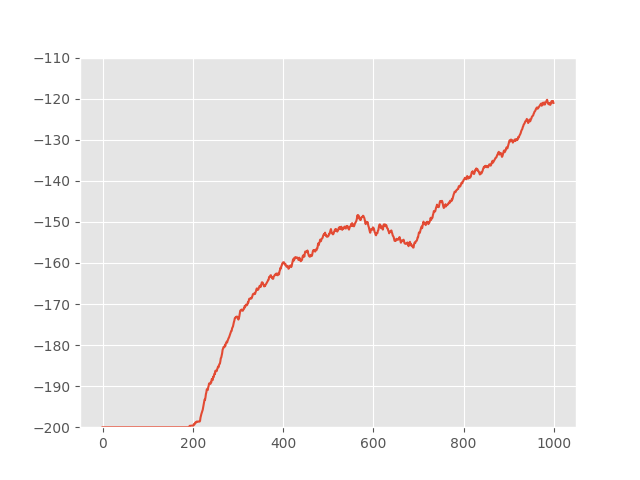


5.4 Ablation Study
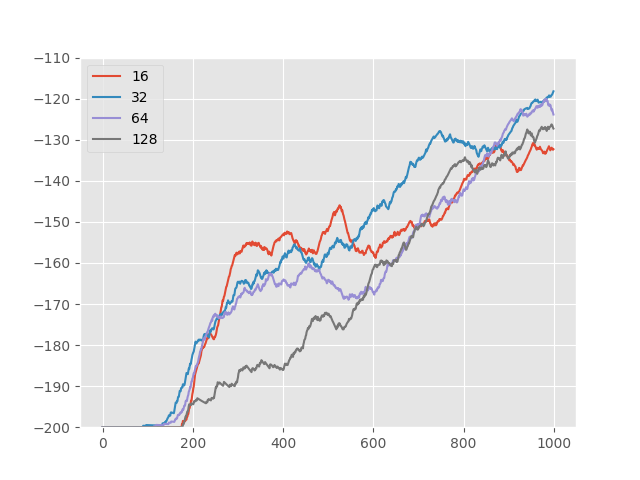
Here we show how each hyperparameter will contribute to the final results of our methods in Figure 4. The hyper-parameter tuned including feature dimension of the state encoder, temperature of crw, batch size during training and learning rate. Except for the parameter of being tuned, other parameters are set as default.



5.5 Discussion
As shown in the results, temperature is an important factor to improve model performance. We find that the reward at 1000 iteration is linearly related to the choice of temperature. Generally, a small temperature with adaptive restart works better. Also, we found that adaptive restart is essential for CRW. When the restart threshold is set smaller, the performance of CRW may drop significantly.
6 Experiments on more complicated environments
Besides the “MountainCar-v0" [11] environment, we also tried to implement our algorithm on the classic atari game “MontezumaRevenge-v0" [2] which has a sparse reward. As a traditional arcade game 5, the observation space of the game is a RGB image with hieght 210 pixels and width 160 pixels. The aim for the agent is to go through different rooms and get as many points as possible. Former work [5] showed that with the help of intrinsic rewards, the agent can get out of the first room and gain points while normal RL algorithms fail to get a single point.

6.1 Implementation Details
For the agent network, we used an actor-critic architecture with cnn state encoder. We use a PPO [18] training method to update the networks, which is a same architecture suggested in the RND model [5]. To get the experience, we implement 64 workers using python multiprocessing. We also set the PPO learning rate . For the CRW model that we proposed, we used a slightly different mean of encoding.
The pre-processing of the observations starts with compressing the image into a 160*160 large image. Getting the compressed image, we split the image into 16 patches, each of 64*64 large. The overlapping region between neighboring patches is used to avoid missing information near the edges. After getting the 16 patches of images, we use a 4-layer convolution network with leakyrelu as activation layer to get the embedding of each patch. With these 16 embedding, we implement the CRW model and get the intrinsic reward. To further extract property of the moving characters, we use a localized method, which also extract 16 smaller patches around the moving character to produce intrinsic reward. We trained the network on a NVIDIA RTX 3080 GPU. More implementation details can be found in the code.
6.2 Results and qualitative analysis
Because of the lack of computational resource, we just tried the implementation for 300 episodes and investigated the change of intrinsic reward. Because 300 episodes were not enough for the agent to get out of the first room, the implementation was in fact a purely exploration problem. As is shown in Figure 6, we can see that as the episode number increase, the intrinsic reward given by our CRW model first increase and then decrease, showing that the exploring first arise curiosity of the world, and then after many states are visited, the model lose the curiosity, thus the loss will drop to a lower value. This implies that our model can do the job of helping the algorithm to explore more unvisited states.

7 Conclusion
We demonstrated a new intrinsic reward with Contrastive Random Walk that achieves better performance than other methods on sparse-reward non-tabular scenarios. This method has a more solid mathematical foundation related to information gain, and whose neural network learns meaningful representations of states. These two advantages ensures our method also has the potential to provide good results in more complicated environments. Our success also provokes thinking on the importance of learning a good representation win the meantime of exploring the environment. It also encourages us to explore the mathematical proof of a faster conversion using this method as future work.
References
- [1] Peter Auer. Using confidence bounds for exploitation-exploration trade-offs. Journal of Machine Learning Research, 3(Nov):397–422, 2002.
- [2] M. G. Bellemare, Y. Naddaf, J. Veness, and M. Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47:253–279, jun 2013.
- [3] Marc Bellemare, Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, and Remi Munos. Unifying count-based exploration and intrinsic motivation. Advances in neural information processing systems, 29, 2016.
- [4] Yuri Burda, Harri Edwards, Deepak Pathak, Amos Storkey, Trevor Darrell, and Alexei A Efros. Large-scale study of curiosity-driven learning. arXiv preprint arXiv:1808.04355, 2018.
- [5] Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation. arXiv preprint arXiv:1810.12894, 2018.
- [6] Ildefons Magrans de Abril and Ryota Kanai. Curiosity-driven reinforcement learning with homeostatic regulation. In 2018 international joint conference on neural networks (ijcnn), pages 1–6. IEEE, 2018.
- [7] R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization. arXiv preprint arXiv:1808.06670, 2018.
- [8] Allan Jabri, Andrew Owens, and Alexei Efros. Space-time correspondence as a contrastive random walk. Advances in neural information processing systems, 33:19545–19560, 2020.
- [9] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. nature, 518(7540):529–533, 2015.
- [10] Shakir Mohamed and Danilo Jimenez Rezende. Variational information maximisation for intrinsically motivated reinforcement learning. Advances in neural information processing systems, 28, 2015.
- [11] Andrew William Moore. Efficient memory-based learning for robot control. Technical report, University of Cambridge, 1990.
- [12] Ofir Nachum, Shixiang Gu, Honglak Lee, and Sergey Levine. Near-optimal representation learning for hierarchical reinforcement learning. arXiv preprint arXiv:1810.01257, 2018.
- [13] Behnam Neyshabur, Zhiyuan Li, Srinadh Bhojanapalli, Yann LeCun, and Nathan Srebro. Towards understanding the role of over-parametrization in generalization of neural networks. arXiv preprint arXiv:1805.12076, 2018.
- [14] Brendan O’donoghue and Emmanuel Candes. Adaptive restart for accelerated gradient schemes. Foundations of computational mathematics, 15(3):715–732, 2015.
- [15] Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised prediction. In International conference on machine learning, pages 2778–2787. PMLR, 2017.
- [16] Deepak Pathak, Dhiraj Gandhi, and Abhinav Gupta. Self-supervised exploration via disagreement. In International conference on machine learning, pages 5062–5071. PMLR, 2019.
- [17] Kate Rakelly, Abhishek Gupta, Carlos Florensa, and Sergey Levine. Which mutual-information representation learning objectives are sufficient for control?, 2021.
- [18] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017.
- [19] Adam Stooke, Kimin Lee, Pieter Abbeel, and Michael Laskin. Decoupling representation learning from reinforcement learning. In International Conference on Machine Learning, pages 9870–9879. PMLR, 2021.
- [20] Stas Tiomkin and Naftali Tishby. A unified bellman equation for causal information and value in markov decision processes. arXiv preprint arXiv:1703.01585, 2017.