Discourse-Aware Emotion Cause Extraction in Conversations
Abstract
Emotion Cause Extraction in Conversations (ECEC) aims to extract the utterances which contain the emotional cause in conversations. Most prior research focuses on modelling conversational contexts with sequential encoding, ignoring the informative interactions between utterances and conversational-specific features for ECEC. In this paper, we investigate the importance of discourse structures in handling utterance interactions and conversation-specific features for ECEC. To this end, we propose a discourse-aware model (DAM) for this task. Concretely, we jointly model ECEC with discourse parsing using a multi-task learning (MTL) framework and explicitly encode discourse structures via gated graph neural network (gated GNN), integrating rich utterance interaction information to our model. In addition, we use gated GNN to further enhance our ECEC model with conversation-specific features. Results on the benchmark corpus show that DAM outperform the state-of-the-art (SOTA) systems in the literature. This suggests that the discourse structure may contain a potential link between emotional utterances and their corresponding cause expressions. It also verifies the effectiveness of conversational-specific features. The codes of this paper will be available on GitHub111http://github.com/.
1 Introduction
Emotion cause extraction in conversations (ECEC) is an important task in conversation analysis. It has received increasing attention Poria et al. (2021); Wang et al. (2021b) with the open conversational data deluge on social media platforms. Similar to text-level emotion cause extraction (ECE) Lee et al. (2010), this task aims to identify utterances that contain explanations for emotional causes in the given conversation. The right part of Fig. 1 shows an example of ECEC. The emotion of the target utterance “That sounds wonderful. Will there be anyone there that I know?” is “happiness”. The cause utterance spans of it are “inviting you to a dinner party”, “it would be fun”, and “It will give my wife a chance to dress up”, It suggests that explicit emotion causes aforementioned could be helpful for many downstream tasks, such as opinion mining Choi et al. (2005); Das and Bandyopadhyay (2010).

ECE has been investigated intensively since early research Lee et al. (2010); Chen et al. (2010). It can be treated as a classification task which requires the contexts of a document as inputs and determine whether each clause is a cause. Recently, several neural models for ECE have been proposed Ding and Kejriwal (2020); Li et al. (2021c); Hu et al. (2021a), using pre-trained language models such as BERT Devlin et al. (2018) and RoBERTa Liu et al. (2019) to represent the plain texts. Compared with text-level ECE, the research of emotion cause extraction in conversation is at its preliminary stage. Poria et al. (2021) propose this task for the first time, and apply neural approaches of text-level emotion cause extraction Wei et al. (2020); Ding et al. (2020a, b).
Above traditional approaches treat conversational contexts as common plain text while using a Transformer-based encoder Liu et al. (2019) to learn the conversational context representation for the ECEC task Poria et al. (2021). These approaches ignore the interaction information between utterances and conversational-specific features. The problem could be serious when performing the ECEC task in long conversations.
The discourse structures in a conversation represent the interactive relationships between utterances. Intuitively, these structures contain the potential links between emotional utterances and their corresponding cause expressions. As shown by the solid arc on the left in Fig. 1, most of the emotion-cause pairs are linked with the target utterance by discourse relations. In addition, several findings of previous studies on ECE support our point of view. For instance, Hu et al. (2021b); Ding et al. (2019) believe that the interaction features between sentences could be useful information for the ECE task.
In this paper, we propose a discourse-aware model for ECEC. Concretely, we model ECEC and discourse parsing in conversations Afantenos et al. (2015) jointly. It uses a shared pre-trained language model (PLM) to represent conversational contexts. The discourse parsing task can integrate rich utterance interactions information into the shared PLM. Besides, we use a gated graph neural network (gated GNN) Li et al. (2016) to explicitly encode discourse structures that generated by the discourse parser. In addition, we follow Wang et al. (2021a), exploiting a gated GNN to further integrate conversation-specific features such as the relative utterance distance and speakers to our model.
We conduct the experiments on the standard benchmark dataset of the ECEC task to verify our DAM model. Experiments show that the utterance interaction features are effective for this task. When the conversation-specific features are integrated by gated GNN, the proposed model is able to obtain further improvements.
To sum up, we make three main contributions as follows:
-
We propose a discourse-aware model for ECEC named DAM using multiple task learning and a gated GNN, which is able to integrate rich utterance interaction features for ECEC.
-
We further exploit a gated GNN to capture conversation-specific features such as the relative utterance distance and speakers for ECEC.
-
We advance the performance of the SOTA models for ECEC.
We organize the rest of this paper as follows. First, in Section 2, we introduce the related work. Following in Section 3, we introduce the proposed model, including the multi-task learning framework, and the gated GNN module. Section 4 and Section 5 describes our experiments on a benchmark dataset, verifying the effectiveness of our proposed approach. Finally, we make conclusions on Section 6.
2 Related Work
Prior research on emotion cause extraction can be divided into two categories according to the source text type: text-level emotion cause extraction (ECE) and emotion cause extraction in conversation (ECEC) Poria et al. (2021). For the ECE task, early research adopts linguistic rules Lee et al. (2010); Chen et al. (2010); Russo et al. (2011) and traditional machine learning Gui et al. (2014, 2016, 2018); Xu et al. (2017). In recently years, several neural network models are introduced to the ECE task with different granularities, such as clause-level Diao et al. (2020); Ding and Kejriwal (2020); Hu et al. (2021a) and span-level Li et al. (2021c, a); Qian et al. (2021); Turcan et al. (2021); Li et al. (2021b). Except for the text-level emotion cause extraction, Poria et al. (2021) introduces a new conversational dataset RECCON and the Transformer-based baseline models.
Many researchers realize that there is a connection between ECE task and emotion recognition task. In order to make full use of the interaction between tasks, researchers use the multi-task framework to carry out ECE task Chen et al. (2018); Wu et al. (2020). In addition, researchers take causal reasoning as an auxiliary task Fan et al. (2020); Turcan et al. (2021) to enhance the reasoning ability of the model. However, most of these methods only focus on the interaction between tasks, without considering the dependency between clauses or utterances, which is easy to cause long-distance information loss. Chen et al. (2020); Hu et al. (2021b) use GCN and other methods to capture the dependency between clauses. Although these methods of ECE have realized the importance of interaction information between clauses, they only use simple structural information such as distance to model the dependency between clauses. We use discourse structures to make full use of the interaction information between utterances, which can be beneficial to encode long-distance dependency.
Most of the existing ECEC works do not consider the influence of the discourse relation between utterances and conversation-specific features. Intuitively, utterance interactions information such as discourse structures are promising for the ECEC task. In this paper, we employ discourse parsing as an auxiliary task by multi-task learning framework He et al. (2021); Fan et al. (2021) to capture utterance interaction information. To model conversation-specific features, we refer Wang et al. (2021a); Li et al. (2016) to utilize a gated graph neural network (gated GNN). We also use gated GNN to further enhance discourse structure by encoding a discourse graph. Finally, a gate controlled mechanism is applied to alleviate the error propagation problem from predicted discourse structures.
3 Our Proposed Model
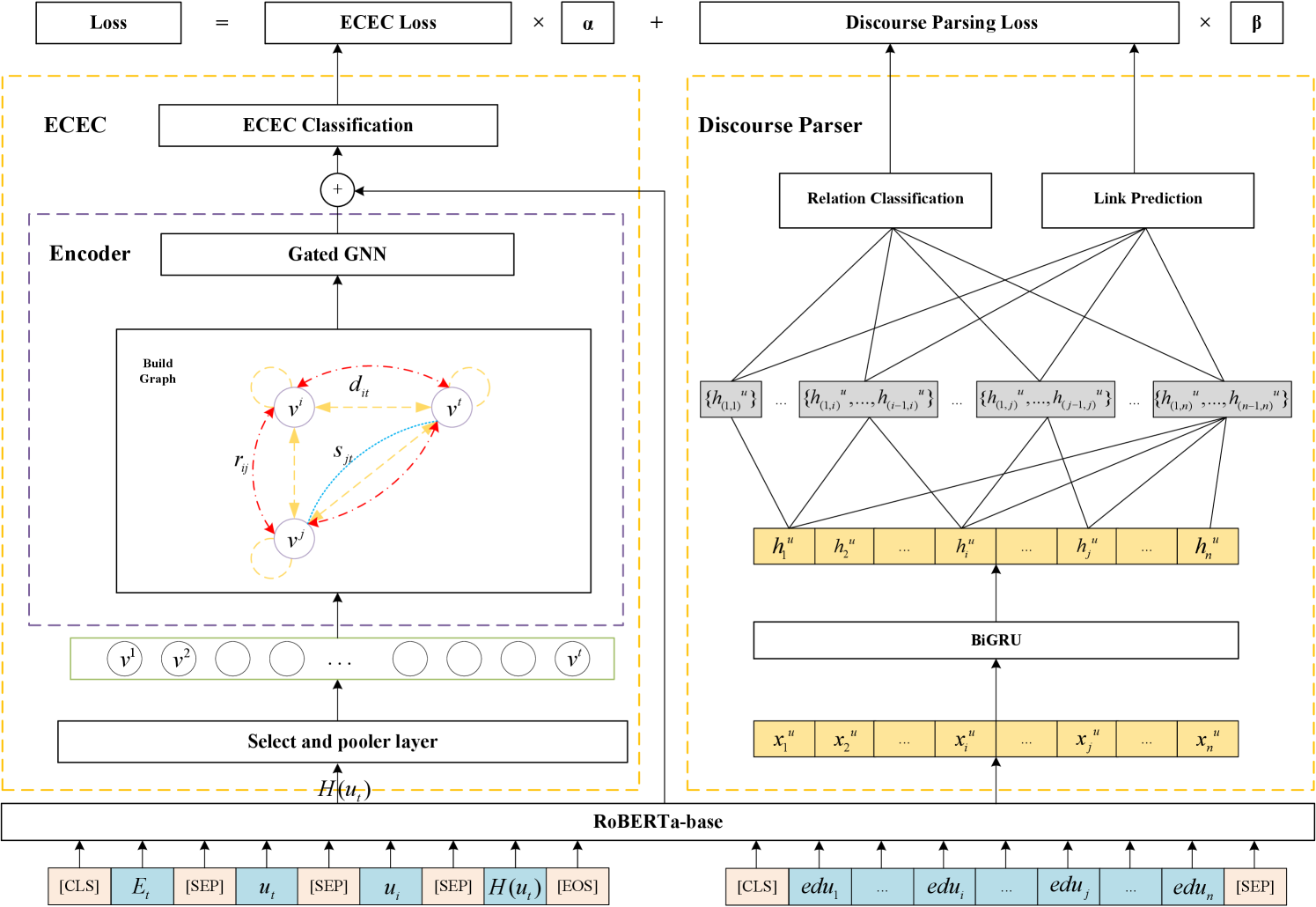
In this section, we present the proposed discourse-aware model (DAM) for ECEC. As shown in Fig. 2, we use an MLT framework to model the ECEC task and discourse parsing jointly. It can integrate rich utterance interaction information to our conversational context representations. We use hard parameter sharing to combine these two task, and use RoBERTa Liu et al. (2019) to obtain the shared conversational context representations.
To further enhance utterance interaction information, we encode conversational discourse structures by gated graph neural network (gated GNN). In addition, we use gated GNN to encode conversation-specific features such as speakers and relative utterance distance. Concretely, we use the gate controlled mechanism to alleviate the error propagation problem caused by predicted discourse relations. After that, we concatenate them with global encoding information and through a linear layer to obtain the classification result of the ECEC task.
As for auxiliary task discourse parsing, we use GRU to further obtain high-level hidden representations (BiGRU) Cho et al. (2014). Then we feed these high-level hidden representations to link predictor and relation classifier to obtain the corresponding discourse relations.
3.1 Multi-Task Learning Framework
3.1.1 ECEC Model
Given a conversation with utterances , for each target utterance with emotion and its historical utterances set , the ECEC task aims to extract the cause utterances set of the emotion expressed by . Therefore, this task can be regarded as a triple classification Poria et al. (2021). For each utterance in , the triple is taken as a positive case if . Otherwise, it is classified as a negative case.
Utterance Representations
To compare with the recent Transformer-based model Poria et al. (2021), we also use a [CLS] token and the emotional label [Et] of the target utterance in front. We concatenate the elements of triplet as extra inputs, as shown in Fig. 2. Before building the graph of gated GNN, we preprocess the input of the ECEC task at the select and pooler layer. We extract the hidden states of the [CLS] token as well as the hidden states of all tokens belonging to for later use. The hidden states of tokens belonging to the DAMe utterance are represented as: , where represents the utterance in , and represents the utterance with total of tokens. For convenience and simplicity, these hidden states are summed as the utterance level representation: .
ECEC Encoder
In the ECEC Encoder, we build a full connected graph according to the discourse relations, speaker, and relative utterance distance. Then, we use the gated GNN layer to encode inter-utterance representations and outputs hidden states . See more details in the Section 3.2.
ECEC Classification
After getting the output hidden states of the encoder, we now use softmax function to get the probability distribution through a linear layer and generate the prediction of inputs as follows:
| (1) |
| (2) |
where are the weight matrix and bias of the linear before softmax.
Loss Function
To train the model, we calculate the negative log-likelihood of train data as loss of the main task as follows:
| (3) |
where is the gold labels set and is the label indicator matrix.
3.1.2 Discourse Parser
Given a conversation with elementary discourse units (EDU) , discourse parsing aims to predict dependency links and the corresponding relation types between the EDUs, where stands for a link of relation type from to .
Discourse Representations
All EDUs from a conversation are fed into RoBERTa to encode token-level information. For EDU , the [CLS] token embedding is taken as the representation of , denoted as . We use Bi-directional GRU (BiGRU) to encode clause-level contextual information. Specifically, we take the representation of EDUs as the input of BiGRU to get hidden representation .
Then we follow Shi and Huang (2019), taking as input of link predictor and relation classifier. The Link predictor predicts the parent of . Relation classifier is responsible for predicting the relationship type between and , if predicted parent of and .
Link Prediction and Relation Classification
Link predictor and relation classifier have similar structures. They first converts the input vector into a hidden representation through a linear layer:
| (4) |
where and are learnable weights, and represent the weights of link predictor and relation classifier respectively. Link predictor adopts softmax function to obtain the probability that is the parent of as follows:
| (5) |
where and also is learnable weights, and is the dimension of . Hence, the predicted is chosen as follows:
| (6) |
The relation classifier predicts the relation type as follows:
| (7) |
and are learnable weights. is number of relation types and is the dimension of .
Loss Function
As DAMe as ECEC, we calculate the negative log-likelihood loss as follows:
| (8) |
| (9) |
| (10) |
where is a conversation of train data and and is golden labels.
3.1.3 Training
During training, two models are learned simultaneously for the two sub-tasks (ECEC and discourse parsing). The bottom RoBERTa encoding layer is shared by the above two tasks. The total training objective is defined as:
| (11) |
where and are hyperparameters.
3.2 ECEC Encoder
3.2.1 Graph Construction
Following Wang et al. (2021a); Li et al. (2016), we adopt a gated graph neural network (gated GNN) to capture conversation-specific features. A fully connected graph is the input of the gated GNN, and each utterance in is regarded as a node of the graph. We explain the construction rules of discourse relations, speaker, and relative distance graph separately as follows.
Discourse Relation Graph:
In order to model discourse relations between two utterances in conversations, we refer to the discourse parser proposed by Wang et al. (2021a) to obtain the discourse relations between utterances. We train discourse parser by the STAC dataset Afantenos et al. (2015). Then, we input an entire conversation into the discourse parser:
| (12) |
where denotes a link of relation type from to , noting that and . We connect an edge if there is a discourse relation between any two nodes. We give different weights to different discourse relation types. These predicted discourse relations are not exactly correct, so it may lead to error propagation in the later use.
Speaker Graph:
Plain text is a continuous document written by a single author, while conversation is the interaction between multiple speakers, which is the most obvious difference between plain text and conversation. Therefore, we incorporate conversation-specific features to the model by a fully connected graph. A DAMe type of edge connects two adjacent utterances of the DAMe speaker.
Relative Distance Graph:
For the ECEC task, it is very important to establish the long-distance dependency between utterances. In order to better model this dependency, we add relative utterance distance features. There is an edge between any two nodes and a self-loop edge on each node. It represents the relative utterance distance between its linked nodes.
3.2.2 Gated GNN
Each node and edge in the graph represents as a learnable vector for gated GNN. We directly use the utterance level representation to initialize the vector representation of the corresponding node. As for the edge between any two nodes, we initialize it by a learnable vector as follows.
| (13) |
where , , respectively denote the speaker, relative utterance distance, and discourse relation type vectors between utterance and utterance . It should be noted that the discourse relation between utterances is predicted by the discourse parser trained on STAC datasets. Therefore, there is a problem of error propagation.
After direct concatenation of three vectors, we adopt a learnable gate module in to selectively forget certain information in neural networks. It can control duplicated discourse information as well as relieving the issue of error propagation, according to our experiments.
| (14) |
where and represents function, dot-product operation separately, are weight matrix and bias.
After that, we conduct structure-aware scaled dot-product attention to update the hidden state of nodes. More details can be seen in Wang et al. (2021a). We will iterate times to update the above hidden states. Eventually, we concatenate the hidden state vectors of two directions in the top layer:
| (15) |
where the subscript represents the and utterance. The GNN encoding representation and the hidden representation of [CLS] in previous stage are concatenated together as the final representation :
| (16) |
where represents the utterance that need to be classified and represents the target utterance that contains the non-neural emotion.
4 Experiment Settings
4.1 Datasets
To verify the effectiveness of utterance interactions information, we conduct experiments on the RECCON Poria et al. (2021) dataset. We use the Fold1 dataset Poria et al. (2021) generated by a negative DAMpling strategy as our experimental dataset. Training, validation, and testing data are 27915, 1185, and 7224 DAMples respectively.
Moreover, we use the STAC Afantenos et al. (2015) dataset to help complete the training of auxiliary task discourse parsing. There are 1091 conversations with 10677 EDUs and 11348 discourse relations in STAC.
4.2 Hyperparameters
We use RoBERTa to encode the conversational contexts, and adopt an AadmW algorithm to optimize the parameters of our model. The initial learning rate is set to 1e-5, batch size sets to 8. set to 1 and 0.25. The dimensions for the edge and the node states in gated GNN are both 768. And the dimensions for and are set to be 192, 192 and 384, respectively. We train 10 epochs on the training set and save the best model according to the performance on the validation set. Based on the best model, we test the performance on the test set.
4.3 Evaluation
For fair comparison, we use F1-scores to evaluate our proposed model. Pos.F1 and Neg.F1 represent the F1-score on the positive and the negative examples, respectively. In addition, we report the overall MacroF1 score based on the Pos.F1 and the Neg.F1.
4.4 Benchmark Models
| Model | Pos.F1 | Neg.F1 | MacroF1 |
|---|---|---|---|
| RankCP | 33.00 | 97.30 | 65.15 |
| ECPE-MLL | 48.48 | 94.68 | 71.59 |
| ECPE-2D | 55.50 | 94.96 | 75.23 |
| SIMP | 64.28 | 88.74 | 76.51 |
| SIMP | 66.23 | 87.89 | 77.06 |
| DAM (ours) | 67.91 | 89.55 | 78.73 |
We first compare our DAM with three ECE SOTA models proposed by previous research in Table 1.
-
1.
RankCP Wei et al. (2020): It used graph attention network to encode the representation of document clause;
-
2.
ECPE-2D Ding et al. (2020a): It integrated the representation, interaction and prediction of 2D emotion-cause pairs by jointing learning;
-
3.
ECPE-MLL Ding et al. (2020b): It used the multi-label learning scheme for training, and obtained a good effect.
Poria et al. (2021) transfer these three models to conversation dataset and propose some simple but better Transformer-based models (SIMP and SIMP).
4.5 Main Results
We can draw the following conclusions. First, because of the differences between plain text and conversation, the previous complex deep learning methods such as RankCP, ECPE-MLL and ECPE-2D for plain text document data perform even worse than the simple SIMP model. Second, our model improves by nearly 2.22% over the baseline model encoded by the DAMe RoBERTa. This can be owing to the potential links between emotional utterances and their corresponding cause expressions contained in the discourse structures. Conversation-specific features can also help models understand conversations.
5 Results and Analysis
We next conduct more experiments to explore which part of our model works and what we have promoted. We also study how to combine these structure information so that making the most of them.
5.1 Ablation Study
| Model | Pos.F1 | Neg.F1 | MacroF1 |
|---|---|---|---|
| DAM | 67.91 | 89.55 | 78.73 |
| W/O multi-task | 65.76 | 87.44 | 76.60 |
| W/O gated-gnn | 66.61 | 88.13 | 77.37 |
| W/O speaker | 65.32 | 89.38 | 77.35 |
| W/O distance | 66.58 | 88.44 | 77.51 |
| W/O gate | 66.32 | 89.02 | 77.67 |
Previous main results show that the effectiveness of our model. As shown in Table 2, the performance of removing auxiliary task decreases by 2.13% over the DAM. It indicates that multi-task framework can help our model capture discourse structures information. This information improves our model’s ability to establish relationships between utterances. The second row shows the model without gated GNN decreases by 1.36% over the DAM, showing the help of encoding conversation context information for understanding conversation. We also verify the influence of speakers and relative utterance distance features respectively, the performance of them all decrease. It demonstrates that these structure information containing conversational features have a significant impact on the model. Finally, it can be found that only remove the gate mechanism, performance decreases by 1.06%. We argue that the existence of the gate module alleviates the error propagation caused by directly using the pseudo discourse relations.
5.2 Long-distance Dependency Analysis
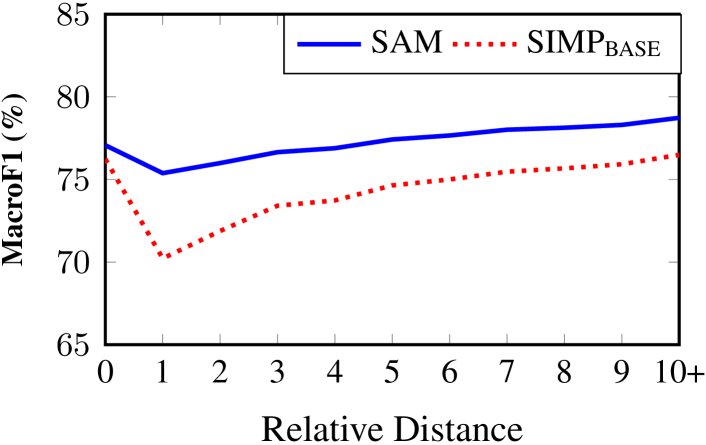
To verify whether our model can alleviate the long-distance dependency problem, we present a set of results of different relative utterance distance between and in Fig 3. Foremost, we can find whatever the relative utterance distance are, our DAM model performs better than previous SIMP model. That means our model is more robust in terms of distance by combining the utterance interaction features. Then we see that our model performs significantly better than the SIMP inside a turn or distance of 3. However, above 3, the performance does not significantly increase. It suggests that in the ECEC task, long-distance dependency problem is significant. Although our approach can help to ameliorate the problem, deep reasoning needs to be further explored in the case of overextended turns or distance.
5.3 Effect of Different Fusion Methods

| Model | Pos.F1 | Neg.F1 | MacroF1 |
|---|---|---|---|
| SIMP | 64.28 | 88.74 | 76.51 |
| SIMP | 66.23 | 87.89 | 77.06 |
| DAM | 67.91 | 89.55 | 78.73 |
| DAM-mtl | 66.61 | 88.13 | 77.37 |
| DAM-cat | 65.04 | 88.36 | 76.70 |
| DAM-gnn | 66.91 | 89.24 | 78.07 |
| DAM-mtl-gnn | 66.32 | 89.02 | 77.67 |
| DAM-arc | 66.70 | 88.87 | 77.79 |
In this section, we study how to integrate discourse relations so that making the most of them. Chen et al. (2020); Ding et al. (2020a) use graph convolutional network or joint learning to model the dependency relations between clauses. In this paper, we design and experiment with six alternative methods for incorporating discourse relations. Table 3 show the performance of these methods, and we can draw the following conclusions. First, we can see that discourse structure information can be strengthened by three strategies (DAM-mtl/cat/gnn). Therefore, bringing better performance than the SIMP that initialized by RoBERTa. However, the improvement of DAM-cat is slight. It may due to that it suffers from the serious error propagation directly using not exactly correct hidden states. When we combine the DAM-mtl and DAM-gnn (DAM-mtl-gnn), the performance degrades. It may be due to the duplicated discourse information or error propagation. We add the gate module (DAM) on the basis of DAM-mtl-gnn that effectively alleviates the above problems and performs best. So we choose this fusion method as final method. Moreover, we also try to not use the specific discourse relation types and instead focus on whether they have discourse relations (DAM-arc) or not, but it still does not comparable with DAM.
5.4 Case Study
For the case study, we select an example in the test dataset to verify that discourse structure information can help our model to better model long-distance dependencies.
Due to space limitations, we only show a subset of emotional cause and discourse relations. As shown in Fig. 4, the cause utterances set of is , and the cause utterances set of is . The SIMP model can only predict the cause utterances with a short relative distance, and its performance ability is not good for the cause utterances with a long relative distance. It can be seen from the discourse relationship diagram that the target utterances and each utterance in the cause utterances set are related to each other. After we incorporate the discourse structure information into the model, the model can better capture long-distance dependencies. Although there are still some cause utterances that have not been successfully found, such as the cause utterance of the target utterance , we guess that this is caused by the error propagation of the discourse parser.
6 Conclusion and Future Work
In this paper, we introduce a discourse-aware model for emotion cause extraction in conversation. Specifically, we model ECEC with discourse parsing in conversations by multi-task framework. It can help share pre-trained language model learning better discourse structure representations of conversations. In addition, this model employ a graph neural network to encode conversation-specific features such as relative utterance distance, and speakers, and further enhance discourse structures. Both of them can help the model integrate rich utterance interactions information and mitigate long-distance dependency problem. Finally, we utilize a gate controlled module to alleviate the error propagation problem from predicted discourse relations. Experiments on the benchmark show that our model reaches the new SOTA.
Our future works may explore how discourse structure information can be used to extract both the emotion and the cause without the target utterance emotion information. Besides, we still need to explore more methods to solve the problem of long-distance dependence and error propagation.
References
- Afantenos et al. (2015) Stergos Afantenos, Éric Kow, Nicholas Asher, and Jérémy Perret. 2015. Discourse parsing for multi-party chat dialogues. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 928–937.
- Chen et al. (2018) Ying Chen, Wenjun Hou, Xiyao Cheng, and Shoushan Li. 2018. Joint Learning for Emotion Classification and Emotion Cause Detection. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 646–651.
- Chen et al. (2020) Ying Chen, Wenjun Hou, Shoushan Li, Caicong Wu, and Xiaoqiang Zhang. 2020. End-to-end emotion-cause pair extraction with graph convolutional network. In Proceedings of the 28th International Conference on Computational Linguistics, pages 198–207.
- Chen et al. (2010) Ying Chen, Sophia Yat Mei Lee, Shoushan Li, and Chu-Ren Huang. 2010. Emotion cause detection with linguistic constructions. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), pages 179–187.
- Cho et al. (2014) Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1724–1734.
- Choi et al. (2005) Yejin Choi, Claire Cardie, Ellen Riloff, and Siddharth Patwardhan. 2005. Identifying Sources of Opinions with Conditional Random Fields and Extraction Patterns. In Proceedings of Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, pages 355–362.
- Das and Bandyopadhyay (2010) Dipankar Das and Sivaji Bandyopadhyay. 2010. Finding Emotion Holder from Bengali Blog Texts— an Unsupervised Syntactic Approach. In Proceedings of the 24th Pacific Asia Conference on Language, Information and Computation, pages 621–628.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805. ArXiv: 1810.04805.
- Diao et al. (2020) Yufeng Diao, Hongfei Lin, Liang Yang, Xiaochao Fan, Yonghe Chu, Di Wu, Kan Xu, and Bo Xu. 2020. Multi-granularity bidirectional attention stream machine comprehension method for emotion cause extraction. Neural Computing and Applications, 32(12):8401–8413. ISBN: 1433-3058 Publisher: Springer.
- Ding and Kejriwal (2020) Jiayuan Ding and Mayank Kejriwal. 2020. An experimental study of the effects of position bias on emotion causeextraction.
- Ding et al. (2019) Zixiang Ding, Huihui He, Mengran Zhang, and Rui Xia. 2019. From Independent Prediction to Reordered Prediction: Integrating Relative Position and Global Label Information to Emotion Cause Identification. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6343–6350.
- Ding et al. (2020a) Zixiang Ding, Rui Xia, and Jianfei Yu. 2020a. ECPE-2D: Emotion-cause pair extraction based on joint two-dimensional representation, interaction and prediction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3161–3170.
- Ding et al. (2020b) Zixiang Ding, Rui Xia, and Jianfei Yu. 2020b. End-to-end emotion-cause pair extraction based on sliding window multi-label learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3574–3583.
- Fan et al. (2020) Chuang Fan, Chaofa Yuan, Jiachen Du, Lin Gui, Min Yang, and Ruifeng Xu. 2020. Transition-based directed graph construction for emotion-cause pair extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3707–3717.
- Fan et al. (2021) Chuang Fan, Chaofa Yuan, Lin Gui, Yue Zhang, and Ruifeng Xu. 2021. Multi-task sequence tagging for emotion-cause pair extraction via tag distribution refinement. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:2339–2350.
- Gui et al. (2016) Lin Gui, Ruifeng Xu, Qin Lu, Dongyin Wu, and Yu Zhou. 2016. Emotion cause extraction, a challenging task with corpus construction. In Chinese National Conference on Social Media Processing, pages 98–109. Springer.
- Gui et al. (2018) Lin Gui, Ruifeng Xu, Dongyin Wu, Qin Lu, and Yu Zhou. 2018. Event-driven emotion cause extraction with corpus construction. In Social Media Content Analysis: Natural Language Processing and Beyond, pages 145–160. World Scientific.
- Gui et al. (2014) Lin Gui, Li Yuan, Ruifeng Xu, Bin Liu, Qin Lu, and Yu Zhou. 2014. Emotion Cause Detection with Linguistic Construction in Chinese Weibo Text. In Natural Language Processing and Chinese Computing, pages 457–464, Berlin, Heidelberg. Springer Berlin Heidelberg.
- He et al. (2021) Yuchen He, Zhuosheng Zhang, and Hai Zhao. 2021. Multi-tasking Dialogue Comprehension with Discourse Parsing. In Proceedings of the 35th Pacific Asia Conference on Language, Information and Computation, pages 69–79.
- Hu et al. (2021a) Guimin Hu, Guangming Lu, and Yi Zhao. 2021a. Bidirectional Hierarchical Attention Networks based on Document-level Context for Emotion Cause Extraction. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 558–568, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Hu et al. (2021b) Guimin Hu, Guangming Lu, and Yi Zhao. 2021b. FSS-GCN: A Graph Convolutional Networks with Fusion of Semantic and Structure for Emotion Cause Analysis. Knowledge-Based Systems, 212:106584.
- Lee et al. (2010) Sophia Yat Mei Lee, Ying Chen, and Chu-Ren Huang. 2010. A text-driven rule-based system for emotion cause detection. In Proceedings of the NAACL HLT 2010 workshop on computational approaches to analysis and generation of emotion in text, pages 45–53.
- Li et al. (2021a) Xiangju Li, Wei Gao, Shi Feng, Daling Wang, and Shafiq Joty. 2021a. Span-Level Emotion Cause Analysis by BERT-Based Graph Attention Network, page 3221–3226. Association for Computing Machinery, New York, NY, USA.
- Li et al. (2021b) Xiangju Li, Wei Gao, Shi Feng, Daling Wang, and Shafiq Joty. 2021b. Span-Level Emotion Cause Analysis with Neural Sequence Tagging. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, pages 3227–3231.
- Li et al. (2021c) Xiangju Li, Wei Gao, Shi Feng, Yifei Zhang, and Daling Wang. 2021c. Boundary Detection with BERT for Span-level Emotion Cause Analysis. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 676–682, Online. Association for Computational Linguistics.
- Li et al. (2016) Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard S. Zemel. 2016. Gated graph sequence neural networks. In 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Poria et al. (2021) Soujanya Poria, Navonil Majumder, Devamanyu Hazarika, Deepanway Ghosal, Rishabh Bhardwaj, Samson Yu Bai Jian, Pengfei Hong, Romila Ghosh, Abhinaba Roy, Niyati Chhaya, and others. 2021. Recognizing emotion cause in conversations. Cognitive Computation, 13(5):1317–1332. Publisher: Springer.
- Qian et al. (2021) Haoda Qian, Qiudan Li, and Zaichuan Tang. 2021. A Multi-Task MRC Framework for Chinese Emotion Cause and Experiencer Extraction. In International Conference on Artificial Neural Networks, pages 99–110. Springer.
- Russo et al. (2011) Irene Russo, Tommaso Caselli, Francesco Rubino, Ester Boldrini, and Patricio Martínez-Barco. 2011. Emocause: An easy-adaptable approach to emotion cause contexts. ACL HLT 2011, page 153.
- Shi and Huang (2019) Zhouxing Shi and Minlie Huang. 2019. A deep sequential model for discourse parsing on multi-party dialogues. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 7007–7014. Issue: 01.
- Turcan et al. (2021) Elsbeth Turcan, Shuai Wang, Rishita Anubhai, Kasturi Bhattacharjee, Yaser Al-Onaizan, and Smaranda Muresan. 2021. Multi-Task Learning and Adapted Knowledge Models for Emotion-Cause Extraction. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 3975–3989, Online. Association for Computational Linguistics.
- Wang et al. (2021a) Ante Wang, Linfeng Song, Hui Jiang, Shaopeng Lai, Junfeng Yao, Min Zhang, and Jinsong Su. 2021a. A structure self-aware model for discourse parsing on multi-party dialogues. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event / Montreal, Canada, 19-27 August 2021, pages 3943–3949. ijcai.org.
- Wang et al. (2021b) Fanfan Wang, Zixiang Ding, Rui Xia, Zhaoyu Li, and Jianfei Yu. 2021b. Multimodal emotion-cause pair extraction in conversations. CoRR, abs/2110.08020.
- Wei et al. (2020) Penghui Wei, Jiahao Zhao, and Wenji Mao. 2020. Effective inter-clause modeling for end-to-end emotion-cause pair extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3171–3181.
- Wu et al. (2020) Sixing Wu, Fang Chen, Fangzhao Wu, Yongfeng Huang, and Xing Li. 2020. A multi-task learning neural network for emotion-cause pair extraction. ECAI 2020, pages 2212–2219.
- Xu et al. (2017) Ruifeng Xu, Jiannan Hu, Qin Lu, Dongyin Wu, and Lin Gui. 2017. An ensemble approach for emotion cause detection with event extraction and multi-kernel SVMs. Tsinghua Science and Technology, 22(6):646–659.