DisaggRec: Architecting Disaggregated Systems for Large-Scale Personalized Recommendation
Abstract
Deep learning-based personalized recommendation systems are widely used for online user-facing services in production datacenters, where a large amount of hardware resources are procured and managed to reliably provide low-latency services without disruption. As the recommendation models continue to evolve and grow in size, our analysis projects that datacenters deployed with monolithic servers will spend up to 12.4 total cost of ownership (TCO) to meet the requirement of model size and complexity over the next three years. Moreover, through in-depth characterization, we reveal that the monolithic server-based cluster suffers resource idleness and wastes up to 30% TCO by provisioning resources in fixed proportions. To address this challenge, we propose DisaggRec, a disaggregated system for large-scale recommendation serving. DisaggRec achieves the independent decoupled scaling-out of the compute and memory resources to match the changing demands from fast-evolving workloads. It also improves system reliability by segregating the failures of compute nodes and memory nodes. These two main benefits from disaggregation collectively reduce the TCO by up to 49.3%. Furthermore, disaggregation enables flexible and agile provisioning of increasing hardware heterogeneity in future datacenters. By deploying new hardware featuring near-memory processing capability, our evaluation shows that the disaggregated cluster achieves 21%43.6% TCO savings over the monolithic server-based cluster across a three-year span of model evolution.
I Introduction
Personalized recommendation is a fundamental service for many Internet services such as search engines, social networks, online retailing, and content streaming [14, 13, 4, 1, 42], all of which are now tightly interwoven into our daily lives. These online services are predominantly powered by recommendation models that leverage modern deep learning technologies to achieve high prediction accuracy and delivery quality individualized user experiences [29]. Following recent algorithmic innovations [17, 63, 34, 16, 15, 10], recommendation models are expected to grow in size at an accelerated pace in order to keep up with the rapidly increasing and evolving data features. Therefore, a large quantity of datacenter hardware serves recommendation queries. This hardware often consists of monolithic servers as basic building blocks, configured with a mix of CPUs, GPUs, and memory (DRAM).
However, as recommendation models continue to evolve and scale up, monolithic servers will face two aggravating challenges. First, these models require tremendous memory capacity that will soon exceed what can be feasibly integrated within a server. Second, model variants will require compute and memory of dissimilar proportions and intensities. Embedding operations will stress memory whereas dense operations are computation-demanding. Because the mix of these operations will continue to evolve and vary across models, no one-size-fits-all design for monolithic servers can simultaneously optimize the cost and energy efficiency across all the model variants.
Resource disaggregation decouples the deployment of compute and memory, allowing system architects to provision and scale resource types independently. Compute nodes (CNs) supply high-performance processors but only a limited amount of memory, whereas memory nodes (MNs) supply many high-capacity DRAM devices. MNs can integrate small processors for general-purpose compute [3, 25, 57, 55, 11, 64, 8], application-specific accelerators [9, 65], or no processing beyond the minimum needed for control and communication [50, 19, 49, 43]. In disaggregated systems, an application receives networked allocations of CNs and MNs that can best match its needs. Previous work has shown disaggregation can benefit resource utilization by up to 50% [57], improve system reliability by 17%–49% [57], and reduce hardware cost by 7% [20]. However, performance may also suffer at the same time when deployed for large-scale production workloads. LegoOS [57] showed 34%–68% performance degradation, and Pond [20] reported a performance loss of more than 25%.
In this paper, we propose DisaggRec to address infrastructure-level challenges from fast-evolving recommendation systems. DisaggRec is a disaggregated system for recommendation serving at scale. The system must meet strict performance and availability targets for the recommendation system is interactive and user-facing. For performance, we characterize task scheduling and optimize disaggregated system configurations to meet the target tail-latency required by the service-level agreement (SLA). For availability, we characterize task loads and component failures, and dynamically provision compute and memory resources to ensure reliable service under occasional system faults. Collectively, our work makes the following contributions.
Quantifying Inefficiency of Monolithic Servers. First, we characterize deployed production-grade recommendation systems comparing scale-up and scale-out strategies using monolithic servers. We find monolithic design is inefficient in terms of the total cost of ownership (TCO). Monolithic servers provision compute and memory in fixed proportions, leading to idle resources and wasted costs of up to 23.1%. Furthermore, they must guard against server failures, resulting in over-provisioned resources and wasted costs of up to 6.8%.
Improving Efficiency with Disaggregation. Second, we co-optimize the partitioning strategies for recommendation models and design strategies for disaggregated CNs and MNs. We minimize the cost subject to latency targets and availability requirements for recommendation queries. DisaggRec experiences minor throughput degradation (2%) and reduces cost by 49.3% when compared to a monolithic design.
Provisioning Heterogeneity with Disaggregation. Hardware accelerators are increasingly deployed in production datacenters to optimize operational efficiency. In addition to compute-centric accelerators for dense computation, near-memory processing DRAM is reaching the market to help accelerate workflows bounded by memory capacity and memory bandwidth. However, monolithic servers are inept and far less flexible in adopting emerging hardware because their tightly bundled hardware components preclude workloads from receiving their most cost-effective resource mixes. The disaggregated cluster addresses these challenges, reducing cost by 21% to 43.6% compared to the monolithic server-based cluster.
II Recommendation Systems
Personalized recommendation models are widely deployed by Internet service providers to enhance user experiences, contributing more than 80% of AI cycles in modern hyperscale datacenters [52]. Figure 1(a) presents the three major computational components of a recommendation model. Pre-processing () employs hash functions to map input signals of raw, sparse features (e.g., user ID, webpage ID) to corresponding indices in the embedding tables. SparseNet () performs sparse, irregular memory lookups with the embedding tables as well as pooling operations. DenseNet () evaluates compute-intensive, fully-connected (FC) layers.
Model Scaling. Recommendation models continue to evolve and scale rapidly, increasing both in size and complexity. In this paper, we focus on two industry-grade models—a memory-intensive RM1 and a compute-intensive RM2. Moreover, in Figure 1(b), we use internal projections to estimate their scaling trends over six model generations that span the next three years. For RM1, SparseNet is the primary growth driver, increasing the model size from 1.4TB to 7.8TB and making memory the main resource bottleneck. In contrast, for RM2, DenseNet is the primary growth driver, increasing the depth and width of FC layers, which in turn increases the number of FLOPs by 18.9 and makes compute the main bottleneck.
Service Requirements. The user-facing recommendation services must provide each query a timely and accurate response. Billions of users around the world expect high availability from these services. Thus, design and management strategies for recommendation systems must navigate complex interactions among latency, throughput, and resilience.
Recommendation systems are required to satisfy the service-level agreement (SLA), a contract between the service provider and the end user. Here, we consider two SLAs for tail-latency and availability. First, the SLA may require the 95th-percentile (p95) latency to be within 100ms. Achieving these performance goals is complicated due to the dynamic query arrival patterns [53, 32]. Figure 2(a) shows the heavy-tailed distribution of incoming query sizes. Second, recommendation systems are deployed on a large fleet of servers to guarantee service availability. Figure 2(b) shows the diurnal loads of recommendation service during a day. Resource allocations tend to be over-provisioned, guarding against machine failures but producing large gaps between typical and peak loads.


Production Recommendation Systems. Production datacenters often customize server design for high-performance recommendation systems to better support a large volume of business-critical services. For example, Meta’s Zion/ZionEX server is tailored to support at-scale recommendation [37, 10], integrating abundant resources within a machine (e.g., four CPU sockets, 1.5TB of DRAM, eight NVIDIA A100 GPUs each with 40GB of HBM). To meet workloads’ increasing demands for computational resources, industry production systems usually follow scale-up or scale-out strategies.
A scale-up strategy deploys additional resources within a single server. For example, the scale-up dual-socket (SU-2S) server (detailed configurations in Table I) is a next-generation platform for larger recommendation models that scales up to use two CPU sockets with 2TB of DRAM and eight A100 GPUs, each with 80GB of HBM.
On the other hand, a scale-out strategy distributes a workload across multiple servers as recommendation models will invariably exhaust the limited resources that can be accommodated by a single server. Distributed inference [35] launches a single large model across a group of servers. Their collective memory capacity holds model parameters. The distributed serving paradigm splits the model into computational sub-graphs, called shards, and uses remote procedure calls (RPCs) for the execution of sub-graphs and the communication between shards [2]. Sharding permits simpler, smaller servers. For example, the scale-out single-socket (SO-1S) server comprises only one processor socket and 1TB of DRAM with varying 1, 2, 4 GPUs configurations to serve diverse workloads with varied memory and compute intensities (Table I).
Optimizing the combination of hardware components for next-generation datacenter servers is increasingly difficult. Domain-specific accelerators and technologies are emerging as component options for system architects. Recommendation model’s DenseNet operations might benefit from compute-centric accelerators such as NVIDIA GPUs, Google TPUs [38], and Alibaba’s Hanguang [56]. While the embedding operations in recommendation models might benefit from near-memory processing (NMP) and processing-in-memory (PIM) [33, 58, 24, 12, 46].
In summary, architects must take a holistic view of system design. As recommendation models evolve and hardware devices diversify, system architects must perform their due diligence prior to procurement and deployment. They must carefully evaluate and identify an efficient choice of server components, balancing scale-up and scale-out strategies. In this paper, we will quantify inefficiencies from monolithic servers and pinpoint opportunities for hardware disaggregation to tackle these system challenges.
III Model Inference on Monolithic Servers
We thoroughly characterize industry-grade recommendation workloads on monolithic servers following scale-up and scale-out strategies, producing two key insights.
-
•
Embedding reduction performed inside SparseNet shards can greatly reduce the amount of data that need to be communicated between local and remote shards; embedding accesses and reduction should be done using local memory to eliminate unbalanced memory utilization in NUMA or unnecessary remote communication in scale-out systems.
-
•
Modern network bandwidth (25 GB/s) is comparable to processor interconnects (55 GB/s), enabling better scale-out systems as recommendation models scale in size and complexity.
These insights guide DisaggRec’s design choices later in Sec IV. All monolithic server configurations used in the following sections are listed in Table I.

III-A Scaling Up – Inference on a Single Server
A scale-up strategy aims to equip a single server node with sufficient resources to serve end-to-end model inference. Figure 3(a) shows the end-to-end model inference configuration on a scale-up dual-socket (SU-2S) server. Two inference tasks are launched in parallel on the two processors. The two front-end network interface cards (NICs) receive incoming queries and return prediction outcomes. Given the dynamic query arrival pattern and the configured batch size, a large query is split into multiple sub-batches and multiple small queries are fused into one large batch. These batches are queued and wait for execution. The inference task exploits three types of parallelism.
Model Parallelism. The model’s computation graph is partitioned into three sub-graphs, preprocessing , SparseNet with embedding tables , and DenseNet . Sub-graphs are launched concurrently and pipelined. and co-locate on the CPU’s 40 cores while runs on the GPUs within a SU-2S server.
Operator Parallelism. Physical cores are statically assigned to one single thread where independent operators inside the computation graph can be executed in parallel. On a SU-2S server, we assign 20 CPU cores to the preprocessing thread and 20 to the SparseNet thread such that ’s random hash operators and ’s embedding operators are executed in parallel on their assigned CPU cores.
Data Parallelism. Query batches are executed in parallel across the GPUs. Each GPU launches a replica of DenseNet’s threads. On a SU-2S, a processor socket is connected to four A100 GPUs and four threads serve batches of intermediate results from .
We observe degraded performance due to non-uniform memory accesses (NUMA) when SparseNet exceeds the memory capacity of a single socket. As embeddings occupy both memory nodes, the two SparseNet threads on the two processors route half of its accesses to local memory and the other half to remote memory via processor socket interconnect—Intel’s Ultra Path Interconnect (UPI)—leading to unbalanced memory bandwidth utilization. Inter-socket bandwidth (55 GB/s at peak) is much lower than local memory bandwidth (145 GB/s at peak).
III-B Scaling Out – Inference on Multiple Servers
Following the scale-out strategy, the model’s SparseNet is sharded and distributed across multiple servers when the embedding tables cannot fit into a single server’s memory. The model’s computational graph is partitioned into three sub-graphs for preprocessing (), SparseNet shards (, ), and DenseNet ().
Figure 3(b) shows the distributed inference [35] across two scale-out single-socket (SO-1S) servers. Each server launches two processes, the primary inference task and one SparseNet shard. The primary task receives incoming queries, performs preprocessing, routes SparseNet’s embedding lookups to the appropriate shards, receives the final summation (Fsum) back from the remote shards, and then executes DenseNet to get the final prediction. The embedding operations in the primary task are issued by remote procedure calls (RPCs) using pre-stored destination metadata (e.g., model ID, SparseNet shard ID). Embedding operations in one SparseNet shard is packed in one packet which is routed to that shard’s serving process hosting targeted SparseNet partitions. The dedicated back-end network connects servers’ back-end NICs using RDMAs, permitting efficient communication between servers.
III-C Comparison of Scaling Up and Scaling Out

To compare the scaling up and scaling out, we perform the end-to-end model inference on a scale-up dual-socket server (SU-2S) with 8 GPUs, and distributed inference on a group of scale-out single-socket servers (SO-1S) with 4 GPUs.
Latency. Figure 4 shows the lifecycle of an incoming query, queuing delay and model inference pipelines. We find the model inference on the SU-2S server suffers from unbalanced local-remote sockets’ memory bandwidth utilization. In Figure 4(b), half of the memory accesses are routed to the local socket’s memory (93 GB/s at peak), and the other half of memory accesses are routed to the remote socket’s memory (only 52 GB/s at peak) that is bounded by UPI links.
To eliminate memory accesses through UPI interconnect, we implement NUMA-aware inference on the SU-2S adopting the SparseNet sharding scheme to perform memory operations inside local sockets. Similar to distributed inference, this optimization shards SparseNet into and . Two shards are separately launched on the two processor sockets in parallel. All memory accesses are routed to the processor socket’s local memory. The embedding reduction is performed inside SparseNet shards before sending them to the remote socket. In Figure 4(a), eliminating NUMA’s effect within the SU-2S server reduces SparseNet execution time by more than 60%. Moreover, the communication overheads are minimal (8%) that only required for the embeddings’ input (lookup indices) and output (Fsum).
The major difference between NUMA-aware inference and distributed inference is the communication interface, UPI links vs NICs. Today’s network communication bandwidth is approaching that of the processor interconnect. In Figure 4(a), the model inference latency of distributed inference on two distributed SO-1S servers only has a minor increment over the NUMA-aware inference on one SU-2S server. The network bandwidth between SO-1S servers achieves 25 GB/s at peak, around half of UPI bandwidth, incurring less than 5% performance degradation for scale-out. One single server will finally meet the difficulty of holding enough resources to serve the model, (e.g., power delivery of one rack). Thus, distributed inference provides higher scalability and is a better strategy to support future model growth.

Throughput. Unlike datacenter batch workloads that only maximize throughput, the recommendation system maximizes throughput subject to a strict latency SLA. During workload initialization, we use a hill-climbing algorithm and a pressure test that sweeps query arrival rates and batch sizes [53]. The algorithm halts when latency-bounded throughput plateaus or decreases. Figure 5(a) shows that the end-to-end latency increases and gets dominated by queuing delay when query arrival rates are high. Figure 5(b) indicates that a batch size of 128 maximizes latency-bounded throughput and further increasing batch size harms throughput. Target latency cannot be met when batch size is 2048 as latency violates the SLA.
IV DisaggRec System Design
Given diverse, evolving characteristics of recommendation workloads, tightly coupling the provision of compute and memory in a monolithic server produces up to 30% wasted cost on idle resources (see Sec VI-B). Resource disaggregation [57] permits independent resource scaling, better failure isolation, and flexible heterogeneity provisioning. We propose DisaggRec to optimize the total cost of ownership when serving large-scale recommendation systems.
At a glance, memory disaggregation may seem like a bad idea for large recommendation models, whose performance is known to be often limited by memory bandwidth. Yet, we show that disaggregated architecture can be an effective solution when embeddeding reduction can be done locally.
IV-A DisaggRec Overview
System Architecture. Figure 6 describes how hardware resources in traditional monolithic servers are disseminated into network-attached compute nodes (CNs) and memory nodes (MNs). This architecture resembles those in prior work [50, 57, 9]. But whereas prior MN designs offer transparent physical memory with no processing power [50, 49, 43], DisaggRec’s MN includes an ASIC or a light-weight processor to perform embedding reduction locally.
The decision to process near memory arises from our insights in Sec III. The embedding reduction performed inside the remote SparseNet shards can reduce communication traffic by transferring only the embeddings’ input and output values (indices, Fsum). Without such processing, the recommendation system would access raw embedding entries at the remote MNs and incur significant network overheads.
An RDMA-supported network topology connects all CNs and MNs together. Every node has a dedicated back-end NIC connected with the back-end ToR switch. The fast network enables low-latency and high-bandwidth communication, leading to only minor latency overhead when transferring embeddings’ indices and Fsum.
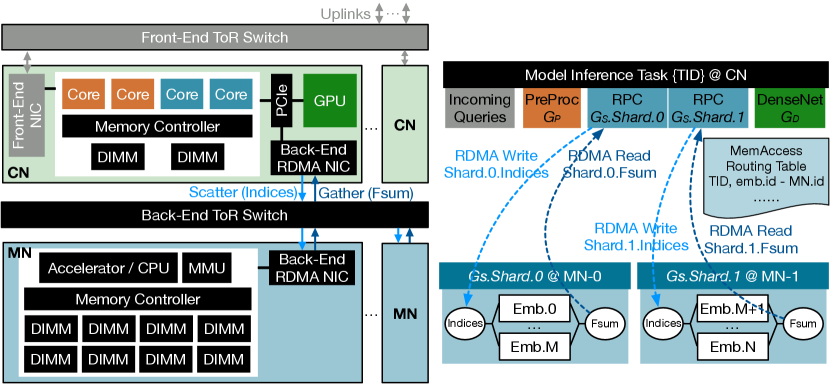


Managing Tasks. Adopting the distributed inference scheme, one serving unit consists of { CNs, MNs}. There are primary inference tasks launched on the CNs, and remote SparseNet serving shards launched on the MNs. Every primary task manages a private local memory region and a shared remote memory region. A CN’s local memory and a GPU’s HBM are mapped to the private local memory region. The remote MNs’ memory is mapped to the shared remote memory region.
Illustrated in Figure 6, a primary task with a unique global task ID (TID) is launched on every CN with dedicated CPUs for preprocessing and GPUs for DenseNet . SparseNet RPC client operators are launched in the primary task. Based on the MemAccess routing table, the input data (i.e., embedding lookup indices) of all embeddings are partitioned into packets and sent to designated MNs via RDMA writes. MNs respond to the primary CN with an acknowledgment signal and the remote memory addresses of the results (embeddings’ Fsum). After receiving acknowledgments from all SparseNet shards, the primary CN loads results from remote MNs to the local GPU’s HBM memory via RDMA reads. Then, DenseNet is launched on the GPU to calculate the final prediction.
Handling Failures. CN and MN failures are independent and handled separately in a disaggregated serving unit (unlike failures in monolithic servers). In Figure 7(b), when a CN in a serving unit fails, only the primary task running on that CN is affected and migrated to a backup, over-provisioned node. The other tasks in the serving unit are unaffected.
When an MN fails, there are two possible scenarios. First, when there are multiple replicas of embedding tables allocated in the MNs, at least one copy of each embedding table is likely still available in the remaining MNs. We only need to update the MemAccess routing table, re-running the greedy routing to evenly distribute the embedding accesses on the remaining MNs. Second, when multiple MN failures lead to a loss of all replicas for an embedding table, memory is re-initialized to re-distribute all embedding tables across MNs after adding backup MNs to the serving unit.
Provisioning Heterogeneous Components. Many emerging hardware technologies, such as compute-centric accelerators [45] and near-memory processing solutions [33], benefit recommendation performance. However, deploying new components in existing datacenter infrastructure is a cumbersome process. As datacenters deploy new servers and platforms to host specific devices, such as ZionEX to host GPUs [10], system architects are exposed to many produces from varied vendors. Resource disaggregation simplifies how new hardware is deployed by introducing a new resource pool and allowing workloads to request desired hardware combinations from multiple pools.
IV-B Intelligent Embedding Management
To balance memory capacity, bandwidth utilization, and fault tolerance, we perform greedy embedding allocation and memory access routing during task initialization. Embedding tables are read-only during inference, so remote memory does not cause data consistency and correctness issues.
Embedding Allocation. In Figure 7(a), one SparseNet shard contains a subset of embedding tables and shards are allocated to MNs. We take the embedding table as the basic unit for memory allocation and greedily assign embedding tables to the MNs following the scheme in Figure 7(c). Given the memory capacity provided by the MNs, the algorithm calculates the number of embedding replicas () that can be held by the MNs. Then, the algorithm picks the top MNs, ranked by available capacity, to allocate the of each embedding table. The replicas of an embedding on different MNs provide the backup when memory node failure happens.
MemAccess Routing. All embeddings’ memory accesses must be routed from the CNs to the MNs. We construct a MemAccess routing table that distributes memory accesses to the MNs. As depicted in Figure 7(c), for every embedding’s memory access, the destination is picked from the MNs where that embedding table is allocated. First, the memory accesses of each individual embedding table is calculated by the average pooling factor multiply the embedding entry’s dimension. The average pooling factor is profiled from embedding pooling operations shown in historical queries. The greedy method selects the destination MN in the MNs that has the minimal memory accessed have been routed to. Once an MN has been selected, the tuple (task ID, embedding table ID, the destination MN) is added as an entry to the MemAccess routing table.
Why Not Random? A naive method would randomly pick of MNs to allocate an embedding table, and also randomly pick the destination MN from the MNs to route the memory accesses. In Figure 7(d), thousands of embedding tables are allocated on 8 MNs. The random embedding management leads to unbalanced memory capacity allocation and memory accesses among the 8 MNs whereas our greedy method balances accesses among the 8 MNs.
IV-C Interleaved versus Sequential Query Processing
DisaggRec uses a task manager to coordinate scheduling within one serving unit. The manager can either perform interleaved or sequential query processing. In distributed inference, we find that sequential query processing offers lower latency and sustains higher throughput while satisfying the SLA.
Figure 8(a) illustrates one serving unit with {2 CNs, 2 MNs}. The embeddings’ request packets are generated from primary tasks on the two CNs and forwarded to SparseNet shards on the two MNs. Interleaved query processing executes the packets on SparseNet shards in first-come-first-serve (FCFS) order, which seems like a natural design to maximize throughput. Under this scheme, packets from different queries are interleaved and both queries finish late. In contrast, sequential query processing starts query execution only after all of its packets are received on all SparseNet shards. This scheme processes packets in lock step to finish one query’s embedding operations together, allowing one of the queries to finish earlier.
As shown in Figure 8(b), interleaved and sequential query processing achieve similar peak throughput if ignoring the latency target. However, when the latency SLA at 250ms needs to be met, the latency-bounded throughput of the sequential scheme is 28% higher than that of the interleaved scheme.
DisaggRec’s global manager performs sequential query processing to maximize latency-bounded throughput. In one serving unit, after all input data (embedding indices) belonging to one query are transferred from one CN to MNs, the global manager starts the query’s embedding operations on the MNs simultaneously. After MNs finish all embedding operations for that query, the global manager schedules the MNs to proceed to the next query. The naive adoption of previous disaggregated designs [57, 9] usually considers interleaved query processing among remote MNs, allowing an MN to respond to multiple packets (for different queries) at the same time to maximize remote memory utilization. However, we find that such interleaving will harm response latency.
IV-D Failure-Aware Resource Allocation
To guarantee quality-of-service for billions of users, cluster resource management must allocate a sufficient number of serving units to ensure availability of the recommendation system. One serving unit consists of { CNs, MNs} in the disaggregated cluster, or servers in the monolithic server-based cluster, as one group to serve a recommendation model. We formulate resource allocation as a constrained optimization problem with two main steps—offline workload characterization and online resource allocation. The optimization’s objective is the efficient allocation of serving units to achieve performance and availability goals.
During offline workload characterization, we measure the throughput and power for each model-system pair, the achieved latency-bounded throughput and the peak power consumption of model launched on one serving unit , are input parameters when optimizing resource allocations for online serving.
During online resource allocation, subject to two constraints, Equation (1) allocates serving units (system type to model ) to minimize the total cost of ownership (TCO) for a time period t (e.g., 10s of minutes) where Capex is the acquisition cost of physical machines and Opex captures the operational cost due to electricity. Constraint (2) states the number of allocated serving units must be sufficient to guarantee availability given the highly-fluctuating diurnal loads and the expected machine failure rates. Backup machines are over-provisioned by % based on historical data on load variance and also by % given a machine failure rate. Constraint (3) states that provisioned power should be sufficient for allocated serving units.
| Minimize | ||||
| subject to | ||||
The failure rate for a machine is dictated by the failure rate of its least reliable component. When any component fails, the whole machine becomes inaccessible and its jobs must migrate to a backup server. Figure 9 details reliability and failure rates in a production datacenter fleet. It reports four types of machine states during a day.
-
•
Server available all day
-
•
Server inaccessible all day (blue region)
-
•
Server becomes available mid-day (green region)
-
•
Server initially available but fails during day (red region)
We guarantee service availability by provisioning backup machines, which assume the responsibilities of failed servers in the fourth category.

Monolithic servers handle failures inefficiently because they bundle resources together despite the distinct reliability characteristics of each system component. We find that CPU servers (with high-capacity memory systems) and GPU servers (with multiple powerful compute GPUs) exhibit very different failure rates. The daily failure rate for GPU servers (7%) is much higher than that for CPU servers (0.4%) in the historical, 90-day datacenter logs. The monolithic SU-2S/SO-1S server deploys CPUs, GPUs, and DRAMs together into single nodes, their failure rates follow the higher rate of 7%. This higher failure rate implies more conservative over-provisioning, specifically on CPU and DRAM.
DisaggRec separates these unnecessarily bundled failures via a disaggregated architecture. It exploits the distinct failure rates of CNs and MNs to reduce the over-provisioning factor, in particular, for the more reliable MNs.
V Experimental Methodology
| Scale-Up and Scale-Out Monolithic Servers | Disaggregated Nodes | |||||||||||||||||
| SU-2S |
|
|
|
|
|
DDR-MN | NMP-MN | |||||||||||
| # Sockets | 2IceLake | 1IceLake | 1CooperLake | 1ASIC Accelerator | ||||||||||||||
| # Channels per Socket | 8 | 8 | 4 | 8 | ||||||||||||||
| # DIMMs per Channel | 2 | 2 | 1 | 2 | ||||||||||||||
| DRAM Device |
|
|
|
|
|
|||||||||||||
| GPU | 8A100 | 4A100 | 2A100 | 1A100 | 4A100 | 1A100 | - | |||||||||||
| NIC | 2Front-End | 1Front-End, 1Back-End | 1Front-End, 1Back-End | 1Back-End | ||||||||||||||
| Devices | Specs | TDP | Market Price | ||
| IceLake CPU |
|
270 W | $4K$5K | ||
| CooperLake CPU |
|
86 W | $2K$3K | ||
| GPU | Nvidia A100 (80GB HBM) | 400 W | $12K$15K | ||
| DDR4-DIMM | 16GB, 1 Rank @ 2400MHz | 5 W | $80 | ||
| 64GB, 2 Ranks @ 3200MHz | 24 W | $350 | |||
| NMP-DIMM | 64GB, 2 Ranks @ 3200MHz | 24 W | Assume $700 | ||
| NIC |
|
20 W | $2.5K |
V-A Measuring Monolithic Servers
Table I describes GPU servers used to evaluate monolithic servers for recommendation systems. These servers are used to evaluate model inference on the state-of-the-art (SOTA) baseline, (a) end-to-end inference on a single scale-up server, and (b) distributed inference on multiple scale-out servers.
SU-2S is a scale-up dual-socket server with two 40-core Intel IceLake CPU processors, two terabytes (TB) of memory, and eight NVIDIA A100 GPUs, each with 80GB HBM. Front-end NICs are attached to the two CPU processors to receive inference queries from the front-end networks.
SO-1S is a scale-out single-socket server with one 40-core Intel IceLake CPU processor, one terabyte (TB) of memory, and four Nvidia A100 GPUs. One front-end NIC is attached to the CPU processor to receive inference queries from the front-end networks. Two back-end NICs are connected through the PCIe switch to communicate intermediate model inference data, embedding indices and Fsum, between the servers multiple SO-1S servers. We emulate different types of SO-1S servers by limiting GPU usage to one, two, or four GPUs.
V-B Emulating DisaggRec System
Table I describes two types of compute nodes (CNs) and memory nodes (MNs) that we consider for the disaggregated system design. We emulate the recommendation system on disaggregated CNs and MuccjbhdcgblnjgulkklltdkkbbjguevbjlkjnjdbnjreedvfcvcdevigiNs by launching stages of the inference pipeline on the CPU and GPU servers. All performance numbers are measured from real systems except those with NMP-enabled memory, which is estimated with cycle-level simulation.
Compute Nodes. One CN is configured with one light-weight CPU and either one or four GPUs, matching the number of GPUs in the two SO-1S configurations. Each CN has one front-end NIC that receives incoming inference queries. It also has one back-end NIC that sends embedding indices to MNs and loads the embedding Fsum from MNs.
CN emulation accounts for two stages of the inference pipeline. Preprocessing is launched on the light-weight CPU server with one Intel CooperLake CPU and 64GB memory. DenseNet is launched on an SO-1S server using the selected number of GPUs.
Memory Nodes. First, the DDR-MN is configured with 1TB memory, matching the memory capacity of the SO-1S server, and a light-weight ASIC as the MN-side processing unit. Alternatively, the NMP-MN represents a memory node with near-memory processing enabled (NMP-DIMMs) [31, 33]. The NMP-MN exploits DIMM- and rank-level parallelism to increase effective memory bandwidth by relative to DDR-MN. DIMM-level parallelism doubles bandwidth by provisioning two NMP-DIMMs on a single memory channel. Rank-level parallelism further doubles the bandwidth by provisioning two ranks on one NMP-DIMM. We conservatively estimate the power dissipated by the MN’s ASIC to be 23.9 Watts based on the power profile of an internal ASIC accelerator fabricated in TSMC 7nm.
DDR-MN emulation launches SparseNet on SO-1S while disabling all GPUs. NMP-MN emulation simulates emerging NMP-DIMMs, following the earlier methodology for NMP studies [61, 31, 62, 6].
Communication. High-performance communication between CNs and MNs is the key for efficiency. One serving unit is defined by CNs and MNs and we explore a range of design points, ranging from the minimum (1 CN, 1 MN) to the maximum (8 CNs, 8 MNs). We emulate communication within the recommendation serving unit by microbenchmarking communication between 16 (8 + 8) GPUs on two SU-2S servers. Communication uses NVIDIA’s Collective Communication Library (NCCL) [51] and RDMAs. For each inference task, a CN sends embedding indices to multiple MNs with a Scatter (one-to-all) operation and the CN loads embedding Fsums from multiple MNs with a Gather (all-to-one) operation.
V-C Total Cost of Ownership
We estimate the total cost of ownership (TCO) using public market prices for all commodity devices and assuming a three-year machine lifetime. Since there is no NMP-DIMM commercially available on the market, we assume the price of one NMP-DIMM is 2 that of a regular DDR-DIMM because NMP-DIMM can theoretically double effective memory bandwidth to the same memory capacity. This estimate is conservative because NMP-DIMM will be a value-added product over today’s DIMM with only a small, fractional increase in cost when the technology is standardized.
V-D Evaluation Framework
For monolithic servers, the performance of model inference on the scale-up single server and the scale-out multiple servers are evaluated on real systems, building atop of the DeepRecSys serving framework [53].
For disaggregated systems, latency and power dissipated in the three pipeline stages are recorded for each inference query. Latency in the three stages—preprocessing on a CPU, SparseNet on DDR-MN, and DenseNet on GPUs—are individually measured and recorded on real systems. During real model inference execution, the dummy serving processes of the corresponding pipeline stages are replayed with the recorded latency for each query for each pipeline stage. When NMP-MNs are evaluated, cycle-level simulation estimates SparseNet performance. CPU and DDR4 power is read from Intel RAPL [18], and GPU power is measured by Nvidia API nvidia-smi.
VI Evaluation Results
VI-A Substantial Cost Increase with Model Evolution
TakeawayA: While system heterogeneity permits server configurations to be tailored for diverse recommendation models, the exponential model growth drives up the datacenter costs substantially.
We consider recommendation services RM1 and RM2 and their respective model evolution for the next three years, as illustrated in Figure 1(c). We explore the server design space and optimize monolithic server configurations to minimize the TCO subject to performance goals. We consider five system configurations, including naive and NUMA-aware model inference on a SU-2S server as well as distributed inference on three types of SO-1S servers with 1, 2, and 4 GPUs. We follow method in Sec. IV-D to estimate the cluster TCO for online serving based on offline measured throughput and power consumption.


In Figure 10, when the model size grows larger than 2TB, one SU-2S server no longer provides sufficient memory capacity, and distributed inference is required. The number of distributed SO-1S servers in one serving unit is determined by the model size. For memory-intensive RM1, distributed inference on SO-1S (1 GPU) servers is the most cost-effective. For compute-intensive RM2, distributed inference on SO-1S (4 GPUs) servers is the best system choice. Thus, a heterogeneous cluster based on monolithic design would host two types of servers. Despite deploying these heterogeneous servers optimize for each recommendation service, as models grow in size and complexity, the datacenter’s TCO increases substantially—by 6.8 for RM1 and 12.4 for RM2—over the three-year period.
VI-B Cost Inefficiency from Monolithic Design
TakeawayB: Because monolithic servers bundle compute and memory in a fixed ratio, up to 30% of datacenter cost is wasted on idle resources (23.1%) and over-provisioned capacity (6.8%). These inefficiencies arise due to unbalanced model pipelines and heterogeneous fault rates.
Figure 11(a) shows server allocation and utilization in the span of a day. The blue region shows the activated capacity for serving queries while the red region represents the over-provisioned capacity assuming a 7% machine failure rate observed from a production datacenter fleet. We assume servers are abundant and workloads always receive their preferred machines, optimally SO-1S (1 GPU) for RM1 and SO-1S (4 GPUs) for RM2.
Figure 11(b) shows resource utilization for active servers. RM1 models are constrained by SparseNet (dark blue for busy) while CPUs and GPUs are under-utilized during the Preprocessing and DenseNet stages (light orange and light green for idling), respectively. RM2 models are first constrained by SparseNet (dark blue), and then by DenseNet (dark green), as RM2 models grow primarily in the DenseNet.
Figure 11(c) shows the percentage of TCO wasted on idle resources attributed by two sources. We assume the CPU costs for carrying out Preprocessing and SparseNet are the same. For both models, over-provisioned capacity accounts for 6.8% of TCO. In addition, RM1’s unbalanced pipeline costs 15.6%–23.1% of TCO while RM2’s costs 2.8%–16.2%. RM1 pays higher for idleness because its DenseNet computation poorly utilizes the expensive GPUs; in contrast, RM2 only pays the toll in less expensive CPUs and memories during Preprocessing and SparseNet.

VI-C Improving Cost Efficiency by Scaling Out
TakeawayC: Scaling the number of monolithic servers used for distributed inference improves latency-bounded throughput and cost efficiency.
We explore the benefits of distributed inference and scaling out monolithic servers by examining the diagonals in Figure 12. A serving unit may scale out with two to eight monolithic SO-1S servers for RM1.V0. Adding more servers helps reduce query response latency, and then improves latency-bounded throughput for serving units that perform sequential (and not interleaved) query processing. In Figure 12(a), a serving unit with two, four, and eight SO-1S servers achieves 65%, 76%, and 90.6% of that serving unit’s peak throughput, respectively. Scaling out causes performance to increase superlinearly as throughput improves by 2.4 and 5.6 with 2 and 4 the number of servers.
A serving unit’s throughput and the over-provisioning ratio based on machine failure rates—which we take to be 7% for SO-1S, 7% for CNs, and 0.04% for MNs—determine how many serving units are required to ensure the cluster satisfies peak query load (Figure 12(d)). The recommendation serving cluster’s cost depends on the number of hosted serving units and their power costs (Figure 12(c)). Our analysis indicates that scaling out with monolithic serves causes normalized TCO to decrease from 2.55 to 1.83 (Figure 12(e), diagonal).
VI-D Improving Cost Efficiency by Disaggregation

TakeawayD: Disaggregation further improves cost efficiency by improving resource utilization and reducing over-provisioned backups for machine failures.
We explore the benefits of distributed inference on disaggregated compute and memory nodes by examining the whole 2D grid in Figure 12. Disaggregation permits a serving unit to scale compute and memory nodes independently, which better matches resources to workload needs. For memory-intensive model RM1.V0, throughput is relatively insensitive to the number of CNs in the serving unit. Disaggregation permits a serving unit with fewer CNs and more MNs, which in turn reduces cost (Figure 12(e), blueish region). A serving unit that deploys 3 CNs and 8 MNs minimizes the TCO with negligible impact on performance. The throughput of this cost-efficient solution is only 2% less than that of eight monolithic SO-1S servers (Figure 12(b)).
Broadening our evaluation, Figure 13 details disaggregation’s benefits for six generations of recommendation models. For memory-intensive RM1, disaggregation reduces the TCO by up to 49.3% compared to distributed inference on monolithic SO-1S servers. Most of the saving (40.9% of 49.3%) comes from reducing the number of CNs, which are equipped with expensive GPUs. The remaining saving comes from exploiting MNs’ low failure rates and over-provisioning resources by a smaller factor.
For compute-intensive RM2, serving units require similar amounts of hardware whether using monolithic servers or using disaggregated CNs and MNs. For example, the optimal configurations for V2, V3, and V4 models use the same ratio of CNs and DDR-MNs. Yet even for these models, disaggregation reduces cost by 4.3% to 9.3%.
The cost savings come from two sources. First, the serving unit with disaggregated nodes is more power-efficient. CNs deploy low-end CPUs and high-end GPUs. MNs deploy ASICs for a modest amount of computation near the data. These CN and MN configurations dissipate less power than the monolithic SO-1S servers deploying a high-end CPU (i.e., 40-core IceLake). Lower operating expenses account for 7.2% of the cost savings. Second, the MN’s lower failure rate permits the serving unit to over-provision resources by a smaller factor.
VI-E Provisioning Heterogeneity by Disaggregation

TakeawayE: Resource disaggregation provides flexible support for resource heterogeneity in production datacenters. Hardware components are organized into disparate resource pools rather than integrated into monolithic servers. This organization improves utilization and reduces costs.
We explore technology scenarios, comparing and contrasting a cluster with monolithic servers and one with disaggregated resources as recommendation models evolve and grow over three years. The initial clusters are built with commodity CPUs, regular DDR-DIMMs, and GPUs. The cluster with monolithic servers optimally deploys SO-1S servers with 1 GPU and DDR-DIMMs for memory-intensive RM1.V0 and optimally deploys SO-1S servers with 4 GPUs and DDR-DIMMS for compute-intensive RM2.V0. On the other hand, the cluster with disaggregated compute and memory nodes optimally deploys {CN with 1 GPU, DDR-MN} and {CN with 4 GPUs, DDR-MN} for RM1.V0 and RM2.V0, respectively. We assume that deployed servers and nodes will remain deployed for their three-year machine lifetimes.
In future model generations, near-memory processing leads to new system components (NMP-DIMM). The cluster with monolithic servers deploys two new server configurations, namely an SO-1S server with 1 GPU and NMP-DIMMs as well as an SO-1S server with 4 GPUs and NMP-DIMMs. On the other hand, the disaggregated cluster deploys NMP-DIMMs as a new type of memory node, NMP-MN (Table I).
Figure 14(a) shows the TCO savings from NMP-DIMMs. When monolithic servers are used, NMP-DIMMs reduce costs for memory-intensive RM1 models but increase costs for compute-intensive RM2 models. Emerging NMP-DIMMs are more expensive than conventional DDR-DIMMs starting in the V2 generation. Their costs are justified only for memory-intensive workloads that experience throughput gains when adopting the technology.
Specifically, NMP-DIMMs increase effective memory bandwidth by 4 through DIMM- and rank-level parallelism. Greater memory bandwidth accelerates embedding operations. The SO-1S server with NMP-DIMMs improves RM1 throughput by up to 3.64. However, for compute-dominated RM2, the memory bandwidth of NMP-DIMMs on the SO-1S server is under-utilized, and the 2 cost of NMP-DIMMs (Table II) over DDR-DIMMs eventually leads to a higher TCO.
In contrast, when disaggregated nodes are used, NMP-DIMMs reduce costs for both RM1 and RM2 models because the emerging technology (NMP-DIMM) is deployed as a new resource pool and allocated flexibly. The independent scaling of CNs and MNs in the disaggregated cluster allows a smaller ratio of MNs in a serving unit, which prevents the under-utilization of NMP-DIMMs’ memory bandwidth.
Figure 14(b) shows total cluster TCOs over multiple model generations when the cluster is provisioned by continuously deploying optimal system configurations for new generations of RM1 and RM2. When monolithic servers are used, the cluster expands capacity for evolving recommendation models by deploying SO-1S servers with 1 GPU and NMP-DIMMs for RM1.V1–V5, and deploying SO-1S servers with 4 GPUs and DDR-DIMMs for RM2.V1–V5. When disaggregated resource nodes are used, the cluster deploys {CN with 1 GPU, NMP-MN} and {CN with 4 GPUs, NMP-MN} for RM1 and RM2, respectively. Overall, the disaggregated cluster allows 21%–43.6% TCO saving over the monolithic server-based cluster across the three-year model evolution.
VII Related Work
Disaggregating organizes different types of resources into separate pools for independent, fine-grained resource allocation. Several studies disaggregate datacenter storage, e.g., [40, 5, 22, 36] where network communication can be hidden by the high storage latency. Given the success of disaggregated storage and rapidly evolving network technologies [7, 41, 21, 39, 44, 48, 54, 47], disaggregated memory systems were proposed for large-scale datacenters [50, 19, 30, 26, 27, 28, 57, 55, 59, 60, 49, 43, 23, 9, 65, 3, 11, 64]. Disaggregated memory promises large memory capacity, independent scale-out for compute and memory resources, improved reliability by separating compute nodes’ failures from memory nodes’, more cost-efficient hardware deployment, etc. Disaggregated memory systems are particularly attractive for deep learning workloads as rapid growth in datasets and models turn DRAM into a major system bottleneck.
Disaggregated systems may deploy memory nodes with and without processing capabilities. MNs without processing are viewed primarily as raw physical memory. Such MNs have been adopted in HPE’s Memory-Driven Computing project [50, 19], the disaggregated hashing system [49] and disaggregated key-value systems [43], also the recent compute express link (CXL)-based memory pooling system [20]. However, for memory-intensive workloads, data movement through the network or CXL interfaces can be significant and become harmful to the performance. MNs with processing often resemble regular servers [25, 57, 55, 3, 11, 64, 8]. Such MNs perform light-weight processing to reduce data movement and network overheads. Given the costs of high-performance CPUs and the light-weight computation required near the data, researchers have proposed MNs that replace the general-purpose processor with light-weight FPGA-based accelerators [65, 9].
In this paper, we perform the first study of disaggregated memory systems for distributed machine learning. We optimize the full system for recommendation, provisioning hardware with CNs and MNs to improve efficiency. We favor MNs with a lightweight CPU/ASIC and show how MN-side computation can support embedding accesses and optimize the full system for recommendation workloads.
To manage disaggregated CNs and MNs, LegoOS [57] proposed a distributed OS supported by an RDMA-based RPC framework. The RDMA-based network protocol is commonly used by disaggregated memory designs [9, 65, 23, 49, 43] to permit remote memory access without involving host processors. RDMAs can efficiently transfer a large chunk of data across server nodes with speeds approaching that of DRAM memory channels [39]
VIII Conclusion
DisaggRec addresses infrastructure challenges for evolving recommendation systems. It improves system efficiency by independently scaling compute and memory resources to better match changing demands future generations of recommendation models. It also improves system reliability by provisioning backups to handle the different failure rates of CNs and MNs. DisaggRec reduces the total cost of ownership by 49.3% through disaggregation. Given the growing trend of increased resource heterogeneity in future datacenters, the flexibility of disaggregation simplifies the deployment of newly added hardware and allows each workload to attain an optimal allocation of hardware resources to maximize the efficiency and the TCO simultaneously. The disaggregated cluster achieves a maximum of 43.6% cost saving over the monolithic server-based cluster for large-scale, multi-generation recommendation systems.
References
- [1] “Breakthroughs in Matching and Recommendation Algorithms by Alibaba.” [Online]. Available: https://www.alibabacloud.com/blog/breakthroughs-in-matching-and-recommendation-algorithms-by-alibaba_593976
- [2] “PyTorch.” [Online]. Available: https://pytorch.org/
- [3] Aleksandar Dragojevic, Dushyanth Narayanan, Orion Hodson, Miguel Castro., “FaRM: Fast Remote Memory.” in NSDI, 2014.
- [4] Amazon Personalize, https://aws.amazon.com/personalize/.
- [5] Amazon S3, https://aws.amazon.com/s3/.
- [6] Bahar Asgari, Ramyad Hadidi, Jiashen Cao, Da Eun Shim, Sung-Kyu Lim, Hyesoon Kim, “FAFNIR: Accelerating Sparse Gathering by Using Efficient Near-Memory Intelligent Reduction,” in HPCA, 2021.
- [7] Cache Coherent Interconnect for Accelerators, https://www.ccixconsortium.com/wp-content/uploads/2019/11/CCIX-White-Paper-Rev111219.pdf.
- [8] Chenxi Wang, Haoran Ma, Shi Liu, Yuanqi Li, Zhenyuan Ruan, Khanh Nguyen, Michael D. Bond, Ravi Netravali, Miryung Kim, Guoqing Harry Xu., “Semeru: A Memory-Disaggregated Managed Runtime,” in OSDI, 2020.
- [9] Dario Korolija, Dimitrios Koutsoukos, Kimberly Keeton, Konstantin Taranov, Dejan Milojicic, Gustavo Alonso, “Farview: Disaggregated Memory with Operator Off-loading for Database Engines,” in CIDR, 2022.
- [10] Dheevatsa Mudigere, Yuchen Hao, Jianyu Huang, Zhihao Jia, Andrew Tulloch, Srinivas Sridharan, Xing Liu, Mustafa Ozdal, Jade Nie, Jongsoo Park, Liang Luo, Jie Amy Yang, Leon Gao, Dmytro Ivchenko, Aarti Basant, Yuxi Hu, Jiyan Yang, Ehsan K. Ardestani, Xiaodong Wang, Rakesh Komuravelli, Ching-Hsiang Chu, Serhat Yilmaz, Huayu Li, Jiyuan Qian, Zhuobo Feng, Yinbin Ma, Junjie Yang, Ellie Wen, Hong Li, Lin Yang, Chonglin Sun, Whitney Zhao, Dimitry Melts, Krishna Dhulipala, KR Kishore, Tyler Graf, Assaf Eisenman, Kiran Kumar Matam, Adi Gangidi, Guoqiang Jerry Chen, Manoj Krishnan, Avinash Nayak, Krishnakumar Nair, Bharath Muthiah, Mahmoud khorashadi, Pallab Bhattacharya, Petr Lapukhov, Maxim Naumov, Ajit Mathews, Lin Qiao, Mikhail Smelyanskiy, Bill Jia, Vijay Rao, “Software-hardware co-design for fast and scalable training of deep learning recommendation models,” in ISCA, 2022.
- [11] Emmanuel Amaro, Christopher Branner-Augmon, Zhihong Luo, Amy Ousterhout, Marcos K. Aguilera, Aurojit Panda, Sylvia Ratnasamy, Scott Shenker, “Can Far Memory Improve Job Throughput?” in EuroSys, 2020.
- [12] Fabrice Devaux, “The True Processing In Memory Accelerator,” in HotChips, 2019.
- [13] Fortune, https://fortune.com/2019/04/30/artificial-intelligence-walmart-stores/.
- [14] Google Cloud Platform, https://cloud.google.com/solutions/recommendations-using-machine-learning-on-compute-engine.
- [15] Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, Kun Gai, “Deep Interest Evolution Network for Click-Through Rate Prediction,” in AAAI, 2019.
- [16] Guorui Zhou, Xiaoqiang Zhu, Chengru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, Kun Gai, “Deep Interest Network for Click-Through Rate Prediction,” in KDD, 2018.
- [17] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, Hemal Shah, “Wide & Deep Learning for Recommender Systems,” in DLRS, 2016.
- [18] Howard David, Eugene Gorbatov, Ulf R Hanebutte, Rahul Khanna, and Christian Le, “RAPL: memory power estimation and capping,” in ISLPED, 2010, pp. 189–194.
- [19] HP: Memory-Driven Computing, https://www.hpe.com/us/en/newsroom/blog-post/2017/05/memory-driven-computing-explained.html.
- [20] Huaicheng Li, Daniel S. Berger, Stanko Novakovic, Lisa Hsu, Dan Ernst, Pantea Zardoshti, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, Mark D. Hill, Marcus Fontoura, Ricardo Bianchini, “Pond: CXL-Based Memory Pooling Systems for Cloud Platforms,” in arXiv preprint arXiv:2203.00241, 2022. [Online]. Available: https://arxiv.org/abs/2203.00241
- [21] Intel High Performance Fabric, https://www.intel.com/content/www/us/en/products/network-io/high-performance-fabrics.html.
- [22] Introducing Bryce Canyon: Our next-generation storage platform, https://engineering.fb.com/2017/03/08/data-center-engineering/introducing-bryce-canyon-our-next-generation-storage-platform/.
- [23] Irina Calciu, M. Talha Imran, Ivan Puddu, Sanidhya Kashyap, Hasan Al Maruf, Onur Mutlu, Aasheesh Kolli, “Rethinking Software Runtimes for Disaggregated Memory,” in ASPLOS, 2021.
- [24] Jin Hyun Kim, Shin-haeng Kang, Sukhan Lee, Hyeonsu Kim, Woongjae Song, Yuhwan Ro, Seungwon Lee, David Wang, Hyunsung Shin, Bengseng Phuah, Jihyun Choi, Jinin So, YeonGon Cho, JoonHo Song, Jangseok Choi, Jeonghyeon Cho, Kyomin Sohn, Youngsoo Sohn, Kwangil Park, Nam Sung Kim, “Aquabolt-XL: Samsung HBM2-PIM with in-memory processing for ML accelerators and beyond,” in HotChips, 2021.
- [25] Juncheng Gu, Youngmoon Lee, Yiwen Zhang, Mosharaf Chowdhury, Kang G. Shin, “Efficient Memory Disaggregation with Infiniswap,” in NSDI, 2017.
- [26] K. Katrinis, D. Syrivelis, D. Pnevmatikatos, G. Zervas, D. Theodoropoulos, I. Koutsopoulos, K. Hasharoni, D. Raho, C. Pinto, F. Espina, S. Lopez-Buedo, Q. Chen, M. Nemirovsky, D. Roca, H. Klosx, T.Berendsx, “Rack-scale disaggregated cloud data centers: The dReDBox project vision,” in DATE, 2016.
- [27] Kevin Lim, Jichuan Chang, Trevor Mudge, Parthasarathy Ranganathan, Steven K. Reinhardt, and Thomas F. Wenisch, “Disaggregated Memory for Expansion and Sharing in Blade Servers,” in ISCA, 2009.
- [28] Kevin Lim, Yoshio Turner, Jose Renato Santos, Alvin AuYoung, Jichuan Chang, Parthasarathy Ranganathan, Thomas F. Wenisch, “System-level implications of disaggregated memory,” in HPCA, 2012.
- [29] Kim Hazelwood, Sarah Bird, David Brooks, Soumith Chintala, Utku Diril, Dmytro Dzhulgakov, Mohamed Fawzy, Bill Jia, Yangqing Jia, Aditya Kalro, James Law, Kevin Lee, Jason Lu, Pieter Noordhuis, Misha Smelyanskiy, Liang Xiong, Xiaodong Wang, “Applied machine learning at Facebook: a datacenter infrastructure perspective,” in HPCA, 2018, pp. 620–629.
- [30] Krste Asanovic, “FireBox: A Hardware Building Block for 2020 Warehouse-Scale Computers,” in FAST, 2014.
- [31] Liu Ke, Udit Gupta, Benjamin Youngjae Cho, David Brooks, Vikas Chandra, Utku Diril, Amin Firoozshahian, Kim Hazelwood, Bill Jia, Hsien-Hsin S. Lee, Meng Li, Bert Maher, Dheevatsa Mudigere, Maxim Naumov, Martin Schatz, Mikhail Smelyanskiy, Xiaodong Wang, Brandon Reagen, Carole-Jean Wu, Mark Hempstead, Xuan Zhang, “RecNMP: Accelerating Personalized Recommendation with Near-Memory Processing,” in ISCA, 2020.
- [32] Liu Ke, Udit Gupta, Mark Hempstead, Carole-Jean Wu, Hsien-Hsin S. Lee, Xuan Zhang, “Hercules: Heterogeneity-Aware Inference Serving for At-Scale Personalized Recommendation,” in HPCA, 2022.
- [33] Liu Ke, Xuan Zhang, Jinin So, Jong-Geon Lee, Shin-Haeng Kang, Sukhan Lee, Songyi Han, YeonGon Cho, JIN Hyun Kim, Yongsuk Kwon, KyungSoo Kim, Jin Jung, Ilkwon Yun, Sung Joo Park, Hyunsun Park, Joonho Song, Jeonghyeon Cho, Kyomin Sohn, Nam Sung Kim, Hsien-Hsin S. Lee, “Near-Memory Processing in Action: Accelerating Personalized Recommendation with AxDIMM,” in IEEE Micro, 2022.
- [34] Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole-Jean Wu, Alisson G. Azzolini, Dmytro Dzhulgakov, Andrey Mallevich, Ilia Cherniavskii, Yinghai Lu, Raghuraman Krishnamoorthi, Ansha Yu, Volodymyr Kondratenko, Stephanie Pereira, Xianjie Chen, Wenlin Chen, Vijay Rao, Bill Jia, Liang Xiong, Misha Smelyanskiy, “Deep Learning Recommendation Model for Personalization and Recommendation Systems,” in arXiv preprint arXiv:1906.00091, 2019. [Online]. Available: https://arxiv.org/abs/1906.00091
- [35] Michael Lui, Yavuz Yetim, Ozgur Ozkan, Zhuoran Zhao, Shin-Yeh Tsai, Carole-Jean Wu, Mark Hempstead, “Understanding Capacity-Driven Scale-Out Neural Recommendation Inference,” in IISWC, 2020.
- [36] Midhul Vuppalapati, Justin Miron, Rachit Agarwal, Dan Truong, Ashish Motivala, Thierry Cruanes, “Building An Elastic Query Engine on Disaggregated Storage,” in NSDI, 2020.
- [37] Misha Smelyanskiy, “Zion: Facebook Next- Generation Large Memory Training Platform,” in HotChips, 2019.
- [38] Norman P. Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, Rick Boyle, Pierre-luc Cantin, Clifford Chao, Chris Clark, Jeremy Coriell, Mike Daley, Matt Dau, Jeffrey Dean, Ben Gelb, Tara Vazir Ghaemmaghami, Rajendra Gottipati, William Gulland, Robert Hagmann, C. Richard Ho, Doug Hogberg, John Hu, Robert Hundt, Dan Hurt, Julian Ibarz, Aaron Jaffey, Alek Jaworski, Alexander Kaplan, Harshit Khaitan, Andy Koch, Naveen Kumar, Steve Lacy, James Laudon, James Law, Diemthu Le, Chris Leary, Zhuyuan Liu, Kyle Lucke, Alan Lundin, Gordon MacKean, Adriana Maggiore, Maire Mahony, Kieran Miller, Rahul Nagarajan, Ravi Narayanaswami, Ray Ni, Kathy Nix, Thomas Norrie, Mark Omernick, Narayana Penukonda, Andy Phelps, Jonathan Ross, Matt Ross, Amir Salek, Emad Samadiani, Chris Severn, Gregory Sizikov, Matthew Snelham, Jed Souter, Dan Steinberg, Andy Swing, Mercedes Tan, Gregory Thorson, Bo Tian, Horia Toma, Erick Tuttle, Vijay Vasudevan, Richard Walter, Walter Wang, Eric Wilcox, Doe Hyun Yoon, “In-datacenter performance analysis of a tensor processing unit,” in ISCA, 2017.
- [39] Nvidia Infiniband Network Solutions, https://www.nvidia.com/en-us/networking/products/infiniband/.
- [40] Pangu: The High Performance Distributed File System by Alibaba Cloud, https://www.alibabacloud.com/blog/pangu-the-high-performance-distributed-file-system-by-alibaba-cloud_594059.
- [41] Patrick Knebel, Dan Berkram, Darel Emmot, Paolo Faraboschi, Gary Gostin, “Gen-Z Chipsetfor Exascale Fabrics,” in HotChips, 2019.
- [42] Paul Covington, Jay Adams, Emre Sargin, “Deep Neural Networks for YouTube Recommendations,” in RecSys, 2016.
- [43] Pengfei Zuo, Jiazhao Sun, Liu Yang, Shuangwu Zhang, and Yu Hua, “Onesided RDMA-Conscious Extendible Hashing for Disaggregated Memory,” in USENIX ATC, 2021.
- [44] Peter X. Gao, Akshay Narayan, Sagar Karandikar, Joao Carreira, Sangjin Han, Rachit Agarwal, Sylvia Ratnasamy, Scott Shenker, “Network Requirements for Resource Disaggregation,” in OSDI, 2016.
- [45] Samuel Hsia, Udit Gupta, Mark Wilkening, Carole-Jean Wu, Gu-Yeon Wei, David Brooks, “Cross-Stack Workload Characterization of Deep Recommendation Systems,” in IISWC, 2020.
- [46] Seong Ju Lee, Kyuyoung Kim, Sanghoon Oh, Joonhong Park, Gimoon Hong, Dong Yoon Ka, Kyudong Hwang, Jeong-Joon Park, Kyeongpil Kang, Jungyeon Kim, Junyeol Jeon, Na Yeon Kim, Yongkee Kwon, Kornijcuk Vladimir, Woojae Shin, Jong-Hak Won, Minkyu Lee, Hyunha Joo, Haerang Choi, Jae-Woo Lee, Dong-Young Ko, Younggun Jun, Kee-yeong Cho, Ilwoong Kim, Choungki Song, Chunseok Jeong, Dae-Han Kwon, Jieun Jang, Il Memming Park, Jun Hyun Chun, Joohwan Cho, “A 1ynm 1.25V 8Gb, 16Gb/s/pin GDDR6-based Accelerator-in-Memory supporting 1TFLOPS MAC Operation and Various Activation Functions for Deep-Learning Applications,” in ISSCC, 2022.
- [47] Seung-seob Lee, Yanpeng Yu, Yupeng Tang, Anurag Khandelwal, Lin Zhong, Abhishek Bhattacharjee, “MIND: In-Network Memory Management for Disaggregated Data Centers,” in SOSP, 2021.
- [48] Shin-Yeh Tsai, Yiying Zhang, “LITE Kernel RDMA Support for Datacenter Applications,” in OSDI, 2017.
- [49] Shin-Yeh Tsai, Yizhou Shan, Yiying Zhang, “Disaggregating Persistent Memory and Controlling Them Remotely: An Exploration of Passive Disaggregated Key-Value Stores,” in USENIX ATC, 2020.
- [50] The Machine: A New Kind of Computer, https://www.hpl.hp.com/research/systems-research/themachine/.
- [51] The NVIDIA Collective Communication Library (NCCL), https://docs.nvidia.com/deeplearning/nccl/index.html.
- [52] Udit Gupta, Carole-Jean Wu, Xiaodong Wang, Maxim Naumov, Brandon Reagen, David Brooks, Bradford Cottel, Kim Hazelwood, Bill Jia, Hsien-Hsin S. Lee, Andrey Malevich, Dheevatsa Mudigere, Mikhail Smelyanskiy, Liang Xiong, Xuan Zhang, “The Architectural Implications of Facebook’s DNN-based Personalized Recommendation,” in HPCA, 2020.
- [53] Udit Gupta, Samuel Hsia, Vikram Saraph, Xiaodong Wang, Brandon Reagen, Gu-Yeon Wei, Hsien-Hsin S. Lee, David Brooks, Carole-Jean Wu, “DeepRecSys: A System for Optimizing End-To-End At-scale Neural Recommendation Inference,” in ISCA, 2020.
- [54] Vishal Shrivastav, Asaf Valadarsky, Hitesh Ballani, Paolo Costa, Ki Suh Lee, Han Wang, Rachit Agarwal, Hakim Weatherspoon, “Shoal: A Network Architecture for Disaggregated Racks,” in NSDI, 2019.
- [55] Vlad Nitu, Boris Teabe, Alain Tchana, Canturk Isci, Daniel Hagimont, “Welcome to Zombieland: Practical and Energy-Efficient Memory Disaggregation in a Datacenter.” in EuroSys, 2018.
- [56] Yang Jiao, Liang Han, Xin Long, and Team, “Hanguang 800 NPU – The Ultimate AI Inference Solution for Data Centers,” in HotChips, 2020.
- [57] Yizhou Shan, Yutong Huang, Yilun Chen, Yiying Zhang, “LegoOS: A Disseminated, Distributed OS for Hardware Resource Disaggregation,” in OSDI, 2018.
- [58] Young Cheon Kwon, Suk Han Lee, Jaehoon Lee, Sang Hyuk Kwon, Je Min Ryu, Jong Pil Son, O. Seongil, Hak Soo Yu, Haesuk Lee, Soo Young Kim, Youngmin Cho, Jin Guk Kim, Jongyoon Choi, Hyun Sung Shin, Jin Kim, Beng Seng Phuah, Hyoung Min Kim, Myeong Jun Song, Ahn Choi, Daeho Kim Soo Young Kim, Eun Bong Kim, David Wang, Shinhaeng Kang, Yuhwan Ro, Seungwoo Seo, Joon Ho Song, Jaeyoun Youn, Kyomin Sohn, Nam Sung Kim, “25.4 a 20nm 6gb function-in-memory dram, based on hbm2 with a 1.2tflops programmable computing unit using bank-level parallelism, for machine learning applications,” in ISSCC, 2021.
- [59] Youngeun Kwon, Minsoo Rhu, “Beyond the Memory Wall A Case for Memory-centric HPC System for Deep Learning,” in MICRO, 2018.
- [60] Youngeun Kwon, Minsoo Rhu, “A Disaggregated Memory System for Deep Learning,” in IEEE Micro, 2019.
- [61] Youngeun Kwon, Yunjae Lee, Minsoo Rhu, “TensorDIMM: A Practical Near-Memory Processing Architecture for Embeddings and Tensor Operations in Deep Learning,” in MICRO, 2019.
- [62] Youngeun Kwon, Yunjae Lee, Minsoo Rhu, “Tensor casting: Co-designing algorithm- architecture for personalized recommendation training,” in HPCA, 2021.
- [63] Zhe Zhao, Lichan Hong, Li Wei, Jilin Chen, Aniruddh Nath, Shawn Andrews, Aditee Kumthekar, Maheswaran Sathiamoorthy, Xinyang Yi, Ed Chi, “Recommending What Video to Watch Next: A Multitask Ranking System,” in RecSys, 2019.
- [64] Zhenyuan Ruan, Malte Schwarzkopf, Marcos K. Aguilera, Adam Belay, “AIFM: High-Performance, Application-Integrated Far Memory,” in OSDI, 2020.
- [65] Zhiyuan Guo, Yizhou Shan, Xuhao Luo, Yutong Huang, Yiying Zhang, “Clio: A Hardware-Software Co-Designed Disaggregated Memory System,” in ASPLOS, 2022.