DIRECT: A Differential Dynamic Programming Based Framework for Trajectory Generation
Abstract
This paper introduces a differential dynamic programming (DDP) based framework for polynomial trajectory generation for differentially flat systems. In particular, instead of using a linear equation with increasing size to represent multiple polynomial segments as in literature, we take a new perspective from state-space representation such that the linear equation reduces to a finite horizon control system with a fixed state dimension and the required continuity conditions for consecutive polynomials are automatically satisfied. Consequently, the constrained trajectory generation problem (both with and without time optimization) can be converted to a discrete-time finite-horizon optimal control problem with inequality constraints, which can be approached by a recently developed interior-point DDP (IPDDP) algorithm. Furthermore, for unconstrained trajectory generation with preallocated time, we show that this problem is indeed a linear-quadratic tracking (LQT) problem (DDP algorithm with exact one iteration). All these algorithms enjoy linear complexity with respect to the number of segments. Both numerical comparisons with state-of-the-art methods and physical experiments are presented to verify and validate the effectiveness of our theoretical findings. The implementation code will be open-sourced111https://github.com/ntu-caokun/DIRECT.
I Introduction
Recent decade has witnessed many emerging applications of unmanned systems, such as search and rescue [1], environmental monitoring [2] and mapping [3], etc. As one of the fundamental problems in robotics and control researches, trajectory planning of mobile robots has been actively studied, see [4, 5, 6].
Although polynomial-based approaches can generate energy-optimal smooth trajectories with fixed time allocation efficiently, they are usually formulated as a quadratic programming problem of big size and solved via various commercial solvers. In addition, although there are several methods considering bi-level optimization on energy and time in view of high nonlinearity and non-convexity of joint energy-time optimization, the computation complexity with respect to the number of segments is unknown in general. On the other hand, although DDP based methods enjoy linear complexity in the length of prediction horizon, they usually can only plan a relatively short time ahead for highly nonlinear systems such as quadrotor as the discretization step should be very fine.


To address these issues, we propose DIRECT, a differential dynamic programming based framework for trajectory generation. In particular, this framework uses a state-space equation to characterize the polynomial trajectory such that half of its coefficients can be saved and the continuity conditions on the derivatives of two consecutive segments can be automatically satisfied. By leveraging the differential flatness of quadrotor systems and this perspective of polynomial trajectory, we further reformulate the trajectory generation problem into a finite-horizon free-end discrete-time optimal control problem such that it can be addressed by DDP algorithm without fine discretization and the help of solvers. Unlike many existing approaches where optimization with respect to time and polynomial coefficients are carried out alternately, this algorithm features joint optimization of all variables directly, which explains the naming of this framework.
The proposed approach is based on the observation that the state at the proximal endpoint of an odd order polynomial is solely determined by half of the coefficients (low-order terms) while the state at the distant endpoint is co-determined by all of the coefficients and time. Along with the continuity condition, a long trajectory of multiple segments can be characterized by the initial state and a sequence of control inputs which are functions of the other half of the coefficients (high-order terms) and time. By incorporating the final state constraint into the terminal cost and introducing the safety and dynamical feasibility constraints on the state and control variables via control points, the optimization problem is reformulated into a discrete-time finite-horizon optimal control problem with inequality constraints. The resulting problem either with or without time optimization can be solved under the same framework via a recently developed IPDDP algorithm in [7] with linear complexity. In addition, we show that this problem can be further simplified to a LQT problem if there is no constraint and hence admits an analytical solution, which is still within the DDP framework (exactly one round of backward forward iteration). Our contributions can be summarized as follows:
-
•
We show that an odd-order piecewise-polynomial trajectory can be characterized by state-space equations;
-
•
We propose a DDP-based framework to generate polynomial trajectories with / without time optimization and constraints;
-
•
We achieve comparable results with state-of-the-art methods and perform extensive real-world experiments. The code will be open-sourced.
The rest of this paper is organized as follows. Some related works are presented in Section II. Section III details the DDP-based framework for trajectory generation. Some specializations of this scheme are discussed in Section IV. Section V gives some comparisons with state-of-the-art methods and real-world implementations. Section VI draws the conclusion.
Notations: In this paper, the sets of real, positive real and nonnegative real numbers are denoted by , and , respectively. Denote by and the sets of -dimensional real vectors and real matrices, respectively. Let and be the sets of positive and nonnegative integers, respectively. Let be the norm of and . Denote by and the transpose and inverse of , respectively. Let be the -dimensional identity matrix and the -dimensional column vector with all entries of . Let denote the Kronecker product and . Let be the -th order derivative of vector and . Denote the vectorization operation by , i.e., .
II Related Works
II-A Trajectory planning for quadrotors
The seminal work [4] firstly proved the differential flatness for quadrotor and proposed the minimum snap piecewise polynomial trajectory generation problem, which can be transformed into a quadratic programming (QP) problem with safety corridors being included as linear constraints on discretized points and hence can be solved efficiently via solver. The time allocation and dynamical feasibility problems were approached by projected gradient with backtracking line search in an outer loop and temporal scaling, respectively. Later, the authors in [5] proposed a closed-form solution for the trajectory generation problem with a generalized cost where the time allocation, safety, and dynamical feasibility aspects are handled by gradient descent of joint energy-time cost, addition of waypoints, and temporal scaling, respectively. In [8], the authors presented an efficient safe flight corridor construction method and a temporal scaling step (similar to [5]) on time allocation to generate safe and dynamical feasible trajectories. To avoid high nonlinearity related to joint space-time optimization, some recent works propose methods that iteratively optimize spatial and time variables in two separate subroutines. The authors in [6] introduced a spatial-temporal optimization method which iteratively refines the geometrical coefficients and time-warping functions via QP and second order cone program (SOCP), respectively. In [9], the authors decomposed the trajectory optimization problem as a bi-level optimization problem where the gradient required in the outer loop is analytically obtained from the dual solution of the inner loop QP. An alternating minimization scheme was proposed in [10] where complex safety constraints were not considered. Recently in [11], the authors formulate an unconstrained nonlinear optimization that can be solved by quasi-Newton methods efficiently, but the safety and dynamical feasibility are enforced as penalty functions on discretized points instead of hard constraints. In terms of large scale trajectory (), the authors in [12] proved that the minimum snap problem with fixed time allocation can be solved in linear complexity by exploiting the structure of optimality conditions. The computational complexity has been further improved in [13] by eliminating a matrix inversion operation. An outer loop with analytical projected gradient was introduced for [12] in [14] such that the time allocation can be optimized. However, the computational complexity is unspecified for the case with safety and dynamical feasibility constraints.
II-B DDP algorithms
The DDP algorithm firstly introduced in [15] enjoys linear computational complexity (w.r.t. horizon) and local quadratic convergence [16] and has been applied in trajectory optimization of various systems, e.g., biped walking [17] and robotic manipulation [18]. Much research has been devoted to generalizing the DDP to the case with inequality constraints and can be generally classified into two categories. The first category converts the constrained problems to unconstrained ones via penalty [19] while the other deals with the constraints explicitly by identifying the active ones [20]. To avoid the combinatorial problem regarding the active constraints, a constrained version of Bellman’s principle of optimality has been introduced in [7, 21], which augments the control input with dual variables. However, these DDP algorithms have only been applied to a short-duration (e.g. , steps of sampling period ) quadrotor planning problem and takes quite long time for simple constraints (, see Table 7 in [21]). In this paper, we shall exploit the differential flatness of quadrotors and the linear complexity property of DDP algorithm to generate long-duration smooth trajectories efficiently.
III DDP based framework for trajectory generation
In this section, we shall first introduce our proposed state-space representation for polynomial trajectories and then present our algorithm for jointly optimizing energy and time.
III-A State-space representation
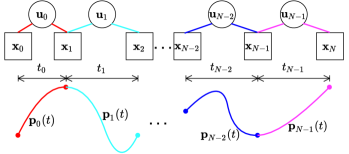
We consider the problem of generating an -segment -th order polynomial trajectory in -dimensional space with the -th segment being parametrized by:
| (1) |
where is the coefficient matrix and is the -order monomial basis. Hence, the entire trajectory on can be defined with
for where and , .
Following [4, 13, 11], we consider the problem of enforcing the smoothness of trajectory up to the -th () order derivative and optimizing on the energy cost up to the -th order derivative.
We consider a single segment . By (1), the collection of trajectory up to -th order derivative can be written as follows:
| (2) |
Collecting both the endpoints, one has:
| (3) |
where can be expressed explicitly with a -by- block matrix [13], i.e., , where each block is of size , and
| ij | (4) | |||
Next, we partition according to the block structure of , i.e., and obtain the following equality:
| (5) |
where was substituted with .
Letting , , and by the continuity condition , one has
| (6) |
where and . As shown in Fig. 2, this operation transfers the original representation of trajectory into a state-space equation, where the system state is the state (position, velocity, acceleration, etc.) at each endpoint and the control input is a concatenation of half of the coefficients of the segment (i.e., ) and duration (i.e., ). Unlike previous application of DDP algorithms in quadrotor planning and control where direct discretization is used, this representation enables the characterization of a long-duration trajectory with fewer number of variables.
III-B Objective function
Previous results on generating polynomial trajectories (e.g., [4, 13]) usually consider the so-called interpolating splines [22], where the spline must pass some prescribed waypoints exactly at specific times. However, for the trajectory generation problem for time-critical aggressive flights, quite often it is sufficient that the generated trajectories only pass through the vicinity of these waypoints, i.e., smoothing splines [23]. In this paper, we aim to find a smoothing spline such that the following objective function can be minimized:
| (7) | ||||
where and . In this cost function, the first term is designed to minimize the discrepancy between the current state and the desired state at the beginning of each segment, which “attracts” the endpoint to a prescribed waypoint; the second and third terms penalize the aggressiveness of planned trajectory up to the -th order and flight time during the -th segment, respectively; the last term penalizes the discrepancy between the terminal state and the goal state ; and , , , (), and denote the weights for each term. It can be found that different from the literature (e.g., [4, 13]) where hard constraints for the endpoints of were used, we have softened these constraints by incorporating them into an objective function.
For usually considered minimum jerk or minimum snap trajectories, , for all and . In this case, one can partition into -by- block matrix with the size of each block being .
Observing that only the right-bottom block is non-zero and denoting it by , one can rewrite (7) as
| (8) |
with and .
III-C Constraints
In general, there are two types of methods handling the safety and dynamical feasibility constraints. The first method discretizes each segment of trajectory and adds inequality constraints on the states at these time instants, while the issue is that the feasibility for the continuous time interval cannot be guaranteed. The other method is to add constraints on a set of control points, which are the vertices of the convex hull containing the segment, but it suffers from conservativeness. A recent work [24] proposes the MINVO basis, which has been shown to be less conservative than the widely used Bezier basis. We use the MINVO basis to construct a set of control points for our polynomial trajectory. Denote the -th order control points by , which can be computed by:
| (9) |
where represents the transformation matrix from polynomial coefficients to the -th order control points.
Assuming that a safe flight corridor (consists of convex polyhedra) can be generated from perception system and polyhedron is represented by hyperplanes. With (9), the safety constraint can be written as:
| (10) |
where each row of and corresponds to the parameters of a single hyperplane in polyhedron .
On the other hand, the dynamical feasibility is encoded by the following box constraint on the -th order control points with :
| (11) |
where and are the lower and upper bounds (e.g., minimal / maximal velocity / acceleration), respectively.
Additionally, one more inequality constraint on time can be introduced to avoid negative time allocation during optimization:
| (12) |
where .
III-D The overall problem and algorithm
With the objective function and constraints constructed above, we can formulate the trajectory generation problem as the following multi-stage constrained optimal control problem:
| (14) | ||||
It should be noted that the constraint and objective function in (14) are respectively in linear and quadratic forms, in fact, all the matrices involved are functions of and hence they are not linear-quadratic. Therefore, we shall solve the formulated problem via IPDDP [7], which generalizes the traditional unconstrained DDP to a constrained version. Similar to DDP, the IPDDP algorithm iterates between backward pass, which computes control inputs to minimize a quadratic approximation of cost in the vicinity of the current trajectory, and forward pass, which updates the current trajectory to a new one, until some terminating condition is triggered.
Define . Let , and for all , where is the Lagrange multiplier. In the following, we shall omit subscript and denote by for clarity. Letting and , one has the following iteration which resembles traditional DDP:
| (15) | ||||
where denotes the tensor contraction and is defined in (6). In addition to the decision variable (i.e., the first order variation of ), the primal-dual version of DDP introduces the additional decision variable . Both and can be represented in an affine form of by solving the optimality conditions of an approximation of constrained Bellman equation (see in [7]), i.e.,
| (16) |
where , , and are the update gains for and , respectively; , , and is a perturbation constant.
With these at hand, the gradient and Hessian of can be updated by
| (17) | ||||
with the following equation:
| (18) | ||||
where was eliminated.
The forward pass resembles the traditional DDP while updating both the control input and the dual variable :
| (19) | ||||
where , , and denote the new state, control variable, and dual variable, respectively.
Algorithm 1 presents the entire algorithm for generating a polynomial trajectory using IPDDP. It should be noted that the presented algorithm requires a feasible initial trajectory. This can be generated from a similar adaptation of the Infeasible-IPDDP algorithm in [7].
IV Specializations
In last section, we have introduced an algorithm for jointly optimizing energy and time subject to safety and dynamical feasibility constraints. In that algorithm, part of the polynomial coefficient (i.e., ) and allocated time for segment are both regarded as control inputs in the formulation (14). In this section, we shall show that this framework can be reduced to two other types of simpler problems.
IV-A Fixed time allocation
It can be easily found that the above algorithm can be used for constrained polynomial trajectory generation with preallocated time. In particular, letting and redefining for all , turns to be a linear-time-varying system and is a linear-time-varying constraint w.r.t. 222The “time-varying” is in the sense of .. The problem can be formally written as:
| (20) | ||||
where . In this case, Algorithm 1 can still be used for solving such type of problem333It is also a typical linear-time-varying model predictive control (MPC) problem, which can be solved by existing MPC algorithms., with all and related terms in (15) being precomputed and saved during the initialization stage instead of being reevaluated at each iteration.
IV-B Fixed time allocation and no constraint
If neither safety nor dynamical feasibility constraint is considered, one has the following problem:
| (21) | ||||
We show that (21) is indeed a LQT problem by proving that . Firstly, the positive semi-definiteness can be easily established by the linearity of integral. Secondly, denoting the last elements of by , one has
On the other hand, can be written as with and . Since the pair is observable, the matrix is nonsingular for any . Therefore,
is positive definite and this shows that (21) is an LQT problem.
Let . The backward iteration for the resulting LQT problem reduces to
| (22) | ||||
where and are the parameters for expressing the new control inputs as a linear form of current state (resembles and in (16)). The forward pass reads:
| (23) | ||||
which iteratively computes the control input and next state.
Algorithm 2 summarizes the above iteration and this gives the analytical solution to the unconstrained fixed-time polynomial trajectory generation problem (21). It should be noted that Algorithm 2 can be regarded as a simplified version of Algorithm 1 with exact one iteration.
V Simulation and Experimental Results
In this section, we shall demonstrate the efficacy of our proposed framework by comparing with state-of-the-art methods as well as performing real-world experiments.
V-A Benchmarks for trajectory generation methods
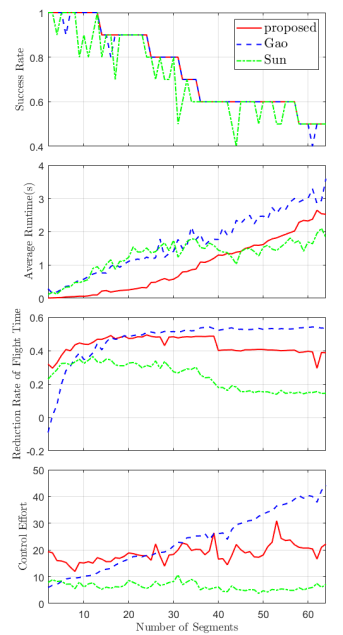
For trajectory generation with time optimization as well as safety and dynamical feasibility constraints, we compare our algorithm with the alternating spatial-temporal optimization[6] and bi-level optimization with analytic gradient[9].444According to Fig. 9 of [11], these two algorithms are the state-of-the-art methods for generating a safe and dynamical feasible trajectory with time optimization. The code for [11] is currently unavailable. In [6] the energy and time costs are separately optimized while in [11] the overall cost function takes a similar form as ours, but without the terminal cost and the time cost takes the form of . The benchmark is conducted using an i7-8550U CPU. Our algorithm is implemented in three steps: initialize our algorithm with Infeasible-IPDDP [7] and zero initial condition to find a feasible solution with and ; feed the obtained solution into Algorithm 1 with and to jointly optimize energy and time; and feed the obtained solution into Algorithm 1 with fixed time allocation setting (see Section IV-A). The algorithm in [6] is implemented as it is (the coefficient of time is set as ). The algorithm in [9] is implemented in C++ with MOSEK555https://www.mosek.com/ solver for the inner loop QP and backtracking line search for the outer loop and the coefficient of time is set as . We randomly generate paths with safety flight corridors (the facet number ranges from to , and is on average) and extract of them to implement these three algorithms. The initial allocation time is set by the subroutine in [6]. We consider the problem of generating minimum jerk trajectory with , where the maximal velocity and acceleration are set as and , respectively. The success rate versus number of segments is shown in Fig. 3. The success rate is dropping in general with the increasing number of segments. The success rate of our algorithm is marginally higher than Gao’s in some cases since the terminal constraint is softened in our formulation. As a result of terminal constraints and enforcing the dynamical feasibility via control points in inner QP, Sun’s method has the lowest success rate. The overall computation time and the reduction rate of the flight time (computed by , where is the initial allocated time for segment and is the optimized allocated time computed by each algorithm) and the control effort are also compared in Fig. 3. It can be found that for middle number of segments (), our algorithm consumes less time than the other two algorithms. For , our algorithm still consumes less time than Gao’s while more than Sun’s. The reason is that the outer loop of Sun’s method terminates in only a few iterations and gets stuck in local minimum in these cases, which can be seen from the relatively low reduction rate in Fig. 3. In addition, there is a trade-off between flight time and control effort: a shorter flight time (i.e., higher reduction rate) corresponds to a higher control effort. Unlike Gao’s method which has increasing reduction rate and control effort w.r.t. , our algorithm maintains relatively consistent reduction rate and level of control energy. Since our formulation also incorporates the terminal cost term (see (14)), the change of this term affects the other two terms and hence causes the fluctuation of control energy in our approach, as observed in Fig. 3. Overall, for the application of trajectory generation with , our algorithm achieves comparable results with Gao’s method while consumes less runtime.
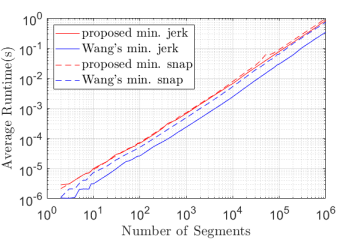
For trajectory generation with fixed time allocation and without constraint, we compare our Algorithm 2 with [13]. Our parameters are set as , , , . We randomly sample times for each number of waypoints and run algorithms ( for minimum jerk trajectory and for minimum snap trajectory). The average runtime versus number of segments is shown in Fig. 4. It can be found that all the algorithms enjoy linear complexity w.r.t. number of segments. Although our algorithm for minimum jerk trajectory consumes around three times the time of [13], the gap for minimum snap trajectory is much narrower(around 1.5 times). Furthermore, based on the results reported in [13], our algorithm is faster than the optimized version of algorithm in [12], which is one order of magnitude slower than [13] (we do not plot the result of [12] as the code is not available.)
V-B Flight experiments
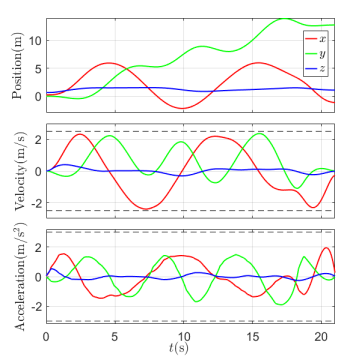
The proposed framework is implemented in ROS and we conduct multiple flight experiments of a small quadrotor executing the trajectories generated using our method. We use stereo camera fusion with IMU[25] for localization and state estimation of the quadrotor in the environment and use the robust and perfect tracking (RPT) controller [26] for trajectory tracking. Firstly, we conduct a set of experiments where a long trajectory is generated in a pre-built map consisting of two rooms and multiple obstacles, as shown in Fig. 1. The trajectory is generated by the i7 onboard computer and executed by the quadrotor immediately. We use multiple settings of dynamical feasibility. The trajectory with maximal velocity and acceleration set as and is shown in Fig. 5. In the second set of experiments the onboard computer generates safe and feasible trajectories online to reach target points set by a commander remotely. The video of the experiments can be found online666https://youtu.be/BM8_ABM_2VM or in the supplemental material.
VI Conclusion and Future Work
In this paper, we have proposed to use a state-space equation to characterize a piecewise-polynomial trajectory such that the trajectory generation problem (either with or without time optimization and constraints) can be subsequently solved via DDP algorithm. The proposed framework is implemented in C++ without the use of solvers, and the efficiency of our proposed framework was demonstrated by comparing with state-of-the-art methods as well as real-world experiments.
The proposed framework opens up opportunity for further developments. For example, the joint energy-time optimization can be extended to a multi-robot scenario with non-collision constraints. The fixed-time optimization can be used for online trajectory replanning due to its fast computation.
References
- [1] J. Hu, J. Xu, and L. Xie, “Cooperative search and exploration in robotic networks,” Unmanned Systems, vol. 1, no. 1, pp. 121–142, 2013.
- [2] P. Ogren, E. Fiorelli, and N. E. Leonard, “Cooperative control of mobile sensor networks: Adaptive gradient climbing in a distributed environment,” IEEE Transactions on Automatic Control, vol. 49, no. 8, pp. 1292–1302, 2004.
- [3] Y. Yue, C. Yang, Y. Wang, P. C. N. Senarathne, J. Zhang, M. Wen, and D. Wang, “A multilevel fusion system for multirobot 3-d mapping using heterogeneous sensors,” IEEE Systems Journal, published online, 2019.
- [4] D. Mellinger and V. Kumar, “Minimum snap trajectory generation and control for quadrotors,” in 2011 IEEE International Conference on Robotics and Automation, pp. 2520–2525, IEEE, 2011.
- [5] A. Bry, C. Richter, A. Bachrach, and N. Roy, “Aggressive flight of fixed-wing and quadrotor aircraft in dense indoor environments,” The International Journal of Robotics Research, vol. 34, no. 7, pp. 969–1002, 2015.
- [6] F. Gao, L. Wang, B. Zhou, X. Zhou, J. Pan, and S. Shen, “Teach-repeat-replan: A complete and robust system for aggressive flight in complex environments,” IEEE Transactions on Robotics, vol. 36, no. 5, pp. 1526–1545, 2020.
- [7] A. Pavlov, I. Shames, and C. Manzie, “Interior point differential dynamic programming,” IEEE Transactions on Control Systems Technology, early access, 2021.
- [8] S. Liu, M. Watterson, K. Mohta, K. Sun, S. Bhattacharya, C. J. Taylor, and V. Kumar, “Planning dynamically feasible trajectories for quadrotors using safe flight corridors in 3-d complex environments,” IEEE Robotics and Automation Letters, vol. 2, no. 3, pp. 1688–1695, 2017.
- [9] W. Sun, G. Tang, and K. Hauser, “Fast uav trajectory optimization using bilevel optimization with analytical gradients,” IEEE Transactions on Robotics, early access, 2021.
- [10] Z. Wang, X. Zhou, C. Xu, J. Chu, and F. Gao, “Alternating minimization based trajectory generation for quadrotor aggressive flight,” IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 4836–4843, 2020.
- [11] Z. Wang, X. Zhou, C. Xu, and F. Gao, “Geometrically constrained trajectory optimization for multicopters,” arXiv preprint arXiv:2103.00190, 2021.
- [12] D. Burke, A. Chapman, and I. Shames, “Generating minimum-snap quadrotor trajectories really fast,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1487–1492, IEEE, 2020.
- [13] Z. Wang, H. Ye, C. Xu, and F. Gao, “Generating large-scale trajectories efficiently using double descriptions of polynomials,” arXiv preprint arXiv:2011.02662, 2020.
- [14] D. Burke, A. Chapman, and I. Shames, “Fast spline trajectory planning: Minimum snap and beyond,” arXiv preprint arXiv:2105.01788, 2021.
- [15] D. Mayne, “A second-order gradient method for determining optimal trajectories of non-linear discrete-time systems,” International Journal of Control, vol. 3, no. 1, pp. 85–95, 1966.
- [16] J. De O. Pantoja, “Differential dynamic programming and newton’s method,” International Journal of Control, vol. 47, no. 5, pp. 1539–1553, 1988.
- [17] J. Morimoto, G. Zeglin, and C. G. Atkeson, “Minimax differential dynamic programming: Application to a biped walking robot,” in Proceedings 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003)(Cat. No. 03CH37453), vol. 2, pp. 1927–1932, IEEE, 2003.
- [18] V. Kumar, E. Todorov, and S. Levine, “Optimal control with learned local models: Application to dexterous manipulation,” in 2016 IEEE International Conference on Robotics and Automation (ICRA), pp. 378–383, IEEE, 2016.
- [19] B. Plancher, Z. Manchester, and S. Kuindersma, “Constrained unscented dynamic programming,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 5674–5680, IEEE, 2017.
- [20] Z. Xie, C. K. Liu, and K. Hauser, “Differential dynamic programming with nonlinear constraints,” in 2017 IEEE International Conference on Robotics and Automation (ICRA), pp. 695–702, IEEE, 2017.
- [21] Y. Aoyama, G. Boutselis, A. Patel, and E. A. Theodorou, “Constrained differential dynamic programming revisited,” arXiv preprint arXiv:2005.00985, 2020.
- [22] Z. Zhang, J. Tomlinson, and C. Martin, “Splines and linear control theory,” Acta Applicandae Mathematica, vol. 49, no. 1, pp. 1–34, 1997.
- [23] S. Sun, M. B. Egerstedt, and C. F. Martin, “Control theoretic smoothing splines,” IEEE Transactions on Automatic Control, vol. 45, no. 12, pp. 2271–2279, 2000.
- [24] J. Tordesillas and J. P. How, “Minvo basis: Finding simplexes with minimum volume enclosing polynomial curves,” arXiv preprint arXiv:2010.10726, 2020.
- [25] T. Qin, J. Pan, S. Cao, and S. Shen, “A general optimization-based framework for local odometry estimation with multiple sensors,” 2019.
- [26] G. Cai, B. M. Chen, and T. H. Lee, Unmanned rotorcraft systems. Springer Science & Business Media, 2011.