Dimension-Grouped Mixed Membership Models for Multivariate Categorical Data
Abstract
Mixed Membership Models (MMMs) are a popular family of latent structure models for complex multivariate data. Instead of forcing each subject to belong to a single cluster, MMMs incorporate a vector of subject-specific weights characterizing partial membership across clusters. With this flexibility come challenges in uniquely identifying, estimating, and interpreting the parameters. In this article, we propose a new class of Dimension-Grouped MMMs (Gro-M3s) for multivariate categorical data, which improve parsimony and interpretability. In Gro-M3s, observed variables are partitioned into groups such that the latent membership is constant for variables within a group but can differ across groups. Traditional latent class models are obtained when all variables are in one group, while traditional MMMs are obtained when each variable is in its own group. The new model corresponds to a novel decomposition of probability tensors. Theoretically, we derive transparent identifiability conditions for both the unknown grouping structure and model parameters in general settings. Methodologically, we propose a Bayesian approach for Dirichlet Gro-M3s to inferring the variable grouping structure and estimating model parameters. Simulation results demonstrate good computational performance and empirically confirm the identifiability results. We illustrate the new methodology through applications to a functional disability survey dataset and a personality test dataset.
Keywords: Bayesian Methods, Grade of Membership Model, Identifiability, Mixed Membership Model, Multivariate Categorical Data, Probabilistic Tensor Decomposition.
1 Introduction
Mixed membership models (MMMs) are a popular family of latent structure models for complex multivariate data. Building on classical latent class and finite mixture models (McLachlan and Peel, , 2000), which assign each subject to a single cluster, MMMs include a vector of probability weights characterizing partial membership. MMMs have seen many applications in a wide variety of fields, including social science surveys (Erosheva et al., , 2007), topic modeling and text mining (Blei et al., , 2003), population genetics and bioinformatics (Pritchard et al., , 2000; Saddiki et al., , 2015), biological and social networks (Airoldi et al., 2008b, ), collaborative filtering (Mackey et al., , 2010), and data privacy (Manrique-Vallier and Reiter, , 2012); see Airoldi et al., (2014) for more examples.
Although MMMs are conceptually appealing and very flexible, with the rich modeling capacity come challenges in identifying, accurately estimating, and interpreting the parameters. MMMs have been popular in many applications, yet key theoretical issues remain understudied. The handbook of Airoldi et al., (2014) emphasized theoretical difficulties of MMMs ranging from non-identifiability to multi-modality of the likelihood. Finite mixture models have related challenges, and the additional complexity of the individual-level mixed membership incurs extra difficulties. A particularly important case is MMMs for multivariate categorical data, such as survey response (Woodbury et al., , 1978; Erosheva et al., , 2007; Manrique-Vallier and Reiter, , 2012). In this setting, MMMs provide an attractive alternative to the latent class model of Goodman, (1974). However, little is known about what is fundamentally identifiable and learnable from observed data under such models.
Identifiability is a key property of a statistical model, meaning that the model parameters can be uniquely obtained from the observables. An identifiable model is a prerequisite for reproducible statistical inferences and reliable applications. Indeed, interpreting parameters estimated from an unidentifiable model is meaningless, and may lead to misleading conclusions in practice. It is thus important to study the identifiability of MMMs and to provide theoretical support to back up the conceptual appeal. Even better would be to expand the MMM framework to allow variations that aid interpretability and identifiability. With this motivation, and focused on mixed membership modeling of multivariate categorical data, this paper makes the following key contributions.
We propose a new class of models for multivariate categorical data, which retains the same flexibility offered by MMMs, while favoring greater parsimony and interpretability. The key innovation is to allow the -dimensional latent membership vector to belong to groups; memberships are the same for different variables within a group but can differ across groups. We deem the new model the Dimension-Grouped Mixed Membership Model (Gro-M3). Gro-M3 improves interpretability by allowing the potentially high-dimensional observed variables to belong to a small number of meaningful groups. Theoretically, we show that both the continuous model parameters, and the discrete variable grouping structure, can be identified from the data for models in the Gro-M3 class under transparent conditions on how the variables are grouped. This challenging identifiability issue is addressed by carefully leveraging the dimension-grouping structure to write the model as certain structured tensor products, and then invoking Kruskal’s fundamental theorem on the uniqueness of three-way tensor decompositions (Kruskal, , 1977; Allman et al., , 2009).
To illustrate the methodological usefulness of the proposed class of models, we consider a special case in which each subject’s mixed membership proportion vector follows a Dirichlet distribution. This is among the most popular modeling assumptions underlying various MMMs (Blei et al., , 2003; Erosheva et al., , 2007; Manrique-Vallier and Reiter, , 2012; Zhao et al., , 2018). For such a Dirichlet Gro-M3, we employ a Bayesian inference procedure and develop a Metropolis-Hastings-within-Gibbs algorithm for posterior computation. The algorithm has excellent computational performance. Simulation results demonstrate this approach can accurately learn the identifiable quantities of the model, including both the variable-grouping structure and the continuous model parameters. This also empirically confirms the model identifiability result.
The rest of this paper is organized as follows. Section 2 reviews existing mixed membership models, introduces the proposed Gro-M3, and provides an interesting probabilistic tensor decomposition perspective of the models. Section 3 is devoted to the study of the identifiability of the new model. Section 4 focuses on the Dirichlet distribution induced Gro-M3 and proposes a Bayesian inference procedure. Section 5 includes simulation studies and Section 6 applies the new model to reanalyze the NLTCS disability survey data. Section 7 provides discussions.
2 Dimension-Grouped Mixed Membership Models
2.1 Existing Mixed Membership Models
In this subsection, we briefly review the existing MMM literature to give our proposal appropriate context. Let be the number of extreme latent profiles. Denote the -dimensional probability simplex by . Each subject has an individual proportion vector , which indicates the degrees to which subject is a member of the extreme profiles. The general mixed membership models summarized in Airoldi et al., (2014) have the following distribution,
| (1) |
where follows the distribution and is integrated out; the refers to some generic population parameters depending on the specific model. The hierarchical Bayesian representation for the model in (1) can be written as follows.
where “i.i.d.” is short for “independent and identically distributed”. The number in (1) is the number of “characteristics”, and is the number of “replications” per characteristic. As shown in (1), for each characteristic , there are a corresponding set of conditional distributions indexed by parameter vectors . Many different mixed membership models are special cases of the general setup (1). For example, the popular Latent Dirichlet Allocation (LDA) (Blei et al., , 2003; Blei, , 2012; Anandkumar et al., , 2014) for topic modeling takes a document as a subject, and assumes there is only distinct characteristic (one single set of topics which are distributions over the word vocabulary) with replications (a document contains words which are conditionally i.i.d. given ); LDA further specifies to be the Dirichlet distribution with parameters .
Focusing on MMMs for multivariate categorical data, there are generally many characteristics with and one replication of each characteristic with in (1). Each variable takes one of unordered categories. For each subject , the observables are a vector of categorical variables. MMMs for such data are traditionally called Grade of Membership models (GoMs) (Woodbury et al., , 1978). GoMs have been extensively used in applications, such as disability survey data (Erosheva et al., , 2007), scholarly publication data (Erosheva et al., , 2004), and data disclosure risk and privacy (Manrique-Vallier and Reiter, , 2012). GoMs are also useful for psychological measurements where data are Likert scale responses to psychology survey items, and educational assessments where data are students’ correct/wrong answers to test questions (e.g. Shang et al., , 2021).
In GoMs, the conditional distribution in (1) can be written as . Hence, the probability mass function of in a GoM is
| (2) |
The hierarchical Bayesian representation for the model in (2) can be written as follows.
See a graphical model representation of the GoM with sample size in Figure 1(b), where individual latent indicator variables are introduced to better describe the data generative process.
We emphasize that the case with and is fundamentally different from the topic models with and , with the former typically involving many more parameters. This is because the “bag-of-words” assumption in the topic model with disregards word order in a document and assumes all words in a document are exchangeable. In contrast, our mixed-membership model for multivariate categorical data does not assume a subject’s responses to the items in a survey/questionnaire are exchangeable. In other words, given a subject’s mixed membership vector , his/her responses to the items are independent but not identically distributed (because they follow categorical distributions governed by different sets of parameters for ); whereas in a topic model, given a document’s latent topic proportion vector , the words in the document are independent and identically distributed, following the categorical distribution with the same set of parameters (here denotes the vocabulary size). In this sense, the GoM model has greater modeling flexibility than topic models and are more suitable for modeling item response data, where it is inappropriate to assume that the items in the survey/questionnaire are exchangeable or share the same set of parameters. This fact is made clear also in Figure 1(b), where for each there is a population quantity, the parameter node (also denoted by for simplicity), that governs its distribution. Thus identifiability is a much greater challenge for GoM models. To our best knowledge, the identifiability issue of the grade-of-membership (GoM) models for item response data considered in Woodbury et al., (1978) and Erosheva et al., (2007) has not been rigorously investigated so far. Motivated by the difficulty of identifying GoM in its original setting due to the large parameter complexity, we next propose a new modeling grouping component to enhance identifiability. Our resulting model still does not make any exchangeability assumption of the items, but rather leverages the variable grouping structure to reduce model complexity.
2.2 New Modeling Component: the Variable Grouping Structure
Generalizing Grade of Membership models for multivariate categorical data, we propose a new structure that groups the observed variables in the following sense: any subject’s latent membership is the same for variables within a group but can differ across groups. To represent the key structure of how the variables are partitioned into groups, we introduce a notation of the grouping matrix . The is a matrix with binary entries, with rows indexed by the variables and columns by the groups. Each row of has exactly one entry of “1” indicating group assignment. In particular,
| (3) |
Our key specification is the following generative process in the form of a hierarchical Bayesian representation,
| Gro-M3: | |||||
| (4) | |||||
where “ind.” is short for “independent”, meaning that conditional on , subject ’s observed responses to items in group are independently generated. Hence, given the population parameters , the probability distribution of can be written as
For a sample with subjects, assume the observed responses are independent and identically distributed according to the above model.
We visualize the proposed model as a probabilistic graphical model to highlight connections to and differences from existing latent structure models for multivariate categorical data. In Figure 1, we show the graphical model representations of two popular latent structure models for multivariate categorical data in (a) and (b), and for the newly proposed Gro-M3 in (c) and (d). The for denotes a matrix with entries . Each column of characterizes a conditional probability distribution of variable given a particular extreme latent profile. We emphasize that the variable grouping is done at the level of the latent allocation variables , and that the parameters are still free without constraints just as they are in traditional LCMs or GoMs. From the visualizations in Figure 1 we can also easily distinguish our proposed model from another popular family of methods, the co-clustering methods (Dhillon et al., , 2003; Govaert and Nadif, , 2013). Co-clustering usually refers to simultaneously clustering the subjects and clustering the variables, where subjects within a cluster exhibit similar behaviors and variables within a cluster also share similar characteristics. Our Gro-M3, however, does not restrict the variables to have similar characteristics within groups, but rather allows them to have entirely free parameters . The “dimension-grouping” happens at the latent level by constraining the latent allocations behind the variables to be grouped into statuses. Such groupings give rise to a novel probabilistic hybrid tensor decomposition visualized in Figure 1(c)–(d); see the next Section 2.3 for details.
Other than facilitating model identifiability (see Section 3), our dimension-grouping modeling assumption is also motivated by real-world applications. In general, our new model Gro-M3 with the variable grouping component can apply to any multivariate categorical data to simultaneously model individual mixed membership and capture variable similarity. For example, Gro-M3 can be applied to survey/questionnaire response data in social sciences, where it is not only of interest to model subjects’ partial membership to several extreme latent profiles, but also of interest to identify blocks of items which share similar measurement goals within each block. We next provide numerical evidence to demonstrate the merit of the variable grouping modeling component. For a dataset simulated from Gro-M3 (in the setting as the later Table 2) and also the real-world IPIP personality test dataset (analyzed in the later Section 6), we calculate the sample Cramer’s V between item pairs. Cramer’s V is a classical measure of association between two categorical variables, which gives a value between 0 and 1, with larger values indicating stronger association. Figure 2 presents the plots of the sample Cramer’s V matrix for the simulated data and the real IPIP data. This figure shows that the pairwise item dependence for the Gro-M3-simulated data looks quite similar to the real-world personality test data. Indeed, after fitting the Gro-M3 to this IPIP personality test dataset, the estimated model-based Cramer’s V shown in Figure 2(c) nicely and more clearly recovers the item block structure. We conjecture that many real world datasets in other applied domains exhibit similar grouped dependence.



2.3 Probabilistic Tensor Decomposition Perspective
The Gro-M3 class has interesting connections to popular tensor decompositions. For a subject , the observed vector resides in a contingency table with cells. Since the MMMs for multivariate categorical data (both traditional GoM and the newly proposed Gro-M3) induce a probability of being in each of these cells, such probabilities can be arranged as a -way array. This array is a tensor with modes and we denote it by ; Kolda and Bader, (2009) provided a review of tensors. The tensor has all the entries nonnegative and they sum up to one, so we call it a probability tensor. We next describe in detail the tensor decomposition perspective of our model; such a perspective will turn out to be useful in the study of identifiability.
The probability mass function of under the traditional GoM model can be written as follows by exchanging the order of product and summation,
| (5) |
Then forms a tensor with modes, and each mode has dimension . Further, this tensor is a probability tensor, because and it is not hard to see that its entries sum up to one. Viewed from a tensor decomposition perspective, this is the popular Tucker decomposition (Tucker, , 1966); more specifically this is the nonnegative and probabilistic version of the Tucker decomposition. The represents the Tucker tensor core, and the product of form the Tucker tensor arms.
It is useful to compare our modeling assumption to that of the the Latent Class Model (LCM; Goodman, , 1974), which follows the graphical model shown in Figure 1(a). The LCM is essentially a finite mixture model assuming each subject belongs to a single cluster. The distribution of under an LCM is
| (6) |
Based on the above definition, each subject has a single variable indicating which latent class it belongs to, rather than a mixed membership proportion vector . Denoting , then (6) corresponds to the popular CP decomposition of tensors (Hitchcock, , 1927), where the CP rank is at most .
Finally, consider our proposed Gro-M3,
| (7) |
where generally denotes the conditional distribution of variable given parameter . In our Gro-M3, specifically refer to the categorical distribution parameters for the random variable ; that is, denotes the probability of responding to item given that the subject’s realization of the latent profile for item is the th extreme latent profile. In this case, forms a tensor with modes, and each mode has dimension . There still is . This reduces the size of the core tensor in the classical Tucker decomposition because . The Gro-M3 incorporates aspects of both the CP and Tucker decompositions, providing a probabilistic hybrid decomposition of probability tensors. The CP is obtained when all variables are in the same group, while the Tucker is obtained when each variable is in its own group; see Figure 1 for a clear illustration of this fact.
Gro-M3 is conceptually related to the collapsed Tucker decomposition (c-Tucker) of Johndrow et al., (2017), though they did not model mixed memberships, used a very different model for the core tensor , and did not consider identifiability. Nonetheless and interestingly, our identifiability results can be applied to establish identifiability of c-Tucker decomposition (see Remark 1 in Section 4). Another work related to our dimension-grouping assumption is Anandkumar et al., (2015), which considered the case of overcomplete topic modeling with the number of topics exceeding the vocabulary size. For such scenarios, the authors proposed a “persistent topic model” which assumes the latent topic assignment persists locally through multiple words, and established identifiability. Our dimension-grouped mixed membership assumption is similar in spirit to this topic persistence assumption. However, the setting we consider here for general multivariate categorical data has the multi-characteristic single-replication nature ( and ); as mentioned before, this is fundamentally different from topic models with a single characteristic and multiple replications ( and ).
3 Identifiability of Dimension-Grouped MMMs
Identifiability is an important property of a statistical model, generally meaning that model parameters can be uniquely recovered from the observables. Identifiability serves as a fundamental prerequisite for valid statistical estimation and inference. The study of identifiability, however, can be challenging for complicated models and especially latent variable models, including the Gro-M3s considered here. In subsections 3.1 and 3.2, we propose easily checkable and practically useful identifiability conditions for Gro-M3s by carefully inspecting the inherent algebraic structures. Specifically, we will exploit the variable groupings to write the model as certain highly structured mixed tensor products, and then prove identifiability by invoking Kruskal’s theorem on the uniqueness of tensor decompositions (Kruskal, , 1977). We point out that such proof procedures share a similar spirit to those in Allman et al., (2009), but the complicated structure of the new Gro-M3s requires some special care to handle. We provide a high-level summary of our proof approach. First, we write the probability mass function of the observed -dimensional multivariate categorical vector as a probabilistic tensor with modes. Second, we unfold this tensor into a -way tensor with each mode corresponding to a variable group. Third, we further concatenate the transformed tensor and leverage Kruskal’s Theorem on the uniqueness of three-way tensor decomposition to establish the identifiability of the model parameters under our proposed Gro-M3. Our theoretical developments provide a solid foundation for performing estimation of the latent quantities and drawing valid conclusions from data.
3.1 Strict Identifiability Conditions
For LDA and closely related topic models, there is a rich literature investigating identifiability under different assumptions (Anandkumar et al., , 2012; Arora et al., , 2012; Nguyen, , 2015; Wang, , 2019). Typically, when there is only one characteristic (), is necessary for identifiability; see Example 2 in Wang, (2019). However, there has been limited consideration of identifiability of mixed membership models with multiple characteristics and one replication, i.e., and . GoM models belong to this category, as does the proposed Gro-M3s, with GoM being a special case of Gro-M3s.
We consider the general setup in (1), where denotes the -mode tensor core induced by any distribution on the probability simplex . The following definition formally defines the concept of strict identifiability for the proposed model.
Definition 1 (Strict Identifiability of Gro-M3s).
A parameter space of a Gro-M is said to be strictly identifiable, if for any valid set of parameters , the following equations hold if and only if and the alternative are identical up to permutations of the extreme latent profiles and permutations of the variable groups,
| (8) |
Definition 1 gives the strongest possible notion of identifiability of the considered population quantities in the model. In particular, the strict identifiability notion in Definition 1 requires identification of both the continuous parameters and , and the discrete latent grouping structure of variables in . The following theorem proposes sufficient conditions for the strict identifiability of Gro-M3s.
Theorem 1.
Under a Gro-M, the following two identifiability conclusions hold.
-
(a)
Suppose each column of contains at least three entries of “1”s, and the corresponding conditional probability table for each of these three has full column rank. Then the and are strictly identifiable.
-
(b)
In addition to the conditions in (a), if satisfies that for each , not all the column vectors of are identical, then is also identifiable.
Example 1.
Denote by a identity matrix. Suppose and the matrix takes the following form,
| (9) |
Also suppose for each , the of size has full column rank . Then the conditions in Theorem 1 hold, so , and are identifiable. Theorem 1 implies that if contains any additional row vectors other than those in (9) the model is still identifiable.
Theorem 1 requires that each of the variable groups contains at least three variables, and that for each of these variables, the corresponding conditional probability table has linearly independent columns. Theorem 1 guarantees not only the continuous parameters are identifiable, but also the discrete variable grouping structure summarized by is identifiable. This is important practically as typically the appropriate variable grouping structure is unknown, and hence needs to be inferred from the data.
The conditions in Theorem 1 essentially requires at least conditional probability tables, each being a matrix of size , to have full column rank. This implicitly requires . Tan and Mukherjee, (2017) proposed a moment-based estimation approach for traditional mixed membership models and briefly discussed the identifiability issue, also assuming with some full-rank requirements. However, the cases where the number of categories ’s are small but the number of extreme latent profiles is much larger can arise in applications; for example, the disability survey data analyzed in Erosheva et al., (2007) and Manrique-Vallier, (2014) have binary responses with while the considered ranges from 2 to 10. Our next theoretical result establishes weaker conditions for identifiability that accommodates , by taking advantage of the dimension-grouping property of our proposed model class.
Before stating the theorem, we first introduce two useful notions of matrix products. Denote by the Kronecker product of matrices and by the Khatri-Rao product. Consider two matrices , ; and another two matrices , , then there are and with
The above definitions show the Khatri-Rao product is the column-wise Kronecker product. The Khatri-Rao product of matrices plays an important role in the technical definition of the proposed dimension-grouped MMM. The following Theorem 2 exploits the grouping structure in to relax the identifiability conditions in the previous Theorem 1.
Theorem 2.
Denote by the set of variables that belong to group . Suppose each can be partitioned into three sets , and for each and the matrix defined below has full column rank .
| (10) |
Also suppose for each , not all the column vectors of are identical. Then the model parameters , , and are strictly identifiable.
Compared to Theorem 1, Theorem 2 relaxes the identifiability conditions by lifting the full-rank requirement on the individual matrices ’s. Rather, as long as the Khatri-Rao product of several different ’s have full column rank as specified in (10), identifiability can be guaranteed. Recall that the Khatri-Rao product of two matrices of size and of size has size . So intuitively, requiring to have full column rank is weaker than requiring each of and to have full column rank . The following Example 2 formalizes this intuition.
Example 2.
Consider , with the following conditional probability tables
Suppose variables belong to the same group, e.g., . Then since , both and can not have full column rank . However, if we consider their Khatri-Rao product, it has size in the following form
Indeed, has full column rank for “generic” parameters ; precisely speaking, for varying almost everywhere in the parameter space (the 6-dimensional hypercube), the subset of that renders rank-deficient has Lebesgue measure zero in . To see this, let such that , then
Based on the last four equations above, one can use basic algebra to obtain the following set of equations about ,
This implies as long as the following inequalities hold, there must be ,
| (11) |
Now note that the subset of the parameter space is a Lebesgue measure zero subset of . This means for such “generic” parameters varying almost everywhere in the parameter space , the implies which means has full column rank .
Example 2 shows that the Khatri-Rao product of two matrices seems to have full rank under fairly mild conditions. This indicates that the conditions in Theorem 2 are much weaker than those in Theorem 1 by imposing the full-rankness requirement only on a certain Khatri-Rao product of the -matrices, instead of on individual s. To be more concrete, the next Example 3 illustrates Theorem 2, as a counterpart of Example 1.
Example 3.
Consider the following grouping matrix with and ,
| (12) |
Then contains six copies of the identity matrix after a row permutation. Thanks to greater variable grouping compared to the previous Example 1, we can use Theorem 2 (instead of Theorem 1) to establish identifiability. Specifically, consider binary responses with and extreme latent profiles. For , define sets , , ; for , define sets , , ; and for , define sets , , . Then for each , the defined in Theorem 2 has size which is , similar to the structure in Example 2. Now from the derivation and discussion in Example 2, we know such a has full rank for almost all the valid parameters in the parameter space. So the conditions in Theorem 2 are easily satisfied, and for almost all the valid parameters of such a Gro-M3, the identifiability conclusion follows.
3.2 Generic Identifiability Conditions
Example 2 shows that the Khatri-Rao product of conditional probability tables easily has full column rank in a toy case, and Example 3 leverages this observation to establish identifiability for almost all parameters in the parameter space using Theorem 2. We next generalize this observation to derive more practical identifiability conditions, under the generic identifiability notion introduced by Allman et al., (2009). Generic identifiability generally means that the unidentifiable parameters belong to a set of Lebesgue measure zero with respect to the parameter space. Its definition adapted to the current Gro-M3s is given as follows.
Definition 2 (Generic Identifiability of Gro-M3s).
Under a Gro-M, a parameter space for is said to be generically identifiable, if there exists a subset that has Lebesgue measure zero with respect to such that for any and an associated matrix, the following holds if and only if and the alternative are identical up to permutations of the extreme latent profiles and that of the variable groups,
Compared to the strict identifiability notion in Definition 1, the generic identifiability notion in Definition 2 is less stringent in allowing the existence of a measure zero set of parameters where identifiability does not hold; see the previous Example 2 for an instance of a measure-zero set. Such an identifiability notion usually suffices for real data analyses (Allman et al., , 2009). In the following Theorem 3, we propose simple conditions to ensure generic identifiability of Gro-M3s.
Theorem 3.
For the notation defined in Theorem 2, suppose each can be partitioned into three non-overlapping sets , such that for each and the following holds,
| (13) |
Then the matrix has full column rank for generic parameters. Further, the , , and are generically identifiable.
Compared to Theorem 2, Theorem 3 lifts the explicit full-rank requirements on any matrix. Rather, Theorem 3 only requires that certain products of ’s should not be smaller than the number of extreme latent profiles, which in turn guarantees that the Khatri-Rao products of matrices have full column rank for generic parameters. Intuitively, the more variables belonging to a group and the more categories each variable has, the easier the identifiability conditions are to satisfy. This illustrates the benefit of dimension-grouping to model identifiability.
4 Dirichlet Gro-M3 and Bayesian Inference
4.1 Dirichlet model and identifiability
The previous section studies identifiability of general Gro-M3s, not restricting the distribution of the mixed membership scores to be a specific form. Next we focus on an interesting special case where is a Dirichlet distribution with unknown parameters . Among all the possible distributions for the individual mixed-membership proportions, the Dirichlet distribution is the most popular. It is widely used in applications including social science survey data (Erosheva et al., , 2007; Wang et al., , 2015), topic modeling (Blei et al., , 2003; Griffiths and Steyvers, , 2004), and data privacy (Manrique-Vallier and Reiter, , 2012). We term the Gro-M3 with following a Dirichlet distribution the Dirichlet Gro-M3, and propose a Bayesian inference procedure to estimate both the discrete variable groupings and the continuous parameters. Such a Dirichlet Gro-M3 has the graphical model representation in Figure 1(d).
For an unknown vector with for all , suppose
| Dirichlet Gro-M3: | (14) |
The vector characterizes the distribution of membership scores. As , the model simplifies to a latent class model in which each individual belongs to a single latent class. For larger ’s, there will tend to be multiple elements of that are not close to or .
Recall that the previous identifiability conclusions in Theorems 1–3 generally apply to , , and , where is the core tensor with entries in our hybrid tensor decomposition. Now with the core tensor parameterized by the Dirichlet distribution in particular, we can further investigate the identifiability of the Dirichlet parameters . The following proposition establishes the identifiability of for Dirichlet Gro-M3s.
Proposition 1.
Remark 1.
Our identifiability results have implications for the collapsed Tucker (c-Tucker) decomposition for multivariate categorical data (Johndrow et al., , 2017). Our assumption that the latent memberships underlying several variables are in one state is similar to that in c-Tucker. However, c-Tucker does not model mixed memberships, and the c-Tucker tensor core, in our notation, is assumed to arise from a CP decomposition (Goodman, , 1974) with . We can invoke the uniqueness of the CP decomposition (e.g., Kruskal, , 1977; Allman et al., , 2009) to obtain identifiability of parameters and . Hence, under our assumptions on the variable grouping structure in Section 3, imposing existing mild conditions on and will yield identifiability of all the c-Tucker parameters.
4.2 Bayesian inference
Considering the complexity of our latent structure model, we adopt a Bayesian approach. We next describe the prior specification for , , and in Dirichlet Gro-M3s. The number of variable groups and number of extreme latent profiles are assumed known; we relax this assumption in Section 5. Recall the indicators are defined as if and only if , so there is a one-to-one correspondence between the matrix and the vector . We adopt the following prior for the ’s,
where is a categorical distribution over categories with proportions and . We choose uniform priors over the probability simplex for and each column of . We remark that if certain prior knowledge about the variable groups is available for the data, then it is also possible to employ informative priors such as those in Paganin et al., (2021) for the ’s. For the Dirichlet parameters , defining and , we choose the hyperpriors and is uniform over the -probability simplex.
Given a sample of size , denote the observed data by . We propose a Metropolis-Hastings-within-Gibbs sampler and also a Gibbs sampler for posterior inference of , , and based on the data .
Metropolis-Hastings-within-Gibbs Sampler.
This sampler cycles through the following steps.
- Step 1–3.
-
Sample each column of the conditional probability tables ’s, the individual mixed-membership proportions ’s, and the individual latent assignments ’s from their full conditional posterior distributions. Define indicator variables and . These posteriors are
- Step 4.
-
Sample the variable grouping structure . The posterior of each is
The posterior of is
- Step 5.
-
Sample the Dirichlet parameters via Metropolis-Hastings sampling. The conditional posterior distribution of (or equivalently, and ) is
which is not an easy-to-sample-from distribution. We use a Metropolis-Hastings sampling strategy in Manrique-Vallier and Reiter, (2012). The steps are detailed as follows.
-
•
Sample each entry of from independent lognormal distributions (proposal distribution ) as
(15) where is a tuning parameter that affects the acceptance ratio of the draw. Based on our preliminary simulations, should be relatively small to avoid the acceptance ratio to be always too close to zero.
-
•
Let . Define
The Metropolis-Hastings acceptance ratio of the proposed is .
-
•
We track the acceptance ratio in the Metropolis-Hastings step along the MCMC iterations in a simulation study. Figure 3 shows the boxplots of the average acceptance ratios for various sample sizes in the same simulation as the later Table 3. This figure shows that the Metropolis-Hastings acceptance ratio is generally high and mostly exceeds 80%.

Gibbs Sampler.
We also develop a fully Gibbs sampling algorithm for our Gro-M3, leveraging the auxiliary variable method in Zhou, (2018) to sample the Dirichlet parameters . Especially, since we have proved in Proposition 1 that the entire Dirichlet parameter vector is identifiable from the observed data distribution, we choose to freely and separately sample all the entries instead of constraining these entries to be equal as in Zhou, (2018). Recall that for each subject , for denotes the latent profile realization for the th group of items. Introduce new notation for and . Then follows the Dirichlet-Multinomial distribution with parameters and . We introduce auxiliary Beta variables for and auxiliary Chinese Restaurant Table (CRT) variables for and . Endowing the Dirichlet parameter with the prior , we have the following Gibbs updates for sampling .
- Step 5⋆
-
Sample the auxiliary variables , and the Dirichlet parameters from the following full conditional posteriors:
Replacing the previous Step 5 in the Metropolis-within-Gibbs sampler with the above Step 5⋆ gives a fully Gibbs sampling algorithm for Gro-M3.
Our simulations reveal the following empirical comparisons between the Gibbs sampler and the Metropolis-Hastings-within-Gibbs (MH-within-Gibbs) sampler. In terms of Markov chain mixing, the Gibbs sampler mixes faster than the MH-within-Gibbs sampler as expected, and requires fewer MCMC iterations to generate quality posterior samples if initialized well. However, in terms of estimation accuracy, we observe that the MH-within-Gibbs sampler tends to have better accuracy in estimating the identifiable model parameters. This is likely because that the MH-within-Gibbs sampler performs better on exploring the entire posterior space through the proposal distributions; whereas the Gibbs sampler tends to be more heavily influenced by the initial value of the parameters and can converge to suboptimal distributions if not initialized well. We next provide the experimental evidence behind the above observations.
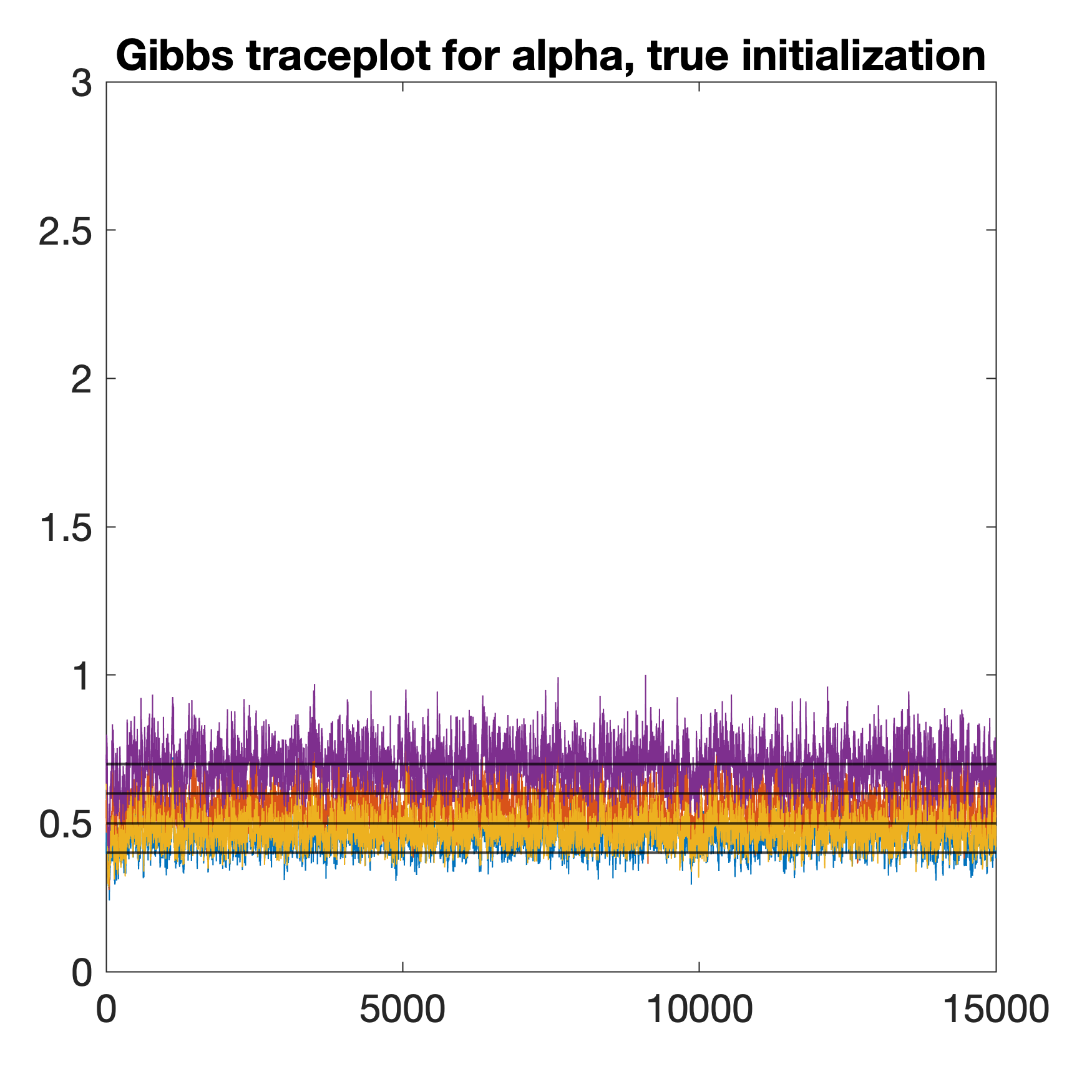
Figure 4 provides typical traceplots for the MH-within-Gibbs sampler (left) and the Gibbs sampler (middle and right) in one simulation trial in the same setting as the later Table 3. The four horizontal lines in each panel denote the true parameter values . The left and middle panels of Figure 4 are traceplots of in MCMC chains initialized randomly with the same initial value, whereas the right panel corresponds to a chain initialized with the true parameter value . Figure 4 shows that when initialized randomly with the same value, the MH-within-Gibbs chain converges to distributions much closer to the truth than the Gibbs sampler; in contrast, the Gibbs chain only manages to converge to the desirable posteriors when initialized with the true . Furthermore, Figure 5 plots the root mean squared error quantitles (25%, 50%, 75%) of estimated using the two samplers from the 50 simulation replicates in each setting. The parameter initialization in each replicate for the two samplers is random and identical. Figure 5 clearly shows that the MH-within-Gibbs sampler has lower estimation error for . In summary, when initialized randomly using the same mechanism, the MH-within-Gibbs sampler has higher parameter estimation accuracy despite that the Gibbs sampler mixes faster. Therefore, we choose to present the estimation results of the MH-within-Gibbs sampler in the later Section 5.



After collecting posterior samples from the output of the MCMC algorithm, for those continuous parameters in the model we can calculate their posterior means as point estimates. As for the discrete variable grouping structure, we can obtain the posterior modes of each . That is, given the posterior samples of for , we define point estimates and with entries
| (16) |
5 Simulation Studies
In this section, we carry out simulation studies to assess the performance of the proposed Bayesian estimation approach, while verifying that identifiable parameters are indeed estimated more accurately as sample size grows. In Section 5.1, we perform a simulation study to assess the estimation accuracy of the model parameters, assuming the number of extreme latent profiles and the number of variable groups are known. This is the same assumption as in many existing estimation methods of traditional MMMs (e.g., Manrique-Vallier and Reiter, , 2012). In Section 5.2, to facilitate the use of our estimation method in applications, we propose data-driven criteria to select and and perform a corresponding simulation study.
5.1 Estimation of Grouping Structure and Model Parameters
In this simulation study, we assess the proposed algorithm’s performance in estimating the in Dirichlet Gro-M3s. We consider various simulation settings, with , or , and , , or . The number of categories of each is specified to be three, i.e., . The true -parameters are specified as follows: in the most challenging case with and , for we specify
As for other simulation settings with smaller and , we specify the ’s by taking a subset of the above matrices and retaining a subset of columns from each of these matrices. The true Dirichlet parameters are set to for , for , and for . The true grouping matrix of size is specified to containing copies of identity submatrices up to a row permutation. Under these specifications, our identifiability conditions in Theorem 2 are satisfied. We consider sample sizes . In each scenario, 50 independent datasets are generated and fitted with the proposed MCMC algorithm described in Section 4. In our MCMC algorithm under all simulation settings, we take hyperparameters to be and . The MCMC sampler is run for 15000 iterations, with the first 10000 iterations as burn-in and every fifth sample is collected after burn-in to thin the chain.
We observed good mixing and convergence behaviors of the model parameters from examining the trace plots. In particular, simulations show that the estimation of the discrete variable grouping structure in matrix (equivalently, vector ) is quite accurate in general, and the posterior means of the continuous and are also close to their truth. Next we first present details of two typical simulation trials as an illustration, before presenting summaries across the independent simulation replicates.
Two random simulation trials were taken from the settings and . All the parameters were randomly initialized from their prior distributions. In Figure 6, the left three plots in each of the first two rows show the sampled in the MCMC algorithm, after the 1st, 201st, and 401st iterations, respectively; the fourth plot show the posterior mode defined in (16), and the last plot shows the simulation truth . If an equals the true after a column permutation then it indicates and induce identical variable groupings. The bottom two plots in Figure 6 show the Adjusted Rand Index (ARI, Rand, , 1971) of the variable groupings of () with respect to the true (true ) along the first 1000 MCMC iterations. The ARI measures the similarity between two clusterings, and it is appropriate to compare a true and an estimated because they each summarizes a clustering of the variables into groups. The ARI is at most , with indicating perfect agreement between two clusterings. The bottom row of Figure 6 shows that in each simulation trial, the ARI measure starts with values around 0 due to the random MCMC initialization, and within a few hundred iterations the ARI increases to a distribution over much larger values. For the simulation with , the posterior mode of exactly equals the truth, and the corresponding plot on the bottom right of Figure 6 shows the ARI is distributed very close to 1 after just about 500 MCMC iterations. In general, our MCMC algorithm has excellent performance in inferring the from randomly initialized simulations; also see the later Tables 1–3 for more details.




We next present estimation accuracy results of both and summarized across 50 simulation replicates in each setting. For continuous parameters , we calculate their Root Mean Squared Errors (RMSEs) to evaluate the estimation accuracy. To obtain the estimation error of after collecting posterior samples, we need to find an appropriate permutation of the extreme latent profiles in order to compare the and the true . To this end, we first reshape each of and to a matrix and , calculate the inner product matrix , and then find the index of the largest entry in each th row of the inner product matrix. Such a vector of indices gives a permutation of the profiles, and we will compare to and compare to . In Tables 1–3, we present the RMSEs of and the ARIs of under the aforementioned 36 different simulation settings. The median and interquartile range of the ARIs or RMSEs across the simulation replicates are shown in these tables.
Tables 1–3 show that under each setting of true parameters with a fixed , the ARIs of the variable grouping generally increase as sample size increases, and the RMSEs of and decreases as increases. This shows the increased estimation accuracy with an increased sample size. In particular, the estimation accuracy of the variable grouping structure is quite high across the considered settings. The estimation errors are slightly larger for larger values of in Table 3 compared to smaller values of in Tables 1 and 2. Overall, the simulation results empirically confirm the identifiability and estimability of the model parameters in our Dirichlet Gro-M3.
| ARI of | RMSE of | RMSE of | ||||||
|---|---|---|---|---|---|---|---|---|
| Median | (IQR) | Median | (IQR) | Median | (IQR) | |||
| 250 | 0.74 | (0.18) | 0.042 | (0.005) | 0.064 | (0.056) | ||
| 500 | 0.88 | (0.17) | 0.030 | (0.004) | 0.031 | (0.043) | ||
| 1000 | 0.91 | (0.29) | 0.023 | (0.014) | 0.027 | (0.028) | ||
| 1500 | 0.91 | (0.31) | 0.018 | (0.022) | 0.026 | (0.045) | ||
| 250 | 0.73 | (0.13) | 0.042 | (0.004) | 0.039 | (0.041) | ||
| 500 | 0.79 | (0.14) | 0.032 | (0.003) | 0.031 | (0.021) | ||
| 1000 | 0.85 | (0.20) | 0.027 | (0.010) | 0.018 | (0.029) | ||
| 1500 | 0.81 | (0.21) | 0.028 | (0.016) | 0.024 | (0.025) | ||
| 250 | 0.95 | (0.05) | 0.042 | (0.003) | 0.045 | (0.045) | ||
| 500 | 1.00 | (0.00) | 0.026 | (0.002) | 0.032 | (0.023) | ||
| 1000 | 1.00 | (0.00) | 0.018 | (0.001) | 0.019 | (0.021) | ||
| 1500 | 1.00 | (0.08) | 0.015 | (0.010) | 0.017 | (0.017) | ||
| ARI of | RMSE of | RMSE of | ||||||
|---|---|---|---|---|---|---|---|---|
| Median | (IQR) | Median | (IQR) | Median | (IQR) | |||
| 250 | 1.00 | (0.00) | 0.045 | (0.004) | 0.046 | (0.048) | ||
| 500 | 1.00 | (0.00) | 0.033 | (0.003) | 0.046 | (0.059) | ||
| 1000 | 1.00 | (0.00) | 0.023 | (0.022) | 0.039 | (0.037) | ||
| 1500 | 1.00 | (0.00) | 0.019 | (0.023) | 0.029 | (0.032) | ||
| 250 | 1.00 | (0.00) | 0.045 | (0.004) | 0.044 | (0.030) | ||
| 500 | 1.00 | (0.00) | 0.032 | (0.002) | 0.030 | (0.018) | ||
| 1000 | 1.00 | (0.00) | 0.023 | (0.002) | 0.021 | (0.017) | ||
| 1500 | 1.00 | (0.00) | 0.018 | (0.002) | 0.020 | (0.017) | ||
| 250 | 1.00 | (0.00) | 0.045 | (0.002) | 0.047 | (0.036) | ||
| 500 | 1.00 | (0.00) | 0.031 | (0.002) | 0.026 | (0.022) | ||
| 1000 | 1.00 | (0.00) | 0.022 | (0.001) | 0.021 | (0.013) | ||
| 1500 | 1.00 | (0.21) | 0.019 | (0.024) | 0.024 | (0.023) | ||
| ARI of | RMSE of | RMSE of | ||||||
|---|---|---|---|---|---|---|---|---|
| Median | (IQR) | Median | (IQR) | Median | (IQR) | |||
| 250 | 1.00 | (0.00) | 0.064 | (0.007) | 0.078 | (0.056) | ||
| 500 | 1.00 | (0.00) | 0.046 | (0.006) | 0.062 | (0.072) | ||
| 1000 | 1.00 | (0.00) | 0.032 | (0.004) | 0.043 | (0.046) | ||
| 1500 | 1.00 | (0.00) | 0.026 | (0.004) | 0.032 | (0.036) | ||
| 250 | 1.00 | (0.00) | 0.064 | (0.005) | 0.060 | (0.031) | ||
| 500 | 1.00 | (0.00) | 0.043 | (0.003) | 0.047 | (0.027) | ||
| 1000 | 1.00 | (0.00) | 0.031 | (0.002) | 0.032 | (0.014) | ||
| 1500 | 1.00 | (0.00) | 0.025 | (0.001) | 0.023 | (0.017) | ||
| 250 | 1.00 | (0.00) | 0.046 | (0.004) | 0.053 | (0.036) | ||
| 500 | 1.00 | (0.00) | 0.041 | (0.003) | 0.037 | (0.022) | ||
| 1000 | 1.00 | (0.00) | 0.029 | (0.001) | 0.026 | (0.027) | ||
| 1500 | 1.00 | (0.00) | 0.024 | (0.001) | 0.026 | (0.020) | ||
Our MCMC algorithm can be viewed as a novel algorithm for Bayesian factorization of probability tensors. To see this, note that the observed response vector ranges in the -way contingency table , and the marginal probabilities of a random vector falling each of the cells therefore form a probability tensor with modes. Our Gro-M3 model provides a general and interpretable hybrid tensor factorization; it reduces to the nonnegative CP decomposition when the grouping matrix equals the one-vector and reduces to the nonnegative Tucker decomposition when the grouping matrix equals the identity matrix. Specifically, our estimated Dirichlet parameters help define the tensor core and our estimated conditional probability parameters constitute the tensor arms. In this regard, we view our proposed MCMC algorithm as contributing a new tensor factorization method with nice uniqueness guarantee (i.e., identifiability guarantee) and good empirical performance.
We conduct a simulation study to empirically verify the theoretical identifiability results. Specifically, in the simulation setting , corresponding to the first setting in Table 3, we now consider more sample sizes . For each sample size, we conducted 50 independent simulation replications and calculated the average root mean squared errors (RMSEs) of the model parameters and . Figure 7 plots the RMSEs versus the sample size and shows that as increases, the RMSEs decrease gradually. This trend provides an empirical verification of identifiability, and corroborates the conclusion that under an identifiable model, the model parameters can be estimated increasingly accurately as one collects more and more samples.


5.2 Selecting and from Data
In Section 3, model identifiability is established under the assumption that and are known, like many other latent structure models; for example, generic identifiability of latent class models in Allman et al., (2009) is established assuming the number of latent classes is known. But in order to provide a practical estimation pipeline applicable to real-world applications, we next briefly discuss how to select and in a data-driven way.
Our basic rationale is to use a practically useful criterion that favors a model with good out-of-sample predictive performance while remaining parsimonious. Gelman et al., (2014) contains a comprehensive review of various predictive information criteria for evaluating Bayesian models. We first considered using the Deviance Information Criterion (DIC, Spiegelhalter et al., , 2002), a traditional model selection criteria for Bayesian models. However, our preliminary simulations imply that DIC does not work well for selecting the latent dimensions in Gro-M3s. In particular, we observed that DIC sometimes severely overselects the latent dimensions in our model, while that the WAIC (Widely Applicable Information Criterion, Watanabe, , 2010) has better performance in our simulation studies (see the next paragraph for details). Our observation about DIC agrees with previous studies on the inconsistency of DIC in several different settings (Gelman et al., , 2014; Hooten and Hobbs, , 2015; Piironen and Vehtari, , 2017).
Watanabe, (2010) proved that WAIC is asymptotically equal to Bayesian leave-one-out cross validation and provided a solid theoretical justification for using WAIC to choose models with relatively good predictive ability. WAIC is particularly useful for models with hierarchical and mixture structures, making it well suited to selecting the latent profile dimension and variable group dimension in our proposed model. Denote the posterior samples by , . For each and , denote
In particular, Gelman et al., (2014) recommended using the following version of the WAIC, where “lppd” refers to log pointwise predictive density and measures the model complexity through the variance,
| WAIC | (17) | |||
where refers to the variance based on posterior samples, with definition . Based on the above definition, the WAIC can be easily calculated based on posterior samples. The model with a smaller WAIC is favored.
We carried out a simulation study to evaluate how WAIC performs on selecting and , focusing on the previous setting where 50 independent datasets are generated from . When fixing the candidate to the truth and varying the candidate , the percentages of the datasets that each of is selected are 0%, 0%, 74% (true ), 20%, 6%, respectively. When fixing the candidate to the truth and varying , the percentages of the datasets that each of is selected are 0%, 80% (true ), 6%, 4%, 10%, respectively. Further, when varying in the grid of 25 possible pairs , the percentage of the datasets for which the true pair is selected by WAIC is 58% and neither nor ever gets underselected. In general, our simulations show that the WAIC does not tend to underselect the latent dimensions and , and that it generally has a reasonably good accuracy of selecting the truth. We remark that here our goal was to pick a practical selection criterion that can be readily applied in real-world applications. To develop a selection strategy for deciding on the number of latent dimensions with rigorous theoretical guarantees under the proposed models would need future investigations.
6 Real Data Applications
6.1 NLTCS Disability Survey Data
In this section we apply Gro-M3 methodology to a functional disability dataset extracted from the National Long Term Care Survey (NLTCS), created by the former Center for Demographic Studies at Duke University. This dataset has been widely analyzed, both with mixed membership models (Erosheva et al., , 2007; Manrique-Vallier, , 2014), and with other models for multivariate categorical data (Dobra and Lenkoski, , 2011; Johndrow et al., , 2017). Here we reanalyze this dataset as an illustration of our dimension-grouped mixed membership approach.
The NLTCS dataset was downloaded from at http://lib.stat.cmu.edu/datasets/. It is an extract containing responses from community-dwelling elderly Americans aged 65 and above, pooled over 1982, 1984, 1989, and 1994 survey waves.
The disability survey contains items, with respondents being either coded as healthy (level 0) or as disabled (level 1) for each item.
Each respondent provides a 16-dimensional response vector , where each variable follows a special categorical distribution with two categories, i.e., a Bernoulli distribution, with parameters specific to item .
Among the NLTCS disability items, functional disability researchers distinguish six activities of daily living (ADLs) and ten instrumental activities of daily living (IADLs).
Specifically, the first six ADL items are more basic and relate to hygiene and personal care: eating, getting in/out of bed, getting around inside, dressing, bathing, and getting to the bathroom or using a toilet.
The remaining ten IADL items are related to activities needed to live without dedicated professional care: doing heavy house work, doing light house work, doing laundry, cooking, grocery shopping, getting about outside, travelling, managing money, taking medicine, and telephoning.
Here, we apply the MCMC algorithm developed for the Dirichlet Gro-M3 to the data; the Dirichlet distribution was also used to model the mixed membership scores in Erosheva et al., (2007). Our preliminary analysis of the NLTCS data indicates the Dirichlet parameters are relatively small, so we adopt a small in the lognormal proposal distribution in Eq. (15) in the Metropolis-Hastings sampling step. For each setting of , we run the MCMC for 40000 iterations and consider the first 20000 as burn-in to be conservative. We retain every 10th sample after the burn-in. The candidate values for the are all the combinations of and .
For selecting the values of latent dimensions in practice, we recommend picking the that provide the lowest WAIC value and also do not contain any empty groups of variables. In particular, for certain pairs of (in our case, for all ) under the NLTCS data, we observe that the posterior mode of the grouping matrix, , has some all-zero columns. If denotes the number of not-all-zero columns in , this means after model fitting, the number of groups occupied by the variables is . Models with are difficult to interpret because empty groups that do not contain any variables cannot be assigned meaning. Therefore, we focus only on models where does not contain any all-zero columns and pick the one with the smallest WAIC among these models. Using this criterion, for the NLTCS data, the model with and is selected. We have observed reasonably good convergence and mixing of our MCMC algorithm for the NLTCS data. The proposed new dimension-grouping model provides a better fit in terms of WAIC and a parsimonious alternative to traditional MMMs.

We provide the estimated under the selected model with and in Figure 8. The estimated variable groupings are given in Figure 8. Out of the groups, there are three groups that contain multiple items. In Figure 8, the item labels of these three groups are colored in blue (), red (), and yellow () for better visualization. These groupings obtained by our model lead to several observations. First, four out of six ADL variables () are categorized into one group. This group of items are basic self-care activities that require limited mobility. Second, the three IADL variables () in one group may be related to traditional gender roles – these items correspond to activities performed more frequently by women than by men. Finally, the two items “getting about outside” and “traveling” that require high level of mobility form another group. Note that such a model-based grouping of the items is different than the established groups (ADL and IADL), and could not have been obtained by applying previous mixed membership models (Erosheva et al., , 2007).
In addition to the variable grouping structures, we plot posterior means of the positive response probabilities in Figure 9 for the selected model. For each survey item and each extreme latent profile , the records the conditional probability of giving a positive response of being disabled on this item conditional on possessing the th latent profile. The profiles are quite well separated and can be interpreted as usual in mixed membership analysis. For example, in Figure 9, the leftmost column for represents a relatively healthy latent profile, the rightmost column for represents a relatively severely disabled latent profile. As for the Dirichlet parameters , their posterior means are . Such small values of the Dirichlet parameters imply that membership score vectors tend to be dominated by one component for a majority of individuals. This observation is consistent with Erosheva et al., (2007). Meanwhile, here we obtain a simpler model than that in Erosheva et al., (2007) as each subject can partially belong to up to latent profiles according to the grouping of variables, rather than ones as in the traditional MMMs.

We emphasize again that the bag-of-words topic models make the exchangeability assumption, which is fundamentally different from, and actually more restrictive than, our Gro-M3 when modeling non-exchangeable item response data. Specifically, the exchangeability assumption would force all the item parameters across all the items to be identical, which is unrealistic for the survey response data (or the personality test data to be analyed in Section 6.2) in which different items clearly have different characteristics. For example, if one were to use a topic model such as LDA to analyze the NLTCS disability survey data, then a plot of the conditional probability table like Figure 9 would not have been possible, because all the items would share the same -dimensional vector of conditional Bernoulli probabilities.
6.2 International Personality Item Pool (IPIP) Personality Test Data
We also apply the proposed method to analyze a personality test dataset containing multivariate polytomous responses: the International Personality Item Pool (IPIP) personality test data. This dataset is publicly available from the Open-Source Psychometrics Project website https://openpsychometrics.org/_rawdata/.
The dataset contains subjects’ responses to Likert rated personality test items in the International Personality Item Pool.
After dropping those subjects who have missing entries in their responses, there are complete response vectors left.
Each subject’s observed response vector is -dimensional, where each dimension ranges in with categories. Each of these 40 items was designed to measure one of the four personality factors: Assertiveness (short as “AS”), Social confidence (short as “SC”), Adventurousness (short as “AD”), and Dominance (short as “DO”). Specifically, items 1-10 measure AS, items 11-20 measure SC, items 21-30 measure AD, and items 31-40 measure DO.
The responses of certain reversely-termed items (i.e., items 7–10, 16–20, 25–30) are preprocessed to be . We apply our new model to analyze this dataset for various numbers of variable groups and extreme latent profiles, and the WAIC selects the model with groups. We plot the posterior mode of the estimated grouping matrix in Figure 10, together with the content of each item.
Figure 10 shows that our new modeling component of variable grouping is able to reveal the item blocks that measure different personality factors in a totally unsupervised manner. Moreover, the estimated variable grouping cuts across the four established personality factors to uncover a more nuanced structure. For example, the group of items AS1, SC4, SC10 concerns the verbal expression aspect of a person; the group of items AS3–AS10, SC5, SC7 concerns a person’s intention to lead and influence other people. In summary, for this new personality test dataset, the proposed Gro-M3 not only provides better model fit than the usual GoM model (since is selected by WAIC), but also enjoys interpretability and uncovers meaningful subgroups of the observed variables.

We also conduct experiments to compare our probabilistic hybrid decomposition Gro-M3 with the probabilistic CP decomposition (the latent class model in Dunson and Xing, (2009)) and the probabilistic Tucker decomposition (the GoM model in Erosheva et al., (2007)) on the IPIP personality test data. After fitting each tensor decomposition method to the data, we calculate the model-based Cramer’s V measure between each pair of items and see how different methods perform on recovering meaningful item dependence structure. Figure 11 presents the model-based pairwise Cramer’s V calculated using the three tensor decompositions, along with the model-free Cramer’s V calculated directly from data. Figure 11 shows that our Gro-M3 decomposition clearly outperforms probabilistic CP and Tucker decomposition in recovering the meaningful block structure of the personality test items.


7 Discussion
We have proposed a new class of mixed membership models for multivariate categorical data, dimension-grouped mixed membership models (Gro-M3s), studied its model identifiability, and developed a Bayesian inference procedure for Dirichlet Gro-M3s. On the methodology side, the new model strikes a nice balance between model flexibility and model parsimony. Considering popular existing latent structure models for multivariate categorical data, the Gro-M3 bridges the parsimonious yet insufficiently flexible Latent Class Model (corresponding to CP decomposition of probability tensors) and the very flexible yet not parsimonious Grade of Membership Model (corresponding to Tucker decomposition of probability tensors). On the theory side, we establish the identifiability of population parameters that govern the distribution of Gro-M3s. The quantities shown to be identifiable include not only the continuous model parameters, but also the key discrete structure – how the variables’ latent assignments are partitioned into groups. The obtained identifiability conclusions lay a solid foundation for reliable statistical analysis and real-world applications. We have performed Bayesian estimation for the new model using a Metropolis-Hastings-within-Gibbs sampler. Numerical studies show that the method can accurately estimate the quantities of interest, empirically validating the identifiability results.
For the special case of binary responses with , as pointed out by a reviewer, models with Bernoulli-to-latent-Poisson link in Zhou et al., (2016) and the Bernoulli-to-latent-Gaussian link in multivariate item response theory models in Embretson and Reise, (2013) are useful tools that can capture certain lower-dimensional latent constructs. Our model differs from these models in terms of statistical and practical interpretation. In our Gro-M3, each subject’s latent variables are a mixed membership vector ranging in the probability simplex , and can be interpreted as that each subject is a partial member of each of the extreme latent profiles. For , the th extreme latent profile also can be directly interpreted by inspecting the estimated item parameters . Geometrically, the entry captures the relative proximity of each subject to the th extreme latent behavioral profile. Such an interpretation of individual-level mixtures are highly desirable in applications such as social science surveys (Erosheva, , 2003) and medical diagnosis (Woodbury et al., , 1978), where each extreme latent profile represents a prototypical response pattern. Therefore, in these applications, the mixed membership modeling is more interpretable and preferable to using a nonlinear transformation of certain underlying Gaussian or Poisson latent variables to model binary matrix data (such as the Bernoulli-to-latent-Poisson or Bernoulli-to-latent-Gaussian link).
We remark that our proposed Gro-M3 covers the usual GoM model as a special case. In fact, the GoM model can be readily recovered by setting our grouping matrix to be the identity matrix (i.e., ). In terms of practical estimation, we can simply fix throughout our MCMC iterations and estimate other quantities in the same way as in our current algorithm. Using this approach, we have compared the performance of our flexible Gro-M3 and the classical GoM model in the real data analyses. Specifically, for both the NLTCS disability survey data and the IPIP personality test data, fixing with variable groups gives larger WAIC values than the selected more parsimonious model with . This indicates that the traditional GoM model is not favored by the information criterion and gives a poorer model fit to the data. We also point out that our MCMC algorithm can be viewed as a novel Bayesian factorization algorithm for probability tensors, in a similar spirit to the existing Bayesian tensor factorization methods such as Dunson and Xing, (2009) and Zhou et al., (2015). Our Bayesian Gro-M3 factorization outperforms usual probabilistic tensor factorizations in recovering the item dependence structure in the IPIP personality data analysis. Therefore, we view our proposed MCMC algorithm as contributing a new type of tensor factorization approach with nice uniqueness guarantee (i.e., identifiability guarantee) and a Bayesian factorization procedure with good empirical performance.
Our modeling assumption of the variable grouping structure can be useful to other related models. For example, Manrique-Vallier, (2014) proposed a longitudinal MMM to capture heterogeneous pathways of disability and cognitive trajectories of elderly population for disability survey data. The proposed dimension-grouping assumption can provide an interesting new interpretation to such longitudinal settings. Specifically, when survey items are answered in multiple time points, it may be plausible to assume that a subject’s latent profile locally persists for a block of items, before potentially switching to a different profile for the next block of items. This can be readily accommodated by the dimension-grouping modeling assumption, with the slight modification that items belonging to the same group should be forced to be close in time. Our identifiability results can be applied to this setup. Similar computational procedures can also be developed. Furthermore, although this work focuses on modeling multivariate categorical data, the applicability of the new dimension-grouping assumption is not limited to such data. A similar assumption may be made in other mixed membership models; examples include the generalized latent Dirichlet models for mixed data types studied in Zhao et al., (2018).
In terms of identifiability, the current work has focused on the population quantities, including the variable grouping matrix , the conditional probability tables , and the Dirichlet parameters . In addition to these population parameters, an interesting future question is the identification of individual mixed membership proportions for subjects in the sample. Studying the identification and accurate estimation of ’s presumably requires quite different conditions from ours. A recent work (Mao et al., , 2020) considered a similar problem for mixed membership stochastic block models for network data. Finally, in terms of estimation procedures, in this work we have employed a Bayesian approach to Dirichlet Gro-M3s, and the developed MCMC sampler shows excellent computational performance. In the future, it would also be interesting to consider method-of-moments estimation for the proposed models related to Zhao et al., (2018) and Tan and Mukherjee, (2017).
This work has focused on proposing a new interpretable and identifiable mixed membership model for multivariate categorical data, and our MCMC algorithm has satisfactory performance in real data applications. In the future, it would be interesting to develop scalable and online variational inference methods, which would make the model more applicable to massive-scale real-world datasets. We expect that it is possible to develop variational inference algorithms similar in spirit to Blei et al., (2003) for topic models and Airoldi et al., 2008a for mixed membership stochastic block models to scale up computation. In addition, just as the hierarchical Dirichlet process (Teh et al., , 2006) is a natural nonparametric generalization of the parametric latent Dirichlet allocation (Blei et al., , 2003) model, it would also be interesting to generalize our Gro-M3 to the nonparametric Bayesian setting to automatically infer and . Developing a method to automatically infer and will be of great practical value, because in many situations there might not be enough prior knowledge for these quantatities. We leave these directions for future work.
Acknowledgements
This work was partially supported by NIH grants R01ES027498 and R01ES028804, NSF grants DMS-2210796, SES-2150601 and SES-1846747, and IES grant R305D200015. This project also received funding from the European Research Council under the European Union’s Horizon 2020 research and innovation program (grant agreement No. 856506). The authors thank the Action Editor Dr. Mingyuan Zhou and three anonymous reviewers for constructive and helpful comments that helped improve this manuscript.
References
- Airoldi et al., (2014) Airoldi, E. M., Blei, D., Erosheva, E. A., and Fienberg, S. E. (2014). Handbook of mixed membership models and their applications. CRC press.
- (2) Airoldi, E. M., Blei, D., Fienberg, S., and Xing, E. (2008a). Mixed membership stochastic blockmodels. Advances in Neural Information Processing Systems, 21.
- (3) Airoldi, E. M., Blei, D. M., Fienberg, S. E., and Xing, E. P. (2008b). Mixed membership stochastic blockmodels. Journal of Machine Learning Research, 9:1981–2014.
- Allman et al., (2009) Allman, E. S., Matias, C., and Rhodes, J. A. (2009). Identifiability of parameters in latent structure models with many observed variables. Annals of Statistics, 37(6A):3099–3132.
- Anandkumar et al., (2012) Anandkumar, A., Foster, D. P., Hsu, D. J., Kakade, S. M., and Liu, Y.-K. (2012). A spectral algorithm for latent Dirichlet allocation. In Advances in Neural Information Processing Systems, pages 917–925.
- Anandkumar et al., (2014) Anandkumar, A., Ge, R., Hsu, D., Kakade, S. M., and Telgarsky, M. (2014). Tensor decompositions for learning latent variable models. Journal of Machine Learning Research, 15:2773–2832.
- Anandkumar et al., (2015) Anandkumar, A., Hsu, D., Janzamin, M., and Kakade, S. (2015). When are overcomplete topic models identifiable? Uniqueness of tensor tucker decompositions with structured sparsity. The Journal of Machine Learning Research, 16(1):2643–2694.
- Arora et al., (2012) Arora, S., Ge, R., and Moitra, A. (2012). Learning topic models–going beyond SVD. In 2012 IEEE 53rd Annual Symposium on Foundations of Computer Science, pages 1–10. IEEE.
- Blei, (2012) Blei, D. M. (2012). Probabilistic topic models. Communications of the ACM, 55(4):77–84.
- Blei et al., (2003) Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent Dirichlet allocation. Journal of Machine Learning Research, 3(Jan):993–1022.
- Dhillon et al., (2003) Dhillon, I. S., Mallela, S., and Modha, D. S. (2003). Information-theoretic co-clustering. In Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 89–98.
- Dobra and Lenkoski, (2011) Dobra, A. and Lenkoski, A. (2011). Copula Gaussian graphical models and their application to modeling functional disability data. Annals of Applied Statistics, 5(2A):969–993.
- Dunson and Xing, (2009) Dunson, D. B. and Xing, C. (2009). Nonparametric bayes modeling of multivariate categorical data. Journal of the American Statistical Association, 104(487):1042–1051.
- Embretson and Reise, (2013) Embretson, S. E. and Reise, S. P. (2013). Item response theory. Psychology Press.
- Erosheva, (2003) Erosheva, E. A. (2003). Bayesian estimation of the grade of membership model. Bayesian Statistics, 7:501–510.
- Erosheva et al., (2007) Erosheva, E. A., Fienberg, S. E., and Joutard, C. (2007). Describing disability through individual-level mixture models for multivariate binary data. Annals of Applied Statistics, 1(2):346.
- Erosheva et al., (2004) Erosheva, E. A., Fienberg, S. E., and Lafferty, J. (2004). Mixed-membership models of scientific publications. Proceedings of the National Academy of Sciences, 101(suppl 1):5220–5227.
- Gelman et al., (2014) Gelman, A., Hwang, J., and Vehtari, A. (2014). Understanding predictive information criteria for Bayesian models. Statistics and Computing, 24(6):997–1016.
- Goodman, (1974) Goodman, L. A. (1974). Exploratory latent structure analysis using both identifiable and unidentifiable models. Biometrika, 61(2):215–231.
- Govaert and Nadif, (2013) Govaert, G. and Nadif, M. (2013). Co-clustering: models, algorithms and applications. John Wiley & Sons.
- Griffiths and Steyvers, (2004) Griffiths, T. L. and Steyvers, M. (2004). Finding scientific topics. Proceedings of the National Academy of Sciences, 101(suppl 1):5228–5235.
- Hitchcock, (1927) Hitchcock, F. L. (1927). The expression of a tensor or a polyadic as a sum of products. Journal of Mathematics and Physics, 6(1-4):164–189.
- Hooten and Hobbs, (2015) Hooten, M. B. and Hobbs, N. T. (2015). A guide to Bayesian model selection for ecologists. Ecological monographs, 85(1):3–28.
- Johndrow et al., (2017) Johndrow, J. E., Bhattacharya, A., and Dunson, D. B. (2017). Tensor decompositions and sparse log-linear models. Annals of Statistics, 45(1):1–38.
- Kolda and Bader, (2009) Kolda, T. G. and Bader, B. W. (2009). Tensor decompositions and applications. SIAM Review, 51(3):455–500.
- Kruskal, (1977) Kruskal, J. B. (1977). Three-way arrays: rank and uniqueness of trilinear decompositions, with application to arithmetic complexity and statistics. Linear Algebra and its Applications, 18(2):95–138.
- Mackey et al., (2010) Mackey, L. W., Weiss, D. J., and Jordan, M. I. (2010). Mixed membership matrix factorization. In International Conference on Machine Learning.
- Manrique-Vallier, (2014) Manrique-Vallier, D. (2014). Longitudinal mixed membership trajectory models for disability survey data. Annals of Applied Statistics, 8(4):2268.
- Manrique-Vallier and Reiter, (2012) Manrique-Vallier, D. and Reiter, J. P. (2012). Estimating identification disclosure risk using mixed membership models. Journal of the American Statistical Association, 107(500):1385–1394.
- Mao et al., (2020) Mao, X., Sarkar, P., and Chakrabarti, D. (2020). Estimating mixed memberships with sharp eigenvector deviations. Journal of the American Statistical Association, pages 1–13.
- McLachlan and Peel, (2000) McLachlan, G. J. and Peel, D. (2000). Finite Mixture Models. John Wiley & Sons.
- Nguyen, (2015) Nguyen, X. (2015). Posterior contraction of the population polytope in finite admixture models. Bernoulli, 21(1):618–646.
- Paganin et al., (2021) Paganin, S., Herring, A. H., Olshan, A. F., and Dunson, D. B. (2021). Centered partition processes: Informative priors for clustering (with discussion). Bayesian Analysis, 16(1):301–370.
- Piironen and Vehtari, (2017) Piironen, J. and Vehtari, A. (2017). Comparison of Bayesian predictive methods for model selection. Statistics and Computing, 27(3):711–735.
- Pritchard et al., (2000) Pritchard, J. K., Stephens, M., and Donnelly, P. (2000). Inference of population structure using multilocus genotype data. Genetics, 155(2):945–959.
- Rand, (1971) Rand, W. M. (1971). Objective criteria for the evaluation of clustering methods. Journal of the American Statistical Association, 66(336):846–850.
- Saddiki et al., (2015) Saddiki, H., McAuliffe, J., and Flaherty, P. (2015). GLAD: a mixed-membership model for heterogeneous tumor subtype classification. Bioinformatics, 31(2):225–232.
- Shang et al., (2021) Shang, Z., Erosheva, E. A., and Xu, G. (2021). Partial-mastery cognitive diagnosis models. Annals of Applied Statistics, 15(3):1529–1555.
- Spiegelhalter et al., (2002) Spiegelhalter, D. J., Best, N. G., Carlin, B. P., and Van Der Linde, A. (2002). Bayesian measures of model complexity and fit. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 64(4):583–639.
- Tan and Mukherjee, (2017) Tan, Z. and Mukherjee, S. (2017). Partitioned tensor factorizations for learning mixed membership models. In International Conference on Machine Learning, pages 3358–3367.
- Teh et al., (2006) Teh, Y. W., Jordan, M. I., Beal, M. J., and Blei, D. M. (2006). Hierarchical dirichlet processes. Journal of the American Statistical Association, 101(476):1566–1581.
- Tucker, (1966) Tucker, L. R. (1966). Some mathematical notes on three-mode factor analysis. Psychometrika, 31(3):279–311.
- Wang, (2019) Wang, Y. (2019). Convergence rates of latent topic models under relaxed identifiability conditions. Electronic Journal of Statistics, 13(1):37–66.
- Wang et al., (2015) Wang, Y. S., Matsueda, R. L., and Erosheva, E. A. (2015). A variational em method for mixed membership models with multivariate rank data: an analysis of public policy preferences. arXiv: Methodology, pages 1452–1480.
- Watanabe, (2010) Watanabe, S. (2010). Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory. Journal of Machine Learning Research, 11(12).
- Woodbury et al., (1978) Woodbury, M. A., Clive, J., and Garson Jr, A. (1978). Mathematical typology: a grade of membership technique for obtaining disease definition. Computers and Biomedical Research, 11(3):277–298.
- Zhao et al., (2018) Zhao, S., Engelhardt, B. E., Mukherjee, S., and Dunson, D. B. (2018). Fast moment estimation for generalized latent Dirichlet models. Journal of the American Statistical Association, 113(524):1528–1540.
- Zhou et al., (2015) Zhou, J., Bhattacharya, A., Herring, A. H., and Dunson, D. B. (2015). Bayesian factorizations of big sparse tensors. Journal of the American Statistical Association, 110(512):1562–1576.
- Zhou, (2018) Zhou, M. (2018). Nonparametric Bayesian negative binomial factor analysis. Bayesian Analysis, 13(4):1065–1093.
- Zhou et al., (2016) Zhou, M., Cong, Y., and Chen, B. (2016). Augmentable Gamma belief networks. Journal of Machine Learning Research, 17(1):5656–5699.
Supplementary Material
This Supplementary Material contains two sections. The first section Supplement A contains the proofs of all the theoretical results in the paper. The second section Supplement B presents a note on the pairwise mutual information measures between categorical variables.
Supplement A: Proofs of Theoretical Results
7.1 Proof of Theorem 1
For notational simplicity, from now on we will omit the subscript of subject-specific random variables without loss of generality; all such variables including and should be understood as associated with a random subject. Denote by a configuration of the latent profiles realized for the groups of variables. Recall that given a fixed grouping matrix , the associated group assignment vector is defined as if and only if . We next introduce a new notation. For each variable , each category , and each possible latent profile configuration , define a new parameter to be
| (18) |
Collect all the -parameters in , then is a three-way array (which is a tensor of size if ) since , , and . For each , we will denote the matrix by for simplicity. The representation in (18) implies that many entries in are equal. Specifically, for two arbitrary latent assignment vectors and with , as long as there would be . We choose to use the over-parameterization in (18) since this notation facilitates the study of identifiability through the underlying tensor decomposition structure, as will be revealed soon. In particular, the ’s have the following property.
Lemma 1.
Under the definition in (18), for any set of indices such that , there is
| (19) |
Now we can equivalently rewrite the previous model specification (7) as follows,
| (20) |
where . Denote by a -th order tensor of size . Denote by the vectorized version of , so is a vector of length ; in particular, this vector has entries defined as follows,
| (21) |
for any . Suppose alternative parameters lead to the same distribution of the observed variables; that is holds for each possible response pattern . Then by the equivalence in (20), we also have for all .
The following two lemmas will be useful.
Lemma 2.
Without loss of generality, suppose the first variables belong to the first group, the second variables belong to the second group, etc. That is, the matrix takes a block-diagonal form. The Gro-M in (20) implies the following identity
| (22) |
Lemma 3.
Suppose there are two disjoint sets of observed variables and satisfying for each . Then
| (23) |
If there further is for some , then up to a permutation of rows there is
| (24) | ||||
We continue with the proof of Theorem 1. Under the conditions of the theorem, without loss of generality we can assume that for each , the first three variables (among the ones) belonging to the th group have their corresponding full-column-rank; denote the indices of these three variables by . For example, if takes the block diagonal form, then for such three variables are indexed by ; for they are indexed by , etc. Define the following sets of variable indices,
Lemmas 2 and 3 imply that we can write under the true parameters as follows
| (25) |
The last equality above follows from Lemma 1, by noting that for each , the index set . The last equality in the above display results from the property of the Khatri-Rao product. Define
It can be seen that the definitions of the above three functions of only depend on the two sets of variable indices and , which in turn are determined by the true grouping matrix . Now (25) can be further written as
So for true parameters and alternative parameters that lead to the same distribution of the observed , we have
| (26) | ||||
Recall that under the assumptions in the theorem and the current notation, for each the matrix has full column rank . According to the property of the Kronecker product, the matrices and each has full column rank . Further, since has full column rank , the Khatri-Rao product must have full column rank . Therefore the matrix also has full column rank . By definition of ’s, the above full-rank assertions indeed mean that , , and all have full column rank .
We next invoke a useful lemma on the uniqueness of three-way tensor decompositions, the Kruskal’s theorem established in Kruskal, (1977), and then proceed similarly as the proof procedures in Allman et al., (2009). For a matrix , its Kruskal rank is defined to be the largest number such that any columns of are linearly independent. Denote the Kruskal rank of matrix by .
Lemma 4 (Kruskal’s Theorem).
Suppose are three matrices of dimension for , are three matrices each with columns, and . If , then there exists a permutation matrix and three invertible diagonal matrices with and for each .
If a matrix has full column rank , then it must also have Kruskal rank by definition. As a corrolary of Lemma 4, if the three matrices all have full column rank , then the condition is satisfied and the uniqueness conclusion follows. We now take , for , and define
then there is . According to our argument right after (26), for . As for , since has full column rank and the entries of are positive, the also has full column rank . Therefore, we can invoke Lemma 4 to establish that there exists a permutation matrix and three invertible diagonal matrices with such that
for .
The next step is to show that the diagonal matrices are all identity matrices. Note that each column of the matrix characterizes the conditional joint distribution of given the latent assignment vector under the true -parameters. And similarly, each column of characterizes the conditional joint distribution of given under the alternative . Therefore the sum of each column of or that of equals one, which implies the diagonal matrix is an identity matrix for or 2. Since Lemma 4 ensures , we also obtain . By far we have obtained for and
| (27) |
Note that the permutation matrix has rows and columns both indexed by latent assignment vectors . For , consider an arbitrary and assume without loss of generality that satisfies that the th entry of matrix is . Then the th column of the matrix equality takes the form
for each ; summing the above equality over the index gives . Note we have generally established whenever , which essentially implies . Note that this shows the identifiability of the tensor core in our hybrid tensor decomposition formulation of the Gro-M3. Further, implies that
Combining the above display to the previous (27), since is a diagonal matrix with positive diagonal entries, we can right multiply the inverse of this matrix with the LHS of (27) and meanwhile right multiply the inverse of with the RHS of (27); this gives .
Our final step of proving the theorem is to show that the established for implies the identifiability of and . First, since is defined as certain Khatri-Rao products of the individual ’s, we claim that the indeed implies that for each . To see this, note that each column of and characterizes the conditional joint distribution of variables given the . So the conditional marginal distribution can be obtained by summing up appropriate row vectors of the matrices and , corresponding to marginalizing out other variables except the th one. Now without loss of generality we can assume that , then gives for all . Now it only remains to show that uniquely determines and . By definition (18) there is . For arbitrary and , we first consider an arbitrary latent assignment such that , then
The above reasoning proves the identifiability of . Thus far we have proved part (a) of Theorem 1.
We next prove part (b) of the theorem. We use proof by contradiction to show the identifiability of the grouping matrix (or equivalently, the identifiability of the vector ). If there exists some such that the th rows of and are different, then ; denote and . Next for arbitrary two different indices and , we consider a latent assignment such that and . Then there are
Since , the above equality means the th and th columns of are identical. Since and are two arbitrary indices, this means all the column vectors in the matrix are identical. This contradicts the assumption in part (b) of the theorem. Therefore we have shown that must hold for an arbitrary . This proves the identifiability of from . This completes the proof of Theorem 1.
7.2 Proof of Theorem 2
The proof of this theorem is similar in spirit to the previous Theorem 1 by exploiting the inherent tensor decomposition structure, but differing in taking advantage of the more dimension-grouping structure under the assumptions here. Recall . We write under the true parameters as
Since each is nonempty under the assumption in the theorem and , we can use Lemma 1 to obtain that
where the second equality above follows from the definition of in the theorem. We now define
Since the theorem has the assumption that each has full column rank , we have that has full rank . Note that each is the Khatri-Rao product of certain ’s and depends on the true grouping matrix . Also note that there is
Now the problem is in exactly the same formulation as that in the proof of Theorem 1, so we can proceed in the same way to establish the identifiability of and individual ’s. The identifiability of further gives the identifiability of and . This finishes the proof of Theorem 2. ∎
7.3 Proof of Theorem 3
We first prove the following claim:
Claim 1. Under condition (13) that in the theorem, the following matrix has full column rank for generic parameters,
The above has the same definition as that in Theorem 2. The proof of this claim is similar in spirit to that of Lemma 13 in Allman et al., (2009). Note that the statement that the matrix does not have full column rank is equivalent to the statement that the maps sending to its minors are all zero maps. There are
such maps, and each of this map is a polynomial with indeterminants ’s. To show that has full column rank for generic parameters, we just need to show that these maps are not all zero polynomials. According to the property of the polynomial maps, it indeed suffices to find one particular set of such that the resulting Khatri-Rao product has full column rank.
Consider a set of distinct prime numbers denoted by . Define
| (28) |
then is a Vandermonde matrix. Generally, for a -dimensional vector , let denote the the Vandermonde matrix with the th entry being , so the defined in (28) can be written as . Now consider a defined as
Under the assumption (13) in the theorem that , the columns of are indeed the first columns in the following Vandermonde matrix
Since by construction the ’s are distinct prime numbers, for each the products are also distinct numbers. Therefore the defined above has full rank . Since and has columns from the first columns of , we have that has full column rank for this particular choice of parameters. Note that the defined in (28) does not have each column summing up to one, as is required in the parameterization of the probability tensor. But performing a positive rescaling of the each column of to a conditional probability table would not change the above reasoning and conclusion about matrix rank; so we have proved the earlier Claim 1 that each has full column rank for generic parameters. Given this conclusion, for generic parameters in the parameter space the situation is reduced back to that under Theorem 2. So the identifiability condition in Theorem 1 carries over, and we can obtain the conclusion that identifiability holds here for generic parameters. This completes the proof of Theorem 3. ∎
7.4 Proof of Proposition 1
Recall that under the conditions of the previous theorem, we already have the conclusion that and are identifiable. Next the question boils down to whether are identifiable from . By the definition, we have
First we consider the case of . Denote . Then according to the moment property of the Dirichlet distribution, there is
Therefore for , consider and defined as follows,
Since and are already identified, then we can solve for and as follows
Since the above reasoning holds for arbitrary pairs of with , we have obtained the identifiability of the entire vector .
Next we consider the general case of . For arbitrary , consider two sequences , . According to the property of the Dirichlet distribution, we have
| (29) | |||
| (30) |
Now that the left hand sides of the above two equations are identified by the previous theorem, we denote them by and . The and are identified constants. Solving for and gives
Since are arbitrary, we have shown that the entire vector is identifiable. This completes the proof of Proposition 1. ∎
7.5 Proof of Supporting Lemmas
Proof of Lemma 1.
First note that the on the right hand side of (19) has size . Further, since , the set is nonempty. So the has columns and hence the left hand side of (19) also has size . Without loss of generality, suppose , where denotes the cardinality of the set . The th entry of the RHS of (19) is , which by definition equals ; this is exactly the th entry of the LHS of (19). This completes the proof of Lemma 1. ∎
Proof of Lemma 2.
First note that both hand sides of (22) are vectors of size . To see this for the right hand side of (22), note the matrix has size , and hence the matrix has size
which is just Further note that the vector has size , so the on the right hand side of (22) has size , matching the size of the left hand side. Next consider the individual entries of both hand sides of (22). First, by definition of the vec() operator, the -th entry of the left hand side of (22) is . Next, according to (20), the can be written in the following way,
The last row in the above display exactly equals the -th entry of the RHS of (22). This proves the equality in (22) and completes the proof of Lemma 2. ∎
Proof of Lemma 3.
In the LHS of (23), the term has size and hence the Kronecker product has size . In the RHS of (23), the term has size , and hence the Khatri-Rao product of two such terms
has size . So both hand sides of (23) has size . The equality (23) can be similarly shown as in the proof of Lemma 2 by writing out and checking the individual elements of the two matrices on the LHS and RHS of (23).
8 Supplement B: Pairwise Cramer’s V between Categorical Variables
According to the definition of mutual information in information theory, for two discrete variables and , their Cramer’s V is
| (31) |
where denotes the marginal distribution of and denotes the joint distribution of and . The Cramer’s V measures the the inherent dependence expressed in the joint distribution of two variables relative to their marginal distributions under the independence assumption. Therefore, Cramer’s V measures the dependence between variables and it equals zero if and only of the two variables are independent; otherwise Cramer’s V is positive.
The expression of Cramer’s V in (31) is the population version. Given a sample with , the population quantities of the marginal and joint distributions in (31) can be replaced by their sample estimates. That is, the previous and are replaced by the following,
Using the sample-based Cramer’s V measure, we calculate the Cramer’s V for all the pairs of variables when and each range from 1 to . For two randomly chosen simulated datasets from the simulations settings and described in Section 5 in the main text, their pairwise Cramer’s V plots are displayed in Figure 12.

By visual inspection, Figure 12 shows a block-diagonal structure of the pairwise Cramer’s V matrix for both simulation settings. In each of these settings, the true grouping matrix used to generate data takes the form that the first variables belong to a same group, the second variables belong to another same group, etc. Therefore, Figure 12 implies in the simulations, the variables belonging to the same group tend to show higher dependence than those variables belonging to different groups.