Digital Twin Assisted Intelligent Network Management for Vehicular Applications
Abstract
The emerging data-driven methods based on artificial intelligence (AI) have paved the way for intelligent, flexible, and adaptive network management in vehicular applications. To enhance network management towards network automation, this article presents a digital twin (DT) assisted two-tier learning framework, which facilitates the automated life-cycle management of machine learning based intelligent network management functions (INMFs). Specifically, at a high tier, meta learning is employed to capture different levels of general features for the INMFs under nonstationary network conditions. At a low tier, individual learning models are customized for local networks based on fast model adaptation. Hierarchical DTs are deployed at the edge and cloud servers to assist the two-tier learning process, through closed-loop interactions with the physical network domain. Finally, a case study demonstrates the fast and accurate model adaptation ability of meta learning in comparison with benchmark schemes.
Index Terms:
Digital twin, vehicular networks, intelligent network management function, meta learning, network automation.I Introduction
The sixth-generation (6G) wireless communication networks are foreseen to support emerging vehicular applications that will dramatically boost vehicle intelligence and revolutionize the transportation systems, such as autonomous driving and augmented reality (AR) entertainment for onboard passengers [1]. These applications usually rely on powerful computing servers to meet real-time performance requirements. A layered network architecture spanning across the user end device, edge, and cloud layers, as illustrated in Fig. 1, supports such vehicular applications by exploiting the edge and cloud computing resources. In the network architecture, there should be various network management functions for different network optimization purposes, such as to coordinate the multi-dimensional resources for computing, communication, sensing, positioning, and storage, to control the task offloading process from vehicle users to edge/cloud servers for delay satisfaction, and to support the mobility of vehicle users via handover and service migration [2, 3]. Formally, network management involves the monitoring, configuration, analysis, evaluation and control of the network elements and resources to meet service quality requirements at a reasonable cost [4].
High dynamics in a vehicular network, such as vehicle density, data traffic volume, computing demand, sensing workload and channel conditions, complicate the network management. To handle such complexity, cost-effective scalable performance optimization solutions and adaptive algorithms are required for intelligent and automated network management [5]. The traditional model-driven approaches follow the “model-then-optimize” manner and rely on domain expert knowledge. They have the advantage of generalities for different networking scenarios, but are limited to simple or small-scale networks, thus becoming inadequate and even intractable in 6G. Emerging data-driven approaches rely on artificial intelligence (AI) and big data, bringing a promising alternative for solving complex network optimization problems. To enhance the overall intelligence of vehicular networks, AI techniques can be employed to embed intelligence in network management, creating intelligent network management functions (INMFs) [4].
The INMFs can potentially capture system dynamics and facilitate the intelligent network management. However, innovative engineering solutions are required towards network management automation. Typically, a machine learning (ML) model converges once it has successfully captured a stationary distribution in the training data, and a trained model can be used for real-time network management under the assumption that the underlying data distribution does not change. However, the assumption is not true if we consider a vehicular network over a long time period or in a large geographical area, where network dynamics exhibit spatio-temporal statistical variations [6]. For example, for different road conditions and time periods, the vehicle density distributions are different, and the resource demand can have significant changes. In such cases, the trained ML models can perform poorly, and a model retraining should be triggered to customize the INMFs for the new scenarios [7]. Typically, retraining from scratch is time-consuming and data-inefficient [5]. A question is how to achieve fast and efficient model adaptation to overcome the spatio-temporal nonstationarity in a vehicular network.

In this study, we take a step further from data-driven network management towards network automation. The former involves individual learning tasks for developing customized ML models of different INMFs in a stationary network scenario. The latter further involves the automated life-cycle management of such ML models under nonstationary conditions. As illustrated in Fig. 2, the life-cycle of a machine learning model includes data collection, model training and re-training, model inference, and performance monitoring. The different phases should be automatically triggered and managed, to enable learning task evolution in a nonstationary network environment [7, 5, 8]. Meta learning, also known as “learning to learn”, aims at learning how to efficiently execute new learning tasks. The key idea is to leverage prior learning experiences to improve the learning process itself and to create meta models that can quickly adapt to new learning tasks with limited data [9, 10]. Here, we discuss meta learning based network management for the spatio-temporal nonstationary vehicular networks, and propose a two-tier learning framework in the three-layer network architecture. Such a framework aims at providing flexibility in learning model life-cycle management, as an initial step towards network automation.
Recently, digital twin (DT) has captured significant attention due to its potential to transform industries by providing a bridge between the physical and digital worlds and including its role in vehicular networks [3, 11, 12]. A DT refers to a virtual representation of a physical system. It should be continuously updated with real-world data to reflect the current state and behavior of the physical counterpart, which allows for simulation, analysis, monitoring, and optimization of the physical system without actually interacting with it. Thus, DTs can potentially assist in our two-tier learning framework. We consider hierarchical DTs, including lower-level DTs deployed at edge servers for individual model learning and higher-level DTs deployed at cloud servers for meta learning.
The remainder of this article is organized as follows. We first introduce preliminaries of fast model adaptation based on meta learning, and then propose the DT-assisted two-tier learning framework. A case study is presented to demonstrate the benefit of meta learning, followed by a conclusion.
II Preliminaries of Fast Model Adaptation

For learning task evolution under a nonstationary network condition, when to trigger model retraining and how to achieve fast model adaptation are critical issues. In theory, a model retraining is required if the system dynamics experience a distribution drift. However, as it is difficult to accurately estimate an unknown probability distribution, we can monitor the model performance and use the performance degradation as a triggering signal in practice.
An ideal model retraining should be fast and accurate to adapt to new network conditions. Retraining from scratch is not a good choice, as the model convergence is slow especially when new training data are scarce. A long retraining time deteriorates the robustness of ML-based network optimization solutions. The old model is not a good initial point either, as it might be overfitted to the old data, which possibly slows down the model retraining especially if the new data distribution significantly deviates from the old one. A desired initial point is a model with good generalization ability. Such a model is referred to as a meta model in the context of meta learning. The core concepts of meta learning include:
-
•
Meta training: A meta model is trained by learning from a diverse set of individual learning tasks, to learn a high-level initialization that quickly adapts to new tasks;
-
•
Meta adaptation: The trained meta model serves as an initial point for fast model adaptation on new learning tasks with a limited amount of data. Such a few-shot learning capability makes meta learning particularly useful in scenarios where data are limited.
Meta learning can be applied in learning frameworks such as supervised learning and reinforcement learning (RL) [9, 10]. We briefly introduce the meta training procedures in the context of RL. Consider an unknown probability distribution over Markov decision process (MDP) tasks for a specific INMF such as resource allocation, task offloading, mobility management, and packet scheduling in vehicular networks. An individual learning task corresponds to a random MDP sampled from such a task distribution, which has unknown but stationary state transition probabilities. RL can be used to solve the MDP, and the RL model is referred to as an individual model. A meta model has the same neural network structure as the individual models, but with a set of different parameters. The meta model aims to learn general features broadly applicable to all MDP tasks sampled from the task distribution, thus can adapt well among different tasks.
Many meta learning algorithms, such as model-agnostic meta learning, use gradient-based optimization techniques that iteratively update meta model parameters to minimize an average adaptation loss on sampled tasks [9]. For each sampled task, the adaptation loss captures the ability of the meta model to quickly adapt its learned knowledge and perform well on the task. In each iteration, a number, , of individual learning tasks are sampled, and the following steps are performed between one meta learning agent and individual learning agents.
-
•
Individual model initialization: The meta learning agent distributes the current meta model to the individual learning agents for individual model initialization;
-
•
First-round data collection: Each individual learning agent collects a set of trajectory data composed of state-action-reward transitions by using the current individual model. They either interact with the real vehicular network environment to obtain the true data or emulate the network operations to obtain the synthetic data;
-
•
Individual model adaptation: With the trajectory data, each individual learning agent performs an individual model adaptation via one gradient descent over the loss function of the individual model (i.e., individual loss);
-
•
Second-round data collection111In some meta learning algorithms such as Reptile, this step is omitted by approximating the adaptation loss gradients as the scaled difference between meta model parameters and adapted individual model parameters [13].: In order to evaluate the adaptation loss of each sampled task, each individual learning agent collects an extra set of trajectory data by using the adapted individual model;
-
•
Adaptation loss evaluation: For each individual learning agent, the adaptation loss is the individual loss with the new trajectory data, and the adaptation loss gradients are computed with regards to the meta model parameters and sent to the meta learning agent;
-
•
Meta model update: Once all sets of adaptation loss gradients are available, the meta learning agent updates the meta model via a gradient descent in the direction of the average adaptation loss gradients, to minimize the average adaptation loss on the sampled tasks.
A meta model is trained once the average adaptation loss on sampled tasks converges after multiple iterations. Then, for any individual learning task from the same task distribution, a customized individual model can be trained via meta adaptation, which may take several gradient descent steps.
III A Digital Twin Assisted Two-Tier Learning Framework

We consider a number of physical local vehicular networks (PLVNs) with nonstationary spatio-temporal characteristics in a geographical region. For each PLVN, a set of ML models should be customized to support multiple INMFs. For each INMF, a PLVN is associated with one individual model, and meta learning is used to capture the general features among the PLVNs. For such meta learning based network management, we propose a digital twin (DT) assisted two-tier learning framework in the three-layer network architecture, as illustrated in Fig. 3. First, we consider hierarchical meta models with different generalization levels. Second, we propose hierarchical DTs to support two-tier learning. Third, we discuss the offline planning and online operation stages of the proposed framework, which enable closed-loop interactions among the cloud, edge, and end device layers, and between the hierarchical DTs and the physical network domain.
III-A Hierarchical Meta Models

For each INMF, a single meta model trained based on random PLVNs is to capture the most high-level features shared among the networks. The “distance” from such a meta model to any individual model is not close due to a very high generalization level, leading to a long model adaptation delay. To balance between generalization and customization, we propose hierarchical meta models for each INMF to capture different levels of general features among the PLVNs. Specifically, we extract network-level attributes (such as hour, city, location, road condition, vehicle number, average workload, and average resources) of the PLVNs, all of which have an impact on the unknown network dynamics models. Based on one attribute or a combination of attributes, the PLVNs fall into different categories. For example, a network can be tagged by a time attribute such as “Day” and “Night”, or a combination of time, city and road attributes such as “Day + Toronto + Highway” and “Night + Vancouver + Local”. To maintain a list of PLVNs for each category, a unique ID is assigned to each PLVN. A meta model is trained for each category to learn the general features within the corresponding PLVN list.
The attributes should be carefully selected and processed. More attributes lead to more fine-grained categories and less-general meta models with a higher customization level. Such meta models require less fine-tuning, enabling faster model adaptation. However, the data inefficiency issue in training the meta models arises, as it takes a longer time to gather sufficient training data from each fine-grained category. Additionally, for the categorization, discretization is needed for continuous attributes. We can normalize those with different units/scales to the range of before discretization.
Fig. 4 illustrates hierarchical meta models for different categories based on time, city and road attributes. The root node represents a super (meta) model that captures the most general features among all PLVNs.
III-B Hierarchical Digital Twins
As shown in Fig. 3, hierarchical DTs are deployed at the edge and cloud layers to assist two-tier learning based network management. A cloud DT is created for high-tier learning among all PLVNs. It trains and maintains sets of hierarchical meta models for multiple INMFs. For each PLVN, an edge DT is created for low-tier learning, specifically for individual model adaptation and customization based on meta models from the cloud DT. The low-tier learning is necessary for both meta training and meta adaptation, as discussed in Section II.
An edge DT is a digital copy of a PLVN, which can be deployed at the nearest edge server. The edge DT has the same ID as the associated PLVN. If a PLVN corresponds to a moving cluster of vehicles, the associated edge DT migrates among edge servers to “follow” the vehicle cluster, thus providing the mobility support. The data of the PLVN such as vehicle trajectories, task information, resource availability, QoS/cost measurements are periodically updated to the edge DT. The edge DT also maintains models of the PLVN for network emulation, which facilitates the coordination of data-driven and model-based network management [3]. Examples of the models include mobility model, task model, data traffic model, communication/computing/sensing models, and QoS/cost/reward models. Such models can be based on domain expert knowledge and enhanced by experience data.
Based on the data and models, the edge DT can support multiple functions to facilitate the low-tier learning for diverse INMFs. For example, the network-level attributes of the associated PLVN can be analyzed based on the collected data. With the attributes, the potentially changing PLVN categories can be determined over time. The ID and categories of each edge DT are recorded by the cloud DT. Then, an edge DT can be involved in a meta training process initiated by the cloud DT for meta models of matching categories. For each INMF requested by the PLVN, if there are multiple available meta models of matching categories at the cloud DT, the least-general one based on known attributes is fetched and then cached at the edge DT. With the cached meta model as an initial point, an individual model can be trained or updated to fit the current network conditions. Otherwise, the super model is used by default for individual model learning.
The cloud DT is a high-level virtual representation of all the PLVNs. To support training a set of hierarchical meta models per INMF, the cloud DT collects high-level data (such as network-level attributes) and adaptation loss gradients from the edge DTs. It also maintains models that capture the overall system characteristics. For example, based on the high-level data, the spatio-temporal nonstationarity among the PLVNs can be analyzed. For a PLVN, the change points in time between stationary network conditions can be detected, and the new network conditions can be predicted [14]. Moreover, a drift of the unknown learning task distribution within each PLVN category can be coarsely detected. For each category, the fractions of PLVNs in all the sub-categories composite a vector. The Euclidean distance between vectors at different time points roughly evaluates the difference in the task distribution. Additionally, a remarkable increase of the meta model’s adaptation loss on sampled tasks implies a task distribution drift. Based on such high-level analyses, meta model training for new categories and meta model update for existing categories can be triggered.
III-C Offline Planning and Online Operation Stages

III-C1 Offline planning stage
This stage can take a long time duration, e.g., several days or weeks. Based on a pre-determined set of attributes, network categories with different granularities can be determined. For each INMF, a meta model is trained for each category at the cloud DT in multiple iterations. In each iteration, a set of PLVNs are uniformly sampled from the category’s PLVN list, and the current meta model is distributed to the associated edge DTs. With the maintained PLVN list, the PLVN sampling can be performed without explicitly knowing the learning task distribution. The edge DTs evaluate the meta model with emulated data trajectories, and compute the adaptation loss gradients which are then returned to the cloud DT for meta model update. Fig. 5(a) illustrates the interactions between the cloud DT and one edge DT for meta training in one iteration. There are two data emulation steps before and after the individual model adaptation. Conventionally, to train an individual model, data trajectories are acquired from the physical network. However, as the individual model adaptation here is for adaptation loss evaluation rather than for formally training an individual model, the network evolution can be emulated to generate synthetic trajectory data based on the data and models in the edge DT, which helps to avoid poor network performance during the long meta training process. Once trained, the hierarchical meta models for each INMF are stored in the cloud DT. To save the computation and storage resources for training and maintaining the meta models, techniques such as multi-task learning can be employed to enable representation sharing among highly-related INMFs.
We do not store individual models in the cloud DT, although a transfer learning technique allows model adaptation from a source individual learning task to a related target task. The reason is that it is difficult to accurately match the PLVNs to existing individual models due to the unavailability of accurate network dynamics models. Correlation analysis based on high-level attributes may help to evaluate the similarity between PLVNs, but its validity and accuracy need more investigation. Such analysis also incurs computation overhead. In comparison, it is more convenient and cost-effective to identify the categories of any PLVN, and find a proper meta model for fast individual model customization.
III-C2 Online operation stage
During this stage, a customized individual model is created for each INMF of a PLVN. Based on the data collected from the PLVN, the edge DT extracts and sends high-level data such as attributes to the cloud DT. If the PLVN belongs to a known category, a meta model is fetched from the cloud DT for each INMF and then cached by the associated edge DT. The edge DT then customizes an individual model for each INMF through several meta adaptation steps, as shown in Fig. 5(b). Each adaptation step requires an interaction between the edge DT and the PLVN. To accelerate the model convergence, a hybrid data collection mode can be employed, where true trajectory data are collected via model inference in the PLVN and synthetic trajectory data are generated in the edge DT. Once the individual models are trained, the edge DT dispatches them to the PLVN for real-time network management based on model inference. During the inference phase, the true trajectory data and performance measurements can be updated to the edge DT, to tune the network emulation models and trigger necessary individual model retraining.
For a PLVN requiring model retraining, if it remains in the same category, a new individual model is retrained based on the cached meta model. If it transfers to another known category, a new meta model should be fetched from the cloud DT. If it transfers to an unknown category, the super model is used for individual model retraining, and a meta model for the new category is trained in the cloud DT. As the individual models are difficult to be matched to a PLVN, the old individual models are deleted once the new ones are trained, to save the caching space. Nevertheless, a list of meta models can be cached at the edge DT, as meta model fetching from the cloud DT incurs long propagation delay through the Internet. For delay improvement, a cache replacement policy can be designed to keep the most popular meta models.
The existing meta models (including the super model) maintained by the cloud DT should be updated if the respective task distributions experience significant changes, which can be fulfilled by the same meta training procedures as shown in Fig. 5(a). Therefore, with the continuous online operation, a complete library of up-to-date meta models for different network categories and INMFs will be gradually established in the cloud DT, and the individual models are automatically created, updated, and deleted at the edge DTs for the spatio-temporal nonstationary PLVNs.
IV Case Study
We discuss one use case for RL-based adaptive cooperative perception among connected and autonomous vehicles (CAVs), and focus on the meta learning aspect. We consider a moving vehicle cluster in the service coverage of a road-side unit (RSU). The vehicle cluster consists of multiple CAV pairs which may perform cooperative perception via vehicle-to-vehicle (V2V) communication, along with human-driven vehicles which have potential vehicle-to-RSU transmission. Due to the radio resource sharing among all the vehicles, the radio resource availability for supporting the cooperative perception of CAV pairs is dynamic. Moreover, due to the vehicle mobility, the perception workloads (i.e., number of nearby objects for detection and classification) and the channel conditions for the CAV pairs vary with time. Under such network dynamics, each CAV pair can switch between a default stand-alone perception (SP) mode and a selective cooperative perception (CP) mode, to ensure consistent delay satisfaction [15]. CP potentially reduces the total computing demand at a feature data transmission cost between CAVs. For delay satisfaction, the CPU frequency for supporting the computation in perception tasks should be scaled up/down on demand. Define the computing efficiency gain of a CAV pair as the reduced amount of computing energy consumption in comparison with that in the default SP mode. Such a gain is equal to zero in the SP mode, and decreases proportionally with computing demand (in CPU cycle) and CPU frequency (in cycle/s) squared in the CP mode [15].
An increase of the perception workload at a CAV pair in the CP mode leads to more reduction in the total computing demand in comparison with the SP mode, at the cost of higher CPU frequency and transmission rate requirements due to a reduced per-object delay budget. The transmitter-receiver distances of the CAV pairs also affect the feature data transmission delay. Hence, the dynamic network state in terms of the available radio resources for V2V transmission, the perception workloads of all CAV pairs, and the transmitter-receiver distances of each CAV pair should be considered in the adaptive perception mode selection, to maximize the total computing efficiency gain while satisfying the delay requirement. We formulate the adaptive cooperative perception problem as an MDP characterized by state, action, and reward. The action is a binary decision vector indicating the selection between the SP and CP modes among all CAV pairs. The reward is the total computing efficiency gain.
We propose an RL solution based on a proximal policy optimization (PPO) algorithm. In PPO, we train a Gaussian stochastic policy network which learns the mean and the standard deviation of a set of Gaussian random variables for all CAV pairs. For each CAV pair, a continuous action is sampled from the corresponding Gaussian distribution and then discretized to a binary cooperation decision. The policy entropy is the average differential entropy of all the Gaussian random variables, which measures the amount of uncertainty or randomness in the stochastic policy.
We conduct simulations to evaluate how meta learning accelerates the model adaptation. The RL agent interacts with a dynamic network environment including CAV pairs and HDVs in consecutive episodes. Each episode contains time slots. At time slot , the amount of available radio resources follows a Normal distribution , where is the mean and is the time-invariant standard deviation. The mean has three possible values in MHz, corresponding to , , and resources, and is set to MHz. An individual RL task is associated with a customized radio resource pattern in each episode, with mean values denoted by sequence . We consider two individual RL tasks with and resource availability respectively. Specifically, mean for each time slot is always MHz ( MHz) for task 1 (task 2). A PPO model is trained from scratch (PPO-random) for both tasks. To train a meta model, we create a set of random network environments associated with random radio resource patterns, by uniformly sampling among MHz. For task 1, two extra PPO models are trained based on meta adaptation (PPO-ML) and transfer learning from task 2 (PPO-TL), respectively.

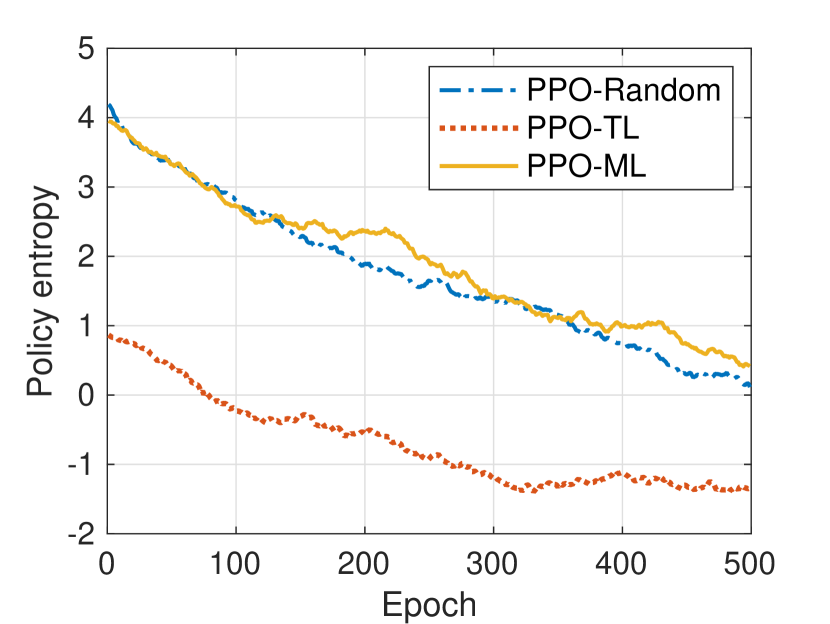
All the PPO models are trained over 500 training epochs, each consisting of episodes. Fig. 6 shows the per-episode average total reward and policy entropy over training epochs for the three PPO models of task 1. As shown in Fig. 6(a), the meta model adapts quickly and well, as indicated by the fast convergence and the comparable average total reward with PPO-random after convergence. In comparison, transfer learning shows inferior performance than meta learning, in terms of both slower convergence and lower average total reward after convergence. The potential reason for the superiority of meta learning can be inferred from Fig. 6(b). As a meta model captures the general features among random learning tasks, its policy entropy is comparable to that of a random model, which encourages better exploration in the right direction during the model adaptation. However, in PPO-TL, as a trained model is customized to a task, the policy entropy is low due to less randomness. This hinders the exploration during the transfer learning process and makes the model more easily stuck at a local optimum, especially when the source and target tasks significantly differ from each other.
V Conclusion
In this article, we present a digital twin assisted two-tier learning framework, to support the automated life-cycle management of AI-based intelligent network management functions for vehicular applications. The cloud digital twin builds a dynamic collection of hierarchical meta models, while the edge digital twin facilitates fast individual model customization. Such a framework aims at a better trade-off between generalization and customization for the intelligent network management in vehicular networks, providing a promising tool towards network automation. In our future work, we will further explore the strengths of digital twin and meta learning for more use cases in vehicular networks, and potentially extend our ideas to space-air-ground integrated networks.
Acknowledgement
The authors would like to thank the undergraduate research assistant, Chinemerem Chigbo, for implementing the meta learning algorithm.
References
- [1] J. Feng and J. Zhao, “Resource allocation for augmented reality empowered vehicular edge metaverse,” IEEE Trans. Commun., 2023, to appear, doi: 10.1109/TCOMM.2023.3314892.
- [2] W. Wu, C. Zhou, M. Li, H. Wu, H. Zhou, N. Zhang, X. Shen, and W. Zhuang, “AI-native network slicing for 6G networks,” IEEE Wirel. Commun., vol. 29, no. 1, pp. 96–103, 2022.
- [3] X. Shen, J. Gao, W. Wu, M. Li, C. Zhou, and W. Zhuang, “Holistic network virtualization and pervasive network intelligence for 6G,” IEEE Commun. Surv. Tutor., vol. 24, no. 1, pp. 1–30, 2022.
- [4] E. Coronado, R. Behravesh, T. Subramanya, A. Fernández-Fernández, S. Siddiqui, X. Costa-Pérez, and R. Riggio, “Zero touch management: A survey of network automation solutions for 5G and 6G networks,” IEEE Commun. Surv. Tutor., vol. 24, no. 4, pp. 2535–2578, 2022.
- [5] C. Benzaid and T. Taleb, “AI-driven zero touch network and service management in 5G and beyond: Challenges and research directions,” IEEE Network, vol. 34, no. 2, pp. 186–194, 2020.
- [6] Y. Yuan, L. Jiao, K. Zhu, X. Lin, and L. Zhang, “AI in 5G: The case of online distributed transfer learning over edge networks,” in Proc. IEEE INFOCOM, 2022, pp. 810–819.
- [7] 3GPP, “Study of enablers for network automation for the 5G system (5GS); phase 3,” 3rd Generation Partnership Project (3GPP), Technical Report (TR) 23.700-81, 2022, version 18.0.0.
- [8] O. T. Ajayi, X. Cao, H. Shan, and Y. Cheng, “Self-renewal machine learning approach for fast wireless network optimization,” in 2023 IEEE 20th International Conf. Mobile Ad Hoc and Smart Systems (MASS), 2023, pp. 134–142.
- [9] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in International Conf. Machine Learning (ICML), 2017, pp. 1126–1135.
- [10] Y. Wang, M. Chen, Z. Yang, W. Saad, T. Luo, S. Cui, and H. V. Poor, “Meta-reinforcement learning for reliable communication in THz/VLC wireless VR networks,” IEEE Trans. Wireless Commun., vol. 21, no. 9, pp. 7778 – 7793, 2022.
- [11] G. Cai, B. Fan, Y. Dong, T. Li, Y. Wu, and Y. Zhang, “Task-efficiency oriented V2X communications: Digital twin meets mobile edge computing,” IEEE Wirel. Commun., 2023, to appear, doi: 10.1109/MWC.012.2200465.
- [12] Q. Guo, F. Tang, T. K. Rodrigues, and N. Kato, “Five disruptive technologies in 6G to support digital twin networks,” IEEE Wirel. Commun., vol. 31, no. 1, pp. 149–155, 2024.
- [13] A. Nichol, J. Achiam, and J. Schulman, “On first-order meta-learning algorithms,” arXiv preprint arXiv:1803.02999, 2018.
- [14] K. Qu, W. Zhuang, X. Shen, X. Li, and J. Rao, “Dynamic resource scaling for VNF over nonstationary traffic: A learning approach,” IEEE Trans. Cogn. Commun. Netw., vol. 7, no. 2, pp. 648–662, 2021.
- [15] K. Qu, W. Zhuang, Q. Ye, W. Wu, and X. Shen, “Model-assisted learning for adaptive cooperative perception of connected autonomous vehicles,” IEEE Trans. Wireless Commun., 2024, to appear, doi: 10.1109/TWC.2024.3354507.