Diffusion-Based Visual Art Creation: A Survey and New Perspectives
Abstract.
The integration of generative AI in visual art has revolutionized not only how visual content is created but also how AI interacts with and reflects the underlying domain knowledge. This survey explores the emerging realm of diffusion-based visual art creation, examining its development from both artistic and technical perspectives. We structure the survey into three phases, data feature and framework identification, detailed analyses using a structured coding process, and open-ended prospective outlooks. Our findings reveal how artistic requirements are transformed into technical challenges and highlight the design and application of diffusion-based methods within visual art creation. We also provide insights into future directions from technical and synergistic perspectives, suggesting that the confluence of generative AI and art has shifted the creative paradigm and opened up new possibilities. By summarizing the development and trends of this emerging interdisciplinary area, we aim to shed light on the mechanisms through which AI systems emulate and possibly, enhance human capacities in artistic perception and creativity.
1. Introduction
As an emerging concept and evolving field, Artificial Intelligence Generated Content (AIGC) has made significant progress and impact over the past several years, especially since the diffusion model was proposed (Ho et al., 2020). On the other hand, visual art, encompassing a wide variety of genres, media, and styles, possesses high artistic value and diverse creativity, sparking widespread interest. However, compared to general method innovations (Song et al., 2020a; Ho and Salimans, 2022) and specific model designs (Esser et al., 2021; Ramesh et al., 2021), relatively limited research focuses on diffusion-based methods for visual art creation. Fewer works thoroughly examine the problem, summarize frameworks, or provide trends and insights for future research.
Relevant surveys approach this problem from both technical and artistic perspectives. Some recent surveys focus on the intersection of artificial intelligence with content generation, examining data modalities and tasks (Li et al., 2023b; Foo et al., 2023) to methodological progressions and applications (Cao et al., 2023a; Bie et al., 2023). These surveys reviewed a series of work on artistic stylization (Kyprianidis et al., 2012), appearance editing (Schmidt et al., 2016), text-to-image transitions (Zhang et al., 2023e), and the newfound applications of AI across multiple data modalities (Zhang et al., 2023d). Methodologically, they span neural style transfer (Jing et al., 2019), GAN inversion (Xia et al., 2022) to attention mechanisms (Guo et al., 2022) and diffusion models (Chen et al., 2024b)—each contributing to the state of the art in their own right. From an application perspective, they explore the transformative integration of AIGC across various domains, and while remarkable, they also highlight challenges that call for further development and ethical consideration (Liu et al., 2023b; Xu et al., 2024). Meanwhile, surveys with an artistic focus unravel the interplay between arts and humanities within the AIGC era, probing into the processing and understanding of art through advanced computational methods (Bengamra et al., 2024; Castellano and Vessio, 2021b; Liu et al., 2023c), the generative potential of AI in creating novel art forms (DePolo et al., 2021; Zhang et al., 2021), and the applicability of its integration in enhancing educational and therapeutic experiences (Mai et al., 2023; Chen et al., 2024a). We noticed a lack of surveys that specifically focus on combining diffusion-based models with visual art creation, and aim to fill this gap with our work.
This survey aims to provide a comprehensive review of the intersection of diffusion-based generative methods and visual art creation. We define the research scope through two independent taxonomies from technical and artistic perspectives, identifying diffusion-based generative techniques as one of the key methods and art as a significant application scenario. Our research goals are to analyze how diffusion models have revolutionized visual art creation and to offer frameworks and insights for future research in this area. We address four main research questions that explore the trending topics, current challenges, employed methods, and future directions in diffusion-based visual art creation.
We first conduct a structural analysis of diffusion-based visual art creation, which highlights current hot topics and evolving trends. Through categorizing data into application, understanding, and generation, we find a concentration of research on generation, specifically in controllable, application-oriented, and historically- or genre-specific art creation (Choi et al., 2021; Wang et al., 2023e; Liu et al., 2023a). Furthermore, we present a new analytical framework that aligns artistic scenarios with data modalities and generative tasks, allowing for a structured approach to the research questions. Temporal analysis suggests a post-diffusion boom in visual art creation, with a steady rise in diffusion-based methods (Saharia et al., 2022; Rombach et al., 2022; Gal et al., 2022). Generative methods have shifted from traditional rule-based simulations to diffusion-model modifications, along with a progression from image-only inputs to more controllable conditional formats, and an increase in dataset generality and process complexity (Ruiz et al., 2023; Zhang et al., 2023c; Mou et al., 2024; Bar-Tal et al., 2023). The emerging trends point towards a technical evolution from basic model frameworks to interactive systems and a shift in focus toward user requirements for creativity and interactivity. These findings set the stage for our survey, which aims to bridge the gap between technological advancements and artistic creation, fostering a synergy that can lead to a new wave of innovation in AIGC.
The exploration from artistic requirements to technical problems forms a cornerstone of our investigation in diffusion-based visual art. We scrutinize the symbiotic relationship between application domains, artistic genres, and their correspondence with data modality and generative tasks. Supported by a robust body of work (Abrahamsen2023InventingAS; Zhang et al., 2024c; Qiao et al., 2022; Huang et al., 2022; Liao et al., 2022), we delve into how different visual art forms and domains drive the development of technical solutions. From complex artistic scenarios to specific genres like traditional Chinese painting (Lyu et al., 2024; Fu et al., 2021; Wang et al., 2024a; Li et al., 2021; Wang et al., 2023a), our approach deciphers the intersection of AI and art, translating artistic goals into computational tasks. We establish a framework that defines these relationships via data modalities—ranging from brush strokes (Li et al., 2024) to 3D models (Dong et al., 2024)—and generative tasks like quality enhancement (He et al., 2023) and controllable generation (Kawar et al., 2023). These tasks are then meticulously tied to artistic objectives, with corresponding evaluation metrics such as CLIP Score for controllability (Radford et al., 2021; Patashnik et al., 2021) and FID for fidelity (Heusel et al., 2017; Salimans et al., 2016). This multifaceted evaluation system ensures that the generated art not only meets technical standards but also fulfills the nuanced demands of artistic creation, aligning with the evolving trends in the post-diffusion era.
We also investigate the intricate designs and applications of diffusion-based methods to explore how these methods enhance the generative process in visual art. We offer a detailed classification of tasks such as controllable generation, content editing, and stylization, each bolstered by novel diffusion-based approaches that prioritize user input and artistic integrity (Choi et al., 2021; Gal et al., 2022). Innovations like ILVR (Choi et al., 2021) and ControlNet (Zhang et al., 2023c) exemplify the strides made in achieving precise control over image attributes, while advances in methods like GLIDE (Nichol et al., 2021) and InstructPix2Pix (Brooks et al., 2023) showcase the growing sophistication in content editing and the ability to adaptively respond to textual prompts. Stylization techniques, such as InST (Zhang et al., 2023b) and DiffStyler (Huang et al., 2024), demonstrate the nuanced application of artistic styles, while quality enhancement tools like eDiff-I (Balaji et al., 2022) and PIXART- (Chen et al., 2023) push the limits of image resolution and fidelity. Furthermore, we categorize these methods based on a unified diffusion model structure, highlighting advancements in individual modules such as encoder-decoders, denoisers, and noise predictors (Lu et al., 2023; Liu et al., 2022; Chefer et al., 2023). These developments manifest in trends that emphasize attention mechanisms, personalization, control, quality, modularity, multi-tasking, and efficiency (Cao et al., 2023b; Ruiz et al., 2023; Kumari et al., 2023). The synthesis of these trends reflects a dynamic evolution in diffusion-based generative models, marking a transformative era in visual art creation.
The frontiers of diffusion-based visual art creation are seen through the lens of technical evolution and human-AI collaboration. Technically, we are witnessing a leap into higher dimensions and more diverse modalities, transcending traditional boundaries to create immersive experiences (Zhang et al., 2022a, 2024a). A synergistic perspective reveals a future where human and AI collaboration is seamless, allowing for interactive systems that augment human creativity and facilitate a deeper reception and alignment with content (Chung and Adar, 2023; Dall’Asen et al., 2023; Guo et al., 2023). These approaches range from the use of human concepts as task inspiration to the generation of content that resonates emotionally and models that encapsulate the essence of creativity (Sartori, 2014; Yang et al., 2024a; Wu, 2022). This multidimensional approach is shifting paradigms, enabling a greater understanding and co-creation between humans and AI (Russo, 2022; Zheng et al., 2024; Zhong et al., 2023). It paints a future where the boundaries between human and AI creativity become blurred, leading to a new era of digital artistry.
In summary, our literature review yields the following contributions:
-
•
A comprehensive dataset and taxonomy of AIGC techniques in visual art creation, coded with multi-dimensional, fine-grained labels.
-
•
A framework for analyzing and categorizing the relationship between diffusion-based generative methods and their applications in visual art creation, with multi-faceted features and relationships as key findings.
-
•
A summary of frontiers, trends, and future outlooks from multiple interdisciplinary perspectives.
2. Background
Prior to the emergence of diffusion models, the field of machine learning in visual art creation had already gone through several significant developments. These stages were marked by various generative models that opened new chapters in image synthesis and editing. One of the earliest pivotal advancements was the introduction of Generative Adversarial Networks (GANs) by Goodfellow et al. (Goodfellow et al., 2014), which introduced a new framework where a generator network learned to produce data distributions through an adversarial process. Following closely, CycleGAN by Zhu et al. (Zhu et al., 2017) overcame the need for paired samples, enabling image-to-image translation without paired training samples. These models gained widespread attention due to their potential in a variety of visual content creation tasks. Simultaneously with the development of GANs, another important class of models was the Variational Autoencoder (VAEs) introduced by Kingma and Welling (Kingma and Welling, 2013), which offered a method to generate continuous and diverse samples by introducing a latent space distribution. This laid the groundwork for controllable image synthesis and inspired a series of subsequent works. With enhanced computational power and innovation in model design, Karras et al. pushed the quality of image generation further with StyleGAN (Karras et al., 2020), a model capable of producing high-resolution and lifelike images, driving more personalized and detailed image generation. The incorporation of attention mechanisms into generative models significantly improved the relevance and detail of generated content. The Transformer by Vaswani et al. (Vaswani et al., 2017), with its powerful sequence modeling capabilities, influenced the entire field of machine learning, and in visual art generation, the successful application of Transformer architecture to image recognition with Vision Transformer (ViT) by Dosovitskiy et al. (Dosovitskiy et al., 2020), and further for high-resolution image synthesis with Taming Transformers by Esser et al. (Esser et al., 2021), showed the immense potential of Transformers in visual generative tasks. Subsequent developments like SPADE by Park et al. (Park et al., 2019) and the time-lapse synthesis work by Nam et al. (Nam et al., 2019) marked significant steps towards more complex image synthesis tasks. These methods provided richer context awareness and temporal dimension control, offering users more powerful creative expression capabilities. The introduction of Denoising Diffusion Probabilistic Models (DDPMs) by Ho et al. (Ho et al., 2020) and the subsequent showcase by Ramesh et al. of DALL·E (Ramesh et al., 2021), which could create images from textual prompts based on such models, marked another leap forward for generative models, adding a new chapter to the history of model development. These models achieved breakthroughs in image quality and also demonstrated new possibilities in terms of controllability and diversity. These developments constitute a rich history of visual art creation in the field of machine learning, laying a solid foundation for the arrival of the diffusion era. In this survey, we will delve deeper into how diffusion models inherit and transcend the boundaries of these prior technologies, opening a new chapter in creative generation.
From an artistic perspective, the advancements in machine learning and generative models have intersected intriguingly with the domain of visual arts, which encompasses a wide variety of genres, media, and styles. Artists have traditionally held the reins of creative power, with the ability to produce works that carry significant artistic value and cultural resonance. The introduction of sophisticated generative algorithms offers a new toolkit for artists, potentially expanding the boundaries of their creativity (Mazzone and Elgammal, 2019). As these technological tools become more accessible and integrated into artistic workflows, they present an opportunity for artists to experiment with novel forms of expression, blending traditional techniques with computational processes (Elgammal et al., 2017). This fusion sparks widespread interest not only within the tech community but also among art enthusiasts who are curious about the new creative possibilities (Miller, 2019). Machine learning models, especially those capable of generating high-quality visual content, are increasingly seen as collaborators in the artistic process. Rather than replacing human creativity, they are enhancing it, enabling artists to explore complex patterns, intricate details, and conceptual depths that were previously difficult or impossible to achieve manually (Gatys et al., 2016). This symbiotic relationship between artist and algorithm is transforming the landscape of visual art. Artists are beginning to harness these models to create works that challenge our understanding of art and authorship (McCormack et al., 2019). As a result, the dialogue between technology and art is becoming richer, with machine learning models contributing to the creation of art that offers greater creative freedom and artistic value. This evolving dynamic prompts both excitement and philosophical reflection on the nature of creativity and the role of artificial intelligence in the future of artistic expression.
3. Related Work
In this section, we provide an overview of the scope of AIGC and contributions of pertinent surveys that concentrate on fields and topics relevant to diffusion-based visual art creation. We first collected 42 surveys and filtered out 30 by relevance. These surveys are primarily categorized by their focus on either technical (17) or artistic (13) aspects. Collectively, they establish the paradigm of this interdisciplinary field and create a platform for our discussion.
3.1. Relevant Surveys with Technical Focus
From a technical view, a tier of surveys focus on the advancements and implications of artificial intelligence in content generation. For example, Cao et al. (Cao et al., 2023a) provides a detailed review of the history and recent advances in AIGC, highlighting how large-scale models have improved the extraction of intent information and the generation of digital content such as images, music, and natural language. We further break down this view into data and task, method, and application perspectives.
3.1.1. Data and Task Perspectives.
A series of surveys inspect AIGC from data and modality and highlight the evolution and challenges in various tasks, including artistic stylization, appearance editing, text-to-image generation, text-to-3D transformation, and AI-generated content across multiple modalities. Prior to the diffusion era, the survey by Kyprianidis et al. (Kyprianidis et al., 2012) delves into the field of nonphotorealistic rendering (NPR), presenting a comprehensive taxonomy of artistic stylization techniques for images and video. It traces the development of NPR from early semiautomatic systems to the automated painterly rendering methods driven by image gradient analysis, ultimately discussing the fusion of higher-level computer vision with NPR for artistic abstraction and the evolution of real-time stylization techniques. Schmidt et al. (Schmidt et al., 2016) review the state of the art in the artistic editing of appearance, lighting, and material, essential for conveying information and mood in various industries. The survey categorizes editing approaches, interaction paradigms, and rendering techniques while identifying open problems to inspire future research in this complex and active area. In the era of large generative models, Bie et al.’s survey on text-to-image generation (TTI) (Bie et al., 2023) explores how the integration with large language models and the use of diffusion models have revolutionized TTI, bringing it to the forefront of machine-learning research and greatly enhancing the fidelity of generated images. The review provides a critical comparison of existing methods and proposes potential improvements and future pathways, including video and 3D generation. Li et al. conducted the first comprehensive survey on text-to-3D (Li et al., 2023b), an active research field due to advancements in text-to-image and 3D modeling technologies. The work introduces 3D data representations and foundational technologies, summarizing how recent developments realize satisfactory text-to-3D results and are used in various applications like avatar and scene generation. Finally, Foo et al.’s survey on AI-generated content (Foo et al., 2023) spans a plethora of data modalities, from images and videos to 3D shapes and audio. It reviews single-modality and cross-modality AIGC methods, discusses the representative challenges and works in each modality, and suggests future research directions.
3.1.2. Method Perspective.
A main body of recent surveys in generative AI and computer vision has been on the evolution of methodologies for style transfer, GAN inversion, attention mechanisms, and diffusion models, which have been instrumental in driving forward the state-of-the-art. Neural Style Transfer (NST) has evolved into a field of its own, with a variety of algorithms aimed at improving or extending the seminal work of Gatys et al. (Jing et al., 2019) provides a taxonomy of NST algorithms and compares them both qualitatively and quantitatively, also highlighting the potential applications and future challenges in the field. In the realm of GANs, the survey on GAN inversion (Xia et al., 2022) details the process of inverting images back into the latent space to enable real image editing and interpreting the latent space of GANs. It outlines representative algorithms, applications, and emerging trends and challenges in this area. The survey on attention mechanisms in computer vision (Guo et al., 2022) categorizes them based on their approach, including channel, spatial, temporal, and branch attention. This comprehensive review links the success of attention mechanisms in various visual tasks to the human ability to focus on salient regions in complex scenes, and it suggests future research directions. Diffusion-based image generation models have seen significant progress, paralleling advancements in large language models like ChatGPT. (Zhang et al., 2023d) examines the issues and solutions associated with these models, particularly focusing on the stable diffusion framework and its implications for future image generation modeling. Text-to-image diffusion models are also reviewed (Zhang et al., 2023e), offering a self-contained discussion on how basic diffusion models work for image synthesis. This includes a review of state-of-the-art methods on text-conditioned image synthesis, applications beyond, and existing challenges. Retrieval-Augmented Generation (RAG) for AIGC is discussed in a survey that classifies RAG foundations and suggests future directions by illuminating advancements and pivotal technologies (Zhao et al., 2024b). The survey provides a unified perspective encompassing all RAG scenarios, summarizing enhancement methods, and surveying practical applications across different modalities and tasks. Finally, an overview of diffusion models addresses their applications, guided generation, statistical rates, and optimization (Chen et al., 2024b). It reviews emerging applications and theoretical aspects of diffusion models, exploring their statistical properties, sampling capabilities, and new avenues in high-dimensional structured optimization.
3.1.3. Application Perspective.
From an application perspective, recent surveys have explored the integration and impact of AIGC across different domains such as brain-computer interfaces, education, and mobile networks, emphasizing its transformative potential. Mai et al.’s survey (Mai et al., 2023) introduces the concept of Brain-conditional Multimodal Synthesis within the AIGC framework, termed AIGC-Brain. This domain leverages brain signals as a guiding condition for content synthesis across various modalities, aiming to decode these signals back into perceptual experiences. The survey provides a detailed taxonomy for AIGC-Brain decoding models, task-specific implementations, and quality assessments, offering insights and prospects for research in brain-computer interface systems. Chen’s systematic literature review (Chen et al., 2024a) addresses AIGC’s application in education, highlighting the profound impact of technologies like ChatGPT. The review identifies key themes such as performance assessment, instructional applications, and the advantages and risks of AIGC in education. It delves into the research trends, geographical distribution, and future agendas to integrate AI more effectively into educational methods, tools, and innovation. Xu et al. (Xu et al., 2024) survey the deployment of AIGC services in mobile networks, focusing on providing personalized and customized content while preserving user privacy. The survey examines the lifecycle of AIGC services, collaborative cloud-edge-mobile infrastructure, creative applications, and the associated challenges of implementation, security, and privacy. It also outlines future research directions for enhancing mobile AIGC networks.
These technically oriented surveys characterize remarkable advancements in the field of generative AI, emphasizing the innovative algorithms and interaction paradigms that enable the creation of diverse content across various data modalities. However, they also point out the existing challenges, including the need for further technical development, the consideration of ethical issues, and the imperative to address potential negative impacts on society.
3.2. Relevant Surveys with Artistic Focus
Another tier of work adopts an artistic view by specifically focusing on arts and humanities in the AIGC era. For example, Liu et al. (Liu et al., 2023b) explore the transformational impact of artificial general intelligence (AGI) on the arts and humanities, addressing critical concerns related to factuality, toxicity, biases, and public safety, and proposing strategies for responsible deployment. We further break the view into processing and understanding, generation, and application perspectives.
3.2.1. Processing and Understanding Perspectives.
The surveys with an artistic focus shed light on the intersection of art and technology, where advanced processing techniques and computational methods are employed to understand and enhance the appreciation of visual arts. Depolo et al.’s review (DePolo et al., 2021) discusses the mechanical properties of artists’ paints, emphasizing the importance of understanding paint material responses to stress through tensile testing data and other innovative techniques. The study highlights how new methods allow for the investigation of historic samples with minimal intervention, utilizing techniques such as nanoindentation, optical methods like laser shearography, computational simulations, and non-invasive approaches to predict paint behavior. Castellano et al. (Castellano and Vessio, 2021b) provides an overview of deep learning in pattern extraction and recognition within paintings and drawings, showcasing how these technological advances paired with large digitized art collections can assist the art community. The goal is to foster a deeper understanding and accessibility of visual arts, promoting cultural diffusion. Zhang et al.’s comprehensive survey on the computational aesthetic evaluation of visual art images (Zhang et al., 2021) tackles the challenge of quantifying aesthetic perception. It reviews various approaches, from handcrafted features to deep learning techniques, and explores applications in image enhancement and automatic generation of aesthetic-guided art, while addressing the challenges and future directions in this field. Liu et al.’s review on neural networks for hyperspectral imaging (HSI) of historical paintings (Liu et al., 2023c) details the application of neural networks for pigment identification and classification. By focusing on processing large spectral datasets, the review contributes to the application of these networks, enhancing artwork analysis and preservation of cultural heritage. Lastly, Bengamra’s survey on object detection in visual art (Bengamra et al., 2024) offers a taxonomy of the methods used in the analysis of artwork images, proposing a classification based on the degree of learning supervision, methodology, and style. It outlines challenges and future directions for improving object detection performance in visual art, contributing to the overall understanding of human history and culture through art.
3.2.2. Generation Perspective.
Surveys focused on the generation of art through AI technologies underscore the transformative role AI plays in both understanding and creating visual arts. Cetinic et al. (Cetinic and She, 2022) offer an integrated review of AI’s dual application in art analysis and creation, including an overview of artwork datasets and recent works tackling various tasks such as classification and computational aesthetics, as well as practical and theoretical considerations in the generation of AI Art. Shahriar et al. (Shahriar, 2022) examine the potential of GANs in art creation, exploring their use in generating visual arts, music, and literary texts. This survey highlights the performance and architecture of GANs, alongside the challenges and future recommendations in the field of computer-generated arts. Liu’s overview of AI in painting (Liu, 2023) reveals the field’s current status and future direction, discussing how AI algorithms can produce unique art forms and automate tasks in traditional painting, thereby promising a revolution in the digital art world and traditional painting processes. Ko et al. (Ko et al., 2023) delve into Large-scale Text-to-Image Generation Models (LTGMs) like DALL-E, discussing their potential to support visual artists in creative works through automation, exploration, and mediation. The study includes an interview and literature review, offering design guidelines for future intelligent user interfaces using LTGMs. Lastly, Maerten et al.’s review on deep neural networks in AI-generated art (Maerten and Soydaner, 2023) examines the evolution of these architectures, from classic convolutional networks to advanced diffusion models, providing a comparison of their capabilities in producing AI-generated art. This review encapsulates the rapid progress and interaction between art and computer science.
3.2.3. Application Perspective.
The surveys with an artistic focus on application delve into the transformative potential of integrating art with other disciplines, particularly science education and therapy, to foster holistic learning and healing experiences. Turkka et al. (Turkka et al., 2017) investigates how art is integrated into science education, revealing through a qualitative e-survey of science teachers (n=66) that while the incorporation of art can enhance teaching, it is infrequently applied in classroom practices. The study presents a pedagogical model for art integration, which characterizes integration through content and activities, and suggests that teacher education should provide more consistent opportunities for art integration to enrich science teaching. The study on art therapy (Hu et al., 2021b) surveys the clinical applications and outcomes of art therapy as a non-pharmacological intervention for mental disorders. The systematic review of 413 literature pieces underscores the clinical effectiveness of art therapy in alleviating symptoms of various mental health conditions, such as depression, anxiety, and cognitive impairments, including Alzheimer’s and autism. It emphasizes the therapeutic power of art in assisting patients to express emotions and providing medical specialists with complementary diagnostic information.
The artistically-oriented surveys reveal how technological advancements—specifically in AI—have revolutionized not only the analysis and preservation of visual arts but also enabled the active creation of innovative art forms. These studies underscore the potential of AI to deeply understand artistic nuances and contribute creatively, thus enriching the artistic domain with new tools and methodologies. However, we observe that while there is existing literature surveying diffusion models and visual art creation individually, there is a gap in research that synthesizes both perspectives. This opens up an opportunity to explore how diffusion models can be specifically applied to the domain of visual art creation, potentially leading to innovative approaches that could transform content production and understanding. We aim to bridge this gap by merging the technical intricacies of generative AI with the creative process of art. By doing so, we seek to contribute to the ongoing dialogue between art and technology, enhancing the creative process and expanding the scope of possibilities in visual art creation.
4. Research Scope and Concepts
In this section, we first define the survey’s research scope and explain relevant concepts. Then, we summarize our research goals and target questions. Together, they establish a coherent context and lay a foundation for the following sections.
4.1. Research Scope
Based on the surveys discussed in the previous section, we identify two independent taxonomies in the technical and artistic realms. The first taxonomy, typical in surveys with a technical focus, categorizes diffusion-based generative techniques as one of the generative methods and art as an application scenario (Cao et al., 2023a; Li et al., 2023b; Foo et al., 2023; Liu et al., 2023b). On the other hand, surveys with an artistic stance commonly adopt historical or theoretical perspectives, categorize relevant research by application scenarios and artistic categories (in Sec. 5.1, we correspond them to different data modalities or applications), and focus more on the implications of generated results (Liu, 2023; Liu et al., 2023c; DePolo et al., 2021; Castellano and Vessio, 2021a; Zhang et al., 2021). We display the two taxonomies and our research scope in Fig. 1. The independent taxonomies are represented as perpendicular axes. Following our motivation, this survey lies in the intersection of these two axes.

4.2. Relevant Concepts
To clearly define our research scope and differentiate it from similar work, we provide an explanation and categorization method for the two most relevant concept realms and their sub-concepts.
4.2.1. Diffusion Model.
In Jan. 2020, Ho et al. proposed Denoising Diffusion Probabilistic Models (Ho et al., 2020) and tested its performance on multiple image synthesis tasks, proclaiming the advent of the post-diffusion era. Ten months later, Song et al. adapted the denoising process to the latent space and significantly improved the generative performance, which is called Denoising Diffusion Implicit Models (Song et al., 2020a). In 2021, different researchers optimized the method by integrating advanced text-image encoders (e.g., CLIP (Radford et al., 2021)) and conditioning methods (e.g., ILVR (Choi et al., 2021)). Another series of work systematically framed the generative task (Nichol et al., 2021) and established relevant benchmarks (Dhariwal and Nichol, 2021), demonstrating surpassing performance than previous state-of-the-art methods.
In early 2022, many technical companies released respective diffusion-based generative frameworks, including DALL·E-2 (Ramesh et al., 2022), Imagen (Saharia et al., 2022), Stable Diffusion (Rombach et al., 2022), etc. These methods feature extensive training and can generate high-quality, artistic images to meet commercial needs. From late 2022, the field has shifted from a common focus to different sub-tracks and downstream applications, by diversifying multiple tasks, introducing different methods, and adapting to various scenarios. Meanwhile, within the AIGC framework, the field of Natural Language Processing (NLP) has also witnessed significant breakthroughs. Researchers proposed foundational models (e.g., the GPT series (OpenAI, 2023)), designed adaptation methods (e.g., LoRA (Hu et al., 2021a)), and achieved comparable performance with humans in NLP tasks (Bubeck et al., 2023). Combined with these advancements, the field of Diffusion Model increased in both width and inclusiveness, becoming more expanded and more interconnected with other fields.
Fig. 2 illustrates the basic structure of how a diffusion model is used as the core structure for a complete generative process (Fig. 2-(a)), and how the model is combined with other pre-trained foundational models (such as CLIP as text-image encoder, Fig. 2-(b)) to accomplish typical text-to-image generative tasks. From a technical perspective, the structure of a diffusion-based generative model typically consists of the following five parts:
-
•
Encoder and Decoder. In image generation, the encoder and decoder connect the pixel space and latent space. During the generation process, the encoder compresses the input data into a latent representation, and the decoder subsequently reconstructs the output from this compressed form.
-
•
Denoiser. As a core component, the denoiser works to remove noise from the latent, in a step-by-step manner, by a set of learned Gaussian noises. Researchers design both new model structures and denoising processes for better performance.
-
•
Noise Predictor. This module predicts key parameters of noise distribution, which is learned during the training process. Setting proper noise can guide the generation process toward intended targets.
-
•
Post-Processor. After the initial output is generated, this module refines the results by enhancing its resolution and final quality.
-
•
Additional Modules. These may include any extra components that supplement the core functionality, such as modules to improve controllability or fulfill specific tasks.
In Sec. 5.4, we will adhere to this framework to categorize different generative methods.

4.2.2. Visual Art.
We break up the topic by three different perspectives of visual art 1) as a conceptual realm under art, 2) as visual contents created by artists, and 3) as generated results with the quality of artistic. Such perspectives will be revisited in the Discussion section (Sec. 6).
-
•
What is Visual Art? Art is broadly understood to encompass a variety of creative expressions that convey ideas, emotions, and concepts through various media. Among them, Visual Art features different visual forms as media (Lazzari and Schlesier, 2008). This field can be further split into different artistic categories, including painting, sketch, sculpture, etc. (where painting is the most common category), and different dimensions, including 1D brush stroke, 2D images, 3D scenes, etc. (where 2D images are the most common representation).
-
•
Who is the Artist? Throughout our history, different schools of criticism have adopted different views on the subject and creation of artwork. One perspective of AIGC is to mimic the role of artists with advanced generative models, which provides a possible future framework for creativity (McCormack and D’Inverno, 2014).
-
•
How is Visual Art Created? In visual art generation, a common way is to incorporate human aesthetics and expertise into both the generative and evaluation processes. Such a system includes data choice, task definition, and model design, which is parallel to the artist’s role as both creators and receivers (e.g., (Elgammal et al., 2017)). However, the process is data-driven and rule-based, which is different from perception, emotion, and creativity as artists’ driving forces.
-
•
What is Artistic? In the artistic realm, the definition of artistic features more psychological and philosophical elements and is also under debate (Dutton, 2009). However, scientific researchers often adopt a common ground and propose more acceptable standards and more approachable metrics. As will be discussed in Sec. 5.3, the commonly referred terms include high quality, stylistic/realistic, controllable, etc.
4.3. Research Goals and Questions
Following the previous discussion and prior work, we summarize two research goals of our paper:
-
G1
Analyze how diffusion-based methods have facilitated and transformed visual art creation. How are diffusion-based generative systems and models used for different Visual Art applications?
-
G2
Provide frameworks, trends, and inspirations for future research in relevant fields. How may human and generative AI inspire each other in Diffusion-Based Visual Art Creation?
Based on the two research goals, we further propose four research questions as the basis of this survey.
-
Q1
What are the most attended topics in diffusion-based Visual Art Creation? This is the basic step to identify hot issues and construct a consistent framework. The question also concerns contrasts between diffusion-based and non-diffusion-based methods, and the temporal features and evolution of this field.
-
Q2
What are current research problems/needs/requirements in diffusion-based Visual Art creation? This question ranges from an artistic/user perspective to a technical/designer perspective. In the following sections, we further break it down to artistic requirements and technical problems, featured by application scenarios, data modalities, and generative tasks, and attempt to establish connections between them.
-
Q3
What are the methods applied in diffusion-based Visual Art creation? For each technical problem, we focus on diffusion-based method design according to its modalities and tasks. As DDPM, DDIM, and their extensions follow similar model structures, we can further categorize and organize the methods based on the unified structure of an extended diffusion model.
-
Q4
What are the frontiers, trends, and future works? We are interested in the following questions: Are there any further problems to solve? How may we leverage the development of a diffusion model and its application in relevant fields to cope with the problems?
5. Findings
In this section, we aim to fulfill G1 by answering questions Q1–Q3.
5.1. Structural Analysis and Framework Construction
5.1.1. Data Classification.
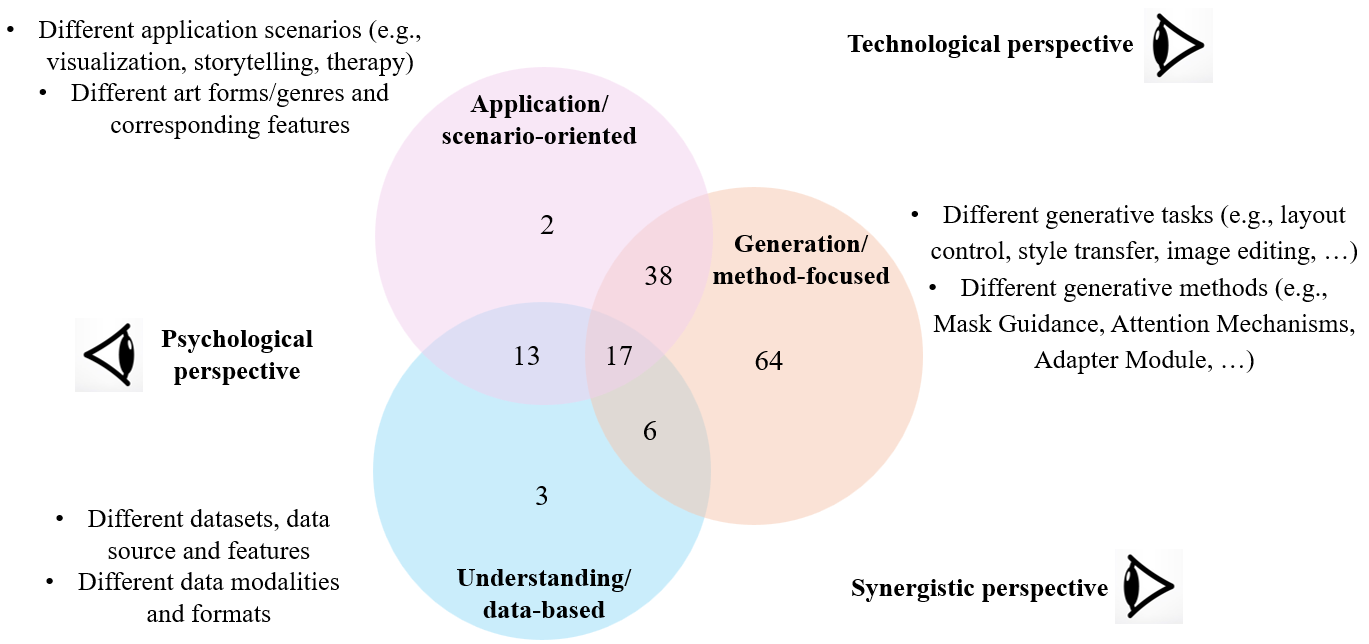
We focus on the first question: What are the currently most attended topics in diffusion-based Visual Art Creation? (Q1) We first summarized different paper codes proposed in Sec. LABEL:sec:_coding along with the index terms of each selected paper. Among them, a major part is closely related to method design, while others concern data, modalities, artistic genres, and application scenarios. We found that these terms basically form three categories and thus applied a Venn Chart to characterize different works, as shown in Fig. 3. The three categories include:
- •
-
•
Understanding. Different data forms and corresponding modalities (e.g., image series (Song et al., 2020b; Suh et al., 2022; Braude et al., 2022), 3D scenes (Dong et al., 2024; Zhang et al., 2024a; Haque et al., 2023)). From an artistic perspective, the first two categories characterize different art forms/genres with corresponding features.
-
•
Generation. Different generative tasks (e.g., style control (Liang et al., 2023; Wu et al., 2023), style transfer (Zhang et al., 2024c, b), image editing (Hertz et al., 2022; Biner et al., 2024)) and Different generative methods (e.g., ControlNet (Xue et al., 2024; Lukovnikov and Fischer, 2024), Textual Inversion (Ahn et al., 2024; Zhang et al., 2023b), LoRA (Shah et al., 2023; Chen et al., 2024c))
With such a categorization method, we can approach the dataset from different perspectives and identify corresponding hot topics. As shown in Fig. 3, most of the selected works lie in four subsets of the seven areas, including:
- •
- •
- •
- •
5.1.2. Framework Construction.
Since most of the work is concentrated at the pole of generation, we dived into the generative part and paid more attention to the intersection areas. We found that 1) Research in Diffusion-Based Visual Art Creation is typically characterized by different artistic scenarios and technical methods. 2) the artistic requirements and technical problems are basically connected by specifying data modality and extracting generative tasks. As a result, we summarized a new framework that can better characterize the current research paradigm (Fig. 4).

Based on the framework, we can further break down Q1 into a series of consequential questions and approach a generative problem from different perspectives:
-
•
Scenario. What are the common features and requirements of different artistic scenarios?
-
•
Modality. What are the data modalities applied, including training dataset, input, conditions, and output?
-
•
Task. What are popular research problems in generating Visual Arts, including their technical statements and classification?
-
•
Method. What are the methods used to augment and adapt diffusion models?
In the following sections, we will refer to this structure to analyze the relationships represented by each red dashed line.
5.2. Temporal Analysis and Trend Detection.
In this part, we investigate how the number of publications, categories, and keywords in different dimensions evolve over time in our dataset. We specifically focus on the difference between pre-diffusion and post-diffusion eras.
5.2.1. Data Distribution.


Fig. 5 displays the temporal distribution of our dataset, including the time when major diffusion-based models are proposed. According to the figure, most of the work is published after Jun. 2022, especially after Feb. 2023, when a series of landmark methods were introduced. We also calculate the proportions of different categories of work and demonstrate the result in Fig. 6. We found that while the proportion of generation research remains essentially the same, understanding research keeps growing in the four years of 2020-2023, and application research witnessed a surge in 2023. On the other hand, the proportion of diffusion-based methods increased steadily, from around 20% in 2020 to over 70% in 2023.
5.2.2. Topic Evolution.
In examining the dataset, we noticed that most methods and some tasks change and upgrade over time, while application scenarios are generally constant. We thus provide a Word Cloud Chart (Fig. 7) to compare methods and tasks in pre-diffusion and post-diffusion eras and illustrate the main application scenarios, artistic categories, method features, and user requirements. According to the figure, most generative tasks stay the same, while some traditional tasks (e.g., NPR) are less mentioned. However, generative methods have undergone a major shift, from SBR (stroke-based rendering), rule-based generation, and physical-based simulation, to a series of modifications based on diffusion models.

5.2.3. Qualitative Comparison.
From a microscopic perspective, we are also interested in how the development of diffusion-based models introduces new methods for solving traditional problems. We thus selected five artistic genres or scenarios, including robotic painting, Chinese landscape painting, ink painting, story visualization, and artistic font synthesis, to compare different approaches for similar problems and tasks.

Fig. 8 displays an example to compare different methods for similar tasks (portrait stylization) before and after the Diffusion Era. According to the similarities between the two workflows, we derived a unified, model-agnostic structure for solving the problem. As shown in Fig. 8, in solving the task of face stylization (stylized portrait generation), both methods generate the new image based on the previous two images. Meanwhile, they both refer to the input image (content reference) for details and local information, and the template image (style reference) for background and global information in the generative process. When traditional tasks meet with new methods, such frameworks provide an interesting perspective to capture the embedded human expertise. On the other hand, the two approaches display multiple differences in result quality, model complexity, computational cost, etc. Based on multiple pairs of selected work in our dataset, we summarize the following trends:
-
•
Input Format: from images only to images and masks as conditional input (controllability↑)
-
•
Dataset: from fixed database to arbitrary image (generalizability↑)
-
•
Generative Process: from explicit/pixel manipulation to implicit/latent manipulation (Complexity↑)
-
•
Method Category: from traditional rule-based image processing to diffusion-based image stylization (Computational cost/Time consumption↑)
5.2.4. A Brief Summary and Outlook.
In the previous section, we have compared methods before and after the Diffusion Era, to borrow frameworks and ideas from the Pre-Diffusion Era and inspire new method design. Here we are further interested in identifying research gaps from temporal trends and task-method relationships in Diffusion-Based Visual Art Creation.
| Year | Method Features | User Requirements |
|---|---|---|
| 2021 | Basic Model, Dataset, Metric, Evaluation | (No specific requirements) |
| 2022 | Framework, Adaptive, Sampling, Fine-tuning | Photorealistic, Multilayer, Artistic, Creative, Coherent |
| 2023 | Tuning-free, Training-free, System, Prompt | Controllable, Subject, Disentanglement, Interaction, Painterly |
| 2024 | Inversion, Dilation, Layer-aware, Step-aware | Personalization, Composition, Visualization, Concept, Context |
In Table 1, we present the top growing keywords in method features and user requirements for the post-diffusion era. We first calculate keyword frequencies for each year from 2020 to 2024 (up until May 2024). We then calculate the difference in each word’s frequency compared to the previous year. The words with the highest frequency growth are identified as ’Top Growing Key Words’. Combine Table 1 with Fig. 7, we identify some major trends in Diffusion-Based Visual Art Creation:
-
•
Technically, the research type developed from a basic model to a generative framework to an interactive system. Researchers’ design focus also shifted from developing benchmarks (dataset, metric, evaluation) to introducing generative methods (sampling, inversion, dilation), with a general trend to simplify the generative process (tuning-free and training-free).
-
•
Artistically, user requirements are diverging from higher quality (photorealistic, artistic, coherent) to multiple diversified needs (controllable, composition, visualization), and research focus has shifted from the generated visual content (multilayer, coherent) to creative subject (personalization, concept, context). The most notable requirement is creative, which emerged two years ago but has not been well resolved until now (Sec. LABEL:sec:_creativity).
-
•
Interdisciplinarily, the keywords also manifested more collaborations between human creators and AI models. On the one hand, experts introduced principles in the diffusion process (e.g., step-aware) and concepts from artistic areas (e.g., layer-aware), to boost controllability and performance. On the other hand, researchers ventured into understanding implicit latent (e.g., disentanglement), adapting the system to user inputs (e.g., prompt), and catering the diffusion model to the human thinking process (e.g., interaction).
In Sec. 6, we will go into detail to discuss the trends and future outlook from multiple perspectives.
5.3. From Artistic Requirements to Technical Problems
In this section, we focus on the upper half of the Rhombus framework (Fig. 4), to summarize current research problems/needs/requirements in Diffusion-Based Visual Art creation (Q2). Specifically, we start from application scenarios and artistic genres, analyze their corresponding data modality and generative task, and dive into their key requirements/goals and computational statements. By doing this, we aim to fill in the three connections and bridge the gap between artistic requirements and technical problems.
5.3.1. Application Domain and Artistic Category.
Among our 143 selected papers, 70 are coded as application/scenario-oriented. Within this subset, 55 papers focus on specific artistic categories (e.g., traditional paintings, human portraits, and specific art genres), and 17 focus on relevant domains (e.g., story visualization, replication prevention, human-AI collaboration). We summarize representative work in different application scenarios, focusing on how they formulate and tackle the domain issues.
The first series of works view visual art (or digital art, fine art) as a general category. Abrahamsen et al. (Abrahamsen2023InventingAS) introduce innovative methods to invent art styles using models trained exclusively on natural images, thereby circumventing the issue of plagiarism in human art styles. Their approach leverages the inductive bias of artistic media for creative expression, harnessing abstraction through reconstruction loss and inspiration from additional natural images to forge new styles. This holds the promise of ethical generative AI use in art without infringing upon human creators’ originality. In a similar vein, Zhang et al. (Zhang et al., 2024c) address the limitations of existing artistic style transfer methods, which either fail to produce highly realistic images or struggle with content preservation, by proposing ArtBank. This novel framework, underpinned by a Pre-trained Diffusion Model and an Implicit Style Prompt Bank (ISPB), adeptly generates lifelike stylized images while maintaining the content’s integrity. The added Spatial-Statistical-based self-attention Module (SSAM) further refines training efficiency, with their method surpassing contemporary artistic style transfer techniques in both qualitative and quantitative evaluations. Meanwhile, Qiao et al. (Qiao et al., 2022) explore the use of image prompts in conjunction with text prompts to enhance subject representation in multimodal AI-generated art. Their annotation experiment reveals that initial images significantly improve subject depiction, particularly for concrete singular subjects, with icons and photos fostering high-quality, aesthetically varied generations. They provide valuable design guidelines for leveraging initial images in AI art creation. Furthermore, Huang et al. (Huang et al., 2022) present the multimodal guided artwork diffusion (MGAD) model, a novel approach to digital art synthesis that leverages multimodal prompts to direct a classifier-free diffusion model, thereby achieving greater expressiveness and result diversity. The integration of the CLIP model unifies text and image modalities, with substantial experimental evidence endorsing the efficacy of the diffusion model coupled with multimodal guidance. Lastly, Liao et al. (Liao et al., 2022) contribute to the field by introducing ArtBench-10, a class-balanced, high-grade dataset for benchmarking artwork generation. It stands out with its clean annotations, high-quality images, and standardized dataset creation process, addressing the skewed class distributions prevalent in prior artwork datasets. Available in multiple resolutions and formatted for seamless integration with prevalent machine learning frameworks, ArtBench-10 facilitates comprehensive benchmarking experiments and in-depth analyses to propel generative model research forward. Collectively, these works illustrate the dynamic intersection of AI and art, where innovative methodologies and datasets are expanding the frontiers of artistic creation, opening avenues for novel styles, ethical considerations, and enhanced representation in the digital art sphere.
The second series of works focus on specific artistic genres or historical contexts, among which traditional Chinese painting is most frequently visited. Wang et al. (Wang et al., 2023e) introduce CCLAP, a pioneering method for controllable Chinese landscape painting generation. By leveraging a Latent Diffusion Model, CCLAP consists of a content generator and style aggregator that together produce paintings with specified content and style, evidenced by both qualitative and quantitative results that showcase the model’s artful composition capabilities. A dedicated dataset, CLAP, has been developed to evaluate the model comprehensively, and the code has been made accessible for broader use. Addressing the issue of low-resolution images in the digital preservation of Chinese landscape paintings, Lyu et al. (Lyu et al., 2024) propose the diffusion probabilistic model CLDiff. It employs iterative refinement steps akin to the Langevin dynamic process to transform Gaussian noise into high-quality, ink-textured super-resolution images, while a novel attention module enhances the U-Net architecture’s generative power. Fu et al. (Fu et al., 2021) tackle the challenge of generating traditional Chinese flower paintings with various styles such as line drawing, meticulous, and ink through a deep learning approach. Their Flower-Generative Adversarial Network framework, bolstered by attention-guided generators and discriminators, facilitates style transfer and overcomes common artifacts and blurs. A new loss function, Multi-Scale Structural Similarity, is introduced to enforce structural preservation, resulting in higher quality multi-style Chinese art paintings. From the perspective of generative teaching aids, Wang et al. (Wang et al., 2024a) present ”Intelligent-paint,” a method for generating the painting process of Chinese artworks. Using a Vision Transformer-based generator and an adversarial learning approach, this method emphasizes the unique characteristics of Chinese painting, such as void and brush strokes, employing loss constraints to align with traditional techniques. The coherence of the generated painting sequences with real painting processes is further validated by expert evaluations, making it a valuable tool for beginners learning Chinese painting. Finally, Li et al. (Li et al., 2021) introduce the novel task of artistically visualizing classical Chinese poems. For this, they construct the Paint4Poem dataset, comprising high-quality poem-painting pairs and a larger collection to assist in training poem-to-painting generation models. Despite the models’ capabilities in capturing pictorial quality and style, reflecting poem semantics remains a challenge. Paint4Poem opens many research avenues, such as transfer learning and text-to-image generation for low-resource data, enriching the intersection of literature and visual art. These works collectively highlight the potential of diffusion-based techniques in enriching the field of traditional Chinese painting, offering advanced tools for both creation and restoration and enhancing the educational process for aspiring artists.
With the development of diffusion-based generative methods, the application scenario has expanded to cover a wide range of artistic categories, including human images, portraits, fonts, and more. Ju et al. (Ju et al., 2023) have crafted the Human-Art dataset to bridge the gap between natural and artificial human representations. Spanning natural and artificial scenes, this dataset is comprehensive, covering 2D and 3D instances, and is poised to enable advancements in various computer vision tasks such as human detection, pose estimation, image generation, and motion transfer. Liu et al. (Liu et al., 2023a) present Portrait Diffusion, a training-free face stylization framework that utilizes text-to-image diffusion models for detailed style transformation. This novel framework integrates content and style images into latent codes, which are then delicately blended using Style Attention Control, yielding precise face stylization. The innovative Chain-of-Painting method allows for gradual redrawing of images from coarse to fine details. In the realm of secondary painting for artistic productions like comics and animation, Ai et al. (Ai and Sheng, 2023) introduce Stable Diffusion Reference Only, a method that accelerates the process with a dual-conditioning approach using image prompts and blueprint images for precise control. This self-supervised model integrates seamlessly with the original UNet architecture, enhancing efficiency and controllability without the need for complex training methods. Wang et al. (Wang et al., 2023a) tackle the challenge of creating nontypical aspect-ratio images with MagicScroll, a diffusion-based image generation framework. It addresses issues of content repetition and style inconsistency by allowing fine-grained control of the creative process across object, scene, and background levels. This model is benchmarked against mediums like paintings, comics, and cinema, demonstrating its potential in visual storytelling. Lastly, Tanveer et al. (Tanveer et al., 2023) introduce DS-Fusion, a method for generating artistic typography that balances stylization with legibility. Utilizing large language models and an unsupervised generative model with a diffusion model backbone, it creates typographies that visually convey semantics while remaining coherent. DS-Fusion is validated through user studies and stands out against prominent baselines and artist-crafted typographies. Together, these advancements signify a major leap in the application of diffusion-based methods to a myriad of artistic categories. By encompassing human-centric datasets, training-free frameworks, speed-enhancing models for artists, tools for visual storytelling, and typography generation techniques, the scope of AI in art creation is being pushed to new, previously unimagined heights.
5.3.2. Representing Scenarios as Modalities and Tasks.
Next, we attempt to structure different application scenarios by their corresponding data modalities and generative tasks. In this way, we aim to approach the embedded technical problems and establish alignment between artistic requirements and technical problems.
Following the common practice in AIGC, we first categorize artistic scenarios by different data modalities:
-
•
Thread/Brushstroke. The first series of work focus on brush stroke generation. The problem has been long-studied and technically attended since around 2000 and can be well solved by traditional rendering and rule-based methods, with little involvement of diffusion-based models (Lee et al., 2005; Yang et al., 2019; Nakano, 2019; Bidgoli et al., 2020; Fang et al., 2018).
- •
- •
- •
-
•
Others. Other artistic genres are commonly believed to possess certain modality features. For example, sketch share both a raster and a vector representation, thus inspiring researchers to take different generative approaches (Li et al., 2024; Wang et al., 2022; Wang, 2022; Wang et al., 2021; Ciao et al., 2024).
Next, we summarize typical tasks in Diffusion-Based Visual Art Creation:
-
•
Quality Enhancement. As the baseline task in content generation and the basic requirement in visual art creation, the generated content should possess higher resolution and better quality. This is commonly realized by aesthetic training data, advanced model structure, more parameters, and result optimization designs. In the post-diffusion era, these methods are integrated into training foundation models (He et al., 2023; Nichol et al., 2021; Chen et al., 2023; Zhang et al., 2024b; Rombach et al., 2022).
-
•
Controllable Generation. The requirement emerges from artists’ need to precisely control each perspective of their generated results, including context, subject, content, and style. Researchers adapt diversified ways, including additional information encoding, cross-attention mechanism, and retrieval augmentation, to support different forms of conditions (Zhang et al., 2023c; Li et al., 2023a; Ye et al., 2023b; Huang et al., 2024; Zhao et al., 2024a).
-
•
Content Editing and Stylization. This task is seen in various scenarios such as iterative generation, collaborative creation, and image inpainting. Following the understanding of high-level concept and low-level style in deep latent structure, experts are also working on decoupling the two aspects, to improve the performance of diffusion-based models on style transfer, style control, style inversion, etc (Hertz et al., 2022; Lu et al., 2023; Brack et al., 2022; Abrahamsen2023InventingAS; Kawar et al., 2023).
-
•
Specialized Tasks. According to different visual art scenarios and inspired by human concepts, experts summarized and proposed new tasks including compositional generation (e.g., concept, layout, layer) and latent manipulation. Still, more research is application-oriented, designed, and optimized for specific data types (e.g., human portrait) or specific scenarios (e.g., multiview art) (Wang et al., 2023a; Wu et al., 2023; Zhou et al., 2023; Chefer et al., 2023; Liu et al., 2022).
5.3.3. From Artistic Goals to Evaluation Metrics.
In Diffusion-Based Visual Art Creation, artistic goals drive the development of generative tasks, and the success of these tasks is measured using specific evaluation metrics. In Table 2, we summarize common artistic goals and list several evaluation metrics as an example:
-
•
Controllability. Achieving precise control over generated outcomes is measured by metrics that evaluate the adherence to user-specified prompts and directions.
-
–
CLIP Score: Assesses alignment between text prompts and generated images using CLIP (Contrastive Language-Image Pretraining) embeddings (Radford et al., 2021).
-
–
CLIP Directional Similarity: Measures the semantic similarity between changes in text prompts and corresponding changes in generated images (Patashnik et al., 2021).
-
–
-
•
Visual Quality. The quality of generated art is quantified by subjective and objective metrics that reflect the aesthetic and technical excellence of the artwork.
-
–
User studies: Subjective evaluations where users rate the visual appeal and aesthetic qualities of generated content (Wang et al., 2023b).
-
–
LAION-AI Aesthetics: A metric that uses a dataset from LAION-AI to objectively evaluate the aesthetic aspects of generated images, such as harmony, balance, and composition (Schuhmann et al., 2021).
-
–
-
•
Fidelity. The fidelity of the generated content to the target data distribution is gauged using metrics that compare the statistical properties of generated and real artwork.
- –
- –
-
•
Interpretability. For the goal of interpretability, metrics assess how well we can understand and manipulate the generative model’s inner workings.
- –
- –
| Artistic Goal | Example Evaluation Metric |
|---|---|
| Controllability | CLIP Score (Radford et al., 2021), CLIP Directional Similarity (Patashnik et al., 2021) |
| Visual Quality | User studies, LAION-AI Aesthetics (Schuhmann et al., 2021) |
| Fidelity | Fréchet Inception Distance (Heusel et al., 2017), Inception Score (Salimans et al., 2016) |
| Interpretability | Disentanglement metrics, feature attribution |
5.4. Design and Application of Diffusion-Based Methods
In the previous discussion, we gradually shifted from an artistic/user perspective to a technical/designer perspective. In this part, we focus on the lower half of the Rhombus framework (Fig. 4), to summarize specific methods applied in Diffusion-Based Visual Art Creation (Q3).
5.4.1. From Generative Tasks to Method Design.
Based on the previously summarized generative tasks, we first categorize representative diffusion-based methods applied to solve each problem. We specifically focus on controllable generation, content editing, and stylization which together take up more than 80% of research focuses in generative/method-based research.
Controllable generation. In the realm of controllable generation, various studies have presented innovative approaches to guide diffusion models effectively. The work by Choi et al. (Choi et al., 2021) introduces Iterative Latent Variable Refinement (ILVR), which conditions denoising diffusion probabilistic models (DDPM) using a reference image. The ILVR method directs a single DDPM to generate images with various attributes informed by the reference, enhancing the controllability and quality of generated images across multiple tasks like multi-domain image translation and image editing. Gal et al. (Gal et al., 2022) propose a method that personalizes text-to-image generation by learning new ”words” to represent user-provided concepts. This approach, named Textual Inversion, adapts a frozen text-to-image model to generate images of unique concepts. By embedding these unique ”words” into natural language sentences, users have the creative freedom to guide the AI in generating personalized images. In another breakthrough, Zhang et al. (Zhang et al., 2023c) present ControlNet, an architecture that adds spatial conditioning controls to pre-trained text-to-image diffusion models. ControlNet takes advantage of ”zero convolutions” and existing deep encoding layers from large models, allowing the fine-tuning of conditional controls like edges and segmentation with robust training across different dataset sizes. Building further on control mechanisms, Zhao et al. (Zhao et al., 2024a) introduce Uni-ControlNet, a unified framework that enables the simultaneous use of multiple control modes, both local and global, without the need for extensive training from scratch. The framework’s unique adapter design ensures cost-effective and composable control, enhancing both controllability and generation quality. Finally, Ruiz et al. (Ruiz et al., 2023) present DreamBooth, a fine-tuning approach that personalizes text-to-image diffusion models to generate novel renditions of subjects in varying contexts using a small reference set. This method, empowered by a class-specific prior preservation loss, maintains the subject’s defining features across different scenes, opening the door to new applications like subject recontextualization and artistic rendering. These studies collectively illustrate the evolving landscape of design and application within diffusion-based methods. They highlight the progress from generative tasks to refined method design and the ongoing pursuit of enhanced controllability in image generation.
Content Editing. The design and application of diffusion-based methods have paved the way for breakthroughs in content editing, offering enhanced photorealism and greater control in the text-guided synthesis and manipulation of images. Nichol et al. (Nichol et al., 2021) delve into text-conditional image generation using diffusion models, contrasting CLIP guidance with classifier-free guidance. The latter is favored for producing realistic images that closely align with human expectations. Their 3.5 billion parameter model outperforms DALL-E in human evaluations, and further demonstrates its flexibility in image inpainting, facilitating text-driven editing capabilities. Hertz et al. (Hertz et al., 2022) introduce an intuitive image editing framework, where modifications are steered solely by textual prompts, bypassing the need for spatial masks. Their analysis highlights the crucial role of cross-attention layers in mapping text to image layout, enabling precise control over local and global edits while preserving fidelity to the original content. Kumari et al. (Kumari et al., 2023) propose an efficient approach for incorporating user-defined concepts into text-to-image diffusion models, Custom Diffusion. By optimizing a subset of parameters, the method allows for rapid adaptation to new concepts and the combination of multiple concepts, yielding high-quality images that outperform existing methods in both efficiency and effectiveness. Brooks et al. (Brooks et al., 2023) present InstructPix2Pix, a conditional diffusion model trained on a dataset generated by combining the expertise of GPT-3 and Stable Diffusion. This model can interpret human-written instructions to edit images accurately, operating swiftly without needing per-example fine-tuning, showcasing its proficiency across a wide array of editing tasks. Lastly, Parmar et al. (Parmar et al., 2023) tackle the challenge of content preservation in image-to-image translation with pix2pix-zero. Through the discovery of editing directions in text embedding space and cross-attention guidance, their method ensures the input image’s content remains intact. They further streamline the process with a distilled conditional GAN, achieving superior performance in both real and synthetic image editing without necessitating additional training. Collectively, these advancements in diffusion-based methods signify a transformative period in content editing, where the synthesis of images is becoming increasingly controllable, customizable, and responsive to textual nuance, greatly expanding the potential for creative expression and practical applications.
Stylization. Recent advancements in diffusion-based methods have significantly enhanced the stylization capabilities in the domain of generative AI, enabling more intuitive and precise artistic expression. Zhang et al. (Zhang et al., 2023b) propose an inversion-based style transfer technique that captures the artistic style directly from a single painting, circumventing the need for complex textual descriptions. This method, named InST, efficiently captures the essence of a painting’s style through a learnable textual description and applies it to guide the synthesis process, thus achieving high-quality style transfer across diverse artistic works. Huang et al. (Huang et al., 2024) present DiffStyler, a novel architecture that leverages dual diffusion processes to control the balance between content and style during text-driven image stylization. By integrating cross-modal style information as guidance and proposing a content image-based learnable noise, DiffStyler ensures that the structural integrity of the content image is maintained while achieving a compelling style transformation. In the realm of artistic image synthesis, Ahn et al. (Ahn et al., 2024) propose DreamStyler, a framework that optimizes multi-stage textual embedding with context-aware text prompts. DreamStyler excels at both text-to-image synthesis and style transfer, providing the flexibility to adapt to various style references and producing images that exhibit high-quality and unique artistic traits. Sohn et al. (Sohn et al., 2024) develop StyleDrop, a method designed to synthesize images that adhere closely to a specific style using a text-to-image model. StyleDrop stands out for its ability to capture intricate style nuances with minimal parameter fine-tuning. It demonstrates impressive results even when provided with a single image, effectively synthesizing styles across different patterns, textures, and materials. Together, these methodologies exemplify the ongoing innovation in the field of image stylization through diffusion-based methods. They afford users an unprecedented level of control and flexibility in generating and editing images, breaking new ground in the creation of stylized artistic content. These tools not only facilitate the expression of visual art but also promise to expand the possibilities for personalized and creative digital media.
Quality Enhancement. The exploration of diffusion-based methods has led to significant enhancements in the quality of text-to-image synthesis, pushing the boundaries of resolution, fidelity, and customization. Balaji et al. (Balaji et al., 2022) propose eDiff-I, an ensemble of text-to-image diffusion models that specialize in different stages of the image synthesis process. This approach results in images that better align with the input text while maintaining visual quality. The models use various embeddings for conditioning and introduce a ”paint-with-words” feature, which allows users to control the output by applying words to specific areas of an image canvas, providing a more intuitive way to craft images. Chang et al. (Chang et al., 2023) introduce Muse, a Transformer model that surpasses diffusion and autoregressive models in efficiency. Muse achieves state-of-the-art performance with a masked modeling task on discrete tokens, informed by text embedding from a large pre-trained language model. This method allows for fine-grained language understanding and diverse image editing applications without additional fine-tuning, such as inpainting and mask-free editing. In the realm of cost-effective and environmentally conscious training, Chen et al. (Chen et al., 2023) present PIXART-, a Transformer-based diffusion model that significantly reduces training time and costs while maintaining competitive image quality. Through a decomposed training strategy, efficient text-to-image Transformer design, and higher informative data, PIXART- demonstrates superior speed, saving resources and minimizing CO2 emissions. It provides a template for startups and the AI community to build high-quality, low-cost generative models. Lastly, He et al. (He et al., 2023) delve into higher-resolution visual generation with ScaleCrafter, an approach that addresses the challenges of object repetition and structure in images created at resolutions beyond those of the training datasets. By re-dilating convolutional perception fields and implementing dispersed convolution and noise-damped classifier-free guidance, ScaleCrafter enables the generation of ultra-high-resolution images without additional training or optimization, setting a new standard for texture detail and resolution in synthesized images. Collectively, these advancements represent a paradigm shift in the quality enhancement of diffusion-based generative models, offering innovative solutions to meet the ever-growing demands for high-quality, customizable, and efficient image generation and editing in the AI-powered creative landscape.
Specialized Tasks. The design and application of diffusion-based methods have extended into specialized tasks, revealing both the potential and the challenges associated with these powerful generative tools. Somepalli et al. (Somepalli et al., 2023) raise concerns about the originality of the content produced by diffusion models, particularly questioning whether these models generate unique art or merely replicate existing training data. Through image retrieval frameworks, they analyze content replication rates in models like Stable Diffusion and stress the significance of diverse and extensive training sets to mitigate direct copying. Zhang et al. (Zhang et al., 2023a) tackle the limitation of personalizing specific visual attributes in generative models. Introducing ProSpect, they utilize the stepwise generation process of diffusion models to represent images with inverted textual token embeddings, corresponding to different stages of image synthesis. This method enhances disentanglement and controllability, enabling attribute-aware personalization in image generation without the need for fine-tuning the diffusion models. In the realm of vector graphics, Jain et al. (Jain et al., 2023) demonstrate that text-conditioned diffusion models trained on pixel representations can be adapted to produce SVG-format vector graphics. Through Score Distillation Sampling loss and a differentiable vector graphics rasterizer, VectorFusion abstracts semantic knowledge from pretrained diffusion models, yielding coherent vector graphics suitable for scalable design applications. Zhang et al. (Zhang and Agrawala, 2024) introduce LayerDiffusion, an innovative approach that equips large-scale pretrained latent diffusion models with the capability to generate transparent images and image layers. By incorporating “latent transparency” into the model’s latent space, LayerDiffusion maintains the quality of the original diffusion model while enabling transparency, facilitating applications like layer generation and structural content control. These specialized applications of diffusion-based methods highlight the versatility of generative AI, addressing the need for authenticity in digital art, personalization of visual attributes, scalability in design formats, and transparency in image layers. As these technologies advance, they promise to reshape the landscape of digital content creation, offering tools that can adapt to an array of specialized tasks while preserving the integrity and quality of the generated materials.
| Task | Method |
|---|---|
| Controllable Generation | ILVR (Choi et al., 2021), Textual Inversion (Gal et al., 2022), ControlNet (Zhang et al., 2023c), Uni-ControlNet (Zhao et al., 2024a), DreamBooth (Ruiz et al., 2023), RPG framework (Yang et al., 2024b), PHDiffusion (Lu et al., 2023) |
| Content Editing | GLIDE (Nichol et al., 2021), Prompt-to-Prompt (Hertz et al., 2022), Custom Diffusion (Kumari et al., 2023), InstructPix2Pix (Brooks et al., 2023), pix2pix-zero (Parmar et al., 2023) |
| Stylization | InST (Zhang et al., 2023b), DiffStyler (Huang et al., 2024), DreamStyler (Ahn et al., 2024), StyleDrop (Sohn et al., 2024) |
| Quality Enhancement | eDiff-I (Balaji et al., 2022), Muse (Chang et al., 2023), PIXART- (Chen et al., 2023), ScaleCrafter (He et al., 2023) |
| Specialized Tasks | ProSpect (Zhang et al., 2023a), VectorFusion (Jain et al., 2023), LayerDiffusion (Zhang and Agrawala, 2024), Diffusion Model Originality (Somepalli et al., 2023) |
In Table 3 we summarize the discussed research and provide more examples, to establish correspondence between different generative tasks and methods.
5.4.2. Method Classification by Diffusion Model Structure.
Based on Sec. 4.2.1 and Fig. 2, we classify different methods to design or refine diffusion-based models by a unified model structure and summarize representative methods to optimize each module.
Encoder-decoder: Lu et al. (Lu et al., 2023) innovate with a dual encoder setup in their PHDiffusion model for painterly image harmonization, which features a lightweight adaptive encoder and a Dual Encoder Fusion (DEF) module, allowing for a more nuanced manipulation of foreground features to blend photographic objects into paintings seamlessly. Yang et al. (Yang et al., 2024b) push the boundaries of text-to-image diffusion models by introducing the RPG framework, which leverages the complex reasoning capabilities of multimodal LLMs. This model employs a global planner that decomposes the image generation task into sub-tasks, enhancing the model’s ability to handle prompts with multiple objects and intricate relationships.
Denoiser: Liu et al. (Liu et al., 2022) propose a compositional visual generation technique that interprets diffusion models as energy-based models. This allows for the combination of multiple diffusion processes, each representing different components of an image, enabling the generation of scenes with a level of complexity not encountered during training. Bar et al. (Bar-Tal et al., 2023) present MultiDiffusion, a framework that fuses multiple diffusion paths for controlled image generation. The key innovation lies in its optimization task that allows for high-quality, diverse image output without requiring re-training or fine-tuning.
Noise Predictor: Chefer et al. (Chefer et al., 2023) introduce an attention-based semantic guidance system, Attend-and-Excite, for text-to-image diffusion models. This method refines the cross-attention units during inference time, ensuring that generated images more faithfully represent the text prompt’s content. Cao et al. (Cao et al., 2023b) develop a tuning-free image synthesis and editing approach, MasaCtrl, which transforms self-attention in diffusion models into mutual self-attention. This allows for consistent generation and editing by querying correlated local content and texture from source images.
Additional modules: Hu et al. (Hu et al., 2021a) innovate in the adaptation of large language models through LoRA, which introduces low-rank matrices into the Transformer architecture, significantly reducing the number of trainable parameters required for downstream tasks. Mou et al. (Mou et al., 2024) create T2I-Adapters, specialized modules that enhance the controllability of text-to-image models. These adapters tap into the models’ implicit knowledge for more nuanced control over the generation outputs, emphasizing color and structure without retraining the entire model.
| Module | Method |
|---|---|
| Encoder-Decoder | RPG framework (Yang et al., 2024b), PHDiffusion (Lu et al., 2023) |
| Denoiser | ILVR (Choi et al., 2021), Compositional Generation(Liu et al., 2022), MultiDiffusion (Bar-Tal et al., 2023), GLIDE (Nichol et al., 2021), Custom Diffusion (Kumari et al., 2023), InstructPix2Pix (Brooks et al., 2023), pix2pix-zero (Parmar et al., 2023) |
| Noise Predictor | Attend-and-Excite (Chefer et al., 2023), MasaCtrl (Cao et al., 2023b) |
| Additional Modules | LoRA (Hu et al., 2021a), T2I-Adapters (Mou et al., 2024), Textual Inversion (Gal et al., 2022), ControlNet (Zhang et al., 2023c), Uni-ControlNet (Zhao et al., 2024a), DreamBooth (Ruiz et al., 2023), eDiff-I (Balaji et al., 2022), Muse (Chang et al., 2023), PIXART- (Chen et al., 2023), ScaleCrafter (He et al., 2023), ProSpect (Zhang et al., 2023a), VectorFusion (Jain et al., 2023), LayerDiffusion (Zhang and Agrawala, 2024) |
Table 4 illustrates Method Categorization by Model Structure. Each of these innovations contributes significantly to the design and application of diffusion models, enhancing their capacity for a range of generative tasks with improved efficiency, control, and output quality.
5.4.3. Summary and Trend Identification.
Following the previous illustration of visual art generative tasks, methods, and diffusion-based model structures, we form them into Table 5 and discuss how they manifest features and trends in diffusion-based method design.
| Module | Conditional Generation | Content Editing | Stylization | Quality Enhancement |
|---|---|---|---|---|
| Encoder |
RPG framework (Yang et al., 2024b),
DreamBooth (Ruiz et al., 2023) |
Glide (Nichol et al., 2021),
InstructPix2Pix (Brooks et al., 2023) |
InST (Zhang et al., 2023b) | eDiff-I (Balaji et al., 2022) |
| Decoder |
Textual Inversion (Gal et al., 2022),
ControlNet (Zhang et al., 2023c) |
Glide (Nichol et al., 2021),
InstructPix2Pix (Brooks et al., 2023) |
DiffStyler (Huang et al., 2024) | PIXART- (Chen et al., 2023) |
| Denoiser |
ILVR (Choi et al., 2021),
Uni-ControlNet (Zhao et al., 2024a) |
Prompt-to-Prompt (Hertz et al., 2022),
Custom Diffusion (Kumari et al., 2023) |
StyleDrop (Sohn et al., 2024),
DiffStyler (Huang et al., 2024) |
ScaleCrafter (He et al., 2023) |
| Noise Predictor | - | - | DreamStyler (Ahn et al., 2024) | Muse (Chang et al., 2023) |
| Additional Modules |
LoRA (Hu et al., 2021a),
Textual Inversion (Gal et al., 2022) |
pix2pix-zero (Parmar et al., 2023),
T2I-Adapters (Mou et al., 2024) |
StyleDrop (Sohn et al., 2024) |
VectorFusion (Jain et al., 2023),
LayerDiffusion (Zhang and Agrawala, 2024) |
This table has multiple implications. In designing a method for specific generative tasks, we may start from a column and select different corresponding modules to test their performance. We may also combine modules from different columns, which may help us accomplish multiple tasks simultaneously. On the other hand, we summarize the following trends in adapting diffusion modules and designing methods for visual art creation:
- •
- •
- •
- •
- •
- •
- •
6. Discussion
In this section, we focus on the frontiers, trends, and future work of Diffusion-Based Visual Art Creation (Q4). Specifically, we adopt a technical and synergistic perspective to better characterize the multidimensional essence of this interdisciplinary field. In this way, we aim to shed light on emerging topics and possible future developments to provide inspiration and guidance for scientific researchers, artistic practitioners, and the whole community (G2).
6.1. Breaking the Fourth Wall: a Technical Perspective
The first trend is facilitating the creation of a more artistic, controllable, and realistic environment through the transcendence of dimensions. Researchers combine higher-dimension visual content and more diverse modalities with advanced computational power to create an immersive experience.
6.1.1. Higher Dimension.
The first series of work revolve around the innovative integration of AI with 3D artistic expression and scene generation. Among them, ARF (Zhang et al., 2022a) presents a method to transfer artistic features from a 2D style image to a 3D scene, using a radiance field representation that overcomes geometric reconstruction errors found in previous techniques. It introduces a nearest neighbor-based loss for capturing style details and a deferred back-propagation method, optimizing memory-intensive radiance fields and improving the visual quality of stylized scenes. CoARF (Zhang et al., 2024a) builds on this by introducing a novel algorithm for controllable 3D scene stylization. It offers fine-grained control over the style transfer process using segmentation masks with label-dependent loss functions, and a semantic-aware nearest neighbor matching algorithm, achieving superior style transfer quality. Instruct-NeRF2NeRF (Haque et al., 2023) proposes a method for editing NeRF scenes with text instructions, using an image-conditioned diffusion model to achieve realistic targeted edits. The technique allows large-scale, real-world scene edits, expanding the possibilities for user-driven 3D content creation. DreamWire (Qu et al., 2023) presents an AI system for crafting multi-view wire art, using a combination of 3D Bézier curves, Prim’s algorithm, and knowledge distillation from diffusion models. This system democratizes the creation of multi-view wire art (MVWA), making it accessible to non-experts while ensuring visual aesthetics. Lastly, RealmDreamer (Shriram et al., 2024) introduces a technique for text-driven 3D scene generation using 3D Gaussian Splatting and image-conditional diffusion models. It uniquely generates high-quality 3D scenes in diverse styles without the need for video or multi-view data, showcasing the potential for 3D synthesis from single images. Together, these papers advance the fusion of generative AI and 3D art, enabling new levels of creativity and control in digital scene creation and artistic expression.
6.1.2. Diverse Modalities.
The second series of works showcase innovations that span across visual and auditory domains, aligning technologies with the nuanced dynamics of human perception and artistic creation. The Human-Art dataset (Ju et al., 2023) addresses a void in computer vision by collating 50k images from both natural and artificial human depictions across 20 different scenarios, marking a leap forward in human pose estimation and image generation tasks. This versatile dataset, with over 123k annotated person instances in both 2D and 3D, stands to offer new insights and research directions as it bridges the gap between natural and artificial scenes. SonicDiffusion (Biner et al., 2024) introduces an audio-driven approach to image generation and editing, leveraging the multimodal aspect of human perception. By translating audio features into tokens compatible with diffusion models, and incorporating audio-image cross-attention layers, SonicDiffusion demonstrates superior performance in creating and editing images conditioned on auditory inputs. Sprite-from-Sprite (Zhang et al., 2022b) unravels the complexity of cartoon animations by decomposing them into basic ”sprites” using a pioneering self-supervised framework that leverages Pixel MLPs. This method cleverly simplifies the decomposition of intricate animated content by first resolving simpler sprites, thus easing the overall process and enhancing the quality of cartoon animation analysis. WonderJourney (Yu et al., 2023) transforms scene generation by introducing a modularized framework designed to create a perpetual sequence of diverse and interconnected 3D scenes from any starting point, be it a textual description or an image. This approach yields imaginative and visually diverse scene sequences, showcasing the framework’s robust versatility. Lastly, Intelligent-paint (Wang et al., 2024a) propels the generation of Chinese painting processes forward. Utilizing a Vision Transformer (ViT)-based generator, adversarial learning, and loss constraints that adhere to the characteristics of Chinese painting, this method vastly improves the plausibility and clarity of intermediate painting steps. The approach not only successfully bridges the gap between generated sequences and real painting processes but also serves as a valuable learning tool for novices in the art of Chinese painting. Collectively, these contributions present a multifaceted view of the convergence between AI technologies and the arts, pushing the boundaries of what can be achieved in terms of human-centric data analysis, multimodal synthesis, and artistic process generation.
6.2. “1 + 1 ¿ 2”: a Synergistic Perspective
The second trend is to promote human and AI’s understanding and collaboration with each other, and finally to unleash human potential and stimulate creativity in diffusion-based visual art creation. Research under this topic are mostly understanding-oriented and application-driven, including creative system design, multiple intuitive interactions, content reception and modality alignment. We summarize different approaches and solutions for the problems and tasks.
6.2.1. Interactive Systems.
Emerging research showcases interactive technologies that amalgamate human intuition with AI’s capabilities to enhance the process of creation across various artistic domains. PromptPaint (Chung and Adar, 2023) revolutionizes text-to-image models by allowing users to intuitively guide image generation through paint-medium-like interactions, akin to mixing colors on a palette. This system enables the iterative application of prompts to canvas areas, enhancing the user’s ability to shape outputs in ways that language alone could not facilitate. Collaborative Neural Painting (Dall’Asen et al., 2023) introduces the task of joint art creation between humans and AI. Through a novel Transformer-based architecture that models the input and completion strokes, users can iteratively shape the artwork, making the painting process both creative and collaborative. ArtVerse (Guo et al., 2023) proposes a human-machine collaborative creation paradigm in the metaverse, where AI participates in artistic exploration and evolution, shaping a decentralized ecosystem for art creation, dissemination, and transaction. ARtVista (Hoang et al., 2024) empowers individuals to bridge the gap between conceptual ideas and their visual representation. By integrating AR and generative AI, ARtVista assists users in creating sketches from abstract thoughts and generating vibrant paintings in diverse styles. Its unique paint-by-number simulation further simplifies the artistic process, enabling anyone to produce stunning artwork without advanced drawing skills. Interactive3D (Dong et al., 2024) framework elevates 3D object generation by granting users unparalleled control over the creation process. Utilizing Gaussian Splatting and InstantNGP representations, this framework allows for comprehensive interaction, including adding, removing, transforming, and detailed refinement of 3D components, pushing the boundaries of precision in generative 3D modeling. Finally, Neural Canvas (Shen et al., 2024) integrates generative AI into a 3D sketching interface, facilitating scenic design prototyping. It transcends the limitations of traditional tools by enabling rapid iteration of visual ideas and atmospheres in 3D space, expediting the design process for both novices and professionals. These contributions collectively demonstrate a synergistic approach where the sum of collaborative human and machine efforts yields greater creative outcomes than either could achieve independently, marking a new era in interactive and generative art-making.
6.2.2. Reception and Alignment.
Another series of work focus on latent space disentanglement and multi-modality alignment, combining the perspectives of content reception and generation for understanding, to enable human and AI better understand each other. For example, a study on multi-sensory experience (Cho, 2021) emphasizes the potential of various sensory elements such as sound, touch, and smell to convey visual artwork elements to visually impaired individuals. By leveraging patterns, temperature, and other sensory cues, this research opens up new avenues for inclusive art appreciation and paves the way for further exploration in multi-sensory interfaces. In the realm of knowledgeable art description, a new framework (Bai et al., 2021) has been introduced for generating rich descriptions of paintings that cover artistic styles, content, and historical context. This multi-topic approach, augmented with external knowledge, has been shown to successfully capture diverse aspects of artwork and its creation, enhancing the viewer’s understanding and engagement with art. Initial Images (Qiao et al., 2022) explores the use of image prompts alongside text to improve the subject representation in AI-generated art. This research demonstrates how image prompts can exert significant control over final compositions, leading to more accurate and user-aligned creations. CLIP-PAE (Zhou et al., 2023) addresses the challenge of disentangled and interpretable text-guided image manipulation by introducing projection-augmentation embedding. This method refines the alignment between text and image features, enabling more precise and controllable manipulations, particularly demonstrated in the context of facial editing. Evaluating text-to-visual generation has been advanced with the introduction of VQAScore (Lin et al., 2024), a metric that utilizes a visual-question-answering model to assess image-text alignment. This approach offers a more nuanced evaluation of complex prompts and has led to the creation of GenAI-Bench, a benchmark for rigorously testing generative AI models against compositional text prompts. Collectively, these contributions signify a synergistic advancement where the combination of multiple approaches, senses, and technologies results in a more profound and aligned interaction between AI and human perception, pushing the boundaries of art creation, appreciation, and evaluation.

Fig. 9 illustrates the paradigm shift in Human and AI’s roles in content creation. With technological advancements, human roles in AIGC are shifting from creators to optimizers to consumers, while AI develops from analyzers to generators to creators. In all, the creative paradigm shifts from human design and AI assistance to human-AI collaboration, where the two counterparts learn from and inspire each other.
7. Conclusion
This survey has charted the course of diffusion-based generative methods within the rich terrain of visual art creation. We began by identifying the research scope, pinpointing diffusion models and visual art as pivotal concepts, and outlining our dual research goals and the quartet of research questions. A robust dataset was assembled, encompassing relevant papers that underwent a rigorous four-phase filtering process, leading to their categorization across seven dimensions within the thematic angles of application, understanding, and generation. Through a blend of structural and temporal analysis, we discovered prevailing trends and constructed a comprehensive analytical framework. Our synthesis of findings crystallized into a paradigm, encompassing the quadrants of scenario, modality, task, and method, which collectively shape the nexus of diffusion-based visual art creation. As we gaze into the future, we propose a novel perspective that intertwines technological and synergistic aspects, characterizing the collaborative ventures between humans and AI in creating visual art. This perspective beckons a future where AI not only complements human artistry but also actively contributes to the creative process. However, amidst the rapid technical strides, we are compelled to ponder the implications of AI potentially surpassing human capacity in both understanding and task execution. In such a scenario, we are prompted to question the pursuits we should embrace. If human aspirations and desires continue to expand, how can AI evolve to meet these ever-growing needs? How can we ensure that the evolution of AI in visual art creation remains aligned with human values and creative aspirations? In conclusion, while we acknowledge the remarkable progress made thus far, this survey also serves as a clarion call to the research community. As the horizon of AI in visual art creation broadens, we must continue to explore, innovate, and critically reflect on the role of AI in this field. The future beckons with a promise of AI that not only mimics but enriches human creativity, forming an indelible part of our artistic and cultural expression.
References
- (1)
- Ahn et al. (2024) Namhyuk Ahn, Junsoo Lee, Chunggi Lee, Kunhee Kim, Daesik Kim, Seung-Hun Nam, and Kibeom Hong. 2024. Dreamstyler: Paint by Style Inversion with Text-to-Image Diffusion Models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 674–681.
- Ai and Sheng (2023) Hao Ai and Lu Sheng. 2023. Stable Diffusion Reference Only: Image Prompt and Blueprint Jointly Guided Multi-Condition Diffusion Model for Secondary Painting. arXiv preprint arXiv:2311.02343 (2023).
- Bai et al. (2024) Qingyan Bai, Yinghao Xu, Zifan Shi, Hao Ouyang, Qiuyu Wang, Ceyuan Yang, Xuan Wang, Gordon Wetzstein, Yujun Shen, and Qifeng Chen. 2024. Real-Time 3D-Aware Portrait Editing from a Single Image. arXiv Preprint arXiv:2402.14000 (2024).
- Bai et al. (2021) Zechen Bai, Yuta Nakashima, and Noa Garcia. 2021. Explain Me the Painting: Multi-Topic Knowledgeable Art Description Generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5422–5432.
- Balaji et al. (2022) Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Qinsheng Zhang, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, et al. 2022. EDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers. arXiv preprint arXiv:2211.01324 (2022).
- Bar-Tal et al. (2023) Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. 2023. Multidiffusion: Fusing Diffusion Paths for Controlled Image Generation. (2023).
- Bengamra et al. (2024) Siwar Bengamra, Olfa Mzoughi, André Bigand, and Ezzeddine Zagrouba. 2024. A Comprehensive Survey on Object Detection in Visual Art: Taxonomy and Challenge. Multimedia Tools and Applications 83, 5 (2024), 14637–14670.
- Bidgoli et al. (2020) Ardavan Bidgoli, Manuel Ladron De Guevara, Cinnie Hsiung, Jean Oh, and Eunsu Kang. 2020. Artistic Style in Robotic Painting: A Machine Learning Approach to Learning Brushstroke from Human Artists. In 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN). IEEE, 412–418.
- Bie et al. (2023) Fengxiang Bie, Yibo Yang, Zhongzhu Zhou, Adam Ghanem, Minjia Zhang, Zhewei Yao, Xiaoxia Wu, Connor Holmes, Pareesa Golnari, David A Clifton, et al. 2023. RenAIssance: A Survey into AI Text-to-Image Generation in the Era of Large Model. arXiv preprint arXiv:2309.00810 (2023).
- Biner et al. (2024) Burak Can Biner, Farrin Marouf Sofian, Umur Berkay Karakaş, Duygu Ceylan, Erkut Erdem, and Aykut Erdem. 2024. SonicDiffusion: Audio-Driven Image Generation and Editing with Pretrained Diffusion Models. arXiv preprint arXiv:2405.00878 (2024).
- Brack et al. (2022) Manuel Brack, Patrick Schramowski, Felix Friedrich, Dominik Hintersdorf, and Kristian Kersting. 2022. The Stable Artist: Steering Semantics in Diffusion Latent Space. arXiv preprint arXiv:2212.06013 (2022).
- Braude et al. (2022) Tom Braude, Idan Schwartz, Alex Schwing, and Ariel Shamir. 2022. Ordered Attention for Coherent Visual Storytelling. In Proceedings of the 30th ACM International Conference on Multimedia. 3310–3318.
- Brooks et al. (2023) Tim Brooks, Aleksander Holynski, and Alexei A Efros. 2023. InstructPix2Pix: Learning to Follow Image Editing Instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18392–18402.
- Bubeck et al. (2023) Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. 2023. Sparks of Artificial General Intelligence: Early Experiments with GPT-4. arXiv preprint arXiv:2303.12712 (2023).
- Cao et al. (2023b) Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xiaohu Qie, and Yinqiang Zheng. 2023b. MASACTRL: Tuning-Free Mutual Self-Attention Control for Consistent Image Synthesis and Editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 22560–22570.
- Cao et al. (2023a) Yihan Cao, Siyu Li, Yixin Liu, Zhiling Yan, Yutong Dai, Philip S Yu, and Lichao Sun. 2023a. A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT. arXiv preprint arXiv:2303.04226 (2023).
- Castellano and Vessio (2021a) Giovanna Castellano and Gennaro Vessio. 2021a. A Brief Overview of Deep Learning Approaches to Pattern Extraction and Recognition in Paintings and Drawings. In International Conference on Pattern Recognition. Springer, 487–501.
- Castellano and Vessio (2021b) Giovanna Castellano and Gennaro Vessio. 2021b. Deep Learning Approaches to Pattern Extraction and Recognition in Paintings and Drawings: An Overview. Neural Computing and Applications 33, 19 (2021), 12263–12282.
- Cetinic and She (2022) Eva Cetinic and James She. 2022. Understanding and Creating Art with AI: Review and Outlook. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) 18, 2 (2022), 1–22.
- Chang et al. (2023) Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T Freeman, Michael Rubinstein, et al. 2023. Muse: Text-to-Image Generation via Masked Generative Transformers. arXiv preprint arXiv:2301.00704 (2023).
- Chefer et al. (2023) Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. 2023. Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models. ACM Transactions on Graphics (TOG) 42, 4 (2023), 1–10.
- Chen et al. (2023) Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, et al. 2023. PixArt-: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis. arXiv preprint arXiv:2310.00426 (2023).
- Chen et al. (2024b) Minshuo Chen, Song Mei, Jianqing Fan, and Mengdi Wang. 2024b. An Overview of Diffusion Models: Applications, Guided Generation, Statistical Rates and Optimization. arXiv preprint arXiv:2404.07771 (2024).
- Chen et al. (2024c) Weifeng Chen, Jiacheng Zhang, Jie Wu, Hefeng Wu, Xuefeng Xiao, and Liang Lin. 2024c. ID-Aligner: Enhancing Identity-Preserving Text-to-Image Generation with Reward Feedback Learning. arXiv preprint arXiv:2404.15449 (2024).
- Chen et al. (2024a) Xiaojiao Chen, Zhebing Hu, and Chengliang Wang. 2024a. Empowering Education Development through AIGC: A Systematic Literature Review. Education and Information Technologies (2024), 1–53.
- Chiang et al. (2018) Pei-Ying Chiang, Chun-Von Lin, and Cheng-Hua Tseng. 2018. Generation of Chinese Ink Portraits by Blending Face Photographs with Chinese Ink Paintings. Journal of Visual Communication and Image Representation 52 (2018), 33–44.
- Cho (2021) Jun Dong Cho. 2021. A Study of Multi-Sensory Experience and Color Recognition in Visual Arts Appreciation of People with Visual Impairment. Electronics 10, 4 (2021), 470.
- Choi et al. (2021) Jooyoung Choi, Sungwon Kim, Yonghyun Jeong, Youngjune Gwon, and Sungroh Yoon. 2021. ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models. arXiv preprint arXiv:2108.02938 (2021).
- Chung and Adar (2023) John Joon Young Chung and Eytan Adar. 2023. PromptPaint: Steering Text-to-Image Generation through Paint Medium-Like Interactions. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. 1–17.
- Ciao et al. (2024) Shen Ciao, Zhongyue Guan, Qianxi Liu, Li-Yi Wei, and Zeyu Wang. 2024. Ciallo: GPU-Accelerated Rendering of Vector Brush Strokes. In Special Interest Group on Computer Graphics and Interactive Techniques Conference Papers ’24 (SIGGRAPH Conference Papers ’24) (2024-07-27/2024-08-01). ACM, New York, NY, USA, 1–11. https://doi.org/10.1145/3641519.3657418
- Cong et al. (2024) Xiaoyan Cong, Yue Wu, Qifeng Chen, and Chenyang Lei. 2024. Automatic Controllable Colorization via Imagination. arXiv preprint arXiv:2404.05661 (2024).
- Couairon et al. (2023) Guillaume Couairon, Marlène Careil, Matthieu Cord, Stéphane Lathuilière, and Jakob Verbeek. 2023. Zero-Shot Spatial Layout Conditioning for Text-to-Image Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2174–2183.
- Dall’Asen et al. (2023) Nicola Dall’Asen, Willi Menapace, Elia Peruzzo, Enver Sangineto, Yiming Wang, and Elisa Ricci. 2023. Collaborative Neural Painting. arXiv preprint arXiv:2312.01800 (2023).
- D’Amico et al. (2021) Sebastiano D’Amico, Valentina Venuti, Emanuele Colica, Vincenza Crupi, Giuseppe Paladini, Sante Guido, Giuseppe Mantella, and Domenico Majolino. 2021. A Combined 3D Surveying, XRF and Raman In-Situ Investigation of The Conversion of St Paul Painting (Mdina, Malta) by Mattia Preti. (2021).
- Dehouche and Dehouche (2023) Nassim Dehouche and Kullathida Dehouche. 2023. What’s in a Text-to-Image Prompt? The Potential of Stable Diffusion in Visual Arts Education. Heliyon 9, 6 (2023).
- DePolo et al. (2021) Gwen DePolo, Marc Walton, Katrien Keune, and Kenneth R Shull. 2021. After the Paint Has Dried: A Review of Testing Techniques for Studying the Mechanical Properties of Artists’ Paint. Heritage Science 9 (2021), 1–24.
- Dhariwal and Nichol (2021) Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion Models Beat GANs on Image Synthesis. Advances in Neural Information Processing Systems 34 (2021), 8780–8794.
- Dong et al. (2024) Shaocong Dong, Lihe Ding, Zhanpeng Huang, Zibin Wang, Tianfan Xue, and Dan Xu. 2024. Interactive3D: Create What You Want by Interactive 3D Generation. arXiv preprint arXiv:2404.16510 (2024).
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv preprint arXiv:2010.11929 (2020).
- Dutton (2009) Denis Dutton. 2009. The Art Instinct: Beauty, Pleasure, & Human Evolution. Oxford University Press, USA.
- Elgammal et al. (2017) Ahmed Elgammal, Bingchen Liu, Mohamed Elhoseiny, and Marian Mazzone. 2017. CAN: Creative Adversarial Networks, Generating ”Art” by Learning about Styles and Deviating from Style Norms. arXiv Preprint arXiv:1706.07068 (2017).
- Esser et al. (2021) Patrick Esser, Robin Rombach, and Bjorn Ommer. 2021. Taming Transformers for High-Resolution Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12873–12883.
- Fang et al. (2018) Xiao-Nan Fang, Bin Liu, and Ariel Shamir. 2018. Automatic Thread Painting Generation. arXiv Preprint arXiv:1802.04706 (2018).
- Foo et al. (2023) Lin Geng Foo, Hossein Rahmani, and Jun Liu. 2023. AI-Generated Content (AIGC) for Various Data Modalities: A Survey. arXiv preprint arXiv:2308.14177 2 (2023).
- Fu et al. (2021) Feifei Fu, Jiancheng Lv, Chenwei Tang, and Mao Li. 2021. Multi-Style Chinese Art Painting Generation of Flowers. IET Image Processing 15, 3 (2021), 746–762.
- Gal et al. (2022) Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. 2022. An Image Is Worth One Word: Personalizing Text-to-Image Generation Using Textual Inversion. arXiv Preprint arXiv:2208.01618 (2022).
- Gatys et al. (2016) Leon A Gatys, Alexander S Ecker, and Matthias Bethge. 2016. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2414–2423.
- Geng et al. (2023) Daniel Geng, Inbum Park, and Andrew Owens. 2023. Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models. arXiv preprint arXiv:2311.17919 (2023).
- Gong et al. (2023) Yuan Gong, Youxin Pang, Xiaodong Cun, Menghan Xia, Yingqing He, Haoxin Chen, Longyue Wang, Yong Zhang, Xintao Wang, Ying Shan, et al. 2023. Interactive Story Visualization with Multiple Characters. In SIGGRAPH Asia 2023 Conference Papers. 1–10.
- Goodfellow et al. (2014) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative Adversarial Nets. Advances in Neural Information Processing Systems 27 (2014).
- Guo et al. (2023) Chao Guo, Yong Dou, Tianxiang Bai, Xingyuan Dai, Chunfa Wang, and Yi Wen. 2023. ArtVerse: A Paradigm for Parallel Human–Machine Collaborative Painting Creation in Metaverses. IEEE Transactions on Systems, Man, and Cybernetics: Systems 53, 4 (2023), 2200–2208.
- Guo et al. (2022) Meng-Hao Guo, Tian-Xing Xu, Jiang-Jiang Liu, Zheng-Ning Liu, Peng-Tao Jiang, Tai-Jiang Mu, Song-Hai Zhang, Ralph R Martin, Ming-Ming Cheng, and Shi-Min Hu. 2022. Attention Mechanisms in Computer Vision: A Survey. Computational Visual Media 8, 3 (2022), 331–368.
- Haque et al. (2023) Ayaan Haque, Matthew Tancik, Alexei A Efros, Aleksander Holynski, and Angjoo Kanazawa. 2023. Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 19740–19750.
- He et al. (2023) Yingqing He, Shaoshu Yang, Haoxin Chen, Xiaodong Cun, Menghan Xia, Yong Zhang, Xintao Wang, Ran He, Qifeng Chen, and Ying Shan. 2023. Scalecrafter: Tuning-Free Higher-Resolution Visual Generation with Diffusion Models. In The Twelfth International Conference on Learning Representations.
- Hertz et al. (2022) Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2022. Prompt-to-Prompt Image Editing with Cross Attention Control. arXiv preprint arXiv:2208.01626 (2022).
- Heusel et al. (2017) Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. Advances in Neural Information Processing Systems 30 (2017).
- Higgins et al. (2017) Irina Higgins, Loic Matthey, Arka Pal, Christopher P Burgess, Xavier Glorot, Matthew M Botvinick, Shakir Mohamed, and Alexander Lerchner. 2017. Beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. ICLR (Poster) 3 (2017).
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. Advances in Neural Information Processing Systems 33 (2020), 6840–6851.
- Ho and Salimans (2022) Jonathan Ho and Tim Salimans. 2022. Classifier-Free Diffusion Guidance. arXiv preprint arXiv:2207.12598 (2022).
- Hoang et al. (2024) Trong-Vu Hoang, Quang-Binh Nguyen, Duy-Nam Ly, Khanh-Duy Le, Tam V Nguyen, Minh-Triet Tran, and Trung-Nghia Le. 2024. ARtVista: Gateway to Empower Anyone into Artist. arXiv preprint arXiv:2403.08876 (2024).
- Hu et al. (2021a) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021a. LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685 (2021).
- Hu et al. (2021b) Jingxuan Hu, Jinhuan Zhang, Liyu Hu, Haibo Yu, and Jinping Xu. 2021b. Art Therapy: A Complementary Treatment for Mental Disorders. Frontiers in Psychology 12 (2021), 686005.
- Huang et al. (2022) Nisha Huang, Fan Tang, Weiming Dong, and Changsheng Xu. 2022. Draw Your Art Dream: Diverse Digital Art Synthesis with Multimodal Guided Diffusion. In Proceedings of the 30th ACM International Conference on Multimedia. 1085–1094.
- Huang et al. (2024) Nisha Huang, Yuxin Zhang, Fan Tang, Chongyang Ma, Haibin Huang, Weiming Dong, and Changsheng Xu. 2024. DiffStyler: Controllable Dual Diffusion for Text-Driven Image Stylization. IEEE Transactions on Neural Networks and Learning Systems (2024).
- Jain et al. (2023) Ajay Jain, Amber Xie, and Pieter Abbeel. 2023. Vectorfusion: Text-to-SVG by Abstracting Pixel-Based Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1911–1920.
- Jin et al. (2024) Xin Jin, Bohan Li, BAAO Xie, Wenyao Zhang, Jinming Liu, Ziqiang Li, Tao Yang, and Wenjun Zeng. 2024. Closed-Loop Unsupervised Representation Disentanglement with -VAE Distillation and Diffusion Probabilistic Feedback. arXiv Preprint arXiv:2402.02346 (2024).
- Jing et al. (2019) Yongcheng Jing, Yezhou Yang, Zunlei Feng, Jingwen Ye, Yizhou Yu, and Mingli Song. 2019. Neural Style Transfer: A Review. IEEE Transactions on Visualization and Computer Graphics 26, 11 (2019), 3365–3385.
- Ju et al. (2023) Xuan Ju, Ailing Zeng, Jianan Wang, Qiang Xu, and Lei Zhang. 2023. Human-ART: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 618–629.
- Karras et al. (2020) Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and Improving the Image Quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8110–8119.
- Kawar et al. (2023) Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. 2023. Imagic: Text-Based Real Image Editing with Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6007–6017.
- Kingma and Welling (2013) Diederik P Kingma and Max Welling. 2013. Auto-Encoding Variational Bayes. arXiv preprint arXiv:1312.6114 (2013).
- Ko et al. (2023) Hyung-Kwon Ko, Gwanmo Park, Hyeon Jeon, Jaemin Jo, Juho Kim, and Jinwook Seo. 2023. Large-Scale Text-to-Image Generation Models for Visual Artists’ Creative Works. In Proceedings of the 28th International Conference on Intelligent User Interfaces. 919–933.
- Kolay (2016) Saptarshi Kolay. 2016. Cultural Heritage Preservation of Traditional Indian Art through Virtual New-Media. Procedia-Social and Behavioral Sciences 225 (2016), 309–320.
- Kowalek et al. (2022) Patrycja Kowalek, Hanna Loch-Olszewska, Łukasz Łaszczuk, Jarosław Opała, and Janusz Szwabiński. 2022. Boosting the Performance of Anomalous Diffusion Classifiers with the Proper Choice of Features. Journal of Physics A: Mathematical and Theoretical 55, 24 (2022), 244005.
- Kumari et al. (2023) Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. 2023. Multi-Concept Customization of Text-to-Image Diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1931–1941.
- Kyprianidis et al. (2012) Jan Eric Kyprianidis, John Collomosse, Tinghuai Wang, and Tobias Isenberg. 2012. State of the ”Art”: A Taxonomy of Artistic Stylization Techniques for Images and Video. IEEE Transactions on Visualization and Computer Graphics 19, 5 (2012), 866–885.
- Lazzari and Schlesier (2008) Margaret Lazzari and Dona Schlesier. 2008. Exploring Art: A Global, Thematic Approach. (No Title) (2008).
- Lee et al. (2021) Lik-Hang Lee, Zijun Lin, Rui Hu, Zhengya Gong, Abhishek Kumar, Tangyao Li, Sijia Li, and Pan Hui. 2021. When Creators Meet the Metaverse: A Survey on Computational Arts. arXiv preprint arXiv:2111.13486 (2021).
- Lee et al. (2005) Tong-Yee Lee, Shaur-Uei Yan, Yong-Nien Chen, and Ming-Te Chi. 2005. Real-Time 3D Artistic Rendering System. In Knowledge-Based Intelligent Information and Engineering Systems: 9th International Conference, KES 2005, Melbourne, Australia, September 14-16, 2005, Proceedings, Part III 9. Springer, 456–462.
- Li et al. (2023b) Chenghao Li, Chaoning Zhang, Atish Waghwase, Lik-Hang Lee, Francois Rameau, Yang Yang, Sung-Ho Bae, and Choong Seon Hong. 2023b. Generative AI Meets 3D: A Survey on Text-to-3D in AIGC Era. arXiv preprint arXiv:2305.06131 (2023).
- Li et al. (2021) Dan Li, Shuai Wang, Jie Zou, Chang Tian, Elisha Nieuwburg, Fengyuan Sun, and Evangelos Kanoulas. 2021. Paint4Poem: A Dataset for Artistic Visualization of Classical Chinese Poems. arXiv preprint arXiv:2109.11682 (2021).
- Li et al. (2024) Hao Li, Zhongyue Guan, and Zeyu Wang. 2024. An Inverse Procedural Modeling Pipeline for Stylized Brush Stroke Rendering. (2024).
- Li et al. (2023a) Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. 2023a. Gligen: Open-Set Grounded Text-to-Image Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22511–22521.
- Liang et al. (2023) Chumeng Liang, Xiaoyu Wu, Yang Hua, Jiaru Zhang, Yiming Xue, Tao Song, Zhengui Xue, Ruhui Ma, and Haibing Guan. 2023. Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples. arXiv preprint arXiv:2302.04578 (2023).
- Liao et al. (2022) Peiyuan Liao, Xiuyu Li, Xihui Liu, and Kurt Keutzer. 2022. The Artbench Dataset: Benchmarking Generative Models with Artworks. arXiv Preprint arXiv:2206.11404 (2022).
- Lin (2023) Haichuan Lin. 2023. Calligraphy to Image. In Proceedings of the 16th International Symposium on Visual Information Communication and Interaction. 1–5.
- Lin et al. (2024) Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. 2024. Evaluating Text-to-Visual Generation with Image-to-Text Generation. arXiv preprint arXiv:2404.01291 (2024).
- Liu et al. (2023a) Jin Liu, Huaibo Huang, Chao Jin, and Ran He. 2023a. Portrait Diffusion: Training-Free Face Stylization with Chain-of-Painting. arXiv preprint arXiv:2312.02212 (2023).
- Liu et al. (2023c) Lingxi Liu, Tsveta Miteva, Giovanni Delnevo, Silvia Mirri, Philippe Walter, Laurence de Viguerie, and Emeline Pouyet. 2023c. Neural Networks for Hyperspectral Imaging of Historical Paintings: A Practical Review. Sensors 23, 5 (2023), 2419.
- Liu (2023) Mingyang Liu. 2023. Overview of Artificial Intelligence Painting Development and Some Related Model Application. In SHS Web of Conferences, Vol. 167. EDP Sciences, 01004.
- Liu et al. (2022) Nan Liu, Shuang Li, Yilun Du, Antonio Torralba, and Joshua B Tenenbaum. 2022. Compositional Visual Generation with Composable Diffusion Models. In European Conference on Computer Vision. Springer, 423–439.
- Liu et al. (2023d) Xingchao Liu, Xiwen Zhang, Jianzhu Ma, Jian Peng, et al. 2023d. Instaflow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation. In The Twelfth International Conference on Learning Representations.
- Liu et al. (2023b) Zhengliang Liu, Yiwei Li, Qian Cao, Junwen Chen, Tianze Yang, Zihao Wu, John Hale, John Gibbs, Khaled Rasheed, Ninghao Liu, et al. 2023b. Transformation vs Tradition: Artificial General Intelligence (AGI) for Arts and Humanities. arXiv preprint arXiv:2310.19626 (2023).
- Lu et al. (2023) Lingxiao Lu, Jiangtong Li, Junyan Cao, Li Niu, and Liqing Zhang. 2023. Painterly Image Harmonization Using Diffusion Model. In Proceedings of the 31st ACM International Conference on Multimedia. 233–241.
- Lukovnikov and Fischer (2024) Denis Lukovnikov and Asja Fischer. 2024. Layout-to-Image Generation with Localized Descriptions Using ControlNet with Cross-Attention Control. arXiv preprint arXiv:2402.13404 (2024).
- Lundberg and Lee (2017) Scott M Lundberg and Su-In Lee. 2017. A Unified Approach to Interpreting Model Predictions. Advances in Neural Information Processing Systems 30 (2017).
- Lyu et al. (2024) Qiongshuai Lyu, Na Zhao, Yu Yang, Yuehong Gong, and Jingli Gao. 2024. A Diffusion Probabilistic Model for Traditional Chinese Landscape Painting Super-Resolution. Heritage Science 12, 1 (2024), 4.
- Maerten and Soydaner (2023) Anne-Sofie Maerten and Derya Soydaner. 2023. From Paintbrush to Pixel: A Review of Deep Neural Networks in AI-Generated Art. arXiv preprint arXiv:2302.10913 (2023).
- Mai et al. (2023) Weijian Mai, Jian Zhang, Pengfei Fang, and Zhijun Zhang. 2023. Brain-Conditional Multimodal Synthesis: A Survey and Taxonomy. arXiv preprint arXiv:2401.00430 (2023).
- Mazzone and Elgammal (2019) Marian Mazzone and Ahmed Elgammal. 2019. Art, Creativity, and the Potential of Artificial Intelligence. In Arts, Vol. 8. MDPI, 26.
- McCormack and D’Inverno (2014) Jon McCormack and Mark D’Inverno. 2014. On the Future of Computers and Creativity. In AISB 2014 Symposium on Computational Creativity, London.
- McCormack et al. (2019) Jon McCormack, Toby Gifford, and Patrick Hutchings. 2019. Autonomy, Authenticity, Authorship and Intention in Computer Generated Art. In International Conference on Computational Intelligence in Music, Sound, Art and Design (Part of EvoStar). Springer, 35–50.
- Miller (2019) Arthur I Miller. 2019. The Artist in the Machine: The World of AI-Powered Creativity. MIT Press.
- Mou et al. (2024) Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. 2024. T2I-Adapter: Learning Adapters to Dig Out More Controllable Ability for Text-to-Image Diffusion Models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 4296–4304.
- Nakano (2019) Reiichiro Nakano. 2019. Neural Painters: A Learned Differentiable Constraint for Generating Brushstroke Paintings. arXiv preprint arXiv:1904.08410 (2019).
- Nam et al. (2024) Jisu Nam, Heesu Kim, DongJae Lee, Siyoon Jin, Seungryong Kim, and Seunggyu Chang. 2024. DreamMatcher: Appearance Matching Self-Attention for Semantically-Consistent Text-to-Image Personalization. arXiv preprint arXiv:2402.09812 (2024).
- Nam et al. (2019) Seonghyeon Nam, Chongyang Ma, Menglei Chai, William Brendel, Ning Xu, and Seon Joo Kim. 2019. End-to-End Time-Lapse Video Synthesis from a Single Outdoor Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1409–1418.
- Nichol et al. (2021) Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. 2021. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. arXiv preprint arXiv:2112.10741 (2021).
- OpenAI (2023) OpenAI. 2023. Model Index for Researchers. https://platform.openai.com/docs/model-index-for-researchers. Accessed: November 2, 2023.
- Park et al. (2019) Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. 2019. Semantic Image Synthesis with Spatially-Adaptive Normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2337–2346.
- Parmar et al. (2023) Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, and Jun-Yan Zhu. 2023. Zero-Shot Image-to-Image Translation. In ACM SIGGRAPH 2023 Conference Proceedings. 1–11.
- Patashnik et al. (2021) Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. 2021. StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2085–2094.
- Qiao et al. (2022) Han Qiao, Vivian Liu, and Lydia Chilton. 2022. Initial Images: Using Image Prompts to Improve Subject Representation in Multimodal AI Generated Art. In Proceedings of the 14th Conference on Creativity and Cognition. 15–28.
- Qu et al. (2023) Zhiyu Qu, Lan Yang, Honggang Zhang, Tao Xiang, Kaiyue Pang, and Yi-Zhe Song. 2023. Wired Perspectives: Multi-View Wire Art Embraces Generative AI. arXiv preprint arXiv:2311.15421 (2023).
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning Transferable Visual Models from Natural Language Supervision. In International Conference on Machine Learning. PMLR, 8748–8763.
- Ramesh et al. (2022) Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv preprint arXiv:2204.06125 1, 2 (2022), 3.
- Ramesh et al. (2021) Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-Shot Text-to-Image Generation. In International Conference on Machine Learning. PMLR, 8821–8831.
- Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10684–10695.
- Ruiz et al. (2023) Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22500–22510.
- Russo (2022) Irene Russo. 2022. Creative Text-to-Image Generation: Suggestions for a Benchmark. In Proceedings of the 2nd International Workshop on Natural Language Processing for Digital Humanities. 145–154.
- Saharia et al. (2022) Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. 2022. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. Advances in Neural Information Processing Systems 35 (2022), 36479–36494.
- Salimans et al. (2016) Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. 2016. Improved Techniques for Training GANs. Advances in Neural Information Processing Systems 29 (2016).
- Sartori (2014) Andreza Sartori. 2014. Affective Analysis of Abstract Paintings Using Statistical Analysis and Art Theory. In Proceedings of the 16th International Conference on Multimodal Interaction. 384–388.
- Schmidt et al. (2016) Thorsten-Walther Schmidt, Fabio Pellacini, Derek Nowrouzezahrai, Wojciech Jarosz, and Carsten Dachsbacher. 2016. State of the Art in Artistic Editing of Appearance, Lighting and Material. In Computer Graphics Forum, Vol. 35. Wiley Online Library, 216–233.
- Schuhmann et al. (2021) Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. 2021. LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs. arXiv Preprint arXiv:2111.02114 (2021).
- Shah et al. (2023) Viraj Shah, Nataniel Ruiz, Forrester Cole, Erika Lu, Svetlana Lazebnik, Yuanzhen Li, and Varun Jampani. 2023. Ziplora: Any Subject in Any Style by Effectively Merging Loras. arXiv preprint arXiv:2311.13600 (2023).
- Shahriar (2022) Sakib Shahriar. 2022. GAN Computers Generate Arts? A Survey on Visual Arts, Music, and Literary Text Generation Using Generative Adversarial Network. Displays 73 (2022), 102237.
- Shen et al. (2024) Yulin Shen, Yifei Shen, Jiawen Cheng, Chutian Jiang, Mingming Fan, and Zeyu Wang. 2024. Neural Canvas: Supporting Scenic Design Prototyping by Integrating 3D Sketching and Generative AI. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–17. https://doi.org/10.1145/3613904.3642096
- Shriram et al. (2024) Jaidev Shriram, Alex Trevithick, Lingjie Liu, and Ravi Ramamoorthi. 2024. RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion. arXiv preprint arXiv:2404.07199 (2024).
- Sohn et al. (2024) Kihyuk Sohn, Lu Jiang, Jarred Barber, Kimin Lee, Nataniel Ruiz, Dilip Krishnan, Huiwen Chang, Yuanzhen Li, Irfan Essa, Michael Rubinstein, et al. 2024. Styledrop: Text-to-Image Synthesis of Any Style. Advances in Neural Information Processing Systems 36 (2024).
- Somepalli et al. (2023) Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. 2023. Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6048–6058.
- Song et al. (2020a) Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020a. Denoising Diffusion Implicit Models. arXiv preprint arXiv:2010.02502 (2020).
- Song et al. (2023) Junrong Song, Bingyuan Wang, Zeyu Wang, and David Kei-Man Yip. 2023. From Expanded Cinema to Extended Reality: How AI Can Expand and Extend Cinematic Experiences. In Proceedings of the 16th International Symposium on Visual Information Communication and Interaction. 1–5.
- Song et al. (2020b) Yun-Zhu Song, Zhi Rui Tam, Hung-Jen Chen, Huiao-Han Lu, and Hong-Han Shuai. 2020b. Character-Preserving Coherent Story Visualization. In European Conference on Computer Vision. Springer, 18–33.
- Suh et al. (2022) Sangho Suh, Jian Zhao, and Edith Law. 2022. Codetoon: Story Ideation, Auto Comic Generation, and Structure Mapping for Code-Driven Storytelling. In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology. 1–16.
- Tanveer et al. (2023) Maham Tanveer, Yizhi Wang, Ali Mahdavi-Amiri, and Hao Zhang. 2023. DS-Fusion: Artistic Typography via Discriminated and Stylized Diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 374–384.
- Turkka et al. (2017) Jaakko Turkka, Outi Haatainen, and Maija Aksela. 2017. Integrating Art into Science Education: A Survey of Science Teachers’ Practices. International Journal of Science Education 39, 10 (2017), 1403–1419.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. Advances in Neural Information Processing Systems 30 (2017).
- Wang et al. (2023a) Bingyuan Wang, Hengyu Meng, Zeyu Cai, Lanjiong Li, Yue Ma, Qifeng Chen, and Zeyu Wang. 2023a. MagicScroll: Nontypical Aspect-Ratio Image Generation for Visual Storytelling via Multi-Layered Semantic-Aware Denoising. arXiv preprint arXiv:2312.10899 (2023).
- Wang et al. (2023d) Bingyuan Wang, Kang Zhang, and Zeyu Wang. 2023d. Naturality: A Natural Reflection of Chinese Calligraphy. In Proceedings of the 16th International Symposium on Visual Information Communication and Interaction. 1–8.
- Wang et al. (2023f) Bingyuan Wang, Pinxi Zhu, Hao Li, David Kei-man Yip, and Zeyu Wang. 2023f. Simonstown: An AI-Facilitated Interactive Story of Love, Life, and Pandemic. In Proceedings of the 16th International Symposium on Visual Information Communication and Interaction. 1–7.
- Wang et al. (2024b) Duotun Wang, Hengyu Meng, Zeyu Cai, Zhijing Shao, Qianxi Liu, Lin Wang, Mingming Fan, Ying Shan, Xiaohang Zhan, and Zeyu Wang. 2024b. HeadEvolver: Text to Head Avatars via Locally Learnable Mesh Deformation. arXiv Preprint arXiv:2403.09326 (2024).
- Wang et al. (2023b) Su Wang, Chitwan Saharia, Ceslee Montgomery, Jordi Pont-Tuset, Shai Noy, Stefano Pellegrini, Yasumasa Onoe, Sarah Laszlo, David J Fleet, Radu Soricut, et al. 2023b. Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18359–18369.
- Wang (2022) Zeyu Wang. 2022. Enhancing the Creative Process in Digital Prototyping. Ph. D. Dissertation. Yale University.
- Wang et al. (2024a) Zunfu Wang, Fang Liu, Zhixiong Liu, Changjuan Ran, and Mohan Zhang. 2024a. Intelligent-Paint: A Chinese Painting Process Generation Method Based on Vision Transformer. Multimedia Systems 30, 2 (2024), 1–17.
- Wang et al. (2021) Zeyu Wang, Sherry Qiu, Nicole Feng, Holly Rushmeier, Leonard McMillan, and Julie Dorsey. 2021. Tracing versus Freehand for Evaluating Computer-Generated Drawings. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1–12.
- Wang et al. (2022) Zeyu Wang, T Wang, and Julie Dorsey. 2022. Learning a Style Space for Interactive Line Drawing Synthesis from Animated 3D Models. PG2022 Short Papers, Posters, and Work-in-Progress Papers (2022).
- Wang et al. (2023c) Zhouxia Wang, Xintao Wang, Liangbin Xie, Zhongang Qi, Ying Shan, Wenping Wang, and Ping Luo. 2023c. StyleAdapter: A Single-Pass LoRA-Free Model for Stylized Image Generation. arXiv preprint arXiv:2309.01770 (2023).
- Wang et al. (2023e) Zhongqi Wang, Jie Zhang, Zhilong Ji, Jinfeng Bai, and Shiguang Shan. 2023e. CCLAP: Controllable Chinese Landscape Painting Generation via Latent Diffusion Model. In 2023 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2117–2122.
- Wu (2022) Xianchao Wu. 2022. Creative Painting with Latent Diffusion Models. In Proceedings of the Second Workshop on When Creative AI Meets Conversational AI. 59–80.
- Wu et al. (2024) You Wu, Kean Liu, Xiaoyue Mi, Fan Tang, Juan Cao, and Jintao Li. 2024. U-VAP: User-Specified Visual Appearance Personalization via Decoupled Self Augmentation. arXiv preprint arXiv:2403.20231 (2024).
- Wu et al. (2023) Yankun Wu, Yuta Nakashima, and Noa Garcia. 2023. Not Only Generative Art: Stable Diffusion for Content-Style Disentanglement in Art Analysis. In Proceedings of the 2023 ACM International Conference on Multimedia Retrieval. 199–208.
- Xia et al. (2022) Weihao Xia, Yulun Zhang, Yujiu Yang, Jing-Hao Xue, Bolei Zhou, and Ming-Hsuan Yang. 2022. GAN Inversion: A Survey. IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 3 (2022), 3121–3138.
- Xiao et al. (2024) Shishi Xiao, Liangwei Wang, Xiaojuan Ma, and Wei Zeng. 2024. TypeDance: Creating Semantic Typographic Logos from Image through Personalized Generation. arXiv preprint arXiv:2401.11094 (2024).
- Xu et al. (2024) Minrui Xu, Hongyang Du, Dusit Niyato, Jiawen Kang, Zehui Xiong, Shiwen Mao, Zhu Han, Abbas Jamalipour, Dong In Kim, Xuemin Shen, et al. 2024. Unleashing the Power of Edge-Cloud Generative AI in Mobile Networks: A Survey of AIGC Services. IEEE Communications Surveys & Tutorials (2024).
- Xue et al. (2024) Youze Xue, Binghui Chen, Yifeng Geng, Xuansong Xie, Jiansheng Chen, and Hongbing Ma. 2024. Strictly-ID-Preserved and Controllable Accessory Advertising Image Generation. arXiv preprint arXiv:2404.04828 (2024).
- Yamada (2024) Moyuru Yamada. 2024. GLoD: Composing Global Contexts and Local Details in Image Generation. arXiv preprint arXiv:2404.15447 (2024).
- Yang et al. (2024a) Jingyuan Yang, Jiawei Feng, and Hui Huang. 2024a. EmoGen: Emotional Image Content Generation with Text-to-Image Diffusion Models. arXiv preprint arXiv:2401.04608 (2024).
- Yang et al. (2019) Lijie Yang, Tianchen Xu, Jixiang Du, and Enhua Wu. 2019. Easy Drawing: Generation of Artistic Chinese Flower Painting by Stroke-Based Stylization. IEEE Access 7 (2019), 35449–35456.
- Yang et al. (2024b) Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, and Bin Cui. 2024b. Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs. arXiv preprint arXiv:2401.11708 (2024).
- Ye et al. (2023b) Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. 2023b. IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models. arXiv Preprint arXiv:2308.06721 (2023).
- Ye et al. (2023a) Yilin Ye, Rong Huang, Kang Zhang, and Wei Zeng. 2023a. Everyone Can Be Picasso? A Computational Framework into the Myth of Human versus AI Painting. arXiv Preprint arXiv:2304.07999 (2023).
- Yu et al. (2023) Hong-Xing Yu, Haoyi Duan, Junhwa Hur, Kyle Sargent, Michael Rubinstein, William T Freeman, Forrester Cole, Deqing Sun, Noah Snavely, Jiajun Wu, et al. 2023. WonderJourney: Going from Anywhere to Everywhere. arXiv preprint arXiv:2312.03884 (2023).
- Zeng et al. (2024) Xingchen Zeng, Ziyao Gao, Yilin Ye, and Wei Zeng. 2024. IntentTuner: An Interactive Framework for Integrating Human Intents in Fine-Tuning Text-to-Image Generative Models. arXiv preprint arXiv:2401.15559 (2024).
- Zhang et al. (2023e) Chenshuang Zhang, Chaoning Zhang, Mengchun Zhang, and In So Kweon. 2023e. Text-to-Image Diffusion Model in Generative AI: A Survey. arXiv preprint arXiv:2303.07909 (2023).
- Zhang et al. (2024a) Deheng Zhang, Clara Fernandez-Labrador, and Christopher Schroers. 2024a. CoARF: Controllable 3D Artistic Style Transfer for Radiance Fields. arXiv preprint arXiv:2404.14967 (2024).
- Zhang et al. (2019) Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. 2019. Self-Attention Generative Adversarial Networks. In International Conference on Machine Learning. PMLR, 7354–7363.
- Zhang et al. (2021) Jiajing Zhang, Yongwei Miao, and Jinhui Yu. 2021. A Comprehensive Survey on Computational Aesthetic Evaluation of Visual Art Images: Metrics and Challenges. IEEE Access 9 (2021), 77164–77187.
- Zhang et al. (2022a) Kai Zhang, Nick Kolkin, Sai Bi, Fujun Luan, Zexiang Xu, Eli Shechtman, and Noah Snavely. 2022a. ARF: Artistic Radiance Fields. In European Conference on Computer Vision. Springer, 717–733.
- Zhang and Agrawala (2024) Lvmin Zhang and Maneesh Agrawala. 2024. Transparent Image Layer Diffusion Using Latent Transparency. arXiv preprint arXiv:2402.17113 (2024).
- Zhang et al. (2023c) Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023c. Adding Conditional Control to Text-to-Image Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3836–3847.
- Zhang et al. (2022b) Lvmin Zhang, Tien-Tsin Wong, and Yuxin Liu. 2022b. Sprite-from-Sprite: Cartoon Animation Decomposition with Self-Supervised Sprite Estimation. ACM Transactions on Graphics (TOG) 41, 6 (2022), 1–12.
- Zhang et al. (2023d) Tianyi Zhang, Zheng Wang, Jing Huang, Mohiuddin Muhammad Tasnim, and Wei Shi. 2023d. A Survey of Diffusion-Based Image Generation Models: Issues and Their Solutions. arXiv preprint arXiv:2308.13142 (2023).
- Zhang et al. (2023a) Yuxin Zhang, Weiming Dong, Fan Tang, Nisha Huang, Haibin Huang, Chongyang Ma, Tong-Yee Lee, Oliver Deussen, and Changsheng Xu. 2023a. Prospect: Prompt Spectrum for Attribute-Aware Personalization of Diffusion Models. ACM Transactions on Graphics (TOG) 42, 6 (2023), 1–14.
- Zhang et al. (2023b) Yuxin Zhang, Nisha Huang, Fan Tang, Haibin Huang, Chongyang Ma, Weiming Dong, and Changsheng Xu. 2023b. Inversion-Based Style Transfer with Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10146–10156.
- Zhang et al. (2024b) Zhanjie Zhang, Quanwei Zhang, Huaizhong Lin, Wei Xing, Juncheng Mo, Shuaicheng Huang, Jinheng Xie, Guangyuan Li, Junsheng Luan, Lei Zhao, et al. 2024b. Towards Highly Realistic Artistic Style Transfer via Stable Diffusion with Step-Aware and Layer-Aware Prompt. arXiv preprint arXiv:2404.11474 (2024).
- Zhang et al. (2024c) Zhanjie Zhang, Quanwei Zhang, Wei Xing, Guangyuan Li, Lei Zhao, Jiakai Sun, Zehua Lan, Junsheng Luan, Yiling Huang, and Huaizhong Lin. 2024c. ArtBank: Artistic Style Transfer with Pre-Trained Diffusion Model and Implicit Style Prompt Bank. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 7396–7404.
- Zhao et al. (2024b) Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, and Bin Cui. 2024b. Retrieval-Augmented Generation for AI-Generated Content: A Survey. arXiv preprint arXiv:2402.19473 (2024).
- Zhao et al. (2024a) Shihao Zhao, Dongdong Chen, Yen-Chun Chen, Jianmin Bao, Shaozhe Hao, Lu Yuan, and Kwan-Yee K Wong. 2024a. Uni-ControlNet: All-in-One Control to Text-to-Image Diffusion Models. Advances in Neural Information Processing Systems 36 (2024).
- Zheng et al. (2024) Yixiao Zheng, Kaiyue Pang, Ayan Das, Dongliang Chang, Yi-Zhe Song, and Zhanyu Ma. 2024. CreativeSeg: Semantic Segmentation of Creative Sketches. IEEE Transactions on Image Processing 33 (2024), 2266–2278.
- Zhong et al. (2023) Shanshan Zhong, Zhongzhan Huang, Shanghua Gao, Wushao Wen, Liang Lin, Marinka Zitnik, and Pan Zhou. 2023. Let’s Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation. arXiv preprint arXiv:2312.02439 (2023).
- Zhou et al. (2023) Chenliang Zhou, Fangcheng Zhong, and Cengiz Öztireli. 2023. CLIP-PAE: Projection-Augmentation Embedding to Extract Relevant Features for a Disentangled, Interpretable and Controllable Text-Guided Face Manipulation. In ACM SIGGRAPH 2023 Conference Proceedings. 1–9.
- Zhu et al. (2024) Chenyang Zhu, Kai Li, Yue Ma, Chunming He, and Li Xiu. 2024. MultiBooth: Towards Generating All Your Concepts in an Image from Text. arXiv Preprint arXiv:2404.14239 (2024).
- Zhu et al. (2017) Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. 2017. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision. 2223–2232.
- Zubala et al. (2021) Ania Zubala, Nicola Kennell, and Simon Hackett. 2021. Art Therapy in the Digital World: An Integrative Review of Current Practice and Future Directions. Frontiers in Psychology 12 (2021), 600070.