Diffusion-based signal refiner for speech separation
Abstract
We have developed a diffusion-based speech refiner that improves the reference-free perceptual quality of the audio predicted by preceding single-channel speech separation models. Although modern deep neural network-based speech separation models have shown high performance in reference-based metrics, they often produce perceptually unnatural artifacts. The recent advancements made to diffusion models motivated us to tackle this problem by restoring the degraded parts of initial separations with a generative approach. Utilizing the denoising diffusion restoration model (DDRM) as a basis, we propose a shared DDRM-based refiner that generates samples conditioned on the global information of preceding outputs from arbitrary speech separation models. We experimentally show that our refiner can provide a clearer harmonic structure of speech and improves the reference-free metric of perceptual quality for arbitrary preceding model architectures. Furthermore, we tune the variance of the measurement noise based on preceding outputs, which results in higher scores in both reference-free and reference-based metrics. The separation quality can also be further improved by blending the discriminative and generative outputs.
Index Terms— speech separation, diffusion models, linear inverse problem
1 Introduction
Single-channel speech separation [1] is one of the most fundamental acoustic signal processing tasks and has been extensively studied as a front-end module for various downstream tasks such as speech recognition [2] and speaker verification [3]. It is widely known as a cocktail party problem that aims to extract each individual speech from a mixture of multiple speakers.
To solve this highly underdetermined problem, data-driven speech separation methods based on deep neural network models have been proposed [4, 5, 6] and performed well on reference-based metrics that require the ground truth signal, e.g., signal-to-noise ratio (SNR) [7], perceptual evaluation of speech quality (PESQ) [8], and short-time objective intelligibility (STOI) [9]. However, these metrics are still not a perfect to match human listening, as the models trained with them often introduce perceptually unnatural distortions that can be harmful for the downstream tasks [10].
Over the last few years, deep generative models such as variational auto-encoders (VAEs) [11, 12], generative adversarial networks (GANs) [13], and diffusion models [14] have been established as part of an unsupervised approach for providing extremely natural and high-quality samples. In particular, the relatively stable learning property of diffusion models has attracted many researchers in the vision field [15, 16]. Although their application to acoustic signal processing is not yet widespread (e.g., speech enhancement [17, 18, 19], dereverberation [20], and separation [21, 22, 23]), these outcomes show the effectiveness of diffusion models and are worth further investigation. Thus motivated, we apply a diffusion model to the speech separation task to improve the perceptual quality of the audio.
The application of diffusion models for speech separation can be classified into two major approaches. In the first, diffusion models are utilized to achieve separation and generation simultaneously [21, 22]. However, since multiple heavy tasks are required for a single model, the performance degrades compared to conventional discriminative models. The second approach refines the outputs of preceding discriminative models by using the diffusion model as a vocoder [23], which results in a better performance than the preceding estimates. The concept of the stochastic regeneration model (StoRM) [18], which was designed for speech enhancement and dereverberation tasks, is also close to this type. However, both of these approaches have their respective drawbacks. In [23], the separation quality is refined by summing up discriminative and generative outputs, where the weight coefficient is predicted by an additional alignment network. The generation, however, is conditioned only on the corresponding preceding estimate of the source and has not been fully investigated for a more flexible design, e.g., a generation with global information of all separated sources from the discriminative model. In [18], the preceding discriminative model and the diffusion-based regenerator are simultaneously trained in an end-to-end manner, which requires the diffusion model to be retrained whenever the preceding model or target dataset is changed.
In this paper, we propose a diffusion-based refiner for speech separation using the denoising diffusion restoration model (DDRM) [24]. DDRM is a conditional generative model that controls the generative output by solving an arbitrary linear inverse problem. Since the evidence lower bound (ELBO) [25] objective of DDRM is rewritten in the same form as that of the denoising diffusion probabilistic model (DDPM) [14], i.e., DDRM and DDPM have a common optimal solution, the proposed method can utilize a pretrained DDPM for the arbitrary preceding speech separation model. Another advantage of DDRM is that it can control the generation by changing the formulation of the linear inverse problem. This makes it possible to design more flexible systems, e.g., we can use a model that compensates by generation only for the area that is not confident in the preceding discriminative output while keeping the original signal for the area of high confidence.
2 Background
As stated above, DDRM features a carefully designed factorized variational distribution conditioned on the user-defined linear inverse problem and is ensured to have the same ELBO optimal value as DDPM [14]. Here, we briefly go through the mathematical formulation of DDPM and explain the powerful traits of DDRM that enable it to handle an arbitrary linear inverse problem with a single diffusion model.
2.1 Learning the data distribution using DDPM
DDPM is a deep generative model that aims to learn the model distributions of data that approximate an unknown data distribution . It generates a sample by following a Markov chain structure whose joint distribution is defined by the following reverse process:
| (1) |
To train the diffusion model, the forward process is defined as the factorized variational inference distribution
| (2) |
which is followed by an ELBO objective on the negative log likelihood. In practice, the distributions of and are assumed to be conditional Gaussian for all , and also follows a Gaussian distribution with variance . This leads to a reduction of the ELBO objective into the denoising autoencoder objective
| (3) |
where is a neural network to estimate given and is a series of tunable parameters.
2.2 Conditional generation with DDRM
DDRM is a diffusion model with a Markov chain structure conditioned on , where the joint distribution is defined as
| (4) |
The likelihood is characterized by the following linear inverse problem:
| (5) |
where is a known degradation matrix and is an i.i.d. additive Gaussian noise with known variance . The corresponding factorized variational distribution to (4) is defined in the same manner as DDPM, after which the ELBO objective is optimized (see detailed derivations in [24]).
DDRM can handle various linear inverse problem designs by switching a couple of variational distributions. The update of DDRM is conducted in a spectral space of the singular value decomposition (SVD) of . The measurements with zero singular value are likely to have no information of the index, so the update formula becomes similar to the regular unconditional generation. In contrast, components with non-zero singular values are further classified by the noise level of measurements in the spectral space compared to that of the diffusion model . The unique property of DDRM is that the ELBO optimal value also corresponds to that of DDPM under a couple of assumptions [14]. This enables us to inherit the pretrained unconditional DDPM as a good approximation to DDRM without having to re-train the diffusion model for different linear inverse problems each time.
3 Speech refiner with shared DDRM update

We propose a novel signal refiner for the -speaker separation problem based on the DDRM update that aims to improve the reference-free perceptual metrics while maintaining the performance of the reference-based metrics of discriminative models.
The overall framework consists of two main modules: a preceding speech separation model and a DDRM-based refiner, as shown in Fig. 1. At inference time, given mixture speech as an input, the first discriminative model separates the signal into tracks of individual speech. The outputs are then fed into the proposed refiner as measurements in the linear observation model, where each generated sample at diffusion step is updated integrally (we call this a shared DDRM update).
3.1 Observation design of refiner
Given the outputs of the preceding model , DDRM can simply refine each signal one by one with a linear observation, as
| (6) |
where is an additive Gaussian noise with known variance . However, this observation design, which we call isolated, gets rid of other speakers’ preceding outputs. This leads to poor refinement of the missing part of the target speech because the preceding models are not always perfect enough to separate out target speech components into a single output channel.
To fully leverage the available information and generate a faithful sample to the reference signal, a shared refiner is contrived with mixture signal as an additional measurement. Here, the observation of the mixture is given by
| (7) |
For example, if , the observation equation in (5) becomes
| (8) |
Let the SVD of be , where are orthogonal matrices and is a rectangular diagonal matrix containing the singular values of the degradation matrix in which . The proposed update is then summarized as Algorithm 1.
3.2 Discussion
Comparison with BASIS separation.
The proposed method was inspired by Bayesian annealed signal source (BASIS) separation [21], which was originally designed for an image separation task based on Langevin dynamics. With only a mixture signal observed, both separation and generation are performed simultaneously. Since the source separation is a highly underdetermined problem, the result under non-stochastic conditions is reportedly subpar with no separation, and reasonable separation can be achieved by performing stochastic noise conditioning and unbalanced user-defined weighting of each source. However, in our preliminary experiments, mixture signal alone seemed insufficient for the separation since each source is equally weighted in the speech separation scenario. Our proposed refiner avoids this innately underdetermined condition by using the outputs of the preceding model as additional measurements, which results in a determined problem.
Task-independent learning of diffusion model
StoRM [18] is a recently proposed speech enhancement (SE) technique that takes a stochastic regeneration approach in which forward and backward processes are applied to the output of a preceding model. However, since the preceding discriminative model and the subsequent diffusion-based regenerator in StoRM are simultaneously trained in an end-to-end manner, we need to retrain the diffusion model whenever the preceding models are changed. In contrast, the diffusion model used in the proposed refiner is preceding-model-agnostic and is theoretically applicable for arbitrary inverse problems, which enables us to inherit the same diffusion model for various designs of linear observation models without retraining.
4 Experiments
In this section, we verify the effectiveness of the proposed method on two-speaker speech separation from three perspectives. First, we compare the separation performance of both discriminative and generative refined results. Second, we evaluate the separation performance from the viewpoint of the design of measurement noise in (8). Finally, we investigate the blending of both discriminative and generative outputs to further improve audio quality.
4.1 Settings
Datasets and evaluation metrics
In this experiment, we used the single speaker subsets of WSJ0-2mix [26] for training. All samples were resampled to kHz. The separation performance was evaluated by both reference-based metrics (SI-SDR [7], PESQ [8], and ESTOI [9]) and a reference-free metric (non-intrusive speech quality assessment (NISQA) 111 https://github.com/gabrielmittag/NISQA [27]). NISQA is a deep neural network utilized to estimate the mean opinion score (MOS) of a target signal without any reference signal. Since the outputs of our generative refiner do not necessarily match the corresponding target reference, NISQA is an appropriate approximation of the perceptual quality of generated speech.
Pretrained separation models and generative refiners
Three pretrained speech separation models were taken from public repositories: Conv-TasNet222 https://zenodo.org/record/3862942#.ZDSjY3bP02w [4], Dual-Path RNN (DPRNN)333 https://zenodo.org/record/3903795#.ZDSjfXbP02w [5], and Sepformer444 https://huggingface.co/speechbrain/sepformer-wsj02mix [6]. All models were trained with the WSJ0-2mix dataset at kHz. As described in Sec.3, isolated and shared refiners were applied for the outputs of those models. The variance of the measurement noise in both refiners was fixed to .
Implementation details
The refiner adopted the U-Net architecture used in openAI guided-diffusion555 https://github.com/openai/guided-diffusion . The input feature was a complex STFT with the window size, hop size, and number of time frames set to , , and , respectively. The model was trained on a single NVIDIA A6000 for steps. An Adam optimizer with a learning rate of was used and the batch size was . An exponential moving average of the model weights was utilized in the evaluation with a weight decay of .
4.2 Results and analysis
| Method | SI-SDR | PESQ | ESTOI | NISQA |
|---|---|---|---|---|
| Clean | – | – | – | 3.53 |
| Mixture | 2.52 | 1.22 | 0.67 | 2.46 |
| Conv-TasNet | 17.5 | 2.93 | 0.92 | 3.20 |
| w/ isolated refiner | 16.8 | 1.97 | 0.92 | 3.76 |
| w/ shared refiner | 16.9 | 2.14 | 0.92 | 3.70 |
| DPRNN | 19.5 | 3.32 | 0.95 | 3.39 |
| w/ isolated refiner | 18.2 | 2.11 | 0.93 | 3.78 |
| w/ shared refiner | 18.6 | 2.36 | 0.94 | 3.73 |
| Sepformer (i) | 23.0 | 3.86 | 0.97 | 3.53 |
| w/ isolated refiner | 20.9 | 2.51 | 0.95 | 3.82 |
| w/ shared refiner (ii) | 22.0 | 2.94 | 0.96 | 3.76 |
| \hdashline (i)+(ii) blended at | 23.1 | 3.87 | 0.97 | 3.63 |

Table 1 lists the separation performance results of each method. As we can see, both the isolated and shared refiners exhibited a significant improvement of the reference-free NISQA, while the reference-based metrics were generally degraded as expected, since the output of the generative model did not necessarily match the ground truth. The shared refiner, however, could recover the performance of the reference-based metrics with a small decrease in NISQA, which corresponds to the hypothesis given in Sec.3 that the isolated refiner may cause a less faithful result to the ground truth. The processed examples are shown in Fig. 2. Thanks to using the proposed refiner, the clearness of the harmonics structure was improved and the non-speech ambient noise was sufficiently suppressed compared to the original output of the Sepformer.
Table 2 summarizes the performance change when different amounts of measurement noise were applied. Since the variance of measurement noise is a tunable parameter for each frequency bin and time frame, users can try a realistic scenario when designing the parameter. For example, since speech separation is basically difficult in areas where the interfering speech is loud, we consider a sigmoid design in which the variance of measurement noise is determined by the target-to-interference ratio of the signal. Specifically, let the variance for all frequency and time indices be
| (9) |
Here, we set , and to , and , respectively, and set the variance for mixture measurement to (same as in the first experiment). All results showed improvement in both reference-based and reference-free metrics, which indicates that choosing an appropriate value for improves the performance. We hypothesize that even larger gains are possible with other choices of .
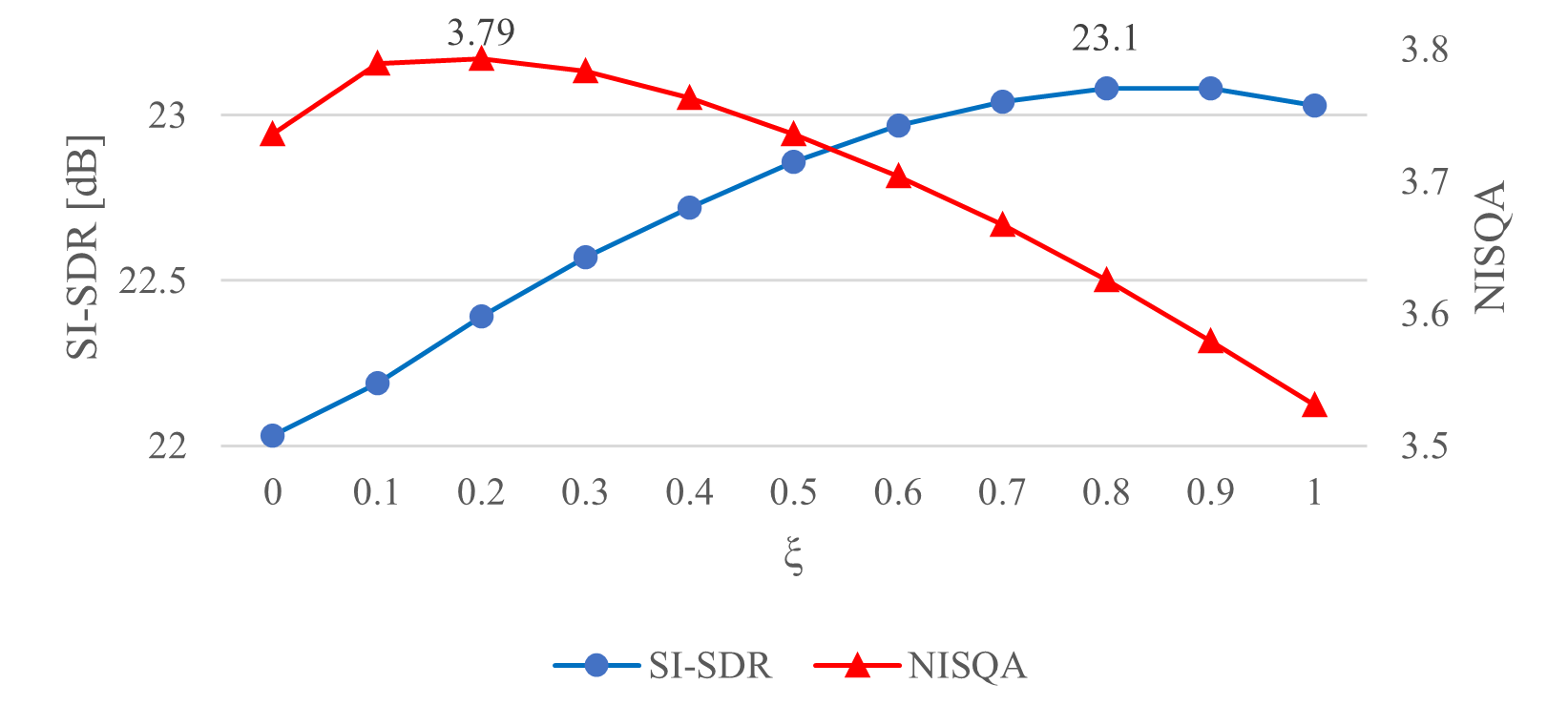
Finally, we can observe that the discriminative and generative outputs each have their own strengths: namely, discriminative outputs are better in the reference-based metrics while generative ones are better in the reference-free ones. This inspires a new hypothesis: i.e., that we can obtain further improved outputs by blending the discriminative output with the generative output by , where is a mixing weight. Fig. 3 shows the results when was changed in by the factor of . Here, we used the separations of Sepformer as a discriminative output and the shared refined outputs as a generative one. The blue and red lines respectively show the scores for SI-SDR and for NISQA. As we can see, there is a clear trade-off with these metrics: the highest SI-SDR was dB achieved at , and the highest NISQA was at . Both are higher than solely using either discriminative or generative output alone, which proves the effectiveness of the blending technique. One of the best blended results, (shown in Table 1), was superior to the original Sepformer in both reference-based and reference-free metrics.
| Method | SI-SDR | PESQ | NISQA | |
|---|---|---|---|---|
| Conv-TasNet | Fixed | 16.9 | 2.14 | 3.70 |
| Sigmoid | 17.0 | 2.26 | 3.77 | |
| DPRNN | Fixed | 18.6 | 2.36 | 3.73 |
| Sigmoid | 18.7 | 2.49 | 3.80 | |
| Sepformer | Fixed | 22.0 | 2.94 | 3.76 |
| Sigmoid | 22.0 | 3.07 | 3.80 |
5 Conclusion
In this paper, we proposed a shared DDRM-based refiner and showed that the performance of preceding models can be improved in terms of the reference-free metric. We also demonstrated that both reference-based and reference-free scores were improved by changing the design of the measurement noise in the DDRM update. Finally, we showed that simple mixing of the discriminative and generative outputs can further improve the separation quality.
In future work, we plan to investigate the design framework of the linear inverse problem. For example, we may consider using the uncertainty of the estimation of the discriminative model to choose the variance of the observation noise.
References
- [1] M. E. Davies and C. J. James, “Source separation using single channel ICA,” Signal Processing, vol. 87, no. 8, pp. 1819–1832, 2007.
- [2] A. B. Nassif, I. Shahin, I. Attili, M. Azzeh, and K. Shaalan, “Speech recognition using deep neural networks: A systematic review,” IEEE access, vol. 7, pp. 19 143–19 165, 2019.
- [3] F. Zhao, H. Li, and X. Zhang, “A robust text-independent speaker verification method based on speech separation and deep speaker,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 6101–6105.
- [4] Y. Luo and N. Mesgarani, “Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation,” IEEE/ACM transactions on audio, speech, and language processing, vol. 27, no. 8, pp. 1256–1266, 2019.
- [5] Y. Luo, Z. Chen, and T. Yoshioka, “Dual-path rnn: efficient long sequence modeling for time-domain single-channel speech separation,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 46–50.
- [6] C. Subakan, M. Ravanelli, S. Cornell, M. Bronzi, and J. Zhong, “Attention is all you need in speech separation,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 21–25.
- [7] J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “Sdr–half-baked or well done?” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 626–630.
- [8] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in 2001 IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No. 01CH37221), vol. 2. IEEE, 2001, pp. 749–752.
- [9] J. Jensen and C. H. Taal, “An algorithm for predicting the intelligibility of speech masked by modulated noise maskers,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 11, pp. 2009–2022, 2016.
- [10] T. Menne, R. Schlüter, and H. Ney, “Investigation into joint optimization of single channel speech enhancement and acoustic modeling for robust asr,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 6660–6664.
- [11] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [12] Y. Takida, T. Shibuya, W. Liao, C.-H. Lai, J. Ohmura, T. Uesaka, N. Murata, S. Takahashi, T. Kumakura, and Y. Mitsufuji, “Sq-vae: Variational bayes on discrete representation with self-annealed stochastic quantization,” arXiv preprint arXiv:2205.07547, 2022.
- [13] A. Creswell, T. White, V. Dumoulin, K. Arulkumaran, B. Sengupta, and A. A. Bharath, “Generative adversarial networks: An overview,” IEEE signal processing magazine, vol. 35, no. 1, pp. 53–65, 2018.
- [14] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in Neural Information Processing Systems, vol. 33, pp. 6840–6851, 2020.
- [15] A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen, “Glide: Towards photorealistic image generation and editing with text-guided diffusion models,” arXiv preprint arXiv:2112.10741, 2021.
- [16] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10 684–10 695.
- [17] Y.-J. Lu, Z.-Q. Wang, S. Watanabe, A. Richard, C. Yu, and Y. Tsao, “Conditional diffusion probabilistic model for speech enhancement,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7402–7406.
- [18] J.-M. Lemercier, J. Richter, S. Welker, and T. Gerkmann, “Storm: A diffusion-based stochastic regeneration model for speech enhancement and dereverberation,” arXiv preprint arXiv:2212.11851, 2022.
- [19] R. Sawata, N. Murata, Y. Takida, T. Uesaka, T. Shibuya, S. Takahashi, and Y. Mitsufuji, “A versatile diffusion-based generative refiner for speech enhancement,” arXiv preprint arXiv:2210.17287, 2022.
- [20] K. Saito, N. Murata, T. Uesaka, C.-H. Lai, Y. Takida, T. Fukui, and Y. Mitsufuji, “Unsupervised vocal dereverberation with diffusion-based generative models,” arXiv preprint arXiv:2211.04124, 2022.
- [21] V. Jayaram and J. Thickstun, “Source separation with deep generative priors,” in International Conference on Machine Learning. PMLR, 2020, pp. 4724–4735.
- [22] R. Scheibler, Y. Ji, S.-W. Chung, J. Byun, S. Choe, and M.-S. Choi, “Diffusion-based generative speech source separation,” arXiv preprint arXiv:2210.17327, 2022.
- [23] S. Lutati, E. Nachmani, and L. Wolf, “Separate and diffuse: Using a pretrained diffusion model for improving source separation,” arXiv preprint arXiv:2301.10752, 2023.
- [24] B. Kawar, M. Elad, S. Ermon, and J. Song, “Denoising diffusion restoration models,” arXiv preprint arXiv:2201.11793, 2022.
- [25] J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” in International Conference on Machine Learning. PMLR, 2015, pp. 2256–2265.
- [26] J. R. Hershey, Z. Chen, J. Le Roux, and S. Watanabe, “Deep clustering: Discriminative embeddings for segmentation and separation,” in 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2016, pp. 31–35.
- [27] G. Mittag, B. Naderi, A. Chehadi, and S. Möller, “Nisqa: A deep cnn-self-attention model for multidimensional speech quality prediction with crowdsourced datasets,” arXiv preprint arXiv:2104.09494, 2021.