Differentially Private Simple Linear Regression
Abstract.
Economics and social science research often require analyzing datasets of sensitive personal information at fine granularity, with models fit to small subsets of the data. Unfortunately, such fine-grained analysis can easily reveal sensitive individual information. We study algorithms for simple linear regression that satisfy differential privacy, a constraint which guarantees that an algorithm’s output reveals little about any individual input data record, even to an attacker with arbitrary side information about the dataset. We consider the design of differentially private algorithms for simple linear regression for small datasets, with tens to hundreds of datapoints, which is a particularly challenging regime for differential privacy. Focusing on a particular application to small-area analysis in economics research, we study the performance of a spectrum of algorithms we adapt to the setting. We identify key factors that affect their performance, showing through a range of experiments that algorithms based on robust estimators (in particular, the Theil-Sen estimator) perform well on the smallest datasets, but that other more standard algorithms do better as the dataset size increases.
1. Introduction
The analysis of small datasets, with sizes in the dozens to low hundreds, is crucial in many social science applications. For example, neighborhood-level household income, high school graduation rate, and incarceration rates are all studied using small datasets that contain sensitive, and often protected, data (e.g., (Chetty et al., 2018)). However, the release of statistical estimates based on these data quantities—if too many and too accurate—can allow reconstruction of the original dataset (Dinur and Nissim, 2003). The possibility of such attacks led to differential privacy (Dwork et al., 2006), a rigorous mathematical definition used to quantify privacy loss. Differentially private (DP) algorithms limit the information that is leaked about any particular individual by introducing random distortion. The amount of distortion, and its effect on utility, are most often studied for large datasets, using asymptotic tools. When datasets are small, one has to be very careful when calibrating differentially private statistical estimates to preserve utility.
In this work, we focus on simple (i.e. one-dimensional) linear regression and show that this prominent statistical task can have accurate differentially private algorithms even on small datasets. Our goal is to provide insight and guidance into how to choose a DP algorithm for simple linear regression in a variety of realistic parameter regimes.
Even without a privacy constraint, small sample sizes pose a problem for traditional statistics, since the variability from sample to sample, called the sampling error, can overwhelm the signal about the underlying trend. A reasonable concrete goal for a DP mechanism, then, is that it not introduce substantially more uncertainty into the estimate. Specifically, we compare the noise added in order to maintain privacy to the standard error of the (nonprivate) OLS estimate. Our experiments indicate that for a wide range of realistic datasets and moderate values of the privacy parameter, , it is possible to choose a DP linear regression algorithm that introduces distortion less than the standard error. In particular, in our motivating use-case of the Opportunity Atlas (Chetty et al., 2014), described below, we design a differentially private algorithm that matches or outperforms the heuristic method currently deployed, which does not formally satisfy differential privacy.
1.1. Problem Setup
1.1.1. Simple Linear Regression
In this paper we consider the most common model of linear regression: one-dimensional linear regression with homoscedastic noise. This model is defined by a slope , an intercept , a noise distribution with mean and variance , and the relationship
where . Our data consists of pairs, , where is the explanatory variable, is the response variable, and each random variable is draw i.i.d. from the distribution . The goal of simple linear regression is to estimate and given the data .
Let , . The Ordinary Least Squares (OLS) solution to the simple linear regression problem is the solution to the following optimization problem:
| (1) |
It is the most commonly used solution in practice since it is the maximum likelihood estimator when is Gaussian, and it has a closed form solution. We define the following empirical quantities:
Then
| (2) |
this paper, we focus on predicting the (mean of the) response variable at a single value of the explanatory variable . For , the prediction at is defined as:
Let be the estimate of the prediction at computed using the OLS estimates and . The quantity is a random variable, where the randomness is due to the sampling process. The standard error is an estimate of the standard deviation of . If we assume that the noise is Gaussian, then we can compute the standard error as follows (see (Yan and Su, 2009), for example):
| (3) |
It can be shown that the variance of approaches as increases.
1.1.2. Differential Privacy
In this section, we define the notion of privacy that we are using: differential privacy (DP). Since our algorithms often include hyperparameters, we include a definition of DP for algorithms that take as input not only the dataset, but also the desired privacy parameters and any required hyperparameters. Let be a data universe and be the space of datasets. Two datasets are neighboring, denoted , if they differ on a single record. Let be a hyperparameter space and be an output space.
Definition 1 (-Differential Privacy (Dwork et al., 2006)).
A randomized mechanism is differentially private if for all datasets , privacy-loss parameters , , and events ,
where the probabilities are taken over the random coins of .
For strong privacy guarantees, the privacy-loss parameter is typically taken to be a small constant less than (note that as ), but we will sometimes consider larger constants such as to match our motivating application (described in Section 1.2).
The key intuition for this definition is that the distribution of outputs on input dataset is almost indistinguishable from the distribution on outputs on input dataset . Therefore, given the output of a differentially private mechanism, it is impossible to confidently determine whether the input dataset was or .
1.1.3. Other Notation
The DP estimates will be denoted by and the OLS estimates by . We will focus on data with values bounded between 0 and 1, so for .
We will be primarily concerned with the predicted values at and , which for ease of notation we denote as and , respectively. Correspondingly, we will use to denote the OLS estimates of the predicted values and to denote the DP estimates. Our use of the 25th and 75th percentiles is motivated by the Opportunity Atlas tool (Chetty et al., 2018), described in Section 1.2, which releases estimates of and for certain regressions done for every census tract in each state.
1.1.4. Error Metric
We will be concerned primarily with empirical performance measures. In particular, we will restrict our focus to high probability error bounds that can be accurately computed empirically through Monte Carlo experiments. The question of providing tight theoretical error bounds for DP linear regression is an important one, which we leave to future work. Since the relationship between the OLS estimate and the true value is well-understood, we focus on measuring the difference between the private estimate and , which is something we can measure experimentally on real datasets. Specifically, we define the prediction error at to be
For a dataset , , and , we define the error bound as
where the dataset is fixed, and the probability is taken over the randomness in the DP algorithm.
We empirically estimate by running many trials of the algorithm on the same dataset :
We term the empirical error bound. We will often drop the reference to from the notation. This error metric only accounts for the randomness in the algorithm, not the sampling error.
When the ground truth is known (eg. for synthetically generated data), we can compute error bounds compared to the ground truth, rather than to the non-private OLS estimate. So, let and be similar to the error bounds described earlier, except that the prediction error is measured as . This error metric accounts for the randomness in both the sampling and the algorithm. When we say the noise added for privacy is less than the sampling error, we are referring to the technical statement that is less than the standard error, .
1.2. Motivating Use-Case: Opportunity Atlas
The Opportunity Atlas, designed and deployed by the economics research group Opportunity Insights, is an interactive tool designed to study the link between the neighbourhood a child grows up in and their prospect for economic mobility (Chetty et al., 2018). The tool provides valuable insights to researchers and policy-makers, and is built from Census data, protected under Title 13 and authorized by the Census Bureau’s Disclosure Review Board, linked with federal income tax returns from the US Internal Revenue Service. The Atlas provides individual statistics on each census tract in the country, with tract data often being refined by demographics to contain only a small subset of the individuals who live in that tract; for example, black male children with low parental income. The resulting datasets typically contain 100 to 400 datapoints, but can be as small as 30 datapoints. A separate regression estimate is released in each of these small geographic areas. The response variable is the child’s income percentile at age 35 and the explanatory variable is the parent’s income percentile, each with respect to the national income distribution. The coefficient in the model is a measure of economic mobility for that particular Census tract and demographic. The small size of the datasets used in the Opportunity Atlas are the result of Chetty et al.’s motivation to study inequality at the neighbourhood level: “the estimates permit precise targeting of policies to improve economic opportunity by uncovering specific neighborhoods where certain subgroups of children grow up to have poor outcomes. Neighborhoods matter at a very granular level: conditional on characteristics such as poverty rates in a child’s own Census tract, characteristics of tracts that are one mile away have little predictive power for a child’s outcomes” (Chetty et al., 2018).
1.3. Robustness and DP Algorithm Design
Simple linear regression is one of the most fundamental statistical tasks with well-understood convergence properties in the non-private literature. However, finding a differentially private estimator for this task that is accurate across a range of datasets and parameter regimes is surprisingly nuanced. As a first attempt, one might consider the global sensitivity (Dwork et al., 2006):
Definition 2 (Global Sensitivity).
For a query , the global sensitivity is
One can create a differentially private mechanism by adding noise proportional to . Unfortunately, the global sensitivity of and are both infinite (even though we consider bounded , the point estimates and are unbounded). For the type of datasets that we typically see in practice, however, changing one datapoint does not result in a major change in the point estimates. For such datasets, where the point estimates are reasonably stable, one might hope to take advantage of the local sensitivity:
Definition 3 (Local Sensitivity (Nissim et al., 2007)).
The local sensitivity of a query with respect to a dataset x is
Adding noise proportional to the local sensitivity is typically not differentially private, since the local sensitivity itself can reveal information about the underlying dataset. To get around this, one could try to add noise that is larger, but not too much larger, than the local sensitivity. As DP requires that the amount of noise added cannot depend too strongly on the particular dataset, DP mechanisms of this flavor often involve calculating the local sensitivity on neighbouring datasets. So far, we have been unable to design a computationally feasible algorithm for performing the necessary computations for OLS. Furthermore, computationally feasible upper bounds for the local sensitivity have, so far, proved too loose to be useful.
The Opportunity Insights (OI) algorithm takes a heuristic approach by adding noise proportional to a non-private, heuristic upper bound on the local sensitivity of data from tracts in any given state. However, their heuristic approach does not satisfy the formal requirements of differential privacy, leaving open the possibility that there is a realistic attack.
The OI algorithm incorporates a “winsorization” step in their estimation procedure (e.g. dropping bottom and top 10% of data values). This sometimes has the effect of greatly reducing the local sensitivity (and also their upper bound on it) due to the possible removal of outliers. This suggests that for finding an effective differentially private algorithm, we should consider differentially private analogues of robust linear regression methods rather than of OLS. Specifically, we consider Theil-Sen, a robust estimator for linear regression proposed by Theil (Theil, 1950) and further developed by Sen (Sen, 1968). Similar to the way in which the median is less sensitive to changes in the data than the mean, the Theil-Sen estimator is more robust to changes in the data than OLS .
In this work, we consider three differentially private algorithms based on both robust and non-robust methods:
-
•
NoisyStats is the DP mechanism that most closely mirrors OLS. It involves perturbing the sufficient statistics and from the OLS computation. This algorithm is inspired by the “Analyze Gauss” technique (Dwork et al., 2014), although the noise we add ensures pure differential privacy rather than approximate differential privacy. NoisyStats has two main benefits: it is as computationally efficient as its non-private analogue, and it allows us to release DP versions of the sufficient statistics with no extra privacy cost.
-
•
DPTheilSen is a DP version of Theil-Sen. The non-private estimator computes the estimates based on the lines defined by all pairs of datapoints for all , then outputs the median of these pairwise estimates. To create a differentially private version, we replace the median computation with a differentially private median algorithm. We will consider three DP versions of this algorithm which use different DP median algorithms: DPExpTheilSen, DPWideTheilSen, and DPSSTheilSen. We also consider more computationally efficient variants that pair points according to one or more random matchings, rather than using all pairs. A DP algorithm obtained by using one matching was previously considered by Dwork and Lei (Dwork and Lei, 2009) (their “Short-Cut Regression Algorithm”). Our algorithms can be viewed as updated versions, reflecting improvements in DP median estimation since (Dwork and Lei, 2009), as well as incorporating benefits accrued by considering more than one matching or all pairs.
-
•
DPGradDescent is a DP mechanism that uses DP gradient descent to solve the convex optimization problem that defines OLS: We use the private stochastic gradient descent technique proposed by Bassily et. al in (Bassily et al., 2014). Versions that satisfy pure, approximate, and zero-concentrated differential privacy are considered.
1.4. Our Results
Our experiments indicate that for a wide range of realistic datasets, and moderate values of , it is possible to choose a DP linear regression algorithm where the error due to privacy is less than the standard error. In particular, in our motivating use-case of the Opportunity Atlas, we can design a differentially private algorithm that outperforms the heuristic method used by the Opportunity Insights team. This is promising, since the error added by the heuristic method was deemed acceptable by the Opportunity Insights team for deployment of the tool, and for use by policy makers. One particular differentially private algorithm of the robust variety, called DPExpTheilSen, emerges as the best algorithm in a wide variety of settings for this small-dataset regime.
Our experiments reveal three main settings where an analyst should consider alternate algorithms:
-
•
When is large and is large, a DP algorithm NoisyStats that simply perturbs the Ordinary Least Squares (OLS) sufficient statistics, and , performs well. This algorithm is preferable in this setting since it is more computationally efficient, and allows for the release of noisy sufficient statistics without any additional privacy loss.
-
•
When the standard error is very small,
DPExpTheilSen can perform poorly. In this setting, one should switch to a different DP estimator based on Theil-Sen. We give two potential alternatives, which are both useful in different situations. -
•
The algorithm DPExpTheilSen requires as input a range in which to search for the output predicted value. If this range is very large and is small () then DPExpTheilSen can perform poorly, so it is good to use other algorithms like NoisyStats that do not require a range for the output (but do require that the input variables and are bounded, which is not required for DPExpTheilSen).
The quantity is connected to the size of the dataset, how concentrated the independent variable of the data is and how private the mechanism is. Experimentally, this quantity has proved to be a good indicator of the relative performance of the DP algorithms. Roughly, when is small, the OLS estimate can be very sensitive to small changes in the data, and thus we recommend switching to differentially private versions of the Theil-Sen estimator. In the opposite regime, when is large, NoisyStats typically suffices and is a simple non-robust method to adopt in practice. In this regime the additional noise added for privacy by NoisyStats can be less than the difference between the non-private OLS and Theil-Sen point estimates. The other non-robust algorithm we consider, DPGradDescent, may be a suitable replacement for NoisyStats depending on the privacy model used (i.e. pure, approximate, or zero-concentrated DP). Our comparison of NoisyStats and DPGradDescent is not comprehensive, but we find that any performance advantages of DPGradDescent over NoisyStats appear to be small in the regime where the non-robust methods outperform the robust ones. NoisyStats is simpler and has fewer hyperparameters, however, so we find that it may be preferable in practice.
In addition to the quantity , the magnitude of noise in the dependent variable effects the relative performance of the algorithms. When the dependent variable is not very noisy (i.e. is small), the Theil-Sen-based estimators perform better since they are better at leveraging a strong linear signal in the data.
These results show that even in this one-dimensional setting, the story is already quite nuanced. Indeed, which algorithm performs best depends on properties of the dataset, such as , which cannot be directly used without violating differential privacy. So, one has to make the choice based on guesses (eg. using similar public datasets) or develop differentially private methods for selecting the algorithm, a problem which we leave to future work. Moreover, most of our methods come with hyperparameters that govern their behavior. How to optimally choose these parameters is still an open problem. In addition, we focus on outputting accurate point estimates, rather than confidence intervals. Computing confidence intervals is an important direction for future work.
1.5. Other Related Work
Linear regression is one of the most prevalent statistical methods in the social sciences, and hence has been studied previously in the differential privacy literature. These works have included both theoretical analysis and experimental exploration, with the majority of work focusing on large datasets.
One of our main findings — that robust estimators perform better than parametric estimators in the differentially private setting, even when the data come from a parametric model — corroborate insights by (Dwork and Lei, 2009) with regard to the connection between robust statistics and differential privacy, and by (Couch et al., 2019) in the context of hypothesis testing.
Other systematic studies of DP linear regression have been performed by Sheffet (Sheffet, 2017) and Wang (Wang, 2018). Sheffet (Sheffet, 2017) considered differentially private ordinary least squares methods and estimated confidence intervals for the regression coefficients. He assumes normality of the explanatory variables, while we do not make any distributional assumptions on our covariates.
Private linear regression in the high-dimensional settings is studied by Cai et al. (Cai et al., 2019) and Wang (Wang, 2018). Wang (Wang, 2018) considered private ridge regression, where the ridge parameter is adaptively and privately chosen, using techniques similar to output perturbation (Chaudhuri et al., 2011). These papers present methods and experiments for high dimensional data (the datasets used contain at least 13 explanatory variables), whereas we are concerned with the one-dimensional setting. We find that even the one-dimensional setting the choice of optimal algorithm is already quite complex.
A Bayesian approach to DP linear regression is taken by Bernstein and Sheldon (Bernstein and Sheldon, 2019). Their method uses sufficient statistic perturbation (similar to our NoisyStats algorithm) for private release and Markov Chain Monte Carlo sampling over a posterior of the regression coefficients. Their Bayesian approach can produce tight credible intervals for the regression coefficients, but unlike ours, requires distributional assumptions on both the regression coefficients and the underlying independent variables. In order to make private releases, we assume the data is bounded but make no other distributional assumptions on the independent variables.
2. Algorithms
In this section we detail the practical differentially private algorithms we will evaluate experimentally. Pseudocode for all efficient implementations of each algorithm described can be found in the Appendix, and real code can be found in our GitHub repository. We will assume throughout that , as in the Opportunity Atlas, where it is achieved by preprocessing of the data. While we would ideally ensure differentially private preprocessing of the data, we will consider this outside the scope of this work.
2.1. NoisyStats
In NoisyStats (Algorithm 1), we add Laplace noise, with standard deviation approximately , to the OLS sufficient statistics, , and then use the noisy sufficient statistics to compute the predicted values. Note that this algorithm fails if the denominator for the OLS estimator, the noisy version of , becomes 0 or negative, in which case we output (failure). The probability of failure decreases as or increases. NoisyStats is the simplest and most efficient algorithm that we will study. In addition, the privacy guarantee is maintained even if we additionally release the noisy statistics and , which may be of independent interest to researchers. We also note that the algorithm is biased due to dividing by a Laplacian distribution centered at .
Lemma 1.
Algorithm 1 (NoisyStats) is -DP.
2.2. DP TheilSen
The standard Theil-Sen estimator is a robust estimator for linear regression. It computes the estimates based on the lines defined by all pairs of datapoints for all , then outputs the median of these pairwise estimates. To create a differentially private version, we can replace the median computation with a differentially private median algorithm. We implement this approach using three DP median algorithms; two based on the exponential mechanism (McSherry and Talwar, 2007) and one based on the smooth sensitivity of (Nissim et al., 2007) and the noise distributions of (Bun and Steinke, 2019).
In the “complete” version of Theil-Sen, all pairwise estimates are included in the final median computation. A similar algorithm can be run on the point estimates computed using random matchings of the pairs. The case amounts to the differentially private “Short-cut Regression Algorithm” proposed by Dwork and Lei (Dwork and Lei, 2009). This results in a more computationally efficient algorithm.
Furthermore, while in the non-private setting is the optimal choice, this is not necessarily true when we incorporate privacy. Each datapoint affects of the datapoints in (using the notation from Algorithm 2) out of the total datapoints. In some private algorithms, the amount of noise added for privacy is a function of the fraction of points in influenced by each , which is independent of – meaning that one should always choose as large as is computationally feasible. However, this is not always the case. Increasing can result in more noise being added for privacy resulting in a trade-off between decreasing the noise added for privacy (with smaller ) and decreasing the non-private error (with larger ).
While intuitively, for small , one can think of using random matchings, we will actually ensure that no edge is included twice. We say the permutations are a decomposition of the complete graph on vertices, into matchings if where . Thus, DPTheilSen(n-1)Match, referred to simply as DPTheilSen, uses all pairs of points. We will focus mainly on , which we will refer to simply as DPTheilSen and , which we will refer to as DPTheilSenMatch. For any other , we denote the algorithm as DPTheilSenkMatch. In the following subsections we discuss the different differentially private median algorithms we use as subroutines. The pseudo-code for DPTheilSenkMatch is found in Algorithm 2.
Lemma 2.
If DPmed for some -DP mechanism , then Algorithm 2 (DPTheilSenkMatch) is -DP.
2.2.1. DP Median using the Exponential Mechanism
The first differentially private algorithm for the median that we will consider is an instantiation of the exponential mechanism (McSherry and Talwar, 2007), a differentially private algorithm designed for general optimization problems. The exponential mechanism is defined with respect to a utility function , which maps (dataset, output) pairs to real values. For a dataset z, the mechanism aims to output a value that maximizes .
Definition 3 (Exponential Mechanism (McSherry and Talwar, 2007)).
Given dataset and the range of the outputs, , the exponential mechanism outputs with probability proportional to , where
One way to instantiate the exponential mechanism to compute the median is by using the following utility function. Let
where #above and #below denote the number of datapoints in z that are above and below in value respectively, not including itself. An example of the shape of the output distribution of this algorithm is given in Figure 1. An efficient implementation is given in the Appendix.

We will write DPExpTheilSenkMatch to refer to DPTheilSenkMatch where DPmed is the DP exponential mechanism described above with privacy parameter . Again, we write DPExpTheilSenMatch when and DPExpTheilSen when .
Lemma 4.
DPExpTheilSenkMatch is -DP.
2.2.2. DP Median using Widened Exponential Mechanism
When the output space is the real line, the standard exponential mechanism for the median has some nuanced behaviour when the data is highly concentrated. For example, imagine in Figure 1 if all the datapoints coincided. In this instance, DPExpTheilSen is simply the uniform distribution on , despite the fact that the median of the dataset is very stable. To mitigate this issue, we use a variation on the standard utility function. For a widening parameter , the widened utility function is
where #above and #below are defined as before. This has the effect of increasing the probability mass around the median, as shown in Figure 2.

The parameter needs to be carefully chosen. All outputs within of the median are given the same utility score, so represents a lower bound on the error. Conversely, choosing too small may result in the area around the median not being given sufficient weight in the sampled distribution. Note that is only required when one expects the datasets to be highly concentrated (for example when the dataset has strong linear signal). We defer the question of optimally choosing to future work.
An efficient implementation of the -widened exponential mechanism for the median can be found in
the Appendix as Algorithm 4. We will use DPWideTheilSenkMatch to refer to DPTheilSenkMatch where DPmed is the -widened exponential mechanism with privacy parameter . Again, we use
DPWideTheilSenMatch when and DPWideTheilSen when .
Lemma 5.
DPWideTheilSenkMatch is -DP.
2.2.3. DP Median using Smooth Sensitivity Noise Addition
The final algorithm we consider for releasing a differentially private median adds noise scaled to the smooth sensitivity – a smooth upper bound on the local sensitivity function. Intuitively, this algorithm should perform well when the datapoints are clustered around the median; that is, when the median is very stable.
Definition 6 (Smooth Upper Bound on (Nissim et al., 2007)).
For , a function is a -smooth upper bound on the local sensitivity of a function if:
where is the distance between datasets z and .
Let to denote the function that transforms a set of point coordinates into estimates for each pair of points in our matchings, so in the notation of Algorithm 2, . The function that we are concerned with the smooth sensitivity of is med, which maps to med. We will use the following smooth upper bound to the local sensitivity:
Lemma 7.
Let be a sorting of . Then
is a -smooth upper bound on the local sensitivity of med.
Proof.
Proof in the Appendix. ∎
The algorithm then adds noise proportional to to med. A further discussion of the formula and pesudo-code can be found in Appendix E. The noise is sampled from the Student’s T distribution. There are several other valid choices of noise distributions (see (Nissim et al., 2007) and (Bun and Steinke, 2019)), but we found the Student’s T distribution to be preferable as the mechanism remains stable across values of
Lemma 8.
DPSSTheilSenkMatch is -DP.
2.3. DP Gradient Descent
Ordinary Least Squares (OLS) for simple 1-dimensional linear regression is defined as the solution to the optimization problem
There has been an extensive line of work on solving convex optimization problems in a differentially private manner. We use the private gradient descent algorithm of (Bassily et al., 2014) to provide private estimates of the 0.25, 0.75 predictions . This algorithm performs standard gradient descent, except that noise is added to a clipped version of the gradient at each round (clipped to range for some setting of ). The number of calls to the gradient needs to be chosen carefully since we have to split our privacy budget amongst the gradient calls. We note that we are yet to fully explore the full suite of parameter settings for this method. See the Appendix for pseudo-code for our implementation and (Bassily et al., 2014) for more information on differentially private stochastic gradient descent. We consider three versions of DPGradDescent: DPGDPure, DPGDApprox, and DPGDzCDP, which are -DP, -DP, and -zCDP algorithms, respectively. Zero-concentrated differential privacy (zCDP) is a slightly weaker notion of differential privacy that is well suited to iterative algorithms. For the purposes of this paper, we set whenever DPGDApprox is run, and set the privacy parameter of DPGDzCDP to allow for a fair comparison. DPGDPure provides the strongest privacy guarantee followed by DPGDApprox and then DPGDzCDP. As expected, DPGDzCDP typically has the best performance.
2.4. NoisyIntercept
We also compare the above DP mechanisms to simply adding noise to the average -value. For any given dataset , this method computes and outputs a noisy estimate as the predicted estimates. This method performs well when the slope is very small.
2.5. A Note on Hyperparameters
We leave the question of how to choose the optimal hyperparameters for each algorithm to future work. Unfortunately, since the optimal hyperparameter settings may reveal sensitive information about the dataset, one can not tune the hyperparameters on a hold-out set. However, we found that for most of the hyperparameters, once a good choice of hyperparameter setting was found, it could be used for a variety of similar datasets. Thus, one realistic way to tune the parameters may be to tune on a public dataset similar to the dataset of interest. For example, for applications using census data, one could tune the parameters on previous years’ census data.
We note that, as presented here, NoisyStats requires no hyperparameter tuning, while DPExpTheilSen and DPSSTheilSen only require a small amount of tuning (they require upper and lower bounds on the output). However, NoisyStats requires knowledge of the range of the inputs , which is not required by the Theil-Sen methods. Both DPGradDescent and DPWideTheilSen can be quite sensitive to the choice of hyperparameters. In fact, DPExpTheilSen is simply DPWideTheilSen with , and we will often see a significant difference in the behaviour of these algorithms. Preliminary experiments on the robustness of DPWideTheilSen to the choice of can be found in the Appendix.
3. Experimental Outline
The goal of this work is to provide insight and guidance into what features of a dataset should be considered when choosing a differentially private algorithm for simple linear regression. As such, in the following sections, we explore the behavior of these algorithms on a variety of real datasets. We also consider some synthetic datasets where we can further explore how properties of the dataset affect performance.
3.1. Description of the Data
3.1.1. Opportunity Insights data
The first dataset we consider is a simulated version of the data used by the Opportunity Insights team in creating the Opportunity Atlas tool described in Section 1.2. In the appendix, we describe the data generation process used by the Opportunity Insights team to generate the simulated data. Each datapoint, , corresponds to a pair, (parent income percentile rank, child income percentile rank) , where parent income is defined as the total pre-tax income at the household level, averaged over the years 1994-2000, and child income is defined as the total pre-tax income at the individual level, averaged over the years 2014-2015 when the children are between the ages of 31-37. In the Census data, every state in the United States is partitioned into small neighborhood-level blocks called tracts. We perform the linear regression on each tract individually. The “best” differentially private algorithm differs from state to state, and even tract to tract. We focus on results for Illinois (IL) which has a total of datapoints divided among 3,108 tracts. The individual datasets (corresponding to tracts in the Census data) each contain between and datapoints. The statistic ranges between 0 and 25, with the majority of tracts having . We use in all our experiments on this data since that is the value approved by the Census for, and currently used in, the release of the Opportunity Atlas (Chetty et al., 2018).
3.1.2. Washington, DC Bikeshare UCI Dataset
Next, we consider a family of small datasets containing data from the Capital Bikeshare system, in Washington D.C., USA, from the years 2011 and 2012111This data is publicly available at http://capitalbikeshare.com/system-data (Fanaee-T and Gama, 2013).. Each datapoint of the dataset contains the temperature () and user count of the bikeshare program () for a single hour in 2011 or 2012. The and values are both normalized so that they lie between 0 and 1 by a linear rescaling of the data. In order to obtain smaller datasets to work with, we segment this dataset into 288 (12x24) smaller datasets each corresponding to a (month, hour of the day) pair. Each smaller dataset contains between and datapoints. We linearly regress the number of active users of the bikeshare program on the temperature. While the variables are positively correlated, the correlation is not obviously linear — in that the data is not necessarily well fit by a line — within many of these datasets, so we see reasonably large standard error values ranging between 0.0003 and 0.32 for this data. Note that our privacy guarantee is at the level of hours rather than individuals so it serves more as an example to evaluate the utility of our methods, rather than a real privacy application. While this is an important distinction to make for deployment of differential privacy, we will not dwell on it here since our goal to evaluate the statistical utility of our algorithms on real datasets. An example of one of these datasets is displayed in Figure 3.

3.1.3. Carbon Nanotubes UCI Dataset
While we are primarily concerned with evaluating the behavior of the private algorithms on small datasets, we also present results on a good candidate for private analysis: a large dataset with a strong linear relationship. In contrast to the Bikeshare UCI data and the Opportunity Insights data, this is a single dataset, rather than a family of datasets. This data is drawn from a dataset studying atomic coordinates in carbon nanotubes (Aci and Avci, 2016). For each datapoint , is the -coordinate of the initial atomic coordinates of a molecule and is the -coordinate of the calculated atomic coordinates after the energy of the system has been minimized. After we filtered out all points that are not contained in , the resulting dataset contains datapoints. A graphical representation of the data is included in Figure 4. Due to the size of this dataset, we run the efficient DPTheilSenMatch algorithm with on this dataset. This dataset does not contain sensitive information, however we have included it to evaluate the behaviour of the DP algorithms on a variety of real datasets.

3.1.4. Stock Exchange UCI Dataset
Our final real dataset studies the relationship between the Istanbul Stock Exchange and the USD Stock Exchange (Akb, 2013). 222This dataset was collected from imkb.gov.tr and finance.yahoo.com. It compares { Istanbul Stock Exchange national 100 index} to { the USD International Securities Exchange}. This dataset has datapoints and a representation is included in Figure 5. This is a a smaller, noisier dataset than the Carbon Nanotubes UCI dataset.

3.1.5. Synthetic Data
The synthetic datasets were constructed by sampling , for , independently from a uniform distribution with and variance . For each , the corresponding is generated as , where , and is sampled from . The datapoints are then clipped to the box . The DP algorithms estimate the prediction at using privacy parameter .
The values of , , , , and vary across the individual experiments. The synthetic data experiments are designed to study which properties of the data and privacy regime determine the performance of the private algorithms. Thus, in these experiments, we vary one of parameters listed above and observe the impact on the accuracy of the algorithms and their relative performance to each other. Since we know the ground truth on this synthetically generated data, we plot empirical error bounds that take into account both the sampling error and the error due to the DP algorithms, . We evaluate DPTheilSenkMatch with in the synthetic experiments rather than DPTheilSen, since the former is computationally more efficient and still gives us insight into the performance of the latter.
3.2. Hyperparameters
| Algorithms | OI/UCI data | Synthetic data |
|---|---|---|
| NoisyStats | None | None |
| NoisyIntercept | None | N/A |
| DPExpTheilSen | ||
| DPWideTheilSen | , | |
| DPSSTheilSen | , | |
| DPGradDescent | , T = 80 | , T = 80 |
Hyperparameters were tuned on the semi-synthetic Opportunity Insights data by experimenting with many different choices, and choosing the best. The hyperparameters are listed in Table 1. We leave the question of optimizing hyperparameters in a privacy-preserving way to future work. Hyperparameters for the UCI and synthetic datasets were chosen according to choices that seemed to perform well on the Opportunity Insights datasets. This ensures that the hyperparameters were not tuned to the specific datasets (ensuring validity of the privacy guarantees), but also leaves some room for improvement in the performance by more careful hyperparameter tuning.
4. Results and Discussion
In this section we discuss the findings from the experiments described in the previous section. In the majority of the real datasets tested, DPExpTheilSen is the best performing algorithm. We’ll discuss some reasons why DPExpTheilSen performs well, as well as some regimes when other algorithms perform better.
A note on the statement of privacy parameters in the experiments. We will state the privacy budget used to compute the pair , however we will only show empirical error bounds for . The empirical error bounds for display similar phenomena. The algorithms NoisyStats and DPGradDescent inherently release both point estimates together so the privacy loss is the same whether we release the pair or just . However, DPExpTheilSen, DPExpWideTheilSen, DPSSTheilSen and the algorithm used by the Opportunity Insights team use half their budget to release and half their budget to release , separately.
4.1. Real Data and the Opportunity Insights Application
Figure 6 shows the results of all the DP linear regression algorithms, as well as the mechanism used by the Opportunity Insights team, on the Opportunity Insights data for the states of Illinois and North Carolina. For each algorithm, we build an empirical cumulative density distribution of the empirical error bounds set over the tracts in that state. The vertical dotted line in Figures 6 intercepts each curve at the point where the noise due to privacy exceeds the standard error. The Opportunity Insights team used a heuristic method inspired by, but not satisfying, DP to deploy the Opportunity Altas (Chetty et al., 2018). Their privacy parameter of was selected by the Opportunity Insights team and a Census Disclosure Review Board by balancing the privacy and utility considerations. Figure 6 shows that there exist differentially private algorithms that are competitive with, and in many cases more accurate than, the algorithm currently deployed in the Opportunity Atlas.
Additionally, while the methods used by the Opportunity Insights team are highly tailored to their setting relying on coordination across Census tracts, in order to compute an upper bound on the local sensitivity, as discussed in Section 1.3, the formally differentially private methods are general-purpose and do not require coordination across tracts.


Figures 7 shows empirical cumulative density distributions of the empirical error bounds on the 288 datasets in the Bikeshare dataset. Figure 8 shows the empirical cumulative density function of the output distribution on the Stockexchange dataset. Note that this is a different form to the empirical CDFs which appear in Figure 6 and Figure 7. Figure 9(a) shows the empirical cumulative density function of the output distribution on the Carbon Nanotubes dataset. Figures 7, 8 and 9(a) show that on the three other real datasets, for a range of realistic values the additional noise due to privacy, in particular using DPExpTheilSen, is less than the standard error.




4.2. Robustness vs. Non-robustness: Guidance for Algorithm Selection
The DP algorithms we evaluate can be divided into two classes, robust DP estimators based on Theil-Sen — DPSSTheilSen, DPExpTheilSen and DPWideTheilSen — and non-robust DP estimators based on OLS — NoisyStats and GradDescent. Experimentally, we found that the algorithm’s behaviour tend to be clustered in these two classes, with the robust estimators outperforming the non-robust estimators in a wide variety of parameter regimes. In most of the experiments we saw in the previous section (Figures 6, 7, 8 and, 9(a)), DPExpTheilSen was the best performing algorithm, followed by DPWideTheilSen and DPSSTheilSen. However, below we will see that in experiments on synthetic data, we found that the non-robust estimators outperform the robust estimators in some parameter regimes.
4.2.1. NoisyStats and DPExpTheilSen
In Figure 10, we investigate the relative performance () of the algorithms in several parameter regimes of , and on synthetically generated data. For each parameter setting, for each algorithm, we plot of the average value of over trials on a single dataset, and average again over independently sampled datasets. Across large ranges for each of these three parameters (; ; , all varied on a logarithmic scale), we see that either DPExpTheilSen, DPGDzCDP, or NoisyStats is consistently the best performing algorithm—or close to it. Note that of these three algorithms, only DPExpTheilSen and NoisyStats fulfill the stronger pure -DP privacy guarantee. We see that DPGDzCDP and NoisyStats trend towards taking over as the best algorithms as increases.
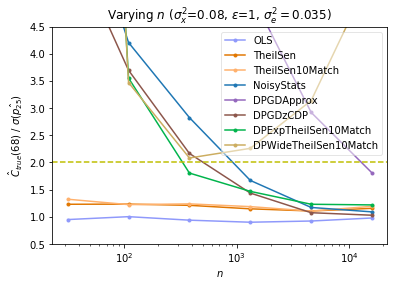








For parameter regimes in which the non-robust algorithms outperform the robust estimators, NoisyStats is preferable to DPGDzCDP since it is more efficient, requires no hyperparameter tuning (except bounds on the inputs and ), fulfills a stronger privacy guarantee, and releases the noisy sufficient statistics with no additional cost in privacy. Experimentally, we find that the main indicator for deciding between robust estimators and non-robust estimators is the quantity (which is a proxy for ). Roughly, when and are both large, NoisyStats is close to optimal among the DP algorithms tested; otherwise, the robust estimator DPExpTheilSen typically has lower error. Hyperparameter tuning and the quantity also play minor roles in determining the relative performance of the algorithms.
4.2.2. Role of
The quantity is related to the size of the dataset, how concentrated the independent variable of the data is and how private the mechanism is. It appears to be a better indicator of the performance of DP mechanisms than any of the individual statistics , or in isolation. In Figure 11 we compare the performance of NoisyStats and DPExpTheilSen10Match as we vary and . For each parameter setting, for each algorithm, the error is computed as the average error over trials and independently sampled datasets. Notice that the blue line presents the error of the non-private OLS estimator, which is our baseline. The quantity we control in these experiments is , although we expect this to align closely with , which is the empirically measurable quantity. In all of our synthetic data experiments, in which the ’s are uniform and the ’s are Gaussian, once and , NoisyStats is close to the best performing algorithm. It is also important to note that once is large, both NoisyStats and DPExpTheilSen perform well. See Figure 11 for a demonstration of this on the synthetic data.
The error, as measured by , of both OLS and Theil-Sen estimators converges to 0 as at the same asymptotic rate. However, OLS converges a constant factor faster than Theil-Sen resulting in its superior performance on relatively large datasets. As increases, the error of NoisyStats decreases, and the outputs of this algorithm concentrate around the OLS estimate. While the outputs of DPExpTheilSen tend to be more concentrated, they converge to the Theil-Sen estimate, which has higher sampling error. Thus, as we increase , eventually the additional noise due to privacy added by NoisyStats is less than the difference between the OLS and Theil-Sen point estimates, resulting in NoisyStats outperforming DPExpTheilSen. This phenomenon can be seen in Figure 10 and Figure 11.
The classifying power of is a result of its impact on the performance of NoisyStats. Recall that NoisyStats works by using noisy sufficient statistics within the closed form solution for OLS given in Equation 2. The noisy sufficient statistic , appears in the denominator of this closed form solution. When is small, this noisy sufficient statistic has constant mass concentrated near, or below, 0, and hence the inverse, , which appears in the NoisyStats, can be an arbitrarily bad estimate of . In contrast, when is large, the distribution of is more concentrated around , so that with high probability is close to .
In Figures 10(a), 10(b) and 10(c), the performance of all the algorithms, including NoisyStats and DPExpTheilSen, are shown as we vary each of the parameters and , while holding the other variables constant, on synthetic data. In doing so, each of these plots is effectively varying as a whole. These plots suggest that all three parameters help determine which algorithm is the most accurate. Figure 11 confirms that is a strong indicator of the relative performance of NoisyStats and DPExpTheilSen, even as other variables in the OLS standard error equation (3) – including the variance of the noise of the dependent variable, , and the difference between and the mean of the values, – are varied.
4.2.3. The Role of
One main advantage that all the DPTheilSen algorithms have over NoisyStats is that they are better able to adapt to the specific dataset. When is small, there is a strong linear signal in the data that the non-private OLS estimator and the DPTheilSen algorithms can leverage. Since the noise addition mechanism of NoisyStats does not leverage this strong signal, its relative performance is worse when is small. Thus, affects the relative performance of the algorithms, even when is large. We saw this effect in Figure 9(a) on the Carbon Nanotubes UCI data, where is large, but NoisyStats performed poorly relative to the DPTheilSen algorithms.
In each of the plots 11(a), 11(c), and 11(e), the quantity is held constant while is varied. These plots confirm that the performance of NoisyStats degrades, relative to other algorithms, when is small. As increases, the relative performance of NoisyStats improves until it drops below the relative performance of the TheilSen estimates. The cross-over point varies with . In Figure 11(a), we see that when is small, the methods based on Theil-Sen are the better choice for all values of studied. When we increase in Figure 11(e) we see a clear cross over point. These plots add evidence to our conjecture that robust estimators are a good choice when and are both small, while non-robust estimators perform well when is large.
4.2.4. The Role of
The final factor we found that plays a role in the relative performance of NoisyStats and DPExpTheilSen is . This effect is less pronounced than that of or , and seems to rarely change the ordering of DP algorithms. In Figures 11(b), 11(d) and 11(f), we explore the effect of this quantity on the relative performance of OLS, TheilSen10Match, DPExpTheilSen10Match, and NoisyStats. We saw in Equation 3 that affects the standard error - the further is from the centre of the data, , the less certain we are about the OLS point estimate. All algorithms have better performance when is small; however, this effect is most pronounced with NoisyStats. In NoisyStats, where and and are the noisy slope and intercepts respectively. Thus, we expect a large to amplify the error present in . We vary between 0 and 1. As expected, the error is minimized when , since . Since we expect the error in to decrease as we increase , this explains why the quantity has a larger effect when is small.
4.2.5. The Role of Hyperparameter Tuning
A final major distinguishing feature between the DPTheilSen algorithms, NoisyStats and DPGradDescent is the amount of prior knowledge needed by the data analyst to choose the hyperparameters appropriately. Notably, NoisyStats does not require any hyperparameter tuning other than a bound on the data. The DPTheilSen algorithms require some reasonable knowledge of the range that and lie in in order to set and . Finally, DPGradDescent requires some knowledge of where the input values lie, so it can set and .
In Figure 9(b), NoisyStats and all three DPGradDescent algorithms outperform the robust estimators. This experiment differs from Figure 9(a) in two important ways: the privacy parameter has decreased from 1 to 0.01, and the feasible output region for the DP TheilSen methods has increased from to . When is large, the DPTheilSen algorithms are robust to the choice of this region since any area outside the range of the data is exponentially down weighted (see Figure 1). However, when is small, the size of this region can have a large effect on the stability of the output. As decreases, the output distributions of the DPTheilSen estimators are flattened, so that they are essentially sampling from the uniform distribution on the range of the parameter. This effect likely explains the poor performance of the robust estimators in Figure 9(b), and highlights the importance of choosing hyperparameters carefully. If is small ( much less than 1) and the analyst does not have a decent estimate of the range of , then NoisyStats may be a safer choice than DPTheilSen.
4.3. Which robust estimator?
In the majority of the regimes we have tested, DPExpTheilSen outperforms all the other private algorithms. While DPSSTheilSen can be competitive with DPExpTheilSen and DPWideTheilSen, it rarely seems to outperform them. However, DPWideTheilSen can significantly outperform DPExpTheilSen when the standard error is small. Figure 12 compares the performance of DPExpTheilSen and DPWideTheilSen on the Bikeshare UCI data. When there is little noise in the data we expect the set of pairwise estimates that Theil-Sen takes the median of to be highly concentrated. We discussed in Section 2.2 why this is a difficult setting for DPExpTheilSen: in the continuous setting, the exponential mechanism based median algorithm can fail to put sufficient probability mass around the median, even if the data is concentrated at the median (see Figure 1). DPWideTheilSen was designed exactly as a fix to this problem. The parameter needs to be chosen carefully. In Figure 9(a), is set to be much larger than the standard error, resulting in DPWideTheilSen performing poorly.

4.4. Which non-robust estimator?
There are two main non-robust estimators we consider: DPGradDescent and NoisyStats. DPGradDescent has three versions – DPGDPure, DPGDApprox, and DPGDzCDP – corresponding to the pure, approximate, and zero-concentrated variants. Amongst the DPGradDescent algorithms, as expected, DPGDzCDP provides the best utility followed by DPGDApprox, and then DPGDPure. But how do these compare to NoisyStats? NoisyStats outperforms both DPGDPure and DPGDApprox for small (e.g. in our experiments). DPGDzCDP consistently outperforms NoisyStats, but the gap in performance is small in the regime where the non-robust estimators beat the robust estimators. Moreover, NoisyStats achieves a stronger privacy guarantee (pure -DP rather than -zCDP). A fairer comparison is to use the natural -zCDP analogue of NoisyStats (using Gaussian noise and zCDP composition), in which case we have found that the advantage of DPGDzCDP significantly shrinks and in some cases is reversed. (Experiments omitted.)
The performance of the DPGradDescent algorithms also depend on hyperparameters that need to be carefully tuned, such as the number of gradient calls and the clip range . Since NoisyStats requires less hyperparameters, this makes DPGradDescent potentially harder to use in practice. In addition, NoisyStats is more efficient and can be used to release the noisy sufficient statistics with no additional privacy loss. Since the performance of the two algorithms is similar in the regime where non-robust methods appear to have more utility than the robust ones, the additional benefits of NoisyStats may make it preferable in practice.
We leave a more thorough evaluation and optimization of these algorithms in the regime of large , including how to optimize the hyperparameters in a DP manner, to future work.
4.5. Analyzing the bias
Let be the prediction estimates produced using the non-private TheilSen estimator. The non-robust DP methods – NoisyStats and DPGradDescent – approach as , while the DPTheilSen methods approach as . For any fixed dataset, and are not necessarily equal. A good representation of this bias can be seen in Figure 9(a). However, both the TheilSen estimator and the OLS estimator are consistent unbiased estimators of the true slope in simple linear regression. That is, as , both and tend to the true value . Thus, all the private algorithms output the true prediction estimates as , for a fixed .
5. Conclusion
It is possible to design DP simple linear regression algorithms where the distortion added by the private algorithm is less than the standard error, even for small datasets. In this work, we found that in order to achieve this we needed to switch from OLS regression to the more robust linear regression estimator, Theil-Sen. We identified key factors that analysts should consider when deciding whether DP methods based on robust or non-robust estimators are right for their application.
Acknowledgements.
We thank Raj Chetty, John Friedman, and Daniel Reuter from Opportunity Insights for many motivating discussions, providing us with simulated Opportunity Atlas data for our experiments, and helping us implement the OI algorithm. We also thank Cynthia Dwork and James Honaker for helpful conversations at an early stage of this work; Garett Bernstein and Dan Sheldon for discussions about their work on private Bayesian inference for linear regression; Sofya Raskhodnikova, Thomas Steinke, and others at the Simons Institute Spring 2019 program on data privacy for helpful discussions on specific technical aspects of this work.References
- (1)
- Akb (2013) 2013. A novel Hybrid RBF Neural Networks model as a forecaster. Statistics and Computing (2013). https://doi.org/10.1007/s11222-013-9375-7
- Abernethy et al. (2016) Jacob Abernethy, Chansoo Lee, and Ambuj Tewari. 2016. Perturbation techniques in online learning and optimization. Perturbations, Optimization, and Statistics (2016), 233.
- Aci and Avci (2016) Mehmet Aci and Mutlu Avci. 2016. Artificial Neural Network Approach for Atomic Coordinate Prediction of Carbon Nanotubes. Applied Physics A 122, 631 (2016).
- Bassily et al. (2014) Raef Bassily, Adam D. Smith, and Abhradeep Thakurta. 2014. Private Empirical Risk Minimization, Revisited. CoRR abs/1405.7085 (2014). http://arxiv.org/abs/1405.7085
- Bernstein and Sheldon (2019) Garrett Bernstein and Daniel R Sheldon. 2019. Differentially Private Bayesian Linear Regression. In Advances in Neural Information Processing Systems 32. 523–533.
- Bun and Steinke (2016) Mark Bun and Thomas Steinke. 2016. Concentrated differential privacy: Simplifications, extensions, and lower bounds. In Theory of Cryptography Conference. Springer, 635–658.
- Bun and Steinke (2019) Mark Bun and Thomas Steinke. 2019. Average-Case Averages: Private Algorithms for Smooth Sensitivity and Mean Estimation. arXiv preprint arXiv:1906.02830 (2019).
- Cai et al. (2019) Tony Cai, Yichen Wang, and Linjun Zhang. 2019. The Cost of Privacy: Optimal Rates of Convergence for Parameter Estimation with Differential Privacy. CoRR abs/1902.04495 (2019). http://arxiv.org/abs/1902.04495
- Chaudhuri et al. (2011) Kamalika Chaudhuri, Claire Monteleoni, and Anand D. Sarwate. 2011. Differentially Private Empirical Risk Minimization. Journal of Machine Learning Research 12 (2011), 1069–1109.
- Chetty and Friedman (2019) Raj Chetty and John N. Friedman. 2019. A Practical Method to Reduce Privacy Loss When Disclosing Statistics Based on Small Samples. American Economic Review Papers and Proceedings 109 (2019), 414–420.
- Chetty et al. (2018) Raj Chetty, John N Friedman, Nathaniel Hendren, Maggie R Jones, and Sonya R Porter. 2018. The opportunity atlas: Mapping the childhood roots of social mobility. Technical Report. National Bureau of Economic Research.
- Chetty et al. (2014) Raj Chetty, Nathaniel Hendren, Patrick Kline, and Emmanuel Saez. 2014. Where is the land of opportunity? The geography of intergenerational mobility in the United States. The Quarterly Journal of Economics 129, 4 (2014), 1553–1623.
- Cormode ([n.d.]) Graham Cormode. [n.d.]. Building Blocks of Privacy: Differentially Private Mechanisms. ([n. d.]), 18–19.
- Couch et al. (2019) Simon Couch, Zeki Kazan, Kaiyan Shi, Andrew Bray, and Adam Groce. 2019. Differentially Private Nonparametric Hypothesis Testing. arXiv preprint arXiv:1903.09364 (2019).
- Dinur and Nissim (2003) Irit Dinur and Kobbi Nissim. 2003. Revealing information while preserving privacy. In Proceedings of the twenty-second ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems. 202–210.
- Dwork and Lei (2009) Cynthia Dwork and Jing Lei. 2009. Differential privacy and robust statistics.. In STOC, Vol. 9. 371–380.
- Dwork et al. (2006) Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam D. Smith. 2006. Calibrating Noise to Sensitivity in Private Data Analysis. In Theory of Cryptography, Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, March 4-7, 2006, Proceedings. 265–284.
- Dwork et al. (2014) Cynthia Dwork, Kunal Talwar, Abhradeep Thakurta, and Li Zhang. 2014. Analyze gauss: optimal bounds for privacy-preserving principal component analysis. In STOC. 11–20.
- Fanaee-T and Gama (2013) Hadi Fanaee-T and Joao Gama. 2013. Event labeling combining ensemble detectors and background knowledge. Progress in Artificial Intelligence (2013), 1–15. https://doi.org/10.1007/s13748-013-0040-3
- McSherry and Talwar (2007) Frank McSherry and Kunal Talwar. 2007. Mechanism Design via Differential Privacy. In 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS 2007), October 20-23, 2007, Providence, RI, USA, Proceedings. 94–103.
- Nissim et al. (2007) Kobbi Nissim, Sofya Raskhodnikova, and Adam D. Smith. 2007. Smooth sensitivity and sampling in private data analysis. In Proceedings of the 39th Annual ACM Symposium on Theory of Computing, San Diego, California, USA, June 11-13, 2007. 75–84.
- Sen (1968) Pranab Kumar Sen. 1968. Estimates of the regression coefficient based on Kendall’s tau. Journal of the American statistical association 63, 324 (1968), 1379–1389.
- Sheffet (2017) Or Sheffet. 2017. Differentially Private Ordinary Least Squares. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017. 3105–3114. http://proceedings.mlr.press/v70/sheffet17a.html
- Theil (1950) Henri Theil. 1950. A rank-invariant method of linear and polynomial regression analysis, 3; confidence regions for the parameters of polynomial regression equations. Indagationes Mathematicae 1, 2 (1950), 467–482.
- Wang (2018) Yu-Xiang Wang. 2018. Revisiting differentially private linear regression: optimal and adaptive prediction & estimation in unbounded domain. CoRR abs/1803.02596 (2018). arXiv:1803.02596 http://arxiv.org/abs/1803.02596
- Yan and Su (2009) Xin Yan and Xiao Gang Su. 2009. Linear Regression Analysis: Theory and Computing. World Scientific Publishing Co., Inc., USA.
Appendix A Opportunity Insights Application
A.1. Data Generating Process for OI Synthetic Datasets
In this subsection, we describe the data generating process for simulating census microdata from the Opportunity Insights team. In the model, assume that each set of parents in tract and state has one child (also indexed by ).
Size of Tract: The size of each tract in any state is a random variable. Let represent the exponential distribution with scale . Then if is the number of people in tract and state , then . This distribution over simulated counts was chosen by the Opportunity Insights team because it closely matches the distribution of tract sizes in the real data.
Linear Income Relationship: Let be the child income given the parent income , then we enforce the following relationship between and :
where and are calculated from public estimates of child income rank given the parent income rank. 333 Gleaned from some tables the Opportunity Insights team publicly released with tract-level (micro) data. See https://opportunityatlas.org/. The dataset used to calculate the is aggregated from some publicly-available income data for all tracts within all U.S. states between 1978 and 1983. Next, is calculated as the parent ’s percentile income within the state ’s parent income distribution (and rounded up to the 2nd decimal place).
Parent Income Distribution: Let denote the public estimate of the mean
household income for tract in state (also obtained from publicly-available income data
used to calculate ).
Empirically, the Opportunity Insights team found that the within-tract
standard deviation of parent incomes is about twice the between-tract standard deviation.
Let denote the sample variance of the estimator . Then
enforce that
where
is the variance of parental income in tract and state .
Furthermore, assume that are lognormally distributed within each tract and draw
from
for , where
and
A.2. The Maximum Observed Sensitivity Algorithm
Opportunity Insights (Chetty and Friedman, 2019) provided a practical method – which they term the “Maximum Observed Sensitivity” (MOS) algorithm – to reduce the privacy loss of their released estimates. This method is not formally differentially private. We use MOS or OI interchangeably to refer to their statistical disclosure limitation method. The crux of their algorithm is as follows: The maximum observed sensitivity, corresponding to an upper envelope on the largest local sensitivity across tracts in a state in the dataset, is calculated and Laplace noise of this magnitude divided by the number of people in that cell is added to the estimate and then released. The statistics they release include 0.25, 0.75 percentiles per cell, the standard error of these percentiles, and the count.
Two notes are in order. First, the MOS algorithm does not calculate the local sensitivity exactly but uses a lower bound by overlaying an grid on the space of possible values. Then the algorithm proceeds to add a datapoint from this grid to the dataset and calculate the maximum change in the statistic, which is then used as a lower bound. Second, analysis are performed only on census tracts that satisfy the following property: they must have at least 20 individuals with 10% of parent income percentiles in that tract above the state parent income median percentile and 10% below. If a tract does not satisfy this condition then no regression estimate is released for that tract.
Appendix B Some Results in Differential Privacy
In this section we will briefly review some of the fundamental definitions and results pertaining to general differentially private algorithms.
For any query function let
called the global sensitivity, be the maximum amount the query can differ on neighboring datasets.
Theorem 1 (Laplace Mechanism (Dwork et al., 2006)).
For any privacy parameter and any given query function and database , the Laplace mechanism outputs
where are i.i.d. random variables drawn from the 0-mean Laplace distribution with scale .
The Laplace mechanism is -DP.
Theorem 2 (Exponential Mechanism (McSherry and Talwar, 2007)).
Given an arbitrary range , let be a utility function that maps database/output pairs to utility scores. Let . For a fixed database and privacy parameter , the exponential mechanism outputs an element with probability proportional to .
The exponential mechanism is -DP.
The following results allow us to use differentially private algorithms as building blocks in larger algorithms.
Lemma 3 (Post-Processing (Dwork et al., 2006)).
Let be an differentially private and be a (randomized) function. Then is an differentially private algorithm.
Theorem 4 (Basic Composition (Dwork et al., 2006)).
For any , let be an differentially private algorithm. Then the composition of the mechanisms is differentially private where and .
Definition 5 (Coupling).
Let z and be two random variables defined over the probability spaces and , respectively. A coupling of z and is a joint variable taking values in the product space such that has the same marginal distribution as z and has the same marginal distribution as .
Definition 6 (-Lipschitz randomized transformations).
A randomized transformation is -Lipschitz if for all datasets , there exists a coupling of the random variables and such that with probability 1,
where denotes Hamming distance.
Lemma 7 (Composition with Lipschitz transformations (well-known)).
Let be an -DP algorithm, and let be a -Lipschitz transformation of the data with respect to the Hamming distance. Then, is -DP.
Proof.
Let denote the distance (in terms of additions and removals or swaps) between datasets and . By definition of the Lipschitz property, . The lemma follows directly from the Lipschitz property on adjacent databases and the definition of -differential privacy. ∎
Appendix C NoisyStats
C.1. Privacy Proof of NoisyStats
Lemma 1.
We are given two vectors . Let
and
Also, let be the means of x and y respectively and be the all ones vector.
Then if and are the global sensitivities of functions ncov and nvar then and .
Proof.
Let and be neighbouring databases differing on the th datapoint 444This is without loss of generality as we can always “rotate” both databases until the index on which they differ becomes the th datapoint.. Let and and note that . Then,
If then . Otherwise,
Since we have , so .
Also,
If and then . If and then . Since and we have . Similarly if and then . Finally, if and , we have
Since, and , we have . ∎
Proof of Lemma 1: (NoisyStats).
The global sensitivity of both and is bounded by (by Lemma 1).
As a result, if we sample then both and are -DP estimates by the Laplace mechanism guarantees (see Theorem 1). By the post-processing properties of differential privacy (Lemma 3), is a private release and the test is also private. As a result, is a -DP release. Now to calculate the private intercept , we use the global sensitivity of which is at most , since the means of can change by at most . 555 Alternatively, to estimate , one could compute , private estimates of by adding Laplace noise from and then compute . The Laplace noise we add ensures the private release of the intercept is -DP.
C.2. On the Failure Rate of NoisyStats

For Tract 800100 in County 31 in IL

For Tract 520100 in County 31 in IL

For Tract 2008 in County 63 in NC

For Tract 603 in County 147 in NC

Unlike all the other algorithms in this paper, NoisyStats (Algorithm 1) can fail by returning . It fails if and only if the noisy sufficient statistic becomes 0 or negative i.e. where . Since the statistic will always be non-negative, we also require the private version of this statistic to be non-negative. Intuitively, we see that is more likely to be less than or equal to 0 if is small or is small. The setting of directly affects the standard deviation of the noise distribution added to ensure privacy. The smaller is, the more spread out the noise distribution is.So we would expect that when or is small, Algorithm 1 would fail more often. We experimentally show this observation holds on some tracts in IL and NC (from the semi-synthetic datasets given to us by the Opportunity Insights team).
In Figures 13(a), 13(b) , 14(a), 14(b), we see the failure rates for both high and low census tracts in both IL and NC as we vary between and . We see that the failure rate is about 40% for any value of in low and is on average less than 5% for high tracts. In Figure 15, we show the failure rate for NoisyStats when evaluated on data from all tracts in IL. The results are averaged over 100 trials. We see that the failure rate for is 0% for the majority of tracts. For tracts with small , the rate of failure is at most 12%. Thus, we can conclude that the failure rate approaches 0 as we increase either or .
Appendix D DPExpTheilSen and DPWideTheilSen
D.1. Privacy Proofs for DPExpTheilSen and DPWideTheilSen
Lemma 1.
Let be the following randomized algorithm. For dataset , let be the complete graph on the datapoints, where edges denote points paired together to compute estimates in Theil-Sen. Then can be decomposed into matchings, . Suppose samples matchings without replacement from the matchings, and computes the corresponding pairwise estimates (up to estimates). Then is a -Lipschitz randomized transformation.
Proof.
Let and denote the multi-sets of estimates that result from applying to datasets and , respectively. We can define a coupling and of z and . First, use matchings sampled randomly without replacement from , , to compute the multi-set of estimates . Now, use the corresponding matchings from to compute a multi-set of estimates . This is a valid coupling because the matchings are sampled randomly without replacement from the complete graphs and , respectively, matching the marginal distributions of z and .
Notice that every datapoint is used to compute exactly estimates in . Therefore, for every datapoint at which and differ, and differ by at most estimates. Therefore, by the triangle inequality, we are done. ∎
Proof of Lemma 2.
D.2. Sensitivity of Hyperparameter
Choosing optimal hyperparameters is beyond the scope of this work. However, in this section we present some preliminary work exploring the behavior of DPWideTheilSen with respect to the choice of . In particular, we consider the question of how robust this algorithm is to the setting of the hyperparameter. Figure 16 shows the performance as a function the widening parameter on synthetic (Gaussian) data. Note that in each graph both axes are on a log-scale so we see very large variation in the quality depending on the choice of hyperparameter.

D.3. Pseudo-code for DPExpTheilSen
In Algorithm 3, we give an efficient method for implementation of the DP median algorithm used as subroutine in DPExpTheilSen, the exponential mechanism for computing medians. To sample efficiently from this distribution, we implement a two-step algorithm following (Cormode, [n.d.]): first, we sample an interval according to the exponential mechanism, and then we will sample an output uniformly at random from that interval. To efficiently sample from the exponential mechanism, we use the fact that sampling from the exponential mechanism is equivalent to choosing the value with maximum utility score after i.i.d. Gumbel-distributed noise has been added to the utility scores (Dwork et al., 2014; Abernethy et al., 2016).
D.4. Pseudo-code for DPWideTheilSen
Appendix E DPSSTheilSen
Suppose we are given a dataset . Consider a neighboring dataset that differs from the original dataset in exactly one row. Let z be the set of point estimates (e.g. the or point estimates) induced by the dataset , and let be the set of point estimates induced by dataset by Theil-Sen. Formally, for , we let denote the function that transforms a set of point coordinates into estimates for each pair of points. Then , . Notice that changing one datapoint in changes at most of the point estimates in z. Assume that both z and are in sorted order. Recall the definition of :
Let
be distance local sensitivity of the dataset z with respect to the median. In order to prove that is a -smooth upper bound on , we will use the observation that
Now Figure 17 outlines the maximal changes we can make to z. For and any interval of points containing the median, we can move the median to one side of the interval by moving points, and to the other side by moving an additional points. Therefore, for ,
| (4) |
so

Proof of Lemma 7.
We need to show that is lower bounded by the local sensitivity and that for any dataset such that , we have .
By definition of , we see that (e.g. when in the formula for ). Next, we see that
| (5) | ||||
| (6) | ||||
| (7) |
which completes our proof. ∎
Lemma 1.
Let , where and are computed according to Algorithm 5. Then, is -DP.
Proof.
Let denote the max-divergence for distributions and . Let be a random variable sampled from StudentsT, where is the degrees of freedom. From Theorem 31 in (Bun and Steinke, 2019), we have that for ,
The parameters and correspond to the translation (shifting) and dilation (scaling) of the StudentsT distribution.
E.1. Sensitivity of Hyperparameters
In Algorithm 5 we set the smoothing parameter to be a specific function of and : and . There were other choices for these parameters. For any , the -DP guarantee is preserved if we set
Algorithm 5 corresponds to setting . Increasing increases , which results in decreasing. However, if increasing also decreases . In Figure 18 we explore the performance of DPSSTheilSen as a function of on synthetic (Gaussian) data. Note that the performance doesn’t seem too sensitive to the choice of and is a good choice on this data.

Appendix F DPGradDescent
There are three main versions of DPGradDescent we consider:
-
(1)
DPGDPure: -DP;
-
(2)
DPGDApprox: -DP; and
-
(3)
DPGDzCDP: -zCDP.
Algorithm 6 is the specification of a -DP algorithm and Algorithm 7 is a -zCDP algorithm, from which we can obtain a -DP algorithm and a -zCDP algorithm. As with traditional gradient descent, there are several choices that have been made in designing this algorithm: the step size, the batch size for the gradients, how many of the estimates are averaged to make our final estimate, how the privacy budget is distributed. We have included this pseudo-code for completeness to show the choices that were made in our experiments. We do not claim to have extensively explored the suite of parameter choices, and it is possible that a better choice of these parameters would result in a better performing algorithm. Differentially private gradient descent has received a lot of attention in the literature. For a more in-depth discussion of DP gradient descent see (Bassily et al., 2014).
Lemma 1.
For any , Algorithm 7 is -zCDP.
Proof.
By composition properties of zCDP, it suffices to show that is -zCDP where represents two (independent) draws from a Normal distribution with standard deviation .
The -sensitivity of is at most and the standard deviation of the Gaussian distribution from which noise is added is . Then by Proposition 1.6 in (Bun and Steinke, 2016), the procedure to compute is -zCDP.
∎
Lemma 2.
For any and any , Algorithm 7 is -DP where
Proof.
Follows from Lemma 3.6 in (Bun and Steinke, 2016). ∎
Lemma 3.
For any , Algorithm 6 is -DP.
Proof.
By basic composition, it suffices to show that is -DP where represents two (independent) draws from a Laplace distribution with scale . This holds since the -sensitivity of is at most . ∎