Diff-Mosaic: Augmenting Realistic Representations in Infrared Small Target Detection via Diffusion Prior
Abstract
Recently, researchers have proposed various deep learning methods to accurately detect infrared targets with the characteristics of indistinct shape and texture. Due to the limited variety of infrared datasets, training deep learning models with good generalization poses a challenge. To augment the infrared dataset, researchers employ data augmentation techniques, which often involve generating new images by combining images from different datasets. However, these methods are lacking in two respects. In terms of realism, the images generated by mixup-based methods lack realism and are difficult to effectively simulate complex real-world scenarios. In terms of diversity, compared with real-world scenes, borrowing knowledge from another dataset inherently has a limited diversity. Currently, the diffusion model stands out as an innovative generative approach. Large-scale trained diffusion models have a strong generative prior that enables real-world modeling of images to generate diverse and realistic images. In this paper, we propose Diff-Mosaic, a data augmentation method based on the diffusion model. This model effectively alleviates the challenge of diversity and realism of data augmentation methods via diffusion prior. Specifically, our method consists of two stages. Firstly, we introduce an enhancement network called Pixel-Prior, which generates highly coordinated and realistic Mosaic images by harmonizing pixels. In the second stage, we propose an image enhancement strategy named Diff-Prior. This strategy utilizes diffusion priors to model images in the real-world scene, further enhancing the diversity and realism of the images. Extensive experiments have demonstrated that our approach significantly improves the performance of the detection network. The code is available at https://github.com/YupeiLin2388/Diff-Mosaic
Index Terms:
Infrared small target detection, Data augmentation, mosaic augmentation, diffusion model.I Introduction

Single-frame infrared small target(SIRST) detection has a wide range of applications in several fields, such as video surveillance [2, 3, 4], early warning systems [5], raining scenes [6, 7, 8] and military surveillance [9]. Accurately detecting small infrared targets is crucial for ensuring safety, proper navigation, and successful mission execution. However, infrared small target detection faces multiple challenges. Firstly, due to the limited number of pixels occupied by small targets in infrared images, they are easily overwhelmed by complex backgrounds and noise, making them difficult to detect. Secondly, infrared small targets often lack distinct shapes and textures, making their detection more challenging. Additionally, these small targets exhibit weak features in the images, requiring overcoming the impact of lighting variations and other environmental factors for accurate detection. Therefore, achieving accurate detection of infrared small targets in the face of these issues remains a challenging problem.
To achieve infrared small target detection, researchers have proposed many traditional methods. These traditional methods include filtering, local contrast and low-rank-based methods. Tophat [10] and New Tophat [11] use artificially designed filters to selectively extract visually prominent targets from infrared images. The 2-D least squares filter [12] predicts the background by estimating the surrounding pixels and detects targets by comparing the difference between the predicted background and the infrared image. The Local Contrast Measure (LCM) [13], WSLCM [14] and TCLCM [15] inspired by the human eye, utilizes local contrast to capture target features. Infrared Patch Image (IPI) models [16] small target detection as a decomposition problem involving low-rank (background) and sparse signal (target). However, these methods require the selection of appropriate features and carefully tuned hyperparameters, making it difficult to adapt to the diverse noise in real-world scenarios. These methods therefore generate many false alarms. In order to deal with diverse datasets in real-world scenarios, researchers have therefore turned to the use of CNN-based networks.
Unlike traditional methods, CNN-based methods can automatically extract and learn the features of infrared small targets from the dataset, which is more suitable for complex and variable infrared small target detection tasks. Asymmetric contextual module (ACM) [17] accurately detects infrared small targets by integrating shallow and deep feature information. MDvsFA-GAN[18] employs an adversarial neural network approach to achieve infrared target recognition by generator learning data distribution. Attentional Local Contrast Network (ALC-Net) [19] achieves excellent detection performance by embedding low-level detail information into high levels. DNA-Net [20] accomplishes accurate target detection using a densely nested interaction module. This module enables progressive interaction between high-level and low-level features, thus maintaining information about small targets in the deep layers. UIU-Net [21] uses a U-Net in U-Net structure which consists of two U-Nets. The two U-Nets are used for feature extraction and feature fusion respectively, and residual connections and jump connections are used to preserve the details of small targets.

These methods enhance detection performance by improving the model but do not consider the aspect of proposing a new data augmentation method. In SIRST detection, researchers commonly employ typical data augmentation techniques such as Mosaic [1], Cut-Mix [22], and Mixup [23]. These techniques involve mixing information from different real images to generate new images. However, these data methods are not specifically tailored for infrared datasets, thus posing two challenges in SIRST detection:
-
•
Diversity. These mainstream data augmentation methods such as Mosaic, and Cut-Mix generate new images by mixing existing data. However, constrained by the limited number of samples, the diversity of images generated by these data augmentation methods is limited.
-
•
Realism. As depicted in Fig. 1, pixel distribution of the samples generated by Mosaic is not coherent due to significant contrast variations among infrared images, leading to a lack of realism.
The limitations of these data augmentation methods significantly impact the performance of the model. Improving the diversity and realism of augmented samples is therefore a critical task that requires urgent attention. Recently, the Denoising Diffusion Probabilistic Model (DDPM) has attracted considerable interest in low-level domains due to its robust generative prior. The diffusion model uses a powerful generative prior to modeling real-world scenarios based on the distribution of image pixels. The images generated by the diffusion model are significantly improved in detail and realism. Generative Diffusion Prior [24] excels in deblurring and image coloring based on its diffusion generative prior. ControlStyle [25] incorporates textual and visual information via Diffusion Prior, enabling high-quality text-driven stylized image generation.
Inspired by such approaches, in this paper we propose Diff-Mosaic, a novel data augmentation method based on the diffusion model. Our method employs a diffusion generative prior to integrating real-world information into the images, thereby enhancing the diversity and realism of the generated samples. Specifically, we propose an enhancement network, Pixel-Prior, based on Mosaic data augmentation, which facilitates the harmonization of image pixels. This network can harmonize images without additional labels, generating high-quality, realistic Mosaic images. Furthermore, we introduce a diffusion model, Diff-Prior, which integrates real-world information by re-sampling the results of the Pixel-Prior using a diffusion generative prior. Diff-Prior incorporates real-world knowledge in resampling, which makes the generated samples more realistic and diverse. Finally, we validated the effectiveness of our method by applying it to the state-of-the-art method in comparison to other detection baselines. As shown in Fig. 2, we compare the visualization results of our method compared to other methods. Our method achieves accurate target detection without false alarms. The contribution of our method is as follows:
-
•
In this paper, we introduce an enhanced network that harmonizes images at the pixel level. It generates numerous effective augmented samples without additional labels, overcoming the lack of realism inherent in traditional data augmentation methods.
-
•
We introduce an image resampling strategy based on a diffusion model prior. This method uses the diffusion model prior to realistically modeling various aspects of the image, including object shapes, textures, and lighting, thus ensuring the realism and diversity of the generated results. In addition, this approach ensures that our method is the first to introduce a diffusion prior to SIRST.
-
•
We apply our proposed data augmentation method on a SOTA baseline. The effectiveness of our method is verified by three evaluation metrics. Ablation studies have shown that each part of the proposed method can improve detection performance.
II Related work
II-A Infrared small target detection
The task of Single-Frame infrared small target (SIRST) detection is to locate abnormal targets in infrared images. Conventional detection methods achieve SIRST detection by comparing the difference between the target and the background. Tophat [10] and New Tophat [11] employ manually designed filters to identify high-response in the target region. The Local Contrast Measure (LCM) [13], WSLCM [14] and TCLCM [15] detect small targets by assessing the contrast between the central pixel and its surrounding neighborhood at various scales. Infrared Patch Image (IPI) model [16] decomposes images into low-rank and sparse signals to achieve SIRST detection. However, due to their inability to capture deep features of images, these methods face challenges in detecting anomalous targets within images characterized by complex backgrounds. To address this issue, researchers have employed Convolutional Neural Networks (CNNs) based method to systematically acquire profound features of infrared images through a data-driven approach.
Unlike traditional methods, CNN-based methods do not rely on any prior knowledge about the target and background. Instead, they learn target features directly from the data through the model. This advantage makes CNN-based methods widely used in downstream tasks of remote sensing, such as classification tasks [26, 27, 28, 29], segmentation tasks [30, 31, 32], and object detection tasks [33]. CNN-based methods can efficiently process large amounts of data and have strong model-fitting capabilities, thus enabling accurate SIRST detection. For example, ALC-Net [19] based on a feature pyramid network proposes an attention local contrast (ALC) network based on the attention mechanism to segment the target region in infrared images. ACM [17] proposes an asymmetric context modulation module and integrates it into U-Net [34] and FPN [35]. DNA-Net [20] uses a dense nested interaction module. Multiple interactions of deep semantic features and shallow detailed features are performed through this module to maintain deep infrared small targets. UIU-Net[21] adopts a U-Net in U-Net architecture, consisting of two U-Net components. These two U-Net modules are dedicated to feature extraction and feature fusion, utilizing residual connections and skip connections to retain the details of small targets.
II-B Diffusion Prior
Recently, Diffusion Denoising Probabilistic Models (DDPM) [36] have made significant progress in computer vision, particularly in image generation. DDPM is divided into two processes: the diffusion process and the reverse process. During the diffusion process, diffusion models progressively introduce Gaussian noise to systematically undermine the input information. This gradual introduction of noise into the modeling process makes it easier to capture the diversity within images, thereby enhancing the richness and realism of the images generated by DDPM. During the reverse process, DDPM then restores the original information by predicting and gradually removing the increased noise. This step-by-step denoising strategy helps the model more effectively reconstruct the original information, particularly demonstrating impressive performance when confronted with complex noise and image degradation scenarios. Thus DDPM has achieved impressive results in image generation. To further improve the efficiency and quality of image generation, researchers have proposed the Latent Diffusion Model (LDM) [37]. LDM improves the efficiency of model training and inference by using autoencoder [38] to compress the information to be learned into a latent space. The large-scale trained LDM model not only generates satisfactory images, but also incorporates real-world information. Therefore, LDM can serve as a powerful generative prior to image enhancement by incorporating real-world information. This diffusion-based generative prior has found applications in various domains. Generative Diffusion Prior [24] and DiffBIR [39] leverage the Diffusion Prior to achieve high-quality blind image restoration and image enhancement. ControlStyle [25] integrates textual and visual information using Diffusion Prior, accomplishing high-quality text-driven stylized image generation.
III Methodology
III-A Observation
As discussed in Section I, the scale of publicly available datasets [17, 20] for SIRST detection is limited. Furthermore, the data augmentation methods employed to expand datasets suffer from issues of both limited diversity and a lack of realism in SIRST detection. As shown in Fig. 1, we compare the generation quality of our method with the traditional data augmentation method Mosaic. It can be observed that the images generated by Mosaic look very unnatural at the splices. The four sub-images used for the stitching are not coordinated in terms of brightness and contrast, resulting in an overall lack of realism. In addition, these augmented images are derived from existing infrared datasets, which lack diversity. In order to address this issue, we propose a novel data augmentation network named Diff-Mosaic.
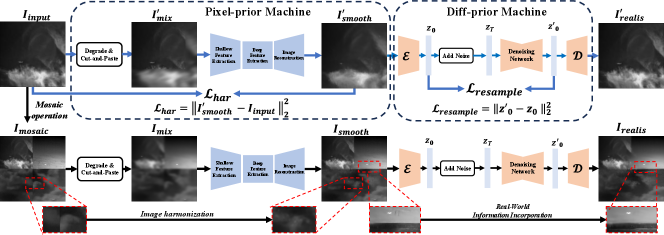
In this work, we aim to utilize a powerful diffusion generative prior to generating realistic and diverse augmentation samples. The Diff-Mosaic framework is divided into two aspects: pixel harmonization and detail refinement, the framework is shown in Fig. 3. Diff-Mosaic has two stages: the training stage and the data generation stage. In the training stage, the pipeline of Diff-Mosaic is organized as follows:
-
•
Pixel-prior Machine: We propose an enhancement network that boosts the quality and realism of images generated by Mosaic. First, the input image was transformed into by applying a degradation module. Then, a cut-and-paste operation was performed to generate a mixed image . Finally, the mixed image was fed into the enhancement network for training to generate a harmonized image .
-
•
Diff-prior Machine: A powerful generative prior is applied to resample the image using the diffusion model, thereby incorporating real-world information. The resampled image not only contains richer details, but also incorporates real-world knowledge and information from pre-trained diffusion models. Therefore the resampled image is more realistic and diverse. To make the generated resampled samples more realistic, we fine-tune the diffusion model.
In the data generation stage, we use the Mosaic augmentation to generate . Subsequently, image degradation and cut-and-paste operations are performed on to generate the mixed image . And is more diverse and has higher image quality than the Mosaic image . Finally, we resample to get the augmented samples via diffusion model. These images will be input into the network as the augmented samples for training. We will describe each step in detail in the following subsections.
III-B Mosaic with Pixel-Prior Machine

In order to solve the problem of uneven distribution existing in Mosaic images and further improve the quality of Mosaic images. We propose Diff-Mosaic to generate image-coordinated Mosaic images. As shown in Fig. 3, in the training stage, we trained a transformer network to enhance the quality of Mosaic images. Specifically, as shown in Fig. 4, we conducted degradation and cut-and-paste operations on the input image to produce the mixed image . This mixed image was then used for training in the enhancement network. The degradation process is expressed as follows:
| (1) |
where denotes the degradation module, which employs a variety of degradation sub-modules, including fuzzy, resize, and noise degradation methods. To improve the quality of the reconstructed image, we use the cut-and-paste operation after degradation. Specifically, we cut a part of the region of the original image and paste it into the corresponding region of the degraded image . The operation is as follows:
| (2) | ||||
where denotes the cut-and-paste operation, and denotes the selection of the region from the original image . The Cut-and-paste operation can improve the diversity and difficulties of the data, which makes the recovered images of the model of higher quality.

Then the mix image is input into the transformer network for reconstruction. The transformer network consists of shallow feature extraction, deep feature extraction, and image reconstruction. The input image is subjected to shallow convolutional layers to extract shallow features. Then it undergoes multiple Residual Swin Transformer Blocks (RSTB) to extract the deep features [40]. Where the RSTB structure consists of multiple Swin Transformer Layers (STL) which collaborate with each other to capture deeper features of the image. Next, we fuse the shallow and deep features to integrate high-frequency and low-frequency information. Finally, the deep features are reduced to the original image space by an upsampling to get the harmonized image . To optimize the network, we compute the gap between the original image and . The loss is expressed as follows:
| (3) |
As shown in Fig. 3, compared to Mosaic image , effectively solves the distribution inconsistency problem and improves the image quality.
In the data generation stage, we have adopted the improved Mosaic process. The images are further enhanced to increase the diversity of the augmented samples. Specifically, first, we used Mosaic to stitch image with other images in the dataset to form . Next, we perform a degradation operation on the image:
| (4) |
Mixed image can improve the diversity of Mosaic, and the mixed image is inputted into the image reconstruction network to generate the Mosaic image that gets the coordinated Mosaic image.
III-C Mosaic with Diffusion-Prior Machine
Compared to , the Pixel-Prior machine-generated image exhibits a more harmonious and smoother texture. However, there is still a gap between and the real image. This discrepancy is due to the use of L2 loss in optimizing the enhancement network, which can magnify differences between minor features. Therefore, the Pixel-Prior machine focuses on the uniformity of the overall pixel values while disregarding the details within the image.
To address this problem, we introduce the diffusion model. Unlike traditional methods of data augmentation, the diffusion model employs a powerful generative prior to simulating real-world scenarios based on the distribution of image pixels. This allows diffusion models to incorporate real-world information and generate images with detailed and realistic approximations. In this paper, we use the Latent Diffusion Model(LDM) [37] as a generative prior.
LDM is an advanced diffusion model. It uses pre-trained autoencoders to map images to latent space for learning data distributions. The autoencoder is composed of an encoder and a decoder , where encodes input images into latent code and reconstructs it. In this model, noise is added times to latent variables , generating Gaussian-distributed codes . Noise predict network is trained to denoise at time step , optimizing with . is calculated as follows:
| (5) |
where is the Gaussian noise and is the latent noise at time step . The large-scale trained diffusion model [37] demonstrates proficiency in comprehending various attributes within images, such as object shapes and textures, and is thus able to generate visually appealing images. To further generate more high-quality and realistic images, we fine-tuned the diffusion model on the SIRST datasets.
As shown in Fig. 3, given , in the training phase we encode the image into the latent space coding via the encoder . Then, the model is subjected to a -step denoising into a noise close to a Gaussian distribution, and then is generated by -step resampling. Finally, the decoder generates the resampled image . To bring the results of the diffusion model resampling closer to our dataset, we reduce the gap between and by . is expressed as follows:
| (6) |
During the data generation stage, images resampled by the fine-tuned LDM have much finer details and are very closely aligned with the distribution of the original dataset. In addition, augmentation sample is more diverse and realistic due to the implementation of generative prior. Notably, this method can capture latent data features without requiring additional labels as input. Therefore, it conveniently produces more realistic and diverse samples for the dataset reconstruction.
In the data generation stage. By employing diffusion prior, we resample to generate .
As shown in Fig. 1, compared to the Mosaic image, becomes more coherent. In addition, the generated result is very different from other images in the dataset due to the fact that it is extracted information from the real world and generated by the diffusion model, which significantly enhances the diversity of the dataset. The generated in the data generation stage will be involved in the training as the augmented sample.
III-D Infrared small target detection
To demonstrate the advantages of our proposed data augmentation method, we utilize a standard detection network for inference. The structure of the detection network is shown in Fig. 5. Firstly the image is fed into the residual attention block to extract the features. The residual attention block is composed of two convolutional layers, channel attention module, and spatial attention module. These two attention modules are designed to enhance the feature information after passing through two convolutional layers. In order to fuse different features, the features are continuously upsampled and downsampled into different residual attention blocks to form a feature pyramid. Finally, these features containing different scale information are fused to generate a robust feature map for predicting the result . Both the real target result and the predicted result are binary images. In order to get the results close to ground truth , the network reduces the gap between and the ground truth by loss , which is expressed as follows:
| (7) |
IV EXPERIMENTS

| Method Description | SIRST(Tr=70%) | NUDT-SIRST(Tr=50%) | |||||
| IoU | IoU | ||||||
| Filtering Based | New Tophat [11] | 34.05 | 66.91 | 743 | 14.51 | 54.4 | 2086 |
| Local Contrast Based | WSLCM [14] | 20.64 | 60.86 | 1342 | 0.85 | 74.6 | 52391 |
| TLLCM [15] | 9.56 | 56.12 | 3046 | 7.06 | 62.01 | 46.12 | |
| Low Rank Based | IPI [16] | 58.2 | 67.1 | 279 | 17.76 | 74.49 | 41.23 |
| CNN Based | ALC-Net [19] | 70 | 71,71 | 23.91 | 72.13 | 78.81 | 21.22 |
| ACM [17] | 76.17 | 86.31 | 16.07 | 71.11 | 85.13 | 22.51 | |
| UIU-Net [21] | 72.03 | 98.1 | 26.15 | 89 | 98.73 | 6.02 | |
| DNA-Net [20] | 76.97 | 95.41 | 3.54 | 88.38 | 97.99 | 4.04 | |
| Ours | 79.44 | 99.99 | 3.19 | 91.18 | 99.47 | 1.91 | |
IV-A Implementation Details
IV-A1 Dataset
To demonstrate the validity of our approach, we chose two datasets for comparison:
-
•
Single-frame InfraRed Small Target Detection (SIRST) is an open-source single-frame infrared small target detection dataset that selects images from sequences, which was designated as a public dataset by the University of Arizona in 2020. It contains representative images of 427 different scenes from real-world videos of hundreds of different scenes. These images were taken at shortwave, mid-wavelength, and 950nm wavelengths. They are labeled in five different forms to support the models for the detection task and the segmentation task. The total amount of dataset is 462 and we used 70% of the SIRST dataset for training and 30% for testing.
-
•
NUDT-SIRST: This dataset is a manually synthesized dataset of five main background scenes including city, field, highlight, sea, and cloud. Each image is synthesized from a real background with different targets (e.g., point, dot, and extended targets) with different SCRs and rich poses. The total amount of data is 1362 and we divide the dataset into 50% for training and 50% for testing.
IV-A2 Implementation Details
To achieve data augmentation for extracting knowledge from real scenes, we trained the Diff-Mosaic. For the degradation part in the Pixel-Prior machine, we used second-order degradation. The blur-resize-noise process is repeated twice for the image input [39]. For the reconstruction network, we set the batch-size to 4, the training epoch to 100, and the learning rate to 0.001. For the Diff-Prior machine, we fine-tune the diffusion model 100 epoch and use the Adam optimizer, and set the learning rate to . In this experiment, we generated 400 augmented samples on the NUDT-SIRST dataset and 100 augmented samples on the SIRST dataset via Diff-Mosaic. The detection network was trained with batch-size 40 and an epoch number of 3000.
IV-A3 Comparison Method
To demonstrate the effectiveness of our method, we compare our method with the SOTA method, including traditional methods (New Tophat, [11] WSLCM [14], TLLCM [15], IPI [16]) and CNN-based methods(ACM [17], ALC-Net [19], UIU-Net [21] and DNA-Net [20]). For a fair comparison, all CNN-based methods were trained with 3000 epochs, and the other configurations were consistent with the original paper. ACM and ALC-Net were implemented using Mxnet, and DNANet and UIUNet were implemented using PyTorch 1.10 and run on an NVIDIA Geforce RTX 3090.
IV-B Evaluation Metrics
To evaluate the detection performance of the CNN-based approach, we use three different evaluation metrics to assess the network performance.
-
•
Intersection over Union (IoU): IoU is a classical pixel-level semantic segmentation evaluation metric to describe the algorithm’s contour description capability. It is defined as the ratio of intersection and concatenation area between predicted values and labels as follows:
(8) where , denotes the interaction region and union region, respectively.
-
•
Probability of detection( ): The probability of detection is a target-level evaluation metric. It measures the ratio of the number of correctly predicted targets to the number of all targets . The definition of is as follows:
(9) -
•
False Alarm Rate() : False Alarm Rate is another target-level evaluation metric. It is used to measure the ratio of incorrectly predicted pixels to all image pixels . The definition of is as follows:
(10)
IV-C Experimental Results
We compared state-of-the-art methods with our method on SIRST and NUDT-SIRST. And three metrics, IoU, , and , were used for evaluation. As shown in Tab. I, our method achieved the best results for the IoU, , metrics on SIRST and NUDT-SIRST. To highlight the superior performance of our method, we visualize our method with other detection models. To highlight the superior performance of our method, we use a red dashed box to circle the target area and zoom in to show it. To more clearly compare the difference between the model detection results and ground truth, we use red pixels to indicate the difference between the method and ground truth. In addition, we marked the regions of model error detection with yellow dashed boxes.
As shown in Fig. 6, we visualize the performance comparison between the state-of-the-art method and our method on general and difficult samples. Where difficult samples are uncommon instances in the dataset. They usually have large dimensions, multiple objects or irregular contours. General samples are usually small, singular, and have regular shapes. ACM and ALC-Net had many false alarms. UIU-Net and DNA-Net [20] show fewer wrongly predicted regions, however, they fail to accurately detect the target in some of the difficult samples (the last two samples). In contrast, detection model trained with the samples generated by Diff-Mosaic performed well in predictions dealing with difficult samples. This suggests that Diff-Mosaic can generate more challenging samples for discriminative training in the detection model.
| Model | Params(M) | Inference times(s) |
|---|---|---|
| ALC-Net | 0.38 | 40.93 |
| ACM-Net | 0.29 | 18.53 |
| DNA-Net | 4.7 | 43.42 |
| UIU-Net | 50.54 | 33.98 |
| Ours | 4.7 | 43.42 |
As shown in Tab. II, we list the computational parameter count and inference time of CNN-based methods. Our approach generates augmented samples using pixel-prior and diffusion-prior mechanisms. This process happens during data generation and produces one sample every 10 seconds without affecting training and inference times. Thus our method is competitive with other methods in terms of the parameter number and inference time.
IV-D Effects of the Scale in Diff-Mosaic Augmentation
| real | 663 | 663 | 663 | 663 |
|---|---|---|---|---|
| synthetic | 0 | 125 | 250 | 400 |
| total | 663 | 788 | 913 | 1063 |
| IoU | 88.38 | 90.11 | 90.21 | 91.18 |
| 97.99 | 98.28 | 98.52 | 99.47 | |
| 4.04 | 3.24 | 3.1 | 1.91 |
We analyzed the effect of different numbers of samples generated by Diff-Mosaic as augmentation samples on the performance of the detection model. As shown in Tab. III, we compare the performance of the models trained with real data alone and when augmented with 125, 250, and 400 additional samples. With an increase in the number of augmentation samples, the performance of the model, as measured by the , and IoU metrics, shows an improvement. This demonstrates the diversity and realism of the augmented samples generated by Diff-Mosaic can improve the robustness of the detection model.

IV-E Ablation Study
| NUDT-SIRST(Tr=50%) | |||
|---|---|---|---|
| IoU( ) | ( ) | ( ) | |
| baseline | 88.38 | 97.99 | 4.04 |
| w/ Mosaic | 89.3 | 98.36 | 2.91 |
| w/ Pixel-Prior | 91.01 | 98.91 | 2.13 |
| w/ Pixel-Prior+ Diff-Prior | 91.18(+0.17) | 99.47(+0.56) | 1.91(-0.22) |
The ablation studies in this section were performed on NUDT-SIRST using the baseline detection Network. We compare the performance of models trained with Mosaic, with Pixel-Prior (‘w/ Pixel-Prior’), and with Diff-Mosaic (‘w/ Pixel-Prior+Diff-Prior’). The comparative results are shown in Tab. IV. Due to the lack of realism and diversity of the samples generated by ‘w/Mosaic’, the improvement of the detection network performance is very limited. And ‘w/ Pixel-Prior’ harmonizes the augmented samples, making them more realistic and therefore improving on all three performance metrics. At last, ’w/ Pixel-Prior+Diff-Prior’ introduces real-world information and generates diverse and realistic augmented samples. Aided by ’w/ Pixel-Prior+Diff-Prior’, the detection network shows significant improvement in all three performance metrics.
IV-F Effects of Diff-Mosaic
| IoU | ||
|---|---|---|
| w/o Diff-Mosaic | 89 | 6.02 |
| w/ Diff-Mosaic | 91.91(+2.91) | 1.40(-4.62) |
| IoU | ||
|---|---|---|
| w/o Diff-Mosaic | 88.38 | 4.04 |
| w/ Diff-Mosaic | 91.18(+2.8) | 1.91(-2.13) |
To demonstrate the effectiveness of the augmentation samples generated by Diff-Mosaic, we used the generated results of Diff-Mosaic as augmentation samples for training on different detection models. In this section, we compare the effects of training without (‘w/o Diff-Mosaic’) and with Diff-Mosaic’s (‘w/ Diff-Mosaic’) augmented samples using UIU-Net and DNA-Net as detection models. As shown in Tab. V, we compare the performance of the UIU-Net model with and without the augmented samples. To highlight the gaps, we use red bold font to indicate how much ‘w/Diff-Mosaic’ improves on IoU and blue bold font to indicate how much ‘w/ Diff-Mosaic’ decreases on . It can be seen that the performance of UIUNet improves significantly on the NUDT-SIRST dataset after training with Diff-Mosaic augmented samples. As shown in Fig. 7, it can be seen that ‘w/o Diff-Mosaic’ has a lot of misdirected targets in its detection results and is inaccurate in detecting the contours of small targets. Furthermore, the detection result of ‘w/ Diff-Mosaic’ has no false detection targets and achieves accurate detection of the contours of small irregular targets.
| FID | KID | |
|---|---|---|
| SwinIR [41] | 181.39 | 0.167 |
| FeMaSR [42] | 200.47 | 0.191 |
| DiffBir [39] | 188.22 | 0.163 |
| diffmosaic | 126.01 | 0.076 |

| Method | IoU() | () | |
|---|---|---|---|
| Baseline model | 88.38 | 97.99 | 4.04 |
| w/ CutMix | 89.24 | 98.62 | 6.25 |
| w/CutMix + our diffusion prior | 90.11 | 99.,15 | 2.04 |
As shown in Tab. VI, we compared the performance of the DNA-Net model with and without the augmented samples generated by Diff-Mosaic. The results indicate a significant improvement in detection performance on the NUDT-SIRST dataset when using augmented samples. As depicted in Fig. 8, it is evident that the ‘w/o Diff-Mosaic” method fails to detect the target in challenging test samples, while the ‘w/ Diff-Mosaic’ method accurately identifies the target with high precision. To show the realism of the images we generate, we input the results of the pixel-prior machine into state-of-the-art image generation techniques, including SwinIR [41], FemaSR [42] and DiffBIR [39], and compare their generated results with our method. As shown in Fig. 9, it can be observed that augmented samples generated by SwinIR, FeMaSR, and DiffBIR fail to integrate the Mosaic strategy well. On the contrary, the augmented samples generated by our diff-mosaic demonstrate a seamless coherence in image distribution and a high level of realism. Additionally, to measure the realism of the generated images, we utilized KID [43] and FID [44] metrics to measure the disparity between them and real infrared images. As shown in tab. VII, our method outperforms others in terms of FID and KID, indicating a significant advantage in enhancing realism.

IV-G Effects of Diffusion-Prior

To demonstrate the effectiveness of diffusion-prior machine, we combined it with CutMix [22]. Subsequently, we generated 400 augmented samples on NUDT-SIRST and input them into the detection network for training. As depicted in Fig. 10, we demonstrate the augmented samples from the original CutMix (‘w/ CutMix’) and the combination with our method (‘w/ CutMix + diffusion prior’). It is evident that the results generated by the original CutMix lack coherence and realism. In contrast, the results generated by ‘w/ CutMix + diffusion prior’ exhibit greater coherence. To validate the effectiveness of our diffusion prior, we compared the performance of the augmented samples generated by ‘w/ CutMix’ and ‘w/ CutMix + our diffusion prior’. As shown in Tab. VIII, it can be observed that ’w/ CutMix’ shows a negligible improvement in the network. In contrast, ’w/ CutMix + diffusion prior’ introduces real-world information, leading to a noticeable improvement in the network’s detection capability.
V Conclusion
In this paper, a novel diffusion-based data augmentation method is proposed to solve the problems of lack of realism and lack of diversity of existing data augmentation methods. Our method generates harmonized augmented samples based on the image pixel distribution, making the samples more realistic. We then use a powerful diffusion model prior that introduces real-world information by resampling the sample. This resampling makes the generated samples realistic and diverse. Extensive experiments show that our method effectively improves the performance of the model. In addition, ablation experiments show that subcomponents of our method are effective and that the augmented samples generated by our method can improve the performance of different baseline detection networks.
References
- [1] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “Yolov4: Optimal speed and accuracy of object detection,” arXiv preprint arXiv:2004.10934, 2020.
- [2] Y. Xiao, Q. Yuan, K. Jiang, J. He, X. Jin, and L. Zhang, “Ediffsr: An efficient diffusion probabilistic model for remote sensing image super-resolution,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [3] M. Hu, K. Jiang, Z. Wang, X. Bai, and R. Hu, “Cycmunet+: Cycle-projected mutual learning for spatial-temporal video super-resolution,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [4] Y. Xiao, Q. Yuan, K. Jiang, X. Jin, J. He, L. Zhang, and C. Lin, “Local-global temporal difference learning for satellite video super-resolution. arxiv 2023,” arXiv preprint arXiv:2304.04421.
- [5] H. Deng, X. Sun, M. Liu, C. Ye, and X. Zhou, “Small infrared target detection based on weighted local difference measure,” IEEE Transactions on Geoscience and Remote Sensing, vol. 54, no. 7, pp. 4204–4214, 2016.
- [6] K. Jiang, Q. Wang, Z. An, Z. Wang, C. Zhang, and C.-W. Lin, “Mutual retinex: Combining transformer and cnn for image enhancement,” IEEE Transactions on Emerging Topics in Computational Intelligence, 2024.
- [7] X. Chen, J. Pan, J. Dong, and J. Tang, “Towards unified deep image deraining: A survey and a new benchmark,” arXiv preprint arXiv:2310.03535, 2023.
- [8] K. Jiang, J. Jiang, X. Liu, X. Xu, and X. Ma, “Fmrnet: Image deraining via frequency mutual revision.”
- [9] S. S. Rawat, S. K. Verma, and Y. Kumar, “Review on recent development in infrared small target detection algorithms,” Procedia Computer Science, vol. 167, pp. 2496–2505, 2020.
- [10] J.-F. Rivest and R. Fortin, “Detection of dim targets in digital infrared imagery by morphological image processing,” Optical Engineering, vol. 35, no. 7, pp. 1886–1893, 1996.
- [11] X. Bai and F. Zhou, “Analysis of new top-hat transformation and the application for infrared dim small target detection,” Pattern Recognition, vol. 43, no. 6, pp. 2145–2156, 2010.
- [12] S. D. Deshpande, M. H. Er, R. Venkateswarlu, and P. Chan, “Max-mean and max-median filters for detection of small targets,” in Signal and Data Processing of Small Targets 1999, vol. 3809. SPIE, 1999, pp. 74–83.
- [13] C. P. Chen, H. Li, Y. Wei, T. Xia, and Y. Y. Tang, “A local contrast method for small infrared target detection,” IEEE transactions on geoscience and remote sensing, vol. 52, no. 1, pp. 574–581, 2013.
- [14] J. Han, S. Moradi, I. Faramarzi, H. Zhang, Q. Zhao, X. Zhang, and N. Li, “Infrared small target detection based on the weighted strengthened local contrast measure,” IEEE Geoscience and Remote Sensing Letters, vol. 18, no. 9, pp. 1670–1674, 2020.
- [15] J. Han, S. Moradi, I. Faramarzi, C. Liu, H. Zhang, and Q. Zhao, “A local contrast method for infrared small-target detection utilizing a tri-layer window,” IEEE Geoscience and Remote Sensing Letters, vol. 17, no. 10, pp. 1822–1826, 2019.
- [16] C. Gao, D. Meng, Y. Yang, Y. Wang, X. Zhou, and A. G. Hauptmann, “Infrared patch-image model for small target detection in a single image,” IEEE transactions on image processing, vol. 22, no. 12, pp. 4996–5009, 2013.
- [17] Y. Dai, Y. Wu, F. Zhou, and K. Barnard, “Asymmetric contextual modulation for infrared small target detection,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 950–959.
- [18] H. Wang, L. Zhou, and L. Wang, “Miss detection vs. false alarm: Adversarial learning for small object segmentation in infrared images,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 8509–8518.
- [19] Y. Dai, Y. Wu, F. Zhou, and K. Barnard, “Attentional local contrast networks for infrared small target detection,” IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 11, pp. 9813–9824, 2021.
- [20] B. Li, C. Xiao, L. Wang, Y. Wang, Z. Lin, M. Li, W. An, and Y. Guo, “Dense nested attention network for infrared small target detection,” IEEE Transactions on Image Processing, vol. 32, pp. 1745–1758, 2022.
- [21] X. Wu, D. Hong, and J. Chanussot, “Uiu-net: U-net in u-net for infrared small object detection,” IEEE Transactions on Image Processing, vol. 32, pp. 364–376, 2022.
- [22] S. Yun, D. Han, S. J. Oh, S. Chun, J. Choe, and Y. Yoo, “Cutmix: Regularization strategy to train strong classifiers with localizable features,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6023–6032.
- [23] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” arXiv preprint arXiv:1710.09412, 2017.
- [24] B. Fei, Z. Lyu, L. Pan, J. Zhang, W. Yang, T. Luo, B. Zhang, and B. Dai, “Generative diffusion prior for unified image restoration and enhancement,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9935–9946.
- [25] J. Chen, Y. Pan, T. Yao, and T. Mei, “Controlstyle: Text-driven stylized image generation using diffusion priors,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 7540–7548.
- [26] Q. Yu, W. Wei, D. Li, Z. Pan, C. Li, and D. Hong, “Hypersinet: A synergetic interaction network combined with convolution and transformer for hyperspectral image classification,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [27] J. Zhang, Q. Cui, and X. Ma, “Deep evidential remote sensing landslide image classification with a new divergence, multi-scale saliency and an improved three-branched fusion,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024.
- [28] G. Wu, X. Ning, L. Hou, F. He, H. Zhang, and A. Shankar, “Three-dimensional softmax mechanism guided bidirectional gru networks for hyperspectral remote sensing image classification,” Signal Processing, vol. 212, p. 109151, 2023.
- [29] A. Jha and B. Banerjee, “Mdfs-net: Multi-domain few shot classification for hyperspectral images with support set reconstruction,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [30] W. Miao, Z. Xu, J. Geng, and W. Jiang, “Ecae: Edge-aware class activation enhancement for semisupervised remote sensing image semantic segmentation,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [31] R. Kou, C. Wang, Y. Yu, Z. Peng, M. Yang, F. Huang, and Q. Fu, “Lw-irstnet: Lightweight infrared small target segmentation network and application deployment,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [32] K. Gao, A. Yu, X. You, W. Guo, K. Li, and N. Huang, “Integrating multiple sources knowledge for class asymmetry domain adaptation segmentation of remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [33] P. Shamsolmoali, J. Chanussot, H. Zhou, and Y. Lu, “Efficient object detection in optical remote sensing imagery via attention-based feature distillation,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [34] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer, 2015, pp. 234–241.
- [35] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125.
- [36] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020.
- [37] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695.
- [38] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [39] X. Lin, J. He, Z. Chen, Z. Lyu, B. Fei, B. Dai, W. Ouyang, Y. Qiao, and C. Dong, “Diffbir: Towards blind image restoration with generative diffusion prior,” arXiv preprint arXiv:2308.15070, 2023.
- [40] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022.
- [41] J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, and R. Timofte, “Swinir: Image restoration using swin transformer,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 1833–1844.
- [42] C. Chen, X. Shi, Y. Qin, X. Li, X. Han, T. Yang, and S. Guo, “Real-world blind super-resolution via feature matching with implicit high-resolution priors,” in Proceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 1329–1338.
- [43] M. Bińkowski, D. J. Sutherland, M. Arbel, and A. Gretton, “Demystifying mmd gans,” in International Conference on Learning Representations, 2018.
- [44] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” Advances in neural information processing systems, vol. 30, 2017.