DexTouch: Learning to Seek and Manipulate Objects
with Tactile Dexterity
Abstract
The sense of touch is an essential ability for skillfully performing a variety of tasks, providing the capacity to search and manipulate objects without relying on visual information. In this paper, we introduce a multi-finger robot system designed to manipulate objects using the sense of touch, without relying on vision. For tasks that mimic daily life, the robot uses its sense of touch to manipulate randomly placed objects in dark. The objective of this study is to enable robots to perform blind manipulation by using tactile sensation to compensate for the information gap caused by the absence of vision, given the presence of prior information. Training the policy through reinforcement learning in simulation and transferring the trained policy to the real environment, we demonstrate that blind manipulation can be applied to robots without vision. In addition, the experiments showcase the importance of tactile sensing in the blind manipulation tasks. Our project page is available at https://lee-kangwon.github.io/dextouch/
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4e809604-446d-4d26-be1e-de9497720a61/x1.png) \captionof
\captionof
figure We propose DexTouch, a dexterous robotic system with tactile-based blind manipulation. The robotic system consisted of a UR5e arm and an AllegroHand with 16 attached touch sensors. Policies were trained in simulation and then deployed to the real environment without fine-tuning.
This research was supported by the Technology Innovation Program (Grant No. 20016252) funded by the Ministry of Trade, Industry and Energy (MOTIE, Korea) and the MOTIE, under the Fostering Global Talents for Innovative Growth Program (P0017307) supervised by the Korea Institute for Advancement of Technology (KIAT) (Corresponding author : Xiaolog Wang, Soo-Chul Lim)
The authors are the Dongguk University, Seoul 04620, South Korea (e-mail: [email protected], [email protected])
The authors are the University of California San Diego, La Jolla, CA 92093, USA (e-mail: [email protected], [email protected])
© 2024 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
I Introduction
Consider a situation of retrieving something from inside of a cabinet or from a tall cupboard where shelves are not visually observable. Despite the fact that we cannot see the object in the high cupboard and don’t know its exact position, we can easily seek and retrieve them. Likewise, we can seek a switch in a dark room or open the door to leave. The reason humans can perform these tasks in daily life is that we can perceive our surroundings or interacting objects through the sense of touch, even when visual information is unavailable.
In many previous studies, touch has primarily been used for dexterous manipulation in robots [1, 2, 3, 4, 5]. However, the use of the tactile sense is not limited to improving performance in manipulation tasks. Robots primarily rely on vision for information while performing manipulation tasks. However, if vision is limited, accurate information cannot be known in addition to the information known in advance, which may cause difficulties in manipulation. As in the previous example, when the approximate location is known but the exact location cannot be visually determined due to limitations in available vision, an information gap occurs. The tactile sense can help compensate for gaps in these situations, aiding the robot in performing tasks successfully.
Our purpose is to enable blind manipulation for robots by compensating for information gaps using tactile information. Previous studies have demonstrated that the tactile sense is useful for blind grasping, which involves grasping objects in an environment without vision. However, vision can be limited in many situations, so it is necessary to extend it to diverse manipulation tasks. In addition, a multi-finger robot hand was utilized to perform these various tasks.
We present DexTouch, a tactile-based multi-finger robot system capable of manipulating objects in environments where vision is not available. We utilize binary tactile state information to overcome the Sim2Real gap, following previous research [6]. The tactile sensors are attached to one side of the hand, covering the fingertips, links, and palm, and equipped with 16 the Force Sensing Resistor (FSR) sensors, as illustrated in Fig. DexTouch: Learning to Seek and Manipulate Objects with Tactile Dexterity. With this system setup, we focus on solving the task of manipulating objects in an environment without vision. To do this, we set three types of tasks that are relevant to our daily lives. These tasks are generally performed using vision, however when the position of the object cannot be accurately determined due to visual limitations, the task becomes significantly more difficult.
We use Reinforcement Learning (RL) on the IsaacGym simulator [7] to train policies for complex movements of a robot hand and arm, which can be deployed in real environments. We demonstrate that RL can be used to manipulate objects in environments where visual observations are not possible by leveraging observable tactile sensations. In our experiments, we test a real world-system for three types of the tasks. The results demonstrate that the touch-based approach is useful for blind manipulation and can be effectively applied in real-world. Additionally, we conduct ablations on our system to validate our design, including tasks such as disabling the touch sensor and adjusting the sensitivity of the binary force sensor.
II Related Work
Dexterous Manipulation allows robots to perform a variety of tasks, allowing them to be applied to a wide range of fields [2, 3, 4]. Particularly, the implementation of the dexterous manipulative ability of robots that manipulate objects is receiving a lot of attention [3, 8, 9]. To address the challenge of dexterous manipulation, model-based approaches to modeling robots and interaction systems were initially proposed [10, 11]. However, approaches utilizing classical controls are based on designed dynamical models, which limits their usefulness for scaling to more complex tasks. To overcome these limitations, methods using deep reinforcement learning have recently been receiving attention [12, 13, 14, 15, 16]. Effective learning and high task success rates can be achieved by utilizing large-scale parallel learning using simulation. Most methods rely on visual input and address issues like occlusion, focusing primarily on dexterous in-hand manipulation limited to small movements. In contrast, our system uses touch sensors to learn movements of robotic arms and hands, aiming to expand into tasks that mimic daily life.
Tactile-based Manipulation can compensate for the loss of information due to the absence of vision [17, 18, 19] and enable manipulation tasks that consider the properties of objects difficult to grasp with vision alone [20]. In particular, tactile detection has been useful for stably grasping large or unfamiliar objects [21]. In addition, tactile sense can be utilized to effectively grasp objects in motion [22] and enable stable gripping of objects without vision, known as blind grasping [23, 24]. These methods model the system or construct control loops with tactile feedback to ensure stable grip on objects. However, due to constraints associated with modeling, their extension to complex tasks is limited. In contrast, we propose a RL-based approach that enables complex object manipulation.
Various approaches have been proposed to identify the surrounding environment and objects in the absence of vision. In particular, a method for identifying unknown objects through iterative grasping has also been studied [25, 26]. An approach that models the environment by utilizing continuous contact between a robot and an object has also been proposed [27]. In addition, research has been conducted on recognizing transparent objects, which are difficult to explore visually, using tactile sense [28], and on estimating the accurate 6-DOF pose of an object in a cluttered environment by utilizing both vision and tactile sense [29]. However, these tactile-based recognition methods have primarily been implemented using grippers with low degrees of freedom. In contrast, we propose a method for performing blind manipulation by applying tactile sensing to a multi-finger robot hand.
III Tactile Robotic System
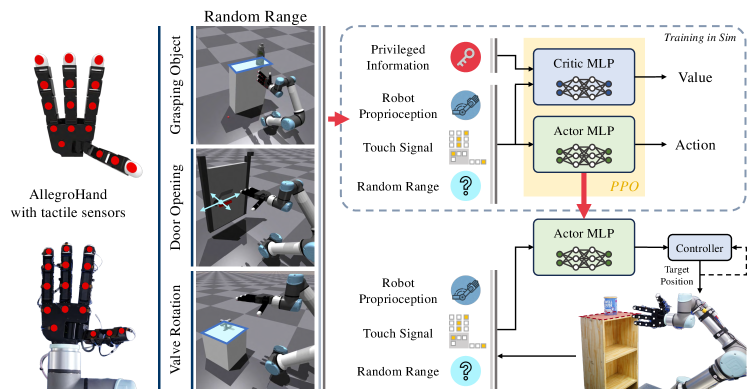
III-A System Setup
Our system is a multi degree-of-freedom (DoF) robot with a total of 22-DoF, consisting of a 6-DoF UR-5e and a 16-DoF AllegroHand. The robot hand has a total of 16 FSR sensors, with 3 sensors attached to each finger and 4 sensors on the palm, as illustrated by the white dots in Fig. 1 and as suggested by [6]. Using an STM32F103 microcontroller, the sensor’s voltage signal is measured at a sampling rate of 125 Hz, passed through a low-pass filter to remove noise, and then transmitted to the main controller. Binary signals are used to reduce the gap between simulation and real robots and simplify the Sim2Real transfer procedure. For this purpose, preprocessing is performed to convert the transmitted voltage signal into a binary contact signal according to a selected threshold before being used.
IssacGym simulator [7] was used for the training of our tactile based robot system. The simulation settings for each task are visualized in Fig. DexTouch: Learning to Seek and Manipulate Objects with Tactile Dexterity (left). A multi-DoF robotic arm-hand system was implemented in the simulation, identical to a real robot. Sixteen virtual contact sensors are configured in the simulation and calculated from the net contact force measured for each step is used as the contact force. Then, using a selected threshold the binary contact signal is calculated in the same way as in real-world environments. The control frequency was set to 10 Hz in both real-world environments and simulations.
III-B Task Description
We study dexterity using a robot’s sense of touch through various types of object manipulation tasks aimed at manipulating objects without vision. In this paper, we mainly focus on three distinct types of benchmark tasks that are relevant to our daily lives as illustrated in Fig. 1. (i) Grasping Object. In this task, inspired by human behavior of retrieving items from a high, invisible shelf, the robot is required to utilize its sense of touch to grasp objects randomly positioned on the table and then bring them to the target point without dropping them. Furthermore, the policy should demonstrate that the robot can also manipulate multiple objects with different shapes. Fifteen objects were selected from the YCB dataset [30], as depicted in the Fig. 2, and experiments were conducted on seven of them in a real-world environment. Three of these are unseen objects. (ii) Door Opening. In this task, the robot needs to locate a door handle that is positioned randomly about the x and y-axes, rotate the door handle, and pull it to open the door. In an invisible environment, the robot should use its sense of touch to locate door handles and learn complex movements to open the door. (iii) Valve Rotating. The purpose of this task is to locate the position of a valve located randomly on a plane and rotate the valve clockwise. Compared to objects in other tasks, the size of the valve is small, requiring more sophisticated exploration ability of the robot.
IV Learning Tactile Manipulation

IV-A Problem Formulation
Our tasks are formulated as a Markov Decision Process (MDP) . Here, is the state space, is the action space, is the reward function, and is the transition dynamics. The objective of robot agent is to find optimal policy to maximize the discounted return . The agent observes state at each time step . Then, it take action calculated by policy and receive a reward . During this process, the agent doesn’t know and . An episode terminates when the agent exceeds the maximum number of steps or achieves the goal of task or reset conditions are achieved.
IV-A1 State
The state of the system consists of the joint position , joint velocity of 6-DoF UR-5e arm and 16-DoF Allegro hand, the binary contact signal , 7-Dof palm pose, 3-Dof linear and 3-Dof angular velocity , 4-fingertip positions relative to robot palm , and task information for each task. consists of the goal position and the length of random range in Grasping Object. In case of Door Opening and Valve Rotating, I consists of only the length of random range . The length of random range refers to the size of the area where objects are randomly spawned. The x-axis corresponds to the horizontal direction of the robot hand, while the y-axis corresponds to the vertical direction. This prior information is the minimum necessary for the robot to recognize that an object exists. Based on this, the robot learns how to manipulate the object using touch.
IV-A2 Action
At each step, the action calculated by the policy network is a normalized vector that consists of two parts, 6-DoF for robot arm and 16-DoF for robot hand. For the robot arm, the first 6-D vector was utilized as a position control command for each joint of the robot arm. In the case of the robot hand, a joint position controller is employed to command the position target of its 16 finger joint angles. Then, both the hand and arm are controlled by PD controllers.

IV-B Reward Design
For a successful application of reinforcement learning, the density of rewards should be enough to facilitate exploration by the agent. At the same time, the agent should be focused on achieving the goal without being distracted from taking actions that deviate from the final goal. To this end, a reward function is proposed that decomposes the task into two phases: reaching the target object and executing the purposeful manipulation task, as illustrated in Fig. 3. Additionally, inspired by [31], a reward function is designed such that the agent can only receive rewards for movements toward the goal.
Reaching the target object. To encourage the robot to get closer to the target object, the reach reward was designed as follows:
| (1) |
This reward is common to all three tasks. Here, and are both the distance between each fingertip and the target object. The target object is the object on the table in Grasping Object, the door handle in Door Opening, the center position of valve in Valve Rotating. is the current distance, and is the closest distance achieved during actions so far. At the beginning of the episode, set . is a relative reward weight.
Executing the manipulation. Since the target manipulation varies for each task, a manipulation reward was designed according to each task. First, for Grasping Object task is designed as follows:
| (2) |
In equation 2, the component rewards the agent for picking up an object, lifting it off the table, and bringing it to the target point. Here, is an indicator function that activates when the height of the object relative to the table becomes 1 above the preset threshold of 10 . At this moment the agent receives an additional bonus reward . and represent the distance between the object and the target point, where is the current distance and is the closest distance achieved during attempt so far. and are relative reward weights.
For Door Opening task, is designed as follows:
| (3) |
In equation 3, the component rewards the agent for actions such as rotating the door handle and opening the door. is an indicator function that becomes 1 when the rotation angle of the door handle exceeds the preset threshold of 1.047 (60 ). and are the door handle angles, is the current door handle angle, and is the maximum door handle angle achieved during attempt. Similarly, and are the door angles, is the current door angle, and is the maximum door angle achieved. When the door handle is rotated beyond the threshold, reward is received, and when the door is opened beyond a preset threshold of 0.873 (50 ), reward is received. and are relative reward weights.
In case of Valve Rotating task, is designed as follows:
| (4) |
In equation 4, the component rewards the agent for the action of rotating the valve. It is similar to the reward for rotating the door handle in the previous task. When the valve is rotated more than 135 , the agent receives a success bonus. is a relative reward weight.
Finally, to prevent unstable jerky movements of the robot, we add a simple adjustable penalty containing the L1 norm of the velocity of each joint to promote smooth movement of the robot agent.
IV-C Training Procedure
The policy is trained using experiences simulated in IsaacGym [7], a highly parallelized GPU-accelerated physics engine. Both the policy and value networks consist of 3 multi-layer perceptrons (MLPs) with sizes 512, 256, and 128, respectively, and ELU [32] as the activation function. To train the control policy, the Proximal Policy Optimization (PPO) [33] algorithm is employed with the following hyper-parameters: clipping , discount factor and 0.016 KL threshold. To reduce the difficulty of learning, asymmetric observation is applied to policy and value networks [12]. Specifically, the value network includes privileged information such as the exact pose of the target object, linear and angular velocities, distance from the robot hand, and physical parameters, and includes information for calculating rewards such as indicator functions depending on the task.
For the IsaacGym simulation, 4096 parallel environments were used in with 2 simulation sub-steps. The action generated by the policy network is executed over 6 steps, corresponding to a control frequency of 10Hz in real-world.
V Experiments
In this part, our DexTouch system was compared to several baselines in both the simulation and real-environments. Experiments are conducted on the proposed tasks, which include grasping objects, opening doors, and rotating valves as defined in the method. Experiments and analyses are mainly conducted on the following perspectives:
(i) For every task, the task success rate of the proposed system on randomly positioned target objects is evaluated. In particular, an ablate study is conducted on how tactile information affects the search of objects in an environment without vision.
(ii) For every task, transfer performance to the real world is evaluated. As in simulation, the success rate of each task is evaluated for objects randomly located within a random range. Details about the random area are shown in Table I. Objects were randomly positioned within the same area as in the simulator for all tasks. For grasping objects, 30 trials were performed for each object. In door opening and valve rotation, 55 experiments were conducted with randomly positioned doors and valves.
V-A Baselines
In experiments, our method is mainly compared with the following baselines.
-
1)
WO-Sensor (Without-Sensor). This PPO policy is learned without any tactile information from the robot. It should use only the robot’s proprioception to manipulate the target object during the task.
-
2)
LQ-Sensor (Low Quality-Sensor). The threshold of the tactile sensor to detect touch was set to 0.3 . In other words, by reducing the sensor’s sensitivity, a lower-quality tactile sensor is employed to train the policy.
-
3)
WO-PInfo (Without-Privileged Information). This PPO policy is learned without privileged information such as the exact pose of the target object, linear and angular velocities, distance from the robot hand, and physical parameters, and includes information for calculating rewards such as indicator functions.
-
4)
DA-Sensor (Deactivation-Sensor). Training is conducted following the same procedure as the proposed method, with the only difference being the deactivation of the tactile sensor during evaluation. This policy is used for ablation purposes and to test the extent to which tactile information is used when applied in a real-world.
| Task | () | () | Z-Pose (rad) |
|---|---|---|---|
| Grasping Object | |||
| Door Opening | - | ||
| Valve Rotating |
In this paper, prior information about the environment is assumed. This information does not provide the exact location of the object, but only the range in which it is likely to exist. Since the height of the furniture or door generally does not change, randomness was applied to the vertical and horizontal distances from the robot, with the height remaining constant. In addition, this was set considering the operating range of the robot because the robot arm is fixed. This randomness was applied consistently in both the simulation and the real-world.
V-B Ablation of tactile sensors during policy training
The Fig. 4 shows the success rate and episodic return of each task according to the training process of the proposed method and baselines and Table II shows the learning results of each method. The findings are highlighted as follows:

| Method | Grasping Object | Door Opening | Valve Rotation | |||
|---|---|---|---|---|---|---|
| Success rate | Reward | Success rate | Reward | Success rate | Reward | |
| LQ-Sensor | 0.37±0.14 | 587.75±172.96 | 0.37±0.17 | 644.11±179.13 | 0.58±0.13 | 1400.99±284.58 |
| WO-Sensor | 0.0±0.0 | 232.80±11.28 | 0.0±0.0 | 142.57±10.03 | 0.02±0.01 | 389.01±59.45 |
| WO-PInfo | 0.15±0.10 | 320.37±134.71 | 0.15±0.09 | 411.89±123.49 | 0.31±0.12 | 771.19±168.35 |
| Fingertips | 0.49±0.10 | 693.12±89.73 | 0.48±0.22 | 792.18±258.47 | 0.69±0.07 | 1677.22±169.42 |
| Palm | 0.36±0.09 | 520.74±82.42 | 0.38±0.23 | 599.27±228.23 | 0.53±0.14 | 1273.58±320.24 |
| F/Tsensor | 0.26±0.11 | 440.17±142.98 | 0.29±0.15 | 516.06±164.20 | 0.50±0.08 | 1243.43±162.25 |
| Ours | 0.72±0.07 | 893.28±65.94 | 0.69±0.12 | 953.99±66.65 | 0.82±0.06 | 2001.71±66.57 |

(i) WO-Sensor, which does not have tactile information, learns by leveraging the location information known in the initial training stage (e.g., position of the table in the case of the grasping object task). However, after that, it fails to learn interactions that involve manipulating the target object to succeed in the task. These results show that it is difficult to detect the position of an object during interaction using a robot’s proprioception alone, and that tactile sensors play an important role in object detection.
(ii) High-quality tactile sensors enhance the success rates of dexterous manipulation tasks. As the sensitivity of the tactile sensor decreases, more force is required for object contact detection. Phenomena such as objects falling or being thrown have been observed during this process. These findings are consistent with previous results showing that highly sensitive tactile sensors aid in reliable object manipulation.
(iii) ‘WO-PInfo’ achieved lower performance than other methods that can utilize privileged information. This is consistent with the general result that using asymmetric observation improves the learning efficiency of reinforcement learning systems. Privileged information is not accessible to the policy network, however it contributes to the efficiency and stability of learning.
V-C Ablation Study I: Analysis of the role of sensors
Ablation studies were conducted to ascertain the tactile sensor most beneficial for manipulation in the absence of vision. Two groups were set for comparison. One group, Fingertips, activates only the sensors on the fingertips, while the other group, Palm, activates only the sensors attached to the palm. Both groups have four activated sensors each, and the touch detection threshold was set to 0.01 , the same as ours. These were trained in the same simulation environment and then compared to our policy. The results are shown in Fig. 4 (b) and Table II. The higher success rate of the fingertips group compared to the palm group indicates that fingertip sensors are more advantageous for object manipulation. In particular, this group achieved similar success rates to ours in the Valve Rotating task because the fingertips were primarily used for valve manipulation behavior, minimizing the impact of deactivating other sensors.
V-D Ablation Study II: Analysis of the usability of sensor types
Force/Torque (F/T) sensors are widely used sensors in robot manipulation. For this reason, they are often considered a good alternative to tactile sensors. We conducted ablation studies to ascertain which type of sensor is more crucial for object manipulation without vision. A new group using F/T sensors on the robot wrist was constructed (F/Tsensor). The 3-axis force and torque were measured using the wrist-mounted F/T sensor and utilized for learning. F/Tsensor was also trained in the same simulation environment and compared with our policy, Fingertips, and Palm. The results are shown in Fig. 4 and Table II. We observed that F/Tsensor achieved lower success rates compared to methods using touch sensors. This suggests that touch sensors attached to the robot hand are more essential than F/T sensors for navigating and manipulating objects without vision.
| Method | Grasping Object | Door Opening | Valve Rotation | ||
|---|---|---|---|---|---|
| LQ-Sensor | 0.27±0.12 | 0.35±0.13 | 0.32±0.18 | ||
| DA-Sensor | 0.09±0.04 | 0.11±0.03 | 0.12±0.05 | ||
| Ours |
|
0.60±0.17 | 0.67±0.17 |
V-E Real-world evaluation with different sensing capabilities
We transfer the trained policies to a real robot without fine-tuning to test whether tactile sensors continue to provide benefits for object manipulation without vision. The results are shown in Table III. We further analyze the tactile policy, as shown in Fig. 5, which illustrates the object manipulation process for each task. In particular, the analysis focuses on the transferability of the ability to manipulate randomly located objects.
In all tasks, the initial reaching process was observed to have similar trajectories. This means that in the initial stages, when information is lacking, approaches are based on what is known. However, in subsequent manipulation behaviors, different performance was observed depending on the extent to which touch was used.
Due to the low sensitivity of the LQ-Sensor, more contact force was required for manipulation. As a result, excessive manipulation, such as dropping objects, has been observed. These observations indicate that sensitive touch is important for the manipulation of objects. The lowest success rate of the DA-Sensor indicates a significant contribution of the touch sensor to manipulation. As a result, inital process similar to our policy was performed, but the lack of a touch sensor prevented the object from being found, making subsequent manipulation tasks difficult.
In contrast, our approach leveraging touch provides benefits for object manipulation. In each task, manipulation attempts were observed based on object contact. For example, it has been observed that the timing of attempted manipulation of an object varies depending on when contact occurs. This suggests that the robot can first move to an area where an object may exist based on prior information, and then manipulate the object without vision based on touch. Additionally, these observations highlight that sensitive touch can be useful for blind manipulation of objects.
Prior information serves as the starting point for the robot to recognize the existence of an object and to perform the task. From this perspective, prior information can influence the initial stage of object manipulation. However, since the robot cannot determine the exact location of the object with prior information alone, it must learn to manipulate the object by compensating for the loss of information with tactile sense. In addition, the properties of objects encountered by the robot during learning can also be included in the prior information. We observed that, among the three unknown objects used in the Grasping object, the tumbler had the lowest success rate. This is due to the heavy weight and slippery surface of the tumbler. Therefore, it suggests that properties not encountered during learning can affect the task success.
The results demonstrated that policies trained in simulation can be successfully transferred to real-world environments. Even in a real environment, the policy is capable of manipulating randomly located target objects according to the task. This indicates that blind manipulation using tactile information can be effectively applied in real-world scenarios, even in the absence of visual information.
VI Conclusion
In this paper, a tactile-based approach has been proposed to enable robots to perform manipulation tasks without vision. Tasks that mimic daily life were defined, and a reinforcement learning framework was presented to learn complex multi-degree-of-freedom movements of the robot arm and hand for each task. The proposed system demonstrated that tactile information can be used to enable robots to perform blind manipulation. The results show that the success rate increases as the tactile sensor becomes more sensitive and is distributed over a wider area. This suggests that objects can be manipulated without relying on visual information, and proves that tactile information is useful for object manipulation in environments where visual information is absent. Future research directions are focused on applying sensors that can provide various tactile information, such as 3-axis force sensors, and expanding the system to study generalizability.
References
- [1] A. R. Sobinov and S. J. Bensmaia, “The neural mechanisms of manual dexterity,” Nature Reviews Neuroscience, vol. 22, no. 12, pp. 741–757, 2021.
- [2] A. M. Okamura, N. Smaby, and M. R. Cutkosky, “An overview of dexterous manipulation,” in IEEE International Conference on Robotics and Automation. Symposia Proceedings, 2000.
- [3] O. M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray et al., “Learning dexterous in-hand manipulation,” The International Journal of Robotics Research, vol. 39, no. 1, pp. 3–20, 2020.
- [4] N. Chavan-Dafle and A. Rodriguez, “Sampling-based planning of in-hand manipulation with external pushes,” in Robotics Research: The 18th International Symposium ISRR. Springer, 2020, pp. 523–539.
- [5] Q. Li, O. Kroemer, Z. Su, F. F. Veiga, M. Kaboli, and H. J. Ritter, “A review of tactile information: Perception and action through touch,” IEEE Transactions on Robotics, vol. 36, no. 6, pp. 1619–1634, 2020.
- [6] Z.-H. Yin, B. Huang, Y. Qin, Q. Chen, and X. Wang, “Rotating without seeing: Towards in-hand dexterity through touch,” Robotics: Science and Systems, 2023.
- [7] V. Makoviychuk, L. Wawrzyniak, Y. Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa et al., “Isaac gym: High performance gpu-based physics simulation for robot learning,” arXiv preprint arXiv:2108.10470, 2021.
- [8] A. Bhatt, A. Sieler, S. Puhlmann, and O. Brock, “Surprisingly Robust In-Hand Manipulation: An Empirical Study,” in Proceedings of Robotics: Science and Systems, Virtual, July 2021.
- [9] A. S. Morgan, K. Hang, B. Wen, K. Bekris, and A. M. Dollar, “Complex in-hand manipulation via compliance-enabled finger gaiting and multi-modal planning,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4821–4828, 2022.
- [10] V. Kumar, Y. Tassa, T. Erez, and E. Todorov, “Real-time behaviour synthesis for dynamic hand-manipulation,” in 2014 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2014, pp. 6808–6815.
- [11] Y. Bai and C. K. Liu, “Dexterous manipulation using both palm and fingers,” in 2014 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2014, pp. 1560–1565.
- [12] A. Handa, A. Allshire, V. Makoviychuk, A. Petrenko, R. Singh, J. Liu, D. Makoviichuk, K. Van Wyk, A. Zhurkevich, B. Sundaralingam et al., “Dextreme: Transfer of agile in-hand manipulation from simulation to reality,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 5977–5984.
- [13] T. Chen, J. Xu, and P. Agrawal, “A system for general in-hand object re-orientation,” in Conference on Robot Learning. PMLR, 2022, pp. 297–307.
- [14] Y. Qin, B. Huang, Z.-H. Yin, H. Su, and X. Wang, “Dexpoint: Generalizable point cloud reinforcement learning for sim-to-real dexterous manipulation,” in Conference on Robot Learning. PMLR, 2023, pp. 594–605.
- [15] Y. Qin, Y.-H. Wu, S. Liu, H. Jiang, R. Yang, Y. Fu, and X. Wang, “Dexmv: Imitation learning for dexterous manipulation from human videos,” in European Conference on Computer Vision. Springer, 2022, pp. 570–587.
- [16] T. Chen, M. Tippur, S. Wu, V. Kumar, E. Adelson, and P. Agrawal, “Visual dexterity: In-hand reorientation of novel and complex object shapes,” Science Robotics, vol. 8, no. 84, p. eadc9244, 2023.
- [17] Y. Chebotar, O. Kroemer, and J. Peters, “Learning robot tactile sensing for object manipulation,” in 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2014, pp. 3368–3375.
- [18] D.-K. Ko, K.-W. Lee, D. H. Lee, and S.-C. Lim, “Vision-based interaction force estimation for robot grip motion without tactile/force sensor,” Expert Systems with Applications, vol. 211, p. 118441, 2023.
- [19] K.-W. Lee, D.-K. Ko, and S.-C. Lim, “Toward vision-based high sampling interaction force estimation with master position and orientation for teleoperation,” IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 6640–6646, 2021.
- [20] H. Liu, Y. Wu, F. Sun, and D. Guo, “Recent progress on tactile object recognition,” International Journal of Advanced Robotic Systems, vol. 14, no. 4, p. 1729881417717056, 2017.
- [21] P. Mittendorfer, E. Yoshida, T. Moulard, and G. Cheng, “A general tactile approach for grasping unknown objects with a humanoid robot,” in 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2013, pp. 4747–4752.
- [22] P. Lynch, M. F. Cullinan, and C. McGinn, “Adaptive grasping of moving objects through tactile sensing,” Sensors, vol. 21, no. 24, p. 8339, 2021.
- [23] H. Dang, J. Weisz, and P. K. Allen, “Blind grasping: Stable robotic grasping using tactile feedback and hand kinematics,” in 2011 ieee international conference on robotics and automation. IEEE, 2011, pp. 5917–5922.
- [24] W. Shaw-Cortez, D. Oetomo, C. Manzie, and P. Choong, “Tactile-based blind grasping: A discrete-time object manipulation controller for robotic hands,” IEEE Robotics and Automation Letters, vol. 3, no. 2, pp. 1064–1071, 2018.
- [25] S. Dragiev, M. Toussaint, and M. Gienger, “Uncertainty aware grasping and tactile exploration,” in 2013 IEEE International conference on robotics and automation. IEEE, 2013, pp. 113–119.
- [26] S. Pai, T. Chen, M. Tippur, E. Adelson, A. Gupta, and P. Agrawal, “Tactofind: A tactile only system for object retrieval,” arXiv preprint arXiv:2303.13482, 2023.
- [27] T. Schneider, B. Belousov, G. Chalvatzaki, D. Romeres, D. K. Jha, and J. Peters, “Active exploration for robotic manipulation,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 9355–9362.
- [28] P. K. Murali, B. Porr, and M. Kaboli, “Touch if it’s transparent! actor: Active tactile-based category-level transparent object reconstruction,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 10 792–10 799.
- [29] P. K. Murali, A. Dutta, M. Gentner, E. Burdet, R. Dahiya, and M. Kaboli, “Active visuo-tactile interactive robotic perception for accurate object pose estimation in dense clutter,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4686–4693, 2022.
- [30] B. Calli, A. Singh, A. Walsman, S. Srinivasa, P. Abbeel, and A. M. Dollar, “The ycb object and model set: Towards common benchmarks for manipulation research,” in 2015 international conference on advanced robotics (ICAR). IEEE, 2015, pp. 510–517.
- [31] A. Petrenko, A. Allshire, G. State, A. Handa, and V. Makoviychuk, “Dexpbt: Scaling up dexterous manipulation for hand-arm systems with population based training,” in RSS, 2023.
- [32] V. Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” in Proceedings of the 27th international conference on machine learning (ICML-10), 2010, pp. 807–814.
- [33] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.