Device-cloud Collaborative Recommendation via Meta Controller
Abstract.
On-device machine learning enables the lightweight deployment of recommendation models in local clients, which reduces the burden of the cloud-based recommenders and simultaneously incorporates more real-time user features. Nevertheless, the cloud-based recommendation in the industry is still very important considering its powerful model capacity and the efficient candidate generation from the billion-scale item pool. Previous attempts to integrate the merits of both paradigms mainly resort to a sequential mechanism, which builds the on-device recommender on top of the cloud-based recommendation. However, such a design is inflexible when user interests dramatically change: the on-device model is stuck by the limited item cache while the cloud-based recommendation based on the large item pool do not respond without the new re-fresh feedback. To overcome this issue, we propose a meta controller to dynamically manage the collaboration between the on-device recommender and the cloud-based recommender, and introduce a novel efficient sample construction from the causal perspective to solve the dataset absence issue of meta controller. On the basis of the counterfactual samples and the extended training, extensive experiments in the industrial recommendation scenarios show the promise of meta controller in the device-cloud collaboration.
1. Introduction
Recommender system (Resnick and Varian, 1997) has been an indispensable component in a range of ubiquitous web services. With the increasing capacity of mobile devices, the recent progress takes on-device modeling (Lin et al., 2020; Dhar et al., 2021) into account for recommendation by leveraging several techniques like network compression (Sun et al., 2020c), split-deployment (Gong et al., 2020) and efficient learning (Yao et al., 2021). The merits of on-device real-time features and reduced communication cost in this direction then attract a range of works in the perspectives of privacy (Yang et al., 2020) and collaboration (Sun et al., 2020a), and boost the conventional industrial recommendation mechanism.
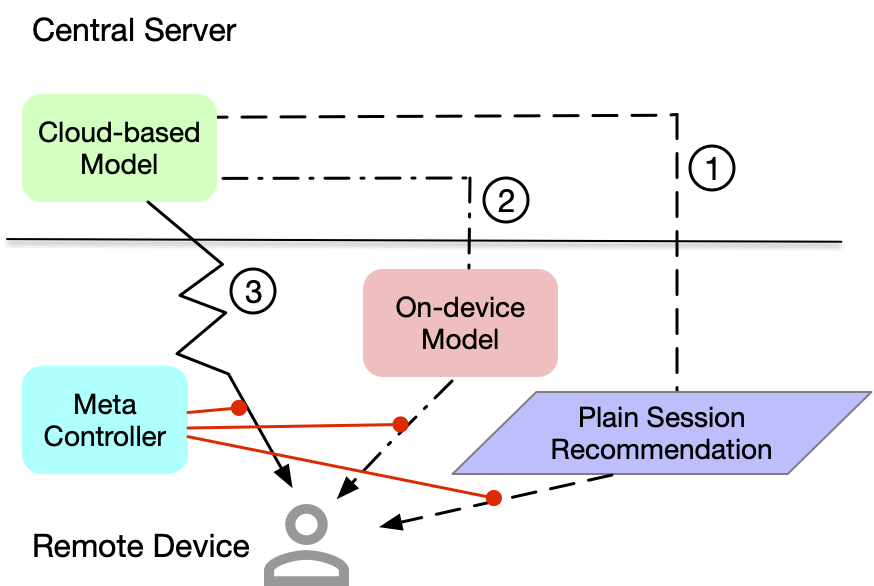
The popular industrial recommender systems mainly benefit from the rapid development of cloud computing (Duc et al., 2019), which constructs a cost-efficient computing paradigm to serve the billion-scale customers. The inherent algorithms progressively evolved from collaborative filtering (Sarwar et al., 2001; Zhao and Shang, 2010), matrix factorization (Koren et al., 2009) to deep learning based methods (Cheng et al., 2016; Guo et al., 2017; Zhou et al., 2018; Sun et al., 2019; Tan et al., 2021) etc., which explore the gain of the low-level feature interaction and high-level semantic understanding. Although the performance is improved by more powerful models, the corresponding computational cost increases concomitantly, requiring the mechanism adjustment of recommendation (Wang et al., 2021) and more expensive accelerations in hardware (Norrie et al., 2021). An exemplar is the E-commerce session recommendation (Jannach et al., 2017) that ranks the top-K candidates in one session to improve the efficiency and reduce the computational burden in the cloud server, especially for the infinite feeds recommendation. The path ① in Figure 1 illustrates this type of recommendation in the industrial scenarios, and when the length of session is 1 in the extreme, i.e., one item in once recommendation, it becomes path ③ in Figure 1, a prohibitively high re-fresh. Note that, the mechanism of the path ③ is usually better than that of the path ①, since it senses the user interaction feedback more frequently. However, it is not scalable due to the bottleneck of the computational resource towards billions of customers, and thus the re-fresh only slightly applies in practice when it is really indispensable compared to other surrogate ways.
The recent development in edge computing (Zhou et al., 2019; Yao et al., 2022) drives the AI models deployed in remote devices to reduce the communication cost and incorporate the fine-grained real-time features. Specifically, for recommendation, there are several explorations (Yang et al., 2020; Sun et al., 2020c; Gong et al., 2020; Yao et al., 2021) to leverage the remote computing power for recommender systems, with the increasing capacity of smart phones and the aid of softwares including TFLite111https://www.tensorflow.org/lite, PyTorch Mobile222https://pytorch.org/mobile/home/ and CoreML333https://developer.apple.com/documentation/coreml. Different from the rich resources of the cloud server in the aspects of storage, energy and computing speed, on-device recommenders must be lightweight by applying the compression techniques (Sun et al., 2020c; Cai et al., 2020) or the split-deployment methods (Gong et al., 2020; Banitalebi-Dehkordi et al., 2021). However, compared to the above constraints, the advantages of on-device recommenders in real-time and personalization are also significant to the E-commerce session recommendation, e.g., EdgeRec (Gong et al., 2020) and DCCL (Yao et al., 2021). Beyond the developed algorithms, the common mechanism behind all aforementioned on-device recommenders is sequentially combined with the cloud-based recommendation, which is illustrated in the path ② of Figure 1. Namely, the on-device model re-ranks the unexposed candidates recommended by the cloud-based model with real-time user interactive features. However, one shortcoming of this mechanism is the number of cached items due to the limit of mobile storage that cannot satisfy dramatic user interest changes.
From the above discussion, we know the current cloud-based and on-device recommenders both have their pros and cons. Yet according to their characteristics, they actually can be complementary to construct a more flexible mechanism for recommendation: When the user interests almost have no changes, the plain session recommendation is enough without invoking on-device recommender to frequently refine the ranking list; When the user interests slightly change, re-ranking the candidates from the item cache by the on-device model according to the real-time features can improve the accuracy of recommendation; When the user interests dramatically change, it will be better to explore more possible candidates from the large-scale item pool by the cloud-based re-fresh. This introduces the idea of “Meta Controller” to achieve the Device-Cloud Collaboration shown in Figure 1 (a similar and concurrent two-mode complementary design can refer to AdaRequest (Qian et al., 2022)). Despite straightforward, it is challenging to collect the training samples for the meta controller, since three mechanisms in Figure 1 are separately executed and so are the observational samples. Naively deploying a random-guess model as a surrogate online to collect the data sometimes is risky or requires a lengthy exploration. To solve this dilemma, we introduce a novel idea from causal inference to compare the causal effect (Künzel et al., 2019; Johansson et al., 2016; Shalit et al., 2017) of three recommendation mechanisms, which implements an efficient offline sample construction and facilitates the training of meta controller. In a nutshell, the contribution of this paper can be summarized as follows.
-
•
Considering the pros and cons of the current cloud-based recommender and the on-device recommender, we are among the first attempts to propose a meta controller to explore the “Device-Cloud Collaborative Recommendation”.
-
•
To overcome the dataset absence issue when training the meta controller, we propose a dual-uplift modeling method to compare the causal effect of three recommendation mechanisms for an efficient offline sample construction.
-
•
Regarding the constrained resources for the cloud-based recommendation re-fresh, we propose a label smoothing method to suppresses the prediction of meta controller during the training to adapt the practical requirements.
The extensive experiments on a range of datasets demonstrate the promise of the meta controller in Device-Cloud Collaboration.
2. Related Works
2.1. Cloud-Based Recommendation
Recommendation on the basis of cloud computing (Duc et al., 2019) has achieved great success in the industrial companies like Microsoft, Amazon, Netflix, Youtube and Alibaba etc. A range of algorithms from the low-level feature interaction to the high-level semantic understanding have been developed in the last decades (Yao et al., 2017a, b). Some popular methods like WideDeep (Cheng et al., 2016) and DeepFM (Guo et al., 2017) explore the combination among features to construct the high-order information, which reduces the burden of the subsequent classifier. Several approaches like DeepFM (Xue et al., 2017), DIN (Zhou et al., 2018) and Bert4Rec (Sun et al., 2019) resort to deep learning to hierarchically extract the semantics about user interests for recommendation (Pan et al., 2021; Zhang et al., 2022). More recent works like MIMN (Pi et al., 2019), SIM (Pi et al., 2020) and Linformer (Wang et al., 2020) solve the scalability and efficiency issues in comprehensively understanding user intention from lifelong sequences. Although the impressive performance has been achieved in various industrial recommendation applications, almost all of them depends on the rich computing power of the cloud server to support their computational cost (Sun et al., 2020a).
2.2. On-Device Recommendation
The cloud-based paradigm greatly depends on the network conditions and the transmission delay to respond to users’ interaction in real time (Yao et al., 2022). With the increasing capacity of smart phones, it becomes possible to alleviate this problem by deploying some lightweight AI models on the remote side to save the communication cost and access some real-time features (Zhou et al., 2019). Previous works in the area of computer vision and natural language processing have explored the possible network compression techniques, e.g., MobileNet (Sandler et al., 2018) and MobileBert (Sun et al., 2020b), and some neural architecture search approaches (Zoph and Le, 2016; Cai et al., 2018). The recent CpRec for on-device recommendation studied the corresponding compression by leveraging the adaptive decomposition and the parameter sharing scheme (Sun et al., 2020c). In comparison, EdgeRec adopted a split-deployment strategy to reduce the model size without compression, which distributed the huge id embeddings on the cloud server and sent them to the device side along with items (Gong et al., 2020). Some other works, DCCL (Yao et al., 2021) and FedRec (Yang et al., 2020), respectively leveraged the on-device learning for the model personalization and the data privacy protection. Nevertheless, the design of the on-device recommendation like EdgeRec and DCCL is sequentially appended after the cloud-based recommendation results, which might be stuck by the limited item cache.
2.3. Causal Inference
Causal inference has been an important research topic complementary to the current machine learning area, which improves the generalization ability of AI models based on the limited data or from one problem to the next (Schölkopf et al., 2021). The broadly review of the causality can be referred to this literature (Pearl and Mackenzie, 2018) and in this paper, we specifically focus on the counterfactual inference to estimate the heterogeneous treatment effect (Künzel et al., 2019). Early studies mainly start from the statistical perspective like S-Learner and X-Learner (Künzel et al., 2019), which alleviates the treatment imbalance issue and leverages the structural knowledge. Recent works explore the combination with deep learning to leverage the advantages of DNNs in representation learning (Johansson et al., 2016; Shalit et al., 2017; Schölkopf et al., 2021). In the industrial recommendation, the idea of causal inference is widely applied for the online A/B testing, debiasing (Zhang et al., 2021) and generalization (Kuang et al., 2020). Except above works, the most related methods about our model are uplift modeling, which is extensively used to estimate the causal effect of each treatment (Olaya et al., 2020). Specifically, the constrained uplift modeling is practically important to meet the requirements of the restricted constraint for each treatment (Zhao and Harinen, 2019). In this paper, we are first to explore its application in solving the dataset absence issue of training the meta controller for device-cloud collaborative recommendation.
3. The Proposed Approach
Given a fixed-length set of historical click items that the -th user interacts before the current session, and all side features (e.g., statistical features) , the cloud-based recommendation is to build the following prediction model that evaluates the probability for the current user interests regarding the -th candidate ,
For the on-device recommendation, the model could leverage the real-time interactions and other fine-grained features (e.g., exposure and prior prediction score from the cloud-based recommendation) in the current session, denoting as and respectively. Similarly, we formulate the on-device prediction model regarding the -th candidate as follows,
As for the recommendation re-fresh, considering its consistency with the common session recommendation, the model actually is shared with the cloud-based recommendation but accessing the richer instead of as input features when invoking. That is, the prediction from the re-fresh mechanism is as follows,
The gain of this mechanism is from the feature perspective instead of the model perspective, namely, the real-time feedback about user interactions in the current session . Specially, we should note that in practice, it directly use the same model without additionally training a new model except the input difference.
3.1. Meta Controller
Given the aforementioned definitions, our goal in this paper is to construct a meta controller that manages the collaboration of the above mechanisms to more accurately recommend the items according to the user interests. Let represents the model of meta controller, which inputs the same features as and is deployed in the device. Assuming represents invoking three recommendation mechanisms in Figure 1 respectively, we expect makes a decision to minimize the following problem.
| (1) |
where is the underlying distribution about the user interaction (click or not) on the item , is the cross-entropy loss function about the label and the model prediction, and corresponds to one of previous recommendation mechanisms based on the choice . Although the above Eq. (1) resembles learning a Mixture-of-Expert problem (Shazeer et al., 2017), it is different as we only learn excluding all pre-trained . In addition, this problem is specially challenging, since we do not have the samples from the unknown distribution to train the meta controller.
Dataset Absence Issue
The generally collected training samples in the industrial recommendation are from the scenarios where the stable recommendation model has been deployed. For example, we can acquire the training samples under the serving of an early-trained session recommendation model, or under the serving of the on-device recommender. However, in the initialing point, we do not have a well-optimized meta controller model that can deploy for online serving and collect the training samples under the distribution . Naively deploying a random-guess model or learning from the scratch online sometimes can be risky or require a lengthy exploration to reach a stationary stage. In the following, we propose a novel offline dataset construction method from the perspective of causal inference (Künzel et al., 2019; Johansson et al., 2016; Shalit et al., 2017).

3.2. Causal Inference for Sample Construction
One important branch of causal inference is counterfactual inference under interventions (Pearl and Mackenzie, 2018), which evaluates the causal effect of one treatment based on the previous observational studies under different treatments. This coincidentally corresponds to the case in device-cloud collaboration to train the meta controller, where we can collect the training samples of three different scenarios, the cloud-based session recommendation, the on-device recommendation, the cloud-based re-fresh, denoting as follows,
Note that, is the user interaction in three scenarios (same to previous definitions), and denotes the binary outcome of , which means under the treatment whether the user will click in the following exposed items in the same session. With these three heterogeneous sample sets, we can leverage the idea of counterfactual inference to compare the causal effect of recommendation mechanisms and construct the training samples of meta controller. To be simple, consider the following estimation of Conditional Average Treatment Effect (CATE)
where we can directly treat the regular cloud-based session recommendation as the control group, on-device recommendation and re-fresh as the treatment groups. Then, by separately training a supervised model for each group, we can approximately compute the CATE of two treatments via T-learner or X-learner (Künzel et al., 2019). Specially, the recent progress in the uplift modeling combined with deep learning (Johansson et al., 2016; Shalit et al., 2017) shows the promise about the gain in the homogeneous representation learning. Empirically, we can share a backbone of representation learning and the base output network among different supervised models (Wenwei Ke, 2021).
In Figure 2, we illustrate the proposed dual-uplift modeling method that constructs the counterfactual samples to train the meta controller. As shown in the figure, we build two uplift networks along with the base network to respectively estimate the CATE of two treatments, and the base network is to build the baseline for the data in the control group. Formally, the base network is defined in the following to align our illustration in Figure 2,
where is the encoder for the historical click interactions or and is the function composition operator444https://en.wikipedia.org/wiki/Function_composition, and is named as the outcome network of the baseline session recommendation in the taxonomy of causal inference (Shalit et al., 2017). Similarly, for the treatment effect of the on-device recommendation, we follow the design of to construct an uplift network to fit the data . As shown in Figure 2, its formulation is as follows,
where is the outcome network of the on-device recommendation. Note that, and share the same feature encoder to make the representation more homogeneous that satisfies the assumption of the causal inference. Finally, for the re-fresh mechanism, we use another uplift network to fit its data , which is denoted by the following equation,
Note that, although the features of and have the same forms, they are actually non-independent-identically-distributed (non-IID) due to different invoking frequencies. Therefore, we use instead of to more flexibly model the outcome of the cloud-based re-fresh mechanism. With the above definitions, we can solve the following optimization problems to learn all surrogate models , and .
| (2) |
where , and are the cross-entropy loss. After learning , and , we can acquire a new counterfactual training dataset by comparing the CATE of each sample under three mechanisms defined as follows.
| (3) | ||||
where means the position indicator (, , or ) of the maximum in three CATEs, and if T-Learner is used. Here, the counterfactual inference is used to compute the CATE of each sample collected under different treatments. Note that, if X-Learner is used, CATE can be computed in a more comprehensive but complex manner and we kindly refer to this work (Künzel et al., 2019).
Remark about the difference of and . Previous paragraphs mentioned different parameterized models e.g., and , which could be classified into two categories by and . Their biggest difference is whether these models will be used online. For the models described in Preliminary, they are all real-world models serving online and in most cases are developed and maintained by different teams in the industrial scenarios. For the -style models described in this paragraph, they are all surrogate models, which are only used for the sample construction and not deployed online. Roughly, it will be better if they can be consistent with the well-optimized -style models, but in some extreme cases they actually can be very different only if the approximate CATE is accurate enough to make the constructed contain the sufficient statistics about the distribution in Eq. (1).
3.3. Training the Meta Controller
Generally, it is straightforward to train the meta controller by a single-label multi-class empirical risk minimization with the aid of the counterfactual dataset in Eq. (3) as follows,
| (4) |
Unfortunately, not all recommendation mechanisms in Figure 1 are cost-effective. Specially, the cloud-based recommendation re-fresh usually suffers from the restricted computing resources in the infinite feeds recommendation, yielding a hard invoking constraint in practice. This then introduces a constrained optimization problem in device-cloud collaboration and breaks the regular training of meta controller like Eq. (4). Actually, this is a classical constrained budget allocation problem, which has been well studied in last decades (Zhao et al., 2019; Meister et al., 2020). In this paper, we introduces a Label Smoothing (LS) solution to generally train the meta controller under the specific constraint on the cloud-based recommendation re-fresh. In detail, given the maximal invoking ratio about the cloud-based re-fresh, we make the relaxation for Eq. (4) via the label smoothing.
| (5) | ||||
where we use to substitute to supervise the model training and is smoothed when the ratio of the batch of predictions is beyond , is the one-hot vector corresponding to the second largest prediction in . The relaxation in Eq. (5) means when the invoking ratio is over-reached, the supervision should be biased to the second possible choice for the prediction of . Note that, when the hard ratio is not reached, still keeps the original label in the default case, namely degenerates to Eq. (4). Note that, Eq. (5) can be easily implemented in the stochastic training manner and after training until the invoking ratio is almost under , we acquire the final meta controller that can be deployed online in the device-cloud collaborative recommendation. Up to now, we describe all the contents of our meta controller method and for clarity, we summarize the whole framework in Algorithm 1.
4. Experiments



In this section, we conduct a range of experiments to demonstrate the effectiveness of the proposed framework. To be specific, we will answer the following questions in our device-cloud collaboration.
-
(1)
RQ1: Whether the proposed method can help train a meta controller to achieve a better performance via device-cloud collaboration compared to previous three types of mechanism? To our best knowledge, we are the first attempt to explore this type of collaboration between cloud-based recommenders and the on-device recommender.
-
(2)
RQ2: Whether the proposed method can adapt to the practical resource constraint after the training of the meta controller by means of Eq. (5). It is important to understand the underlying trade-off in performance under the practical constraint in the device-cloud collaboration.
-
(3)
RQ3: How is the potential degeneration from the collaboration of three recommendation mechanisms to the arbitrary two of them, and how is the ablation study that comprehensively analyzes the exemplar intuition support, the training procedure, the inherit parameter characteristics?
4.1. Experimental Setup
4.1.1. Datasets
We implement the experiments on two public datasets Movienlens and Amazon, and one real-world large-scale backgroud word dataset, termed as Alipay for simplicity. The statistics of three datasets are summarized in Table 1. Generally, each dataset contains five training sets, i.e., two sets to train the base cloud recommender and on-device recommender respectively, three sets to learn the meta controller. As for the test sets of each dataset, one set is used to measure the CATE of meta controller, and the other one is to measure the click-through rate (CTR) performance of the models. Note that, Movielens and Amazon do not have the session information, and we thus manually simulate the session to meet the setting of this study. More details about the simulations of Movielens and Amazon are kindly referred to the appendix.
| Dataset | Type | #user | #item | #sample |
|---|---|---|---|---|
| Movielens | CTR-Cloud | 7,900,245 | ||
| CTR-Device | 26,998,425 | |||
| CATE-Cloud | 6,040 | 3,706 | 4,819,845 | |
| CATE-Device | 4,819,845 | |||
| CATE-Refresh | 4,819,845 | |||
| Amazon | CTR-Cloud | 17,444,825 | ||
| CTR-Device | 285,809,710 | |||
| CATE-Cloud | 49,814 | 36,997 | 2,588,895 | |
| CATE-Device | 2,588,895 | |||
| CATE-Refresh | 2,588,895 | |||
| Alipay | CTR-Cloud | 10.5M | 10K | 31M |
| CTR-Device | 5.4M | 14M | ||
| CATE-Cloud | 0.6M | 1M | ||
| CATE-Device | 66K | 0.2M | ||
| CATE-Refresh | 0.3M | 0.3M |
4.1.2. Baselines & Our methods
We compare the meta controller mechanism with previous three existing mechanisms, i.e., the cloud-based session recommendation, the on-device recommendation and the cloud-based re-fresh. In three mechanisms, we all leverage DIN (Zhou et al., 2018) as the backbone, which takes the candidates as the query w.r.t. the user historical behaviors to learn a user representation for prediction, but it correspondingly incorporates different features as in , and . To be simple, we term the models in previous three mechanisms respectively as (cloud-based session recommender), (cloud-based re-fresh) and (on-device recommender), and we call our method (the Meta-Controller-based recommender). Besides, we also provide a baseline that randomly mixes three types of the existing recommendation mechanisms, termed as . For the network structure details e.g., the dimensions and the training schedules of DINs in CRec, CRRec, ORec, RMixRec and MCRec, please refer to the appendix.
| Methods | Movielens | Amazon | Alipay | ||||||
|---|---|---|---|---|---|---|---|---|---|
| HitRate1 | NDCG5 | AUC | HitRate1 | NDCG5 | AUC | HitRate1 | NDCG5 | AUC | |
| CRec | 32.22 | 50.13 | 92.46 | 16.27 | 27.36 | 77.04 | 17.85 | 34.96 | 72.39 |
| ORec | 36.98 | 55.31 | 93.70 | 17.31 | 28.94 | 77.95 | 17.88 | 35.02 | 72.80 |
| CRRec | 37.28 | 55.85 | 93.88 | 17.56 | 29.24 | 78.98 | 18.09 | 35.41 | 73.35 |
| RMixRec | 35.52 | 53.76 | 93.34 | 17.06 | 28.51 | 77.99 | 17.90 | 35.06 | 72.83 |
| MCRec (w/o constraint) | 37.84 | 56.20 | 93.90 | 17.70 | 29.48 | 79.05 | 18.26 | 35.77 | 73.86 |
| MCRec () | 37.87 | 56.19 | 93.88 | 17.68 | 29.48 | 79.03 | 18.14 | 35.62 | 73.45 |
| MCRec () | 37.62 | 55.88 | 93.80 | 17.61 | 29.38 | 78.79 | 17.98 | 35.33 | 73.32 |
| MCRec () | 37.16 | 55.45 | 93.67 | 17.50 | 29.21 | 78.38 | 17.91 | 35.17 | 73.03 |
4.1.3. Evaluation Protocols
The process of training Meta Controller consists of two phases as summarized in Algorithm 1, and thus the metrics we used in this paper will evaluate these two phases respectively. For the phase of the dataset construction, we mainly measure the causal effect, namely CATE of the synthetic dataset based on the counterfactual inference. While for the training phase, we mainly evaluate the click-through rate (CTR) performance of the recommenders including baselines and our method. For the dataset construction stage, we use the AUUC (Diemert et al., 2018) and QINI coefficients (Radcliffe, 2007) as the evaluation metrics, which are defined as follows,
where calculates the relative gain from the top-n control group to the top-n treatment group (sorted by prediction scores) (Diemert et al., 2018), is the normalizing ratio, is a random sort baseline to characterize the data randomness. Regarding the final recommendation performance, first, we give some notations that is the user set, is the indicator function, is the rank generated by the model for the ground truth item and user , is the model to be evaluated and , is the positive and negative sample sets in testing data. Then, the widely used HitRate, AUC and NDCG respectively is used, which are defined by the following equations.
4.2. Experimental Results and Analysis
| Dataset | Movielens | Amazon | Alipay | |||
|---|---|---|---|---|---|---|
| AUUC | QINI | AUUC | QINI | AUUC | QINI | |
| CRec | - | - | - | |||
| ORec | 0.0337 | 0.0322 | 0.0025 | 0.0043 | 0.024 | 0.010 |
| CRRec | 0.0338 | 0.0322 | 0.0065 | 0.0111 | 0.037 | 0.033 |
4.2.1. RQ1
To show the promise of dataset construction via causal inference and the performance of the Meta-Controller-based recommendation, we conduct a range of experiments on Movielens, Amazon and Alipay. Specifically, we shows the uplift between different recommendation mechanisms in Figure 3 and summarize the AUUC performance and their corresponding QINI scores compared to the plain session recommendation in Table 3. The CTR performance of all recommendation mechanisms measured by AUC, HitRate and NDCG is summarized in Table 2.
According to the uplift curve in Figure 3, both the on-device recommendation and the cloud-based re-fresh achieve the positive gain on the basis of the plain session recommendation. This demonstrates that the real-time feedback from the user is important to improve the recommendation performance, no matter it is incorporated by the lightweight on-device model or the cloud-based model. However, the comparison between the on-device recommendation and the cloud-based re-fresh are indefinite as shown in the right panel of Figure 3. In comparison with the plain session recommendation, we can find that the AUUC score and the QINI score of ORec and CRRec in Table 3 are positive, which further confirms that two treatments practically enhances the long-term gain of the session recommendation. Therefore, meta controller targets to distinguish their diverse merits and invoke the proper recommender.
Regarding the CTR performance in Table 2, CRec is usually not better than ORec and CRRec, and MCRec generally achieves a larger improvement by properly mixing three type of mechanisms. In comparison, RMixRec that randomly mixes them only achieves the better performance than CRec on Movienlens and Amazon, and shows the minor improvement over ORec on Alipay. These results confirms CRec, ORec and CRRec are complementary, requiring to selectively activate one of recommendation mechanisms instead of the random choice. In a nutshell, MCRec is an effective way to manage the device-cloud collaborative recommendation.


4.2.2. RQ2
To consider the computational constraint of the cloud resource, we apply the RSLS method defined by Eq. (5) to incorporate the invoking ratio on the cloud-based re-fresh. Specifically, we set different constraints e.g., , , , which requires the invoking of the cloud-based re-fresh among all selection from three mechanisms not to outperform the constraint. By applying LS to learn the meta controller, the partial results of the CTR performance are summarized in Table 2 and the trade-off between the recommendation performance of meta controller and is plot in Figure 4. According to the results, we can see that with decreasing, namely increasing the invoking constraint about the cloud-based re-fresh, the performance of MCRec all approximately monotonically decreases. On one hand, this indicates the cloud-based re-fresh is an important way to complement the current session recommendation. On the other hand, it is also limited to the real-world computing resources available especially for the large-scale industrial scenarios where there are billions of customers. Therefore, it is still a trade-off between the better performance and more computation resources. Nevertheless, the discounted performance of meta controller (e.g., MCRec () in Table 2) still shows the gain by the proper mixing compared to CRec and ORec.
| Dataset | Movielens | Amazon | Alipay | |||
|---|---|---|---|---|---|---|
| HR1 | AUC | HR1 | AUC | HR1 | AUC | |
| ①+② | 36.72 | 93.60 | 17.31 | 77.95 | 17.82 | 72.78 |
| ①+③ | 37.27 | 93.88 | 17.56 | 78.98 | 17.95 | 73.21 |
| ②+③ | 37.88 | 93.90 | 17.70 | 79.05 | 17.98 | 73.34 |
4.2.3. RQ3
Here, we present more analysis about meta controller.
For the first ablation study, we discuss the degeneration of meta controller from the mixture of three kinds of recommendation mechanisms to arbitrary two types of recommendation mechanisms. Correspondingly, the arbitrary two of three sets during the sample construction stage are used and the 3-category classification problem is then reduced to 2-category classification in meta controller. As shown in Table 4, among three cases of collaboration, the combination between on-device recommender and the cloud-based re-fresh achieves the best performance. This indicates the merits of real-time features are important to improve the final model performance. However, in terms of the independent CRRec in Table 2, such performance is comparable on Alipay. One potential explanation is, in addition to the benefit from the real-time user behavior, the cloud-based recommender provides the sufficient capacity to consider the case of the slowly-changing user interests, which is more complementary to ORec and CRRec together.
For the second ablation study, we investigate the effect of the hyperparameter to control the invoking ratio under different constraints . Considering the limited space, we only conduct the experiments on Alipay and illustrate the curves in Figure 6. From the figure, we can see that a larger that introduces a stronger penalty on invoking the cloud-based re-fresh in Eq. (5), leads to a lower invoking rate. The resulted invoking ratio (the read line) in meta controller almost satisfy the constraints characterized by the dashed line in Figure 6. Note that, when , does not change. It is because the original invoking ratio in meta controller is smaller than the constraint, and thus there is no need to penalize. In summary, our label smoothing method can flexibly handle the practical invoking constraints for the cloud-based re-fresh.

To visualize how the meta controller manages the device-cloud collaboration, we present one exemplar from the Alipay dataset in Figure 5. As shown in the figure, when the user behavior is lack of diversity, namely only focuses on one content, the plain session recommender is chosen by meta controller and recommend the fixed candidate. When the user behavior exhibits the small variance, namely interested in the homogeneous contents, the on-device recommender is chosen to slightly adjust the recommendation on the basis of the limited device cache. When the user interests dramatically change as reflected by the diverse historical behaviors, the meta controller invokes the cloud-based re-fresh to adjust the recommendation results from the large-scale cloud item pool. From these exemplars, meta controller dynamically senses the diversity of user interests and actives the corresponding recommender.
5. Conclusion
In this paper, we explore a novel device-cloud collaborative recommendation via meta controller. Different from on-device recommendation or the cloud-based recommendation, our method targets to manage the collaboration among these recommendation mechanisms by complementing their pros. To overcome the dataset absence issue, we propose an efficient offline sample construction method, which leverages the causal effect estimation technique to infer the counterfactual label. Besides, considering the real-world computational constraints, we introduces a label smoothing method to regularize the training procedure of meta controller. We demonstrate the promise of our proposed method on two public datasets and one large-scale real-world datasets. In the future, more recommendation scenarios could be explored from the perspective device-cloud collaborative recommendation to improve the efficiency of the conventional cloud-based recommendation.
References
- (1)
- Banitalebi-Dehkordi et al. (2021) Amin Banitalebi-Dehkordi, Naveen Vedula, Jian Pei, Fei Xia, Lanjun Wang, and Yong Zhang. 2021. Auto-Split: A General Framework of Collaborative Edge-Cloud AI. In SIGKDD.
- Cai et al. (2018) Han Cai, Tianyao Chen, Weinan Zhang, Yong Yu, and Jun Wang. 2018. Efficient architecture search by network transformation. In AAAI.
- Cai et al. (2020) Han Cai, Chuang Gan, Ligeng Zhu, and Song Han. 2020. TinyTL: Reduce Memory, Not Parameters for Efficient On-Device Learning. NeurIPS (2020).
- Cheng et al. (2016) Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In DLRS.
- Dhar et al. (2021) Sauptik Dhar, Junyao Guo, Jiayi Liu, Samarth Tripathi, Unmesh Kurup, and Mohak Shah. 2021. A survey of on-device machine learning: An algorithms and learning theory perspective. TIOT (2021).
- Diemert et al. (2018) Eustache Diemert, Artem Betlei, Christophe Renaudin, and Massih-Reza Amini. 2018. A large scale benchmark for uplift modeling. In SIGKDD.
- Duc et al. (2019) Thang Le Duc, Rafael García Leiva, Paolo Casari, and Per-Olov Östberg. 2019. Machine learning methods for reliable resource provisioning in edge-cloud computing: A survey. CSUR (2019).
- Gong et al. (2020) Yu Gong, Ziwen Jiang, Yufei Feng, Binbin Hu, Kaiqi Zhao, Qingwen Liu, and Wenwu Ou. 2020. EdgeRec: recommender system on edge in Mobile Taobao. In CIKM.
- Guo et al. (2017) Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. In IJCAI.
- Jannach et al. (2017) Dietmar Jannach, Malte Ludewig, and Lukas Lerche. 2017. Session-based item recommendation in e-commerce: on short-term intents, reminders, trends and discounts. UMUAI (2017).
- Johansson et al. (2016) Fredrik Johansson, Uri Shalit, and David Sontag. 2016. Learning representations for counterfactual inference. In ICML.
- Koren et al. (2009) Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization techniques for recommender systems. Computer (2009).
- Kuang et al. (2020) Kun Kuang, Lian Li, Zhi Geng, Lei Xu, Kun Zhang, Beishui Liao, Huaxin Huang, Peng Ding, Wang Miao, and Zhichao Jiang. 2020. Causal inference. Engineering (2020).
- Künzel et al. (2019) Sören R Künzel, Jasjeet S Sekhon, Peter J Bickel, and Bin Yu. 2019. Metalearners for estimating heterogeneous treatment effects using machine learning. PNAS (2019).
- Lin et al. (2020) Ji Lin, Wei-Ming Chen, Yujun Lin, Chuang Gan, Song Han, et al. 2020. MCUNet: Tiny Deep Learning on IoT Devices. NeurIPS (2020).
- Meister et al. (2020) Clara Meister, Elizabeth Salesky, and Ryan Cotterell. 2020. Generalized Entropy Regularization or: There’s Nothing Special about Label Smoothing. In ACL.
- Norrie et al. (2021) Thomas Norrie, Nishant Patil, Doe Hyun Yoon, George Kurian, Sheng Li, James Laudon, Cliff Young, Norman Jouppi, and David Patterson. 2021. The Design Process for Google’s Training Chips: TPUv2 and TPUv3. IEEE Micro (2021).
- Olaya et al. (2020) Diego Olaya, Kristof Coussement, and Wouter Verbeke. 2020. A survey and benchmarking study of multitreatment uplift modeling. DMKD (2020).
- Pan et al. (2021) Yujie Pan, Jiangchao Yao, Bo Han, Kunyang Jia, Ya Zhang, and Hongxia Yang. 2021. Click-through Rate Prediction with Auto-Quantized Contrastive Learning. arXiv preprint arXiv:2109.13921 (2021).
- Pearl and Mackenzie (2018) Judea Pearl and Dana Mackenzie. 2018. The book of why: the new science of cause and effect.
- Pi et al. (2019) Qi Pi, Weijie Bian, Guorui Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Practice on long sequential user behavior modeling for click-through rate prediction. In SIGKDD.
- Pi et al. (2020) Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. In CIKM.
- Qian et al. (2022) Xufeng Qian, Yue Xu, Fuyu Lv, Shengyu Zhang, Ziwen Jiang, Qingwen Liu, Xiaoyi Zeng, Tat-Seng Chua, and Fei Wu. 2022. Intelligent Request Strategy Design in Recommender System. In SIGKDD.
- Radcliffe (2007) Nicholas Radcliffe. 2007. Using control groups to target on predicted lift: Building and assessing uplift model.
- Resnick and Varian (1997) Paul Resnick and Hal R Varian. 1997. Recommender systems. Commun. ACM (1997).
- Sandler et al. (2018) Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. 2018. Mobilenetv2: Inverted residuals and linear bottlenecks. In CVPR.
- Sarwar et al. (2001) Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2001. Item-based collaborative filtering recommendation algorithms. In WWW.
- Schölkopf et al. (2021) Bernhard Schölkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. 2021. Toward causal representation learning. IEEE (2021).
- Shalit et al. (2017) Uri Shalit, Fredrik D Johansson, and David Sontag. 2017. Estimating individual treatment effect: generalization bounds and algorithms. In ICML.
- Shazeer et al. (2017) Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. ICLR (2017).
- Sun et al. (2020a) Chuan Sun, Hui Li, Xiuhua Li, Junhao Wen, Qingyu Xiong, and Wei Zhou. 2020a. Convergence of recommender systems and edge computing: A comprehensive survey. IEEE Access (2020).
- Sun et al. (2019) Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In CIKM.
- Sun et al. (2020c) Yang Sun, Fajie Yuan, Min Yang, Guoao Wei, Zhou Zhao, and Duo Liu. 2020c. A generic network compression framework for sequential recommender systems. In SIGIR.
- Sun et al. (2020b) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou. 2020b. Mobilebert: a compact task-agnostic bert for resource-limited devices. arXiv preprint arXiv:2004.02984 (2020).
- Tan et al. (2021) Qiaoyu Tan, Jianwei Zhang, Jiangchao Yao, Ninghao Liu, Jingren Zhou, Hongxia Yang, and Xia Hu. 2021. Sparse-interest network for sequential recommendation. In WSDM.
- Wang et al. (2021) Shoujin Wang, Longbing Cao, Yan Wang, Quan Z Sheng, Mehmet A Orgun, and Defu Lian. 2021. A survey on session-based recommender systems. CSUR (2021).
- Wang et al. (2020) Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. 2020. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768 (2020).
- Wenwei Ke (2021) Xiangfu Shi Yiqiao Dai Philip S. Yu Xiaoqiang Zhu Wenwei Ke, Chuanren Liu. 2021. Addressing Exposure Bias in Uplift Modeling for Large-scale Online Advertising. In ICDM.
- Xue et al. (2017) Hong-Jian Xue, Xinyu Dai, Jianbing Zhang, Shujian Huang, and Jiajun Chen. 2017. Deep Matrix Factorization Models for Recommender Systems.. In IJCAI.
- Yang et al. (2020) Liu Yang, Ben Tan, Vincent W Zheng, Kai Chen, and Qiang Yang. 2020. Federated recommendation systems. In Federated Learning.
- Yao et al. (2021) Jiangchao Yao, Feng Wang, Kunyang Jia, Bo Han, Jingren Zhou, and Hongxia Yang. 2021. Device-Cloud Collaborative Learning for Recommendation. In SIGKDD.
- Yao et al. (2017a) Jiangchao Yao, Yanfeng Wang, Ya Zhang, Jun Sun, and Jun Zhou. 2017a. Joint latent Dirichlet allocation for social tags. TMM 20, 1 (2017), 224–237.
- Yao et al. (2022) Jiangchao Yao, Shengyu Zhang, Yang Yao, Feng Wang, Jianxin Ma, Jianwei Zhang, Yunfei Chu, Luo Ji, Kunyang Jia, Tao Shen, et al. 2022. Edge-Cloud Polarization and Collaboration: A Comprehensive Survey. TKDE (2022).
- Yao et al. (2017b) Jiangchao Yao, Ya Zhang, Ivor Tsang, and Jun Sun. 2017b. Discovering user interests from social images. In MMM. 160–172.
- Zhang et al. (2022) Shengyu Zhang, Lingxiao Yang, Dong Yao, Yujie Lu, Fuli Feng, Zhou Zhao, Tat-seng Chua, and Fei Wu. 2022. Re4: Learning to Re-Contrast, Re-Attend, Re-Construct for Multi-Interest Recommendation. In Proceedings of the ACM Web Conference. 2216–2226.
- Zhang et al. (2021) Shengyu Zhang, Dong Yao, Zhou Zhao, Tat-Seng Chua, and Fei Wu. 2021. Causerec: Counterfactual user sequence synthesis for sequential recommendation. In SIGIR. 367–377.
- Zhao et al. (2019) Kui Zhao, Junhao Hua, Ling Yan, Qi Zhang, Huan Xu, and Cheng Yang. 2019. A Unified Framework for Marketing Budget Allocation. In SIGKDD.
- Zhao and Harinen (2019) Zhenyu Zhao and Totte Harinen. 2019. Uplift modeling for multiple treatments with cost optimization. In DSAA.
- Zhao and Shang (2010) Zhi-Dan Zhao and Ming-Sheng Shang. 2010. User-based collaborative-filtering recommendation algorithms on hadoop. In SIGKDD.
- Zhou et al. (2018) Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. In SIGKDD.
- Zhou et al. (2019) Zhi Zhou, Xu Chen, En Li, Liekang Zeng, Ke Luo, and Junshan Zhang. 2019. Edge intelligence: Paving the last mile of artificial intelligence with edge computing. Proc. IEEE (2019).
- Zoph and Le (2016) Barret Zoph and Quoc V Le. 2016. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578 (2016).
Appendix A Reproducibility Details
A.1. Dataset Generation
Amazon and Movielens-1M We preprocess the datasets to guarantee that users and items have been interacted at least 10 times in Amazon dataset, 20 times in Movielens-1M dataset. The rated movies and reviewed goods are regarded as positive samples. For both datasets, the last 5 interacted items of each user are kept for test and the left sequences are used for training. We randomly sample un-interacted movies or goods of the user as negative samples and the ratio between positive and negative samples is set to 1:4 in training sets and 1:100 in testing sets. To simulate the on-device recommendation process, we make different restrictions for cloud models and device models. Specifically, the cloud models take user sequences with a length up to 50 as inputs, but are not accessible to the user activities in the next session, where users make 5 further interactions. The device models, however, can make use of the most recent interactions in the current session, but are not accessible to the more historical behaviors saved in cloud. To train the CATE estimation model, we evaluate cloud models and device models on all samples and set treatment effect to 1 if the model could rank the positive sample to the first position.
Alipay dataset is collected from the Alipay App in the continuous 7 days. The treatment datasets are respectively collected under different treatment interventions online. Except training datasets aforementioned in the experimental parts, the test datasets consist of two parts, one part is for the CATE estimation and the other one is for the CTR comparison.
A.2. Parameter Settings
Table 5 shows the hyper-parameter setting on three datasets.
| Dataset | Parameters | Setting |
| Amazon | cloud item embedding dimension | 32 |
| device item embedding dimension | 8 | |
| cloud position embedding dimension | 32 | |
| device position embedding dimension | 8 | |
| encoder layer | 2 | |
| encoder size | 32 | |
| attention dimension(Q,K,V) | 32 | |
| classifer dimension | 128,64 | |
| activation function | tanh | |
| batch size | 256 | |
| learning rate | 1e-3 | |
| optimizer | Adam | |
| Movielens-1M | item embedding dimension | 32 |
| device item embedding dimension | 8 | |
| cloud position embedding dimension | 32 | |
| device position embedding dimension | 8 | |
| encoder layer | 2 | |
| encoder size | 32 | |
| attention dimension(Q,K,V) | 32 | |
| classifer dimension | 128,64 | |
| activation function | tanh | |
| batch size | 256 | |
| learning rate | 1e-3 | |
| optimizer | Adam | |
| Alipay | item embedding ( and all ) | 128 |
| item embedding () | 64 | |
| sequence length | 50 | |
| learning rate | 5e-3 | |
| optimizer | Adam | |
| training epoches | 10 | |
| batch size | 1024 | |
| activation function | relu | |
| attention dimension(Q,K,V) | 128 | |
| classifer dimension | 128-64-2 | |
| sequence length | 50 | |
| see 4.2.3 |