Date of publication xxxx 00, 0000, date of current version xxxx 00, 0000. 10.1109/ACCESS.2023.0322000
Corresponding author: Pakizar Shamoi (e-mail: [email protected]).
Detection and Analysis of Stress-Related Posts in Reddit’s Acamedic Communities
Abstract
Nowadays, the significance of monitoring stress levels and recognizing early signs of mental illness cannot be overstated. Automatic stress detection in text can proactively help manage stress and protect mental well-being. In today’s digital era, social media platforms reflect various communities’ psychological well-being and stress levels. This study focuses on detecting and analyzing stress-related posts in Reddit’s academic communities. Due to online education and remote work, these communities have become central for academic discussions and support. We classify text as stressed or not using natural language processing and machine learning classifiers, with Dreaddit as our training dataset containing labeled Reddit data. Next, we collect and analyze posts from various academic subreddits. We identified that the most effective individual feature for stress detection is the Bag of Words, paired with the Logistic Regression classifier, achieving a 77.78% accuracy rate and an F1 score of 0.79 on the pre-labeled DReaddit dataset. To validate our model’s applicability to detect stress in the specific context of academia, we conducted a supplementary experiment by manually annotating 100 posts from academic subreddits, achieving a 72% accuracy rate.
Our key findings reveal that the overall stress level in academic texts is 29%. Posts and comments in professors’ Reddit communities are the most stressful compared to other academic levels, including bachelor’s, graduate’s, and Ph.D. students. This research contributes to our understanding of the stress levels within academic communities. It can help academic institutions and online communities effectively develop measures and interventions to address this issue.
Index Terms:
Stress detection, Reddit, academia, social media analysis, natural language processing, machine learning, academic stress factors, logistic regression, mental health, emotion detection.=-21pt
I Introduction
In our fast-paced world, stress affects countless individuals, impacting their mental well-being. Among 48% of Gen Z adults report feeling anxious, sad, depressed, experiencing FOMO (fear of missing out), and having lowered self-esteem or insecurity[1][2][3]. According to these findings, Gen Z adults’ stress levels may rise due to social media-related worries, highlighting the importance of efficient stress detection and support mechanisms in digital platforms.
Stress statistics worldwide indicate the need for effective stress management [4]. Stress permeates various aspects of people’s lives, from the workplace to educational institutions and domestic environments. Automatic stress detection has the potential to address this global health concern, providing support and resources to those in need. Kazakhstan, like many regions around the world, grapples with the multifaceted challenges of mental health and stress. In the context of this Central Asian nation, several factors have been identified as significant contributors to mental health problems, such as education, traditional belief systems, stigma, and shame[5].
One key aspect to consider is that individuals may be unaware of their stress levels or underestimate their symptoms. Stress can often go unnoticed until it reaches a critical stage. Automatic textual stress detection can help bridge this awareness gap by identifying stress markers that might go unnoticed.
Moreover, societal factors like the stigma surrounding mental health and the hesitance to seek professional help create barriers to receiving timely support [6] [7]. While psychological help is valuable, it can be expensive and inaccessible for many individuals. Automatic stress detection can be an accessible and complementary tool to traditional services, assessing stress levels without direct interaction with specialists. This tool can help individuals overcome hesitations and encourage early intervention by specialists by identifying individuals who require further assistance.
As for the existing psychological tests, they rely heavily on self-reporting [8], which can be influenced by biases or individuals not acknowledging their stress levels. Automatic stress detection of texts in social media offers a data-driven approach, reducing reliance on self-reported data.
In the dynamic landscape of higher education, marked by rigorous academic demands and the pursuit of future goals, stress has become a pervasive issue for both students and pedagogical staff [9, 10, 11]. The other study reveals that students aged 18-19 exhibited more symptoms of common mental disorders than non-students, though the effect size was small[12]. Another study identified that a substantial portion of Ph.D. participants were at high risk for depression [13]. It was found that unhealthy working conditions and increased mental health risks among Ph.D. students. Identified life satisfaction, perceived stress, and negative support as primary predictors of anxiety and depression, and the impact of supervision and the work environment on the mental health and overall well-being of Ph.D. students. Detecting and addressing stress early is essential to prevent it from developing into more severe issues like anxiety or burnout.
Nowadays, people share their stressful experiences and challenges with mental health through online forums, micro-blogs, and tweets as Internet usage has grown [14]. A 2019 survey conducted by Hill Holiday revealed that 94% of Gen Z adults (individuals born between the mid-1990s and early 2010s) reported having at least one social media account[3]. So, the alarming prevalence of stress worldwide highlights the urgent need for innovative approaches to address this issue.
Reddit is one of the most popular social networks. It consists of thousands of communities called “subreddits” (r/subredditname) that focus on specific interests, hobbies, or themes. Every post strongly follows the topic and rules of the subreddit where it was posted, which makes it easy to analyze the behavior and opinions of the community. Posts on Reddit have a score that is responsible for popularity and it is calculated with the sum of upvotes and downvotes. Reddit was chosen as the data source due to its community’s open and supportive nature, allowing longer posts where people readily share their problems, including those related to anxiety [15]. This choice aligns with the importance of studying online platforms like Reddit in the context of well-being and the recognition of the presence of toxicity and anxiety within Reddit communities [16] [17].

The present paper aims to use Natural Language Processing (NLP) and Machine Learning (ML) classification algorithms to automatically detect stress in social media such as Reddit. We further apply the proposed method to analyze the stress levels in texts of professors, bachelor’s, graduate, and Ph.D. students. For that, we collected and analyzed a dataset containing 1,584 posts and 122,684 comments on academia-related topics from the Reddit social network.
The contributions of this paper are presented as follows:
-
•
Comparative analysis of ML classifiers for stress detection
-
•
Evaluation of the applicability of the method in the context of academia. We initiated the annotation process to evaluate our method further due to the absence of available academic stress-related datasets labeled by humans.
-
•
Identification of the prevailing emotions associated with stress messages at different levels of academia.
-
•
Understanding stress patterns across various academic levels, including professors, Ph.D. students, graduate students, and bachelor students.
-
•
Use of long-length text that can capture stress indicators.
The rest of the paper is organized as follows. Section I is this Introduction. Section II provides a literature review of research in stress detection. Section III describes Methods, including data preprocessing, feature extraction, and classification. Data collection, description, and annotation procedures are also presented there. Section IV compares the results and presents the most powerful machine-learning method for stress detection. We also present the results of stress evaluation within Reddit’s academic communities. Section V compares our results with those of similar studies. Finally, Section VI offers concluding remarks. Additionally, it offers suggestions for how the technique might be enhanced in the future.
The following section provides an overview of stress detection techniques.
II Related work
This section provides an overview of stress detection studies in Social Media.
There are different ways of detecting stress, including Physiological Signals [18, 19, 20] (e.g., Heart Rate, Humidity response, Temperature response), Audio [21, 22], Facial Expression [23], Interviewing or Psychological tests [24, 25, 26], and Text-based approaches [27, 28, 29, 30] (see Figure 1).
Many text-based approaches for stress detection were proposed, and some of them identified that the Bidirectional Long Short-Term Memory (BLSTM) with attention mechanism is the most effective approach [31], [32]. The other study focuses on continuous lexical embedding and the BLSTM model [33]. Another study introduces the KC-Net, a mental state knowledge–aware and contrastive network effective for early stress detection [34]. A light and robust method to detect depressive texts in social media was proposed in [35]. The authors used an attention-based bidirectional LSTM and CNN-based model. Some works focus on applying the SVM-based approach [36], achieving the 0.75 accuracy. To increase classification accuracy, some approaches combine lexicon-based features with distributional representations [37]. The other work proposes a TensiStrength method to identify the stress or relaxation level in the text, it applies a lexical approach and a set of rules [38].
Some works concentrate on the analysis of textual data in social media. In the study of Nijhawan et al. [27], the authors employ large Twitter datasets, machine learning techniques, and BERT to classify sentiment. They also use Latent Dirichlet Allocation, an unsupervised ML approach, to find document patterns and forecast pertinent subjects. These algorithms simplify the process of identifying people’s feelings on internet platforms.
In the other study, authors look at the use of emotion detection for explainable psychological stress detection [39]. They research multi-task learning and the empathetic modification of language models. Their models, trained by the Dreaddit dataset [29], produce results comparable to BERT models. Another work that used the dataset Dreaddit is [40]. They used various NLP tools, BERT tokenizers, and a Bag of Words method to prepare textual data for machine learning models. Each method’s outcomes are reviewed, with an accuracy of 76%. The study [41] classified the Dreaddit data using the VM, LSTM, and BLSTM algorithms, and reported that BLSTM had the best accuracy. However, they did not specify how much accuracy was achieved.
Authors of the related paper [30] discuss the suggested technique for classifying stress, which combines Word2Vec, GloVe, and FastText word embeddings with lexicon-based characteristics. It gets strong classification results with 84.87% F-Score utilizing word embeddings on the Dreaddit dataset and 82.57% F-Score using lexicon-based features. While balancing performance and computing resources, their approach shows potential in reliably diagnosing stress from the text. Notably, the technique beats more intricate systems like BERT.
Next, the other study presented Stress Annotated Dataset (SAD)[42], and by developing a model and exploring how it may be used in mental health contexts, they demonstrate how the dataset can be used in real-world situations. The study provides a classification method for everyday stress, a collection of SMS-like phrases that represent stressors, and an assessment of the method’s efficiency in categorizing various themes.
While Chauhan et al. [18], [19] concentrate on physiological markers like body temperature, GSR, and blood pressure to detect stress, Raichur et al. [23] use image-processing techniques. Both strategies, however, have limitations since they depend on actual presence. While physiological measures demand specialized equipment and can be intrusive, image processing requires controlled conditions and may not be effective in all circumstances. Researchers are investigating several non-invasive, scalable approaches, such as analyzing textual data, voice, and behavioral clues to solve these constraints. Researchers want to create more adaptable and user-friendly methods for precisely detecting stress levels by extending the spectrum of stress detection techniques beyond a physical presence.
As we can see, stress detection is challenging and worthy of further exploration for several reasons, including subjectivity, context dependency, and multimodal nature. Research on textual stress detection is still limited in using short-length texts for analysis. Short-length text can be enough for sentiment analysis, but when it comes to detecting mental health problems detections, including stress detection it would be proper to use long texts as they are more informative[43].
III Methods
In this research paper, we build a system that classifies whether the text is stressful. The schematic representation of the approach is shown in the Figure 2. To implement it, we need to collect data from various sources or datasets and use the NLP techniques such as word embedding, and Bag of Words(BoW). They are intended to create word/sentence data that can be fed to ML models.

III-A Data Collection
We used the following datasets in our study:
III-A1 DReaddit
To train the model, we used Dreaddit, a text data collection specifically designed for detecting stress[29]. It is a publicly available dataset that contains a collection of Reddit posts and associated metadata. A total of 190 thousand posts from Reddit are included in the dataset, of which 3553 were labeled manually. The authors offer initially supervised learning algorithms for stress detection that combine neural and traditional methodologies. The data corpus contains stress-indicative posts in 5 domains: abuse (703 posts), anxiety (728 posts), financial (717 posts), PTSD (711 posts), and social (694 posts). Table I demonstrates the examples of stressed posts for each domain.
| Post | Stress label | Domain |
|---|---|---|
| I’ve mostly come to terms with it but every time I see his name or face or his girlfriend’s it comes back. My question is, when the justice system fails, how do you deal with living near a child molester when you can’t just pick up and leave?.. | 1 | abuse |
| I cried for hours and at one point, something came over me and just slammed my head into my bathroom door. Sadly, since I’m in a dorm, it’s a shitty hollow core door and it broke bad and now there is a hole that I have to figure out how to fix. It’s a $100 fine if I can’t figure out what to do with it so that’s just compounding on the already existing stress. … | 1 | anxiety |
| I asked for nothing but a declaration (a document detailing finances) from the divorce. He stole from me. I asked for nothing but restitution. He fought, forced me to hire a lawyer (more money), dragged out the case, and led to having alimony imposed upon if he failed to make restitution… | 1 | financial |
| I cried for hours and at one point, something came over me and just slammed my head into my bathroom door. Sadly, since I’m in a dorm, it’s a shitty hollow core door and it broke bad and now there is a hole that I have to figure out how to fix. It’s a $100 fine if I can’t figure out what to do with it so that’s just compounding on the already existing stress. … | 1 | ptsd |
| That’s it. My mom made me delete it and said “that’s what is wrong with your generation, you act too grown”. Nothing about my picture was “grown” I was actually wearing a long white t-shirt and boyfriend jeans. Even when we go to the beach with my siblings, me and my sister were wearing the exact same bikini and she said something to me about “needing to sit my fast-tailed butt down”… | 1 | social |
III-A2 Test Datasets - Reddit Academic Communities
For this study, data was collected from the most popular posts based on scores of various subreddits connected with academic topics (“r/Professors”, “r/PhD”, “r/GradSchool”, “r/csMajors”, and “r/EngineeringStudents”) from Reddit using a Python module “PRAW” 111https://github.com/praw-dev/praw(Python Reddit API Wrapper).
PRAW is a Python library that provides easy access to Reddit’s API. PRAW aspires to be user-friendly and adheres to all of Reddit’s API restrictions. Reddit API has limits, saying it allows 60 requests for one minute.
| Subreddit | # of posts | # of comments |
|---|---|---|
| r/Professors | 313 | 37235 |
| r/PhD | 386 | 22406 |
| r/GradSchool | 785 | 44762 |
| r/csMajors | 70 | 9436 |
| r/EngineeringStudents | 30 | 8845 |
| 1584 | 122684 |
III-B Data Description
Using Reddit Scrapper we collected 1584 posts and 122684 comments for the posts. The data was collected on June 2, 2023. Each piece of data has information about Date, Title, Text, Score, Tag. Reddit is frequently used as a platform for online discussions within various communities or “subreddits”. Table II illustrates the distribution of posts and comments among subreddits that were scrapped. We only took those posts with “self-text,” the main text beside the title. On Reddit users can make posts with title and image, video and gif, or title and text, it is impossible to combine them. This explains why r/csMajors and r/EngineeringStudents have less data: they tend to post memes more than graduates or professors and usually do not categorize their posts with tags.
Posts on Reddit can have a flair or tag; the number and topic of tags vary from subreddit to subreddit. They specify the post’s topic, and by looking at tags, we can understand what kind of posts are usually popular and get attention. Table III, Table IV, Table V, and Table VI present the distribution of scraped posts and comments across various tags. Even if not every post was tagged, we can see some tendencies. Posting memes are quite common for all communities (“Humor”, “Fun and & Humor”, “Shitposting”, “Memes”). Another theme common to all communities is asking for advice, which is a general topic on Reddit, as each subreddit can be considered a separate online forum. Professors and Ph.D. students/graduates have the same habit of venting.
| Tag | # of posts | # of comments |
|---|---|---|
| Rants / Vents | 40 | 5968 |
| Humor | 18 | 1892 |
| Advice / Support | 6 | 1320 |
| Academic Integrity | 3 | 296 |
| Teaching / Pedagogy | 3 | 358 |
| Mindblown | 1 | 336 |
| COVID-19 | 1 | 69 |
| Other (Editable) | 1 | 28 |
| Where Humor and Rants Collide | 1 | 159 |
| FML | 1 | 83 |
| Technology | 1 | 118 |
| Untagged | 237 | 26608 |
| 313 | 37235 |
| Tag | # of posts | # of comments |
|---|---|---|
| Health & Work/Life Balance | 84 | 5908 |
| Fun & Humour | 36 | 2185 |
| Academics | 38 | 1804 |
| Research | 18 | 998 |
| Professional | 8 | 639 |
| Finance | 8 | 796 |
| Admissions & Applications | 9 | 589 |
| News | 4 | 295 |
| Untagged | 580 | 31548 |
| 785 | 44762 |
| Tag | # of posts | # of comments |
|---|---|---|
| Vent | 128 | 9684 |
| Post-PhD | 36 | 1610 |
| Dissertation | 75 | 3197 |
| Other | 92 | 4975 |
| Humor | 26 | 1490 |
| Admissions | 3 | 134 |
| Preliminary Exam | 7 | 260 |
| Need Advice | 10 | 773 |
| Untagged | 9 | 283 |
| 386 | 22406 |
| Tag | # of posts | # of comments |
|---|---|---|
| Shitpost | 12 | 818 |
| Flex | 4 | 296 |
| Others | 4 | 770 |
| Rant | 5 | 972 |
| Company Question | 2 | 91 |
| Advice | 3 | 541 |
| Course Help | 1 | 303 |
| Untagged | 69 | 14490 |
| 100 | 18281 |


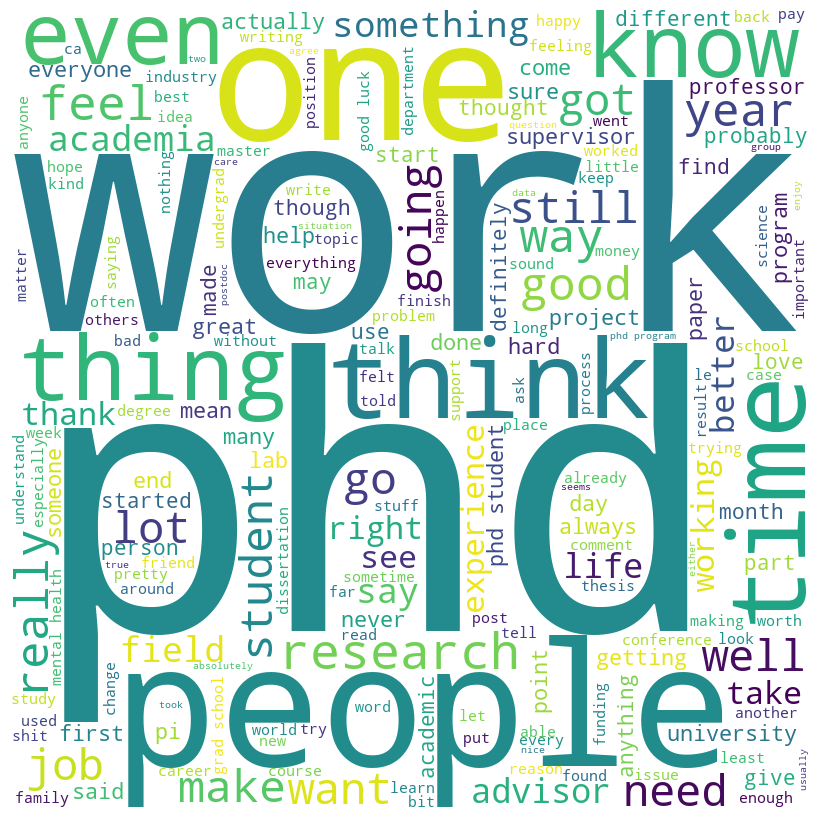

Next, Figure 3 presents word clouds of text from posts we scrapped from Reddit communities. Common words for all communities are “think”(13330 overall occurrences from all communities), “time” (19460), “work” (18730) and “people” (16842). In total, the Reddit data encompassed 43,209 distinct words. Figure 3 also shows us that bachelors write a lot about getting a job, companies, interviews, and internships. This can be because our data is from Computer Science and Engineering communities. Bachelors used 16085 unique words.
Graduates and Ph.D. students are different with words like “dissertation”, “advisor”, “research”, “paper”, “lab”, “academic” or “academia”, etc. Graduate and Ph.D. students used 32449 unique words. In addition, Figure 3 illustrates that professors mainly discuss students, emails, classes, teaching, grading/evaluation, parents, and online education. Professors used 25266 unique words. Bachelors and professors have a connection regarding words like “lecture”, “class”, “professor”, and “grade”.
III-C Stress Detection
III-C1 Pre-processing

Before applying ML algorithms, posts were preprocessed. During the preprocessing stage, various necessary adjustments were made to prepare the text data for ML classification. The preprocessing steps applied to the dataset are as follows (see Figure 4):
-
1.
Lowercase: All text data has been converted to lowercase to ensure consistency and uniformity of references.
-
2.
Removal of non-characters: Removed non-characters, such as letters and special characters, from the text data: removing HTML tags, “@”, “_”, and other special characters. This step helps eliminate unnecessary noise and information.
-
3.
Tokenization: The text was tokenized using a tokenizer, which splits the text into individual tokens. This step is necessary to divide the text into basic units.
-
4.
Stopword Removal: Common English stopwords (e.g., “and”, “the”, “in”) are removed from the tokenized text. Grammatical terms are often discarded because they have no special meaning for classification tasks.
-
5.
Stemming: The stem process was used to reduce the remaining words to their original form. This helps form similar words and simplifies vocabulary.
-
6.
Combining Words: Finally, the preprocessed words are recombined as coherent text strings, ready to be used in machine learning classification.
Together, these preprocessing steps improve the quality and usability of the texture data, making it more suitable for subsequent ML classification tasks. The difference between raw and processed data can be seen in Fig. 5.
If the data is labeled, it goes to the classification step; otherwise, it goes to the Feature extraction step.

III-C2 Feature extraction
Reducing the dimensionality of the original raw data is achieved by feature extraction, resulting in more manageable groupings that can be processed quickly [44]. Different feature extraction techniques, like BERT embeddings, Word2Vec with TF-IDF weights, bigram TF-IDF, unigram TF-IDF, and Bag of Words, are available. In this work, we use Bag of Words.
Bag of Words

The principle of BoW is computing the frequency of occurrence for each word while considering the complete text data [44]. Figure 6 illustrates the principle of how Bag-of-Words works. Following that, the terms are mapped to their corresponding frequencies. This method ignores word order while accounting for the frequency of each word.
TF-IDF
A statistical tool called TF-IDF evaluates a word’s significance inside a document or set of documents. It combines inverse document frequency (IDF), representing a word’s rarity throughout the corpus, with term frequency (TF), which determines how frequently a word appears in a text. To capture their relative significance, TF-IDF gives terms common in a text but uncommon in the corpus larger weights.
Word Embedding
A feature of the learning method called word embedding uses the contextual hierarchy of words to map them to vectors. The feature vectors of comparable words will be the same. For example, the places of the words “dog” and “puppy” are closer, because of their meaning.
III-C3 Classification
To estimate the presence of stress in text, we employ approaches to classification to estimate the likelihood of stress within the users. The following ML algorithms have been used:
SVM
An ML approach called the Support Vector Machine (SVM) is generally employed for classification tasks. It establishes a decision boundary that divides the data into several classes to optimize the margin or separation between the decision boundary and the support vectors. Using kernel functions, SVM can handle data that may be separated into linear and non-linear categories. It has been widely used for successful categorization across many fields [43, 20, 45, 46].
Logistic Regression
Consider a contextual setting within regression analysis wherein the dependent variable exclusively manifests two potential outcomes, specifically 0 or 1. This configuration aligns with the framework of binary logistic regression. In contrast, applying multinomial logistic regression becomes pertinent when the dependent variable encompasses a multitude of potential outcomes that surpass the binary domain. These values might be assigned based on qualitative observations. Consider a model structured as follows: [47]. Because of its interpretability and simplicity, it is a well-known algorithm that can quickly train and evaluate [43, 20].
The Binary Logistic Regression model estimates the probability that the dependent variable equals 1 given input . It uses the logistic (sigmoid) function to transform a linear combination of input features into a probability value between 0 and 1 as in Equation 1.
| (1) |
Where: is the likelihood that equals 1 given input . The model coefficients are values learned during training, and represent the input features.
The logistic function converts a linear combination of input data into a probability value between 0 and 1. The data point is given to the positive class (1) if the estimated probability is greater than or equal to 0.5; otherwise, it is assigned to the negative class (0).
Naive Bayes
An efficient probabilistic approach for classification tasks is Naive Bayes. Given the class label, it assumes that the characteristics are conditionally independent, making the probability calculation easier. The effectiveness and scalability of Naive Bayes in handling huge datasets are well established[43, 20, 45].
LSTM
Long Short-Term Memory (LSTM) can recognize long-term relationships in sequential data. It is commonly utilized in jobs involving sequential data and natural language processing. To effectively simulate sequential patterns, LSTM features an internal memory system that enables it to preserve and selectively forget information across extended durations [48, 49].
III-D Dataset Annotation on an 11-point scale
We initiated the annotation process to evaluate our method due to the absence of available academic stress-related datasets labeled by humans. The trial dataset comprised 100 posts or comments (25 for each academic level) randomly sampled from our unlabeled stress-related Reddit dataset. 5 annotators, including four regular humans and one psychologist, assessed the stress levels of the posts using an 11-point scale. Each annotator was instructed to score the sentiment from -5 (strong stress) to +5 (unstressed).
It is desired that data annotation is done by someone who has a full understanding of the topic, hence a psychologist (Ph.D. in Psychology) was requested to contribute. She was given double weight because she is more familiar with the context’s terminology. The human raters labeled the stress levels of the posts using separate Google sheets obtained online. Figure 7 shows a screenshot of the form (Google Sheets).
We applied the strategies described in [50]: if 60% or more of annotator labels are considered outliers, the annotator judgments are removed from the job. However, we decreased the threshold to 40% for more accurate resultant annotations.
We use the following formula - Equation 2 to identify if a judgement is an outlier [50]:
| (2) |
where is the index of a particular annotator, and is the index of a specific tweet/post. The notation is the standard deviation of all scores given for a tweet/post .
One annotator, with a 41% outlier rate, had their annotations excluded from the analysis, and we recalculated the weighted average scores for each post.

IV Experimental Results
IV-A Accuracy evaluation

Figure 8 illustrates a schematic representation of how the accuracy of the proposed model was evaluated in our study using different datasets. In the initial evaluation phase, the Dreaddit dataset, comprising 3553 human-labeled posts, served as the foundational training set for our model. The accuracy of the model reached 77.78% on this dataset when employing Logistic Regression and the Bag of Words methodology.
Following this, in the academic evaluative phase, we employed a collection of unlabeled posts from an academic context. We performed data annotation on a small dataset involving five annotators (including a psychologist) and applied the model, resulting in an accuracy of 72%. This comprehensive approach allowed us to evaluate the model’s performance thoroughly. The detailed description is provided in the following subsections.
IV-A1 Dreaddit (Training Dataset)
The feature extraction method BoW was paired with the SVM, Naive Bayes, Logistic regression, and Word Embeddings with the LSTM algorithm to classify stressed or non-stressed texts.
Table VII shows the result of a preprocessing tool, in cases when the model made incorrect predictions because of preprocessing. The text must be classified as stressed in the first row, but let us look at the preprocessed data and consider the words separately. If we look at the words “mom”, “hit”, “newspaper”, “shock”, “like”, “play”, it is difficult to understand that in the original text, the mother hits the author with the newspaper, and that’s why the author was shocked. A recap of the third text is that the author helps the homeless lady. However, the words of preprocessed data made the model think that the author may be an anxious person or a homeless who needs food and money.
| Text | Preprocessed | Expected | Actual |
|---|---|---|---|
| My mom then hit me with the newspaper and it shocked me that she would do this, she knows I don’t like play hitting, smacking, striking, hitting or violence of any sort on my person… | mom hit newspaper shock would know like play hit smack strike hit violence sort person …send vibe ask universe yesterday decide take friend go help not friend move new place drive friend move strike shoulder | 1 | 0 |
| No place in my city has shelter space for us, and I won’t put my baby on the literal street… | place city shelter space us put baby liter street … | 1 | 1 |
| but I’m really, really afraid of public embarrassment and awkward situations. So I was in the train station and saw this homeless lady asking for food and money. I always help homeless people if I have a change in my wallet. I walked up to her, took out my wallet, and pulled out this £5 cash to give her. | really really afraid public embarrass awkward stat train station saw homeless laid ask food money away help homeless people chang wallet walk took wallet pull cash give kinda old perfect physics health | 0 | 1 |
The models’ accuracies have been calculated and are presented in Table IV-A1. Notably, the Logistic Regression model achieves the highest accuracy at 77.78%.
| Features | ML | Accuracy,% | Precision | Recall | F score |
| BoW | SVM | 69.90 | 0.69 | 0.50 | 0.58 |
| BoW | Naive | ||||
| Bayes | 71.31 | 0.69 | 0.61 | 0.65 | |
| BoW | Logistic | ||||
| Regression | 77.78 | 0.80 | 0.78 | 0.79 | |
| Word Embeddings | LSTM | 70.2 | 71.23 | 52.10 | 60.19 |
We use metrics such as Accuracy, Precision, Recall, and score to evaluate the classification algorithms. Precision estimates how many positively recognized samples are correct, while Recall estimates the fraction of positive samples correctly identified. The higher the F1 score, the closer both values are.
Precision. Correct positive predictions relative to total positive predictions [52]:
Recall. Correct positive predictions relative to total actual positives [52]:
score is [52]:
Accuracy. Correct predictions to the total prediction [52]:
Our results are closely aligned with the findings of the creators of the Dreaddit dataset [29]. Their best-performing model achieved an F1-score of 0.798 using Logistic Regression with domain-specific Word2Vec and additional features. Using the Bag of Words approach paired with Logistic Regression, our model achieved a comparable F1 score of 0.79 on the same dataset.
IV-A2 Reddit Academic Dataset
Let us use the human-annotated dataset discussed earlier to evaluate the performance of the proposed approach.
In the annotation experiment, we classified 100 post texts using the proposed model (BoW + Logistic Regression). The experiment involved five participants, including one psychologist and four outliers. The psychologist’s labels were given higher importance due to their expertise, indicated by a weight of 2. The calculated accuracy of 72% reflects the model’s performance in correctly classifying the texts based on the input from all participants, with a higher emphasis on the psychologist’s judgments. Figure 9 shows the heat map with correlations of ratings provided by annotators. We can see that annotator 3 correlates highly with annotators 1 and 2.

The calculated agreement on labeled data is , using Fleiss’s Kappa inter-annotator agreement [53]. According to the interpretation of Fleiss’s Kappa, the value shows slight agreement between annotators.

The model’s performance is assessed using a confusion matrix, which provides insights into the model’s ability to classify texts accurately. The confusion matrix for our experiment is as follows in Figure 10.
| Dataset | Stressed upvote mean | Stressed upvote median | Stressed upvote std | Not stressed upvote mean | Not stressed upvote median | Not stressed upvote std |
|---|---|---|---|---|---|---|
| Bachelor students | 39.5 | 2.0 | 255.1 | 27.0 | 2.0 | 163.6 |
| Graduate students | 26.7 | 4.0 | 97.6 | 19.9 | 3.0 | 71.4 |
| Ph.D. students | 20.4 | 3.0 | 67.6 | 13.8 | 2.0 | 50.7 |
| Professors | 35.6 | 7.0 | 120.8 | 25.7 | 6.0 | 84.2 |
| Human-annotated dataset | 41.1 | 9.0 | 70.5 | 12.5 | 2.5 | 26.0 |
Our results do not corroborate the findings of [54] on the influence of the sentiment on information diffusion. According to their research, positive messages reach a larger audience, meaning that individuals are more willing to repost positive information, a phenomenon known as positive bias. Figure 11 shows upvotes of posts and comments as a function of the average stress score assigned by the annotators. The graph shows that most viral posts are neutral or slightly stressed, rather than excessively not stressed.
Table IX shows us the mean and median upvotes of posts and comments of different academic levels in the human-annotated dataset classified as stressed/not stressed. By the phenomenon of positivity bias, it is said that people tend to like positive views on life (not stressful) rather than negative (stressful) [54]. It also implies that people like and share online posts that do not evoke negative emotions. However, after analyzing our datasets, we see that this does not apply to our case. This can possibly be explained by the nature of the Reddit social network.

IV-B Stress detection Results - Academic Communities in Reddit
| Level in Academia | Subreddit name | # of posts | # of comments | Total | Stressed | Stressed, % | Not stressed | Not stressed, % |
|---|---|---|---|---|---|---|---|---|
| Bachelor students | r/csMajors, r/EngineeringStudents | 100 | 18281 | 18381 | 5389 | 29.3% | 12992 | 70.7% |
| Graduate students | r/GradSchool | 785 | 44762 | 45547 | 14156 | 31.1% | 31391 | 68.9% |
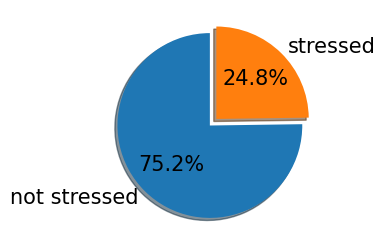
| PhD students | r/PhD | 386 | 22406 | 22792 | 5647 | 24.8% | 17145 | 75.2% |
| Professors | r/Professors | 313 | 37235 | 37548 | 11455 | 30.5% | 26093 | 69.5% |
For our experiment, we analyzed posts and comments in popular Reddit communities of professors, bachelors, graduates, and Ph.D. students. The most successful model trained on the Dreaddit dataset utilizes the BoW representation in combination with Logistic Regression. This model achieved an accuracy rate of 77.78% and score of 0.79. So, this model is used to make an experiment using the dataset that we parsed from Reddit.
Table X presents the stress detection results in considered academic levels: professors, bachelor, graduate, and Ph.D. students.



We used NRCLex 222https://github.com/metalcorebear/NRCLex Python library [55, 56] to retrieve negative emotional affect(anger, fear, sadness, disgust, surprise) from Reddit data that were classified as stressed. NRCLex is based on the National Research Council Canada (NRC) affect lexicon and the NLTK library’s WordNet synonym sets. NRCLex analyzes the text based on the words used and returns the frequency of emotional affect within the text. We filtered emotions with a value of 0.3 or higher to capture the most prevalent ones.
Table XI represents some comments on Reddit from different levels of academia that were classified as stressed. Along with academic level and text, emotion frequency was detected with NRCLex.
Academic Level Text Prevaling emotion Professors My grandfather died the day before an exam. I attended the exam in mourning clothes. sadness: 0.33 PhD You don’t want to hear this but it’s worse in industry. They tell you this then just fire you :/ fear: 1.0 Graduates I understand how you feel. It is a very frustrating thing to be trying to tackle grad school and mental health at the same time! :( anger: 0.33 Bachelors Is it too late to change if I wasted my freshman year (going into sophomore in the fall)? Always felt and still feel too intimidated to try these things.’ sadness: 0.5
| Bachelors | Graduates | PhD | Professors |
|---|---|---|---|
| ’work’, 1290 | ’work’, 6762 | ’phd’, 2700 | ’student’, 10841 |
| ’get’, 1174 | ’school’, 5220 | ’work’, 2665 | ’class’, 5076 |
| ’people’, 1123 | ’get’, 4871 | ’get’, 2280 | ’work’, 3189 |
| ’like’, 1100 | ’student’, 4835 | ’like’, 2095 | ’one’, 3017 |
| ’class’, 1036 | ’time’, 4833 | ’time’, 2030 | ’get’, 2979 |
| ’engine’, 997 | ’like’, 4266 | ’people’, 1520 | ’would’, 2539 |
| ’time’, 879 | ’go’, 4247 | ’go’, 1472 | ’time’, 2487 |
| ’go’, 834 | ’grad’, 4126 | ’think’, 1438 | ’make’, 2353 |
| ’one’, 806 | ’people’, 3704 | ’know’, 1337 | ’like’, 2312 |
| ’say’, 794 | ’think’, 3677 | ’one’, 1248 | ’think’, 2113 |
Table XII shows a lexicon of more common terms among academic stressed data. The most common words at all academic levels are “work”, “time”, and “get”. It is noticeable that graduate students and professors use the word “student” more frequently than “people” than bachelor and Ph.D. students. It is also interesting that undergraduate students are more likely to use the word “say” when others are more often using the word “think”.
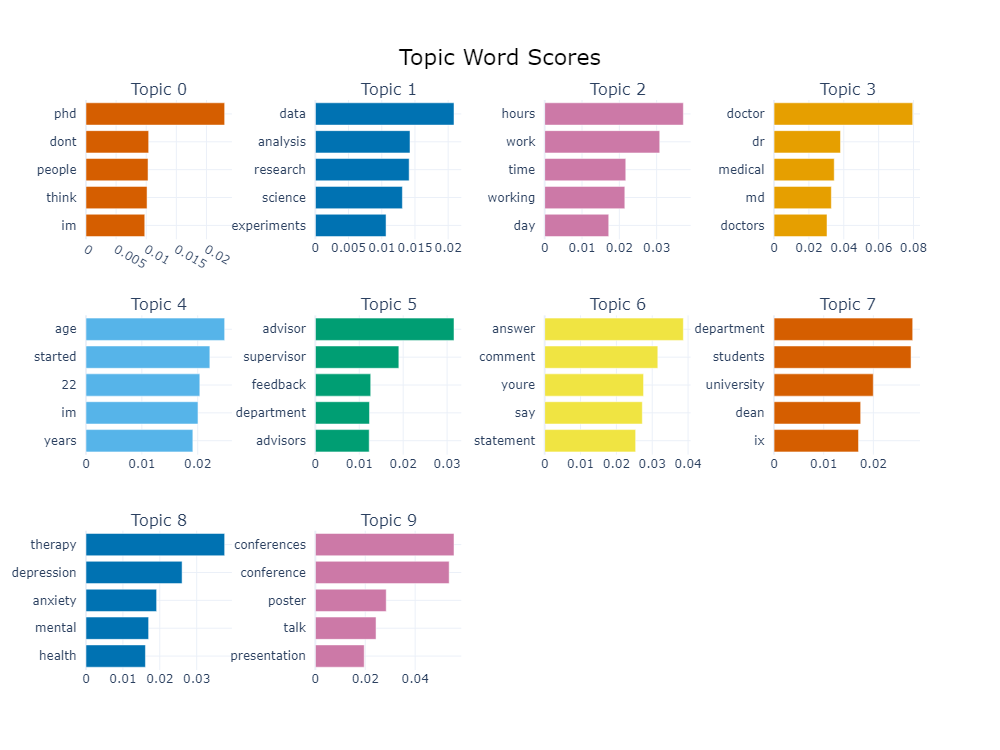
Words alone don’t tell us much about stressed posts and comments. To get an idea of the key factors contributing to academic stress, we performed topic modeling, and the results can be seen in Figure 13. For identifying topics, we used the BERT language representation model[57]. BERT, which stands for Bidirectional Encoder Representations from Transformers, is a comprehensive tool for analyzing short texts with little context and is less time-consuming. We can see what kinds of words are frequently used together, and it gives us a little understanding of topics mostly discussed on Reddit posts and comments that can be considered as stressed. The posts and comments about studying and classes, professors and their English skills, major IT companies and internships, and sleep resonate the most with stress among bachelor students. Balancing jobs and education, research, and defense of a master’s dissertation probably are stressful for graduate students. Research and supervisors, working, mental health and therapy, and talking to big audiences at conferences are topics mostly associated with stress among Ph.D. students. Everything connected with teaching and students, answering their questions, grading them, classes, and responding to emails is stressful for professors.



Some sample students’ posts (or comments) classified as stressed and unstressed are presented in Figure 14.

Figure 15 shows the stress change among professors, bachelor, graduate, and Ph.D. students during the year (stress tracking). Posts/comments classified as stressed were categorized monthly, starting in September and ending in August, to match the academic year. The illustrated bar charts show that professors and graduate students tend to be stressed throughout the year. Specifically, there are noticeable spikes in stress for all levels of academia, which coincides with months (December and May) when exams are usually conducted. Bachelor students’ stress levels remain relatively stable throughout the academic year except in October, and stress levels are lower during summer. It may appear that bachelor students experience less stress compared to other academic levels, but this is mostly due to the smaller size of the parsed Reddit dataset used for analysis.









Figures 16 and 17 present line and whisker plots depicting the distribution of identified emotion ratings in stressed Reddit posts/comments from various academic levels. Line plots represent how emotions change throughout the academic year. A clear pattern for all academic levels is a low level of negative emotions in the summer months, which then rises from September until the end of the academic year. As we can see prevailing emotions of stressful posts across all academic levels are sadness and fear. The whisker plot illustrates how emotions are overall distributed and the outliers that appear there.
V Discussion
Let us consider how the current research findings compare to previous studies. Mental stress has become a significant issue among young people, affecting various aspects of their lives.
With nearly 55 million daily active users and millions of posts publicly broadcasted to a large audience, Reddit is one of the most popular social networking sites [15]. Several works employ machine-learning algorithms to detect stress [58], [59]. Some works focused on the identification of the presence of depression in Reddit texts using ML and NLP techniques [15], [60], Reddit Comment Toxicity Score Prediction using BERT [17].
Our findings support previous research that found stress factors in students: academic, teaching, and learning-related stressors [11]. The same topics were detected in our research and are shown in Figure 13. In contrast, our results presented in Table IX do not support the phenomenon of positive bias discussed in [54], according to which people tend to share and like news and posts on the Internet that do not evoke negative emotions.
We challenge the findings of [11], asserting that lower-grade students experience more stress than sixth-year medical students. Our research findings indicate that students in higher grades, specifically those pursuing Master’s degrees (the same age as medical students in the 5th–6th grades), demonstrate the highest stress levels. This is likely attributed to increased responsibilities, the demand for studying complex topics, completing a Master’s dissertation, and the challenges of combining academic work with other commitments.
As we see, previously, similar research had been conducted, but on much broader topics such as mental health, depression, disorders, etc. We narrowed our focus and studied the stress levels in academia and the associated emotions and topics. We also analyze the stress levels of various academic representatives and do not rely on self-reporting (through questionnaires). Studies investigating such broad concepts as stress based on questionnaires are limited [61].
VI Conclusion
This research uses ML and NLP techniques to recognize and evaluate stress-related posts and comments in Reddit’s academic communities.
Automatic stress detection is crucial in mitigating stress risks and improving mental health outcomes. By enabling early detection, addressing hesitancy to seek help, and providing a preliminary assessment, such systems can revolutionize stress management and positively impact individuals’ well-being. Stress detection from textual data in social media platforms presents a promising solution, considering its effectiveness and ease of access to data.
We achieved the highest predictive performance on the Dreaddit dataset with Bag of Words and Logistic regression, with an accuracy of 77.78% and an F1 score of 0.79. To validate our model’s applicability in academia, we conducted a supplementary experiment by manually annotating 100 posts from academic subreddits, achieving a 72% accuracy rate.
Our findings suggest that the overall stress level in academic texts is 29%, with the key emotions being sadness and fear. Moreover, the key factors contributing to this stress are:
-
•
For bachelor students, these include studying classes, professors and their English skills, major IT companies, internships, and sleep.
-
•
For graduate students - balancing job and education, research, and defense of a master’s dissertation.
-
•
For PhD students, it is research and their supervisors, mental health and therapy, and talking to big audiences at conferences.
-
•
For professors - students, and teachers, responding to questions and emails.
Our findings can assist universities in building better-targeted interventions and support systems by identifying and quantifying stress levels at different academic levels early. This tailored approach to managing academic stress-related issues can improve students’ and faculty’s mental health and well-being. Administrators and educators can use the current study’s findings to adopt policies and practices that reduce stress and foster a better learning and working environment.
The study has some limitations. Estimates of academic stress levels were based solely on one social network, Reddit. The other limitation is the relatively small dataset size. These are issues that need to be addressed in future work. We also plan to experiment with other Machine Learning techniques (Bert, Random Forest, Decision Tree, XGBoost) and Computing with Words technique [62, 63] to increase the accuracy.
The majority of approaches for stress identification focus on physical aspects only or require a psychological test, which can lead to inaccurate results. Stress can manifest through various modalities, including text, speech, and physiological signals. Integrating these diverse data sources to improve detection accuracy is a complex but important challenge we plan to explore.
References
- [1] M. Milyavskaya, M. Saffran, N. Hope, and R. Koestner, “Fear of missing out: prevalence, dynamics, and consequences of experiencing fomo,” Motivation and Emotion, vol. 42, 10 2018.
- [2] L. Tomczyk and E. Lizde, “Fear of missing out (fomo) among youth in bosnia and herzegovina — scale and selected mechanisms,” Children and Youth Services Review, vol. 88, 03 2018.
- [3] “2019 gen z report.key.” [Online]. Available: https://brand-news.it/wp-content/uploads/2019/10/2019-Gen-Z-Report.pdf
- [4] S. Mahmud, S. Hossain, A. Muyeed, M. M. Islam, and M. Mohsin, “The global prevalence of depression, anxiety, stress, and, insomnia and its changes among health professionals during covid-19 pandemic: A rapid systematic review and meta-analysis,” Heliyon, vol. 7, no. 7, p. e07393, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S2405844021014961
- [5] M. H. Akhand, “Factors contributing to mental health problems in kazakhstan: literature review,” 2019.
- [6] Corrigan, P. W, and A. C. Watson, “Understanding the impact of stigma on people with mental illness,” Procedia Computer Science, vol. 1.1, pp. 16–20, 2022.
- [7] H. J. Lim, L. Moxham, C. Patterson, D. Perlman, V. Lopez, and Y. S. Goh, “Students’ mental health clinical placements, clinical confidence and stigma surrounding mental illness: A correlational study,” Nurse Education Today, vol. 84, p. 104219, 2020.
- [8] K. Masood, B. Ahmed, J. Choi, and R. Gutierrez-Osuna, “Consistency and validity of self-reporting scores in stress measurement surveys,” in 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society. IEEE, Aug. 2012. [Online]. Available: https://doi.org/10.1109/embc.2012.6347091
- [9] T. W. Wong, Y. Gao, and W. Tam, “Anxiety among university students during the sars epidemic in hong kong,” Stress and Health, vol. 23, pp. 31 – 35, 02 2007.
- [10] K. Shamsuddin, F. Fadzil, W. S. W. Ismail, S. A. Shah, K. Omar, N. A. Muhammad, A. Jaffar, A. Ismail, and R. Mahadevan, “Correlates of depression, anxiety and stress among malaysian university students,” Asian Journal of Psychiatry, vol. 6, no. 4, pp. 318–323, 2013, this issue includes a special section on Psychiatric Nosology. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1876201813000592
- [11] M. Al-Shahrani, B. Alasmri, R. Al-Shahrani, N. Al-Moalwi, A. Qahtani, and A. Siddiqui, “The prevalence and associated factors of academic stress among medical students of king khalid university: An analytical cross-sectional study,” Healthcare, vol. 11, p. 2029, 07 2023.
- [12] T. McCloud, S. Kamenov, C. Callender, G. Lewis, and G. Lewis, “The association between higher education attendance and common mental health problems among young people in england: evidence from two population-based cohorts,” The Lancet Public Health, vol. 8, pp. e811–e819, 10 2023.
- [13] J. Friedrich, A. Bareis, M. Bross, Z. Bürger, Á. C. Rodríguez, N. Effenberger, M. Kleinhansl, F. Kremer, and C. Schröder, ““how is your thesis going?”–ph.d. students’ perspectives on mental health and stress in academia,” PLoS ONE, vol. 18, 7 2023.
- [14] “Digital 2023: Global overview report.” [Online]. Available: https://datareportal.com/reports/digital-2023-global-overview-report
- [15] M. M. Tadesse, H. Lin, B. Xu, and L. Yang, “Detection of depression-related posts in reddit social media forum,” IEEE Access, vol. 7, pp. 44 883–44 893, 2019.
- [16] H. Almerekhi, H. Kwak, and B. J. Jansen, “Investigating toxicity changes of cross-community redditors from 2 billion posts and comments,” PeerJ Computer Science, vol. 8, p. e1059, Aug. 2022. [Online]. Available: https://doi.org/10.7717/peerj-cs.1059
- [17] R. Shounak, S. Roy, V. Kumar, and V. Tiwari, “Reddit comment toxicity score prediction through bert via transformer based architecture,” in 2022 IEEE 13th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), 2022, pp. 0353–0358.
- [18] M. Chauhan, S. V. Vora, and D. Dabhi, “Effective stress detection using physiological parameters,” vol. 2018-January. Institute of Electrical and Electronics Engineers Inc., 7 2017, pp. 1–6.
- [19] G. Shanmugasundaram, S. Yazhini, E. Hemapratha, and S. Nithya, “A comprehensive review on stress detection techniques,” in 2019 IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), 2019, pp. 1–6.
- [20] S. Gedam and S. Paul, “A review on mental stress detection using wearable sensors and machine learning techniques,” IEEE Access, vol. 9, pp. 84 045–84 066, 2021.
- [21] A. Triantafyllopoulos, S. Zänkert, A. Baird, J. Konzok, B. M. Kudielka, and B. W. Schuller, “Insights on modelling physiological, appraisal, and affective indicators of stress using audio features,” in 2022 44th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 2022, pp. 2619–2622.
- [22] P. Chyan, A. Achmad, I. Nurtanio, and I. S. Areni, “A deep learning approach for stress detection through speech with audio feature analysis,” in 2022 6th International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE), 2022, pp. 1–5.
- [23] N. Raichur, N. Lonakadi, P. Mural, and E. B. Bengaluru, “Detection of stress using image processing and machine learning techniques,” vol. 9, 2017.
- [24] E.-H. Lee, “Review of the psychometric evidence of the perceived stress scale,” Asian Nursing Research, vol. 6, p. 121–127, 12 2012.
- [25] G. Singh, D. Kaur, and H. Kaur, “Presumptive stressful life events scale (psles) – a new stressful life events scale for use in india,” Indian journal of psychiatry, vol. 26, pp. 107–14, 04 1984.
- [26] A. Kanner, J. Coyne, C. Schaefer, and R. Lazarus, “Comparison of two modes of stress measurement: Daily hassles and uplifts versus major life events,” Journal of behavioral medicine, vol. 4, pp. 1–39, 04 1981.
- [27] T. Nijhawan, G. Attigeri, and T. Ananthakrishna, “Stress detection using natural language processing and machine learning over social interactions,” Journal of Big Data, vol. 9, 12 2022.
- [28] S. Jadhav, A. Machale, P. Mharnur, P. Munot, and S. Math, “Text based stress detection techniques analysis using social media,” in 2019 5th International Conference On Computing, Communication, Control And Automation (ICCUBEA), 2019, pp. 1–5.
- [29] E. Turcan and K. McKeown, “Dreaddit: A reddit dataset for stress analysis in social media,” LOUHI@EMNLP 2019 - 10th International Workshop on Health Text Mining and Information Analysis, Proceedings, pp. 97–107, 2019. [Online]. Available: https://aclanthology.org/D19-6213https://github.com/gillian850413/InsightStressAnalysis
- [30] S. Muñoz and C. A. Iglesias, “A text classification approach to detect psychological stress combining a lexicon-based feature framework with distributional representations,” Information Processing and Management, vol. 59, 9 2022.
- [31] S. Jadhav, A. Machale, P. Mharnur, P. Munot, and S. Math, “Text based stress detection techniques analysis using social media,” in 2019 5th International Conference On Computing, Communication, Control And Automation (ICCUBEA), 2019, pp. 1–5.
- [32] D. William and D. Suhartono, “Text-based depression detection on social media posts: A systematic literature review,” Procedia Computer Science, vol. 179, pp. 582–589, 2021, 5th International Conference on Computer Science and Computational Intelligence 2020. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1877050921000491
- [33] Y. Zheng, Y. Li, Z. Wen, B. Liu, and J. Tao, “Text-based sentential stress prediction using continuous lexical embedding for mandarin speech synthesis,” in 2016 10th International Symposium on Chinese Spoken Language Processing (ISCSLP), 2016, pp. 1–5.
- [34] K. Yang, T. Zhang, and S. Ananiadou, “A mental state knowledge–aware and contrastive network for early stress and depression detection on social media,” Information Processing and Management, vol. 59, no. 4, p. 102961, 2022. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0306457322000796
- [35] T. Ghosh, M. H. A. Banna, M. J. A. Nahian, M. N. Uddin, M. S. Kaiser, and M. Mahmud, “An attention-based hybrid architecture with explainability for depressive social media text detection in bangla,” Expert Systems with Applications, vol. 213, p. 119007, 2023. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0957417422020255
- [36] M. R. Febriansyah, Nicholas, R. Yunanda, and D. Suhartono, “Stress detection system for social media users,” Procedia Computer Science, vol. 216, pp. 672–681, 2023, 7th International Conference on Computer Science and Computational Intelligence 2022. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S187705092202261X
- [37] S. Muñoz and C. A. Iglesias, “A text classification approach to detect psychological stress combining a lexicon-based feature framework with distributional representations,” Information Processing and Management, vol. 59, no. 5, p. 103011, 2022. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0306457322001212
- [38] M. Thelwall, “Tensistrength: Stress and relaxation magnitude detection for social media texts,” Information Processing and Management, vol. 53, no. 1, pp. 106–121, 2017. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0306457316302321
- [39] E. Turcan, S. Muresan, and K. Mckeown, “Emotion-infused models for explainable psychological stress detection,” pp. 2895–2909. [Online]. Available: https://www.apa.org/news/press/https://github.com/eturcan/emotion-infused
- [40] S. Inamdar, R. Chapekar, S. Gite, and B. Pradhan, “Machine learning driven mental stress detection on reddit posts using natural language processing,” Human-Centric Intelligent Systems 2023, vol. 1, pp. 1–12, 3 2023. [Online]. Available: https://link.springer.com/article/10.1007/s44230-023-00020-8
- [41] P. C. C. of Engineering, I. of Electrical, E. E. P. Section, I. of Electrical, and E. Engineers, 2019 Fifth International Conference on Computing Communication Control and Automation (ICCUBEA) : proceedings : (19th to 21st September, 2019).
- [42] M. L. Mauriello, T. Lincoln, G. Hon, D. Simon, D. Jurafsky, and P. Paredes, “Sad: A stress annotated dataset for recognizing everyday stressors in sms-like conversational systems.” Association for Computing Machinery, 5 2021.
- [43] R. A. Rahman, K. Omar, S. A. Mohd Noah, M. S. N. M. Danuri, and M. A. Al-Garadi, “Application of machine learning methods in mental health detection: A systematic review,” IEEE Access, vol. 8, pp. 183 952–183 964, 2020.
- [44] “Why do we need feature extraction?” [Online]. Available: https://www.analyticsvidhya.com/blog/2022/01/nlp-tutorials-part-ii-feature-extraction/
- [45] Y. Ding, X. Chen, Q. Fu, and S. Zhong, “A depression recognition method for college students using deep integrated support vector algorithm,” IEEE Access, vol. 8, pp. 75 616–75 629, 2020.
- [46] P. Bobade and M. Vani, “Stress detection with machine learning and deep learning using multimodal physiological data,” in 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), 2020, pp. 51–57.
- [47] D. Montgomery, E. Peck, and G. Vining, Introduction to Linear Regression Analysis, ser. Wiley Series in Probability and Statistics. Wiley, 2013.
- [48] S. Ghosh and T. Anwar, “Depression intensity estimation via social media: A deep learning approach,” IEEE Transactions on Computational Social Systems, vol. 8, no. 6, pp. 1465–1474, 2021.
- [49] M. Awais, M. Raza, N. Singh, K. Bashir, U. Manzoor, S. U. Islam, and J. J. P. C. Rodrigues, “Lstm-based emotion detection using physiological signals: Iot framework for healthcare and distance learning in covid-19,” IEEE Internet of Things Journal, vol. 8, no. 23, pp. 16 863–16 871, 2021.
- [50] A. Ghosh, G. Li, T. Veale, P. Rosso, E. Shutova, A. Reyes, and J. Barnden, “Semeval-2015 task 11: Sentiment analysis of figurative language in twitter,” in Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), 2015, 06 2015.
- [51] E. Shamoi, A. Turdybay, P. Shamoi, I. Akhmetov, A. Jaxylykova, and A. Pak, “Sentiment analysis of vegan related tweets using mutual information for feature selection,” PeerJ Computer Science, vol. 8, p. e1149, Dec. 2022. [Online]. Available: https://doi.org/10.7717/peerj-cs.1149
- [52] “F1 score vs. accuracy: Which should you use? - statology.” [Online]. Available: https://www.statology.org/f1-score-vs-accuracy/
- [53] J. L. Fleiss, “Measuring nominal scale agreement among many raters: Fleiss’ kappa,” Psychological Bulletin, vol. 76, no. 5, p. 378–382, 1977.
- [54] E. Ferrara and Z. Yang, “Quantifying the effect of sentiment on information diffusion in social media,” PeerJ Computer Science, vol. 1, p. e26, Sep. 2015. [Online]. Available: https://doi.org/10.7717/peerj-cs.26
- [55] S. M. Mohammad and P. D. Turney, “Crowdsourcing a word-emotion association lexicon,” Computational Intelligence, vol. 29, no. 3, pp. 436–465, 2013.
- [56] S. Mohammad and P. Turney, “Emotions evoked by common words and phrases: Using Mechanical Turk to create an emotion lexicon,” in Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text. Los Angeles, CA: Association for Computational Linguistics, Jun. 2010, pp. 26–34. [Online]. Available: https://aclanthology.org/W10-0204
- [57] J. Devlin, M.-W. Chang, K. Lee, and K. N. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” 2018. [Online]. Available: https://arxiv.org/abs/1810.04805
- [58] R. Ahuja and A. Banga, “Mental stress detection in university students using machine learning algorithms,” Procedia Computer Science, vol. 152, pp. 349–353, 2019, international Conference on Pervasive Computing Advances and Applications- PerCAA 2019. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1877050919306581
- [59] M. Gupta and S. Vaikole, “Recognition of human mental stress using machine learning paradigms,” SSRN Electronic Journal, 01 2020.
- [60] L. D’Cruz, V. Dubey, and P. Thakur, “Depression prediction from combined reddit and twitter data using machine learning,” in 2023 2nd International Conference for Innovation in Technology (INOCON), 2023, pp. 1–5.
- [61] G. Barbayannis, M. Bandari, X. Zheng, H. Baquerizo, K. W. Pecor, and X. Ming, “Academic stress and mental well-being in college students: Correlations, affected groups, and covid-19,” Frontiers in Psychology, vol. 13, May 2022. [Online]. Available: http://dx.doi.org/10.3389/fpsyg.2022.886344
- [62] P. Shamoi and A. Inoue, “Computing with words for direct marketing support system,” in Proceedings of the 23rd Midwest Artificial Intelligence and Cognitive Science Conference, MAICS 2012, 2012, pp. 19–26.
- [63] A. Kali, P. Shamoi, Y. Zhangbyrbayev, and A. Zhandaulet, Computing with Words for Industrial Applications. Springer International Publishing, Sep. 2022, p. 257–271. [Online]. Available: http://dx.doi.org/10.1007/978-3-031-16075-2_17
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/5dffc2ba-2af0-44f2-a965-073674a29182/nazzere.jpg) |
Nazzere Oryngozha received the B.S. degree in systems of information security from the International Information Technology University, Almaty, Kazakhstan, in 2022. Since 2022, he has been a tutor with the Cybersecurity Department, at the same university. She is currently pursuing M. S. degree in software engineering at the School of Information Technology and Engineering, Kazakh-British Technical University, Almaty, Kazakhstan, and works as a backend developer (Python). |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/5dffc2ba-2af0-44f2-a965-073674a29182/pakita.jpg) |
Pakizar Shamoi received the B.S. and M.S. degrees in information systems from the Kazakh-British Technical University, Almaty, Kazakhstan in 2011 and 2013, and the Ph.D. degree in engineering from Mie University, Tsu, Japan, in 2019. In her academic journey, she has held various teaching and research positions at Kazakh-British Technical University, where she has been serving as a professor in the School of Information Technology and Engineering since August 2020. Her commitment to education and contributions to the field have been recognized with the prestigious Best University Teacher Award in Kazakhstan in 2022. She is the author of 1 book and more than 28 scientific publications. Awards for the best paper at conferences were received four times. Her research interests include artificial intelligence and machine learning, focusing on fuzzy sets and logic, soft computing, representing and processing colors in computer systems, natural language processing, computational aesthetics, and human-friendly computing and systems. She took part in the organization and worked in the org. committee (as head of the session and responsible for special sessions) of several international conferences - IFSA-SCIS 2017, Otsu, Japan; SCIS-ISIS 2022, Mie, Japan; EUSPN 2023, Almaty, Kazakhstan. She served as a reviewer at several international conferences, including IEEE: SIST 2023, SMC 2022, SCIS-ISIS 2022, SMC 2020, ICIEV-IVPR 2019, ICIEV-IVPR 2018. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/5dffc2ba-2af0-44f2-a965-073674a29182/ayan.jpg) |
Ayan Igali is currently a 3rd-year bachelor student at the School of Information Technology and Engineering, Kazakh-British Technical University, Almaty, Kazakhstan, his major is information systems. His research interests include Machine Learning, NLP, emotion detection, and human-friendly systems. |