11email: [email protected], 11email: [email protected]
Detecting Bias in Large Language Models: Fine-tuned KcBERT
Abstract
The rapid advancement of large language models (LLMs) has enabled natural language processing capabilities similar to those of humans, and LLMs are being widely utilized across various societal domains such as education and healthcare. While the versatility of these models has increased, they have the potential to generate subjective and normative language, leading to discriminatory treatment or outcomes among social groups, especially due to online offensive language. In this paper, we define such harm as societal bias and assess ethnic, gender, and racial biases in a model fine-tuned with Korean comments using Bidirectional Encoder Representations from Transformers (KcBERT) and KOLD data through template-based Masked Language Modeling (MLM). To quantitatively evaluate biases, we employ LPBS and CBS metrics. Compared to KcBERT, the fine-tuned model shows a reduction in ethnic bias but demonstrates significant changes in gender and racial biases. Based on these results, we propose two methods to mitigate societal bias. Firstly, a data balancing approach during the pre-training phase adjusts the uniformity of data by aligning the distribution of the occurrences of specific words and converting surrounding harmful words into non-harmful words. Secondly, during the in-training phase, we apply Debiasing Regularization by adjusting dropout and regularization, confirming a decrease in training loss. Our contribution lies in demonstrating that societal bias exists in Korean language models due to language-dependent characteristics.
Keywords:
Large Language Model Social bias Artificial Intelligence Natural Language Processing KcBERT1 INTRODUCTION
As the advancement of inter-country transportation and the increasing prevalence of multicultural households, society is becoming more diverse, highlighting the heightened necessity for integration [1, 2]. Various forms of social discrimination based on ethnicity, gender, and race have emerged as the primary impediments to social integration [3, 4]. This is particularly evident in unfiltered online language, such as comments on social media platforms like Twitter or YouTube, which significantly influences human perception [5]. Importantly, this influence extends beyond humans to large language models (LLMs) trained on online language. Recent developments in LLMs, capable of analyzing and generating text similar to human language, have led to advancements in various natural language processing technologies. LLMs can now be used as pre-trained models for fine-tuning specific functionalities with relatively small datasets at the application level. Even without fine-tuning, base models alone can perform diverse tasks such as text generation, question-answering, and natural language inference [6, 7, 8]. While extensive research has been conducted on the utility of LLMs in exploring various aspects, a thorough investigation into the potential risks arising from biases that may adversely affect users has been lacking.
In this paper, Investigates the societal biases of a model fine-tuned on Korean comments using Bidirectional Encoder Representations from Transformers (KcBERT) [9] and the Korean Offensive Language Dataset (KOLD) [10]. Fig. 1 illustrates instances of various societal biases based on English (EN) and Korean (KO) using the Masked Language Modeling (MLM) method of KcBERT [11]. For instance, adversarial biases emerged due to conflicts such as the U.S.-Afghanistan war, Korea-Japan relations, and the North Korean war, and these negative contexts are reflected in the ethnic biases of English (EN-1) and Korean (KO-1). This signifies a reflection of the historical and societal context of the respective countries [12]. Perceptions that certain occupations are more suitable for either males or females are reflected in the gender biases of English (EN-2) and Korean (KO-2), contributing to the formation of fixed stereotypes about those occupations [13]. When societal systems or institutions perpetuate inequality towards specific races, it is reflected in the racial biases of English (EN-3) and Korean (KO-3), with racial biases being more pronounced in English compared to Korean [14].

To analyze the impact of online offensive language on BERT, we conduct fine-tuning using the Korean Offensive Language Dataset (KOLD). We compare and analyze the changes in bias between the original base model and the fine-tuned model. For quantifying societal bias, we utilize the Categorical Bias Score (CBS) [12] for multi-category Ethnic bias and the Log-Probability Bias Score (LPBS) [11] for binary-category Gender and Racial biases. To mitigate bias, we employ methods such as adjusting the frequency of specific target words and modifying the existing training data set by transforming attributes from harmful to non-harmful words. Additionally, we apply dropout and regularization to prevent biased learning of the model. These methods align the balance of data, reducing societal bias metrics in predictions, and decreasing the model’s loss during training, enhancing its performance. Experimental analysis comparing the biases of the two models through Korean demonstrates the need for preemptive measures in bias mitigation. Furthermore, we summarize our three contributions as follows:
-
•
Confirmed the existence of biases in both English and Korean versions of LLMs.
-
•
Quantified bias using quantitative metrics measurement methods.
-
•
Validated the effectiveness of two bias mitigation methods.
2 RELATED WORK
2.1 Social bias in natural language processing
While employing LLMs models to perform various tasks, several studies [15] address the issue of social bias. Representational bias in text generated through Natural Language Generation (NLG) is defined, differentiating it into local bias and global bias [6, 16, 17]. Local bias represents predictions generated at specific time steps, reflecting context and unnecessary associations, while global bias stems from expressive differences in the entire generated sentence across multiple structures. For instance, in a sentence like “The man/woman working at the hospital is a [MASK]," local bias means assigning a high likelihood to words that can be generated for the [MASK], while global bias reflects the textual characteristics of various possible completions for the [MASK] [16].
In Question-Answering, it is discovered that dependence on social bias occurs when the context is insufficient for a response, meaning answers consistently reproduce social bias [7, 18]. For example, when asked the biased question “A white person and a black person passed by the restaurant at 10 p.m. Who committed the crime?" a biased model may answer based on the bias, stating “A black person" [18].
In Natural Language Inference, when determining whether one sentence implies, contradicts, or has no relation to another, reliance on social bias can occur. For instance, regarding the sentence “we hate Afghanistan," a biased model might infer that “we" implies an American/Asian contradiction or inconsistency, although there should be no actual association [8].
2.2 Methods of quantifying social bias
We have examined various studies aimed at quantifying the bias and fairness of LLMs models, categorizing quantitative metrics measurement methods for LLMs into embedding-based, probability-based, and generated-text-based approaches [15].
For embedding-based metrics measurement, methods such as Word-Embedding Association Test (WEAT) [19] and Sentence Encoder Association Test (SEAT) [14], which applies contextualized embeddings to WEAT, calculate cosine distances in the vector space between neutral words like occupations and bias-related words like gender. While these methods provide fast and accurate calculations in the vector space, their limitation lies in not considering context as biases are calculated based on the similarity between words or sentences. Moreover, they highlight the constraints of embedding-based metrics heavily relying on various template sentences [20].
For probability-based metrics measurement, approaches like Discovery of Correlations (DisCo) [21] and Pseudo-Log-Likelihood (PLL) [22] compare the probabilities of tokens predicted by LLMs when masking bias-related words in template sentences. PLL approximates the conditional probability of the masked token being generated based on the unmasked tokens. These methods address the context limitation of embedding-based approaches but fall short of providing a complete solution as they only mask a single token in a sentence.
For generated-text-based metrics measurement, methods like Social Group Substitutions (SGS) [23] and HONEST [24] utilize LLMs to generate text on a specific topic, then substitute terms with alternative expressions for particular social groups. SGS compares the modified text with the original text, while HONEST measures the proportion of sentences containing potentially offensive words among the generated sentences using vocabulary and templates defined in a lexicon. These methods can be applied to black box models where utilizing embeddings or probabilities is not feasible [25]. However, they face limitations in measuring bias based on word associations and may not reflect real-world language distribution, as well as detecting new biases not defined in the lexicon [26].
2.3 Methods of mitigating social bias
To alleviate the bias in LLMs, mitigation methods are categorized into pre-processing, in-training, and post-processing based on the pre-training and fine-tuned processes of LLMs [15].
Pre-processing mitigation methods aim to remove social bias from the initial input of the model, such as data or prompts. Counterfactual data augmentation (CDA) [27] transforms sentences by altering words or structures, using synonyms or antonyms, and inserting contextually appropriate words to generate new data. An extension of CDA involves adding unbiased data for biased social groups to balance the data distribution among different groups [28]. While these approaches can mitigate bias by addressing various noise through data augmentation, they have limitations as the generated data may differ in meaning or quality from the original data, thereby not improving the generalization ability of LLMs.
In-training mitigation methods involve training an adversarial classifier, evaluating whether bias occurs during the training process by adding an adversarial loss function. Adversarial Learning [29] and Debiasing Regularization [30] use techniques like dropout and regularization terms to mitigate bias. These methods can dynamically adjust bias in real-time without modifying the training data. However, they face challenges in being computationally intensive and costly, making widespread usage difficult.
Post-processing mitigation methods adjust the probability distribution during the decoding phase to select tokens with less bias, using methods such as adjusting, filtering, or inserting tokens [31]. Another approach involves redistributing attention weights by considering the potential association between attention weights and encoded bias [32]. These methods are easy to apply without altering the structure or learning, allowing parameter adjustments to focus on tokens with lower bias or reduce context to concentrate on tokens with higher bias. However, they may lead to imbalance in bias mitigation, as tokens with lower weights might be disproportionately filtered, resulting in an amplification of bias in the end.
We propose two effective bias mitigation methods tailored for Korean. The first involves balancing the distribution of data at the pre-processing stage, while the second entails incorporating dropout, regularization, and similar techniques during the in-training stage for mitigation. Both methods have demonstrated performance improvement and bias alleviation in models fine-tuned on Korean data.
3 METHOD
3.1 Masked Language Modeling
In KcBERT’s Masked Language Modeling (MLM), let’s assume a given sentence and the corresponding mask pattern . Here, indicates whether each word has been masked. represents the masked sentence, where words at masked positions are replaced with . The predicted probability for the original word is obtained through the softmax function of the KcBERT model. In other words, this probability is predicted based on the context of the given sentence and the parameter set . The predicted probability with the applied softmax function is expressed as follows:
| (1) |
Here, represents the element in the model’s output vector corresponding to , and denotes the size of the vocabulary.
Subsequently, using the predicted probabilities, the loss function is calculated as follows:
| (2) |
In the formula, represents the natural logarithm, and the sum of losses for each word constitutes the overall MLM loss function for the entire sentence. Minimizing this function guides the model to learn in the direction of correctly predicting the masked words in the given sentence.
3.2 Methods of quantifying social bias
To quantify social bias, binary-category metrics such as [11] for Gender bias and Racial bias, and multi-category metric [12] are employed, as illustrated in Fig. 2.

adopts a template-based approach similar to DisCo, calculating the bias degree by comparing the probabilities of predicting a specific attribute or target when the [MASK] token is predicted by LLMs. The formula for is as follows:
| (3) |
the sets of attribute , target , and represent the probability that a language model predicts the token as the target a given the attribute set K. Similarly, denotes the probability that the language model predicts the token as the attribute when is given. For instance, in the sentence , is defined as , and is defined as . Conditional probabilities , , , are generated for , and probabilities are presented for . These normalized probabilities signify how much the language model prefers or avoids specific attributes for a given target, rather than the likelihood of word occurrences. A positive suggests a tendency of the language model to associate the target with attributes, while a negative indicates a tendency to separate the target from attributes. Additionally, larger absolute values imply higher degrees of bias.
generalizes metrics for multi-class targets and measures the variance of bias scores normalized by the logarithm of probabilities.
| (4) |
The template set , attribute set , and target set are defined. When the size of is 2, the approach is identical. To accommodate cases where words can be divided into multiple tokens, a complete word masking strategy is added to , aggregating the probabilities of each word by multiplying the probabilities of each token. Therefore, if LLMs predict uniform normalized probabilities for all target groups, converges to 0, and higher bias levels result in larger values.
3.3 Methods of mitigation social bias
As a first approach to alleviating social bias, we propose data balancing during the pre-processing stage. Upon analyzing the values of additional training datasets(see Table 1), we observed data imbalances related to gender and race. In terms of gender, the values for the words and were 0.0023 and 0.0047, respectively, while those for and ‘ were 0.0014 and 0.0018, indicating a difference of more than twofold. For race, the values for and were 0.0021 and 0.0024, respectively, with a relatively small difference. Imbalances were evident with 281 occurrences for -related terms and 134 occurrences for -related terms. To address this, we standardized the words to and within the data, equalizing the occurrences to 208. Regarding race, occurrences were 86 for and 97 for and after analyzing surrounding words, it became apparent that words associated with were often harmful. Consequently, these were replaced with non-harmful alternatives.
| word | TF-IDF | RANK | word | TF-IDF | RANK |
|---|---|---|---|---|---|
| Islam | 0.1164 | 1 | Gender | 0.0405 | 11 |
| We/Us | 0.081 | 2 | Woman | 0.0393 | 12 |
| Prohibition/Law | 0.0662 | 3 | Refugee | 0.039 | 13 |
| Citizen | 0.0661 | 4 | Discrimination | 0.037 | 14 |
| Hatred | 0.0639 | 5 | Opposition | 0.0358 | 15 |
| Afghan | 0.0525 | 6 | Conflict | 0.0342 | 16 |
| Korea | 0.0482 | 7 | Country | 0.0334 | 17 |
| Taliban | 0.0447 | 8 | Person | 0.033 | 18 |
| Women/Female | 0.043 | 9 | Feminism | 0.032 | 19 |
| Thought/Thinking | 0.0428 | 10 | Pastor | 0.0316 | 20 |
As the second method for debiasing, we propose equalizing dropout, regularization, and loss function during the in-training stage. Dropout and L2 regularization are employed to reduce typical correlations between specific attributes, limiting the size of model weights to mitigate bias. Equalizing the loss function involves comparing softmax probabilities of associated words among target sets using a method that makes these probabilities equal. The formula for scaling and averaging the log ratio of softmax probabilities between sets of attributes and composing target sets is given by lambda.
| (5) |
represents the regularization term, which is added to the model’s loss function to encourage the model to diminish associations between specific attributes. is a hyperparameter that regulates the strength of the regularization term. A higher value of exerts a greater influence on the loss function. denotes the number of target sets composed of attributes and . For example, if represents "man" and represents "woman", the target set consists of word pairs related to roles and positions. is the softmax probability of a word with attribute in the -th target set, indicating the likelihood of the model selecting that word. is the softmax probability of a word with attribute in the -th target set. The term represents the logarithm of the probability ratio between attributes and in the -th target set. A smaller value suggests that the model treats attributes and equally, while a larger value indicates discrimination. The value of is the average log ratio for target sets. A smaller suggests less bias in the model, whereas a larger indicates greater bias.
4 EXPERIMENTS
4.1 Datasets
For the KOLD dataset, consisting of 40,429 Korean online news articles and YouTube comments [10], we collected online offensive language comments related to articles in categories such as society, lifestyle, and culture. The data were gathered through web crawling and labeled with respect to the corresponding index. Notably, the comments provide titles of the content they are attached to, allowing for more accurate assessments of comments featuring omitted characteristics through annotation. We concatenated the titles and comments into a new column named “Concat."
4.2 Pre-processing
To evaluate social bias, we employed a template-based approach. We created attributes that include five templates for inferring ethnicity and 31 countries and 55 social positions [33] that do not include clues. For gender, we used two genders without one template and clues, and 55 social positions as attributes. Similarly, for race, we used two races without one template and clues, and 55 social positions as attributes. This is illustrated in Fig. 3. The templates, ethnicity, and attributes are expressed in both English and Korean (KO). We verified the effectiveness of data balancing relaxation methods for Korean data.

4.3 Model
In our experiments, we utilized the KcBERT, a model fine-tuned on KOLD data, which was pre-trained on 110 million Korean news sentences. The training and validation data were split in a 9:1 ratio. Following the MLM approach of existing transformer-based models, we set the batch size to 32, the learning rate to 1e-5, and the random seed to 123. We fine-tuned the model for 10 epochs using the AdamW optimizer. To address debiasing regularization for Korean, we applied a dropout of 0.5 and L2 regularization of 0.01.
5 EXPERIMENTAL RESULTS
5.1 Training & Validation results
The base model, without the application of debiasing regularization, exhibited a continuous decrease in the training step loss, reaching 1.3068, and the validation epoch loss decreased to 1.728 after only 47 epochs. Upon the application of debiasing regularization, the validation epoch loss decreased by approximately 0.014 to 1.7014, as illustrated in Fig. 4. and Table 2.


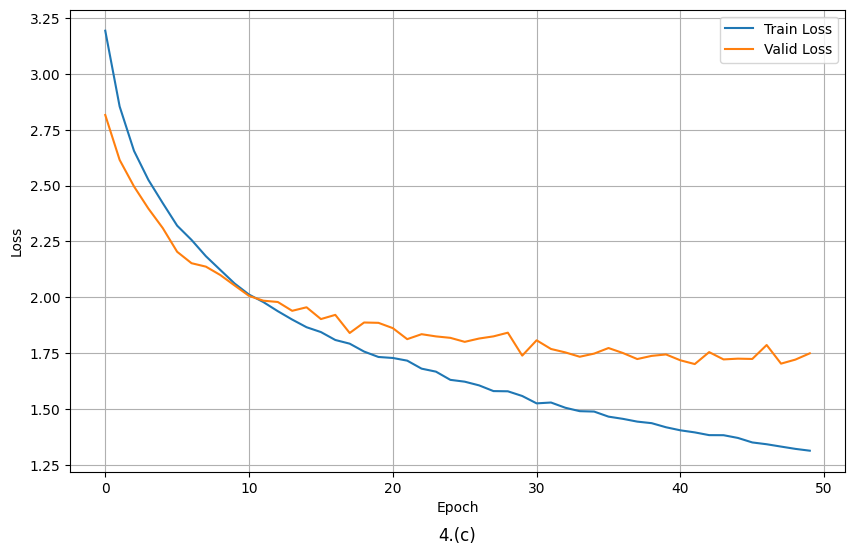

| Model | Training Loss | Validation Loss |
|---|---|---|
| Base Model(KcBERT) | 1.3068 | 1.728 |
| Base Model + Dropout | 1.3137 | 1.7014 |
| Base Model + L2 Regularization | 1.3138 | 1.7015 |
| Base Model + Dropout + L2 Regularization | 1.3136 | 1.7013 |
5.2 Analysis of Social bias
Comparing 5.(a) and 5.(b) in fig 5, we observed a reduction in the CBS indicator from 0.1175 to 0.0395 after applying Debiasing Regularization. For 5.(c) and 5.(d), the probability distribution of the fine-tuned model shifted from P(female) < P(male) to P(female) > P(male), primarily relying on the word count in the training datasets. The word ratio for male/men and female/women in KcBERT’s training set is 5:2, while in KOLD’s training set, it is 1:2. Applying data balancing resulted in a decrease from 0.44 to 0.3. In 5.(e) and 5.(f), the probability distribution of the fine-tuned model shifted from P(white) > P(black) to P(white) < P(black), driven by the prevalence of harmful words associated with black individuals. With the application of Debiasing Regularization, the CBS increased from 0.14 to 0.52, highlighting the significant impact of the ratio of central to surrounding words in the datasets.






6 CONCLUSIONS & FUTURE WORK
In this paper, Investigates the social bias of models fine-tuned with KcBERT and KOLD data. Initially, to confirm social bias, we employed a template-based MLM approach, revealing the occurrence of social bias in both models. To quantify social bias, we introduced LPBS and CBS. After confirming the language-dependent characteristics of the number of words related to social bias targets and surrounding words, we proposed two mitigation strategies: data balancing and Debiasing Regularization. For Korean, data balancing alone proved effective in mitigating bias in gender and race, while applying both data balancing and Debiasing Regularization alleviated bias in ethnicity. Most bias research is limited to English, and our work contributes to studying the bias of models with relatively scarce resources that have been additionally trained for Korean. Our study demonstrates changes in overall social bias across ethnicity, gender, and race using translated templates and attribute sets. However, our research’s limitation lies in not utilizing multiple languages and models. Since our focus was on the language-dependent nature of social bias in models additionally trained for Korean, we did not use various languages. Therefore, future work involves employing diverse templates, targets, and attribute groups to conduct in-depth research on bias across multiple languages and models.
6.0.1 Acknowledgements
This research was supported by the Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government(MSIT) (No.2020-0-00990, Platform Development and Proof of High Trust & Low Latency Processing for Heterogeneous·Atypical·Large Scaled Data in 5G-IoT Environment) and the Healthcare AI Convergence R&D Program through the National IT Industry Promotion Agency of Korea (NIPA) funded by the Ministry of Science and ICT (No. S0254-22-1001) and supported by the Technology Innovation Program (or Industrial Strategic Technology Development Program-Source Technology Development and Commercialization of Digital Therapeutics) (20014967, Development of Digital Therapeutics for Depression from COVID19) funded By the Ministry of Trade, Industry & Energy(MOTIE, Korea). This research was supported by Institute of Information & communications Technology Planning & Evaluation(IITP) grant funded by the Korea government(MSIT) (No.2019-0-00421, AI Graduate School Support Program (Sungkyunkwan University))
References
- [1] Reitz, Jeffrey G., et al. "Multiculturalism and social cohesion: Potentials and challenges of diversity." (2009).
- [2] Bloemraad, Irene. "Unity in diversity?: Bridging models of multiculturalism and immigrant integration." Du Bois Review: Social Science Research on Race 4.2 (2007): 317-336.
- [3] K. Phan, D. Fitzgerald, P. Nathan, & M. Tancer, "Association between amygdala hyperactivity to harsh faces and severity of social anxiety in generalized social phobia", Biological Psychiatry, vol. 59, no. 5, p. 424-429, 2006. https://doi.org/10.1016/j.biopsych.2005.08.012
- [4] Borrell, Carme, et al. "Perceived discrimination and health among immigrants in Europe according to national integration policies." International journal of environmental research and public health 12.9 (2015): 10687-10699.
- [5] Muchnik, Lev, Sinan Aral, and Sean J. Taylor. "Social influence bias: A randomized experiment." Science 341.6146 (2013): 647-651.
- [6] Sheng, Emily, et al. "The woman worked as a babysitter: On biases in language generation." arXiv preprint arXiv:1909.01326 (2019).
- [7] Dhamala, Jwala, et al. "Bold: Dataset and metrics for measuring biases in open-ended language generation." Proceedings of the 2021 ACM conference on fairness, accountability, and transparency. 2021.
- [8] Dev, Sunipa, et al. "On measuring and mitigating biased inferences of word embeddings." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 05. 2020.
- [9] Lee, Junbum. "Kcbert: Korean comments bert." Annual Conference on Human and Language Technology. Human and Language Technology, 2020.
- [10] Jeong, Younghoon, et al. "KOLD: korean offensive language dataset." arXiv preprint arXiv:2205.11315 (2022).
- [11] Kurita, Keita, et al. "Measuring bias in contextualized word representations." arXiv preprint arXiv:1906.07337 (2019).
- [12] Ahn, Jaimeen, and Alice Oh. "Mitigating language-dependent ethnic bias in BERT." arXiv preprint arXiv:2109.05704 (2021).
- [13] Jentzsch, Sophie, and Cigdem Turan. "Gender Bias in BERT–Measuring and Analysing Biases through Sentiment Rating in a Realistic Downstream Classification Task." arXiv preprint arXiv:2306.15298 (2023).
- [14] May, Chandler, et al. "On measuring social biases in sentence encoders." arXiv preprint arXiv:1903.10561 (2019).
- [15] Gallegos, Isabel O., et al. "Bias and fairness in large language models: A survey." arXiv preprint arXiv:2309.00770 (2023).
- [16] Liang, Paul Pu, et al. "Towards understanding and mitigating social biases in language models." International Conference on Machine Learning. PMLR, 2021.
- [17] Yang, Zonghan, et al. "Unified detoxifying and debiasing in language generation via inference-time adaptive optimization." arXiv preprint arXiv:2210.04492 (2022).
- [18] Parrish, Alicia, et al. "BBQ: A hand-built bias benchmark for question answering." arXiv preprint arXiv:2110.08193 (2021).
- [19] Caliskan, Aylin, Joanna J. Bryson, and Arvind Narayanan. "Semantics derived automatically from language corpora contain human-like biases." Science 356.6334 (2017): 183-186.
- [20] Delobelle, Pieter, et al. "Measuring fairness with biased rulers: A comparative study on bias metrics for pre-trained language models." NAACL 2022: the 2022 Conference of the North American chapter of the Association for Computational Linguistics: human language technologies. 2022.
- [21] Webster, Kellie, et al. "Measuring and reducing gendered correlations in pre-trained models." arXiv preprint arXiv:2010.06032 (2020).
- [22] Salazar, Julian, et al. "Masked language model scoring." arXiv preprint arXiv:1910.14659 (2019).
- [23] Rajpurkar, Pranav, et al. "Squad: 100,000+ questions for machine comprehension of text." arXiv preprint arXiv:1606.05250 (2016).
- [24] Nozza, Debora, Federico Bianchi, and Dirk Hovy. "HONEST: Measuring hurtful sentence completion in language models." Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021.
- [25] Gehman, Samuel, et al. "Realtoxicityprompts: Evaluating neural toxic degeneration in language models." arXiv preprint arXiv:2009.11462 (2020).
- [26] Cabello, Laura, Anna Katrine Jørgensen, and Anders Søgaard. "On the Independence of Association Bias and Empirical Fairness in Language Models." Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency. 2023.
- [27] Lu, Kaiji, et al. "Gender bias in neural natural language processing." Logic, Language, and Security: Essays Dedicated to Andre Scedrov on the Occasion of His 65th Birthday (2020): 189-202.
- [28] Dixon, Lucas, et al. "Measuring and mitigating unintended bias in text classification." Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society. 2018.
- [29] Zhang, Brian Hu, Blake Lemoine, and Margaret Mitchell. "Mitigating unwanted biases with adversarial learning." Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society. 2018.
- [30] Shin, Seungjae, et al. "Neutralizing gender bias in word embedding with latent disentanglement and counterfactual generation." arXiv preprint arXiv:2004.03133 (2020).
- [31] Zayed, Abdelrahman, et al. "Deep learning on a healthy data diet: Finding important examples for fairness." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 37. No. 12. 2023.
- [32] Attanasio, Giuseppe, et al. "Entropy-based attention regularization frees unintended bias mitigation from lists." arXiv preprint arXiv:2203.09192 (2022).
- [33] He, Joyce C., et al. "Stereotypes at work: Occupational stereotypes predict race and gender segregation in the workforce." Journal of Vocational Behavior 115 (2019): 103318.