Dense Feature Interaction Network for Image Inpainting Localization
Abstract
Image inpainting, which is the task of filling in missing areas in an image, is a common image editing technique. Inpainting can be used to conceal or alter image contents in malicious manipulation of images, driving the need for research in image inpainting detection. Existing methods mostly rely on a basic encoder-decoder structure, which often results in a high number of false positives or misses the inpainted regions, especially when dealing with targets of varying semantics and scales. Additionally, the absence of an effective approach to capture boundary artifacts leads to less accurate edge localization. In this paper, we describe a new method for inpainting detection based on a Dense Feature Interaction Network (DeFI-Net). DeFI-Net uses a novel feature pyramid architecture to capture and amplify multi-scale representations across various stages, thereby improving the detection of image inpainting by better revealing feature-level interactions. Additionally, the network can adaptively direct the lower-level features, which carry edge and shape information, to refine the localization of manipulated regions while integrating the higher-level semantic features. Using DeFI-Net, we develop a method combining complementary representations to accurately identify inpainted areas. Evaluation on five image inpainting datasets demonstrate the effectiveness of our approach, which achieves state-of-the-art performance in detecting inpainting across diverse models.
Index Terms:
Image Inpainting Detection, Image Local Manipulation, Image Forensics.I Introduction
Image inpainting is a common image editing technique that restores damaged or missing regions with visually credible structures and textures based on the other part of the image. Inpainting has applications such as photo restoration, obstacle removal, and augmented reality. Traditional inpainting methods formulate it as an optimization problem [1], where the goal is to find the most suitable information to fill in the gaps while maintaining overall coherence in the reconstructed image. It is mainly divided into two branches: pixel propagation based [2, 3, 4], and image patches matching based [5, 6, 7, 8, 9]. The rapid advancements of learning-based methods, especially the recent generative AI tools such as OpenAI DALL-E111https://openai.com/dall-e-2, Stable Diffusion222https://huggingface.co/runwayml/stable-diffusion-inpainting, and Adobe Firefly333https://www.adobe.com/products/firefly.html have enabled users to create and perform image editing, including inpainting, by simply providing some text prompts. The generative AI backed inpainting method exacerbates the negative impacts of malicious use of image inpainting as a means of disinformation. A notable recent example is the case where nudity images created with AI-powered image inpainting were spread for cyber targeting female students in a California middle school444https://www.latimes.com/california/story/2024-02-26/beverly-hills-middle-school-is-the-latest-to-be-rocked-by-deepfake-scandal.

To date, many methods have been developed to expose local image manipulation [11, 12, 10, 13, 14, 15]. Yet locating inpainted regions is still a challenging problem, which can be attributed to the following two factors. First, unlike traditional copy-move and splicing manipulations, which often result in noticeable artifacts such as duplicated pixels or inconsistent patterns in semantic and color, advanced image inpainting algorithms mitigate signal and visual artifacts by preserving statistical properties [16] extracted not only from surrounding pixels but also inferred from massive datasets in a data-driven manner. Additionally, the varied sizes of inpainted regions, ranging from large object editing to small watermark, signature, or trademark removal, pose further challenges in the detection process.
Although several studies have dedicated exclusively to identifying image inpainting, such as using high-pass fully convolutional network [17], Neural Architecture Search (NAS) based model[18], Transformer architecture[19], or primary–secondary network [20], most of them adopt conventional encoder-decoder architectures, prioritizing deep high-level555 In this paper, we use “level” to indicate the abstraction level of extracted information, “stage” to describe a group of layers in CNN models, and “layer” as the basic building blocks of CNN architecture. information while overlooking shallow features that contain crucial contextual details essential for uncovering inpainting artifacts, such as subtle inconsistencies in edge and shapes. Furthermore, for learning inconsistencies at inpainting boundaries, relying solely on ordinary convolution combinations and fixed edge extraction operators makes it challenging to capture representative artifact features. Such limitations reduce the model’s ability to address complex or small inpainting areas, resulting in false positives or diminished localization accuracy.

We use the insight that features at various layers [22] within deep learning networks can expose the subtle inconsistencies introduced by the inpainting operation in a different while complementary manner (refer to Fig. 1). Low-level features are closer to the input layer and have smaller receptive fields, thus primarily capturing signal artifacts, like edges and corners lacking semantic information [23]. Features at the middle level represent more abstract patterns and object parts, while high-level semantic features describing entire objects, scenes, or concepts are derived from the network’s deeper layers. Our goal is to fully leverage and enhance the diverse contributions of these features towards localizing image inpainting. To this end, we develop a new method for inpainting detection based on a Dense Feature Interaction Network (DeFI-Net). DeFI-Net uses a feature pyramid architecture to capture and amplify multi-scale representations across various stages, which can more effectively reveal the feature-level interactions for detecting image inpainting. This structure adaptively directs the lower-level features, which carry edge and shape information, to refine the localization of manipulated edges while integrating the higher-level semantic features. Using DeFI-Net, we have developed a priori feature-guided edge attention module, incorporating inpainting edge prediction as an auxiliary task to enhance feature representation and improve localization accuracy at edge details. Evaluation on five image inpainting datasets demonstrate the effectiveness of our approach, which achieves state-of-the-art performance in detecting inpainting across diverse models. The main contributions of our work can be summarized as follows.
-
We introduce the DeFI-Net to highlight how layered features aid inpainting detection, with a dense feature pyramid architecture hierarchically and thoroughly encoding multi-view features through dense connections.
-
We further design a complementary supervision approach by adding edge supervision with reverse attention on lower-layer features to the inpainting region localization using multi-level features.
-
To effectively integrate multi-level features, we design a spatial weight learning module that adaptively assigns fusion weights to different levels of features, providing representative and compact contexts for recognizing inpainting.
-
Our method beats top algorithms in identifying traditional and DL-based inpainting, showing strong generalization ability to advanced inpainting techniques.
II Related Work
II-A Image inpainting manipulation
Inpainting is a long-standing problem in image processing and computer vision [16]. The task is ill-posed because there is no unique solution based on the remaining part of the image, and various prior information is needed to hallucinate the missing region. Early inpainting methods using non-learning algorithms aim to recover lost pixels using pixel redundancy and local continuity priors, either propagating information from the surrounding areas [24] or using patch-based completion in a Markov random field model[25]. More recent effective inpainting methods are obtained with deep neural networks (DNNs) trained on large datasets [1], which allow for automatic feature learning and more context-aware inpainting results. Various types of DNN models have been explored, including the Generative Adversarial Network (GAN) [26, 27], Shift-Net [28] used U-Net architecture, coarse-to-fine network [29, 30], recent Fast Fourier Convolution models [16, 31, 32, 33], and decoupled probabilistic modeling [34]. The emergence of diffusion-based image generation models, such as DALLE 2[35] and Stable Diffusion[36] further significantly improve the performance of image inpainting [37, 38, 39, 40]. The diffusion-based image inpainting leads to more natural and realistic results that pose challenges to detection algorithms.

II-B Image inpainting detection
Detecting of image inpainting is often solved with machine learning based on convolutional neural networks (CNNs) [41]. These CNN-based approaches exploit hierarchical neural networks to automatically learn discriminative features for detecting inpainted regions. Zhu et al. [42] pioneered CNN-based image inpainting detection by employing a label matrix to guide automatic feature learning and the weighted cross-entropy as the loss function. Several studies [43, 44, 45] employed Long Short-Term Memory (LSTM) models to learn artifacts for manipulation localization. HP-FCN [17] was proposed to enhance inpainting traces via high-pass filtering and learn discriminative features from image residuals. Similarly, IID-Net [18] used various combined filters to enhance inpainting features, and introduced a Neural Architecture Search (NAS) algorithm to adjust feature extraction cells. These conventional encoder-decoder structures without pooling layers may hinder the model’s capability to detect intricate tampering and result in spatial information loss. Several methods [46, 11, 47, 14] introduces multi-branch models to combine features from noise/frequency domains or patches [48]. New feature extraction models, including Transformer-based architectures [19, 49] or DenseNet-based approaches [50, 20] have been used for inpainting detection. Furthermore, researchers have explored multi-scale feature learning techniques. For example, MVSS-Net [13, 14] employed features learned from different stages of the backbone network and incorporated a two-branch supervision method considering RGB domain and noise patterns. Liu et al. [10] introduced PSCC-Net, leveraging the multi-stage features learned from the HRNet [51] for progressive mask prediction. GCA-Net [21] designed a gated context attention network to capture fine image discrepancies in inpainted images. To improve global context representations and minimize feature loss, they refer to the UNet++ [52] architecture, which utilizes multi-scale bottom-up feature propagation in the decoding process. Recently, Yu et al. introduced DiffForensics [15], which employs a self-supervised denoising diffusion paradigm integrated with an encoder-decoder architecture to detect and localize tampering.
Unlike existing methods, this work highlights the complementary features of neural networks, and designs a dense feature interaction network tailored for capturing rich and discriminative patterns in image inpainting detection, as depicted in Fig. 2. For the additional task of inpainting edge detection, edge extraction operator [13, 14, 53] and ordinary convolutional structures [54] are susceptible to interference from noise (shapes and boundaries of other authentic objects). Therefore, a priori feature-guided edge attention module is developed in this work to help the model focus on subtle differences inside and outside the boundary and improve the localization accuracy at edges.
III DeFI-Net
In this work, we introduce the DeFI-Net for image inpainting localization, as shown in Fig. 3. Taking an RGB image as input, the model will output a single-channel edge mask and region mask . The model begins with multiple stages of feature extraction from the backbone network. The multi-stage features are interacted and fused by three components: 1) a Dense Feature Pyramid Learning structure (DFPL) to introduce multi-scale features containing detailed texture, contextual and semantic information (see Sec. III-A); 2) a Reverse Edge-Attention Enhancement (REAE), with low-mid-level features as a prior guiding the model to focus on edge inconsistencies caused by inpainting (see Sec. III-B); 3) a Spatial Adaptive Feature Fusion (SA-FF) aims to learn the fusion weights of the high-level and mid-low-level features adaptively, unifying the representation of inpainting to achieve accurate detection results ( see Sec. III-C).
III-A Dense Feature Pyramid Learning
Different layers in a Convolutional Neural Network (CNN) model have receptive fields of different sizes and extract image features of different levels of detail. Generally, early or shadow layers mostly extract low-level and generic image cues (e.g., edges and corners), and the middle layers carry shapes and textural patterns. In contrast, deeper layers capture high-level semantics or specific image cues [55, 44, 23]. Artifacts of image inpainting may be reflected at all three levels of features, each contributing in a complementary manner. For example, pixel filling can cause distortions or blur at edges, detectable by low-level features. Middle-level features mainly capture texture inconsistencies in the filled areas, like structural mismatches or color discordance. Differently, high-level features identify changes in an image’s semantic content, such as missing object parts or altered scene interpretation, aiding the model in identifying inpainting areas.
Our goal is to design an effective extraction and fusion of these complementary features (as shown in Fig. 1) to identify image inpainting. We first use the backbone network to extract multi-stage features from the input image. Using a CNN (e.g., [56]) divided into five stages as an example, we define the shallow features from Stage 1 and Stage 2 as low-level features and , the features extracted from Stage 3 as mid-level feature , while the more complex deep features from Stage 4 as high-level features . Inspired by the Feature Pyramid Network (FPN) [22] and Path Aggregation Network (PANet) [57], we design a multi-directional, multi-scale fusion method, as shown in Fig. 4. Differently, we treat multi-level features as independent entities, emphasizing the specificity of features at different stages. Our densely connected fusion approach improves the efficiency of information interaction between adjacent and cross layers, progressively enhancing context awareness.
Taking a single-scale feature as an example, our DFPL module considers the features of the same scale and all the neighboring features to fully exploit and enhance the useful context information for image inpainting localization. Specifically, to obtain the feature (where denotes the stage of the backbone to which the current feature belongs, and represents the state of the feature in DFPL, as 1 for the initial state involving channel reduction, 2 for the bottom-up path, and 3 for the top-down path), we concatenate its neighboring features in the channel dimension and use convolution to integrate and select features. This process can be expressed by the equation below, where we have removed the max pooling, upsampling operations and cases with in the boundary condition for simplicity.

| (1) |
refers to concatenating the required features in the channel dimension, and represents convolution layer.
III-B Reverse Edge Attention Enhancement
Filling content to a specific area in an image can leave detectable traces between the altered region and its surroundings. Therefore, leveraging these edge artifacts is crucial for detecting inpainting, which the mid-lowe-level features can guide. Nevertheless, mid-low-level features not only contain inconsistencies caused by inpainting but also a large amount of detail and structural noise, such as texture, shape, and object boundaries. Using traditional edge extraction operators [14, 53] or convolutional structures [54] will weaken the representation of inpainting artifacts. Leveraging context-rich features that include the structural information of the restoration region as a prior can effectively suppress irrelevant semantic noise and guide boundary learning.
We develop a method for detecting and enhancing edge artifacts using reverse attention called REAE, which uses the structural details in the mid-level feature as a guide, directing the attention of low-level features toward subtle boundary changes of the inpainting area. This promotes learning distinctive features to differentiate between inpainting edges and natural boundaries. As shown in Fig. 3(a), the REAE module accepts mid-level features and low-level features and as input. Its upper branch aggregates structural information of suspicious regions through average pooling, max pooling, and convolution. Subsequently, the sigmoid output is inverted to obtain a reverse attention map emphasizing edges, expressed by Eq. (III-B). Meanwhile, the lower branch of the REAE progressively combines , , and for through convolution, Batch Normalization (BN), and bilinear interpolation upsampling. Finally, we use Eq. (3) to fuse the feature for edge supervision and output the edge mask through a prediction head composed of multiple convolutional layers.
| (2) |
| (3) |
where denotes a convolution layer. and are defined as average pooling and max pooling, respectively. is the prediction head, composed of two convolutional layers with and kernels, which outputs a single-channel edge mask.

III-C Spatial Adaptive Feature Fusion
Due to the nature of neural networks, deep features exhibit a significantly stronger response to the target region compared to shallow features.The difference in receptive field inevitably leads the model to bias towards the side with a more robust response during the fusion process, allocating more weights to the deep features, which can severely suppress the role of shallow features. Shallow features can provide detailed edge positioning and structural information, significantly impacting the detection accuracy.
To unify the feature representation of the inpainting region, we design a spatial adaptive feature fusion module (SA-FF) to fuse high-level features and mid-low-level features to correct the bias brought by response intensity. Normalization can limit the response of different features to a similar magnitude, effectively eliminating the interference of response intensity. After normalization, the model can treat deep and shallow features fairly, making it easier to learn effective fusion weights. Specifically, we reduce the channels of and to 2 through a convolution, followed by normalization. The process can be expressed as: Eq. (4) and (5).
| (4) |
| (5) |
For different spatial locations, there exists a disparity in the contribution of deep and shallow features. Deep features, rich in context, are semantically accurate but lose many spatial and geometric details. Shallow features better retain these aspects, and we hope that the model trusts shallow features more in the boundary area and uses the information provided by deep features to fill the target area. As shown in the Fig. 5, we designed a spatially adaptive weight learner to adjust the fusion weights according to positional features, fully utilizing both advantages. Specifically, we feed the features used for learning weights into alternating connection blocks composed of convolution, BN, and ReLU to generate position-aware fusion weights . Then, the final fusion output is obtained according to element-wise multiplication and element-wise addition, as shown in Eq. (8). Finally, a region mask is output through a prediction head composed of convolutional layers.
| (6) |
| (7) |
| (8) |
where denotes the concatenation of and after rearranging them in channel order. represents the ordinary concatenation along the channel dimension. and denote the element-wise multiplication and element-wise addition, respectively. is defined as the slicing operation of the channel dimension. Note that in our design, W will learn different weights for each spatial position of each channel, totaling weights.
III-D Loss Function
To train our DeFI-Net, we use an objective function that combines the region loss and the edge loss functions. The region loss enhances the model’s sensitivity to the inpainting region from a global perspective. It promotes the overlap between the predicted mask and the ground truth. In contrast, the edge loss guides the model to learn non-semantic detail differences from a local perspective, achieving more precise localization. According to [58], we define the region loss function as . Compared with the traditional BCE loss, assigns different weights to pixels in different positions, paying more attention to the target area and hard pixels in the area (locations such as boundaries prone to classification errors). The IoU loss assigns greater weight to the target area, prompting the network to pay attention to the global structure. For the edge loss, we use the similar to supervise the edge prediction, denoted as . The overall loss function is a convex combination of two losses: .
IV Experiments
IV-A Experimental Settings
Datasets. To evaluate the performance of our DeFI-Net, we use five diverse image inpainting datasets, considering variations in inpainting model, region size, and image content. Table I summarizes the datasets. IID-84K [18] comprises 74K inpainted images created using the Gated Convolution (GC) model [59] on images sourced from Places [60] (with JPEG lossy compression) and Dresden [61] (with NEF lossless compression). Additionally, it includes a subset with 1K GC images for in-domain testing (denoted as IID-GC) and another 9K images (denoted as IID-9K) generated by four other deep learning inpainting models (CA [29], SH [28], LB [30], RN [62]) and five traditional inpainting models (TE [63], NS [2], PM [64], SG [65], LR [66]) on images from CelebA [67] and ImageNet [68]. DEFACTO [69] contains different manipulation types while our primary focus lies on 20K inpainting images and 4K authentic images (DE-24K) for training, along with a validation set (DE-1K) and a test set (DE-3K). In addition, we consider the diverse inpainted images in Korus [70], Photoshop [20], and AutoSplice [38] to evaluate the generalization ability of our method.
| Dataset | Training | Testing | Data Source | |||||||
| #Sample | Model | #Sample | Model | |||||||
| IID-84K [18] | 74K | GC | 10K |
|
|
|||||
| DEFACTO[69] | 24K | Exemplar [71] | 3K | Exemplar [71] | MSCOCO [72] | |||||
| Korus [70] | - | - | 57 |
|
|
|||||
| Photoshop [20] | - | - | 300 | Photoshop | Places [60] | |||||
| AutoSplice [38] | - | - | 3.6K | DALLE-2 | Visual News [73] | |||||
Evaluation Metrics. Our evaluation metrics include the Area Under the receiver operating characteristic Curve (AUC), F1 score, and Intersection over Union (IoU). AUC and F1 measure the accuracy of binary classification (authentic or inpainted) at the pixel level, while IoU quantifies the overlap between the predicted region and the ground truth. These three metrics have a range of [0, 100] percent, where higher values indicate better performance. We use a threshold of 0.5 for F1 and IoU evaluation.
Implementation Details. We use the HRNet [51] initialized with pre-trained weights from ImageNet[68] as an example. Our model is implemented in Pytorch and trained using the Adam optimizer. During the training phase, we set the size of the input image to and the batch size to 16. The initial learning rate is 2e-4 and will be halved if the AUC on the validation set fails to increase for five epochs until the convergence. In the DFPL module, the channels of all-level features are reduced to . In addition, we set the and for the region and edge loss to 5 and 1, respectively.
IV-B Quantitative Comparisons
In-domain Localization. We first compare our DeFI-Net with several open-source methods, including MT-Net [45], HP-FCN [17], IID-Net [18], PS-Net [20], PSCC-Net [10], MVSS-Net [14]. For fairness, we train our method and all baselines using the same settings on the GC-74K and DE-24K datasets, respectively. Table II presents the localization results under in-domain testing. Our method achieves the best performance on both datasets. Specifically, our AUC, F1, and IoU scores are , , and higher than those of the second-place method, respectively. On the DE-3K dataset, single-scale encoding-decoding methods (such as IID-Net) experienced a notable performance drop due to the challenges in identifying small inpainting regions in this dataset. Our DeFI-Net outperforms the comparison methods significantly, particularly achieving a 23.3% lead over the second-place PSCC-Net in terms of the IoU metric. This demonstrates the effectiveness and superiority of our dense feature pyramid learning design in facilitating sufficient interaction among multi-scale features, thereby enhancing the detection ability even for small inpainting targets.
| Dataset | Metric |
|
|
|
|
|
|
|
||||||||||||||
| IID-GC | AUC | 93.83 | 97.05 | 97.54 | 97.53 | 85.09 | 91.19 | 98.61 | ||||||||||||||
| IID-GC | F1 | 63.62 | 80.07 | 89.08 | 88.36 | 63.55 | 88.07 | 91.91 | ||||||||||||||
| IID-GC | IoU | 50.73 | 70.19 | 77.89 | 79.90 | 26.35 | 75.52 | 83.66 | ||||||||||||||
| DE-3K | AUC | - | - | 55.98 | 72.84 | 62.98 | 68.27 | 79.36 | ||||||||||||||
| DE-3K | F1 | - | - | 49.85 | 58.01 | 60.09 | 45.47 | 71.62 | ||||||||||||||
| DE-3K | IoU | - | - | 1.50 | 13.78 | 4.87 | 8.10 | 37.08 | ||||||||||||||
Generalized Localization. To assess the generalization capability of the proposed DeFI-Net in localizing unknown inpainting techniques and types, we conducted a comparison. This involved applying the methods trained on the GC model to detect nine unseen inpainting models in the IID-9K dataset. The results in Table III demonstrate that our method achieved the highest performance across the averaged AUC, F1 score, and IoU metrics. It is worth noting that the PSCC-Net exhibits slightly better performance than our methods in detecting image inpainting from the LB, PM, SG, and LR models, indicating its generalizability benefited from the coarse to fine-grained multilevel supervision and progressive feature fusion strategy. We also noted the latest diffusion-based detection algorithm[15] and further compare our method with baselines on more diverse image inpainting models. Table IV shows that our dense feature network exhibits strong generalization capabilities in localizing various inpainting models, including software-based and generative AI models.
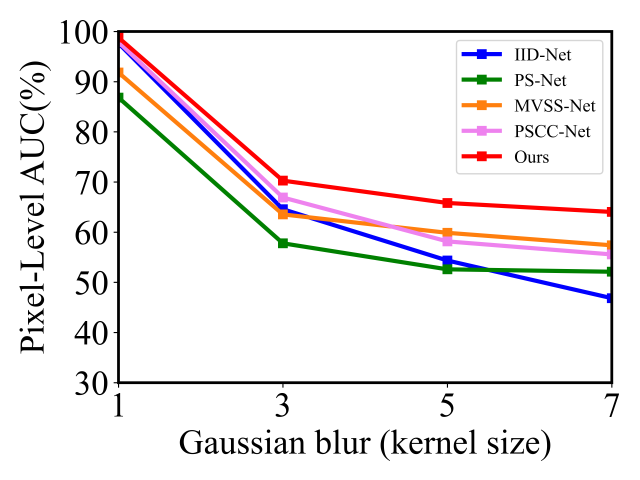
Robustness Evaluation. Inpainted images will inevitably undergo various post-processing operations when disseminated. Malicious editors may also use post-processing to conceal operation traces; thus, robustness is of vital significance. To evaluate the model’s robustness to post-processing, we consider four common operations: JPEG compression, adding Gaussian noise, adding salt and pepper noise perturbation, and blurring. For each post-processing method, we conduct a comprehensive evaluation of the quality of JPEG compression (from 85 to 100), the standard deviation of Gaussian noise (from 0 to 1.5), the proportion of Salt&Pepper noise (from 0 to 0.15), and the kernel size of Gaussian blur (from 1 to 7). The results obtained from employing all pre-trained models on post-processed IID-9K data are presented in Fig 10. We can observe that our DeFI-Net exhibits great robustness to noise perturbation and JPEG compression. Yet, MVSS-Net, PS-Net, and IID-Net rely on the features of the noise stream, resulting in a weak anti-interference capability. The performance of all methods deteriorates on Gaussian blurred images. This is because blurring eliminates typical features left by the inpainting in the boundary region, effectively concealing the inpainting operation. However, the AUC of DeFI-Net still outperforms the baseline by 5% to 8%.
| Model | Metric | DL-based Inpainting | Traditional Inpainting | Average | |||||||
| CA [29] | SH [28] | LB [30] | RN [62] | TE [63] | NS [2] | PM [64] | SG [65] | LR [66] | |||
| MT-Net [45] | AUC | 87.46 | 97.67 | 97.54 | 93.75 | 91.36 | 80.12 | 95.36 | 98.42 | 89.15 | 92.31 |
| HP-FCN [17] | 92.41 | 93.54 | 84.98 | 97.44 | 89.74 | 95.91 | 98.23 | 99.85 | 98.90 | 94.56 | |
| IID-Net [18] | 95.26 | 99.02 | 99.23 | 97.95 | 94.85 | 94.79 | 99.15 | 99.90 | 98.75 | 97.66 | |
| PSCC-Net [10] | 96.63 | 99.62 | 99.57 | 99.04 | 94.67 | 95.27 | 99.12 | 99.88 | 98.35 | 98.02 | |
| MVSS-Net [14] | 93.06 | 94.68 | 95.03 | 90.90 | 94.77 | 94.57 | 82.39 | 97.17 | 83.85 | 91.82 | |
| PS-Net [20] | 83.99 | 92.55 | 91.80 | 91.32 | 85.51 | 82.83 | 76.62 | 91.50 | 85.36 | 86.83 | |
| DeFI-Net (Ours) | 97.26 | 99.68 | 99.19 | 99.29 | 98.10 | 96.56 | 99.17 | 99.86 | 98.65 | 98.64 | |
| MT-Net [45] | F1 | 61.05 | 77.45 | 83.88 | 65.00 | 61.46 | 35.92 | 37.71 | 70.32 | 29.32 | 58.01 |
| HP-FCN [17] | 69.36 | 66.05 | 42.09 | 79.50 | 64.81 | 78.41 | 52.95 | 88.51 | 69.16 | 67.87 | |
| IID-Net [18] | 84.98 | 92.90 | 93.22 | 82.87 | 85.03 | 81.80 | 77.28 | 95.86 | 78.75 | 85.85 | |
| PSCC-Net [10] | 83.41 | 93.91 | 94.54 | 92.66 | 82.34 | 83.39 | 85.08 | 95.04 | 88.01 | 88.71 | |
| MVSS-Net [14] | 73.28 | 80.15 | 72.09 | 68.36 | 84.17 | 84.18 | 54.46 | 75.77 | 60.33 | 72.53 | |
| PS-Net [20] | 83.24 | 93.44 | 93.19 | 92.36 | 84.06 | 82.16 | 80.54 | 93.14 | 87.57 | 87.74 | |
| DeFI-Net (Ours) | 89.65 | 95.54 | 92.42 | 94.08 | 89.81 | 86.69 | 81.99 | 95.22 | 83.38 | 89.87 | |
| MT-Net [45] | IoU | 42.29 | 65.76 | 74.57 | 49.98 | 48.39 | 24.22 | 24.57 | 57.90 | 18.51 | 45.13 |
| HP-FCN [17] | 56.82 | 51.34 | 29.08 | 67.38 | 51.31 | 67.73 | 37.99 | 79.99 | 55.49 | 55.24 | |
| IID-Net [18] | 67.77 | 80.90 | 82.30 | 58.80 | 69.36 | 61.11 | 41.21 | 85.86 | 47.56 | 66.10 | |
| PSCC-Net [10] | 72.60 | 83.01 | 84.87 | 80.22 | 69.90 | 71.82 | 56.52 | 83.15 | 65.58 | 74.19 | |
| MVSS-Net [14] | 42.94 | 55.59 | 41.98 | 34.32 | 63.22 | 63.05 | 6.43 | 43.76 | 16.32 | 40.85 | |
| PS-Net [20] | 63.83 | 81.49 | 81.51 | 79.01 | 66.94 | 61.27 | 46.13 | 77.57 | 64.66 | 69.16 | |
| DeFI-Net (Ours) | 77.73 | 87.10 | 80.13 | 83.59 | 79.11 | 71.87 | 50.29 | 84.01 | 56.82 | 74.52 | |
| Model |
|
|
|
|
Average | ||||||||
| IID-Net [18] | 55.40 | 33.98 | 46.66 | 27.17 | 40.80 | ||||||||
| PSCC-Net [10] | 61.49 | 26.17 | 58.77 | 31.33 | 44.44 | ||||||||
| MVSS-Net [14] | 41.07 | 42.06 | 55.18 | 41.68 | 44.99 | ||||||||
| PS-Net [20] | 46.13 | 44.15 | 49.20 | 33.76 | 43.31 | ||||||||
| DiffForensics*[15] | 50.70 | 25.70 | - | - | 38.20 | ||||||||
| DeFI-Net (Ours) | 67.96 | 48.89 | 77.94 | 43.88 | 59.66 | ||||||||



Image
GT
PSCC-Net [10]
MVSS-Net [14]
IID-Net [18]
PS-Net [20]
DeFI-Net (Ours)




















IV-C Qualitative Comparisons
In Fig. 7, we demonstrate the qualitative results on several image inpainting datasets. Our method achieves outstanding accuracy in localizing image inpainting across diverse manipulation regions and models, significantly surpassing the baseline methods. The segmentation results produced by DeFI-Net are closest to the ground truth, with rare occurrences of false positives. Specifically, DeFI-Net exhibits excellent performance when dealing with random regions (first and third columns) and specific semantic objects (second, fourth, fifth, and sixth columns) for inpainting. In contrast, MVSS-Net, IID-Net, and PS-Net give unsatisfactory results, with many mis-segmented regions and even overlooking the correct targets. PSCC-Net achieves decent results on some datasets, but it is prone to misjudgment in some challenging cases (such as slender, small targets) due to the influence of semantic information. In response to this issue, DeFI-Net obtains precise predictions thanks to our proposed dense feature pyramid learning strategy. This strategy delves into the potential relationships among multi-level features, better learning the inconsistencies in image details, structure, and semantics, enabling the model to response inpainting at different scales better. Moreover, the reverse edge attention enhancement effectively enhances edge features and suppresses the impact of semantic noise on inpainting representation, resulting in clearer boundary localization. Overall, DeFI-Net achieves satisfactory results.
In addition, we found that DeFI-Net significantly improved the localization of small target inpainting compared to existing methods. Removing unnecessary people or objects in the background is the most commonly used application scenario for image inpainting. Tiny inpainting makes minor changes to the semantics of the image and leaves behind artifacts that are difficult to detect, which greatly increases the localization difficulty. As shown in Fig. 8, IID-Net and MVSS-Net have failed, and PS-Net and PSCC-Net have many false positives, while our method achieves accurate localization. This primarily benefits from our DFPL and SA-FF, which dig deep into the correlation between multi-scale information and skillfully combine them.
IV-D Computational Complexity Comparisons
To comprehensively evaluate the proposed method, we present comparisons of time consumption and computational complexity in Table V. All the compared methods are evaluated on the same device (GeForce RTX 3090 GPUs) with images. We can see that the proposed DeFI-Net introduces little computation overhead, and achieves comparable performance to existing models in terms of inference time.





IV-E Visualization Results
To further present the discriminative and complementary features learned from various levels by DeFI-Net, we provide the visualization results of the feature maps at the low, middle, and high levels, as shown in Fig. 9. We can observe that the feature maps progressively capture the required discriminative information from low-level to high-level, including details, local structures, and global abstract semantics. Low-level features capture discriminative patterns around edges, middle-level features focus on texture inconsistencies in the filled areas, while high-level features identify changes in an image’s semantic content, such as localizing the entire objects. By effectively integrating these features, our model achieves precise localization across various inpainting regions and generation models.
IV-F Ablation Studies
Essentially, DeFI-Net mainly benefits from three modules: DFPL, REAE, and SA-FF. Dense Feature Pyramid Learning (DFPL) highlights the specificity of features at different stages in the neural network, interacts quickly with neighboring layers in a densely connected manner, and improves the representation capability of features from other perspectives. Reverse Edge Attention Enhancement (REAE) enables the model to capture subtle differences at the boundaries by utilizing structural information provided by mid-level features as a priori guide. Spatial Adaptive Feature Fusion (SA-FF) adaptively learns how high-level features are fused with low and mid-layer features. To evaluate the effectiveness of DFPL, REAE, and SA-FF, we removed them separately from DeFI-Net and evaluated the inpainting detection performance on the IID-10K dataset with the ablation setup shown in Table VI. In addition, we performed ablation analysis for each module separately to demonstrate the effectiveness of their design.
Effect of DFPL. Previous works only use top-down [22] or bottom-up [57] for information interaction among features of different stages. While alleviating the efficiency problem of top-level or shallow-level information propagation in the opposite direction, it neglects the specificity of multilevel features. On the other hand, the densely connected method can fully utilize the adjacent and cross-layer information to enhance the context-awareness of features at each level. As can be observed from Table VII, compared with Var#1 (FPN [22]) and Var#2 (PANet [57]), DPFL significantly enhances performance and effectively promotes the spreading and utilization of multi-level features. An interesting phenomenon can be found from these results, where the performance of DPFL with concatenation fusion slightly outperforms that with addition fusion. The addition method may submerge shallow information, whereas dimension reduction with a convolution after concatenation can be viewed as a process of feature combination selection, which aids in the interaction of shallow features.
AutoSplice






IID
Photoshop
DEFACTO
| Setup | Components | AUC | F1 |
| Var#0 | Original HRNet [51] | 92.50 | 74.88 |
| Var#1 | HRNet+DPFL | 97.24 | 85.39 |
| Var#2 | HRNet+DFPL+REAE | 98.25 | 89.40 |
| Var#3 | HRNet+DFPL+SA-FF | 98.15 | 88.14 |
| DeFI-Net | HRNet+DFPL+REAE+SA-FF | 98.63 | 90.07 |
| Setup | Components | AUC | F1 |
| Var#1 | w/ FPN [22] | 93.30 | 75.10 |
| Var#2 | w/ PANet [57] | 95.87 | 76.59 |
| Var#3 | w/ DFPL (add) | 96.78 | 84.22 |
| DeFI-Net | w/ DFPL (concat) | 97.24 | 85.39 |
Effect of REAE. Next, we evaluated the impact of the REAE module and presented the results in Table VIII. Comparisons with ordinary convolutional structure Var#1 and traditional edge extraction operator Var#2 verify the superiority of a priori learning, significantly improving the network’s performance. The selection of guidance features greatly affects the performance of the REAE. The results from Var#4 (namely our DeFI-Net model) demonstrate that using mid-level features as guidance yields the best performance. In fact, after DFPL, mid-level features fully integrate both shallow and deep information, and boundary learning leveraging REAE with strong contextual priors effectively suppresses noisy information.
| Setup | Components | AUC | F1 |
| Var#0 | w/o Edge supervision | 98.15 | 88.14 |
| Var#1 | w/ Conv | 98.35 | 89.23 |
| Var#2 | w/ Sobel operator | 98.38 | 89.21 |
| Var#3 | w/ REAE (low-level guide) | 98.42 | 89.62 |
| DeFI-Net | w/ REAE (mid-level guide) | 98.63 | 90.07 |
Effect of SA-FF. The fusion of high-level semantics and mid-low-level details is an effective method for enhancing localization accuracy. The SA-FF module dynamically allocates weights to different spatial positions simply. Table IX demonstrates the effectiveness of the SA-FF, where we compare different fusion methods, namely Var#1 (add fusion), Var#2 (concat fusion) and Var#3 (Dual attention [53]). The model can learn more universal fusion weights by adapting different attributes of specific inputs. Furthermore, we analyze the impact of different features used for learning weights. As indicated by Var#4 (mid-low-level) and Var#5 (high-level, namely our DeFI-Net model), the high-level features are more suitable for learning weights, probably due to their aggregation of more global information, which aids in understanding the broader context.
| Setup | Components | AUC | F1 |
| Var#1 | Add fusion | 98.38 | 89.62 |
| Var#2 | Concat fusion | 98.37 | 89.28 |
| Var#3 | w/ Dual attention | 98.13 | 90.23 |
| Var#4 | w/ SA-FF (mid-low-level) | 98.40 | 89.88 |
| DeFI-Net | w/ SA-FF (high-level) | 98.63 | 90.07 |
Effect of different loss terms. Furthermore, we thoroughly explored the effects of various loss terms. We have evaluated several parameter combinations for and , corresponding to the coefficients of and , respectively. The results are shown in Table X. When is greater than , the model’s performance improves. We ultimately select (=5, =1) as the default parameters for the loss function.
| Setup | Hyperparameters | AUC | F1 |
| Loss#0 | 98.25 | 88.87 | |
| Loss#1 | 98.45 | 89.72 | |
| Loss#2 | 98.30 | 89.80 | |
| Loss#3 | 98.27 | 88.09 | |
| DeFI-Net | 98.63 | 90.07 |
IV-G Failure Cases
Fig. 10 illustrates cases where our DeFI-Net does not yield accurate localization results, notably in scenarios featuring multiple tiny regions (the first two columns), images with in dark lighting conditions (the third column), and full-size synthesis (the last column). It is worth noting that even under these circumstances, our DeFI-Net still demonstrates highly competitive performance compared to existing methods.




Image




GT




Ours
V Conclusion
In this work, we describe a new dense feature interaction network for image inpainting localization. Unlike existing methods, our model can effectively leverage the diverse and complementary information extracted from features at various stages within the backbone architecture. We employ a dense feature pyramid structure to capture multi-level and interactive traces left by inpainting. To mitigate the impact of semantic noise on the learning of artifact representation restoration, we propose a prior-guided edge enhancement strategy. Additionally, we present an effective spatially adaptive fusion technique for combining complementary representations, facilitating the adaptive fusion of mid-low-level features containing edge and shape information with high-level semantic features to achieve precise localization. Extensive evaluation demonstrates improved performance of our method. Our approach has limitations when handling large inpainting regions, particularly in fully manipulated images. In future works, we would like to investigate the generalization ability of more recent generative models. Additionally, it is important to investigate using adversarial training strategies to fortify our models against sophisticated post-processing or potential attacks.
References
- [1] H. Xiang, Q. Zou, M. A. Nawaz, X. Huang, F. Zhang, and H. Yu, “Deep learning for image inpainting: A survey,” Pattern Recognition, vol. 134, p. 109046, 2023.
- [2] M. Bertalmio, A. L. Bertozzi, and G. Sapiro, “Navier-stokes, fluid dynamics, and image and video inpainting,” in Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, vol. 1. IEEE, 2001, pp. I–I.
- [3] I. Drori, D. Cohen-Or, and H. Yeshurun, “Fragment-based image completion,” in ACM SIGGRAPH 2003 Papers, 2003, pp. 303–312.
- [4] Levin and Zomet, “Learning how to inpaint from global image statistics,” in Proceedings Ninth IEEE international conference on computer vision. IEEE, 2003, pp. 305–312.
- [5] A. Criminisi, P. Pérez, and K. Toyama, “Region filling and object removal by exemplar-based image inpainting,” IEEE Transactions on image processing, vol. 13, no. 9, pp. 1200–1212, 2004.
- [6] H. Ting, S. Chen, J. Liu, and X. Tang, “Image inpainting by global structure and texture propagation,” in Proceedings of the 15th ACM international conference on Multimedia, 2007, pp. 517–520.
- [7] C. Barnes, E. Shechtman, A. Finkelstein, and D. B. Goldman, “Patchmatch: A randomized correspondence algorithm for structural image editing,” ACM Trans. Graph., vol. 28, no. 3, p. 24, 2009.
- [8] S. Darabi, E. Shechtman, C. Barnes, D. B. Goldman, and P. Sen, “Image melding: Combining inconsistent images using patch-based synthesis,” ACM Transactions on graphics (TOG), vol. 31, no. 4, pp. 1–10, 2012.
- [9] D. Ding, S. Ram, and J. J. Rodríguez, “Image inpainting using nonlocal texture matching and nonlinear filtering,” IEEE Transactions on Image Processing, vol. 28, no. 4, pp. 1705–1719, 2018.
- [10] X. Liu, Y. Liu, J. Chen, and X. Liu, “Pscc-net: Progressive spatio-channel correlation network for image manipulation detection and localization,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 11, pp. 7505–7517, 2022.
- [11] Y. Zhai, T. Luan, D. Doermann, and J. Yuan, “Towards generic image manipulation detection with weakly-supervised self-consistency learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 390–22 400.
- [12] X. Guo, X. Liu, Z. Ren, S. Grosz, I. Masi, and X. Liu, “Hierarchical fine-grained image forgery detection and localization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 3155–3165.
- [13] X. Chen, C. Dong, J. Ji, J. Cao, and X. Li, “Image manipulation detection by multi-view multi-scale supervision,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 14 185–14 193.
- [14] C. Dong, X. Chen, R. Hu, J. Cao, and X. Li, “Mvss-net: Multi-view multi-scale supervised networks for image manipulation detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3539–3553, 2022.
- [15] Z. Yu, J. Ni, Y. Lin, H. Deng, and B. Li, “Diffforensics: Leveraging diffusion prior to image forgery detection and localization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 765–12 774.
- [16] T. Chu, J. Chen, J. Sun, S. Lian, Z. Wang, Z. Zuo, L. Zhao, W. Xing, and D. Lu, “Rethinking fast fourier convolution in image inpainting,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 23 195–23 205.
- [17] H. Li and J. Huang, “Localization of deep inpainting using high-pass fully convolutional network,” in proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 8301–8310.
- [18] H. Wu and J. Zhou, “Iid-net: Image inpainting detection network via neural architecture search and attention,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 3, pp. 1172–1185, 2021.
- [19] Y. Li, L. Hu, L. Dong, H. Wu, J. Tian, J. Zhou, and X. Li, “Transformer-based image inpainting detection via label decoupling and constrained adversarial training,” IEEE Transactions on Circuits and Systems for Video Technology, 2023.
- [20] Y. Zhang, Z. Fu, S. Qi, M. Xue, X. Cao, and Y. Xiang, “Ps-net: A learning strategy for accurately exposing the professional photoshop inpainting,” IEEE Transactions on Neural Networks and Learning Systems, 2023.
- [21] S. Das, M. S. Islam, and M. R. Amin, “Gca-net: utilizing gated context attention for improving image forgery localization and detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 81–90.
- [22] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125.
- [23] H. Lee, R. Grosse, R. Ranganath, and A. Y. Ng, “Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations,” in Proceedings of the 26th annual international conference on machine learning, 2009, pp. 609–616.
- [24] M. Bertalmio, G. Sapiro, V. Caselles, and C. Ballester, “Image inpainting,” in Proceedings of the 27th annual conference on Computer graphics and interactive techniques, 2000, pp. 417–424.
- [25] T. Ružić and A. Pižurica, “Context-aware patch-based image inpainting using markov random field modeling,” IEEE transactions on image processing, vol. 24, no. 1, pp. 444–456, 2014.
- [26] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros, “Context encoders: Feature learning by inpainting,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2536–2544.
- [27] S. Iizuka, E. Simo-Serra, and H. Ishikawa, “Globally and locally consistent image completion,” ACM Transactions on Graphics (ToG), vol. 36, no. 4, pp. 1–14, 2017.
- [28] Z. Yan, X. Li, M. Li, W. Zuo, and S. Shan, “Shift-net: Image inpainting via deep feature rearrangement,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 1–17.
- [29] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang, “Generative image inpainting with contextual attention,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 5505–5514.
- [30] H. Wu, J. Zhou, and Y. Li, “Deep generative model for image inpainting with local binary pattern learning and spatial attention,” IEEE Transactions on Multimedia, pp. 4016 – 4027, 2021.
- [31] C. Hu, S. Jia, F. Zhang, and X. Li, “A saliency-guided street view image inpainting framework for efficient last-meters wayfinding,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 195, pp. 365–379, 2023.
- [32] R. Suvorov, E. Logacheva, A. Mashikhin, A. Remizova, A. Ashukha, A. Silvestrov, N. Kong, H. Goka, K. Park, and V. Lempitsky, “Resolution-robust large mask inpainting with fourier convolutions,” in Proceedings of the IEEE/CVF winter conference on applications of computer vision, 2022, pp. 2149–2159.
- [33] J. Jain, Y. Zhou, N. Yu, and H. Shi, “Keys to better image inpainting: Structure and texture go hand in hand,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 208–217.
- [34] W. Li, X. Yu, K. Zhou, Y. Song, and Z. Lin, “Image inpainting via iteratively decoupled probabilistic modeling,” in The Twelfth International Conference on Learning Representations, 2023.
- [35] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with clip latents,” arXiv preprint arXiv:2204.06125, vol. 1, no. 2, p. 3, 2022.
- [36] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695.
- [37] S. Yang, X. Chen, and J. Liao, “Uni-paint: A unified framework for multimodal image inpainting with pretrained diffusion model,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 3190–3199.
- [38] S. Jia, M. Huang, Z. Zhou, Y. Ju, J. Cai, and S. Lyu, “Autosplice: A text-prompt manipulated image dataset for media forensics,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 893–903.
- [39] C. Corneanu, R. Gadde, and A. M. Martinez, “Latentpaint: Image inpainting in latent space with diffusion models,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 4334–4343.
- [40] S. Xie, Z. Zhang, Z. Lin, T. Hinz, and K. Zhang, “Smartbrush: Text and shape guided object inpainting with diffusion model,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 428–22 437.
- [41] F. Z. Mehrjardi, A. M. Latif, M. S. Zarchi, and R. Sheikhpour, “A survey on deep learning-based image forgery detection,” Pattern Recognition, p. 109778, 2023.
- [42] X. Zhu, Y. Qian, X. Zhao, B. Sun, and Y. Sun, “A deep learning approach to patch-based image inpainting forensics,” Signal Processing: Image Communication, vol. 67, pp. 90–99, 2018.
- [43] J. H. Bappy, A. K. Roy-Chowdhury, J. Bunk, L. Nataraj, and B. Manjunath, “Exploiting spatial structure for localizing manipulated image regions,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 4970–4979.
- [44] G. Mazaheri, N. C. Mithun, J. H. Bappy, and A. K. Roy-Chowdhury, “A skip connection architecture for localization of image manipulations.” in CVPR workshops, 2019, pp. 119–129.
- [45] Y. Wu, W. AbdAlmageed, and P. Natarajan, “Mantra-net: Manipulation tracing network for detection and localization of image forgeries with anomalous features,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 9543–9552.
- [46] F. Guillaro, D. Cozzolino, A. Sud, N. Dufour, and L. Verdoliva, “Trufor: Leveraging all-round clues for trustworthy image forgery detection and localization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 20 606–20 615.
- [47] M.-J. Kwon, S.-H. Nam, I.-J. Yu, H.-K. Lee, and C. Kim, “Learning jpeg compression artifacts for image manipulation detection and localization,” International Journal of Computer Vision, vol. 130, no. 8, pp. 1875–1895, 2022.
- [48] C. Kong, A. Luo, S. Wang, H. Li, A. Rocha, and A. C. Kot, “Pixel-inconsistency modeling for image manipulation localization,” arXiv preprint arXiv:2310.00234, 2023.
- [49] J. Wang, Z. Wu, J. Chen, X. Han, A. Shrivastava, S.-N. Lim, and Y.-G. Jiang, “Objectformer for image manipulation detection and localization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2364–2373.
- [50] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708.
- [51] J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, D. Liu, Y. Mu, M. Tan, X. Wang et al., “Deep high-resolution representation learning for visual recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 10, pp. 3349–3364, 2020.
- [52] Z. Zhou, M. M. Rahman Siddiquee, N. Tajbakhsh, and J. Liang, “Unet++: A nested u-net architecture for medical image segmentation,” in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 20, 2018, Proceedings 4. Springer, 2018, pp. 3–11.
- [53] D. Li, J. Zhu, M. Wang, J. Liu, X. Fu, and Z.-J. Zha, “Edge-aware regional message passing controller for image forgery localization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 8222–8232.
- [54] P. Zhou, B.-C. Chen, X. Han, M. Najibi, A. Shrivastava, S.-N. Lim, and L. Davis, “Generate, segment, and refine: Towards generic manipulation segmentation,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 13 058–13 065.
- [55] M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional networks,” in Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I 13. Springer, 2014, pp. 818–833.
- [56] S.-H. Gao, M.-M. Cheng, K. Zhao, X.-Y. Zhang, M.-H. Yang, and P. Torr, “Res2net: A new multi-scale backbone architecture,” IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 2, pp. 652–662, 2019.
- [57] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, “Path aggregation network for instance segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8759–8768.
- [58] J. Wei, S. Wang, and Q. Huang, “F3Net: fusion, feedback and focus for salient object detection,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 12 321–12 328.
- [59] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang, “Free-form image inpainting with gated convolution,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4471–4480.
- [60] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1452–1464, 2017.
- [61] T. Gloe and R. Böhme, “The’dresden image database’for benchmarking digital image forensics,” in Proceedings of the 2010 ACM symposium on applied computing, 2010, pp. 1584–1590.
- [62] T. Yu, Z. Guo, X. Jin, S. Wu, Z. Chen, W. Li, Z. Zhang, and S. Liu, “Region normalization for image inpainting,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 12 733–12 740.
- [63] A. Telea, “An image inpainting technique based on the fast marching method,” Journal of graphics tools, vol. 9, no. 1, pp. 23–34, 2004.
- [64] J. Herling and W. Broll, “High-quality real-time video inpaintingwith pixmix,” IEEE Transactions on Visualization and Computer Graphics, vol. 20, no. 6, pp. 866–879, 2014.
- [65] J.-B. Huang, S. B. Kang, N. Ahuja, and J. Kopf, “Image completion using planar structure guidance,” ACM Transactions on graphics (TOG), vol. 33, no. 4, pp. 1–10, 2014.
- [66] Q. Guo, S. Gao, X. Zhang, Y. Yin, and C. Zhang, “Patch-based image inpainting via two-stage low rank approximation,” IEEE transactions on visualization and computer graphics, vol. 24, no. 6, pp. 2023–2036, 2017.
- [67] T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” arXiv preprint arXiv:1710.10196, 2017.
- [68] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255.
- [69] G. Mahfoudi, B. Tajini, F. Retraint, F. Morain-Nicolier, J. L. Dugelay, and P. Marc, “Defacto: Image and face manipulation dataset,” in 2019 27Th european signal processing conference (EUSIPCO). IEEE, 2019, pp. 1–5.
- [70] P. Korus and J. Huang, “Multi-scale analysis strategies in prnu-based tampering localization,” IEEE Trans. on Information Forensics & Security, 2017.
- [71] M. Daisy, P. Buyssens, D. Tschumperlé, and O. Lézoray, “A smarter exemplar-based inpainting algorithm using local and global heuristics for more geometric coherence,” in 2014 IEEE International Conference on Image Processing (ICIP). IEEE, 2014, pp. 4622–4626.
- [72] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer, 2014, pp. 740–755.
- [73] F. Liu, Y. Wang, T. Wang, and V. Ordonez, “Visual news: Benchmark and challenges in news image captioning,” arXiv preprint arXiv:2010.03743, 2020.