Denoising Bottleneck with Mutual Information Maximization
for Video Multimodal Fusion
Abstract
Video multimodal fusion aims to integrate multimodal signals in videos, such as visual, audio and text, to make a complementary prediction with multiple modalities contents. However, unlike other image-text multimodal tasks, video has longer multimodal sequences with more redundancy and noise in both visual and audio modalities. Prior denoising methods like forget gate are coarse in the granularity of noise filtering. They often suppress the redundant and noisy information at the risk of losing critical information. Therefore, we propose a denoising bottleneck fusion (DBF) model for fine-grained video multimodal fusion. On the one hand, we employ a bottleneck mechanism to filter out noise and redundancy with a restrained receptive field. On the other hand, we use a mutual information maximization module to regulate the filter-out module to preserve key information within different modalities. Our DBF model achieves significant improvement over current state-of-the-art baselines on multiple benchmarks covering multimodal sentiment analysis and multimodal summarization tasks. It proves that our model can effectively capture salient features from noisy and redundant video, audio, and text inputs. The code for this paper is publicly available at https://github.com/WSXRHFG/DBF.
1 Introduction

With the rapid development of social platforms and digital devices, more and more videos are flooding our lives, which leads video multimodal fusion an increasingly popular focus of NLP research. Video multimodal fusion aims to integrate the information from two or more modalities (e.g., visual and audio signals) into text for a more comprehensive reasoning. For example, multimodal sentiment analysis (Poria et al., 2020) utilizes contrast between transcript and expression to detect sarcam, multimodal summarization (Sanabria et al., 2018) complete summary with information only exists in visual signal.
However, as shown in the Figure 1, there exist plenty of redundancy and noise in video multimodal fusion: 1) high similarity across consecutive frames brings video redundancy; 2) useless information, such as the distracting background, introduces frame noise; 3) weak alignment between visual stream and text also introduces misalignment noise. To alleviate the problem of redundancy and noise in video multimodal fusion, Liu et al. (2020) control the flow of redundant and noisy information between multimodal sequences by a fusion forget gate. The fusion forget gate impairs the impact of noise and redundancy in a coarse grain of the whole modality, so it will also filter out some representative information in the filtered modality.
In order to remove noise and redundancy while preserving critical information in video multimodal fusion, we propose a denoising fusion bottleneck (DBF) model with mutual information maximization (MI-Max). Firstly, inspired by Nagrani et al. (2021), we introduce a bottleneck module to restrict the redundant and noisy information across different modalities. With the bottleneck module, inputs can only attend to low-capacity bottleneck embeddings to exchange information across different modalities, which urges redundant and noisy information to be discarded. Secondly, in order to prevent key information from being filtered out, we adopt the idea of contrastive learning to supervise the learning of our bottleneck module. Specifically, under the noise-contrastive estimation framework (Gutmann and Hyvärinen, 2010), for each sample, we treat all the other samples in the same batch as negative ones. Then, we aim to maximize the mutual information between fusion results and each unimodal inputs by distinguishing their similarity scores from negative samples. Two aforementioned modules complement each other, the MI-Max module supervises the fusion bottleneck not to filter out key information, and in turn, the bottleneck reduces irrelevant information in fusion results to facilitate the maximization of mutual information.
We conduct extensive experiments on three benchmarks spanning two tasks. MOSI (Zadeh et al., 2016) and MOSEI (Zadeh et al., 2018b) are two datasets for multimodal sentiment analysis. How2 (Sanabria et al., 2018) is a benchmark for multimodal summarization. Experimental results show that our model achieves consistent improvements compared with current state-of-the-art methods. Meanwhile, we perform comprehensive ablation experiments to demonstrate the effectiveness of each module. In addition, we visualize the attention regions and tensity to multiple frames to intuitively show the behavior of our model to reduce noise while retaining key information implicitly.
Concretely, we make the following contributions: (i) We propose a denoising bottleneck fusion model for video multimodal fusion, which reduces redundancy and noise while retaining key information. (ii) We achieve new state-of-the-art performance on three benchmarks spanning two video multimodal fusion tasks. (iii) We provide comprehensive ablation studies and qualitative visualization examples to demonstrate the effectiveness of both bottleneck and MI-Max modules.
2 Related Work
We briefly overview related work about multimodal fusion and specific multimodal fusion tasks including multimodal summarization and multimodal sentiment analysis.
2.1 Video Multimodal Fusion
Video multimodal fusion aims to join and comprehend information from two or more modalities in videos to make a comprehensive prediction. Early fusion model adopted simple network architectures. Zadeh et al. (2017); Liu et al. (2018a) fuse features by matrix operations; and Zadeh et al. (2018a) designed a LSTM-based model to capture both temporal and inter-modal interactions for better fusion. More recently, models influenced by prevalence of Transformer (Vaswani et al., 2017) have emerged constantly: Zhang et al. (2019) injected visual information in the decoder of Transformer by cross attention mechanism to do multimodal translation task; Wu et al. (2021) proposed a text-centric multimodal fusion shared private framework for multimodal fusion, which consists of the cross-modal prediction and sentiment regression parts. And now vision-and-language pre-training has become a promising practice to tackle video multimodal fusion tasks. (Sun et al., 2019) firstly extend the Transformer structure to video-language pretraining and used three pre-training tasks: masked language prediction, video text matching, masked video prediction.
In contrast to existing works, we focus on the fundamental characteristic of video: audio and visual inputs in video are redundant and noisy (Nagrani et al., 2021) so we aim to remove noise and redundancy while preserving critical information.
2.2 Video Multimodal Summarization
Video multimodal summarization aims to generate summaries from visual features and corresponding transcripts in videos. In contrast to unimodal summarization, some information (e.g., guitar) only exists in the visual modality. Thus, for videos, utilization of both visual and text features is necessary to generate a more comprehensive summary.
For datasets, Li et al. (2017) introduced a multimodal summarization dataset consisting of 500 videos of news articles in Chinese and English. Sanabria et al. (2018) proposed the How2 dataset consists of 2,000 hours of short instructional videos, each coming with a summary of two to three sentences.
For models, Liu et al. (2020) proposed a multistage fusion network with a fusion forget gate module, which controls the flow of redundant information between multimodal long sequences. Meanwhile, Yu et al. (2021a) firstly introduced pre-trained language models into multimodal summarization task and experimented with the optimal injection layer of visual features.
We also reduce redundancy in video like in (Yu et al., 2021a). However, we do not impair the impact of noise and redundancy in a coarse grain with forget gate. Instead, we combine fusion bottleneck and MI-Max modules to filter out noise while preserving key information.
2.3 Multimodal Sentiment Analysis
Multimodal sentiment analysis (MSA) aims to integrate multimodal resources, such as textual, visual, and acoustic information in videos to predict varied human emotions. In contrast to unimodal sentiment analysis, utterance in the real situation sometimes contains sarcasm, which makes it hard to make accurate prediction by a single modality. In addition, information such as expression in vision and tone in acoustic help assist sentiment prediction. Yu et al. (2021b) introduced a multi-label training scheme that generates extra unimodal labels for each modality and concurrently trained with the main task. Han et al. (2021) build up a hierarchical mutual information maximization guided model to improve the fusion outcome as well as the performance in the downstream multimodal sentiment analysis task. Luo et al. (2021) propose a multi-scale fusion method to align different granularity information from multiple modalities in multimodal sentiment analysis.
Our work is fundamentally different from the above work. We do not focus on complex fusion mechanisms, but take the perspective of information in videos, and stress the importance of validity of information within fusion results.
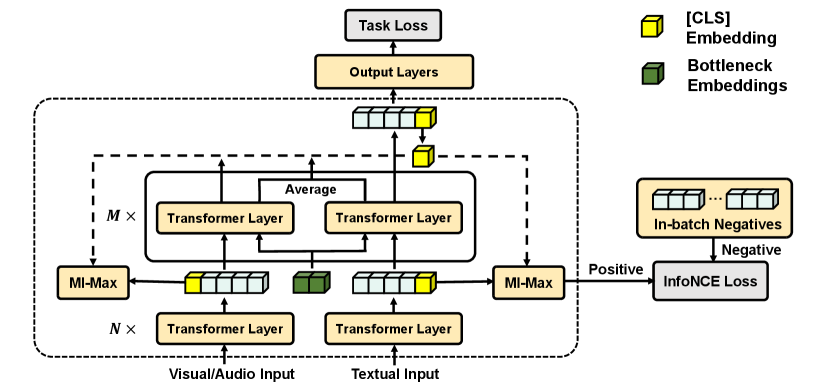
3 Methodology
Our denoising fusion bottleneck (DBF) model aims to fuse multimodal inputs from videos to make a comprehensive prediction. The overall architecture of DBF is shown in Figure 2. It first employs a fusion bottleneck module with a restrained receptive field to filter out noise and redundancy when fusing different modalities in videos. Then, DBF maximizes mutual information between fusion results and unimodal inputs to supervise the learning of the fusion bottleneck, aiming to preserve more representative information in fusion results.
3.1 Problem Definition
In video multimodal fusion tasks, for each video, the input comprises three sequences of encoded features from textual (), visual (), and acoustic () modalities. These input features are represented as , where , and and denote the sequence length and feature dimension for modality , respectively. The goal of DBF is to extract and integrate task-related information from these input representations to form a unified fusion result . In this paper, we evaluate the quality of the fusion result on two tasks: video multimodal sentiment analysis and video multimodal summarization.
For sentiment analysis, we utilize to predict the emotional orientation of a video as a discrete category from a predefined set of candidates
| (1) |
or as a continuous intensity score
| (2) |
where denotes the model parameters.
For summarization, we generate a summary sequence based on :
| (3) |
3.2 Fusion Bottleneck
As shown in Figure 2, we first employ a fusion bottleneck with a restrained receptive field to perform multimodal fusion and filter out noise and redundancy in videos. Specifically, fusion bottleneck forces cross-modal information flow passes via randomly initialized bottleneck embeddings with a small sequence length, where denotes dimension of features and . The restrained receptive field of forces model to collate and condense unimodal information before sharing it with the other modalities.
With a small length , embedding acts like a bottleneck in cross-modal interaction. In the fusion bottleneck module, unimodal features cannot directly attend to each other and they can only attend to the bottleneck embeddings to exchange information in it. Meanwhile, the bottleneck can attend to all of the modalities, which makes information flow across modalities must pass through the bottleneck with a restrained receptive field. The fusion bottleneck module forces the model to condense and collate information and filter out noise and redundancy.
Specifically, in the fusion bottleneck module, with bottleneck embeddings and unimodal features , the fusion result is calculated as follows:
| (4) |
| (5) |
where denotes the layer number and denotes the concatenation operation. As shown in Equation 4 and 5, each time a Transformer layer is passed, bottleneck embedding is updated by unimodal features. In turn, unimodal features integrate condensed information from other modalities through bottleneck embeddings . Finally, we output the text features of the last layer , which are injected with condensed visual and audio information, as the fusion result.
3.3 Fusion Mutual Information Maximization
The fusion bottleneck module constrains information flow across modalities in order to filter out noise and redundancy. However, it may result in loss of critical information as well when fusion bottleneck selects what information to be shared. To alleviate this issue, we employ a mutual information maximization (MI-Max) module to preserve representative and salient information from redundant modalities in fusion results.
Mutual information is a concept from information theory that estimates the relationship between pairs of variables. Through prompting the mutual information between fusion results and multimodal inputs , we can capture modality-invariant cues among modalities (Han et al., 2021) and keep key information preserved by regulating the fusion bottleneck module.
Since direct maximization of mutual information for continuous and high-dimensional variables is intractable (Belghazi et al., 2018), we instead minimize the lower bound of mutual information as Han et al. (2021) and Oord et al. (2018). To be specific, we first construct an opposite path from to predict by an MLP . Then, to gauge correlation between the prediction and , we use a normalized similarity function as follows:
| (6) |
where generates a prediction of from , is the Euclidean norm, and denotes element-wise product. Then, we incorporate this similarity function into the noise-contrastive estimation framework (Gutmann and Hyvärinen, 2010) and produce an InfoNCE loss (Oord et al., 2018) which reflects the lower bound of the mutual information:
| (7) |
where is the negative unimodal inputs that are not matched to the fusion result in same batch. Finally, we compute loss for all modalities as follows:
| (8) |
where is a hyper-parameter that controls the impact of MI-Max.
By minimizing , on the one hand, we maximize the lower bound of the mutual information between fusion results and unimodal inputs; on the other hand, we encourage fusion results to reversely predict unimodal inputs as well as possible, which prompts retaining of representative and key information from different modalities in fusion results.
| Method | MOSI | ||||
|---|---|---|---|---|---|
| MAE() | Corr() | Acc-7() | Acc-2() | F1() | |
| MulT (Tsai et al., 2019) | 0.871 | 0.698 | 40.0 | - / 83.0 | - / 82.8 |
| TFN (Zadeh et al., 2017) | 0.901 | 0.698 | 34.9 | - / 80.8 | - / 80.7 |
| LMF (Liu et al., 2018b) | 0.917 | 0.695 | 33.2 | - / 82.5 | - / 82.4 |
| MFM (Tsai et al., 2018) | 0.877 | 0.706 | 35.4 | - / 81.7 | - / 81.6 |
| ICCN (Sun et al., 2020) | 0.860 | 0.710 | 39.0 | - / 83.0 | - / 83.0 |
| MISA (Hazarika et al., 2020) | 0.783 | 0.761 | 42.3 | 81.8 / 83.4 | 81.7 / 83.6 |
| Self-MM (Yu et al., 2021b) | 0.712 | 0.795 | 45.8 | 82.5 / 84.8 | 82.7 / 84.9 |
| MMIM† (Han et al., 2021) | 0.700 | 0.800 | 46.7 | 84.2 / 86.1 | 84.0 / 86.0 |
| DBF | 0.693 | 0.801 | 44.8 | 85.1 / 86.9 | 85.1 / 86.9 |
| Method | MOSEI | ||||
|---|---|---|---|---|---|
| MAE() | Corr() | Acc-7() | Acc-2() | F1() | |
| MulT (Tsai et al., 2019) | 0.580 | 0.703 | 51.8 | - / 82.3 | - / 82.5 |
| TFN (Zadeh et al., 2017) | 0.593 | 0.700 | 50.2 | - / 82.1 | - / 82.5 |
| LMF (Liu et al., 2018b) | 0.677 | 0.695 | 48.0 | - / 82.1 | - / 82.0 |
| MFM (Tsai et al., 2018) | 0.717 | 0.706 | 51.3 | - / 84.3 | - / 84.4 |
| ICCN (Sun et al., 2020) | 0.565 | 0.713 | 51.6 | - / 84.2 | - / 84.2 |
| MISA (Hazarika et al., 2020) | 0.555 | 0.756 | 52.2 | 83.8 / 85.3 | 83.6 / 85.5 |
| Self-MM (Yu et al., 2021b) | 0.529 | 0.767 | 53.5 | 82.7 / 85.0 | 83.0 / 84.9 |
| MMIM† (Han et al., 2021) | 0.526 | 0.772 | 54.2 | 82.2 / 86.0 | 82.7 / 85.9 |
| DBF | 0.523 | 0.772 | 54.2 | 84.3 / 86.4 | 84.8 / 86.2 |
4 Experiments
4.1 Tasks, Datasets, and Metrics
We evaluate fusion results of DBF on two video multimodal tasks: video multimodal sentiment analysis and video multimodal summarization.
Video Multimodal Sentiment Analysis
Video multimodal sentiment analysis is a regression task that aims to collect and tackle data from multiple resources (text, vision and acoustic) to comprehend varied human emotions. We do this task on MOSI (Zadeh et al., 2016) and MOSEI (Zadeh et al., 2018b) datasets. The MOSI dataset contains 2198 subjective utterance-video segments, which are manually annotated with a continuous opinion score between [-3, 3], where -3/+3 represents strongly negative/positive sentiments. The MOSEI dataset is an improvement over MOSI, which contains 23453 annotated video segments (utterances), from 5000 videos, 1000 distinct speakers and 250 different topics.
Following (Hazarika et al., 2020), we use the same metric set to evaluate sentiment intensity predictions: MAE (mean absolute error), which is the average of absolute difference value between predictions and labels; Corr (Pearson correlation) that measures the degree of prediction skew; Acc-7 (seven-class classification accuracy) ranging from -3 to 3; Acc-2 (binary classification accuracy) and F1 score computed for positive/negative and non-negative/negative classification results.
Video Multimodal Summarization
The summary task aims to generate abstractive summarization with videos and their corresponding transcripts. We set How2 dataset (Sanabria et al., 2018) as benchmark for this task, which is a large-scale dataset consists of 79,114 short instructional videos, and each video is accompanied by a human-generated transcript and a short text summary.
Following (Yu et al., 2021a), to evaluate summarization, we use metrics as follows: ROUGE (Lin and Hovy, 2003) (ROUGE-1, 2, L) and BLEU (Papineni et al., 2002) (BLEU-1, 2, 3, 4), which calculate the recall and precision of n-gram overlaps, respectively; METEOR (Denkowski and Lavie, 2011), which evaluates matching degree of word stems, synonyms and paraphrases; CIDEr (Vedantam et al., 2015) is an image captioning metric to compute the cosine similarity between TF-IDF weighted n-grams.
4.2 Experimental Settings
For sentiment analysis task, we use BERT-base (Devlin et al., 2018) to encode text input and extract the [CLS] embedding from the last layer. For acoustic and vision, we use COVAREP (Degottex et al., 2014) and Facet 111https://imotions.com/platform/ to extract audio and facial expression features. The visual feature dimensions are 47 for MOSI, 35 for MOSEI, and the audio feature dimensions are 74 for both MOSI and MOSEI.
For summarization, we use BART (Lewis et al., 2019) as the feature extractor and inject visual information in the last layer of the BART encoder. For vision, a 2048-dimensional feature representation is extracted for every 16 non-overlapping frames using a 3D ResNeXt-101 model (Hara et al., 2018), which is pre-trained on the Kinetics dataset (Kay et al., 2017). Details of the hyper-parameters are given in Appendix A. For frameworks and hardware, we use the deep learning framework PyTorch (Paszke et al., 2017) and Huggingface 222https://huggingface.co/ to implement our code. We use a single Nvidia GeForce A40 GPU for sentiment analysis experiments and two for summarization.
4.3 Overall Results
| Method | How2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | B-1 | B-2 | B-3 | B-4 | METEOR | CIDEr | |
| HA (RNN) (Palaskar et al., 2019) | 60.3 | 42.5 | 55.7 | 57.2 | 47.7 | 41.8 | 37.5 | 28.8 | 2.48 |
| HA (TF) (Palaskar et al., 2019) | 60.2 | 43.1 | 55.9 | 58.6 | 48.3 | 43.3 | 38.1 | 28.9 | 2.51 |
| MFFG (RNN) (Liu et al., 2020) | 62.3 | 46.1 | 58.2 | 59.1 | 50.4 | 45.1 | 41.1 | 30.1 | 2.69 |
| MFFG (TF) (Liu et al., 2020) | 61.6 | 45.1 | 57.4 | 60.0 | 50.9 | 45.3 | 41.3 | 29.9 | 2.67 |
| VG-GPLMs† (Yu et al., 2021a) | 68.0 | 51.4 | 63.3 | 65.2 | 56.3 | 50.4 | 46.0 | 34.0 | 3.28 |
| DBF | 70.1 | 54.7 | 66.0 | 67.2 | 58.9 | 53.3 | 49.0 | 35.5 | 3.56 |
| Model | MOSI | MOSEI | ||
|---|---|---|---|---|
| MAE () | F1 () | MAE () | F1 () | |
| 1) Ours | 0.693 | 85.07 / 86.88 | 0.523 | 84.78 / 86.19 |
| 2) (-) MI-Max | 0.697 | 83.08 / 85.28 | 0.536 | 80.94 / 85.58 |
| 3) (-) bottleneck | 0.750 | 82.84 / 83.63 | 0.537 | 77.52 / 83.81 |
| 4) (-) Language | 1.391 | 55.54 / 54.95 | 0.817 | 67.63 / 64.01 |
| 5) (-) Visual | 0.700 | 82.78 / 84.33 | 0.541 | 78.42 / 84.05 |
| 6) (-) Audio | 0.720 | 83.02 / 85.86 | 0.536 | 80.22 / 85.02 |
| 7) Visual-based | 1.372 | 57.06 / 57.83 | 0.536 | 83.41 / 85.47 |
| 8) Audio-based | 1.194 | 67.95 / 70.49 | 0.537 | 83.80 / 85.76 |

We compare performance against DBF by considering various baselines as below: For multimodal sentiment analysis, we compare with MulT (Tsai et al., 2019), TFN (Zadeh et al., 2017), LMF (Liu et al., 2018b), MFM (Tsai et al., 2018), ICCN (Sun et al., 2020), MISA (Hazarika et al., 2020), Self-MM (Yu et al., 2021b) and MMIM (Han et al., 2021). For multimodal summarization, we compare with HA (Palaskar et al., 2019) MFFG (Liu et al., 2020) VG-GPLMs (Yu et al., 2021a). Details of baselines are in Appendix B. The comparative results for sentiment analysis are presented in Table 1 (MOSI) and Table 2 (MOSEI). Results for summarization are presented in Table 3 (How2).
We find that DBF yields better or comparable results to state-of-the-art methods. To elaborate, DBF significantly outperforms state-of-the-art in all metrics on How2 and in most of metrics on MOSI and MOSEI. For other metrics, DBF achieves very closed performance to state-of-the-art. These outcomes preliminarily demonstrate the efficacy of our method in video multimodal fusion.
From the results, we can observe that our model achieves more significant performance improvement on summary task than sentiment analysis. There could be two reasons for this: 1) the size of two datasets is small, yet DBF requires a sufficient amount of data to learn noise and redundancy patterns for this type of video. 2) Visual features are extracted by Facet on sentiment analysis task and more 3D ResNeXt-101 on summary task respectively. Compared to sentiment analysis task, summary task employ a more advanced visual extractor and DBF is heavily influenced by the quality of visual features.
4.4 Ablation Study
Effect of Fusion Bottleneck and MI-Max
As shown in Table 4, we first remove respectively MI-Max module and exchange fusion bottleneck module with vanilla fusion methods to observe the effects on performance. We observe that fusion bottleneck and MI-Max both help better fusion results, and the combination of them further improves performance, which reflects the necessity of removing noise while maintaining representative information.
Effect of Modalities
Then we remove one modality at a time to observe the effect on performance. Firstly, we observe that the multimodal combination provides the best performance, indicating that our model can learn complementary information from different modalities. Next, we observe that the performance drops sharply when the language modality is removed. This may be due to the fact that text has higher information density compared to redundant audio and visual modalities. It verifies two things: 1) It is critical to remove noise and redundancy to increase information density of visual and audio modalities when doing fusion. 2) Text-centric fusion results may help improve performance on multimodal summary and sentiment analysis tasks.
Effect of Center Modality
As mentioned above, text-centric fusion results tend to perform better as low information intensity and high redundancy in other modalities. Thus, we evaluate fusion results based on acoustic and vision modality respectively on downstream tasks. We observe an obvious decline in performance when audio or visual modality is used as the central modality.
4.5 Case Study
In this section, we first calculate standard deviation and normalized entropy over visual attention scores in the Grad-CAM heatmaps (Selvaraju et al., 2017) for DBF and baseline method VG-GPLMs (Yu et al., 2021a) respectively. These two metrics show the sharpness of visual attention scores, indicating whether the model focuses more on key frames and ignores redundant content. Then, we compute visualizations on Grad-CAM heatmaps acquired before to show the ability of DBF to filter out redundancy and preserve key information.
Statistics of Visualization Results
Grad-CAM is a visualization method of images, it obtains visualization heatmaps by calculating weights and gradients during backpropagation, and in this paper we extend Grad-CAM to videos. Further, to quantify this sharpness of visual attention, we calculate standard deviation and normalized entropy on Grad-CAM heatmaps over the test split on How2 dataset. For results, DBF gets 0.830, 0.008, baseline gets 0.404, 0.062 in deviation and normalized entropy respectively. DBF holds a higher deviation and lower entropy, which indicates sharper visual attention maps to discriminate redundancy and key frames.
Visualization Example
Figure 3 provides Grad-CAM visualizations of DBF and baseline method. As we can see, DBF has more sharp attention over continuous frames and ignores redundancy while preserving critical information in visual inputs.
5 Conclusion
In this paper, we propose a denoising video multimodal fusion system DBF which contains a fusion bottleneck to filter out redundancy with noise, a mutual information module to preserve key information in fusion results. Our model alleviates redundancy and nosie problem in video multimodal fusion and makes full use of all representative information in redundant modalities (vision and acoustic). In the experiments, we show that our model significantly and consistently outperforms state-of-the-art video multimodal models. In addition, we demonstrate that DBF can appropriately select necessary contents and neglect redundancy in video by comprehensive ablation and visualization studies.
In the future, we will explore the following directions: (1) We will try to extend the proposed DBF model to more multimodal fusion tasks such as humor detection. (2) We will incorporate vision-text pretraining backbones into our DBF model to further improve its performance.
Limitations
First, limited by the category of video multimodal fusion tasks, we do not perform experiments on more tasks to better validate the effectiveness of our method, and we hope to extend our model to more various and complete benchmarks in future work. Secondly, as shown in Section 4.3, our model achieves relatively slight performance improvement on sentiment analysis task. For reasons, our model may be dependent on the scale of datasets to learn noise and redundancy patterns in video, which needs to be further improved and studied.
Acknowledgement
This paper is supported by the National Key Research and Development Program of China 2020AAA0106700 and NSFC project U19A2065.
References
- Belghazi et al. (2018) Mohamed Ishmael Belghazi, Aristide Baratin, Sai Rajeswar, Sherjil Ozair, Yoshua Bengio, Aaron Courville, and R Devon Hjelm. 2018. Mine: mutual information neural estimation. arXiv preprint arXiv:1801.04062.
- Degottex et al. (2014) Gilles Degottex, John Kane, Thomas Drugman, Tuomo Raitio, and Stefan Scherer. 2014. Covarep—a collaborative voice analysis repository for speech technologies. In 2014 ieee international conference on acoustics, speech and signal processing (icassp), pages 960–964. IEEE.
- Denkowski and Lavie (2011) Michael Denkowski and Alon Lavie. 2011. Meteor 1.3: Automatic metric for reliable optimization and evaluation of machine translation systems. In Proceedings of the sixth workshop on statistical machine translation, pages 85–91.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Gutmann and Hyvärinen (2010) Michael Gutmann and Aapo Hyvärinen. 2010. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 297–304. JMLR Workshop and Conference Proceedings.
- Han et al. (2021) Wei Han, Hui Chen, and Soujanya Poria. 2021. Improving multimodal fusion with hierarchical mutual information maximization for multimodal sentiment analysis. arXiv preprint arXiv:2109.00412.
- Hara et al. (2018) Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. 2018. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 6546–6555.
- Hazarika et al. (2020) Devamanyu Hazarika, Roger Zimmermann, and Soujanya Poria. 2020. Misa: Modality-invariant and-specific representations for multimodal sentiment analysis. In Proceedings of the 28th ACM international conference on multimedia, pages 1122–1131.
- Kay et al. (2017) Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. 2017. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950.
- Lewis et al. (2019) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. 2019. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
- Li et al. (2017) Haoran Li, Junnan Zhu, Cong Ma, Jiajun Zhang, and Chengqing Zong. 2017. Multi-modal summarization for asynchronous collection of text, image, audio and video. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 1092–1102.
- Lin and Hovy (2003) Chin-Yew Lin and Eduard Hovy. 2003. Automatic evaluation of summaries using n-gram co-occurrence statistics. In Proceedings of the 2003 human language technology conference of the North American chapter of the association for computational linguistics, pages 150–157.
- Liu et al. (2020) Nayu Liu, Xian Sun, Hongfeng Yu, Wenkai Zhang, and Guangluan Xu. 2020. Multistage fusion with forget gate for multimodal summarization in open-domain videos. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1834–1845.
- Liu et al. (2018a) Zhun Liu, Ying Shen, Varun Bharadhwaj Lakshminarasimhan, Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency. 2018a. Efficient low-rank multimodal fusion with modality-specific factors. arXiv preprint arXiv:1806.00064.
- Liu et al. (2018b) Zhun Liu, Ying Shen, Varun Bharadhwaj Lakshminarasimhan, Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency. 2018b. Efficient low-rank multimodal fusion with modality-specific factors. arXiv preprint arXiv:1806.00064.
- Luo et al. (2021) Huaishao Luo, Lei Ji, Yanyong Huang, Bin Wang, Shenggong Ji, and Tianrui Li. 2021. Scalevlad: Improving multimodal sentiment analysis via multi-scale fusion of locally descriptors. arXiv preprint arXiv:2112.01368.
- Nagrani et al. (2021) Arsha Nagrani, Shan Yang, Anurag Arnab, Aren Jansen, Cordelia Schmid, and Chen Sun. 2021. Attention bottlenecks for multimodal fusion. Advances in Neural Information Processing Systems, 34:14200–14213.
- Oord et al. (2018) Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748.
- Palaskar et al. (2019) Shruti Palaskar, Jindrich Libovickỳ, Spandana Gella, and Florian Metze. 2019. Multimodal abstractive summarization for how2 videos. arXiv preprint arXiv:1906.07901.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
- Paszke et al. (2017) A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. Devito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. 2017. Automatic differentiation in pytorch.
- Poria et al. (2020) Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, and Rada Mihalcea. 2020. Beneath the tip of the iceberg: Current challenges and new directions in sentiment analysis research. IEEE Transactions on Affective Computing.
- Sanabria et al. (2018) Ramon Sanabria, Ozan Caglayan, Shruti Palaskar, Desmond Elliott, Loïc Barrault, Lucia Specia, and Florian Metze. 2018. How2: a large-scale dataset for multimodal language understanding. arXiv preprint arXiv:1811.00347.
- Selvaraju et al. (2017) Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pages 618–626.
- Sun et al. (2019) Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. 2019. Videobert: A joint model for video and language representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
- Sun et al. (2020) Zhongkai Sun, Prathusha Sarma, William Sethares, and Yingyu Liang. 2020. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8992–8999.
- Tsai et al. (2019) Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. 2019. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the conference. Association for Computational Linguistics. Meeting, volume 2019, page 6558. NIH Public Access.
- Tsai et al. (2018) Yao-Hung Hubert Tsai, Paul Pu Liang, Amir Zadeh, Louis-Philippe Morency, and Ruslan Salakhutdinov. 2018. Learning factorized multimodal representations. arXiv preprint arXiv:1806.06176.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30.
- Vedantam et al. (2015) Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. 2015. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575.
- Wu et al. (2021) Yang Wu, Zijie Lin, Yanyan Zhao, Bing Qin, and Li-Nan Zhu. 2021. A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4730–4738.
- Yu et al. (2021a) Tiezheng Yu, Wenliang Dai, Zihan Liu, and Pascale Fung. 2021a. Vision guided generative pre-trained language models for multimodal abstractive summarization. arXiv preprint arXiv:2109.02401.
- Yu et al. (2021b) Wenmeng Yu, Hua Xu, Ziqi Yuan, and Jiele Wu. 2021b. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 10790–10797.
- Zadeh et al. (2017) Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2017. Tensor fusion network for multimodal sentiment analysis. arXiv preprint arXiv:1707.07250.
- Zadeh et al. (2018a) Amir Zadeh, Paul Pu Liang, Navonil Mazumder, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2018a. Memory fusion network for multi-view sequential learning. In Proceedings of the AAAI conference on artificial intelligence, volume 32.
- Zadeh et al. (2016) Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. 2016. Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos. arXiv preprint arXiv:1606.06259.
- Zadeh et al. (2018b) AmirAli Bagher Zadeh, Paul Pu Liang, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2018b. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2236–2246.
- Zhang et al. (2019) Zhuosheng Zhang, Kehai Chen, Rui Wang, Masao Utiyama, Eiichiro Sumita, Zuchao Li, and Hai Zhao. 2019. Neural machine translation with universal visual representation. In International Conference on Learning Representations.
Appendix
Appendix A Hyper-parameters
We set hyper-parameters as shown in Table 5 for best performance. For optimization, we utilize the Adam optimizer with warmup. The training duration of each model is governed by early-stopping strategy with a patience of 10 epochs.
| Hyper-Parameter | MOSI | MOSEI | How2 |
| Batch size | 32 | 96 | 80 |
| Bottleneck length | 2 | 4 | 8 |
| Num of bottleneck layers | 4 | 4 | 4 |
| 0.05 | 0.1 | 0.1 | |
| Learning rate | 2e-05 | 2e-03 | 3e-04 |
| Learning rate | 1e-04 | 5e-05 | 6e-05 |
| Fusion size | 128 | 128 | 768 |
Appendix B Baselines
For multimodal sentiment analysis:
MulT (Tsai et al., 2019) :
a multimodal transformer architecture model with directional pairwise cross-attention, which translates one modality to another.
TFN (Zadeh et al., 2017)
based on tensor outer product to capture multiple-modal interactions.
LMF (Liu et al., 2018b) :
an advanced version of TFN model.
MFM (Tsai et al., 2018) :
a model that factorizes representations into two sets of independent factors: multimodal discriminative and modality-specific generative factors.
ICCN (Sun et al., 2020) :
an adversarial encoder-decoder classifier framework-based model to learn a modality-invariant embedding space.
MISA (Hazarika et al., 2020)
projects each modality to two distinct subspaces.
Self-MM (Yu et al., 2021b)
propose a label generation module based on the self-supervised learning strategy to acquire independent unimodal supervision.
MMIM (Han et al., 2021)
hierarchically maximizes the mutual information in unimodal input pairs and between multimodal fusion result and unimodal input.
For multimodal summarization, We compare DBF with the following baselines:
HA (Palaskar et al., 2019) :
a sequence-to-sequence multimodal fusion model with hierarchical attention.
MFFG (Liu et al., 2020) :
a multistage fusion network with the fusion forget gate module, which controls the flow of redundant information between multimodal long sequences via a forgetting module.
VG-GPLMs (Yu et al., 2021a) :
a BART-based and vision guided model for multimodal summarization task, which use attention-based add-on layers to incorporate visual information.