Delving into the Frequency: Temporally Consistent Human Motion Transfer in the Fourier Space
Abstract.
Human motion transfer refers to synthesizing photo-realistic and temporally coherent videos that enable one person to imitate the motion of others. However, current synthetic videos suffer from the temporal inconsistency in sequential frames that significantly degrades the video quality, yet is far from solved by existing methods in the pixel domain. Recently, some works on DeepFake detection try to distinguish the natural and synthetic images in the frequency domain because of the frequency insufficiency of image synthesizing methods. Nonetheless, there is no work to study the temporal inconsistency of synthetic videos from the aspects of the frequency-domain gap between natural and synthetic videos. Therefore, in this paper, we propose to delve into the frequency space for temporally consistent human motion transfer. First of all, we make the first comprehensive analysis of natural and synthetic videos in the frequency domain to reveal the frequency gap in both the spatial dimension of individual frames and the temporal dimension of the video. To close the frequency gap between the natural and synthetic videos, we propose a novel Frequency-based human MOtion TRansfer framework, named FreMOTR, which can effectively mitigate the spatial artifacts and the temporal inconsistency of the synthesized videos. FreMOTR explores two novel frequency-based regularization modules: 1) the Frequency-domain Appearance Regularization (FAR) to improve the appearance of the person in individual frames and 2) Temporal Frequency Regularization (TFR) to guarantee the temporal consistency between adjacent frames. Finally, comprehensive experiments demonstrate that the FreMOTR not only yields superior performance in temporal consistency metrics but also improves the frame-level visual quality of synthetic videos. In particular, the temporal consistency metrics are improved by nearly 30% than the state-of-the-art model.
†Wu Liu and Juan Cao are corresponding authors.
‡The authors are at the Key Lab of Intelligent Information Processing of Chinese Academy of Sciences and the University of Chinese Academy of Sciences .
1. Introduction
Motion Transfer (HMT) aims to synthesize photo-realistic videos in which one person can imitate the motions of others (Chan et al., 2019). Specifically, given an image of a source person and a target video with the desired motion, the human motion transfer method can generate a video of the source person performing the target motion. It is an emerging topic due to the potential applications like movie editing, virtual try-on, and online education (Liu et al., 2021). Benefiting from the Generative Adversarial Networks (GANs) (Goodfellow et al., 2014; Wang et al., 2019) with the pixel domain supervision, frame-level visual quality of some synthetic videos is significantly improved. However, as shown in Fig. 1, the results of current methods still suffer from artifacts and noise which lead to obvious temporal inconsistency and unsatisfied frame quality. The temporal consistency of the synthetic videos is far from satisfactory yet neglected by the community, and thus this paper focuses on temporally consistent human motion transfer.

Most existing human motion transfer methods mainly focus on the appearance of persons in the pixel domain. In recent studies on the diagnosis of deep neural networks and GANs, frequency domain analysis has been proved to be an effective tool (Rahaman et al., 2019). Some works have tried to utilize the frequency discrepancies between GAN-generated images and natural images for fake image detection (Dzanic et al., 2020; Frank et al., 2020; Tancik et al., 2020). They discovered that existing generative methods cannot effectively model the frequency-domain distribution of natural images, which causes the loss of information in specific frequencies in generated images. Nonetheless, they simply adopt the frequency difference as loss, rather than make full use of the frequency domain characteristics. In this paper, we propose to regularize the appearance with frequency-aware networks to reduce the noise and improve the frame-level quality.
Moreover, recent human motion transfer methods mainly focus on frame-level quality with precise human structure representations such as 2D human pose (Balakrishnan et al., 2018; Tulyakov et al., 2018), human parsing (Dong et al., 2018; Liu et al., 2019c, d), 3D human pose (Wang et al., 2018), and other 3D informationl (Liu et al., 2018, 2022; Sun et al., 2022; Zheng et al., 2022; Liu et al., 2019b, 2021). Although some methods try to use a multi-frame smoothing loss (Wang et al., 2019) or optical flow (Wei et al., 2021b) in the pixel domain to improve the temporal consistency, the temporal artifacts still cannot be effectively eliminated in the pixel domain. These temporal artifacts can be easily perceived by the human visual system and significantly degrade the quality of videos (Seshadrinathan and Bovik, 2010). However, there is seldom work to study whether the temporal inconsistency of synthetic videos arises from the frequency-domain gap between natural videos and synthetic videos, let alone how to eliminate them in the frequency domain.
In this paper, we delve into the Fourier space for temporally consistent human motion transfer from two perspectives as shown in Fig. 2. First, we explore a Frequency-domain Appearance Regularization (FAR) method that models the frame-level characteristics in both pixel and frequency domains to reduce noise in individual frames. Second, we discover and close the temporal frequency domain gap between natural videos and synthetic videos by a Temporal Frequency Regularization (TFR) module. By reducing noise in individual frames and improving the long-term coherency, both the frame-level quality and temporal consistency of generated motion videos are improved.
First, we synthesize coarse frames with HMT backbones and regularize the appearance for a finer appearance. The FAR works on the single coarse frames. To improve the frequency insufficiency of current generative method, Fast Fourier Convolution is adopted instead of the traditional convolution block to focus on characteristics in both pixel and frequency domain. By regularizing the original image in the frequency domain and then reconstructing the image, FAR reduces noise and artifacts in the frame.
The TFR is designed with the observation that the temporal changes in amplitude and phase spectra of synthetic videos are significantly different from the ones of natural videos, which is shown in Fig. 4. This phenomenon demonstrates that existing methods cannot reproduce the frequency-domain distribution as natural videos using only pixel-domain supervision. To this end, we design a Weighted Temporal Frequency Regularization (WTFR) loss for human motion transfer methods, which applies regularization to make the temporal changes between adjacent frames of synthetic videos approximate to natural videos in the frequency domain. In particular, the WTFR loss is applied to the amplitude and phase spectrum separately, because the temporal variations of amplitude and phase demonstrate different patterns for natural videos and synthetic videos (Seshadrinathan and Bovik, 2010). For example, the phase spectrum of natural videos has more changes in the high-frequency components compared with the amplitude spectrum, as the spectra changes of natural videos shown in Fig. 4. More specifically, to alleviate the fluctuation of high-frequency components, we add a frequency-aware weighting term in the loss function. The WFTR loss can be integrated into existing human motion transfer methods without any modification to model structures. With the WTFT loss, these methods can learn to close the temporal frequency discrepancy between synthetic and natural videos.
Both quantitative and qualitative evaluations show that the temporal consistency of synthetic videos is significantly improved, as shown in Fig. 1. Our main contributions are summarized as follows:
-
1)
To the best of our knowledge, we make the first attempt to reveal the temporal gap between natural videos and synthetic videos in the frequency domain.
-
2)
More importantly, we build the Temporal Frequency Prior into deep networks through a well-designed WTFR loss, which can effectively guide the GANs to model the temporal frequency changes of natural videos.
-
3)
To reduce the noise and artifacts in frames, the FAR is proposed to regularize the generation process in both pixel and frequency domains.
Experiments show that our method can effectively improve the temporal consistency of the generated videos. In particular, the Temporal Consistency Metrics (Yao et al., 2017) are improved by nearly 30% than the state-of-the-art models. The frame-level metrics are also improved a bit, while the qualitative analyses demonstrate that the improvement is significant for visual perception.
2. Related Work
2.1. Human Motion Transfer
Human motion transfer has been studied for over two decades. Early methods are focused on retrieval-based pipelines to retarget the subject in a video to the desired motion with optical flow (Efros et al., 2003) or 3D human skeleton (Xu et al., 2011). Recent methods usually adopt deep neural networks, especially GANs (Goodfellow et al., 2014), and exploit 2D human pose (Tulyakov et al., 2018; Balakrishnan et al., 2018; Siarohin et al., 2019; Chan et al., 2019; Wang et al., 2019), human parsing (Dong et al., 2018; Liu et al., 2019c, d; Wei et al., 2021a), 3D human pose (Wang et al., 2018), and other 3D information (Liu et al., 2018, 2022; Sun et al., 2022; Zheng et al., 2022) for human motion transfer (Liu et al., 2019b, 2021).
However, most of these methods only model the appearance mapping between individual source and target frames in the pixel domain, while the frequency domain and temporal consistency are usually neglected. Although some methods like vid2vid (Wang et al., 2018, 2019) and EDN (Chan et al., 2019) take multiple frames as the input to improve temporal coherence in the pixel domain for temporal smoothing, the synthesized motion videos are still with obvious temporal artifacts. Most recently, Wei et al. (2021b) proposed C2F-FWN with a Flow Temporal Consistency Loss to explicitly constrain temporal coherence by optical flow, but optical flow estimation could bring high extra computation cost and noise. Therefore, this paper focuses on exploring a more effective method to explicitly improve the temporal consistency for human motion transfer.
2.2. Frequency Domain Analysis for GANs
In recent research, frequency domain analysis for deep neural networks, especially GANs, has been proved an effective tool for network diagnose (Rahaman et al., 2019; Durall et al., 2020), GAN generated image detection (Zhang et al., 2019; Frank et al., 2020; Dzanic et al., 2020), and improving the capability of GANs for image generation (Tancik et al., 2020; Chen et al., 2021). For example, Rahaman et al. (2019) used Fourier analysis to highlight the bias of deep networks towards low-frequency functions. Durall et al. (2020) discovered that the up-sampling or up-convolnution operations made GANs fail to reproduce the spectral distributions of natural images. Dzanic et al. (2020) explored the Fourier spectrum discrepancies of high-frequency components between natural and generated images for fake image detection. Chen et al. (2021) observed missing of high-frequency information in discriminators of GANs. Nevertheless, there is no prior work to study whether the temporal inconsistency of synthetic videos is caused by the frequency discrepancies between natural videos and synthetic videos.
2.3. Video Temporal Consistency
Temporal consistency is an essential aspect for video quality assessment (Seshadrinathan and Bovik, 2010), video processing (Yao et al., 2017; Liu et al., 2019a), video frame prediction (Bhattacharjee and Das, 2017), and blind video temporal consistency (Bonneel et al., 2015; Lai et al., 2018; Lei et al., 2020). For example, Seshadrinathan and Bovik (2010) designed the motion-based video integrity evaluation index, which adopted Gabor filters in the frequency domain for evaluating dynamic video fidelity. Yao et al. (2017) proposed an occlusion-aware temporal warping algorithm to achieve temporal consistency for video processing. Bhattacharjee and Das (2017) proposed a temporal coherency criterion for video frame prediction using GANs. Lei et al. (2020) proposed to learn a Deep Video Prior from natural and processed videos and achieved superior temporal consistency on seven video processing or generation tasks. This paper presents a novel temporal consistency regularization loss using Temporal Frequency Prior obtained by Fourier analysis. It can be used for existing human motion transfer methods without any modification on models and exhibit state-of-the-art performance.
3. FreMOTR
3.1. Fourier Transform of Image
The Fourier Transform convert the image in pixel domain into the frequency domain. In our study, we adopt the 2D-Discrete Fourier Transform (2D-DFT) to obtain the frequency spectrum of a frame. Specifically, given a frame represented by a discrete 2D signal , its frequency spectrum value at coordinate is obtained by
| (1) |
The frequency spectrum can be denoted as where is the real part and is the imaginary part. The amplitude that reflects the intensity is obtained by , while the phase that reflects the position is denoted by . Hence the frequency spectrum can be divided into the amplitude spectrum and the phase spectrum. For visualization in the following figures, both spectra are shifted so that the centers denote low-frequency components while the corners denote the high-frequency components, and the amplitude spectrum is further converted into logarithmic units.

3.2. Frequency-domain Appearance Regularization
The incoherent appearance like noise and artifacts can be easily perceived by the human visual system and significantly degrade the quality of videos (Seshadrinathan and Bovik, 2010). However, these signals cannot be easily described in the pixel domain. To catch and reduce these signals, we process the image in the frequency domain with Fast Fourier Convolution (FFC) (Chi et al., 2020). In addition, FFC can catch the global information without the limitation of receptive field, which will benefit the coherency of the appearance.
3.2.1. Fast Fourier Convolution
The workflow of a FFC block is presented in Fig. 3, which contains two main streams.The input is first divided into two parts. The top stream adopts traditional convolution to capture local information (i.e., ). The bottom stream processes the feature in the frequency domain (i.e., Spectral Transform) to capture frequency information and global information (i.e., ). Two streams complement each other by exchanging local and global information as follows:
| (2) | ||||
In the Spectral Transform (), as shown in the right figure of Fig. 3, the feature is processed sequentially with Real 2-D FFT, frequency domain convolution, and Inverse Real 2-D FFT.
3.2.2. Regularize Appearance with FFC
As shown in the top of Fig. 2, we regularize the appearance in the frequency domain with FFC blocks. The Frequency-domain Appearance Regularization (FAR) is trained to reduce the noise and artifacts in the coarse frame to make the appearance consistent for adjacent frames. First, the coarse frames are downsampled with 3 FFC blocks. Then the frame features are processed with several FFC residual blocks in both pixel and frequency domain, aiming to reduce the artifacts and noise which are abnormal or discontinuous. At last, the final features are upsampled with 3 FFC blocks to reconstruct the frame.

3.3. Temporal Frequency Regularization
For natural videos, short segments of video without any scene changes contain local image patches undergoing translation, which will lead to major phase changes and minor amplitude changes in the frequency domain (Seshadrinathan and Bovik, 2010). Inspired by the flaw of GANs in the frequency domain, we discover the temporal frequency gap and build a targeted regularization to close the gap in this part.
3.3.1. Temporal Frequency Changes of Adjacent Frames
To discover the gap between natural and synthetic videos, we analyze the temporal changes of adjacent frames in amplitude and phase separately, which is shown in the bottom of Fig. 2. We define the Temporal Frequency Change (TFC), i.e., the Temporal Amplitude Change (TAC) of and Temporal Phase Change (TPC) of between adjacent frames and in a video, as
| (3) | ||||
We analyzed the synthetic frames with low temporal consistency and drawn several observations, and several example heatmaps of TFC are shown in Fig. 4. First, for adjacent synthetic frames with low temporal consistency, TFCs scatter over various frequencies with larger values, while the ones of natural videos are mainly in the low-frequency components with smaller values. Second, the phase spectrum of natural videos contains more changes in the high-frequency components compared with the amplitude spectrum. This observation is consist with the conclusions in (Seshadrinathan and Bovik, 2010). The main content (i.e., intensity of the pixels) of adjacent frames does not change too much, which is reflected in the amplitude strum. The position of the pixels change but not very intensely, which is reflected in the phase spectrum.

3.3.2. Weighted Temporal frequency Regularization
Based on the above observation, we present how to utilize the findings for temporally consistent human motion transfer. The overview of the proposed framework is shown in bottom of Fig. 2. For any GAN-based human motion transfer model, we first calculate the temporal frequency changes (TFCs) between adjacent frames of referred videos and generated videos. Then a Weighted Temporal Frequency Regularization (WTFR) loss is obtained from the TFCs to guide the training of the model. By this means, the model can make the temporal patterns of generated videos approximate to natural videos in the frequency domain.
Given a source image and a frame sequence with the referenced motion, the model aims to synthesize a frame sequence conditioned on the appearance in and the motion in , where is the length of the referenced sequence. Motions in adjacent frames exhibit temporal frequency changes which reflect different magnitudes in amplitude and phase spectra. To make the model learn the TFC of natural videos, we define the WTFR loss, which regularizes TAC and TPC of adjacent frames separately. For TAC, the loss function is formulated by
| (4) |
and the loss function for TPC is formulated by
| (5) |
where is a weighting term to penalize high-frequency components based on the observation that TFCs in natural videos are relatively small in high-frequency components as shown in Fig. 4). is a hyper-parameter to scale the magnitude.
Finally, the WTFR loss is denoted as
| (6) |
where and are hyper-parameters. With the WTFR loss, the model can learn to approximate the frequency distribution of natural videos by minimizing the distance of TFCs between the referenced video and the synthetic video.
4. Experiments
In this section, we conduct experiments to answer the following evaluation questions:
-
EQ1
Can FreMOTR improve the metrics of temporal consistency as well as the frame-level image quality? (in Sec. 4.2)
-
EQ2
Does FreMOTR indeed reduce the inconsistent and unnatural components from the visual perception aspect? (in Sec. 4.3.1)
-
EQ3
Can FreMOTR reduce the discovered temporal frequency gap? (in Sec. 4.3.2)
-
EQ4
How each components improve the temporal consistency? And for temporal frequency regularization, are amplitude and phase spectrum both helpful? (in Sec. 4.4)
4.1. Experimental Setups
4.1.1. Dataset
SoloDance (Wei et al., 2021b) We adopted C2F-FWN as our backbone, and thus we adopted the SoloDance dataset released by C2F-FWN for comparison. The SoloDance dataset contains 179 solo dance videos with 53,700 frames collected from the Internet. There are 143 human subjects with various clothes and performing complex solo dances in various backgrounds. This dataset is split into 153 and 26 videos for training and testing, respectively.
4.1.2. Methods for Comparison
To validate the effectiveness of the FreMOTR, we compare the performance with the following HMT methods: FSV2V (Wang et al., 2019) that takes multi frames as input to improve temporal coherence, SGWGAN (Dong et al., 2018) and LWGAN (Liu et al., 2019b) that warp the features, ClothFlow (Han et al., 2019) that warp the image, and C2F-FWN (Wei et al., 2021b) that constrains temporal coherence by optical flow.

The C2F-FWN is the backbone in our experiments, but the authors did not release pretrained weights. Therefore, we trained the C2F-FWN based on the released code and settings, and report the reproduced performance. Performances of other methods are from (Wei et al., 2021b).
4.1.3. Implementation Details
We adopt the C2F-FWN that achieves the SOTA temporal consistency as the backbone for the SoloDance dataset. We adopt a three-stage training strategy. During the first stage, we train the backbone using the settings and hyper-parameters in the released codes of C2F-FWN until converge, then the parameters are fixed. During the second stage, the FAR is combined and trained with general image generation loss like adversarial loss (Goodfellow et al., 2014) and perceptual loss (Johnson et al., 2016) until converge. Finally, the WTFR is added to the general losses to finetune the FAR.
The experiments are conducted on four NVIDIA Tesla P40 GPUs with 24GB memory based on PyTorch (Adam et al., 2019). Following C2F-FWN, the input frames are resized and cropped to 192256. The Adam optimizer (Kingma and Ba, 2015) is used for optimization with a batch size of 8. The hyper-parameters , , and for the WTFR loss in Eq. 6 are set to , , and , respectively, to make the WTFR has the same order of magnitude of other losses. The FAR has 3 downsampling blocks, 3 upsampling blocks, and 18 residual blocks. The initialization of FAR is based on the pretrained FFC provided by Suvorov et al. (2022).
We also adopt only WTFR for ablation. After the first stage that the backbone is well trained, the WTFR is used to finetune the backbone until converge.
4.1.4. Evaluation Metrics
To measure the frame-level image quality, we adopt SSIM (Wang et al., 2004), PSNR, and LPIPS (Richard et al., 2018) following previous works (Wei et al., 2021b). Specifically, SSIM, PSNR, and LPIPS compare the pairwise similarity of synthetic frames and ground-truth frames. Higher value is better for SSIM and PSNR, while lower value is better for LPIPS. The frame-level metrics are averaged over all frames of all synthetic videos.
To evaluate the temporal consistency, we adopt Temporal Consistency Metric (TCM) (Yao et al., 2017). TCM is calculated from the warping error between frames. We first obtain the optical flow between adjacent referenced frames and using Flownet 2.0 (Ilg et al., 2017). The optical flow is used to obtain two adjacent frames by warping and . Finally, TCM is obtained by the ratio of warping errors as
| (7) |
where is the warping operation. The temporal metrics are averaged over all adjacent frames of all synthetic videos.
4.2. Quantitative Analysis (EQ1)
The quantitative metrics of the results are presented in Table 1. In general, compared with all other methods , the proposed FreMOTR improves both temporal consistency and frame-level image quality. Specifically, the FreMOTR significantly improves the TCM by about 30% compared with the state of the art. In addition, FreMOTR improves the frame quality metric (i.e., LPIPS and PSNR). The quantitative analysis reveals that our frequency-domain method can effectively improve existing methods that are only optimized by pixel-domain supervision. Although SSIM of FreMOTR is not the best, such frame-quality metrics only evaluate specific aspects and are for reference. The results of FreMOTR have fewer artifacts and unnatural patches in the synthetic image, which are demonstrated in the qualitative analysis.
| HMT method | Temporal | Frame Quality | ||||
|---|---|---|---|---|---|---|
| TCM | LPIPS | PSNR | SSIM | |||
| FSV2V (Wang et al., 2019) | 0.106 | 0.132 | 20.84 | 0.721 | ||
| SGWGAN (Dong et al., 2018) | 0.166 | 0.124 | 20.54 | 0.763 | ||
| ClothFlow (Han et al., 2019) | 0.322 | 0.072 | 22.06 | 0.843 | ||
| LWGAN (Liu et al., 2019b) | 0.176 | 0.106 | 20.87 | 0.786 | ||
| C2F-FWN (Wei et al., 2021b) | 0.523 | 0.060 | 22.17 | 0.821 | ||
| FreMOTR | 0.678 | 0.059 | 22.25 | 0.780 | ||

4.3. Qualitative Analysis (EQ2&3)
4.3.1. Improvement of the Visual Performance (EQ2)
We present some of the synthesized frames in Fig. 5, from top to bottom are ground truth, results from C2F-FWN, and results from our FreMOTR. The results of C2F-FWN often contain artifacts, and the consistency of the appearance cannot be preserved even in three successive frames.
The visual results demonstrate that with the FFC that mitigates the incoherent appearance and the WTFR that closes the temporal frequency gap, FreMOTR significantly reduces the inconsistency between successive frames. Therefore, the FreMOTR can achieve a long-time consistency, and a sample is shown in Fig. 6. More results can be found in the appendix. The proposed FreMOTR eliminate irrational temporal inconsistency like the artifacts and noise, and thus the visual quality of individual frames is improved at the same time, which is consistent with the results in Table 1.
4.3.2. Improvement of the Temporal Frequency Gap (EQ3)
We combined the WTFR directly with the backbone to analyze the effectiveness of WTFR (i.e., only WTFR). We visualize the video-level TFC to obtain an observation of overall improvement. For a video with frames, the mean TFC (i.e., for amplitude and phase over the entire video (i.e., and ) are formulated as
| (8) | ||||
where is the coordinate on the spectra. Several samples are shown in Fig. 7. C2F-FWN considers temporal consistency based on optical flow, and the patterns of from C2F-FWN is similar with the ones of ground truth. However, the values are larger in general, especially in the low-frequency components. Our proposed WTFR can improve the synthetic results, making not only the distribution of and but also the values closer to natural videos.
The experimental results demonstrate that the proposed frequency-domain regularization (i.e., WTFR) indeed makes the temporal frequency changes of synthetic videos closer to the ones of natural videos, which component the pixel-domain supervision for human motion transfer. More comparisons of frames and spectra can be found in the appendix materials.
4.4. Ablation Study (EQ4)
4.4.1. Ablation of the FreMOTR Components
We first conducted the ablation study on the two components of FreMOTR. The results are presented in Table 1. “only FFC” refers to the model trained from the second stage without WTFR finetuning “only WTFR” refers to the backbone model finetuned with WTFR.
Specifically, the WTFR significantly improves the frame-level image quality, especially the LPIPS and PSNR. WTFR improves the TCM a lot at the same time. We analyze that WTFR reduce the irrational noise like artifacts, noise, and jitters that suddenly appear, and thus achieves better image quality and temporal consistency.
The FAR significantly improve the TCM. We infer that FAR mainly mitigate the incoherent appearance of the person and achieve much better temporal consistency. To make the entire image more natural, the FAR takes the entire image as input rather than only the body region, and the background may be slightly influenced, which lead to unsatisfied frame quality metrics. However, by observing the results, we did not observe image quality descending. In contrary, as shown in the qualitative analysis, although FreMOTR and “only FFC”” have similar or even worse image quality metrics with C2F-FWN, they have less obvious artifacts and unnatural patches.
For human motion transfer, both frame-level image quality and temporal consistency are important, and the Full FreMOTR achieves a well trade-off. The temporal consistency metric of FreMOTR is much better than the backbone and slightly worse than “only FFC”, while the image quality metrics like LPIPS and PSNR is better than “only FFC” and the backbone. It is reasonable that the smooth Furthermore, the qualitative analysis in Sec. 4.3 demonstrates that beyond the frame-level image quality, the visual performance is significantly improved. These results demonstrate that all the components of FreMOTR works, which benefit temporally consistent human motion transfer in different aspects.
| Components | Temporal | Frame Quality | ||||
|---|---|---|---|---|---|---|
| TCM | LPIPS | PSNR | SSIM | |||
| Full FreMOTR | 0.678 | 0.059 | 22.25 | 0.780 | ||
| only WTFR | 0.592 | 0.052 | 22.86 | 0.839 | ||
| only FAR | 0.681 | 0.060 | 22.11 | 0.780 | ||
| backbone | 0.523 | 0.060 | 22.17 | 0.821 | ||
4.4.2. Ablation of the Frequency Spectrum
WTFR is composed with amplitude and phase. To study the roles of each components, we combined the converged backbone (i.e., C2F-FWN (Wei et al., 2021b)) with several variation of WTFR, and the results are presented in Table 3. The WTFR is defined in Eq. 4, Eq. 5, and Eq. 6. In the table, “Phase” refers to phase only (i.e., in Eq. 6), “Amplitude” refers to amplitude only (i.e., in Eq. 6). “TFR” means removing the weighted term (i.e., in Eq. 4 and Eq. 5). For the Mixed setting, only one of the components uses the weighted term. “AMP.+WP” means amplitude without the weighted term and phase with the weighted term , while “PH.+WA” means phase without the weighted term and amplitude with the weighted term .
First, the results demonstrate that all variations improve the temporal consistency, while the frame-level quality can also be improved. The amplitude part and phase part of WTFR are both effective. The TCM metrics of generated videos are improved by 11% 14% than the original models.
Second, the amplitude part is more important than the phase. As described in Sec. 3.1, amplitude reflects the intensity of the pixels while phase reflects the position. Therefore, minimizing amplitude fluctuation can guarantee the consistency of pixel intensity, which reduces irrational components that suddenly appear.
Third, the comparison between results of WTFR, TFR, and Mixed shows that the mixed variation of “PH. + WA” works best. The weighting term in WTFR is important for the model to pay more attention to high-frequency components, especially for the amplitude. This phenomenon is consistent with the observation in Fig. 4. The main content (i.e., intensity of the pixels) of adjacent frames does not change too much, and thus we should adopt larger penalty to the high-frequency changes for amplitude spectrum to make the synthetic frames more natural. On the other hand, the position of the pixels change but not very intensely, and thus we just adopt a uniform penalty for all components in the phase spectrum.
| TFR Type | Setting | Temp. | Frame Quality | |||
|---|---|---|---|---|---|---|
| TCM | LPIPS | PSNR | SSIM | |||
| backbone | — | 0.523 | 0.060 | 22.172 | 0.821 | |
| TFR | Phase | 0.590 | 0.056 | 22.535 | 0.833 | |
| Amplitude | 0.589 | 0.054 | 22.652 | 0.833 | ||
| Both | 0.583 | 0.052 | 22.772 | 0.836 | ||
| WTFR | Phase | 0.584 | 0.053 | 22.797 | 0.838 | |
| Amplitude | 0.591 | 0.052 | 22.860 | 0.838 | ||
| Both | 0.591 | 0.053 | 22.846 | 0.838 | ||
| Mixed | AMP.+WP | 0.591 | 0.052 | 22.820 | 0.838 | |
| PH.+WA | 0.592 | 0.052 | 22.857 | 0.839 | ||
5. Conclusion
In this paper, we delve into the frequency space for temporally consistent human motion transfer. We make the first comprehensive analysis of natural and synthetic videos in the frequency domain to reveal the frequency gap. We propose a novel FreMOTR framework that can effectively mitigate the spatial artifacts and the temporal inconsistency of the generated videos with two novel frequency-based regularization modules. Experiments results demonstrate that the FreMOTR not only yields superior performance in temporal consistency metrics but also improves the frame-level visual quality of synthetic videos. In particular, the temporal consistency metrics are improved by nearly 30% than the state-of-the-art models.
Acknowledgements.
This work was supported by the National Key R&D Program of China (No.2020AAA0103800), the Zhejiang Provincial Key R&D Program of China (No. 2021C01164), and the Project of Chinese Academy of Sciences (E141020). Juan Cao thanks the Nanjing Government Affairs and Public Opinion Research Institute for the support of ”CaoJuan Studio” and thanks Chi Peng, Jingjing Jiang, Qiang Liu, and Yu Dai for their help.References
- (1)
- Adam et al. (2019) Paszke Adam, Gross Sam, Francisco Mass, Lerer Adam, Bradbury James, Chanan Gregory, Killeen Trevor, Lin Zeming, Gimelshein Natalia, Antiga Luca, et al. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems. 8026–8037.
- Balakrishnan et al. (2018) Guha Balakrishnan, Amy Zhao, Adrian V. Dalca, Frédo Durand, and John V. Guttag. 2018. Synthesizing Images of Humans in Unseen Poses. In IEEE Conference on Computer Vision and Pattern Recognition. 8340–8348.
- Bhattacharjee and Das (2017) Prateep Bhattacharjee and Sukhendu Das. 2017. Temporal Coherency based Criteria for Predicting Video Frames using Deep Multi-stage Generative Adversarial Networks. In Advances in Neural Information Processing Systems. 4268–4277.
- Bonneel et al. (2015) Nicolas Bonneel, James Tompkin, Kalyan Sunkavalli, Deqing Sun, Sylvain Paris, and Hanspeter Pfister. 2015. Blind video temporal consistency. ACM Trans. Graph. 34, 6 (2015), 196:1–196:9.
- Chan et al. (2019) Caroline Chan, Shiry Ginosar, Tinghui Zhou, and Alexei A. Efros. 2019. Everybody Dance Now. In IEEE International Conference on Computer Vision. 5932–5941.
- Chen et al. (2021) Yuanqi Chen, Ge Li, Cece Jin, Shan Liu, and Thomas Li. 2021. SSD-GAN: Measuring the Realness in the Spatial and Spectral Domains. In AAAI Conference on Artificial Intelligence.
- Chi et al. (2020) Lu Chi, Borui Jiang, and Yadong Mu. 2020. Fast fourier convolution. Advances in Neural Information Processing Systems 33 (2020), 4479–4488.
- Dong et al. (2018) Haoye Dong, Xiaodan Liang, Ke Gong, Hanjiang Lai, Jia Zhu, and Jian Yin. 2018. Soft-Gated Warping-GAN for Pose-Guided Person Image Synthesis. In Advances in Neural Information Processing Systems. 472–482.
- Durall et al. (2020) Ricard Durall, Margret Keuper, and Janis Keuper. 2020. Watch Your Up-Convolution: CNN Based Generative Deep Neural Networks Are Failing to Reproduce Spectral Distributions. In IEEE Conference on Computer Vision and Pattern Recognition. 7887–7896.
- Dzanic et al. (2020) Tarik Dzanic, Karan Shah, and Freddie D. Witherden. 2020. Fourier Spectrum Discrepancies in Deep Network Generated Images. In Advances in Neural Information Processing Systems.
- Efros et al. (2003) Alexei A. Efros, Alexander C. Berg, Greg Mori, and Jitendra Malik. 2003. Recognizing Action at a Distance. In IEEE International Conference on Computer Vision. 726–733.
- Frank et al. (2020) Joel Frank, Thorsten Eisenhofer, Lea Schönherr, Asja Fischer, Dorothea Kolossa, and Thorsten Holz. 2020. Leveraging Frequency Analysis for Deep Fake Image Recognition. In International Conference on Machine Learning, Vol. 119. 3247–3258.
- Goodfellow et al. (2014) Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. 2014. Generative Adversarial Nets. In Advances in Neural Information Processing Systems. 2672–2680.
- Han et al. (2019) Xintong Han, Xiaojun Hu, Weilin Huang, and Matthew R Scott. 2019. Clothflow: A flow-based model for clothed person generation. In IEEE/CVF International Conference on Computer Vision. 10471–10480.
- Ilg et al. (2017) Eddy Ilg, Mayer Nikolaus, Saikia Tonmoy, Keuper Margret, Dosovitskiy Alexey, and Brox Thomas. 2017. Flownet 2.0: Evolution of optical flow estimation with deep networks. In IEEE Conference on Computer Vision and Pattern Recognition. 2462–2470.
- Johnson et al. (2016) Justin Johnson, Alexandre Alahi, and Li Fei-Fei. 2016. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision. 694–711.
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. In International Conference on Learning Representations.
- Lai et al. (2018) Wei-Sheng Lai, Jia-Bin Huang, Oliver Wang, Eli Shechtman, Ersin Yumer, and Ming-Hsuan Yang. 2018. Learning Blind Video Temporal Consistency. In European Conference on Computer Vision, Vol. 11219. 179–195.
- Lei et al. (2020) Chenyang Lei, Yazhou Xing, and Qifeng Chen. 2020. Blind Video Temporal Consistency via Deep Video Prior. In Advances in Neural Information Processing Systems.
- Liu et al. (2018) Kun Liu, Wu Liu, Chuang Gan, Mingkui Tan, and Huadong Ma. 2018. T-C3D: Temporal convolutional 3D network for real-time action recognition. In Proceedings of the AAAI conference on artificial intelligence, Vol. 32.
- Liu et al. (2019c) Lingjie Liu, Weipeng Xu, Michael Zollhöfer, Hyeongwoo Kim, Florian Bernard, Marc Habermann, Wenping Wang, and Christian Theobalt. 2019c. Neural Rendering and Reenactment of Human Actor Videos. ACM Trans. Graph. 38, 5 (2019), 139:1–139:14.
- Liu et al. (2022) Wu Liu, Qian Bao, Yu Sun, and Tao Mei. 2022. Recent advances in monocular 2d and 3d human pose estimation: A deep learning perspective. Comput. Surveys (2022).
- Liu et al. (2019b) Wen Liu, Zhixin Piao, Jie Min, Wenhan Luo, Lin Ma, and Shenghua Gao. 2019b. Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis. In IEEE International Conference on Computer Vision. 5903–5912.
- Liu et al. (2021) Wen Liu, Zhixin Piao, Zhi Tu, Wenhan Luo, Lin Ma, and Shenghua Gao. 2021. Liquid Warping GAN with Attention: A Unified Framework for Human Image Synthesis. IEEE Trans. Pattern Anal. Mach. Intell. (2021).
- Liu et al. (2019a) Xinchen Liu, Wu Liu, Meng Zhang, Jingwen Chen, Lianli Gao, Chenggang Yan, and Tao Mei. 2019a. Social Relation Recognition From Videos via Multi-Scale Spatial-Temporal Reasoning. In IEEE Conference on Computer Vision and Pattern Recognition. 3566–3574.
- Liu et al. (2019d) Xinchen Liu, Meng Zhang, Wu Liu, Jingkuan Song, and Tao Mei. 2019d. BraidNet: Braiding Semantics and Details for Accurate Human Parsing. In ACM Conference on Multimedia, Laurent Amsaleg, Benoit Huet, Martha A. Larson, Guillaume Gravier, Hayley Hung, Chong-Wah Ngo, and Wei Tsang Ooi (Eds.). 338–346.
- Rahaman et al. (2019) Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred A. Hamprecht, Yoshua Bengio, and Aaron C. Courville. 2019. On the Spectral Bias of Neural Networks. In International Conference on Machine Learning, Vol. 97. 5301–5310.
- Richard et al. (2018) Zhang Richard, Isola Phillip, Efros Alexei A, Shechtman Eli, and Oliver Wang. 2018. The unreasonable effectiveness of deep features as a perceptual metric. In IEEE Conference on Computer Vision and Pattern Recognition. 586–595.
- Seshadrinathan and Bovik (2010) Kalpana Seshadrinathan and Alan C. Bovik. 2010. Motion Tuned Spatio-Temporal Quality Assessment of Natural Videos. IEEE Trans. Image Process. 19, 2 (2010), 335–350.
- Siarohin et al. (2019) Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. 2019. Animating Arbitrary Objects via Deep Motion Transfer. In IEEE Conference on Computer Vision and Pattern Recognition. 2377–2386.
- Sun et al. (2022) Yu Sun, Wu Liu, Qian Bao, Yili Fu, Tao Mei, and Michael J Black. 2022. Putting people in their place: Monocular regression of 3d people in depth. In IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13243–13252.
- Suvorov et al. (2022) Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. 2022. Resolution-robust Large Mask Inpainting with Fourier Convolutions. In IEEE/CVF Winter Conference on Applications of Computer Vision. 2149–2159.
- Tancik et al. (2020) Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. 2020. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains. In Advances in Neural Information Processing Systems.
- Thies et al. (2020) Justus Thies, Mohamed Elgharib, Ayush Tewari, Christian Theobalt, and Matthias Nießner. 2020. Neural Voice Puppetry: Audio-Driven Facial Reenactment. In European Conference on Computer Vision, Vol. 12361. 716–731.
- Tulyakov et al. (2018) Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, and Jan Kautz. 2018. MoCoGAN: Decomposing Motion and Content for Video Generation. In IEEE Conference on Computer Vision and Pattern Recognition. 1526–1535.
- Wang et al. (2019) Ting-Chun Wang, Ming-Yu Liu, Andrew Tao, Guilin Liu, Bryan Catanzaro, and Jan Kautz. 2019. Few-shot Video-to-Video Synthesis. In Advances in Neural Information Processing Systems. 5014–5025.
- Wang et al. (2018) Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Nikolai Yakovenko, Andrew Tao, Jan Kautz, and Bryan Catanzaro. 2018. Video-to-Video Synthesis. In Advances in Neural Information Processing Systems. 1152–1164.
- Wang et al. (2004) Zhou Wang, Bovik Alan C, Sheikh Hamid R, and Simoncelli Eero P. 2004. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13, 4 (2004), 600–612.
- Wei et al. (2021a) Dongxu Wei, Haibin Shen, and Kejie Huang. 2021a. GAC-GAN: A General Method for Appearance-Controllable Human Video Motion Transfer. IEEE Trans. Multim. 23 (2021), 2457–2470.
- Wei et al. (2021b) Dongxu Wei, Xiaowei Xu, Haibin Shen, and Kejie Huang. 2021b. C2F-FWN: Coarse-to-Fine Flow Warping Network for Spatial-Temporal Consistent Motion Transfer. In AAAI Conference on Artificial Intelligence. 2852–2860.
- Xu et al. (2011) Feng Xu, Yebin Liu, Carsten Stoll, James Tompkin, Gaurav Bharaj, Qionghai Dai, Hans-Peter Seidel, Jan Kautz, and Christian Theobalt. 2011. Video-based characters: creating new human performances from a multi-view video database. ACM Trans. Graph. 30, 4 (2011), 32.
- Yao et al. (2017) Chun-Han Yao, Chia-Yang Chang, and Shao-Yi Chien. 2017. Occlusion-aware Video Temporal Consistency. In ACM International Conference on Multimedia. 777–785.
- Zhang et al. (2019) Xu Zhang, Svebor Karaman, and Shih-Fu Chang. 2019. Detecting and Simulating Artifacts in GAN Fake Images. In IEEE International Workshop on Information Forensics and Security. 1–6.
- Zheng et al. (2022) Jinkai Zheng, Xinchen Liu, Wu Liu, Lingxiao He, Chenggang Yan, and Tao Mei. 2022. Gait Recognition in the Wild With Dense 3D Representations and a Benchmark. In IEEE Conference on Computer Vision and Pattern Recognition. 20228–20237.
Appendix A Overview of the appendix
In the appendix, we provide additional materials , including:
-
•
Additional samples:
Additional comparisons of heatmaps of like the ones shown in Fig.7.
Additional comparisons of synthetic frames like the ones shown in Fig. 5 and Fig. 6.
-
•
Discussion:
Broader impacts of the work.
Limitations of the work.
Appendix B Additional Samples
In this section, we provide additional samples to support the paper.
B.1. Heatmaps
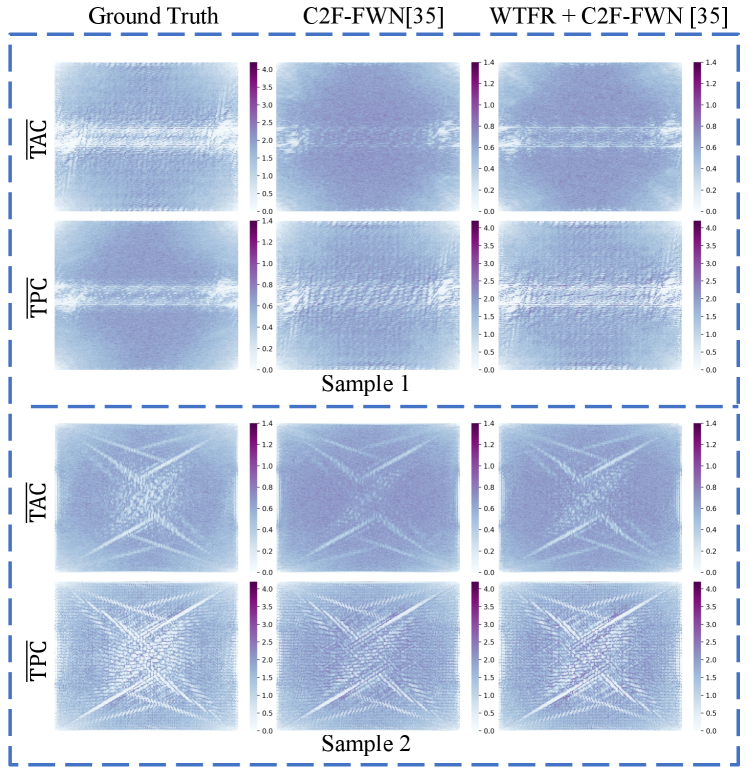
The FreMORT proposed in this paper significantly improves the temporal consistency, which has been quantitatively evaluated in the Experiments section. To demonstrate that the proposed WTFR indeed narrows the discovered temporal frequency gap, we present additional examples in SUPP-Fig. 8 to supplement Fig. 7.
The examples in SUPP-Fig. 8 reflect that existing GAN-based methods cannot effectively model the frequency-domain distribution of natural videos with only pixel-domain supervision. In contrast, the proposed WTFR complements the gap between synthetic and natural videos in the frequency domain, which makes the of synthetic videos closer to that of natural videos.

B.2. Comparison of Synthetic Frames
Additional comparisons of synthetic frames are shown in SUPP-Fig. 9, SUPP-Fig. 10, and SUPP-Fig. LABEL:supp_case3. The frames synthesized by the original model contain inconsistent components, and both the temporal consistency and frame-level image quality get improved with the proposed FreMOTR, which is identical to the quantitative analyses in the main paper. More importantly, the proposed FreMOTR can achieve a long-time consistency for successive frames.


Appendix C Discussion
C.1. Broader Impacts
We propose a novel perspective to analyze and improve human motion transfer in the frequency domain.
To narrow the temporal frequency gap, a model-agnostic method (i.e., WTFR) is designed, which can be employed by any other GAN-based human motion transfer methods. We also calculated the WTFR loss when reproducing the backbone without backward propagation. We observe that the WTFR loss decreased when the models converged gradually, and the trend of WTFR loss is similar to other losses like reconstruction loss, perceptual loss, and attention regularization loss. This phenomenon demonstrates that the proposed WTFR is related to not only temporal consistency but also image quality.
The proposed FreMOTR makes the synthetic videos more temporally consistent and photo-realistic, while the generation of videos without permissions may lead to negative social impact. But at the same time, the discovered gap in the frequency domain between synthetic and natural videos still exists even with the proposed FreMOTR. Therefore, the frequency domain analysis will be an effective tool that helps detect synthetic videos like DeepFake.
C.2. Limitations
We regularize the appearance conditioned on the coarse frames synthesized by the backbone, and thus the final performance is subject to the backbone. The overall appearance of the frame synthesized by the backbone may collapse due to various reasons. Although our FreMOTR can significantly improve the temporal consistency, some extremely bad cases cannot be completely handled,e.g., a man without a face. In contrast, a stronger backbone that can synthesize fine single frames will benefit more from our FreMOTR.
In addition, the face and facial structure become a bit blurred, as we regularize the entire image directly. An additional face reenactment method like (Thies et al., 2020) many further improves the frame quality, which is not included in the framework.
The WTFR considers temporal consistency that enhances the training process based on adjacent frames. Like other sequence-to-sequence tasks that consider successive inputs and outputs, the accumulated error from previous frames may influence the training process. The strategy to reduce the influence of error accumulation needs to be explored in the future.