Degrees of Randomness in Rerandomization Procedures
Degrees of Randomness in Rerandomization Procedures
Degrees of Randomness in Rerandomization Procedures
Abstract
Randomized controlled experiments are susceptible to imbalance on covariates predictive of the outcome. Rerandomization and deterministic treatment assignment are two proposed solutions. This paper explores the relationship between rerandomization and deterministic assignment, showing how deterministic assignment is an extreme case of rerandomization. The paper argues that in small experiments, both fully randomized and fully deterministic assignment have limitations. Instead, the researcher should consider setting the rerandomization acceptance probability based on an analysis of covariates and assumptions about the data structure to achieve an optimal alignment between randomness and balance. This allows for the calculation of minimum -values along with valid permutation tests and fiducial intervals. The paper also introduces tools, including a new, open-source R package named fastrerandomize, to implement rerandomization and explore options for optimal rerandomization acceptance thresholds.
Keywords: Rerandomization;
Design of experiments;
Design-based inference;
Optimally balanced randomization
1 Introduction
Although randomized controlled experiments are now a cornerstone of causal inference in the medical and social sciences, researchers have known since at least [14] that in finite samples, random assignment will often result in imbalance between the treated and control groups on covariates predictive of the outcome. This imbalance will generate conditional bias on estimates of the average treatment effect while adding noise to treatment effect estimates.
In a 2012 paper, Morgan and Rubin propose a solution: rerandomization [22]. They argue that if experimenters provide a quantitative definition of imbalance in advance, they can safely discard randomizations that are too imbalanced and obtain more precise estimates of treatment effects. After rerandomization, researchers adjust exact significance tests and fiducial intervals by excluding randomizations that would not have been accepted according to the initial acceptance threshold. Researchers can also calculate fiducial intervals by exploiting the duality between intervals and tests. Rerandomization has already gained traction as a best practice for field researchers: it is included as a recommended practice for minimizing covariate imbalance in the Handbook of Field Experiments [12].
At the same time, [17] revived a decades-old debate between Gossett (writing as “Student”) and Fisher by arguing that “experimenters might not want to randomize in general” because “[t]he treatment assignment that minimizes conditional expected loss is in general unique if there are continuous covariates, so that a deterministic assignment strictly dominates all randomized assignments.” A similar argument is made in [27, 3, 16] and proven in a theoretical framework by [2], who show that Bayesians and near-Bayesians should not randomize.
In this paper, we begin by formalizing the idea that these two solutions to the problem of covariate imbalance in randomized controlled trials – rerandomization (the Morgan and Rubin approach) and deterministic choice of an optimally balanced treatment assignment vector (the Kasy approach)—are closely related but very much in conflict.111[17] discusses the relationship between the two ideas in concept, writing that “I very much agree with this [Morgan and Rubin’s] argument; one way to think of the present paper is that it provides a formal foundation for this argument and takes it to its logical conclusion.” In particular, we discuss how the deterministic approach in [17] is a case of the [22] approach, but with the threshold for acceptable randomizations set so high that there is only one acceptable treatment assignment vector—and thus an undefined minimum possible -value and no way to carry out a randomization test.
This discussion is particularly useful in the context of very small experiments, which can arise in contexts such as clinical medicine and development economics. As [10] points out, if there is an experiment in which two villages are to be assigned to treatment and two to control, there are only six possible allocations of the treatment conditions, one of which would have been the self-selected allocation. Even with “hundreds of villages,” Deaton writes, “whether or not balance happens depends on how many factors have to be balanced, and nothing stops the actual allocation being the self-selected allocation that we would like to avoid.” Rerandomization, though, would stop the actual allocation from being a specific unbalanced application that we would like to avoid, and we formalize an approach to arriving at an optimum rerandomization that achieves covariate balance without being overly deterministic—thereby allowing use of randomization tests even with close-to-optimal balance.
The issues discussed here have resonance with long-standing issues raised by Neyman’s foundational 1923 paper. As Donald Rubin wrote in 1990, this paper “represents the first attempt to evaluate, formally or informally, the repeated-sampling properties over their nonnull randomization distributions…this contribution is uniquely and distinctly Neyman’s” (Rubin 1990). The insight that variance could be—and indeed needs to be—calculated in part based on variations over these distributions is a key conceptual piece of the modern potential outcomes framework.
One component of variance calculations over randomization distributions is expressed, in early form, in Neyman (1923)’s description of “true yields,” which Neyman describes as “ repeat[ed]…measurement of the yield on the same fixed plot under the same conditions” (Neyman 1923). Rubin characterizes this as a way of describing “[v]ariation in efficacy of randomly chosen versions of the same treatment” (Rubin 1990), and this idea—that there can be variation in outcomes over randomly chosen version of the same treatment—that has its echo in current work on rerandomization. Our contribution here is to probe some of the consequences of researcher choices in the rerandomization context for exact significance tests for treatment effects, focusing on the ways in which there may or may not be an optimal degree of randomness in treatment assignment.
In the remainder of the paper, we answer the question of where experimenters should set the acceptance threshold for rerandomization, especially in small experiments. Our argument proceeds in three parts. First, we discuss how the minimum -value achievable under a rerandomization scheme is a function of the acceptance probability, . Then, we discuss how the minimum -value determines the width of fiducial intervals when these intervals are generated using permutation-based tests that account for the rerandomization procedure. Finally, we propose a simple pre-experiment analysis to explore the optimal degree of randomness under varying assumptions about the data-generating process. In brief, the experimenter can use knowledge of the covariates and prior assumptions about the data structure to select the degree of randomness allowed via the rerandomization threshold optimally.
We make these rerandomization tools available in open-source software. The repository, available at github.com/cjerzak/fastrerandomize-software contains tutorials on how to deploy this package on real data.
| Criteria | Neyman | Fisher | Rerandomization |
|---|---|---|---|
| Objective | Estimate causal effects and obtain unbiased estimates | Randomize to ensure the validity of significance tests | Balance covariates to improve causal effect precision |
| Statistical Assumption | Potential outcomes are fixed; random assignment of | Random assignment of | Random assignment of |
| Pre-design data requirements | Knowledge of number of observations (if completely randomizing) | Knowledge of number of observations (if completely randomizing) | Knowledge of number of observations (if completely randomizing); baseline pre-treatment covariates |
| Efficiency | Focused on deriving efficient estimators | Focused on exactness | Can improve efficiency, maintain exactness |
| Balance | Often achieved via stratification | Not guaranteed unless blocking, depends on sample size | Explicitly aims for balance |
2 Application to a Modern Agricultural Experiment: An Introduction
We motivate methodological problems discussed in this paper using a recent randomized experiment on agricultural tenancy contracts [7]. In this study, researchers randomized the assignment of five different tenancy contracts across three treatment arms to 304 tenant farmers in 237 Ugandan villages. The impetus for this study comes from the longstanding hypothesis in microeconomics that one reason for low agricultural production among tenant farmers is that tenancy contracts which turn a large share (e.g., half) of a tenant farmer’s crops to the landowner effectively incentivize low output [21]. This hypothesis is most prominently due to Alfred Marshall and thus is sometimes called Marshallian inefficiency.
To test this empirically, the authors randomized tenants into three treatment arms reflecting three different tenancy contracts: one where tenants kept 50% of their crop (the standard tenancy contract in Uganda, labeled the Control arm in the study), one where they kept 75% (labeled Treatment 1 in the study), and one where they kept 50% of their output but earned an additional fixed payment—either as a cash transfer (labeled Treatment 2A) or as part of a lottery (labeled Treatment 2B).
Consistent with the idea of Marshallian inefficiency, [7] find that, when tenants are able to keep more of their own output (75% versus 50%, Treatment 1 and Control in the study), they generate 60% greater agricultural output. Treatment 2—the additional payment—does not lead to greater output compared to the control tenancy contract.
This experiment has much in common with the experiments that Neyman was researching in the early twentieth century. Its aim is to improve agricultural yields, just as in many of the classic experiments that both Neyman and Fisher designed. And because there is variation between farms, plots, and farmer characteristics, it is critical that, at baseline (pre-experimentation), the studied units are balanced on covariates that could affect farm yield.
This study had a large number of units—large enough that any rerandomization strategy would probably not meaningfully have changed the main results (since rerandomization and t-tests are asymptotically equivalent [25]). However, it was carried out in partnership with one of the largest non-governmental organizations in Uganda, and researchers unable to work with such a large and well-funded partner might not have the opportunity to carry out such a large trial. Small trials where rerandomization is critical to finding an unbiased treatment effect with a narrow confidence interval are not uncommon in general, especially in clinical medicine [25].
Figure 1 displays imbalance in the full and a randomly selected 10% subset of the Treatment 1 and Control units is shown below. As we see, with a larger sample size, finite-sample balance is approximately maintained, but with a small experiment, there are larger differences between the treatment and control groups. These imbalances contribute to increased variance in ATE estimates, as an uncertainty estimate for the ATE in the full sample (s.e. 0.05) is much smaller than in the reduced sample (s.e. 0.29). Add to this some of the issues associated with small samples regarding degrees of randomness we shall discuss, we see that the study of rerandomization in small studies is of practical importance.


In this context, could we have improved precision of the treatment effect estimates for a 10% sample of the data using rerandomization-based approaches? Does rerandomization provide a route to precise treatment effect estimates in the case of possible covariate imbalance? If so, how should the rerandomization process proceed? We turn to this issue in the next section.
3 Rerandomization in Small Samples
3.1 Notation & Assumptions
Before we present our main arguments, it is useful to introduce the notation we will use going forward. Following the notation in [22], we assume that the experiment of interest is , meaning there is one experimental factor with two levels (i.e., a treatment and control level). Let if unit is treated and if unit is control. Say . The vector denotes treatment assignment. Let denote the data matrix containing pre-treatment covariates relevant to the outcome of interest. We are interested in the outcome matrix , where denotes the complete potential outcomes under control and denotes the complete potential outcomes under treatment. If denotes the vector of observed outcome values, . If we assume the sharp null hypothesis (zero treatment effect for every unit) and if we leave “ fixed and simulating many acceptable randomization assignments, , we can empirically create the distribution of any estimator,” conditional on the null hypothesis [22]. We make the additional assumption that the experimenter is interested in using Fisherian inference and that the treatment effects are constant and additive. Next, we define randomization-based fiducial intervals because these intervals are the core of both [22]’s insight and our contribution to the literature. Researchers can also exploit the duality between intervals and tests to form a fiducial interval from a randomization test.
3.2 Rerandomization and the Limits of Randomization Inference
Is it possible to take rerandomization “too far” in the sense that exact tests are no longer informative? We argue that it is indeed possible, in the sense of accepting so few randomizations that it is no longer possible to perform a meaningful randomization test. This important method of assessing significance in exact tests becomes non-informative.
Consider the following example: there are 8 experimental units, and we would like to test the effect of one factor at two levels (one treatment group and one control group). There is one background covariate, , which denotes the hour a test is conducted. For simplicity, assume that there are 8 observed values for , ranging from to . We can quantify the randomization balance with the square root of the quadratic loss:
| (1) |
where smaller values of are more desirable because they indicate better balance on . If the experiment is completely randomized and no rerandomization done, the smallest possible -value is and the average value is . If the experiment is pair-matched and complete randomization occurs within pairs for whom , the average improves to . However, the minimum possible -value in randomization inference is now . The minimum possible -value does not vary linearly with the maximum acceptable in completely randomized experiments (see Table 2).
| Maximum acceptable balance score | Minimum -value |
|---|---|
| 4 | 0.125 |
| 3 | 0.028 |
| 2 | 0.018 |
| 1 | 0.015 |
| 0 | 0.014 |
This example illustrates that low acceptance thresholds can invalidate the estimation of uncertainty in the sense that the minimum possible -value will eventually increase above . In addition, the minimum possible -value varies nonlinearly with the level of strictness the researcher adopts in accepting randomizations. These considerations suggest that it may be possible to systematically establish an acceptance criterion that will minimize the minimum possible -value while maximizing the balance improvement from rerandomization.
This insight formalizes the intuition, described in [10], that including every possible combination of treatment allocations will inevitably involve including a large number of irrelevant treatment allocations that do not help the researcher understand a possible treatment effect. “Randomization, after all, is random,” Deaton writes, “and searching for solutions at random is inefficient because it considers so many irrelevant possibilities.” One intuitive way to understand our approach to optimal rerandomization is that it has the advantage of, as Deaton writes, “provid[ing] the basis for making probabilistic statements about whether or not the difference [between treatment and control groups] arose by chance,” without the disadvantage of including many irrelevant treatment allocations, including ones which the researcher would specifically like to avoid.
3.3 Randomness in Rerandomization and Implications for Exact Randomization Tests
An important theoretical principle here is that
| Minimum -value |
This expression is true because the exact -value is defined as the fraction of hypothetical randomizations showing results as or more extreme than the observed value. If there are acceptable randomizations, then at least of the randomizations is as or more extreme than the observed value, so the minimum fraction is . When the set of acceptable randomizations gets smaller, the minimum -value invariably gets larger.
Setting in Figure 2, we see the clear non-linear relationship between and the minimum -value. This figure is consistent with the later Monte Carlo results of Figure 3.
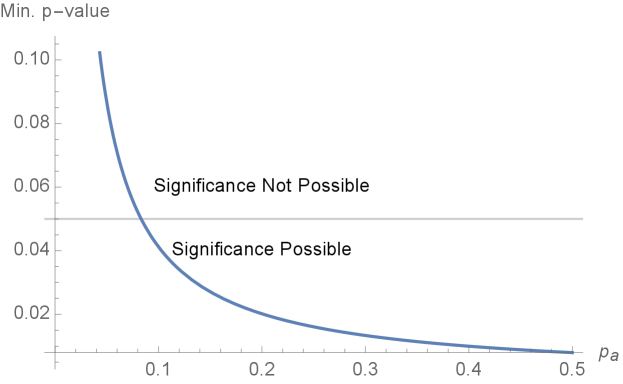
The preceding expression shows how there is a point after which, as experimenters reduce further , fiducial intervals get wider as well, since it becomes more and more difficult to reject for any . In the extreme, if the minimum -value is above , randomization-based fiducial interval will become non-informative at .
For the sake of illustration, we briefly examine an example from simulations that we will later explore more carefully (see §5.1 for design information). For each candidate randomization, we calculate , where
where denotes the fixed proportion of treated units and denotes the sample covariance matrix of . We then accept the top -th fraction of randomizations (in terms of balance) across all possible randomizations.222Note: We could also accept with probability based on the inverse CDF of . Due to the Multivariate Normality of X, we see that ; results are similar across approach.
We see in Figure 3 how, in small samples, different rerandomization acceptance thresholds induce different expected exact -values, where the expectation averages across the data-generating process. More stringent acceptance probabilities reduce imbalance and therefore finite-sample bias and sampling variability of estimated treatment effects (see [19], also [6]). However, at a certain point, the size of the acceptable rerandomization set no longer supports significant results, as eventually there is only one acceptable randomization (leading to a minimum and expected -value of 1).


As a consequence of this discussion, as the acceptance threshold gets more stringent, despite improved sampling variability of the treatment effect estimate, exact fiducial intervals will eventually become non-informative as the interval width goes to because the size of the rerandomization set can only yield a -value above 0.05. The exact threshold when non-informativity is reached will vary with the experimental design, but the general pattern is theoretically inevitable: if we shrink the size of the set in which a random choice gets made, we also shrink the reference set for assessing uncertainty. This simulation shows that the interval widths do not necessarily get monotonically smaller until the point of non-informativity but can start to increase well before that point (the exact change point will require future theoretical elucidation). In this context, how can we characterize “optimal” ways to rerandomize? What sources of uncertainty affect this optimization?

We can state these ideas more formally as follows.
Let denote the set of all possible ways of assigning observational units to treatment or control. Let denote the set of all algorithms that take as an input and give as an output a reduced set of acceptable assignments, . A subset of , denoted produces an such that . This subset contains [17]’s algorithm as a member, as well as any algorithm for returning a strictly optimal treatment vector (according to some imbalance measure).
Observation 1. Any member of the set, , yields infinitely wide fiducial intervals and has no ability to reject any null hypothesis using randomization tests.
Proof of Observation 1. By construction, the minimum possible -value of non-parametric randomization tests for any member of is
| Minimum -value |
When by definition, we have
| Minimum -value when is |
Thus, all -values will be greater than for , directly implying no ability to reject any exact null hypothesis. Moreover, by the construction of intervals from tests, it follows that every candidate endpoint of the fiducial interval will fail to be rejected. As a consequence, the fiducial interval will span the entire range of the outcome variable and will be infinitely wide for continuous outcomes. In sum, optimal treatment assignment leads to non-informative exact tests and confidence intervals. (We note that the problem of obtaining Neymanian randomization-based distributions for the test statistic is different and outside the scope of this work; see the discussion in [15, 4]).
There is an interesting connection to the discussion of randomness in rerandomization approaches here to the literature on matching contains a non-informativity of a similar nature. In that context, researchers must decide how much dissimilarity to allow between matches. This dissimilarity is often set with a caliper. [9], [1], and others have made recommendations about the optimal caliper size in the context of propensity score matching. These recommendations seek to reduce the imbalance as much as possible without ending up with no actual matches: if the caliper were exactly 0 and if the sample space were continuous, the analysis would be non-informative as no units could be matched. In both matching and rerandomization, then, we would like to create a situation where treated and control units are as similar as possible to one another. However, whereas achieving no acceptable matches affects point estimates, achieving a single acceptable randomization affects the evaluation of null hypotheses using exact inference.
This section illustrates an important tradeoff in rerandomization involving small samples: more stringent acceptance thresholds improve balance and reduce sampling variability in treatment effect estimates, but too stringent thresholds lead to non-informative hypothesis tests. Balancing these considerations, the choice of the rerandomization acceptance probability (or equivalently, the threshold ) is critical. In the next section, we will explore several approaches for setting the acceptance threshold.
4 Approaches to Choice of Rerandomization Threshold
The choice of involves considering multiple factors including improved covariate balance, number of acceptance randomizations, and computational time to randomization acceptance. The first two issues have been discussed already. The last issue is relevant because of the waiting time until an acceptable randomization is distributed according to a Geometric() distribution in the Multivariate Normal case. In general, we would expect to generate randomizations before accepting a single one. In the context of this tradeoff, there are several possible approaches.
4.1 An a priori threshold
As Morgan and Rubin write, “for small samples, care should be taken to ensure the number of acceptable randomizations does not become too small, for example, less than ” (p. 7, [22]). This view suggests that should be set as low as possible so long as the number of acceptable randomizations is greater than a fixed threshold that is determined a priori. In this sense, one decision rule might be to set such that
| minimum -value given |
The value of which yields can easily be found by inverting the formula for the minimum -value. On the one hand, it is difficult to know whether a given threshold is reasonable given the number of units available, the number of covariates observed pre-treatment, and the computational resources at researchers’ disposal. On the other hand, a threshold is easy to interpret and does not involve additional optimization steps.
4.2 Heuristic Tradeoff
Our simulations illustrated how the fiducial interval widths do not get monotonically smaller with until the point of non-informativity; rather, they can start to increase before that point in small samples. Thus, in selecting , there is a tradeoff between the variance gains from rerandomization and the decreasing size of the acceptable randomization set. We could therefore propose an alternative procedure to determine a value that explicitly trades off the costs and benefits of rerandomization.
Following [22], let . Let , where loosely denotes the remaining variance between treatment and control covariate means on a percentage basis. This notation allows us to emphasize the duality between setting and , where is defined as the acceptance probability and is defined as the acceptance threshold for .
We want both the minimum -value given and to be small: when the minimum -value is small, we can form tight fiducial intervals; when is small, we achieve a large reduction in variance for each covariate. Furthermore, both and are bounded between and . Thus, we want to set (or, equivalently ) such that
where determines the tradeoff between the variance reduction and the minimum possible -value. It is possible to derive an efficient solution to this optimization problem using gradient descent.
The optimization framework described here has several attractive features. First, given a minimum -value, we can also back out the value that this implies. Thus, this framing therefore allows for the evaluation of threshold choices. Second, when and there is only one covariate, the minimum -value will always be less than 0.05. Third, conditional on number of covariates, describes the same relative place on the objective function no matter the sample size, so in this sense, it is comparable across experiments. Finally, has an intuitive interpretation in that it captures the point at which we have gained most of the variance-reducing benefits of rerandomization but have not incurred significant inferential costs.
4.3 Optimal Rerandomization Threshold with Prior Design Information
The preceding discussion of heuristic tradeoffs describes dynamics regarding the choice of randomization threshold when no prior information is available. However, when prior design information on units is accessible, we can incorporate that information explicitly to help improve exact tests in a design-based manner.
Considerations of optimal precision have a long history in the analysis of treatment effects. For example, [23] and [24] discuss minimizing confidence interval width via stratum-size informed stratified sampling [18]. In general, in the Neymanian framework, optimal experimental design is that which generates unbiased and minimal variance estimates, usually under the condition of no prior assumptions on the data-generating process.
While discussions of power in the rerandomization framework are developed in [5] and the weighting of covariates in the rerandomization [20], there is less guidance in the literature about how to consider optimality in randomization choice from a Neymanian-informed Fisherian perspective—a task we turn to in this section.
Because rerandomization-based inference is simulation-based, the a priori calculation of the optimal acceptable balance threshold is difficult (although as mentioned asymptotic results are available [19]). We here show how we can use prior information on background covariates and (b) prior information about the plausible range of treatment effects to select the covariate balance threshold so as to explicitly minimize the acceptable randomization threshold minimizing the expected -value. The expectation is taken over the aforementioned sources of prior information, with the intuition being that when we have an estimate for how prior information is relevant for predicting the outcome, we can use this estimate for determining how to select an optimal point on the tradeoff between better balance and sufficient randomness to perform exact rerandomization inference.
Formally, we select the rerandomization threshold using knowledge of the design—in particular, the covariates and prior assumptions on plausible distributions over treatment effect and relationships between the baseline covariates and outcome:
with being the vector of individual treatment effects, defining the parameters of the potential outcome model, denoted using , and defining the distribution over the treatment assignment vector as a function of the acceptance probability, . The approach here involves simulating potential outcomes under prior knowledge, calculating the expected -value under various acceptance thresholds, and selecting the threshold minimizing this quantity (thereby maximizing power to reject the exact null).
By deciding on the acceptance threshold before analyzing the data, we use the principles of design-based inference pioneered by Neyman and contemporaries. And, by incorporating rerandomization, we improve treatment effect estimates while maintaining the ability to calculate valid exact intervals in a way that incorporates information about the structure of randomness in the randomization inference.
In summary, selecting the best rerandomization threshold in a given experiment is difficult to do in small experiments given without guidance from asymptotic results. However, we can use simulation-based methods to form an approximation for how -values will on average operate under the prior design knowledge. These approximations are then useful in pre-analysis design decisions, especially as investigators can select the acceptance threshold minimizing a priori expected -values.
5 Exploring Degrees of Randomness in Rerandomization via Simulation
5.1 Simulation Design
We explore the impact of varying levels of randomness in rerandomization on inference through simulation. We simulate potential outcomes under a linear model:
where covariates, are drawn from a Multivariate Gaussian with diagonal covariance and where are independent Gaussian error terms. We study an environment where errors are , allowing us to assess robustness to noise in the potential outcomes. We also study results across low and high treatment effect strength conditions (where ). Finally, we vary the number of observations, .
We then generate a sequence of acceptable randomizations, ranging from 10 to the set of all possible completely randomized treatment vectors, to evaluate performance at different rerandomization acceptance thresholds. We run the pre-analysis design procedure described in §4.3, which returns an estimated expected -value using the prior design information. We compute the estimated expected -value from each Monte Carlo iteration. We then compare the range of estimates against the true expected -value minimizer, analyzing both bias and relative RMSE, where for interpretability the RMSE estimate has been normalized by the expected RMSE under uniform selection of the acceptable randomization threshold, . We assess performance averaging over randomness in the covariates and outcome.
5.2 Simulation Results
Figure 5 displays the main results. In the left panel, we see that the Bayesian selection procedure for the rerandomization threshold described in §4.3 is somewhat downwardly biased under the non-informative priors specified here, both in the small (“S”) and large (“L”) treatment effect cases. In other words, it yields an acceptance probability that is somewhat lower than what we find to be optimal via Monte Carlo. However, in the right panel, we see that the procedure generates lower relative RMSE compared to uniform selection of across the interval . This finding, again robust to treatment effect size, indicates that there is a systematic structure in the randomness surrounding the rerandomization problem that can be leveraged in pre-design analysis decisions.

Overall, we find a large decrease in relative root mean squared error (RMSE) when using the pre-analysis rerandomization threshold selection procedure described §4.3. Rerandomization allows robust causal inference in cases with high noise levels and smaller sample sizes.
6 Application to a Modern Agricultural Experiment, Revisited
Having shown the possible improvements with our optimal rerandomization approach via simulation, we now explore the same dynamics using data from the real agricultural experiment on tenancy contracts discussed in §2.
To do this, we first take a random 10% subsample of the units in the experiment, to illustrate what it would have been like to carry out a much smaller, less costly experiment than done by the original authors. We then carry out a semi-synthetic simulation involving the experimental data.
We first fit an OLS model on the full data to estimate outcome model parameters (along with variance-covariances). We then sample these coefficients from a Multivariate Gaussian to simulate counterfactual outcomes for the potential outcomes of each unit in random 10% subsamples. We need this semi-synthetic simulation protocol to generate the complete potential outcomes table. We use the fixed covariate profiles of units, and average uncertainty in the outcome imputations when reporting assessing performance.
With this semi-synthetic setup where true causal effects are known (and non-zero), we find, as shown in Figure 6, that the true acceptance probability that minimizes the expected -value is 0.008. This is quite close to the selected value from the pre-design procedure described in §4.3 (value near 0.008; non-informative Gaussian priors for assumed structural parameters used). The implication of these results for practice are that investigators should in this case employ some rerandomization so that there are about 128 acceptable randomization in terms of balance out of the set of all possible 184,756 complete randomizations. When they do so, they would based on the prior design structure expect a -value of 0.027 compared to 0.10 without any rerandomization.
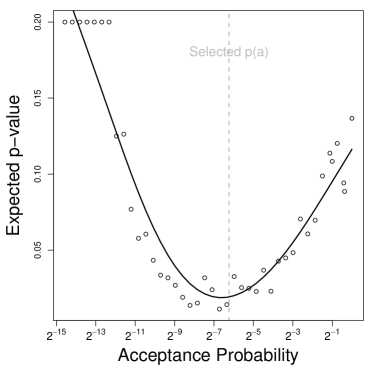
We next observe in Figure 7 the degree to which the difference-in-means estimates for the ATE fluctuate across repeated samples in relation to the acceptance probability. When the acceptance probability remains high, there’s a corresponding increase in the average imbalance—and therefore sampling variability. As the acceptance probability diminishes, estimation variance shrinks in tandem with improved balance. The selection procedure elucidated previously selects an acceptance probability that not only ensures a precisely estimated ATE (where precision is meant in terms of sampling variability) but also a testing framework leading to improved power to reject the null, evident from the minimum expected -value we noticed in Figure 6.
Without rerandomization, the finite-sample ’s deviate 14% or more from the true in this semi-synthetic design, whereas with the rerandomization specified by the pre-experimental design analysis, they deviate by less than 5%.

7 Discussion of Limitations & Future Work
The discussion presented in this paper relies on several key assumptions that are worth highlighting.
First, we focus our discussion on Fisherian permutation-based inference. As mentioned, the story of how significance tests interact with rerandomization threshold choice may differ for Neymanian repeated sampling inference. However, we note that some of the principles we have discussed here apply (at least in the extreme) for other kinds of randomization-based inference that test null hypotheses beyond the exact null—e.g., the conditional independence null used in [8] where randomization inference is performed using draws from the assignment distribution over treatment vector.
Second, our simulation results assume additivity and constancy of treatment effects. This rules out treatment effect heterogeneity or interactions between covariates and treatment. While rerandomization can still be beneficial under weaker assumptions, the relationship between the acceptance probability and inference may differ in more complex settings. Investigating rerandomization with heterogeneous effects is an important area for continued work.
Finally, we note that the task of achieving very low rerandomization thresholds is computationally intensive for experiments involving many units. While the computational tools introduced in the fastrerandomize package accompanying paper make possible the analysis of the full permutation set over treatment vectors ranging in size into the hundreds of millions using an accelerated linear algebra compiler, further computational effort to adaptively build this set would enable researchers to achieve better balance while maintaining use of exact inference or conditional randomization tests.
8 Conclusion
In this paper, we formalize the idea that rerandomization can be taken “too far,” in the sense that the variance-reduction benefits of rerandomization can be outweighed by the costs of having undesirably wide permutation-based fiducial intervals when acceptance probabilities are low. We accomplish this formalization by deriving the minimum possible -value, which turns out to be a function of the acceptance threshold and the number of units.
In this light, we presented a unified approach to the problem of determining an optimal acceptance threshold. While the decision for a rerandomization threshold traditionally operates in the absence of prior information, the availability of prior design details helps structure the randomness in a way that can be leveraged in the design phase. By leveraging this information, researchers can hone experimental precision in a design-centric fashion, a concept rooted in the foundations set in [23] and [24]. Drawing from the Neymanian ethos, the ideal experimental design offers unbiased and variance-minimized estimates, typically devoid of data-generating presumptions. Notably, as the rerandomization framework is inherently simulation-based, determining an a priori optimal balance threshold can be intricate, despite some extant asymptotic results [19].
Although Fisherian and Neymanian approaches to experimental treatment effect estimation differ, and although rerandomization—because it is grounded in randomization inference—is more aligned with a Fisherian approach, both researchers were concerned with the efficient use of data. Rerandomization can make better use of available data by improving covariate balance, thereby serving the interests of efficiency from both Fisherian and Neymanian perspectives.
We have contributed to the understanding of rerandomization as a kind of slippery slope: at the top of this slope, all randomizations are accepted and, at the bottom, only one randomization is accepted but it becomes impossible to estimate uncertainty using important non-parametric tests. Our paper thus helps experimenters to understand where they are on this slope, where they might most prefer to be, and how they can arrive there.
Over thirty years ago, [26] pointed out that, even though Fisher’s and Neyman’s approaches to hypothesis testing were distinct, they were “complementary.” While Fisher relied on a sharp null and Neyman took a repeated-sampling approach over nonnull distributions, both have the intuition that examining all ways that treatments could be assigned can help researchers understand how the treatment changed outcomes for treated units relative to similarly situated control units. In this paper, we hope to suggest one method that uses these same intuitions to make a methodological contribution in today’s very different world of ubiquitous randomized experiments and immense computing power. By strategically winnowing down the set of possible randomizations to an optimum number, we contribute an approach that emphasizes balance while reaping the benefits of random variation.
Data availability statement: Data and code to replicate results, as well as a tutorial in installing and using the fastrerandomize package, are or will be available at github.com/cjerzak/fastrerandomize-software.
References
- 1 Peter C Austin “Optimal Caliper Widths for Propensity-Score Matching When Estimating Differences in Means and Differences in Proportions in Observational Studies” In Pharmaceutical Statistics 10.2, 2011, pp. 150–161 DOI: 10.1002/pst.433
- 2 Abhijit Banerjee, Sylvain Chassang, Sergio Montero and Erik Snowberg “A Theory of Experimenters”, 2017
- 3 Dimitris Bertsimas, Mac Johnson and Nathan Kallus “The Power of Optimization Over Randomization in Designing Experiments Involving Small Samples” In Operations Research 63.4 INFORMS, 2015, pp. 868–876
- 4 Zach Branson and Tirthankar Dasgupta “Sampling-Based Randomized Designs for Causal Inference Under the Potential Outcomes Framework” In arXiv preprint arXiv:1808.01691, 2018
- 5 Zach Branson, Xinran Li and Peng Ding “Power and Sample Size Calculations for Rerandomization” In arXiv preprint arXiv:2201.02486, 2022
- 6 Zach Branson and Luke Miratrix “Randomization Tests that Condition on Non-Categorical Covariate Balance” In Journal of Causal Inference 7.1, 2019
- 7 Konrad B Burchardi, Selim Gulesci, Benedetta Lerva and Munshi Sulaiman “Moral Hazard: Experimental Evidence from Tenancy Contracts” In The Quarterly Journal of Economics 134.1 Oxford University Press, 2019, pp. 281–347
- 8 Emmanuel Candes, Yingying Fan, Lucas Janson and Jinchi Lv “Panning for Gold: Model-X Knockoffs for High Dimensional Controlled Variable Selection” In Journal of the Royal Statistical Society Series B: Statistical Methodology 80.3 Oxford University Press, 2018, pp. 551–577
- 9 William G. Cochran and Donald B. Rubin “Controlling Bias in Observational Studies: A Review” In Sankhya: The Indian Journal of Statistics, Series A (1961-2002) 35.4, 1973, pp. 417–446 URL: http://www.jstor.org/stable/25049893
- 10 Angus Deaton “Randomization in the Tropics Revisited: A Theme and Eleven Variations”, 2020
- 11 Peng Ding and Xinran Li “General Forms of Finite Population Central Limit Theorems with Applications to Causal Inference” In Journal of the American Statistical Association 112.520, 2017, pp. 1759–1796
- 12 Esther Duflo and Abhijit Banerjee “Handbook of Field Experiments” Elsevier, 2017
- 13 Paul H. Garthwaite “Confidence Intervals from Randomization Tests” In Biometrics 52.4, 1996, pp. 1387–1393 DOI: 10.2307/2532852
- 14 William S. Gosset “Comparison Between Balanced and Random Arrangements of Field Plots” In Biometrika JSTOR, 1938, pp. 363–378
- 15 Guido W. Imbens and Donald B. Rubin “Causal Inference for Statistics, Social, and Biomedical Sciences” Cambridge: Cambridge University Press, 2015 URL: http://www.cambridge.org/US/academic/subjects/statistics-probability/statistical-theory-and-methods/causal-inference-statistics-social-and-biomedical-sciences-introduction
- 16 Nathan Kallus “Optimal A Priori Balance in the Design of Controlled Experiments” In Journal of the Royal Statistical Society: Series B (Statistical Methodology) 80.1 Wiley Online Library, 2018, pp. 85–112
- 17 Maximilian Kasy “Why Experimenters Might Not Always Want to Randomize, and What They Could Do Instead” In Political Analysis 24.3, 2016, pp. 324–338
- 18 Adam P Kubiak and Paweł Kawalec “Prior Information in Frequentist Research Designs: The Case of Neyman’s Sampling Theory” In Journal for General Philosophy of Science 53.4 Springer, 2022, pp. 381–402
- 19 Xinran Li, Peng Ding and Donald B. Rubin “Asymptotic Theory of Rerandomization in Treatment-Control Experiments” In Proceedings of the National Academy of Sciences 115.37 National Academy of Sciences, 2018, pp. 9157–9162 DOI: 10.1073/pnas.1808191115
- 20 Zhaoyang Liu, Tingxuan Han, Donald B Rubin and Ke Deng “Bayesian Criterion for Re-Randomization” In arXiv preprint arXiv:2303.07904, 2023
- 21 Alfred Marshall “The Principles of Economics”, 1890
- 22 Kari Lock Morgan and Donald B. Rubin “Rerandomization to Improve Covariate Balance in Experiments” In The Annals of Statistics 40.2, 2012, pp. 1263–1282 URL: http://projecteuclid.org.ezp-prod1.hul.harvard.edu/euclid.aos/1342625468
- 23 Jerzy Neyman “Zarys Teorji I Praktyki Badania Struktury Ludności Metodą Reprezentacyjna” Z zasiłkiem Kasy im Mianowskiego Instytutu Popierania Nauki, 1933
- 24 Jerzy Neyman “Recognition of Priority” In Jour. Roy. Stat. Soc 115, 1952, pp. 602
- 25 Michael A Proschan and Lori E Dodd “Re-randomization Tests in Clinical Trials” In Statistics in medicine 38.12 Wiley Online Library, 2019, pp. 2292–2302
- 26 Donald B Rubin “Comment: Neyman (1923) and Causal Inference in Experiments and Observational Studies” In Statistical Science 5.4 Citeseer, 1990, pp. 472–480
- 27 Leonard Jimmie Savage “Subjective Probability and Statistical Practice” Mathematical Sciences Directorate, Office of Scientific Research, US Air Force, 1959
- 28 Jose F. Soares and C.F.J. Wu “Optimality of Random Allocation Design for the Control of Accidental Bias in Sequential Experiments” In Journal of Statistical Planning and Inference 11.1, 1985, pp. 81–87 DOI: 10.1016/0378-3758(85)90027-8
9 Appendix
9.1 Defining Randomization-based Fiducial Intervals
Randomization intervals incorporate randomness only through variation in the treatment vector, and do not explicitly make a reference to repeated experiments (as in Neyman’s classical confidence intervals). In this case, we can produce an interval by finding the set of all null hypotheses that the observed data would fail to reject. If we recall the constant and additive treatment effect assumption (), then the hypotheses can be written as
An -level fiducial interval for consists of the set of such that the observed test statistic would not lead to a rejection of the null hypothesis at significance-level . Here, when , the randomization test is conducted by constructing
Then, keeping fixed, we permute the treatment assignment vector, and calculate by adding to the treatment group outcomes under the permutation. This procedure generates a distribution of under the null . We can use this distribution to calculate a -value for under the null. We can form an interval for by finding the values of which generate a -value greater than or equal to . [13] discuss an efficient algorithm for obtained randomization-based fiducial intervals, which searches for the interval endpoints using a procedure based on the Robbins-Monro search process.
9.2 Proofs of Observations 1
In this section, we define for notational convenience. We assume that the covariates are Multivariate Gaussian and the imbalance metric is the Mahalanobis distance between treated and control means. Then, we can appeal to the finite-population Central Limit Theorem to assume is Multivariate Normal and therefore that [11].
9.2.1 Proof of Observation 1
For rerandomization, each accepted is equally likely to have been drawn (since each , accepted or not, was drawn with probability ). Recall that, if all outcomes are equally likely, the probability of the event given is equal to the number of outcomes in which that event occurs (which is ) divided by the total number of outcomes (which is ). This means
Another way to see this is to consider how
where the last line uses the fact that . The average waiting time for the first acceptance is governed by a Geometric distribution with probability parameter . By the independence of the sampling process, the waiting time until the acceptance is given by .
9.3 Kasy (2016) in the Rerandomization Framework
We argued in the above that Kasy’s optimal assignment procedure is a special case of rerandomization in which the only acceptable randomization is the one that provides optimal covariate balance. Let the matrix include all observed covariates that the experimenter seeks to balance. Let denote the -dimensional treatment assignment vector indicating the treatment group for each unit. In the notation of Morgan and Rubin, the rerandomization criterion can be written as
With the appropriate , Kasy’s non-deterministic assignment procedure can be considered a special case of rerandomization. That is, we will obtain Kasy’s optimal assignment if we define as follows, letting denote either Bayesian or minimax risk, letting denote the choice of estimator, and letting denote a generic randomization procedure independent of and ,
With units, we will obtain a such that with probability . The expected wait time until obtaining this is given by a Geometric distribution, with mean . This calculation implies that, as soon as , the expected wait-time will exceed million rerandomization draws if rerandomization is used [28].
This section has put our discussion in closer dialogue Kasy’s work in order to further illustrate how Kasy’s deterministic procedure for optimal treatment assignment is a special case of rerandomization developed in [22].