Deformed semicircle law and concentration of nonlinear random matrices for ultra-wide neural networks
Abstract.
In this paper, we investigate a two-layer fully connected neural network of the form , where is a deterministic data matrix, and are random Gaussian weights, and is a nonlinear activation function. We study the limiting spectral distributions of two empirical kernel matrices associated with : the empirical conjugate kernel (CK) and neural tangent kernel (NTK), beyond the linear-width regime (). We focus on the ultra-wide regime, where the width of the first layer is much larger than the sample size . Under appropriate assumptions on and , a deformed semicircle law emerges as and . We first prove this limiting law for generalized sample covariance matrices with some dependency. To specify it for our neural network model, we provide a nonlinear Hanson-Wright inequality that is suitable for neural networks with random weights and Lipschitz activation functions. We also demonstrate non-asymptotic concentrations of the empirical CK and NTK around their limiting kernels in the spectral norm, along with lower bounds on their smallest eigenvalues. As an application, we show that random feature regression induced by the empirical kernel achieves the same asymptotic performance as its limiting kernel regression under the ultra-wide regime. This allows us to calculate the asymptotic training and test errors for random feature regression using the corresponding kernel regression.
1. Introduction
Nowadays, deep neural networks have become one of the leading models in machine learning, and many theoretical results have been established to understand the training and generalization of neural networks. Among them, two kernel matrices are prominent in deep learning theory: Conjugate Kernel (CK) [Nea95, Wil97, RR07, CS09, DFS16, PLR+16, SGGSD17, LBN+18, MHR+18] and Neural Tangent Kernel (NTK) [JGH18, DZPS19, AZLS19]. The CK matrix defined in (1.5), which has been exploited to study the generalization of random feature regression, is the Gram matrix of the output of the last hidden layer on the training dataset. While the NTK matrix, defined in (1.8), is the Gram matrix of the Jacobian of the neural network with respect to training parameters, characterizing the performance of a wide neural network through gradient flows. Both are related to the kernel machine and help us explore the generalization and training process of the neural network.
We are interested in the behaviors of CK and NTK matrices at random initialization. A recent line of work has proved that these two random kernel matrices will converge to their expectations when the width of the network becomes infinitely wide [JGH18, ADH+19b]. Although CK and NTK are usually referred to as these expected kernels in literature, we will always call CK and NTK the empirical kernel matrices in this paper, with a slight abuse of terminology.
In this paper, we study the random CK and NTK matrices of a two-layer fully connected neural network with input data , given by such that
| (1.1) |
where is the weight matrix for the first layer, are the second layer weights, and is a nonlinear activation function applied to the matrix element-wisely. We assume that all entries of and are independently identically distributed by the standard Gaussian . We will always view the input data as a deterministic matrix (independent of the random weights in and ) with certain assumptions.
In terms of random matrix theory, we study the difference between these two kernel matrices (CK and NTK) and their expectations with respect to random weights, showing both asymptotic and non-asymptotic behaviors of these differences as the width of the first hidden layer is growing faster than the number of samples . As an extension of [FW20], we prove that when , the centered CK and NTK with appropriate normalization have the limiting eigenvalue distribution given by a deformed semicircle law, determined by the training data spectrum and the nonlinear activation function. To prove this global law, we further set up a limiting law theorem for centered sample covariance matrices with dependent structures and a nonlinear version of the Hanson-Wright inequality. These two results are very general, which makes them potentially applicable to different scenarios beyond our neural network model. For the non-asymptotic analysis, we establish concentration inequalities between the random kernel matrices and their expectations. As a byproduct, we provide lower bounds of the smallest eigenvalues of CK and NTK, which are essential for the global convergence of gradient-based optimization methods when training a wide neural network [OS20, NM20, Ngu21]. Because of the non-asymptotic results for kernel matrices, we can also describe how close the performances of the random feature regression and the limiting kernel regression are with a general dataset, which allows us to compute the limiting training error and generalization error for the random feature regression via its corresponding kernel regression in the ultra-wide regime.
1.1. Nonlinear random matrix theory in neural networks
Recently, the limiting spectra of CK and NTK at random initialization have received increasing attention from a random matrix theory perspective. Most of the papers focus on the linear-width regime , using both the moment method and Stieltjes transforms. Based on moment methods, [PW17] first computed the limiting law of the CK for two-layer neural networks with centered nonlinear activation functions, which is further described as a deformed Marchenko–Pastur law in [Péc19]. This result has been extended to sub-Gaussian weights and input data with real analytic activation functions by [BP21], even for multiple layers with some special activation functions. Later, [ALP22] generalized their results by adding a random bias vector in pre-activation and a more general input data matrix. Similar results for the two-layer model with a random bias vector and random input data were analyzed in [PS21] by cumulant expansion. In parallel, by Stieltjes transform, [LLC18] investigated the CK of a one-hidden-layer network with general deterministic input data and Lipschitz activation functions via some deterministic equivalent. [LCM20] further developed a deterministic equivalent for the Fourier feature map. With the help of the Gaussian equivalent technique and operator-valued free probability theory, the limit spectrum of NTK with one-hidden layer has been analyzed in [AP20]. Then the limit spectra of CK and NTK of a multi-layer neural network with general deterministic input data have been fully characterized in [FW20], where the limiting spectrum of CK is given by the propagation of the Marchenko–Pastur map through the network, while the NTK is approximated by the linear combination of CK’s of each hidden layer. [FW20] illustrated that the pairwise approximate orthogonality assumption on the input data is preserved in all hidden layers. Such a property is useful to approximate the expected CK and NTK. We refer to [GLBP21] as a summary of the recent development in nonlinear random matrix theory.
Most of the results in nonlinear random matrix theory focus on the case when is proportional to as . We build a random matrix result for both CK and NTK under the ultra-wide regime, where and . As an intrinsic interest of this regime, this exhibits the connection between wide (or overparameterized) neural networks and kernel learning induced by limiting kernels of CK and NTK. In this article, we will follow general assumptions on the input data and activation function in [FW20] and study the limiting spectra of the centered and normalized CK matrix
| (1.2) |
where . Similar results for the NTK can be obtained as well. To complete the proofs, we establish a nonlinear version of Hanson-Wright inequality, which has previously appeared in [LLC18, LCM20]. This nonlinear version is a generalization of the original Hanson-Wright inequality [HW71, RV13, Ada15], and may have various applications in statistics, machine learning, and other areas. In addition, we also derive a deformed semicircle law for normalized sample covariance matrices without independence in columns. This result is of independent interest in random matrix theory as well.
1.2. General sample covariance matrices
We observe that the random matrix defined above has independent and identically-distributed rows. Hence, is a generalized sample covariance matrix. We first inspect a more general sample covariance matrix whose rows are independent copies of some random vector . Assuming and both go to infinity but , we aim to study the limiting empirical eigenvalue distribution of centered Wishart matrices in the form of (1.2) with certain conditions on . This regime is also related to the ultra-high dimensional setting in statistics [QLY21].
This regime has been studied for decades starting in [BY88], where has i.i.d. entries and . In this setting, by the moment method, one can obtain the semicircle law. This normalized model also arises in quantum theory with respect to random induced states (see [Aub12, AS17, CYZ18]). The largest eigenvalue of such a normalized sample covariance matrix has been considered in [CP12]. Subsequently, [CP15, LY16, YXZ22, QLY21] analyzed the fluctuations for the linear spectral statistics of this model and applied this result to hypothesis testing for the covariance matrix. A spiked model for sample covariance matrices in this regime was recently studied in [Fel21]. This kind of semicircle law also appears in many other random matrix models. For instance, [Jia04] showed this limiting law for normalized sample correlation matrices. Also, the semicircle law for centered sample covariance matrices has already been applied in machine learning: [GKZ19] controlled the generalization error of shallow neural networks with quadratic activation functions by the moments of this limiting semicircle law; [GZR22] derived a semicircle law of the fluctuation matrix between stochastic batch Hessian and the deterministic empirical Hessian of deep neural networks.
For general sample covariance, [WP14] considered the form with deterministic and , where consists of i.i.d. entries with mean zero and variance one. The same result has been proved in [Bao12] by generalized Stein’s method. Unlike previous results, [Xie13] tackled the general case, only assuming has independent rows with some deterministic covariance . Though this is similar to our model in Section 4, we will consider more general assumptions on each row of , which can be directly verified in our neural network models.
1.3. Infinite-width kernels and the smallest eigenvalues of empirical kernels
Besides the above asymptotic spectral fluctuation of (1.2), we provide non-asymptotic concentrations of (1.2) in spectral norm and a corresponding result for the NTK. In the infinite-width networks, where and are fixed, both CK and NTK will converge to their expected kernels. This has been investigated in [DFS16, SGGSD17, LBN+18, MHR+18] for the CK and [JGH18, DZPS19, AZLS19, ADH+19b, LRZ20] for the NTK. Such kernels are also called infinite-width kernels in literature. In this current work, we present the precise probability bounds for concentrations of CK and NTK around their infinite-width kernels, where the difference is of order . Our results permit more general activation functions and input data only with pairwise approximate orthogonality, albeit similar concentrations have been applied in [AKM+17, SY19, AP20, MZ22, HXAP20].
A corollary of our concentration is the explicit lower bounds of the smallest eigenvalues of the CK and the NTK. Such extreme eigenvalues of the NTK have been utilized to prove the global convergence of gradient descent algorithms of wide neural networks since the NTK governs the gradient flow in the training process, see, e.g., [COB19, DZPS19, ADH+19a, SY19, WDW19, OS20, NM20, Ngu21]. The smallest eigenvalue of NTK is also crucial for proving generalization bounds and memorization capacity in [ADH+19a, MZ22]. Analogous to Theorem 3.1 in [MZ22], our lower bounds are given by the Hermite coefficients of the activation function . Besides, the lower bound of NTK for multi-layer ReLU networks is analyzed in [NMM21].
1.4. Random feature regression and limiting kernel regression
Another byproduct of our concentration results is to measure the difference of performance between random feature regression with respect to and corresponding kernel regression when . Random feature regression can be viewed as the linear regression of the last hidden layer, and its performance has been studied in, for instance, [PW17, LLC18, MM19, LCM20, GLK+20, HL22, LD21, MMM21, LGC+21] under the linear-width regime111This linear-width regime is also known as the high-dimensional regime, while our ultra-wide regime is also called a highly overparameterized regime in literature, see [MM19].. In this regime, the CK matrix is not concentrated around its expectation
| (1.3) |
under the spectral norm, where is the standard normal random vector in . But the limiting spectrum of CK is exploited to characterize the asymptotic performance and double descent phenomenon of random feature regression when proportionally. Several works have also utilized this regime to depict the performance of the ultra-wide random network by letting first, getting the asymptotic performance and then taking (see [MM19, YBM21]). However, there is still a difference between this sequential limit and the ultra-wide regime. Before these results, random feature regression has already attracted significant attention in that it is a random approximation of the RKHS defined by population kernel function such that
| (1.4) |
when width is sufficiently large [RR07, Bac13, RR17, Bac17]. We point out that Theorem 9 of [AKM+17] has the same order of the approximation as ours, despite only for random Fourier features.
In our work, the concentration between empirical kernel induced by and the population kernel matrix defined in (1.4) for leads to the control of the differences of training/test errors between random feature regression and kernel regression, which were previously concerned by [AKM+17, JSS+20, MZ22, MMM21] in different cases. Specifically, [JSS+20] obtained the same kind of estimation but considered random features sampled from Gaussian Processes. Our results explicitly show how large width should be so that the random feature regression gets the same asymptotic performance as kernel regression [MMM21]. With these estimations, we can take the limiting test error of the kernel regression to predict the limiting test error of random feature regression as and . We refer [LR20, LRZ20, LLS21, MMM21], [BMR21, Section 4.3] and references therein for more details in high-dimensional kernel ridge/ridgeless regressions. We emphasize that the optimal prediction error of random feature regression in linear-width regime is actually achieved in the ultra-wide regime, which boils down to the limiting kernel regression, see [MM19, MMM21, YBM21, LGC+21]. This is one of the motivations for studying the ultra-wide regime and the limiting kernel regression.
In the end, we would like to mention the idea of spectral-norm approximation for the expected kernel , which helps us describe the asymptotic behavior of limiting kernel regression. For specific activation , kernel has an explicit formula, see [LLC18, LC18, LCM20], whereas generally, it can be expanded in terms of the Hermite expansion of [PW17, MM19, FW20]. Thanks to pairwise approximate orthogonality introduced in [FW20, Definition 3.1], we can approximate in the spectral norm for general deterministic data . This pairwise approximate orthogonality defines how orthogonal is within different input vectors of . With certain i.i.d. assumption on , [LRZ20] and [BMR21, Section 4.3], where the scaling , for , determined which degree of the polynomial kernel is sufficient to approximate . Instead, our theory leverages the approximate orthogonality among general datasets to obtain a similar approximation. Our analysis presumably indicates that the weaker orthogonality has, the higher degree of the polynomial kernel we need to approximate the kernel .
1.5. Preliminaries
Notations
We use as the normalized trace of a matrix and . Denote vectors by lowercase boldface. is the spectral norm for matrix , denotes the Frobenius norm, and is the -norm of any vector . is the Hadamard product of two matrices, i.e., . Let and be the expectation and variance only with respect to random vector . Given any vector , is a diagonal matrix where the main diagonal elements are given by . is the smallest eigenvalue of any Hermitian matrix .
Before stating our main results, we describe our model with assumptions. We first consider the output of the first hidden layer and empirical Conjugate Kernel (CK):
| (1.5) |
Observe that the rows of matrix are independent and identically distributed since only is random and is deterministic. Let the -th row of be , for . Then, we obtain a sample covariance matrix,
| (1.6) |
which is the sum of independent rank-one random matrices in . Let the second moment of any row be (1.3). Later on, we will approximate based on the assumptions of input data .
Next, we define the empirical Neural Tangent Kernel (NTK) for (1.1), denoted by . From Section 3.3 in [FW20], the -th entry of can be explicitly written as
| (1.7) |
where is the -th row of weight matrix , is the -th column of matrix , and is -th entry of the output layer . In the matrix form, can be written by
| (1.8) |
where the -th column of is given by
| (1.9) |
We introduce the following assumptions for the random weights, nonlinear activation function , and input data. These assumptions are basically carried on from [FW20].
Assumption 1.1.
The entries of and are i.i.d. and distributed by .
Assumption 1.2.
Activation function is a Lipschitz function with the Lipschitz constant . Assume that is centered and normalized with respect to such that
| (1.10) |
Define constants and by
| (1.11) |
Furthermore, satisfies either of the following:
-
(1)
is twice differentiable with , or
- (2)
Analogously to [HXAP20], our Assumption 1.2 permits to be the commonly used activation functions, including ReLU, Sigmoid, and Tanh, although we have to center and normalize the activation functions to guarantee (1.10). Such normalized activation functions exclude some trivial spike in the limit spectra of CK and NTK [BP21, FW20]. The foregoing assumptions ensure our nonlinear Hanson-Wright inequality in the proof. As a future direction, going beyond Gaussian weights and Lipschitz activation functions may involve different types of concentration inequalities.
Next, we present the conditions of the deterministic input data and the asymptotic regime for our main results. Define the following -orthonormal property for our data matrix .
Definition 1.3.
For given any , matrix is -orthonormal if for any distinct columns in , we have
and also
Assumption 1.4.
Let such that
-
(a)
;
-
(b)
is -orthonormal such that as ;
-
(c)
The empirical spectral distribution of converges weakly to a fixed and non-degenerate probability distribution on .
In above (b), the -orthonormal property with is a quantitative version of pairwise approximate orthogonality for the column vectors of the data matrix . When , it holds, with high probability, for many random with independent columns , including the anisotropic Gaussian vectors with and , vectors generated by Gaussian mixture models, and vectors satisfying the log-Sobolev inequality or convex Lipschitz concentration property. See [FW20, Section 3.1] for more details. Specifically, when ’s are independently sampled from the unit sphere , is -orthonormal with high probability where and as . In this case, for any , we have . In our theory, we always treat as a deterministic matrix. However, our results also work for random input independent of weights and by conditioning on the high probability event that satisfies -orthonormal property. Unlike data vectors with independent entries, our assumption is promising to analyze real-world datasets [LGC+21] and establish some -dependent deterministic equivalents like [LCM20].
The following Hermite polynomials are crucial to the approximation of in our analysis.
Definition 1.5 (Normalized Hermite polynomials).
The -th normalized Hermite polynomial is given by
Here form an orthonormal basis of , where denotes the standard Gaussian distribution. For , the inner product is defined by
Every function can be expanded as a Hermite polynomial expansion
where is the -th Hermite coefficient defined by
In the following statements and proofs, we denote . Then for any , we have
| (1.12) |
Specifically, . Let . We define the inner-product kernel random matrix by applying entrywise to . Define a deterministic matrix
| (1.13) |
where the -th entry of is for . We will employ as an approximation of the population covariance in (1.3) in the spectral norm when .
For any Hermitian matrix with eigenvalues , the empirical spectral distribution of is defined by
We write if weakly as . The main tool we use to study the limiting spectral distribution of a matrix sequence is the Stieltjes transform defined as follows.
Definition 1.6 (Stieltjes transform).
Let be a probability measure on . The Stieltjes transform of is a function defined on the upper half plane by
For any Hermitian matrix , the Stieltjes transform of the empirical spectral distribution of can be written as . We call the resolvent of .
2. Main results
2.1. Spectra of the centered CK and NTK
Our first result is a deformed semicircle law for the CK matrix. Denote by the distribution of with sampled from the distribution . The limiting law of our centered and normalized CK matrix is depicted by , where is the standard semicircle law and the notation is the free multiplicative convolution in free harmonic analysis. For full descriptions of free independence and free multiplicative convolution, see [NS06, Lecture 18] and [AGZ10, Section 5.3.3]. The free multiplicative convolution was first introduced in [Voi87], which later has many applications for products of asymptotic free random matrices. The main tool for computing free multiplicative convolution is the -transform, invented by [Voi87]. -transform was recently utilized to study the dynamical isometry of deep neural networks [PSG17, PSG18, XBSD+18, HK21, CH23]. Some basic properties and intriguing examples for free multiplicative convolution with can also be found in [BZ10, Theorems 1.2, 1.3].
Theorem 2.1 (Limiting spectral distribution for the conjugate kernel).
Suppose Assumptions 1.1, 1.2 and 1.4 of the input matrix hold, the empirical eigenvalue distribution of
| (2.1) |
converges weakly to
| (2.2) |
almost surely as . Furthermore, if as , then the empirical eigenvalue distribution of
| (2.3) |
also converges weakly to the probability measure almost surely, whose Stieltjes transform is defined by
| (2.4) |
for each , where is the unique solution to
| (2.5) |
Suppose that we additionally have , i.e. . In this case, our Theorem 2.1 shows that the limiting spectral distribution of (1.2) is the semicircle law, and from (2.2), the deterministic data matrix does not have an effect on the limiting spectrum. See Figure 1 for a cosine-type with . The only effect of the nonlinearity in is the coefficient in the deformation .



Figure 2 is a simulation of the limiting spectral distribution of CK with activation function given by after proper shifting and scaling. More simulations are provided in Appendix B with different activation functions. The red curves are implemented by the self-consistent equations (2.4) and (2.5) in Theorem 2.1. In Section 4, we present general random matrix models with similar limiting eigenvalue distribution as whose Stieltjes transform is also determined by (2.4) and (2.5).



Theorem 2.1 can be extended to the NTK model as well. Denote by
| (2.6) |
As an approximation of in the spectral norm, we define
| (2.7) |
where ’s are defined in (1.13), is defined in (1.11), and the -th Hermite coefficient of is
| (2.8) |
Then, similar deformed semicircle law can be obtained for the empirical NTK matrix .
Theorem 2.2 (Limiting spectral distribution of the NTK).
Under Assumptions 1.1, 1.2 and 1.4 of the input matrix , the empirical eigenvalue distribution of
| (2.9) |
weakly converges to almost surely as and . Furthermore, suppose that , then the empirical eigenvalue distribution of
| (2.10) |
weakly converges to almost surely, where and are defined in (1.13) and (2.7), respectively.
2.2. Non-asymptotic estimations
With our nonlinear Hanson-Wright inequality (Corollary 3.5), we attain the following concentration bound on the CK matrix in the spectral norm.
Theorem 2.3.
With Assumption 1.1, assume satisfies for a constant , and is -Lipschitz with . Then with probability at least ,
| (2.11) |
where is a universal constant.
Remark 2.4.
Theorem 2.3 ensures that the empirical spectral measure of the centered random matrix has a bounded support for all sufficiently large . Together with the global law in Theorem 2.1, our concentration inequality (2.11) is tight up to a constant factor. Additionally, by the weak convergence of to proved in Theorem 2.1, we can take a test function to obtain that
almost surely, as and . Therefore, the fluctuation of around under the Frobenius norm is exactly of order .
Based on the foregoing estimation, we have the following lower bound on the smallest eigenvalue of the empirical conjugate kernel, denoted by .
Theorem 2.5.
Remark 2.6.
A related result in [OS20, Theorem 5] assumed for all , , and obtained We relax the assumption on the column vectors of , and extend the range of down to , to guarantee that is lower bounded by an absolute constant, with an extra assumption that . This assumption can always be satisfied by shifting the activation function with a proper constant. Our bound for is derived via Hermite polynomial expansion, similar to [OS20, Lemma 15]. However, we apply an -net argument for concentration bound for around , while a matrix Chernoff concentration bound with truncation was used in [OS20, Theorem 5].
Additionally, the concentration for the NTK matrix can be obtained in the next theorem. Recall that is defined by (1.8) and the columns of are defined by (1.9) with Assumption 1.1.
Theorem 2.7.
Suppose , and is -Lipschitz. Then with probability at least ,
| (2.12) |
Moreover, if the assumptions in Theorem 2.3 hold, then with probability at least ,
| (2.13) |
Remark 2.8.
Compared to Proposition D.3 in [HXAP20], we assume is a Gaussian vector instead of a Rademacher random vector and attain a better bound. If , then one can apply matrix Bernstein inequality for the sum of bounded random matrices. In our case, the boundedness condition is not satisfied. Section S1.1 in [AP20] applied matrix Bernstein inequality for the sum of bounded random matrices when is a Gaussian vector, but the boundedness condition does not hold in Equation (S7) of [AP20].
Based on Theorem 2.7, we get a lower bound for the smallest eigenvalue of the NTK.
Theorem 2.9.
Remark 2.10.
We relax the assumption in [NMM21] to for the 2-layer case and our result is applicable beyond the ReLU activation function and to more general assumptions on . Our proof strategy is different from [NMM21]. In [NMM21], the authors used the inequality where is the -th column of . Then getting the lower bound is reduced to show the concentration of the -norm of the column vectors of . Here we apply a matrix concentration inequality to and gain a weaker assumption on to ensure the lower bound on .
Remark 2.11.
In Theorems 2.5 and 2.9, we exclude the linear activation function. When , it is easy to check both and will trivially determined by , which can be vanishing. In this case, the lower bounds of the smallest eigenvalues of CK and NTK rely on the assumption of or the distribution of . For instance, when the entries of are i.i.d. Gaussian random variables, has been analyzed in [Sil85].
2.3. Training and test errors for random feature regression
We apply the results of the preceding sections to a two-layer neural network at random initialization defined in (1.1), to estimate the training errors and test errors with mean-square losses for random feature regression under the ultra-wide regime where and . In this model, we take the random feature and consider the regression with respect to based on
with training data and training labels . Considering the ridge regression with ridge parameter and squared loss defined by
| (2.14) |
we can conclude that the minimization has an explicit solution
| (2.15) |
where is defined in (1.5). When is nonlinear, by Theorem 2.5, it is feasible to take inverse in (2.15) for any . Hence, in the following results, we will focus on nonlinear activation functions222As Remark 2.11 stated, when , of CK may be possibly vanishing. To include the linear activation function, we can alternatively assume that the ridge parameter is strictly positive and focus on random feature ridge regressions.. In general, the optimal predictor for this random feature with respect to (2.14) is
| (2.16) |
where we define an empirical kernel as
| (2.17) |
The -dimension row vector is given by
| (2.18) |
and the entry of is defined by , for .
Analogously, consider any kernel function . The optimal kernel predictor with a ridge parameter for the kernel ridge regression is given by (see [RR07, AKM+17, LR20, JSS+20, LLS21, BMR21] for more details)
| (2.19) |
where is an matrix such that its entry is , and is a row vector in similarly with (2.18). We compare the characteristics of the two different predictors and when the kernel function is defined in (1.4). Denote the optimal predictors for random features and kernel on training data by
respectively. Notice that, in this case, defined in (1.3) and is the random empirical CK matrix defined in (1.5).
We aim to compare the training and test errors for these two predictors in ultra-wide random neural networks, respectively. Let training errors of these two predictors be
| (2.20) | ||||
| (2.21) |
In the following theorem, we show that, with high probability, the training error of the random feature regression model can be approximated by the corresponding kernel regression model with the same ridge parameter for ultra-wide neural networks.
Theorem 2.12 (Training error approximation).
Next, to investigate the test errors (or generalization errors), we introduce further assumptions on the data and the target function that we want to learn from training data. Denote the true regression function by . Then, the training labels are defined by
| (2.23) |
where is the training label noise. For simplicity, we further impose the following assumptions, analogously to [LD21].
Assumption 2.13.
Assume that the target function is a linear function , where random vector satisfies . Then, in this case, the training label vector is given by where independent with .
Assumption 2.14.
Suppose that training dataset satisfies -orthonormal condition with , and a test data is independent with and such that is also -orthonormal. For convenience, we further assume the population covariance of the test data is .
Remark 2.15.
Our Assumption 2.14 of the test data ensures the same statistical behavior as training data in , but we do not have any explicit assumption of the distribution of . It is promising to adopt such assumptions to handle statistical models with real-world data [LC18, LCM20]. Besides, it is possible to extend our analysis to general population covariance for .
For any predictor , define the test error (generalization error) by
| (2.24) |
We first present the following approximation of the test error of a random feature predictor via its corresponding kernel predictor.
Theorem 2.16 (Test error approximation).
Theorems 2.12 and 2.16 verify that the random feature regression achieves the same asymptotic errors as the kernel regression, as long as . This is closely related to [MMM21, Theorem 1] with different settings. Based on that, we can compute the asymptotic training and test errors for the random feature model by calculating the corresponding quantities for the kernel regression in the ultra-wide regime where .
Theorem 2.17 (Asymptotic training and test errors).
Suppose Assumptions 1.1 and 1.2 hold, and is not a linear function. Suppose the target function , training data and test data satisfy Assumptions 2.13 and 2.14. For any , let the effective ridge parameter be
| (2.26) |
If the training data has some limiting eigenvalue distribution as and , then when and , the training error satisfies
| (2.27) |
and the test error satisfies
| (2.28) |
where the bias and variance functions are defined by
| (2.29) | ||||
| (2.30) |
We emphasize that in the proof of Theorem 2.17, we also get -dependent deterministic equivalents for training/test errors of the kernel regression to approximate the performance of random feature regression. This is akin to [LCM20, Theorem 3] and [BMR21, Theorem 4.13], but in different regimes. In the following Figure 3, we present implementations of test errors for random feature regressions on standard Gaussian random data and their limits (2.28). For simplicity, we fix , only let , and use empirical spectral distribution of to approximate in and , which is actually the -dependent deterministic equivalent. However, for Gaussian random matrix , is actually a Marchenko-Pastur law with ratio , so and can be computed explicitly according to [LD21, Definition 1].

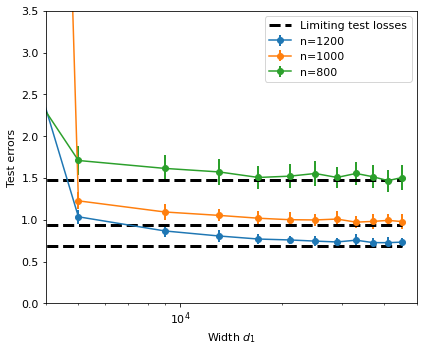
Remark 2.18 (Implicit regularization).
For nonlinear , the effective ridge parameter (2.26) can be viewed as an inflated ridge parameter since and . This leads to implicit regularization for our random feature and kernel ridge regressions even for the ridgeless regression with [LR20, MZ22, JSS+20, BMR21]. This effective ridge parameter also shows the effect of the nonlinearity in the random feature and kernel regressions induced by ultra-wide neural networks.
Remark 2.19.
For convenience, we only consider the linear target function , but in general, the above theorems can also be obtained for nonlinear target functions, for instance, is a nonlinear single-index model. Under -orthonormal assumption with , our expected kernel is approximated in terms of
| (2.31) |
whence, this kernel regression can only learn linear functions. So if is nonlinear, the limiting test error should be decomposed into the linear part as (2.28) and the nonlinear component as a noise [BMR21, Theorem 4.13]. For more conclusions of this kernel machine, we refer to [LR20, LRZ20, LLS21, MMM21].
Remark 2.20 (Neural tangent regression).
In parallel to the above results, we can obtain a similar analysis of the limiting training and test errors for random feature regression in (2.16) with empirical NTK given by either or . This random feature regression also refers to neural tangent regression [MZ22]. With the help of our concentration results in Theorem 2.7 and the lower bound of the smallest eigenvalues in Theorem 2.9, we can directly extend the above Theorems 2.12, 2.16 and 2.17 to this neural tangent regression. We omit the proofs in these cases and only state the results as follows.
If with expected kernel defined by (2.6), the limiting training and test errors of this neural tangent regression can be approximated by the kernel regression with respect to , as long as . Analogously to (2.31), we have an additional approximation
| (2.32) |
Under the same assumptions of Theorem 2.17 and replacing with , we can conclude that the test error of this neural tangent regression has the same limit as (2.28) but changing the effective ridge parameter (2.26) into . This result is akin to [MZ22, Corollary 3.2] but permits more general assumptions on . The limiting training error of this neural tangent regression can be obtained by slightly modifying the coefficient in (2.27).
Similarly, if defined by (1.8) possesses an expected kernel , this neural tangent regression in (2.16) is close to kernel regression (2.19) with kernel
under the ultra-wide regime, . Combining (2.31) and (2.32), Theorem 2.17 can directly be extended to this neural tangent regression but replacing (2.26) with . Section 6.1 of [AP20] also calculated this limiting test error when data is isotropic Gaussian.
Organization of the paper
The remaining parts of the paper are structured as follows. In Section 3, we first provide a nonlinear Hanson-Wright inequality as a concentration tool for our spectral analysis. Section 4 gives a general theorem for the limiting spectral distributions of generalized centered sample covariance matrices. We prove the limiting spectral distributions for the empirical CK and NTK matrices (Theorem 2.1 and Theorem 2.2) in Section 5. Non-asymptotic estimates in subsection 2.2 are proved in Section 6. In Section 7, we justify the asymptotic results of the training and test errors for the random feature model (Theorem 2.12 and Theorem 2.16). Auxiliary lemmas and additional simulations are included in Appendices.
3. A non-linear Hanson-Wright inequality
We give an improved version of Lemma 1 in [LLC18] with a simple proof based on a Hanson-Wright inequality for random vectors with dependence [Ada15]. This serves as the concentration tool for us to prove the deformed semicircle law in Section 5 and provide bounds on extreme eigenvalues in Section 6. We first define some concentration properties for random vectors.
Definition 3.1 (Concentration property).
Let be a random vector in . We say has the -concentration property with constant if for any -Lipschitz function , we have and for any ,
| (3.1) |
There are many distributions of random vectors satisfying -concentration property, including uniform random vectors on the sphere, unit ball, hamming or continuous cube, uniform random permutation, etc. See [Ver18, Chapter 5] for more details.
Definition 3.2 (Convex concentration property).
Let be a random vector in . We say has the -convex concentration property with the constant if for any -Lipschitz convex function , we have and for any ,
We will apply the following result from [Ada15] to the nonlinear setting.
Lemma 3.3 (Theorem 2.5 in [Ada15]).
Let be a mean zero random vector in . If has the -convex concentration property, then for any matrix and any ,
for some universal constant .
Theorem 3.4.
Let be a random vector with -concentration property, be a deterministic matrix. Define , where is -Lipschitz, and . Let be an deterministic matrix.
-
(1)
If , for any ,
(3.2) where is an absolute constant.
-
(2)
If , for any ,
for some constant .
Proof.
Let be any -Lipschitz convex function. Since , is a -Lipschitz function of . Then by the Lipschitz concentration property of in (3.1), we obtain
Therefore, satisfies the -convex concentration property. Define , then is also a convex -Lipschitz function and . Hence also satisfies the -convex concentration property. Applying Theorem 3.3 to , we have for any ,
| (3.3) |
Since , the inequality above implies (3.2). Note that
Hence,
| (3.4) |
Since is a -Lipschitz function of , by the Lipschitz concentration property of , we have
| (3.5) |
Then combining (3.3), (3), and (3.5), we have
This finishes the proof. ∎
Since the Gaussian random vector satisfies the -concentration inequality with (see for example [BLM13]), we have the following corollary.
Corollary 3.5.
Let , be a deterministic matrix. Define , where is -Lipschitz, and . Let be an deterministic matrix.
-
(1)
If , for any ,
(3.6) for some absolute constant .
-
(2)
If , for any ,
(3.7) (3.8) where
(3.9)
Remark 3.6.
Compared to [LLC18, Lemma 1], we identify the dependence on and in the probability estimate. By using the inequality , we obtain a similar inequality to the one in [LLC18] with a better dependence on . Moreover, our bound in is independent of , while the corresponding term in [LLC18, Lemma 1] depends on and . In particular, when and is -orthonormal, is of order 1. Hence, (3.8) with the special choice of is the key ingredient in the proof of Theorem 2.3 to get a concentration of the spectral norm for CK.
Proof of Corollary 3.5.
We only need to prove (3.8), since other statements follow immediately by taking . Let be the -th column of . Then
Let . We have
| (3.10) |
Therefore
| (3.11) | ||||
and (3.8) holds.
∎
We include the following corollary about the variance of , which will be used in Section 5 to study the spectrum of the CK and NTK.
Corollary 3.7.
Under the same assumptions of Corollary 3.5, we further assume that , and . Then as ,
Proof.
Notice that . Thanks to Theorem 3.5 (2), we have that for any ,
| (3.12) |
where constant only relies on , , and . Therefore, we can compute the variance in the following way:
as . Here, we use the dominant convergence theorem for the first integral in the last line. ∎
4. Limiting law for general centered sample covariance matrices
Independent of the subsequent sections, this section focuses on the generalized sample covariance matrix where the dimension of the feature is much smaller than the sample size. We will later interpret such sample covariance matrix specifically for our neural network applications. Under certain weak assumptions, we prove the limiting eigenvalue distribution of the normalized sample covariance matrix satisfies two self-consistent equations, which are subsumed into a deformed semicircle law. Our findings in this section demonstrate some degree of universality, indicating that they hold across various random matrix models and may have implications for other related fields.
Theorem 4.1.
Suppose are independent random vectors with the same distribution of a random vector . Assume that , , where is a deterministic matrix whose limiting eigenvalue distribution is . Assume for some constant . Define and . For any and any deterministic matrices with , suppose that as and ,
| (4.1) |
and
| (4.2) |
Then the empirical eigenvalue distribution of matrix weakly converges to almost surely, whose Stieltjes transform is defined by
| (4.3) |
for each , where is the unique solution to
| (4.4) |
In particular, .
Remark 4.2.
In [Xie13], it was assumed that where and as . By martingale difference, this condition implies (4.1). However, we are not able to verify a certain step in the proof of [Xie13]. Hence, we will not directly adopt the result of [Xie13] but consider a more general situation without assuming . The weakest conditions we found are conditions (4.1) and (4.2), which can be verified in our nonlinear random model.
The self-consistent equations we derived are consistent with the results in [Bao12, Xie13], where they studied the empirical spectral distribution of separable sample covariance matrices in the regime under different assumptions. When and , our goal is to prove that the Stieltjes transform of the empirical eigenvalue distribution of and point-wisely converges to and , respectively.
For the rest of this section, we first prove a series of lemmas to get -dependent deterministic equivalents related to (4.3) and (4.4) and then deduce the proof of Theorem 4.1 at the end of this section. Recall , , and is a random vector independent of with the same distribution of .
Lemma 4.3.
Under the assumptions of Theorem 4.1, for any , as ,
| (4.5) |
where is any deterministic matrix such that , for some constant .
Proof.
Let where and . Let
where ’s are independent copies of defined in Theorem 4.1. Notice that, for any deterministic matrix ,
| (4.6) | ||||
| (4.7) |
Without loss of generality, we assume . Taking normalized trace, we have
| (4.8) |
For each , Sherman–Morrison formula (Lemma A.2) implies
| (4.9) |
where the leave-one-out resolvent is defined as
Hence, by (4.9), we obtain
| (4.10) |
Combining equations (4.8) and (4.10), and applying expectation at both sides implies
| (4.11) |
because of the assumption that all ’s have the same distribution as vector for all . With (4.11), to prove (4.5), we will first show that when ,
| (4.12) | |||
| (4.13) | |||
| (4.14) |
Recall that
and spectral norms due to Proposition C.2 in [FW20]. Notice that . Hence, we can deduce that
as The same argument can be applied to the error of . Therefore (4.12) and (4.13) hold. For (4.14), we denote and observe that
| (4.15) |
Let be the eigen-decomposition of . Then
| (4.16) |
is the Stieltjes transform of a discrete measure . Then, we can control the real part of by Lemma A.4:
| (4.17) |
We now separately consider two cases in the following:
- •
- •
Lemma 4.4.
Proof.
Let us denote
, and . In other words, can be expressed by
Observe that for . Thus, has the same expectation as the last term
since we can first take the expectation for conditioning on the resolvent and then take the expectation for . Besides, notice that uniformly. Hence, converges to zero uniformly and there exists some constant such that
| (4.22) |
for all large and . In addition, observe that
where is defined in the proof of Lemma 4.3. In terms of (4.18) and (4.19), we verify that
| (4.23) |
where is some constant depending on . Next, recall that condition (4.2) exposes that
| (4.24) |
as . The first convergence is derived by viewing and taking expectation conditional on . To sum up, we can bound based on (4.22) and (4.23) in the subsequent way:
Here, and is uniformly bounded by some constant. Then, by Hölder’s inequality, (4.24) implies that , as approaching to infinity. This concludes converges to zero.
∎
Lemma 4.5.
Under assumptions of Theorem 4.1, we can conclude that
holds for each and deterministic matrix with uniformly bounded spectral norm.
Proof.
Based on Lemma 4.3 and Lemma 4.4, (4.21) and (4.5) yield
As and are bounded by some constants uniformly and almost surely, for sufficiently large and , and
as . Hence,
| (4.25) |
Considering in (4.1), we can get almost sure convergence for to zero. Thus by dominated convergence theorem,
So we can replace the third term at the right-hand side of (4.25) with
to obtain the conclusion. ∎
Proof of Theorem 4.1.
Fix any . Denote the Stieltjes transform of empirical spectrum of and its expectation by and respectively. Let and . Notice that and are all in and uniformly and almost surely bounded by some constant. By choosing in Lemma 4.5, we conclude
| (4.26) |
Likewise, in Lemma 4.5, we consider . Let
Because is uniformly bounded, . In terms of Lemma A.6, we only need to provide a lower bound for the imaginary part of . Observe that since and . Thus, for all . Meanwhile, we have the equation and hence,
So applying Lemma 4.5 again, we have another limiting equation . In other words,
| (4.27) |
Thanks to the identity
we can modify (4.26) and (4.27) to get
| (4.28) |
Since and are uniformly bounded, for any subsequence in , there is a further convergent sub-subsequence. We denote the limit of such sub-subsequence by and respectively. Hence, by (4.27) and (4.28), one can conclude
Because of the convergence of the empirical eigenvalue distribution of , we obtain the fixed point equation (4.4) for . Analogously, we can also obtain (4.3) for and . The existence and the uniqueness of the solutions to (4.3) and (4.4) are proved in [BZ10, Theorem 2.1] and [WP14, Section 3.4], which implies the convergence of and to and governed by the self-consistent equations (4.3) and (4.4) as , respectively.
Then, by virtue of condition (4.1) in Theorem 4.1, we know and . Therefore, the empirical Stieltjes transform converges to almost surely for each . Recall that the Stieltjes transform of is . By the standard Stieltjes continuity theorem (see for example, [BS10, Theorem B.9]), this finally concludes the weak convergence of empirical eigenvalue distribution of to .
Now we show . The fixed point equations (4.3) and (4.4) induce
| (4.29) |
since for any . Together with (4.3), we attain the same self-consistent equations for the convergence of the empirical spectral distribution of the Wigner-type matrix studied in [BZ10, Theorem 1.1].
Define , the -by- Wigner matrix, as a Hermitian matrix with independent entries
The Wigner-type matrix studied in [BZ10, Definition 1.2] is indeed . Hence, such Wigner-type matrix has the same limiting spectral distribution as defined in Theorem 4.1. Both limits are determined by self-consistent equations (4.3) and (4.29).
On the other hand, based on [AGZ10, Theorem 5.4.5], and are almost surely asymptotically free, i.e. the empirical distribution of converges almost surely to the law of , where s and d are two free non-commutative random variables (s is a semicircle element and d has the law ). Thus, the limiting spectral distribution of is the free multiplicative convolution between and . This implies in our setting. ∎
5. Proof of Theorem 2.1 and Theorem 2.2
To prove Theorem 2.1, we first establish the following proposition to analyze the difference between Stieltjes transform of (2.1) and its expectation. This will assist us to verify condition (4.1) in Theorem 4.1. The proof is based on [FW20, Lemma E.6].
Proposition 5.1.
Proof.
Define function by . Fix any where , and let . We want to verify is a Lipschitz function in with respect to the Frobenius norm. First, recall
where the last two terms are deterministic with respect to . Hence,
where is the Hadamard product, and is applied entrywise. Here we utilize the formula
and . Lemma A.6 in Appendix A implies that Therefore, based on the assumption of , we have
for some constant . For the first term in the product on the right-hand side,
For the second term,
Thus, . This holds for every such that , so is -Lipschitz in with respect to the Frobenius norm. Then the result follows from the Gaussian concentration inequality for Lipschitz functions. ∎
Next, we investigate the approximation of via the Hermite polynomials . The orthogonality of Hermite polynomials allows us to write as a series of kernel matrices. Then we only need to estimate each kernel matrix in this series. The proof is directly based on [GMMM19, Lemma 2]. The only difference is that we consider the deterministic input data with the -orthonormal property, while in Lemma 2 of [GMMM19], the matrix is formed by independent Gaussian vectors.
Lemma 5.2.
Proof.
By Assumption 1.2, we know that
For any fixed , . This is because is a Lipschitz function and by triangle inequality , we have, for ,
| (5.1) |
For , let and the Hermite expansion of can be written as
where the coefficient . Let unit vectors be , for . So for , the entry of is
where is a Gaussian random vector with mean zero and covariance
| (5.2) |
By the orthogonality of Hermite polynomials with respect to and Lemma A.5, we can obtain
which leads to
| (5.3) |
For any , let be an -by- matrix with -th entry
| (5.4) |
Specifically, for any , we have
where is the diagonal matrix .
At first, we consider twice differentiable in Assumption 1.2. Similar with [GMMM19, Equation (26)], for any and , we take the Taylor approximation of at point , then there exists between and such that
Replacing by and taking expectation, since is uniformly bounded, we can get
| (5.5) |
For , the Lipschitz condition for yields
| (5.6) |
where constant does not depend on . As for piece-wise linear , it is not hard to see
| (5.7) |
Now, we begin to approximate separately based on (5.5), (5.6) and (5.7). Denote the diagonal submatrix of a matrix .
(1) Approximation for . At first, we estimate the norm with respect to of the function . Recall that Because and is a Lipschitz function, we have
| (5.8) | ||||
| (5.9) |
Hence, is uniformly bounded with some constant for all large . Next, we estimate the off-diagonal entries of when . From (5.4), we obtain that
| (5.10) |
when is sufficiently large.
(2) Approximation for . Recall and by Gaussian integration by part,
Then, we have
If is twice differentiable, then as well.
Thus, taking in (5.5) and (5.7) implies that for any
| (5.11) |
Define , then . Recall the definition of in (1.13). Then, (5.11) ensures that
Applying the -orthonormal property of yields
| (5.12) |
Hence the difference between and is controlled by
| (5.13) |
(3) Approximation for for . For , Assumption 1.4 and (5.6) show that
| (5.14) |
when is sufficiently large. Notice that , where is the diagonal matrix. Hence, by (5.14),
And for by the triangle inequality,
When , and . When ,
From Lemma A.1 in Appendix A, we have that
| (5.15) |
So the left-hand side of (5.15) is bounded. Analogously, we can verify is also bounded. Therefore, we have
| (5.16) |
for some constant and when is sufficiently large.
(4) Approximation for . Since , we know
First, by (5.8) and (5.9), we can claim that
Second, in terms of (5.14), we obtain
for and . Combining these together, we conclude that
| (5.17) |
Recall
In terms of approximations (5.10), (5.13), (5.16) and (5.17), we can finally manifest
| (5.18) |
for some constant as . The spectral norm bound of is directly deduced by the spectral norm bound of based on (5.12) and (5.15), together with (5.18). ∎
Remark 5.3 (Optimality of ).
For general deterministic data , our pairwise orthogonality assumption with rate is optimal for the approximation of by in the spectral norm. If we relax the decay rate of in Assumption 1.4, the above approximation may require including terms of higher-degree for in , which will lead to the invalidation of some of our following results and simplifications. Subsequent to the initial completion of our paper, this weaker regime has been considered in our follow-up work [WZ22].
Next, we continue to provide an additional estimate for , but in the Frobenius norm to further simplify the limiting spectral distribution of .
Proof.
By the definition of , we know that . As a direct deduction of Lemma 5.2, the limiting spectrum of is identical to the limiting spectrum of . To prove this lemma, it suffices to check the Frobenius norm of the difference between and . Notice that
By the definition of vector and the assumption of , we have
| (5.19) |
For , the Frobenius norm can be controlled by
Hence, as , we have
as . Then we conclude that
Hence, is the same as when due to Lemma A.7 in Appendix A. ∎
Moreover, the proof of Lemma 5.4 can be modified to prove (2.32), so we omit its proof. Now, based on Corollary 3.7, Proposition 5.1, Lemma 5.2, and Lemma 5.4, applying Theorem 4.1 for general sample covariance matrices, we can finish the proof of Theorem 2.1.
Proof of Theorem 2.1.
Based on Corollary 3.7 and Proposition 5.1, we can verify the conditions (4.1) and (4.2) in Theorem 4.1. By Lemma 5.2 and Lemma 5.4, we know that the limiting eigenvalue distributions of and are identical and is uniformly bounded. So the limiting eigenvalue distribution of denoted by is just . Hence, the first conclusion of Theorem 2.1 follows from Theorem 4.1.
Next, we move to study the empirical NTK and its corresponding limiting eigenvalue distribution. Similarly, we first verify that such NTK concentrates around its expectation and then simplify this expectation by some deterministic matrix only depending on the input data matrix and nonlinear activation . The following lemma can be obtained from (2.12) in Theorem 2.7.
Lemma 5.5.
Suppose that Assumption 1.1 holds, and . Then if , we have
| (5.20) |
almost surely as . Moreover, if as , then almost surely
| (5.21) |
Lemma 5.6.
Proof.
We can directly apply methods in the proof of Lemma 5.2. Notice that (1.7) and (1.9) imply
for any standard Gaussian random vector . Recall that (2.8) defines the -th coefficient of Hermite expansion of by for any Then, Assumption 1.2 indicates and . For , we introduce and the Hermite expansion of this function as
where the coefficient . Let , for . So for , the -entry of is
where is a Gaussian random vector with mean zero and covariance (5.2). Following the derivation of formula (5.3), we obtain
| (5.23) |
For any , let be an -by- matrix with entry
We can write for any , where is . Then, adopting the proof of (5.16), we can similarly conclude that
for some constant and , when is sufficiently large. Likewise, (5.10) indicates
and a similar proof of (5.17) implies that
Based on these approximations, we can conclude the result of this lemma. ∎
6. Proof of the concentration for extreme eigenvalues
In this section, we obtain the estimates of the extreme eigenvalues for the CK and NTK we studied in Section 5. The limiting spectral distribution of tells us the bulk behavior of the spectrum. An estimation of the extreme eigenvalues will show that the eigenvalues are confined in a finite interval with high probability. We first provide a non-asymptotic bound on the concentration of under the spectral norm. The proof is based on the Hanson-Wright inequality we proved in Section 3 and an -net argument.
Proof of Theorem 2.3.
For any fixed , we have
| (6.1) |
where
and column vector is the concatenation of column vectors . Then
with block matrix
Notice that
Denote . With (3.11), we obtain
where the last line is from the assumptions on and . When , applying (3.8) to (6.1) implies
Let be a -net on with (see e.g. [Ver18, Corollary 4.2.13]), then
Taking a union bound over yields
We then can set
to conclude
Since
the upper bound in (2.11) is then verified. When , we can apply (3.6) and follow the same steps to get the desired bound. ∎
By the concentration inequality in Theorem 2.3, we can get a lower bound on the smallest eigenvalue of the conjugate kernel as follows.
Lemma 6.1.
Assume satisfies for a constant , and is -Lipschitz with . Then with probability at least ,
| (6.2) |
The lower bound in (6.2) relies on . Under certain assumptions on and , we can guarantee that is bounded below by an absolute constant.
Lemma 6.2.
Assume is not a linear function and is Lipschitz. Then
| (6.3) |
Proof.
Suppose that is finite. Then is a polynomial of degree at least from our assumption, which is a contradiction to the fact that is Lipschitz. Hence, (6.3) holds. ∎
Lemma 6.3.
Assume Assumption 1.2 holds, is not a linear function, and satisfies -orthonormal property. Then,
| (6.4) |
Remark 6.4.
This bound will not hold when is a linear function. Suppose is a linear function, under Assumption 1.2, we must have and . Then we will not have a lower bound on based on the Hermite coefficients of .
Proof of Lemma 6.3.
and, from Weyl’s inequality [AGZ10, Theorem A.5], we have
Note that where , and each column of is given by the -th Kronecker product . Hence, is positive semi-definite.
∎
Next, we move on to non-asymptotic estimations for NTK. Recall that the empirical NTK matrix is given by (1.8) and the -th column of is defined by , for , in (1.9).
The -th row of is given by and , where is the -th entry of . Define for . We can rewrite as
Let us define and further expand it as follows:
| (6.5) | ||||
| (6.6) |
Here is a centered random matrix, and we can apply matrix Bernstein’s inequality to show the concentration of . Since does not have an almost sure bound on the spectral norm, we will use the following sub-exponential version of the matrix Bernstein inequality from [Tro12].
Lemma 6.5 ([Tro12], Theorem 6.2).
Let be independent Hermitian matrices of size . Assume
for any integer . Then for all ,
| (6.7) |
Proof of Theorem 2.7.
From (6.6), , and
where and where is the -th entry of the second layer weight . Then
So we can take in (6.7) and obtain
Hence, defined in (6.5) has a probability bound:
Take . Under the assumption that , we conclude that, with high probability at least ,
| (6.8) |
Thus, as a corollary, the two statements in Lemma 5.5 follow from (6.8). Meanwhile, since
We now proceed to provide a lower bound of from Theorem 2.7.
Proof of Theorem 2.9.
Note that from (1.8), (2.6) and (6.5), we have
Then with Lemma 5.6, we can get
Therefore, from Theorem 2.7, with probability at least ,
Since is Lipschitz and non-linear, we know is not a linear function (including the constant function) and is bounded. Suppose that has finite many non-zero Hermite coefficients, is a polynomial, then we get a contradiction. Hence, the Hermite coefficients of satisfy
| (6.9) |
This finishes the proof. ∎
7. Proof of Theorem 2.12 and Theorem 2.17
By definitions, the random matrix is and the kernel matrix is defined in (1.3). These two matrices have been already analyzed in Theorem 2.3 and Theorem 2.5, so we will apply these results to estimate how great the difference between training errors of random feature regression and its corresponding kernel regression.
Proof of Theorem 2.12.
Denote . From the definitions of training errors in (2.20) and (2.21), we have
| (7.1) |
Here, in (7.1), we employ the identity
| (7.2) |
for and , and the fact that and . Next, before providing uniform upper bounds for and in (7.1), we can first get a bound for the last term of (7.1) as follows:
| (7.3) |
for some constant , with probability at least , where the last bound in (7.3) is due to Theorem 2.3 and Lemma A.9 in Appendix A. Additionally, combining Theorem 2.3 and Theorem 2.5, we can easily get
| (7.4) |
for all large and some universal constant , under the same event that (7.3) holds. Theorem 6.3 also shows for all large . Hence, with the upper bounds for and , (2.22) follows from the bounds of (7.1) and (7.3). ∎
For ease of notation, we denote and . Hence, from (2.24), we can further decompose the test errors for and into
| (7.5) | ||||
| (7.6) | ||||
Let us denote
As we can see, to compare the test errors between random feature and kernel regression models, we need to control and . Firstly, it is necessary to study the concentrations of
and
Lemma 7.1.
Proof.
We consider , its corresponding kernels and . Under Assumption 2.14, we can directly apply Theorem 2.3 to get the concentration of around , namely,
| (7.8) |
with probability at least . Meanwhile, we can write and as block matrices:
Since the -norm of any row is bounded above by the spectral norm of its entire matrix, we complete the proof of (7.7). ∎
Lemma 7.2.
Assume that training labels satisfy Assumption 2.13 and , then for any deterministic , we have
where constant only depends on and . Moreover,
Proof.
We follow the idea in Lemma C.8 of [MM19] to investigate the variance of the quadratic form for the Gaussian random vector by
| (7.9) |
for any deterministic square matrix and standard normal random vector . Notice that the quadratic form
| (7.10) |
where is a standard Gaussian random vector in . Similarly, the second quadratic form can be written as
Let
By (7.9), we know and . Since
and similarly for a constant , we can complete the proof. ∎
As a remark, in Lemma 7.2, for simplicity, we only provide a variance control for the quadratic forms to obtain convergence in probability in the following proofs of Theorems 2.16 and 2.17. However, we can actually apply Hanson-Wright inequalities in Section 3 to get more precise probability bounds and consider non-Gaussian distributions for and .
Proof of Theorem 2.16.
Based on the preceding expansions of and in (7.5) and (7.6), we need to control the right-hand side of
In the subsequent procedure, we first take the concentrations of and with respect to normal random vectors and , respectively. Then, we apply Theorem 2.3 and Lemma 7.1 to complete the proof of (2.25). For simplicity, we start with the second term
| (7.11) |
where and are quadratic forms defined below
and their expectations with respect to random vectors and are denoted by
We first consider the randomness of the weight matrix in and define the event where both (7.4) and (7.8) hold. Then, Theorem 2.5 and the proof of Lemma 7.1 indicate that event occurs with probability at least for all large . Notice that does not rely on the randomness of test data .
We now consider in Lemma 7.2. Conditioning on event , we have
| (7.12) | ||||
| (7.13) |
for some constant , where we utilize the assumption . Hence, based on Lemma 7.2, we know , for some constant . By Chebyshev’s inequality and event ,
| (7.14) |
for any . Hence, with probability , when and .
Likewise, when , we can apply (7.2) and
| (7.15) |
due to Lemma A.9 in Appendix A, to obtain conditionally on event . Then, similarly, Lemma 7.2 shows . Therefore, (7.14) also holds for .
Moreover, conditioning on the event ,
| (7.16) | ||||
| (7.17) | ||||
| (7.18) |
for some constant . In the same way, with (7.15), on the event . Therefore, from (7.11), we can conclude for any , with probability , when and .
Analogously, the first term is controlled by the following four quadratic forms
where we define by for and
Similarly with (7.13) and (7.18), it is not hard to verify and conditioning on the event . Then, like (7.14), we can invoke Lemma 7.2 for each to apply Chebyshev’s inequality and conclude with probability when , for any . ∎
Lemma 7.3.
Proof.
Proof of Theorem 2.17.
From (2.22) and (2.25), we can easily conclude that
| (7.21) | ||||
| (7.22) |
as and . Therefore, to study the training error and the test error of random feature regression, it suffices to analyze the asymptotic behaviors of and for the kernel regression, respectively. In the rest of the proof, we will first analyze the test error and then compute the training error under the ultra-wide regime.
Recall that and the test error is given by
| (7.23) |
where , . The spectral norm of is bounded from above and the smallest eigenvalue is bounded from below by some positive constants.
We first focus on the last two terms and in the test error. Let us define
Then, we obtain two quadratic forms
where and are at most for some constant , due to Lemma 7.3. Hence, applying Lemma 7.2 for these two quadratic forms, we have as . Additionally, Lemma 7.2 and the proof of Lemma 7.3 verify that and are vanishing as . Therefore, converges to zero in probability for . So we can move to analyze and instead. Copying the above procedure, we can separately compute the variances of and with respect to and , and then apply Lemma 7.2. Then, and will converge to zero in probability as , where
To obtain the last approximation, we define and
| (7.24) |
We aim to replace by in and . Recalling the identity (7.2), we have
Since is not a linear function, . Then, with (7.4), the proof of Lemma 5.4 indicates
| (7.25) |
where we apply the fact that . Let us denote
| (7.26) | ||||
| (7.27) |
Notice that for any matrices , Then, with the help of (7.25) and uniform bounds of the spectral norms of , and , we obtain that
as , and . Combining all the approximations, we conclude that and have identical limits in probability for . On the other hand, based on the assumption of and definitions in (7.24), (7.26) and (7.27), it is not hard to check that
Therefore, and converge in probability to the above limits, respectively, as . In the end, we apply the concentration of the quadratic form in (7.23) to get . Then, by (7.22), we can get the limit in (2.28) for the test error . As a byproduct, we can even use and to form an -dependent deterministic equivalent of as well.
Thanks to Lemma 7.2, the training error, , analogously, concentrates around its expectation with respect to and , which is . Moreover, because of (7.25), we can further substitute by defined in (7.24). Hence, we know that, asymptotically,
where as ,
| (7.28) | ||||
| (7.29) |
The last two limits are due to as . Therefore, by (7.21), we obtain our final result (2.27) in Theorem 2.17. ∎
Acknowledgements
Z.W. is partially supported by NSF DMS-2055340 and NSF DMS-2154099. Y.Z. is partially supported by NSF-Simons Research Collaborations on the Mathematical and Scientific Foundations of Deep Learning. This material is based upon work supported by the National Science Foundation under Grant No. DMS-1928930 while Y.Z. was in residence at the Mathematical Sciences Research Institute in Berkeley, California, during the Fall 2021 semester for the program “Universality and Integrability in Random Matrix Theory and Interacting Particle Systems”. Z.W. would like to thank Denny Wu for his valuable suggestions and comments. Both authors would like to thank Lucas Benigni, Ioana Dumitriu, and Kameron Decker Harris for their helpful discussion.
Appendix A Auxiliary lemmas
Lemma A.1 (Equation (3.7.9) in [Joh90]).
Let be two matrices, be positive semidefinite, and be the Hadamard product between and . Then,
| (A.1) |
Lemma A.2 (Sherman–Morrison formula, [Bar51]).
Suppose is an invertible square matrix and are column vectors. Then
| (A.2) |
Lemma A.3 (Theorem A.45 in [BS10]).
Let be two Hermitian matrices. Then and have the same limiting spectral distribution if as .
Lemma A.4 (Theorem B.11 in [BS10]).
Let and be the Stieltjes transform of a probability measure. Then .
Lemma A.5 (Lemma D.2 in [NM20]).
Let such that and . Let be the -th normalized Hermite polynomial given in (1.5). Then
| (A.3) |
Lemma A.6 (Proposition C.2 in [FW20]).
Suppose , are real symmetric, and is invertible with . Then is invertible with .
Lemma A.7 (Proposition C.3 in [FW20]).
Let be two sequences of Hermitian matrices satisfying
as . Suppose that, as , for a probability distribution on , then .
Lemma A.8.
Proof.
When is twice differentiable in Assumption 1.2, this result follows from Lemma D.3 in [FW20]. When is a piece-wise linear function defined in case 2 of Assumption 1.2, the second inequality follows from (5.7) with . For the first inequality, the Hermite expansion of is given by (5.3) with coefficients for . Observe that the piece-wise linear function in case 2 of Assumption 1.2 satisfies
| (A.6) | ||||
| (A.7) |
because of condition (1.10) for . Recall and . Then, analogously to the derivation of (5.10), there exists some constant such that
| (A.8) | ||||
| (A.9) |
for and -orthonormal . This completes the proof of this lemma. ∎
With the above lemma, the proof of Lemma D.4 in [FW20] directly yields the following lemma.
Appendix B Additional simulations
Figures 4 and 5 provide additional simulations for the eigenvalue distribution described in Theorem 2.1 with different activation functions and scaling. Here, we compute the empirical eigenvalue distributions of centered CK matrices in histograms and the limiting spectra in terms of self-consistent equations. All the input data ’s are standard random Gaussian matrices. Interestingly, in Figure 5, we observe an outlier that emerges outside the bulk distribution for the piece-wise linear activation function defined in case 2 of Assumption 1.2. The analysis of the emergence of the outlier, in this case, would be interesting for future work.









References
- [Ada15] Radoslaw Adamczak. A note on the Hanson-Wright inequality for random vectors with dependencies. Electronic Communications in Probability, 20, 2015.
- [ADH+19a] Sanjeev Arora, Simon Du, Wei Hu, Zhiyuan Li, and Ruosong Wang. Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks. In International Conference on Machine Learning, pages 322–332. PMLR, 2019.
- [ADH+19b] Sanjeev Arora, Simon S Du, Wei Hu, Zhiyuan Li, Ruslan Salakhutdinov, and Ruosong Wang. On exact computation with an infinitely wide neural net. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, pages 8141–8150, 2019.
- [AGZ10] Greg W Anderson, Alice Guionnet, and Ofer Zeitouni. An introduction to random matrices. Cambridge university press, 2010.
- [AKM+17] Haim Avron, Michael Kapralov, Cameron Musco, Christopher Musco, Ameya Velingker, and Amir Zandieh. Random fourier features for kernel ridge regression: Approximation bounds and statistical guarantees. In International Conference on Machine Learning, pages 253–262. PMLR, 2017.
- [ALP22] Ben Adlam, Jake A Levinson, and Jeffrey Pennington. A random matrix perspective on mixtures of nonlinearities in high dimensions. In International Conference on Artificial Intelligence and Statistics, pages 3434–3457. PMLR, 2022.
- [AP20] Ben Adlam and Jeffrey Pennington. The neural tangent kernel in high dimensions: Triple descent and a multi-scale theory of generalization. In International Conference on Machine Learning, pages 74–84. PMLR, 2020.
- [AS17] Guillaume Aubrun and Stanisław J Szarek. Alice and Bob meet Banach, volume 223. American Mathematical Soc., 2017.
- [Aub12] Guillaume Aubrun. Partial transposition of random states and non-centered semicircular distributions. Random Matrices: Theory and Applications, 1(02):1250001, 2012.
- [AZLS19] Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via over-parameterization. In International Conference on Machine Learning, pages 242–252, 2019.
- [Bac13] Francis Bach. Sharp analysis of low-rank kernel matrix approximations. In Conference on Learning Theory, pages 185–209. PMLR, 2013.
- [Bac17] Francis Bach. On the equivalence between kernel quadrature rules and random feature expansions. The Journal of Machine Learning Research, 18(1):714–751, 2017.
- [Bao12] Zhigang Bao. Strong convergence of esd for the generalized sample covariance matrices when . Statistics Probability Letters, 82(5):894–901, 2012.
- [Bar51] Maurice S Bartlett. An inverse matrix adjustment arising in discriminant analysis. The Annals of Mathematical Statistics, 22(1):107–111, 1951.
- [BLM13] Stéphane Boucheron, Gábor Lugosi, and Pascal Massart. Concentration inequalities: A nonasymptotic theory of independence. Oxford university press, 2013.
- [BMR21] Peter L Bartlett, Andrea Montanari, and Alexander Rakhlin. Deep learning: a statistical viewpoint. Acta numerica, 30:87–201, 2021.
- [BP21] Lucas Benigni and Sandrine Péché. Eigenvalue distribution of some nonlinear models of random matrices. Electronic Journal of Probability, 26:1–37, 2021.
- [BS10] Zhidong Bai and Jack W Silverstein. Spectral analysis of large dimensional random matrices, volume 20. Springer, 2010.
- [BY88] Zhidong Bai and Y. Q. Yin. Convergence to the semicircle law. The Annals of Probability, pages 863–875, 1988.
- [BZ10] ZD Bai and LX Zhang. The limiting spectral distribution of the product of the Wigner matrix and a nonnegative definite matrix. Journal of Multivariate Analysis, 101(9):1927–1949, 2010.
- [CH23] Benoit Collins and Tomohiro Hayase. Asymptotic freeness of layerwise jacobians caused by invariance of multilayer perceptron: The haar orthogonal case. Communications in Mathematical Physics, 397(1):85–109, 2023.
- [COB19] Lénaïc Chizat, Edouard Oyallon, and Francis Bach. On lazy training in differentiable programming. Advances in Neural Information Processing Systems, 32:2937–2947, 2019.
- [CP12] Binbin Chen and Guangming Pan. Convergence of the largest eigenvalue of normalized sample covariance matrices when and both tend to infinity with their ratio converging to zero. Bernoulli, 18(4):1405–1420, 2012.
- [CP15] Binbin Chen and Guangming Pan. CLT for linear spectral statistics of normalized sample covariance matrices with the dimension much larger than the sample size. Bernoulli, 21(2):1089–1133, 2015.
- [CS09] Youngmin Cho and Lawrence K Saul. Kernel methods for deep learning. In Advances in Neural Information Processing Systems, pages 342–350, 2009.
- [CYZ18] Benoît Collins, Zhi Yin, and Ping Zhong. The PPT square conjecture holds generically for some classes of independent states. Journal of Physics A: Mathematical and Theoretical, 51(42):425301, 2018.
- [DFS16] Amit Daniely, Roy Frostig, and Yoram Singer. Toward deeper understanding of neural networks: The power of initialization and a dual view on expressivity. In Advances In Neural Information Processing Systems, pages 2253–2261, 2016.
- [DZPS19] Simon S Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh. Gradient descent provably optimizes over-parameterized neural networks. In International Conference on Learning Representations, 2019.
- [Fel21] Michael J Feldman. Spiked singular values and vectors under extreme aspect ratios. arXiv preprint arXiv:2104.15127, 2021.
- [FW20] Zhou Fan and Zhichao Wang. Spectra of the conjugate kernel and neural tangent kernel for linear-width neural networks. In Advances in Neural Information Processing Systems, volume 33, pages 7710–7721. Curran Associates, Inc., 2020.
- [GKZ19] David Gamarnik, Eren C Kızıldağ, and Ilias Zadik. Stationary points of shallow neural networks with quadratic activation function. arXiv preprint arXiv:1912.01599, 2019.
- [GLBP21] Jungang Ge, Ying-Chang Liang, Zhidong Bai, and Guangming Pan. Large-dimensional random matrix theory and its applications in deep learning and wireless communications. Random Matrices: Theory and Applications, page 2230001, 2021.
- [GLK+20] Federica Gerace, Bruno Loureiro, Florent Krzakala, Marc Mézard, and Lenka Zdeborová. Generalisation error in learning with random features and the hidden manifold model. In International Conference on Machine Learning, pages 3452–3462. PMLR, 2020.
- [GMMM19] Behrooz Ghorbani, Song Mei, Theodor Misiakiewicz, and Andrea Montanari. Limitations of lazy training of two-layers neural networks. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, pages 9111–9121, 2019.
- [GZR22] Diego Granziol, Stefan Zohren, and Stephen Roberts. Learning rates as a function of batch size: A random matrix theory approach to neural network training. J. Mach. Learn. Res, 23:1–65, 2022.
- [HK21] Tomohiro Hayase and Ryo Karakida. The spectrum of Fisher information of deep networks achieving dynamical isometry. In International Conference on Artificial Intelligence and Statistics, pages 334–342. PMLR, 2021.
- [HL22] Hong Hu and Yue M Lu. Universality laws for high-dimensional learning with random features. IEEE Transactions on Information Theory, 2022.
- [HW71] David Lee Hanson and Farroll Tim Wright. A bound on tail probabilities for quadratic forms in independent random variables. The Annals of Mathematical Statistics, 42(3):1079–1083, 1971.
- [HXAP20] Wei Hu, Lechao Xiao, Ben Adlam, and Jeffrey Pennington. The surprising simplicity of the early-time learning dynamics of neural networks. In Advances in Neural Information Processing Systems, volume 33, pages 17116–17128. Curran Associates, Inc., 2020.
- [JGH18] Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: convergence and generalization in neural networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, pages 8580–8589, 2018.
- [Jia04] Tiefeng Jiang. The limiting distributions of eigenvalues of sample correlation matrices. Sankhyā: The Indian Journal of Statistics, pages 35–48, 2004.
- [Joh90] C.R. Johnson. Matrix Theory and Applications. AMS Short Course Lecture Notes. American Mathematical Society, 1990.
- [JSS+20] Arthur Jacot, Berfin Simsek, Francesco Spadaro, Clément Hongler, and Franck Gabriel. Implicit regularization of random feature models. In International Conference on Machine Learning, pages 4631–4640. PMLR, 2020.
- [LBN+18] Jaehoon Lee, Yasaman Bahri, Roman Novak, Samuel S Schoenholz, Jeffrey Pennington, and Jascha Sohl-Dickstein. Deep neural networks as Gaussian processes. In International Conference on Learning Representations, 2018.
- [LC18] Zhenyu Liao and Romain Couillet. On the spectrum of random features maps of high dimensional data. In International Conference on Machine Learning, pages 3063–3071. PMLR, 2018.
- [LCM20] Zhenyu Liao, Romain Couillet, and Michael W. Mahoney. A random matrix analysis of random fourier features: beyond the gaussian kernel, a precise phase transition, and the corresponding double descent. In 34th Conference on Neural Information Processing Systems, 2020.
- [LD21] Licong Lin and Edgar Dobriban. What causes the test error? going beyond bias-variance via anova. Journal of Machine Learning Research, 22(155):1–82, 2021.
- [LGC+21] Bruno Loureiro, Cédric Gerbelot, Hugo Cui, Sebastian Goldt, Florent Krzakala, Marc Mézard, and Lenka Zdeborová. Learning curves of generic features maps for realistic datasets with a teacher-student model. Advances in Neural Information Processing Systems, 34, 2021.
- [LLC18] Cosme Louart, Zhenyu Liao, and Romain Couillet. A random matrix approach to neural networks. The Annals of Applied Probability, 28(2):1190–1248, 2018.
- [LLS21] Fanghui Liu, Zhenyu Liao, and Johan Suykens. Kernel regression in high dimensions: Refined analysis beyond double descent. In International Conference on Artificial Intelligence and Statistics, pages 649–657. PMLR, 2021.
- [LR20] Tengyuan Liang and Alexander Rakhlin. Just interpolate: Kernel “ridgeless” regression can generalize. The Annals of Statistics, 48(3):1329–1347, 2020.
- [LRZ20] Tengyuan Liang, Alexander Rakhlin, and Xiyu Zhai. On the multiple descent of minimum-norm interpolants and restricted lower isometry of kernels. In Conference on Learning Theory, pages 2683–2711. PMLR, 2020.
- [LY16] Zeng Li and Jianfeng Yao. Testing the sphericity of a covariance matrix when the dimension is much larger than the sample size. Electronic Journal of Statistics, 10(2):2973–3010, 2016.
- [MHR+18] Alexander G de G Matthews, Jiri Hron, Mark Rowland, Richard E Turner, and Zoubin Ghahramani. Gaussian process behaviour in wide deep neural networks. In International Conference on Learning Representations, 2018.
- [MM19] Song Mei and Andrea Montanari. The generalization error of random features regression: Precise asymptotics and the double descent curve. Communications on Pure and Applied Mathematics, 2019.
- [MMM21] Song Mei, Theodor Misiakiewicz, and Andrea Montanari. Generalization error of random feature and kernel methods: hypercontractivity and kernel matrix concentration. Applied and Computational Harmonic Analysis, 2021.
- [MZ22] Andrea Montanari and Yiqiao Zhong. The interpolation phase transition in neural networks: Memorization and generalization under lazy training. The Annals of Statistics, 50(5):2816–2847, 2022.
- [Nea95] Radford M Neal. Bayesian learning for neural networks. PhD thesis, University of Toronto, 1995.
- [Ngu21] Quynh Nguyen. On the proof of global convergence of gradient descent for deep relu networks with linear widths. In International Conference on Machine Learning, pages 8056–8062. PMLR, 2021.
- [NM20] Quynh Nguyen and Marco Mondelli. Global convergence of deep networks with one wide layer followed by pyramidal topology. In 34th Conference on Neural Information Processing Systems, volume 33, 2020.
- [NMM21] Quynh Nguyen, Marco Mondelli, and Guido F Montufar. Tight bounds on the smallest eigenvalue of the neural tangent kernel for deep relu networks. In International Conference on Machine Learning, pages 8119–8129. PMLR, 2021.
- [NS06] Alexandru Nica and Roland Speicher. Lectures on the combinatorics of free probability, volume 13. Cambridge University Press, 2006.
- [OS20] Samet Oymak and Mahdi Soltanolkotabi. Toward moderate overparameterization: Global convergence guarantees for training shallow neural networks. IEEE Journal on Selected Areas in Information Theory, 1(1):84–105, 2020.
- [Péc19] S Péché. A note on the Pennington-Worah distribution. Electronic Communications in Probability, 24, 2019.
- [PLR+16] Ben Poole, Subhaneil Lahiri, Maithra Raghu, Jascha Sohl-Dickstein, and Surya Ganguli. Exponential expressivity in deep neural networks through transient chaos. In Advances in Neural Information Processing Systems, pages 3360–3368, 2016.
- [PS21] Vanessa Piccolo and Dominik Schröder. Analysis of one-hidden-layer neural networks via the resolvent method. Advances in Neural Information Processing Systems, 34, 2021.
- [PSG17] Jeffrey Pennington, Samuel Schoenholz, and Surya Ganguli. Resurrecting the sigmoid in deep learning through dynamical isometry: theory and practice. Advances in neural information processing systems, 30, 2017.
- [PSG18] Jeffrey Pennington, Samuel Schoenholz, and Surya Ganguli. The emergence of spectral universality in deep networks. In International Conference on Artificial Intelligence and Statistics, pages 1924–1932. PMLR, 2018.
- [PW17] Jeffrey Pennington and Pratik Worah. Nonlinear random matrix theory for deep learning. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- [QLY21] Jiaxin Qiu, Zeng Li, and Jianfeng Yao. Asymptotic normality for eigenvalue statistics of a general sample covariance matrix when and applications. arXiv preprint arXiv:2109.06701, 2021.
- [RR07] Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. In Proceedings of the 20th International Conference on Neural Information Processing Systems, pages 1177–1184, 2007.
- [RR17] Alessandro Rudi and Lorenzo Rosasco. Generalization properties of learning with random features. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- [RV13] Mark Rudelson and Roman Vershynin. Hanson-wright inequality and sub-gaussian concentration. Electronic Communications in Probability, 18:1–9, 2013.
- [SGGSD17] Samuel S Schoenholz, Justin Gilmer, Surya Ganguli, and Jascha Sohl-Dickstein. Deep information propagation. In International Conference on Learning Representations, 2017.
- [Sil85] Jack W Silverstein. The smallest eigenvalue of a large dimensional wishart matrix. The Annals of Probability, pages 1364–1368, 1985.
- [SY19] Zhao Song and Xin Yang. Quadratic suffices for over-parametrization via matrix Chernoff bound. arXiv preprint arXiv:1906.03593, 2019.
- [Tro12] Joel A Tropp. User-friendly tail bounds for sums of random matrices. Foundations of computational mathematics, 12(4):389–434, 2012.
- [Ver18] Roman Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018.
- [Voi87] Dan Voiculescu. Multiplication of certain non-commuting random variables. Journal of Operator Theory, pages 223–235, 1987.
- [WDW19] Xiaoxia Wu, Simon S Du, and Rachel Ward. Global convergence of adaptive gradient methods for an over-parameterized neural network. arXiv preprint arXiv:1902.07111, 2019.
- [Wil97] Christopher KI Williams. Computing with infinite networks. In Advances in Neural Information Processing Systems, pages 295–301, 1997.
- [WP14] Lili Wang and Debashis Paul. Limiting spectral distribution of renormalized separable sample covariance matrices when . Journal of Multivariate Analysis, 126:25–52, 2014.
- [WZ22] Zhichao Wang and Yizhe Zhu. Overparameterized random feature regression with nearly orthogonal data. arXiv preprint arXiv:2211.06077, 2022.
- [XBSD+18] Lechao Xiao, Yasaman Bahri, Jascha Sohl-Dickstein, Samuel Schoenholz, and Jeffrey Pennington. Dynamical isometry and a mean field theory of CNNs: How to train 10,000-layer vanilla convolutional neural networks. In International Conference on Machine Learning, pages 5393–5402. PMLR, 2018.
- [Xie13] Junshan Xie. Limiting spectral distribution of normalized sample covariance matrices with . Statistics Probability Letters, 83:543–550, 2013.
- [YBM21] Zitong Yang, Yu Bai, and Song Mei. Exact gap between generalization error and uniform convergence in random feature models. In Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 11704–11715. PMLR, 18–24 Jul 2021.
- [YXZ22] Long Yu, Jiahui Xie, and Wang Zhou. Testing Kronecker product covariance matrices for high-dimensional matrix-variate data. Biometrika, 11 2022. asac063.