Defending Against Backdoor Attack on Graph Nerual Network by Explainability
Abstract.
Backdoor attack is a powerful attack algorithm to deep learning model. Recently, GNN’s vulnerability to backdoor attack has been proved especially on graph classification task. In this paper, we propose the first backdoor detection and defense method on GNN. Most backdoor attack depends on injecting small but influential trigger to the clean sample. For graph data, current backdoor attack focus on manipulating the graph structure to inject the trigger. We find that there are apparent differences between benign samples and malicious samples in some explanatory evaluation metrics, such as fidelity and infidelity. After identifying the malicious sample, the explainability of the GNN model can help us capture the most significant subgraph which is probably the trigger in a trojan graph. We use various dataset and different attack settings to prove the effectiveness of our defense method. The attack success rate all turns out to decrease considerably.
1. Introduction
Machine learning (ML) models are increasingly deployed to make decisions on our behalf on various (mission-critical) tasks. In the fields of computer image processing, natural language processing and complex applications, medical image analysis, automatic driving, face payment, etc. have achieved very remarkable results.
However, the neural network (referred to as: model) with deep learning as the core has some shortcomings. For example, the function of the model can be easily disabled after being attacked by malicious attack such as backdoor attack(ref10, ; ref34, ). Specifically, in backdoor attack:
-
(1)
The backdoor is embedded so stealthily that it cannot be easily discovered, but an attacker can activate the backdoor using specific means to cause harm. For example, adding predefined conditions (”triggers”) to the training data. During the model’s inference phase, all the trigger-embedded samples are misclassified to the attacker’s pre-defined target label.(i.e. attack effectiveness)
-
(2)
Backdoor attack will not affect the normal performance of the system. In a deep learning system, that is, it will not affect or significantly reduce the prediction accuracy of the model for clean samples(i.e. attack evasiveness).
Backdoor detection and defense have been extensively studied in the image domain (ref2, ; ref3, ; ref4, ; ref5, ).With the development of GNN, researchers have also found that GNN can be easily attacked by backdoor attack (ref26, ; ref27, ; ref78, ). In order to implement backdoor attack in graph data, attackers must find a new kind of trigger. Unlike images whose data is structured and continuous, graph data is inherently unstructured and discrete, requiring triggers to be of the same nature. In the graph classification task, GNN predicts according to the topological structure and node features. It’s easy to come up with an idea that attackers can use a subgraph as a trigger. After injecting the triggers into training data, the model will acquire a “shortcut” function from the trigger structure to the attacker’s target label. During the model’s inference phase, if the input graph includes the pre-defined trigger structure, GNN model will predict the target label. Until now, backdoor detection and defense on GNNs are unexplored. Concretely, it is because backdoor defense on graph data has the following difficulties.
1.1. Defense is Challenging
-
For those malicious image training sample which is marked by a wrong label, we can easily detect them by our eyes. For example, it’s easy for us to identify the label of the picture in most dataset such as MINIST dataset and CIFAR-10 dataset. But for graph data, most of the time we can’t discriminate the true label only via observing the topological structure and node features.
-
Triggers can be of any shape and pattern, may be located anywhere on the input, and have indeterminate size. Moreover, the trigger can be a sparse subgraph or dense subgraph. It is extremely hard to predict the properties of the attacker’s trigger. Consequently, some methods like dense-subgraph detection is invalid. In other word, defenders must prepare to cope variety of triggers.
1.2. Our work and contribution
Given these challenges, we propose the first backdoor detection and defense method for GNNs. We reveal that triggers are much more influential than benign subgraphs. Compared to clean samples, trigger-embedded samples show completely different characters in some explainability evaluation metrics such as fidelity and infidelity. In essence, removing the trigger in the graph will affect the prediction probability considerably, whereas removing a benign subgraph will not cause the such condition. In this paper, we introduce Explainability score(ES) to quantify such characteristics and to distinguish the malicious samples and clean samples.
After identifying the backdoor samples, we utilize the explainability method to find the most influential subgraph in backdoor samples, that is, the trigger. Once we delete the trigger, this malicious sample will transform into a clean sample. Then this backdoor attack is not effective anymore.
We summarize our contributions as below:
-
(1)
We perform the first backdoor detection and defense method on GNNs. Our approach detects whether the input is trojaned or not. Once we find a malicious input sample, our approach can delete the trigger in this graph. Hence invalidate the backdoor attack.
-
(2)
Our method can cope with a variety of triggers. That is to say, no matter what structure the trigger is, our method still performs well.
-
(3)
We evaluate our method on three popular graph classification datasets with different attack settings. We achieve both low false acceptance rate(FAR) and low false rejection rate(FRR).

2. Background
2.1. Graph Neural Network
Graphs have been widely used to model complex interactions between entities. For instance, In an urban transportation network, cities and connected roads can be modeled as a graph, where cities are nodes, and edges between two nodes represent road connections between cities. In a social network, a user and his friends can be modeled as a graph, where the user and his online friends are nodes, and the edges between the two nodes represent the relationships and interactions between them.
Graph Neural Network (GNN) takes a graph as an input, including topological structures and node features, and generates a representation for each node . Most GNNs work with a neighborhood aggregation strategy:
| (1) |
where represents for the adjacency matrix of the input graph and is the node embeddings after k-th iteration. It also depend on the trainable parameters and the node embeddings from the previous iteration. is usually initialized as input graph’s node features. In order to obtain the graph embeddings , the READOUT functions pools the node embeddings from the final iteration :
| (2) |
Graph classification is a basic graph analytics tool and has many applications such as, in cheminformatics, the mutagenicity, toxicity, anticancer activity, etc. of compound molecules are judged by classifying molecular graphs(ref1, ; ref7, ); In bioinformatics, protein network classification is used to judge whether a protein is an enzyme or not. It has the ability to treat a certain disease (ref8, ; ref9, ). From this point of view, graph classification research is of great significance. GNN based graph classification extends neural network to graph data. We can build an end to end framework for graph classification by applying a multilayer perceptron and a Softmax layer to graph representations.
2.2. Attack method
adversarial attack:The goal of the adversarial attack is to select a class in advance and then choose the attack method. Make the model classify the sample into another class as much as possible, and increase the difference between the probability and the original class probability. The adversarial attack happens in the model’s inference phase. There are basically two kinds of adversarial attack: targeted attack and untargeted attack. The difficulty of these two kinds of adversarial attack are different. In targeted attack, the attacker wants the model to generate a specific wrong label. In untargeted attack, attacker doesn’t focus on making the model wrongly generate a specific label. As long as it is not divided into the correct label. One of the challenges of adversarial attacks is that the change is not obvious. The measurement standard of the image field can be that the changed image looks similar to the eyes. In the graph field, we can ensure unnoticeable perturbations in our setting through graph structure preserving-perturbations and feature statistics preserving perturbations.(ref22, ; ref24, ; ref23, ).
backdoor attack:Compared with adversarial attack, backdoor attack happens throughout the entire process. During the training phase, attacker hope to inject malicious trigger into target systems in some way. The injected backdoor is triggered by the attacker. During the inference process, if the input sample doesn’t contain trigger, the backdoor will not be activated and the attacked model behaves similarly to the normal model temporarily; But if a trigger-embedded sample is fed into the model, then the backdoor will be activated and the output of the model becomes the target label prespecified by the attacker to achieve malicious purposes.
Currently, poisoning training data is the most direct and common method of backdoor attacks. In poisoning-based attacks, the attacker modifies some training samples through preset triggers (such as a small subgraph). The labels of these modified samples are replaced by the target labels specified by the attacker, resulting in poisoned samples(ref25, ; ref26, ; ref27, ; ref1, ). These poisoned samples and benign samples will be used for training at the same time to obtain a model with a backdoor.
2.3. Research about the explainability in GNN
In recent years, several methods for Explainability in Graph Neural Networks have been proposed, such as XGNN (ref41, ) , gnnexplainer (ref42, ), PGExplainer (ref43, ) , etc.These approaches focus on different aspects of graphical models and provide different perspectives to understand these models. They generally start from several questions to realize the interpretation of the graphical model: Which input edges are more important? Which input nodes are more important? Which node features are more important?
Explanation techniques of deep learning models aim to find the parts of the input data which is the most influentialto the prediction results, providing input-dependent explanations for each input graph. And depending on how feature importance scores are obtained, these approaches can be divided into four distinct branches:
Gradient/feature-based methods (ref49, ; ref50, ) employ gradients or eigenvalues to represent the importance of different input features. Perturbation-based methods (ref42, ; ref43, ; ref49, ; ref52, ; ref44, ) monitor the changes in predicted values under different input perturbations, thereby learning the importance scores of input features. Decomposition-based methods (ref49, ; ref50, ; ref54, ; ref55, ) first decompose prediction scores, such as predicted probabilities, to the neurons of the last hidden layer. Such scores are then back-propagated layer by layer until the input space, and the decomposition score is taken as the importance score. Agent-based methods (ref56, ; ref57, ; ref58, ) first draw samples from a dataset from the neighbors of a given example. The next step is to fit a simple and interpretable model, such as a decision tree, to the sampled data set. Interpretation of the original predictions is achieved through the interpretive surrogate model.
2.4. Threat Model
Our threat model is largely inspired by backdoor attacks in the image domain (ref6, ; ref10, ; ref30, ; ref34, ; ref38, ; ref39, ).
2.4.1. Attakers’ goal and capability
Attacker’s goal:An attacker has two goals. First, the backdoored model performs well with most benign inputs, which makes the backdoor attack stealthy(attack evasiveness). Second, when the input contained attacker-predefined triggers, it showed targeted misclassification(attack effectiveness).
Attacker’s capability:The attacker can poison a small fraction of training graphs in the training dataset. Specifically, the attacker can inject a trigger to some training graph, and change these samples’ labels to an attacker-chosen target label. For instance, malicious users under an attacker’s control can provide the user with poisoned training graphs. Moreover, the attacker can inject the triggers into testing graphs.
2.4.2. Defenders’ goal and capability
Defenders’ goal:A defender has three goals. First, the defender needs to identify the backdoor samples as much as possible. Second, the defense method should not influence the accuracy on benign samples. Finally, the defender disables the backdoors. For instance, the defender can remove malicious samples or patch the network to remove backdoors).
Defenders’ capability:From the defender side, we reason that defenders hold a small collection of validation datasets which is used to set the detection boundary between the clean sample and malicious sample.
3. Our Explainability based Backdoor Defense
3.1. Defense System Design
Our defense system is dipicted in Figure 1 and summarized in Algorithm 1. There are mainly two processes in our defense system, namely backdoor detection and backdoor defense. The key to our backdoor detection is to identify the malicious samples successfully.
How to search and remove the triggers is the key to our backdoor defense. For those suspected samples, we manage to delete the trigger in it to invalidate the backdoor. After removing the trigger, this backdoor sample can be regarded as a clean sample so that we can feed into the model again to get the original output.
backdoor detection:Defender holds a small collection of clean samples called validation dataset. In the validation dataset, we calculate the explainability score(ES) for each graph. In particular, ES will be detailed in Section 3.2.4. We use the highest ES in validation dataset as a detection boundary to facilitate the classification on whether the input sample is malicious or not.
Then we can deploy our defense system. We calculate the ES for every incoming input x. If the ES is higher than the detection boundary, it is judged as a malicious sample, and if it is lower than the detection boundary, it is judged as a benign sample.
backdoor defense: Once we suspect an input graph is malicious. Since the attack’s effectiveness depends on the trigger, there is no denying that the trigger must be the most influential subgraph in this graph. Using the explainability of the model can help us find the most important subgraph. That’s just what we want to delete.
3.2. Explainability in GNN
Intuitively, as defenders, we do not know the trigger’s information. Although the triggers can be of a variety of patterns and structures, they still have one thing in common – trigger always plays an extremely important role in the model’s prediction. Then the problem that how to discriminate between malicious samples and benign samples becomes the problem that how to distinguish the importance of trigger subgraph and benign subgraph. The Explainability of the model can help us identify input features that are important to the results. At the same time, there are two evaluation metrics called fidelity and infidelity which can quantify the importance of the features we find. This is the inspiration for our solution.
First, the explanation should be faithful to the model. To evaluate this, the Fidelity (ref50, ) metric was recently proposed. The key idea is that if the important input features (node/edge/node features) identified by the explainability technique are important to the classification result, then the model’s predictions should change significantly when those features are removed. As for the benign samples, there is always a benign subgraph which can increase the probability that the model will make a correct prediction. But for the backdoor samples, with the appearance of the trigger, increases the likelihood that the model will predict the attacker’s pre-defined target label. Moreover, this increment is much bigger than the former, otherwise, our model will still make a correct prediction rather than the target label. In other words, as long as we try to remove the most important features in the sample, the probability of the original prediction will reduce. But for the backdoor sample, this reduction will be much bigger than the benign sample.
Concretely, In order to distinguish the importance of different edges to the classification results. explainability technique generates the importance map . The explanations can be considered as a hard importance map where each element is 0 or 1 to indicate if the corresponding feature is influential. If the graph contains 37 edges. Then the explainability method can generate a (37,) tensor called edge mask. Each element indicates the importance of this edge for our model to make this prediction. For some methods like GNNExplainer, the important values are continuous values from 0 to 1. Then the importance map can be obtained by normalization and thresholding.
3.2.1. Fidelity
, defined as the difference in probability between the original prediction and the new prediction after removing important input features(ref77, ), which is a measure of the difference between the two prediction results. Several techniques are proposed to generated the importance map (ref42, ; ref44, ; ref49, ; ref59, ).Finally, the Fidelity of prediction accuracy can be computed as:
| (3) |
where is the original prediction of graph and is the number of graphs. Here means the complementary mask that removes the important input features. Higher fidelity indicates better explanations results and more discriminative features are identified. For malicious samples, trigger is its ”only creed”, and deleting most triggers will lead to judgment results change, so the Fidelity value of backdoor samples will be much larger than the clean sample.
3.2.2. Infidelity
, In contrast to the Fidelity metric, which studies prediction changes by removing important node/edge/node features, The Infidelity metric investigates prediction changes by retaining important input features and removing unimportant features. Obviously, important features should contain discriminative information, so even if unimportant features are removed, they should lead to similar predictions to the original predictions. Formally, the metric Infidelity can be calculated as:
| (4) |
where is the new graph when keeping important features of based on explanation . Unlike fidelity, lower infidelity values indicate less importance information for deletions and therefore better explanations of results. Compared with benign samples, the unimportant features in backdoor samples seem more unimportant. Backdoor samples tend to have lower infidelity.
Now we own the method to distinguish between backdoor samples and benign samples. In order to invalidate backdoor, we only need to remove the most important edges in backdoor samples according to explanations. But there is still one critical problem. Because many advanced explainability method output continuous important values, how to set a proper threshold between important edges and unimportant edges. Concretely, for backdoor samples with big trigger size, deleting less edges is not enough to remove the whole trigger. The trigger may still work. For backdoor samples with small trigger size, although deleting edges can easily remove the trigger, it can also do damage to the natural structure of the graph because we may delete some edges belonging to benign subgraphs.
In essence, we need to estimate the trigger size approximately. But actually, the defender doesn’t know anything about the structure of the trigger. Hence we need to find other things that are relevant to the trigger size. Trigger size determines the number of edges in the trigger. That is to say, trigger with a big trigger size owns more edges. In that case, there will be a lot of really important edges. Compared with small size trigger, the importance map of big size trigger is more concentrative.
For example, for a malicious sample with 100 edges, we assume the trigger has 80 edges. It’s pretty hard to say which edges are the most important. Simply speaking, these 80 edges form the trigger together. The influence of the trigger is distributed to 80 edges. Consequently, there is no big difference in importance among these edges. But if the trigger has 10 edges. It’s apparent that these 10 edges will be extremely important compared with other 90 edges. It’s just like the situation that there are 100 persons. Distributing 100 dollars to 80 persons will not cause a huge gap of wealth among them. While distributing 100 dollars to 10 persons will increase the gap of wealth to some degree. To sum up, small size trigger’s importance map will have a high degree of dispersion while big size trigger will not.
Figure 2 shows the map distribution when trigger size is 0.2. Trigger size density is the subgraph’s number of nodes.
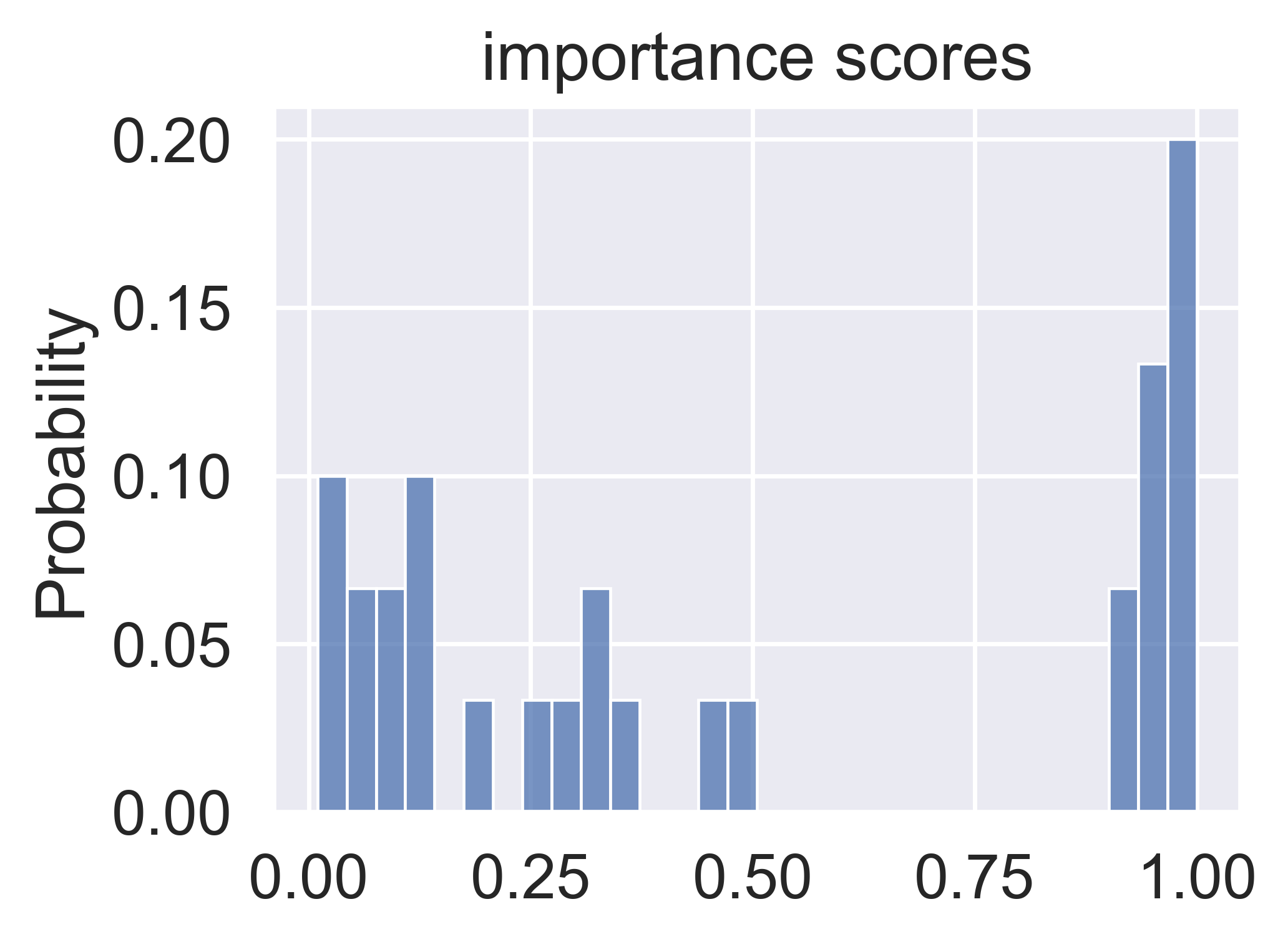

On the contrary ,from Figure 3, when trigger size is 0.6, the importance map is more concentrative. Compared with using a fixed threshold, using adaptive sparsity can greatly improve the generalization performance of the model. As a defender, we don’t know the information of the attacker’s trigger size and structure. Using adaptive sparsity can help us choose an appropriate set of edges to delete. When trigger is big, it means that if we want to remove the whole trigger, we need to delete many edges. In other words, we need a small Sparsity. However, when the trigger is small, we only need to delete a few edges. In this case, big Sparsity is what we need.
So our goal is to set an appropriate threshold to transform the continuous importance map to a hard importance map only including 0 and 1. Specifically, importance values higher than thresholding will be set to 1 otherwise will be set to 0. 0 represents unimportant edges while 1 represents important edges. After that, we can remove the trigger in the backdoor sample by deleting the edges whose hard importance score is 1. If the trigger size is big, we will need to set relatively low thresholding to generate more ”important edges” so that we can delete more edges belonging to the trigger.
Until now we set up a relation among trigger size, degree of dispersion of the importance map, and thresholding. We use one evaluation metric called Sparsity to relate them.
3.2.3. Sparsity
, To analyze the performance of explanation methods from the perspective of input graph data, explanation methods should be sparse. it should capture the most important input features and ignore irrelevant features, which can be measured by the Sparsity metric such a feature. Specifically, it measures the score selected as an important feature by the explainability method. Formally, giving the graph and its hard importance map , the Sparsity metric can be computed as:
| (5) |
where denotes the number of important input features (node/edge/node features) identified in , and denotes the total number of features in the original graph . Higher Sparsity values indicate the sparser the model features and tend to only capture the most important input information. Here we use this metric in reverse, that is, we use it to transform the continuous importance map to a hard importance map . Actually, sparsity is another form of thresholding. Setting high thresholding equals setting high sparsity.
Then we introduce the Coefficient of Variation to quantify the degree of dispersion of the importance map:
| (6) |
where denotes the standard deviation, denotes the average value. Big represents that the edges’ important values are highly discrete. On contrary, small means all the edges’ significance is similar. Actually, before the process of calculating and we firstly set the sparsity via calculate the of the importance map. Then the continuous importance map can be transformed to a hard importance map according to the sparsity and can be used to calculate and .
Finally, we can put them all together, our reasoning can be summarized in Figure 4. It solves the problem that how to regulate sparsity. We find that and sparsity have the same trend. So we control the Coefficient of Variation between 0 and 1 to replace the sparsity.

3.2.4. Explainability score(ES):
, To do binary classification of input samples, we introduce a new metric, Explainability score (). Formally, the can be computed as:
| (7) |
As we deduced above, backdoor samples always have high fidelity and low infidelity. combine both of them together. So high value represents a high probability of backdoor sample. In conclusion, there are significant differences in between clean and backdoor samples. This provides the defender with a tool for backdoor detection. We use the highest value of the validation dataset as the detection boundary. For every incoming input graph, if its value is higher than the detection boundary, we will suspect that it’s a backdoor sample. In order to disable the backdoor, we delete some most important edges in this input graph according to the hard importance map .



4. Defense Evaluation
4.1. Experimental settings
4.1.1. Dataset
Datasets: We also evaluate our defense on the three datasets
-
AIDS (ref47, )- molecular structure graphs of active and inactive compounds;
-
bitcoin (ref14)- an anonymized Bitcoin transaction network with each node (transaction) labeled as legitimate or illicit
-
MUTAG (ref15, )- A dataset of chemical molecules and compounds, with atoms representing nodes and bonds representing edges.
4.1.2. explainer:captum
A Pytorch-based model interpretation library. The library provides explainability for many new algorithms (eg: ResNet, BERT, some semantic segmentation networks, etc.) to better understand the specific features, neurons, and neural network layers that contribute to model predictions. For the graph classification problem, it can quickly locate some nodes that affect the results and display them visually.
Integrated gradients is one of the primary attribution algorithm implemented in captum. Integrated gradients is a simple, yet powerful axiomatic attribution method (ref61, ). Integrated gradients represent the integral of gradients with respect to inputs along the path from a given baseline to input. Herefore, the integral gradient algorithm only considers the input and output of the model, and the function is differentiable everywhere, without the participation of the internal details of the model(it requires almost no modification of the original network.)
4.1.3. models
4.1.4. metrics
To evaluate attack effectiveness, we use Attack Success Rate (ref27, ), which measures the likelihood that the backdoor classifier predicts the trigger-embedded inputs to the target label designated by the attacker.
| (8) |
As for the defender, we want the to drop hugely after we deploy the defense system. Apart from it, our defense system should not influence the model to make a correct prediction on clean samples. In other word, defense system should have a low (ref29, ). Here we introduce . Given a clean testing dataset , we define as model’s accuracy on clean samples after deploying the defense system. Formally, we have the following:
| (9) |
represents for the model deployed with the defense system. Intuitively, should be close to the clean model’s(without deploying defense system) accuracy.
4.2. Results
Figure 5 shows the difference in value on three datasets between benign samples and backdoor samples, It turns out that backdoor samples always have extremely high ES. The red dotted line signifies the highest in the validation dataset. For every incoming sample, if its is higher than it, we will suspect that it’s a backdoor sample.
Because the defender does not know the attacker’s trigger information, this disadvantage imposes a requirement on the generalization performance of the defense model. We tested the defense ability under different trigger attributes (Trigger size, Tigger density, Poisoning intensity) and different datasets.
As shown in Figure 6, in different cases, the of the model decreases significantly after deploying the defense system, For instance, when the trigger size is 20% (Tigger density=0.8, Poisoning intensity=0.05) of the average number of nodes per graph, The indicator is 0.77 before defense, but the ASR after defense reduces to 0.05 on MUTAG dataset. In some cases, we can even decrease the to 0, which proves the effectiveness of our defense system.
Figure 7 shows the result of our defense system on Defense accuracy indicators. it proves that our backdoor defense has a small impact on the accuracies for clean testing graphs. Recall that one of our defender’s goals is that the accuracy on clean samples should not be influenced by our defense method. Specifically, Defense accuracy is slightly smaller than clean accuracy. For instance, when the trigger size is 20% of the average number of nodes per graph, the defense accuracy is 0.04 smaller than the clean accuracy on AIDS dataset.
In fact, the importance of features of clean samples is more dispersed than that of malicious samples. The decision result is often determined by the joint action of multiple edges. Even if we misjudge a benign sample to a malicious sample and then we remove some edges from this graph, we can still get the correct decision results from the remaining features. For example, when we distinguish cats and dogs, we judge their categories from multiple features, rather than one feature. Therefore, we seldom make mistakes because of the deletion of a certain feature (such as covering the cat’s ears or nose, etc.). On the contrary, as for backdoor sample, the model’s decision is almost totally determined by the trigger. Once we remove the trigger, the model’s prediction will change a lot. It also proves why backdoor samples will have high . These properties can reduce accidental damage to clean samples by defensive methods.
5. Discussion and Limitations
First, during the experiment, we found that the model’s complexity has a strong correlation with the of backdoor attacks. In the case of low model complexity, when the model achieves the expected accuracy on benign samples, the metric is still at a low level. Therefore, the user is likely to use early stopping(ref62, ) to avoid overfitting, which indirectly leads to the failure of the attacker’s attack. Lower model complexity means that the model’s expressive power is weak. Therefore, it is not easy for the model to discover the ”importance” of the trigger at a fewer number of training times. Once model ignores the trigger, the backdoor attack will not succeed. On the other hand, when the model’s expressive ability is stronger, rises much faster than before. The model can quickly capture the ”importance” of the trigger to the classification results, making it easier for attackers to achieve their goals.

As shown in figure 8, when the expressive ability of the model is insufficient (the number of model parameters is 4611), the rises slowly as the number of epochs increases. And when the accuracy on clean samples reaches the highest value, is still at a low level. If the victim uses the skill of early stopping and finishes training at epoch=50, it will almost completely invalidate the backdoor attack. From this point of view, backdoor attack is somewhat similar to overfitting. In essence, overfitting is a phenomenon that the model learns too much about the nonessential features but ignores the essential features in the sample. When overfitting occurs, the model will have an abnormally high training accuracy and a low testing accuracy. Compared with overfitting, the nonessential feature in backdoor attack is the trigger’s feature, and the low testing accuracy mentioned above is actually manifested as the model’s pretty low accuracy on trigger-embedded samples(They are all misclassified to the target label). At the same time, those triggers also have a pre-defined structure instead of a random structure generated from the nature, which makes the model learns a ”regular” noise. Learning this noise is so easy that the model really trusts it, i.e. the model is overfitting to the trigger.

On the contrary, in figure 9. When the model has the sufficient expressive ability (the number of model parameters is 27973), the rises rapidly and reaches the highest value almost simultaneously with the indicator.

We also prove that a larger trigger can accelerate the rise of . However, if the trigger is too large, it is easier for users to find errors in the data, so the attacker needs to make a trade-off between the success rate of the attack and the concealment of the trigger.
We believe that the limitations of this attack algorithm may provide ideas for future research on new defense algorithms (such as using some specific method to make the model’s expressive ability only meet clean samples but unable to learn trigger features)
The proposed defense method mainly uses the topology information of the graph to judge whether it is a clean graph or a malicious graph. Therefore, there are certain requirements for the topological characteristics of the graph. Specifically, when the input graph is sparse, each edge is important to the prediction result. The operation of deleting edges is very damaging to the information of the graph. It’s hard to tell if its edge is a trigger (or if the graph itself is a trigger)
Our empirical results in Figure 10 show that when our defense detection fails to identify the backdoor trigger, the case where the input graph is sparse accounts for the vast majority of the proportion. It shows our method’s weakness in discriminating backdoor samples with small size.
6. Conclusion and Future work
In this work, we propose the first backdoor detection and defense method on GNN. Specifically, the defender can calculate the highest ES value in the validation dataset as a threshold to identify the incoming backdoor samples. The samples whose ES is greater than the threshold in the input are regarded as malicious samples. Then remove the edges in it under the control of an adaptive Sparsity so as to achieve the purpose of destroying the trigger. Our empirical evaluation results on three real-world datasets show that our backdoor defense achieves high effectiveness with a small impact on the GNN’s accuracy for clean testing graphs.
The explainability and robustness of GNN model is an important issue, and this work provides necessary insights for deeper research. In the future, we are planning to further improve the defense capability of the method on sparse graphs. With the development of the model’s explainability, our method is expected to be applied to more complicated engineering problems to further prove its potential for real-life applications.
References
- [1] Asim, Kumar, Debnath, Rosa, L., Lopez, de, Compadre, Gargi, and Debnath and. Structure-activity relationship of mutagenic aromatic and heteroaromatic nitro compounds. correlation with molecular orbital energies and hydrophobicity. Journal of Medicinal Chemistry, 34(2):786–797, 1991.
- [2] Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In International conference on machine learning, pages 274–283. PMLR, 2018.
- [3] Karsten M Borgwardt, Hans Peter Kriegel, S V N Vishwanathan, and Nicol N Schraudolph. Graph kernels for disease outcome prediction from protein-protein interaction networks. In PubMed, pages 4–15, 2007.
- [4] Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. Targeted backdoor attacks on deep learning systems using data poisoning. arXiv preprint arXiv:1712.05526, 2017.
- [5] H. Dai, H. Li, T. Tian, X. Huang, L. Wang, J. Zhu, and L. Song. Adversarial attack on graph structured data. 2018.
- [6] R. Feinman, R. R. Curtin, S. Shintre, and A. B. Gardner. Detecting adversarial samples from artifacts. 2017.
- [7] Matthias Fey and Jan Eric Lenssen. Fast graph representation learning with pytorch geometric. arXiv preprint arXiv:1903.02428, 2019.
- [8] A. Fout, J. Byrd, B. Shariat, and A. Ben-Hur. Protein interface prediction using graph convolutional networks. In Neural Information Processing Systems, 2017.
- [9] Thorben Funke, Megha Khosla, and Avishek Anand. Hard masking for explaining graph neural networks. 2020.
- [10] Y. Gao, C. Xu, D. Wang, S. Chen, Damith C Ranasinghe, and S. Nepal. Strip: A defence against trojan attacks on deep neural networks. 2019.
- [11] Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. In International Conference on Learning Representations, 2014.
- [12] T. Gu, B. Dolan-Gavitt, and S. Garg. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv, 2017.
- [13] T. Gu, B. Dolan-Gavitt, and S. Garg. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv, 2017.
- [14] Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, and Been Kim. A benchmark for interpretability methods in deep neural networks. Advances in neural information processing systems, 32, 2019.
- [15] W. Hu and Y. Tan. Generating adversarial malware examples for black-box attacks based on gan. 2017.
- [16] Qiang Huang, Makoto Yamada, Yuan Tian, Dinesh Singh, and Yi Chang. Graphlime: Local interpretable model explanations for graph neural networks. IEEE Transactions on Knowledge and Data Engineering, 2022.
- [17] Qiang Huang, Makoto Yamada, Yuan Tian, Dinesh Singh, and Yi Chang. Graphlime: Local interpretable model explanations for graph neural networks. IEEE Transactions on Knowledge and Data Engineering, 2022.
- [18] W. Li, J. Yu, X. Ning, P. Wang, Q. Wei, Y. Wang, and H. Yang. Hu-fu: Hardware and software collaborative attack framework against neural networks. In 2018 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), 2018.
- [19] Y. Liu, S. Ma, Y. Aafer, W. C. Lee, and X. Zhang. Trojaning attack on neural networks. In Network and Distributed System Security Symposium, 2017.
- [20] Y. Liu, R. Wen, X. He, A. Salem, Z. Zhang, M. Backes, E De Cristofaro, M. Fritz, and Y. Zhang. Ml-doctor: Holistic risk assessment of inference attacks against machine learning models. 2021.
- [21] D. Luo, W. Cheng, D. Xu, W. Yu, and X. Zhang. Parameterized explainer for graph neural network. 2020.
- [22] Mahe, Vert, and JP. Graph kernels based on tree patterns for molecules. MACH LEARN, 2009.
- [23] C. Morris, M. Ritzert, M. Fey, William L Hamilton, J. E. Lenssen, G. Rattan, and M. Grohe. Weisfeiler and leman go neural: Higher-order graph neural networks. 2018.
- [24] Phillip E Pope, Soheil Kolouri, Mohammad Rostami, Charles E Martin, and Heiko Hoffmann. Explainability methods for graph convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10772–10781, 2019.
- [25] Lutz Prechelt. Early stopping-but when? In Neural Networks: Tricks of the trade, pages 55–69. Springer, 1998.
- [26] Ryan Rossi and Nesreen Ahmed. The network data repository with interactive graph analytics and visualization. In Twenty-ninth AAAI conference on artificial intelligence, 2015.
- [27] Michael Sejr Schlichtkrull, Nicola De Cao, and Ivan Titov. Interpreting graph neural networks for nlp with differentiable edge masking. arXiv preprint arXiv:2010.00577, 2020.
- [28] Thomas Schnake, Oliver Eberle, Jonas Lederer, Shinichi Nakajima, Kristof T Schütt, Klaus-Robert Müller, and Grégoire Montavon. Higher-order explanations of graph neural networks via relevant walks. arXiv preprint arXiv:2006.03589, 2020.
- [29] Robert Schwarzenberg, Marc Hübner, David Harbecke, Christoph Alt, and Leonhard Hennig. Layerwise relevance visualization in convolutional text graph classifiers. arXiv preprint arXiv:1909.10911, 2019.
- [30] A. Smalter, J. Huan, and G. Lushington. Graph wavelet alignment kernels for drug virtual screening. Journal of Bioinformatics & Computational Biology, 7(03):473–497, 2009.
- [31] Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International conference on machine learning, pages 3319–3328. PMLR, 2017.
- [32] B. Tran, J. Li, and A. Madry. Spectral signatures in backdoor attacks. 2018.
- [33] Minh Vu and My T Thai. Pgm-explainer: Probabilistic graphical model explanations for graph neural networks. Advances in neural information processing systems, 33:12225–12235, 2020.
- [34] Xiang Wang, Yingxin Wu, An Zhang, Xiangnan He, and Tat-seng Chua. Causal screening to interpret graph neural networks. 2020.
- [35] Z. Xi, R. Pang, S. Ji, and T. Wang. Graph backdoor. 2020.
- [36] Jing Xu, Minhui Xue, and Stjepan Picek. Explainability-based backdoor attacks against graph neural networks. In Proceedings of the 3rd ACM Workshop on Wireless Security and Machine Learning, pages 31–36, 2021.
- [37] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? arXiv preprint arXiv:1810.00826, 2018.
- [38] R. Ying, D. Bourgeois, J. You, M. Zitnik, and J. Leskovec. Gnnexplainer: Generating explanations for graph neural networks. Advances in neural information processing systems, 32:9240–9251, 2019.
- [39] H. Yuan, J. Tang, X. Hu, and S. Ji. Xgnn: Towards model-level explanations of graph neural networks. In KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2020.
- [40] V. Zantedeschi, M. I. Nicolae, and A. Rawat. Efficient defenses against adversarial attacks. In Acm Workshop on Artificial Intelligence & Security, pages 39–49, 2017.
- [41] Yue Zhang, David Defazio, and Arti Ramesh. Relex: A model-agnostic relational model explainer. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pages 1042–1049, 2021.
- [42] Z. Zhang, J. Jia, B. Wang, and N. Z. Gong. Backdoor attacks to graph neural networks. In SACMAT ’21: The 26th ACM Symposium on Access Control Models and Technologies, 2021.
- [43] D Zügner, A. Akbarnejad, and S Günnemann. Adversarial attacks on neural networks for graph data. In the 24th ACM SIGKDD International Conference, 2018.