Deep Residual Learning for Channel Estimation in Intelligent Reflecting Surface-Assisted Multi-User Communications
Abstract
Channel estimation is one of the main tasks in realizing practical intelligent reflecting surface-assisted multi-user communication (IRS-MUC) systems. However, different from traditional communication systems, an IRS-MUC system generally involves a cascaded channel with a sophisticated statistical distribution. In this case, the optimal minimum mean square error (MMSE) estimator requires the calculation of a multidimensional integration which is intractable to be implemented in practice. To further improve the channel estimation performance, in this paper, we model the channel estimation as a denoising problem and adopt a deep residual learning (DReL) approach to implicitly learn the residual noise for recovering the channel coefficients from the noisy pilot-based observations. To this end, we first develop a versatile DReL-based channel estimation framework where a deep residual network (DRN)-based MMSE estimator is derived in terms of Bayesian philosophy. As a realization of the developed DReL framework, a convolutional neural network (CNN)-based DRN (CDRN) is then proposed for channel estimation in IRS-MUC systems, in which a CNN denoising block equipped with an element-wise subtraction structure is specifically designed to exploit both the spatial features of the noisy channel matrices and the additive nature of the noise simultaneously. In particular, an explicit expression of the proposed CDRN is derived and analyzed in terms of Bayesian estimation to characterize its properties theoretically. Finally, simulation results demonstrate that the performance of the proposed method approaches that of the optimal MMSE estimator requiring the availability of the prior probability density function of channel.
Index Terms:
Intelligent reflecting surface (IRS), channel estimation, deep learning, Bayesian estimation.I Introduction
Recently, intelligent reflecting surface (IRS), which has the capability of shaping the wireless channels between the users and the base station (BS) to enhance the system performance, has been proposed as a promising technology for the future smart radio environment [2, 3, 4, 5, 6]. In particular, thanks to the development of advanced materials, a reconfigurable and passive metasurface made of electromagnetic materials has been introduced to design the IRS to make it deployable and sustainable in practice [7, 8]. Generally, an IRS is composed of a large number of passive reflecting elements while each element is reconfigurable and can be independently controlled to adapt its phase shift to the actual environment to alter the reflection of the incident signals. As such, by jointly adjusting the phase shifts of all the passive elements, a desirable reflection pattern can be obtained which establishes a favourable wireless channel to improve the transmission quality with a low system power consumption [9, 10, 11]. Based on this, an IRS can be adopted in communication systems to enhance the energy efficiency or the spectral efficiency of communication networks through passive beamforming techniques, i.e., designing an efficient configuration of phase shifts to improve the received signal-to-noise ratio (SNR) at the desired receivers [12]. Therefore, IRS-assisted communication systems and the related studies such as the network capacity or received SNR maximization [13, 14], the energy efficiency or spectral efficiency maximization [15, 16], and the IRS-assisted physical layer security [17, 18], etc., have drawn vast attention from both the academia and the industry.
In practice, the promised performance gain brought by an IRS relies on accurate channel state information (CSI) for beamforming. Yet, the aforementioned studies were conducted under the assumption of perfect knowledge of CSI, which is usually not available. In fact, an indispensable task for realizing IRS-assisted communication systems is to perform accurate channel estimation. In contrast to the channel estimation in traditional systems, the IRS is passive and cannot perform training sequence transmission/reception or signal processing, i.e., the channel of IRS to user/BS is generally not available separately and only a cascaded channel of user-to-IRS-to-BS can be estimated. More importantly, the cascaded channel brings two main challenges to IRS-assisted communication systems which are listed as follows: (i) Limited channel estimation accuracy: Note that the cascaded user-to-IRS-to-BS channel does not follow the conventional Rayleigh fading model. In this case, the optimal minimum mean square error (MMSE) estimator involves a multidimensional integration which is overly computationally intensive for practical implementation. Meanwhile, the performance of the available linear MMSE (LMMSE) and least squares (LS) estimators still has a large gap compared with that of the optimal MMSE estimator. Thus, the channel estimation accuracy is unsatisfactory for practical IRS-assisted communication systems. (ii) Large channel estimation training overhead: The IRS generally consists of a large number of elements. Thus, the cascaded channel is with a high dimension and the corresponding channel estimation via conventional methods, e.g., the LS method and the LMMSE method, is computationally costly.
To overcome the challenge of limited channel estimation performance in IRS-assisted systems (i.e., challenge (i)), a variety of effective algorithms and efficient schemes have been proposed recently. For example, in [19], a binary reflection controlled least squares (LS) channel estimation scheme was developed for single-user systems by switching on only one reflecting element of the IRS and switching off the rest reflecting elements for each time slot. In this case, the BS only receives interference from the direct link and does not receive any interference from the other reflection elements [20]. Thus, the BS can estimate the cascaded channel successively, which paves the way for the channel estimation in IRS-assisted systems. However, since the binary reflection scheme only active one element each time, only a small received SNR can be obtained at the BS for estimation. Besides, an exceeding long delay may introduce to the system if there is a large number of IRS elements. To further improve the received SNR and shorten the required time for channel estimation, [21] proposed to switch on all the reflecting elements of the IRS for each time slot. In particular, the authors proposed a discrete Fourier transform (DFT) training sequence-based minimum variance unbiased estimator which can achieve satisfactory estimation accuracy. Moreover, the authors in [22] developed two parallel factor (PARAFAC)-based methods where the LS estimator was first adopted to obtain coarse channel coefficients and then more accurate estimation results can be obtained through exploiting the least squares Khatri-Rao factorization and the bilinear estimation techniques. On the other hand, some initial attempts have been devoted to the design of efficient schemes to reduce the required training overhead of channel estimation (i.e., challenge (ii)). For instance, [23] and [24] developed a subsurface-based channel estimation scheme where the IRS is divided into several independent subsurfaces and each subsurface is composed of multiple adjacent reflecting elements applying one common phase shift. Hence, by adopting the sharing strategy, the training overhead is dramatically reduced. Besides, [25] introduced a cascaded channel estimation framework and proposed the related algorithm based on the sparse matrix factorization and the matrix completion. Moreover, [26] studied the channel estimation in IRS-aided multiple-input multiple-output (MIMO) systems. Specifically, the authors first formulated the channel estimation as a problem of recovering a sparse channel matrix and then proposed a compressed sensing-based scheme to explore the sparsity of the cascaded channel. Also, in [27] and [28], the authors investigated the application of an IRS to a multi-user system and developed a three-phase channel estimation framework to shorten the required time duration for channel estimation by exploiting the redundancy in the reflecting channels of different users. Different from the previous works, [29] developed a novel IRS architecture equipped with a single active radio frequency (RF) chain for channel estimation at the IRS side, which further shortens the training overhead. However, despite the significant research efforts devoted in the aforementioned literature, the problem of limited channel estimation performance in (i) has not been well addressed, thus an effective and practical algorithm which can further improve the estimation accuracy is expected.
Recently, in contrast to the traditional model-driven approaches, data-driven deep learning (DL) techniques [30, 31, 32] have proved their effectiveness in IRS-assisted communication systems, such as the DL-based passive beamforming design [33, 34, 35, 36], the deep reinforcement learning (DRL)-based phase shift optimization [37], and the DRL-based secure wireless communications for IRS-MUC systems [38]. Although these DL-based methods are promising, they still require the availability of perfect CSI for implementation in IRS-assisted systems. Note that the channel estimation problem is essentially a denoising problem. In particular, the DL technique, especially the deep residual learning (DReL) which adopts a deep residual network (DRN) to improve the network performance and accelerate the network training speed, has been recognized by its powerful capability in denoising in various research areas [39, 40, 41]. Motivated by these facts, in this paper, we focus on IRS-assisted multi-user communication (IRS-MUC) systems and adopt a DReL approach to intelligently exploit the channel features to further improve the channel estimation accuracy. Note that different from the existing work in [33] where the IRS requires the installation of additional active channel sensors, our work focuses on a general IRS without deploying any active sensors to address the challenging channel estimation problem in IRS-assisted communication systems. Besides, in contrast to the MMSE channel estimation [42, 43, 44], our proposed method adopts the LS-based channel estimation value as the initial coarse estimated value, models the channel estimation as a denoising problem, and exploits the neural network to design a denoiser. Thus, our proposed method is model-free and does not require any prior statistical information. The main contributions of this work are listed as follows111 Note that this paper mainly focuses on improving the estimation accuracy of CSI, but not on reducing the training overhead. As such, the proposed method in this paper adopts the LS-based channel estimation value as the network input and exploits a neural network to further improve the estimation accuracy. In this case, the training overhead of our proposed method comes from the LS method which can be addressed by adopting the low overhead grouping scheme for IRS elements [23, 24].:
-
(1)
In contrast to existing channel estimation methods, e.g., [19, 21, 22, 23, 24, 25, 26, 27, 28, 42, 43, 44], we model the channel estimation problem in IRS-MUC systems as a denoising problem and develop a DReL-based channel estimation framework which adopts a DRN to implicitly learn the residual noise for recovering the channel coefficients from the noisy pilot-based observations. Specifically, according to the MMSE criterion, a DRN-based MMSE (DRN-MMSE) estimator is derived in terms of Bayesian philosophy which enables the design of an efficient estimator.
-
(2)
To realize the developed framework, we adopt a convolutional neural network (CNN) to facilitate the DReL and propose a CNN-based DRN (CDRN) for channel estimation, in which a CNN-based denoising block with an element-wise subtraction structure is specifically designed to exploit both the spatial features of the noisy channel matrices and the additive nature of the noise simultaneously. Inheriting from the superiorities of CNN and DReL in feature extraction and denoising, the proposed CDRN method could further improve the estimation accuracy.
-
(3)
Although it is generally intractable to analyze the performance of a neural network, we formulate the proposed CDRN as a mathematical function and derive an explicit expression of the proposed CDRN estimator to explain the mechanism of the proposed algorithm theoretically, which proves that the proposed CDRN estimator can achieve the same performance as that of the LMMSE estimator.
-
(4)
Extensive simulations have been conducted to verify the efficiency of the proposed method in terms of the impacts of SNR and channel size on normalized MSE (NMSE), respectively. Additionally, visualizations of the proposed CDRN are also provided to illustrate the denoising process. Our results show that the performance of the proposed method approaches that of the optimal MMSE estimator requiring the computation of a prior probability density function (PDF) of cascaded channel.
The reminder of our paper is organized as follows. Section \@slowromancapii@ introduces the system model of the IRS-MUC system and derives the optimal MMSE estimator, the LMMSE estimator, and the LS estimator as benchmarks. In Section \@slowromancapiii@, we model the channel estimation as a denoising problem and develop a versatile DReL-based channel estimation framework. As a realization of the developed framework, a CDRN architecture and a CDRN-based channel estimation algorithm are designed in Section \@slowromancapiv@. Extensive simulation results are provided in Section \@slowromancapv@ to verify the effectiveness of the proposed scheme, and finally Section \@slowromancapvi@ concludes the work of this paper.
The notations used in our paper are listed as follows. The superscripts and are used to represent the transpose and conjugate transpose, respectively. Terms and denote the sets of real numbers and complex numbers, respectively. Term denotes the set of integers. is the circularly symmetric complex Gaussian (CSCG) distribution where and are the mean vector and the covariance matrix, respectively. The matrix represents the -by- identity matrix and the vector represents a zero vector. denotes the operation of the matrix inverse. and are used to represent the operations of extracting the real part and the imaginary part of a complex-valued matrix, respectively. is the trace of a matrix and represents the construction of a diagonal matrix. are used to denote the Frobenius norm of a matrix. In addition, indicates the exponential function, represents the statistical expectation operation, and denotes the indicator function of an event .
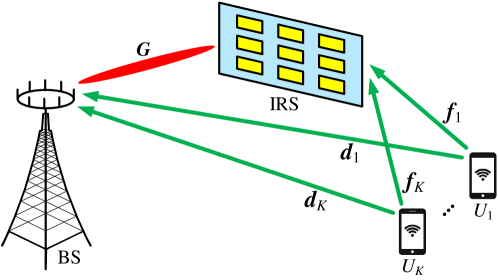
II System Model
In this paper, we consider an IRS-MUC system adopting the time division duplex (TDD) protocol, which consists of one base station (BS), one IRS, and users, as shown in Fig. 1. The BS is equipped with an -element antenna array and passive reflecting elements are installed at the IRS to assist the BS to serve the single-antenna users. By joint beamforming design at both the BS and the IRS, the throughput of the IRS-MUC system could be further enhanced. However, the downlink beamforming design critically depends on the availability of accurate CSI. Due to the property of channel reciprocity in TDD systems, the downlink CSI could be acquired from the uplink channel estimation in the IRS-MUC system. The uplink system model is illustrated in Fig. 1, where , , denotes the -th user. The channels of the -BS link, the -IRS link, and the IRS-BS link are represented by , , and , respectively. The reflecting link -IRS-BS can be regarded as a dyadic backscatter channel [2, 7], where each element at IRS combines all the arriving signals and re-scatters them to the BS behaving as a single point source. Denote with as the phase-shift matrix, where and are the amplitude and the phase shift at the -th, , element of IRS, respectively. The channel response from to the BS via the IRS can be expressed as . In this case, the channel response of the reflecting link -IRS-BS can be altered through adjusting the phase-shift matrix at the IRS. Since it is obvious that , the channel of reflecting link -IRS-BS can be expressed as . Therefore, the objective of the uplink channel estimation is to estimate
| (1) |
where
| (2) |
is a cascaded channel. Therefore, the downlink channels can be obtained by the conjugate transpose of the uplink channels via exploiting the channel reciprocity in TDD systems.
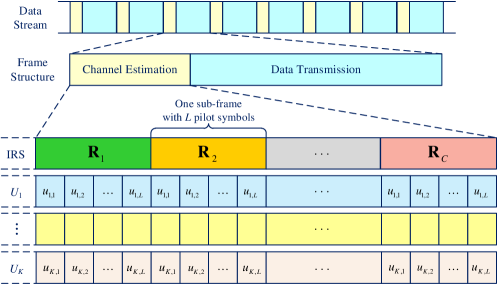
Based on these, we then develop a channel estimation protocol for the considered IRS-MUC system. As shown in Fig. 2, each frame in the data stream has an identical frame structure which consists of a channel estimation phase and a data transmission phase. In this paper, we mainly focus on the channel estimation phase to estimate as defined in (1). In the channel estimation phase, the IRS generates , , different reflection patterns through different phase-shift matrices, denoted by
| (3) |
Here, is the -th, , phase-shift matrix with , where and are the amplitude and the phase shift at the -th element of the IRS under the -th phase-shift matrix, respectively. In addition, orthogonal pilot sequences are adopted to distinguish different users, i.e., for , , a pilot sequence with a length of , , is adopted for each IRS phase-shift matrix, denoted by with and , where is the power of each user, , and . According to Fig. 2, the channel estimation phase consists of sub-frames and each sub-frame consists of pilot symbols. For the IRS, the phase-shift matrix keeps unchanged within one sub-frame and it switches to different phase-shift matrices for different sub-frames. As for the -th user, , , it sends its identity pilot sequence in each sub-frame. Therefore, the -th, , received pilot signal vector at the BS in the -th sub-frame can be expressed as
| (4) | ||||
| (5) |
Here, is the channel matrix needed to be estimated as defined in (1) and . Equation (5) is due to the property of . In addition, is the -th sampling noise vector at the BS in the -th sub-frame. Generally, is assumed to be a CSCG random vector, i.e., , where denotes the noise variance of each antenna at the BS. Stacking the received pilot signal vectors at the BS during the -th sub-frame into a matrix form:
| (6) |
where and . Since the pilot sequences of each two users are orthogonal, the received signal from can be separated by multiplying a sequence with in (6), i.e.,
| (7) |
Here, is the received signal vector at the BS from within the -th sub-frame. with , where is the variance of each element of . Based on this and after subframes, we can then obtain the matrix form of (7): which can be expressed as
| (8) |
where with as defined in (5) and . According to [21], an optimal scheme of in terms of improving received signal power at the BS is to design as a discrete Fourier transform (DFT), i.e.,
| (9) |
where and . The different phase-shift matrices defined in (3) are set based on in (9).
Therefore, the task of channel estimation in IRS-MUC is to recover , , by exploiting and . Based on the models in (8) and (9), we then first introduce three commonly adopted methods as three benchmarks, namely the LS method, the MMSE method, and the LMMSE method.
(a) LS Channel Estimator:
According to [45], the estimated using LS estimator is given by
| (10) |
where denotes the pseudoinverse of .
(b) MMSE Channel Estimator:
Different from the LS method where is assumed to be an unknown but deterministic constant, the Bayesian approach assumes that is a random variable with a prior PDF . Therefore, the Bayesian approach can take advantage of prior knowledge to further improve the estimation accuracy. According to [46], the optimal Bayesian estimator is the MMSE estimator which can be expressed as
| (11) |
where is the posterior PDF and is the conditional PDF.
(c) LMMSE Channel Estimator:
Note that the optimal MMSE estimator in (11) is computationally intensive to be implemented in practice when the channel distribution is complicated. Thus, the LMMSE estimator can be selected as a more practical approach with a simple explicit expression222Note that the proposed joint optimization approach in [47] is an effective scheme for realizing the LMMSE estimation in IRS-assisted systems. However, the system model in [47] is a downlink channel estimation model requiring the design of a new training sequence while our work focuses on the uplink channel estimation model for a given training sequence. Thus, the developed approach in [47] cannot be directly adopted in our work and the extension of our work to the downlink scenario is left for our future work due to the page limitation. [46]:
| (12) |
where denotes the statistical channel correlation matrix [45].
Note that the LS estimator requires no prior knowledge of channel and is widely used in practice. If the channel follows the Rayleigh fading model and the statistical channel correlation matrix is available, the optimal MMSE estimator is equivalent to the LMMSE estimator [46] and it can be adopted to capture the statistical characteristics of the channel to further improve the estimation performance. However, for IRS-MUC systems, includes a cascaded channel which generally does not follow the Rayleigh fading model. In this case, the optimal MMSE estimator involves the calculation of a multidimensional integration and thus it is intractable to be implemented in practice due to its intensive computational cost. Meanwhile, the LMMSE estimator still has a performance gap compared with the optimal MMSE estimator [46].
To further improve the estimation performance, in the next section, we still retain the MSE criterion but adopt a data driven DL approach to design a practical channel estimation method, i.e., a DReL-based channel estimation scheme.
III Deep Residual Learning-based Channel Estimation Framework
Note that the additive noise in the system model is a key obstruction for recovering the channel coefficients. In this section, we first model the channel estimation as a denoising problem and then develop a DReL-based framework to learn the residual noise from the noisy observations for paving the way in recovering the channel coefficients. In the developed DReL framework, a DRN with a subtraction architecture is designed to exploit both the features of received observations and the additive nature of the noise to further improve the estimation performance. In the following, we will introduce the derived denoising model and the developed DReL-based channel estimation framework, respectively.
III-A Denoising Model for Channel Estimation
Since a salient feature of the LS estimator is that it does not require any statistical characterization of the data, it is widely adopted in practice due to its convenience of implementation. According to (10), the estimation error of the LS estimator is [45]
| (13) | ||||
It can be observed that is essentially a function of the noise power and its value decreases with the increase of .
Therefore, if we exploit the LS-based channel estimation value as the initial coarse estimated value, then the channel estimation in the IRS-MUC system can be regarded as a denoising problem: recovering from a noisy observation
| (14) |
where is the noisy observation based on the LS estimator and denotes the noise component. According to (14), includes a cascaded channel of which the prior PDF is not a Gaussian PDF, thus, the data model in (14) is not a Bayesian general linear model [46]. In this case, it is intractable to derive a Bayesian estimator with an explicit expression as the one adopted in the model driven approach. In contrast, we will adopt a data-driven approach to develop a DReL-based channel estimation framework for IRS-MUC systems in the following section.
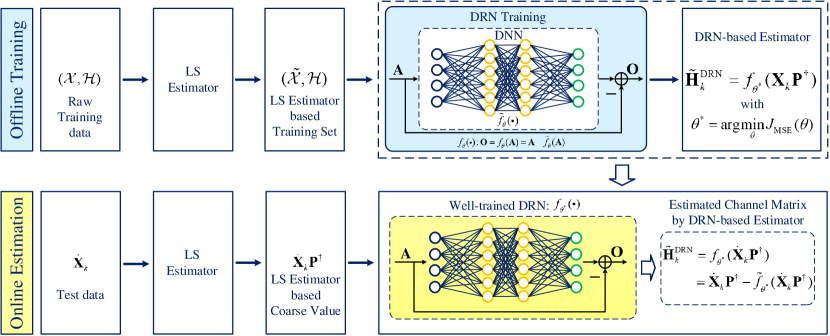
III-B The Developed DReL-based Channel Estimation Framework
Based on the denoising model, we develop a DReL-based channel estimation framework which consists of an offline training phase and an online estimation phase, as shown in Fig. 3. In the offline training phase, a DRN training process is operated to obtain a well-trained DRN, i.e., the DRN-based channel estimator. For the online estimation phase, the test data is sent to the well-trained DRN to obtain the estimated channel coefficients directly. In the following, we will introduce the phases of offline training and online estimation, respectively.
1) Offline Training:
Denote by
| (15) |
the raw training set, where and are the input and the ground truth of the -th, , training example, respectively. To obtain the coarse estimated channel coefficients as defined in the denoising problem of (14), we then send to the LS estimator in (10) and obtain the LS-based training set:
| (16) |
where is the -th training example of . According to Fig. 3, is then sent to DRN for training. The DRN consists of a DNN and an element-wise subtraction operator between the DNN input and the DNN output. Note that the DNN can be any kind of neural networks, e.g., multi-layer perception [48], CNN [49], etc. Denote by the expression of the DNN where denotes the total parameters of DNN, the output of the DRN can be expressed as
| (17) |
where and are the input and output of DRN, and denotes the expression of DRN.
In the following, we select the cost function for DRN training. According to the MMSE criterion, the optimal MMSE estimator is derived by minimizing the Bayesian MSE, i.e.,
| (18) |
where and denote the estimated channel matrix and the ground truth of the channel matrix. To achieve the optimal performance, an intuitive selection of the cost function is the Bayesian MSE expression. However, the number of training examples is finite in practice and thus the statistical Bayesian MSE is not available and only the empirical MSE can be adopted which is defined as
| (19) |
where is the -th estimated channel matrix based on by the DRN. In this case, we can only select the empirical MSE as the cost function which can be expressed as
| (20) |
Based on this, the DRN can adopt the backpropagation (BP) algorithm to obtain a well-trained DRN by progressively updating the network parameters. Therefore, the well-trained DRN, i.e., the DRN-based MMSE (DRN-MMSE) estimator can be expressed as
| (21) |
where represents an arbitrary LS-based input and denotes the well-trained network parameters by minimizing .
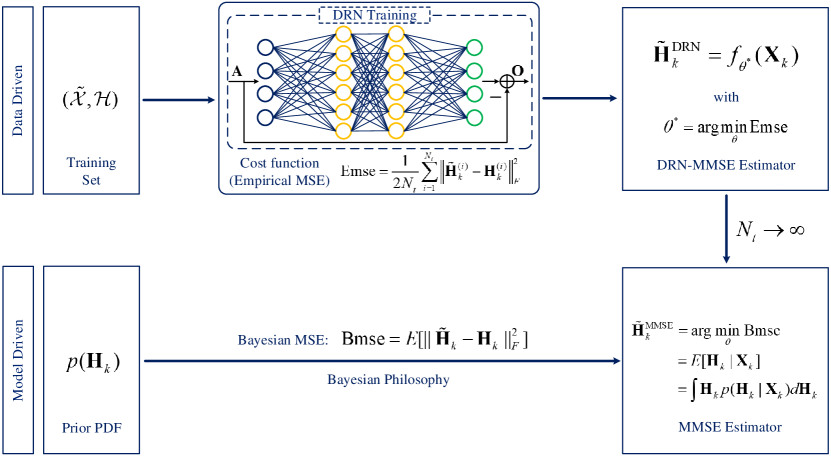
For further understanding, we then analyze the performance of the DRN-based estimator in terms of Bayesian philosophy. As shown in Fig. 4, there are two approaches to design the MMSE estimator: model driven approach and data driven approach. Traditionally, given a prior PDF, the MMSE estimator can be derived by minimizing the Bayesian MSE in a model driven manner. However, for the cascaded channel, it is intractable to implement the MMSE estimator due to a lack of closed-form expression and the associated high-cost in computation. Alternatively, the proposed DRN-MMSE estimator is obtained by minimizing the empirical MSE based on the training set in a data driven approach. Note that it is obvious that
| (22) |
Hence, the DRN estimator converges to the MMSE estimator when . As a summary, the DRN estimator is a data driven approach by minimizing the empirical MSE based on a training set while the optimal MMSE is a model driven approach by minimizing Bayesian MSE based on a prior PDF. In particular, the performance of the DRN estimator converges to the optimal MMSE estimator when the training set is sufficiently large. Next, we will introduce the online estimation phase of the developed framework.
2) Online Estimation:
Given the test data , we first adopt the LS estimator to obtain the initial coarse channel estimation and then send it to the well-trained DRN to operate the channel estimation, as shown in Fig. 3. Finally, the estimated channel coefficients by the proposed DRN estimator can be expressed as
| (23) |
Remark 1: Note that the DRN in the developed DReL framework can be realized by any kind of DNN architecture, e.g., the dense neural network [48] and the CNN [31]. Therefore, the developed DReL based channel estimation framework is a universal channel estimation framework which can strike a balance between system performance and computational complexity via the selection of DRN. Specifically, the DRN makes the best use of the DNN with an element-subtraction operator to exploit both the channel features and additive nature of noise to further improve the channel estimation performance for IRS-MUC systems.
IV CNN-based Deep Residual Network for Channel Estimation
In this section, we introduce a practical approach for implementing the developed DReL framework via a CNN. Note that CNN has powerful capability in extracting features from the noisy observation matrices, meanwhile the subtraction structure of DReL contributes to exploiting the additive nature of the noise [39, 40, 41]. Therefore, we adopt a CNN to facilitate the application of DReL, resulting a CDRN for channel estimation. In the following, we will introduce the CDRN architecture and the CDRN-based channel estimation algorithm, respectively.
IV-A CDRN Architecture
As shown in Fig. 5, the CDRN consists of one input layer, denoising blocks, and one output layer. The denoising block utilizes the CNN with a subtraction structure to learn the residual noise from the noisy channel matrix for denoising. In addition, considering the channel matrix is a complex-valued matrix, we divide the input into two different parts: the real part and the imaginary part for the convenience of extracting features333Since the real part and the imaginary part of the input channel matrix are generally orthogonal [50], we divide the neural network input into two independent parts and adopt the real-valued convolution to exploit features from the real part and the imaginary part of channel matrix, respectively.. The hyperparameters of CDRN are summarized in Table I and the details of each layer of CDRN are introduced as follows.
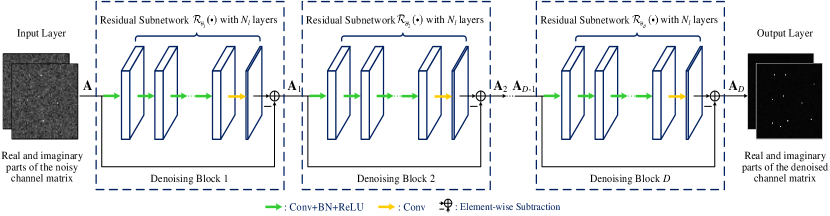
| Input: Noisy channel matrix with the size of | ||
| Denoising Block: | ||
| Layers | Operations | Filter Size |
| 1 | Conv + BN + ReLU | |
| Conv + BN + ReLU | ||
| Conv | ||
| Output: Denoised channel matrix with the size of | ||
a) Input Layer:
To extract features from the complex-valued noisy channel matrix, it is necessary to adopt two neural network channels for the real part and imaginary part of the noisy channel matrix, respectively. Thus, the input layer can be expressed as
| (24) |
where is the input of CDRN, represents the mapping function, and is the LS-based input from an arbitrary training example.
b) Denoising Blocks:
In CDRN, we adopt denoising blocks to gradually enhance the denoising performance and all denoising blocks have an identical structure. Specifically, a denoising block consists of a residual subnetwork and an element-wise subtraction operator, as depicted in Fig. 5. The residual subnetwork of each denoising block has layers. For the first layers, the “Conv+BN+ReLU” operations denoted by the green arrows are adopted for each of the first layers. The convolution (Conv) operation and the rectified linear unit (ReLU) are adopted together to exploit the spatial features of the channel matrix. To improve the stability of the network and to accelerate the training speed of CDRN, a batch normalization (BN) [51] is added between Conv and ReLU. For the last layer, a convolution operation denoted by the yellow arrows is finally adopted to obtain the residual noise matrix for the subsequent element-wise subtraction. Since the noise in the received signals is of additive nature, an element-wise subtraction is added between the input and the output of the residual subnetwork to obtain the denoised channel matrix.
Denote by the function expression of the -th, , residual subnetwork where is the network parameters. The -th denoising block can be expressed as
| (25) |
where , and are the input and the output of the -th denoising block, respectively.
c) Output Layer:
The output layer is the the denoised channel matrix based on denoising blocks, i.e., the output of the -th denoising block:
| (26) |
According to (25) and (26), the output of the CDRN can be finally expressed as
| (27) |
where denotes the function expression of CDRN with parameters and represents the residual noise component. Therefore, the denoised channel matrix is the result of the element-wise subtraction between the noisy channel matrix and the residual noise component .
Remark 2: Note that the neural network is of powerful scalability [48]. Although the channel size changes with the settings of the IRS-MUC systems, the proposed CDRN architecture is still scalable and can be easily extended to different shapes accordingly, as will be shown in the simulation results of Section \@slowromancapv@.
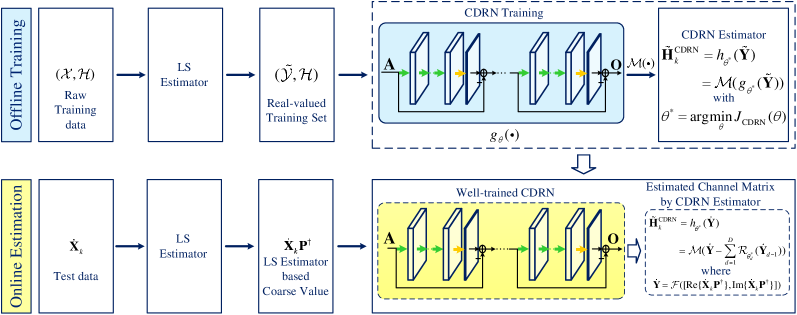
IV-B CDRN-based Channel Estimation Algorithm
Based on the designed CDRN, we apply it to the developed DReL framework and propose a CDRN-based channel estimation algorithm, as shown in Fig. 6. The proposed CDRL algorithm consists of an offline training and an online estimation.
a) Offline Training of CDRN Algorithm:
Based on the LS-based training set defined in (16), we can obtain the following training set:
| (28) |
where and represents the -th training example of . According to (20) and (27), the cost function of CDRN can be expressed as
| (29) |
Here, where represents a function that builds the complex-valued matrix based on the real-valued matrices. As shown in Fig. 6, we can then use the BP algorithm to progressively update the network parameters to finally obtain the well-trained CDRN, i.e., the CDRN estimator:
| (30) |
where denotes the input matrix and is the function expression of the well-trained CDRN with the well-trained network parameters and is the complex-valued form of .
b) Online Estimation of CDRN Algorithm:
Given a test data denoted by , we first send it to the LS estimator to obtain a coarse channel estimation denoted by , and then send it to the CDRN estimator to obtain a refined channel estimate matrix:
| (31) |
where , , and and are the input and output of the -th denoising block of CDRN as defined in (25).
c) CDRN-based Channel Estimation Algorithm Steps:
Based on the above analysis, we then summarize the proposed CDRN-based channel estimation algorithm in Algorithm 1, where we use and to denote the iteration index and the maximum iteration number, respectively.
| Algorithm 1 CDRN-based Channel Estimation Algorithm |
|---|
| Initialization: , real-valued training set |
| Offline Training: |
| 1: Input: Training set |
| 2: while do |
| 3: Update by BP algorithm to minimize |
| 4: end while |
| 5: Output: Well-trained |
| Online Estimation: |
| 6: Input: Test data |
| 7: do Channel Estimation using CDRN estimator in (30) |
| 8: Output: . |
IV-C Theoretical Analysis
To offer more insight of the proposed estimation algorithm, we then analyze the proposed CDRN and characterize its properties theoretically. Although it is difficult to analyze the neural network which consists of a large number of parameters, we formulate the proposed CDRN as an explicit mathematical function and analyze the output of the CDRN theoretically.
As shown in Fig. 5, the CDRN involves identical denoising blocks and the -th denoising block can be expressed as the subtraction between the input and the output of the residual subnetwork . For the convenience of analysis, a simplified real-valued channel matrix is considered as the network input and it can be easily extended to a complex-valued model via a similar approach as in [46]. In this case, the input matrix becomes two-dimension matrix and the function should be removed for (29)-(31). Note that consists of convolutional layers and both BN and ReLU operations have been shown to be able to improve the network stability and the training speed [48], [52]. For simplicity, we mainly focus on the effect of the convolution and ReLU operations on the network output. Since the convolution operation can be expressed as the production of two matrices [48], for each residual subnetwork, we have
| (32) | ||||
Here, , where is the pseudoinverse of and represents the network weights at the -th, , layer. In addition, denotes the ReLU activation function. Note that although the output of the -th residual subnetwork can be expressed as the product of two matrices, the elements in are obtained through the non-linear operation and the residual subnetwork is still a non-linear network. Thus, the output of the -th denoising block can be expressed as
| (33) |
where as defined in (25) and . Based on (33), the equation (32) can be rewritten as
| (34) |
Thus, substituting (34) into (27), the expression of CDRN can be written as
| (35) |
where with . Note that we adopt the coarse estimated value obtained by the LS method as the input of the proposed CDRN. Therefore, through learning from a large amount of LS-based training examples, the proposed CDRN estimator can exploit distinguishable features for denoising the LS-based input, i.e., our proposed method can further improve the estimation accuracy compared with the LS method. Based on this, we have . In this case, the CDRN estimator, i.e., the well-trained CDRN can be formulated as
| (36) |
where denotes the well-trained matrix obtained from a well-trained network with parameter . Thus, the proposed CDRN is a data-driven non-linear estimator which can exploit more distinguishable features from a large amount of training examples to further improve estimation accuracy. On the other hand, according to (10) and (12), the LMMSE estimator can be rewritten as [46]
| (37) | ||||
Based on (36) and (37), the proposed CDRN estimator is equivalent to the LMMSE estimator when is adopted. That is, the proposed CDRN estimator is a generalized framework which subsumes an LMMSE estimator in a data driven manner as a subcase.
According to the universal approximation theorem [53], the neural network has powerful capability in algorithmic learning and has been proven to be a universal function approximator. Therefore, based on (36), (37), and the universal approximation theorem, the proposed CDRN estimator is capable of approximating the LMMSE estimator through exploiting distinguishable features from a large amount of training examples, i.e., the proposed CDRN estimator can achieve the same performance as that of the LMMSE estimator. Specifically, since the optimal MMSE estimator behaves the same as the LMMSE estimator when the prior PDF of is a Gaussian PDF, the proposed CDRN estimator may achieve the optimal performance for the case of a Rayleigh fading channel. On the other hand, when the prior PDF of is not a Gaussian PDF, the optimal MMSE estimator does not admit a closed-form. Then, the proposed CDRN estimator can exploit more distinguishable features from a large amount of training examples to achieve satisfactory estimation performance, while the LMMSE estimator can only obtain the limited estimation performance which is merely based on a second order channel correlation matrix. These observations will be verified through simulations in the following section.
| Parameters | Default Values |
|---|---|
| Path loss exponent of -BS | |
| Path loss exponent of IRS-BS | |
| Path loss exponent of -IRS | |
| Rician factor of -BS | |
| Rician factor of IRS-BS | |
| Rician factor of -IRS |
V Numerical Results
In this section, extensive simulations are provided to verify the efficientness of the proposed algorithm. In the simulations, an IRS-MUC system consists of a BS equipped with antennas, an IRS with reflecting elements, and single-antenna users is considered, as defined in Fig. 1. Unless further specified, the IRS operates with continuous phase shifts and the default settings of the considered IRS-MUC system are , , , and . A path loss model is adopted in the simulations and the path losses of each channel can be modeled as , , and , where , , is the path loss exponent, is the reference distance, is the path loss at the reference distance, and , , and represent the distances of -BS, -IRS, and IRS-BS, respectively. Specifically, we set m, m, and m. In addition, a Rician fading model is considered for all the channels to characterize the small-scale fading. In this case, the channel of IRS-BS link can be expressed as
| (38) |
where represents the Rician factor of IRS-BS channel, and and are the line-of-sight (LOS) component and the Rayleigh component, respectively. Note that the above model expression is a general model which involves both the LOS channel model (when ) and the Rayleigh channel model (when ). The channels of BS- and IRS- are generated similarly as defined in (38). Similarly, we define the Rician factors of channels of -BS and -IRS as and , respectively. To consider the impacts of path loss factors, the elements in should then be multiplied by . The detailed settings of the simulations are summarized in Table \@slowromancapii@, where the settings of -BS link, i.e., and , are due to the rich scattering environment and the relatively large distance between and the BS. Specifically, a normalized MSE (NMSE) is adopted as the estimation performance metric: where and denote the estimated channel and the ground truth of the channel, respectively. In addition, the signal-to-noise ratio (SNR) used in the simulation results refers to the transmit SNR, i.e., . To evaluate the estimation performance, we also provide the simulation of the following algorithms for comparisons: the optimal MMSE method [46], the LMMSE method [46], the LS method [45], the bilinear alternating least squares (BALS) method [22], and the binary reflection controlled LMMSE (B-LMMSE) method. For the B-LMMSE method, we exploit the binary reflection controlled strategy proposed in [19] and then adopt the LMMSE estimator for channel estimation. In addition, a CDRN equipped with denoising blocks is adopted for our proposed method and the hyperparameters of CDRN are set according to Table \@slowromancapi@. Each simulation point of the presented results is obtained by averaging the performance over Monte Carlo realizations444The source code is available at https://github.com/XML124/CDRN-channel-estimation-IRS..
Next, we will verify the channel estimation performance of the proposed CDRN method in terms of NMSE and unveil its relationship with SNR and channel dimensionality, respectively. Besides, visualizations of our proposed CDRN are provided to illustrate the denoising process. Finally, the complexity analysis is also investigated to evaluate the computational complexity.
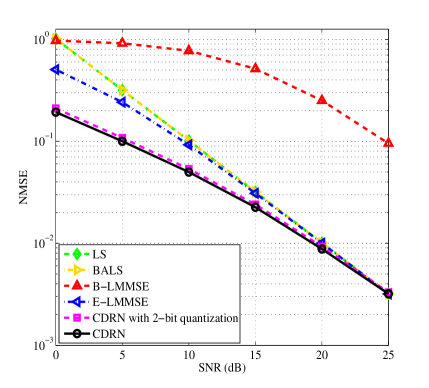
V-A NMSE versus SNR
The results of NMSE under different SNRs are presented in Fig. 7. Since the cascaded channel does not follow the Rayleigh fading model, it is generally intractable to design the optimal MMSE estimator and derive the closed-form of LMMSE estimator. Hence, only an empirical LMMSE (denoted by E-LMMSE) can be obtained where the required statistical channel correlation matrix is replaced by a Monte Carlo based empirical channel correlation matrix. As expected, the NMSEs of all the algorithms decrease with the increase of SNR since a higher transmit power can effectively mitigate the impact of noise. Now, we first investigate the estimation performance in terms of different IRS control strategies. It can be seen that the DFT controlled methods (denoted by LS, E-LMMSE, and CDRN) outperform the B-LMMSE method significantly, especially under the high SNR regions. This is because for each time slot, all the elements are switched on for reflecting the incident signals when adopting the DFT controlled strategy, while only one element is switched on under the binary controlled strategy, leading to insufficient received signal power for channel estimation. We then discuss the performance of the schemes adopting the DFT controlled methods. It is noticed that the LS method has a performance gap compared with the E-LMMSE method since the E-LMMSE can capture the statistical knowledge of the channel, while the LS method is designed by treating the channel as a deterministic but unknown constant. Compared with LMMSE, the proposed CDRN method further improves the estimation performance and thus achieves the best performance among all the considered algorithms. For example, the proposed CDRN method achieves a SNR gain of dB in terms of the NMSE compared with the E-LMMSE method. The reason is that the E-LMMSE method is developed based on the constrained linear estimator. In contrast, the proposed method adopts the non-linear CDRN to recover the channels by intelligently exploiting the spatial features of channels in a data driven approach. Besides, it can be observed from Fig. 7 that our proposed method can achieve a better NMSE performance compared with the BALS method. This is because the BALS method does not explore the statistical features of channels. In contrast, our proposed method can further improve the estimation performance by exploiting the channel statistical features from a large amount of LS-based training examples. On the other hand, low-quality phase shifters with a small number of quantization levels may be deployed to reduce the implementation cost [8, 12, 24]. Therefore, it is necessary to investigate if the proposed channel estimation scheme is robust against the quantization of IRS phase shifts. As shown in Fig. 7, the proposed CDRN method with a 2-bit uniformly quantized IRS phase shift [8, 24] (denoted by CDRN with 2-bit quantization) almost behaves the same as the CDRN method with a continuous IRS phase shift. This is because through offline training, the proposed CDRN can learn distinguishable features to address the introduced noise terms by the phase quantization errors.
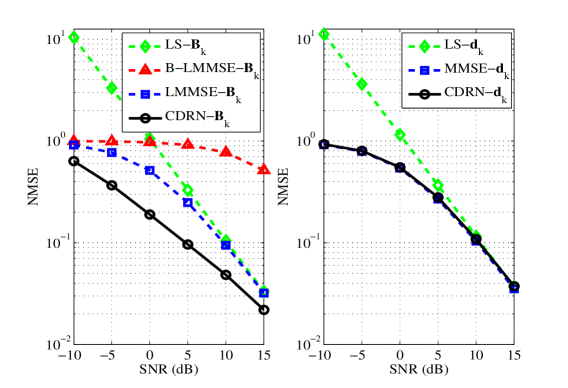
(a) for reflecting link. (b) for direct link.
To further evaluate the estimation performance, we present the NMSE results of the direct channel and the reflection channel in Fig. 8(a) and Fig. 8(b), respectively. Similar to the results in Fig. 7, Fig. 8(a) shows that the proposed CDRN still achieves the best performance in terms of the channel estimation of the reflection channel . Since the direct channel follows Rayleigh fading model, the optimal MMSE method and the LMMSE method achieve the same performance as they have the same mathematical expression as in (12). Therefore, we compare three methods in Fig. 8(b): the LS method, the optimal MMSE method, and the proposed CDRN method. It is shown that the CDRN method outperforms the LS method and achieves almost the same estimation performance as that of the optimal MMSE method, which presents the optimality of the proposed method.
V-B NMSE versus Channel Dimensionality
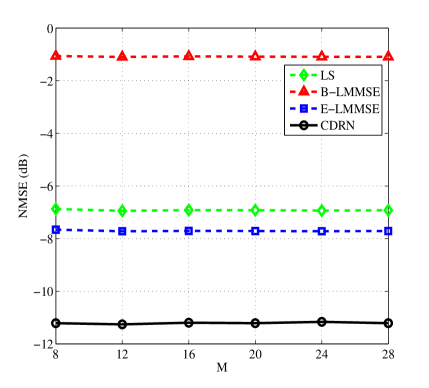
Note that the channel dimensionality is also an important parameter which affects the estimation performance. To illustrate the scalability of the proposed CDRN, we conduct simulations to evaluate the estimation performance with different channel dimensionality. Specifically, the number of elements of IRS, denoted by , directly affects the number of columns of channel matrix and thus Fig. 9 plots the curves of NMSE versus for different algorithms. It can be seen that the NMSE of DFT controlled methods (denoted by LS, E-LMMSE, and CDRN) decrease with the increase of , while the NMSE binary controlled strategy based method, i.e., the B-MMSE method, remains almost a constant value for different . This is because the B-MMSE method only switches on one element each time slot despite the total number of reflecting elements at the IRS. In addition, the proposed CDRN method still achieves the best performance among all the considered algorithms since it is able to exploit more distinguishable features of channels from a larger size of input channel matrix. Besides , the number of antennas at the BS, denoted by , determines the number of rows of which also plays an important role in estimation performance. Therefore, Fig. 10 investigates the effect of on the NMSE performance. It is obvious that the NMSE is insensitive to the change of . This is because in the metric of NMSE, the array gain due to the increase of achieved in the numerator is neutralized by the one in the denominator.
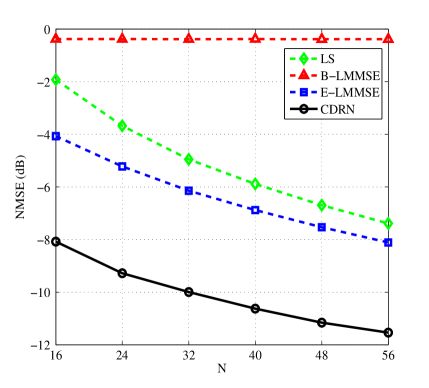
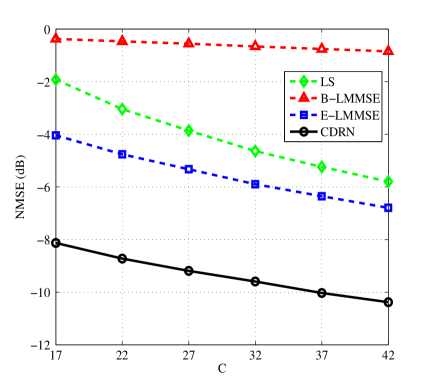
Moreover, the number of pilots has also impacts on the NMSE. It is shown in Fig. 11 that the NMSEs of all the algorithms decrease with the increase of the number of pilots and different methods have different slopes with respect to . In particular, the NMSE of B-LMMSE method decreases gently with the increase of , while the NMSEs of LS, E-LMMSE, and CDRN methods decrease sharply. The reason is that for the B-LMMSE method, the power of the received signal at the BS is very limited which is only times of that of the other methods. In addition, the proposed CDRN could exploit more distinguishable spatial features from a larger scale input matrix to enhance the estimation accuracy, and thus achieves the best performance among all the considered algorithms, as presented in Fig. 11.
V-C Visualization of CDRN
To offer more insights of our proposed CDRN, we present the visualization of the outputs of each denoising block of a well-trained CDRN. For the convenience of understanding, we only present the denoising process of ten points of a channel matrix, i.e., only these ten points are the received signals at the BS while the remaining points are the noise samples. For visualization, we transform the input matrix and the output matrices of each denoising block to the grayscale images. In particular, the elements of each matrix are normalized to an interval of , where and are represented by black color and white color, respectively.
According to Fig. 5, the input of CDRN, the output of the first, second, and last denoising blocks are represented by , , , and , respectively. The grayscaled image of is shown in Fig. 12, where the ten distinguishable bright pixels are the interest channel coefficients while the remaining pixels are the noise samples. The cluttered noise pixels indicate that the noise samples have a large variance. Subsequently, Fig. 12 and Fig. 12 are the visualizations of and , where we find that the noise pixels become tidy, i.e., the noisy channel matrix are denoised progressively. Finally, the output of , i.e., the output of CDRN is visualized in Fig. 12, where the noise pixels are largely eliminated and thus a denoised channel matrix is obtained. In fact, the proposed CDRN method adopts a stage-by-stage denoising mechanism and achieves a satisfactory performance.



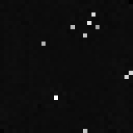
V-D Complexity Analysis
Finally, we analyze the computational complexities of the considered algorithms and summarize the results in Table III. Here, denotes the input dimension, and represent the number of neural network channels and the spatial size (length of side) of the filter of the -th, , convolutional layer, respectively. In addition, and are both defined in Algorithm 1. Specifically, both the B-LMMSE method and the E-LMMSE method have the same computational complexity, thus we use LMMSE to denote the B-LMMSE/E-LMMSE method. Note that the computational complexities of the LS and LMMSE methods only arise from the online estimation, while the proposed CDRN method has an additional computational complexity due to the offline training. Specifically, the LS method can be realized via the inverse fast Fourier transform (IFFT). While the computational cost of the LMMSE method mainly comes from the matrix inversions. As for the proposed method, its computational cost is dominated by the computations of the CDRN [54] and the LS-based input. For simplicity, we only present the highest order terms of the complexities in Table III, as commonly adopted in e.g., [55]. It can be seen from Table III that compared with the LS and LMMSE methods, the proposed CDRN method can achieve the best system performance at the expense of a higher computational complexity. On the other hand, although the proposed CDRN involves a large number of parameters, the required actual online estimation time can be greatly reduced by exploiting the parallelization of a graphics processing unit (GPU) [48]. This conclusion can be verified in Table IV, where each result is obtained by executing the algorithms on a desktop computer with an i7-8700 3.20 GHz central processing unit (CPU) and a Nvidia GeForce RTX 2070 GPU. Therefore, although the proposed CDRN method has a relatively higher computational complexity compared with the LS and LMMSE methods, the associated computation time can be greatly reduced through exploiting the parallel computing of GPU.
| Algorithm | Online Estimation | Offline Training |
|---|---|---|
| LS | - | |
| LMMSE | - | |
| CDRN |
| Algorithm | Online Estimation | Offline Training |
|---|---|---|
| LS | - | |
| LMMSE | - | |
| CDRN |
VI Conclusion
This paper proposed a data-driven DReL approach to address the channel estimation problem for IRS-MUC systems operating with TDD protocol. Firstly, we formulated the channel estimation problem in IRS-MUC systems as a denoising problem and developed a versatile DReL-based channel estimation framework. Specifically, according to the Bayesian MMSE criterion, a DRN-based MMSE was derived and analyzed in terms of Bayesian philosophy. Under the developed DReL-based framework, we then designed a CDRN to denoise the noisy channel matrix for channel recovery. For the proposed CDRN, a CNN-based denoising block with an element-wise subtraction structure was specifically designed to exploit both the spatial features of the noisy channel matrices and the additive nature of the noise simultaneously. Taking advantages of the superiorities of CNN and DReL in feature extraction and denoising, the proposed CDRN estimation algorithm can further improve the estimation accuracy. Simulation results demonstrated that the proposed method can achieve almost the same estimation accuracy as that of the optimal MMSE estimator based on a prior PDF of channel.
References
- [1] C. Liu, X. Liu, D. W. K. Ng, and J. Yuan, “Deep residual network empowered channel estimation for IRS-assisted multi-user communication systems,” in Proc. IEEE Int. Conf. Commun. (ICC), 2021 [To appear].
- [2] S. Gong, X. Lu, D. T. Hoang, D. Niyato, L. Shu, D. I. Kim, and Y.-C. Liang, “Towards smart wireless communications via intelligent reflecting surfaces: A contemporary survey,” IEEE Commun. Surveys Tuts., vol. 22, no. 4, 4th Quart. 2020.
- [3] J. Zhao and Y. Liu, “A survey of intelligent reflecting surfaces (IRSs): Towards 6G wireless communication networks,” arXiv preprint arXiv:1907.04789, 2019.
- [4] C. Liaskos, S. Nie, A. Tsioliaridou, A. Pitsillides, S. Ioannidis, and I. Akyildiz, “A new wireless communication paradigm through software-controlled metasurfaces,” IEEE Comm. Mag., vol. 56, no. 9, pp. 162–169, Sept. 2018.
- [5] V. W. S. Wong, R. Schober, D. W. K. Ng, and L.-C. Wang, Key technologies for =5G wireless systems. Cambridge University Press, 2017.
- [6] J. Zhang, E. Björnson, M. Matthaiou, D. W. K. Ng, H. Yang, and D. J. Love, “Prospective multiple antenna technologies for beyond 5G,” IEEE J. Sel. Areas Commun., vol. 38, no. 8, pp. 1637–1660, Aug. 2020.
- [7] H. Yang, X. Cao, F. Yang, J. Gao, S. Xu, M. Li, X. Chen, Y. Zhao, Y. Zheng, and S. Li, “A programmable metasurface with dynamic polarization, scattering and focusing control,” Sci. Rep., vol. 6, no. 35692, pp. 1–11, Oct. 2016.
- [8] Q. Wu and R. Zhang, “Towards smart and reconfigurable environment: Intelligent reflecting surface aided wireless network,” IEEE Comm. Mag., vol. 58, no. 1, pp. 106–112, Jan. 2020.
- [9] M. Di Renzo et al., “Smart radio environments empowered by reconfigurable AI meta-surfaces: An idea whose time has come,” EURASIP J. Wireless Commun. Netw., vol. 2019, no. 129, pp. 1–20, May 2019.
- [10] C. Huang, S. Hu, G. C. Alexandropoulos, A. Zappone, C. Yuen, R. Zhang, M. Di Renzo, and M. Debbah, “Holographic MIMO surfaces for 6G wireless networks: Opportunities, challenges, and trends,” IEEE Wireless Commun., vol. 27, no. 5, pp. 118–125, Oct. 2020.
- [11] G. C. Alexandropoulos, G. Lerosey, M. Debbah, and M. Fink, “Reconfigurable intelligent surfaces and metamaterials: The potential of wave propagation control for 6G wireless communications,” IEEE ComSoc TCCN Newsl., vol. 6, no. 1, pp. 25–37, Jun. 2020.
- [12] Q. Wu and R. Zhang, “Intelligent reflecting surface enhanced wireless network via joint active and passive beamforming,” IEEE Trans. Wireless Commun., vol. 18, no. 11, pp. 5394–5409, Nov. 2019.
- [13] S. Zhang and R. Zhang, “Capacity characterization for intelligent reflecting surface aided MIMO communication,” IEEE J. Sel. Areas Commun., vol. 38, no. 8, pp. 1823–1838, Aug. 2020.
- [14] H. Guo, Y.-C. Liang, J. Chen, and E. G. Larsson, “Weighted sum-rate maximization for reconfigurable intelligent surface aided wireless networks,” IEEE Trans. Wireless Commun., vol. 19, no. 5, pp. 3064–3076, May 2020.
- [15] C. Huang, A. Zappone, G. C. Alexandropoulos, M. Debbah, and C. Yuen, “Reconfigurable intelligent surfaces for energy efficiency in wireless communication,” IEEE Trans. Wireless Commun., vol. 18, no. 8, pp. 4157–4170, Aug. 2019.
- [16] S. Zhou, W. Xu, K. Wang, M. Di Renzo, and M.-S. Alouini, “Spectral and energy efficiency of IRS-assisted MISO communication with hardware impairments,” IEEE Wireless Commun. Lett., vol. 9, no. 9, Sept. 2020.
- [17] Z. Chu, W. Hao, P. Xiao, and J. Shi, “Intelligent reflecting surface aided multi-antenna secure transmission,” IEEE Wireless Commun. Lett., vol. 9, no. 1, pp. 108–112, Jan. 2020.
- [18] X. Guan, Q. Wu, and R. Zhang, “Intelligent reflecting surface assisted secrecy communication: Is artificial noise helpful or not ?,” IEEE Wireless Commun. Lett., vol. 9, no. 6, pp. 778–782, Jan. 2020.
- [19] D. Mishra and H. Johansson, “Channel estimation and low-complexity beamforming design for passive intelligent surface assisted MISO wireless energy transfer,” in Proc. IEEE Int. Conf. Acoust. Speech Signal Process. (ICASSP), pp. 4659–4663, Brighton, United Kingdom, May 2019.
- [20] Y. Yang, B. Zheng, S. Zhang, and R. Zhang, “Intelligent reflecting surface meets OFDM: Protocol design and rate maximization,” IEEE Trans. Commun., vol. 68, no. 7, pp. 4522–4535, Jul. 2020.
- [21] T. L. Jensen and E. De Carvalho, “An optimal channel estimation scheme for intelligent reflecting surfaces based on a minimum variance unbiased estimator,” in Proc. IEEE Int. Conf. Acoust. Speech Signal Process. (ICASSP), pp. 5000–5004, Barcelona, Spain, May 2020.
- [22] G. T. de Araújo and A. L. F. de Almeida, “PARAFAC-based channel estimation for intelligent reflective surface assisted MIMO system,” in Proc. IEEE Sens. Array Multichannel Signal Process. Workshop (SAM), pp. 1–5, Hangzhou, China, Jun. 2020.
- [23] B. Zheng and R. Zhang, “Intelligent reflecting surface-enhanced OFDM: Channel estimation and reflection optimization,” IEEE Wireless Commun. Lett., vol. 9, no. 4, pp. 518–522, Apr. 2020.
- [24] C. You, B. Zheng, and R. Zhang, “Intelligent reflecting surface with discrete phase shifts: Channel estimation and passive beamforming,” in Proc. IEEE Int. Conf. Commun. (ICC), pp. 1–6, Dublin, Ireland, Jun. 2020.
- [25] J. Chen, Y.-C. Liang, H. V. Cheng, and W. Yu, “Channel estimation for reconfigurable intelligent surface aided multi-user MIMO systems,” arXiv preprint arXiv:1912.03619, 2019.
- [26] Z.-Q. He and X. Yuan, “Cascaded channel estimation for large intelligent metasurface assisted massive MIMO,” IEEE Wireless Commun. Lett., vol. 9, no. 2, pp. 210–214, Feb. 2020.
- [27] Z. Wang, L. Liu, and S. Cui, “Channel estimation for intelligent reflecting surface assisted multiuser communications,” in Proc. IEEE Wireless. Commun. Netw. Conf. (WCNC), Seoul, Korea (South), May 2020.
- [28] Z. Wang, L. Liu, and S. Cui, “Channel estimation for intelligent reflecting surface assisted multiuser communications: Framework, algorithms, and analysis,” IEEE Trans. Wireless Commun., vol. 19, no. 10, pp. 6607–6620, Oct. 2020.
- [29] G. C. Alexandropoulos and E. Vlachos, “A hardware architecture for reconfigurable intelligent surfaces with minimal active elements for explicit channel estimation,” in Proc. IEEE Int. Conf. Acoust. Speech Signal Process. (ICASSP), pp. 9175–9179, Barcelona, Spain, May 2020.
- [30] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science, vol. 313, no. 5786, pp. 504–507, Jul. 2006.
- [31] Y. Lecun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, May 2015.
- [32] T. Wang, C.-K. Wen, H. Wang, F. Gao, T. Jiang, and S. Jin, “Deep learning for wireless physical layer: Opportunities and challenges,” China Commun., vol. 14, no. 11, pp. 92–111, Nov. 2017.
- [33] A. Taha, M. Alrabeiah, and A. Alkhateeb, “Enabling large intelligent surfaces with compressive sensing and deep learning,” arXiv preprint arXiv:1904.10136, 2019.
- [34] A. Taha, M. Alrabeiah, and A. Alkhateeb, “Deep learning for large intelligent surfaces in millimeter wave and massive mimo systems,” in Proc. IEEE Global Telecommun. Conf. (GLOBECOM), pp. 1–6, Waikoloa, HI, USA, Dec. 2019.
- [35] C. Huang, G. C. Alexandropoulos, C. Yuen, and M. Debbah, “Indoor signal focusing with deep learning designed reconfigurable intelligent surfaces,” in Proc. IEEE Int. Workshop Signal Process. Adv. Wireless Commun. (SPAWC), pp. 1–5, Cannes, France, Jul. 2019.
- [36] G. C. Alexandropoulos, S. Samarakoon, M. Bennis, and M. Debbah, “Phase configuration learning in wireless networks with multiple reconfigurable intelligent surfaces,” arXiv preprint arXiv:2010.04376, 2020.
- [37] K. Feng, Q. Wang, X. Li, and C.-K. Wen, “Deep reinforcement learning based intelligent reflecting surface optimization for MISO communication systems,” IEEE Wireless Commun. Lett., vol. 9, no. 5, pp. 745–749, May 2020.
- [38] H. Yang, Z. Xiong, J. Zhao, D. Niyato, and L. Xiao, “Deep reinforcement learning based intelligent reflecting surface for secure wireless communications,” IEEE Trans. Wireless Commun., Sept. 2020, [Early Access].
- [39] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 770–778, Las Vegas, NV, USA, Jun. 2016.
- [40] K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang, “Beyond a =Gaussian denoiser: =Residual learning of deep =CNN for image denoising,” IEEE Trans. Image Proc., vol. 26, no. 7, pp. 3142–3155, Jul. 2017.
- [41] H. He, C.-K. Wen, S. Jin, and G. Y. Li, “Deep learning-based channel estimation for beamspace mmwave massive MIMO systems,” IEEE Wireless Commun. Lett., vol. 7, no. 5, pp. 852–855, Oct. 2018.
- [42] D. Neumann, T. Wiese, and W. Utschick, “Learning the MMSE channel estimator,” IEEE Trans. Signal Proc., vol. 66, no. 11, pp. 2905–2917, Jun. 2018.
- [43] X. Chen and M. Jiang, “Adaptive statistical bayesian MMSE channel estimation for visible light communication,” IEEE Trans. Signal Proc., vol. 65, no. 5, pp. 1287–1299, Mar. 2017.
- [44] J. Mirzaei, F. Sohrabi, R. Adve, and S. ShahbazPanahi, “MMSE-based channel estimation for hybrid beamforming massive MIMO with correlated channels,” in Proc. IEEE Int. Conf. Acoust. Speech Signal Process. (ICASSP), pp. 5015–5019, Barcelona, Spain, May 2020.
- [45] M. Biguesh and A. B. Gershman, “Training-based MIMO channel estimation: A study of estimator tradeoffs and optimal training signals,” IEEE Trans. Signal Proc., vol. 54, no. 3, pp. 884–893, Mar. 2006.
- [46] S. M. Kay, Fundamentals of statistical signal processing, volume =I: Estimation theory. Prentice Hall, 1993.
- [47] J.-M. Kang, “Intelligent reflecting surface: Joint optimal training sequence and refection pattern,” IEEE Commun. Lett., vol. 24, no. 8, pp. 1784–1788, Aug. 2020.
- [48] I. Goodfellow, Y. Bengio, A. Courville, and Y. Bengio, Deep learning. MIT Press Cambridge, 2016.
- [49] C. Liu, J. Wang, X. Liu, and Y.-C. Liang, “Deep =CM-CNN for spectrum sensing in cognitive radio,” IEEE J. Sel. Areas Commun., vol. 37, no. 10, pp. 2306–2321, Oct. 2019.
- [50] D. Tse and P. Viswanath, Fundamentals of wireless communication. Cambridge University Press, 2005.
- [51] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in Proc. IEEE Int. Conf. Mach. Learn. (ICML), pp. 448–456, Lille, France, Jul. 2015.
- [52] X. Glorot, A. Bordes, and Y. Bengio, “Deep sparse rectifier neural networks,” in Proc. Int. Conf. Artif. Intell. Stat., pp. 315–323, Fort Lauderdale, USA, Apr. 2011.
- [53] K. Hornik, M. Stinchcombe, and H. White, “Multilayer feedforward networks are universal approximators,” Neural Networks, vol. 2, no. 5, pp. 359–366, 1989.
- [54] K. He and J. Sun, “Convolutional neural networks at constrained time cost,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 5353–5360, Boston, MA, USA, Jun. 2015.
- [55] S. Arora and B. Barak, Computational complexity: A modern approach. Cambridge University Press, 2009.