Deep Partial Multi-View Learning
Abstract
Although multi-view learning has made significant progress over the past few decades, it is still challenging due to the difficulty in modeling complex correlations among different views, especially under the context of view missing. To address the challenge, we propose a novel framework termed Cross Partial Multi-View Networks (CPM-Nets), which aims to fully and flexibly take advantage of multiple partial views. We first provide a formal definition of completeness and versatility for multi-view representation and then theoretically prove the versatility of the learned latent representations. For completeness, the task of learning latent multi-view representation is specifically translated to a degradation process by mimicking data transmission, such that the optimal tradeoff between consistency and complementarity across different views can be implicitly achieved. Equipped with adversarial strategy, our model stably imputes missing views, encoding information from all views for each sample to be encoded into latent representation to further enhance the completeness. Furthermore, a nonparametric classification loss is introduced to produce structured representations and prevent overfitting, which endows the algorithm with promising generalization under view-missing cases. Extensive experimental results validate the effectiveness of our algorithm over existing state of the arts for classification, representation learning and data imputation.
Index Terms:
Multi-view learning, cross partial multi-view networks, latent representation.1 Introduction
In real-word applications, data is usually represented with different views, including multiple modalities or various types of features. Several studies [1, 2, 3] have empirically demonstrated that different views can complement each other, leading to ultimate performance improvement. Unfortunately, the unknown and complex correlations among different views often disrupt the integration of different modalities in the model. Moreover, data with missing views further aggravates the modeling difficulty. Conventional multi-view learning usually holds the assumption that each sample is associated with a unified set of observed views and that all views are available for each sample. However, in practical applications, there are usually incomplete cases for multi-view data [4, 5, 6, 7, 8]. For example, in medical applications, different types of examinations are usually conducted for different subjects, and in Web analysis, some websites may contain texts, pictures and videos, but others may only contain one or two types, which produces data with missing views. The view-missing patterns (i.e., combinations of available views) become even more complex for the data with more views.
Projecting different views into a common space (e.g., CCA: Canonical Correlation Analysis and its variants [9, 10, 11]) is impeded by view-missing issue. Several methods have been proposed to keep on exploiting the correlations of different views. One straightforward strategy is to complete the missing views, after which off-the-shelf multi-view learning algorithms can be adopted. The missing views are basically blockwise and thus low-rank based completion [12, 13] is not applicable, as has been widely recognized in [5, 14]. Missing modality imputation methods [15, 5] usually require samples with two paired modalities to train the networks which can predict the missing modality from the observed one. To explore the complementarity among multiple views, another natural strategy is to manually group samples according to the availability of data sources [16], and to subsequently learn multiple models on these groups for late fusion. Although it is more effective than learning on each individual view, the grouping strategy is not flexible, especially for data with a large number of views.
Therefore, it is more challenging and important to endow the algorithm with high effectiveness and adaptive capacity under complex view-missing cases. In this paper, we advocate focusing on completeness and flexibility for partial multi-view representation learning to fully exploit multiple views. We propose a novel deep partial multi-view learning algorithm, i.e., Cross Partial Multi-View Networks (CPM-Nets), as shown in Fig. 2. The model comprehensively encodes information from different views into a latent representation which is versatile with theoretical guarantee compared to each single view and adaptive to complex correlations among different views. The model is flexible for arbitrary view-missing patterns with latent representations and the completeness is further enhanced with adversarial strategy. For classification, we introduce a non-parametric loss to learn clustering-structured representations introducing simple bias for generalization especially important for the partial view setting. Specifically, benefiting from the learned common latent representation from the encoding networks, all samples and all views can be jointly exploited regardless of view-missing patterns. For the multi-view representation, CPM-Nets jointly considers completeness and structure, making them mutually improve each other to obtain the representation reflecting the underlying patterns. Theoretical analysis and empirical results validate the effectiveness of the proposed CPM-Nets in exploiting partial multi-view data. The contributions of this paper are summarized as follows:
-
•
We propose a novel framework - CPM-Nets - to conduct partial multi-view learning, which jointly considers completeness and structure to learn a unified latent representation, endowing the algorithm with high flexibility and generalization for partial multi-view data.
-
•
The latent representation encoded from observations is complete and versatile, and thus enhances the prediction performance, while the clustering-like classification schema in turn enhances the separability of the latent representation. Theoretical analysis and empirical results in classification validate the effectiveness of the proposed CPM-Nets in exploiting partial multi-view data.
-
•
For unsupervised learning, using degradation strategy, the information from observed views is flexibly encoded into the learned representation. Meanwhile, benefiting from the adversarial strategy, the imputation is further stabilized, which in turn improves the latent representation.
-
•
Extensive experiments on diverse multi-view data validate that the proposed CPM-Nets can improve the unified representation, classification and data imputation compared with the current state-of-the-art results.

1.1 Related Work
Multi-View Learning (MVL) aims to jointly utilize information from different views. Multi-view clustering algorithms [17, 18, 19, 20, 21, 22, 23] usually search for consistent clustering hypotheses across different views, where the representative methods include co-regularization based [17], co-training based [18] and high-order multi-view clustering [19]. Under the metric learning framework, multi-view classification methods [24, 25] jointly learn multiple metrics for multiple views. The representative multi-view representation learning methods are CCA based, including kernelized CCA [10], deep neural network based CCA [11, 26], DVCCA [27] and semi-paired and semi-supervised generalized correlation analysis (S2GCA) [28]. DVCCA has the advantages in learning nonlinear correlations and disentanglement of variables instead of handling complex missing patterns.
Cross-View Learning (CVL) essentially searches for mappings between two views, where the similarity between the samples from different modalities can be measured directly. It has been widely applied in real applications [29, 30, 31, 32, 33, 34]. With adversarial training, the embedding spaces of two individual views are learned and aligned simultaneously [30]. The cross-modal convolutional neural networks are regularized to obtain a shared representation which is agnostic to the modality for cross-modal scene images [31]. In [34], an analogical embedding space is learned for both views and then information is distilled across views. Meanwhile the cross-view learning can be also utilized for missing view imputation [35, 14].
Learning on Incomplete Data. A straightforward method of learning on incomplete data is to conduct data imputation and then existing models (e.g., clustering/classification) can be applied. The representative global imputation algorithms include SVD imputation (SVDimpute) [36] and Bayesian principal component analysis (BPCA) [37]. In contrast to global strategy, local imputation algorithms exploit local similarity structure in the dataset for missing value imputation [38, 39, 40]. The hybrid strategy captures both global and local correlation information [41]. Recently proposed imputation methods [5, 35] complete the missing views by leveraging the power of deep neural networks. There are also a few algorithms which can directly conduct learning without imputation. The grouping strategy [16] divides all samples according to the availability of data sources, and then multiple classifiers are learned for late fusion. This strategy cannot scale well for data with a large number of views or small-sample-size cases. Another line [42] incorporates semi-supervised deep matrix factorization, correlated subspace learning, and multi-view label prediction into a unified framework. Further, [43] learns the classifiers by leveraging the intrinsic view consistency and extrinsic unlabeled information.
2 Cross Partial Multi-View Networks
In this work, we focus on classification based on data with missing views termed Partial Multi-View Classification (see definition 2.1), where samples with different view-missing patterns are involved. The proposed cross partial multi-view networks enable the comparability for samples with different combinations of views rather than only two views, which generalizes the concept of cross-view learning. There are three main challenges for partial multi-view representation learning: (1) project samples with arbitrary view-missing patterns (flexibility) into a comprehensive latent space (completeness) for comparability (in section 2.1); (2) make the learned representation reflect class distribution (structured representation) for separability (in section 2.2); (3) reduce the gap between representations obtained in test stage and training stage for consistency (in section 2.3). For clarification, we first provide the formal definition of partial multi-view classification as follows:
Definition 2.1.
(Partial Multi-View Classification (PMVC)) Given the training set , where is a subset of the complete observations (i.e., ) and is the class label with and being the number of samples and views, respectively, PMVC trains a classifier by using training data containing view-missing samples, to classify a new instance with an arbitrary view-missing pattern.
2.1 Multi-View Complete Representation
Considering the first challenge, where the desired latent representation should encode the information from observed views, we provide the definition of completeness for multi-view representation (inspired by the reconstruction point of view [44]) as follows:
Definition 2.2.
(Completeness for Multi-View Representation) A multi-view representation is complete if each observation, i.e., from , can be reconstructed from a mapping , i.e., .
Intuitively, we can reconstruct each view from a complete representation in a numerically stable way. Furthermore, we show that the completeness is achieved under the assumption that each view is conditionally independent given the shared multi-view representation [45]. Similar to each view from , the class label can also be considered as one (semantic) view, in which case we have
| (1) |
where . We can obtain the common representation by maximizing .
Based on multiple views in , we model the likelihood with respect to given observations as
| (2) |
where are parameters governing the reconstruction mapping from common representation to partial observations , with being the reconstruction loss. From the view of class label, we model the likelihood with respect to given class label as
| (3) |
where are parameters of the classification function based on , and defines the classification loss. Accordingly, assuming data are independent and identically distributed (IID), the log-likelihood function is
| (4) | ||||
where denotes the available views for the th sample. On one hand, we encode the information from available views into a latent representation and denote the encoding loss as . On the other hand, the learned representation should be consistent with the class distribution, which is implemented by minimizing the loss to penalize any disagreement with the class label.
Effectively encoding information from different views is the key requirement for multi-view representation, and thus we seek a common representation that can recover the partial (available) observations. Accordingly, the following loss is induced
| (5) | ||||
where is implemented with the reconstruction loss . indicates the availability of the th sample in the th view, i.e., and indicate available and unavailable views, respectively. is the reconstruction network for the th view parameterized by . In this way, encodes information from available views, and different samples (regardless of their missing patterns) are associated with representations in a common space, making them comparable.
Ideally, minimizing Eq. (5) will induce a complete representation. Since the complete representation encodes information from different views, it should be more versatile compared with using any single view. We provide the definition of versatility for multi-view representation as follows:
Definition 2.3.
(Versatility for Multi-View Representation) Given the observations from views, the multi-view representation is of versatility if with , there exists a mapping satisfying , where is the corresponding multi-view representation for sample .
Accordingly, we have the following theoretical result:
Proposition 2.1.
Proof 2.1.
The proof for proposition 2.1 is as follows. Ideally, according to Eq. (5), , there exists , where is the mapping from to . Hence, with , there exists a mapping satisfying by defining . This proves the versatility of the latent representation based on multi-view observations .
In practical cases, it is usually difficult to guarantee the exact versatility for latent representation, so the goal is to minimize the error (i.e., ) which is inversely proportional to the degree of versatility. Fortunately, it is easy to show that with from Eq. (5) is the upper bound of if is Lipschitz continuous, with being the Lipschitz constant.
Although the proof is inferred under the condition that all views are available, it is intuitive and easy to generalize the results for view-missing cases.
2.2 Classification on Structured Latent Representation
Multiclass classification remains challenging due to possible confusing classes [46]. For the second challenge, we thus aim to ensure that the learned representation is structured for separability, using a clustering-like loss. Specifically, we should minimize the following classification loss
| (6) |
where and , with being the feature mapping function for , and being the set of latent representation from class . In our implementation, we set for simplicity and effectiveness. By jointly considering classification and representation learning, the misclassification loss is specified as
| (7) | ||||
Compared with the cross entropy loss, which is most commonly used in parametric classification, the clustering-like loss not only penalizes the misclassification but also guarantees a structured representation. represents a part of loss and a conditional margin between corrected and incorrected classifications as well. Specifically, for a correctly classified sample (i.e., ), we have = 0. For an incorrectly classified sample (i.e., ), we have = 1, indicating the similarity between and the centroid corresponding to class is larger than that between and the centroid corresponding to class (wrong label) by a margin of . In this way, acts as the indicator of correct classification, as well as the margin between correct and incorrect classifications. Hence, the proposed non-parametric loss naturally leads to a representation with clustering structure.
Based on the above considerations, the overall objective function is induced as
| (8) |
where balances the degree of completeness from multiple views and structure according to class labels.
2.3 Test: Towards Consistency with Training Stage
The last challenge lies in narrowing the gap between training and test stages in representation learning. To classify a test sample with incomplete views , a straightforward way is to optimize the objective, , to encode the information from into . However, in this way, the gap originates from the difference between the objectives corresponding to training and test stages. To address this issue, we introduce a re-tuning strategy. In training stage, we obtain which encodes information from partial multi-view features . As for fine-tuning procedure, we optimize equation (5) (instead of the overall objective function (8)) with , and accordingly the networks can be retuned into . In this way, ensures the consistency of obtaining latent representations between training and testing stages. Subsequently, in test stage, we can solve the following objective - to obtain the latent representations which are consistent with those in training stage. The optimization of the proposed CPM-Nets and the test procedure are summarized in Algorithm 1.

Discussion on Key Components. The CPM-Nets is composed of two key components, i.e., encoding networks and clustering-like classification. As these are different from conventional components, detailed explanations are provided.
-
•
Encoding schema. To encode the information from multiple views into a common representation, there is an alternative route, i.e., . This is different from the schema used in our model shown in Eq. (5), i.e., . The underlying assumption in our model is that information from different views originates from a latent representation , and hence it can be mapped to each individual view. Whereas for the alternative, it assumes that the latent representation can be obtained from (mapping) each single view, which is often not the case in real applications. Further for the alternative, ideally, minimizing the loss will force the representations of different views to be the same, which is not reasonable especially for highly independent views. The theoretical results in subsection 2.1 further support this analysis.
-
•
Classification model. For classification, the widely used strategy is to learn a classification function based on , i.e., parameterized with . Compared with this manner, the reasons for using the clustering-like classifier instead in our model are as follows. First, jointly learning the latent representation and parameterized classifier is likely an under-constrained problem which may find representation that can well fit the training data but not well reflect the underlying patterns, and thus the generalization ability may be affected [47]. Second, the clustering-like classification produces compactness within the same class and separability between different classes for the learned representation, making the classifier interpretable. Finally, the non-parametric strategy reduces the load of parameter tuning and reflects a simpler inductive bias, which is especially beneficial to small-sample-size problems [48].
3 Enhanced Completeness with Adversarial Strategy
Generative adversarial networks (GANs) [49] have shown remarkable performance in lots of tasks. A typical GAN model consists of two modules: a generative model to learn the distribution over data , and a discriminative model to recognize whether a sample is from training data or from . The minimax objective function is
| (9) | |||
We will introduce the adversarial strategy to promote our model in missing view imputation and latent representation learning as well.
In classification, learning latent representation is simultaneously guided by the observed data and labels. The unsupervised setting is more challenging, especially for extensive missing cases and lack of labels. Therefore, we aim to effectively utilize both observed and unobserved views for learning latent representations. Specifically, this is achieved by improving the imputation for missing views and thus promoting latent representations. To ensure the rationality of the imputation, we introduce adversarial strategy to enforce the generated data for missing ones in each view to obey distribution of the observed data, as shown in Fig. 2. Then, the adversarial loss is induced as:
| (10) | ||||
where indicates whether or not the th sample in the th view needs to be imputed. and are the generator (degradation networks) and discriminator for the th view parameterized by and , respectively. are the available data in the th view, with the total number of samples being . In this way, all the available data act as positive samples to train the discriminators. The missing data generated by the generator are updated iteratively to approximate the distribution of observed data.
Accordingly, the overall objective function for unsupervised CPM-Nets is induced as:
| (11) | ||||
| with |
where is the reconstruction loss which is actually supervised by the observed data. In this way, the missing data are considered as variables to be jointly optimized with the latent representations, and thus the latent representation and the missing views are updated alternatively to improve each other.
Although both use adversarial strategy, there are several key differences between generative adversarial networks (GAN) and our model: (1) the inputs of GAN are fixed, which are sampled from one specific distribution, while in our algorithm the latent representations acting as inputs are variables to be optimized; (2) different from original GAN, our model of representation learning is performed in a sample-to-sample supervision manner [50],[51]; (3) in our model, there are multiple discriminators (each one for a view), which are used to make the generated missing data obey the distribution of the observed data to stabilize the imputation and thus enhance the representation learning. The optimization of the proposed CPM-GAN is summarized in Algorithm 2.























4 Experiments
4.1 Experimental Settings
We conduct experiments on the following datasets: Handwritten333https://archive.ics.uci.edu/ml/datasets/Multiple+Features: This dataset contains 10 categories from digits ‘0’ to ‘9’, and 200 images in each category with six types of image features are used. Animal [52] : The dataset consists of 10,158 images from 50 classes with two types of deep features extracted with DECAF [53] and VGG19 [54]. CUB [55]: This dataset contains different categories of birds, where the first 10 categories are used. Deep visual features from GoogLeNet and text features using doc2vec [56] are employed as two views. 3Sources-complete444http://mlg.ucd.ie/datasets/3sources.html: is collected from three online news sources: BBC, Reuters, and Guardian. In total 169 samples of stories are used, which are reported by all three sources. Football555http://mlg.ucd.ie/aggregation/index.html: A collection of 248 English Premier League football players and clubs active on Twitter. The disjoint ground truth communities correspond to 20 individual clubs in the league. Politics666http://mlg.ucd.ie/aggregation/index.html: A collection of Irish politicians and political organisations, assigned to seven disjoint ground truth groups according to their affiliation. For both football and politics datasets, 9 views are provided including follows, followedby, mentions, mentionedby, retweets, retweetedby, listmerged, lists, and tweets. ADNI777http://www.loni.usc.edu/ADNI: The dataset consists of 774 subjects from ADNI-1, including 226 normal controls (NC), 362 MCI and 186 AD subjects. There are only 379 subjects with complete MRI and PET data, including 101 NC, 185 MCI, and 93-AD, where the missing rate is up to 0.26. We use 93-dimensional ROI-based features from both MRI and PET data, respectively. 3Sources-partial888http://erdos.ucd.ie/datasets/3sources.html: is collected from three well-known online news sources: BBC, Reuters, and Guardian, in which some stories are not reported by all three sources (i.e., view missing). The missing rate of 3Sources-partial is 0.24.
We compare the proposed CPM-Nets with the following methods: (1) FeatConcate simply concatenates multiple types of features from different views. (2) CCA [9] maps multiple types of features into one common space, and subsequently concatenates the low-dimensional features of different views. (3) DCCA (Deep Canonical Correlation Analysis) [11] learns low-dimensional features with neural networks and concatenates them. (4) DCCAE (Deep Canonical Correlated AutoEncoders) [26] employs autoencoders for common representations, and then combines these projected low-dimensional features together. (5) KCCA (Kernelized CCA) [10] employs feature mappings induced by positive-definite kernels. (6) MDcR (Multi-view Dimensionality co-Reduction) [57] applies kernel matching to regularize the dependence across multiple views and projects each view into a low-dimensional space. (7) DMF-MVC (Deep Semi-NMF for Multi-View Clustering) [58] utilizes a deep structure through semi-nonnegative matrix factorization to seek a common feature representation. (8) ITML (Information-Theoretic Metric Learning) [59] characterizes the metric using a Mahalanobis distance function and solves the problem as a particular Bregman optimization. (9) LMNN (Large Margin Nearest Neighbors) [60] searches a Mahalanobis distance metric to optimize the -nearest neighbours classifier. For metric learning methods, the original features of multiple views are concatenated, and then the new representation can be obtained with the projection induced by the learned metric matrix.



















For all methods, we tune the parameters with five-fold cross validation. For CCA-based methods, we select two views for the best performance. For our CPM-Nets, we set the dimensionality () of the latent representation from and tune the parameter from the set for all datasets. We run each method 10 times and report the average values and standard deviations.
4.2 Network Architectures and Parameter Settings
For our CPM-Nets, we employ the fully connected networks equipped with sigmoid activation for all datasets, and -norm regularization is used with the value of the tradeoff parameter being . The dimensionalities of the input, hidden and output layers are denoted as , and , respectively. The dimensionality of the input layer (i.e., the dimensionality of the latent representation) is selected from the set . The main architectures are the same with detailed differences described as follows:
-
•
Handwritten. We employ three-layer (i.e., input/hidden/ouput layers) fully connected networks. The dimensionalities of the input, hidden and output layers are , and (240, 76, 216, 47, 64 and 6 respectively for six views). The learning rate is set as .
-
•
CUB. We employ two-layer (i.e., input/ouput layers) fully connected networks. The dimensionalities of the input and output layers are , and (1024 and 300 respectively for two views). The learning rate is set as .
-
•
Animal. We employ four-layer (i.e., input/two hidden/ouput layers) fully connected networks. The dimensionalities of the input, hidden and output layers are , (512 and 1024 respectively for two hidden layers) and (4096 for both views). The learning rate is set as .
-
•
Football. We employ three-layer (i.e., input/hidden/ouput layers) fully connected networks. The dimensionalities of the input, hidden and output layers are , and (248, 248, 248, 248, 248, 248, 3601, 7814 and 11806 respectively for 9 views). The learning rate is set as .
-
•
Politics. We employ three-layer (i.e., input/hidden/ouput layers) fully connected networks. The dimensionalities of the input, hidden and output layers are , and (348, 348, 348, 348, 348, 348, 1051, 1047 and 14377 respectively for 9 views). The learning rate is set as .
-
•
3Source-complete. We employ three-layer (i.e., input/hidden/ouput layers) fully connected networks. The dimensionalities of the input, hidden and output layers are , and (3560, 3631 and 3068 respectively for 3 views). The learning rate is set as .
-
•
ADNI. We employ three-layer (i.e., input/hidden/ouput layers) fully connected networks. The dimensionalities of the input, hidden and output layers are , and (93 for both views). The learning rate is set as .
-
•
3Source-partial. We employ three-layer (i.e., input/hidden/ouput layers) fully connected networks. The dimensionalities of the input, hidden and output layers are , and (3560, 3631 and 3068 respectively for 3 views). The learning rate is set as .
4.3 Supervised Experimental Results
Firstly, we evaluate our algorithm by comparing it with state-of-the-art multi-view representation learning methods, investigating the performance with respect to various missing rates. The missing rate is defined as , where indicates the number of samples without the th view. Since datasets may be associated with different numbers of views, samples are randomly selected as missing multi-view ones, and the missing views are randomly selected by guaranteeing that at least one of them is available. As a result, partial multi-view data are obtained with diverse missing patterns. For compared methods, the missing views are filled with average values according to available samples within the same class. From the results in Fig. 3, we have the following observations: (1) Without missing, our algorithm achieves very competitive performance on all datasets, which validates the stability of our algorithm for complete multi-view data. (2) As the missing rate increases, the performance degradations of the compared methods are much larger than that of ours. Taking the results on CUB for example, ours and LMNN obtain an accuracy of 89.48% and 86.27%, respectively, while with increasing the missing rate, the performance gap becomes much larger; (3) Our model is rather robust to view-missing data, since our algorithm usually performs relatively promising with heavily missing cases. For example, the performance decline (on Handwritten) is less than 5% with increasing the missing rate from to . We also note that the standard deviations are relatively small () on Animal, and the possible reason is that this dataset is much larger than others, producing more stable results.
Furthermore, we also fill the missing views with recently proposed imputation method - Cascaded Residual Autoencoder (CRA) [5]. Since CRA needs a subset of samples with complete views in training, we set of data as complete-view samples and the remaining are samples with missing views (missing rate ). The comparison results are shown in Fig. 4. It is observed that filling with CRA is generally better than that of using average values due to capturing the correlation of different views. Although the missing views are filled with CRA by using part of samples with complete views, our proposed algorithm still demonstrates clear superiority. According to the experimental results, our model performs as the best on all multi-modal datasets (CUB, 3Sources-complete, Football and Politics), outperforming the second performer with , , , , respectively. On average, our method achieves higher performance than the second performers on multi-feature datasets (Animal and Handwritten), and on all multi-modal datasets (CUB, Politics, Football, 3Sources-complete), which steadily verifies the superiority of our model. Our model also performs as the best on real-world partial multi-view data (ADNI and 3Sources-partial), achieving and higher performance than the second performer, respectively.
We visualize the representations from different methods on Handwritten to investigate the improvement of CPM-Nets. As shown in Fig. 5, the subfigures (a)-(c) show the results of representations obtained in an unsupervised manner. As can be observed, the latent representation from our algorithm reveals the underlying class distribution much better. With introducing label information, the representation from CPM-Nets are further improved, where the clusters are more compact and the margins between different classes become more clear. This validates the effectiveness of using clustering-like loss. It is worth noting that we jointly exploit all samples and views for random view-missing patterns in experiments, demonstrating the flexibility in handling partial multi-view data, while Fig. 5 supports the claim of structured representation.

4.3.1 Parameter Tuning and Convergence
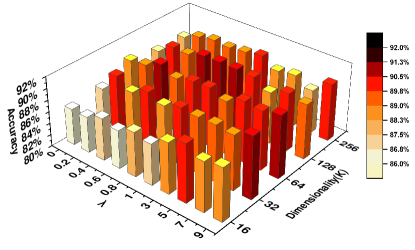
There are two main parameters in our algorithm, i.e., the tradeoff factor () and the dimensionality () of the latent representation. We visualize the parameter tuning on Handwritten (with missing rate ) as shown in Fig. 11. We tune the parameters from fine-grained sets, i.e., selecting from and the dimensionality () from the set . Five-fold cross-validation is employed with the average values of accuracy reported. It can be observed that: (1) when = 0 which corresponds to that the label information is not used, it leads to very poor performance; (2) as gradually increases, the overall trend becomes better, which implies the role of supervisory information. Our model is not sensitive to the trade-off factor. For example, when the dimensionality (K) is fixed as 128, the performance is very promising with in range 0.6-3; (3) differences between with and without supervisory information can also be found in Fig. 5 (c) and (f), where with given labels the intra-class representation is more compact, and inter-class margin is more obvious.
For relatively small datasets, the model parameters of CPM-Nets can be updated by processing the whole training data. For large datasets, it can be solved through mini-batch training. As shown in Fig. 12, we empirically investigate the convergence property on the dataset Animal with mini-batch gradient descent. For each mini-batch, 10% of samples from each class are used.
4.3.2 Fine-tuning evaluation
The reason for obtaining fine-tuning is that labels are used to train encoding networks, while in testing phase labels are not available. Thus there will be a gap between these two phases. To validate the effect of the fine-tuning, we conduct experiments on Handwritten and CUB to compare performance between with- and without- fine-tune procedure. According to Fig. 6, the performance with fine-tuning will be improved over without fine-tuning for most cases.
4.4 Unsupervised Experimental Results
To investigate the proposed CPM-GAN for view-missing data, we compare it with four baselines as follows: (1) Average [61] simply imputes missing parts with average value of all samples in each view; (2) SVD [9] is a matrix completion method by iterative soft thresholding of singular value decomposition; (3) CRA [5] is composed of a set of stacked residual autoencoders, which can learn complex relationship among data from different modalities; (4) CPM-without-GAN provides the comparative version of the CPM-Nets without adversarial strategy.
For our CPM-GAN, the fully-connected networks of CPM-Nets can be regarded as generators. As for the discriminators, for simplicity, we use the same structure as the generators. For the purpose of discrimination, a sigmoid layer is imposed on the output layer of each discriminator network. We note that promising performance can be expected with relatively shallow networks for most datasets, i.e., the number of network layers is set as for all datasets. We select the dimensionality () of the latent representation from . To be fair, the experimental settings for both CPM-GAN and CPM-without-GAN are the same. We run each method 10 times and report the average values and standard deviations.
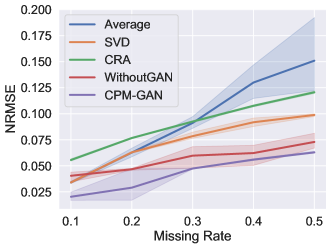
4.4.1 Imputation Performance
Our model can jointly learn latent representations and perform missing view imputation. To validate the effectiveness of imputation, we run different methods under different missing rates, where the views are abandoned at random. We evaluate the imputation performance in terms of Normalized Root Mean Square Error (NRMSE) [9]. The imputation performance under different missing rates is shown in Fig. 7. The following observations can be drawn from the experiments: (1) When the ratio of missing views increases, the imputation performance of all methods consistently declines; (2) CPM-GAN outperforms all the comparative methods with all missing rates on all six datasets, validating the effectiveness of our model. (3) CPM-GAN consistently outperforms CPM-without-GAN on all datasets, which empirically validates the motivation of adversarial strategy. (4) According to the proposition 2.1, the latent representations will be more complete and versatile due to the more promising imputation results.
4.4.2 Clustering Performance
Note that, different from the standard GAN whose inputs for the generator are sampled from a fixed distribution and do not change, the inputs (a.k.a latent representations) in our CPM-GAN are dynamically updated to encode complementary information. To evaluate the latent representations, we conduct clustering with k-means on six datasets. The metrics Accuracy (ACC) and Normalized Mutual Information (NMI) are used to measure the performance.
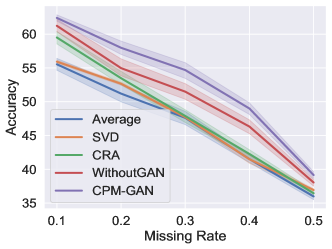
According to Fig. 8, we have the following observations: (1) In terms of both ACC and NMI, CPM-GAN and CPM-without-GAN both achieve relatively promising performance compared with all baselines, validating the effectiveness of CPM-Nets. (2) Although simple, directly averaging the observed values for missing data is unreasonable and risky, since the performance from ‘Average’ is quite unpromising; (3) Compared with CPM-without-GAN, CPM-GAN consistently performs better, especially under high missing rate. We also note that CPM-without-GAN sometimes slightly outperforms CPM-GAN under low missing rate (on Football or CUB). A possible reason is that the latent representation from CPM-Nets is stable under low missing rate. While as the missing rate increases, adversarial strategy improves the imputation and thus the latent representation as well; (4) Although the baselines can also achieve promising performance at low missing rate, clear performance degeneration can be observed under high missing rate. (5) Our model outperforms all compared algorithms on all multi-modal datasets. Taking the missing rate ( = 0.5) for example, on average, our method improves the performance and over the second performers in terms of ACC and NMI, respectively. According to Fig. 9, our method still outperforms other comparison methods on the naturally partial multi-view datasets in terms of both ACC and NMI. The above observations further validate the advantages of CPM-Nets in encoding complementary information and the robustness of adversarial strategy.
We also conduct experiments on CUB and Animal (these two-view datasets are suitable for VIGAN) to compare the VIGAN [35] with ours in terms of unsupervised clustering performance. VIGAN needs a part of complete-view samples to train an encoder, and thus we use complete data to train the VIGAN. Though using training data, it can be seen from Fig. 10 that our model still outperforms VIGAN in terms of both Accuracy and NMI.
5 Conclusions
We propose a novel algorithm for representation learning on partial multi-view data, which can jointly exploit all samples and views, and is flexible for arbitrary view-missing patterns. Our algorithm focuses on learning a complete and thus versatile representation to handle the complex correlations among multiple views. The common representation also endows flexibility for handling data with an arbitrary number of views and complex view-missing patterns, which is different from existing ad hoc methods. Equipped with a clustering-like classification loss, the learned representation is well structured, making the classifier interpretable. We empirically validate that the proposed algorithm is relatively robust to heavy and complex view-missing data.
Acknowledgment
This work was supported partially by National Natural Science Foundation of China (No. 61976151), the Natural Science Foundation of Tianjin of China (No. 19JCYBJC15200) and the National Key Research and Development Program of China (No. 2019YFB2101901).
References
- [1] T. Baltrušaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,” IEEE TPAMI, vol. 41, no. 2, pp. 423–443, 2019.
- [2] C. Xu, D. Tao, and C. Xu, “A survey on multi-view learning,” arXiv preprint arXiv:1304.5634, 2013.
- [3] P. Dhillon, D. Foster, and L. Ungar, “Multi-view learning of word embeddings via cca,” in NIPS, 2011, pp. 199–207.
- [4] S.-Y. Li, Y. Jiang, and Z.-H. Zhou, “Partial multi-view clustering,” in AAAI, 2014, pp. 1968–1974.
- [5] L. Tran, X. Liu, J. Zhou, and R. Jin, “Missing modalities imputation via cascaded residual autoencoder,” in CVPR, 2017, pp. 1405–1414.
- [6] X. Liu, X. Zhu, M. Li, L. Wang, C. Tang, J. Yin, D. Shen, H. Wang, and W. Gao, “Late fusion incomplete multi-view clustering,” IEEE TPAMI, 2018.
- [7] M. Liu, J. Zhang, P.-T. Yap, and D. Shen, “Diagnosis of alzheimer’s disease using view-aligned hypergraph learning with incomplete multi-modality data,” in MICCAI, 2016, pp. 308–316.
- [8] A. Trivedi, P. Rai, H. Daumé III, and S. L. DuVall, “Multiview clustering with incomplete views,” in NIPS Workshop, vol. 224, 2010.
- [9] H. Hotelling, “Relations between two sets of variates,” Biometrika, vol. 28, no. 3/4, pp. 321–377, 1936.
- [10] S. Akaho, “A kernel method for canonical correlation analysis,” arXiv preprint cs/0609071, 2006.
- [11] G. Andrew, R. Arora, J. Bilmes, and K. Livescu, “Deep canonical correlation analysis,” in ICML, 2013, pp. 1247–1255.
- [12] J.-F. Cai, E. J. Candès, and Z. Shen, “A singular value thresholding algorithm for matrix completion,” SIAM Journal on Optimization, vol. 20, no. 4, pp. 1956–1982, 2010.
- [13] R. Mazumder, T. Hastie, and R. Tibshirani, “Spectral regularization algorithms for learning large incomplete matrices,” JMLR, vol. 11, no. Aug, pp. 2287–2322, 2010.
- [14] L. Cai, Z. Wang, H. Gao, D. Shen, and S. Ji, “Deep adversarial learning for multi-modality missing data completion,” in KDD, 2018, pp. 1158–1166.
- [15] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng, “Multimodal deep learning,” in ICML, 2011, pp. 689–696.
- [16] L. Yuan, Y. Wang, P. M. Thompson, V. A. Narayan, and J. Ye, “Multi-source learning for joint analysis of incomplete multi-modality neuroimaging data,” in KDD, 2012, pp. 1149–1157.
- [17] A. Kumar, P. Rai, and H. Daume, “Co-regularized multi-view spectral clustering,” in NIPS, 2011, pp. 1413–1421.
- [18] A. Kumar and H. Daumé, “A co-training approach for multi-view spectral clustering,” in ICML, 2011, pp. 393–400.
- [19] C. Zhang, H. Fu, S. Liu, G. Liu, and X. Cao, “Low-rank tensor constrained multiview subspace clustering,” in ICCV, 2015, pp. 1582–1590.
- [20] C. Zhang, Q. Hu, H. Fu, P. Zhu, and X. Cao, “Latent multi-view subspace clustering,” in CVPR, 2017, pp. 4279–4287.
- [21] Z. Yang, Q. Xu, W. Zhang, X. Cao, and Q. Huang, “Split multiplicative multi-view subspace clustering,” IEEE Transactions on Image Processing, 2019.
- [22] J. Guo, W. Yin, Y. Sun, and Y. Hu, “Multi-view subspace clustering with block diagonal representation,” IEEE Access, pp. 84 829–84 838, 2019.
- [23] X. Gong, L. Huang, and F. Wang, “Feature sampling based unsupervised semantic clustering for real web multi-view content.” AAAI Press, 2019, pp. 102–109.
- [24] H. Zhang, T. S. Huang, N. M. Nasrabadi, and Y. Zhang, “Heterogeneous multi-metric learning for multi-sensor fusion,” in 14th International Conference on Information Fusion, 2011, pp. 1–8.
- [25] H. Zhang, V. M. Patel, and R. Chellappa, “Hierarchical multimodal metric learning for multimodal classification,” in CVPR, 2017, pp. 3057–3065.
- [26] W. Wang, R. Arora, K. Livescu, and J. Bilmes, “On deep multi-view representation learning,” in ICML, 2015, pp. 1083–1092.
- [27] W. Wang, H. Lee, and K. Livescu, “Deep variational canonical correlation analysis,” CoRR, vol. abs/1610.03454, 2016.
- [28] X. Chen, S. Chen, H. Xue, and X. Zhou, “A unified dimensionality reduction framework for semi-paired and semi-supervised multi-view data,” Pattern Recognition, vol. 45, no. 5, pp. 2005–2018, 2012.
- [29] N. Rasiwasia, J. Costa Pereira, E. Coviello, G. Doyle, G. R. Lanckriet, R. Levy, and N. Vasconcelos, “A new approach to cross-modal multimedia retrieval,” in ACM MM, 2010, pp. 251–260.
- [30] Y.-A. Chung, W.-H. Weng, S. Tong, and J. Glass, “Unsupervised cross-modal alignment of speech and text embedding spaces,” in NIPS, 2018, pp. 7365–7375.
- [31] L. Castrejon, Y. Aytar, C. Vondrick, H. Pirsiavash, and A. Torralba, “Learning aligned cross-modal representations from weakly aligned data,” in CVPR, 2016, pp. 2940–2949.
- [32] J. T. Zhou, I. W. Tsang, S. J. Pan, and M. Tan, “Multi-class heterogeneous domain adaptation,” Journal of Machine Learning Research, vol. 20, no. 57, pp. 1–31, 2019.
- [33] J. T. Zhou, S. J. Pan, and I. W. Tsang, “A deep learning framework for hybrid heterogeneous transfer learning,” Artificial Intelligence, 2019.
- [34] A. Li, H. Hu, P. Mirowski, and M. Farajtabar, “Cross-view policy learning for street navigation,” CoRR, 2019.
- [35] C. Shang, A. Palmer, J. Sun, K.-S. Chen, J. Lu, and J. Bi, “Vigan: Missing view imputation with generative adversarial networks,” in ICBD, 2017, pp. 766–775.
- [36] O. G. Troyanskaya, M. N. Cantor, G. Sherlock, P. O. Brown, T. Hastie, R. Tibshirani, D. Botstein, and R. B. Altman, “Missing value estimation methods for dna microarrays,” Bioinform, pp. 520–525, 2001.
- [37] S. Oba, M. Sato, I. Takemasa, M. Monden, K. Matsubara, and S. Ishii, “A bayesian missing value estimation method for gene expression profile data,” Bioinform., pp. 2088–2096, 2003.
- [38] O. G. Troyanskaya, M. N. Cantor, G. Sherlock, P. O. Brown, T. Hastie, R. Tibshirani, D. Botstein, and R. B. Altman, “Missing value estimation methods for dna microarrays,” Bioinform., pp. 520–525, 2001.
- [39] T. H. Bù, B. Dysvik, and I. Jonassen, “Lsimpute: accurate estimation of missing values in microarray,” 2004.
- [40] H. Kim, G. H. Golub, and H. Park, “Missing value estimation for DNA,” Bioinform., pp. 1410–1411, 2006.
- [41] R. Jörnsten, H. Wang, W. J. Welsh, and M. Ouyang, “DNA microarray data imputation,” Bioinform., pp. 4155–4161, 2005.
- [42] Z. Xue, J. Du, D. Du, W. Ren, and S. Lyu, “Deep correlated predictive subspace learning for incomplete multi-view semi-supervised classification.” ijcai.org, 2019, pp. 4026–4032.
- [43] Y. Yang, D. Zhan, X. Sheng, and Y. Jiang, “Semi-supervised multi-modal learning with incomplete modalities.” ijcai.org, 2018, pp. 2998–3004.
- [44] T. S. Lee, “Image representation using 2d gabor wavelets,” IEEE TPAMI, vol. 18, no. 10, pp. 959–971, 1996.
- [45] M. White, X. Zhang, D. Schuurmans, and Y.-l. Yu, “Convex multi-view subspace learning,” in NIPS, 2012, pp. 1673–1681.
- [46] W. Liu, I. W. Tsang, and K.-R. Müller, “An easy-to-hard learning paradigm for multiple classes and multiple labels,” The Journal of Machine Learning Research, vol. 18, no. 1, pp. 3300–3337, 2017.
- [47] L. Le, A. Patterson, and M. White, “Supervised autoencoders: Improving generalization performance with unsupervised regularizers,” in NIPS, 2018, pp. 1–11.
- [48] J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,” in NIPS, 2017, pp. 1–11.
- [49] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio, “Generative adversarial networks,” CoRR, vol. abs/1406.2661, 2014.
- [50] A. B. L. Larsen, S. K. Sønderby, H. Larochelle, and O. Winther, “Autoencoding beyond pixels using a learned similarity metric,” in ICML, 2016, pp. 1558–1566.
- [51] M. Liu, T. Breuel, and J. Kautz, “Unsupervised image-to-image translation networks,” in NIPS, 2017, pp. 700–708.
- [52] C. H. Lampert, H. Nickisch, and S. Harmeling, “Attribute-based classification for zero-shot visual object categorization,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 3, pp. 453–465, 2014.
- [53] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in NIPS, 2012, pp. 1097–1105.
- [54] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in ICLR, 2015.
- [55] C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, “The caltech-ucsd birds-200-2011 dataset,” 2011.
- [56] Q. Le and T. Mikolov, “Distributed representations of sentences and documents,” in ICML, 2014, pp. 1188–1196.
- [57] C. Zhang, H. Fu, Q. Hu, P. Zhu, and X. Cao, “Flexible multi-view dimensionality co-reduction,” IEEE TIP, vol. 26, no. 2, pp. 648–659, 2017.
- [58] H. Zhao, Z. Ding, and Y. Fu, “Multi-view clustering via deep matrix factorization.” in AAAI, 2017, pp. 2921–2927.
- [59] J. V. Davis, B. Kulis, P. Jain, S. Sra, and I. S. Dhillon, “Information-theoretic metric learning,” in ICML, 2007, pp. 209–216.
- [60] K. Q. Weinberger and L. K. Saul, “Distance metric learning for large margin nearest neighbor classification,” JMLR, vol. 10, no. Feb, pp. 207–244, 2009.
- [61] C. Enders, Applied Missing Data Analysis. Guilford Press, 2010.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fb72c0cd-f97f-405e-9bee-9086104d7840/zhangchangqingC.jpg) |
Changqing Zhang received the B.S. and M.S. degrees from the College of Computer, Sichuan University, Chengdu, China, in 2005 and 2008, respectively, and the Ph.D. degree in Computer Science from Tianjin University, China, in 2016. He is an associate professor in the College of Intelligence and Computing, Tianjin University. He has been a postdoc research fellow in the Department of Radiology and BRIC, School of Medicine, University of North Carolina at Chapel Hill, NC, USA. His current research interests include machine learning, computer vision and medical image analysis. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fb72c0cd-f97f-405e-9bee-9086104d7840/cuiyajie.jpg) |
Yajie Cui received the B.S. degree in computer science and technology from Northeastern University, Qinhuangdao, China, in 2018. She is currently working towards the M.S. degree in the College of Intelligence and Computing, Tianjin University, Tianjin, China. Her research interests include multi-view representation and machine learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fb72c0cd-f97f-405e-9bee-9086104d7840/hanzongbo.jpg) |
Zongbo Han received the B.S. degree in electronics and communication engineering from Dalian University of Technology, Dalian, China, in 2019. He is currently working toward the M.S. degree in the College of Intelligence and Computing, Tianjin University, Tianjin, China. His research interests include machine learning and computer vision. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fb72c0cd-f97f-405e-9bee-9086104d7840/Tianyi.jpg) |
Joey Tianyi Zhou is currently a scientist, PI and group manager with the Institute of High Performance Computing (IHPC) in Agency for Science, Technology, and Research (A*STAR), Singapore. He is currently leading the AI Group with more than 30 research staff members. He is also holding an adjunct faculty position in National University of Singapore (NUS). Before working in IHPC, he was a senior research engineer with SONY US Research Center in San Jose, USA. Joey Zhou received a Ph.D. degree in computer science from Nanyang Technological University (NTU), Singapore. His current interests mainly focus on low-resource machine learning and their applications in natural language processing and computer vision tasks. Dr. Zhou co-organized ACML’16 workshop on Learning on Big Data workshop and IJCAI’19 workshop on Multi-output Learning, ICDCS’20 workshop on Efficient AI; has served as an Associate/Guest Editor for IEEE Access, IET Image Processing, IEEE Multimedia, and ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), Springer Nature Computer Science and TPC Chair in Mobimedia 2020; and received NIPS Best Reviewer Award in 2017. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fb72c0cd-f97f-405e-9bee-9086104d7840/fuhuazhuC.jpg) |
Huazhu Fu (SM’18) is a Senior Scientist at Inception Institute of Artificial Intelligence, Abu Dhabi, United Arab Emirates. He received his Ph.D. from Tianjin University in 2013, and was a Research Fellow at Nanyang Technological University for two years. From 2015 to 2018, he was a Research Scientist in Institute for Infocomm Research at Agency for Science, Technology and Research. His research interests include computer vision, machine learning, and medical image analysis. He currently serves as an Associate Editor of IEEE TMI, IEEE JBHI, and IEEE Access. He also serves as a co-chair of OMIA workshop and co-organizer of ocular image series challenge (i-Challenge). |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fb72c0cd-f97f-405e-9bee-9086104d7840/huqinghuaC.jpg) |
Qinghua Hu (SM’13) received the B.S., M.S., and Ph.D. degrees from the Harbin Institute of Technology, Harbin, China, in 1999, 2002, and 2008, respectively. He was a Post-Doctoral Fellow with the Department of Computing, Hong Kong Polytechnic University, Hong Kong, from 2009 to 2011. He is currently a Full Professor there. He has authored over 150 journal and conference papers in the areas of granular computing-based machine learning, reasoning with uncertainty, pattern recognition, and fault diagnosis. His current research interests include multi-modality learning, metric learning, uncertainty modeling and reasoning with fuzzy sets, rough sets and probability theory. Prof. Hu was the Program Committee Co-Chair of the International Conference on Rough Sets and Current Trends in Computing in 2010, the Chinese Rough Set and Soft Computing Society in 2012 and 2014, and the International Conference on Rough Sets and Knowledge Technology and the International Conference on Machine Learning and Cybernetics in 2014, and the General Co-Chair of IJCRS 2015. |