Deep Lossy Plus Residual Coding for
Lossless and Near-lossless Image Compression
Abstract
Lossless and near-lossless image compression is of paramount importance to professional users in many technical fields, such as medicine, remote sensing, precision engineering and scientific research. But despite rapidly growing research interests in learning-based image compression, no published method offers both lossless and near-lossless modes. In this paper, we propose a unified and powerful deep lossy plus residual (DLPR) coding framework for both lossless and near-lossless image compression. In the lossless mode, the DLPR coding system first performs lossy compression and then lossless coding of residuals. We solve the joint lossy and residual compression problem in the approach of VAEs, and add autoregressive context modeling of the residuals to enhance lossless compression performance. In the near-lossless mode, we quantize the original residuals to satisfy a given error bound, and propose a scalable near-lossless compression scheme that works for variable bounds instead of training multiple networks. To expedite the DLPR coding, we increase the degree of algorithm parallelization by a novel design of coding context, and accelerate the entropy coding with adaptive residual interval. Experimental results demonstrate that the DLPR coding system achieves both the state-of-the-art lossless and near-lossless image compression performance with competitive coding speed.
Index Terms:
Deep Learning, Image Compression, Lossless Compression, Near-lossless Compression, Lossy Plus Residual Coding.1 Introduction
In many important technical fields, such as medicine, remote sensing, precision engineering and scientific research, imaging in high spatial, spectral and temporal resolutions is instrumental to discoveries and innovations. As achievable resolutions of modern imaging technologies steadily increase, users are inundated by the resulting astronomical amount of image and video data. For example, pathology imaging scanners can easily produce 1GB or more data per specimen. For the sake of cost-effectiveness and system operability (e.g., real-time access via clouds to high-fidelity visual objects), acquired raw images of high resolutions in multiple dimensions have to be compressed.
Unlike in consumer applications (e.g., smartphones and social media), where users are mostly interested in the appearlingness of decompressed images and can be quite oblivious to compression distortions at the signal level, high fidelity of decompressed images is of paramount importance to professional users in many technical fields. In the latter case, the current gold standard is mathematically lossless image compression. The Shannon’s source coding theorem [1] establishes the theoretical foundation of lossless image compression, which proves the lower bound of the expected codelength given real probability distribution of image data, i.e., the information entropy. In practice, the compression performance of any specific lossless image codec depends on how well it can approximate the unknown real probability distribution, in order to approach the theoretical lower bound. Despite years of research, typical compression ratios of traditional lossless image codecs [2, 3, 4, 5] are limited between 2:1 and 3:1. An alternative way to improve the compression performance while keeping the high fidelity of decompressed images is near-lossless image compression [6, 7]. Instead of mathematically lossless, near-lossless image compression imposes strict constraints on the decompressed images requiring the maximum reconstruction error of each pixel to be no larger than a given tight numerical bound. By introducing the constrained error bound, near-lossless image compression can guarantee the reliability of each pixel while break the theoretical compression limit of lossless image compression. When the tight error bound is set to zero, near-lossless image compression is equivalent to lossless image compression. Traditional lossless image codecs, such as JPEG-LS [2] and CALIC [3, 8], provide users with both lossless and near-lossless image compression in order to meet the requirements of bandwidth and cost-effectiveness for diverse imaging and vision systems.
With the fast progress of deep neural networks (DNNs), learning-based image compression has achieved tremendous progress over the last five years. However, most of these methods are designed for rate-distortion optimized lossy image compression [9], which cannot realize lossless or near-lossless image compression even with sufficient bit-rates. Recently, a number of research teams embark on developing end-to-end optimized lossless image compression methods [10, 11, 12, 13, 14, 15, 16, 17]. These methods take advantage of sophisticated deep generative models, such as autoregressive models [18, 19, 20], flow models [21] and variational auto-encoder (VAE) models [22], to learn the unknown probability distribution of given image data and entropy encode the image data to bitstreams according to the learned models. While superior compression performance is achieved beyond traditional lossless image codecs, existing learning-based lossless image methods usually suffer from excessively slow coding speed and can hardly be applied to practical full resolution image compression tasks. It is also regrettable that, unlike traditional JPEG-LS [2] and CALIC [3, 8], no studies (except our recent work [23]) are carried out on learning-based near-lossless image compression, given its great potential as aforementioned.
In this paper, we propose a unified and powerful deep lossy plus residual (DLPR) coding framework for both lossless and near-lossless image compression, which addresses the challenges of learning-based lossless image compression to a large extent. The remarkable characters of the DLPR coding system includes: the state-of-the-art lossless and near-lossless image compression performance, scalable near-lossless image compression with variable bounds in a single network and competitive coding speed on even 2K resolution images. Specifically, for lossless image compression, the DLPR coding system first performs lossy compression and then lossless coding of residuals. Both the lossy image compressor and the residual compressor are designed with advanced neural network architectures. We solve the joint lossy image and residual compression problem in the approach of VAEs, and add autoregressive context modeling of the residuals to enhance lossless compression performance. Note that our VAE model is different from transform coding based VAE for simply lossy image compression [24, 25] or bits-back coding based VAEs [26] for lossless image compression. For near-lossless image compression, we quantize the original residuals to satisfy a given error bound, and compress the quantized residuals instead of the original residuals. To achieve scalable near-lossless compression with variable error bounds, we derive the probability model of the quantized residuals by quantizing the learned probability model of the original residuals for lossless compression, without training multiple networks. Because residual quantization leads to the context mismatch between training and inference, we propose a scalable quantized residual compressor with bias correction scheme to correct the bias of the derived probability model. In order to expedite the DLPR coding, the bottleneck is the serialized autoregressive context model in residual and quantized residual compression. We thus propose a novel design of coding context to increase the degree of algorithm parallelization, and further accelerate the entropy coding with adaptive residual interval. Finally, the lossless or near-lossless compressed image is stored including the bitstreams of the encoded lossy image, the encoded original residuals or the quantized residuals.
In summary, the major contributions of this research are as follows:
-
•
We propose a unified DLPR coding framework to realize both lossless and near-lossless image compression. The framework can be interpreted as a VAE model and end-to-end optimized. Though lossless and near-lossless modes have been supported in traditional lossless image codecs, such as JPEG-LS or CALIC, we are the first to support both the two modes in learning-based image compression.
-
•
We realize scalable near-lossless image compression with variable error bounds. Given the bounds, we quantize the original residuals and derive the probability model of the quantized residuals from the learned probability model of the original residuals for lossless image compression, instead of training multiple networks. A bias correction scheme further improves the compression performance.
-
•
To expedite the DLPR coding system, we propose a novel design of coding context to increase the degree of algorithm parallelization without compromising the compression performance. Meanwhile, we further introduce an adaptive residual interval scheme to reduce the entropy coding time.
Experimental results demonstrate that the DLPR coding system achieves both the state-of-the-art lossless and near-lossless image compression performance, and achieves competitive PSNR while much smaller error compared with lossy image codecs at high bit rates. At the same time, the DLPR coding system is practical in terms of runtime, which can compress and decompress 2K resolution images in several seconds.
Note that this paper is the non-trivial extension of our recent work [23]. First, this paper focuses on both lossless and near-lossless image compression, rather than simply near-lossless image compression in [23]. Second, we improve the network architectures of lossy image compressor, residual compressor and scalable quantized residual compressor beyond [23], leading to more powerful while concise DLPR coding system. Third, to expedite the DLPR coding system, we introduce a novel design of context coding to increase the degree of algorithm parallelization and an adaptive residual interval scheme to accelerate the entropy coding. Finally, we conduct comprehensive experiments to demonstrate that the resulting DLPR coding system achieves the state-of-the-art lossless and near-lossless image compression performance, significantly outperforms its prototype in [23], while enjoys much faster coding speed.
The rest of the paper is organized as follows. We provide a brief review of related works in Sec. 2. We theoretically analyze lossless and near-lossless image compression problems, and formulate the DLPR coding framework in Sec. 3. The network architecture and acceleration of DLPR coding framework are presented in Sec. 4. Experiments and conclusions are in Sec. 5 and Sec. 6, respectively.
2 Related Work
This section reviews related works from three aspects, including learning-based lossy image compression, learning-based lossless image compression and near-lossless image compression. Our DLPR coding framework takes advantages of the recent progress of learning-based lossy image compression, and achieves the state-of-the-art performance of lossless and near-lossless image compression.
2.1 Learning-based Lossy Image Compression
Early learning-based lossy image compression methods with DNNs are based on recurrent neural networks (RNNs), starting from the work of Toderici et al. [27]. Toderici et al. [27] proposed a long short-term memory (LSTM) network to progressively encode images or residuals, and achieved multi-rate image compression with the increase of RNN iterations. Following [27], Toderici et al. [28] and Johnston et al. [29] improved RNN-based lossy image compression by modifying the RNN architectures, introducing LSTM-based entropy coding and adding spatially adaptive bit allocation.
Apart from RNN-based methods, a general end-to-end convolutional neural network (CNN) based compression framework was proposed by Ballé et al. [24] and Theis et al. [30], which can be interpreted as VAEs [22] based on transform coding [31]. In this framework, raw images are transformed to latent space, quantized and entropy encoded to bitstreams at encoder side. At decoder side, the quantized latent variables are recovered from the bitstreams and then inversely transformed to reconstruct lossy images. During training, the compression rates are approximated and minimized with the entropy of the quantized latent variables, while the reconstruction distortion is usually minimized with PSNR or MS-SSIM [32], leading to the rate-distortion optimization [1]. This framework is followed by most recent learned lossy image compression methods and is improved from three aspects, i.e., transform (network architectures) [33, 34, 35], quantization [36, 37, 38] and entropy coding [25, 39, 40, 41, 42, 43, 44, 45].
Inspired by the recent progress of learned lossy image compression, we propose a DLPR coding framework for both lossless and near-lossless image compression, by integrating lossy image compression with residual compression. The DLPR coding system achieves the state-of-the-art lossless and near-lossless image compression performance with competitive coding speed.
2.2 Learning-based Lossless Image Compression
Lossless image compression can usually be solved in two steps: 1) statistical modeling of given image data; 2) encoding the image data to bitstreams according to the statistical model, with entropy encoding tools such as arithmetic coder [46] or asymmetric numerical systems [47]. Given the strong connections between lossless compression and unsupervised machine learning, deep generative models are introduced to solve the first step of lossless image compression, which is a challenging task due to the complexity of unknown probability distribution of raw images. There are three dominant kinds of deep generative models used in lossless image compression, including autoregressive models, flow models and VAE models.
Autoregressive models. Oord et al. [18, 19] proposed PixelRNN and PixelCNN that estimated the joint distribution of pixels in an image as the product of the conditional distributions over the pixels. The masked convolution was used to ensure that the conditional probability estimation of the current pixel only depends on the previously observed pixels. Following [18, 19], Salimans et al. [20] proposed PixelCNN++ that improved the implementation of PixelCNN with several aspects. Reed et al. [48] proposed multi-scale parallelized PixelCNN that allowed efficient probability density estimation. Zhang et al. [49] studied the out-of-distribution generalization of autoregressive models and utilized a local PixelCNN for lossless image compression.
Flow models. Hoogeboom et al. [14] proposed a discrete integer flow (IDF) model for lossless image compression that learned rich invertible transforms on discrete image data. The latent variables resulting from IDF were assumed to enjoy simpler distributions leading to efficient entropy coding, and were able to recover raw images losslessly. Following [14], Berg et al. [50] further proposed a IDF++ model improving several aspects of the IDF model, such as the network architecture. In [34], Ma et al. proposed a wavelet-like transform for lossy and lossless image compression, which can be considered as a special flow model. In [15], Ho et al. proposed a local bit-back coding scheme and realized lossless image compression with continuous flows. In [16], Zhang et al. proposed a invertible volume-preserving flow (iVPF) model to achieve discrete bijection for lossless image compression. Beyond [16], Zhang et al. [17] further proposed a iFlow model composed of modular scale transforms and uniform base conversion systems, leading to the state-of-the-art performance.
VAE models. Townsend et al. [26] proposed bits-back with asymmetric numeral systems (BB-ANS) that performed lossless image compression with VAE models. The bits-back coding scheme estimated posterior distributions of latent variables conditioned on given images and decoded the latent variables from auxiliary bits accordingly. Kingma et al. [12] further generalized BB-ANS with a bit-swap scheme based on hierarchical VAE models, to avoid large amount of auxiliary bits. In [13], Townsend et al. proposed an alternative hierarchical latent lossless compression (HiLLoC) method integrating BB-ANS with hierarchical VAE models, and adopted FLIF [4] to compress parts of image data as auxiliary bits. Besides bits-back coding scheme, Mentzer et al. [10] proposed a practical lossless image compression (L3C) model, which can also be translated as a hierarchical VAE model.
Instead of the above mentioned methods, we propose a DLPR coding framework, which can be utilized for lossless image compression and interpreted in terms of VAE models. In [11], Mentzer et al. used the traditional BPG lossy image codec [51] to compress raw images and proposed a CNN model to compress the corresponding residuals, which is a special case of our framework. We further design our network architecture by integrating the VAE model with an autoregressive context model, leading to superior lossless image compression performance. Meanwhile, we further propose novel design of coding context to increase coding parallelization, making the DLPR coding system practical for real image compression tasks.
2.3 Near-lossless Image Compression
Near-lossless image compression requires the maximum reconstruction error of each pixel to be no larger than a given tight numerical bound, i.e., the error bound. It is a challenging task to realize near-lossless image compression, because the error bound is non-differentiable and must be strictly satisfied.
Traditional near-lossless image compression methods can be divided into three categories: 1) pre-quantization: adjusting raw pixel values to the error bound, and then compressing the pre-processed images with lossless image compression, such as near-lossless WebP [52]; 2) predictive coding: predicting subsequent pixels based on previously encoded pixels, then quantizing predication residuals to satisfy the error bound, and finally compressing the quantized residuals, such as, [53, 7], near-lossless JPEG-LS [2] and near-lossless CALIC [8]; 3) lossy plus residual coding: similar to 2), but replacing predictive coder with lossy image coder, and both the lossy image and the quantized residuals are encoded, as discussed in [6]. Compared with learning-based lossy and lossless image compression, learning-based near-lossless image compression is still in its infancy.
In this paper, we propose a DLPR coding framework inspired by traditional lossy plus residual coding, which can be utilized for near-lossless image compression. The DLPR coding framework supports scalable near-lossless image compression with variable bounds without training multiple networks, and achieves the state-of-the-art compression performance. Recently, Zhang et al. [54] proposed a learning-based soft-decoding method to improve the reconstruction performance of near-lossless CALIC. Though PSNR is improved, the soft-decoding method cannot strictly guarantee the error bound.
3 Deep Lossy Plus Residual Coding
In this section, we introduce a DLPR coding framework for lossless and near-lossless image compression, by integrating lossy image compression with residual compression. We theoretically analyze lossless and near-lossless image compression problems, and formulate the DLPR coding framework in terms of VAEs.
3.1 DLPR coding for Lossless Image Compression
Lossless image compression guarantees that raw image are perfectly reconstructed from the compressed bitstreams. Assuming that raw images ’s are sampled from an unknown probability distribution , the shortest expected codelength of the compressed images with lossless image compression is theoretically lower-bounded by the information entropy [1, 55]:
| (1) |
In practice, the compression performance of any specific lossless image compression method depends on how well it can approximate with an underlying model . The corresponding compression performance is given by the cross entropy [1, 55]:
| (2) |
where (2) holds only if .
In order to approximate , the latent variable model is extensively employed for this purpose and is formulated by a marginal distribution:
| (3) |
where is an unobserved latent variable and denote the parameters of this model. Since directly learning the marginal distribution with (3) is typically intractable, one alternative way is to optimize the evidence lower bound (ELBO) via VAEs [22]. By introducing an inference model to approximate the posterior , the logarithm of the marginal likelihood can be rewritten as:
| (4) |
where is the Kullback-Leibler (KL) divergence. denote the parameters of the inference model . Because and , ELBO is the lower bound of . Thus, we have
| (5) |
and can minimize the expectation of negative ELBO as a proxy for the expected codelength .
In order to minimize the expectation of negative ELBO, we propose a DLPR coding framework. We first adopt lossy image compression based on transform coding [31] to compress the raw image and obtain its lossy reconstruction . The expectation of negative ELBO can be reformulated as follows:
| (6) |
where is the quantized result of continuous latent representation and is deterministically transformed from . Like [25], we relax the quantization of by adding noise from , and assume . Thus, is dropped from (6). For simply lossy image compression, such as [24, 25, 40, 33], the second term of (6) can be regarded as the distortion loss between and its lossy reconstruction from . The third term can be regarded as the rate loss of lossy image compression. Only needs to be encoded to the bitstreams and stored.
Beyond lossy image compression, we further take residual compression into consideration. The residual is computed by . We have the following Proposition 1.
Proposition 1.
.
Proof.
For each and all pairs satisfying , we have . Following Bayes’ rule, we have . Thus, we have . Because the lossy reconstruction is computed by the deterministic inverse transform of , there is only one with and the other ’s are with . Thus, we can have . ∎
Based on (6) and Proposition 1, we substitute for and achieve the DLPR coding formulation:
| (7) |
where the first term and the second term of (7) are the expected codelengths of entropy encoding and with and , respectively. During training, we relax the quantization of by adding noise from , and have consistent with the precondition of the Proposition 1. Because (7) is equivalent to the expectation of negative ELBO (5), the proposed DLPR coding framework is the upper-bound of the expected codelength and can be minimized as a proxy.
Note that no distortion loss of lossy image compression is specified in (7). Therefore, we can embed arbitrary lossy image compressors and minimize (7) to achieve lossless image compression. A special case is the previous lossless image compression method [11], in which the BPG lossy image compressor [51] with a learned quantization parameter classifier minimizes and a CNN-based residual compressor minimizes .
3.2 DLPR coding for Near-lossless Image Compression
We further extend the DLPR coding framework for near-lossless image compression. Given a tight error bound , near-lossless methods compress a raw image satisfying the following distortion constraint:
| (8) |
where is the near-lossless reconstruction of the raw image . and are the pixels of and , respectively. denotes the -th spatial position in a pre-defined scan order, and denotes the -th channel. If , near-lossless image compression is equivalent to lossless image compression.
In order to satisfy the constraint (8), we extend the DLPR coding framework by quantizing the residuals. First, we still obtain a lossy reconstruction of the raw image through lossy image compression. Although lossy image compression methods can achieve high PSNR results at relatively low bit rates, it is difficult for these methods to ensure a tight error bound of each pixel in . We then compute the residual and suppose that is quantized to . Let , the reconstruction error is equivalent to the quantization error of . Thus, we adopt a uniform residual quantizer whose bin size is and quantized value is [2, 8]:
| (9) |
where denotes the sign function. and are the elements of and , respectively. With (9), we now have for each in , satisfying the tight error bound (8). Because residual quantization (9) is deterministic, the DLPR coding framework for near-lossless image compression can be formulated as:
| (10) |
where the first term of (10) is the expected codelength of the quantized residual with , rather than that of the original residual in (7). Finally, we concatenate the bitstream of with that of , leading to the near-lossless image compression result.
4 Network Architecture and Acceleration
4.1 Network Architecture of DLPR Coding
We propose the network architecture of our DLPR coding framework including a lossy image compressor (LIC), a residual compressor (RC) and a scalable quantized residual compressor (SQRC), as illustrated in Fig. 1. With LIC and RC, we realize DLPR coding for lossless image compression. With LIC and SQRC, we further realize DLPR coding for near-lossless image compression with variable bounds in a single network, instead of training multiple networks for different ’s. We next specify each of the three components in the following subsections.

4.1.1 Lossy Image Compressor
In LIC, we employ sophisticated image encoder and decoder while efficient hyper-prior model [25], as shown in Fig. 2. The image encoder and decoder are composed of analysis, synthesis and Swin-Attention blocks following the philosophy of residual and self-attention learning [56, 57, 33], as detailed in Fig. 3. In Swin-Attention blocks, we adopt the window and shifted window based multi-head self-attention (W-MSA/SW-MSA) in [58] to aggregate information within and across local windows adaptively, which improve the representation ability of and with moderate computational complexity. With and , we transform an input raw image to its latent representation , quantize to , and reversely transform to the lossy reconstruction .
Because the sophisticated image encoder and decoder can largely reduce the spatial redundancies in , the burden of entropy coding is relieved and we decide to employ the efficient hyper-prior model [25] without any context models to ensure the coding parallelization on GPUs. The hyper-prior model extracts side information to model the probability distribution of , where is the hyper-encoder. We assume a factorized Gaussian distribution model for where is the hyper-decoder, and a non-parametric factorized density model for . The in (7) and (10) is thus extended by
| (11) |
where is the cost of encoding both and .


4.1.2 Residual Compressor
Given the raw image and its lossy reconstruction from LIC, we have the residual . We next introduce RC to estimate the probability mass function (PMF) of and compress with arithmetic coding [46] accordingly.
Denote by , where the feature is generated from by . The and the image decoder share the network except the last convolutional layer, as shown in Fig. 1. We interpret as the feature of the residual given and . The feature shares the same height and width with and has 256 channels. Unlike the latent representation of which the spatial redundancies are largely reduced by the image encoder, the residual in the pixel domain has spatial redundancies that cannot be fully exploited by only the feature . Therefore, we further introduce the autoregressive model into the statistical modeling of , leading to
| (12) |
where denotes the elements of encoded or decoded before in a pre-defined scan order. In practice, we implement spatial autoregressive model using a mask convolutional layer with a specific receptive field, rather than depending on all elements in . We regard the receptive field of the mask convolutional layer as the context . Based on (12) and , we reformulate the in (7) as
| (13) |
Specifically, we utilize a mask convolutional layer with 256 channels to extract the context from . The is shared by of all channels. For RGB images with three channels, we have
| (14) |
We further adopt a channel autoregressive scheme over , , [20] and reformulate as
| (15) | ||||
We model the PMF of with discrete logistic mixture likelihood [20] and propose a sub-network to estimate the corresponding entropy parameters, including mixture weights , means , variances and mixture coefficients . denotes the index of the -th logistic distribution. denotes the channel index of . The network architecture of the entropy model is shown in Fig. 4. We utilize a mixture of logistic distributions. The channel autoregressive scheme over is implemented by updating the means using:
| (16) |
With , and , we have
| (17) |
where denotes the logistic distribution. For discrete , we evaluate as [20]:
| (18) |
where denotes the sigmoid function. and . The probability inference scheme of is sketched in Fig. 5a.
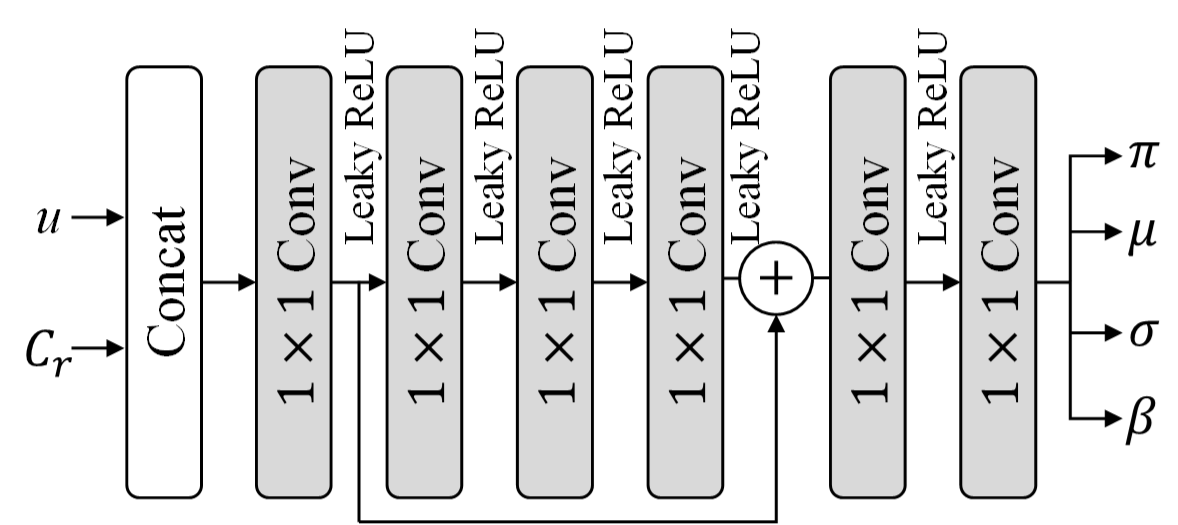
4.1.3 Scalable Quantized Residual Compressor

We finally introduce SQRC to realize scalable near-lossless image compression with variable bound . Though near-lossless image compression given a specific can be realized by optimizing (10), this -specific scheme in Fig. 5b leads to two problems:
-
•
Relaxation problem of residual quantization. Unlike rounding quantization, the bin size of the residual quantization (9) is much larger. Moreover, the original residuals are not uniformly distributed in each bin, and thus cannot be relaxed by adding uniform noise.
-
•
Storage problem of multiple networks. To deploy the near-lossless codec, we have to transmit and store multiple networks for different ’s, which is storage-inefficient.
Instead, we propose a scalable near-lossless image compression scheme, which can circumvent the relaxation of residual quantization and utilize a single network to satisfy variable error bound . Specifically, the scalable compression scheme is based on the learned lossless compression with the DLPR coding framework. We keep the lossy reconstruction fixed and quantize the original residual to with variable ’s by (9). To encode the quantized , we can derive the PMF of from the learned PMF of the original . Given and the learned PMF of original , the PMF of quantized can be computed by the following PMF quantization:
| (19) |
We show an illustrative example in Fig. 6. Together with (14) and (15), we can derive the probability model of , which is optimal given the learned of . The resulting cost of encoding , denoted by , is reduced significantly with the increase of .
However, encoding with results in undecodable bitstreams, since the original residual is unknown to the decoder. cannot be evaluated without and causal context . Instead, we can evaluate PMF using the quantized residual , i.e., we evaluate and derive with (19), leading to for the encoding of . Because of the mismatch between training (with ) and inference (with ) phases, it leads to biased PMF , and . The above probability inference scheme is sketched in Fig. 5c.

SQRC for Bias Correction: Because of the discrepancy between the oracle and the biased , encoding with degrades the compression performance. In order to tackle this problem, we propose SQRC for bias correction to close the gap between the oracle and the biased , while the resulting bitstreams are still decodable. The components of SQRC are illustrated in Fig. 1. The masked convolutional layer in SQRC is shared with that in RC. The conditional entropy model has the same network architecture as the entropy model illustrated in Fig. 4, but replaces the convolutional layers with the conditional convolutional layers [19, 60] illustrated in Fig. 7.
The probability inference scheme with SQRC is sketched in Fig. 5d. For , we still select the entropy model in RC to estimate to encode . For , we select the conditional entropy model in SQRC to estimate conditioned on . We then derive with (19) to encode , where denote the parameters of SQRC. As approximates the oracle better than the biased , the compression performance can be improved. Since evaluating is independent of , the resulting bitstreams are decodable. In experiments, we demonstrate that the proposed scalable near-lossless compression scheme with SQRC in Fig. 5d can outperform both the -specific near-lossless scheme in Fig. 5b and the scalable near-lossless compression scheme without SQRC in Fig. 5c.
4.2 Training Strategy of DLPR coding

4.2.1 Training LIC and RC
The full loss function for jointly optimizing LIC and RC, i.e., DLPR coding for lossless image compression, is
| (20) |
where and are the learned parameters of LIC and RC. Besides rate terms in (11) and in (13), we further introduce a distortion term to minimize the mean square error (MSE) between the raw image and its lossy reconstruction :
| (21) |
As discussed in [25], minimizing MSE loss is equivalent to learn a LIC that fits residual to a factorized Gaussian distribution. However, the discrepancy between the real distribution of and the factorized Gaussian distribution is usually large. Therefore, we utilize a sophisticated discrete logistic mixture likelihood model to encode in our DLPR coding framework.
The in (20) is a “rate-distortion” trade-off parameter between the lossless compression rate and the MSE distortion. When , the loss function (20) is consistent with the theoretical DLPR coding formulation (7), and becomes a latent variable without any constraints. In experiments, we study the effects of ’s on the lossless and near-lossless image compression performance. We set leading to the best lossless image compression, while set leading to robust near-lossless image compression with variable ’s.
4.2.2 Training SQRC
For training SQRC, we generate random and quantize to with (9). Given and the extracted context from quantized , we use the conditional entropy model to estimate conditioned on different ’s, and minimize
| (22) |
where denote the learned parameters of the conditional entropy model. is estimated by the entropy model in RC. can be considered as an approximate KL-divergence or relative entropy [55] between and .
SQRC is trained together with LIC and RC, but minimizing (22) only updates the parameters of the conditional entropy model as shown in Fig. 1. The masked convolutional layer is shared with that in RC, and thus can be updated by minimizing (20). This leads to three advantages: 1) We can achieve the target conditional entropy model to close the gap between training with and inference with ; 2) We can circumvent the aforementioned relaxation problem of residual quantization; 3) We can avoid degrading the estimation of in RC caused by training with randomly generated . Because the entropy model in RC receives the context extracted from the original residual , approximates the true distribution better than . Thus, is the lower bound of on average.
4.3 Acceleration of DLPR Coding
In order to realize practical DLPR coding, the bottleneck is the serialized autoregressive model in RC and SQRC, which severely limits the coding speed on GPUs. We thus propose a novel design of context coding to increase the degree of algorithm parallelization, and further accelerate the entropy coding with adaptive residual interval.
4.3.1 Context Design and Parallelization





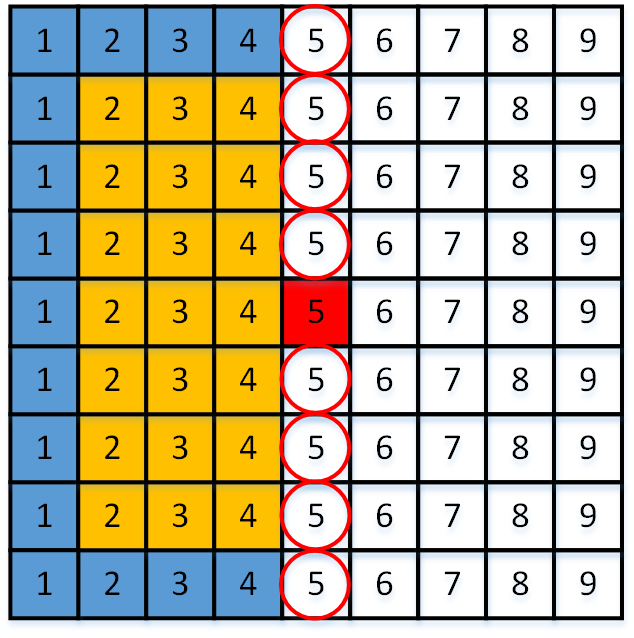
Generally, autoregressive models suffer from serialized decoding and cannot be efficiently implemented on GPUs. Given an image, we need to compute times context model to decode all pixels sequentially. In lossy image compression, checkerboard context model [45] and channel-wise context model [44] were introduced to accelerate the probability inference of latent variables. However, these two context models are too weak for our residual coding and result in significant performance degradation, without the help of transform coding.
To improve the parallelization of residual coding, we first adopt a common operation to split an image into multiple non-overlapping patches and code all patches in parallel, reducing times sequential context computations to times. We next propose a novel design of context coding to improve the algorithm parallelization given the patches and mask convolution, as illustrated in Fig. 8. Assuming that and , we need sequential decoding steps in raster scan order for the commonly used context model shown in Fig. 8a. The number in each pixel denotes the time step at which the pixel is decoded. Since is usually satisfied, the currently decoded pixel only depends on some of the previously decoded pixels. For example, the red pixel is decoded currently and the yellow pixels are its context. The blue pixels are previously decoded pixels but are not included in the context of the red pixel. Hence, there are pixels that can be potentially decoded in parallel by revising the scan order. By using degree parallel scan, the pixels with the same number can be decoded simultaneously, as shown in Fig. 8b. The number of decoding steps is reduced from to . In this case, we use parallel scan, leading to sequential decoding steps. The similar scan order was also used in [61]. Moreover, we can remove one context pixel in the upper right of the currently decoded pixel. The newly designed context model leads to degree parallel scan and reduces decoding steps to . As shown in Fig. 8c, we use parallel scan and decoding steps with this context model. When more upper-right context pixels are removed, the coding parallelization can be further improved while the compression performance is gradually compromised on. As shown in Fig. 8d, the context model leads to degree parallel scan and decoding steps, i.e., parallel scan and decoding steps in our example. When parallel scan is reached, this special case is the zig-zag scan [43] and we need decoding steps, as shown in Fig. 8e. Finally, the fastest case is shown in Fig. 8f. We can use parallel scan and only decoding steps.
In summary, the proposed design of context coding demonstrates that: given image patches and mask convolution with , we can design a series of context models leading to parallel decoding steps, by gradually adjusting the context pixels. The corresponding scan angles are , respectively. In experiments, we set , and select the context model shown in Fig. 8d. The enjoys almost the same compression performance as in Fig. 8a and Fig. 8b, but needs much fewer coding steps.
4.3.2 Adaptive Residual Interval
Since the pixels of both a raw image and its lossy reconstruction are in the interval , the element of the corresponding residual is in the interval . To entropy coding each , we need to compute and utilize PMF with elements, which is relatively large and slows down the entropy coding process.
In practice, the theoretical interval of can hardly be filled up. Hence, we can compute and record and of each image, and reduce the domain of PMF to the adaptive interval with elements. The overheads of recording the and can be amortized and ignored. For near-lossless image compression with , we can similarly compute and record the quantized and of each image, and the domain of the quantized PMF can be further reduced to the adaptive interval , i.e., elements in total. The reduction of residual intervals can significantly accelerate the entropy coding on average.
5 Experiments
5.1 Experimental Settings
We train the DLPR coding system on DIV2K high resolution training dataset [62] consisting of 800 2K resolution RGB images. Although DIV2K is originally built for image super-resolution task, it contains large number of high-quality images that is suitable for training our codec. During training, the 2K images are first cropped into non-overlapped patches with the size of . We then flip these patches horizontally and vertically with a random factor , and further randomly crop the flipped patches to the size of . We optimize the proposed network for epochs using Adam [63] with minibatches of size . The learning rate is initially set to and is decayed by at the epoch .
We evaluate the trained DLPR coding system on six image datasets:
- •
-
•
DIV2K. DIV2K high resolution validation dataset [62] consists of 100 2K color images sharing the same domain with the DIV2K high resolution training dataset.
-
•
CLIC.p. CLIC professional validation dataset111https://www.compression.cc/challenge/ consists of 41 color images taken by professional photographers. Most images in CLIC.p are in 2K resolution but some of them are of small sizes.
-
•
CLIC.m. CLIC mobile validation dataset1 consists of 61 2K resolution color images taken with mobile phones. Most images in CLIC.m are in 2K resolution but some of them are of small sizes.
-
•
Kodak. Kodak dataset [66] consists of 24 uncompressed color images, widely used in evaluating lossy image compression methods.
-
•
Histo24. Besides natural images, we build a Histo24 dataset consisting of 24 uncompressed histological images, in order to evaluate our codec on images of different modality. These histological images are randomly cropped from high resolution ANHIR dataset [67], which is originally used for histological image registration task.
The DLPR coding system is implemented with Pytorch. We train the DLPR coding system on NVIDIA V100 GPU, while evaluate the compression performance and running time on Intel CPU i9-10900K, 64G RAM and NVIDIA RTX3090 GPU. We use torchac [10], an arithmetic coding tool in Pytorch, for entropy coding.
5.2 Lossless Results of DLPR coding
| Codec | ImageNet64 | DIV2K | CLIC.p | CLIC.m | Kodak | Histo24 |
| PNG | 5.42 | 4.23 | 3.93 | 3.93 | 4.35 | 3.79 |
| JPEG-LS [2] | 4.45 | 2.99 | 2.82 | 2.53 | 3.16 | 3.39 |
| CALIC [3] | 4.71 | 3.07 | 2.87 | 2.59 | 3.18 | 3.48 |
| JPEG2000 [68] | 4.74 | 3.12 | 2.93 | 2.71 | 3.19 | 3.36 |
| WebP [52] | 4.36 | 3.11 | 2.90 | 2.73 | 3.18 | 3.29 |
| BPG [51] | 4.42 | 3.28 | 3.08 | 2.84 | 3.38 | 3.82 |
| FLIF [4] | 4.25 | 2.91 | 2.72 | 2.48 | 2.90 | 3.23 |
| JPEG-XL [5] | 4.94 | 2.79 | 2.63 | 2.36 | 2.87 | 3.07 |
| L3C [10] | 4.48 | 3.09 | 2.94 | 2.64 | 3.26 | 3.53 |
| RC [11] | 3.08 | 2.93 | 2.54 | |||
| Bit-Swap [12] | 5.06 | |||||
| HiLLoC [13] | 3.90 | |||||
| IDF [14] | 3.90 | |||||
| IDF++ [50] | 3.81 | |||||
| LBB [15] | 3.70 | |||||
| iVPF [16] | 3.75 | 2.68 | 2.54 | 2.39 | ||
| iFlow [17] | 3.65 | 2.57 | 2.44 | 2.26 | ||
| DLPR (Ours) | 3.69 | 2.55 | 2.38 | 2.16 | 2.86 | 2.96 |
| Codec | ImageNet64 | DIV2K | CLIC.p | CLIC.m | Kodak | Histo24 | |
| WebP nll[52] | 1 | 3.61 | 2.45 | 2.26 | 2.11 | 2.41 | 2.31 |
| 2 | 3.11 | 2.04 | 1.89 | 1.85 | 2.01 | 1.76 | |
| 4 | 2.70 | 1.83 | 1.73 | 1.75 | 1.82 | 1.73 | |
| JPEG-LS[2] | 1 | 4.01 | 2.62 | 2.34 | 2.44 | 2.90 | 1.99 |
| 2 | 3.25 | 2.07 | 1.80 | 1.89 | 2.30 | 1.58 | |
| 4 | 2.49 | 1.53 | 1.28 | 1.35 | 1.68 | 1.24 | |
| CALIC[8] | 1 | 3.69 | 2.45 | 2.18 | 2.28 | 2.75 | 1.78 |
| 2 | 2.94 | 1.88 | 1.62 | 1.70 | 2.14 | 1.28 | |
| 4 | 2.41 | 1.31 | 1.07 | 1.13 | 1.51 | 0.84 | |
| DLPR (Ours) | 1 | 2.59 | 1.69 | 1.56 | 1.50 | 1.81 | 1.71 |
| 2 | 2.06 | 1.26 | 1.13 | 1.09 | 1.37 | 1.23 | |
| 4 | 1.55 | 0.84 | 0.69 | 0.67 | 0.90 | 0.65 |
We evaluate the lossless image compression performance of the proposed DLPR coding system, measured by bit per subpixel (bpsp). Each RGB pixel has three subpixels. We compare with eight traditional lossless image codecs including PNG, JPEG-LS [2], CALIC [3], JPEG2000 [68], WebP [52], BPG [51], FLIF [4] and JPEG-XL [5], and nine recent learning-based lossless image compression methods including L3C [10], RC [11], Bit-Swap [12], HiLLoC [13], IDF [14], IDF++ [50], LBB [15], iVPF [16] and iFlow [17]. For Bit-Swap, HiLLoC, IDF, IDF++ and LBB, their codes can hardly be applied on practical full resolution image compression tasks, and thus only be evaluated on ImageNet64 dataset. For RC, iVPF and iFlow, we report the compression performance published by their authors, because their codes are either difficult to be generalized to arbitrary datasets or unavailable. We set in (20) leading to the best lossless image compression performance.
As reported in Table I, the proposed DLPR coding system achieves the best lossless compression performance on DIV2K validation dataset, which shares the same domain with the training dataset. The DLPR coding system also achieves the best compression performance on CLIC.p, CLIC.m, Kodak and Histo24 datasets, and achieves the second best compression performance on ImageNet64 validation dataset. Though iFlow outperforms ours on ImageNet64 validation dataset, it is trained on ImageNet64 training dataset sharing the same domain while ours is trained on DIV2K. The above results demonstrate that the DLPR coding system achieves the state-of-the-art lossless image compression performance and can be effectively generalized to images of various domains and modalities.
5.3 Near-lossless Results of DLPR coding










We next evaluate the near-lossless image compression performance of the proposed DLPR coding system. We set leading to the robust near-lossless image compression results with variable ’s. We compare with near-lossless WebP (WebP nll) [52], near-lossless JPEG-LS [2] and near-lossless CALIC [8], as reported in Table II. Near-lossless WebP adjusts pixel values to error bound and compresses the pre-processed images losslessly. Near-lossless JPEG-LS and CALIC adopt predictive coding schemes, and encode the residuals quantized by (9). These three codecs handcraft the pre-processor, predictors and probability estimators, which are not efficient enough for variable ’s. More efficiently, our DLPR coding system is based on jointly trained LIC, RC and SQRC. We employ (9) to realize variable error bound ’s and the probability distributions of the quantized residuals are derived from the learned SQRC. Therefore, our DLPR coding system outperforms near-lossless WebP, JPEG-LS and CALIC by a wide margin.
Besides existing near-lossless image codecs, we also compare our near-lossless DLPR coding system with six traditional lossy image codecs, i.e., JPEG [69], JPEG2000 [68], WebP [52], BPG [51], Lossy FLIF [4] and VVC [70], and three representative learned lossy image compression methods, i.e., Ballé[MSE] [25], Minnen[MSE] [40] and Cheng[MSE] [33], as shown in Fig. 9. Because recent learned lossy image compression methods are all trained at relatively low bit rates ( 2 bpp 0.67 bpsp on Kodak), we re-implement Ballé[MSE], Minnen[MSE] and Cheng[MSE] at high bit-rates ( 0.8 bpsp on Kodak). Though Cheng[MSE] outperforms Ballé[MSE] and Minnen[MSE] at low bit rates, it performs worse than Ballé[MSE] and Minnen[MSE] at high bit rates because the sophisticated analysis and synthesis transforms hinder it from reaching very high-quality reconstructions. In terms of the rate-distortion performance measured by error, our DLPR coding consistently yields the best results among all codecs. Besides error, we also compare the rate-distortion performance of all codecs measured by PSNR. Our DLPR coding can achieve competitive performance at bit rates higher than 0.8 bpsp, even though PSNRs of near-lossless reconstructions are not our optimization objective.
5.4 Runtime of DLPR coding
We evaluate the runtime of our DLPR coding on images of three different sizes. We compare with four representative traditional lossless image codecs including JPEG-LS [2], BPG [51], FLIF [4] and JPEG-XL [5]. We also compare with the practical learned lossless image compression method L3C [10] and the learned lossy image compression method Minnen[MSE] [40] with a serial autoregressive model. Note that the reported runtime includes both inference time and entropy coding time.
As reported in Table III, our lossless DLPR coding is almost as fast as FLIF with respect to encoding speed, much faster than BPG, JPEG-XL, L3C and lossy Minnen[MSE]. Although our lossless DLPR coding is slower than traditional codecs with respect to decoding speed, it is still practical for 2K resolution images and much faster than the learned L3C and lossy Minnen[MSE]. When , the near-lossless DLPR coding can be even faster because the entropy coding time is reduced by the adaptive residual interval scheme. Based on the above results, we demonstrates the practicability of the DLPR coding system and its great potential to be employed in real lossless and near-lossless image compression tasks.
| Codec | 768512 | 996756 | 20401356 |
| JPEG-LS [2] | 0.12/0.12 | 0.23/0.22 | 0.83/0.80 |
| BPG [51] | 2.38/0.13 | 4.46/0.27 | 16.52/0.98 |
| FLIF [4] | 0.90/0.16 | 1.84/0.35 | 7.50/1.35 |
| JPEG-XL [5] | 0.73/0.08 | 12.48/0.14 | 40.96/0.42 |
| L3C [10] | 8.17/7.89 | 15.25/14.55 | OOM* |
| Minnen[MSE] [40] | 2.55/5.18 | 5.13/10.36 | 18.71/37.97 |
| DLPR lossless | 1.26/1.80 | 2.28/3.24 | 8.20/11.91 |
| DLPR () | 0.79/1.24 | 0.98/1.86 | 2.09/5.56 |
| DLPR () | 0.75/1.20 | 0.92/1.78 | 1.87/5.24 |
| DLPR () | 0.73/1.18 | 0.89/1.74 | 1.68/5.03 |
5.5 Ablation Study
| Conv. [25] | A/S Blks. | Attn. [33] | Swin-Attn. | ImageNet64 | DIV2K | CLIC.m |
| 3.75 (+0.06) | 2.60 (+0.05) | 2.20 (+0.04) | ||||
| 3.71 (+0.02) | 2.57 (+0.02) | 2.18 (+0.02) | ||||
| 3.71 (+0.02) | 2.56 (+0.01) | 2.17 (+0.01) | ||||
| 3.69 | 2.55 | 2.16 |
| ImageNet64 | DIV2K | CLIC.m | ||
| 4.03 (+0.34) | 2.91 (+0.36) | 2.47 (+0.31) | ||
| 3.78 (+0.09) | 2.64 (+0.09) | 2.24 (+0.08) | ||
| 3.69 | 2.55 | 2.16 |
Network architectures of LIC and RC. In Table IV, we study the relationships between different network architectures of LIC and lossless compression performance. Compared with the convolutional layers used in [25] and the attention blocks used in [33], the proposed analysis/synthesis blocks and Swin attention blocks can effectively improve the lossless image compression performance. These results also demonstrate that LIC plays an important role in our DLPR coding system.
In Table V, we study the relationships between different network architectures of RC and lossless image compression performance. Both the feature and context can effectively improve the lossless image compression performance, which demonstrates the effectiveness of the proposed network architecture of RC. In Table. VI, we further compare the lossless and near-lossless image compression performance of the logistic mixture model, Gaussian single model and Gaussian mixture model for RC and SQRC. The logistic mixture model and Gaussian mixture model achieve almost identical performance, outperforming the Gaussian single model for complex real distributions of and . We utilize the logistic mixture model because its cumulative distribution function (CDF) is a sigmoid function, making it easier to compute the probability of each discrete residual using (18). In contrast, the CDF of the Gaussian distribution is the more complex Gauss error function.
| model | ImageNet64 | DIV2K | CLIC.m |
| lmm.(lossless) | 3.69 | 2.55 | 2.16 |
| gsm. (lossless) | 3.78 (+0.09) | 2.57 (+0.02) | 2.22 (+0.06) |
| gmm.(lossless) | 3.70 (+0.01) | 2.55 (=) | 2.17 (+0.01) |
| lmm.() | 2.59 | 1.69 | 1.50 |
| gsm. () | 2.61 (+0.02) | 1.72 (+0.03) | 1.52 (+0.02) |
| gmm.() | 2.59 (=) | 1.68 (0.01) | 1.50 (=) |
-specific vs. scalable. As aforementioned in Sec. 4.1.3, -specific near-lossless image compression scheme leads to the challenging relaxation problem of residual quantization. In order to compare with our scalable near-lossless image compression scheme, we realize the -specific models by relaxing residual quantization with straight-through (copying gradients from quantized to original ). As shown in Fig. 12, the resulting -specific models perform worse than our scalable model in most cases, due to the gradient bias during training.

In Fig. 13, we show lossless to near-lossless image compression performance of each images compressed by our scalable model with on Kodak dataset. , on average, accounts for about 16% of at . With the increase of , the bit-rate of the quantized residual is significantly reduced. Especially the near-lossless mode saves about 39% bit rates compared with the lossless mode.

SQRC for bias correction. In Fig. 14, we demonstrate the efficacy of SQRC for bias correction. Because of the discrepancy between the oracle and the biased , encoding with (without SQRC) degrades the compression performance. Instead, we encode with (with SQRC) resulting in lower bit rates. With the increase of , the PMF of is quantized by larger bins and becomes coarser. Thus, the compression performance with SQRC approaches the oracle. However, the gap between the compression performance without SQRC and the oracle remains large, as the discrepancy between and is also magnified with the increasing . Note that the compression performance of our DLPR coding without SQRC is still better than near-lossless WebP, JPEG-LS and CALIC.

Discussion on different ’s. The ’s in (20) adapts the lossless compression rate of the raw image and the distortion of the lossy reconstruction . In Table VII, we evaluate the effects of different ’s on lossless image compression performance on Kodak dataset. With the increase of , both the rate and the PSNR of become higher. While the rate of residual decreases at the same time, the decrease of is smaller than the increase of , leading to the degradation of lossless image compression performance. leads to the best lossless compression performance. We visualize lossy reconstruction ’s, residual ’s and feature ’s resulting from different ’s in Fig. 15. Interestingly, DLPR coding with learns to set and . The LIC becomes a special feature compressor extracting feature for lossless image compression (proved effective in Table V). This special case of DLPR coding with is similar to PixelVAE [71].
In Fig. 16, we further study the effects of different ’s on the near-lossless image compression performance. Though leads to the best lossless compression performance, it is unsuitable for near-lossless compression since the residual quantization (9) is adopted on the . For near-lossless compression, we set . Compared with and , the quantized residual of results in much lower entropy and smaller context bias, since most elements of and are zeros or close to zeros. The reduction of of compensates for larger with the increase of . Compared with , enjoys similar but lower . Therefore, achieves the most robust near-lossless image compression performance only slightly worse than and at .
| Total Rate | (PSNR) | |||
| 0 | 2.86 | 0.04 | 2.82 | 6.78 |
| 0.001 | 2.94 | 0.13 | 2.81 | 29.80 |
| 0.03 | 2.99 | 0.49 | 2.50 | 38.77 |
| 0.06 | 3.02 | 0.59 | 2.43 | 39.74 |



| Context () | ImageNet64 | DIV2K | CLIC.p | CLIC.m | Kodak | Histo24 |
| (Fig. 8a & 8b) | 3.69 | 2.55 | 2.37 | 2.15 | 2.86 | 2.96 |
| (Fig. 8c) | 3.70 (+0.01) | 2.56 (+0.01) | 2.39 (+0.02) | 2.16 (+0.01) | 2.87 (+0.01) | 2.97 (+0.01) |
| (Fig. 8d, Selected) | 3.69 (=) | 2.55 (=) | 2.38 (+0.01) | 2.16 (+0.01) | 2.86 (=) | 2.96 (=) |
| (Fig. 8e) | 3.71 (+0.02) | 2.59 (+0.04) | 2.40 (+0.03) | 2.19 (+0.04) | 2.95 (+0.09) | 3.01 (+0.05) |
| (Fig. 8f) | 3.88 (+0.19) | 2.74 (+0.19) | 2.56 (+0.19) | 2.34 (+0.19) | 2.95 (+0.09) | 3.24 (+0.28) |
| checkerboard | 3.86 (+0.17) | 2.73 (+0.18) | 2.54 (+0.17) | 2.33 (+0.18) | 2.95 (+0.09) | 3.19 (+0.23) |
| channel-only | 4.03 (+0.34) | 2.91 (+0.36) | 2.70 (+0.33) | 2.47 (+0.32) | 3.09 (+0.23) | 3.48 (+0.52) |
| w/o context | 4.47 (+0.78) | 3.37 (+0.82) | 3.19 (+0.82) | 3.14 (+0.99) | 3.61 (+0.75) | 3.45 (+0.49) |
| Context (77) | AdaRI. | Enc./Dec. Time |
| (Fig. 8a, Serial) | 12.46/23.24 | |
| (Fig. 8a, Serial) | 11.93 (-0.53)/22.74 (-0.50) | |
| (Fig. 8b) | 1.47 (-10.99)/2.30 (-20.94) | |
| (Fig. 8d, Selected) | 1.24 (-11.22)/1.75 (-21.49) |
Rate-distortion performance of LIC. We conduct an ablation study to show the rate-distortion performance of our LIC in DLPR coding framework in Fig. 17. Besides lossy reconstruction , our LIC also generates feature of residual and is jointly trained with RC. Therefore, the rate of our LIC not only carries the information from lossy reconstruction but also carries part of the information from residual . As a result, the rate-distortion performance of our LIC in DLPR coding framework is between Ballé[MSE] [25] and JPEG2000 on Kodak dataset.
Context design and adaptive residual interval. In Table VIII, we study the lossless image compression performance resulting from the designed context models in Fig. 8. The context model is set as the anchor. Based on the experimental results, the selected context model removing two upper-right context pixels from achieves almost the same lossless image compression performance as , even slightly better than . At the same time, reduces about 40% parallel coding steps from to , compared with . Though the context model (zigzag) and can be faster, the corresponding lossless compression performance drops significantly. Besides, we also show the compression performance resulting from checkerboard context model [45]. Without the help of transform coding, the compression performance of checkerboard context model is only slightly better than context and worse than context in our DLPR coding framework. We further switch off spatial context models and show the compression performance resulting from only channel-wise autoregressive scheme in (15) and (16). The channel-only setting cannot reduce spatial redundancies among residuals, resulting in worse compression performance. We also evaluate the compression performance without both spatial and channel context models. Compared with the channel-only setting, the w/o context setting ignoring channel redundancies results in the worst compression performance, except on Histo24. This is because the color properties of stained histological images differ from natural images, and the channel autoregressive model trained on DIV2K does not generalize as well on Histo24 as on other datasets. In Table IX, we finally shows that the designed context models and the adaptive residual interval scheme can effectively reduce the runtime of DLPR coding in practice.
6 Conclusion
In this paper, we propose a unified DLPR coding framework for both lossless and near-lossless image compression. The DLPR coding framework consists of a lossy image compressor, a residual compressor and a scalable quantized residual compressor, which is formulated in terms of VAEs and is solved with end-to-end training. The DLPR coding framework supports scalable near-lossless image compression with variable -constraint ’s in a single network, instead of multiple networks for different ’s. We further propose a novel design of context coding and an adaptive residual interval scheme to significantly accelerate the coding process. Extensive experiments demonstrate that the DLPR coding system achieves not only the state-of-the-art compression performance, but also competitive coding speed for practical full resolution image compression tasks.
References
- [1] C. E. Shannon, “A mathematical theory of communication,” The Bell system technical journal, vol. 27, no. 3, pp. 379–423, 1948.
- [2] M. J. Weinberger, G. Seroussi, and G. Sapiro, “The loco-i lossless image compression algorithm: Principles and standardization into jpeg-ls,” IEEE Transactions on Image Processing, vol. 9, no. 8, pp. 1309–1324, 2000.
- [3] X. Wu and N. Memon, “Context-based, adaptive, lossless image coding,” IEEE Transactions on Communications, vol. 45, no. 4, pp. 437–444, 1997.
- [4] J. Sneyers and P. Wuille, “Flif: Free lossless image format based on maniac compression,” in IEEE International Conference on Image Processing. IEEE, 2016, pp. 66–70.
- [5] J. Alakuijala, R. Van Asseldonk, S. Boukortt, M. Bruse, I.-M. Comsa, M. Firsching, T. Fischbacher, E. Kliuchnikov, S. Gomez, R. Obryk et al., “Jpeg xl next-generation image compression architecture and coding tools,” in Applications of Digital Image Processing XLII, vol. 11137. SPIE, 2019, pp. 112–124.
- [6] R. Ansari, N. D. Memon, and E. Ceran, “Near-lossless image compression techniques,” Journal of Electronic Imaging, vol. 7, no. 3, pp. 486 – 494, 1998.
- [7] L. Ke and M. W. Marcellin, “Near-lossless image compression: minimum-entropy, constrained-error dpcm,” IEEE Transactions on Image Processing, vol. 7, no. 2, pp. 225–228, 1998.
- [8] W. Xiaolin and P. Bao, “ constrained high-fidelity image compression via adaptive context modeling,” IEEE Transactions on Image Processing, vol. 9, no. 4, pp. 536–542, 2000.
- [9] Y. Hu, W. Yang, Z. Ma, and J. Liu, “Learning end-to-end lossy image compression: A benchmark,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 8, pp. 4194–4211, 2022.
- [10] F. Mentzer, E. Agustsson, M. Tschannen, R. Timofte, and L. V. Gool, “Practical full resolution learned lossless image compression,” in IEEE Conference on Computer Vision and Pattern Recogition, 2019, pp. 10 621–10 630.
- [11] F. Mentzer, L. Van Gool, and M. Tschannen, “Learning better lossless compression using lossy compression,” in IEEE Conference on Computer Vision and Pattern Recogition, 2020.
- [12] F. H. Kingma, P. Abbeel, and J. Ho, “Bit-swap: Recursive bits-back coding for lossless compression with hierarchical latent variables,” in International Conference on Machine Learning, 2019.
- [13] J. Townsend, T. Bird, J. Kunze, and D. Barber, “Hilloc: Lossless image compression with hierarchical latent variable models,” in International Conference on Learning Representations, 2020.
- [14] E. Hoogeboom, J. Peters, R. van den Berg, and M. Welling, “Integer discrete flows and lossless compression,” in Advances in Neural Information Processing Systems, 2019, pp. 12 134–12 144.
- [15] J. Ho, E. Lohn, and P. Abbeel, “Compression with flows via local bits-back coding,” in Advances in Neural Information Processing Systems, vol. 32, 2019.
- [16] S. Zhang, C. Zhang, N. Kang, and Z. Li, “ivpf: Numerical invertible volume preserving flow for efficient lossless compression,” in IEEE Conference on Computer Vision and Pattern Recogition, 2021, pp. 620–629.
- [17] S. Zhang, N. Kang, T. Ryder, and Z. Li, “iflow: Numerically invertible flows for efficient lossless compression via a uniform coder,” in Advances in Neural Information Processing Systems, vol. 34, 2021.
- [18] A. v. d. Oord, N. Kalchbrenner, and K. Kavukcuoglu, “Pixel recurrent neural networks,” in International Conference on Machine Learning. JMLR.org, 2016, pp. 1747–1756.
- [19] A. van den Oord, N. Kalchbrenner, L. Espeholt, O. Vinyals, and A. Graves, “Conditional image generation with pixelcnn decoders,” in Advances in Neural Information Processing Systems, 2016, pp. 4790–4798.
- [20] T. Salimans, A. Karpathy, X. Chen, and D. P. Kingma, “Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications,” in International Conference on Learning Representations, 2017.
- [21] I. Kobyzev, S. J. Prince, and M. A. Brubaker, “Normalizing flows: An introduction and review of current methods,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 11, pp. 3964–3979, 2020.
- [22] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in International Conference on Learning Representations, 2014.
- [23] Y. Bai, X. Liu, W. Zuo, Y. Wang, and X. Ji, “Learning scalable -constrained near-lossless image compression via joint lossy image and residual compression,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, June 2021, pp. 11 946–11 955.
- [24] J. Ballé, V. Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,” in International Conference on Learning Representations, 2017.
- [25] J. Ballé, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” in International Conference on Learning Representations, 2018.
- [26] J. Townsend, T. Bird, and D. Barber, “Practical lossless compression with latent variables using bits back coding,” in International Conference on Learning Representations, 2019.
- [27] G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, and R. Sukthankar, “Variable rate image compression with recurrent neural networks,” in International Conference on Learning Representations, 2016.
- [28] G. Toderici, D. Vincent, N. Johnston, S. Jin Hwang, D. Minnen, J. Shor, and M. Covell, “Full resolution image compression with recurrent neural networks,” in IEEE Conference on Computer Vision and Pattern Recogition, 2017, pp. 5306–5314.
- [29] N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, S. J. Hwang, J. Shor, and G. Toderici, “Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks,” in IEEE Conference on Computer Vision and Pattern Recogition, 2018, pp. 4385–4393.
- [30] L. Theis, W. Shi, A. Cunningham, and F. Huszár, “Lossy image compression with compressive autoencoders,” in International Conference on Learning Representations, 2017.
- [31] V. K. Goyal, “Theoretical foundations of transform coding,” IEEE Signal Processing Magazine, vol. 18, no. 5, pp. 9–21, 2001.
- [32] Z. Wang, E. P. Simoncelli, and A. C. Bovik, “Multiscale structural similarity for image quality assessment,” in The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, vol. 2. Ieee, 2003, pp. 1398–1402.
- [33] Z. Cheng, H. Sun, M. Takeuchi, and J. Katto, “Learned image compression with discretized gaussian mixture likelihoods and attention modules,” in IEEE Conference on Computer Vision and Pattern Recogition, 2020, pp. 7939–7948.
- [34] H. Ma, D. Liu, N. Yan, H. Li, and F. Wu, “End-to-end optimized versatile image compression with wavelet-like transform,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 3, pp. 1247–1263, 2022.
- [35] Y. Zhu, Y. Yang, and T. Cohen, “Transformer-based transform coding,” in International Conference on Learning Representations, 2022.
- [36] M. Li, W. Zuo, S. Gu, J. You, and D. Zhang, “Learning content-weighted deep image compression,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [37] F. Mentzer, E. Agustsson, M. Tschannen, R. Timofte, and L. V. Gool, “Conditional probability models for deep image compression,” in IEEE Conference on Computer Vision and Pattern Recogition, 2018, pp. 4394–4402.
- [38] E. Agustsson, F. Mentzer, M. Tschannen, L. Cavigelli, R. Timofte, L. Benini, and L. V. Gool, “Soft-to-hard vector quantization for end-to-end learning compressible representations,” in Advances in Neural Information Processing Systems, vol. 30, 2017.
- [39] Y. Hu, W. Yang, and J. Liu, “Coarse-to-fine hyper-prior modeling for learned image compression,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 11 013–11 020.
- [40] D. Minnen, J. Ballé, and G. D. Toderici, “Joint autoregressive and hierarchical priors for learned image compression,” in Advances in Neural Information Processing Systems, 2018, pp. 10 771–10 780.
- [41] Y. Qian, Z. Tan, X. Sun, M. Lin, D. Li, Z. Sun, H. Li, and R. Jin, “Learning accurate entropy model with global reference for image compression,” in International Conference on Learning Representations, 2021.
- [42] Y. Qian, M. Lin, X. Sun, Z. Tan, and R. Jin, “Entroformer: A transformer-based entropy model for learned image compression,” in International Conference on Learning Representations, 2022.
- [43] M. Li, K. Ma, J. You, D. Zhang, and W. Zuo, “Efficient and effective context-based convolutional entropy modeling for image compression,” IEEE Transactions on Image Processing, vol. 29, pp. 5900–5911, 2020.
- [44] D. Minnen and S. Singh, “Channel-wise autoregressive entropy models for learned image compression,” in IEEE International Conference on Image Processing. IEEE, 2020, pp. 3339–3343.
- [45] D. He, Y. Zheng, B. Sun, Y. Wang, and H. Qin, “Checkerboard context model for efficient learned image compression,” in IEEE Conference on Computer Vision and Pattern Recogition, 2021.
- [46] I. H. Witten, R. M. Neal, and J. G. Cleary, “Arithmetic coding for data compression,” Communications of the ACM, vol. 30, no. 6, pp. 520–540, 1987.
- [47] J. Duda, “Asymmetric numeral systems,” arXiv preprint arXiv:0902.0271, 2009.
- [48] S. Reed, A. Oord, N. Kalchbrenner, S. G. Colmenarejo, Z. Wang, Y. Chen, D. Belov, and N. Freitas, “Parallel multiscale autoregressive density estimation,” in International Conference on Machine Learning. PMLR, 2017, pp. 2912–2921.
- [49] M. Zhang, A. Zhang, and S. McDonagh, “On the out-of-distribution generalization of probabilistic image modelling,” in Advances in Neural Information Processing Systems, vol. 34, 2021.
- [50] R. v. d. Berg, A. A. Gritsenko, M. Dehghani, C. K. Sønderby, and T. Salimans, “Idf++: Analyzing and improving integer discrete flows for lossless compression,” in International Conference on Learning Representations, 2021.
- [51] F. Bellard, “BPG image format,” https://bellard.org/bpg/.
-
[52]
Google, “Webp image format,”
https://developers.google.com/
speed/webp/. - [53] K. Chen and T. V. Ramabadran, “Near-lossless compression of medical images through entropy-coded dpcm,” IEEE Transactions on Medical Imaging, vol. 13, no. 3, pp. 538–548, 1994.
- [54] X. Zhang and X. Wu, “Ultra high fidelity deep image decompression with -constrained compression,” IEEE Transactions on Image Processing, vol. 30, pp. 963–975, 2021.
- [55] T. M. Cover and J. A. Thomas, Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing). USA: Wiley-Interscience, 2006.
- [56] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in IEEE Conference on Computer Vision and Pattern Recogition, 2016, pp. 770–778.
- [57] Y. Zhang, K. Li, K. Li, B. Zhong, and Y. Fu, “Residual non-local attention networks for image restoration,” in International Conference on Learning Representations, 2019.
- [58] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in International Conference on Computer Vision, 2021, pp. 10 012–10 022.
- [59] J. Ballé, V. Laparra, and E. P. Simoncelli, “Density modeling of images using a generalized normalization transformation,” in International Conference on Learning Representations, 2016.
- [60] Y. Choi, M. El-Khamy, and J. Lee, “Variable rate deep image compression with a conditional autoencoder,” in International Conference on Computer Vision, 2019, pp. 3146–3154.
- [61] M. Zhang, J. Townsend, N. Kang, and D. Barber, “Parallel neural local lossless compression,” arXiv preprint arXiv:2201.05213, 2022.
- [62] E. Agustsson and R. Timofte, “NTIRE 2017 challenge on single image super-resolution: dataset and study,” in IEEE Conference on Computer Vision and Pattern Recogition Workshop, July 2017.
- [63] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in International Conference on Learning Representations, 2015.
- [64] P. Chrabaszcz, I. Loshchilov, and F. Hutter, “A downsampled variant of imagenet as an alternative to the cifar datasets,” arXiv preprint arXiv:1707.08819, 2017.
- [65] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in IEEE Conference on Computer Vision and Pattern Recogition. Ieee, 2009, pp. 248–255.
- [66] E. Kodak, “Kodak lossless true color image suite (photocd pcd0992),” http://r0k.us/graphics/kodak/, 1993.
- [67] J. Borovec, J. Kybic, I. Arganda-Carreras, D. V. Sorokin, G. Bueno, A. V. Khvostikov, S. Bakas, I. Eric, C. Chang, S. Heldmann et al., “Anhir: automatic non-rigid histological image registration challenge,” IEEE Transactions on Medical Imaging, vol. 39, no. 10, pp. 3042–3052, 2020.
- [68] A. Skodras, C. Christopoulos, and T. Ebrahimi, “The jpeg 2000 still image compression standard,” IEEE Signal Processing Magazine, vol. 18, no. 5, pp. 36–58, 2001.
- [69] G. K. Wallace, “The jpeg still picture compression standard,” IEEE Transactions on Consumer Electronics, vol. 38, no. 1, pp. xviii–xxxiv, 1992.
- [70] J.-R. Ohm and G. J. Sullivan, “Versatile video coding–towards the next generation of video compression,” in Picture Coding Symposium, 2018.
- [71] I. Gulrajani, K. Kumar, F. Ahmed, A. A. Taiga, F. Visin, D. Vazquez, and A. Courville, “Pixelvae: A latent variable model for natural images,” in International Conference on Learning Representations, 2017.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ed9bf348-377a-4d95-ac90-836ad94a0144/Yuanchao_Bai.jpg) |
Yuanchao Bai (Member, IEEE) received the B.S. degree in software engineering from Dalian University of Technology, Liaoning, China, in 2013. He received the Ph.D. degree in computer science from Peking University, Beijing, China, in 2020. He was a postdoctoral fellow in Peng Cheng Laboratory, Shenzhen, China, from 2020 to 2022. He is currently an assistant professor with the School of Computer Science and Technology, Harbin Institute of Technology, Harbin, China. His research interests include image/video compression and processing, deep unsupervised learning, and graph signal processing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ed9bf348-377a-4d95-ac90-836ad94a0144/Xianming.jpg) |
Xianming Liu (Member, IEEE) is a Professor with the School of Computer Science and Technology, Harbin Institute of Technology (HIT), Harbin, China. He received the B.S., M.S., and Ph.D degrees in computer science from HIT, in 2006, 2008 and 2012, respectively. In 2011, he spent half a year at the Department of Electrical and Computer Engineering, McMaster University, Canada, as a visiting student, where he then worked as a post-doctoral fellow from December 2012 to December 2013. He worked as a project researcher at National Institute of Informatics (NII), Tokyo, Japan, from 2014 to 2017. He has published over 60 international conference and journal publications, including top IEEE journals, such as T-IP, T-CSVT, T-IFS, T-MM, T-GRS; and top conferences, such as CVPR, IJCAI and DCC. He is the receipt of IEEE ICME 2016 Best Student Paper Award. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ed9bf348-377a-4d95-ac90-836ad94a0144/KaiWang.jpg) |
Kai Wang received the B.S. degree in software engineering from Harbin Engineering University, Harbin, China, in 2020 and received the M.S. degree of electronic information in software engineering from Harbin Institute of Technology, Harbin, China, in 2022. He is currently pursuing the docter degree in electronic information in Harbin Institute of Technology, Harbin, China. His research interests include image/video compression and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ed9bf348-377a-4d95-ac90-836ad94a0144/Xiangyang_Ji.jpg) |
Xiangyang Ji (Member, IEEE) received the B.S. degree in materials science and the M.S. degree in computer science from the Harbin Institute of Technology, Harbin, China, in 1999 and 2001, respectively, and the Ph.D. degree in computer science from the Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China. He joined Tsinghua University, Beijing, in 2008, where he is currently a Professor with the Department of Automation, School of Information Science and Technology. He has authored over 100 referred conference and journal papers. His current research interests include signal processing, image/video compressing, and intelligent imaging. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ed9bf348-377a-4d95-ac90-836ad94a0144/wu_xiaolin.jpg) |
Xiaolin Wu (Fellow, IEEE) received the B.Sc. degree in computer science from Wuhan University, China, in 1982, and the Ph.D. degree in computer science from the University of Calgary, Canada, in 1988. He started his academic career in 1988. He was a Faculty Member with Western University, Canada, and New York Polytechnic University (NYU-Poly), USA. He is currently with McMaster University, Canada, where he is a Distinguished Engineering Professor and holds an NSERC Senior Industrial Research Chair. His research interests include image processing, data compression, digital multimedia, low-level vision, and network-aware visual communication. He has authored or coauthored more than 300 research articles and holds four patents in these fields. He served on technical committees of many IEEE international conferences/workshops on image processing, multimedia, data compression, and information theory. He was a past Associated Editor of IEEE TRANSACTIONS ON MULTIMEDIA. He is also an Associated Editor of IEEE TRANSACTIONS ON IMAGE PROCESSING. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ed9bf348-377a-4d95-ac90-836ad94a0144/WenGao.jpg) |
Wen Gao (Fellow, IEEE) received the Ph.D. degree in electronics engineering from The University of Tokyo, Japan, in 1991. He is currently a Boya Chair Professor in computer science at Peking University. He is the Director of Peng Cheng Laboratory, Shenzhen. Before joining Peking University, he was a Professor with Harbin Institute of Technology from 1991 to 1995. From 1996 to 2006, he was a Professor at the Institute of Computing Technology, Chinese Academy of Sciences. He has authored or coauthored five books and over 1000 technical articles in refereed journals and conference proceedings in the areas of image processing, video coding and communication, computer vision, multimedia retrieval, multimodal interface, and bioinformatics. He served on the editorial boards for several journals, such as ACM CSUR, IEEE TRANSACTIONS ON IMAGE PROCESSING (TIP), IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (TCSVT), and IEEE TRANSACTIONS ON MULTIMEDIA (TMM). He served on the advisory and technical committees for professional organizations. He was the Vice President of the National Natural Science Foundation (NSFC) of China from 2013 to 2018 and the President of China Computer Federation (CCF) from 2016 to 2020. He is the Deputy Director of China National Standardization Technical Committees. He is an Academician of the Chinese Academy of Engineering and a fellow of ACM. He chaired a number of international conferences, such as IEEE ICME 2007, ACM Multimedia 2009, and IEEE ISCAS 2013. |