Deep Graph Attention Networks
Abstract
Graphs are useful for representing various real-world objects. However, graph neural networks (GNNs) tend to suffer from over-smoothing, where the representations of nodes of different classes become similar as the number of layers increases, leading to performance degradation. A method that does not require protracted tuning of the number of layers is needed to effectively construct a graph attention network (GAT), a type of GNN. Therefore, we introduce a method called “DeepGAT” for predicting the class to which nodes belong in a deep GAT. It avoids over-smoothing in a GAT by ensuring that nodes in different classes are not similar at each layer. Using DeepGAT to predict class labels, a 15-layer network is constructed without the need to tune the number of layers. DeepGAT prevented over-smoothing and achieved a 15-layer GAT with similar performance to a 2-layer GAT, as indicated by the similar attention coefficients. DeepGAT enables the training of a large network to acquire similar attention coefficients to a network with few layers. It avoids the over-smoothing problem and obviates the need to tune the number of layers, thus saving time and enhancing GNN performance.
Index Terms:
Graph Neural Network, Graph Attention Network, Reproductive Property of Probability DistributionI Introduction
The graph is a useful data structure to represent various objects in the real world. For example, accounts and links in social networks correspond to nodes and edges in graphs, respectively, and relationships in the networks are represented as graphs. Atoms and chemical bonds in molecules also correspond to nodes and edges in graphs, respectively, and the molecules are thus represented as graphs. Various other objects, such as hyperlink structures and function calls in computer programs, can also be represented by graphs. Because various objects can be stored as graph data, technologies for analyzing such data have been attracting a great deal of attention in recent years [9, 23, 19].
The graph neural network (GNN) [23] is a representative deep learning method for graph data. GNNs convolve features of neighboring nodes of a node to the representation of . GNNs with layers repeat this convolution times, and obtain the representation of . Once each node is represented in vector form, various conventional machine learning methods such as classification, clustering, and regression can be applied to the graph data, including for node classification, node clustering, and link prediction.
Representative GNNs include the graph convolutional network (GCN) [9] and graph attention network (GAT) [19]. Figure 1 shows the difference between convolutions of GCN and GAT; the features of nodes in the darker blue background greatly affect the representation of . For each node , GCN uniformly convolves the features with steps from to the representation of , whereas GAT non-uniformly convolves the features to the representation of using the attention coefficient. Thus, GCN convolves the features of red nodes in Fig. 1 to the representation of , whereas GAT does not always convolve the features to the representation of , which results in different representations of the structure around learned by GCNs and GATs.

Most GNNs, including GCNs and GATs, have a common drawback called over-smoothing [13, 15, 2, 29], which is a phenomenon in which the representations of nodes belonging to different classes are similar to each other when the number of layers is increased. This results in degradation of GNN performance. For this reason, low-layer GCNs or GATs with 2-3 layers are often used in actual operations. However, for some graph datasets, even a deep GAT can provide high performance, so we must tune the number of layers by starting with a low-layer GAT and gradually increasing . This tuning requires considerable time. Therefore, a methodology that can construct a deep GAT for many datasets without spending time tuning would be useful.
To achieve this, this paper [8] proposes a method for predicting which class each node belongs to at each layer in a deep GAT, in which the prediction error at each layer is incorporated into the loss function. On the basis of the prediction, if a node has neighbors that belong to the same class as , only features of the neighbors are convolved into the representation of . Unlike the case of over-smoothing, the likelihood that features of nodes belonging to a different class from are convolved into is small, and thus the representations of nodes belonging to different classes are not similar to each other; therefore, over-smoothing can be avoided.
The contributions of this paper are summarized as follows:
-
•
First, our proposed method, called DeepGAT, achieves a 15-layer GAT with the same level of performance as a 2-layer GAT. Instead of starting with a small and gradually increasing its value, the DeepGAT with 15 layers can be constructed without tuning .
-
•
Second, we mathematically show why DeepGAT can avoid over-smoothing, on the basis of the reproductive property of the probability distribution (see Lemma 2). We also show mathematically that the overlap in distributions of representations of nodes belonging to different classes is small, and we demonstrate that this is also true for benchmark datasets.
II Preliminaries
A graph whose nodes have features is represented as , where is a set of nodes, is a set of edges, and is a set of feature vectors. We define a neighborhood of vertex as . Each node belongs to one of two classes 111In this paper, we address the binary classification of nodes, although the proposed method can be extended to multi-class node classification, multi-label node classification, and graph classification., and we denote nodes belonging to the class as . In addition, we assume that feature of node has the following properties: .
We call a sequence of edges satisfying a path, and the length of the path. Paths in this paper are not always simple, and we allow the path to satisfy . We denote a set of paths of length from node to node as . In addition, we denote a vector representing the numbers of paths of length from as , where is the -dimensional one-hot vector whose -th element is 1. By using these notations, we define and .
Given a graph and the ground-truth class labels for nodes as input, the problem addressed in this paper is the accurate prediction of class labels for nodes via learning node representations for from and .
III Related Works and their Drawbacks
We will now discuss GAT, which is a type of GNN in which node representations are obtained from a graph. For each node in a graph, GAT convolves the features of nodes to the feature of . The convolution of GAT consists of Aggregate and Combine, as shown below:
| (1) | |||||
| (2) |
where is the learnable matrix and is the activation function. In addition, is the attention coefficient computed from and . Starting from , GAT repeats this convolution times and then outputs as the representation for node 222Although GATs usually use multi-head attention, we discuss GATs with single-head attention until Section 4 of this paper. The software used in Section 5 is implemented with multi-head attention..
GAT is an extension of GCN. in GCN does not depend on and , and is . In contrast, GAT aggregates features of neighboring nodes with similar features to node into a representation of . Thus, it does not convolve uniform features of nodes with steps from , but instead convolves while selecting features of nodes in particular directions, as shown in Fig. 1. The following equations are used for computing attention coefficients between two vectors and :
where is a learnable vector, is a function to obtain the number of dimensions of a vector, is a dot product, and is an operation to concatenate two vectors. Using one of these attention functions, is computed by
GAT has been actively applied to various methods. For example, the gated attention network [26] calculates importance values of multi-heads. Heterogenous GANs [21] can learn heterogeneous graphs with GAT, and the signed GAN [7] combines directed code networks and GAT. The relational GAN [27] adds new attention networks that can learn the dependencies between emotional polarity and opinion words, called aspects, in sentences.
One of the major challenges for GNNs, including GATs, is over-smoothing. Over-smoothing is a phenomenon in which node representations are similar to each other when the number of layers in the GNN is increased, resulting in a decrease in classification accuracy. Yajima and Inokuchi proved with the following lemma that the distribution followed by in a GCN is normal, using the reproductive property of probability distributions.
Lemma 1 ([24])
We assume that in a GCN is the identity function. The representations in the GCN follow the normal distribution defined below.
where .
According to Lemma 1, the mean of the distribution followed by to be used for classification is . For large , because the ratio approaches the class ratio , internally divides and in the ratio. Because the representations of nodes belonging to the two classes follow a distribution with an identical mean for large , they are similar to each other. This also holds true for GATs. Therefore, GCNs and GATs often have two or three layers.
The objective of this paper is to extend GAT, i.e., to derive a multiple-layer GAT to achieve high classification accuracy while preventing over-smoothing, by taking advantage of the properties of the representations shown in Lemma 1.
According to the article [11], there are three main approaches to reduce over-smoothing: Normalization, Residual connection, and Change of GNN Dynamics. Typical methods of the first approach are DropEdge [16] and PairNorm [28]. DropEdge randomly removes a certain number of edges from the input graph at each training epoch. PairNorm transfoms input features in prepossessing as follows.
where is the hyper-parameter. In the second approach, the residual connection [6, 12] allows the input to bypass one or more layers and be added directly to the output of a later layer. One of implementations is represented as . This technique helps mitigate the vanishing gradient problem, enabling the training of deeper networks. GCNII [3] using residual connection demonstrated that the over-smoothing is reduced in 64-layer GNNs. The third approach qualitatively changes the dynamics of message passing propagation. For example, in Gradient Gating (G2) [10], local gradients due to differences between features are harnessed to further modulate convolution as follows.
where is the hyper-parameter and is the Hadamard product.
IV DeepGAT
IV-A GAT with Oracle Predicting
In this subsection, we assume that there exists the following oracle that can output exactly whether two nodes and belong to the same class.
For node , only features of nodes belonging to the same class as are convolved into the representation of , when we use . In this case, we obtain the following lemma.
Lemma 2
Let paths consisting of only nodes belonging to the same class as among be . We define as . When the activation functions are the identify functions, the representation of belonging to the class in GAT with the oracle follows
| (3) |
Proof 1
The linear sum of random variables and that follows the identical distribution also follows . Therefore, because Eq. (1) aggregates features that follow an identical distribution in the first layer of GAT, in which the oracle controls attention coefficients, follows . Because the linear transformation of random variables that follows the normal distribution generates random variables that follow another normal distribution, follows . In the -layer GAT with the oracle, the number of features convolved to the representation of is consistent with the number of paths . Therefore, the distribution that follows is expressed as Eq. (3).
The mean of the distribution followed by representations of nodes belonging to the class never depends on the mean for the other class . When is orthogonal, the variance of Eq. (3) becomes . holds, and the variance decreases with an increase of . Because representations of nodes belonging to the class follow a different distribution from the distribution that of nodes belonging to follow, and as the variance in the distributions decreases with an increase of , increasing in turn increases the likelihood that the GAT with the oracle can classify correctly.
Fig. 2 shows the distribution of the input feature vectors . Two bell-shaped distributions are class 0 and class 1, and the gray areas are the overlap of those distributions. The overlap is related to the Bayes error rate. The Bayes error rate is the lowest possible error rate for any classifier, representing the limit of classification accuracy given the inherent noise in the data. It is the probability that a randomly chosen data point is misclassified by an optimal classifier that knows the true underlying distributions. Under the presence of oracles, the variances of the distributions of are reduced by convolving times, and the overlap of the distributions is correspondingly reduced. Therefore, at each layer, if we can correctly predict the class to which each node belongs, we can expect to reduce the over-smoothing.

IV-B Implementation of the Oracle in DeepGAT
This subsection discusses how to implement the oracle. Because a GAT with a few layers can predict class labels with reasonably high accuracy, the proposed DeepGAT method predicts the class labels of nodes in each layer. To achieve this, DeepGAT linearly transforms each representation in each layer into a -dimensional representation , and then computes from the representations in each layer, where is the probability of belonging to class predicted in the -th layer. If the prediction is completely correct, then coincides with . Therefore, let be .
Algorithm 1 shows the pseudo code of the feedforward procedures of our DeepGAT. For comparison, the pseudo-code for the conventional GAT is shown in Algorithm 2. The correct convolution of DeepGAT depends on the accuracy of the prediction at each layer. Various previous researches have demonstrated that incorporating class label information as additional input can improve GNN performance. To facilitate the accuracy of this prediction, we combine DeepGAT with this label propagation [25, 20, 22, 17]. Here, is the raw label matrix whose rows corresponding to nodes with graph-truth labels are one-hot vectors and the other rows for nodes are filled with zeros. in Line 3 of Algorithm 1 is the row-normalized form of adjacency matrix of , is the -th power of , and the function sets the diagonal elements of the matrix to zero in order to avoid the label leakage [25]. In Line 6, the concatenation of the representation and label aggregation is linearly transformed with the learnable parameter , and then the class labels for are predicted in Line 7. In Lines 9 and 10, attention coefficients are computed from the predicted class labels. The convolutions using the attention coefficients are repeated for layers, and class labels are predicted in the final layer.
DeepGAT learns and from graph-truth labels. According to Subsection IV-A, if DeepGAT can correctly predict labels of nodes in each layer, the variance of representations in the final layer will be smaller. Since prediction errors in the layers close to the input layer propagate toward the output layer, the correctness of predictions in the layers close to the output layer depends on the correctness of predictions in the layers close to the input layer. Therefore, in order to suppress prediction errors in the layers close to the input layer, we use the following loss function.
| (4) | |||
The underlined part of Eq. (4) is the cross-entropy loss function for the -th layer, and it is multiplied by which decreases monotonically with increasing the hyperparameter and converges to 1. By using the loss function (4), the proposed DeepGAT method aims to both
V Experimental Evaluation
V-A Experimental Setting
| Datasets | # of graphs | avg. | max. | hub node | diameter | density | avg. cluster | ||||
| degree | degree | rate [%] | coefficient | ||||||||
| Cora | 1 | 2,708 | 10,556 | 1,433 | 7 | 9.8 | 338 | 2.18% | 19 | 0.18% | 24.07% |
| CiteSeer | 1 | 3,327 | 9,104 | 3,703 | 6 | 7.5 | 200 | 1.23% | 28 | 0.11% | 14.15% |
| CS | 1 | 18,333 | 163,788 | 6,805 | 15 | 19.9 | 274 | 18.04% | 24 | 0.05% | 34.25% |
| Physics | 1 | 34,493 | 495,924 | 8,415 | 3 | 30.8 | 766 | 36.40% | 17 | 0.04% | 37.76% |
| Flickr | 1 | 89,250 | 899,756 | 500 | 7 | 22.2 | 10,852 | 11.57% | 8 | 0.01% | 3.30% |
| PPI | 24 | 56,944 | 818,716 | 50 | 121 | 28.3 | 721 | 27.43% | – | – | 27.06% |

This section demonstrates that DeepGAT prevents over-smoothing by comparing DeepGAT with the original GAT. In the experiments in this paper, the proposed method is not compared with state-of-the-art GNNs, but only with GAT. By comparing only with GAT, we verify whether predicting which class each node belongs to at each layer and convolving representations of nodes based on the prediction is effective. If we find that it is effective, we can use our ideas in various methods that use GAT. Comparisons with the world’s best GNNs and GNNs that have achieved depths of over 100 layers are included in future plans. We implemented DeepGAT with Pytorch and Pytorch Geometric. See config.yaml at https://github.com/JNKT215/DeepGAT_CANDAR for the hyperparameter settings for each model.
Table I summarizes the benchmark datasets used in our experimental evaluation. Cora, CiteSeer, CS, and Physics are datasets for article citation networks, PPI is a network for protein-protein interactions, and Flickr is a network of images. We treated those networks as undirected graphs. PPI is a dataset for the multi-label node classification, and the other datasets are used for multi-class node classification. So, the label propagation in Lines 3 and 4 of Algorithm 1 was not used for PPI. We treated nodes with degree greater than 30 as hub nodes, and the hub node rate was set to . Figure 3 shows the performance degradation of the GAT which is defined as the difference between the best micro-F1 score for various on each dataset and a micro-F1 score at the maximum that could be computed in an acceptable time. The performance degradation of GAT with respect to CS and Physics is significant, while one with respect to Cora and CiteSeer is not significant. The former datasets have the hub node rates, and many of them also have higher cluster coefficients . When there are more hub nodes in the graph, the average distance between any two nodes is smaller, so the number of layers for a feature at one node to propagate as a representation of another node is smaller. This makes over-smoothing more likely to occur. In the next subsection, we report whether the proposed method can mitigate over-smoothing for CS, Physics, Flickr, and PPI whose hub node rates are more than 10%.
V-B Experimental Results
V-B1 Micro-F1 Scores with Various Numbers of Layers
First, we confirmed that DeepGAT prevents over-smoothing when the number of layers is increased. Figure 4 shows the micro-F1 scores for DeepGAT and GAT with various numbers of layers and the CS, Physics, and Flickr datasets. DP and SD indicate the dot-product attention and scaled dot-product attention, respectively. To suppress prediction errors and reduce computation time for layers close to the input layer, label propagation in Lines 3 and 4 of Algorithm 1 was limited to the first through the third layers.
When is increased, the micro-F1 scores of GAT decrease significantly due to over-smoothing. In contrast, the DeepGAT with 15 layers for CS and Physics and one with 9 layers for Flickr maintain a relatively high micro-F1 score compared with the DeepGAT with 2 layers, which indicates that DeepGAT has the ability to prevent over-smoothing. The reason why the scores slightly decrease is that the same amount of data was used to train for DeepGATs with 2 and 15 layers. Despite the fact that the difference between Algorithms 1 and 2 is slight, the difference in their performance is very large. Table II shows the best micro-F1 score (denoted by “best”) for various on each dataset and a micro-F1 score (denoted by “max.”) at the maximum that could be computed in an acceptable time. The numbers in parentheses in Table II represent the numbers of layers at the time the scores were obtained, and the numbers in bold are the highest scores for each dataset. Table II shows that DeepGAT is superior to GAT and the use of DeepGAT allows for the construction of deeper networks than GAT.

(a) Micro-F1 scores for CS.

(b) Micro-F1 scores for Physics.

(c) Micro-F1 scores for Flickr.

(d) Micro-F1 scores for PPI.
| Model | CS | Physics | Flickr | PPI | |
|---|---|---|---|---|---|
| DeepGAT | best | 91.5 (2) | 93.6 (4) | 54.6 (2) | 98.9 (7) |
| (DP) | max. | 83.1 (15) | 91.8 (15) | 53.2 (9) | 98.8 (9) |
| DeepGAT | best | 90.4 (2) | 93.6 (5) | 53.8 (4) | 99.2 (8,9) |
| (SD) | max. | 82.7 (15) | 90.8 (15) | 47.2 (9) | 99.2 (9) |
| GAT | best | 90.5 (2) | 93.4 (2) | 52.4 (3) | 92.5 (3) |
| (DP) | max. | 9.3 (15) | 28.1 (15) | 42.3 (9) | 44.0 (9) |
| GAT | best | 90.6 (2) | 92.5 (2) | 52.9 (3) | 99.1 (6) |
| (SD) | max. | 4.6 (15) | 12.3 (15) | 42.3 (9) | 98.9 (9) |
 (a) CS
(a) CS
 (b) Physics
(b) Physics
 (c) Flickr
(c) Flickr
 (d) PPI
(d) PPI
|
V-B2 Comparison between Attention Coefficients at 2 Layers
Next, we confirmed that DeepGAT with a large number of layers can acquire appropriate attention coefficients as well as DeepGAT with a small number of layers. In concrete terms, we compute the KL divergence between attention coefficients for DeepGAT with 2 layers and for DeepGAT with layers. If the impact of over-smoothing on DeepGAT is small, should be almost the same as for DeepGATs with both large and small numbers of layers. Therefore, by measuring the difference between and by Eq. (5), we can determine how accurately the features of the nodes adjacent to that belong to the same class as are convolved to the representation of in DeepGAT.
| (5) |
Figure 5 shows a box-and-whisker diagram of computed for various nodes . The figure shows that the variance of for DeepGAT is smaller than that for GAT. Thus, DeepGAT with a large number of layers is trained to acquire similar attention coefficients to DeepGAT with a small number of layers. These results show that for each node , DeepGAT with larger layers convolves only a small number of features of ’s neighborhood belonging to a different class than into the representation of compared with the original GAT.
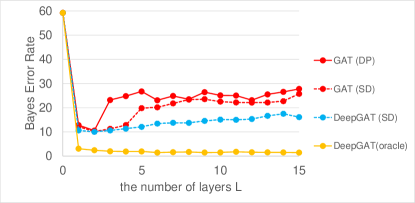
V-B3 Error Rate using the Nearest Neighbor Method
(a) CS

(b) Physics

(c) Flickr
In the discussion immediately following the proof of Lemma 2, we noted that in the presence of an oracle, the variance of the distribution that the representation follows decreases as increases. The smaller the overlap between the distribution followed by the representation of node belonging to class 0 and the distribution followed by the representation of node belonging to class 1, the more accurate we can expect the classification to be. The overlap is called the Bayes error rate and it is the lowest possible error rate for any classifiers for the given dataset. A low rate suggests that a useful representation is obtained for classification by learning the representation. In practice, however, it is difficult to know the exact probability distribution from . Thus, we estimate the upper and lower bounds of the Bayes error rate with an error rate by the nearest neighbor method with a large number of prototypes in the low-dimensional space. According to previous studies [4, 5],
where . Therefore, the upper and lower bounds of the Bayes error rate are given by
for . Figure 6 shows for the CS, Physics and Flickr datasets when the number of layers was increased. Figure 6 does not include for PPI, because PPI is the dataset for the multi-label node classification. In Fig. 6, the yellow broken line is obtained by replacing in Line 5 of Algorithm 1 into the oracle . The error rate represented by the line gradually decreases as increases, which demonstrates that the variance of the distribution for each class decreases as discussed after the proof of Lemma 2. In contrast, when is computed from representations but not the oracle, increases slightly with an increase of from 1. This is because computed from the learned representation does not exactly match . However, for DeepGAT is always smaller than for GAT, which indicates that the overlap between the distributions and followed by representations learned from DeepGAT is small.
VI Conclusion
GNNs tend to suffer from over-smoothing leading to performance degradation. Therefore, this paper introduced DeepGAT for predicting the class to which network nodes belong in a deep GAT. It avoids over-smoothing in a GAT by ensuring that nodes in different classes are not similar at each layer. Using DeepGAT to predict class labels, a 15-layer network could be constructed without the need to tune the number of layers. DeepGAT prevented over-smoothing and achieved a 15-layer GAT with similar performance to a 2-layer GAT, as indicated by the similar attention coefficients. DeepGAT enables the training of a large network to acquire similar attention coefficients to a network with few layers. It avoids the over-smoothing problem and obviates the need to tune the number of layers, thus saving time and enhancing GNN performance.
References
- [1] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. Proc. of International Conference on Learning Representations, 2015.
- [2] Deli Chen, Yankai Lin, Wei Li, Peng Li, Jie Zhou, and Xu Sun: Measuring and Relieving the Over-Smoothing Problem for Graph Neural Networks from the Topological View. Proc. of the AAAI Conference on Artificial Intelligence, 3438–3445, 2020.
- [3] Ming Chen, Zhewei Wei, Zengfeng Huang, Bolin Ding, and Yaliang Li: Simple and Deep Graph Convolutional Networks. Proc. of International Conference on Machine Learning, 1725–1735, 2020.
- [4] Thomas M. Cover and Peter E. Hart: Nearest neighbor pattern classification. IEEE Transactions on Information Theory, 13(1), 21–27, 1967.
- [5] Keinosuke Fukunaga and Donald M. Hummels: Bias of Nearest Neighbor Error Estimates. IEEE Transactions on Pattern Analysis and Machine Intelligence, 9(1), 103–112, 1987.
- [6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun: Deep Residual Learning for Image Recognition. Proc. of IEEE Conference on Computer Vision and Pattern Recognition, 770–778, 2016.
- [7] Junjie Huang, Huawei Shen, Liang Hou, and Xueqi Cheng: Signed Graph Attention Networks. Proc. of ICANN Workshop and Special Sessions, 566–577, 2019.
- [8] Jun Kato, Airi Mita, Keita Gobara, and Akihiro Inokuchi. Deep Graph Attention Networks. Proc. of International Workshop on GPU Computing and AI, 2024 (to appear).
- [9] Thomas N. Kipf and Max Welling. Semi-Supervised Classification with Graph Convolutional Networks. Proc. of International Conference on Learning Representations, 2017.
- [10] T. Konstantin Rusch, Benjamin Paul Chamberlain, Michael W. Mahoney, Michael M. Bronstein, and Siddhartha Mishra: Gradient Gating for Deep Multi-Rate Learning on Graphs. Proc. of International Conference on Learning Representations, 2023.
- [11] T. Konstantin Rusch, Michael M. Bronstein, and Siddhartha Mishra: A Survey on Oversmoothing in Graph Neural Networks. arXiv preprint arXiv:2303.10993, 2023.
- [12] Guohao Li, Matthias Müller, Ali K. Thabet, and Bernard Ghanem: DeepGCNs: Can GCNs Go As Deep As CNNs? Proc of IEEE/CVF International Conference on Computer Vision, 9266–9275, 2019.
- [13] Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper Insights Into Graph Convolutional Networks for Semi-Supervised Learning. Proc. of AAAI Conference on Artificial Intelligence, 3538–3545, 2018.
- [14] Thang Luong, Hieu Pham, and Christopher D. Manning: Effective Approaches to Attention-based Neural Machine Translation. Proc. of Conference on Empirical Methods in Natural Language Processing, 1412–1421, 2015.
- [15] Kenta Oono and Taiji Suzuki: Graph Neural Networks Exponentially Lose Expressive Power for Node Classification. Proc. of International Conference on Learning Representations, 2020.
- [16] Yu Rong, Wenbing Huang, Tingyang Xu, and Junzhou Huang: DropEdge: Towards Deep Graph Convolutional Networks on Node Classification. Proc. of International Conference on Learning Representations, 2020.
- [17] Yunsheng Shi, Zhengjie Huang, Shikun Feng, Hui Zhong, Wenjing Wang, and Yu Sun: Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification. Proc. of International Joint Conference on Artificial Intelligence, 1548–1554, 2021.
- [18] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is All you Need. Proc. of Annual Conference on Neural Information Processing Systems, 5998–6008, 2017.
- [19] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph Attention Networks. Proc. of International Conference on Learning Representations, 2018.
- [20] Hongwei Wang and Jure Leskovec: Unifying Graph Convolutional Neural Networks and Label Propagation. arXiv preprint arXiv:2002.06755. 2020.
- [21] Xiao Wang, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S. Yu: Heterogeneous Graph Attention Network. The World Wide Web Conference, 2022–2032, 2019.
- [22] Yangkun Wang, Jiarui Jin, Weinan Zhang, Yong Yu, Zheng Zhang, David Wipf: Bag of Tricks of Semi-Supervised Classification with Graph Neural Networks. arXiv preprint arXiv:2103.13355, 2021.
- [23] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How Powerful are Graph Neural Networks? Proc. of International Conference on Learning Representations, 2019.
- [24] Yuta Yajima and Akihiro Inokuchi. Why Deeper Graph Neural Network Performs Worse? Discussion and Improvement About Deep GNNs. Proc. of International Conference on Artificial Neural Networks (2). 731–743, 2022.
- [25] Xiaocheng Yang, Mingyu Yan, Shirui Pan, Xiaochun Ye, and Dongrui Fan: Simple and Efficient Heterogeneous Graph Neural Network. Proc. of AAAI Conference on Artificial Intelligence, 10816–10824, 2023.
- [26] Jiani Zhang, Xingjian Shi, Junyuan Xie, Hao Ma, Irwin King, and Dit-Yan Yeung: GaAN: Gated Attention Networks for Learning on Large and Spatiotemporal Graphs. Proc. of Conf. on Uncertainty in Artificial Intelligence, 339–349, 2018.
- [27] Jiani Zhang, Xingjian Shi, Junyuan Xie, Hao Ma, Irwin King, and Dit-Yan Yeung: Relational Graph Attention Network for Aspect-based Sentiment Analysis. Proc. of Annual Meeting of Association for Computational Linguistics, 3229–3238, 2020.
- [28] Lingxiao Zhao and Leman Akoglu: PairNorm: Tackling Oversmoothing in GNNs. Proc. of International Conference on Learning Representations, 2020.
- [29] Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun: Graph Neural Networks: A review of Methods and Applications. AI Open 1: 57–81, 2020.