Deep Equilibrium Multimodal Fusion
Abstract
Multimodal fusion integrates the complementary information present in multiple modalities and has gained much attention recently. Most existing fusion approaches either learn a fixed fusion strategy during training and inference, or are only capable of fusing the information to a certain extent. Such solutions may fail to fully capture the dynamics of interactions across modalities especially when there are complex intra- and inter-modality correlations to be considered for informative multimodal fusion. In this paper, we propose a novel deep equilibrium (DEQ) method towards multimodal fusion via seeking a fixed point of the dynamic multimodal fusion process and modeling the feature correlations in an adaptive and recursive manner. This new way encodes the rich information within and across modalities thoroughly from low level to high level for efficacious downstream multimodal learning and is readily pluggable to various multimodal frameworks. Extensive experiments on BRCA, MM-IMDB, CMU-MOSI, SUN RGB-D, and VQA-v2 demonstrate the superiority of our DEQ fusion. More remarkably, DEQ fusion consistently achieves state-of-the-art performance on multiple multimodal benchmarks. The code will be released.
1 Introduction
Humans routinely receive and process signals through interactions across multiple modalities, supporting the unique human capacity to perceive the world. With the rise and development of deep learning, there has been a steady momentum of innovation that leverage multimodal data for learning deep models [39, 35, 49]. Multimodal fusion, the essence of multimodal learning, aims to integrate the information from different modalities into a unified representation, and has made great success in real-world applications, e.g., sentiment analysis [70], multimodal classification [3], medical analysis [9, 60], object detection [52], visual question answering [15], etc.
A common practice for deep multimodal learning is to first exploit modality-specific deep neural networks to extract modality-wise features, and then capitalize on multimodal fusion to combine the information from all modalities. The recent progress in computer vision and natural language processing area has convincingly pushed the limits of modality-specific learning [18, 58, 31], whereas multimodal fusion remains challenging for multimodal learning. Most conventional approaches are dedicated to deliberately designing fusion strategies [33, 40, 36], which have proceeded along three dimensions of early fusion, mid fusion, and late fusion, with respect to the placement of fusion module in the whole framework. In general, these fusion strategies perform statically during training and inference, i.e., the fusion architectures are often fixed. As a result, these approaches seldom explore modality importance, and the exchange of information within and across modalities is reinforced only to a certain degree. That might result in the generalization problem to various multimodal tasks, especially for some complicated multimodal correlations, e.g., the evolving temporal modality correlations. Moreover, for simple modality inputs, these static approaches might be excessive and potentially encode redundant, unstable, and even noisy information.
In an effort to improve the static fusion approaches, recent works endow the fusion mechanism with more power of leveraging three ways: 1) stabilizing and aligning signals from different modalities [13]; 2) integrating interactions across modalities ranging from low level to high level [21, 41]; 3) dynamically perceiving the effective information and removing the redundancy from each modality [16, 64]. To the best of our knowledge, there is no unified multimodal fusion framework that looks into all three aspects simultaneously. This motivates us to develop a dynamic multimodal fusion architecture to adaptively model the cross-modality interactions from low level, middle level, to high level, making the architecture generic for various multimodal tasks.
To consolidate the above idea, we present a new deep equilibrium (DEQ) method for multimodal fusion in this paper. Our launching point is to recursively execute nonlinear projections on modality-wise features and the fused features until the equilibrium states are found. Specifically, our contributions include: 1) we seek the equilibrium state of features to jointly stabilize intra-modality representations and inter-modality interactions; 2) our method continuously applies nonlinear projections to modality-wise features and the fused features in a recursive manner. As such, the cross-modality interactions are reinforced at every level for multimodal fusion; 3) we devise a purified-then-combine fusion mechanism by introducing a soft gating function to dynamically perceive modality-wise information and remove redundancy. Our DEQ fusion generalizes well to various multimodal tasks on different modalities and is readily pluggable to existing multimodal frameworks for further improvement.
We evaluate our DEQ fusion approach on several multimodal benchmarks built on different modalities, including medical breast invasive carcinoma PAM50 subtype classification on BRCA, image-text movie genre classification on MM-IMDB, audio-text sentiment analysis on CMU-MOSI, RBG-point 3D object detection on SUN RGB-D, and image-question visual question answering on VQA-v2. Our DEQ fusion approach consistently achieves new state-of-the-art performance on all benchmarks, demonstrating the superiority of modeling modality information from low level to high level in a dynamic way for multimodal fusion.
2 Related Works
Multimodal Fusion aims to integrate modality-wise features into a joint representation to solve multimodal learning tasks. Early works distinguished fusion approaches into feature-level early fusion and decision-level late fusion, depending on where fusion is performed in the model [4]. [38] and [63] adopted early fusion approach to integrating features from multiple modalities for speech recognition and video retrieval respectively. [51] proposed to use two separate branches for spatial and temporal modalities and perform a simple late fusion for video action recognition. Alternatively, [37] fused the outputs by computing a weighted average. [66] proposed a robust late fusion using rank minimization. More recently, with the advancement of deep learning approaches, the idea of early fusion has been extended to the concept of mid fusion, where fusion happens at multiple levels [49]. [24] learned the fused representation by gradually fusing across multiple fusion layers. Similarly, [59] proposed a multilayer approach for fusion by introducing a central network linking all modality-specific networks. [43] came up with an architecture search algorithm to find the optimal fusion architecture. [20, 36] incorporated attention mechanism for multimodal fusion. [61] proposed to exchange feature channels between modalities for multimodal fusion. [41] introduced bilinear pooling to attention blocks, and demonstrated its superiority in capturing higher-level feature interactions by stacking multiple attention blocks for image captioning. More recently, attention has been moved to dynamic fusion, where the most suitable fusion strategy is selected from a set of candidate operations depending on input from different modalities [16, 64]. Such dynamic approaches are more flexible to different multimodal tasks than static methods. Motivated by the success of capturing higher-level feature interactions and the dynamic fusion designs in multimodal fusion, our work aims to integrate the information within and across modalities at different levels by recursively applying nonlinear projections over intra- and inter-modality features, while generalizing well to multimodal tasks involving different modalities.
Implicit Deep Learning is a new family of deep neural networks and has grown rapidly in recent years. Traditional explicit deep models are often associated with a predefined architecture, and the backward pass is performed in reverse order through the explicit computation graphs. In contrast, implicit models compute their outputs by finding the root of some equations and analytically backpropagating through the root [7]. Previous works mainly focus on designing the hidden states of implicit models. [45] proposed an implicit backpropagation method for recurrent dynamics. [1] proposed optimization layers to model implicit layers. Neural ODEs find the root of differentiable equations to model a recursive residual block [11]. Deep equilibrium models (DEQ) find a fixed point of the underlying system via black-box solvers, and are equivalent to going through an infinite depth feed-forward network [6, 7]. These implicit deep learning approaches have demonstrated competitive performance in multiple applications while vastly reducing memory consumption, e.g., generative models [34, 46], optical flow [54, 5], graph modeling [26], etc. [8] also proposed a Jacobian regularization method to stabilize DEQs. Our work takes advantage of DEQs to adapt the number of recursion steps by finding the equilibrium state of intra- and inter-modality features jointly, and to speed up training and inference of our recursive fusion design.

3 Deep Equilibrium Fusion
In this section, we first revisit the formulation of basic deep equilibrium models (DEQ) and then elaborate the formulation of our DEQ fusion for multimodal fusion.
3.1 Revisiting Deep Equilibrium Model
Our DEQ fusion is particularly built on deep equilibrium models to recursively capture intra- and inter-modality interactions for multimodal fusion. The traditional deep neural networks have finite depth and perform the backward pass through every layer. Two interesting observations are that the hidden layers tend to converge to some fixed points, and employing the same weight in each layer of the network, so-called weight tying, still achieves competitive results. That leads to the design principles of deep equilibrium models and the goal is to simulate an infinite depth weight-tied deep network, producing high-level and stable feature representations.
Formally, the standard DEQ [6] is formulated as a weight-tied network, and such a network with parameter and a depth of computes a hidden state as
| (1) |
where the untransformed input is injected at each layer, is the hidden state at layer and . As claimed in [6], the core idea of DEQ is that when there are infinite layers (), the system tends to converge to an equilibrium state such that
| (2) |
In practice, naively computing the equilibrium state requires excessive runtime. One convergence acceleration is to formulate Eq. 2 into a root-finding problem:
| (3) |
Some root solvers can then be applied to the residual to find the equilibrium state
| (4) |
Instead of backpropagating through each layer, we can compute gradients analytically as
| (5) |
where is a loss between and the target , is the inverse Jacobian of at . As it is expensive to compute the inverse Jacobian term, [6] proposed to alternatively solve a linear system by involving a vector-Jacobian product
| (6) |
With the formulation above, DEQ represents an infinite depth network with just one layer , which converges to an equilibrium state, and can be backpropagated implicitly with a single computation.
3.2 Deep Equilibrium Multimodal Fusion
Next, we formulate our DEQ fusion method. Given a set of unimodal features from modalities, our goal is to find a unified feature that integrates the information from all modalities. To ensure the informativeness of our final integrated feature, we first execute another nonlinear projection to extract higher-level information within each modality:
| (7) |
where is the -th output of the layer for modality and is initialized to . is the injected input feature for modality . Our fusion design is flexible from the standpoint that can be altered arbitrarily to fit multiple modalities. In our case, is designed to be similar to a simple residual block [18]. Following [7], we adopt group normalization [62] instead of batch normalization [22] for stability. Hence, is formulated as
| (8) |
where and are the weights, and are the bias. Given this set of modality-wise features computed from , where , our target is to fuse them to obtain a unified feature integrating the information from all modalities. In addition, considering that the dimension of this unified feature is limited, it necessitates dynamically selecting the most representative information from each modality-wise feature to reduce redundancy.
We propose a dynamic purify-then-combine fusion strategy for this purpose. We account for feature correlation between the fused feature and the modality-wise features by applying a soft gating function , to dynamically model feature correlation via computing a weight for each modality:
| (9) |
where is the fused feature from the -th layer and is initialized to . and are the weight and bias. The gating function assigns the larger weights to parts of the fused feature that better encode the information from modality . We purify the fused feature with the correlation weight for modality :
| (10) |
where represents element-wise multiplication. could be interpreted as the significant feature purified from the fused feature that represents the information of modality from previous layers. We then combine these purified features and adopt a simplified residual block to obtain the unified feature as
| (11) |
where is the injected input fused feature computed from the set of modality-wise features for , and are the weight and bias. In shallow layers (small ), encodes low-level modality interactions. As we continuously summarize the purified feature , i.e., gets larger and larger, tends to capture higher-level modality interactions while recursively integrating low-level information from previous iterations. By doing so, the final integrates the cross-modality interactions and correlations ranging from low level to high level. Moreover, our approach is flexible on the ways to compute the injected fused feature . In our case, we compute it with a simple weighted sum:
| (12) |
where is a learnable weight associated with modality representing modality importance.
We denote the above-proposed fusion module in Eqs. 9, 10 and 11 as a nonlinear function such that
| (13) |
where for is the set of the injected modality-wise features. Ideally, a superior unified feature should capture the information from all modalities at every level and thus we progressively model modality interactions from low-level to high-level feature space. Technically, we present to recursively interchange intra- and inter-modality information until the equilibrium state is reached, to obtain such an informative unified representation in a stable feature space for multimodal learning. To achieve this goal, we leverage the idea of DEQs into our multimodal fusion framework. Considering for and as DEQ layers, we aim to find equilibrium states such that
| (14) |
where and , , are the fused feature and all unimodal features in equilibrium states respectively. Note that we also keep track of computation for each unique modality-wise feature, so that the information from different modalities can be aligned and captured at a stable level together with the fused feature. We conduct ablation studies to demonstrate the superiority of our purify-then-combine fusion strategy compared to other fusion variants involving DEQs. Please refer to Section 4.2 for more details.
The fixed points in Eq. 14 can be reformulated into residual functions for the root-finding problem:
| (15) |
| (16) |
Finally, we can solve for features in equilibrium states via a black-box solver by minimizing the residuals for and :
| (17) |
where and for . Fig. 1 illustrates an overview of our deep equilibrium fusion architecture.
3.3 Backpropagation
A benefit of using DEQs compared to stacking conventional networks is that the gradients can be computed analytically without tracing through the forward pass layer-by-layer.
Theorem 1.
(Gradient of Deep Equilibrium Multimodal Fusion) Let for be the equilibrium states of the modality-wise features and fused feature, and be the ground-truth. Suppose we have a function which is the head for some downstream tasks (e.g., classification), we can compute a loss function between the prediction and the target. We can backpropagate implicitly through the unimodal features by computing the gradients with respect to using implicit function theorem:
| (18) |
where is the inverse Jacobian of evaluated at .
The proof for Theorem 1 is provided in Appendix A. The gradients with respect to parameters of DEQ layers can be computed following Eq. 5.

4 Experiments
We empirically verify the merit of our DEQ fusion on five multimodal tasks: 1) breast invasive carcinoma PAM50 subtype classification BRCA111BRCA can be acquired from The Cancer Genome Atlas program., associated with mRNA expression, DNA methylation, and miRNA expression data; 2) movie genre classification on MM-IMDB [3], which categorizes movies based on posters and text descriptions; 3) sentiment analysis on CMU-MOSI [70], which manually labels sentiment of video clips ranging from -3 to 3, where -3 indicates highly negative and 3 indicates highly positive; 4) 3D object detection on SUN RGB-D [52], one of the most challenging large-scale benchmarks for regressing 3D object bounding bbox offsets and predicting its category; and 5) visual question answering on VQA-v2 [15], the most commonly used large-scale VQA benchmark dataset containing human-annotated question-answer relating to images. Fig. 2 illustrates some data examples. In order to demonstrate the generalizability and plug-and-play nature of our approach, we only replace the fusion module of the existing methods and remain all the other components the same for comparison. The detailed experimental setup is demonstrated in Appendix B.
4.1 Discussion
| Modality | Acc(%) | WeightedF1(%) | MacroF1(%) | |
|---|---|---|---|---|
| GRridge [57] | mR+D+miR | 74.51.6 | 72.62.5 | 65.62.5 |
| GMU [3] | mR+D+miR | 80.03.9 | 79.85.8 | 74.65.8 |
| CF [19] | mR+D+miR | 81.50.8 | 81.50.9 | 77.10.9 |
| MOGONET [60] | mR+D+miR | 82.91.8 | 82.51.7 | 77.41.7 |
| TMC [17] | mR+D+miR | 84.20.5 | 84.40.9 | 80.60.9 |
| MM-Dynamics [16] | mR+D+miR | 87.70.3 | 88.00.5 | 84.50.5 |
| MM-Dynamics + DEQ Fusion | D+miR | 78.91.6 | 79.22.3 | 75.83.0 |
| MM-Dynamics + DEQ Fusion | mR+miR | 87.60.7 | 88.10.7 | 85.11.7 |
| MM-Dynamics + DEQ Fusion | mR+D | 88.70.7 | 89.30.7 | 86.90.9 |
| MM-Dynamics + DEQ Fusion | mR+D+miR | 89.10.7 | 89.70.7 | 87.61.0 |
BRCA. We compare our DEQ fusion approach with several baseline fusion methods, including the best competitor MM-Dynamics [16], in Table 1. It is noticeable that the complementarity of some modalities is significant, as approximately -10% performance drop is observed without mRNA data. This also somewhat manifests the advantage of dynamic modeling to take multiple modality signals into account. Similar to our dynamic design with a soft gating function, MM-Dynamics models feature and modality informativeness dynamically for trustworthy multimodal fusion. Our DEQ fusion additionally considers intra- and inter-modality features at every level, outperforming MM-Dynamics in all evaluation metrics. Notably, our method with two modalities of mRNA and DNA methylation already attains better performance in all evaluation metrics compared to MM-Dynamics which leverages all three modalities. All above results demonstrate the effectiveness of capturing modality interactions ranging from low level to high level in our deep equilibrium fusion design.
| Modality | MicroF1(%) | MacroF1(%) | |
| Unimodal Image | I | 40.31 | 25.76 |
| Unimodal Text | T | 59.37 | 47.59 |
| Early Fusion | I+T | 56.00 | 49.36 |
| LRMF [33] | I+T | 58.95 | 50.73 |
| MFM [56] | I+T | 56.44 | 48.53 |
| MI-Matrix [23] | I+T | 55.87 | 46.77 |
| RMFE [14] | I+T | 58.67 | 49.82 |
| CCA [53] | I+T | 60.31 | 50.45 |
| RefNet [50] | I+T | 59.45 | 51.51 |
| DynMM [64] | I+T | 60.35 | 51.60 |
| Late Fusion | I+T | 59.02 | 50.27 |
| DEQ Fusion | I+T | 61.52 | 53.38 |
MM-IMDB. We compare our DEQ fusion strategy with various baseline fusion methods in Table 2. It is clear that text modality is more representative than image modality for this classification task, as unimodal text models exhibit significantly better performance than unimodal image models. As such, existing approaches which do not involve dynamic modeling of modality information, attain either similar performance or minor improvement compared to the unimodal text baseline. A dynamic fusion strategy is seemingly crucial to further leverage the information from the relatively weak image signal for better performance. DynMM [64] capitalizes on hard gating to select the most appropriate fusion strategy from a set of predefined operations to achieve better results. We experiment with a late fusion strategy by simply replacing the original concatenation fusion with our DEQ fusion module. With this simple modification, we obtain the state-of-the-art results of 61.52% and 53.38% for micro and macro F1 scores respectively on MM-IMDB benchmark, which is a significant improvement of 2.50% and 3.11% against the late fusion baseline, also 1.17% and 1.78% improvement compared to DynMM.
| Modality | Acc-7(%) | Acc-2(%) | F1(%) | MAE | Corr | |
| Early Fusion LSTM | T+A+V | 33.7 | 75.3 | 75.2 | 1.023 | 0.608 |
| LRMF [33] | T+A+V | 32.8 | 76.4 | 75.7 | 0.912 | 0.668 |
| MFN [68] | T+A+V | 34.1 | 77.4 | 77.3 | 0.965 | 0.632 |
| MARN [69] | T+A+V | 34.7 | 77.1 | 77.0 | 0.968 | 0.625 |
| RMFN [27] | T+A+V | 38.3 | 78.4 | 78.0 | 0.922 | 0.681 |
| MFM [56] | T+A+V | 36.2 | 78.1 | 78.1 | 0.951 | 0.662 |
| MCTN [44] | T+A+V | 35.6 | 79.3 | 79.1 | 0.909 | 0.676 |
| MulT [55] | T+A+V | 40.0 | 83.0 | 82.8 | 0.871 | 0.698 |
| BERT [12] | T | 41.5 | 83.2 | 82.3 | 0.784 | 0.774 |
| CM-BERT [65] | T+A | 44.9 | 84.5 | 84.5 | 0.729 | 0.791 |
| CM-BERT + DEQ Fusion | T+A | 46.1 | 85.4 | 85.4 | 0.737 | 0.797 |
CMU-MOSI. We compare our fusion approach with several baseline fusion methods, including the state-of-the-art CM-BERT [65], in Table 3. It is worth noting that BERT-based methods exhibit better performance than other baseline approaches. For instance, vanilla BERT [12], leveraging only text modality, already surpasses other non-BERT methods which involve the utilization of all three modalities. We speculate that text modality provides more significant information for sentiment analysis task than the other two modalities. CM-BERT exploits audio modality in addition to BERT for further performance boost. Our DEQ fusion benefits from the dynamic and stable modality information modeling, and interaction exchange at every level with our recursive fusion design, outperforming CM-BERT by 1.2%, 0.9%, and 0.9% in Acc7, Acc2, and F1 score, respectively.
| Method + Fusion Method | Modality | [email protected] | [email protected] | Gain on [email protected] |
| GroupFree [32] | P | 63.0 | 45.2 | - |
| GroupFree [32] + Simple Appending | P+RGB | 62.1 | 42.7 | -0.5 |
| VoteNet [48] | P | 57.7 | - | - |
| VoteNet [48] + Simple Appending | P+RGB | 56.3 | - | -1.4 |
| VoteNet [48] + TupleInfoNCE [30] | P+RGB+H | 58.0 | - | +0.3 |
| ImVoteNet [47] | P+RGB | 63.4 | - | - |
| ImVoteNet [47] repro. | P+RGB | 61.9 | 45.6 | - |
| ImVoteNet [47] repro. + DEQ Fusion | P+RGB | 62.7 | 46.4 | +0.8 |
SUN RGB-D. We report mean Average Precision (mAP) with 3D IoU thresholds of 0.25 and 0.5 measured on multiple 3D object detection methods in Table 4. Interestingly, adding the additional RGB modality without advanced fusion mechanism harms the performance, e.g., including RGB modality into GroupFree [32] and VoteNet [48] with simple appending fusion leads to -0.5% and -1.4% performance drop. This is a strong indication of the difficulty in fusing useful RGB information into the extensive point cloud information. TupleInfoNCE [30] designs a contrastive loss for multimodal representation learning, and contributes to a performance gain of +0.3% on [email protected] from VoteNet baseline with additional RGB and height modalities. In addition to VoteNet, ImVoteNet [47] additionally proposes image votes to boost 3D object detection performance. By plugging our DEQ fusion into ImVoteNet, we obtain +0.8% gain on [email protected] compared to ImVoteNet baseline. Note that the performance of our reproduced ImVoteNet (ImVoteNet repro.) is slightly lower than the one reported in the original paper, and our experiments are based on our reproduced implementation.
| Basic Settings | Fusion Method | Yes/no | Number | Other | Overall |
|---|---|---|---|---|---|
| Skip-thoughts + BottomUp | Mutan [10] | 82.40 | 42.63 | 54.85 | 63.73 |
| Skip-thoughts + BottomUp | DEQ Fusion | 82.91 | 45.40 | 55.70 | 64.57 |
| GloVe + BottomUp + Self-Att + Guided-Att | MCAN [67] | 84.67 | 48.44 | 58.52 | 67.02 |
| GloVe + BottomUp + Self-Att + Guided-Att | DEQ Fusion | 85.17 | 49.07 | 58.69 | 67.38 |
VQA-v2. Our experimental results on VQA-v2 based on Mutan [10] and MCAN [67] are shown in Table 5. Mutan [10] initializes GRU with pretrained Skip-thoughts models [25] to process questions, whereas MCAN [67] leverages pretrained GloVe word embeddings [42]. Both methods use bottom-up attention visual features. In addition, MCAN introduces self-attention and guided-attention units to model intra- and inter-modality interactions. Following their basic settings, we replace the fusion method with our DEQ fusion for comparison. We achieve consistent improvements over all evaluation metrics on both baselines, suggesting the superiority of our method.
| F1(%) | |||||
|---|---|---|---|---|---|
| DEQ | Acc(%) | Weighted | Macro | ||
| 87.60.4 | 87.90.4 | 84.30.8 | |||
| 86.20.6 | 86.50.6 | 82.90.9 | |||
| 88.80.4 | 89.40.4 | 87.20.8 | |||
| 88.30.5 | 88.80.5 | 86.01.0 | |||
| 89.10.7 | 89.70.7 | 87.61.0 | |||
4.2 Ablation Studies
We conduct extensive ablation experiments to study the effectiveness of our proposed deep equilibrium fusion method from different perspectives. Table 6 details the results. All ablation studies are evaluated on BRCA benchmark using all three modalities, following the same experimental setup stated in Appendix B. Additional ablation studies on other benchmarks are in Appendix C.
Effectiveness of seeking equilibrium. We first examine the effectiveness of computing the equilibrium state to extract and integrate stable modality information at every level. We first discard all components, i.e., directly fusing with a weighted sum approach: , where is a learnable weight associated with modality . As shown in Table 6, this baseline fusion method obtains similar performance to [16]. Next, we disable the recursive computation in our DEQ fusion module, i.e., all and are only applied once without finding the equilibrium states. Since all inputs are initialized to zero, this approach is equivalent to the weighted sum approach but with an additional nonlinear projection applied to all modality-wise features. Interestingly, introducing additional parameters without DEQ even harms performance compared to the weighted sum baseline. Results from both ablation studies demonstrate the importance of seeking the equilibrium states for multimodal fusion.
Different fusion variants involving DEQ. We compare our DEQ fusion strategy against several variants involving DEQ in Table 6. First, we disable the purified-then-combine fusion strategy, i.e., ablating our fusing projection by simply summating all modality-wise features: . Our full DEQ fusion notably improves all evaluation metrics compared to the runs without the proposed purified-then-combine fusion strategy. Next, we ablate all modality projections as identity functions by setting . Specifically, given a set of features from modalities , we set . and proceed fusion with . We notice a decline in all evaluation metrics without modality-wise nonlinear projections. These studies demonstrate that our proposed fusion variant produces the most encouraging results across all evaluation metrics.
| DEQ | Acc(%) | WeightedF1(%) | MacroF1(%) | |||
|---|---|---|---|---|---|---|
| 88.40.8 | 89.00.8 | 86.11.1 | ||||
| 89.10.7 | 89.70.7 | 87.61.0 |
Impact of soft gating function. Motivated by the success of dynamically perceiving information from modalities, we develop a soft gating function to capture the important information within each modality. We further validate the effectiveness of the proposed soft gating function . Specifically, we set for Eq. 10 to disable the soft gating function. As shown in Table 7, DEQ fusion without soft gating function leads to about -1% performance drop among all evaluation metrics. Note that since is a part of , disabling automatically removes . The soft gating function combined with all other components leads to the most superior result.
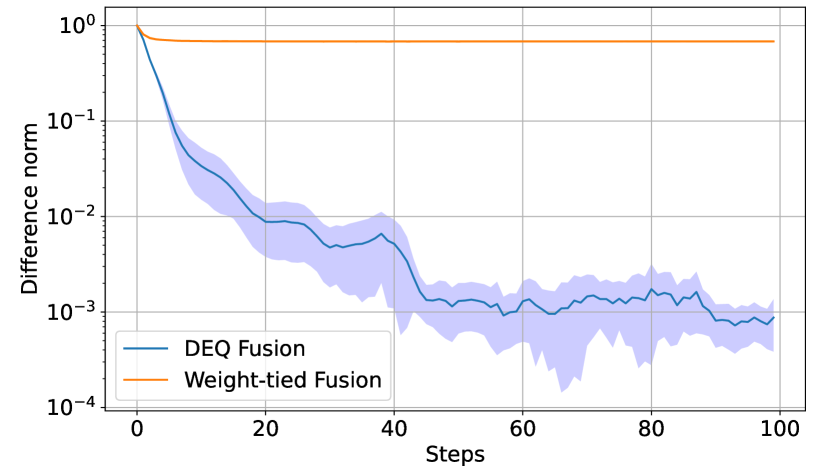
Convergence of DEQ Fusion. We examine the convergence of our DEQ fusion, which is an important assumption since fusion may collapse if it fails to find the equilibrium. We train a model with our DEQ fusion from scratch, and track the relative difference norm evaluated as over 100 solver steps during inference. We compare it with a weight-tied fusion approach which simply iterates our fusion layer and performs backward pass layer-by-layer. Fig. 3 depicts the empirical results. It is notable that the difference norm of our DEQ fusion quickly drops below 0.01 on average within 20 solver steps, whereas the weight-tied fusion oscillates around a relatively high value. Benefiting from fixed point solvers and analytical backward pass, our DEQ fusion has much quicker and stabler convergence to the fixed point than the weight-tied approach.
5 Conclusion
We have presented an adaptive deep equilibrium (DEQ) approach for multimodal fusion. Our approach recursively captures intra- and inter-modality feature interactions until an equilibrium state is reached, encoding cross-modal interactions ranging from low level to high level for effective downstream multimodal learning. This deep equilibrium approach can be readily pluggable into existing multimodal learning frameworks to obtain further performance gain. More remarkably, our DEQ fusion constantly achieves new state-of-the-art performances on multiple multimodal benchmarks, showing its high generalizability and extendability. A common drawback of DEQ in applications is its additional training costs for solving root-finding and uncertain computation costs during inference. Although accelerating DEQ training and inference is not a focus of this work, improving the convergence of DEQs is an important direction, which we leave as future works.
References
- [1] Brandon Amos and J Zico Kolter. Optnet: Differentiable optimization as a layer in neural networks. In International Conference on Machine Learning, pages 136–145. PMLR, 2017.
- [2] Donald G Anderson. Iterative procedures for nonlinear integral equations. Journal of the ACM (JACM), 12(4):547–560, 1965.
- [3] John Arevalo, Thamar Solorio, Manuel Montes-y Gómez, and Fabio A González. Gated multimodal units for information fusion. arXiv preprint arXiv:1702.01992, 2017.
- [4] Pradeep K Atrey, M Anwar Hossain, Abdulmotaleb El Saddik, and Mohan S Kankanhalli. Multimodal fusion for multimedia analysis: a survey. Multimedia Systems, 16(6):345–379, 2010.
- [5] Shaojie Bai, Zhengyang Geng, Yash Savani, and J Zico Kolter. Deep equilibrium optical flow estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 620–630, 2022.
- [6] Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Deep equilibrium models. Advances in Neural Information Processing Systems, 32, 2019.
- [7] Shaojie Bai, Vladlen Koltun, and J Zico Kolter. Multiscale deep equilibrium models. Advances in Neural Information Processing Systems, 33:5238–5250, 2020.
- [8] Shaojie Bai, Vladlen Koltun, and J Zico Kolter. Stabilizing equilibrium models by jacobian regularization. arXiv preprint arXiv:2106.14342, 2021.
- [9] Oresti Banos, Claudia Villalonga, Rafael Garcia, Alejandro Saez, Miguel Damas, Juan A Holgado-Terriza, Sungyong Lee, Hector Pomares, and Ignacio Rojas. Design, implementation and validation of a novel open framework for agile development of mobile health applications. Biomedical Engineering Online, 14(2):1–20, 2015.
- [10] Hedi Ben-Younes, Rémi Cadene, Matthieu Cord, and Nicolas Thome. Mutan: Multimodal tucker fusion for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, pages 2612–2620, 2017.
- [11] Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. Advances in Neural Information Processing Systems, 31, 2018.
- [12] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [13] Jiali Duan, Liqun Chen, Son Tran, Jinyu Yang, Yi Xu, Belinda Zeng, and Trishul Chilimbi. Multi-modal alignment using representation codebook. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15651–15660, 2022.
- [14] Itai Gat, Idan Schwartz, Alexander Schwing, and Tamir Hazan. Removing bias in multi-modal classifiers: Regularization by maximizing functional entropies. Advances in Neural Information Processing Systems, 33:3197–3208, 2020.
- [15] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6904–6913, 2017.
- [16] Zongbo Han, Fan Yang, Junzhou Huang, Changqing Zhang, and Jianhua Yao. Multimodal dynamics: Dynamical fusion for trustworthy multimodal classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20707–20717, 2022.
- [17] Zongbo Han, Changqing Zhang, Huazhu Fu, and Joey Tianyi Zhou. Trusted multi-view classification. arXiv preprint arXiv:2102.02051, 2021.
- [18] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.
- [19] Danfeng Hong, Lianru Gao, Naoto Yokoya, Jing Yao, Jocelyn Chanussot, Qian Du, and Bing Zhang. More diverse means better: Multimodal deep learning meets remote-sensing imagery classification. IEEE Transactions on Geoscience and Remote Sensing, 59(5):4340–4354, 2020.
- [20] Chiori Hori, Takaaki Hori, Teng-Yok Lee, Ziming Zhang, Bret Harsham, John R Hershey, Tim K Marks, and Kazuhiko Sumi. Attention-based multimodal fusion for video description. In Proceedings of the IEEE International Conference on Computer Vision, pages 4193–4202, 2017.
- [21] Ming Hou, Jiajia Tang, Jianhai Zhang, Wanzeng Kong, and Qibin Zhao. Deep multimodal multilinear fusion with high-order polynomial pooling. Advances in Neural Information Processing Systems, 32, 2019.
- [22] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning, pages 448–456. PMLR, 2015.
- [23] Siddhant M. Jayakumar, Jacob Menick, Wojciech M. Czarnecki, Jonathan Schwarz, Jack W. Rae, Simon Osindero, Yee Whye Teh, Tim Harley, and Razvan Pascanu. Multiplicative interactions and where to find them. In International Conference on Learning Representations, 2020.
- [24] Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1725–1732, 2014.
- [25] Ryan Kiros, Yukun Zhu, Russ R Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Skip-thought vectors. Advances in Neural Information Processing Systems, 28, 2015.
- [26] Guohao Li, Matthias Müller, Bernard Ghanem, and Vladlen Koltun. Training graph neural networks with 1000 layers. In International Conference on Machine Learning, pages 6437–6449. PMLR, 2021.
- [27] Paul Pu Liang, Ziyin Liu, Amir Zadeh, and Louis-Philippe Morency. Multimodal language analysis with recurrent multistage fusion. arXiv preprint arXiv:1808.03920, 2018.
- [28] Paul Pu Liang, Yiwei Lyu, Xiang Fan, Zetian Wu, Yun Cheng, Jason Wu, Leslie Chen, Peter Wu, Michelle A Lee, Yuke Zhu, et al. Multibench: Multiscale benchmarks for multimodal representation learning. arXiv preprint arXiv:2107.07502, 2021.
- [29] Yuanzhi Liang, Yalong Bai, Wei Zhang, Xueming Qian, Li Zhu, and Tao Mei. Vrr-vg: Refocusing visually-relevant relationships. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10403–10412, 2019.
- [30] Yunze Liu, Qingnan Fan, Shanghang Zhang, Hao Dong, Thomas Funkhouser, and Li Yi. Contrastive multimodal fusion with tupleinfonce. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 754–763, 2021.
- [31] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021.
- [32] Ze Liu, Zheng Zhang, Yue Cao, Han Hu, and Xin Tong. Group-free 3d object detection via transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2949–2958, 2021.
- [33] Zhun Liu, Ying Shen, Varun Bharadhwaj Lakshminarasimhan, Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency. Efficient low-rank multimodal fusion with modality-specific factors. arXiv preprint arXiv:1806.00064, 2018.
- [34] Cheng Lu, Jianfei Chen, Chongxuan Li, Qiuhao Wang, and Jun Zhu. Implicit normalizing flows. arXiv preprint arXiv:2103.09527, 2021.
- [35] Youssef Mroueh, Etienne Marcheret, and Vaibhava Goel. Deep multimodal learning for audio-visual speech recognition. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2130–2134. IEEE, 2015.
- [36] Arsha Nagrani, Shan Yang, Anurag Arnab, Aren Jansen, Cordelia Schmid, and Chen Sun. Attention bottlenecks for multimodal fusion. Advances in Neural Information Processing Systems, 34:14200–14213, 2021.
- [37] Pradeep Natarajan, Shuang Wu, Shiv Vitaladevuni, Xiaodan Zhuang, Stavros Tsakalidis, Unsang Park, Rohit Prasad, and Premkumar Natarajan. Multimodal feature fusion for robust event detection in web videos. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 1298–1305. IEEE, 2012.
- [38] Ara V. Nefian, Luhong Liang, Xiaobo Pi, Xiaoxing Liu, and Kevin P. Murphy. Dynamic bayesian networks for audio-visual speech recognition. EURASIP Journal on Advances in Signal Processing, 2002:1–15, 2002.
- [39] Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee, and Andrew Y Ng. Multimodal deep learning. In International Conference on Machine Learning, 2011.
- [40] Juan DS Ortega, Mohammed Senoussaoui, Eric Granger, Marco Pedersoli, Patrick Cardinal, and Alessandro L Koerich. Multimodal fusion with deep neural networks for audio-video emotion recognition. arXiv preprint arXiv:1907.03196, 2019.
- [41] Yingwei Pan, Ting Yao, Yehao Li, and Tao Mei. X-linear attention networks for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10971–10980, 2020.
- [42] Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, 2014.
- [43] Juan-Manuel Pérez-Rúa, Valentin Vielzeuf, Stéphane Pateux, Moez Baccouche, and Frédéric Jurie. Mfas: Multimodal fusion architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6966–6975, 2019.
- [44] Hai Pham, Paul Pu Liang, Thomas Manzini, Louis-Philippe Morency, and Barnabás Póczos. Found in translation: Learning robust joint representations by cyclic translations between modalities. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6892–6899, 2019.
- [45] Fernando Pineda. Generalization of back propagation to recurrent and higher order neural networks. In Neural Information Processing Systems, 1987.
- [46] Ashwini Pokle, Zhengyang Geng, and Zico Kolter. Deep equilibrium approaches to diffusion models. arXiv preprint arXiv:2210.12867, 2022.
- [47] Charles R Qi, Xinlei Chen, Or Litany, and Leonidas J Guibas. Imvotenet: Boosting 3d object detection in point clouds with image votes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4404–4413, 2020.
- [48] Charles R Qi, Or Litany, Kaiming He, and Leonidas J Guibas. Deep hough voting for 3d object detection in point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9277–9286, 2019.
- [49] Dhanesh Ramachandram and Graham W Taylor. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Processing Magazine, 34(6):96–108, 2017.
- [50] Sethuraman Sankaran, David Yang, and Ser-Nam Lim. Multimodal fusion refiner networks. arXiv preprint arXiv:2104.03435, 2021.
- [51] Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. Advances in Neural Information Processing Systems, 27, 2014.
- [52] Shuran Song, Samuel P Lichtenberg, and Jianxiong Xiao. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 567–576, 2015.
- [53] Zhongkai Sun, Prathusha Sarma, William Sethares, and Yingyu Liang. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8992–8999, 2020.
- [54] Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In European Conference on Computer Vision, pages 402–419. Springer, 2020.
- [55] Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the conference. Association for Computational Linguistics. Meeting, volume 2019, page 6558. NIH Public Access, 2019.
- [56] Yao-Hung Hubert Tsai, Paul Pu Liang, Amir Zadeh, Louis-Philippe Morency, and Ruslan Salakhutdinov. Learning factorized multimodal representations. arXiv preprint arXiv:1806.06176, 2018.
- [57] Mark A Van De Wiel, Tonje G Lien, Wina Verlaat, Wessel N van Wieringen, and Saskia M Wilting. Better prediction by use of co-data: adaptive group-regularized ridge regression. Statistics in Medicine, 35(3):368–381, 2016.
- [58] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017.
- [59] Valentin Vielzeuf, Alexis Lechervy, Stéphane Pateux, and Frédéric Jurie. Centralnet: a multilayer approach for multimodal fusion. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, pages 0–0, 2018.
- [60] Tongxin Wang, Wei Shao, Zhi Huang, Haixu Tang, Jie Zhang, Zhengming Ding, and Kun Huang. Mogonet integrates multi-omics data using graph convolutional networks allowing patient classification and biomarker identification. Nature Communications, 12(1):1–13, 2021.
- [61] Yikai Wang, Wenbing Huang, Fuchun Sun, Tingyang Xu, Yu Rong, and Junzhou Huang. Deep multimodal fusion by channel exchanging. Advances in Neural Information Processing Systems, 33:4835–4845, 2020.
- [62] Yuxin Wu and Kaiming He. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), pages 3–19, 2018.
- [63] Huijuan Xu, Kun He, Leonid Sigal, Stan Sclaroff, and Kate Saenko. Text-to-clip video retrieval with early fusion and re-captioning. arXiv preprint arXiv:1804.05113, 2018.
- [64] Zihui Xue and Radu Marculescu. Dynamic multimodal fusion. arXiv preprint arXiv:2204.00102, 2022.
- [65] Kaicheng Yang, Hua Xu, and Kai Gao. Cm-bert: Cross-modal bert for text-audio sentiment analysis. In Proceedings of the 28th ACM International Conference on Multimedia, pages 521–528, 2020.
- [66] Guangnan Ye, Dong Liu, I-Hong Jhuo, and Shih-Fu Chang. Robust late fusion with rank minimization. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 3021–3028. IEEE, 2012.
- [67] Zhou Yu, Jun Yu, Yuhao Cui, Dacheng Tao, and Qi Tian. Deep modular co-attention networks for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6281–6290, 2019.
- [68] Amir Zadeh, Paul Pu Liang, Navonil Mazumder, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Memory fusion network for multi-view sequential learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- [69] Amir Zadeh, Paul Pu Liang, Soujanya Poria, Prateek Vij, Erik Cambria, and Louis-Philippe Morency. Multi-attention recurrent network for human communication comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- [70] Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos. arXiv preprint arXiv:1606.06259, 2016.
Appendix A Proof for Backpropagation of DEQ Fusion
Proof of Theorem 1.
Our proof is similar to [6]. We know from Eq. 14, we can first differentiate two sides implicitly with respect to :
| (19) | ||||
Rearranging Eq. 19, we obtain
| (20) |
Differentiating Eq. 15 with respect to , we obtain the Jacobian
| (21) |
Therefore .
Similarly, we have from Eq. 14. Differentiating both sides with respect to :
| (22) | ||||
Rearranging Eq. 22, we have
| (23) |
Similar to computation in Eq. 21, we have:
| (24) |
Thus .
Finally, we can differentiate loss with respect to :
| (25) | ||||
∎
Appendix B Experimental Setup
We conduct the experiments on NVIDIA Tesla V100 GPUs and use Anderson acceleration [2] as the default fixed point solver for all our experiments.
BRCA. We experiment based on the current state-of-the-art approach [16] by replacing the original concatenation fusion with our DEQ fusion. Following [16], the learning rate is set to 0.0001 and decays at the rate of 0.2 every 500 steps. As the dataset is relatively small, we additionally leverage dropout in fusion layer and early stopping to prevent overfitting. Jacobian regularization loss with a loss weight of 20 is employed to stabilize training. We report the mean and standard deviation of the experimental results over 10 runs.
MM-IMDB. Our implementation and experiments on MM-IMDB are based on MultiBench [28]. We follow the data split and feature extraction methods presented in [3] for data preprocessing. Jacobian regularization loss with a loss weight of 0.1 is exploited. To further stabilize training, we additionally set a smaller learning rate of 0.0001 for our DEQ fusion module, and 0.001 for all other weights.
CMU-MOSI. We conduct the experiments with the state-of-the-art CM-BERT [65] by replacing the original simple addition fusion strategy with our DEQ fusion. We follow [8] and use Jacobian regularization loss with a loss weight of 0.01 to stabilize DEQ training.
SUN RGB-D. We conduct the experiments based on ImVoteNet [47]. We use the public train-test split (5,285 vs 5,050). We follow the hyperparameter settings and training details in the officially released codebase222https://github.com/facebookresearch/imvotenet except that we trained the models on 4 GPUs with a batch size of 32 for 140 epochs for fast convergence.
VQA-v2. Our experiments are based on Mutan [10] and MCAN [67]. All methods are trained on the train set (444k samples) and evaluated on the validation set (214k samples). Our Mutan333https://github.com/Cadene/vqa.pytorch and MCAN444https://github.com/MILVLG/mcan-vqa results are reproduced based on their official codebases respectively. For a fair comparison, we apply the bottom-up-attention visual features for all experiments and only use the VQA-v2 training set (disabled VisualGenome and VQA-v2 val set) for model training. Our reproduced Mutan baseline has better performance than the other reproduced version in [29] (63.73% vs. 62.84% in overall accuracy) under the same settings. For MCAN, we select its “Large” model setting as our baseline.
Appendix C Additional Ablation Studies
We additionally conduct ablation studies on MM-IMDB and CMU-MOSI, the results are shown in Table 8. The same experimental setup as demonstrated in Appendix B is used. Note that if is not used, is automatically disabled (denoted as “-”). The conclusions are similar to the one made in Section 4.2, except that we do not observe the performance drop with our additional and (first row and second row). A potential reason is that BRCA is a relatively small dataset, and thus can be easily overfitted with more weights. Nonetheless, all empirical results demonstrate that DEQ fusion with all proposed components leads to the most superior results.
| MM-IMDB | CMU-MOSI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| DEQ | MicroF1 | MacroF1 | Acc-7 | Acc-2 | F1 | MAE | Corr | |||
| - | 58.76 | 49.63 | 43.3 | 83.3 | 83.2 | 0.755 | 0.786 | |||
| 60.73 | 52.64 | 43.0 | 83.6 | 83.6 | 0.757 | 0.787 | ||||
| - | 59.80 | 49.27 | 43.7 | 84.8 | 84.9 | 0.741 | 0.782 | |||
| 60.76 | 53.09 | 45.3 | 84.4 | 84.3 | 0.747 | 0.782 | ||||
| 60.83 | 52.67 | 43.8 | 83.1 | 83.1 | 0.751 | 0.789 | ||||
| 61.52 | 53.38 | 46.1 | 85.4 | 85.4 | 0.737 | 0.797 | ||||
| Dataset | step 1 | step 10 | step 20 | step 40 | step 100 |
|---|---|---|---|---|---|
| BRCA | 7.06e-1 | 3.38e-2 | 8.80e-3 | 5.18e-3 | 1.29e-3 |
| MM-IMDB | 2.86e-1 | 9.17e-4 | 7.65e-5 | 8.87e-6 | 2.17e-6 |
| CMU-MOSI | 3.09e-2 | 4.16e-7 | 6.94e-8 | 5.66e-8 | 5.66e-8 |
In addition to the convergence ablation study on BRCA, we further examine the convergence of DEQ fusion on MM-IMDB and CMU-MOSI. The results are in Table 9. DEQ fusion successfully converges on all three benchmarks, whereas the convergence rate on MM-IMDB and CMU-MOSI is considerably faster than on BRCA.