Deep convolutional neural networks for face and iris presentation attack detection: Survey and case study
Abstract
Biometric presentation attack detection is gaining increasing attention. Users of mobile devices find it more convenient to unlock their smart applications with finger, face or iris recognition instead of passwords. In this paper, we survey the approaches presented in the recent literature to detect face and iris presentation attacks. Specifically, we investigate the effectiveness of fine tuning very deep convolutional neural networks to the task of face and iris antispoofing. We compare two different fine tuning approaches on six publicly available benchmark datasets. Results show the effectiveness of these deep models in learning discriminative features that can tell apart real from fake biometric images with very low error rate. Cross-dataset evaluation on face PAD showed better generalization than state of the art. We also performed cross-dataset testing on iris PAD datasets in terms of equal error rate which was not reported in literature before. Additionally, we propose the use of a single deep network trained to detect both face and iris attacks. We have not noticed accuracy degradation compared to networks trained for only one biometric separately. Finally, we analyzed the learned features by the network, in correlation with the image frequency components, to justify its prediction decision.
1 Introduction
Biometric recognition has been increasingly used in recent application that need authentication and verification. Instead of normal username and password or token-based authentication, the use of biometric traits like face, iris or fingerprints are more convenient to the users and so has gained a lot of popularity specially after the wide spread of smartphones and its usage in a lot of areas, such as payment. However, with the increase of technology, spoofing these biometric traits has become more easy. For example, an attacker can use a photograph or a video replay of the face or iris or a person to gain access to his/her smartphone or any application that needs authorization. Such act is referred to by the ISO/IEC 30107-1:2016 standard as presentation attack (PA) and the biometric or object used in PA is called an artifact or presentation attack instrument (PAI). This has lead to the increase of interest in designing algorithms that guard against these attacks, and so are called presentation attack detection (PAD) algorithms.
Lots of research has been done in this area, starting with methods that basically depend on designing and extracting hand-crafted features from the acquired images then using conventional classifiers to detect bona-fide (real) from attack presentations. Literature shows that methods relying on manually engineered features are suitable for solving the PAD problem for face and iris recognition systems. However, the design and selection of handcrafted feature extractors is mainly based on expert knowledge of researchers on the problem. Consequently, these features often reflect limited aspects of the problem and are often sensitive to varying acquisition conditions, such as camera devices, lighting conditions and PAIs. This causes their detection accuracy to vary significantly among different databases, indicating that the handcrafted features have poor generalizability and so do not completely solve the PAD problem.
In recent years, deep learning has evolved and the use of deep neural networks or convolutional neural networks (CNN) has proven to be effective in many computer vision tasks especially with the availability of new advanced hardware and large data. CNNs have been successfully used for vision problems like image classification and object detection. This has encouraged many researchers to incorporate deep learning in the PAD problem, and rely on a deep network or CNN to learn features that discriminate between bona-fide and attack face 319_18_f ; 317_18_f or iris 305_18_i ; 306_18_i or both 312_18_fi , instead of using hand-crafted features. Several of these researches used CNN only for feature extraction followed by a classic classifier like SVM, others designed custom networks or combined information from CNN and hand-crafted features.
Several surveys for presentation attack detections in either face or iris recognition are available in literature. Czajka and Bowyer provided a thorough assessment of the state-of-the-art for iris PAD in 183_18 and concluded that PAD for iris recognition is not a solved problem yet. Their main focus was on iris presentation attack categories, their countermeasures, competitions and applications.
For PAD in face recognition systems, Raghavendra and Bush provided a comprehensive survey in 526_17_f describing different types of presentation attack and face artifacts, and showing the vulnerability of commercial face recognition systems to presentation attack. They survey and evaluate fourteen state-of-the-art face PAD algorithms on CASIA face-spoofing database and discuss the remaining challenges and open issues for a robust face presentation attack detection system. In 503_17_f , Ghaffar and Mohd focused their review on face PAD systems on smartphones with recent face datasets captured with mobile devices.
Later, Li et al. 502_18_f provided a comprehensive review of more recent PAD algorithms in face recognition, discussing the available datasets and reported results. They proposed a color-LBP based countermeasure as a case study and evaluated it on two benchmark face datasets highlighting the importance of cross-dataset testing.
In this work, we survey most of the recent PAD approaches proposed in literature for both face and iris recognition applications, along with the competitions and benchmark datasets. Then for a case study, we assess the performance of recent well-known deep CNN architectures on the task of face and iris presentation attack detection.
For assessment we use 3 different face datasets and 3 iris datasets. Using just the RGB images as input, we finetune the deep network’s weights then perform intra and cross-dataset evaluation to discuss the generalization ability of these deep models. The experiments are first done with separate models trained for each of face and iris biometric, then we experiment with training a single network to generally tell apart bona-fide from attack samples whether the sample is a face or an iris image. Such generic PAD network could perfectly differentiate between the real and attack images. The specific features learned by this network are analyzed showing that these features are highly related to high frequency regions in the input images. We finally use gradient-weighted class activation maps gradcam to visualize what the network focuses on when deciding if a sample is bona-fide or not.
Hence, the main contributions of this work include: (1) Survey the recent methods for presentation attack detection in both face and iris modalities with competitions and datasets, (2) Demonstrate the effectiveness of CNN for the PAD problem, by finetuning and comparing recent deep CNN architectures on 3 benchmark face datasets and 3 benchmark iris datasets, experimenting with two finetuning approaches and applying cross-dataset evaluation, (3) Train a single network for presentation attack detection of the two biometric modalities, and compare the results with networks trained on single biometric, (4) Analyze specific features learned by the commonly-trained network and (5) Finally, visualize the class activation maps of the trained network on sample bona-fide and attack images.
The rest of the paper is organized as follow, we first review the PAD approaches which can broadly be categorized into active (Section 2) vs passive (Section 3) PAD techniques. Then in Section 4, we summarize the face and iris PAD competitions and benchmark databases, followed by Section 5 where we explain the proposed PAD approach. Experiments, results and analysis are presented in Section 6 and finally conclusion and future work in Section 7.
2 Active PAD
Active Presentation Attack Detection can either be hardware-based or depending on challenge-response, both will be highlighted in details in this section.
2.1 Hardware-based
Such methods depend on capturing the automatic response of the biometric trait (face/iris) to a certain stimulus. For example in iris liveness detection, the use of eye hippus, which is the permanent oscillation that the eye pupil presents even under uniform lighting conditions, or the dilation of pupil in reaction to sudden illumination changes 111_04 ; 104_12 ; 107_06 ; 150_15 ; 172_14 . Variations of pupil dilation were calculated by Bodade et al. 148_09 from multiple iris images while Huang et al. 149_13 used pupil constriction to detect iris liveness. Other researchers used the iris image brightness variations after light stimuli in some predefined iris regions 119_07 . Or the reflections of infrared light on the moist cornea when stimulated with light sources positioned randomly in space. Lee et al. 145_10 used additional infrared sensors during iris image acquisition to construct the full 3d shape of the iris to aid in the detection of fake iris images or contact lenses. These approaches rely on an external specific device to be added to the sensor/camera, hence the naming "hardware-based techniques". However, not all hardware-based methods are active, some such approaches detect facial thermogram hwp1_15_f ; hwp2_15_f , blood pressure, fingerprint sweat, gait etc passively in a non-intrusive manner.
2.2 Challenge-response
2.3 Drawbacks of active PAD methods
Although active spoof detection methods may provide higher presentation attack detection rates and robustness against different presentation attack types, they are more expensive and less convenient to users than the software-based approaches which do not include any additional devices beside the standard camera. For the rest of this survey we will focus on software-based methods; they are more generic, less expensive, less intrusive and can easily be incorporated in real-world applications and smartphones. Table 2.3 summarizes the different approaches used in literature for detection of presentation attacks.
PAD methods in literature. \toprule PAD Method Advantage Weakness \midrule Active (Hardware-based or Challenge-response) - Eye hippus or Pupil-dilation: 111_04 ; 104_12 ; 107_06 ; 150_15 ; 172_14 ; 148_09 ; 149_13 ; 119_07 ; 145_10 - Challenge: "blink eye" or "rotate head": 531_11_f ; 562_15_f ; 528_08_f ; 563_13_f Robust against different PA types Higher PA detection rates More expensive Less convenient to users Rely on an external device \midrule Passive (Software-based): Liveness-detection - Eye blinking: 529_09_f ; 528_08_f ; 513_13_f ; 506_07_f ; 318_16_f - Facial expression changes, head and/or mouth movements: 521_12_f ; 520_08_f ; 519_07_f - Eye movements and gaze estimationf for iris: 152_13 ; 174_15 ; 175_14 ; 178_15 Utilize features extracted from consecutive frames. Detect signs of life in captured biometric data. Can be easily fooled by a replay video or by adding liveness properties to a still face image by cutting the eye/mouth parts Recapturing-detection - Detect abnormal movements in the video due to a hand holding the presenting media 523_16_f ; 507_10_f - Track the relative movements between different facial parts 508_09_f ; 509_09_f - Motion magnification 511_16_f ; 513_13_f - Visual rhythm analysis 535_12_f . - Contextual analysis of 531_11_f ; 530_13_f ; 521_12_f ; varF_13_f - 3d reconstruction thrD_13_f Very effective for replay attacks Fail if the attack is done using an artifact like a mask Texture-based (Hand-crafted features) - Texture-reflectance 538_13_f ; 537_13_f ; 536_13_f - Frequency 518_04_f ; 507_10_f ; b_12_f ; 534_13_f ; 109_13 - Image Quality analysis 104_12 ; 108_09 ; 119_07 ; 155_14 ; 164_14 ; 514_16_f ; 515_15_f ; 516_14_f ; 500_18_fi ; 505_17_fi ; 104_12 - Color analysis 515_15_f ; 550_15_f ; 545_16_f ; 546_17_f ; compet_f3 ; 518_04_f ; 187_16 ; 555_18_f . - Local-descriptors 533_11_f ; 543_13_f ; 544_15_fi ; 552_13_f ; 540_13_f ; 532_11_f ; 547_12_f ; 548_13_f ; 549_12_f ; 556_15_f ; 553_16_f ; 546_17_f ; 548_13_f ; 549_12_f ; 541_11_f ; 530_13_f ; 310_15_f ; 554_11_f ; 507_10_f ; 541_11_f ; 161_15 ; 171_15 ; 544_15_fi ; 558_14_fi - Fusion 542_11_f ; 541_11_f ; 540_13_f ; 543_13_f ; 311_16_f ; 558_14_fi ; 305_18_i ; 306_18_i Detect effects caused by printers and display devicesFaster than temporal or motion-based analysis Operate with only one image sample, or a selection of images, instead of video sequence. Design and selection of feature extractors is based on expert knowledge. Sensitive to varying acquisition conditions, such as camera devices, lighting conditions and PAIs. Have poor generalizability. Learned-features - Extract deep features, classify classic 315_16_f ; 318_16_f ; 304_18_f - Combine with temporal information 311_16_f ; 310_15_f - Other 301_17_f ; 300_18_f ; 302_18_f ; 300_18_f ; 313_14_f ; 319_18_f ; 314_17_f ; 316_17_f ; 317_18_f - For iris 305_18_i ; 306_18_i ; 307_17_i ; 309_15_i ; 320_18_i ; 321_18_i - Face and iris 308_15_fi ; 312_18_fi Instead of hand engineering features Deep network learns features that discriminate between bona-fide and attack samples Can be used jointly with hand-crafted features or motion-analysis Requires more data Can fail to generalize to unseen sensors \botrule
3 Passive Software-based PAD
Passive software-based antispoofing methods can be categorized into several groups. Temporal, or motion-analysis, based approaches which utilize features extracted from consecutive frames captured for the face or iris. Or texture-based methods that use single image of the biometric trait and does not depend on motion features. Such texture-based PAD methods can further be classified into either a group that depends on hand-crafted features vs. another group of recent methods that opt to learn these discriminative features.
3.1 Liveness-detection
The earliest category include approaches that identify whether the presented biometric is live or an artifact, such approaches are known as "liveness-detection". An artifact can be a mask or paper in case of face spoofing and paper or a glass-eye for iris. These methods depend on detecting signs of life in captured biometric data. Examples in the case of face PAD are eye blinking 529_09_f ; 528_08_f ; 513_13_f ; 506_07_f ; 318_16_f , facial expression changes, head and/or mouth movements 521_12_f ; 520_08_f ; 519_07_f . For the iris PAD, Komogortsev et al. 152_13 extracted liveness cues from eye movement in a simulated scenario of an attack by a mechanical replica of the human eye. The authors further investigated in this line and published more iris liveness detection methods, based on eye movements and gaze estimation, in later years 174_15 ; 175_14 ; 178_15 .
Liveness-detection methods are considered temporal-based and can be easily fooled by a replay video of the face or iris or by adding liveness properties to a still face image by cutting the eye/mouth parts.
3.2 Recapturing-detection / contextual information
Another approach that belongs to the temporal-based category are methods that simply detect if the biometric data is a replay of a recorded sample, referred to as recapturing-detection. These methods analyze the scene and environment to detect abnormal movements in the video due to a hand holding the presenting 2D mobile device or paper 523_16_f ; 507_10_f . Such movements are different than movement of a real face with a static background. Sometimes these techniques are referred to as motion-analysis depending on motion cues from planar objects. Some use optical flow to capture and track the relative movements between different facial parts to determine spoofing 508_09_f ; 509_09_f , while other researches use motion magnification 511_16_f ; 513_13_f , Haralick features 510_16_f or visual rhythm analysis 535_12_f . Other types depend on contextual analysis of the scene 531_11_f ; 530_13_f ; 521_12_f ; varF_13_f or 3d reconstruction thrD_13_f .
The recapture detection methods fail if the attack is done using an artifact like a mask, because no replay is present to detect. So a better and more generic approach is using texture-based methods which utilize features that can tell the difference between real live biometric data and a replay or an artifact being presented to the sensor.
3.3 Texture-based (Hand-crafted features)
The category of texture-based methods assumes that the texture, color and reflectance characteristics captured by genuine face images are different from those resulting from presentation attacks. For example, blur and other effects caused by printers and display devices lead to detectable color artifacts and texture patterns, which can then be explored to detect presentation attacks.
Researchers use handcrafted image feature extraction methods to extract image features from face or iris images. They then use a classification method such as support vector machines (SVM) to classify images into two classes of bona-fide or presentation attack based on the extracted image features. Such techniques are faster than temporal or motion-based analysis, as they can operate with only one image sample, or a selection of images, instead of having to analyze a complete video sequence.
3.3.1 Texture-reflectance
These techniques analyze appearance properties of face or iris, such as the face reflectance or texture. The reflectance and texture of a real face or iris are different than those acquired from a spoofing material; either printed paper, screen of a mobile device, mask 538_13_f ; 537_13_f ; 536_13_f or glass eye.
3.3.2 Image Quality analysis
Techniques that depend on analysis of image quality try to detect the presence of image distortion usually found in the spoofed face or iris image.
(1) Deformation for Face
For example, in print attacks, the face might be skewed with deformed shape if an imposter bends it while holding.
(2) Frequency
Based on the assumption that the reproduction of previously captured images or videos affects the frequency information of the image when displayed in front of the sensor. The attack images or videos have more blur and less sharpness than the genuine ones, and so their high frequency components are affected. Hence frequency domain analysis can be used as a face PAD method as in 518_04_f ; 507_10_f ; b_12_f or frequency entropy analysis by Lee et al. 534_13_f . For iris, Czajka 109_13 analyzed printing regularities left in printed irises and explored some peaks in the frequency spectrum. Frequency-based approaches might fail in case of high-quality spoof images or videos being presented to the camera.
(3) Quality metrics
Some other methods explore the potential of quality assessment to identify real and fake face or iris samples acquired from a high quality printed image. This is assuming that many image quality metrics are distorted by the display device or paper. Some researches used individual quality-based features, while others used a combination of quality metrics to better detect spoofing and differentiate between bona-fide and attack iris 104_12 ; 108_09 ; 119_07 ; 155_14 ; 164_14 or face 514_16_f ; 515_15_f ; 516_14_f or both 500_18_fi ; 505_17_fi . For example, Gabally et al. 104_12 investigated 22 iris-specific quality features and used feature selection to choose the best combination of features that discriminate between live and fake iris images. Later, in a follow-up work 565_14_fi , they assessed 25 general image-quality metrics and not only applied on iris PAD but also used the method for face and fingerprint PAD. Other different approach by Garicia et al. 524_15_f was to analyze moire patterns which may be produced during image acquisition then display on mobile devices.
(4) Color analysis
Another type of algorithms utilize the fact that the distribution of color in images taken from bona-fide face or iris, is different than the distribution found in images taken from printed papers or display device. Methods for face PAD adopt solutions in a different input domain than RGB space in order to improve the robustness to illumination variation, like HSV and YCbCr color space 515_15_f ; 550_15_f ; 545_16_f ; 546_17_f ; compet_f3 or Fourier spectrum 518_04_f . For iris PAD, color adaptive quantized patterns were used in 187_16 instead of using a gray-textured image. Z. Boulkenafeta et al. studied the generalization of color-texture analysis methods in 555_18_f .
3.3.3 Local-descriptors
A different group of methods use hand-crafted features which extract local-texture for PAD 533_11_f ; 543_13_f . A large variety of local image descriptors have been compared with respect to their ability to identify spoofed iris, fingerprint, and face data 544_15_fi and some highly successful texture descriptors have been extensively used for this purpose. For example, in face PAD methods, descriptors such as local binary pattern (LBP) 552_13_f ; 540_13_f ; 532_11_f ; 547_12_f ; 548_13_f ; 549_12_f ; 556_15_f , SIFT 553_16_f , SURF 546_17_f , HoG 548_13_f ; 549_12_f ; 541_11_f ; 530_13_f ; 310_15_f , DoG 554_11_f ; 507_10_f and GLCM 541_11_f have been studied showing good results in discriminating real from attack face images. For PAD in iris recognition, boosted LBP was first used by He et al. 114_09 , weighted LBP by Zhang et al. 124_10 for contact lens detection and later, binarized statistical image features (BSIF) 161_15 ; 171_15 . Local phase quantization (LPQ) was investigated for biometric PAD in general, including both face and iris, by Gragnaniello et al. 544_15_fi , and census transform (CT) was used for mobile PAD in 558_14_fi . Such local texture descriptors were then used with a traditional classifier like SVM, LDA, neural networks and Random Forest.
3.3.4 Drawback of hand-crafted texture-based methods
Results of above methods show that the manually engineered features are suitable for solving the PAD problem for face and iris recognition systems. However, their drawback is that the design and selection of handcrafted feature extractors is mainly based on expert knowledge of researchers on the problem. Consequently, these features often only reflect limited aspects of the problem and are often sensitive to varying acquisition conditions, such as camera devices, lighting conditions and presentation attack instruments (PAIs). This causes their detection accuracy to vary significantly among different databases, indicating that the handcrafted features have poor generalizability and so do not completely solve the PAD problem. The available cross-database tests in the literature suggest that the performance of hand-engineered texture-based techniques can degrade dramatically when operating in unknown conditions. Leading to the need of automatically extracting vision meaningful features directly from the data using deep representations to assist in the task of presentation attack detection.
3.4 Fusion
The presentation attack detection accuracy can be enhanced by using feature-level or score-level fusion methods to obtain a more general countermeasure effective against a various types of presentation attack. For face PAD, Tronci et al. 542_11_f propose a linear fusion at a frame and video level combination between static and video analysis. In 541_11_f , Schwartz et al. introduce feature level fusion by using Partial Least Squares (PLS) regression based on a set of low-level feature descriptors. Some other works 540_13_f ; 543_13_f obtain an effective fusion scheme by measuring the level of independence of two anti-counterfeiting systems. While Feng et al. in 311_16_f integrated both quality measures and motion cues then used neural networks for classification.
In the case of iris anti-spoofing, Z. Akhtar et al. 558_14_fi proposed to use decision-level fusion on several local descriptors in addition to global features. More recently Nguyen et al. 305_18_i ; 306_18_i explored both feature-level and score-level fusion of hand-crafted features with CNN extracted features, and obtained least error using the proposed score-level fusion methodology.
3.5 Smartphones
In the last few years, research based on smartphone and mobile device PAD is gaining popularity. Many different algorithms have been developed and datasets were released to test their performance. These databases became publicly available and we will list in this section some of these datasets together with the algorithm proposed by the authors.
One of the first databases that was dedicated for face PAD on smartphones is MSU-MFSD 515_15_f , the authors Wen et al. used a PAD method depending on image distortion analysis. Later, the same group released MSU-USSA 553_16_f and used a combination of texture analysis (LBP and color) and image analysis techniques. In 2016, the IDIAP Research Institute released the Replay-Mobile 564_16_f database and again a combinations of the Image Quality Analysis and Texture Analysis (Gabor-jets) were used as the proposed PAD.
In the field of Iris spoofing, MobBioFake dataset 155_14 ; 166_14 was presented in 2014 that was the first to use visible spectrum instead of near-infrared for iris spoofing where the acquisition sensor is a mobile device. Sequeira et al. 155_14 used texture-based iris PAD algorithm, they combined several image quality features at the feature level and used SVM for classification. Gragnaniello et al. 154_15 proposed a solution based on local-descriptors but with very low complexity and required low CPU power suitable for mobile applications. They evaluated on MobBioFake and MICHE 559_14_fi datasets and achieved good performance.
3.6 Learned-features
In recent years, deep learning has evolved and the use of deep neural networks or convolutional neural networks (CNN) has proved to be effective in many computer vision tasks especially with the availability of new advanced hardware and large data. CNNs have been successfully used for vision problems like image classification and object detection. This has encouraged many researchers to incorporate deep learning in the PAD problem. Instead of using hand-crafted features, rely on a deep network or CNN to learn features that discriminate between bona-fide and attack face 311_16_f ; 313_14_f ; 315_16_f ; 318_16_f ; 319_18_f ; 314_17_f ; 316_17_f ; 317_18_f or iris 305_18_i ; 306_18_i ; 307_17_i ; 309_15_i or both 308_15_fi ; 312_18_fi . Some proposed to use hybrid features that combine information from both handcrafted and deeply-learnt features.
Several works use a pretrained CNN as a feature extractor, then use a normal classifier as SVM for classification, like in 315_16_f . Li et al. 315_16_f finetune a pretrained VGG CNN model on ImageNet p1_15 , use it to extract features, reduce dimensionality by principal component analysis (PCA) then classify with SVM. Combining deep features with motion cues was proposed in several face video spoof detection. In 318_16_f , Patel et al. finetuned a pretrained VGG for texture features extraction in addition to using frame difference as motion cue. Similarly, Nguyen et al. 304_18_f used VGG for deep feature extraction then fused it with multi-level LBP features, and used SVM for final classification. Feng et al. 311_16_f combine image quality information together with motion information from optical flow as input to a neural network for classification of bona-fide or attack face. Xu et al.propose an LSTM-CNN architecture to utilize temporal information for binary classification in 310_15_f .
Atoum et al. 301_17_f propose a two-steam CNN-based face PAD method using texture and depth, they utilized both full face and patches from the face with different color spaces instead of RGB. They evaluated on three benchmark databases but did not perform cross-dataset evaluation. Later, Liu et al. 300_18_f extended and refined this work by learning another auxiliary information, rPPG signal, from the face video and evaluated their depth-supervised learning approach on more recent datasets OULU-NPU oulu and SiW. Wang et al. 302_18_f did not consider depth as an auxiliary supervision like in 300_18_f , however, they used multiple RGB frames to estimate face depth information, and used two modules to extract short and long-term motion. Four benchmark datasets were used to evaluate their approach.
Use of CNN by itself for the sake of classifying attack vs bona-fide iris images has been investigated in recent years. Andrey K. et al. 320_18_i proposed to use a lightweight CNN on binarized statistical image features extracted from the iris image, they evaluated their proposed algorithm on LivDet-Warsaw 2017 182_17 and other 3 benchmark datasets. In 321_18_i Hoffman et al. proposed to use 25 patches of the iris image as input to the CNN instead of the full iris image. Then a patch-level fusion method is used to fuse scores from the input patches based on the percentage of iris and pupil pixels inside each patch. They performed cross-dataset evaluation on LivDet-Iris 2015 Warsaw, CASIA-Iris-Fake, and the BERC-Iris-Fake datasets and used true detection rate (TDR) at 0.2% false detection rate (FDR) as their evaluation metric.
4 Competitions and Databases
In this section, we summarize the face and iris PAD competitions held in addition to benchmark datasets used to evaluate performance of the face or iris presentation attack detection solutions. All these databases are publicly available upon request from the authors. Table 4.1 shows summary of information about all six datasets used.
4.1 Competitions
Since 2011, several competitions were held to assess the status of presentation attack detection for either face or iris. Such competitions were very useful for collecting new benchmark datasets and creating a common framework for evaluating the different PAD methods.
For face presentation attack detection, three competitions were carried out since 2011. The first competition was held during 2011 compet_f1 on the IDIAP Print-Attack dataset 533_11_f with six competing teams, the winning methodology was using hand-engineered texture-based approaches which proved to be very effective to detect print attacks. After two years, the second face PAD competition was carried out in 2013 compet_f2 with 8 participating teams, on the Replay-Attack dataset 547_12_f . Most of the teams relied only on texture-based methods, while 3 teams used hybrid approaches combining both texture and motion based countermeasures. Two of these hybrid approaches reached 0% HTER on the test set of the Replay-Attack database.
Later in 2017, a competition was held on generalized software-based face presentation attack detection in mobile scenarios compet_f3 . Thirteen teams participated and four protocols were used for evaluation. The winning team that showed best generalization to unseen cameras and attack types, used a combination of color, texture and motion-based features.
More recently, after the release of the large-scale multi-modal face anti-spoofing dataset, CASIA-SURF 303_19_f ; the Chalearn LAP Multi-Modal Face anti-spoofing Attack Detection Challenge chalearn_19_f was held in 2019. Thirteen teams were qualified for the final round with all submitted face PAD solutions relying on CNN-based feature extractors. The top 3 teams utilized ensembles of feature extractors and classifiers. For future work, the challenge paper suggested to take full advantage of the multi-modal dataset, by defining a set of cross-modal testing protocols, as well as introducing 3D mask attacks in addition to the 2D attacks. These recommendations were later fulfilled in the following year, at the Chalearn Multi-modal Cross-ethnicity Face anti-spoofing Recognition Challenge, using the CASIA-SURF CeFA db_19_f dataset.
For iris presentation attack detection, the first competition was LivDet-Iris 2013 159_14 then two more sequels for this competition were held in 2015 181_15 and 2017 182_17 . Images in LivDet-Iris included iris printouts and textured contact lenses which were more difficult to detect than printouts. For LivDet-Iris 2017, the test images were split into known and unknown parts, where the known part contained images that were taken under similar conditions with the same sensor as training images. On the other hand, the unknown partition consisted of images taken in different environment with different properties. Results on known partition were much better than those on the unknown part. In 2014, another competition was held in 2014 specifically for mobile authentication; Mobile Iris Liveness Detection Competition (MobILive 2014) 156_14 . A mobile device was used to capture images of iris printouts in visible light; MobBioFake dataset, not infra-red light as datasets used in LivDet-Iris competitions. Six teams participated and the winning team achieved perfect detection of presentation attack. For a more thorough assessment of these iris competitions, refer to Czajka and Bowyer 183_18 .
Properties of used face and iris databases. \topruleDatabase Number of samples Resolution FPS / Video (Attack + Bona-fide) ( W * H ) duration (face videos) \midruleReplay-Attack (Face) (videos) 25 / 9-15 seconds MSU-MFSD (Face) (videos) 30 / 9-15 seconds Replay-Mobile (Face) 640 + 390 (videos) 30 / 10-15 seconds Warsaw 2013 (Iris) (images) - ATVS-FIr (Iris) (images) - MobBioFake (Iris) (images) - \botrule
Face databases details. \topruleDataset Sensor used for authentication PA artifact PAI (Presentation Attack Instrument) Lighting conditions (bona-fide / attack) Subjects (train / dev / test) Videos per subject (bona-fide + attack) Videos per subset (bona-fide + attack) \midrule Replay-Attack (2012) (1) W in MacBook laptop () 1) PH 2) 720p high-def V : Canon PowerShot SX150 IS 1) PR (A4) 2) VR on M (iPhone) 3) VR on T (iPad) 2 / 2 50 (15/15/20) 4 + 20 Train : 60+300 Dev : 60+300 Test : 80+400 \midrule CASIA-FASD (2012) 1) Low Q: longtime-used USB C () 2) Normal Q: new USB C () 3) High Q: Sony NEX-5 () 1) PH 2) 720p high-def V : Sony NEX-5 1) PR (copper A4) - Warped 2) PR (copper A4) - Cut 3) VR on T (iPad) 1 / 1 50 (20/-/30) 3 + 9 Train : 60+180 Test : 90+270 \midrule MSU-MFSD (2014) 1) W in MacBook Air () 2) FC of Google Nexus 5 M () 1) PH (Canon PowerShot 550D SLR) 2) 1080p high-def V (Canon PowerShot 550D SLR) 3) 1080p M V (BC of iPhone S5) 1) PR (A3) 2) high-def VR on T (iPad) 3) M VR on M (iPhone) 1 / 1 35 (15/-/20) 2 + 6 Train : 30+90 Test : 40+120 \midrule Replay-Mobile (2016) 1) FC of iPad Mini2 T () 2) FC of LG-G4 M () 1) PH (Nikon coolix P520) 2) 1080p M V (BC of LG-G4 M) 1) PR (A4) 2) VR on matte-screen (Philips 227ELH screen) 5 / 2 40 (12/16/12) 10 + 16 Train : 120+192 Dev : 160+256 Test : 110+192 \midrule OULU-NPU (2017) FC of 6 M () 1) PH 2) high-res M V : BC of Samsung Galaxy S6 Edge M 1-2) PR (glossy A3) - 2 Printers 3) High-res VR on 19 inch Dell display 4) High-res VR on 13 inch Macbook 3 / 3 55 (20/15/20) 36+72 4 Protocols Total: 1980+3960 \midrule SiW (2018) 1) High Q C: Canon EOS T6 () 2) High Q C: Logitech C920 W () 1) PH (5, 184 x 3, 456) 2) Use same live videos 1) PR 2) PR of frontal-view frame from a live V 3-6) VR on 4 screens: Samsung S8, iPhone7, iPad Pro, PC 1 / 1 165 (90/-/75) 8 + 20 3 Protocols Total: 1320+3300 \midrule CASIA-SURF (2018) 1) RealSense SR300 - RGB: () - Depth/IR: () 1) PH 1) PR (A4) 1 / 1 1000 (300/100/600) 1 + 6 Train: 900+5400 Dev: 300+1800 Test: 1800+10800 \midrule CASIA-SURF CeFA (2019) 1) Intel Realsense - RGB/Depth/IR - all () 1) PH 2) Same live videos 3) 3D print face mask 4) 3D silica gel face mask 1) PR 2) VR 1 / 2 (2D) 0 / 6 0 / 4 1500 (600/300/600) 99 (0/0/99) 8 (0/0/8) 1 + 3 0 + 18 0 + 8 4 Protocols: 4500+13500 0+5346 0+196 \botrule C: Camera, BC: Back-Camera, FC: Front-Camera, W: built-in webcam, T: Tablet, M: Mobile Smartphone, Q: Quality, PH: High-res photo, V: Video, PR: Hard-copy print of high-res photo, VR: Video replay
4.2 Face spoofing Databases
In Table 4.1 we add details on the presentation media and presentation attack instruments (PAI) of the used face video datasets.
4.2.1 Replay-Attack






One of the earliest datasets presented in literature in 2012 for the problem of face spoofing is the Replay-Attack dataset 547_12_f , as a sequel to its Print-Attack version introduced in 2011 533_11_f . The database contains a total of 1200 short videos between 9 and 15 seconds. The videos are taken at resolution from 50 different subjects. Each subject has 4 bona-fide videos and 20 spoofed ones, so the full dataset has 200 bona-fide videos and 1000 spoofed videos. The dataset is divided into 3 subject-disjoint subsets one for training, one for development and one for testing. The training as well as the development subset each has 15 subjects, while the test subset has videos from the remaining 20 subjects. Results on this dataset is reported as the HTER (Half Total Error Rate) on the test subset when the detector threshold is set on the EER (Equal Error Rate) of the development set. For both the real and spoof videos, each subject was recorded twice with a regular webcam in two different lighting settings; controlled and adverse.
As for the spoofed videos, first high-resolution videos were taken of the subject with a Canon PowerShot SX150 IS camera, then three techniques were used to generate 5 spoofing scenarios: (1) "hard-copy print-attack", where high-resolution digital photographs are presented to the camera. The photographs are printed with a Triumph-Adler DCC 2520 color laser printer on A4 paper. (2) "mobile-attack" using a photo once and replay of the recorded video on an iPhone 3GS screen (with resolution pixels) once, (3) "high-definition" attack by displaying a photo or replaying the video on "high-resolution screen" using an iPad (first generation, with a screen resolution of pixels). Each of the 5 scenarios was recorder in two different lighting conditions as stated above, then presented to the sensor in 2 different ways. Either with a "fixed" tripod, or by an attacker holding the presenting device (printed paper or replay device) with his/her "hand", leading to a total of 20 attack videos per subject. More details of the dataset can be found at the IDIAP Research Institute website 111http://www.idiap.ch/dataset/replayattack.
4.2.2 MSU Mobile Face Spoofing Database (MSU-MFSD)








The MSU-MFSD dataset 515_15_f was introduced in 2014 by the Michigan State University (MSU). It’s main aim was to tackle the problem of face spoofing on smartphones where some mobile phone applications use face for authentication and unlocking the phone. The dataset includes real and spoofed videos from 35 subjects with a duration between 9 and 15 seconds. Unlike Replay-Attack dataset where only a webcam was used for authentication, in MSU-MFSD two devices were used, the built-in webcam of a MacBook Air 13" with resolution and the front facing camera of the Google Nexus 5 smartphone with resolution. So for each subject there are 2 bona-fide videos, one from each device, and six attack videos, 3 from each device. Leading to a total of 280 videos, 210 attack and 70 bona-fide videos. The attack scenarios are all presented to the authentication sensor with a fixed support unlike Replay-Attack which has videos with fixed and others using hand-held devices. Three attack scenarios were used (1) print-attack on A3 paper (2) video replay attacks on the screen of an iPad Air and (3) video replay attacks on Google Nexus 5 smartphone. The dataset is divided into two subject-disjoint subsets, one for training with 15 subjects, and the other for testing with 20 subjects. The EER on the test set is used as the evaluation metrics on the MSU-MFSD database.
4.2.3 Replay-Mobile








In 2016, the IDIAP research institute that released Replay-Attack, released a new dataset Replay-Mobile 564_16_f . This was after the widespread of face authentication on mobile devices and the increase of the need for face-PAD evaluation sets to capture the characteristics of mobile devices. The dataset has 1200 short recordings from 40 subjects captured by two mobile devices at resolution . Ten bona-fide accesses were recorded for each subject, in addition to 16 attack videos taken under different attack modes. Like Replay-Attack, the dataset was divided into training, development and testing subsets of 12, 16 and 12 subjects respectively, and results are reported as HTER on the test set.
Five lighting condition were used in recording real-accesses; controlled, adverse, direct, lateral and diffuse). For presentation attack, high-resolution photos and videos from each client were taken under two different lighting conditions (lighton, lightoff).
Attack was performed in two ways, (1) photo-print attacks where the printed high-resolution photo was presented to the capturing device using either fixed or hand support, (2) matte-screen attack displaying digital-photo or video with fixed supports.
4.2.4 Others
Some other datasets for face PAD are also available but were not used in this paper.
CASIA-FASD b_12_f
was released in 2012, having 50 subjects. Three different imaging qualities were used (Low, Normal and High), and three types of attacks are generated from the high quality records of the genuine faces. Namely, cut-photo attack, warped-photo attack and video attack on iPad were used. The dataset is split into training set of 20 subjects, and a testing set including the other 30 subjects.
OULU-NPU oulu
A mobile face PAD dataset was released in 2017 of 55 subjects captured in three different lighting conditions and background with six different mobile devices. Both print and video-replay attacks are included using two different PAIs each. Four protocols were proposed in the paper to evaluate the generalization of PAD algorithms against different conditions.
Spoof in the Wild (SiW) 300_18_f
Contains 8 real and 20 attack videos for 165 subjects; more subjects that any previous dataset, and released in 2018. Bona-fide videos are captured with two high-quality cameras and collected with different orientations, facial expressions and lighting conditions. Attack samples are either high-quality print attacks, or replay videos on 4 different PA devices.
CASIA-SURF 303_19_f
Later in same year; 2018, a large-scale multi-modal dataset CASIA-SURF was released containing 21000 videos for 1000 subjects. Each video has three modalities, namely, RGB, Depth and IR captured by Intel RealSense camera. Only 2D print attack was performed with 6 different combinations of used photo state (either full or cut) and 3 different operations like bending the printed paper or movement with different distance from the camera.
CASIA-SURF CeFA db_19_f
Although CASIA-SURF dataset 303_19_f is large-scale, it only includes one ethnicity (Chinese) and one attack type (2D print). So in 2019, CASIA-SURF cross-ethnicity Face Anti-spoofing (CeFA) was released to provide a wider range of ethnicity and attack types, in addition to multiple modalities as CASIA-SURF. The dataset include videos for 1607 subjects, covering three ethnicities (Africa, East Asia, and Central Asia), three modalities, and 4 attack types. Attack types are 2D print attacks, replay attacks in addition to 3D mask and silica gel attacks.
4.3 Iris spoofing Databases






Many publicly available benchmark datasets were published for the iris presentation attack problem. Some are captured with commercial iris recognition sensors operating with near-infrared illumination like BioSec-ATVS-FIr 104_12 or LivDet datasets 109_13 ; 181_15 ; 182_17 , while more recent datasets were introduced, captured in the visible light illumination using smartphones, e.g MobBioFake 155_14 ; 166_14 . Below are details of the databases used in this paper.
4.3.1 Biosec ATVS-FIr
The ATVS-FIr dataset was introduced in 2012 104_12 from the Biosec dataset 103_08 . It contains 800 bona-fide and 800 attack photos of 50 different subjects. The attack is performed by enhancing quality of the bona-fide iris photo, printing it on high-quality paper using HP printers, then presenting it to the same LG Iris Access EOU3000 sensor used to capture the bona-fide irises. All images have resolution and are grayscale. For each user 16 different bona-fide photos were captured from which 16 attack photos were generated. Four photos were taken from each of the two eyes in two sessions, so for each user bona-fide and same for fake attacks. Each eye of the 50 subjects was considered a subject on its own, then the total of 100 subjects were divided into a training set of 25 subjects (200 bona-fide + 200 attack) and a test set of 75 subjects (600 bona-fide + 600 attack)
4.3.2 LivDet Warsaw 2013
Warsaw University of Technology published the first LivDet Warsaw Iris dataset in 2013 109_13 as part of the first international iris liveness competition in 2013 159_14 . Two more versions of this dataset were later published in 2015 181_15 and 2017 182_17 . The LivDet-Iris-2013-Warsaw contains 852 bona-fide and 815 attack printout images from 237 subjects. For attack images, the real iris was printed using two different printers, then captured by the same IrisGuard AD100 sensor as the bona-fide photos.
4.3.3 MobBioFake
The first competition for iris PAD in mobile scenarios was the Mobi-live competition in 2014 156_14 . The MobBioFake iris spoofing dataset 155_14 was generated from the iris images of the MobBIO Multimodal Database 166_14 . It comprises 800 bona-fide and 800 attack images captured by the back camera (8MP resolution) of an Android mobile smartphone (Asus Transformer Pad TF 300T) in the visible light not in near-infrared like previous iris datasets. The images are color RGB and have a resolution of . The MobBioFake database has 100 subjects, each has 8 bona-fide + 8 attack images captured under different illumination and occlusion settings. The attack samples were generated from printed images of the original ones under similar conditions with the same device. The images are split evenly between training and test subsets.
5 Proposed PAD Approach / Methodology / Algorithm
Although several previous studies use CNN for presentation attack detection, they either used custom designed networks, e.g. Spoofnet 308_15_fi ; 309_15_i , or used pre-trained CNN to extract features that are later classified with conventional classification algorithms such as SVM. In this paper, we propose to train deeper CNNs for the direct classification of bona-fide and presentation attack images. We choose to assess the state-of-the-art modern deep convolutional neural networks that achieved high accuracies in the task of image classification on ImageNet p1_15 . This PAD approach is a passive software texture-based method that does not require additional hardware nor cooperation from the user.
In addition, we compare two different fine-tuning approaches starting from network weights trained on ImageNet classification dataset. A decision can be made to either retrain the whole network weights given the new datasets of the problem, or choose to freeze the weights of most of the network layers and finetune only a set of selected last layers from the network including the final classification layer.
Figure 5 shows the building blocks of the full pipeline proposed to classify face videos or iris images as bona-fide attempts or spoofed attacks. First, the face or iris image is preprocessed and resized, then input to the CNN to a series of convolutional, pooling, and dropout layers. Finally, the last fully connected layer of each network is altered to output a binary bona-fide/attack classification using sigmoid activation instead of the 1000 classes of ImageNet.

5.1 Preprocessing
5.1.1 Face videos
Each of the face benchmark datasets used in this paper have face coordinates for each frame of each video provided. These coordinates are used to crop a square to be used as input to the network. The square is cropped such that the region of interest (ROI) includes the face and some background in order to account for some contextual information. The side of this square is chosen empirically to be equal twice the minimum of the width and height of the face groundtruth box. The cropped bounding box containing the face is then resized to each network’s default size, to be used as input to the first convolutional layer of the CNN.
5.1.2 Iris images
When using iris images for recognition or presentation attack detection, most studies in the literature first extract and segment the iris region. However, in this paper we directly use the full iris image captured by the NIR sensor or smartphone camera, in order to make the approach as simple as possible. This helps the the network to learn the best regions, from the full periocular area, that affect the classification problem. The presence of some contextual information like paper borders can also be useful for the attack detection.
5.2 Generalization / Data augmentation
It is known that deep networks have a lot of parameters to train which can cause it to overfit if the training set is not big enough. Data augmentations is a very helpful technique that is used to artificially increase the size of the available training set and to simulate real-life distortions and variations that may not be present in the original set. So during training, for each mini-batch pulled from the training set, images in this batch are randomly cropped, rotated slightly with a random angle, scaled or translated in the x or y axis, so the exact same image is not seen twice by the network. This leads to an artificially simulated larger training dataset and a more generalized network that is robust to changes in pose and illumination.
5.3 Modern deep CNN architectures
Based on official results published for recent CNN networks on the ImageNet dataset p1_15 , three of the networks that achieved less than 10% top-5 accuracies are InceptionV3 p2_15 , ResNet50 p3_15 , and MobileNetV2 p4_18 . Table 5.3 states the single-model top-1 and top-5 error for each of these network on the ImageNet validation dataset, its depth and number of parameters, ordered by ascending top-5 error values. One thing that can be noticed about the higher accuracy networks is the increased number of layers, these networks are much deeper than for example the well-known VGG p6_14 .
Performance of selected Deep CNN architectures on ImageNet in terms of Single-model Error % reported in each model’s paper \toprule top-1 (single-crop / multi-crop ) top-5 (single-crop / multi-crop ) # parameters # layers \midrule InceptionV3 p2_15 21.2 / 19.47 (12-crop) 5.6 / 4.48 (12-crop) 23.9M 159 \midrule MobileNetV2 (alpha=1.4) p4_18 25.3 / - / - 6.2M 88 \midrule MobileNetV2 (default alpha=1.0) p4_18 28 / - / - 3.5M 88 \midruleVGG16 p6_14 - / 24.4 / 7.1 138.4M 23 \botrule ⋆ Not available in paper, reported by Keras https://keras.io/
For the purpose of this paper, we chose networks that have less than 30 million parameters to finetune. And for the sake of diversity, we selected two networks, one with relatively high-number of parameters; InceptionV3 p2_15 ( 24 M parameters with 5.6% top-5 accuracy), then a more recent and less deep network with far less number of parameters MobilenetV2 p4_18 ( 4 M parameters with 9.9% top-5 accuracy) which makes it very suitable for mobile applications. Even though all three networks have significantly less parameters than VGG, they are much deeper and have higher accuracy.
In each architecture, its final prediction softmax layer is removed and the output of the preceding global average pooling layer is fed into a dropout layer (dropout rate of 0.5) then a sigmoid activation layer for final binary prediction.
Number of all parameters in each model and the number of parameters to learn if finetuning only the final block is done. \topruleModel Total # of parameters Last block To train First trainable layer # parameters to learn \midruleInceptionV3 21,804,833 Block after mixed9 (train mixed9_1 until mixed10) conv2d_90 6,075,585 MobileNetV2 2,259,265 last "_inverted_res_block" block_16_expand 887,361 \botrule
5.4 Fine-tuning approaches
As stated previously, the available datasets are small sized and the used networks have millions of parameters to learn. This will probably lead the model parameters to overfit these small sets if the network weights were trained from scratch; i.e. starting from random weights. The training model will get stuck into a local minima, leading to a poor generalization ability. A better approach is initializing the weights of the network with weights pre-trained on ImageNet, then we have three training options, (1) use transfer learning: feed the images to the network to extract features from the last layer before prediction, then use these features instead of raw image pixels for classification using an SVM or NN, (2) finetune weights of only several last layers of the network while fixing the weights of previous layers to their ImageNet-trained values, or (3) finetune the whole network weights using the new input dataset.
We experiment with only fine-tuning, either the whole network or a few top layers, which we choose to be the last convolutional block. For the approach of fine-tuning the last convolutional block, we state in Table 5.3, for each architecture, the name of the last block’s first layer, and the number of parameters in this block to be finetuned.
5.5 Single model with multiple biometrics
In addition to training/testing with datasets that belong to same biometric source, i.e face only or iris only, we experiment with training a single generic presentation attack detection network to detect presentation attack whether the presented biometric is a face or an iris. We train with different combinations of face+iris sets then cross evaluate the trained models on the other face and iris datasets, to see if this approach is comparable to training on only face images or iris images.
6 Experiments and Results
In this section, we describe images and videos preprocessing method used, explain the followed training strategy and experimental setup.
6.1 Preprocessing
6.1.1 Preparing images
For iris images, only the MobBioFake database consists of color images captured using a smartphone. The other datasets, ATVS-FIr and Warsaw, were obtained with near-infrared sensors producing grayscale images. Since all networks used in this paper were pretrained on colored images of ImageNet, their input layer only accepts color images with three channels and so for grayscale iris images, the single gray channel is replicated two times to form a 3-channel image passed as the network input. The whole iris image is used without cropping nor iris detection and segmentation.
On the other hand, all face PAD datasets consist of color videos. Duration of videos range from 9 to 15 seconds, videos of Replay-Attack database have 25 frames per second (fps), while those of MSU-MFSD have 30 fps. Not all video frames are used, to avoid redundancy and over-fitting to the subjects, so we use frame skipping to sample one frame every 20 frames. This frame dropping leads to sampling around 10 to 19 frames per video based on its length. For each sampled frame, instead of using the whole frame as the network input, it is first cropped to either include only the face region or a box that has approximately twice the face area to include some background context. Annotated face bounding boxes have a side length ranging from to in Replay-Attack videos, and from to for MSU-MFSD.
Table 6.1.1 shows the training, validation and testing sizes (in number of images) for each of the datasets used in the experiments (after frame dropping in videos). Emphasized in bold is the total number of images available for training the CNN for each database.
Number of images used in training and testing. For face datasets, number of videos is shown followed by number of frames between (). For iris datasets, only number of dataset images is mentioned. \topruleDatabase Subset Number of videos (frames⋆) Attack + bona-fide \midruleReplay-Attack train devel test \midruleMSU-MFSD train test \midruleReplay-Mobile train devel test \midruleATVS-FIr train test \midruleWarsaw 2013 train test \midruleMobBioFake train test \botrule (frames: skipping every 20 frames)
The images are then resized according to the default input size values for each of the used networks. That is for MobilenetV2, and for InceptionV3. The RGB values of input images to the InceptionV3 and the MobilenetV2 networks are first scaled to have a value between -1 and 1.
6.1.2 Data augmentation
As shown in Table 6.1.1, the total number of images available from each dataset to train the CNN is relatively much smaller than sizes of datasets usually used for deep networks training. This could cause the network to memorize these small set of samples instead of learning useful features and so fail to generalize. So in order to reduce overfitting, data augmentation is used during training. Images are randomly transformed before feeding to the network with one or more of the following transformations: Horizontal flip, Rotation between 0 and 10 degrees, Horizontal translation by 0 to 20 percent of image width, Vertical translation by 0 to 20 percent of image height, or Zooming by 0 to 20 percent
6.2 Training strategy and Hyperparameters
For training the CNN networks, we used Adam optimizer adam with , , and learning rate .We trained the network for max of 50 epochs but added a stopping criteria if the training or validation accuracy reached 99.95% or validation accuracy did not improve (with ) for 40 epochs.
Intermediate models with high validation accuracy were saved and finally the model with the least validation error was chosen for inference. Because of the randomness introduced by the data augmentation and the dropout, several training sessions may produce slightly different results, specially in cross-validation, for this reason, three runs were performed for each configuration (model + dataset + fine-tuning approach) and the min error is reported.
Intra and cross-dataset results. Test HTER reported with Replay-Attack and Replay-Mobile testing, otherwise Test EER. \topruleTrain Database Test Database Finetune Approach (A) Finetune Approach (B) InceptionV3 MobilenetV2 InceptionV3 MobilenetV2 \midruleReplay-Attack Replay-Attack 6.9% 1.6% 0% 0.63% MSU-MFSD 33% 30% 17.5% 22.5% Replay-Mobile 35.8% 43.4% 64.7% 56.7% \midruleMSU-MFSD Replay-Attack 34.7% 22.9% 23.8% 13.7% MSU-MFSD 7.5% 2.05% 0% 2.08% Replay-Mobile 32.6% 26.8% 24.6% 23.7% \midruleReplay-Mobile Replay-Attack 33.2% 45.1% 31.1% 45.5% MSU-MFSD 35.4% 30% 32.9% 37.5% Replay-Mobile 3.6% 3.2% 0% 0% \midruleATVS-FIr ATVS-FIr 0% 0% 0% 0% Warsaw 2013 1.9% 5.4% 0.16% 1.6% MobBioFake (Grayscale) 44% 39% 36.5% 39% \midruleWarsaw 2013 ATVS-FIr 0% 1% 0.17% 0.5% Warsaw 2013 0% 0.32% 0% 0% MobBioFake (Grayscale) 43% 39% 32.8% 47% \midruleMobBioFake ATVS-FIr 10% 30% 18.7% 20.2% Warsaw 2013 15.7% 32% 23.4% 18.8% MobBioFake 8.75% 7% 0.5% 0.75% \midruleMobBioFake (Grayscale) ATVS-FIr 2.5% 23.7% 12% 16.2% Warsaw 2013 6.2% 17.3% 10.1% 17.2% MobBioFake (Grayscale) 10.5% 7.3% 0.25% 1.25% \botrule
6.3 Evaluation
6.3.1 Videos scoring
The CNN accepts images as input, so we treated each frame in the face video as a separate image. Then at reporting the final score for each video we perform score-level fusion by averaging scores of the samples from the same video. Accuracy and errors can then be calculated based on these video-level scores not frame-level scores as some reported results in literature.
6.3.2 Evaluation metrics
The equal-error-rate (EER) is used to report the error of the test set. EER is defined as the rate at which both the False Rejection Rate (FRR) and the False Acceptance Rate (FAR) are equal. FRR is the probability of the algorithm rejecting bona-fide samples as attack ones, which is equal to , while FAR is the probability by which the algorithm might accept attack samples and consider them bona-fide, .
For datasets that have a separate development subset; e.g. Replay-Attack, first a score threshold is calculated that achieves EER on the devel set. Then this threshold is used to calculate error in the test set known as half-total error rate (HTER) which is equal to the summation of the False Rejection Rate (FRR) and the False Acceptance Rate (FAR) at a threshold, divided by two, .
An ISO/IEC international standard for PAD testing was described in ISO/IEC 30107-3:2017 222https://www.iso.org/obp/ui/##iso:std:iso-iec:30107:-3:ed-1:v1:en where PAD subsystems are to be evaluated using two metrics; attack presentation classification error rate (APCER) and bona-fide presentation classification error rate (BPCER). However, we report results in this paper using HTER and EER to be able to compare with state-of-the-art published results, EER can also be understood as the rate at which APCER is equal to BPCER.
6.3.3 Cross-dataset evaluation
In order to test the generalization ability of the used networks, we perform cross-dataset evaluation where we train on a dataset and test on another dataset. For the iris datasets, we know of no previous work to have performed EER cross-dataset evaluation on iris PAD databases before.
6.4 Experimental setup
For implementation we used Keras 333https://github.com/keras-team/keras with tensorflow 444https://www.tensorflow.org/ backend for the deep CNN models, and for datasets management and experiments pipelines we used Bob package bob2012 ; bob2017 . Experiments were performed on NVIDIA GeForce 840m GPU with CUDA version 9.0.
Training with Face+Iris images. Intra and cross-dataset results. Test HTER reported with Replay-Attack and Replay-Mobile testing, otherwise Test EER. \toprule Train Iris Database: ATVS-FIr Warsaw 2013 MobBioFake (RGB) MobBioFake (Grayscale) \midruleTrain Face Database Test Database InceptionV3 MobilenetV2 InceptionV3 MobilenetV2 InceptionV3 MobilenetV2 InceptionV3 MobilenetV2 \midruleReplay-Attack – Number of training epochs 2 6 3 6 4 9 2 8 Replay-attack 0% 0.63% 0% 0% 0.25% 1.5% 0% 1.4% MSU-MFSD 29.6% 20.4% 15% 20% 19.6% 25% 30% 17.5% Replay-Mobile 58.1% 48.7% 57.3% 35.4% 60.6% 58.1% 39% 40% ATVS-FIr 0% 0% 10.5% 2.7% 5.17% 8.8% 3.5% 12.3% Warsaw 2013 0.16% 0.16% 0% 0% 4.13% 1.62% 15.2% 5.7% MobBioFake (RGB) 58.5% 71.3% 56% 45.5% 0.75% 0.25% 1.75% 2% MobBioFake (Grayscale) 50% 69% 56.3% 38.5% 1.5% 0.75% 1.25% 1% \midruleMSU-MFSD – Number of training epochs 4 6 3 5 10 9 7 9 Replay-Attack 22.8% 14.5% 25.3% 11.9% 22.8% 27.7% 16.6% 21.6% MSU-MFSD 0% 2.08% 0.4% 2.08% 2.5% 2.08% 0.4% 2.5% Replay-Mobile 28.7% 26.1% 19.2% 24.8% 22.7% 26.8% 25.2% 17% ATVS-FIr 0% 0% 0.33% 2.3% 11.8% 12.5% 0.8% 12.33% Warsaw 2013 0.6% 0.8% 0% 0% 43.9% 6.55% 7.4% 9.1% MobBioFake (RGB) 52.5% 39.2% 45.5% 42% 2% 1.25% 2.5% 2.5% MobBioFake (Grayscale) 45.3% 38.5% 34.5% 43% 22% 4.25% 1.75% 2% \midruleReplay-Mobile – Number of training epochs 2 3 1 3 4 7 5 4 Replay-Attack 24.2% 42.6% 31% 35.7% 41.6% 64.3% 33.7% 54.6% MSU-MFSD 32.5% 30.4% 32.5% 42.5% 60% 52.5% 40% 44.6% Replay-Mobile 0% 0% 0% 0% 0% 0.26% 0% 0.46% ATVS-FIr 0% 0% 0.83% 6% 15.5% 22.5% 6.5% 28.2% Warsaw 2013 2.1% 4% 0% 0% 9.6% 28.9% 22.1% 26.1% MobBioFake (RGB) 46.5% 53% 49.3% 54.3% 1% 0.75% 8.8% 3.25% MobBioFake (Grayscale) 33.5% 43.3% 41.7% 45.8% 5.3% 6.5% 2% 1.75% \botrule (bold-underlined): best cross-dataset error for each test dataset, (bold): best cross-dataset error for each test dataset in each row (i.e: given a certain face train set)
Best cross-dataset results and comparison with SOTA. Test HTER reported with Replay-Attack testing, otherwise Test EER. Underlined is the best cross-dataset error for the test dataset. \topruleTrain Database Test Database SOTA / corresponding intra-dataset error Our Best / corresponding intra-dataset error Model trained with only 1 biometric Model trained with face + iris \midruleReplay-Attack MSU-MFSD 28.5% / 8.25% 17.5% / 0% 15% / 0% GuidedScale-LBP 560_18_f "LGBP" "InceptionV3 (B)" "InceptionV3" (Warsaw 2013) Replay-Mobile 49.2% / 3.13% 35.8% / 6.9% 35.4% / 0% GuidedScale-LBP 560_18_f "LBP+ GS-LBP" "InceptionV3 (A)" "MobilenetV2" (Warsaw 2013) \midruleMSU-MFSD Replay-Attack 21.40% / 1.5% 13.7% / 2.08% 11.9% / 2.08% Color-texture 555_18_f "MobilenetV2 (B)" "MobilenetV2" (Warsaw 2013) Replay-Mobile 32.1% / 8.5% 23.7% / 2.08% 17% / 2.5% GuidedScale-LBP 560_18_f "LBP+ GS-LBP" "MobilenetV2 (B)" "MobilenetV2" (MobBioFake (Gray)) \midruleReplay-Mobile Replay-Attack 46.19% / 0.52% 31.1% / 0% 24.2% / 0% GuidedScale-LBP 560_18_f "LGBP" "InceptionV3 (B)" "InceptionV3" (ATVS-FIr) MSU-MFSD 33.56% / 0.98% 30% / 3.2% 30.4% / 0% GuidedScale-LBP 560_18_f "LBP+ GS-LBP" "MobilenetV2 (A)" "MobilenetV2" (ATVS-FIr) \midruleATVS-FIr Warsaw 2013 None available 0.16% / 0% 0.16% / 0% "InceptionV3 (B)" "Any" (Replay-Attack) MobBioFake (Gray) None available 36.5% / 0% 33.5% / 0% "InceptionV3 (B)" "InceptionV3" (Replay-Mobile) \midruleWarsaw 2013 ATVS-FIr None available 0% / 0% 0.33% / 0% "InceptionV3 (A)" "InceptionV3" (MSU-MFSD) MobBioFake (Gray) None available 32.8% / 0% 34.5% / 0% "InceptionV3 (B)" "InceptionV3" (MSU-MFSD) \midruleMobBioFake (Gray) ATVS-FIr None available 2.5% / 10.5% 0.8% / 1.75% "InceptionV3 (A)" "InceptionV3" (MSU-MFSD) Warsaw 2013 None available 6.2% / 10.5% 5.7% / 1% "InceptionV3 (A)" "MobilenetV2" (Replay-Attack) \botrule
6.5 Experiment 1 Results
In the first experiment, we compare the two different finetuning approaches explained in Section 5.4. For this experiment, training and testing was done using face only or iris only datasets. We performed intra and cross-dataset testing to evaluate the effectiveness and generalization of the proposed approach, and used benchmark datasets to be able to compare against state-of-the-art. For each finetuning approach, we performed three runs and reported the minimum error obtained. In Table 6.2 we refer to the first finetuning approach as (A) where the weights of only the last block is finetuned, while approach (B) is when all the layers’ weights are finetuned using the given dataset.
It can be noticed from Table 6.2 that finetuning all the network weights achieved better results than fixing weights of first layers to their ImageNet-trained values and only finetuning just the final few layers. For intra-datasets error, we achieved State-of-the-art (SOTA) 0% test error for all datasets using InceptionV3, while MobilenetV2 achieved 0% for most datasets and 1-2% on MSU-MFSD and MobBioFake. The table also shows that cross-dataset errors on the iris datasets ATVS-FIr and Warsaw are much lower when grayscale version of the MobBioFake iris dataset was used for training instead of using the original color images of the dataset, without much affecting the intra-dataset error on MobBioFake itself.
6.6 Experiment 2 Results
For the second experiment, we only use finetuning approach (B); adjusting the weights of all the network’s layers using the training images. Here we use both face and iris images as train images input to a single model for classifying bona-fide from attack presentation in general regardless the biometric type.
Results in Table 6.4 show that using both face and iris images in training a single model to differentiate between bona-fide and presentation attack images achieved very good results on both face and iris test sets. For some cases in face datasets, this combination boosted the performance for cross-dataset testing where for example on Replay-Attack test dataset 11.9% HTER was achieved when training a MobilenetV2 using MSU-MFSD and Warsaw Iris dataset, vs 13.7% HTER when only MSU-MFSD was used for training as reported in Table 6.2.
Table 6.4 also confirms findings from Table 6.2; that training with grayscale version of the MobBioFake iris dataset gives better cross-dataset error on the other gray iris datasets, without much affecting the intra-dataset error on the MobBioFake dataset itself. Not only this, but it also achieves lower cross-dataset error rates when evaluating on face datasets, by helping the network to focus on color features when only testing is performed on a face image, since all training face images were colored but all iris training images were grayscale.





![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/Training_0088_REAL_R_3.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/Training_0088_REAL_R_3_png_hpf_r100_overlayed1.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/Training_0088_REAL_R_3_png_fmap867.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/Training_0088_REAL_R_3_png_fmap573.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/Training_0050_PRNT_R_2_png_fmap867.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/Training_0050_PRNT_R_2_png_fmap573.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/Training_0088_PRNT_R_3.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/Training_0088_PRNT_R_3_png_hpf_r100_overlayed1.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/Training_0088_PRNT_R_3_png_fmap867.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/Training_0088_PRNT_R_3_png_fmap573.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_real_client103_session01_webcam_authenticate_controlled_2.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_real_client103_session01_webcam_authenticate_controlled_2_hpf_r100_overlayed1.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_real_client103_session01_webcam_authenticate_controlled_2_fmap881.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_real_client103_session01_webcam_authenticate_controlled_2_fmap1237.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_attack_hand_attack_mobile_client002_session01_mobile_photo_controlled.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_attack_hand_attack_mobile_client002_session01_mobile_photo_controlled_hpf_r100_overlayed_only.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_attack_hand_attack_mobile_client002_session01_mobile_photo_controlled_fmap881.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_attack_hand_attack_mobile_client002_session01_mobile_photo_controlled_fmap1237.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_attack_hand_attack_mobile_client103_session01_mobile_photo_controlled.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_attack_hand_attack_mobile_client103_session01_mobile_photo_controlled_hpf_r100_overlayedOnly.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_attack_hand_attack_mobile_client103_session01_mobile_photo_controlled_fmap881.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/d29b91eb-bea5-4228-94a9-149a8127503a/train_attack_hand_attack_mobile_client103_session01_mobile_photo_controlled_fmap1237.jpg)























6.7 Comparison with state of the art
In Table 6.4 we compare our best achieved cross-datasets evaluation error with the state-of-the-art (SOTA). This table shows that our cross-dataset testing results surpass SOTA on face datasets. For models trained on single biometric, InceptionV3 achieved best cross-dataset error on most datasets, except when training with MSU-MFSD, where MobilenetV2 achieved best test HTER on Replay-Attack and Replay-Mobile. While both models interchangeably achieved better error rate when network was trained using both face and iris images.
6.8 Analysis and discussion
Given results in Table 6.4, we feel that it is important to analyze features learnt by the networks that were trained on two biometrics.
6.8.1 Filters Activation and frequency components
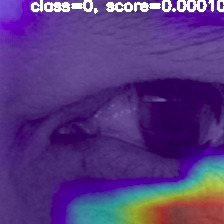
By training the network on several biometrics, we believe that the network is forced to learn to recognize specific patterns and texture in case of real presentations in general, which are not present in attack samples and vice-versa. An approach to prove that, is to visualize the response of certain feature maps from the network, given sample input images. For this task, we chose a MobilenetV2 network, trained with Iris-Warsaw and Face Replay-Attack datasets, from which we selected to visualize response of some filters from the final convolutional block before classification.
In addition to visualizing network activation response, we were also interested in viewing the distribution of high frequency components on the input images. We applied high pass filter to remove most of the low frequencies and keep only the high frequency components of an image, then we overlay these high frequency regions on the input image for better understanding of where high frequency is concentrated in bona-fide images vs attack images.
The steps for obtaining the regions with high frequency in image are depicted in Figure 6. Fourier transform was first applied to get frequency components in the image, High-pass-filter is then used to remove most of the low frequencies. After that, inverse Fourier is used to obtain an image with only the high frequency regions visible, and finally these regions are overlayed on original image to highlight those regions on the input image.
Regarding the chosen filters to visualize, the final layer before classification is consisted of 1280 filter, when an input image is of size , the feature maps resulting from these final 1280 filters have size . From these 1280 filters, we selected two filters for each biometric. One that had highest average activation response by real images, we call it realF, and the other filter that was highly activated by attack images, called attackF. We then visualize the activation response of these filters for some bona-fide and attack samples belonging to the same subject.
Figure 2.3 shows samples from the iris Warsaw dataset with their high frequency regions highlighted in addition to activation response of realF and attackF features. The visualization clearly shows that for real iris samples, high frequency areas are concentrated at the bright regions around the inner eye corner and the lash-line, however, for attack presentations, high frequency regions mostly focus on noise patterns scattered on the attack medium (paper). The trained network could successfully recognize the real features highly represented at the eye corner, by realF giving high response at those regions in real image, while failing to detect them in attack samples. AttackF also manages to detect paper noise patterns in attack samples. which are missing in the real images.
Similar visualization for face images of Replay-Attack dataset is shown in Figure 2.3. The attack presentation in these samples is achieved using handheld mobile device showing a photo of the subject. We can notice the absence of high frequency response around the face edges, mouth and eyes, which are present in real samples and detected by the network through realF feature. On the other hand, these attack images contain certain noise patterns on the clear background area which are detected successfully by the attackF of the network.
By visualizing the high frequency regions in the images, it was proven that high frequency variations in case of real images, focus on certain edges and changes in the 3d real biometric presented. While in case of attack presentations, high frequency components represented noise, either spread on paper in case of paper attack medium, or noise patterns resulting from the display monitor of a mobile attack device. Our trained CNN network managed to correctly localize such features and lead to successful classification.
6.8.2 Gradient-weighted class activation maps
Another approach to analyze what the network learned, is by using gradient-weighted class activation maps gradcam ; grad-cam, which highlights the areas that contributed most to the network’s classification decision for an input image.
We chose the trained MobilenetV2 network, on Replay-Attack face dataset and MobbioFake gray iris dataset, to analyze the activation maps for some bona-fide and attack test images from the 6 datasets. Figure 9 shows the grad-cam for the bona-fide class given some real test samples that were either correctly of incorrectly classified, and Figure 10 shows the same but for presentation attack images.
The visualizations in these figures show clearly that the network focuses on features of the face and iris centers to make its decision for a bona-fide presentation, and in cases when these center areas have lower activations, the network decides the image is an attack. And although the network was trained on two different biometrics, it could perfectly focus on the important center parts for each biometric individually.
7 Conclusion and future work
In this paper, we surveyed the different face and iris presentation attack detection methods proposed in literature with focus on the use of very deep modern CNN architectures to tackle the PAD problem in both face and iris recognition.
We compared two different networks; InceptionV3 and MobileNetV2, with two finetuning approaches starting from network weights that were trained on ImageNet dataset. Experimental results show that InceptionV3 achieved 0% SOTA intra-dataset error on 6 publicly available benchmark datasets when finetuning the whole network’s weights. The problem of small datasets sizes with very deep networks was overcome by augmenting the original data with random flipping, slight rotation and translation. In addition to starting the network training with non-random weights already pretrained on ImageNet dataset. This was to avoid the weights overfitting the small training dataset, however, for future work, we would like to check the effect of training these deep networks from scratch using the available PAD datasets.
The generalization ability of these networks has been tested by performing cross-dataset evaluation and better-than-SOTA results were reported for the face datasets. As far as we know this is the first paper to include cross-dataset Equal-Error-Rate evaluation for the three iris PAD datasets used, for which we achieved close to 0% test EER.
Not only cross-dataset evaluation was performed, but we also trained a single network using multiple biometric data; face and iris images. This commonly trained network achieved less cross-dataset error rates than networks trained with a single biometric type. This approach can be later applied on other biometric traits; such as the ear, to further demonstrate the effectiveness of using several biometric traits for training the PAD algorithm.
Finally, we provided analysis of the features learned by the networks, and showed their correlation with the frequency components present in input images regardless the biometric type. We also visualized the class heatmaps generated by the network for the bona-fide class which showed that the center of the face or iris are the most important parts that cause a network to select a bona-fide classification decision. For future work, we would like to apply patch-based CNN and identify the regions that contribute most to the attack detection in hope for improving the generalization of the approach by using a region-based CNN method.
References
- [1] Jourabloo, A., Liu, Y., Liu, X.: ‘Face de-spoofing: Anti-spoofing via noise modeling’, CoRR, 2018,
- [2] Nagpal, C., Dubey, S.R.: ‘A performance evaluation of convolutional neural networks for face anti spoofing’, CoRR, 2018,
- [3] Nguyen, D., Rae.Baek, N., Pham, T., Ryoung.Park, K.: ‘Presentation attack detection for iris recognition system using nir camera sensor’, Sensors, 2018, 18, pp. 1315
- [4] Nguyen, D.T., Pham, T.D., Lee, Y.W., Park, K.R.: ‘Deep learning-based enhanced presentation attack detection for iris recognition by combining features from local and global regions based on nir camera sensor’, Sensors, 2018, 18, (8)
- [5] Pinto, A., Pedrini, H., Krumdick, M., Becker, B., Czajka, A., Bowyer, K.W., et al. Counteracting Presentation Attacks in Face Fingerprint and Iris Recognition. In: ‘Deep learning in biometrics’. (CRC Press, 2018. p. 49
- [6] Czajka, A., Bowyer, K.W.: ‘Presentation attack detection for iris recognition: An assessment of the state-of-the-art’, ACM Computing Surveys, 2018, 51, (4), pp. 86:1–86:35
- [7] Ramachandra, R., Busch, C.: ‘Presentation attack detection methods for face recognition systems: A comprehensive survey’, ACM Computing Surveys, 2017, 50, (1), pp. 8:1–8:37
- [8] Abdul.Ghaffar, I., Norzali, M., Haji.Mohd, M.N.: ‘Presentation attack detection for face recognition on smartphones: A comprehensive review’, Journal of Telecommunication, Electronic and Computer Engineering, 2017, 9
- [9] Li, L., Correia, P.L., Hadid, A.: ‘Face recognition under spoofing attacks: countermeasures and research directions’, IET Biometrics, 2018, 7, pp. 3–14(11)
- [10] Selvaraju, R.R., Das, A., Vedantam, R., Cogswell, M., Parikh, D., Batra, D.: ‘Grad-cam: Why did you say that? visual explanations from deep networks via gradient-based localization’, CoRR, 2016, Available from: http://arxiv.org/abs/1610.02391
- [11] Daugman, J. ‘Iris recognition and anti-spoofing countermeasures’. In: 7th International Biometrics Conference. (, 2004.
- [12] Galbally, J., Ortiz.Lopez, J., Fierrez, J., Ortega.Garcia, J. ‘Iris liveness detection based on quality related features’. In: 2012 5th IAPR International Conference on Biometrics (ICB). (, 2012. pp. 271–276
- [13] Pacut, A., Czajka, A.: ‘Aliveness detection for iris biometrics’, 40th Annual IEEE International Carnahan Conferences Security Technology, 2006, pp. 122 – 129
- [14] Czajka, A.: ‘Pupil dynamics for iris liveness detection’, IEEE Transactions on Information Forensics and Security, 2015, 10, (4), pp. 726–735
- [15] Czajka, A. ‘Pupil dynamics for presentation attack detection in iris recognition’. In: International Biometric Performance Conference (IBPC), NIST, Gaithersburg. (, 2014. pp. 1–3
- [16] Bodade, R., Talbar, S. ‘Dynamic iris localisation: A novel approach suitable for fake iris detection’. In: 2009 International Conference on Ultra Modern Telecommunications Workshops. (, 2009. pp. 1–5
- [17] Huang, X., Ti, C., Hou, Q., Tokuta, A., Yang, R. ‘An experimental study of pupil constriction for liveness detection’. In: 2013 IEEE Workshop on Applications of Computer Vision (WACV). (, 2013. pp. 252–258
- [18] Kanematsu, M., Takano, H., Nakamura, K. ‘Highly reliable liveness detection method for iris recognition’. In: SICE Annual Conference 2007. (, 2007. pp. 361–364
- [19] Lee, E.C., Ryoung.Park, K.: ‘Fake iris detection based on 3d structure of iris pattern’, International Journal of Imaging Systems and Technology, 2010, 20, pp. 162 – 166
- [20] Mohd, M.N.H., Kashima, M., Sato, K., , Watanabe, M.: ‘Internal state measurement from facial stereo thermal and visible sensors through svm classification’, ARPN J Eng Appl Sci, 2015, 10, (18), pp. 8363–8371
- [21] Mohd, M., M..N..H., K., M., S., K., W.: ‘A non-invasive facial visual-infrared stereo vision based measurement as an alternative for physiological measurement’, Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2015, 10, (18), pp. 684–697
- [22] Pan, G., Sun, L., Wu, Z., Wang, Y.: ‘Monocular camera-based face liveness detection by combining eyeblink and scene context’, Telecommunication Systems, 2011, 47, (3), pp. 215–225
- [23] Smith, D.F., Wiliem, A., Lovell, B.C.: ‘Face recognition on consumer devices: Reflections on replay attacks’, IEEE Transactions on Information Forensics and Security, 2015, 10, (4), pp. 736–745
- [24] Kollreider, K., Fronthaler, H., Bigun, J. ‘Verifying liveness by multiple experts in face biometrics’. In: 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. (, 2008. pp. 1–6
- [25] Ali, A., Deravi, F., Hoque, S. ‘Directional sensitivity of gaze-collinearity features in liveness detection’. In: 2013 Fourth International Conference on Emerging Security Technologies. (, 2013. pp. 8–11
- [26] Wang, L., Ding, X., Fang, C.: ‘Face live detection method based on physiological motion analysis’, Tsinghua Science and Technology, 2009, 14, (6), pp. 685–690
- [27] Bharadwaj, S., Dhamecha, T.I., Vatsa, M., Singh, R. ‘Computationally efficient face spoofing detection with motion magnification’. In: 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops. (, 2013. pp. 105–110
- [28] Sun, L., Wu, Z., Lao, S., Pan, G. ‘Eyeblink-based anti-spoofing in face recognition from a generic webcamera’. In: 2007 11th IEEE International Conference on Computer Vision(ICCV). (, 2007. pp. 1–8
- [29] Patel, K., Han, H., Jain, A.K. ‘Cross-database face antispoofing with robust feature representation’. In: You, Z., Zhou, J., Wang, Y., Sun, Z., Shan, S., Zheng, W., et al., editors. Biometric Recognition. (Cham: Springer International Publishing, 2016. pp. 611–619
- [30] Marsico, M.D., Nappi, M., Riccio, D., Dugelay, J. ‘Moving face spoofing detection via 3d projective invariants’. In: 2012 5th IAPR International Conference on Biometrics (ICB). (, 2012. pp. 73–78
- [31] Pan, G., Wu, Z., Sun, L. ‘Liveness detection for face recognition’. In: Delac, K., Grgic, M., Bartlett, M.S., editors. Recent Advances in Face Recognition. (Rijeka: IntechOpen, 2008.
- [32] Kollreider, K., Fronthaler, H., Faraj, M.I., Bigun, J.: ‘Real-time face detection and motion analysis with application in “liveness” assessment’, IEEE Transactions on Information Forensics and Security, 2007, 2, (3), pp. 548–558
- [33] Komogortsev, O.V., Karpov, A. ‘Liveness detection via oculomotor plant characteristics: Attack of mechanical replicas’. In: 2013 International Conference on Biometrics (ICB). (, 2013. pp. 1–8
- [34] Komogortsev, O.V., Karpov, A., Holland, C.D.: ‘Attack of mechanical replicas: Liveness detection with eye movements’, IEEE Trans Inf Forens Security, 2015, 10, (4), pp. 716–725
- [35] Rigas, I., Komogortsev, O.V.: ‘Gaze estimation as a framework for iris liveness detection’, IEEE International Joint Conference on Biometrics, 2014, pp. 1–8
- [36] Rigas, I., Komogortsev, O.V.: ‘Eye movement-driven defense against iris print-attacks’, Pattern Recogn Lett, 2015, 68, (P2), pp. 316–326
- [37] Akhtar, Z., Foresti, G.L.: ‘Face spoof attack recognition using discriminative image patches’, Journal of Electrical and Computer Engineering, 2016, 2016, pp. 1–14
- [38] Tan, X., Li, Y., Liu, J., Jiang, L. ‘Face liveness detection from a single image with sparse low rank bilinear discriminative model’. In: Daniilidis, K., Maragos, P., Paragios, N., editors. Computer Vision – ECCV 2010. (Berlin, Heidelberg: Springer Berlin Heidelberg, 2010. pp. 504–517
- [39] Kollreider, K., Fronthaler, H., Bigun, J.: ‘Non-intrusive liveness detection by face images’, Image Vision Comput, 2009, 27, (3), pp. 233–244
- [40] Bao, W., Li, H., Li, N., Jiang, W. ‘A liveness detection method for face recognition based on optical flow field’. In: Image Analysis and Signal Processing. (, 2009. pp. 233–236
- [41] Siddiqui, T.A., Bharadwaj, S., Dhamecha, T.I., Agarwal, A., Vatsa, M., Singh, R., et al.: ‘Face anti-spoofing with multifeature videolet aggregation’, 2016 23rd International Conference on Pattern Recognition (ICPR), 2016, pp. 1035–1040
- [42] d. S..Pinto, A., Pedrini, H., Schwartz, W., Rocha, A. ‘Video-based face spoofing detection through visual rhythm analysis’. In: 2012 25th SIBGRAPI Conference on Graphics, Patterns and Images. (, 2012. pp. 221–228
- [43] Komulainen, J., Hadid, A., Pietikäinen, M.: ‘Context based face anti-spoofing’, 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), 2013, pp. 1–8
- [44] Kim, S., Yu, S., Kim, K., Ban, Y., Lee, S.: ‘Face liveness detection using variable focusing’, ICB, 2013, pp. 1–6
- [45] Wang, T., Yang, J., Lei, Z., Liao, S., Li, S.Z.: ‘Face liveness detection using 3d structure recovered from a single camera’, ICB, 2013, pp. 1–6
- [46] Kose, N., Dugelay, J. ‘Reflectance analysis based countermeasure technique to detect face mask attacks’. In: 2013 18th International Conference on Digital Signal Processing (DSP). (, 2013. pp. 1–6
- [47] Erdogmus, N., Marcel, S. ‘Spoofing in 2d face recognition with 3d masks and anti-spoofing with kinect’. In: 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS). (, 2013. pp. 1–6
- [48] Erdogmus, N., Marcel, S. ‘Spoofing 2d face recognition systems with 3d masks’. In: 2013 International Conference of the BIOSIG Special Interest Group (BIOSIG). (, 2013. pp. 1–8
- [49] Li, J., Wang, Y., Tan, T., Jain, A.K. ‘Live face detection based on the analysis of Fourier spectra’. In: Jain, A.K., Ratha, N.K., editors. Biometric Technology for Human Identification. vol. 5404. (, 2004. pp. 296–303
- [50] Zhang, Z., Yan, J., Liu, S., Lei, Z., Yi, D., Li, S.Z. ‘A face antispoofing database with diverse attacks’. In: 2012 5th IAPR International Conference on Biometrics (ICB). (, 2012. pp. 26–31
- [51] Lee, T., Ju, G., Liu, H., Wu, Y. ‘Liveness detection using frequency entropy of image sequences’. In: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. (, 2013. pp. 2367–2370
- [52] Czajka, A. ‘Database of iris printouts and its application: Development of liveness detection method for iris recognition’. In: 2013 18th International Conference on Methods Models in Automation Robotics (MMAR). (, 2013. pp. 28–33
- [53] Wei, Z., Qiu, X., Sun, Z., Tan, T. ‘Counterfeit iris detection based on texture analysis’. In: ICPR 2008 19th International Conference on Pattern Recognition(ICPR). (, 2009. pp. 1–4
- [54] Sequeira, A.F., Murari, J., Cardoso, J.S. ‘Iris liveness detection methods in mobile applications’. In: 2014 International Conference on Computer Vision Theory and Applications (VISAPP). vol. 3. (, 2014. pp. 22–33
- [55] Sequeira, A.F., Murari, J., Cardoso, J.S. ‘Iris liveness detection methods in the mobile biometrics scenario’. In: Proceedings of International Joint Conference on Neural Networks (IJCNN). (, 2014. pp. 3002–3008
- [56] Unnikrishnan, S., Eshack, A. ‘Face spoof detection using image distortion analysis and image quality assessment’. In: 2016 International Conference on Emerging Technological Trends (ICETT). (, 2016. pp. 1–5
- [57] Wen, D., Han, H., Jain, A.K.: ‘Face spoof detection with image distortion analysis’, IEEE Transactions on Information Forensics and Security, 2015, 10, (4), pp. 746–761
- [58] Galbally, J., Marcel, S. ‘Face anti-spoofing based on general image quality assessment’. In: 2014 22nd International Conference on Pattern Recognition. (, 2014. pp. 1173–1178
- [59] Söllinger, D., Trung, P., Uhl, A.: ‘Non-reference image quality assessment and natural scene statistics to counter biometric sensor spoofing’, IET Biometrics, 2018, 7, (4), pp. 314–324
- [60] Bhogal, A.P.S., Söllinger, D., Trung, P., Uhl, A.: ‘Non-reference image quality assessment for biometric presentation attack detection’, 2017 5th International Workshop on Biometrics and Forensics (IWBF), 2017, pp. 1–6
- [61] Boulkenafet, Z., Komulainen, J., Hadid, A. ‘Face anti-spoofing based on color texture analysis’. In: 2015 IEEE International Conference on Image Processing (ICIP). (, 2015. pp. 2636–2640
- [62] Boulkenafet, Z., Komulainen, J., Hadid, A.: ‘Face spoofing detection using colour texture analysis’, IEEE Transactions on Information Forensics and Security, 2016, 11, (8), pp. 1818–1830
- [63] Boulkenafet, Z., Komulainen, J., Hadid, A.: ‘Face antispoofing using speeded-up robust features and fisher vector encoding’, IEEE Signal Processing Letters, 2017, 24, (2), pp. 141–145
- [64] Boulkenafet, Z., Komulainen, J., Akhtar, Z., Benlamoudi, A., Samai, D., Bekhouche, S.E., et al. ‘A competition on generalized software-based face presentation attack detection in mobile scenarios’. In: 2017 IEEE International Joint Conference on Biometrics (IJCB). (, 2017. pp. 688–696
- [65] Raja, K.B., Raghavendra, R., Busch, C. ‘Color adaptive quantized patterns for presentation attack detection in ocular biometric systems’. In: Proceedings of the 9th International Conference on Security of Information and Networks. SIN ’16. (New York, NY, USA: ACM, 2016. pp. 9–15
- [66] Boulkenafet, Z., Komulainen, J., Hadid, A.: ‘On the generalization of color texture-based face anti-spoofing’, Image Vision Comput, 2018, 77, pp. 1–9
- [67] Anjos, A., Marcel, S. ‘Counter-measures to photo attacks in face recognition: A public database and a baseline’. In: 2011 International Joint Conference on Biometrics (IJCB). (, 2011. pp. 1–7
- [68] Komulainen, J., Hadid, A., Pietikäinen, M., Anjos, A., Marcel, S. ‘Complementary countermeasures for detecting scenic face spoofing attacks’. In: 2013 International Conference on Biometrics (ICB). (, 2013. pp. 1–7
- [69] Gragnaniello, D., Poggi, G., Sansone, C., Verdoliva, L.: ‘An investigation of local descriptors for biometric spoofing detection’, IEEE Transactions on Information Forensics and Security, 2015, 10, (4), pp. 849–863
- [70] de Freitas.Pereira, T., Anjos, A., De.Martino, J.M., Marcel, S. ‘Lbp − top based countermeasure against face spoofing attacks’. In: Park, J.I., Kim, J., editors. Computer Vision - ACCV 2012 Workshops. (Berlin, Heidelberg: Springer Berlin Heidelberg, 2013. pp. 121–132
- [71] de Freitas.Pereira, T., Anjos, A., Martino, J.M.D., Marcel, S. ‘Can face anti-spoofing countermeasures work in a real world scenario?’. In: 2013 International Conference on Biometrics (ICB). (, 2013. pp. 1–8
- [72] Määttä, J., Hadid, A., Pietikäinen, M. ‘Face spoofing detection from single images using micro-texture analysis’. In: 2011 International Joint Conference on Biometrics (IJCB). (, 2011. pp. 1–7
- [73] Chingovska, I., Anjos, A., Marcel, S. ‘On the effectiveness of local binary patterns in face anti-spoofing’. In: 2012 BIOSIG - Proceedings of the International Conference of Biometrics Special Interest Group (BIOSIG). (, 2012. pp. 1–7
- [74] Yang, J., Lei, Z., Liao, S., Li, S.Z. ‘Face liveness detection with component dependent descriptor’. In: 2013 International Conference on Biometrics (ICB). (, 2013. pp. 1–6
- [75] Maatta, J., Hadid, A., Pietikainen, M.: ‘Face spoofing detection from single images using texture and local shape analysis’, IET Biometrics, 2012, 1, (1), pp. 3–10
- [76] Benlamoudi, A., Samai, D., Ouafi, A., Bekhouche, S.E., Taleb.Ahmed, A., Hadid, A. ‘Face spoofing detection using local binary patterns and fisher score’. In: 2015 3rd International Conference on Control, Engineering Information Technology (CEIT). (, 2015. pp. 1–5
- [77] Patel, K., Han, H., Jain, A.K.: ‘Secure face unlock: Spoof detection on smartphones’, IEEE Transactions on Information Forensics and Security, 2016, 11, (10), pp. 2268–2283
- [78] Schwartz, W.R., Rocha, A., Pedrini, H. ‘Face spoofing detection through partial least squares and low-level descriptors’. In: 2011 International Joint Conference on Biometrics (IJCB). (, 2011. pp. 1–8
- [79] Xu, Z., Li, S., Deng, W. ‘Learning temporal features using lstm-cnn architecture for face anti-spoofing’. In: 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR). (, 2015. pp. 141–145
- [80] Peixoto, B., Michelassi, C., Rocha, A. ‘Face liveness detection under bad illumination conditions’. In: 2011 18th IEEE International Conference on Image Processing. (, 2011. pp. 3557–3560
- [81] Raghavendra, R., Busch, C.: ‘Robust scheme for iris presentation attack detection using multiscale binarized statistical image features’, IEEE Transactions on Information Forensics and Security, 2015, 10, (4), pp. 703–715
- [82] Doyle, J.S., Bowyer, K.W.: ‘Robust detection of textured contact lenses in iris recognition using bsif’, IEEE Access, 2015, 3, pp. 1672–1683
- [83] Akhtar, Z., Micheloni, C., Piciarelli, C., Foresti, G.L. ‘Mobio_livdet: Mobile biometric liveness detection’. In: 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). (, 2014. pp. 187–192
- [84] Tronci, R., Muntoni, D., Fadda, G., Pili, M., Sirena, N., Murgia, G., et al. ‘Fusion of multiple clues for photo-attack detection in face recognition systems’. In: 2011 International Joint Conference on Biometrics (IJCB). (, 2011. pp. 1–6
- [85] Feng, L., Po, L.M., Li, Y., Xu, X., Yuan, F., Cheung, T.C.H., et al.: ‘Integration of image quality and motion cues for face anti-spoofing: A neural network approach’, Journal of Visual Communication and Image Representation, 2016, 38, pp. 451 – 460
- [86] Li, L., Feng, X., Boulkenafet, Z., Xia, Z., Li, M., Hadid, A. ‘An original face anti-spoofing approach using partial convolutional neural network’. In: 2016 Sixth International Conference on Image Processing Theory, Tools and Applications (IPTA). (, 2016. pp. 1–6
- [87] Nguyen, T.D., Pham, T.D., Baek, N.R., Park, K.R. ‘Combining deep and handcrafted image features for presentation attack detection in face recognition systems using visible-light camera sensors’. In: Sensors. (, 2018.
- [88] Atoum, Y., Liu, Y., Jourabloo, A., Liu, X. ‘Face anti-spoofing using patch and depth-based cnns’. In: 2017 IEEE International Joint Conference on Biometrics (IJCB). (, 2017. pp. 319–328
- [89] Liu, Y., Jourabloo, A., Liu, X.: ‘Learning deep models for face anti-spoofing: Binary or auxiliary supervision’, CoRR, 2018,
- [90] Wang, Z., Zhao, C., Qin, Y., Zhou, Q., Lei, Z.: ‘Exploiting temporal and depth information for multi-frame face anti-spoofing’, CoRR, 2018,
- [91] Yang, J., Lei, Z., Li, S.Z.: ‘Learn convolutional neural network for face anti-spoofing’, CoRR, 2014,
- [92] Gan, J., Li, S., Zhai, Y., Liu, C. ‘3d convolutional neural network based on face anti-spoofing’. In: 2017 2nd International Conference on Multimedia and Image Processing (ICMIP). (, 2017. pp. 1–5
- [93] Lucena, O., Junior, A., Moia, V., Souza, R., Valle, E., de Alencar.Lotufo, R. In: ‘Transfer learning using convolutional neural networks for face anti-spoofing’. (, 2017. pp. 27–34
- [94] Czajka, A., Bowyer, K.W., Krumdick, M., VidalMata, R.G.: ‘Recognition of image-orientation-based iris spoofing’, IEEE Transactions on Information Forensics and Security, 2017, 12, (9), pp. 2184–2196
- [95] Silva, P., Luz, E., Baeta, R., Pedrini, H., Falcão, A., Menotti, D. ‘An approach to iris contact lens detection based on deep image representations’. In: 2015 28th SIBGRAPI Conference on Graphics, Patterns and Images. (, 2015. pp. 157–164
- [96] Kuehlkamp, A., da Silva.Pinto, A., Rocha, A., Bowyer, K.W., Czajka, A.: ‘Ensemble of multi-view learning classifiers for cross-domain iris presentation attack detection’, CoRR, 2018,
- [97] Hoffman, S., Sharma, R., Ross, A. ‘Convolutional neural networks for iris presentation attack detection: Toward cross-dataset and cross-sensor generalization’. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). (, 2018. pp. 1701–17018
- [98] Menotti, D., Chiachia, G., Pinto, A., Schwartz, W.R., Pedrini, H., Falcão, A.X., et al.: ‘Deep representations for iris, face, and fingerprint spoofing detection’, IEEE Transactions on Information Forensics and Security, 2015, 10, (4), pp. 864–879
- [99] Agarwal, A., Singh, R., Vatsa, M.: ‘Face anti-spoofing using haralick features’, 2016 IEEE 8th International Conference on Biometrics Theory, Applications and Systems (BTAS), 2016, pp. 1–6
- [100] Galbally, J., Marcel, S., Fierrez, J.: ‘Image quality assessment for fake biometric detection: Application to iris, fingerprint, and face recognition’, IEEE Transactions on Image Processing, 2014, 23, (2), pp. 710–724
- [101] Garcia, D.C., de Queiroz, R.L.: ‘Face-spoofing 2d-detection based on moiré-pattern analysis’, IEEE Transactions on Information Forensics and Security, 2015, 10, (4), pp. 778–786
- [102] He, Z., Sun, Z., Tan, T., Wei, Z. ‘Efficient iris spoof detection via boosted local binary patterns’. In: Tistarelli, M., Nixon, M.S., editors. Advances in Biometrics. (Berlin, Heidelberg: Springer Berlin Heidelberg, 2009. pp. 1080–1090
- [103] Zhang, H., Sun, Z., Tan, T. ‘Contact lens detection based on weighted lbp’. In: 2010 20th International Conference on Pattern Recognition. (, 2010. pp. 4279–4282
- [104] Costa.Pazo, A., Bhattacharjee, S., Vazquez.Fernandez, E., Marcel, S. ‘The replay-mobile face presentation-attack database’. In: 2016 International Conference of the Biometrics Special Interest Group (BIOSIG). (, 2016. pp. 1–7
- [105] Sequeira, A.F., Monteiro, J.C., Rebelo, A., Oliveira, H.P. ‘Mobbio: A multimodal database captured with a portable handheld device’. In: 2014 International Conference on Computer Vision Theory and Applications (VISAPP). vol. 3. (, 2014. pp. 133–139
- [106] Gragnaniello, D., Sansone, C., Verdoliva, L.: ‘Iris liveness detection for mobile devices based on local descriptors’, Pattern Recogn Lett, 2015, 57, (C), pp. 81–87
- [107] Marsico, M.D., Galdi, C., Nappi, M., Riccio, D.: ‘Firme: Face and iris recognition for mobile engagement’, Image Vision Comput, 2014, 32, pp. 1161–1172
- [108] Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al.: ‘Imagenet large scale visual recognition challenge’, International Journal of Computer Vision, 2015, 115, (3), pp. 211–252
- [109] Boulkenafet, Z., Komulainen, J., Li, L., Feng, X., Hadid, A. ‘Oulu-npu: A mobile face presentation attack database with real-world variations’. In: 2017 12th IEEE International Conference on Automatic Face Gesture Recognition (FG 2017). (, 2017. pp. 612–618
- [110] Yambay, D., Becker, B., Kohli, N., Yadav, D., Czajka, A., Bowyer, K.W., et al. ‘Livdet iris 2017 - iris liveness detection competition 2017’. In: 2017 IEEE International Joint Conference on Biometrics, IJCB 2017, Denver, CO, USA, October 1-4, 2017. (, 2017. pp. 733–741
- [111] Chakka, M.M., Anjos, A., Marcel, S., Tronci, R., Muntoni, D., Fadda, G., et al. ‘Competition on counter measures to 2-d facial spoofing attacks’. In: 2011 International Joint Conference on Biometrics (IJCB). (, 2011. pp. 1–6
- [112] Chingovska, I., Yang, J., Lei, Z., Yi, D., Li, S.Z., Kahm, O., et al. ‘The 2nd competition on counter measures to 2d face spoofing attacks’. In: 2013 International Conference on Biometrics (ICB). (, 2013. pp. 1–6
- [113] Zhang, S., Wang, X., Liu, A., Zhao, C., Wan, J., Escalera, S., et al. ‘A dataset and benchmark for large-scale multi-modal face anti-spoofing’. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). (, 2019. pp. 919–928
- [114] Liu, A., Wan, J., Escalera, S., Jair.Escalante, H., Tan, Z., Yuan, Q., et al. ‘Multi-modal face anti-spoofing attack detection challenge at cvpr2019’. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. (, 2019.
- [115] Liu, A., Tan, Z., Li, X., Wan, J., Escalera, S., Guo, G., et al.. ‘Static and dynamic fusion for multi-modal cross-ethnicity face anti-spoofing’. (, 2019
- [116] Yambay, D., Jr., J.S.D., Bowyer, K.W., Czajka, A., Schuckers, S. ‘Livdet-iris 2013 - iris liveness detection competition 2013’. In: IEEE International Joint Conference on Biometrics, Clearwater, IJCB 2014, FL, USA, September 29 - October 2, 2014. (, 2014. pp. 1–8
- [117] Yambay, D., Walczak, B., Schuckers, S., Czajka, A. ‘Livdet-iris 2015 - iris liveness detection competition 2015’. In: IEEE International Conference on Identity, Security and Behavior Analysis, ISBA 2017, New Delhi, India, February 22-24, 2017. (, 2017. pp. 1–6
- [118] Sequeira, A.F., Oliveira, H.P., Monteiro, J.C., Monteiro, J.P., Cardoso, J.S. ‘Mobilive 2014 - mobile iris liveness detection competition’. In: Proceedings of the International Joint Conference on Biometrics (IJCB). (, 2014. pp. 1–6
- [119] Ruiz.Albacete, V., Tome.Gonzalez, P., Alonso.Fernandez, F., Galbally, J., Fierrez, J., Ortega.Garcia, J. ‘Direct attacks using fake images in iris verification’. In: Schouten, B., Juul, N.C., Drygajlo, A., Tistarelli, M., editors. Biometrics and Identity Management. (Berlin, Heidelberg: Springer Berlin Heidelberg, 2008. pp. 181–190
- [120] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: ‘Rethinking the inception architecture for computer vision’, CoRR, 2015, abs/1512.00567
- [121] He, K., Zhang, X., Ren, S., Sun, J.: ‘Deep residual learning for image recognition’, CoRR, 2015, abs/1512.03385
- [122] Sandler, M., Howard, A.G., Zhu, M., Zhmoginov, A., Chen, L.: ‘Inverted residuals and linear bottlenecks: Mobile networks for classification, detection and segmentation’, CoRR, 2018, abs/1801.04381
- [123] Simonyan, K., Zisserman, A.: ‘Very deep convolutional networks for large-scale image recognition’, CoRR, 2014, abs/1409.1556
- [124] Kingma, D.P., Ba, J.: ‘Adam: A method for stochastic optimization’, CoRR, 2014, abs/1412.6980
- [125] Anjos, A., Shafey, L.E., Wallace, R., Günther, M., McCool, C., Marcel, S. ‘Bob: a free signal processing and machine learning toolbox for researchers’. In: 20th ACM Conference on Multimedia Systems (ACMMM), Nara, Japan. (, 2012.
- [126] Anjos, A., Günther, M., de Freitas.Pereira, T., Korshunov, P., Mohammadi, A., Marcel, S. ‘Continuously reproducing toolchains in pattern recognition and machine learning experiments’. In: International Conference on Machine Learning (ICML). (, 2017.
- [127] Peng, F., Qin, L., Long, M.: ‘Face presentation attack detection using guided scale texture’, Multimedia Tools and Applications, 2018, 77, (7), pp. 8883–8909