Deep Backward and Galerkin Methods for the Finite State Master Equation
Abstract.
This paper proposes and analyzes two neural network methods to solve the master equation for finite-state mean field games (MFGs). Solving MFGs provides approximate Nash equilibria for stochastic, differential games with finite but large populations of agents. The master equation is a partial differential equation (PDE) whose solution characterizes MFG equilibria for any possible initial distribution. The first method we propose relies on backward induction in a time component while the second method directly tackles the PDE without discretizing time. For both approaches, we prove two types of results: there exist neural networks that make the algorithms’ loss functions arbitrarily small and conversely, if the losses are small, then the neural networks are good approximations of the master equation’s solution. We conclude the paper with numerical experiments on benchmark problems from the literature up to dimension , and a comparison with solutions computed by a classical method for fixed initial distributions.
Keywords: Mean field game, deep Galerkin, deep backward, master equation, neural network, Nash equilibrium, PDE, stochastic differential game.
1. Introduction
1.1. Introduction to MFGs
In 1950, John Nash introduced the concept of a Nash equilibrium, an idea that describes when players trying to minimize an individual cost have no incentive to change their strategy [45]. Nash proved that, under mild conditions, a Nash equilibrium always exists in mixed strategies. The question remained however, even when a Nash equilibrium was known to exist, whether there is an algorithmic way to solve for it. It turns out that, in general, computing a Nash equilibrium is a very difficult task [17].
The origins of limiting models for many-agent games can be traced back to [3] and to [51], both addressing one-shot games. In the realm of stochastic dynamical games, mean field game (MFG) theory was pioneered by [40, 41], along with an independent development by [36]. MFG paradigms study situations in which a very large number of agents interact in a strategic manner. Specifically, MFGs provide one way to approximate Nash equilibria of large, anonymous, symmetric finite-player games.
In characterizing an equilibrium in MFGs, we introduce a representative player who, instead of reacting to players, responds to a flow of measures. The MFG equilibrium is consequently defined by a fixed point, ensuring that the distribution of the dynamics of the representative player under optimality aligns with the flow of measures to which they respond. It is worth noting that Nash equilibria in finite-player games are similarly described using fixed points.
Returning to the motivating question for -player games, an MFG equilibrium provides an approximate Nash equilibrium in a corresponding finite-player game: if all the players use the strategy determined by the MFG, each player can be at most better off by choosing another strategy, and converges to zero as . This approximation is valid for games in which players are homogeneous and the interactions are symmetric, in the sense that they occur through the players’ empirical distribution. While static games are prevalent in game theory for the sake of simplicity, dynamic games are more realistic for applications. In this work, we consider the MFG studied by [5, 15, 30] which approximates an -player stochastic differential game with a finite number of states.
Classically, an MFG equilibrium can be described by a coupled forward-backward system of equations, called the MFG system. The backward equation is a Bellman-type equation describing the evolution of a representative player’s value function (the optimal cost), from which the optimal strategy can be deduced. The forward equation describes the evolution of the population’s distribution, which coincides with the distribution of one representative player over the state space. We refer to the books by [7] and [12] for more details on this approach using partial differential equations (PDEs) or stochastic differential equations (SDEs). In finite-state MFGs as we will consider in this work, the forward-backward system is a system of ordinary differential equations (ODEs); the interested reader is referred to [12, Chapter 7.2].
The solution to the forward-backward system depends on the initial distribution of the population. The representative player’s value function and control depend only implicitly on the population distribution. This dependence can be expressed explicitly through the notion of a decoupling field. The MFG equilibrium can be described by the so-called master equation, introduced by [43]. The interested reader is referred to the monograph by [11] for a detailed analysis of the master equation and the question of convergence of finite-player Nash equilibria to MFG equilibria. The solution to this equation is a function of the time, the representative player’s state, and the population distribution, which will be denoted respectively by , and . The master equation derives from the MFG system (see Proposition 1 below), whose structure is crucial for our analysis. Besides fully characterizing the MFG equilibrium for any initial distribution, the master equation is also used to study the convergence of the finite player equilibrium to its MFG counterpart [11, 19, 20]. In this paper, we are interested in the finite state, finite horizon master equation studied by [5, 15]:
| (1) |
Above, is the state space, is the terminal time of the game, is the Hamiltonian (defined in Section 2), and is a terminal condition. The function denotes the minimizer of the Hamiltonian, which under regularity assumptions is equal to the gradient of the Hamiltonian. The variables are the time , the state , and the distribution , which lies in the -dimensional simplex . We use the notation for each . Derivatives on the simplex, denoted by , can be thought of as usual directional derivatives and will be explicitly defined in Section 2.
Note that (1) is, in general, a nonlinear PDE, for which there is no analytical solution and the question of well-posedness is challenging (for an overview, see the book by [22]). In fact, even computing numerically an approximate solution is a daunting problem. When , traditional methods such as finite difference schemes can be employed. However, the computational cost of these methods becomes prohibitive for dimensions greater than . For example, in grid-based methods, the number of points grows exponentially quickly in . Other methods include Markov chain approximations, see [4]. We refer to [38] for an overview of classical methods for PDEs and [1, 42] for an overview of classical methods for MFGs. Besides, many applications require . And additionally, [8] recently demonstrated that MFGs with a continuous state space can be approximated by MFGs with finite, but large, state spaces. This approximation relies on the convergence of the solution of the associated master equations as the number of states tends to infinity. Neural networks provide one avenue to mitigate the curse of dimensionality, and this has triggered interest for machine learning-based methods, as we discuss in the next section.
The value function under the unique Nash equilibrium in the -player game converges to the solution to the master equation up to an error of order (and so do the optimal controls) [5, 15]. Then, we prove that the two algorithms we propose, the deep backward master equation (DBME) and deep Galerkin master equation (DGME) methods, approximate the master equation which, as discussed in the prior paragraph, is not easy to solve analytically. So while the primary object of interest for this paper is the master equation, our main contribution completes the picture for how to provably approximate the solution to the -player game.
1.2. Overview of Machine Learning for PDEs
In this work, we propose and rigorously analyze deep learning methods to tackle the master equation (1) for finite-state MFGs beyond what is possible with traditional numerical methods. Our numerical methods build upon the recent development of deep learning approaches for PDEs. In the past few years, numerous methods have been proposed along these lines, such as the deep BSDE method [21], the deep Galerkin method [53], physics informed neural networks [49] and deep backward dynamic programming [48]. In the context of MFGs and mean field control problems, deep learning methods have been applied using the probabilistic approach [14, 24, 28] or the analytical approach [2, 10, 13, 50]. The aforementioned works consider neural networks whose inputs are only the individual state and possibly time. A few works have considered neural networks taking as inputs a representation of the mean field. The paper by [27] proposed a deep backward method for mean field control problems. As with the first method (called DBME) we present below, it is based on a discrete-time, backward scheme. The rate of convergence in terms of number of particles was studied in [29]. However, this method solves the Bellman equation for mean field control problems while we solve the master equation for MFGs, which fails to satisfy a comparison principle. Furthermore, [27] considered a continuous space model using particle-based approximations while we focus on a finite space model. Work by [18] solves continuous space mean field control problems using population-dependent controls by directly learning the control function instead of using a backward dynamic programming equation. As for MFG with population-dependent controls, [47] proposed a deep reinforcement learning method for finite-state MFGs based on a fictitious play and deep Q-networks. In contrast, our two methods do not rely on reinforcement learning and we provide a detailed analysis of the algorithms’ errors. We refer to the overview of [35] for a review of deep learning methods in optimal control and games.
In this work, we will focus on two types of methods. The first approach finds its roots in the pioneering work of [21], which exploits the connection between SDEs and PDEs: using Feynman–Kac type formulas, the PDE solution satisfies a backward SDE, that is, they satisfy a terminal condition. Corresponding to the SDE, the PDE has a terminal condition. Such SDEs and PDEs crop up often in mathematical finance, most iconically in the Black–Scholes equation for pricing European options [9]. While the original method of [21] consists in replacing the BSDE by a shooting method for a forward SDE, subsequent works exploit the backward structure differently. In particular, deep backward methods were explored in control problems in the nonlinear and fully-nonlinear cases [37, 48]. The Deep Backward Dynamic Programming algorithm (DBDP) from [37] (more specifically their DBDP2 algorithm) uses a sequence of neural networks on a discretization of . Training is done by starting from the terminal time and, going backward in time, the neural network for a given time step is trained to minimize a loss function which involves the neural network at the following time step.
The second method we propose is the DGME, introduced as the deep Galerkin method by [53]. The PDE solution is approximated by a neural network, which is a function of the time and space variables. Training is done by minimizing an empirical loss which captures the residual of the PDE, as well as possible boundary conditions. The loss is computed over points sampled inside the domain and, if needed, on its boundary. In this way, the method does not require any discretization of space or time. The solution is learned over the whole domain thanks to the generalization capability of neural networks.
For these methods, most theoretical results rely on universal approximation theorems for suitable classes of functions related to the regularity of PDE solutions. In that sense, other classes of approximators could be used instead of neural networks. However, neural networks seem to be a very suitable choice to solve PDEs. Two of the main limitations of neural networks are the lack of explainability and the large amount of data required for training, but these are not issues when solving PDEs with the aforementioned methods. Indeed, explainability is not a priority when approximating PDE solutions, and data points are obtained by sampling over the PDE domain as many times as desired.
1.3. Contributions and Challenges
While the well-posedness of (1) was studied by [5] and [15], no analytical solution is known. Therefore we provide two algorithms, we prove their correctness, and numerically solve the master equation (1) for some examples.
1.3.1. DBME
The first method we propose, called deep backward master equation (DBME), is inspired by the DBDP of [37], although there are key differences. An important disparity lies in the corresponding stochastic model for each setting: the diffusion dynamics found in the underlying DBDP problem are substituted with jump dynamics in the finite state MFG. Essentially, in the DBDP the target function is twice differentiable; this allows the use of correspondence between certain martingale and loss terms that would otherwise be hard to bound. Unfortunately in the case of the master equation, it is not necessarily true that the solution is twice differentiable. Another crucial distinction lies in the fact that the DBDP is designed to fit Hamilton–Jacobi–Bellman equations originating from optimal control problems. In contrast, the MFG solution manifests as a fixed point of a best response mapping within a control problem and consequently, the master equation lacks a so-called comparison principle, which leads us to design distinct algorithms and proofs of convergence. To establish the convergence, we leverage the transformation of the master equation into the coupled, forward-backward MFG system for a fixed initial distribution. At a technical level, another difference lies in the fact that the DBME minimizes a maximum-based error, while the DBDP minimizes an -error. All these differences necessitate a different algorithm and a different analysis. To overcome these difficulties, the analysis for the DBME, like that of the DGME, makes use of the MFG system directly. Our approach contrasts with that of the DBDP which uses propagation by SDEs.
1.3.2. DGME
The second algorithm we consider builds upon the DGM of [53] and adapts it to solve the master equation (1), as explored by [42, Algorithm 7]. That DGM adaptation is recalled here in Algorithm 2, with a modification. As used by [42], the DGM minimizes the expectation of an -error. In our formulation, the DGME minimizes a worst-case loss function formulated as a maximum that is, in practice, sampled and not a true maximum over the entire state space. While applying the DGM to the master equation is not novel, the finite state master equation is a different form of PDE than that studied by [53] and so the convergence theorem (Theorem 7.3) of their work does not apply. Moreover, no proofs of DGM convergence were offered by [42].
We prove the convergence of our DGME algorithm to the unique master equation solution in Theorem 4. Our result is analogous to that of [53, Theorem 7.3], but as previously mentioned, since the PDE structure differs, our proof requires entirely different methods. Namely, recall that the master equation can be constructed from the MFG system and our proof relies on the structure of the MFG system. Using the neural network trained by the DGME, we construct an approximate MFG system and use MFG techniques (specifically, MFG duality) to compare the approximate solution and the true solution. As a consequence of our modification and the structure of the master equation, we obtain convergence of the neural network approximation to the true solution in the supremum norm, which is different from and arguably stronger than the -convergence obtained by [53]. Broadly speaking, this choice allows us to deal with the maximum over all states instead of an expectation and hence our analysis is state-agnostic. One more subtle difference is that [53] tackle the case of a neural network with one-hidden layer for simplicity’s sake, while the proofs we offer for the DGME apply to feedforward networks of arbitrary depth. This generality comes from our use of the universal approximation theorem [34, Theorem 3.1].
1.3.3. The convergence results
For each algorithm, we have two main types of results. The first type of result, found in Theorems 1 and 3, builds on universal approximation properties of neural networks. We show that there exist neural networks that approximate the master equation solution and that when this is the case, the algorithms’ loss functions are small.
The second type of result, found in Theorems 2 and 4, asserts that when the algorithm results in a neural network (or in the case of the DBME, a family of neural networks) with small loss, then the obtained network is in fact close to the true solution in supremum norm. The rate of convergence in each case depends on the loss value and, in the case of the DBME only, the size of the time partition. Note that the empirical loss achievable in practice by the algorithm depends on the depth and width of the neural network, the number of epochs it is trained for, the amount of training data, and so on. This type of bound is morally different from that of [37], which uses a constant obtained from universal approximation.
1.4. Structure of the Paper
We begin by defining notation in Section 2 before providing a description of the MFG model and recalling the major results concerning the MFG and the master equation in Section 3. In Section 4 we outline the architecture of the neural networks we consider. Then in Sections 5 and 6, we describe and analyze the DBME and DGME, respectively. Finally, in Section 7, we present numerical results for two examples using these algorithms.
2. Notation
We let be the finite set of states. The finite difference notation for a vector is , . Generally, unless otherwise stated. A probability measure over is identified with the -dimensional simplex in , which we denote ; by this we mean that:
Unless otherwise stated, . For a vector in , , denotes the usual Euclidean norm. When is a finite set, denotes the cardinality of the set. For any Euclidean spaces and any measurable function , , we denote by the supremum norm of . In the case that some arguments of are specified, the essential supremum is taken over only the unspecified arguments. To alleviate the notations, we will denote by the supremum norm of a bounded function , and by the Lipschitz constant of a Lipschitz function .
The measure derivative on the simplex is written (where the direction of the derivative is specified below). Since the simplex is finite-dimensional, one can think of as the usual directional derivative; that is, for each and for each , such that , we define:
| (2) |
where is the -th standard basis vector of minus the -th, and is a measurable function such that the limit exists. Also, is a vector. Note that by definition . Furthermore, in equation (1) this derivative is multiplied by , so its definition at does not affect the expression. Additionally, in (1) is multiplied by , which does not represent a rate of transition. Alternatively, we could define the derivatives for only and use the double sum in (1) as .
Let be the set of -valued functions defined on , where the time derivative is continuous and whose measure derivative is Lipschitz. The space can be thought of as combining the Banach space of continuously differentiable, real-valued functions with the Hölder space as defined in [22, Section 5.1]. Let be a Euclidean space and, for a given differentiable function with derivative , we define the -Hölder seminorm as:
The first “” in the notation refers to the order of the derivative, while the second refers to the modulus of continuity. Then, the -Hölder norm is:
With this in mind, we endow the space with the norm:
| (3) |
where is defined in (2), and recall that, by definition of , the supremum is taken over all . Note that is a Banach space with .
A few times in the paper we will mention the space of continuously differentiable functions where is either or with and where is some subset of euclidean space. We endow this space with the norm:
making it Banach.
3. The Finite State Master Equation and the MFG
In this section, we continue with structure and the notation adopted by [5, 15] with only minor additions. For readability, we recall the notation here. Throughout we fix , a filtered probability space in the background satisfying the usual conditions.
3.1. The MFG
We consider a representative player that uses Markovian controls taking values in a set of rates . We will consider rates bounded in a compact set; that is, , with . A Markovian control is a measurable function where , and:
Here, for any , is the rate of transition at time to move from state to state and as usual with continuous-time Markov chains, . We denote by the set of transition-rate matrices with rates in . We denote by the set of measurable mappings .
Fix to be the initial time. The jump dynamics of the representative player’s state are given by:
| (4) |
where is a Poisson random measure with intensity measure given by
| (5) |
with , where Leb is the Lebesgue measure on , and is any Borel measurable set. We can think of as the -projection of , the set of rates for each state transition; thus, is the set of transition rates from state .
In order to set up the MFG equilibrium, we describe the cost structure of the game with respect to a representative player, who selects a Markovian control in order to play against a smooth flow of measures . We emphasize that the representative player’s cost includes the flow of measures . In this work, we make use of the regularity result from [15], which assumes that the total running cost is separable in the form . The running cost is , a function of the current state and control, while the mean field cost is , a function of the state and mean field distribution. Recall that does not represent a rate, thus is assumed independent of as a technicality. Given a flow of distributions, the representative agent’s control problem is to minimize:
| (6) |
over all where . Given the flow of measure and an initial state , the distribution (or law) of the representative player, denoted , is a fully deterministic flow of measures on . Formally, when and minimizes the cost:
we say that we have a mean field game equilibrium and we refer to this optimal cost as the value function. To be mathematically precise, the MFG equilibrium is a fixed point, as described next.
Definition 1 (MFG equilibrium).
Fix and . A pair is a MFG equilibrium over the interval for the initial distribution if the following two conditions are satisfied. First, is an optimal control for and second, for every , , where solves (4) controlled by .
Crucially, notice that the equilibrium is defined for a fixed initial distribution . For different initial distributions, we generally obtain different equilibrium controls and mean field flows. The master equation characterizes MFG equilibria for any initial distribution.
As explained below in Section 3.3, the equilibrium can be characterized using optimality conditions which involve the Hamiltonian, defined as:
where,
At times, using rather than will simplify the presentation of the PDE.
Remark 1.
The separability of the cost and the Hamiltonian is a standard assumption in the MFG literature. This, combined with the monotonicity assumption on functions and , leads to the uniqueness of the MFG solution and the corresponding master equation solution, see e.g., [11, 5, 15] as well as [12, P. 652]. It is important to note that while these are the prevalent assumptions, there are alternative conditions in the literature, such as alternative monotone conditions, see e.g., [25, 26, 33], that imply the uniqueness of solutions to MFG systems and the well-posedness of the corresponding master equations; or the anti-monotonicity condition, which can also establish global well-posedness for mean field game master equations with nonseparable Hamiltonians, see [44].
We emphasize that the goal of this paper is to leverage the established results from previous works to solve the master equation, rather than to propose new conditions for achieving uniqueness in the solution of the master equation.
3.2. Assumptions
In this section, we list the assumptions made on our MFG model. Such assumptions are standard and appear in previous work by [5, 15, 16].
Recall that the action set is where .111In the papers by [5, 16] it is assumed that ; however in his thesis, Cecchin managed to relax the assumption to allow for [15].
Assumption 1.
The Hamiltonian has a unique minimizer to which we refer to as the optimal rate selector and is denoted:
| (7) |
The optimal rate selector is a measurable function.
We note that since is given by (7), one sufficient condition to guarantee this is when is strictly convex in .
As for the mean field cost , and the terminal cost , we assume
Assumption 2.
The functions and are continuously differentiable in with Lipschitz derivative; namely, for any and is Lipschitz. Moreover, and are Lasry–Lions monotone, meaning: for both ,
| (8) |
Intuitively, the Lasry–Lions monotonicity condition means that a representative player would prefer to avoid congestion to decrease their cost.
In the following assumption, we specify the regularity of , which, since it is defined through implicitly defines most of the necessary regularity for . Moreover, since is defined on a compact set, its regularity assumptions imply it is bounded.
Assumption 3.
Assume is bounded. We let
| (9) |
and we assume that, on the compact set , the derivatives and exist and are Lipschitz in . Moreover, there exists a positive constant such that:
| (10) |
Note that when is differentiable, [31, Proposition 1] proved:
| (11) |
In order to keep this level of generality for the regularity of (namely, that these additional assumptions hold on but not necessarily globally), we will on occasion prove that a particular -argument of is uniformly bounded by . For the purpose of this paper, the assumption on in (9) is not too restrictive. Computations with the Hamiltonian only appear with the argument or , where is a neural network specified in the following sections that approximates . As we explain in detail in Remark 5, both of these arguments are bounded by from (9) and hence the Hamiltonian will always be regular enough when it is required.
Remark 2.
From the above assumption on , we have that is locally Lipschitz. Note that a sufficient condition is that is uniformly convex in .
Throughout the paper denotes a generic, positive constant that depends only on the problem’s parameters (that is, the parameters introduced above). To alleviate excessive notation, ’s value may change from one line to another.
3.3. Known Results
Next up, we recall some established results from the study of finite-state, finite-horizon MFGs and master equations.
The functions and are defined in a moment but we first describe their meanings. The measure is the evolving MFG equilibrium as in Definition 1. The value function is the value function (optimal cost) of the MFG starting at time with initial distribution along the MFG equilibrium. So, the value is the remaining optimal cost to a player in state at time until the game ends, at time .
The MFG system is:
| (12) | ||||
Note that the system is composed of a forward equation and a backward equation. The above ODE system characterizes the MFG equilibrium for a given initial condition . However, our goal is to compute the MFG equilibrium for every initial condition. This would require solving a continuum of ODE systems, which is not feasible. Instead, we will focus on the master equation. Informally, it encompasses the continuum of ODE systems and its solution captures the dependence of the value function on the mean field. More precisely, the master equation’s solution is defined through its MFG system. The following proposition is a combination of the results from [15, Proposition 1, Proposition 5, Theorem 6]222In fact, we reuse the argument from Proposition 1, but applied to the MFG system. and [11, Section 1.2.4].
Proposition 1.
There exists a unique solution, denoted by , in to (LABEL:eqn:mfg). Let be defined by:
| (13) |
Then is the unique classical solution to the master equation (1). Moreover, the consistency relation holds: for all ,
| (14) |
Additionally, for every . Moreover,
| (15) | ||||
where the second line is by definition of , see (6). As a consequence of (15),
| (16) |
Recalling the definition of in (9), note that .
Remark 3.
By (15), we can think of as the value of the MFG equilibrium when the initial time is , the initial state is , and the initial distribution is . Moreover, is the rate matrix under the mean field equilibrium; namely, these are the rates that dictate how quickly the representative player transitions from one state to another under this equilibrium. By (14), we have , which are precisely the transition rates in the Kolmogorov equation for from (LABEL:eqn:mfg).
Remark 4.
Recall that the motivation for investigating the master equation in the first place was to solve the corresponding -player game. Per [5, Theorem 2.1] or [15, Theorem 1], the -player game’s value function (cost under the unique Nash equilibrium) converges to the master equation’s solution with rate . Moreover by [15, Theorem 2, Theorem 4], the -player Nash equilibrium results in an empirical distribution of players whose trajectory converges to the MFG equilibrium, with rate depending on the notion of convergence.
4. Neural Networks
With the major points from the MFG literature in hand, we can switch to the neural network side. We define the neural networks to be used as function approximators and outline their parameters. From a proof perspective, the DBME and DGME algorithms require networks with slightly different levels of regularity, so here we only describe what features the networks used for each algorithm have in common.
Throughout the paper, the use of neural networks is justified by the Universal Approximation Theorem, specifically the version from [34, Theorem 3.1]. This version of the Universal Approximation Theorem asserts that any differentiable function defined on a compact domain in Euclidean space is arbitrarily well-approximated (and has derivative arbitrarily well-approximated) by a neural network (and its derivative). This is relevant in our case since we are concerned with the master equation solution, , and we may identify with a compact subset of .
We will denote the total number of dense hidden layers of a deep, feed-forward, fully-connected neural network as , with the number of parameters in layer as for all . By convention, the first layer will always be the input layer. For any such neural network, define as the number of parameters. Throughout, the parameters are represented by a trainable vector .
Depending on the algorithm at hand, the input dimension of the neural networks will differ. For the DBME method, the input dimension is since the time component is discretized as part of the algorithm. In the DGME, the input vector is , which is of dimension ; so is either or when accounting for the affine transformation parameters in the neural network. We will give a concrete example later in (20). In either case, the output dimension is .
For simplicity, the activation function will be the same for all layers. We will denote it by . So that necessary theoretical results are accessible, must be smooth and nonlinear so the neural networks we consider are smooth universal approximators; for example, the hyperbolic tangent function or the sigmoid function are good choices. We use to denote the set of all such neural networks using activation function . We denote the subset:
| (17) |
Note that what we mean by a neural network is not simply an architecture but an architecture with fixed values for the parameters. The constraints in (17) are constraints on the parameters of the neural network.
The restriction in (17) on implies that we are interested in Lipschitz neural networks. Recent machine learning research emphasizes that Lipschitz neural networks ensure robustness of a solution to new or unforeseen data [23, 32, 46, 54].
Using the version provided by [34, Theorem 3.1], the Universal Approximation Theorem asserts that is dense in with the norm defined in (3). We also define:
| (18) |
Since we are only concerned with the master equation’s solution, which is a Lipschitz function with Lipschitz derivatives (see Proposition 1), it will be appropriate at times to deal with this restricted set.
5. The DBME Algorithm and Convergence Results
Having given the necessary background, we now present a deep-learning-based backward algorithm for learning the master equation termed Deep Backward Master Equation (DBME).
5.1. The DBME Algorithm 1
First, we introduce some notation relevant to the algorithm. Then, we justify some assumptions made on the neural networks under consideration, and introduce an auxiliary Kolmogorov forward ODE, before introducing the DBME algorithm itself.
The time interval will be partitioned into , with increments denoted . Define
Throughout we assume that there exist such that:
| (19) |
that is, is roughly proportional to . For functions and random variables at time , we will often use only a subscript as opposed to for brevity.
For the time , we approximate the master equation’s solution by with input dimension . Its parameters are denoted by and we use the notation . We will sometimes use the shorthand notation , where the vector of parameters optimizes a loss function defined in the sequel. We will not use a neural network at the last time in the partition and simply set .
Let for instance and . For the vector of parameters , denote the parameters from the scaling inside the activation function by . We can write a neural network as:
| (20) |
where , , , for all , and these parameters make up the entries in and . In the case , we note that is a -matrix with real entries and denote as the matrix operator -norm. Per [32, Section 4], we know that when , some positive real number, the Lipschitz constant of the network with parameters is no more than (possibly after modifying to account for the Lipschitz constant of the activation function ). So, for the rest of this section, which focuses on the DBME algorithm, we define the following set of parameters:
| (21) |
where recall that is the Lipschitz constant of depending only on the problem parameters that can be computed from [15, Section 3]. Thus any network where is Lipschitz with constant no more than .
Remark 5.
Previously in (17), we introduced the class of neural networks as appropriate for approximating . In this remark, we elaborate further. By (16), the master equation solution is uniformly bounded by the constant , given in (16). So, we are justified in truncating the neural network by replacing with . This ensures that will always be uniformly bounded. Using a result of [16, Lemma 3.1] and the boundedness of implies:
Because of the restriction of to , the same kind of computation holds for as in the previous display. Consequently, (9) holds and the local regularity assumptions on the Hamiltonian given in (10) are in force with the neural network as an argument; namely the derivatives and are Lipschitz and there exists a positive constant such that:
for all and all . The local regularity assumptions will be useful in the proof of algorithmic convergence. The upshot of this remark is that for any ,
One final element to introduce before presenting the algorithm is the solution of a forward Kolmogorov’s equation. This equation mirrors the flow of measures in the MFG equilibrium. However, instead of utilizing the master equation’s solution in the dynamics, we employ a neural network. This solution is a key element in the algorithm’s loss function. In details: for any , any , and any , define , where uniquely solves the (forward) ODE:
| (22) | ||||
The previous display is Kolmogorov’s forward equation over the time interval with initial distribution , and which corresponds to a non-linear Markov chain with rate matrix . Note that the control’s input is the difference of the neural network , rather than that of ; in light of (14), this is similar to the MFG system (LABEL:eqn:mfg). Moreover, appears within the rate matrix, which makes the Markov chain non-linear. The equation (LABEL:eqn:M_theta_i_def) is well-posed because the neural network and are Lipschitz. The notation can be thought of as the terminal distribution of this non-linear Markov chain at time ; that is, the effect of propagating the initial distribution by a control using neural network values, parameterized by .
| (23) |
The next remark motivates the algorithm’s structure and the form of the loss function (23) in the algorithm.
Remark 6.
From (LABEL:eqn:mfg) and (13)–(14) it follows that:
when is small. Recall that the dynamics of , the flow of measures under equilibrium from (LABEL:eqn:mfg), depends on the master equation solution, making it unsuitable for the loss function. To address this, in the loss function, we replace by , defined through equation (LABEL:eqn:M_theta_i_def), which is similar to the equation for in (LABEL:eqn:mfg) but with the neural network appearing in its dynamics instead of the function . Notice that, while the loss uses the forward ODE (LABEL:eqn:M_theta_i_def), it does not explicitly make use of the backward ODE. This is because the master equation captures the value function, see (14).
Next, note that the algorithm goes backward in time. The value at terminal time is known. Then at time , assuming that we have an estimation for for any , we go backward in time. In the analysis to follow, we use the structure of the loss function and (LABEL:eqn:M_theta_i_def) to define a forward-backward system that resembles the MFG system (LABEL:eqn:mfg) up to a small error that emerges from the loss function. It is the comparison between these two systems that yields the convergence result of Theorem 2.
5.2. Remarks for the Practitioner
We now make a few remarks on the algorithm that are relevant for its implementation.
Remark 7.
The reader may wonder how to ensure that the vector of parameters obtained at each step in Algorithm 1 lies in the set defined in (21). One solution proposed by [32, Algorithm 2] is to project the weights at each step of stochastic gradient descent. Projection guarantees and that the network obtained is Lipschitz. However, given a large enough upper bound , where previously in (20) we chose , the projection will not occur in practice and the algorithm can essentially run normal SGD. The result from [32] is preferred here because of its theoretical guarantees; however many other methods may be used to improve the regularity of a neural network, for instance dropout layers, learning rate schedulers, random initialization, and so on.
Remark 8.
In practice, we cannot compute a maximum over infinitely many elements as we write in Algorithm 1. Therefore in the implementation, we uniformly generate samples in and compute the propagation for each before minimizing the loss by SGD. In what follows we remark on the order of this error due to the approximation. Denote the set of all samples by . Define:
so that is related to the algorithm’s loss as:
For any , and , choose the following:
Lemma 1 (Approximation of Sampled Loss to Theoretical).
With , the sampled maximum, as defined above, denote the cardinality of by . Then, there exists a constant depending on the parameters of the problem and the dimension such that:
The proof, together with an explicit expression for , can be found in the appendix.
Remark 9.
Note that the maximum is in general not smooth and yet we aim to eventually take the gradient of the loss function which requires the loss to be differentiable. In practice, the maximum is computed as a smooth maximum; that is, a smooth function that approximates a maximum. For prior work applying stochastic gradient descent to a maximized loss function, and comments on its robustness, see [52].
Remark 10.
It is important to note that computing explicitly is only possible when the Hamiltonian is computable or at least approximable. This is true for instance in both numerical examples that we consider later in Section 7. In greater generality, when the running cost function is convex in its control argument, this amounts to solving a convex optimization problem at each time step.
5.3. DBME Main Results
Recalling the definition of from (23), define:
| (24) | ||||
Note that because in the algorithm, we set . Nonetheless we include in (24) in order to use the notation instead of .
We can now state our two main results with respect to the DBME. Each result is, loosely speaking, converse to the other. The first theorem says that there exist neural networks close to the true solution in our desired class, and when a neural network is close to the true function, the loss from the algorithm is small.
We recall that is defined in (16) and that and are bounds on the maximum norms of and respectively, and is a bound on the Lipschitz constant of .
Theorem 1 (DBME Approximation).
Set:
| (25) |
For every , there exist neural networks with parameters such that for all :
| (26) |
Moreover, for any neural network satisfying (26), the DBME algorithm’s loss is bounded as:
| (27) |
where we recall that is a constant depending only on the model parameters.
The second theorem provides an upper bound on the difference between the neural networks and the true master equation solution in terms of the algorithm’s error. Intuitively, it says that any network trained by the algorithm that minimizes the loss is in fact close to the true master equation solution.
Theorem 2 (DBME Convergence).
There exist and depending only on the problem’s data with the following property. For every and for every , letting denote a neural network with parameters minimizing the loss in the DBME Algorithm 1, we have:
Remark 11.
We note that the order of this error—that is, in one term and in the other—is like the error bound from [37], but with a smaller order of in the second term. The larger order of in [37] likely comes from their use of random propagation in the algorithm and corresponding fixed point system. In our case, the propagation is deterministic and the error is defined differently.
Remark 12.
To minimize the right hand side of the theorem, one first selects the number of time steps large enough to minimize the left error term. Then one selects the number of parameters large enough so that is small enough. Notice that the definition of takes into account the approximation error but not the training error (which stems from the optimization method used, such as SGD or Adam). However, we can expect that with a large enough number of training steps, the realized error can also be made small enough.
5.4. Auxiliary Lemma and Proof
In this section we prove a measure bound lemma that comes into play in the proofs of Theorem 1 and Theorem 2. For every , we denote as the solution to (LABEL:eqn:mfg) on with . In the following sections, we write to mean the sup-max norm taken over all and all , that is: , where .
Lemma 2 (Measure Bound).
There exists depending only on the problem data such that for all small enough and every and ,
| (28) |
Proof.
Recall the definition of the loss function in (23). For every , define the mapping by:
| (29) |
Recalling (LABEL:eqn:M_theta_i_def), , (29) rewrites:
| (30) |
Note that we initialized the DBME algorithm with ; also, going backwards with , on each time interval , we may think about (30) as a backward finite-difference equation, with as the terminal condition. We refer to (30) and (LABEL:eqn:M_theta_i_def) together as a forward-backward system.
The difference solves an ODE that after integrating yields: for every ,
Since is bounded and locally Lipschitz (see Remark 2), for every
where we recall that depend only on the model parameteres and not on the neural network or the time discretization. Taking the supremum over all for the last term in the above display and a maximum over the state in the left hand side yields:
Again taking another supremum bound with respect to and combining like terms, and then using the consistency property (14), we obtain (28).
∎
5.5. Proof of Theorem 1
We recall that is a generic, positive constant that depends only on the problem’s parameters and in particular is independent of and . We allow to change from one line to the next as needed.
Recall the parameters and from (25). We notice that (see (18)). Indeed, by (16), Due to Proposition 1, we know that is Lipschitz with Lipschitz constant (in fact, is Lipschitz). So, Now, by [34, Theorem 3.1], the Universal Approximation Theorem asserts that is dense in : for any , there exists such that . This neural network satisfies: and . For , we deduce that and , so it belongs to the class .
Next, we show (27). Since Lemma 2 is proved in greater generality, we will use it here for . We will denote
| (31) |
Let . Let . By integrating (LABEL:eqn:mfg) and by (30), along with (14),
| (32) |
Solving for above, and using triangle inequality, yields:
We are going to bound each term of the right hand side, using the Lipschitz continuity of the triangle inequality again, Lemma 2 and the Lipschitz continuity of , the fact (by integrating in time the forward equation and using the fact that is bounded) that , the boundedness of , and (26).
For the first term,
For the second term,
For the third term,
Combining these bounds, we obtain:
∎
5.6. Proof of Theorem 2
Fix . Recall (LABEL:eqn:M_theta_i_def). For any and any minimizing in (23), set
Note that for any ,
So when ,
| (33) |
where we recall is defined in (24). Like in (33), by the definition of the loss (29) and (31), .
Once more integrating (LABEL:eqn:mfg), by (30), and using (14),
| (34) |
Furthremore, by the Lipschitz continuity of ,
Going back to (34), taking the supremum over , using the fact that , and combining like terms,
Note that the above inequality requires , which is true for large enough, as we assume in the statement. Using the triangle inequality,
| (35) |
Next, we will use the fact that is Lipschitz, (28), triangle inequality, the fact that is Lipschitz, that , and the fact that
in order to update the generic constant .
We note that:
where we used the fact that is bounded by a constant depending only on the model’s parameters.
Going back to (35) and using the above bound, we obtain:
For the rest of the proof, we denote by the constant appearing in the above right-hand side. That is, we are fixing to be at this particular point in the proof, but later on will be generic as usual. Rearranging terms, there exists depending only on and such that:
| (36) | ||||
Taking , we have for all small enough that:
Note that:
Recalling (19), and noting that:
monotonically as , we have for all small enough that:
| (37) |
Returning to (LABEL:eqn:step_1_sus), we know that for , the terminal conditions agree and therefore,
By backward induction with (LABEL:eqn:step_1_sus) and then using (37),
This inequality holds for all and therefore we can take a maximum over all to conclude the proof.
∎
6. The DGME Algorithm and Convergence Results
In what follows, we describe the DGME adaptation of the DGM to solve the master equation, and we then provide two novel theoretical results. Recall that denotes the unique classical solution to (1) and that for all . By some previous remarks and from [34, Theorem 3.1], it is known that is dense in .
In Algorithm 2, we introduce the DGME, modified with the loss to a maximum from the expectation of a squared quantity. We also note that unlike the DBME, in which we restricted our attention to , in the DGME we can take without restriction.
| (38) | ||||
As we noted in Remark 8, we cannot, in practice, compute the maximum over the infinitely many elements in . So, like for the DBME and the original DGM formulation, we randomly sample the space instead. As in Remark 8, we note that uniformly sampling the space results is an estimator for the maximum where for samples, we get error for the estimator. The master equation we study in this paper only involves first-order derivatives with respect to the inputs and . Hence computing the gradient with respect to the neural network parameters of the loss function (38) only requires computing second-order derivatives, which can be done by automatic differentiation. 333If a second-order term was involved in the PDE, then the computation of the gradient of the loss would require third-order derivatives. Using automatic differentiation would probably be prohibitive in high dimension. In such cases, our method could perhaps be modified, using approximate second-order derivative computations, as proposed in [53, Section 3].
The following two theorems establish convergence of the DGME and are analogous to results from [53, Theorem 7.1, Theorem 7.3], but these results do not apply to the master equation due to its distinct form. Instead, we use the structure of the MFG system itself in order to obtain useful bounds. Yet another difference is that our results are given in the supremum norm while those of [53] are in norm.
In the theorem below, we note that the density of the neural networks implies there always exists a neural network uniformly close to the master equation solution ; then, we write that any close network satisfies the master equation (1) in an approximate sense. As we mentioned in the introduction, the two main results of each section are, loosely speaking, converse to one another. The first result deals with existence of networks close to the true solution and shows that when a network is close, the corresponding algorithm’s loss is small.
Theorem 3 (DGME Approximation).
For every , there exists a neural network such that:
| (39) |
Moreover, let be defined by:
| (40) | ||||
Then is measurable and there exists a positive constant , depending only on the problem data and independent of , such that:
| (41) | ||||
We stress that Theorem 3 has two parts. The first part, namely (39), holds by universal approximation theorem and is straightforward given the (known) regularity of the master equation solution. It is not directly related to the algorithm. The second part, namely (41), provides a bound on the residual of the PDE (including the terminal condition) when using a neural network which gives (39). This provides an upper bound on the loss function of Algorithm 2, which is simply the PDE residual.
We now present the main DGME result concerning convergence. This theorem asserts that if the DGME finds a network with small error in its loss function, then that network must be uniformly close to the master equation’s solution .
Theorem 4 (DGME Convergence).
The proof is based on a careful analysis of the master equation, and its connection with forward-backward ODE systems characterizing the MFG equilibrium for each initial condition. To the best of our knowledge, the result cannot be deduced from the literature. In particular, the analysis of the DGM in [53] is only for a specific class of (quasilinear, parabolic) PDEs, which does not cover ours. Furthermore, the master equation, despite some similarities, is not an HJB equation and does not enjoy a comparison principle.
Remark 13.
6.1. Proof of Theorem 3
We note that (39) is immediate from the universal approximation result of [34, Theorem 3.1]. It suffices to prove (40)–(41). Recall that is a generic constant independent of and , and may change from one line to the next.
From (39), for any and any , there exists a neural network such that:
Since (39) holds for all , we may write to mean without ambiguity. Note that:
so is bounded above by the right hand side of (9). When is small enough, is restricted to the interval and note that is locally Lipschitz on by assumption. We may therefore treat as Lipschitz.
Recall the definition of from (40). For brevity, we write as during the proof. Since solves (1), we find that:
| (43) |
We can check that, for the last line of (43):
Using the facts that is bounded and Lipschitz, that the classical master equation solution has bounded, and (39), we can bound the above quantity by:
where is independent of . Going back to (43), using the Lipschitz continuity of and of , and again (39), we obtain: In other words, satisfies (40)–(41). ∎
In the following section, we prove a lemma that is at the heart of Theorem 4. The lemma allows us to circumvent the unfortunate fact that the master equation has no comparison principle; thus we introduce an approximate MFG system and use duality.
6.2. Approximate MFG System
In the following lemma, we define the function through the network and we use the fact that it satisfies an approximate Hamilton–Jacobi–Bellman equation. Its evolution is coupled with a function , which solves a forward Kolmogorov equation of a non-linear Markov chain. That is, define as the solution to:
on . Note that is well-defined by the Picard–Lindelöf Theorem.
Lemma 3 (Approximate MFG System and Network Bound).
Let . Let be a neural network obtained by the DGME. Let the error function be defined as in (40). Assume (41) holds. Then, by setting , we get that solves the approximate MFG system on :
| (44) | ||||
Moreover, for all and when is small enough:
where is defined in (41) and is defined in (9). Hence, the regularity assumptions on given in (10) apply.
Remark 14.
The careful reader may wonder why the bound on above does not immediately follow from Theorem 3. This is because Lemma 3 and Theorem 4 deal with a network obtained from the DGME, while Theorem 3 does not. Theorem 3 shows that running the DGME is not hopeless since there exist neural networks with the properties we are seeking. Offhand, we only know that the network considered in Lemma 3 and Theorem 4 satisfies the master equation in some approximate way; therefore, we use only this fact to prove is bounded.
6.3. Proof of Lemma 3
We use the structure of the MFG system to obtain important estimates. That is, we fix and and set to be the unique solution to the Kolmogorov equation in (LABEL:eqn:mfg_appx) on .
For defined on , we use the fact that satisfies (40) to get:
where the error function is defined in (40). So together, solves (LABEL:eqn:mfg_appx). It remains to show the bound on .
Let be a jump process on with rate matrix given by ; namely, its infinitesimal generator is given by . Set . By an application of Itô’s lemma, and using the boundary conditions with (40), we have for any ,
Then,
So by definition of , by (41), since and are bounded, and since was arbitrary,
| (45) |
By (45), is uniformly bounded. Moreover, since , for all ( is defined in (9)). On the input then, (10) holds. ∎
In particular, from Lemma 3, we have that for all :
This observation will be useful in the following proof.
6.4. Proof of Theorem 4
The proof relies on an approximate MFG system on the time interval with initial distribution . We compare its solution to the true solution using MFG duality, that is, integrating the backward equation’s solution as a test function in the forward equation to obtain estimates on the solution. The MFG solution is related to the master equation as discussed in Section 3, and since and are arbitrary, we obtain convergence to the master equation solution.
The proof proceeds in three steps. Already we formulated the approximate MFG system (LABEL:eqn:mfg_appx) defined through a neural network and meant to mimic the MFG. We then proved a bound on the solution to the approximate system. In the subsequent steps, we will take advantage of the fact that the approximate MFG system is structured like the MFG system. In Step 1, we use the duality of the MFG and approximate MFG systems to obtain several estimates. That is, we treat the approximate MFG value as a test function to integrate against, in order to derive our estimates. In Steps 2 and 3, we integrate the differences of solution and combine these estimates with duality to finish the proof.
Step 1: Duality
Fix and let solve (LABEL:eqn:mfg) on with . For ease of notation, we suppress the superscript and simply write instead. Define and . Using (LABEL:eqn:mfg) and (LABEL:eqn:mfg_appx), solves:
| (46) | ||||
Using the product rule and (46):
We use the definition of , the terminal condition on , and the fact that the rates sum to zero (namely, for any and , ) to get:
By assumption, and are Lasry–Lions monotone and hence the left-hand side of the above display is non-negative. Hence,
| (47) | ||||
By Lemma 3, we may apply (11) and (10). That is, there exists such that for all and all :
Using the above display in (47) and rearranging terms,
| (48) | ||||
where recall that denotes a generic positive constant and its value may change from one line to the next.
Step 2: Integrating the backward equation from (46)
Step 3: Integrating the forward equation from (46)
Integrating the measure equation from (46) on , adding and subtracting a term, and using the boundedness of , and the Lischitz continuity of (over the range to which the inputs belongs):
Using Jensen’s inequality and Gronwall’s inequality:
| (50) |
In the above display, using Jensen’s inequality, (LABEL:eqn:appx_dual), and a supremum bound imply,
So by Young’s inequality,
Combining this estimate with (49), and using (41), we obtain:
The above reasoning holds for every . Recalling the definitions of , , and (13), we obtain (42). ∎
7. Numerical experiments
In this section, both the DBME and DGME algorithms were implemented in Python using TensorFlow 2. Both programs were run on the Great Lakes computing cluster, a high-performance computing cluster available for University of Michigan research. All algorithms were run on the cluster’s standard nodes, each of which consists of thirty-six cores per node. We expect further improvement in run-time given a practitioner switches to a specialized, GPU-enabled node. We also note that, in the original formulation of the DGM, [53] use an LSTM-like architecture while we are using a vanilla, fully-connected, feed-forward architecture. For all networks featured, we used four layers of sixty nodes each, with sigmoid activation function, excluding the input and output layers. The output layers used ELU. Code for the DGME and DBME algorithms, data for models used, and code used to create the visualizations in this section can be found on GitHub at https://github.com/ethanzell/DGME-and-DBME-Algorithms.
7.1. Example of Quadratic Cost
A classical example in MFG literature is that of quadratic costs. In this section, we adapt the examples of [15, Example 1] and [5, Example 3.1] to solve the corresponding master equation using the DGME and DBME algorithms.
Namely, we set the running costs and terminal cost, respectively:
where will be chosen later. Fix also . In our case, the Hamiltonian is:
So when the minimum is attained in the interior of , we have for all that:
| (51) | ||||
and so:
Note that, should (51) hold, the Hamiltonian satisfies the regularity we assume at the very beginning of the paper in (10). We will now explicitly verify the form of . Along the way, we will show that this form for is not guaranteed for all problem parameter choices; however, we will prove that certain parameter choices will guarantee this form of and thus also the regularity required for the class of problems we consider. First, we will show why (51) holds when .
The Hamiltonian has minimizer := :
Note that: occurs if and only if:
| (52) |
With this observation in mind, we are now interested in finding values of such that
as this will lead to the desired form of the Hamiltonian in (51).
The -argument of will always be for some and so we are interested in a bound on this quantity. We will derive a bound for in terms of . Then, by selecting and in concert with one another, we may guarantee (52) and therefore confirm (51) holds for all inputs to .
Let be the control that always chooses rate . Using (15), the fact that is a minimizer, the choice of , and the fact that , for we have:
So we can guarantee that by requiring that: We thus choose and and this guarantees the smoothness of the Hamiltonian for any value of the master equation solution and also for any number of states . While we could have chosen other values, these choices result in an easily interpretable picture as a consequence of the strong cost of rate selection and more prompt horizon.
7.2. Quadratic Cost—Low Dimensional Results
Now we present numerical results for the low-dimensional cases corresponding to this example. We begin with the case ; the following graphs are from the DGME.
7.2.1. The master equation’s solution for , visualizations via DGME
Here, we take an in-depth look at Figure 1. The horizontal axis of the graph indicates , the fraction of in state at time . The vertical axis is the value of the approximated master equation solution. The neural network is evaluated at a series of time steps and each time step is given a distinct color, as indicated by the legend on the right.
 |
 |
While there is no known explicit formula to sanity check our solution, we can make several qualitative judgements at the start. At the terminal time , the graph indicates that the function is approximately zero; this agrees with the fact that the terminal condition is and . Second, the graph appears to respect the monotonicity of the cost. That is, for any fixed time the graph satisfies:
for all in the interior of , and whenever is small enough so that is defined. The reverse inequality is true for . We expect this cost monotonicity to come from the mean field cost since a representative player experiences a lower cost when a smaller fraction from the distribution are in his or her own state. Finally, by (15) and definition of , we expect monotonically as and indeed this is the case.
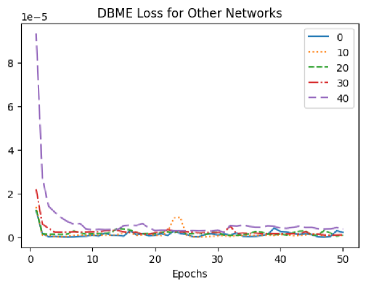
7.2.2. Measuring DGME and DBME Losses
In Figure 2 we give loss graphs for the DGME and DBME algorithms. The DGME algorithm trains one neural network to the entire master equation and so its loss graph is straightforward: for every epoch, we average the losses over the thirty steps in that epoch and present the losses. The DBME however is the result of neural networks being trained on the output of a neural network at a future time step, and so the DBME returns networks. Moreover, recall that the final DBME “neural network” is set to be the terminal cost and so the first neural network that is trained with an actual loss function is the penultimate network . In practice, we found that training for more epochs than the other networks resulted in better results for networks closer to the initial time. Therefore, Figure 2 also presents three graphs for the DBME trained with a constant-sized partition of . The first DBME graph depicts the losses of by itself plotted on a log scale, while the second graph gives the losses for the networks , , and .
 |
 |
 |
7.2.3. Agreement between the DGME and DBME algorithms
The result from the DBME appears similar given the partition step size is small enough. In Figure 3 we graph the error between the prior DGME model and its DBME counterpart over all times in the partition . The error is computed as the average difference over the state space and the horizontal axis is the difference on .

In Figure 3, for the partitions such that , the DGME and DBME algorithms agree on the value of on average. For larger values of , there is some error that propagates backward and worsens the estimate at the initial time .
7.2.4. The master equation’s solution for , visualizations via DGME
Here, we break down the result in Figure 4. It is qualitatively similar to Figure 1 (for ) but we present it differently. In Figure 4, each sub-plot corresponds to a different time. The simplex is identified with a triangle in dimension 2, where the x-axis corresponds to the density in state and the y-axis corresponds to the density in state . The horizontal axis is while the vertical axis is . The color intensity gives the value of the approximate master equation solution. For clarification, the bottom left corner is the point in where . In the first image of Figure 4 we notice the same cost monotonicity as in the two-dimensional case. Meanwhile, we note that the final image (where ) is approximately zero as desired.
 |
 |
 |
 |
 |
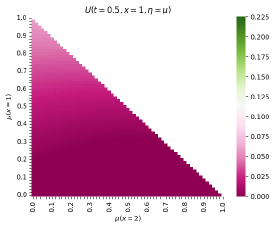 |
Once we have approximately learned the master equation solution, we may compute the corresponding control by plugging the solution into the rate selector . Then, we are able to plot the trajectory of the player population over time. In Figure 5, we plot the trajectory as a proportion for a chosen initial state, and then on the simplex . On , the dark purple end of the line corresponds to the initial state , while the light yellow end corresponds to the terminal state .
 |
 |
7.3. Quadratic Cost—High Dimensional Results
How the DGME and DBME deal with the curse of dimensionality is of particular interest. To study the run-time efficiency as dimension increases, we compute the relative increase in run-time for each dimension by dividing the corresponding running time by the running time required for the previous dimension.

In Figure 6, we note that the DBME run-time increases at around the rate of increase in dimension; meanwhile, the DGME run-time increases faster with an equivalent increase in dimension. The lower relative increase for the DBME run-time indicates that it may be better suited to high-dimensional problems. Moreover, the rate of relative increase for the DBME agrees with other known deep backward schemes; see for example the deep backward scheme for an optimal switching problem studied in [6, Figure 2].
We also note that the size of our state space increases quadratically in . Namely, we are considering . The simplex is -dimensional and so the size of our state space is .
7.4. Cybersecurity Example
In this section, we study another popular MFG model that represents the cybersecurity of a network of computers. The cybersecurity model was introduced by [39], revisited by [12, Section 7.2.3], and computed numerically by [42, Section 7.2]. We recall the problem here, detail its master equation, and solve using the DGME and DBME methods.
In the cybersecurity MFG model, a continuum of agents try to minimize their costs that come from two sources: being infected with a computer virus, and paying for computer security software. An agent’s computer can be infected by another infected computer or by a hacker (considered exogenous to the model). Intuitively, the mean field interaction comes through the infection of a computer by other infected computers. Once infected, a computer can recover back to its original state. Agents that elect to defend their computers with the software are infected at a slower rate than undefended computers.
So, every agent has two internal states: defended/undefended () and susceptible/infected (). Hence there are four states (): Every agent pays a cost while infected, , and a cost while defending, . The agent pays the most cost per second when both infected and defending. Specifically, the running cost is given by:
The mean field cost and terminal cost are both set to zero, The agent’s only choice is to switch his or her defended or undefended status; this occurs with rate , and the corresponding action set is .
The rate a hacker hacks into any computer is determined by the parameter which for defended or undefended computers is augmented by and , respectively. Correspondingly, the recovery parameters are and . Infections from defended and undefended computers are augmented by the parameters in the following rate matrix. Namely, agents transition according to the rate matrix:
where
and where the asterisk denotes the negative of the sum of the elements along that row. Note that agents can only determine their rate matrix by choosing either or and all other parameters are fixed. That said, and change based on the proportion of infected undefended and defended agents’ computers, respectively; it is through these terms that the agents experience a mean field-type interaction.
With this said, we can write down the pre-Hamiltonians, the functions inside the Hamiltonian’s minimum, for each state:
Taking the minimum over yields the usual Hamiltonian. We can then write the optimal rate matrix:
So, we can write the master equation as: for all , , and ,
By running either algorithm then, we can reconstruct the optimal control and hence the trajectory of the measure. Recall the MFG system (LABEL:eqn:mfg) and its solution (removing the superscripts). We demonstrate the measure trajectory in the first row of Figure 7, using the solution computed by the DGME. The corresponding cost is displayed in the second row of Figure 7. In Figure 7, the legend depicts the four states , , , and ; the prefix of DGM shows the DGME’s result against a finite difference method solver. Further results for other initial distributions are provided in Appendix Appendix B. Additional Results for the Cybersecurity Example.
 |
 |
8. Conclusion
Motivated by the computation of Nash equilibria in games with many players, we proposed two algorithms, the DBME and the DGME, that can numerically solve the master equation of finite-state MFGs. For each method, we proved two results: the loss can be made arbitrarily small by some neural network, and conversely, if a neural network makes the loss small, then this neural network is close to the real solution of the master equation. Besides the theoretical analysis, we provided two in-depth numerical examples applying the methods and compare them at different dimensions. We found that the relative increase in computation time is superior for the DBME. Our numerical tests show that the proposed methods allow us to learn the master equation solution for any initial distribution, in contrast with traditional forward-backward methods, which work only for a single fixed initial distribution. Hence our methods open new potential applications of MFGs, when the initial distribution is not known in advance or when the population distribution may deviate from its expected trajectory.
Several directions are left for future work. First, our methods have the same limitations as the DBDP and the DGM, and will benefit from progress made on these methods. For instance, performance might be improved with a better understanding of how to choose the neural network architecture depending on the PDE under consideration. It should also be possible to improve the training speed by a suitable choice of sampling method. In particular, we leave for future work the incorporation of active sampling to the proposed methods.
On the theoretical side, we have mostly focused on the approximation error. It would be interesting to obtain an error rate in terms of the number of neurons and the dimension, that is, the number of states of the MFG. At this stage, numerical evidence suggests that our approaches work well even with a large number of states. However, as for many other methods, such as the DGM and the DBDP in particular, it is not clear how to prove rigorously that neural networks break the curse of dimensionality. Furthermore, it would also be interesting to study other error sources, whether from sampling regimes or gradient descent convergence. Ultimately, the goal would be to comprehensively understand the generalization error of neural network-based methods for master equations.
Last, real-world applications are beyond the scope of the present paper. This would involve studying in detail the link between the master equation in MFGs and systems of Bellman PDEs in finite-player games. Such systems can also be solved by deep learning. When the number of players is small, it is doable and more accurate to solve directly the PDE system. But as the number of players grows, it becomes easier to solve the master equation, and the MFG provides a good approximation of the finite-player game equilibrium. However, the precise trade-off depends on the model under consideration, which is left for future work in a case-by-case study.
Acknowledgement. We thank the anonymous AE and the referee for their insightful comments, which helped us improve our paper.
Appendix A. Proof of Lemma 1
Let denote the -norm in and define . Choose:
so that:
Since ,
Pick such that:
Then,
Using the above display, the definition of , and the assumption that the neural networks are uniformly Lipschitz, as well as the Lipschitz continuity of , there exists depending on these Lipschitz constants such that:
| (53) |
So it suffices to bound the right hand side of the above display in expectation. Let be the projection onto the first -coordinates of a vector in . Using that , and the Cauchy–Schwartz inequality:
Plugging this result into (53),
Recalling that is a minimum, noting that the difference is bounded above by the case when , then since for all , we have:
Combining the two previous displays,
| (54) |
Recall that sampling uniformly on the simplex is equivalent to creating exponentially distributed random variables (with rate ), and then setting each component of :
Therefore,
where by the last part of the expression we mean that has beta distribution with parameters and . So in terms of the incomplete beta function and the beta function , we can state the cumulative distribution function as:
Using this fact, an integral identity, the fact that the ’s are sampled i.i.d.:
| (55) |
Performing the substitution , we get:
Notice that the integrand on the right hand side is the unnormalized probability density function of a beta distribution with parameters and . Therefore the previous display is bounded above by extending the integral, then using Stirling’s approximation:
| (56) | ||||
where:
and where we used the facts that:
So plugging in (55) into (54), using (56), and setting , we get:
∎
Appendix B. Additional Results for the Cybersecurity Example
In Figures 8 and 9, we provide the plots for the cybersecurity example, but for many more initial conditions than offered earlier. The same labeling convention as in Figure 7 is adopted: the legend depicts the four states , , , and ; the prefix of DGM shows the DGME’s result against a finite difference method solver. In each figure, we provide a plot for every initial condition such that for all . Figure 8 displays the equilibrium trajectory according according to the specified while Figure 9 displays the cost along that equilibrium, . The shape of the cost shows that the costliest situation for every initial condition and every time occurs when a player is both defended and infected. The cheapest situation is undefended and susceptible. For all initial conditions, there is a point in time when it is cheaper to be defended and susceptible than undefended and infected. Intuitively, since being infected carries a steep cost, one may want to pay for the computer’s cybersecurity software to have a lower rate of incoming infection; if infected, transitioning to susceptible is more costly toward the end of the scenario because paying for the security software is costly and, without paying for the software, the transition to susceptible is slow. That said, the difference in total cost between defended susceptible and undefended infected in the latter part of the game is small, and all costs eventually converge to zero.


References
- [1] Y. Achdou and M. Laurière. Mean field games and applications: Numerical aspects. Mean Field Games, page 249, 2020.
- [2] A. Al-Aradi, A. Correia, G. Jardim, D. de Freitas Naiff, and Y. Saporito. Extensions of the deep galerkin method. Applied Mathematics and Computation, 430:127287, 2022.
- [3] R. J. Aumann. Markets with a continuum of traders. Econometrica, 32:39–50, 1964.
- [4] E. Bayraktar, A. Budhiraja, and A. Cohen. A numerical scheme for a mean field game in some queueing systems based on Markov chain approximation method. SIAM Journal on Control and Optimization, 56, 2017.
- [5] E. Bayraktar and A. Cohen. Analysis of a finite state many player game using its master equation. SIAM Journal on Control and Optimization, 56(5):3538–3568, 2018.
- [6] E. Bayraktar, A. Cohen, and A. Nellis. A neural network approach to high-dimensional optimal switching problems with jumps in energy markets, 2022.
- [7] A. Bensoussan, J. Frehse, and P. Yam. Mean field games and mean field type control theory. SpringerBriefs in Mathematics. Springer, New York, 2013.
- [8] C. Bertucci and A. Cecchin. Mean field games master equations: from discrete to continuous state space. arXiv e-prints, page arXiv:2207.03191, July 2022.
- [9] F. Black and M. Scholes. The pricing of options and corporate liabilities. J. Polit. Econ., 81(3):637–654, 1973.
- [10] H. Cao, X. Guo, and M. Laurière. Connecting GANs, MFGs, and OT. arXiv preprint arXiv:2002.04112, 2020.
- [11] P. Cardaliaguet, F. Delarue, J.-M. Lasry, and P.-L. Lions. The master equation and the convergence problem in mean field games, volume 201 of Annals of Mathematics Studies. Princeton University Press, 2019.
- [12] R. Carmona and F. Delarue. Probabilistic theory of mean field games with applications. I, volume 83 of Probability Theory and Stochastic Modelling. Springer, Cham, 2018.
- [13] R. Carmona and M. Laurière. Convergence analysis of machine learning algorithms for the numerical solution of mean field control and games I: The ergodic case. SIAM Journal on Numerical Analysis, 59(3):1455–1485, 2021.
- [14] R. Carmona and M. Laurière. Convergence analysis of machine learning algorithms for the numerical solution of mean field control and games: II—the finite horizon case. The Annals of Applied Probability, 32(6):4065–4105, 2022.
- [15] A. Cecchin and G. Pelino. Convergence, fluctuations and large deviations for finite state mean field games via the master equation. Stochastic Processes and their Applications, 129(11):4510 – 4555, 2019.
- [16] A. Cohen and E. Zell. Analysis of the Finite-State Ergodic Master Equation. Applied Mathematics and Optimization, 87, 2023.
- [17] C. Daskalakis, P. W. Goldberg, and C. H. Papadimitriou. The complexity of computing a nash equilibrium. Communications of the ACM, 52(2):89–97, 2009.
- [18] G. Dayanikli, M. Lauriere, and J. Zhang. Deep learning for population-dependent controls in mean field control problems. Accepted for an extended abstract to AAMAS’23 (arXiv preprint arXiv:2306.04788), 2023.
- [19] F. Delarue, D. Lacker, and K. Ramanan. From the master equation to mean field game limit theory: a central limit theorem. Electron. J. Probab., 24, 2019.
- [20] F. Delarue, D. Lacker, and K. Ramanan. From the master equation to mean field game limit theory: Large deviations and concentration of measure. Annals of Probability, 48(1):211–263, 2020.
- [21] W. E, J. Han, and A. Jentzen. Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations. Commun. Math. Stat., 5(4):349–380, 2017.
- [22] L. C. Evans. Partial differential equations, volume 19 of Graduate Studies in Mathematics. American Mathematical Society, Providence, RI, second edition, 2010.
- [23] M. Fazlyab, A. Robey, H. Hassani, M. Morari, and G. Pappas. Efficient and accurate estimation of lipschitz constants for deep neural networks. Advances in Neural Information Processing Systems, 32, 2019.
- [24] J.-P. Fouque and Z. Zhang. Deep learning methods for mean field control problems with delay. Frontiers in Applied Mathematics and Statistics, 6(11), 2020.
- [25] W. Gangbo and A. R. Mészáros. Global well-posedness of master equations for deterministic displacement convex potential mean field games. Comm. Pure Appl. Math., 75(12):2685–2801, 2022.
- [26] W. Gangbo, A. R. Mészáros, C. Mou, and J. Zhang. Mean field games master equations with nonseparable Hamiltonians and displacement monotonicity. Ann. Probab., 50(6):2178–2217, 2022.
- [27] M. Germain, M. Laurière, H. Pham, and X. Warin. Deepsets and their derivative networks for solving symmetric PDEs. Journal of Scientific Computing, 91(2):63, 2022.
- [28] M. Germain, J. Mikael, and X. Warin. Numerical resolution of McKean-Vlasov FBSDEs using neural networks. Methodology and Computing in Applied Probability, 24(4):2557–2586, 2022.
- [29] M. Germain, H. Pham, and X. Warin. Rate of convergence for particle approximation of PDEs in wasserstein space. Journal of Applied Probability, 59(4):992–1008, 2022.
- [30] D. A. Gomes, J. Mohr, and R. R. Souza. Discrete time, finite state space mean field games. J. Math. Pures Appl. (9), 93(3):308–328, 2010.
- [31] D. A. Gomes, J. Mohr, and R. R. Souza. Continuous time finite state mean field games. Appl. Math. Optim., 68(1):99–143, 2013.
- [32] H. Gouk, E. Frank, B. Pfahringer, and M. J. Cree. Regularisation of neural networks by enforcing Lipschitz continuity. Mach. Learn., 110(2):393–416, 2021.
- [33] P. J. Graber and A. R. Mészáros. On monotonicity conditions for mean field games. J. Funct. Anal., 285(9):Paper No. 110095, 45, 2023.
- [34] K. Hornik, M. Stinchcombe, and H. White. Universal approximation of an unknown mapping and its derivatives using multilayer feedforward networks. Neural Networks, 3:551–560, 1990.
- [35] R. Hu and M. Laurière. Recent developments in machine learning methods for stochastic control and games. arXiv preprint arXiv:2303.10257, 2023.
- [36] M. Huang, R. P. Malhamé, and P. E. Caines. Large population stochastic dynamic games: Closed-loop McKean-Vlasov systems and the Nash certainty equivalence principle. Commun. Inf. Syst., 6(3):221–251, 2006.
- [37] C. Huré, H. Pham, and X. Warin. Deep backward schemes for high-dimensional nonlinear PDEs. Math. Comp., 89(324):1547–1579, 2020.
- [38] P. Knabner and L. Angermann. Numerical methods for elliptic and parabolic partial differential equations, volume 44 of Texts in Applied Mathematics. Springer, Cham, extended edition, 2021. With contributions by Andreas Rupp.
- [39] V. N. Kolokoltsov and A. Bensoussan. Mean-field-game model for botnet defense in cyber-security. Appl. Math. Optim., 74(3):669–692, 2016.
- [40] J.-M. Lasry and P.-L. Lions. Jeux à champ moyen. II. Horizon fini et contrôle optimal. C. R. Math. Acad. Sci. Paris, 343(10):679–684, 2006.
- [41] J.-M. Lasry and P.-L. Lions. Mean field games. Jpn. J. Math., 2(1):229–260, 2007.
- [42] M. Laurière. Numerical methods for mean field games and mean field type control. In Mean field games, volume 78 of Proc. Sympos. Appl. Math., pages 221–282. Amer. Math. Soc., Providence, RI, 2021.
- [43] P.-L. Lions. Estimées nouvelles pour les équations quasilinéaires. Seminar in Applied Mathematics at the Collège de France., 2014.
- [44] C. Mou and J. Zhang. Mean Field Game Master Equations with Anti-monotonicity Conditions. arXiv e-prints, page arXiv:2201.10762, Jan. 2022.
- [45] J. Nash. Non-cooperative games. Annals of mathematics, pages 286–295, 1951.
- [46] P. Pauli, A. Koch, J. Berberich, P. Kohler, and F. Allgöwer. Training robust neural networks using lipschitz bounds. IEEE Control Systems Letters, 6:121–126, 2021.
- [47] S. Perrin, M. Laurière, J. Pérolat, R. Élie, M. Geist, and O. Pietquin. Generalization in mean field games by learning master policies. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 9413–9421, 2022.
- [48] H. Pham, X. Warin, and M. Germain. Neural networks-based backward scheme for fully nonlinear PDEs. Partial Differ. Equ. Appl., 2(1):Paper No. 16, 24, 2021.
- [49] M. Raissi, P. Perdikaris, and G. E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics, 378:686–707, 2019.
- [50] L. Ruthotto, S. J. Osher, W. Li, L. Nurbekyan, and S. W. Fung. A machine learning framework for solving high-dimensional mean field game and mean field control problems. Proceedings of the National Academy of Sciences, 117(17):9183–9193, 2020.
- [51] D. Schmeidler. Equilibrium points of nonatomic games. J. Statist. Phys., 7:295–300, 1973.
- [52] S. Shalev-Shwartz and Y. Wexler. Minimizing the maximal loss: How and why. In Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pages 793–801. PMLR, 2016.
- [53] J. Sirignano and K. Spiliopoulos. DGM: a deep learning algorithm for solving partial differential equations. J. Comput. Phys., 375:1339–1364, 2018.
- [54] P. Tseng. An incremental gradient(-projection) method with momentum term and adaptive stepsize rule. SIAM J. Optim., 8(2):506–531, 1998.