Decoupling and Interacting Multi-Task Learning Network for Joint Speech and Accent Recognition
Abstract
Accents, as variations from standard pronunciation, pose significant challenges for speech recognition systems. Although joint automatic speech recognition (ASR) and accent recognition (AR) training has been proven effective in handling multi-accent scenarios, current multi-task ASR-AR approaches overlook the granularity differences between tasks. Fine-grained units capture pronunciation-related accent characteristics, while coarse-grained units are better for learning linguistic information. Moreover, an explicit interaction of two tasks can also provide complementary information and improve the performance of each other, but it is rarely used by existing approaches. In this paper, we propose a novel Decoupling and Interacting Multi-task Network (DIMNet) for joint speech and accent recognition, which is comprised of a connectionist temporal classification (CTC) branch, an AR branch, an ASR branch, and a bottom feature encoder. Specifically, AR and ASR are first decoupled by separated branches and two-granular modeling units to learn task-specific representations. The AR branch is from our previously proposed linguistic-acoustic bimodal AR model and the ASR branch is an encoder-decoder based Conformer model. Then, for the task interaction, the CTC branch provides aligned text for the AR task, while accent embeddings extracted from our AR model are incorporated into the ASR branch’s encoder and decoder. Finally, during ASR inference, a cross-granular rescoring method is introduced to fuse the complementary information from the CTC and attention decoder after the decoupling. Our experiments on English and Chinese datasets demonstrate the effectiveness of the proposed model, which achieves / AR accuracy relative improvement and / ASR error rate relative reduction over a published standard baseline, respectively.
Index Terms:
ASR-AR multi-task learning, LASAS, two-granularity modeling unitsI Introduction
Accents refer to the variations in standard pronunciation that are influenced by factors such as the speaker’s education level, region, or native language [1, 2]. For instance, when English is spoken with a Mandarin accent, it is considered a foreign accent, whereas Cantonese-influenced Mandarin is categorized as a regional accent. Despite the significant progress made in end-to-end automatic speech recognition (E2E ASR) in recent years, accents remain a significant challenge to user equality in speech recognition, leading to a decline in the performance of ASR models trained on standard pronunciation data [3, 4, 5, 6]. As a result, there has been a growing interest in multi-accent ASR.
The multi-task ASR-AR framework has become a widely-used solution for overcoming the challenges posed by multi-accent [7, 8, 9]. This framework typically consists of a shared encoder and two branches dedicated to ASR and AR tasks, respectively. The shared encoder is responsible for extracting acoustic features from the input speech for both branches, and backpropagation from these two branches enables the shared encoder to learn how to extract both linguistic and accent representations. Although it has been shown effective in joint modeling ASR and AR [8], the granularity difference between tasks suggests that simultaneously extracting features via a shared encoder may not be an optimal strategy. Additionally, the ASR and AR branches currently exhibit limited interaction, impeding the full utilization of information from the opposing branch [10, 11].
Granularity difference between ASR and AR: E2E ASR is a linguistic-related task, in which coarse-grained units like byte-pair encodings (BPEs) [12] or characters are often used for better representing linguistic information, such as spelling and words. In contrast, the AR task is pronunciation-related and requires capturing small acoustic variations like pitch, intonation, and stress, where fine-grained modeling units such as phonemes or syllables are more suitable [13]. Therefore, incorporating two-granularity modeling units into the multi-task ASR-AR is more appropriate. Nevertheless, the sequence lengths of the two-granularity units are inconsistent, making simultaneous encoding by a single shared encoder challenging.
Improving AR with ASR: Earlier AR models directly extracted low-level features such as frequency and timbre [14, 15, 16], which could lead to overfitting on speaker and channel characteristics [17, 18]. Recent studies have shown that leveraging linguistic information from ASR can effectively mitigate the overfitting issue in AR tasks [19, 7, 4, 8]. Initializing the AR encoder with a pre-trained ASR encoder [4] or jointly training a multi-task ASR-AR network [8, 20] are the commonly used approaches, both of which have demonstrated their effectiveness on various datasets. Different from implicitly integrating linguistic information into AR models, in our previous study [21], we proposed a novel linguistic-acoustic similarity-based accent shift (LASAS) AR model. To estimate the accent shift of an accented speech utterance, we first map the frame-level aligned text to multiple accent-associated anchor spaces and then leverage the similarities between the acoustic embedding and those anchors as an accent shift. Compared with pure acoustic embedding, the learned accent shift takes full advantage of both linguistic and acoustic information, which can effectively improve AR performance.
Improving ASR with AR: Likewise, knowing the accent embedded in the speech utterance is also beneficial to speech recognition. Plenty of studies have explored using complementary accent information to improve ASR performance on accent speech [7, 22]. In the multi-task ASR-AR framework, accent embeddings from the AR branch can be leveraged to enhance accent information in the ASR branch. However, the effectiveness of different types of accent embeddings on ASR performance can vary significantly. The hidden states of the DNN-based accent classifier [3] provide rich and stable utterance-level accent information, while the AR posterior probabilities are more straightforward and interpretable. On the other hand, the accent shifts in the LASAS [21] method capture accent variations and provide more detailed information. Moreover, incorporating accent embeddings into either the encoder [3] or decoder [22] of the ASR model allows for the model to adapt to variations in pronunciation or linguistics, leading to varying effects on ASR performance. Thus, comprehensive studies to investigate the interpretability and ASR performance of each approach are essential.
The objective of this study is to overcome the challenge of unit-granularity differences and promote full interaction between the ASR and AR branches in a multi-task setting. To achieve this, we present a Decoupling and Interacting Multi-task Network (DIMNet) for joint speech and accent recognition, which includes a connectionist temporal classification (CTC) [23] branch, an AR branch, an ASR branch, and a bottom feature encoder. Specifically, AR and ASR are first decoupled by separated branches and two-granular modeling units to learn task-specific representations. The AR branch is from our previously proposed LASAS [21] AR model and the ASR branch is an encoder-decoder-based Conformer [24] model. Then, for the task interaction, the CTC branch is optimized with the same modeling units as the AR branch to provide linguistic features for the AR task, while latent accent embeddings extracted from our AR model are used to improve the ASR branch. We also conduct comprehensive studies to explore the choice of accent embeddings and the fusion strategies for the ASR branch. Finally, a cross-granular rescoring method is introduced to effectively fuse the probabilities from CTC and attention decoder during ASR inference. Our experiments on English and Chinese datasets demonstrate the effectiveness of the proposed model, which achieves / AR accuracy relative improvement and / ASR error rate relative reduction over a published standard baseline, respectively.
II Related Works
In this section, we present a brief summary of multi-accent ASR-AR frameworks and the applications of two-granularity modeling units.
II-A Multi-Accent ASR-AR
Current approaches for multi-accent ASR-AR can be classified into three categories: cascade [18, 3], multi-task [25, 8, 26, 27, 28], and single-task [19, 29]. For the cascade ASR-AR framework, ASR and AR models are trained separately and used in a sequential manner. Typically, an AR model is first trained to extract accent features from the input speech, which is then utilized to assist the ASR model. Deng et al. [18] proposed a cascade ASR-AR based on pre-trained wav2vec 2.0 [30], achieving state-of-the-art (SOTA) performance on the AESRC dataset [4] due to the powerful acoustic modeling capabilities of wav2vec 2.0. In [3, 31], Gong and Qian et al. also obtained competitive results using a cascade ASR-AR scheme. Their AR component has a phonetic posteriorgrams (PPG) extractor and a time delay neural network (TDNN) based classifier [32, 33], while the ASR component incorporates accent information into the encoder through adapter layers in a CTC/attention framework. Although each model could be optimized with a large amount of in-domain data, the cascade strategy also introduces inevitable error propagation and increased computation complexity. For the multi-task structure, a shared encoder is generally utilized to simultaneously extract accent and linguistic information. In [25], Zhang et al. regarded ASR as an auxiliary task for AR. By extracting phoneme-level accent variations, their method effectively improves AR performance, which provides evidence of ASR’s helpfulness in AR tasks. In [8], Zhang et al. incorporated an AR branch into a CTC/attention ASR and used a shared encoder to simultaneously learn accent and linguistic representations, leading to improved ASR adaptation to accents. Finally, single-task ASR-AR splices accent and text labels together, using a unified encoder-decoder structure to predict two kinds of labels simultaneously. Following this direction, Gao et al. [19] proposed a single-task scheme for accent prediction, which extends the output token list by inserting accent labels into the text transcripts and yields good results without modifying the E2E model structure.
In contrast to existing multi-task ASR-AR approaches, our proposed DIMNet incorporates decoupling and interacting, resulting in improved transfer and fusion of linguistic and acoustic information. To achieve this, we employ distinct branches and two granular modeling units to decouple the AR and ASR tasks, allowing them to focus on pronunciation-related and semantic-related aspects, respectively. Additionally, we introduce interacting between these branches through LASAS AR and encoder-decoder accent embedding fusion within DIMNet.
II-B Two-granularity Unit Modeling
Research on the use of two-granularity modeling units in ASR-AR frameworks is relatively scarce. One notable approach was proposed by Rao et al. [34], which involved a multi-accent ASR that utilized phoneme-grapheme two-granularity modeling units. This model generated both phoneme and grapheme (a-z) outputs with multiple CTC decoders added to the encoder intermediate layers and a final CTC decoder stacked after the encoder. The number of CTCs in the intermediate layer was consistent with the accent types. However, unlike typical two-granularity schemes, the final outputs of this model were graphemes, which are finer-grained than the phoneme-based middle outputs. Two-granularity modeling units have also been used in pure ASR studies. For example, Chan et al. [35] introduced syllable/character units to an early attention-based ASR model with two decoders, but only the character decoder was used for inference. Other studies [36, 37, 38, 39, 40] employed cascade audio-to-phoneme (A2P) and phoneme-to-word (P2W) schemes. Their experiments demonstrated that, compared with the acoustic embedding of the encoder, the pure-text phoneme inputs for P2W lack sufficient acoustic information. Thus, this two-stage independent structure leads to error accumulation, which requires a large amount of P2W data to mitigate. To address this problem, Zhang et al. [41] fused a P2W model and an attention decoder together in autoregressive decoding, which fully utilized the phoneme text and acoustic embedding. Alternatively, Yang et al. [42] directly utilized a Transformer decoder [43] to complete the P2W transcription. This method is elegant and concise but only supports two-granularity modeling units with the same sequence lengths, such as Chinese syllables and characters.
Unlike the aforementioned methods that directly apply fine-grained units to the ASR task, our DIMNet incorporates these units into the AR task, resulting in significant enhancements. Additionally, DIMNet avoids the inclusion of cascade A2P and P2W structure, effectively mitigating the accumulation of errors.
II-C Decoupling and Interacting Multi-Task Learning
The efficacy of decoupling and interacting multi-task learning has been evident in various domains, including speech and speaker recognition [44], object detection [11], and sentiment analysis [10]. Tang et al. [44] introduced a collaborative joint training approach for speech and speaker recognition, where the output of one task is backpropagated to the other task, resulting in enhanced performance on both speech and speaker recognition tasks compared to single-task systems. Furthermore, similar decoupling and interacting methodologies have been employed to extract information at different scales. Pang et al. [11] proposed aggregate interaction modules to integrate features from adjacent levels, enabling the extraction of multi-scale image features. And He et al. [10] presented an interactive multi-task learning network capable of jointly learning token-level and document-level sentiment information.
In the AR-ASR tasks, a major challenge in the interaction process is the limited ability of AR to directly leverage linguistic information from ASR. Our DIMNet tackles this challenge by incorporating the LASAS AR model, which utilizes ASR aligned text as one of its inputs. This distinguishes DIMNet from other approaches in decoupling and interacting multi-task learning methods.

III Method
Fig. 1 overviews the architecture of our proposed DIMNet, which uses a CTC/attention ASR [45] model as the backbone. In addition, we incorporate a LASAS AR [21] model and a triple-encoder structure, resulting in three branches within the DIMNet. The accent and attention branches are dedicated to the AR and ASR tasks, respectively, while the CTC branch provides complementary information to assist the other two branches. We will illustrate these components of the DIMNet in the following subsections.
III-A Decoupling of AR and ASR
Decoupling AR and ASR tasks can improve their respective performance by allowing for independent modeling of accent and linguistic information. Furthermore, a decoupled framework can enhance the clarity and interpretability of the interaction between the two tasks.
For decoupling the DIMNet to allow each task to focus on different levels of information, we introduce a two-granularity modeling approach. Specifically, we use fine-grained units for the CTC branch to obtain aligned text as the inputs of the accent branch, and use coarse-grained units for the attention branch instead. The fine-grained units discussed here need to be pronunciation-related, such as the ARPAbet phoneme set [46] for English and Pinyin syllables for Chinese. On the contrary, for coarse-grained units, it is important for them to be semantic-related. In this paper, we use BPE and Char as coarse-grained units for English and Chinese, respectively. The use of pronunciation-related fine-grained units allows the accent characteristics to be captured effectively in the AR task. On the other hand, semantic-related coarse-grained units are helpful in providing contextual linguistic information for the ASR task. Hence, the two-granularity decoupling helps enhance the performance of both tasks simultaneously.
As mentioned in Section I, sequence length inconsistency is a significant challenge in two-granularity modeling. To address this issue, we introduce the triple-encoder structure in the DIMNet. In this approach, a shared encoder is used to learn pronunciation-related shallow acoustic information, while two lightweight encoders are used for the CTC and attention branches to extract linguistic information in different granularity. The outputs of the triple encoders can be denoted as:
| (1) |
where is the acoustic features of the input speech, which can be MFCC or Fbank, and denotes the last layer’s output of the shared encoder. The is an accent embedding extracted from the accent branch, which will be introduced in Section III-C.
By stacking additional encoders after the shared encoder, our approach can alleviate the sequence-length inconsistency of the two-granularity unit modeling. And then, the computation of the losses for the CTC and attention decoders are denoted as:
| (2) |
| (3) |
where and are the transcription labels with fine-grained and coarse-grained units, respectively. The could be translated to with a lexicon. is the attention posterior probabilities of the given labels .
The total loss of our multi-task ASR-AR consists of the ASR loss , the CTC loss , and the AR loss , which can be formulated as:
| (4) |
where and are tunable hyperparameters. The details of will be introduced in Section III-B.
III-B Improving AR with ASR
The traditional AR models only utilize acoustic features as input. When being integrated into a multi-task ASR-AR, their ability to fully interact with the ASR task is limited, which can hinder their performance. In our previous study [21], we proposed an AR model named LASAS that uses aligned text and acoustic features as input. This model explicitly and fully utilizes linguistic information, resulting in a significant improvement in AR performance. To enhance the ASR’s assistance to AR, in this study, we first introduce LASAS into the multi-task framework by feeding it with the aligned text output from the CTC decoder and acoustic features output from the shared encoder. In addition, we further improve LASAS to make it adaptable to the multi-task ASR-AR.
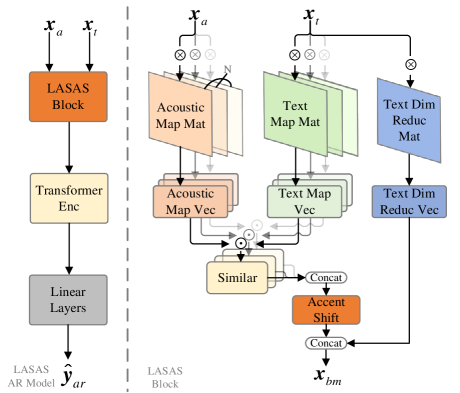
The left part of Fig. 2 shows the structure of the LASAS AR model, which consists of a LASAS block, a Transformer encoder [43], and several linear layers. The details of the LASAS block are depicted in the right part of Fig. 2, where the acoustic embedding and frame-level aligned text serve as inputs to LASAS, provided by the shared encoder and CTC decoder, respectively. The computation of and can be denoted as:
| (5) |
where , , and denote the outputs of the shared encoder’s layers at the 1/3, 2/3, and 3/3 positions, respectively. For instance, if the shared encoder comprises 9 layers, then , , and correspond to the outputs of the 3-rd, 6-th, and 9-th layers, respectively. The greedy search used here retains both the blanks and repeated tokens of CTC, which differs from the conventional scheme. And Regular means to replace blanks with subsequent predicted token IDs, constructing a frame-level aligned text with only repeated token IDs. It is worth noting that we use greedy search instead of prefix beam search to predict only one aligned text for the accent branch in both the training and inference stages. If prefix beam search is used during the training process, the time consumption will skyrocket to an unacceptable level. Moreover, through experimental observations, we find that the AR performance of the model does not exhibit significant improvement (only a relative ) when using greedy search during training and switching to prefix beam search during inference. This lack of improvement can be attributed to the mismatch between the training process and the utilization of prefix beam search, despite its ability to generate text with a lower error rate.
The right part of Fig. 2 illustrates the details of the LASAS block, which begins by mapping an aligned text vector to multiple Euclidean spaces as anchors . These anchors are related to the speech content and aligned with the speech at a frame level. Next, we map an acoustic embedding to the same dimension as the text anchor , denoted as . Using a scaled dot-product frame by frame, we obtain a similarity value between an anchor and a mapped acoustic embedding . Finally, we concatenate a set of similarities to form , which reflects the shift directions and similarity degrees of different accents. The computation of the accent shift can be denoted as:
| (6) |
where and is the number of mapping spaces. The and are mapping matrix. The , , and are the dimensions of features.
Since the accent shift is a relative representation, a textual reference is necessary for the subsequent classifier. In order to represent pure textual information, we establish a dimension reduction matrix to reduce the dimension of the input text OneHot vector. By concatenating the accent shift and the dimension-reduced text , we can obtain a linguistic-acoustic bimodal representation , which can then be used as input for the subsequent classifier. Given the aligned text vector and accent shift , the bimodal representation can be calculated as:
| (7) |
where , , and is the time steps of frames.
Finally, the classifier is composed of a lightweight Transformer encoder and multiple linear layers. The encoder is used to extract context-sensitive accent information. After passing through the classifier, we obtain either a frame-level or utterance-level accent prediction. Utterance-level accent prediction tends to achieve better performance on AR tasks, while frame-level accent is more suitable as an embedding to assist ASR tasks. We will analyze and discuss the choice of the level in Section V. Computation of the final accent prediction can be denoted as:
| (8) |
where represents the posterior probabilities for accent, and refers to the predicted accent outcome from the accent branch.
To improve the adaptation of the original LASAS AR model [21] to the multi-task ASR-AR, we detach the aligned text and accent embedding, as depicted in Figure 1. This decouples the accent branch and allows for separate optimization of the CTC/attention and accent branches during back-propagation without mutual interference. The decoupling reduces learning difficulty and improves the performance of both the accent and attention branches. The loss of the accent branch is denoted as:
| (9) |
where is an accent label.
III-C Improving ASR with AR
In a multi-accent ASR-AR, high-quality accent information can guide the ASR task to learn accent-specific pronunciation and expression. Fully utilizing accent information could significantly improve the performance of the ASR task. Therefore, it is worthwhile to study better approaches for utilizing accent information.
In a multi-task ASR-AR, accent embeddings can be chosen from the hidden embedding before the last linear layer , the posterior probabilities of classification , or the accent shifts . These three choices can be denoted as:
| (10) |
where UpProject represents a dimension expanding of the embeddings by a linear layer. Since the dimension of is significantly larger than that of and , for a fair comparison, we use the up-project operation. The provides rich and stable accent information, the is intuitive and concise, and using the can provide text-related frame-level accent viriations. In this paper, we compare these three accent embeddings in experiments to determine which one is better.
Moreover, we also investigate the effectiveness of different fusion strategies between accent and the ASR task. In our triple-encoder scheme, accent information can be fused both implicitly and explicitly. Implicit fusion occurs when the shared encoder learns to extract accent information through the back-propagation of the accent branch, even without the help of an accent embedding. Explicit fusion occurs when an accent embedding is integrated into the attention branch for the ASR task. In the multi-task ASR-AR, implicit fusion is inevitable due to the existence of the accent branch, while explicit fusion is optional. We classify accent fusion into four schemes based on the use of an accent embedding:
-
•
: Only implicit accent fusion is used in ASR.
(11) -
•
: Both implicit and explicit (to encoder) accent fusions are used in ASR.
(12) -
•
: Both implicit and explicit (to decoder) accent fusions are used in ASR.
(13) -
•
: Both implicit and explicit (to encoder and decoder) accent fusions are used in ASR.
(14)
In the aforementioned schemes, the effectiveness of , , and has been proven in different studies [8, 18, 22]. To the best of our knowledge, has not been extensively explored. However, considering the encoder and decoder respectively focus on linguistic and acoustic information, the incorporation has the potential to achieve optimal performance. Thanks to the triple-encoder structure, we can easily apply scheme to the attention branch.
III-D Two-granularity Rescoring
After the decoupling, within our DIMNet, the CTC decoder focuses on pronunciation while the attention decoder emphasizes linguistic information. By leveraging the complementarity between these two types of information, a two-granularity rescoring approach is expected to achieve a better ASR performance compared to single-granularity rescoring. However, the current mainstream CTC rescoring [47, 48] and attention rescoring [45] necessitate matching sequence lengths between the modeling units of both decoders, making them unsuitable for direct application in two-granularity scenarios. In order to solve this problem, we develop a two-granularity rescoring method based on the CTC rescoring technique [47] to merge scores from both the CTC and attention decoder.

As shown in Fig. 3, the two-granularity rescoring method involves two-pass decoding. In the first pass, hypotheses and their corresponding posterior probability scores are obtained through autoregressive beam search decoding. The modeling units of these hypotheses are coarse-grained, which can be mapped into fine-grained units through a lexicon, without the need for training a translation model. This process can be represented as:
|
|
(15) |
where and represents the beam size used for beam search decoding.
Given the fine-grained hypotheses , we can use the CTC forward algorithm to calculate the scores in the second pass. According to [23], the CTC forward algorithm computes the negative logarithm of the conditional probabilities of the CTC encoder outputs and a given text. If the given text is the transcription label , the CTC loss is computed. However, if the given text is the hypothesis , the conditional probabilities of and can be calculated and used for rescoring. Specifically, the conditional probabilities can be computed as:
| (16) |
Finally, the ASR prediction using the two-granularity rescoring method is obtained by:
| (17) |
where , , and are tunable parameters. Here, is optional language model scores.
IV Experiments Setup
IV-A Dataset
We conduct extensive experiments on publicly-available English and Chinese datasets to evaluate the proposed DIMNet. For the English experiments, we use the AESRC dataset [4], while for the Chinese experiments, we use the KeSpeech dataset [49]. Details of the two datasets are shown in Table I. Besides, following the setup of [4, 8, 13], the additional Librispeech [50] dataset is also used for the AESRC experiments.
| Dataset |
|
|
|
Style | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AESRC | 8 | 160 | 16 | Reading | ||||||
| KeSpeech | 9 | 1542 | 16 | Reading |
In this study, we use BPE-phoneme as the two-granularity modeling units for English, and char-syllable for Chinese. This choice is based on the unique characteristics of each language and the effectiveness of these units in capturing phonetic and semantic features. To convert the coarse-grained units to fine-grained units, we utilize CMUdict111Available at http://www.speech.cs.cmu.edu/cgi-bin/cmudict and Pypinyin222Available at https://pypi.org/project/pypinyin/ lexicons, respectively. Refer to Table II for detailed information.
| Language | Coarse-grained Units Num | Fine-grained Units Num | Lexicon |
|---|---|---|---|
| English | 5002 (BPE) | 40 (Phoneme) | |
| Chinese | 5687 (Char) | 419 (Syllable) |
IV-B Model Configurations
Our baseline model is based on a triple-branch structure, which utilizes the hidden embedding before the last linear layer in the accent branch to generate accent embeddings. The encoders are based on Conformer [24], while the attention decoder is Transformer [43]. The shared encoder, CTC encoder, and attention encoder are comprised of 9, 3, and 3 Conformer blocks, respectively, while the attention decoder consists of 6 blocks. The Conformer blocks have 2048 inner dimensions for feed-forward networks (FFN), 256 model dimensions, 4 attention heads, and utilize a CNN kernel size of 15. During training, the loss weights assigned to the CTC, AR, and ASR branches are 0.3, 0.4, and 0.3, respectively. We specifically lightly amplify the AR loss weight due to its relatively smaller absolute loss value. In addition, for the LASAS AR model, we set the mapping spaces to 8, and the rest parameters are the same as [21]. Our experiments include SpecAugment, model average, and a 2-layer-Transformer based language model (LM).
In English experiments, our model is first trained for 70 epochs on the mixture of the AESRC and LibriSpeech datasets and then fine-tuned 50 epochs on the AESRC alone. In the first stage, we update the CTC and attention branches using both the AESRC and LibriSpeech datasets, while only the AESRC dataset is used to update the accent branch. In the Chinese experiments, we train the model for 100 epochs without finetuning. Similarly, we use all the available data to update the CTC and attention branches, while only the accent data is used to update the accent branch. It is worth noting that the accent data referred to here is denoted as Phase 1 in [49], which includes a subset of Mandarin. To account for the large differences in data amount for different accents in the KeSpeech dataset, we use unbalanced weights for the CE loss in the AR task, which is set as the ratio of the number of accent utterances with respect to the Mandarin subset.
V Experiments Results
This section presents the experimental results of our proposed DIMNet. We first introduce the results of baselines and our ablation and comparison experiments on the AESRC dataset to demonstrate the effectiveness of each module. Next, we compare our approach to the general A2P+P2W cascade modeling schemes of two-granularity units. Finally, we compare the performance of DIMNet to previous studies on both the AESRC and KeSpeech datasets.
V-A Effectiveness of DIMNet
In Table III, represent CTC/attention ASR and multi-task ASR-AR baselines, while represents our proposed DIMNet. Specifically, is a classic CTC/attention ASR model using only coarse-grained BPE units, and is derived from by replacing the BPE units with phonemes in the CTC branch. Both and have no AR branch. is a widely-used multi-task ASR-AR model as described in study [8], which comprises a shared encoder and three branches: CTC decoder, AR, and attention decoder. The AR branch incorporates pooling and linear layers. In addition, to ensure a fair comparison, we incorporate the accent embedding fusion into the attention decoder with the detach operation. In , we substitute the shared encoder of with the triple encoder structure utilized in DIMNet. Essentially, can be viewed as replacing the LASAS AR of DIMNet with a basic AR model.
The comparison between and highlights the effect of two-granularity units. The direct introduction of phonemes in a CTC/attention framework can only lead to a slight improvement in ASR performance. After integrating an AR branch, the ASR performance of enhanced compared to , which is a widely verified phenomenon. Comparing with , the introduction of the triple encoder structure yields a mere average relative impact of on accent accuracy, while it improves the ASR task by an average relative . Ultimately, when comparing with , it becomes evident that DIMNet exhibits clear advantages in both AR and ASR, underscoring the benefits of DIMNet beyond modeling units and multi-task learning.
| ID | Model | CTC/ATT Units | Triple Encoders | LASAS | Accent Embedding | Accent Fusion | Rescoring |
|
|
||||||
| Dev | Test | Dev | Test | ||||||||||||
| B1 | B/B | ✗ | ✗ | ✗ | - | - | 5.96 | 6.91 | |||||||
| B2 | P/B | ✗ | ✗ | ✗ | - | - | 5.96 | 6.88 | |||||||
| B3 | P/B | ✗ | 79.12 | 74.02 | 5.83 | 6.76 | |||||||||
| B4 | CTC/ATT AR-ASR Baseline | P/B | ✓ | ✗ | ✗ | 79.08 | 73.84 | 5.78 | 6.68 | ||||||
| D1 |
|
P/B | ✓ | ✓ | ✗ | 86.47 | 78.82 | 5.55 | 6.27 | ||||||
| D2 | Decoupling Ablation | G/B | ✓ | ✓ | ✗ | 81.52 | 73.58 | 5.54 | 6.38 | ||||||
| D3 | B/B | ✓ | 81.9 | 75.68 | 5.74 | 6.41 | |||||||||
| D4 | P/B | ✗ | 86.15 | 79.78 | 5.87 | 6.63 | |||||||||
| D5 | w/o Text Input | 76.54 | 71.28 | 5.88 | 6.61 | ||||||||||
| D6 | w/o Detach | 80.47 | 74.67 | 5.55 | 6.32 | ||||||||||
| D7 | AR Ablation | P/B | ✓ | w/o Frame Level | ✗ | 85.7 | 80.15 | 5.55 | 6.3 | ||||||
| D8 | ✗ | 85.04 | 80.15 | 5.71 | 6.49 | ||||||||||
| D9 | 85.25 | 79.4 | 5.52 | 6.32 | |||||||||||
| D10 | 84.88 | 79.42 | 5.55 | 6.3 | |||||||||||
| D11 | 85.11 | 79.4 | 5.47 | 6.36 | |||||||||||
| D12 | ASR Ablation | P/B | ✓ | ✓ | ✗ | 85.89 | 80.2 | 5.64 | 6.4 | ||||||
| D13 |
|
P/B | ✓ | ✓ | ✓ | 86.47 | 78.82 | 5.41 | 6.13 | ||||||
V-B Decoupling of AR and ASR
In and , we examine the influence of modeling units on DIMNet. Specifically, we employ grapheme-BPE instead of phoneme-BPE units in , while utilizing BPE-BPE units in . Comparing and , it becomes apparent that not all fine-grained units are compatible with DIMNet. Graphemes, in comparison to phonemes, exhibit semantic relevance but lack adequate pronunciation information. As a result, they are unable to effectively enhance the performance of AR tasks, consequently indirectly diminishing ASR performance. When comparing and , it is clear that utilizing phonemes-BPE two-granularity units leads to enhanced performance for DIMNet in terms of both accent accuracy (ACC) and word error rate (WER). However, if coarse-grained BPE units are employed in both the CTC and attention branches, we observe a significant decrease in results. Specifically, there is a relative drop of and in the AR task, as well as a relative drop of and in the ASR task. This result clearly demonstrates that decoupling the modeling units is a crucial factor in improving both AR and ASR performance, even when utilizing the same interactive structure. However, the use of a two-granularity modeling unit presents challenges for the ASR task without the triple-encoder structure. To demonstrate this, we consider the setup of , where we remove the CTC encoder and attention encoder in Fig. 1, keeping only a 12-layer shared encoder, and directly put the accent embedding to the attention decoder. Comparing and , we observe that while achieves a similar AR accuracy to , its ASR performance significantly degrades by and respectively. This finding suggests that the triple-encoder structure effectively decouples the modeling process of different units, enabling the CTC and attention branches to output units with different granularity.
Generally, accent utterances not only contain accent words but also include standard pronounced common words. Therefore, we conduct further analysis to investigate whether performance improvement of the ASR and AR is evident in accent words. Table IV illustrates that the use of fine-grained phoneme units can improve the accuracy of all accents in the AR task. This suggests that fine-grained phonemes are more effective for AR tasks than coarse-grained BPE, and this advantage applies to all accents. We assume that the phonemes with the highest PER in the CTC branch represent accent pronunciation, and list them in Table IV. As shown in the table, these high-PER phonemes align with our general knowledge and previous findings in accent linguistic research [51, 52, 53]. This finding suggests that the phonemes which cause difficulties for the DIMNet indeed contain accents, and that our proposed model effectively captures accent-specific pronunciation-related information. Furthermore, we count the WERs of the attention branch for words that contain the top 5 PER phonemes which are listed in Table IV and compare them to the average WERs of each accent in Fig. 4. As depicted in Fig. 4, the WERs of these accent words are higher than the average WERs, suggesting that they are more difficult to recognize in the ASR task, and hence contribute to the increase in the average WER. However, the introduction of two-granularity units results in a decrease in the WER of difficult words in each accent, compared to the case without it. This finding clearly demonstrates the effectiveness of our proposed scheme in improving the recognition of difficult words in different accents.
| Accent | AR ACC (%) | Phonemes of Top 5 PER§ | |
|---|---|---|---|
| w/ TGM† | w/o TGM‡ | ||
| CHN | 80.68 | 79.98 | [ZH], [EH], [AO], [TH], [EY] |
| IND | 93.30 | 91.05 | [OY], [ZH], [SH], [JH], [TH] |
| JPN | 72.30 | 68.90 | [ZH], [L], [OW], [R], [AO] |
| KR | 83.15 | 79.39 | [ZH], [OW], [AE], [AO], [UH] |
| PT | 80.76 | 75.92 | [ZH], [UH], [AE], [AO], [EH] |
| RU | 74.49 | 70.39 | [OY], [AE], [JH], [OW], [UH] |
| UK | 94.32 | 93.49 | [NG], [AO], [OW], [ER], [AA] |
| US | 58.36 | 53.64 | [UH], [AE], [AA], [ZH], [OW] |
-
•
†: This model is in the Table III.
-
•
‡: This model is in the Table III.
-
•
§: Correspondence between ARPABET and IPA phoneme sets: https://en.wikipedia.org/wiki/ARPABET

V-C Improving AR with ASR
To investigate the impact of ASR on AR, we conduct the experiment presented in Table III. In this experiment, we remove the text input of the LASAS-based accent branch in the model and replace it with the outputs of the shared encoder. This design allowed us to eliminate the fusion of linguistic information from the ASR to the AR while keeping the total parameters of the DIMNet model unchanged. After comparing the performance of and , it is apparent that the exclusion of linguistic information from the CTC branch has a substantial impact on the accuracy of the accent branch, resulting in a decrease in the AR performance. This outcome clearly demonstrates the significance of the linguistic information from the CTC branch in enhancing the performance of AR tasks.
Furthermore, we evaluate the modifications made to the original LASAS AR model [21] for its adaptation to the multi-task framework. Comparison of and reveals that the detach operation of linguistic inputs and accent outputs in Fig. 1 of the accent branch has a significant positive impact on the performance of AR. In both the dev and test sets, the relative improvements are up to and , respectively. The detach operation enables the AR task to focus solely on accent-specific information, thereby improving the effectiveness of accent branch optimization. Additionally, the detach operation reduces interference from the AR task to the ASR task, thereby improving ASR performance to some extent. These results demonstrate the significance of the detach operation of the accent branch in multi-task ASR-AR. By comparing and , we can analyze the impact of frame-level and utterance-level CE loss on accent prediction. The AR accuracy of is slightly lower than that of in the dev set, but the opposite is observed in the test set. This suggests that the utterance-level loss used in can enhance the model’s generalization and mitigate overfitting. However, the frame-level accent information used in achieves a slightly better performance in the ASR task. We believe this is because the frame-level accent information can help correct fine-grained errors caused by accents in the ASR task. In our experience, accent speech utterances often consist of a small portion of words that exhibit accent characteristics, while the remaining words are pronounced in a standard manner. In other words, the accent words in a sentence pose a challenge for the ASR task but are easier to recognize for the AR task. Therefore, although utterance-level pooling operation indeed improves the overall accuracy in the AR task, it may not capture the distinguishing details of the accent words as effectively as without pooling. Hence, the selection of frame-level or utterance-level CE loss depends on the practical application and trade-off between the AR and ASR tasks.
V-D Improving ASR with AR
We further investigate the benefits of incorporating AR information into the ASR task, similar to Section V-C. We first consider the experiment in Table III, where no accent embedding is fused to the attention branch. Comparing and , we find that although lacks explicit accent embedding, it can still implicitly extract accent information through the shared encoder. This leads to significant improvements in the ASR task compared to . Specifically, the relative improvement in implicit accent fusion on the ASR dev and test sets is approximate and , respectively. However, when comparing with , we observe that explicit fusion of the accent embedding to the ASR branch leads to better results, which underscores the value of AR-to-ASR interaction.
Next, the impact of different accent embeddings is analyzed. ASR performance can be used to evaluate the quality of accent embedding since it serves the ASR task. The results in Table III show that performs the best, while performs moderately well, and performs the worst. contains utterance-level accent classification information that is relatively stable, which is easier for an ASR model to recognize. On the other hand, loses a significant amount of acoustic information valuable to the ASR model due to compression by the final DNN layer. In addition, although and have the same dimensions in our experiments, is better. This finding suggests that accent shifts also have utility in improving ASR performance. However, since operate at the frame level, they are inherently more complex and variable, which presents a challenge for ASR models to effectively leverage this information.
In experiments and , we compare two additional accent fusion schemes and , both of which explicitly integrate an accent embedding into the attention branch of the ASR task. Comparing the performance of , , and , we find that using an encoder to process an accent embedding is more effective than using a decoder, but the best performance is achieved when both are used. The effectiveness of using an encoder to fuse accent embeddings is widely acknowledged, as the encoder can focus on acoustic information and be adjusted based on accent embedding. This enables the generation of a context representation that is easier for the decoder to understand. Although there are limited studies on fusing accent embeddings to a decoder, our experiments suggest that it is also an effective approach, as the decoder focuses more on linguistic information, and accent embeddings can help correct accent-specific words. The complementary roles of the encoder and decoder in utilizing accent embeddings explain why outperforms both and . Therefore, integrating accent embeddings into both the encoder and decoder is essential to achieve better performance. Thanks to the triple-encoder structure, this can be easily accomplished in the attention branch.
V-E Two-granularity Rescoring
In Table V, we evaluate the effectiveness of two-granularity rescoring. As shown in the table, attention rescoring yields an average relative reduction in WER of within the CTC/attention framework. To mitigate the framework’s impact, we also assessed the effects of CTC rescoring on the DIMNet with single-granularity BPE units. The average WER decrease observed in this case is similar to that of attention rescoring, approximately relative . In comparison to these two classic rescoring techniques, our proposed two-granularity rescoring achieves an average relative WER decrease of . In the DIMNet model, the CTC and attention branches operate independently, and each branch has a different and complementary focus in terms of information granularity. Two-granularity rescoring effectively integrates the prediction scores of the two-granularity units, thereby complementing the limitations of the decoupling operation and leading to further improvements in the DIMNet model’s performance.
| ID | Model | Decode Pass | WER (%) | ||
|---|---|---|---|---|---|
| 1-st | 2-nd | Dev | Test | ||
| B1 | CTC/ATT | ATT | - | 5.96 | 6.91 |
| B1+ARS | CTC | ATT | 5.86 | 6.80 | |
| D3 | DIMNet w/o TGM | ATT | - | 5.74 | 6.41 |
| D3+CRS | ATT | CTC | 5.65 | 6.33 | |
| D1 | DIMNet | ATT | - | 5.55 | 6.27 |
| D1+TRS† | ATT | CTC | 5.41 | 6.13 | |
-
•
†: This model is in the Table III.
V-F A2P+P2W vs. A2P+A2W for Two-granularity Units
As mentioned in Section II, a common approach for two-granularity modeling in ASR involves phoneme recognition and translation of phonemes into words or BPEs (A2P+P2W). However, this approach faces the challenges of error accumulation in the P2W stage. In contrast, the DIMNet directly recognizes phonemes and BPEs from audio features (A2P+A2W). In this section, we compare the two approaches.
| Model |
|
|
||||
|---|---|---|---|---|---|---|
| A2P + A2W† | 4.41 | 6.27 | ||||
|
4.59 | 6.4 | ||||
|
4.61 | 7.54 |
-
•
†: This model is in the Table III.
Table VI presents the results of two models that translate soft embeddings and hard OneHot vectors of phonemes into BPE, both based on the DIMNet. In both models, we maintain the triple-encoder structure, but modify the input of the attention encoder to CTC phoneme information instead of the shared encoder outputs, while keeping the accent embedding concatenation unchanged. We aim for the attention branch to act as a P2W model in both schemes. To achieve this, we detach the outputs of the CTC branch as well as the accent branch to ensure that the attention branch solely focuses on translating phonemes into BPE. The results show that the change in PER for the CTC decoder is minimal because detaching the CTC phonemes makes the CTC branch relatively independent, ensuring a fair comparison of the P2W process. As shown in Table VI, Firstly, the WER of A2P+Soft P2W and A2P+Hard P2W is inferior to that of A2P+A2W, indicating the superiority of the DIMNet. Secondly, when the input phoneme sequence’s PER is equivalent, the WER of using soft embeddings is relative higher than that of using OneHot vectors. This is because the CTC encoder outputs contain richer linguistic and acoustic information, while regular phonemes only contain linguistic information. However, in most two-granularity unit ASR, hard OneHot vectors of phonemes are used as inputs, which limits the performance of P2W. Moreover, the use of completely correct phonemes during training and hypothesis phonemes during inference in P2W can cause a mismatch and error accumulation. In contrast, our triple-encoder scheme independently models phonemes and BPEs by the CTC encoder and attention encoder, respectively, which can help mitigate error accumulation.
V-G Comparison with Previous Studies
In Table VII, we present a comparison of our DIMNet with several other typical approaches on the AESRC dataset. The second row shows an ASR-AR cascade scheme [3] that achieves top-level performance on this dataset. Comparing it with our DIMNet, we can see that their model achieves a better result in the AR task, which is mainly due to extensive data augmentation. Without the data augmentation, their AR accuracy on the dev set is , which is slightly lower than that of the DIMNet. Apart from the second row, the DIMNet significantly outperforms other schemes in the AR task. In particular, the DIMNet surpasses our previous LASAS AR model [21], which demonstrates the value of our improvements in the original LASAS. These results indicate that the DIMNet is highly competitive in AR tasks. In the ASR task, the first row is a CTC/attention ASR, while the second to fourth rows are typical multi-task ASR-AR introduced in Section II. Except for the first row, the rest of the models do not use language models. In a comparable situation, our DIMNet’s ASR performance surpasses the above schemes. This indicates that the DIMNet also has significant advantages in the ASR task. Moreover, the last row shows that after adding the LM, the performance of the DIMNet can be further improved. By comparing the DIMNet in the last row and the CTC/attention-based baseline in the first row, we obtain relative improvements of and on the test sets of AR and ASR tasks, respectively. This fully demonstrates that our scheme is effective in English.
| Model |
|
|
||||||
|---|---|---|---|---|---|---|---|---|
| Dev | Test | Dev | Test | |||||
| AESRC Baseline [4] | 76.1 | 64.9 | 6.92 | 8.29 | ||||
| ASR-AR Cascade [3] | 91.13 | 83.63 | 5.53 | 6.56 | ||||
| STJR [8]: ASR-AR Single-task | 77 | 72.2 | 5.8 | 6.6 | ||||
| MTJR [8]: ASR-AR Multi-task | 82.4 | 75.2 | 6.2 | 7.1 | ||||
| LASAS [21]: Only AR task | 84.88 | 77.42 | - | - | ||||
| DIMNet w/ TRS† | 86.47 | 78.82 | 5.41 | 6.13 | ||||
| DIMNet w/ TRS+LM | 86.47 | 78.82 | 5.03 | 5.61 | ||||
-
•
†: This model is in the Table III.
Table VIII presents the experimental results on the KeSpeech dataset [49]. In the ASR task, the first row represents an official baseline model [49] trained using the Espnet [47] tool, incorporating an LM. The second and third rows correspond to baselines that we trained ourselves using the Wenet [45] tools. All three rows are to CTC/attention frameworks. For the AR task, the KeSpeech baseline [49] is a ResNet34 [54] model. We train the CTC/attention and DIMNet models under a comparable conditions. As shown in the table, the DIMNet outperforms both baselines significantly on both AR and ASR tasks. Specifically, the DIMNet achieves a relative improvement of over the KeSpeech baseline on the AR task and a relative improvement on the ASR task, demonstrating the effectiveness of the DIMNet in Chinese. Notably, unlike phoneme/BPE units, syllable/char units have the same time steps, indicating the robustness of the DIMNet to the time steps of coarse and fine-grained units, which makes it applicable to other languages as well.
| Model |
|
|
||||||
|---|---|---|---|---|---|---|---|---|
| Dev | Test | Dev | Test | |||||
| KeSpeech Baseline [49] | - | 61.13 | - | 10.38 | ||||
| CTC/ATT w/ ARS | - | - | 6.05 | 9.54 | ||||
| CTC/ATT w/ ARS + LM | - | - | 5.95 | 9.39 | ||||
| DIMNet w/ TRS | 80.06 | 78.57 | 5.90 | 9.40 | ||||
| DIMNet w/ TRS + LM | 80.06 | 78.57 | 5.71 | 8.87 | ||||
VI Conclusions
In this paper, we propose the DIMNet, a multi-task framework for joint ASR-AR tasks. Our approach first decouples the AR and ASR tasks using a triple-encoder structure that can model two-granularity units in each task. Then we enhance the interaction between the two tasks by introducing and improving the LASAS AR model and studying the selection and fusion of accent embeddings. Finally, we develop a two-granularity rescoring scheme that effectively combines two-granularity scores to further enhance ASR performance. Experimental results demonstrate that our scheme achieves relative improvements in AR accuracy of and , as well as relative reductions in ASR error rate of and on test sets of the AESRC and KeSpeech datasets, respectively, compared to the E2E baselines. Looking forward, we aim to further reduce the computational complexity of the DIMNet and extend its application to multilingual ASR tasks.
References
- [1] R. Lippi-Green, English with an accent: Language, ideology, and discrimination in the United States. Routledge, 2012.
- [2] C. Huang, T. Chen, and E. Chang, “Accent issues in large vocabulary continuous speech recognition,” International Journal of Speech Technology, vol. 7, no. 2, pp. 141–153, 2004.
- [3] Y. Qian, X. Gong, and H. Huang, “Layer-wise fast adaptation for end-to-end multi-accent speech recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP), vol. 30, pp. 2842–2853, 2022.
- [4] X. Shi, F. Yu, Y. Lu, Y. Liang, Q. Feng, D. Wang, Y. Qian, and L. Xie, “The accented English speech recognition challenge 2020: Open datasets, tracks, baselines, results and methods,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6918–6922.
- [5] Y. Yang, H. Shi, Y. Lin, M. Ge, L. Wang, Q. Hou, and J. Dang, “Adaptive attention network with domain adversarial training for multi-accent speech recognition,” in International Symposium on Chinese Spoken Language Processing (ISCSLP), 2022, pp. 6–10.
- [6] K. Deng and P. C. Woodland, “Adaptable end-to-end asr models using replaceable internal lms and residual softmax,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5.
- [7] A. Jain, M. Upreti, and P. Jyothi, “Improved accented speech recognition using accent embeddings and multi-task learning,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2018, pp. 2454–2458.
- [8] J. Zhang, Y. Peng, P. Van Tung, H. Xu, H. Huang, and E. S. Chng, “E2E-based multi-task learning approach to joint speech and accent recognition,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2021, pp. 876–880.
- [9] S. Toshniwal, T. N. Sainath, R. J. Weiss, B. Li, P. Moreno, E. Weinstein, and K. Rao, “Multilingual speech recognition with a single end-to-end model,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 4904–4908.
- [10] R. He, W. S. Lee, H. T. Ng, and D. Dahlmeier, “An interactive multi-task learning network for end-to-end aspect-based sentiment analysis,” in Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2019, pp. 504–515.
- [11] Y. Pang, X. Zhao, L. Zhang, and H. Lu, “Multi-scale interactive network for salient object detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2020, pp. 9413–9422.
- [12] R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” in Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2016, pp. 1715–1725.
- [13] H. Huang, X. Xiang, Y. Yang, R. Ma, and Y. Qian, “AISpeech-SJTU accent identification system for the accented English speech recognition challenge,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6254–6258.
- [14] M. Najafian, A. DeMarco, S. Cox, and M. Russell, “Unsupervised model selection for recognition of regional accented speech,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2014.
- [15] A. Hanani and R. Naser, “Spoken Arabic dialect recognition using X-vectors,” Natural Language Engineering, vol. 26, no. 6, pp. 691–700, 2020.
- [16] M. A. T. Turan, E. Vincent, and D. Jouvet, “Achieving multi-accent ASR via unsupervised acoustic model adaptation,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2020, pp. 1286–1290.
- [17] S. A. Chowdhury, A. M. Ali, S. Shon, and J. R. Glass, “What does an end-to-end dialect identification model learn about non-dialectal information?” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2020, pp. 462–466.
- [18] K. Deng, S. Cao, and L. Ma, “Improving accent identification and accented speech recognition under a framework of self-supervised learning,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2021, pp. 881–885.
- [19] Q. Gao, H. Wu, Y. Sun, and Y. Duan, “An end-to-end speech accent recognition method based on hybrid CTC/attention Transformer ASR,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 7253–7257.
- [20] S. Sun, C.-F. Yeh, M.-Y. Hwang, M. Ostendorf, and L. Xie, “Domain adversarial training for accented speech recognition,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 4854–4858.
- [21] Q. Shao, J. Yan, J. Kang, P. Guo, X. Shi, P. Hu, and L. Xie, “Linguistic-acoustic similarity based accent shift for accent recognition,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2022, pp. 3719–3723.
- [22] R. Imaizumi, R. Masumura, S. Shiota, and H. Kiya, “Dialect-aware modeling for end-to-end Japanese dialect speech recognition,” in Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2020, pp. 297–301.
- [23] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks,” in Proceedings of the International Conference on Machine Learning (ICML), 2006, pp. 369–376.
- [24] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu et al., “Conformer: Convolution-augmented Transformer for speech recognition,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2020, pp. 5036–5040.
- [25] Z. Zhang, Y. Wang, and J. Yang, “Accent recognition with hybrid phonetic features,” Sensors, vol. 21, no. 18, p. 6258, 2021.
- [26] H. Hu, X. Yang, Z. Raeesy, J. Guo, G. Keskin, H. Arsikere, A. Rastrow, A. Stolcke, and R. Maas, “Redat: Accent-invariant representation for end-to-end ASR by domain adversarial training with relabeling,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6408–6412.
- [27] T. Viglino, P. Motlicek, and M. Cernak, “End-to-end accented speech recognition,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2019, pp. 2140–2144.
- [28] X. Yang, K. Audhkhasi, A. Rosenberg, S. Thomas, B. Ramabhadran, and M. Hasegawa-Johnson, “Joint modeling of accents and acoustics for multi-accent speech recognition,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 1–5.
- [29] A. Yadavalli, G. Mirishkar, and A. K. Vuppala, “Multi-task end-to-end model for Telugu dialect and speech recognition,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2022, pp. 1387–1391.
- [30] A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “Wav2Vec 2.0: A framework for self-supervised learning of speech representations,” Advances in Neural Information Processing Systems (NIPS), vol. 33, pp. 12 449–12 460, 2020.
- [31] X. Gong, Y. Lu, Z. Zhou, and Y. Qian, “Layer-wise fast adaptation for end-to-end multi-accent speech recognition,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2021, pp. 4501–4505.
- [32] B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2020, pp. 3830–3834.
- [33] A. Waibel, T. Hanazawa, G. Hinton, K. Shikano, and K. J. Lang, “Phoneme recognition using time-delay neural networks,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 37, no. 3, pp. 328–339, 1989.
- [34] K. Rao and H. Sak, “Multi-accent speech recognition with hierarchical grapheme based models,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 4815–4819.
- [35] W. Chan and I. R. Lane, “On online attention-based speech recognition and joint Mandarin character-pinyin training,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2016, pp. 3404–3408.
- [36] S. Zhou, L. Dong, S. Xu, and B. Xu, “A comparison of modeling units in sequence-to-sequence speech recognition with the Transformer on Mandarin Chinese,” in International Conference on Neural Information Processing (ICONIP), 2018, pp. 210–220.
- [37] Z. Chen, Q. Liu, H. Li, and K. Yu, “On modular training of neural acoustics-to-word model for LVCSR,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 4754–4758.
- [38] S. Zhou, L. Dong, S. Xu, and B. Xu, “Syllable-based sequence-to-sequence speech recognition with the Transformer in Mandarin Chinese,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2018, pp. 791–795.
- [39] J. Yuan, X. Cai, D. Gao, R. Zheng, L. Huang, and K. Church, “Decoupling recognition and transcription in Mandarin ASR,” in IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2021, pp. 1019–1025.
- [40] X. Wang, Z. Yao, X. Shi, and L. Xie, “Cascade RNN-transducer: Syllable based streaming on-device Mandarin speech recognition with a syllable-to-character converter,” in IEEE Spoken Language Technology Workshop (SLT), 2021, pp. 15–21.
- [41] S. Zhang, J. Yi, Z. Tian, Y. Bai, J. Tao et al., “Decoupling pronunciation and language for end-to-end code-switching automatic speech recognition,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6249–6253.
- [42] Y. Yang, B. Du, and Y. Li, “Multi-level modeling units for end-to-end Mandarin speech recognition,” arXiv preprint arXiv:2205.11998, 2022.
- [43] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in Neural Information Processing Systems (NIPS), vol. 30, 2017.
- [44] Z. Tang, L. Li, D. Wang, and R. Vipperla, “Collaborative joint training with multitask recurrent model for speech and speaker recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP), vol. 25, pp. 493–504, 2016.
- [45] Z. Yao, D. Wu, X. Wang, B. Zhang, F. Yu, C. Yang, Z. Peng, X. Chen, L. Xie, and X. Lei, “Wenet: Production oriented streaming and non-streaming end-to-end speech recognition toolkit,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2021, pp. 2093–2097.
- [46] A. Klautau, “Arpabet and the timit alphabet,” an archived file. https://web.archive.org/web/20160603180727/http://www.laps.ufpa.br/aldebaro/papers/ak_arpabet01.pdf (Accessed Mar. 12, 2020), 2001.
- [47] S. Watanabe, T. Hori, S. Kim, J. R. Hershey, and T. Hayashi, “Hybrid CTC/attention architecture for end-to-end speech recognition,” IEEE Journal of Selected Topics in Signal Processing, vol. 11, no. 8, pp. 1240–1253, 2017.
- [48] J. Li, Y. Wu, Y. Gaur, C. Wang, R. Zhao, and S. Liu, “On the comparison of popular end-to-end models for large scale speech recognition,” arXiv preprint arXiv:2005.14327, 2020.
- [49] Z. Tang, D. Wang, Y. Xu, J. Sun, X. Lei, S. Zhao, C. Wen, X. Tan, C. Xie, S. Zhou et al., “KeSpeech: An open source speech dataset of Mandarin and its eight subdialects,” 2021.
- [50] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210.
- [51] C. Yarra, R. Aggarwal, A. Rajpal, and P. K. Ghosh, “Indic TIMIT and Indic English lexicon: A speech database of Indian speakers using TIMIT stimuli and a lexicon from their mispronunciations,” in Conference of the Oriental COCOSDA International Committee for the Co-ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA), 2019, pp. 1–6.
- [52] K. Igarashi and I. Wilson, “Improving Japanese English pronunciation with speech recognition and feed-back system,” in SHS Web of Conferences, 2020, p. 02003.
- [53] F. Han, “Pronunciation problems of Chinese learners of English,” ORTESOL Journal, vol. 30, pp. 26–30, 2013.
- [54] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.