Decomposing and Coupling Saliency Map for Lesion Segmentation in Ultrasound Images
Abstract
Complex scenario of ultrasound image, in which adjacent tissues (i.e., background) share similar intensity with and even contain richer texture patterns than lesion region (i.e., foreground), brings a unique challenge for accurate lesion segmentation. This work presents a decomposition-coupling network, called DC-Net, to deal with this challenge in a (foreground-background) saliency map disentanglement-fusion manner. The DC-Net consists of decomposition and coupling subnets, and the former preliminarily disentangles original image into foreground and background saliency maps, followed by the latter for accurate segmentation under the assistance of saliency prior fusion. The coupling subnet involves three aspects of fusion strategies, including: 1) regional feature aggregation (via differentiable context pooling operator in the encoder) to adaptively preserve local contextual details with the larger receptive field during dimension reduction; 2) relation-aware representation fusion (via cross-correlation fusion module in the decoder) to efficiently fuse low-level visual characteristics and high-level semantic features during resolution restoration; 3) dependency-aware prior incorporation (via coupler) to reinforce foreground-salient representation with the complementary information derived from background representation. Furthermore, a harmonic loss function is introduced to encourage the network to focus more attention on low-confidence and hard samples. The proposed method is evaluated on two ultrasound lesion segmentation tasks, which demonstrates the remarkable performance improvement over existing state-of-the-art methods.
Index Terms:
Lesion segmentation, ultrasound image, saliency map, complex scenario, deep learningI Introduction
Ultrasound imaging, as one of the most common imaging schemes in clinical practices, has been extensively applied to the early detection of many diseases (e.g., breast cancer and thyroid nodule) in view of its safety and efficiency [1, 2]. Clinically, radiologists can make preliminary diagnosis by screening ultrasound images, which is experience-dependent and may suffer from high inter-observer variation even for well-trained radiologists [3]. For decades, computer-aided diagnosis (CAD) system based on ultrasound images is developed to help radiologists improve diagnostic accuracy and reduce individual subjectivity [4], in which lesion segmentation acts as a significant step towards sensitivity and efficiency improvement [5]. Therefore, it has attracted much attention on automatic and robust segmentation methods for advancing the development of CAD system [2, 6].
In recent years, many segmentation methods have been proposed for automatic lesion delineation in ultrasound images, among which deep learning methods, especially convolutional neural networks (CNNs), have showed the superior performance to most of conventional models (e.g., model-based and region-based approaches) [7, 8]. However, complex scenario still poses a unique challenge for accurate lesion segmentation [9, 10]. For intuitive illustration, Fig. 1 exhibits the histogram statistics of several representative cases from two ultrasound image databases. We can observe that lesion regions (i.e., foreground) generally show low-intensity signals, while the surrounding tissues (i.e., background) share similar intensity profiles with and even contain richer texture patterns than foreground, making it difficult to accurately separate foreground from background. In consideration of such scenario, recent studies have tried the utilization of the cues provided by saliency maps to boost model’s generalization performance on foreground segmentation [11, 12, 13, 14]. These methods commonly cluster and highlight visually salient regions to assist subsequent segmentation models, which, however, is a standalone preprocessing step that requires the prior of interactive hand-clicked seeds. A desirable but rare way is to deal with this challenge in a (foreground-background) saliency map disentanglement-fusion manner, in which saliency map generation and lesion segmentation are conducted in a collaborative manner without manual intervention.
In general, the vast majority of segmentation networks on ultrasound images, as the variants of fully convolutional network (FCN) [15] and U-Net [16], equip with a contracting path (i.e., encoder) for morphological context extraction as well as a symmetric expanding path (i.e., decoder) for precise localization and segmentation [15, 16]. However, the performance gain of those methods is hindered by insufficient information fusion. For encoder, it typically utilizes the pooling layer to aggregate regional features so as to reduce feature dimension and enlarge receptive field. Although the pooling layer can efficiently alleviate the overfitting issue and help capture global information, it inevitably results in information dropout especially on relatively small lesions. As to decoder, the skip connectivity operator is exploited to transmit morphological features from encoding path to decoding one for preserving the low-level characteristics of images, which commonly ignores the inner association during the fusion process of low-level visual information and high-level semantic representation. On the other hand, most of existing methods may prefer to optimize the segmentation of easy samples with distinct edge and appearance during the training stage, but inattention to low-confidence and hard samples limits the generalisation of models. We argue that the network can work better on ultrasound lesion segmentation task when it can deal with the aforementioned issues.

In this paper, we propose a decomposition-coupling network (DC-Net) to incorporate saliency map generation into the model for ultrasound lesion segmentation. Decomposition and coupling subnets jointly constitute to form DC-Net, in which the former preliminarily disentangles the original image into foreground and background saliency maps, while the latter conducts accurate lesion segmentation by coupling the saliency prior of foreground with that of background. The coupling subnet consists of an encoder, a decoder and a coupler, involving three aspects of fusion strategies: 1) The encoder is armed with a differentiable context pooling strategy to aggregate regional features, which can adaptively preserve local contextual details with the larger receptive field during dimension reduction. 2) The decoder conducts relation-aware representation fusion of low-level visual characteristics and high-level semantic features during resolution restoration. 3) A coupler is embedded to reinforce foreground-salient representation by incorporating the complementary information derived from background representation based on its dependency on foreground. Furthermore, we present a harmonic loss function for extra performance improvement by compelling the network to focus on low-confidence samples in addition to hard ones. The main contributions of this paper lie in the following aspects:
-
–
We try a saliency map disentanglement-fusion manner for lesion segmentation in complex-scenario ultrasound images by the introduction of DC-Net which simultaneously conducts saliency map generation and lesion segmentation without manual intervention.
-
–
We devise a coupling subnet, involving three aspects of fusion strategies, including regional feature aggregation (via differentiable context pooling operator in the encoer), relation-aware representation fusion (cross-correlation fusion module in the decoder) and dependency-aware prior incorporation (via coupler).
-
–
We propose a harmonic loss function to prevent low-confidence samples as well as hard ones from being overwhelmed during the training stage by lifting or keeping their gradients. Interestingly, the harmonic loss can degenerate into the focal loss and cross-entropy loss under certain conditions.
-
–
Extensive experiments on two ultrasound lesion segmentation tasks (i.e., breast ultrasound segmentation and thyroid ultrasound segmentation tasks) demonstrate its superiority.
The remaining portion of this paper is organized as follows. In Section II, we briefly review the related work. We detail our specific method in Section 3. Section 4 presents experimental settings and results. The discussion and conclusion are drawn in Section 5 and 6, respectively.
II Related Work
II-A Saliency Prior-based Segmentation Approaches
Many studies have recently demonstrated the potential of the cues provided by saliency prior to help improve model’s generalization performance [17, 18, 19], especially on medical image segmentation tasks [20, 21]. These methods commonly cluster and highlight visually salient regions to assist downstream segmentation models. For example, Luo et al. [22] considered the exponentialized geodesic distance as saliency map and took it as additional input of the network. Feng et al. [20] utilized the saliency cue from interactive manual correction on the prediction map in an iterative manner. Vakanski et al. [12] generated the visual saliency map and integrated it into the model via attention mechanism for accurate lesion segmentation. However, most methods only focus on foreground saliency prior and ignore the structural characteristics contained by background, which may result in sub-optimal solutions especially in the complex scenario of ultrasound images. Actually, several studies have manifested that the introduction of background prior also contributes to the performance gain [23, 11, 24, 13]. For instance, Xu et al. [23] transformed user-provided positive and negative clicks into foreground and background saliency maps, for boosting the network’s capability of learning target-related representation. Wang et al. [11] proposed to form the geodesic distance maps of foreground and background based on the initial prediction map and concatenate them with the original image as model’s input for refining segmentation results. Ning et al. [13] tried to generate hierarchical foreground and background saliency maps that were hinted by three random seeds to assist downstream lesion segmentation model. However, existing methods generally neglect the potential associations between foreground and background, which may lead to inadequate exploitation of complementary information. Additionally, most methods adopt standalone generation algorithms that usually require interactive hand-clicked seeds to produce saliency prior, which, however, is time-consuming and experience-dependent. In other word, the learning of saliency map and segmentation model is carried out in two separated processes and it may lead to a sub-optimal result, even though each of these two processes could achieve their individual optimization. An appealing way is to integrate saliency map generation and lesion segmentation into a unified framework without manual intervention, and exploit complementary information derived from background representation based on its dependency on foreground to reinforce foreground-salient representation learning for accurate lesion segmentation.
II-B Ultrasound Lesion Segmentation Networks
Convolutional neural networks have revolutionized ultrasound lesion segmentation over the last few years [25, 26, 27], most of which belong to the variants of FCN and U-Net. For instance, Wang [28] et al. stacked two DeeplabV3plus to perform coarse-to-fine thyroid nodule segmentation and obtained promising results. Yap et al. [29] developed several FCN-based variants for the semantic segmentation of breast lesion. However, existing methods are still confronted with some difficulties in feature fusion during dimension reduction and resolution restoration. For the former, pooling operator in the encoder is commonly used to aggregate neighborhood features for reducing spatial resolution and enlarging receptive field. For lesion segmentation networks, default pooling operators include average pooling [30], max pooling [31, 32] and stride convolution due to their widespread adoption and proven efficacy [33]. Although these pooling operators are straightforward to aggregate regional features and alleviate the overfitting issue, they may also result in detail information dropout especially on relatively small lesions. Currently, some works have suggested that local detail preservation during the pooling stage is beneficial to model’s generalization [34, 35]. For example, Saeedan et al. [35] proposed a detail-preserving pooling strategy to magnify spatial changes and reserve structural patterns. Gao et al. [34] devised a local importance-based pooling operator to aggregate features within the window for detail preservation. However, these methods only concentrate on feature aggregation at the specified pooling window with a fixed receptive field, neglecting the significant contextual details inherent in neighborhoods (naturally with larger receptive field). As to the feature fusion during resolution restoration, skip connectivity mechanism [36] (commonly with channel-wise concatenation [13, 37, 12, 38, 39, 40, 41, 30] or pixel-wise addition [42]) is introduced to transmit the morphological context features from encoding blocks to decoding ones. To promote the efficiency of feature transmission and fusion, some works have ameliorated the skip connection strategy [43, 44]. For example, Liu et al. [43] modified U-Net with the redesigned skip connection operator to merge multi-scale semantic features for thyroid nodule stratification. Zhu et al. [44] introduced a multi-skip-connection strategy that cooperated with the squeeze-and-excitation block to fuse the feature maps from encoder and decoder. Nevertheless, most of them ignore the inner relationship between low-level visual information and high-level semantic representation, and previous studies have demonstrated that feature fusion based on correlation would reduce feature redundancy and is conducive to feature propagation [45, 46, 47].
As another challenge for ultrasound image segmentation, the hard or low-confidence samples/pixels (around blur edge and appearance) generally occupy a smaller proportion than the easy ones, which means the easy samples would dominate gradient descent during the training stage and might result in sub-optimal performance [48]. To this end, some researches have designed supervision functions based on focal loss for emphasizing on training a sparse set of hard samples [49, 50, 51]. For example, Li et al. [50] proposed to combine focal loss and dice loss to promote the model’s capability of segmenting hard samples. Yeung et al. [51] presented a unified focal loss that generalized dice loss and cross-entropy loss for coping with hard samples. Compared with cross-entropy (CE) loss, focal loss introduces a factor to adjust the loss assigned to samples, which relatively raises the network’s concern for hard samples. However, as increases, focal loss further down-weights easy samples, but concurrently overwhelms some relatively low-confidence ones (e.g., ). Actually, those samples still have positive effects on network training, which might be one of the reasons for the best choice of small in most methods [49, 50]. Therefore, we advocate to enforce the network to simultaneously focus on hard and low-confidence samples.
III Methods
III-A Problem Formulation
We aim to distinguish lesion region (foreground) from its surrounding tissues (background) in ultrasound images. Denote as a dataset containing instances, where Ii and Yi represent the -th original image and its corresponding pixel-wise annotation, respectively. An automated segmentation model can be formulated as
| (1) |
where denotes the estimated label for the input image.
In practice, it is difficult to construct a satisfactory segmentation model only based on original ultrasound images due mainly to blur boundary and appearance encountered in the complex scenario. Thus, recent studies have sought help from foreground and background saliency maps [11, 13, 24]. Accordingly, given and as foreground and background saliency maps, respectively, the segmentation model is learned based on the saliency maps in addition to the original images, which is formulated as
| (2) |
where denotes the loss function. Generally, the generation of saliency maps requires the interactive hand-clicked seeds, which is time-consuming and experience-dependent. To address this issue, we first try to conduct lesion segmentation in a saliency map disentanglement-fusion manner and integrate saliency map generation and lesion segmentation into a collaborative framework without manual intervention. Let and represent the mapping functions that transform the original image into saliency maps, i.e., and . Then, Eq.(2) can be rewritten as
| (3) |
where denotes and . Based on Eq.(3), we propose DC-Net which includes two major components, namely a decomposition subnet (i.e., ) for saliency map generation and a coupling subnet (i.e., ) for lesion segmentation with the assistance of saliency prior fusion, as illustrated in Fig. 2(a). Notably, the decomposition subnet is utilized to produce foreground and background saliency maps simultaneously.

III-B Decomposition Subnet
Different from previous methods that utilize manual intervention to generate saliency prior [11, 13], the decomposition subnet (Fig. 2(a)) disentangles the original image into foreground and background saliency maps in a data-driven fashion. It is primarily composed of an attention backbone which contains a convolutional unit and five attention blocks (Fig. 2(b)), and a saliency decomposition module (Fig. 2(c)).
III-B1 Attention Backbone
Given an input image I, a convolutional unit 111Unless otherwise specified, the convolutional unit used in this paper, which consists of an convolutional layer, a batch normalization layer and a ReLU activation operation, is denoted as . is first utilized to mine shallow feature from I. Then, five attention blocks with the same architecture are inserted for learning region-salient representations. For the -th block , it takes Bj-1 (i.e., or the output of ) as input and generates the feature via a . Subsequently, a global average pooling layer and a fully-connected layer are carried on to obtain channel-wise weight vector that is activated by a softmax function . After that, is adopted to enhance the significant channels of j, which is further merged by another to get the representation :
| (4) |
where denotes the channel-wise multiplication operation. Note that all blocks contain two convolutional layers and their channel numbers are empirically set to , , , and , respectively. And two max-pooling layers are respectively placed behind the first two blocks for resolution reduction, while two up-sampling layers in front of the last two blocks for resolution restoration, as shown in Fig. 2(a-b). Meanwhile, the skip connectivity operator is used to concatenate the output features of / and the input features of /.
III-B2 Saliency Decomposition Module
A saliency decomposition (SD) module is constructed for the generation of foreground and background saliency maps. In this module, as shown in Fig. 2(c), we first apply a self-reversal activation operator to B5 (also named as Bf for convenience), so as to obtain complementary background representation Bb:
| (5) |
where denotes the channel number of Bf. Then, a convolutional layer and a sigmoid activation function are plugged to get foreground and background saliency maps (i.e., and ). Furthermore, we adopt a weakly-supervised manner, that is using the foreground mask Y and background mask as collaborative supervision signals rather than complex manual saliency prior, to train the network. Consequently, based on the dataset , it can be formulated as
| (6) |
where and denote the loss functions for learning foreground and background saliency maps, respectively.
Remark 1:
This restricted form of previous saliency map generation methods limits their generality and usability since additional interactive knowledge is needed to specify visual focal points. By comparison, disentangling directly from original image about saliency maps is a promising alternative which is first work we are aware of that has been integrated into the downstream segmentation model and optimized jointly.
III-C Coupling Subnet
The coupling subnet is proposed for accurate lesion segmentation under the assistance of saliency maps, consisting of an encoder, a decoder and a coupler. Unlike prior ultrasound lesion segmentation networks [13, 37, 38, 40, 41, 30], the coupling subnet involves three fusion modifications: 1) A differentiable context pooling (DCP) operator is devised and inserted in the encoder to aggregate regional features and adaptively preserve local contextual details during dimension reduction; 2) The decoder is armed with a cross-correlation fusion (CCF) module to model the relation between low-level and high-level features and fuse them during resolution restoration; 3) A coupler is embedded to reinforce foreground-salient representation learning by incorporating complementary information derived from background-salient cues based on its dependency on foreground.
III-C1 Encoder
In Fig. 2(a), the encoder is constructed based on five blocks , and all blocks share the same architecture except for the block that removes the pooling operator. For the -th block , it intakes (i.e., 222We denote the concatenation of original image and foreground saliency map as , namely . or the output of the aggregation unit ). Then, a convolutional unit is used to extract features, followed by a DCP operator to aggregate regional features, shrink the spatial size of the feature maps and obtain the representation .
DCP Operator: In general, most pooling methods can be regarded as a convex combination of local neuron activations [52]. Given the -th feature map from , such pooling operation can be formulated as
| (7) |
where and represent the features and pooling kernel within the -th sliding window , respectively, and denotes the number of sliding windows and is computed by . Generally speaking, is non-learnable and sharable for all windows. However, Eq.(7) only concentrates on the specified window with a fixed receptive field, neglecting the contextual information inherent in neighborhoods. Recent work has demonstrated that contexts enable the network to retain essential details and understand image structure in ultrasound images [13]. To this end, we rethink the pooling operator from the perspective of matrix manipulation. We first define the pooling kernel as a matrix that contains non-sharable pooling kernels, i.e., . Then, as shown in Fig. 2(d), and are flattened based on the window and stacked as and , respectively. We further project into a latent space by :
| (8) |
where the entry () denotes the representation that is obtained by using the -th kernel to map the features within the -th window.
Considering that contexts generally appear in local neighborhoods, we introduce an indicator matrix to activate such as to extract and aggregate contextual details (to generate ) as follows:
| (9) |
where is an all-ones vector, is a smooth factor, and H is essentially a band matrix and has the following definition.
Definition 1 (Indicator Matrix ).
Given the matrix , all entries are 0 outside a diagonally bordered band whose range is determined by constant , and the rest is equal to 1. More formally, it can be defined as
| (10) |
Through H, Eq.(9) can on one hand preserve local contextual details and on the other hand enlarge receptive field when neighborhoods are referred. For instance, if H is a tridiagonal matrix, it associates eight neighborhoods of a window and the receptive field is concomitantly enlarged to eight times as against conventional pooling strategies. Intuitively, when H is an identity matrix (i.e., neglecting contexts), we can obtain two special cases of Eq.(9) as follows: i) if is a constant matrix and its entry () equals to , Eq.(9) is an average pooling operator in essence; ii) if is binary and is equal to 1 in the condition that has the largest value in the -th row (i.e., the -th window in ), Eq.(9) can be considered as a max pooling operator. Additionally, as a remedy, it is expected that is learnable and adaptive for input features. Consequently, we introduce a differentiable pooling kernel that can be learned in a task-driven manner, and thus Eq.(9) can be reformulated as
| (11) |
where is implemented by applying a convolutional layer to Z.
Finally, we reshape to form (i.e., ) that is used as the output of DCP operator.
Remark 2:
We formulate DCP operator from the perspective of matrix manipulation, which generalizes conventional pooling approaches to aggregate regional features.
This operator enables the network to adaptively preserve local contextual details to alleviate information dropout issue while enlarging receptive field.
III-C2 Decoder
Fig. 2(a) shows the architecture of decoder that includes five blocks . For the first four blocks, each of them consists of a convolutional unit and a cross-correlation fusion (CCF) module for resolution restoration, while the block involves a convolutional layer and a sigmoid function for segmentation map estimation. In the -th block (where ), a convolutional unit is applied to to generate , and then a CCF module is developed to obtain the up-sampled representation by fusing the low-level visual characteristic and high-level semantic representation . For the block , it receives and outputs to compute the loss to the annotation Y for the network training. Given the dataset , it can be formulated as
| (12) |
where denotes the loss function.
CCF Module: Prior methods [13, 37, 12, 38, 39, 40, 41, 30, 42] generally utilize the skip connectivity operator to bridge the features from encoding and decoding blocks, which typically ignores their potential relation and may result in feature redundancy. With this in mind, we propose a CCF module to fuse them under the prior of correlation. For convenience, let and denote the low-level and high-level representations from encoding and decoding blocks, respectively. As illustrated in Fig. 2(e), is first up-sampled as to obtain the same spatial resolution with . Then, both of them are flattened into two feature matrices (i.e., and ). After that, we calculate the relation matrix by
| (13) |
Intuitively, the -th row vector of M (i.e., ) represents the correlation between the -th channel of and all channels of , while the -th column vector of M (i.e., ) records the correlation between the -th channel of and all channels of . However, or only reflects channel-wise relationship and lacks a global perspective to explore the relationship patterns. Therefore, we utilize a mapping function to learn the global relation along horizontal and vertical directions, which can be computed by
| (14) |
where and represent two global relation vectors and denotes the mapping function that is implemented via a vertical convolution operation with the kernel size of . Subsequently, and are used to enhance the significant channels of and , respectively:
| (15) |
Finally, and are concatenated and merged via a convolutional unit whose output is considered as the output of a CCF module.
Remark 3: Different from previous fusion strategies, CCF module conducts relation-aware fusion so as to reduce redundant information and strengthen the efficiency of feature propagation.
III-C3 Coupler
The coupler is composed of an auxiliary stream and an aggregation stream, as shown in Fig. 2(a).
The auxiliary stream aims to learn background-salient representation, while the aggregation stream is to reinforce foreground-salient representation learning with complementary background-salient information.
Auxiliary Stream:
The auxiliary stream receives the concatenation of original image and background saliency map as input333We denote the concatenation of original image and background saliency map as , namely ., which contains five contracting blocks and four expanding blocks .
For each block (or ), its architecture is similar to that of (or ), and substitutes a pooling (or upsampling) layer for the DCP (or CCF) module to generate (or ).
Such architecture design lies on two reasons as follows: 1) For auxiliary background path, it poses a slack requirement on elaborate detail preservation.
2) Plugging more DCP or CCF modules would increase the amount of parameters and is inclined to overfitting issue, which is thankless.
Aggregation Stream:
The aggregation stream is constructed based on a group of aggregation units, i.e., .
The -th aggregation unit takes the foreground feature and background feature as input for , while and for .
And two convolutional units and are first plugged to map (or ) and (or ) into foreground and background embeddings, respectively.
These two embeddings are fed into a dependency-aware reinforcement (DaR) module to generate feature .
DaR Module: Recent work has demonstrated that complementary information from background can contribute to foreground representation learning via some fusion mechanisms (e.g., channel-wise concatenation [13] and addition strategy [24]), which, however, generally neglects the dependency between foreground and background representations and results in sub-optimal performance. To this end, the DaR module is introduced to generate the enhanced representation by modeling dependencies across foreground and background information. For simplicity, the foreground and background embeddings are denoted as and , respectively. As illustrated in Fig. 2(f), is reshaped as with the size of . Meanwhile, is fed into the self-reversal activation operator to get . Then, we compress into two semantic prototypes (i.e., and ) via two pyramidal branches. In each branch, three convolutional units with the dilation rate of and the channel number of are concurrently utilized to extract multi-scale representations:
| (16) |
The features with different scales are then concatenated alone channel direction, i.e., and , which are further merged by a global average pooling and a convolutional layer to obtain K and V. These two compact prototypes from the background embedding are used to explore and broadcast foreground complementary information, accompanied with modeling their dependeny on foreground-salient representation. Specifically, the dependency is computed by exploiting to query and activate the foreground-related features of K, which is then matched with V to obtain the foreground complementary representation :
| (17) |
Subsequently, is reshaped into the size of , followed by a convolutional unit to generate . Finally, F is added to the concatenation of and to reinforce foreground representation, namely , which is regarded as the output of a DaR module.
Remark 4: Coupler, as a novel component, is introduced to learn background-salient representation and explore its dependency on foreground, upon which complementary information derived from background is incorporated to reinforce foreground-salient representation learning.
III-D Optimization Function
We design a hybrid loss to effectively train the proposed DC-Net, in which the decomposition subnet and coupling subnet are optimized jointly. According to Eq.(6) and Eq.(12), the total loss can be formulated as
| (18) |
where , , and are weight coefficients.
Insufficient attention to hard samples encountered during the training stage is still a challenge for accurate ultrasound lesion segmentation, since these samples (i.e., pixels around blur edge and appearance) generally occupy a smaller proportion compared to the easy ones.
Although focal loss [50, 53] has shown its efficacy on increasing the network’s attention to hard samples by reshaping CE loss such that it down-weights the loss assigned to well-segmented samples, it also reduces the loss amplitude of all samples and suppresses relatively low-confidence samples (e.g., ) especially when increases.
It is expected that, in the scenario of easy samples being down-weighted, the loss margin and gradient of hard samples can still be preserved and even increased to achieve continuous attention, while the range of suppression can be narrowed so as to guarantee the network to focus on low-confidence samples.
Therefore, we introduce a harmonic loss function for ultrasound lesion segmentation.
Definition 2 (Harmonic Loss Function ).
The harmonic loss function is defined as
| (19) |
where and are harmonic parameters, equals to for and for , and and denote the estimated probability and label of a pixel, respectively.
We can derive several interesting properties as follows:
P-1. The function is non-negative, continuous and differentiable.
P-2. , if .
P-3. , if .
P-4. , if .
P-5. , if .
Obviously, the P-1 holds, thus it is suitable as a loss function. The P-2 suggests that degenerates into CE loss with the modulating factor when approaches zero. Inspired by [54], we rewrite and in a Taylor expansion form:
| (20) |
| (21) |
Accordingly, their gradients can be computed by summating series polynomials as follows:
| (22) |
| (23) | ||||
Intuitively, provides a smaller constant gradient than , which can prevent the model from emphasizing the majority class (i.e., easy samples) [54]. Thus, it can be regarded as an improved CE loss. Similarly, P-3 indicates is an equivalent variant of focal loss if approaches the infinite, and their gradients can be calculated by
| (24) |
| (25) |
It is apparent that is equivalent to shifting all the polynomial coefficients of by 1. As to P-4 and P-5, they suggest that additionally introduces the amplification factors and for and , respectively, when the conditions of and are satisfied.

Furthermore, we integrative different settings of and for , and provide an intuitive comparison among , and in Fig. 3. Several key points can be observed as follows: 1) Compared with , down-weights easy samples as does; 2) almost preserves and even elevates the loss margin and gradient of hard samples; 3) narrows down the suppression range to prevent low-confidence samples from being overwhelmed, and the range would shrinkage as either or decreases. Additionally, we introduce a weighting factor to alleviate imbalance between foreground and background, and the Eq.(19) can be rewritten as
| (26) |
where if , otherwise ( is a hyper-parameter).
Considering that compound loss function would help obtain a robust and accurate model for medical image segmentation [55], we design by incorporating with dice similarity coefficient (Dice) loss [56]:
| (27) |
where is a weight coefficient. Since decomposition subnet aims to preliminarily disentangles the original image into saliency maps and it does not require accurate estimation, we thus set and to reduce the computational cost.
Remark 5: Compared with focal loss, our harmonic loss can not only down-weights easy samples, but also preserves the loss margin and gradient of hard ones. More importantly, it can adjust the suppression range to prevent low-confidence samples from being overwhelmed via the harmonic parameters or .
IV Experiments and Results
In this section, we first introduce datasets and experimental settings. Then, we present experimental results, including comparison analysis as well as ablation analysis.
IV-A Datasets and Experimental Settings
We evaluated our proposed method on two different ultrasound lesion segmentation tasks, i.e., breast ultrasound (BUS) segmentation and thyroid ultrasound (TUS) segmentation.
Five multi-site BUS datasets that contains 2862 images and a TUS dataset which enrolls 646 images were used to develop and assess the proposed method.
Brief sample distribution of BUS and TUS datasets is summarized in TABLE I.
BUS.
S1: Dataset1 collects 1812 BUS images offered by the SonoSkills and Hitachi Medical Systems Europe444https://www.ultrasoundcases.info/;
S2: Dataset2 has 200 BUS images acquired by the Ultrasonix SonixTouch Research ultrasound scanner with a L14-5/38 linear array transducer [57];
S3: Dataset3 contains 163 BUS images provided by the UDIAT Diagnostic Center with a Siemens ACUSON Sequoia C512 system and a 17L5 HD linear array transducer ( MHZ) [29].
S4: Dataset4 enrolls 506 BUS images derived from the Baheya Hospital with a LOGIQ E9 ultrasound system or LOGIQ E9 Agile ultrasound system [58].
S5: Dataset5 includes 181 BUS images obtained by a Philips iU22 ultrasound scanner at Thammasat University Hospital [59].
The ground-truths of all datasets have been provided by the organizers except for Dataset3.
Thus, the annotations of Dataset3 have been manually delineated by a radiologist with two years of clinical experience and confirmed by another radiologist with seven years of clinical experience.
Also, they have reviewed the annotations of other datasets and removed partial poor-quality images that may result in inconsistent suggestions.
TUS.
The dataset recruits 646 B-mode TUS images and their ground-truths, which is provided by the IDIME Ultrasound Department in Colombia [60].
The radiologists have been also invited to review and confirm image’s quality as well as annotation.
| BUS | TUS | |||||
| Dataset1 | Dataset2 | Dataset3 | Dataset4 | Dataset5 | – | |
| Benign | 818 | 96 | 110 | 383 | 121 | 66 |
| Malignant | 907 | 104 | 53 | 123 | 60 | 380 |
| Unknow | 87 | - | - | - | - | 200 |
| Total | 1812 | 200 | 163 | 506 | 181 | 646 |
For BUS segmentation task, we trained the model on two sites (i.e., S1 and S2 [57], 2012 images in total) via inner 5-fold cross-validation strategy and tested on three sites (i.e., S3 [29], S4 [58] and S5 [59], 850 images in total) to assess model’s generalization capability on multiple sites. As for TUS segmentation task, we utilized 5-fold cross-validation strategy to evaluate the proposed method in view of the limited sample size [60]. All images were resized into a fixed size of and the intensity values in each image were normalized into the range of [0, 1] by Min-Max normalization. The performance of model was assessed in terms of dice similarity coefficient (Dice), mean intersection over union (m-IoU), precision and 95% hausdorff distance (95HD). The parameters , , , , , and were experimentally set to 0.5, 0.5, 1, 10, 0.001, 5 and 0.25, respectively. Notably, the influence of key parameters on model’s performance has been discussed in the section of Discussion. We initialized all parameters with "he_normal" and adopted Adam solver with the momentum of 0.9 for network training. The batch size, learning rate and epoch number were set to 4, and 200, respectively. All intensive calculations were offloaded to two 12 GB NVIDIA Pascal Titan X GPU.
IV-B Comparison with the State-of-the-art Methods
We first compared the proposed method with the state-of-the-art deep learning approaches in ultrasound lesion segmentation. The competing methods include: 1) Classical medical image segmentation models: DeepLab V3+ [61], U-Net [16], U-Net++ [45], and AU-Net [62]; 2) Breast lesion segmentation models: RDAU-Net [37], AE-Net [12], ConvEDNet [63], SK-Net [38], CF2-Net [39], MNFE-Net [64], and CSwin-PNet [65]; 3) Thyroid nodule segmentation models: TNSCUI-R1 [28], TNSCUI-R2 [66], resDU-Net [40], JU-Net [41], and SGU-Net [30], FDE-Net [67], and BPAT-UNet [68]. As not all comparison methods have been evaluated on the same datasets, we reimplemented them based on the details and source codes provided by their work. Table II shows the experimental results.
| Methods | DeepLab V3+ | U-Net | U-Net++ | AU-Net | RDAU-Net | AE-Net | ConvEDNet | CF2-Net | SK-Net | MNFE-Net | CSwin-PNet | DC-Net |
| Dice | 63.131.63 | 63.853.04 | 65.821.60 | 67.371.54 | 61.940.96 | 66.881.78 | 68.900.72 | 69.041.94 | 70.331.22 | 66.700.61 | 70.991.75 | 73.960.36 |
| m-IoU | 52.111.91 | 53.293.25 | 55.221.58 | 57.311.54 | 51.900.94 | 56.691.75 | 58.000.65 | 59.622.31 | 60.871.45 | 55.880.77 | 61.162.48 | 64.260.48 |
| Precision | 61.553.34 | 60.904.23 | 63.232.44 | 65.072.16 | 62.071.63 | 64.432.57 | 66.871.06 | 67.663.01 | 69.812.41 | 67.002.64 | 70.161.96 | 75.821.16 |
| 95HD | 6.450.19 | 6.670.44 | 6.350.22 | 6.240.14 | 6.380.11 | 6.220.18 | 5.920.07 | 5.900.23 | 5.880.07 | 6.100.16 | 5.750.07 | 5.440.10 |
| p-value | 7.59e-05 | 2.82e-03 | 7.68e-04 | 5.69e-04 | 2.90e-06 | 9.05e-04 | 1.78e-05 | 6.14e-03 | 2.94e-03 | 1.78e-05 | 3.10e-02 | — |
| Methods | DeepLab V3+ | U-Net | U-Net++ | AU-Net | TNSCUI-R1 | resDU-Net | JU-Net | SGU-Net | TNSCUI-R2 | FDE-Net | BPAT-UNet | DC-Net |
| Dice | 62.673.81 | 71.652.22 | 67.351.94 | 73.401.89 | 62.812.66 | 64.362.01 | 69.790.76 | 72.070.35 | 72.132.37 | 69.551.11 | 73.400.95 | 76.251.89 |
| m-IoU | 48.634.42 | 59.132.52 | 53.932.19 | 61.322.06 | 49.032.89 | 50.112.03 | 56.800.57 | 59.330.60 | 61.252.69 | 56.611.83 | 61.071.26 | 65.282.24 |
| Precision | 64.166.52 | 73.252.45 | 67.551.95 | 76.994.08 | 64.714.23 | 64.292.84 | 72.521.68 | 75.462.42 | 72.061.64 | 73.432.74 | 74.215.54 | 79.351.92 |
| 95HD | 7.640.43 | 6.810.27 | 7.260.17 | 6.560.23 | 7.280.24 | 7.410.21 | 6.830.11 | 6.860.10 | 9.460.06 | 6.810.27 | 6.600.12 | 6.220.26 |
| p-value | 4.80e-03 | 6.90e-05 | 2.02e-04 | 4.17e-03 | 5.44e-04 | 2.51e-04 | 4.89e-04 | 4.32e-03 | 4.12e-02 | 5.42e-03 | 3.81e-02 | — |
We have several key observations. First, all U-Net variants outperform DeepLab V3+ on both ultrasound lesion segmentation tasks, which might benefit from the skip connectivity operator in U-Net variants. Second, AU-Net obtains remarkable performance gain than most U-Net variants, especially on TUS segmentation task. It further indicates that attention mechanism can help boost model’s performance for lesion segmentation [62]. Third, multi-scale strategy is competitive across model’s capability of learning features for lesions in complex-scenario images. For example, SK-Net produces higher segmentation accuracy by expanding receptive field to extract multi-scale contexts via the dilated convolution, while TNSCUI-R2 adopts the ensemble refinement mechanism to iteratively optimize the network with multi-resolution images. Fourth, ConvEDNet displays pretty promising in BUS segmentation and is competitive with CF2-Net. It is likely that the utilization of edge constraint advances edge recognition in low-contrast and blurry-boundary images.

Fifth, well pre-trained backbones may help to improve model performance. For example, CSwin-PNet and BPAT-UNet introduced pre-trained transformer blocks to improve the network’s capability of extracting long-range dependency and achieved better segmentation results. Finally, the proposed DC-Net which we find to reach the noticeably higher performance in terms of all evaluation metrics when compared with other methods. Several potential advantages exist in the proposed method: 1) It integrates saliency map generation and lesion segmentation into a unified framework, and introduces a coupler to reinforce foreground-salient representation learning by incorporating complementary information derived from background-salient cues. 2) It performs regional feature aggregation via DCP operator to alleviate the issue of information dropout by adaptively preserving local important contextual details and enlarging receptive field. 3) It strengthens the connection of information from encoding and decoding streams (via CCF) to efficiently conduct relation-aware representation fusion of low-level and high-level features. 4) The harmonic loss encourages the network to focus more attention on hard and low-confidence samples during the training stage, which helps improve generalization ability. In Fig. 4, we also provide the visualization results of all competing methods on some representative cases for further comparison. From Fig. 4, we can find that DC-Net can more accurately locate the lesion than others, which mainly credits to the utilization of the cues provided by saliency maps. Also, DC-Net can work well in the scenario where lesion region shares similar intensity with surrounding tissues, especially on the aspect of edge’s integrity.


IV-C Efficacy of Saliency Map and DaR Module
The saliency map is one of core components of DC-Net and DaR module helps couple the saliency maps of background and foreground. In this part, we aim to validate their efficacy by developing and evaluating various variants. For convenience, we name these variants as follows. 1) DC-Net_woB (DC-Net_woF): It removes coupler and only uses the concatenation of original image and foreground (background) saliency map as the input of coupling subnet; 2) DC-Net_woC: It removes both decomposition subnet and coupler, and only takes the original image as the input of coupling subnet. 3) DC-Net_woD: It abandons DaR module and links foreground-salient and background-salient representations by channel-wise concatenation operation. The experimental results are shown in Fig. 5. The DC-Net_woC is inferior to others on two segmentation tasks, which verifies the conclusion that saliency map is a significant step towards complex-scenario ultrasound lesion segmentation [23, 11, 13]. And DC-Net significantly overpasses both DC-Net_woB and DC-Net_woF, owing to the coupler that can extract discriminative information derived from background to complement foreground-salient representation, especially when background contains richer texture patterns than foreground. Also, the DC-Net_woD is found to suffer from a profound performance degradation, and this degradation suggests DaR module can better help reinforce foreground-salient representation compared to simple concatenation operation that may introduce more irrelevant information. Fig. 8 shows the attention map (i.e., ) in the DaR module on some representative cases from BUS and TUS datasets. From the Fig. 8, we can find that the attention map mainly concentrates on the foreground (i.e., lesion region), which can be utilized to mine foreground-dependent complementary information derived from background and reinforce the foreground-salient representation learning. To further investigate the effectiveness of supervision strategy for decomposition subnet, we implement DC-Net with only the minor modification of using different supervision schemes. 1) DC-Net_woSf (DC-Net_woSb): It discards the supervision of foreground (background) mask on saliency map generation; 2) DC-Net_woS: It trains decomposition subnet in an unsupervised manner; 3) DC-Net_wSB: It replaces the precise mask with bounding box to optimize saliency map generation. In Fig. 7, as we expected, DC-Net_woS underperforms other variants, since supervision signal can restrain the uncertainty of parameters and accelerate the convergence of model. Additionally, DC-Net surpasses DC-Net_woSf and DC-Net_woSb, which indicates that the cooperation of foreground and background masks can help to efficiently disentangle the original image into foreground and background saliency maps and strengthen model’s performance. Interestingly, DC-Net_wSB is also likely to achieve promising performance, implying proxy annotation may be an alternative choice for training saliency map generation. Fig. 6 displays some representative cases from BUS and TUS datasets for further comparison. From Fig. 6, we can see that the model can show better segmentation performance by simultaneously learning foreground and background representation under the assistance of foreground and background saliency maps.

IV-D Efficacy of DCP Operator
We additionally experimented with equipping the network with the following pooling approaches to help specify the efficacy of DCP operator. 1) Classical pooling methods in lesion segmentation network: average pooling (AveP), max pooling (MaxP) and mix-pooling (MixP); 2) Local detail-based pooling approaches: stride convolution (StrC), polynomial pooling (PolyP) [69], local importance-based pooling (LIP) [34] and detail-preserving pooling (DPP) [35]; 3) Context aggregation strategies: atrous spatial pyramid pooling (ASPP) [61] and switchable ASPP (SAC) [70]; 4) The variant of DCP (denoted as ) that neglects context aggregation. From Fig. 9, we can observe some key points. First, the model with MixP achieves the best performance among three classical pooling methods, perhaps because a compound pooling mode can remedy the pattern dropout caused by single one. Second, the models with local detail-based pooling approaches (also including DCP and ) work better than those with three classical pooling methods and context aggregation-based methods in general. A potential reason is that these methods aggregate local features via the learnable estimation rather than the prior statistics (e.g., local mean or maximum value). Finally, the DCP method shows more promising results than others, which may owe to three aspects, including 1) learning the adaptive pooling kernel; 2) preserving local contextual details; 3) enlarging the receptive field. Fig. 10 gives the visualization results of variants with various pooling strategies on some representative cases from BUS and TUS datasets. Obviously, our proposed DCP can reduce the error in separating the lesion region from surrounding tissues that shares similar intensity. To analyze the complexity of different pooling strategies, we also calculated the trainable parameters, floating point operations (FLOPs) and the inference time of each image for the model with different pooling operators. All results are reported in Table III. From Table III,we can observe that the increasing model parameters with DCP operator is marginal when compared with other operators, which suggests the proposed DCP is relatively efficient.

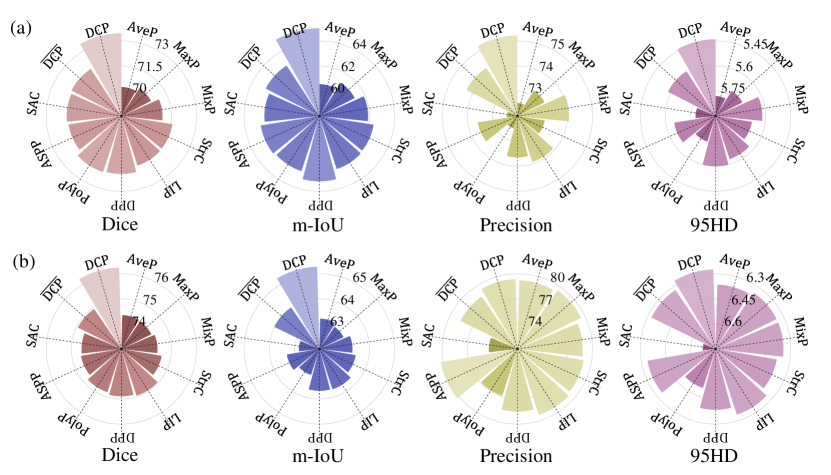
| Methods | AveP | MaxP | MixP | StrC | DPP | LIP | ASPP | SAC | PolyP | DC-Net | |
| Params (M) | 54.4 | 54.0 | 54.4 | 55.2 | 54.4 | 55.2 | 63.4 | 54.1 | 54.4 | 54.4 | 54.4 |
| FLOPs (M) | 108.9 | 107.9 | 108.9 | 110.4 | 108.9 | 110.4 | 126.7 | 108.3 | 108.8 | 108.9 | 108.9 |
| Infer (ms) | 0.107 | 0.107 | 0.107 | 0.109 | 0.111 | 0.116 | 0.120 | 0.077 | 0.071 | 0.110 | 0.135 |



IV-E Efficacy of CCF Module
This ablation study is to validate the effectiveness of CCF module by comparing it with other methods. Concretely, these methods include: 1) Baseline: it removes the CCF from DC-Net; 2) Concat/Add/RMSC: it replaces the CCF with the channel-wise concatenation operation, channel-wise addition operation and residual multi-scale connection strategy [44], respectively. From Fig. 11, we can observe that the model with Concat or Add performs better than Baseline. It demonstrates the skip connection strategy that transmits low-level features from encoder to supplement morphological information for decoder contributes to the performance improvement by a large amount. It is worthwhile mentioning that the model with RMSC overpasses those with Concat and Add on two tasks. The performance gain may benefit from the multi-scale skip fusion strategy and attention mechanism. In addition, CCF is superior to other competing methods, which implies that fusing low-level visual information with high-level semantic representations under the prior of correlation can reduce redundant information and strengthen information connection. Fig. 12 displays the integrated (via pixel-wise addition operation) low-level and high-level feature maps (i.e., , , , , and ) from CCF module. As shown in Fig. 12, low-level feature maps contain rich textural information (see Fig. 12(a)(d)), while high-level ones have better capability of lesion localization (see Fig. 12(b)(e)). Also, the prior of channel correlation can enhance the network’s ability of capturing detail information, such as shape and boundary (as shown in Fig. 12(a)(b) and (d)(e)). Therefore, feature integration under the prior of channel correlation can strengthen the efficiency of feature propagation. Fig. 13 displays the visualization results to qualitatively compare various skip connection strategies. Though all methods can accurately locate the lesion, the model with CCF shows better ability in fitting the lesion shape, regardless of it with large-size or small-size.


IV-F Efficacy of Optimization Function
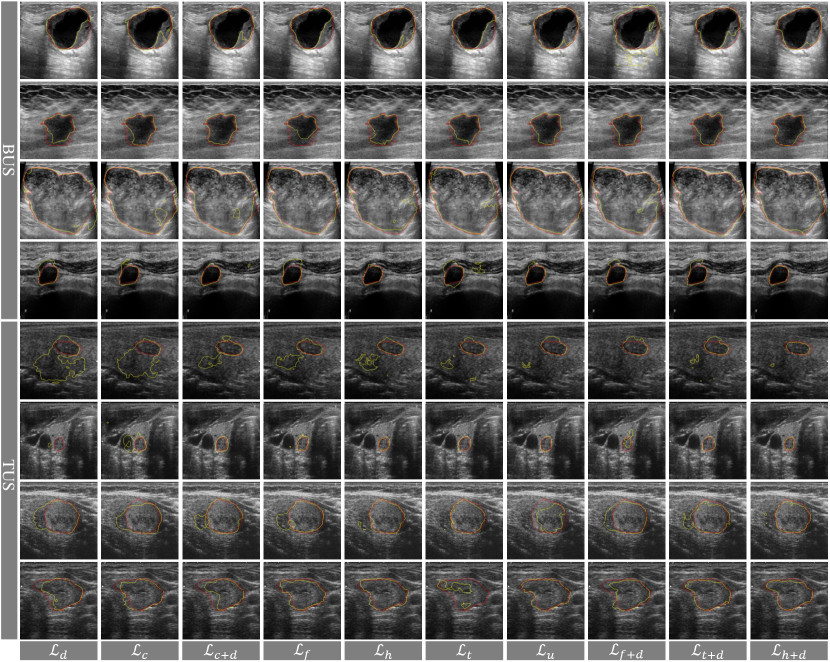
Here, we mainly make a comparison the proposed optimization loss (i.g., harmonic loss and its hybrid version with Dice loss ) with the following losses: 1) Single function: CE loss , Dice loss , focal loss , topk loss [71]; 2) Hybrid function: joint CE loss and Dice loss , generalized Dice and CE-based loss [51], joint focal loss and Dice loss , joint topk loss and Dice loss . Fig. 14 shows the experimental results. Generally speaking, the models trained with hybrid loss functions work better compared to those trained with single loss functions, which further verifies the conclusion stated by [55]. As expected, is inferior to its generalized variants (i.e., , , , and ), as the latter compels the network to give more attention to hard samples during the training stage.

The models with and achieve the highest metric scores among those models with single functions and hybrid functions, respectively. Unlike , and , the proposed can down-weight easy samples, preserve and even lift the loss margin and gradient of hard samples. More importantly, it can also narrow down the suppression range to prevent low-confidence samples from being overwhelmed. Fig. 15 visualizes some representative cases from BUS and TUS datasets for qualitative comparison of various loss functions. It can be found that the output of model trained with can approximately coincide with the ground truth. Meanwhile, we also notice helps model work in the blurry-boundary scenario, especially on TUS datasets. Fig. 16 shows the gradient maps of several representative losses on the same prediction map from previous training epoch. We mainly focus on the comparison of cross-entropy loss and its advanced variants (i.e., focal loss , topk loss and harmonic loss ) to analyze their influence on easy, low-confidence and hard samples. From Fig. 16, we have the following findings. 1) still produces gradients for easy samples/pixels (e.g., purple pixels in ). Although these gradients are weak, they may dominant and affect the direction of network optimization due to the large proportion of easy samples in the whole image. 2) Compared with , can obviously suppress the gradient of easy samples (e.g., those pixels changes from purple to black), but it also suppresses the low-confidence ones (e.g., has more incomplete contours of some lesions in BUS images than ). 3) relatively alleviates the aforementioned issues, but it still pays insufficient attention to low-confidence samples, which results in flawy boundaries of some lesions. 4) can not only suppress the gradient of easy samples, but also focus on the hard and low-confidence samples around the boundary (e.g., yellow and purple pixels in ), so as to obtain promising segmentation performance.
V Discussion
V-A Comparison with Saliency Map-based Methods
In this subsection, we compare the proposed DC-Net with several saliency map-based methods, including iFCN [23], DeepIGeoS [11], and SMU-Net [13]. All of them require interactive saliency map generation. For deeper comparison, we run the DC-Net by using the interactively-generated saliency maps from other methods as input, and also feed the automatically-generated saliency map from DC-Net into other methods. For convenience, we mark those methods based on interactively-generated and automatically-generated saliency maps with the tails of "interac" and "automac", respectively. Experimental results are shown in Table IV. From Table IV, we have several observations as follows. 1) DC-Net demonstrates enhanced performance when utilizing interactively-generated saliency maps from SMU-Net. But, it experiences significant performance degradation when employing interactively-generated saliency maps from DeepIGeoS. The saliency maps from SMU-Net cover low-level and high-level image structures that help distinguish lesion from background. However, subtle gray difference between lesion and background leads to the blurry boundary in the geodesic distance map (i.e., interactively-generated saliency maps from DeepIGeoS), which may give wrong prompt and hinders the performance improvement. Even so, both of them require interactive hand-clicked seeds, thus are time-consuming and experience-dependent. It is worth mentioning that the proposed method has smaller model parameters than SMU-Net (54.4M vs. 103.3M). 2) When the same saliency maps are used, DC-Net can achieve comparable and even higher results than others, which demonstrates its efficacy.
| Methods | Dice | m-IoU | Precision | 95HD | |
| BUS | DeepIGeoS (interac) | 64.461.47 | 53.951.70 | 61.591.93 | 6.570.18 |
| DeepIGeoS (automac) | 65.072.04 | 54.602.28 | 62.882.67 | 6.450.30 | |
| DC-Net (interac) | 67.602.23 | 57.981.92 | 68.140.35 | 5.940.05 | |
| DC-Net (automac) | 73.960.36 | 64.260.48 | 73.950.36 | 5.440.10 | |
| iFCN (interac) | 73.980.59 | 63.120.80 | 71.441.22 | 5.710.09 | |
| iFCN (automac) | 69.500.79 | 59.150.82 | 69.591.08 | 5.830.08 | |
| DC-Net (interac) | 74.180.93 | 64.011.08 | 75.752.29 | 5.540.15 | |
| DC-Net (automac) | 73.960.36 | 64.260.48 | 73.950.36 | 5.440.10 | |
| SMU-Net (interac) | 80.810.87 | 71.201.05 | 80.491.89 | 4.960.08 | |
| SMU-Net (automac) | 73.870.65 | 63.400.84 | 74.371.26 | 5.520.02 | |
| DC-Net (interac) | 80.760.17 | 71.170.30 | 83.980.95 | 4.930.02 | |
| DC-Net (automac) | 73.960.36 | 64.260.48 | 73.950.36 | 5.440.10 | |
| TUS | DeepIGeoS (interac) | 71.970.47 | 59.620.98 | 75.122.44 | 6.680.22 |
| DeepIGeoS (automac) | 72.981.05 | 60.811.53 | 75.032.84 | 6.630.18 | |
| DC-Net (interac) | 70.192.33 | 57.612.38 | 74.331.74 | 6.780.12 | |
| DC-Net (automac) | 76.251.89 | 65.282.24 | 76.251.89 | 6.220.26 | |
| iFCN (interac) | 74.021.98 | 60.992.53 | 76.242.85 | 6.640.22 | |
| iFCN (automac) | 67.151.40 | 54.401.43 | 67.222.86 | 7.050.18 | |
| DC-Net (interac) | 74.721.90 | 62.022.41 | 77.193.42 | 6.640.11 | |
| DC-Net (automac) | 76.251.89 | 65.282.24 | 76.251.89 | 6.220.26 | |
| SMU-Net (interac) | 76.341.77 | 63.912.16 | 77.372.72 | 6.400.20 | |
| SMU-Net (automac) | 72.842.47 | 59.592.84 | 75.132.85 | 6.620.19 | |
| DC-Net (interac) | 80.761.87 | 69.742.41 | 83.382.25 | 6.400.20 | |
| DC-Net (automac) | 76.251.89 | 65.282.24 | 76.251.89 | 6.220.26 |
V-B Parameters Analysis
In this part, we discuss the influence of key parameters in our proposed method, including , , in Eq.(18), in Eq.(27), and , , in Eq.(26). 1) To determine the ratio of , , , we tested the model under different settings on two tasks. As shown in Fig. 17 (a)-(b), the model gets the best performance when the ratio is set to 0.5: 0.5: 1. It is not surprising about that as focusing more attention on final precise segmentation (via the couple subnet) is beneficial to performance improvement. We further investigate the ratio of and . From Fig. 17 (c)-(d), as we expected, a large is a better choice, which assigns a large weight to the harmonic loss. And the best results are obtained when the ratio equals to 1:10. 2) We conducted experiments by varying the value of , and in the range of , and , respectively, for having an insight into their influence on the proposed model. In addition, we also designed two unique settings for , including 1) removing from the harmonic loss (denoted as "none") and 2) adaptively determining according to the proportion of the foreground to the whole image (denoted as "adp"). From Fig. 18, we can observe that the model with , and outperforms those with other settings, for both tasks. As illustrated in Fig. 18, the harmonic loss with and can suppress easy samples (with in the range of (0.75, 1]) and enhance the gradient of low-confident samples (with in the range of [0.4, 0.75]).


V-C Complexity Analysis
To discuss the model’s complexity, we calculated the number of model parameters, FLOPs and the inference time of each image for several representative algorithms, including DeepLabV3+, U-Net, U-Net++, AU-Net, DeepIGeoS, iFCN, and SMU-Net. Table V shows all comparison results. The complexity of DC-Net approximates that of DeepLab V3+, but is higher than most of other methods. It is worth mentioning that both SMU-Net and DC-Net contain special streams or branches to deal with foreground and background representation, and they experience a significant performance improvement at the cost of a relatively high complexity. But, compared to SMU-Net, DC-Net seems to be more efficient and is free of manual interaction.
VI Conclusion
In this paper, we present a decomposition-coupling network, referred to as DC-Net, for lesion segmentation in complex-scenario ultrasound images by integrating saliency map generation and lesion segmentation into a collaborative framework. We devise a differentiable context pooling operator and a cross-correlation fusion module for dimension reduction and resolution restoration, respectively. And a novel coupler is proposed to conduct dependency-aware reinforcement of foreground-salient representation with the complementary background information. We further introduce a harmonic loss function to take into account the efficient optimization of low-confidence samples in additional to hard ones. Extensive experiments and evaluations on two ultrasound lesion segmentation tasks have demonstrated the proposed method outperforms several recent deep learning methods.
| Methods | DeepLabV3+ | U-Net | U-Net++ | AU-Net | DeepIGeoS | iFCN | SMU-Net | DC-Net |
| Params (M) | 41.0 | 31.4 | 23.8 | 34.9 | 1.64 | 14.7 | 103.3 | 54.4 |
| FLOPs (M) | 163.7 | 62.8 | 47.5 | 69.8 | 3.28 | 29.5 | 206.7 | 108.9 |
| Infer (ms) | 0.052 | 0.097 | 0.102 | 0.104 | 0.251 | 0.126 | 0.124 | 0.135 |
References
- [1] J. A. Noble and D. Boukerroui, “Ultrasound image segmentation: a survey,” IEEE Trans. Med. Imaging, vol. 25, no. 8, pp. 987–1010, 2006.
- [2] Q. Huang, F. Zhang, and X. Li, “Machine learning in ultrasound computer-aided diagnostic systems: a survey,” Biomed. Res. Int., vol. 2018, 2018.
- [3] A. P. James and B. V. Dasarathy, “Medical image fusion: a survey of the state of the art,” Information fusion, vol. 19, pp. 4–19, 2014.
- [4] M. I. Daoud, A. A. Atallah, F. Awwad, M. Al-Najjar, and R. Alazrai, “Automatic superpixel-based segmentation method for breast ultrasound images,” Expert Syst. Appl., vol. 121, pp. 78–96, 2019.
- [5] R. J. G. van Sloun, R. Cohen, and Y. C. Eldar, “Deep learning in ultrasound imaging,” Proc. IEEE, vol. 108, no. 1, pp. 11–29, 2020.
- [6] I. Qureshi, J. Yan, Q. Abbas, K. Shaheed, A. B. Riaz, A. Wahid, M. W. J. Khan, and P. Szczuko, “Medical image segmentation using deep semantic-based methods: a review of techniques, applications and emerging trends,” Information Fusion, 2022.
- [7] M. Xian, Y. Zhang, H. D. Cheng, F. Xu, B. Zhang, and J. Ding, “Automatic breast ultrasound image segmentation: a survey,” Pattern Recognit., vol. 79, pp. 340–355, 2018.
- [8] J. Clough, N. Byrne, I. Oksuz, V. Zimmer, J. Schnabel, and A. King, “A topological loss function for deep-learning based image segmentation using persistent homology.” IEEE Trans. Pattern Anal. Mach. Intell., 2020.
- [9] H. Shao, Y. Zhang, M. Xian, H. D. Cheng, F. Xu, and J. Ding, “A saliency model for automated tumor detection in breast ultrasound images,” in ICIP, 2015, pp. 1424–1428.
- [10] S. Liu, Y. Wang, X. Yang, B. Lei, L. Liu, S. X. Li, D. Ni, and T. Wang, “Deep learning in medical ultrasound analysis: a review,” Engineering, vol. 5, no. 2, pp. 261–275, 2019.
- [11] G. Wang, M. A. Zuluaga, W. Li, R. Pratt, P. A. Patel, M. Aertsen, T. Doel, A. L. David, J. Deprest, S. Ourselin, and T. Vercauteren, “Deepigeos: a deep interactive geodesic framework for medical image segmentation,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 7, pp. 1559–1572, 2018.
- [12] A. Vakanski, M. Xian, and P. E. Freer, “Attention-enriched deep learning model for breast tumor segmentation in ultrasound images,” Ultrasound Med. Biol., vol. 46, no. 10, pp. 2819–2833, 2020.
- [13] Z. Ning, S. Zhong, Q. Feng, W. Chen, and Y. Zhang, “Smu-net: saliency-guided morphology-aware u-net for breast lesion segmentation in ultrasound image,” IEEE Trans. Med. Imaging, vol. 41, no. 2, pp. 476–490, 2022.
- [14] C. Chu, J. Zheng, and Y. Zhou, “Ultrasonic thyroid nodule detection method based on u-net network,” Comput. Methods Programs Biomed., vol. 199, p. 105906, 2021.
- [15] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in IEEE Trans. Pattern Anal. Mach. Intell., 2015, pp. 3431–3440.
- [16] O. Ronneberger, P. Fischer, and T. Brox, “U-net: convolutional networks for biomedical image segmentation,” in MICCAI, 2015, pp. 234–241.
- [17] S. Minaee, Y. Y. Boykov, F. Porikli, A. J. Plaza, N. Kehtarnavaz, and D. Terzopoulos, “Image segmentation using deep learning: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., 2021.
- [18] H. K. Cheng, Y. W. Tai, and C. K. Tang, “Modular interactive video object segmentation: interaction-to-mask, propagation and difference-aware fusion,” in CVPR, 2021, pp. 5559–5568.
- [19] C. Nieuwenhuis and D. Cremers, “Spatially varying color distributions for interactive multilabel segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 5, pp. 1234–1247, 2012.
- [20] R. Feng, X. Zheng, T. Gao, J. Chen, W. Wang, D. Z. Chen, and J. Wu, “Interactive few-shot learning: limited supervision, better medical image segmentation,” IEEE Transactions on Medical Imaging, vol. 40, no. 10, pp. 2575–2588, 2021.
- [21] S. Cho, H. Jang, J. W. Tan, and W. K. Jeong, “Deepscribble: interactive pathology image segmentation using deep neural networks with scribbles,” in ISBI, 2021, pp. 761–765.
- [22] X. Luo, G. Wang, T. Song, J. Zhang, M. Aertsen, J. Deprest, S. Ourselin, T. Vercauteren, and S. Zhang, “Mideepseg: minimally interactive segmentation of unseen objects from medical images using deep learning,” Med. Image Anal., vol. 72, p. 102102, 2021.
- [23] N. Xu, B. Price, S. Cohen, J. Yang, and T. S. Huang, “Deep interactive object selection,” in CVPR, 2016, pp. 373–381.
- [24] J.-W. Zhang, W. Chen, K. I. Ly, X. Zhang, F. Yan, J. Jordan, G. Harris, S. Plotkin, P. Hao, and W. Cai, “Dins: deep interactive networks for neurofibroma segmentation in neurofibromatosis type 1 on whole-body mri,” IEEE J. Biomed. Health. Inf., 2021.
- [25] D. Avola, L. Cinque, A. Fagioli, G. Foresti, and A. Mecca, “Ultrasound medical imaging techniques: a survey,” ACM Comput. Surv., vol. 54, no. 3, pp. 1–38, 2021.
- [26] M. Komatsu, A. Sakai, A. Dozen, K. Shozu, S. Yasutomi, H. Machino, K. Asada, S. Kaneko, and R. Hamamoto, “Towards clinical application of artificial intelligence in ultrasound imaging,” Biomedicines, vol. 9, no. 7, p. 720, 2021.
- [27] S. Wang, M. E. Celebi, Y.-D. Zhang, X. Yu, S. Lu, X. Yao, Q. Zhou, M.-G. Miguel, Y. Tian, J. M. Gorriz, and I. Tyukin, “Advances in data preprocessing for biomedical data fusion: an overview of the methods, challenges, and prospects,” Information Fusion, vol. 76, pp. 376–421, 2021.
- [28] M. Wang, C. Yuan, D. Wu, Y. Zeng, S. Zhong, and W. Qiu, “Automatic segmentation and classification of thyroid nodules in ultrasound images with convolutional neural networks,” in MICCAI, 2020, pp. 109–115.
- [29] M. H. Yap, G. Pons, J. Marti, S. Ganau, M. Sentis, R. Zwiggelaar, A. K. Davison, and R. Marti, “Automated breast ultrasound lesions detection using convolutional neural networks,” IEEE journal of biomedical and health informatics, vol. 22, no. 4, pp. 1218–1226, 2017.
- [30] H. Pan, Q. Zhou, and L. J. Latecki, “Sgunet: semantic guided unet for thyroid nodule segmentation,” in ISBI, 2021, pp. 630–634.
- [31] H. Gong, G. Chen, R. Wang, X. Xie, M. Mao, Y. Yu, F. Chen, and G. Li, “Multi-task learning for thyroid nodule segmentation with thyroid region prior,” in ISBI, 2021, pp. 257–261.
- [32] H. Lee, J. Park, and J. Y. Hwang, “Channel attention module with multiscale grid average pooling for breast cancer segmentation in an ultrasound image,” IEEE Trans. Ultrason. Ferroelectr. Freq. Control., vol. 67, no. 7, pp. 1344–1353, 2020.
- [33] H. Zou, X. Gong, J. Luo, and T. Li, “A robust breast ultrasound segmentation method under noisy annotations,” Comput. Methods Programs Biomed., vol. 209, p. 106327, 2021.
- [34] Z. Gao, L. Wang, and G. Wu, “Lip: local importance-based pooling,” in ICCV, 2019, pp. 3355–3364.
- [35] F. Saeedan, N. Weber, M. Goesele, and S. Roth, “Detail-preserving pooling in deep networks,” in CVPR, 2018, pp. 9108–9116.
- [36] M. Drozdzal, E. Vorontsov, G. Chartrand, S. Kadoury, and C. Pal, “The importance of skip connections in biomedical image segmentation,” in DLMIA. Springer, 2016, pp. 179–187.
- [37] Z. Zhuang, N. Li, A. N. Joseph Raj, V. G. Mahesh, and S. Qiu, “An rdau-net model for lesion segmentation in breast ultrasound images,” Plos One, vol. 14, no. 8, p. e0221535, 2019.
- [38] M. Byra, P. Jarosik, A. Szubert, M. Galperin, H. Ojeda-Fournier, L. Olson, M. O’Boyle, C. Comstock, and M. Andre, “Breast mass segmentation in ultrasound with selective kernel u-net convolutional neural network,” Biomed. Signal Process. Control, vol. 61, p. 102027, 2020.
- [39] Z. Ning, K. Wang, S. Zhong, Q. Feng, and Y. Zhang, “Cf2-net: coarse-to-fine fusion convolutional network for breast ultrasound image segmentation,” arXiv:2003.10144, 2020.
- [40] A. Shahroudnejad, R. Vega, A. Forouzandeh, S. Balachandran, J. Jaremko, M. Noga, A. R. Hareendranathan, J. Kapur, and K. Punithakumar, “Thyroid nodule segmentation and classification using deep convolutional neural network and rule-based classifiers,” in EMBC, 2021, pp. 3118–3121.
- [41] J. Wu, Z. Zhang, J. Zhao, and Y. Qiang, “Ultrasound image segmentation of thyroid nodules based on joint up-sampling,” in JPCS, vol. 1651, no. 1, 2020, p. 012157.
- [42] H. Yang, C. Shan, A. Bouwman, A. F. Kolen, and P. H. de With, “Efficient and robust instrument segmentation in 3d ultrasound using patch-of-interest-fusenet with hybrid loss,” Med. Image Anal., vol. 67, p. 101842, 2021.
- [43] M. Liu, X. Yuan, Y. Zhang, K. Chang, Z. Deng, and J. Xue, “An end to end thyroid nodule segmentation model based on optimized u-net convolutional neural network,” in ISAIMS, 2020, pp. 74–78.
- [44] Z. Honghan, D. C. Liu, L. Jingyan, P. Liu, H. Yin, and Y. Peng, “Rms-se-unet: a segmentation method for tumors in breast ultrasound images,” in ICCCS, 2021, pp. 328–334.
- [45] Z. Zhou, M. M. R. Siddiquee, N. Tajbakhsh, and J. Liang, “Unet++: a nested u-net architecture for medical image segmentation,” in DLMIA, 2018, pp. 3–11.
- [46] K. Han, Y. Wang, Q. Tian, J. Guo, C. Xu, and C. Xu, “Ghostnet: more features from cheap operations,” in CVPR, 2020, pp. 1580–1589.
- [47] X. Wang and X. Y. Stella, “Tied block convolution: leaner and better cnns with shared thinner filters,” in AAAI, 2021, pp. 10 227–10 235.
- [48] Z. Zheng, Y. Zhong, J. Wang, and A. Ma, “Foreground-aware relation network for geospatial object segmentation in high spatial resolution remote sensing imagery,” in CVPR, 2020, pp. 4096–4105.
- [49] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, “Focal loss for dense object detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 2, pp. 318–327, 2020.
- [50] J. Li, L. Cheng, T. Xia, H. Ni, and J. Li, “Multi-scale fusion u-net for the segmentation of breast lesions,” IEEE Access, vol. 9, pp. 137 125–137 139, 2021.
- [51] M. Yeung, E. Sala, C. B. Schönlieb, and L. Rundo, “Unified focal loss: generalising dice and cross entropy-based losses to handle class imbalanced medical image segmentation,” Comput. Med. Imaging Grap., vol. 95, p. 102026, 2022.
- [52] T. Kobayashi, “Gaussian-based pooling for convolutional neural networks,” NeurIPS, vol. 32, 2019.
- [53] W. Zhu, Y. Huang, L. Zeng, X. Chen, Y. Liu, Z. Qian, N. Du, W. Fan, and X. Xie, “Anatomynet: deep learning for fast and fully automated whole-volume segmentation of head and neck anatomy,” Med. Phys., vol. 46, no. 2, pp. 576–589, 2019.
- [54] Z. Leng, M. Tan, C. Liu, E. D. Cubuk, X. Shi, S. Cheng, and D. Anguelov, “Polyloss: a polynomial expansion perspective of classification loss functions,” in ICLR, 2021.
- [55] J. Ma, J. Chen, M. Ng, R. Huang, Y. Li, C. Li, X. Yang, and A. L. Martel, “Loss odyssey in medical image segmentation,” Medical Image Analysis, vol. 71, p. 102035, 2021.
- [56] F. Milletari, N. Navab, and S.-A. Ahmadi, “V-net: fully convolutional neural networks for volumetric medical image segmentation,” in 3DV, 2016, pp. 565–571.
- [57] H. Piotrzkowska Wróblewska, K. Dobruch Sobczak, M. Byra, and A. Nowicki, “Open access database of raw ultrasonic signals acquired from malignant and benign breast lesions,” Med. Phys., vol. 44, no. 11, pp. 6105–6109, 2017.
- [58] W. Al-Dhabyani, M. Gomaa, H. Khaled, and A. Fahmy, “Dataset of breast ultrasound images,” Data. Brief, vol. 28, p. 104863, 2020.
- [59] A. Rodtook, K. Kirimasthong, W. Lohitvisate, and S. S. Makhanov, “Automatic initialization of active contours and level set method in ultrasound images of breast abnormalities,” Pattern Recognit., vol. 79, pp. 172–182, 2018.
- [60] L. Pedraza, C. Vargas, F. Narváez, O. Durán, E. Muñoz, and E. Romero, “An open access thyroid ultrasound image database,” in ISMIPA, vol. 9287, 2015, p. 92870W.
- [61] L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 801–818.
- [62] O. Oktay, J. Schlemper, L. L. Folgoc, M. Lee, M. Heinrich, K. Misawa, K. Mori, S. McDonagh, N. Y. Hammerla, B. Kainz, B. Glocker, and D. Rueckert, “Attention u-net: learning where to look for the pancreas,” arXiv:1804.03999, 2018.
- [63] C. Bian and R. Lee, “Boundary regularized convolutional neural network for layer parsing of breast anatomy in automated whole breast ultrasound,” in MICCAI, 2017, pp. 259–266.
- [64] G. Liu, J. Wang, D. Liu, and B. Chang, “A multiscale nonlocal feature extraction network for breast lesion segmentation in ultrasound images,” IEEE Transactions on Instrumentation and Measurement, 2023.
- [65] H. Yang and D. Yang, “Cswin-pnet: a cnn-swin transformer combined pyramid network for breast lesion segmentation in ultrasound images,” Expert Systems with Applications, vol. 213, p. 119024, 2023.
- [66] H. Chen, S. Song, X. Wang, R. Wang, D. Meng, and L. Wang, “Lrthr-net: a low-resolution-to-high-resolution framework to iteratively refine the segmentation of thyroid nodule in ultrasound images,” in Seg. Class. Regis. Multi-modal. Med. Imaging Data, 2021, pp. 116–121.
- [67] H. Chen, M.-a. Yu, C. Chen, K. Zhou, S. Qi, Y. Chen, and R. Xiao, “Fde-net: frequency-domain enhancement network using dynamic-scale dilated convolution for thyroid nodule segmentation,” Computers in Biology and Medicine, vol. 153, p. 106514, 2023.
- [68] H. Bi, C. Cai, J. Sun, Y. Jiang, G. Lu, H. Shu, and X. Ni, “Bpat-unet: boundary preserving assembled transformer unet for ultrasound thyroid nodule segmentation,” Computer Methods and Programs in Biomedicine, vol. 238, p. 107614, 2023.
- [69] Z. Wei, J. Zhang, L. Liu, F. Zhu, F. Shen, Y. Zhou, S. Liu, Y. Sun, and L. Shao, “Building detail-sensitive semantic segmentation networks with polynomial pooling,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7115–7123.
- [70] S. Qiao, L.-C. Chen, and A. Yuille, “Detectors: detecting objects with recursive feature pyramid and switchable atrous convolution,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 10 213–10 224.
- [71] Z. Wu, C. Shen, and A. v. d. Hengel, “Bridging category-level and instance-level semantic image segmentation,” arXiv preprint arXiv:1605.06885, 2016.